一个简单的字典工具(C++源码)
大数据建模练习(习题卷2)

大数据建模练习(习题卷2)第1部分:单项选择题,共39题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]在黑盒测试方法中,设计测试用例的主要根据是A)程序流程图B)程序内部逻辑C)程序外部功能D)程序数据结构答案:C解析:2.[单选题]以下关于字典类型的描述,正确的是:A)字典类型可迭代,即字典的值还可以是字典类型的对象B)表达式 for x in d: 中,假设d是字典,则x是字典中的键值对C)字典类型的值可以是任意数据类型的对象D)字典类型的键可以是列表和其他数据类型答案:C解析:3.[单选题]已知数据中时间字段的格式为2021-01-01 00:00:00,如果使用过滤算子,过滤出2021年5月1日以来的数据,以下哪个是正确的设置A)大于2021-05-01 00:00:00B)小于2021-05-01 00:00:00C)大于等于2021-05-01 00:00:00D)小于等于2021-05-01 00:00:00答案:C解析:4.[单选题]Jupyter notebook的记事本文件扩展名为:A)mB)pyC)pycD)ipynb答案:D解析:5.[单选题]修改数据库表结构用以下哪一项( )A)UPDATEB)CREATEC)UPDATEDD)ALTER答案:D解析:C)ORDER BY NAME DESCD)ORDER BY DESC NAME答案:A解析:7.[单选题]个栈的初始状态为空。
现将元素 1、2、3、4、5、A、B、C、D、E依次入栈,然后再依次出栈,则元素出栈的顺序是A)12345ABCDEB)EDCBA54321C)54321EDCBAD)ABCDE12345答案:B解析:8.[单选题]在Excel中,数据透视表是汇总、分析、浏览和呈现汇总数据的方法。
插入数据透视表之后,选择一个(),可以实现单元格区域的验证A)单元格B)表/区域C)公式D)文件答案:B解析:9.[单选题]在select语句的where子句中,使用正则表达式过滤数据的关键字是( )A)likeB)againstC)matchD)regexp答案:D解析:10.[单选题]如果要统计某家店铺当天的收益总和,需要按照日期分组,且对收益的统计方式是A)最大B)最小C)总数D)总和答案:D解析:11.[单选题]耦合性和内聚性是对模块独立性度量的两个标准。
VBA中,字典(Dictionary)应用的实例讲解

VBA中,字典(Dictionary)应⽤的实例讲解⼤家好,我们今⽇继续讲解VBA代码解决⽅案的第126讲内容:在VBA中字典的应⽤。
也许许多的朋友对此⽐较陌⽣,在有的语⾔⾥字典也称之为MAP,应⽤也是⽐较⼴泛的。
字典,其实就是⼀些“键-值”对。
使⽤起来⾮常⽅便,有类似于微型数据库的作⽤,可⽤于临时保存⼀些数据信息。
⼀ VBA中创建字典:⽤的是WSH引⽤。
Dim myd As ObjectSet myd = CreateObject("Scripting.Dictionary")⼆字典的⽅法,有Add、Exists、Keys、Items、Remove、RemoveAll,六个⽅法。
① Add ⽤于添加内容到字典中。
如myd.Add key, item 第⼀个参数为键,第⼆个参数为键对应的值② Exists⽤于判断指定的关键词是否存在于字典(的键)中。
如myd.Exists(key)。
如果存在,返回True,否则返回False。
通常会在向字典中添加条⽬的时候使⽤,即先判断字典中是否已存在这个记录,如果不存在则新增,否则进⾏其它的操作。
③ Keys获取字典所有的键,返回类型是数组。
如myd.Keys()④ Items获取字典所有的值,返回类型是数组。
如myd.Items()⑤ Remove从字典中移除⼀个条⽬,是通过键来指定的。
myd.Remove(key)如果指定的键不存在,会发⽣错误。
⑥ RemoveAll 清空字典。
三字典的属性有Count、Key、Item、ConpareMode四种属性① Count⽤于统计字典中键-值对的数量。
也可以简单理解为统计字典中键的个数;② Key⽤于更改字典中已有的键。
如:myd.Key("oapp") = "Orange" 如果指定的键不存在,则会产⽣错误。
③Item⽤于写⼊或读取字典中指定键的值,如果指定的键不存在,则会新增。
UltraEdit 使用说明及技巧(大全)——经典整合版
file://C:\Documents and Settings\Administrator\Local Settings\Temp\~hh4A38.htm 2010-12-25
UltraEdit的下载和安装
Page 1 of 3
UltraEdit的下载和安装 要想获得UltraEdit的安装文件你可以到以下网站去下载/、
UltraEdit的下载和安装
Page 3 of 3
从这里你可以开始编辑你的东西了。
file://C:\Documents and Settings\Administrator\Local Settings\Temp\~hhB97C.htm 2010-12-25
UltraEdit工具栏介绍
Page 1 of 8
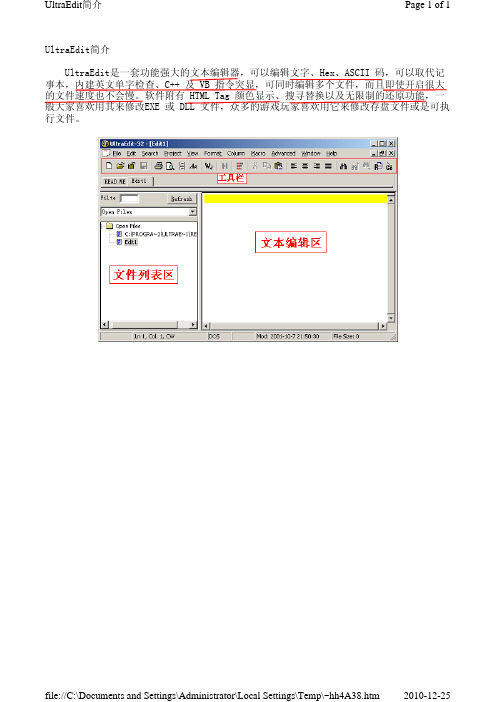
UltraEdit简介
Page 1 of 1
UltraEdit简介
UltraEdit是一套功能强大的文本编辑器,可以编辑文字、Hex、ASCII 码,可以取代记 事本,内建英文单字检查、C++ 及 VB 指令突显,可同时编辑多个文件,而且即使开启很大 的文件速度也不会慢。软件附有 HTML Tag 颜色显示、搜寻替换以及无限制的还原功能,一 般大家喜欢用其来修改EXE 或 DLL 文件,众多的游戏玩家喜欢用它来修改存盘文件或是可执 行文件。
UltraEdit工具栏介绍
Page 4 of 8
在工具条下面会出现文件切换条,你既可以用鼠标单击相应条目来切换文件,也可以按下 Ctrl+F6键或Ctrl+Shift+F6键按顺序切换。这样进行编辑和修改就非常得心应手了。
UltraEdit拼写检查
我们在编辑文件的时候,经常会有许多外语单词出现,怎样才能检查这些外语单词的拼 写是否正确呢?选择“Edit”菜单下的“Spell Check”命令,可以进行拼写检查,这项功能 很好用,感觉很象Word。
C源码生成一个自己的口令字典

