序列数据库--核酸序列数据库
ncbi使用方法

ncbi使用方法(原创版4篇)《ncbi使用方法》篇1CBI(National Center for Biotechnology Information)是美国国家生物技术信息中心的缩写,它提供了许多生物学和生命科学相关的数据库和工具。
以下是使用NCBI 的一些基本方法:1. 核酸序列数据库(Nucleotide Sequence Database):在NCBI 主页上,可以选择核酸序列数据库,输入序列名称或序列号,然后点击“Search”按钮即可查询序列信息。
2. 蛋白质序列数据库(Protein Sequence Database):在NCBI 主页上,可以选择蛋白质序列数据库,输入蛋白质名称或蛋白质号,然后点击“Search”按钮即可查询蛋白质信息。
3. 基因组数据库(Genome Database):在NCBI 主页上,可以选择基因组数据库,输入基因组名称或基因组号,然后点击“Search”按钮即可查询基因组信息。
4. 代谢通路数据库(Metabolic Pathway Database):在NCBI 主页上,可以选择代谢通路数据库,输入代谢通路名称或代谢通路号,然后点击“Search”按钮即可查询代谢通路信息。
5. 生物投影数据库(BioProject Database):在NCBI 主页上,可以选择生物投影数据库,输入生物投影名称或生物投影号,然后点击“Search”按钮即可查询生物投影信息。
6. 序列比对工具(Sequence Alignment Tool):NCBI 提供了一款名为“Clustal Omega”的序列比对工具,可以在NCBI 主页上使用该工具进行序列比对。
7. 基因表达数据库(Gene Expression Database):NCBI 提供了一款名为“GEO”的基因表达数据库,可以在NCBI 主页上查询基因表达数据。
8. 蛋白质结构数据库(Protein Structure Database):NCBI 提供了一款名为“RCSB PDB”的蛋白质结构数据库,可以在NCBI 主页上查询蛋白质结构信息。
(2)第二章核酸数据库及核酸序列的分析(第二节序列数据库检索)

生物信息学
杭州师范大学生命与环境科学学院 向太和
生物信息学
杭州师范大学生命与环境科学学院 向太和
作者姓名检索
在检索框内按照姓+名缩写(不用标点)的格式键入 作者姓名,如Smith JA,Huang JF,系统会自动 在作者字段内进行检索。 可以在姓名后加[AU]或[au] au—author
生物信息学
杭州师范大学生命与环境科学学院 向太和
3)获取原文及相关资源
联机获取原文(linkout )
相关文献查找(related article) NCBI其他数据库资源(生物信息学等)
生物信息学
杭州师范大学生命与环境科学学院 向太和
PubMed与MEDLINE光盘检索比较
PubMed
内容涉及:医学、药学、牙医学、护理学、卫生 保健、兽医学等专业。
记录标注[PubMed - indexed for MEDLINE]
生物信息学
杭州师范大学生命与环境科学学院 向太和
OLDMEDLINE for pre-1966 citations
In-process citations
是临时性医学文献数据库,每天接收新数 据,经MeSH词表标引后,每周向medline 移加一次。
生物信息学
杭州师范大学生命与环境科学学院 向太和
生物信息学
杭州师范大学生命与环境科学学院 向太和
自动词语匹配:
PubMed能自动利用它的“自动词语匹配”功能将 重要的词语结合在一起,并将不规范的词语转换成 规范的用词。 如:输入vitamin c common cold,系统会将自动转换成
7种文献类型限制 7种语种 12种子集
生物信息学
生物信息学相关数据库资源介绍

CSNDB - Cell Signaling Networks db
DNA和蛋白质相互作用数据库
DPInteract - DNA-Proteins interactions db
特定基因或蛋白质的数据库
AAA - AAA family of ATPases server Acetylcholinesterases ALDH - Aldehyde dehydrogenase (醛脱氢酶, 醛氧化酶)gene superfamily db Aminoacyl-tRNA synthetases in SWISS-PROT List of aminoacyl-tRNA synthetases in SWISSPROT AARSDB - Aminoacyl-tRNA synthetases db Allergens in SWISS-PROT - Nomenclature and index(命名和索引) of allergens(过敏原) in SWISS-PROT
tmRDB - tmRNA dB
tRNA - tRNA compilation(编辑) from the University of Bayreuth
uRNADB - uRNA db
5)其他核酸数据库
RNA editing - RNA editing site
RNAmod db - RNA modification db
5)其它核酸数据库
PlantCARE - Plant cis-acting regulatory DNA elements db
生物信息学 第4章 蛋白质序列数据库

