结构方程模型分析过程应用案例
AMOS结构方程模型分析

AMOS结构方程模型分析AMOS(Analysis of Moment Structures)是一种常用的结构方程模型(SEM)分析软件,可用于研究各种不同领域的问题和假设。
SEM是一种统计方法,用于测试和量化复杂的因果关系假设,以及评估模型拟合优度。
本文将介绍AMOS的基本原理、应用案例和分析步骤。
AMOS的基本原理是使用路径图表示模型中的因果关系,然后通过最小二乘估计法对模型进行参数估计。
AMOS还可以用来评估模型拟合度、进行模型比较,以及检验模型中的因果关系。
一个常见的应用案例是研究变量之间的因果关系。
例如,一个研究者可能想要了解自尊对学术成绩的影响。
在这种情况下,自尊是自变量,学术成绩是因变量。
通过收集数据,研究者可以使用AMOS来构建一个模型,来评估这两个变量之间的因果关系,并确定自尊对学术成绩的影响。
使用AMOS进行结构方程模型分析的步骤如下:1.确定研究目的和问题:首先,需要明确研究的目的和问题,确定需要评估的模型。
2.收集数据:根据研究问题,需要收集相关的数据。
数据可以是自己收集的,也可以是从其他研究中获取的。
3.确定模型的变量和参数:根据研究问题和收集到的数据,需要确定模型中的变量和参数。
变量可以是观察变量(直接测量)或潜变量(隐性构念)。
参数可以是路径系数、截距、测量误差等。
4.构建路径图:使用AMOS的图形界面,根据模型的变量和参数,构建路径图。
路径图可以直观地展示变量之间的因果关系。
5.估计模型参数:根据收集到的数据,使用最小二乘估计法对模型参数进行估计。
AMOS会自动计算最优参数估计和拟合度指标。
6.评估模型拟合度:使用拟合度指标(如X2统计量、均方差逼近指数、规范化拟合指数等),评估模型的拟合度。
较小的X2值、较大的均方差逼近指数和规范化拟合指数表示模型拟合度较好。
7.进行模型修正:如果模型的拟合度不满足要求,可以通过增加、删除或修改模型的路径和变量,进行模型修正。
8.进行统计推断:使用AMOS进行统计推断,来确定模型中的因果关系是否显著。
结构方程SEM模型案例分析

结构方程SEM模型案例分析什么是SEM模型?结构方程模型(Structural equation modeling, SEM)是一种融合了因素分析和路径分析的多元统计技术。
它的强势在于对多变量间交互关系的定量研究。
在近三十年内,SEM大量的应用于社会科学及行为科学的领域里,并在近几年开始逐渐应用于市场研究中.顾客满意度就是顾客认为产品或服务是否达到或超过他的预期的一种感受。
结构方程模型(SEM)就是对顾客满意度的研究采用的模型方法之一。
其目的在于探索事物间的因果关系,并将这种关系用因果模型、路径图等形式加以表述。
如下图:图: SEM模型的基本框架在模型中包括两类变量:一类为观测变量,是可以通过访谈或其他方式调查得到的,用长方形表示;一类为结构变量,是无法直接观察的变量,又称为潜变量,用椭圆形表示。
各变量之间均存在一定的关系,这种关系是可以计算的。
计算出来的值就叫参数,参数值的大小,意味着该指标对满意度的影响的大小,都是直接决定顾客购买与否的重要因素。
如果能科学地测算出参数值,就可以找出影响顾客满意度的关键绩效因素,引导企业进行完善或者改进,达到快速提升顾客满意度的目的。
SEM的主要优势第一,它可以立体、多层次的展现驱动力分析。
这种多层次的因果关系更加符合真实的人类思维形式,而这是传统回归分析无法做到的。
SEM根据不同属性的抽象程度将属性分成多层进行分析。
第二,SEM分析可以将无法直接测量的属性纳入分析,比方说消费者忠诚度。
这样就可以将数据分析的范围加大,尤其适合一些比较抽象的归纳性的属性。
第三,SEM分析可以将各属性之间的因果关系量化,使它们能在同一个层面进行对比,同时也可以使用同一个模型对各细分市场或各竞争对手进行比较。
SEM模型案例分析某通信分公司屡次位居榜尾,于是痛下决心改革。
该分公司有三类业务:固话业务、小灵通业务以及上网业务。
围绕着这三类业务产品的销售,该通信分公司还提供了售前、售中和售后三个环节多方面的服务。
结构方程模型案例