{
printf("%s\n", s1);
if(isalpha(ts1[0]))
{
if(k1 != 3) printf("%s\n", capstr(strcpy(ts1,s1)));
if(k1 != 2) printfቤተ መጻሕፍቲ ባይዱ"%s\n", upperstr(ts1));
strcpy(ts1, s1);
if(strcmp(s1, capstr(strcpy(ts1, s1))) == 0) k1 = 3;
else if(strcmp(s1, upperstr(ts1)) == 0) k1 = 2;
else if(strcmp(s1, lowerstr(ts1)) == 0) k1 = 1;
#include <string.h>
#include <ctype.h>
#define MAX_STRING_LEN 20
#define MAX_PWS 300
char *upperstr(char *str)
{
}
if(mode == 2)
{
if(!isalpha(ts2[0])) return disp_pd(s1, s2);
disp_pd(s1, upperstr(ts2));
disp_pd(s1, lowerstr(ts2));
if(k2 == 0 || k2 == 3) disp_pd(s1, s2);
n = strlen((char *)str);
for(i = 0; i < n; i++)
浅谈C#Dictionary实现原理

浅谈C#Dictionary实现原理使⽤C#已经有好多年头了,然后突然有⼀天被问到C#Dictionary的基本实现,这让我反思到我⼀直处于拿来主义,能⽤就好,根本没有去考虑和学习⼀些底层架构,想想令⼈头⽪发⿇。
下⾯开始学习⼀些我平时⽤得理所当然的东西,今天先学习⼀下字典,Dictionary⼀、Dictionary源码学习Dictionary实现我们主要对照源码来解析,⽬前对照的源码版本是.Net Framwork4.8,。
这边主要介绍Dictionary中⼏个⽐较关键的类和对象,然后跟着代码来⾛⼀遍插⼊、删除和扩容的流程。
1、Entry结构体⾸先,我们引⼊Entry这样⼀个结构体,它的定义如下⾯代码所⽰,这是Dictionary中存放数据的最⼩单位,调⽤Add(Key,Value)⽅法添加的元素都会被封装在这样的⼀个结构体中。
1private struct Entry2 {3public int hashCode; // Lower 31 bits of hash code, -1 if unused4public int next; // Index of next entry, -1 if last5public TKey key; // Key of entry6public TValue value; // Value of entry7 }2、其他关键私有变量1private int[] buckets; // Hash桶2private Entry[] entries; // Entry数组,存放元素3private int count; // 当前entries的index位置4private int version; // 当前版本,防⽌迭代过程中集合被更改5private int freeList; // 被删除Entry在entries中的下标index,这个位置是空闲的6private int freeCount; // 有多少个被删除的Entry,有多少个空闲的位置7private IEqualityComparer<TKey> comparer; // ⽐较器8private KeyCollection keys; // 存放Key的集合9private ValueCollection values; // 存放Value的集合3、Dictionary的构造1private void Initialize(int capacity)2 {3int prime = HashHelpers.GetPrime(capacity);4this.buckets = new int[prime];5for (int i = 0; i < this.buckets.Length; i++)6 {7this.buckets[i] = -1;8 }9this.entries = new Entry<TKey, TValue>[prime];10this.freeList = -1;11 }我们看到,Dictionary在构造的时候做了以下⼏件事:1、初始化⼀个this.buchkets=new int[prime]2、初始化⼀个this.entries=new Entry<TKey,TValue>[prime]3、Bucket和entries的容量都为⼤于字典容量的⼀个最⼩的质数其中this.buckets主要⽤来进⾏Hash碰撞,this.entries⽤来存储字典的内容,并且标识下⼀个元素的位置。
人工智能基础(习题卷55)