ftp:///sequin/
EMBL数据库
EMBL建立于1980年,EMBL核苷序列数据库(http:// /embl/)是欧洲主要的核苷序列收集单位,欧洲生物 信息中心EBI(即EMBL在德国海德堡的站点)维护这个数据库
EMBL: European Molecular Biology Laboratory EBI: European Bioinformatics Institute
核苷数据来自基因组测序中心、世界各地的科学家、欧洲专利局、以 及与合作伙伴DDBJ (Japan)和GenBank (USA)交换的数据。
EMBL数据库
DDBJ数据库
日本DNA数据库(DDBJ: www.ddbj.nig.ac.jp )是在亚洲唯一 的核酸序列数据库,是搜集研究者公认的测定核酸序列的数据 库,并且发放给数据提交者国际认证的核酸序列编号。 由于DDBJ每天将搜集的数据与EMBL-Bank/EBI和 GenBank/NCBI进行交换,使得三个核酸数据库几乎在任何时 候都享有相同数据。
/nuccore/221078348?report=fasta
Genbank格式
Genbank格式
Genbank格式
Genbank格式
电子提交序列到Genbank
两种主要的电子提交途径
1、互联网交互方式的提交 2、软件提交,Sequin
DDBJ主要收集来自日本研究者获得的序列数据,但也收集数据 和发放编号给任何其他国家的研究者。
DDBJ数据库
INSDC
1998年,GenBank、EMBL和DDBJ共同成立了国际 核酸序列数据库协会 (International Nucleotide Sequence Database Collaboration,INSDC) 三大核酸数据库之间每天将新测定或更新的数据进 行交换共享,保证数据信息的完整与同步,每两个 月更新一次版本。 /
生物序列的数据库信息检索

Gene Ontology
/
相互作用的蛋白质数据库 DIP
收集了由实验验证的蛋白质-蛋白质相互作 用; 包括蛋白质的信息、相互作用的信息和检测 相互作用的实验技术三个部分; 用户可以根据蛋白质、生物物种、蛋白质超 家族、关键词、实验技术或引用文献来查询 DIP数据库;
RefSeq: The Reference Sequence Database 蛋白质序列数据库
UniProt (Swiss-prot & TrEMBL, PIR)
基因组数据库: Ensembl
NCBI数据资源
Nucleotide: 核酸序列数据库 PubMed: 生物医学科学文摘数据库 GEO:基因表达谱数据库。收集存储微阵列基因 表达数据 Protein: 蛋白质序列数据库 SNP: 单核苷酸多态性数据库 Taxonomy: 物种分类学数据库 Gene: 基因数据库。提供序列及基因描述信息 Structure: 大分子三维结构数据库 3D Domains: 特定功能域的三维结构数据库 UniGene: GenBank分离的非冗余基因簇。包含 已确定基因和EST。每个簇包含唯一的非冗余的 基因序列、表达的组织类型和基因图谱位点。
Entres-Gene数据库
序列来源于Refseq数据库; 详尽的注释信息,包括基因在基因组的定位, 基因名称、蛋白质名称,基因结构等; 基因的命名主要来自权威命名委员会的官方 符号以及Refseq记录中的基因名,由NCBI 工作人员进行数据收集并注释。NLM的索引 部门对基因功能进行阐述。 沿用人类孟德尔遗传网(OMIM)中的疾病 名称并与NCBI其他数据库形成交互链接。
核酸数据库有哪些?

核酸数据库有哪些?核酸序列数据库在生物科学和生物信息学领域中扮演着重要的角色。
无论是基因组注释、生物多样性研究、功能预测和基因表达分析还是药物研发和疾病研究,核酸序列数据库为生物科学和生物信息学研究提供了宝贵的资源,帮助研究人员理解生物的遗传信息、功能和进化关系,推动生物医学研究和药物研发的进展。
但需要注意的是,核酸数据库有很多种类,除了常用的BioXFinder、GenBank、EMBL(European Molecular Biology Laboratory)、DDBJ(DNA Data Bank of Japan)等核酸数据库,研究人员通常会使用多个数据库来获取更全面和准确的数据。
此外,还有其他一些重要的核酸序列数据库,如RefSeq、UniProt等,它们在特定领域或特定类型的序列数据上具有特殊的优势。
为此笔者通过网站数据调研,找出了核酸数据库应用最为广泛的TOP60数据库,并对前面几个应用做了深层次优缺点对比,供大家作为选用依据(不分排名先后)。
1.BioXFinderBioXFinder是国内第一个也是目前唯一国内中英双版的生物数据库,是一款针对生物科研工作者的综合性生物数据检索及分析平台,汇集了核酸、蛋白、蛋白结构、代谢通路和信号通路信息,同时集成了BLAST、生存分析、基因ID转换等生信分析工具。
用户可高效的搜寻到自己想要的信息,并且在无代码的情况下完成生信分析。
2.GenBankGenBank是最早建立的核酸序列数据库之一,拥有丰富的序列数据资源,涵盖了广泛的物种和基因组。
提供了详细的注释信息,包括基因的位置、结构、功能以及相关的文献引用。
支持多种查询和下载方式,方便用户获取所需的数据。
缺点是由于数据量庞大,有时查询和下载速度可能较慢。
注释信息的质量和一致性可能存在一定的变化,因为数据的提交来自不同的实验室和研究机构。
3.EMBLEMBL是一个国际性的核酸序列数据库,与GenBank和DDBJ合作共享数据。
生物信息学二级数据库及数据库的格式

