统计学(第三版,袁卫主编)样卷及答案
统计学课后题答案(袁卫_庞皓_曾五一_贾俊平_)

版权归wagxjysys所有违者必究第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
袁卫《统计学》(第3版)课后习题-相关与回归分析(圣才出品)

称为总体回归函数(简记为 PRF)。 (2)如果把因变量 y 的样本条件期望表示为自变量 x 的某种函数,这个函数称为样本
回归函数(简记为 SRF)。 (3)总体回归函数和样本回归函数的区别
2 / 24
量以外的所有因素对 y 的影响,称为随机误差项。
(2)因变量 y 的实际观测值 yi 并不完全等于样本条件期望 yˆi ,二者之偏差称为残差项 或剩余项,用 ei 表示,则 yi − yˆi = ei 。
(3)总体回归函数中的 i 是不可直接观测的,而样本回归函数中的 ei 是只要估计出样
本回归的参数就可以计算的数值。
圣才电子书 十万种考研考证电子书、题库视频学习平台
①总体回归函数虽然未知,但它是确定的;而由于从总体中每次抽样都能获得一个样本, 就都可以拟合一条样本回归线,所以样本回归线是随抽样的样本而变化的,可以有许多条。 所以,样本回归线还不是总体回归线,至多只是未知总体回归线的近似表现。
圣才电子书
十万种考研考证电子书、题库视频学习平台
第 7 章 相关与回归分析
思考题 1.相关分析与回归分析的区别和联系是什么? 答:(1)相关分析与回归分析的联系 相关分析与回归分析具有共同的研究对象,都是对变量间相关关系的分析,二者可以相 互补充。相关分析可以表明变量间相关关系的性质和程度,只有当变量间存在相当程度的相 关关系时,进行回归分析去寻求变量间相关的具体数学形式才有实际的意义。同时,在进行 相关分析时,如果要具体确定变量间相关的具体数学形式,又要依赖于回归分析,而且在多 个变量的相关分析中相关系数的确定也是建立在回归分析基础上的。 (2)相关分析与回归分析的区别 ①从研究目的上看,相关分析是用一定的数量指标(相关系数)度量变量间相互联系的 方向和程度;回归分析却是要寻求变量间联系的具体数学形式,是要根据自变量的固定值去 估计和预测因变量的平均值。 ②从对变量的处理看,相关分析对称地对待相互联系的变量,不考虑二者的因果关系, 也就是不区分自变量和因变量,相关的变量不一定具有因果关系,均视为随机变量;回归分 析是在变量因果关系分析的基础上研究其中的自变量的变动对因变量的具体影响,必须明确 划分自变量和因变量,所以回归分析中对变量的处理是不对称的,在回归分析中通常假定自 变量在重复抽样中是取固定值的非随机变量,只有因变量是具有一定概率分布的随机变量。
统计学袁卫期末复习及课后练习参考答案

《统计学》课程期末复习(一)单项选择题1.社会经济统计学是一门()A.自然科学B.实质性科学C.社会科学D.新兴科学2.统计有三种涵义,其中( )是基础.是源。
A.统计学B.统计资料C.统计活动D.统计方法3.下列变量中属于连续变量的是()A.职工人数B.设备台数C.学生的年龄D.工业企业数4.数量指标是反映( )A.总体的绝对数量指标B.总体内部数量关系的指标C.总体单位数量指标D.总体的相对数量指标5.质量指标是说明()A.总体内部数量关系的指标B.总体的绝对数量指标C.总体单位数的指标D.总体单位质量的指标6.()是统计的根本准则,是统计的生命线。
A.及时性B.真实性C.全面性D.总体性7.某市1995年工业企业经济活动成果的统计年报的呈报时间为1996年元月31日,则调查时间为( )A.1年零1个月B.1年C.1个月D.1天8.对我国各铁路交通枢纽的货运量进行的调查,属于()A.普查B.重点调查C.抽样调查D.典型调查9.某手表厂为了解手表产品质量情况而进行的调查,属于()A.普查B.重点调查C.抽样调查D.典型调查10.某市1995年社会商品零售总额统计年报的呈报时间为1996年元月31日,则调查期限为( )A.1年零1个月B.1年C.1个月D.1天11.按照计划,今年产量比上年增加30%,实际比计划少完成10%,同上年比今年产量实际增长程度为()。
A.75%B.40%C.13%D.17%12.某厂2003年完成产值2000万元,2004年计划增长10%,实际完成2310万元,超额完成计划()。
A.5.5%B.5%C.115.5%D.15.5%13.甲.乙两数列的平均数分别为100和14.5,它们的标准差为12.8和3.7,则( )。
A.甲数列平均数的代表性高于乙数列B.乙数列平均数的代表性高于甲数列C.两数列平均数的代表性相同D.两数列平均数的代表性无法比较14.事先将总体各单位按某一标志排列,然后依排列顺序和按相同的间隔来抽选调查单位的抽样称为( )。
袁卫《统计学》(第3版)课后习题-概率、概率分布与抽样分布(圣才出品)

5.离散型随机变量和连续型随机变量的概率分布的描述有哪些不同?连续型随机变量
的概率密度与分布函数之间是什么关系?