人工智能基础(习题卷55)说明:答案和解析在试卷最后第1部分:单项选择题,共50题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]以下哪个函数可以生成一个指定范围的随机数组?A)randint()B)rand()C)random()2.[单选题]Iou表示的是()A)两个框之间的重叠程度B)两个框的总面积C)两个框的相对大小D)一个框面积与周长比值3.[单选题]以下_____领域不是主要依赖于图像识别技术。
A)文字识别B)视频监控C)语音识别D)自动驾驶4.[单选题]RGB模型可以组合出( )种颜色。
A)256B)73578C)1735666D)167772165.[单选题]我们常说“人类是智能回路的总开关”,即人类智能决定着任何智能的高度、广度和深度,下面哪一句话对这个观点的描述不正确A)人类智能是机器智能的设计者B)机器智能目前无法完全模拟人类所有智能C)机器智能目前已经超越了人类智能D)机器智能和人类智能相互协同所产生的智能能力可超越人类智能或机器智能6.[单选题]一个简单的Series是由( )的数据组成的A)两个数组B)三个数组C)一个数组D)四个数组7.[单选题]假设n为整数,那么表达式 n&1 == n%2 的值为_______。
A)TRUEB)FALSEC)1D)28.[单选题]LSTM是一种什么网络?A)卷积神经网B)前馈神经网C)循环神经网D)孪生网络9.[单选题]下列哪个不是激活函数()。
A)sigmodB)reluC)tanhD)hidden10.[单选题]用户在求解问题时提供的初始证据,以及在推理中用前面推出的结论作为当前推理的证 据。
称为( )。
A)知识不确定性的表示B)证据不确定性的表示C)结论不确定性的表示D)过程不确定性的表示11.[单选题]关于列表、字典,下列描述那个不对?A)列表、字典不能互相嵌套B)字典各个键值对之间,没有先后顺序C)列表元素的序号从0开始D)列表中的数据可为任意类型,没有限制12.[单选题]()服务实现主.配网模型元数据定义和差异对比;实现模型规范在线发布;实现元数据版本管理和数据版本管理。
Python中文手册(汉译)Word文字可编辑版

Python 手册Python中文社区Python 手册向上:Python 文档索引向后:前言Python 手册Guido van RossumFred L. Drake, Jr., editorPythonLabsEmail: **********************Release 2.3July 29, 2003前言目录1. 开胃菜2. 使用Python解释器2.1 调用解释器2.1.1 传递参数2.1.2 交互模式2.2 解释器及其工作模式2.2.1 错误处理2.2.2 执行 Python 脚本2.2.3 源程序编码2.2.4 交互环境的启动文件3.初步认识Python3.1 像使用计算器一样使用Python3.1.1 数值3.1.2 字符串3.1.3 Unicode 字符串3.1.4 链表3.2 开始编程4. 流程控制4.1 if 语法4.2 for 语法4.3 range() 函数4.4 break 和continue 语法以及else 子句在循环中的用法4.5 pass 语法4.6 定义函数4.7 定义函数的进一步知识4.7.1 定义参数变量4.7.2 参数关键字4.7.3 可变参数表4.7.4 Lambda 结构4.7.5 文档字符串5. 数据结构5.1 深入链表5.1.1 将链表作为堆栈来使用5.1.2 将链表作为队列来使用5.1.3 函数化的编程工具5.1.4 链表的内含(Comprehensions)5.2 del 语法5.3 Tuples 和 Sequences5.4 字典(Dictionaries)5.5 循环技巧5.6 深入条件控制5.7 Sequences 和其它类型的比较6. 模块6.1 深入模块6.1.1 模块搜索路径6.1.2 “编译” Python 文件6.2 标准模块6.3 dir() 函数6.4 包6.4.1 从包中导入所有内容(import * )6.4.2 隐式包引用6.4.3 包中的多重路径7. 输入和输出7.1 格式化输出7.2 读写文件7.2.1 文件对象的方法7.2.2 pickle 模块8. 错误和异常8.1 语法 Errors8.2 异常8.3 捕获异常8.4 释放异常8.5 用户自定义异常8.6 定义 Clean-up Actions9. 类9.1 一个术语9.2 Python 的生存期和命名空间9.3 类(Classes)的初步印像9.3.1 类定义语法9.3.2 类对象9.3.3 实例对象9.3.4 方法对象9.4 自由标记(Random Remarks)9.5 继承9.5.1 多继承9.6 私有变量9.7 零杂技巧9.8 异常也是类9.9 迭代子(Iterators)9.10 发生器(Generators)10. 接下来?A. 交互式编辑和历史回溯A.1 行编辑A.2 历史回溯A.3 快捷键绑定A.4 注释B. 浮点计算:问题与极限B.1 表达错误C. 历史和授权C.1 本软件的历史C.2 修改和使用Python的条件(Terms and conditions for accessing or otherwise usingPython)关于本文档Python 手册向上:Python 文档索引向后:前言Release 2.3, documentation updated on July 29, 2003.See A bout this document... for information on suggesting changes.Python中文社区前言Python中文社区Python 指南向前:Python 指南向上: P ython 指南向下:目录前言Copyright © 2001, 2002, 2003 Python Software Foundation. All rights reserved.Copyright © 2000 . All rights reserved.Copyright © 1995-2000 Corporation for National Research Initiatives. All rights reserved.Copyright © 1991-1995 Stichting Mathematisch Centrum. All rights reserved.See the end of this document for complete license and permissions information.概要:Python 是一种容易学习的强大语言。
C#Dictionary(字典)源码解析效率分析