..125
Homo. Sapiens Medline4,. gluco- transcriptional TGT..
......
Corticoid regulator, ..
receptor
Fig 2.7 GenBank数据库的组织. 常被计算机检索程序ENTREZ利用。
2 EMBL序列格式
• The European Molecular Biology Laboratory(EMBL)序列 条目与GenBank类似,通过大量信息来描述每个序列。该 信息组织成一个个字段,每个字段有一个标识符。这些标 识符缩写成两个字母,某些字段还有次级字段。每行序列 后面的数字显示片断的位置。
BASE COUNT count of A, C, G, T and other symbols
ORIGIN
text indicating start of sequence
1 gaattcgata aatctctggt ttattgtgca gtttatggtt ccaaaatcgc
51 atatactcac agcataactg tatatacacc cagggggcgg aatgaaagcg
Prosite的网址:
/prosite/
3、蛋白质结构二级数据库
DSSP (Definition of Secondary Structure of Proteins) 蛋白质二级结构构象参数数据库 DSSP的网址:
http://www.cmbi.kun.nl/gv/dssp/
source range of sequence, source organism
misc_signal range of sequence, type of function or signal
review

PAM vs. BLOSUM
BLOSUM90 BLOSUM80 BLOSUM62 BLOSUM45
PAM30
PAM120
PAM180
PAM250
亲缘关系近 低趋异度 小鼠和大鼠RBP
亲缘关系远 高趋异度 小鼠和细菌lipocalin
亲缘关系越远、相似度越低的序列,在比对的时候,采用 PAM矩阵的编号越大,采用BLOSUM矩阵的编号越小。
FASTA文件格式
• 第1行 以大于号”>”开始,序列描述 • 第2行 核苷酸或氨基酸序列,不含无效字符如数 字和空格等 • 一般来讲,每一行的长度不超过80个英文字符 • 例:
>MCHU - Calmodulin - Human, rabbit, bovine, rat, and chicken ADQLTEEQIAEFKEAFSLFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGNGTID FPEFLTMMARKMKDTDSEEEIREAFRVFDKDGNGYISAAELRHVMTNLGEKLTDEEVDEMIREA DIDGDGQVNYEEFVQMMTAK
序列相似性(位置相关)
• 引入空格的生物学意义
– 序列的差异都是由突变(mutation)引起的,常见的突 变包括替换(substitution)、插入(insertion)和删除 (deletion),后两者都导致在比对中引入空格。 – 一个碱基的替换可能导致对应位置氨基酸的变化,也 可能不变(silent mutation) – 一个碱基的插入和删除一定会导致对应位置及后续氨 基酸的变化 – 突变是否显著地影响蛋白质的功能,取决于突变的位 置是否在关键性的结构域
全局 Needleman-Wunsch
ncbi核酸序列features