答:(1)离散型随机变量 X 只取有限个可能的值 x1,x2,…, xn ,而且是以确定的概
率取这些值,即
P(X=xi)=pi( i =1,2,…,n)。因此,可以列出 X 的所有可能取值 x1,x2,…, xn ,以 及取每个值的概率 p1,p2,…, pn ,将它们用表格的形式表现出来,就是离散型随机变量
1 / 26
圣电子书
(3)主观概率
十万种考研考证电子书、题库视频学习平台
古典概率和统计概率都属于客观概率,它们的确定完全取决于对客观条件的理论分析或
是大量重复试验的事实,不以个人的意志为转移。而有些事件,特别是未来的某一事件,既
不能通过等可能事件个数来计算,也不能根据大量重复试验的频率来估计,但决策者又必须
,
对于连续型随机变量,其均值和方差分别为:
= E(X ) = xf (x)dx, 2 = E(X 2) − E2(X ) = − x2 f (x)dx
−
−
7.二项分布与超几何分布的适用场合有什么不同?它们的均值和方差有什么区别?
答:(1)从理论上讲,二项分布只适合于重复抽样(即从总体中抽出一个个体观察完后
对其进行估计从而作出相应的决策,那就需要应用主观概率。
主观概率需要人们根据经验、专业知识、对事件发生的众多条件或影响因素进行分析,
以此确定主观概率。
3.概率密度函数和分布函数的联系与区别表现在哪些方面? 答:(1)区别 概率密度函数只是给出了连续型随机变量某一特定值的函数值,这一函数值不是真正意 义上的取值概率,连续型随机变量在给定区间内取值的概率对应的是概率密度函数 f(x)曲 线(或直线)在该区间上围成的面积,这一特征恰恰意味着连续型随机变量在某一点的概率 值为 0,因为它对应的面积为 0。而分布函数 F 在 x 处的取值,就是随机变量 X 的取值落在 区间(-∞,x)的概率。 (2)联系
袁卫《统计学》配套题库【课后习题】第1章~第3章【圣才出品】

第二部分课后习题第1章数据与统计学1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学,其目的是探索数据内在的数量规律性。
统计学是由收集、整理、显示和分析统计数据的方法组成的,这些方法来源于对统计数据的研究,目的也在于对统计数据的研究。
离开了统计数据,统计方法乃至统计学就失去了其存在的意义。
2.试举出日常生活或工作中统计数据及其规律性的例子。
答:(1)对人类性别比例的调查,新生婴儿男女性别比为105:100,如果没有人为的干扰,其规律是婴幼儿时男性略多于女性,中青年时男女人数大致相同,老年时女性又略多于男性。
(2)施肥量与粮食产量之间的数量关系的调查研究,其规律性为某种粮食作物的产量会随某种施肥量的增加而增加。
当开始增加施肥量时,产量增加较快。
以后增加同样的施肥量,粮食产量的增加量逐渐减少。
当施肥量增加到一定数值量,产量不再增加。
这时如果再增加肥料,产量反而会减少。
(3)商品广告费用与销售额的关系的调查,其规律性为,随着广告费用的增加,商品的知名度和销售额会相应增加。
3.联系实际简要说明统计数据的来源。
答:统计数据的来源大致分为两种,其中来源于直接组织的调查、观察和科学试验的数据,称为第一手数据或直接的数据;来源于已有的数据,称为第二手数据或间接的数据。
4.直接获取统计数据的渠道主要有哪些?答:(1)对于社会经济管理和决策而言,主要是通过统计调查的方式获取数据,如客户满意度调查、电视收视率调查、家庭收支情况调查、居民闲暇时间利用调查等。
(2)在自然科学和工程的研究领域,通常是通过科学实验的方法获得研究的统计数据。
5.简要说明抽样误差和非抽样误差。
答:(1)抽样误差是利用样本推断总体时产生的误差;抽样误差对任何一个随机样本来讲都是不可避免的。
但它又是可以计量的,并且是可以控制的。
在坚持随机原则的条件下,一般来讲,样本量越大,抽样误差就越小。
(2)非抽样误差是由于调查过程中各有关环节工作失误造成的。
统计学教材课后答案 第三版 袁卫 庞皓 曾五一 贾俊平主编