C#Dictionary(字典)源码解析效率分析 通过查阅⽹上相关资料和查看微软源码,我对Dictionary有了更深的理解。
Dictionary,翻译为中⽂是字典,通过查看源码发现,它真的内部结构真的和平时⽤的字典思想⼀样。
我们平时⽤的字典主要包括两个两个部分,⽬录和正⽂,⽬录⽤来进⾏第⼀次的粗略查找,正⽂进⾏第⼆次精确查找。
通过将数据进⾏分组,形成⽬录,正⽂则是分组后的结果。
⽽Dictionary对应的是 int[] buckets 和 Entry[] entries,buckets⽤来记录要查询元素分组的起始位置(这么写是为了⽅便理解,其实是最后⼀个插⼊元素的位置没有元素为-1,查找同组元素通过 entries 元素中的 Next 遍历,后⾯会提到),entries记录所有元素。
分组依据是计算元素 Key 的哈希值与 buckets 的长度取余,余数就是分组,指向buckets 位置。
通过先查找 buckets 确定元素分组的起始位置,再遍历分组内元素查找到准确位置。
与对应的⽬录和正⽂相同,buckets的长度⼤于等于 entries(我理解是为扩展做准备的),buckets 的长度使⽤HashHelpers.GetPrime(capacity) 计算,是⼀个计算得到的最优值。
capacity是字典的容量,⼤于等于字典中实际存储元素个数。
Dictionary与真实的字典不同之处在于,真实字典的分组结果的物理位置是连续的,⽽ Dictionary 不是,他的物理位置顺序就是插⼊的顺序,⽽分组信息记录在 entries 元素中的 Next 中,Next 是个 int 字段,⽤来记录同组元素的下⼀个位置(若当前为该组第⼀个插⼊元素则记录-1,第⼀个插⼊元素在分组遍历的最后⼀个)解析⼀下Dictionary的⼏个关键⽅法1.Add(Insert 新增&更新⽅法) Add和使⽤[]更新实际就是调⽤的Insert,代码如下。
Python语言程序设计刘卫国第7章 字典与集合 配源代码

3.字典复制与删除的方法 d.copy():返回字典d的副本。 d.clear():删除字典d中的全部元素, d变成一个空字典。 d.pop(key):是从字典d中删除关键 字key并返回删除的值。 d.popitem():删除字典的“关键字: 值”对,并返回关键字和值构成的元组。
4.get()方法和pop()方法 d.get(key[,value]):如果字典d中存在 关键词key,则返回关键字对应的值,若 key在字典中不存在,则返回value的值, value默认为None。该方法不改变原对象 的数据。 d.pop(key[,value]):和get方法相似。 如果字典d中存在关键词key,删除并返回 关键词对应的值;若key在字典中不存在, 则返回value的值,value默认为None。
在Python中,用大括号将集合元素 括起来,这与字典的创建类似,但{}表 示空字典,空集合用set()表示。例如: >>> s3={} >>> type(s3) <class 'dict'> >>> s4=set() >>> s4 set() >>> type(s4) <class 'set'>
2.keys()、values()、items()方法 d.keys():返回一个包含字典所有关键 字的列表。 d.values():返回一个包含字典所有值 的列表。 d.items():返回一个包含所有(关键 字,值)元组的列表。 >>> d={'name':'alex','sex':'man'} >>> d.keys() dict_keys(['sex', 'name'])
es修改拼音分词器源码实现汉字拼音简拼混合搜索时同音字不匹配

es修改拼⾳分词器源码实现汉字拼⾳简拼混合搜索时同⾳字不匹配[版权声明]:本⽂章由danvid发布于,如需转载或部分使⽤请注明出处 在业务中经常会⽤到拼⾳匹配查询,⼤家都会⽤到拼⾳分词器,但是拼⾳分词器匹配的时候有个问题,就是会出现同⾳字匹配,有时候这种情况是业务不希望出现的。
业务场景:我输⼊"纯⽣pi酒"进⾏搜索,⽂档中有以下数据:doc[1]:{"name":"纯⽣啤酒"}doc[2]:{"name":"春⽣啤酒"}doc[3]:{"name":"纯⽣劈酒"}以上业务点是我输⼊"纯⽣pi酒"理论上业务希望只返回doc[1]:{"name":"纯⽣啤酒"}和doc[3]:{"name":"纯⽣劈酒"}其他的不是我要的数据,因为从业务⾓度来看,我已经输⼊"纯⽣"了,理论上只需要返回有"纯⽣"的数据(当然也有很多情况,会希望把"春⽣"也返回来),正常使⽤拼⾳分词器,会把doc[2]也会返回,原因是拼⾳分词器会把doc[2]变成:{"tokens": [{"token": "c","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "chun","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "s","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "sheng","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "p","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "pi","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "j","start_offset": 3,"end_offset": 4,"type": "word","position": 3},{"token": "jiu","start_offset": 3,"end_offset": 4,"type": "word","position": 3}]}由于"纯⽣"和"春⽣"是同⾳字,分词结果doc[1]和doc[2]是⼀样的,所以把doc[2]匹配上就是理所当然了,那么如何解决? 其实我们的需求是就当输⼊搜索⽂本时(搜索⽂本中可能同时存在中⽂/拼⾳),搜索⽂本中有[中⽂] 则按[中⽂]匹配,有[拼⾳]则按[拼⾳]匹配即可,这样就屏蔽掉了输⼊中⽂时匹配到同⾳字的问题。
密码词典 密码生成代码,源代码

{
acle(argv[2],argv[3],argv[4],argv[5]);
}
if(!strcmp(argv[1],"-u"))
{
turn(argv[2],argv[3]);
}
else
{
for(i=m;i<=n;i++)
fprintf(fp,"%d%d%ld\n",w,p,i);
}
rewind(fp);
while((ch=fgetc(fp))!=EOF)
void acle(char *,char *,char *,char *); /*文件每行删除特定的字符串*/
void cut(char *,char *,char *,char *); /*保留文件每行中特定字符前面的字符串*/
void txt2dic(char *,char *,char *,char *); /*过滤特定字符串*/
txt2dic(argv[2],argv[3],argv[4],argv[5]);
}
if(!strcmp(argv[1],"-g"))
{
grep(argv[2],argv[3],argv[4]);
}
void tel(char *,char *,char *,char *); /*电话密码*/
void create(char *,char *,char *,char *); /*穷举密码*/
void adle(char *,char *,char *,char *); /*文件每行加入特ar *a,char *b,char *c,char *d,char *e) /*手机字典生成函数*/
CANopen源代码框架说明