ncbi核酸序列featuresNCBI(National Center for Biotechnology Information)是一个提供生物医学和基因组学数据库的综合性资源。
它集成了全球范围内的核酸序列数据和相关的生物信息学工具,为科学家和研究人员提供了一个重要的研究平台。
在这篇文章中,我将从不同角度探讨NCBI核酸序列数据库的特点,并试图解答您提出的问题。
NCBI核酸序列数据库是公共资源,其特点之一是海量的数据存储。
数据库中包含来自各种来源的核酸序列,涵盖了广泛的物种和组织类型。
这使得该数据库成为了全球科学家进行基因组学和生物医学研究的重要平台。
无论是分析全基因组的序列,还是针对特定基因的研究,NCBI都提供了丰富的数据资源,可供用户检索和利用。
其次,NCBI核酸序列数据库具有可靠的数据质量。
为确保数据库中的数据准确可靠,NCBI采用了严格的质量控制流程。
在提交新序列之前,数据经过多个阶段的验证和确认,以确保其准确性和可靠性。
此外,NCBI还允许用户通过提交反馈或举报错误来纠正和完善数据质量,促进了共同修订和更新。
NCBI核酸序列数据库提供了丰富的功能和工具,适合于多种研究需求。
用户可以根据关键词、序列相似性、物种等条件进行数据检索。
此外,NCBI还提供了各种数据分析和比较工具,例如BLAST等,帮助用户对序列进行比对、注释和功能分析。
这些功能和工具使得科学家可以更好地理解和探索生物基因组的复杂性。
此外,NCBI核酸序列数据库是一个开放的、共享的平台。
所有的数据和工具都是免费提供给用户使用的,无论是学术界的研究人员还是工业界的专业人士都可以充分利用这些资源。
这种共享的模式促进了科学研究的快速进展和合作,为解决重大生物医学问题提供了有力的支持。
在解答了问题的前提下,我将进一步探讨一些与NCBI核酸序列数据库相关的应用和发展趋势。
首先,NCBI核酸序列数据库的广泛应用不仅限于基础研究,还包括了生物医学的多个领域。
EMBL 和GenBank 核酸序列数据库中各子库名称
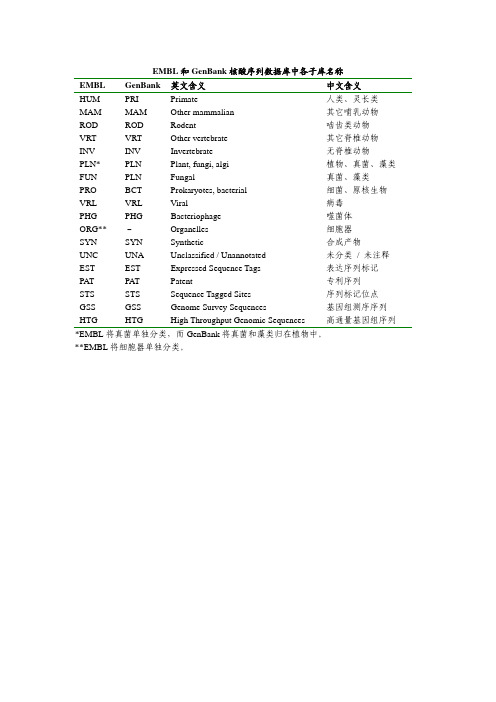
EMBL和GenBank核酸序列数据库中各子库名称
英文含义中文含义
EMBL GenBank
HUM PRI Primate 人类、灵长类
mammalian 其它哺乳动物MAM MAM Other
ROD ROD Rodent 啮齿类动物
vertebrate 其它脊椎动物VRT VRT Other
INV INV Invertebrate 无脊椎动物
PLN* PLN Plant, fungi, algi 植物、真菌、藻类FUN PLN Fungal 真菌、藻类
bacterial 细菌、原核生物PRO BCT Prokaryotes,
VRL VRL Viral 病毒
PHG PHG Bacteriophage 噬菌体
ORG** - Organelles 细胞器
SYN SYN Synthetic 合成产物
Unannotated 未分类 / 未注释UNC UNA Unclassified
/
Tags 表达序列标记EST EST Expressed
Sequence
PAT PAT Patent 专利序列
Sites 序列标记位点
Tagged
STS STS Sequence
Sequences 基因组测序序列GSS GSS Genome
Survey
Sequences 高通量基因组序列
Genomic
Throughput
HTG HTG High
*EMBL将真菌单独分类,而GenBank将真菌和藻类归在植物中。
**EMBL将细胞器单独分类。
生物数据库介绍——NCBI

⽣物数据库介绍——NCBINCBI(National Center for Biotechnology Information,美国国家⽣物技术信息中⼼)除了维护GenBank核酸序列数据库外,还提供数据分析和检索资源。
NCBI资源包括Entrez、Entrez编程组件、MyNCBI、PubMed、PudMed Central、PubReader、Gene、the NCBI Taxonomy Browser、BLAST、Pimer-Blast、COBALT、RefSeq、UniGene、HomoloGene、ProtEST、dbMHC、dbSNP、dbVar、Epigenomics、the Genetic Testing Registry、Genome和相关⼯具、⽐对查看器、跟踪存档、Sequence Read Archive、BioProject、BioSample、ClinVar、MedGen、HIV-1/⼈类蛋⽩质相互作⽤数据库、Gene Expression Omnibus、Probe、Online Mendelian Inheritance in Animals、the Molecular Modeling Database、the Conserved Domain Database、the Conserved Domain Architecture Retrieval Tool、Biosystem、Protein Clusters and thePubChem suite of small molecule databases,所有这些资源可以在NCBI主页找到。
Databases⼀个提供有关基因组组装结构,装配名称和其他元数据,统计报告以及基因组序列数据链接等信息的数据库。
⼀个有关培养物、动植物样本和其他⾃然样本的精选元数据集。
记录显⽰样本状态,有关馆藏的机构的信息,以及NCBI中相关数据链接。
核酸数据库