第四章、参数估计1.简述评价估计量好坏的标准答:评价估计量好坏的标准主要有:无偏性、有效性和相合性。
设总体参数θ的估计量有1ˆθ和2ˆθ,如果()1ˆE θθ=,称1ˆθ是无偏估计量;如果1ˆθ和2ˆθ是无偏估计量,且()1ˆD θ小于()2ˆD θ,则1ˆθ比2ˆθ更有效;如果当样本容量n →∞,1ˆθθ→,则1ˆθ是相合估计量。
2.说明区间估计的基本原理答:总体参数的区间估计是在一定的置信水平下,根据样本统计量的抽样分布计算出用样本统计量加减抽样误差表示的估计区间,使该区间包含总体参数的概率为置信水平。
置信水平反映估计的可信度,而区间的长度反映估计的精确度。
3.解释置信水平为95%的置信区间的含义答:总体参数是固定的,未知的,置信区间是一个随机区间。
置信水平为95%的置信区间的含义是指,在相同条件下多次抽样下,在所有构造的置信区间里大约有95%包含总体参数的真值。
4.简述样本容量与置信水平、总体方差、允许误差的关系答:以估计总体均值时样本容量的确定公式为例:()22/22z n E ασ= 样本容量与置信水平成正比、与总体方差成正比、与允许误差成反比。
练习题:●1.解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25,(1)样本均值的抽样标准差σ5=0.7906 (2)已知置信水平1-α=95%,得 α/2Z =1.96,于是,允许误差是E =α/2Z 6×0.7906=1.5496。
●2.解:(1)已假定总体标准差为σ=15元,则样本均值的抽样标准误差为x σ15=2.1429(2)已知置信水平1-α=95%,得 α/2Z =1.96,于是,允许误差是E=α/2Z 6×2.1429=4.2000。
(3)已知样本均值为x =120元,置信水平1-α=95%,得 α/2Z =1.96,这时总体均值的置信区间为±α/2x Z 0±4.2=124.2115.8 可知,如果样本均值为120元,总体均值95%的置信区间为(115.8,124.2)元。
统计学习题答案(袁卫主编第三版)

为大家谋福利,低价供应第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:C B C ED B C C B C(1) 指出上面的数据属于什么类型;用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
解:(1)由于表2.21中的数据为服务质量的等级,可以进行优劣等级比较,但不能计算差异大小,属于顺序数据。
统计学(第三版)课后答案 袁卫等主编

统计学第一章1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.答:(1)有两个总体:A品牌所有产品、B品牌所有产品(2)变量:口味(如可用10分制表示)(3)匹配样本:从两品牌产品中各抽取1000瓶,由1000名消费者分别打分,形成匹配样本。
(4)从匹配样本的观察值中推断两品牌口味的相对好坏。
第二章、统计数据的描述思考题1描述次数分配表的编制过程答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2.解释洛伦兹曲线及其用途答:洛伦兹曲线是20世纪初美国经济学家、统计学家洛伦兹根据意大利经济学家帕累托提出的收入分配公式绘制成的描述收入和财富分配性质的曲线。
洛伦兹曲线可以观察、分析国家和地区收入分配的平均程度。
3. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。
袁卫《统计学》(第3版)【章节题库】详解 第4章~第6章【圣才出品】

十万种考研考证电子书、题库视频学习平台
第 4 章 参数估计
一、单项选择题 1.估计量是指( )。 A.总体参数的名称 B.总体参数的具体数值 C.用来估计总体参数的统计量的名称 D.用来估计总体参数计算出来的统计量的具体数值 【答案】C
【解析】在参数估计中,用来估计总体参数的统计量的名称为估计量,用符号ˆ 表示。