结构方程模型案例结构方程模型(Structural Equation Modeling, SEM)是一种用于建立和验证研究假设的统计分析方法。
它结合了因果关系和测量模型,可以用来探索变量之间的关系以及对研究模型进行验证。
在本文中,我们将介绍一个结构方程模型的案例,以展示其在实际应用中的作用和价值。
假设我们想研究人们对环境保护的态度对其环保行为的影响。
为了建立一个结构方程模型,我们需要明确我们的研究假设和测量指标。
在这个案例中,我们假设人们对环境保护的态度会对其环保行为产生积极的影响。
首先,我们需要选择合适的测量指标来度量人们对环境保护的态度和环保行为。
在这个案例中,我们选择了以下指标:1. 人们对环境保护的态度:我们采用了一个问卷调查,包括了一系列与环境保护相关的问题,例如“您认为环境保护对社会的重要性是?”和“您是否愿意为环境保护做出自己的贡献?”等。
每一个问题都使用了一个5点量表来度量人们的态度,从彻底不允许到彻底允许。
2. 环保行为:我们通过观察人们在日常生活中的实际行为来度量环保行为。
例如,我们可以观察他们是否进行垃圾分类、是否使用可再生能源等。
接下来,我们需要建立一个结构方程模型来分析这些指标之间的关系。
我们假设人们对环境保护的态度会对其环保行为产生积极的影响。
因此,我们将人们对环境保护的态度作为自变量,环保行为作为因变量。
在结构方程模型中,我们需要考虑到测量误差的影响。
因此,我们引入了一个潜在变量——人们对环境保护的態度。
这个潜在变量可以通过测量指标来进行估计。
为了验证我们的模型,我们需要采集一些数据。
我们可以通过随机抽样的方式选择一定数量的参预者,并要求他们填写我们设计的问卷。
此外,我们还可以观察他们的实际行为来采集环保行为的数据。
采集到数据后,我们可以使用结构方程模型来进行分析。
通过计算测量指标和潜在变量之间的关系,以及潜在变量和因变量之间的关系,我们可以得出结论。
如果我们的模型能够很好地拟合数据,并且相关系数达到统计显著水平,那末我们的研究假设就得到了支持。
结构方程模型(SEM)及其应用举例

结构方程模型(SEM)及其应用举例结构方程模型(SEM)及其应用举例该分公司有三类业务:无线业务、宽带业务以及综合业务。
围绕着这三类业务产品的销售,该通信分公司还提供了售前、售中和售后三个环节多方面的服务。
结合该通信分公司的主要产品情况,从顾客满意度着手,重点分析并找出影响顾客满意的关键因素,从而为制定有效的顾客满意度提升方案提供数据支持。
1.设计满意度模型根据该公司的业务具体情况,设计出了顾客满意度模型,如下图:图:某通信分公司顾客满意度SEM模型上图显示,该公司重点要考察的是产品满意度和服务满意度对顾客满意度的影响。
图中的Xn是待构建的测量指标,λ值表示各指标对上级指标的影响大小,ζn和δn表示误差,是受模型外因素影响的部分,如价格满意度等其他因素。
结构方程模型 - 结构方程模型的优点(一)同时处理多个因变量结构方程分析可同时考虑并处理多个因变量。
在回归分析或路径分析中,就算统计结果的图表中展示多个因变量,其实在计算回归系数或路径系数时,仍是对每个因变量逐一计算。
所以图表看似对多个因变量同时考虑,但在计算对某一个因变量的影响或关系时,都忽略了其他因变量的存在及其影响。
(二)容许自变量和因变量含测量误差态度、行为等变量,往往含有误差,也不能简单地用单一指标测量。
结构方程分析容许自变量和因变量均含测量误差。
变量也可用多个指标测量。
用传统方法计算的潜变量间相关系数,与用结构议程分析计算的潜变量间相关系数,可能相差很大。
(三)同时估计因子结构和因子关系假设要了解潜变量之间的相关,每个潜变量者用我个指标或题目测量,一个常用的做法是对每个潜变量先用因子分析计算潜变量(即因子)与题目的关系(即因子负荷),进而得到因子得分,作为潜变量的观测值,然后再计算因子得分,作为潜变量之间的相关系数。
这是两个独立的步骤。
在结构方程中,这两步同时进行,即因子与题目之间的关系和因子与因子之间的关系同时考虑。
(四)容许更大弹性的测量模型传统上,我们只容许每一题目(指标)从属于单一因子,但结构方程分析容许更加复杂的模型。
结构方程模型案例