生物科学09 0909503127 陈晓敏一、1、GenBank 数据库GenBank是NIH遗传序列数据库(/),它收集了可以公开获得的DNA 序列和注释。
该数据库的容量以指数形式增长,核酸碱基数目大概每14个月就翻一个倍。
目前拥有来自47,000个物种的30亿个碱基。
GenBank核酸序列数据库涵盖了从完整基因组到单个基因等序列数据及部分注释信息,称一次数据库。
此外,还有些更有针对性的基因组资源,或称专用数据库。
这些专用数据库既包括了上述一次数据库的部分数据,也包括从其它数据库资源获得的信息或交叉链接。
这种专门数据库主要分为两大类,一类是模式生物基因组数据库,另一类则与特殊的测序技术有关。
这类数据库尽管也包含序列数据,但它们的特色主要是为某一特定的模式生物提供一个完整的数据资源,如酵母(Saccharomyces cerevisiae)、线虫(Caenorhabditis elegans)、果蝇(Drosophila melanogaster)、拟南芥(Arabidopsis thaliana)、幽门螺杆菌(Helicobacter pylori)等。
这些数据库从各个不同层次上搜集整理有关信息,以便对某个模式生物全基因组有一个更加完整的了解。
2、EMBL(/embl/)是欧洲主要的核苷序列收集单位。
这个数据库是由欧洲生物信息中心EBI(欧洲分子生物学实验室(EMBL)在德国 Heidelberg 的站点)维护的。
核苷数据来自基因组测序中心、个别科学家、欧洲专利局、以及跟合作伙伴DDBJ (Japan)和GenBank (USA)交换的数据。
为了达到最佳的同步性,每天在DDBJ/EMBL/GenBank之间都要交换最新的数据。
用户只要进入任意一个数据库都能得到最新数据。
这三个数据库之间坚持统一的文件指导方针,它规范了数据库登录的内容和语法。
这种指导方针确保了这些数据库的信息以一种格式便捷的交换,它与当今的生物信息学软件兼容,反映了分子生物学领域的发展。
Genbank,EMBLE,DDBJ

一前言Genbank核酸序列数据库是由美国国立生物技术信息中心(NCBI)建立和维护的。
它包含了所有已知的核酸序列和蛋白质序列,以及与它们相关的文献著作和生物学注释。
它的数据直接来源于测序工作者提交的序列。
EMBL数据提交方式主要有三种,即通过Webin、Sequin或 Data Submission Form三种方式提交数据,目前EMBL数据库已停止接受email 格式的提交方式。
日本DNA数据库DDBJ(DNA Data Bank of Japan),于1984年建立,是世界三大DNA 数据库之一。
二本论2 Genbank简介Genbank核酸序列数据库是由美国国立生物技术信息中心(NCBI)建立和维护的。
它包含了所有已知的核酸序列和蛋白质序列,以及与它们相关的文献著作和生物学注释。
它的数据直接来源于测序工作者提交的序列;由测序中心提交的大量EST序列和其它测序数据;以及与其它数据机构协作交换数据而来。
2.1GenBank的序列提交提交序列有两种方式,一个是在线的页面提交序列bankit,另一个是通过NCBI的Sequin 软件提交序列。
Sequin也是一种很好的利用了NCBI数据模型ASN.1编辑工具。
BankIt 用于一条或者少数条提交的基于WWW的提交工具软件,适合于独立测序工作者提交少量序列,而不适合大量序列的提交,也不适合提交很长的序列,EST序列和GSS序列也不应用于BankIt提交。
BankIt是一系列表单,包括联络信息、发布要求、引用参考信息、序列来源信息、以及序列本身的信息等。
并且在提交前用 VecScreen 去除载体。
1、进入GenBank /genbank/ 点击BankIt2、在BankIt使用的时候先进行注册,点击右上角的Sign in to NCBI,在如果使第一次使用则需要注册,点击Register for an account, 如果已经创建用户名,则输入用户名、密码直接登录即可。
生物信息学:第一讲数据库介绍

�
生物信息学实验
第一讲 数一级数据库(primary databases): ): Genbank数据库,EMBL核酸库和 数据库, 核酸库和DDBJ数据库; 数据库; 数据库 核酸库和 数据库 SWISS-PROT数据库,PIR数据库,PDB数据库 数据库, 数据库, 数据库 数据库 数据库 等等. 等等. 二级数据库( 二级数据库(secondary databases): ): 人类基因组图谱库GDB,真核生物基因表达调 , 人类基因组图谱库 控因子数据库TRANSFAC,蛋白质结构家族分 控因子数据库 , 类库SCOP 等等. 等等. 类库
(五)蛋白质结构与分类数据库
PDB(蛋白质结构数据库 : 蛋白质结构数据库): 蛋白质结构数据库 /pdb/ PROSITE(Motif数据库 : 数据库): 数据库 /prosite/ SCOP(蛋白质结构分类数据库 : 蛋白质结构分类数据库): 蛋白质结构分类数据库 /scop CATH(蛋白质结构与功能关系分类数据库 : 蛋白质结构与功能关系分类数据库): 蛋白质结构与功能关系分类数据库 /bsm/cath/
(三)基因组数据库
GDB(人类基因组数据库 : 人类基因组数据库): 人类基因组数据库
euGenes(真核生物基因综合知识库 : 真核生物基因综合知识库): 真核生物基因综合知识库 /
(四)蛋白质序列数据库
SWISS-PROT(无冗余蛋白序列数据库 : 无冗余蛋白序列数据库): 无冗余蛋白序列数据库 /sprot/ PIR(蛋白质信息资源库 : 蛋白质信息资源库): 蛋白质信息资源库 /pirwww OWL(复合蛋白序列数据库 : 复合蛋白序列数据库): 复合蛋白序列数据库 /dbbrowser/OWL/
核酸序列数据库主要有GenBankEMBLDDBJ等