1,2 包括真值的概率,称为置信概率,也称作置信水平或置信系数;估计区间 1,2
称作参数θ的置信水平 1- 的置信区间,区间的边界称为置信限,1 为置信下限, 2 为
置信下限。在其他条件不变的情况下,置信概率 越大,未知参数的 1- 置信区间长度
越小。
10.在样本量和抽样方式不变的情况下,若提高置信度,则置信区间的宽度( )。 A.会缩小 B.会增大 C.可能缩小,也可能增大 D.不受影响 【答案】B 【解析】在进行估计时,总是希望提高估计的可靠程度。但在一定的样本量下,要提高 估计的可靠程度(置信水平),就应扩大置信区间,而过宽的置信区间在实际估计中往往是 没有意义的。如果想要缩小置信区间,又不降低置信程度,就需要增加样本量。
5.一个估计量的一致性是指( )。 A.该估计量的数学期望等于被估计的总体参数 B.该估计量的方差比其他估计量小 C.随着样本量的增大该估计量的值越来越接近被估计的总体参数
2 / 58
圣才电子书 十万种考研考证电子书、题库视频学习平台
D.该估计量的方差比其他估计量大 【答案】C 【解析】一致性是指随着样本量的增大,点估计量的值越来越接近被估总体的参数。
11.设总体 X 服从期望为μ,方差为 2 的正态分布,其中μ, 2 均为未知参数,(X1,
X2,…,Xn)是从 X 中抽取的样本,记
统计学(第三、四版)答案 (作 者: 袁卫庞皓 曾五一 贾俊平主编—)

统计学(第三、四版)作者:袁卫庞皓曾五一贾俊平主编第2章统计数据的描述练习:2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):1521241291161001039295127104105119114115871031181421351251171081051101071371201361171089788123115119138112146113126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
2.3某百货公司连续40天的商品销售额如下(单位:万元):41252947383430384340463645373736454333443528463430374426384442363737493942323635根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
2.4为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:700716728719685709691684705718706715712722691708690692707701708729694681695685706661735665668710693697674658698666696698706692691747699682698700710722694690736689696651673749708727688689683685702741698713676702701671718707683717733712683692693697664681721720677679695691713699725726704729703696717688(1)利用计算机对上面的数据进行排序;(2)以组距为10进行等距分组,整理成频数分布表,并绘制直方图;(3)绘制茎叶图,并与直方图作比较。
统计学(第3版)练习与思考答案

统计学(第3版)练习与思考答案练习与思考答案第一章一、判断题1.√2.×3.×4.×5.√6.√7.√8.×9.√10.×二、单项选择题1.b2.c3.b4.d5.d6.c三、简答题(略)第二章一、判断题1.×2.×3.×4.√5.×6.×7.×8.×二、单项选择题1.c2.a3.b4.a5.c三、简答题(略)四、计算题(1)、(2)见到如下表中:工人按日加工零件数分组(件)110以下110――120120――130130――140140――150150以上合计频数(人)31324104155频率(%)5.4523.6443.6418.187.271.82100.00总计频数(人)向上总计31640505455――向上总计5552391551――总计频率(%)向上总计5.4529.9172.7390.9198.18100.00向上总计100.0094.5570.9127.279.091.82(3)(略);(4)钟型原产。