结构方程模型案例结构方程模型 (Structural Equation Modeling, SEM) 是一种统计分析方法,用于建立和检验变量之间的因果关系模型。
这种模型可以用于解决许多复杂的研究问题,如预测变量之间的关系、检验理论模型以及估计和测试不同截面之间的因果关系。
本文将通过一个实际案例来说明如何使用结构方程模型。
案例背景:公司想要了解员工满意度对工作绩效的影响,以及工作环境对员工满意度和工作绩效的影响。
公司采集了员工的满意度、工作绩效和工作环境的数据,并希望通过结构方程模型来分析这些变量之间的关系。
理论模型:基于现有研究和理论,研究者提出了以下理论模型:工作环境->员工满意度->工作绩效变量测量:为了构建结构方程模型,首先需要测量各个变量。
在这个案例中,工作环境通过一个问卷调查来测量,员工满意度通过一个满意度调查来测量,工作绩效通过员工的绩效评价来测量。
每个变量通过多个观测指标来测量,例如,工作环境包括工作安全、工作福利、工作周围环境等指标。
模型估计:模型分析:经过模型估计后,可以进行模型分析来检验理论模型的拟合度。
在这个案例中,我们可以使用路径系数(standardized path coefficients)来解释变量之间的因果关系。
例如,路径系数的大小表示一个变量对另一个变量的直接影响程度,路径系数的方向则表示两个变量之间的关系是正向还是负向。
结果解释:通过模型分析,研究者可以得到一个具有统计显著性的结构方程模型。
然后,研究者可以通过路径系数解释变量之间的关系。
在这个案例中,结果可能显示工作环境对员工满意度有正向影响,员工满意度对工作绩效有正向影响。
这意味着改善工作环境可能会提高员工满意度,从而提高工作绩效。
结论与建议:最后,研究者可以根据结构方程模型的结果提出结论和建议。
在这个案例中,研究者可以建议公司改善工作环境,以提高员工满意度和工作绩效。
此外,研究者还可以进一步研究其他影响员工满意度和工作绩效的因素,以完善这个模型。
结构方程模型在抽样检验中的应用及案例介绍

结构方程模型在抽样检验中的应用及案例介绍引言结构方程模型(Structural Equation Modeling,简称SEM)是一种统计方法,用于估计和验证变量之间的关系以及模型的适配度。
它将测量模型和结构模型相结合,既可以分析变量之间的因果关系,也可以评估模型的适配度。
在抽样检验中,结构方程模型广泛应用于不同领域,如社会科学、教育研究、生物医学等。
本文将介绍结构方程模型在抽样检验中的应用,并通过案例分析加深理解。
结构方程模型结构方程模型是一种基于协方差矩阵的多变量分析方法,用于测量和估计潜变量之间的关系。
它包括两个部分:测量模型和结构模型。
测量模型是用于测量潜变量的可观测指标的模型。
它采用观测数据,并根据潜在的隐变量构建指标。
测量模型通过指标的共变异来估计潜变量的值,并为结构模型提供输入。
结构模型用于描述潜变量之间的关系。
它通过路径系数表示变量之间的直接或间接影响关系,并可以通过模型拟合指标(如χ^2拟合度检验、RMSEA)评估模型的适配度。
结构方程模型在抽样检验中的优势相比传统的统计方法,结构方程模型在抽样检验中具有以下优势:1.模型估计和测试:结构方程模型能够同时估计和测试测量模型和结构模型,提供对模型的全面评估。
2.潜变量的估计和解释:结构方程模型能够估计潜变量的值,并探索潜变量之间的关系,从而更全面地理解研究对象。
3.模型适应度评估:结构方程模型提供了多种指标用于评估模型的适应度,包括χ^2拟合度检验、比较拟合指数(CFI)、根均方误差估计(RMSEA)等。
4.变量的建模:结构方程模型能够处理多变量的复杂关系,并提供灵活的变量建模方法。
案例介绍:教育领域中的结构方程模型应用在教育研究中,结构方程模型被广泛应用于理解学生学业成绩的影响因素。
以下是一个关于学业成绩的结构方程模型案例。
研究研究目的是探索学生的学业成绩与多个影响因素之间的关系。
研究假设包括学习动机、学习时间、学习策略和社会支持对学业成绩有直接或间接的影响。
结构方程模型估计案例