基因组数据库的发展历史(续)
DNA序列数据库最早于1982年在欧洲分子 生物学实验室诞生,随即就开始了一个数据 库爆炸的时代。(如下图)
此后不久因一项NIH与洛斯阿拉莫斯国家实 验室的合同而诞生了GenBank。
日本的DNA数据库(DDBJ),在几年后加 入了数据收集的合作。
3
基因组数据库的发展历史(续)
1988年一次三方会议之后(现在称之为 “国际DNA序列数据库合作计划”)达成了 一项协议,对数据库的记录采用共同的格式, 并且每个数据库只负责更新提交到这一数据 库的那些数据。
现在三个中心都收集直接提交的数据,并在 三者之间发布。
4
基因组数据库的发展历史(续)
5
基因组数据库的发展历史(续)
EST - expressed sequence tag GSS - genome survey sequence HTC - high throughput cDNA sequencing HTG - high throughput genomic sequencing STS - sequence tagged site
EMBL核酸序列数据库 由欧洲生物信息学研究所(EBI)维护的核酸序列数据构成,查询检索 可以通过通过因特网上的序列提取系统(SRS)服务完成。 数据库网址是:/embl/。
DDBJ数据库 日本DNA数据仓库(DDBJ)也是一个全面的核酸序列数据库,与 Genbank和EMBL核酸库合作交换数据。使用其主页上提供的SRS工 具进行数据检索和序列分析。 DDBJ的网址是:http://www.ddbj.nig.ac.jp/。
SYN - Synthetic and chimeric PAT - Patent
NRNT,Taxonomy和RefSeq——三种NCBI常见数据库

NRNT,Taxonomy和RefSeq——三种NCBI常见数据库速来围观!——三种NCBI常见数据库在微⽣物测序分析中,常常需要对未知的核酸或蛋⽩序列进⾏物种,功能或类别注释。
注释⽅法种类较多,其中最常⽤的是与⼀些标准数据库进⾏相似性搜索,也就是序列⽐对。
因此,数据库的优劣对注释结果⾄关重要。
本期⼩编为⼤家带来的是NCBI上的三个重要的数据库—NR/NT,Taxonomy和RefSeq。
NR/NT 数据库NR(Non-Redundant Protein Sequence Database)⾮冗余蛋⽩库,所有GenBank+EMBL+DDBJ+PDB中的⾮冗余蛋⽩序列,对于所有已知的或可能的编码序列,NR记录中都给出了相应的氨基酸序列(通过已知或可能的读码框推断⽽来)以及专门蛋⽩数据库中的序列号。
NR库相当于⼀个以核酸序列为基础的交叉索引,将核酸数据和蛋⽩数据联系起来。
NT(Nucleotide Sequence Database),核酸序列数据库,是NR 库的⼦集。
NR和NT库都可以通过NCBI(National Center for Biotechnology Information,美国国⽴⽣物技术信息中⼼)进⾏在线BLAST,也可以在ftp:///blast/db地址中将数据直接下载下来,需要注意的是,NR和NT库是被切分为以数字命名的⼦数据库上传的(如下图所⽰),将所有的⼦数据库放到同⼀个⽬录下,解压缩后构建索引⽂件即可。
Taxonomy 数据库NCBI的分类数据库,包括⼤于7万余个物种的名字和种系,这些物种都⾄少在遗传数据库中有⼀条核酸或蛋⽩序列。
其⽬的是为序列数据库建⽴⼀个⼀致的种系发⽣分类学。
截⽌发稿⽇为⽌该数据库所包含的物种数⽬统计表如下:表1 Taxnomoy数据库物种数⽬统计表下载⽂件:taxdump.tar.gz⾥包含两个重要⽂件,即names.dmp和nodes.dmp;names.dmpnames.dmp⽂件共包含4列,以“|”分割,各列描述如下:其中tax_id即为taxonomy的记录号,name_txt即对应tax_id号的物种名称。
ncbi使用指导