五、课堂教学题(略)第三章一、判断题1.×2.√3.×4.×5.×6.×7.×8.×9.×10.√二、单项选择题1.b2.c3.c4.b5.c6.d7.a8.c9.c10.c11.d12.d三、简答题(略)四、计算题1、平均时速=109.09(公里/时)2、顾客占到了昂贵,因为如果两条鲫鱼分离卖,则平均价格为16.92元/公斤。
在这次交易中,顾客所占到的昂贵就是11元-10.4元=0.6元。
原因就是鲫鱼重量有权数促进作用。
3、(1)平均每个企业利润额=203.70(万元);(2)全公司平均资金利润率=13.08%。
4、(1)全厂总合格率、平均合格率和平均废品率分别是92.17%、97.32%和2.68%;(使用几何平均法)(2)全厂总合格率、平均合格率和平均废品率分别是97.31%、97.31%和2.69%;(采用调和平均法)(3)全厂总合格率、平均值合格率和平均值废品率分别就是97.38%、97.38%和2.62%。
统计学第三版练习+答案 袁卫 庞皓
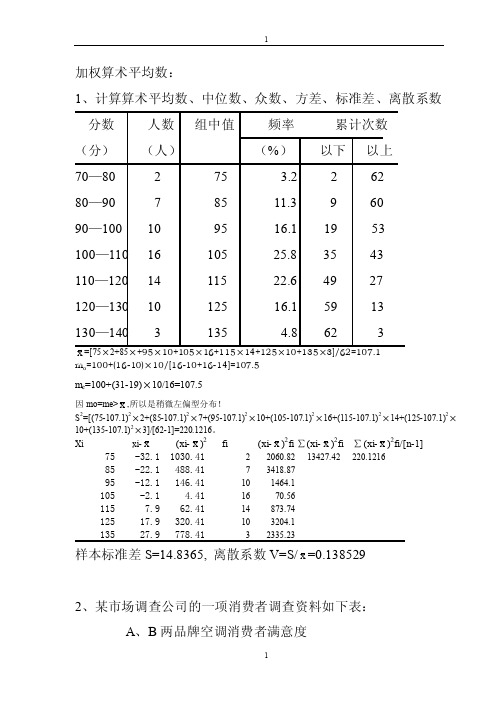
(2).P(X>2)=1-P(X≤2)=C6 0 0.20 0.86 + C6 1 0.21 0.85 + C62 0.22 0.84 = 0.90112
5
6
第五章
抽样分布课堂练习
抽样分布:全部可能样本统计量的概率分布叫做抽样分布。以下是一个极端的例子: ▲ 案例 1:假定一个实验小组有四人 N=4,其写作成绩分别为:21、20、19、18(分) (25 为满分) 。若样本容量 n=2,则全部可能样本(不重复抽样)是 6 个,6 个样本及它们 的平均数、标准差如下表: 21+20; 21+19; 21+18; 20+19; 20+18; 19+18
x ~N(50,18 /36),P(48≤ x <52)=2Ф0(2/3)-1=„„
2
▲习题 3:从阿根廷、加拿大、美国到货三批玉米,分别为 600 包、6000 包、60000 包。 合同规定三批玉米平均每包重量都是 80 公斤,标准差都是 4 公斤。要求: (1)若从每批 玉米中都抽取 300 包为样本,分别计算它们的平均数分布。有何启示?(要求都使用修 正系数) (2)分别计算三批玉米平均重量少于 79.5 公斤的概率?
750 1750 2700 9625 4875 3000
22700 263.9535
4:极差 某商场两类商品半年净收入如下: SE : (万美元/月) 23 PM: (万美元/月)29 5:方差与标准差 (1) 总体方差与标准差 某项心理测试(被试者年龄 18—35 岁)分数如下表:
测试分数(分)被试者 f 组中值 40—60 60—80 80—100 100—120 120—140 140—160 160—180 合计 1 4 12 16 9 5 3 50 50 70 90 110 130 150 Xf 50 280 1080 1760 1170 750 (X-112 )2f
袁卫《统计学》(第3版)课后习题-国民经济统计基础知识(圣才出品)

答: (1)国内总产出是指一定时期内用货币计量的各单位、各部门生产的社会总产品 的总量;
从价值形态看,国内总产出是社会总产品完全价值的总和,其价值构成为:①生产资料
的实物形态与之对应。
从价值构成看:国内生产净值扣除一部分生产资料价值转移,没有任何重复计算的社会
新创新成果。
国内生产总值是一个包含了部分重复计算的社会生产成果指标,而国内生产净值则是一
个没有任何重复计算的社会新创成果的指标。但是,由于在实际核算中,固定资产损耗的影