结构方程模型估计案例
一、案例背景
本案例涉及一所位于美国的研究型大学,本案例旨在通过结构方程模
型估计学生参与大学课程的因素。
为此,本案例采用了一份包含180个受
访者的调查数据,每个受访者均为本校大学生。
二、研究假设
●学生投入的时间越多,他们的学习成绩就会越高。
●当学生有充足的资源可用时,他们的学习成绩会更高。
●学生对学习任务的兴趣和动机越高,他们的学习成绩也会越高。
●学生的学习成绩受到家庭背景和家庭环境的影响。
三、研究模型
本案例选择结构方程模型(SEM)进行模型估计,此模型包含四个变量,即学习时间(T)、学习资源(R)、兴趣/动机(I)和家庭环境(E)。
根据协方差矩阵,这四个变量都会对学生学习成绩(O)产生影响。
四、数据收集
本案例的数据收集工作包括:
1.对学生进行面对面访谈,收集学生投入课程的时间、学习资源、兴
趣/动机和家庭环境的信息,以及他们的学习成绩。
2.使用定量数据分析方法(如SPSS和AMOS)进行数据分析,以获得
研究要求的结果。
三、结构方程模型。
结构方程模型原理以及经典案例研究

结构方程模型原理以及经典案例研究结构方程模型(Structural Equation Modeling, SEM)是一种统计分析方法,主要用于建立和检验复杂的因果关系模型。
该模型可以同时考虑多个观测变量和潜在变量之间的关系,从而更准确地评估变量之间的关联性和因果性。
SEM的基本原理是基于路径分析和因子分析的组合。
路径分析可以用来建立变量之间的因果关系模型,并通过评估路径系数来分析变量之间的直接和间接影响。
因子分析用于构建潜在变量,并通过潜在变量与观测变量之间的关系来解释观测变量的变异。
经典的SEM案例研究可以帮助我们更好地理解SEM的应用和优势。
以下是一个经典的SEM案例研究:假设研究者想要探究家庭背景对学生学业成绩的影响。
研究者收集了500名学生的数据,包括学业成绩、家庭背景因素(例如家庭收入、父母教育水平)、自我效能感和学习动机等变量。
首先,研究者使用因子分析方法构建潜在变量模型。
他们将家庭收入、父母教育水平等观测变量组合起来,构建了一个“家庭背景”潜在变量,用以测量学生的家庭背景因素。
同样地,他们根据相关的观测变量构建了“自我效能感”和“学习动机”两个潜在变量。
接下来,研究者使用路径分析方法建立因果关系模型。
他们假设家庭背景对学生学业成绩有直接和间接的影响。
间接影响通过自我效能感和学习动机来实现。
路径分析模型将家庭背景作为独立变量,学业成绩作为因变量,自我效能感和学习动机作为中介变量。
研究者在模型中还考虑了其他潜在变量(例如学习时间、学校环境),以控制其他可能的影响因素。
最后,研究者使用SEM方法对模型进行参数估计和假设检验。
他们通过评估路径系数来确定各个变量之间的直接和间接关系。
如果路径系数显著不为零,则可以断定两个变量之间存在关系。
通过SEM方法,研究者可以对研究模型进行全面的分析,包括直接和间接关系、回归系数、误差方差等。
通过以上案例,我们可以看到SEM的优势在于可以同时处理多个因素的复杂关系。
AMOS结构方程模型修正经典案例

AMOS结构方程模型修正经典案例第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
2.1、顾客满意模型中各因素的具体范畴1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav”。
参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,3正向的,采用Likert10级量度从“非常低”到“非常高”本次调查共发放问卷500份,收回有效样本436份。
AMOS结构方程模型修正经典案例
AMOS结构方程模型修正经典案例第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
2.1、顾客满意模型中各因素的具体范畴1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav”。
参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,3正向的,采用Likert10级量度从“非常低”到“非常高”本次调查共发放问卷500份,收回有效样本436份。
结构方程模型的例子

y2 =λ8η1 +ε2
x3 =λ3ξ1 +δ3
y3 =λ9η1 +ε3
x4 =λ4ξ2 +δ4
y4 =λ10η2 +ε4
x5 =λ5ξ2 +δ5
y5 =λ11η2 +ε5
x6 =λ6ξ2 +δ6
y6 =λ12η2 +ε6
「结构方程模型」的分析特点
透过所有「观察变项」之间的变异量和共 变量,来验证理如图一的理论模型(因此 有些研究人员也把「结构方程模型」称 为「共变量结构分析」;Covariance Structure Analysis) 。
「Three indicators were established for each multi-item measure by first fitting a single factor solution to each set of items and then averaging the items with highest and lowest loadings to form the first indicator, averaging the items with the next highest and lowest loadings to form the second indicator, and so forth until all items were assigned to one of the three indicators for each variable.
(2)模型二设定的限制较模型一多,例如在图一的模型中 我们再设定γ1和γ3的数值是相同的;及/或Φ1的数值为 零(即两个自变项之间没有关系)。
结构方程模型及其应用举例