2015年12月摘要:本文主要介绍五部分内容:商业版代码与开源代码的详细区别;CANopen 协会-CiA 的各重要子协议的代码包情况介绍;代码包重要服务;代码包框架介绍和使用说明;支持的MCU 列表和升级情况。
首先先介绍一下开源代码和商业版代码的区别,当然这其实已经是“公开的秘密”,只是我们没有去详细总结而已:1、费用:商业版代码收费,开源代码免费;商业版代码节省了很多研发人员和测试人员的时间,节省了很多人力成本。
2、技术支持和文档:遇到问题,商业版有人负责解答,有完整的操作文档和手册(将近五百页的详细说明书),开源无人解答--问题解决的几率小、风险不确定性大。
3、代码质量和稳定性:商业版本有质量保证,代码的质量、优化和效率;使用开源代码存在质量风险大大提高;4、开发难度和时间:商业版有完整的多款不同硬件平台的demo 提供,大大降低开发移植难度和时间。
(研发人员的薪资也是成本,产品质量和推出市场的时间也是机遇与挑战)。
商业版代码的研发工作量增加、后期测试难度和时间也增加。
5、测试和调试配套:商业版有完整的工具链和测试方法提供,开源代码没有。
完整的测试工具包括:网络组网和管理以及测试(导入EDS 文件组网并修改对应的数据,快速图形化PDO mapping )、报文分析、快速创建对象字典生成EDS 文件、USB-CAN 卡采集数据等等。
6、培训:提供一天在线培训,开源代码无任何培训和技术支持7、后期延展性很好:SO-877-VP 或者SO-1063-VP 提供30多种不同MCU 平台的demo ,并且每年不断更新和增加,如果项目需要更换MCU ,可以快速移植,不需要额外的开发工作量。
而开源代码没有这方面的资源。
如果要做serious 的产品,一般用商业版的代码更有保障,这也是为什么很多标杆企业采用商业版代码的原因。
国内运动控制行业、医疗行业、轨道交通等行业用户最广的代码供应商。
德国SYS TEC的商用版代码这个代码非常大的好处在于:1、提供完全开放的代码;2、买断式的使用权限(当然,仅限本公司本地址);3、一个价格,购买三十多种MCU 的demo ,这无疑为公司的其他项目或者以后的升级提供了很多的便利。
计算机二级选择题题库(142道)

计算机二级选择题1、程序测试的目的是()——[单选题]A 发现并改正程序中的错误B 诊断和改正程序中的错误C 发现程序中的错误D 执行测试用例正确答案:C2、下面属于系统软件的是()——[单选题]A 编辑软件WordB 杀毒软件C 财务管理系统D 数据库管理系统正确答案:D3、下面不属于软件设计阶段任务的是()——[单选题]A 软件的总体结构设计B 软件的数据分析C 软件的需求分析D 软件的详细设计正确答案:C4、下面不属于软件需求分析阶段主要工作的是()——[单选题]A 需求变更申请B 需求获取C 需求分析D 需求评审正确答案:A5、软件生命周期可分为定义阶段、开发阶段和维护阶段,下面不属于开发阶段任务的是()——[单选题]A 测试B 实现C 可行性研究D 设计正确答案:C6、构成计算机软件的是()——[单选题]A 程序和数据B 程序、数据及相关文档C 程序和文档D 源代码正确答案:B7、算法有穷性是指()——[单选题]A 算法只能被有限的用户使用B 算法程序的运行时间是有限的C 算法程序的长度是有限的D 算法程序所处理的数据量是有限的正确答案:B8、在排序过程中,每一次数据元素的移动会产生新的逆序的排序方法是()——[单选题]A 快速排序B 冒泡排序C 简单插入排序D正确答案:A9、下列链表中,其逻辑结构属于非线性结构的是()——[单选题]A 二叉链表B 双向链表C 循环链表D 带链的栈正确答案:A10、下列与队列结构有关联的是()——[单选题]A 多重循环的执行B 函数的递归调用C 先到先服务的作业调度D 数组元素的引用正确答案:C11、下列叙述中正确的是()——[单选题]A 算法的时间复杂度与空间复杂度没有直接关系B 一个算法的时间复杂度大,则其空间复杂度必定小C 一个算法的空间复杂度大,则其时间复杂度页必定大D 一个算法的空间复杂度大,则其时间复杂度必定小正确答案:A12、为了对有序表进行对分查找,则要求有序表()——[单选题]A 任何存储方式B 可以顺序存储页可以链式存储C 只能链式存储D 只能顺序存储正确答案:D13、在最坏情况下()——[单选题]A 快速排序的时间复杂度与希尔排序的时间复杂度是一样的B 希尔排序的时间复杂度比直接插入排序的时间复杂度要小C 快速排序的时间复杂度比冒泡的时间复杂度要小D 快速排序的时间复杂度比希尔排序的复杂度要小正确答案:B14、线性表的链式存储结构与顺序存储结构相比,链式存储结构的优点有()——[单选题]A 排序时减少元素的比较次数B 节省存储空间C 插入与删除运算效率高D 便于查找正确答案:C15、非空循环链表所表示的数据结构()——[单选题]A 有根结点也有叶子结点B 没有根结点也没有叶子结点C 有根结点但没有叶子结点D 没有根结点但有叶子结点正确答案:A16、下来叙述中错误的是()——[单选题]A 数据结构中的元素不能是另一数据结构B 数据结构中的数据元素可以是另一数据结构C 非空数据结构可以没有根结点D 空数据结构是线性结构也可以是非线性结构正确答案:A17、下列叙述中正确的是()——[单选题]A 多重链表比定是非线性结构B 堆可以用完全二叉树表示,其中序遍历序列是有序序列C 排序二叉树的中序遍历序列是有序序列D 任何二叉树只能采用链式存储结构正确答案:C18、下列叙述中正确的是()——[单选题]A 算法设计只需考虑结果的可靠性B 数据的存储结构会影响算法的效率C 算法复杂度是指算法控制结构的复杂程度D 算法复杂度是用算法中指令的条数来度量的正确答案:B19、下列叙述中错误的是()——[单选题]A 二分查找法只适用于顺序存储的线性有序表B 所有二叉树都叧能用二叉链表表示C 有多个指针域的链表也有可能是线性结构D 循环队列是队列的存储结构正确答案:B20、下列数据结构中,不能采用顺序存储结构的是()——[单选题]A 非完全二叉树B 堆C 栈D 队列正确答案:A21、下列各组的排序方法中,最坏情况下比较次数相同的是()——[单选题]A 快速排序与希尔排序B 简单插入排序与希尔排序C 冒泡排序与快速排序D 堆排序与希尔排序正确答案:C22、下列叙述中正确的是()——[单选题]A 循环队列是队列的一种链式存储结构B 循环队列是队列的一种顺序存储结构C 循环队列是一种逻辑结构D 循环队列是非线性结构正确答案:B23、下列叙述中错误的是()——[单选题]A 在二叉链表中,可以从根结点开始遍历到所有结点B 在线性单链表中,可以从任何一个结点开始直接遍历到所有结点C 在循环链表中,可以从任何一个结点开始直接遍历到所有结D 在双向链表中,可以从任何一个结点开始直接遍历到所有结点正确答案:B24、对于循环队列,下列叙述中正确的是()——[单选题]A 队头指针一定大于队尾指针B 队头指针是固定不变的C 队头指针可以大于队尾指针,也可以小于队尾指针D 队头指针一定小于队尾指针正确答案:C25、下列叙述中正确的是()——[单选题]A 存储穸间不连续的所有链表一定是非线性结构B 能顺序存储的数据结构一定是线性结构C 结点中有多个指针域的所有链表一定是非线性结构D 带链的栈与队列是线性结构正确答案:D26、下列叙述中正确的是()——[单选题]A 在链表中,如果每个结点有两个指针域,则该链表一定是线性结构B 在链表中,如果有两个结点的同一个指针域的值相等,则该链表一定是线性结构C 在链表中,如果每个结点有两个指针域,则该链表一定是非线性结构D 在链表中,如果有两个结点的同一个指针域的值相等,则该链表一定是非线性结构正确答案:D27、下列叙述中正确的是()——[单选题]A 只有一个根结点,且只有一个叶子结点的数据结构一定是线性结构B 所有数据结构必须有终端结点(即叶子结点)C 没有根结点或没有叶子结点的数据结构一定是非线性结构D 所有数据结构必须有根结点正确答案:C28、下列叙述中正确的是()——[单选题]A 对同一批数据作同一种处理,如果数据存储结构不同,不同算法的时间复杂度肯定相同。
国家二级C语言机试程序设计基础软件工程基础-试卷1_真题(含答案与解析)-交互