ncbi使用指导摘要:一、NCBI 简介1.NCBI 的定义和作用2.NCBI 的主要数据库二、NCBI 数据库使用方法1.基因数据库查询2.蛋白质数据库查询3.核酸序列数据库查询4.文献数据库查询三、NCBI 工具使用方法1.BLAST 工具2.ClustalW 工具3.Primer-BLAST 工具四、NCBI 的高级功能1.基因变异数据库查询2.基因表达数据库查询3.基因组数据库查询正文:一、NCBI 简介CBI(National Center for Biotechnology Information,美国国家生物技术信息中心)是一个提供生物科学和生物医学研究的公共资源网站。
它包含了大量的生物学和医学信息,为科研工作者提供了便捷的生物信息学资源。
NCBI 的主要数据库包括基因数据库、蛋白质数据库、核酸序列数据库和文献数据库等。
二、NCBI 数据库使用方法1.基因数据库查询基因数据库(Gene Database)是NCBI 的核心数据库之一,包含了大量已知的基因信息。
用户可以通过基因名称、序列标签、转录因子结合位点等信息进行查询。
查询结果包括基因的详细信息、基因序列、表达数据等。
2.蛋白质数据库查询蛋白质数据库(Protein Database)包含了大量已知的蛋白质信息,包括蛋白质序列、功能域、结构域等。
用户可以通过蛋白质名称、序列、功能等信息进行查询。
查询结果包括蛋白质的详细信息、序列、结构等。
3.核酸序列数据库查询核酸序列数据库(Nucleotide Database)包含了大量已知的核酸序列信息,包括基因组序列、cDNA 序列等。
用户可以通过序列名称、物种等信息进行查询。
查询结果包括核酸序列的详细信息、序列等。
4.文献数据库查询文献数据库(PubMed Database)是生物医学领域的文献摘要数据库,收录了大量的生物学和医学文献。
用户可以通过关键词、作者、杂志等信息进行查询。
查询结果包括文献的详细信息、摘要等。
NCBI使用方法