响因素很复杂,且具体的折旧计算方法又很多,每种方法都存在一定的假定性,全社会在计
算折旧时也难以做到客观、统一。
3 / 12
圣才电子书 十万种考研考证电子书、题库视频学习平台
5.请判断以下论述正确与否,并说明理由。 (1)第三产业的所有部门都属于非物质生产部门。 【答案】× 【解析】所谓物质生产部门,在我国主要是指农业、工业、建筑业、运输邮电业和商业 这五个部门。第三产业是指凭借一定的物质技术设备,为生产和生活服务的部门。它包括四 个层次。第三产业中的第一层次和第二层次中的一部分应为物质生产部门。 (2)一国的国内生产总值总是小于国民可支配总收入。 【答案】× 【解析】国民可支配总收入=国内生产总值+来自国外的要素收入与经常转移收入净额, 来自国外净要素收入与来自国外经常转移净额都可能大于零,也可能小于零。故
由一组从事相同或相近经济活动的机构型单位组成的部门,就形成机构部门。 (2)从数量上研究国民经济,不仅要把握其静态总量,而且要探寻其内部结构、数量 关系和动态循环过程,这就必须对国民经济进行分类。通过分类,旨在将大量、丰富的国民 经济核算资料分门别类地加工整理,使之条理化、系统化。也只有以科学的国民经济分类为 基础,才能正确地说明国民经济各部门、各环节、各要素、各方面的相互联系和比例关系, 进而深刻地反映出国民经济的内在结构机制和运行规律性。总之,国民经济分类是国民经济 统计和宏观经济分析的重要基础性工作。
袁卫《统计学》(第3版)笔记和课后习题(含考研真题)详解

袁卫《统计学》(第3版)笔记和课后习题(含考研真题)详解第1章数据与统计学1>.1 复习笔记一、统计数据与统计学1>.统计学的概念统计学是研究如何搜集数据、整理数据、分析数据,以便从中做出正确推断的认识方法论科学。
实际上,它是一门方法论的科学而不是实质性科学。
2>.统计学和统计数据的关系统计学是由收集、整理、显示和分析统计数据的方法组成的,这些方法来源于对统计数据的研究,目的也在于对统计数据的研究。
离开了统计数据,统计方法乃至统计学就失去了其存在的意义。
二、统计学的产生和发展最早的统计是作为国家重要事项的记录,从统计的产生和发展过程来看,可以把统计学划分为三个时期:一是统计学的萌芽时期,主要有国势学派和政治算术学派;二是统计学的近代时期,主要有数理统计学派和社会统计学派;三是统计学的现代期,主要表现为统计学吸收数学营养的程度越来越迅速;统计学向其他学科领域渗透的能力越来越强;统计学的应用日趋广泛和深入,所发挥的功效日益增强。
三、统计学的内容统计学的内容由描述统计和推断统计组成。
描述统计是用图形、表格和概括性的数字对数据进行描述的统计方法。
推断统计是根据样本信息对总体进行估计、假设检验、预测或其他推断的统计方法。
推断统计主要有两种类型,即参数估计和假设检验。
四、统计数据的来源统计数据来源于直接组织的调查、观察和科学试验,称之为第一手数据或直接的数据;或者来源于已有的数据,称之为第二手数据或间接的数据。
五、统计数据的质量1>.抽样误差是由于抽样的随机性引起的样本结果与总体真值之间的误差。
这种误差虽然不可避免,但是可以控制。
2>.非抽样误差是相对于抽样误差而言的,是指除了抽样误差之外的,由于其他原因引起的样本观察值与总体真值之间的差异。
非抽样误差特别是其中的系统偏差是可以避免,但如果不注意,这类误差造成的结果对调查质量来说是致命的。
六、统计学的基本概念1>.总体:是指包含所研究的全部个体的集合。
统计学(第三版袁卫_庞皓_曾五一_贾俊平主编)各章节课后习题答案
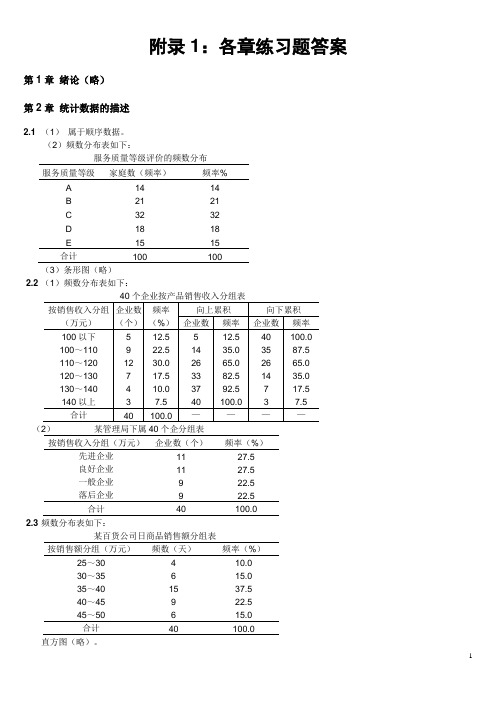
附录1:各章练习题答案第1章绪论(略)第2章统计数据的描述2.1 (1)属于顺序数据。