国家二级C语言机试(程序设计基础、软件工程基础)-试卷1(总分68, 做题时间90分钟)1. 选择题1.下列描述中,不符合良好程序设计风格要求的是SSS_SINGLE_SELA 程序的效率第一,清晰第二B 程序的可读性好C 程序中要有必要的注释D 输入数据前要有提示信息分值: 2答案:A解析:一般来讲,程序设计风格是指编写程序时所表现出的特点、习惯和逻辑思路。
程序设计风格总体而言应该强调简单和清晰,程序必须是可以理解的。
著名的“清晰第一,效率第二”的论点已成为当今主导的程序设计风格。
2.下列选项中不属于结构化程序设计原则的是SSS_SINGLE_SELA 可封装B 自顶向下C 模块化D 逐步求精分值: 2答案:A解析:结构化设计方法的主要原则可以概括为自顶向下、逐步求精、模块化、限制使用goto语句。
3.下列选项中不属于结构化程序设计方法的是SSS_SINGLE_SELA 自顶向下B 逐步求精C 模块化D 可复用分值: 2答案:D解析:结构化程序设计方法的主要原则可以概括为:自顶向下,步求精,模块化,限制使用goto语句。
自顶向下是指程序设计时应先考虑总体,后考虑细节:先考虑全局目标,后考虑局部目标。
逐步求精是指对复杂问题应设计一些子目标过渡,逐步细化。
模块化是把程序要解决的总目标先分解成分目标,再进一步分解成具体的小目标,把每个小目标称为一个模块。
可复用性是指软件元素不加修改成稍加修改便可在不同的软件开发过程中重复使用的性质。
软件可复用性是软件工程追求的目标之一,是提高软件生产效率的最主要方法,不属于结构化程序设计方法。
4.下列选项中不符合良好程序设计风格的是SSS_SINGLE_SELA 源程序要文档化B 数据说明的次序要规范化C 避免滥用goto语句D 模块设计要保证高耦合、高内聚分值: 2答案:D解析:一般来讲,程序设计风格是指编写程序时所表现出的特点、习惯和逻辑思路。
程序设计风格总体而言应该强调简单和清晰,程序必须是可以理解的。
全国计算机等级考试二级Python真题及解析(11)