结构方程模型及其应用举例结构方程模型(Structural Equation Modeling,简称SEM)是一种统计分析方法,用于评估和验证复杂的因果关系模型。
它结合了因子分析、路径分析和回归分析等多种分析方法,可以用来研究多个变量之间的因果关系,提供一种统一的框架来检验理论假设。
SEM的核心思想是将观察到的变量分为显性变量和潜变量,并构建一个模型来描述它们之间的关系。
潜变量是无法直接观察到的变量,通常用多个测量指标来衡量。
显性变量则是直接观察到的变量。
SEM的模型可以包括多个潜变量和显性变量之间的因果关系。
SEM的应用范围很广泛,以下是一些常见的应用举例:1.人力资源管理研究:SEM可以用于分析员工的工作满意度和组织绩效之间的关系。
研究者可以通过测量员工的满意度和组织绩效,并构建一个SEM模型来测试员工满意度对组织绩效的影响程度。
2.教育研究:SEM可以用于研究教育政策对学生学业成绩的影响。
研究者可以测量学生的学业成绩、家庭背景、教育政策等变量,并构建一个SEM模型来评估这些变量之间的关系。
3.社会科学研究:SEM可以用于研究社会现象和心理健康之间的关系。
研究者可以测量社交支持、心理健康等变量,并构建一个SEM模型来评估这些变量之间的因果关系。
4.金融研究:SEM可以用于分析股价和财务指标之间的关系。
研究者可以测量公司的财务指标和股价,并构建一个SEM模型来测试财务指标对股价的影响程度。
除了上述应用举例,SEM还可以用于医学研究、市场研究、环境科学研究等领域。
SEM具有很多优点,例如可以处理多变量系统、可以估计测量误差、可以同时考虑观察变量和潜变量等。
然而,使用SEM也存在一些挑战,例如需要大样本和复杂计算等。
在实际应用中,研究者需要根据自己的研究问题和数据情况,选择合适的SEM模型和估计方法。
然后,他们需要通过模型拟合度指标(如卡方拟合度检验、均方根误差、比较拟合指数等)来评估模型的拟合度。
结构方程模型案例

结构方程模型案例一、引言结构方程模型(Structural Equation Modeling, SEM)是一种统计分析方法,用于研究变量之间的关系和模型的适配度。
它可以同时考虑观测变量和潜在变量之间的关系,适用于各种研究领域,如社会科学、教育学、心理学等。
本文将介绍一个关于教育质量的结构方程模型案例。
二、研究背景教育质量是一个重要的社会指标,对社会经济发展和个人成长具有重要影响。
本研究旨在探究教育质量的影响因素和作用机制,以提供改善教育质量的参考。
三、研究目的本研究的目的是构建一个结构方程模型,分析教育质量与学生学业成绩、教师素质、学校资源等变量之间的关系,并评估模型的适配度。
四、研究变量和假设1. 自变量:a. 学生学业成绩b. 教师素质c. 学校资源2. 因变量:教育质量3. 假设:a. 学生学业成绩对教育质量有正向影响b. 教师素质对教育质量有正向影响c. 学校资源对教育质量有正向影响五、研究方法1. 数据收集:通过问卷调查的方式收集学生学业成绩、教师素质、学校资源和教育质量的数据。
2. 数据分析:使用结构方程模型进行数据分析,包括模型拟合度检验、参数估计和路径分析等。
六、数据分析结果1. 模型拟合度检验:通过比较实际观测数据和模型预测数据的差异,评估模型的适配度。
适配度指标包括χ^2值、自由度、标准化拟合指数(CFI)、均方根误差逼近指数(RMSEA)等。
2. 参数估计:通过估计结构方程模型中的路径系数,判断变量之间的关系强度和方向。
3. 路径分析:根据参数估计结果,分析学生学业成绩、教师素质、学校资源对教育质量的直接和间接影响。
七、讨论与结论根据数据分析结果,我们得出以下结论:1. 学生学业成绩对教育质量有显著正向影响;2. 教师素质对教育质量有显著正向影响;3. 学校资源对教育质量有显著正向影响;4. 教师素质在学生学业成绩和教育质量之间起到中介作用。
八、研究局限性和建议本研究存在以下局限性:1. 样本选择有限,可能不具有代表性;2. 数据收集方式可能存在主观性和记忆偏差;3. 变量的测量可能存在误差。
结构方程模型分析过程应用案例