(2)频数分布表如下:服务质量等级评价的频数分布服务质量等级家庭数(频率)频率%A1414B2121C3232D1818E1515合计100100(3)条形图(略)2.2 (1)频数分布表如下:(2)某管理局下属40个企分组表按销售收入分组(万元)企业数(个)频率(%)先进企业良好企业一般企业落后企业11119927.527.522.522.5合计40 100.0 2.3 频数分布表如下:某百货公司日商品销售额分组表按销售额分组(万元)频数(天)频率(%)25~30 30~35 35~40 40~45 45~5046159610.015.037.522.515.0合计40 100.0 直方图(略)。
2.4 (1)排序略。
(2)频数分布表如下:100只灯泡使用寿命非频数分布按使用寿命分组(小时)灯泡个数(只)频率(%)650~660 2 2660~670 5 5670~680 6 6680~690 14 14690~700 26 26700~710 18 18710~720 13 13720~730 10 10730~740 3 3740~750 3 3合计100 100 直方图(略)。
2.5 (1)属于数值型数据。
(2)分组结果如下:分组天数(天)-25~-20 6-20~-15 8-15~-10 10-10~-5 13-5~0 120~5 45~10 7合计60(3)直方图(略)。
2.6 (1)直方图(略)。
(2)自学考试人员年龄的分布为右偏。
2.7 (1(2)A 班考试成绩的分布比较集中,且平均分数较高;B 班考试成绩的分布比A 班分散,且平均成绩较A 班低。
2.82.9 (1)x =274.1(万元);Me=272.5 ;Q L =260.25;Q U =291.25。
(2)17.21=s (万元)。
2.10 (1)甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
( 首
页 )
均值 易受极端值影响 数学性质优良 数据对称分布或接近对称分布时应用 2.简述方差分析的基本原理 (10 分) 检验多个总体均值是否相等 通过分析数据的误差判断各总体均值是否相等 比较的基础是反映系统和偶然误差的组间方差与反映偶然方差的组内方差的方差比 如果系统(处理)误差明显地不同于随机误差,则均值就是不相等的;反之,均值就是相等的 三、计算题 (50 分) 1. 从某大学一年级学生中随机抽取 36 人,对公共理论课的考试面绩进行调查,结果如下: 67 90 66 80 67 65 74 70 87 85 83 75 58 67 54 65 79 86 89 95 78 97 76 78 82 94 56 60 93 88 76 84 79 76 77 76 要求: (1)根据以上数据将考试成绩等距分为 5 组,组距为 10,并编制成次数分布表,绘制 次数分布直方图; 分) (5
( 首
页 )
(A 卷)
课程名称: 考生学号: 管理统计学 适用专业年级:市场营销 2010 级 考 生 姓 名:
……………………………………………………………………………………………………… 一、 单项选择题(每小题 3 分,共 30 分) 1.某种商品的销售量连续四年增长速度分别为 8%、10%、9%、12%,该商品销售量的年平均增 长速度为(D ) A. (8%+10%+9%+12%)÷4 B.{(108%×110%×109%×120%)-1}÷4 C.3√108%×110%×109%×120% -1 D.4√108%×110%×109%×120% -1 2.以样本统计量估计总体参数,要求估计量的数学期望等于被估计的总体参数,这一数学性 质称之为( C ) 。 A. 一致性 B.有效性 C.无偏性 D.期望性 3. 在一元线性回归方程^yi=a+bxi 中,回归系数 b 的实际意义是(B ) A.当 x=0 时,y 的期望值 B.当 x 变动一个单位时,y 的平均变动数额 C.当 x 变动一个单位时,y 增加的总数额 D.当 y 变动一个单位时,x 的平均变动数额 4. 在左侧检验中,H1:μ <μ 0,则拒绝域为( D ) A.Z≤Za B.|Z|≤Za C.Z≤Z a/2 D.Z <- Za 5、 在进行区间估计时(A ) A.置信水平越小,相应的置信区间也越小 B.