全国计算机等级考试二级Python真题及解析(11)全国计算机等级考试二级Python真题及解析(11)一、选择题1.以下选项对于import保留字描述错误的是A import可以用于导入函数库或者库中的函数B可以使用from jieba import lcut引入jieba库C使用import jieba as jb,引入函数库jieba,取别名jbD使用import XXX引入jieba库正确答案:B2.以下选项中不可用作Python标识符的是A3.14B姓名C__Name__D Pi正确答案:A3. Python可以将一条长语句分成多行显示的续行符号是:A\B#C;D‘正确答案:A4.关于Python语言的特点,以下选项描述正确的是 A Python语言不支持面向对象B Python语言是解释型语言C Python语言是编译型语言D Python语言是非跨平台语言正确答案:B15.关于Python整数类型,以下选项描述正确的是:A 3.14不是整数类型的数值B type(100)表达式结果可能是<class 'int'>,也可能是<class 'float'>C oct(100)表达式结果取得十六进制数D hex(100)表达式结果获得八进制数正确答案:A6.运行以下程序,输出结果的是:A 3B 2C 2.5D 2.50正确答案:CA字符串类型B浮点数类型C整数类型D复数类型精确谜底:B8.上面代码的输出结果是:>>> XXX "Pi=3.">>> eval(TempStr[3:-1])A3.B3.C Pi=3.14D3.1416正确答案:A29.以下关于异常处理的描述,错误的选项是:A Python通过try、except等保留字提供异常处理功能B ZeroDivisionError 是一个变量未命名错误C NameError是一种异常类型D反常语句可以与else和finally语句配合使用精确谜底:B10. for或者while与else搭配使用时,关于履行else语句块描述精确的是A仅轮回非一般竣事后履行(以break竣事)B仅轮回一般竣事后履行C总会履行D永不履行精确谜底:B11.以下代码执行的输出结果是:for i in range(1,4)print(chr()*(2*i-1))A咎XXXXXXB咎XXXXXXC咎XXXXXXD出错精确谜底:B312.以下关于TensorFlow库的应用领域的描述,正确的选项是A机器研究B数据可视化C Web开发D文本分析精确谜底:A13.以下不属于Python深度研究第三方库的选项是:A ArcadeB TensorFlowC Caffe2D XXX正确答案:A14.以下属于Python文本处理第三方库的选项是:A matplotibXXXXXXD vispy精确谜底:B15. random库的seed(a)函数的作用是A生成一个[0.0, 1.0)之间的随机小数B生成一个k比特长度的随机整数C设置初始化随机数种子aD生成一个随机整数正确答案:C16.下面代码的输出结果是4for n in range(400,500):i = n // 100j = n // 10 % 10k = n % 10if n == i ** 3 + j ** 3 + k ** 3:print(n)A 407B 408C 153D 159正确答案:A17.给出上面代码:a = input("").split(",")x = 0while x < len(a):print(a[x],end="")x += 1代码履行时,从键盘取得Python语言,是,脚本,语言则代码的输出结果是A执行代码出错B Python语言,是,脚本,语言C Python语言是脚本语言D无输出精确谜底:C18.关于函数的描述,毛病的选项是A Python使用del保存字定义一个函数B函数能完成特定的功能,对函数的使用不需要了解函数内部实现原理,只要了解函数的输入输出方式即可。
cpython的使用

cpython的使⽤这个的学习主要是因为在运⾏⽬标检测的代码时总是会出现下⾯的错误:from Cython.Build import cythonizeModuleNotFoundError: No module named 'Cython'----------------------------------------ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.安装:pip install CythonCollecting CythonDownloading Cython-0.29.19-cp37-cp37m-macosx_10_9_x86_64.whl (1.9 MB)所以打算学学这个模块是怎么⽤的,以及⽤在哪⾥的Python有时候太慢,如果⼿动编译C或者是C++来写#include<Python.h>的⽂件也⽐较⿇烦。
CPython⽆疑是⼀个⽐较好的选择。
改进的理由1. 每⼀⾏的计算量很少,因此python解释器的开销就会变的很重要。
2. 数据的局部性原理:很可能是,当使⽤C的时候,更多的数据可以塞进CPU的cache中,因为Python的元素都是Object,⽽每个Object都是通过字典实现的,cache对这个数据不很友好。
项⽬Hello World项⽬第⼀个项⽬是Hello world。
创建⼀个⽂件helloworld.pyx,内容如下:print("Hello world!")保存后,创建setup.py⽂件,内容如下:from distutils.core import setupfrom Cython.Build import cythonizesetup(ext_modules = cythonize("helloworld.pyx"))保存后,命令⾏进⼊setup.py所在⽬录,并输⼊python setup.py build_ext --inplace,如下:$python setup.py build_ext --inplaceCompiling helloworld.pyx because it changed.[1/1] Cythonizing helloworld.pyx/anaconda3/envs/deeplearning/lib/python3.7/site-packages/Cython/Compiler/Main.py:369: FutureWarning: Cython directive 'language_level' not set, using2for now (Py2). This will change in a later release! File: /Users/user/pytorch/NLP学习/learn tree = Parsing.p_module(s, pxd, full_module_name)running build_extbuilding 'helloworld' extensioncreating buildcreating build/temp.macosx-10.9-x86_64-3.7gcc -Wno-unused-result -Wsign-compare -Wunreachable-code -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -I/anaconda3/envs/deeplearning/include -arch x86_64 -I/anaconda3/envs/deeplearning/include -arch x86_64 -I/anaconda3/envs/de gcc -bundle -undefined dynamic_lookup -L/anaconda3/envs/deeplearning/lib -arch x86_64 -L/anaconda3/envs/deeplearning/lib -arch x86_64 -arch x86_64 build/temp.macosx-10.9-x86_64-3.7/helloworld.o -o /Users/user/pytorch/NLP学习/learning_2运⾏完这个命令后,该⽬录下就会⽣成三个⽂件:build helloworld.pyxhelloworld.c setup.pyhelloworld.cpython-37m-darwin.so然后创建⼀个调⽤⽂件test.py,内容为:import helloworld运⾏返回:i$ python test.pyHello world!.pyx⽂件:pyx⽂件是python的c扩展⽂件,代码要符合cython的规范,⽤什么编辑器写都⾏。
常见字典用法整编及代码详解(全)蓝桥玄霜