结构方程模型分析过程应用案例第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表1。
1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav”。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
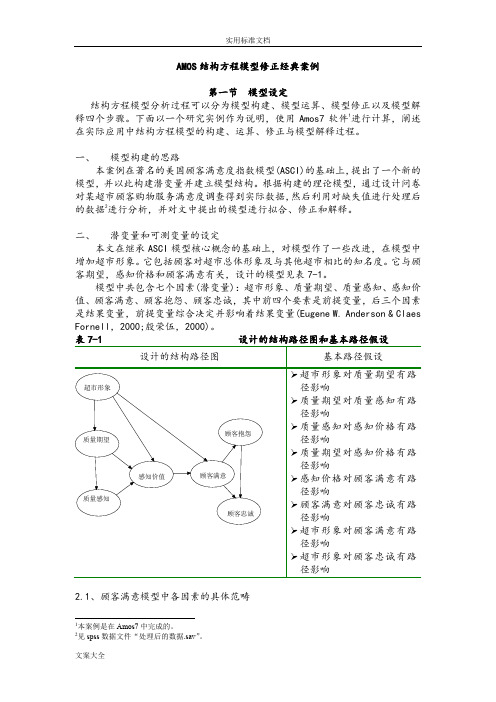
表 1 设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表2。
表2 模型变量对应表3正向的,采用Likert10级量度从“非常低”到“非常高”三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
AMOS结构方程模型修正经典案例
AMOS结构方程模型修正经典案例第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
2.1、顾客满意模型中各因素的具体范畴1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav”。
参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,3正向的,采用Likert10级量度从“非常低”到“非常高”本次调查共发放问卷500份,收回有效样本436份。
结构方程模型(SEM)方法——以手机产品为例

从总体上看来,虽然各潜变量与其自身的可测变量之间的路径 系数都有所变化,但其相对权重(即相对重要程度)的大小基 本不变。
例如在消费者偏好模型中对于显示屏(D2)而言,V4(屏幕尺寸) 的路径系数大于V5(屏幕外形)的路径系数,即屏幕尺寸的相对重 要性高于屏幕外形,在该模型中同样如此下表是标准化的系数。
结构方程模型(SEM)方法— —以手机产品为例
1.消费者偏好的结构方程模型的构建
根据感性工学现有的研究理论,参照结构方程 模型的规则构建消费者偏好的结构方程模型, 如下图所示:
(三)研究成果
翻盖手机外观造型要素分类表(部分)
1.消费者偏好的结构方程模型的构建
模型中各潜变量和可测变量所对应的符号及解释见 下表
1.消费者偏好的结构方程模型的构建
对于消费者偏好影响较大的造型要素是D2,即显示屏的设计。 其中显示屏尺寸(V04)的路径系数达到了0.787,影响为正, 表明目前年轻消费者比较关注一款直板手机的显示屏的大小。 D4中机身轮廓(V10)对消费者偏好的影响较大,数据显示 有相当部分的年轻消费者偏向于略有腰线且下端微收的轮廓 设计,并且对不对称设计也有较高的喜好度,可以看出年轻 消费者追求外观流线化的趋势,不再满足于传统的平行直线 的轮廓。 从结构方程模型中可以看出,目前年轻消费者追求个性化、 创新性,更看重一款手机的时尚感和创新感,同时比较注重 手机显示屏和机身轮廓的设计。因此,设计人员在设计过程 中可以参考相应的路径系数,在显示屏、机身尺寸和按键排 布方式上寻求突破,以吸引年轻消费者的注意。
0,1
e30, e20, e1
1
1 0,1
e13
0,1 e60, 1
e50, e4
W02 W15 W04 W14 W01 W06 W07 W08 W12 W11 W16 W09 W05
结构方程模型估计案例