置信水平越小,相应的置信区间越大 C.置信水平越大,相应的置信区间越小 D.置信水平的大小不影响置信区间的大小 6. 从某生产线上每隔 55 分钟抽取 5 分钟的产品进行检验,这种抽样方式属于(A ) A.系统抽样 B.类型抽样 C.整群抽样 D.简单随机抽样 7. 一数列 500 以上为末组,其相邻组的组中值为 480,则末组组中值为 ( A ) A、520 B、530 C、540 D、500 8. 对统计分组结果表述正确的是( C ) 。 A.组内同质性,组间同质性 B.组内差异性,组间差异性 C.组内同质性,组间差异性 D. 组内差异性,组间同质性 9.单因素 k 水平方差分析中,计算 F 统计量,其分子与分母的自由度各为( C) A k,n B k-n,n-k C k-1.n-k D n-k,k-1 10. 在方差分析中, D )反映的是样本数据与该组平均值的差异 ( A 总离差 B 组间误差 C 抽样误差 D 组内误差 二、简答题(20 分) 1.比较众数、中位数、均值的特点及应用场合?(10 分) 众数 不受极端值影响 具有不惟一性 数据分布偏斜程度较大时应用 中位数 不受极端值影响 数据分布偏斜程度较大时应用
接收 55 65 75 85 95
14 12 10 8 6 4 2 0
频数 4 7 12 9 4
频率 11.11% 19.44% 33.33% 25.00% 11.11%
累计百分 比 11.11% 30.56% 63.89% 88.89% 100.00%
60
70
80
90
100
Байду номын сангаас
(2)根据分组后的数据计算考试面绩的中位数和众数。 (10 分) Me=70+(50-30.56)/(63.89-30.56)*10=75.83 Mo=70+(12-7)/( (12-7)+(12-9) )*10=76.25 2. 近几年武汉科技大学一年级英语 4 级考试的平均成绩为 73 分,方差为 220.5,今年随机 抽取 200 名学生得其平均成绩为 71.15,当显著性水平为 5%时,今年学生的考试成绩是否低 于往年?(10 分) μ 0=73 σ 2=220.5 n=200 x =71.15 = 0.05 z=1. 65 H0: μ 》73 H1: μ 〈73 z=( x -μ 0)/ σ x =(71.15-73)/sqrt(220.5/200)=-1.76 z=-1.65 z=-1.76〈-z=-1.65
注:1、教师命题时题目之间不留空白;
2、考生不得在试题纸上答题,教师只批阅答题册正面部分。
注:1、教师命题时题目之间不留空白; 2、考生不得在试题纸上答题,教师只批阅答题册正面部分。
( 首
页 )
- 拒绝 H0 该校高数考试成绩是否比往年有所下降 3.(15 分) 某企业上半年产品产量与单位成本资料如下: 月 份 产量 x(千件) 单位成本 y(元) 1 2 73 2 3 72 3 4 71 4 3 73 5 4 69 6 5 68 (1)计算相关系数,说明两个变量相关的密切程度。 分)r=-0.9090 (3 (2)建立回归方程(6 分)
Intercept 产量 x(千件)
Coefficients 77.36363636 -1.818181818
(3)配合回归方程,指出产量每增加 1000 件时,单位成本平均变动多少?减少 1.818 (3 分) (4)假定产量为 6000 件时,单位成本为多少元?(3 分)y=77-1.82*6=66 4. 在某乡 2 万亩水稻中按重复抽样方法抽取 400 亩,得知平均亩产量为 609 斤,样本标准差 为 80 斤.要求以 95%(za/2=1.96)的置信水平估计该乡水稻的平均亩产量的置信区间. (10 分) n=400 x=609 s=80 z2.5%=1.96 E= z2.5%*s/sqrt(200)=1.96*80/sqrt(200)=11 该乡水稻的平均亩产量的 95%置信水平的置信区间为 x+-E=609+-11 =(598,620)