NCBI 使用方法默认分类2008-03-24 15:14 阅读2903 评论12 字号:大中小NCBI (National Center for Biotechnology Information), 美国国家生物技术信息中心[url]/[/url] NCBI 是NIH 的国立医学图书馆(NLM)的一个分支。
NCBI 提供检索的服务包括:1.GenBank(NIH 遗传序列数据库):一个可以公开获得所有的DNA 序列的注释过的收集。
Gen Bank 是由NCBI 受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL 和DDBJ)交换数据建立起数据库的。
它同日本和欧洲分子生物学实验室的DNA 数据库共同构成了国际核酸序列数据库合作。
这三个组织每天交换数据。
其中的数据以指数形式增长,最近的数据为它已经有来自47000 个物种的30 亿个碱基。
2.Molecular Databases(分子数据库):Nucleotide Sequence(核酸序列库):从NCBI 其他如Genbank 数据库中收集整理核酸序列,提供直接的检索。
Protein Sequence (蛋白质序列库):与核酸类似,也是从NCBI 多个不同资源中编译整理的,方便研究者的直接查询。
Structure(结构)-——关于NCBI 结构小组的一般信息和他们的研究计划,另外也可以访问三维蛋白质结构的分子模型数据库(MMDB)和用来搜索和显示结构的相关工具。
MMDB:分子模型数据库—一个关于三维生物分子结构的数据库,结构来自于X-ray 晶体衍射和NMR 色谱分析。
Taxonomy(分类学)——NCBI 的分类数据库,包括大于7 万余个物种的名字和种系,这些物种都至少在遗传数据库中有一条核酸或蛋白序列。
其目的是为序列数据库建立一个一致的种系发生分类学。
3.Literature Databases(文献数据库)(1)PubMed 是NLM 提供的一项服务,能够对MEDLINE 上超过1200 万条的上世纪六十年代中期至今的杂志引用和其他的生命科学期刊进行访问,并可以连接到参与的出版商网络站点的全文文章和其他相关资源。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
GenBank
DDBJ
EMBL
可编辑版
3
1.常用核酸序列数据库
国际上权威的核酸序列数据库
欧洲分子生物学实验室的EMBL http://www.embl-heidelberg.de
美国生物技术信息中心的GenBank /Web/Genbank/
4.2 序列数据库
序列数据库
核酸序列数据库 蛋白序列数据库
可编辑版
1
4.2 序列数据库—核酸数据库
4.2.1 核酸数据库 4.2.2 数据库序列格式 4.2.3 数据库的查询 4.2.4 数据库搜索 4.2.5 数据提交 4.2.6 核酸数据库使用实例
可编辑版
2
4.2.1 核酸数据库
机网络提供该数据库文件
可编辑版
16
GenBank序列文件的结构
GenBank序列文件由单个的序列条目组成 序列条目由字段组成 每个字段由关键字起始,后面为该字段的
具体说明 有些字段又分若干子字段,以次关键字或
特性表说明符开始 每个序列条目以双斜杠“//”作结束标记
可编辑版
17
序列文件: 序列条目 字段 关键字 “//”
目前由欧洲生物信息学研究所EBI ( European Bioinformatic Institurte) 负责管理。
可编辑版
9
可编辑版
10
DDBJ
DDBJ是DNA Data Base of Japan的简 称,创建于1986年,由日本国家遗传学 研究所负责管理。
可编辑版
11
可编辑版
12
2.其它常用核酸序列数据库
完整的GenBank数据库包括 序列文件 索引文件 其它有关文件
索引文件是根据数据库中作者、参考 文献等建立的,用于数据库查询。
可编辑版
15
GenBank序列文件
GenBank中最常用的是序列文件 序列文件的基本单位是序列条目,包括
核酸碱基排列顺序和注释两部分。 目前,许多生物信息资源中心通过计算
日本遗传研究所的DDBJ http://www.ddbj.nig.ac.jp/
可编辑版
4
1988年,EMBL、GenBank 与DDBJ共同成立 了国际核酸序列联合数据库中心,建立了合作 关系。
根据协议,这三个数据中心各自搜集世界各国 有关实验室和测序机构所发布的序列数据,并 通过计算机网络每天都将新发现或更新过的数 据进行交换,以保证这三个数据库序列信息的 完整性。
可编辑版
19
EMBL数据库结构
EMBL数据库的基本单位也是序列条目, 包括核甘酸碱基排列顺序和注释两部分
序列条目由字段组成 每个字段由标识字起始,后面为该字段的
具体说明。有些字段又分若干次子字段, 以次标识字或特性表说明符开始 最后以双斜杠“//”作本序列条目结束标记
可编辑版
20
EMBL条目的关键字
可编辑版
18
GenBank序列条目的关键字
LOCUS (序列名称) DEFINITION (说明) ACCESSION (接收编号) NID (核酸标识) KEYWORDS (关键词) SOURCE (数据来源) REFERENCE (文献) FEATURES (特性表) BASE COUNT (碱基组成) ORIGIN (碱基排列顺序)
REFERENCE 1 (bases 1 to 4639221)
可编辑版
21
4.2.2 数据库序列格式
GenBank和EMBL数据结构对比 E. coli k-12全基因组序列文件为例
可编辑版
22
GenBank
LOCUS
U000968
DEFINITION Escherichia coli K-12 MG1655 complete genome.
ACCESSION U00096
KEYWORDS .
SOURCE Escherichia coli.
ORGANISM Escherichia coli
Bacteria; Proteobacteria; gamma subdivision; Enterobacteriaceae;
Escherichia.
后移交给国家生物技术信息中心NCBI,隶属于 NIH下设的国家医学图书馆(National Liabraty of Medicine,简称NLM)
可编辑版
7
可编辑版
8
EBI —EMBL
EMBL是由欧洲分子生物学实验(European Molecular Biology Laboratory) 于1982年 创建的
ID(序列名称) DE(序列简单说明) AC(序列编号) SV(序列版本号) KW(与序列相关的关键词) OS(序列来源的物种名),OC(序列来源的物种学名和分类学位置) RN(相关文献编号或递交序列的注册信息),RA(相关文献作者或递交序列的
作者),RT(相关文献题目),RL(相关文献杂志名或递交序列的作者单 位),RX(相关文献 Mediline引文代码),RC(相关文献注释),RP(相关文 献其他注释) CC(关于序列的注释信息) DR(相关数据库交叉引用号) FH(序列特征表起始),FT(序列特征表子项) SQ(碱基种类统计数)
可编辑版
5
三个数据库中的数据基本一致,仅在数 据格式上有所差别,对于特定的查询, 三个数据库的响应结果一样。
这三个数据库是综合性的DNA和RNA 序列数据库,每条记录代表一个单独、 连续、附有注释的DNA或RNA片段。
可编辑版
6
NCBI—GenBank
美国国家健康研究院(National Institurte of Health,简称NIH) 于80年代初委托洛斯阿拉莫 斯(Los Alamos)国家实验室建立GenBank, 1982年正式运行
dbEST UniGene dbSNP ……
可编辑版
13
3.GenBank、EMBL数据库结构
了解序列数据库的格式,有助于更好地 使用,提高数据库检索的效率和准确性
DDBJ数据库的内容和格式与GenBank 相同
下面分别介绍EMBL和GenBank的数据 库结构
可编辑版
14
GenBank数据库结构