结构方程模型估计案例结构方程模型(Structural Equation Modeling,SEM)是一种常用的多变量统计分析方法,可以用来建立因果关系模型,并对模型中的参数进行估计。
以下是一个使用结构方程模型进行估计的案例。
假设我们要研究一些城市中大学生的幸福感,该模型包含三个潜在变量:经济条件(Economic Conditions)、社交支持(Social Support)和幸福感(Well-being)。
经济条件和社交支持通过各自的指标变量进行测量,幸福感由经济条件和社交支持两个潜在变量作为预测变量进行建模。
首先,我们需要收集一些数据来进行分析。
假设我们随机选择了1000名大学生,并针对每个大学生进行问卷调查,获取以下数据:1.经济条件指标变量的测量方法:- 房产数量(Property):测量每个大学生拥有的房产数量。
- 家庭资产(Wealth):测量每个大学生家庭的总资产。
2.社交支持指标变量的测量方法:- 朋友数量(Friends):测量每个大学生拥有的朋友数量。
- 亲友支持(Support):测量每个大学生从亲友那里获得的支持程度。
- 社交活动(Activities):测量每个大学生参与的社交活动的频率。
3.幸福感指标变量的测量方法:- 主观幸福感(Subjective Well-being):通过问卷让每个大学生评估自己的主观幸福感程度。
- 心理健康(Mental Health):通过问卷让每个大学生评估自己的心理健康状况。
接下来,我们可以使用结构方程模型对这些数据进行分析和估计。
首先,我们需要建立模型。
可以采用如下模型:-经济条件→幸福感-社交支持→幸福感然后,我们需要根据数据对模型中的参数进行估计。
可以使用最小二乘法来估计参数。
在估计过程中,我们还可以考虑一些控制变量,如性别、年龄等,以控制其他可能影响幸福感的因素。
最后,我们可以进行模型拟合度检验,检查模型是否与实际数据拟合得好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
结构方程模型分析过程应用案例第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表1。
1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav”。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表 1 设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表2。
表2 模型变量对应表3正向的,采用Likert10级量度从“非常低”到“非常高”三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,7个人口变量,量表采用了Likert10级量度,如对超市形象的测量:本次调查共发放问卷500份,收回有效样本436份。
四、缺失值的处理采用表列删除法,即在一条记录中,只要存在一项缺失,则删除该记录。
最终得到401条数据,基于这部分数据做分析。
五、数据的的信度和效度检验1.数据的信度检验信度(reliability)指测量结果(数据)一致性或稳定性的程度。
一致性主要反映的是测验内部题目之间的关系,考察测验的各个题目是否测量了相同的内容或特质。
稳定性是指用一种测量工具(譬如同一份问卷)对同一群受试者进行不同时间上的重复测量结果间的可靠系数。
如果问卷设计合理,重复测量的结果间应该高度相关。
由于本案例并没有进行多次重复测量,所以主要采用反映内部一致性的指标来测量数据的信度。
折半信度(split-half reliability)是将测量工具中的条目按奇偶数或前后分成两半,采用Spearman-brown公式估计相关系数,相关系数高提示内部一致性好。
然而,折半信度系数是建立在两半问题条目分数的方差相等这一假设基础上的,但实际数据并不一定满足这一假定,因此信度往往被低估。
Cronbach在1951年提出了一种新的方法(Cronbach's Alpha系数),这种方法将测量工具中任一条目结果同其他所有条目作比较,对量表内部一致性估计更为慎重,因此克服了折半信度的缺点。
本章采用SPSS16.0研究数据的内部一致性。
在Analyze菜单中选择Scale下的Reliability Analysis(如图1),将数据中在左边方框中待分析的24个题目一一选中,然后点击,左边方框中待分析的24个题目进入右边的items方框中,使用Alpha模型(默认),得到图2,然后点击ok即可得到如表3的结果,显示Cronbach's Alpha系数为0.892,说明案例所使用数据具有较好的信度。
图1 信度分析的选择图2 信度分析变量及方法的选择表3 信度分析结果另外,对问卷中每个潜变量的信度分别检验结果如表4所示4表4 潜变量的信度检验。
从表4可以看到,除顾客抱怨量表Cronbaca’s Alpha系数为0.255,比较低以外,其它分量表的Alpha系数均在0.7以上,且总量表的Cronbach’s Alpha系数达到了0.891,表明此量表的可靠性较高。
由信度检验的结果可知顾客抱怨的测量指标的信度远低于0.7,因此在路径图中去掉顾客抱怨因子,即初始模型中包括6个潜变量、21个可测变量。
潜变量可测变量个数Cronbach’s Alpha4操作过程同前,不同的是在图7-14中选入右边方框items中是相应潜变量对应的题目。
如对超市形象潜变量,只需要把a1、a2和a3题目选入到右边方框items中即可。
超市形象 3 0.858 质量期望 5 0.889 质量感知 5 0.862 感知价格 2 0.929 顾客满意 3 0.948 顾客抱怨 3 0.255 顾客忠诚 30.7382.数据的效度检验效度(validity )指测量工具能够正确测量出所要测量的特质的程度,分为内容效度(content validity )、效标效度(criterion validity )和结构效度(construct validity )三个主要类型。
内容效度也称表面效度或逻辑效度,是指测量目标与测量内容之间的适合性与相符性。
对内容效度常采用逻辑分析与统计分析相结合的方法进行评价。
逻辑分析一般由研究者或专家评判所选题项是否“看上去”符合测量的目的和要求。
准则效度又称效标效度、实证效度、统计效度、预测效度或标准关联效度,是指用不同的几种测量方式或不同的指标对同一变量进行测量,并将其中的一种方式作为准则(效标),用其他的方式或指标与这个准则作比较,如果其他方式或指标也有效,那么这个测量即具备效标效度。
例如,X 是一个变量,我们使用1X 、2X 两种工具进行测量。
如果使用1X 作为准则,并且1X 和2X 高度相关,我们就说2X 也是具有很高的效度。
当然,使用这种方法的关键在于作为准则的测量方式或指标一定要是有效的,否则越比越差。
现实中,我们评价效标效度的方法是相关分析或差异显著性检验,但是在调查问卷的效度分析中,选择一个合适的准则往往十分困难,也使这种方法的应用受到一定限制。
结构效度也称构想效度、建构效度或理论效度,是指测量工具反映概念和命题的内部结构的程度,也就是说如果问卷调查结果能够测量其理论特征,使调查结果与理论预期一致,就认为数据是具有结构效度的。
它一般是通过测量结果与理论假设相比较来检验的。
确定结构效度的基本步骤是,首先从某一理论出发,提出关于特质的假设,然后设计和编制测量并进行施测,最后对测量的结果采用相关分析或因子分析等方法进行分析,验证其与理论假设的相符程度。
在实际操作的过程中,前面两种效度(内容效度和准则效度)往往要求专家定性研究或具有公认的效标测量,因而难以实现的,而结构效度便于可以采用多种方法来实现:第一种方法是通过模型系数评价结构效度。
如果模型假设的潜变量之间的关系以及潜变量与可测变量之间的关系合理,非标准化系数应当具有显著的统计意义。
特别地,通过标准化系数5第二种方法是通过相关系数评价结构效度。
如果在理论模型中潜可以比较不同指标间的效度。
从表17可以看出在99%的置信度下所有非标准化系数具有统计显著性,这说明修正模型的整体结构效度较好。
5关于标准化系数的解释见本章第五节。
变量之间存在相关关系,可以通过潜变量的相关系数来评价结构效度:显著的相关系数说明理论模型假设成立,具有较好的结构效度。
第三种方法是先构建理论模型,通过验证性因子分析的模型拟合情况来对量表的结构效度进行考评。
因此数据的效度检验就转化为结构方程模型评价中的模型拟合指数评价。
对于本案例,从表16可知理论模型与数据拟合较好,结构效度较好。
六、结构方程模型建模构建如图7.3的初始模型。
图3 初始模型结构图4 Amos Graphics初始界面图第二节 Amos实现6一、Amos基本界面与工具打开Amos Graphics,初始界面如图4。
其中第一部分是建模区域,默认是竖版格式。
如果要建立的模型在横向上占用较大空间,只需选择View菜单中的Interface Properties选项下的Landscape(如图7.5),即可将建模区域调整为横板格式。
图2中的第二部分是工具栏,用于模型的设定、运算与修正。
相关工具的具体功能参见书后附录二。
6这部分的操作说明也可参看书上第七章第二节:Amos实现。
图5 建模区域的版式调整图6 建立潜变量二、Amos模型设定操作1.模型的绘制在使用Amos进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。
相关软件操作如下:第一步,使用建模区域绘制模型中的七个潜变量(如图6)。
为了保持图形的美观,可以使用先绘制一个潜变量,再使用复制工具绘制其他潜变量,以保证潜变量大小一致。
在潜变量上点击右键选择Object Properties,为潜变量命名(如图7)。
绘制好的潜变量图形如图8。
第二步设置潜变量之间的关系。
使用来设置变量间的因果关系,使用来设置变量间的相关关系。
绘制好的潜变量关系图如图9。
图7 潜变量命名图8 命名后的潜变量第三步为潜变量设置可测变量及相应的残差变量,可以使用绘制,也可以使用和自行绘制(绘制结果如图10)。
在可测变量上点击右键选择Object Properties,为可测变量命名。
其中Variable Name一项对应的是数据中的变量名(如图11),在残差变量上右键选择Object Properties为残差变量命名。
最终绘制完成模型结果如图12。
图10 设定可测变量及残差变量图11 可测变量指定与命名图12 初始模型设置完成2.数据文件的配置Amos可以处理多种数据格式,如文本文档(*.txt),表格文档(*.xls、*.wk1),数据库文档(*.dbf、*.mdb),SPSS文档(*.sav)等。
为了配置数据文件,选择File菜单中的Data Files(如图13),出现如图14左边的对话框,然后点击File name按钮,出现如图14右边的对话框,找到需要读入的数据文件“处理后的数据.sav”,双击文件名或点击下面的“打开”按钮,最后点击图14左边的对话框中“ok”按钮,这样就读入数据了。
图13 数据配置图14 数据读入第三节模型拟合一、参数估计方法选择模型运算是使用软件进行模型参数估计的过程。
Amos提供了多种模型运算方法供选择7。