常见字典用法集锦及代码详解蓝桥玄霜前言凡是上过学校的人都使用过字典,从新华字典、成语词典,到英汉字典以及各种各样数不胜数的专业字典,字典是上学必备的、经常查阅的工具书。
有了它们,我们可以很方便的通过查找某个关键字,进而查到这个关键字的种种解释,非常快捷实用。
凡是上过EH论坛的想学习VBA里面字典用法的,几乎都看过研究过northwolves狼版主、oobird版主的有关字典的精华贴和经典代码。
我也是从这里接触到和学习到字典的,在此,对他们表示深深的谢意,同时也对很多把字典用得出神入化的高手们致敬,从他们那里我们也学到了很多,也得到了提高。
字典对象只有4个属性和6个方法,相对其它的对象要简洁得多,而且容易理解使用方便,功能强大,运行速度非常快,效率极高。
深受大家的喜爱。
本文希望通过对一些字典应用的典型实例的代码的详细解释来给初次接触字典和想要进一步了解字典用法的朋友提供一点备查的参考资料,希望大家能喜欢。
给代码注释估计是大家都怕做的,因为往往是出力不讨好的,稍不留神或者自己确实理解得不对,还会贻误他人。
所以下面的这些注释如果有不对或者不妥当的地方,请大家跟帖时指正批评,及时改正。
字典的简介字典(Dictionary)对象是微软Windows脚本语言中的一个很有用的对象。
附带提一下,有名的正则表达式(RegExp)对象和能方便处理驱动器、文件夹和文件的(FileSystemObject)对象也是微软Windows脚本语言中的一份子。
字典对象相当于一种联合数组,它是由具有唯一性的关键字(Key)和它的项(Item)联合组成。
就好像一本字典书一样,是由很多生字和对它们对应的注解所组成。
比如字典的“典”字的解释是这样的:“典”字就是具有唯一性的关键字,后面的解释就是它的项,和“典”字联合组成一对数据。
常用关键字英汉对照:Dictionary 字典Key 关键字Item 项,或者译为条目字典对象的方法有6个:Add方法、Keys方法、Items方法、Exists方法、Remove方法、RemoveAll方法。
python一级试卷(2022

python一级试卷(2022.8.19)一、单选题(共30题,每题2分,共60分)您的姓名: [填空题] *_________________________________1. 假设a=20,b=3,那么a or b的结果是() [单选题] *A. 20(正确答案)B. 0C. 1D. 3答案解析:A2. 假设a=2,b=3,那么a-b*b的值是() [单选题] *A. -3B. -2C. -7(正确答案)D. -11答案解析:C3. 下面哪一段代码是绘制一个圆() [单选题] *A. circle(50,steps=3)B. circle(50)(正确答案)C. circle(50,180)D. circle(50,0)答案解析:B4. 下列Turtle库中画笔属性说法错误的是:() [单选题] *A. turtle.pensize():设置画笔的宽度;B. turtle.pencolor():设置画笔的颜色;C. turtle.speed():设置画笔移动速度;D. turtle.distance():设置画笔移动距离(正确答案)答案解析:D5. Python中,下列哪个函数用于输出内容到终端?() [单选题] *A. print()(正确答案)B. output()C. import()D. echo()答案解析:A6. 变量x的值为字符串类型的“2”,如何将他转换为整型?() [单选题] *A. float(x)B. str(x)C. int(x)(正确答案)D. list(x)答案解析:C7. 以下设置画布命令正确的是:() [单选题] *A. turtle.screensize(800,blue, "600")B. turtle.screensize(800,600, "green")(正确答案)C. turtle.screensize("green";800;600)D. turtle.screensize("800","600", "green")答案解析:B8. 下列导入Turtle库的方式正确的是?() [单选题] *A. import turtle(正确答案)B. import (turtle)C. class turtleD. def turtle答案解析:A9. 下面的运算符中,按照运算优先级哪一个是最高级() [单选题] *A. ==B. *(正确答案)C.AndD. <答案解析:B10. Pthon中的>=代表的是() [单选题] *A. 把左边的值赋值给右边;B. 判断是否大于等于;(正确答案)C. 比较两边大小;D. 把右边值赋值给左边;答案解析:B11. a=10,b=20,那么print(b == a)运算的结果是() [单选题] *A. 10B. TrueC. False(正确答案)D. 20答案解析:C12. 下面哪一个不是Python的数据类型?() [单选题] *A. 列表(List)B. 元组(Tuples)C. 字典(Dictionary)D. 类(class)(正确答案)答案解析:D13. Python中,以下哪个变量赋值方式是正确的?() [单选题] *A. var a = 2B. int a = 2C.A = 2(正确答案)D. if a = 2答案解析:C14. 抛硬币,只有反正两种情况,为了统计方便,在程序中怎样做是最合理的?() [单选题] *A. 只需要一个变量,统计一种情况;B. 需要两个变量,统计两种情况;(正确答案)C. 需要三个变量,统计两种情况和总次数;D. 需要用到随机数,没有规律可找;答案解析:B15. 将4、5、6三个数不重复的排列为三位数,有几种排列?() [单选题] *A. 3B. 6(正确答案)C. 9D. 2答案解析:B16. 在Python中,以下哪个标记是用作多行注释的?() [单选题] *A. """(正确答案)B. ###C. ///D. ***答案解析:A17. 假设a=2,b=1,c = a and b - 1,那么c的值是() [单选题] *A. 3B. 1C. 2D. 0(正确答案)答案解析:D18. turtle.goto(x,y)的含义为?() [单选题] *A. 以目前坐标为原点,画一个边长为x和y的矩形(正确答案)B. 画笔提笔,移动到x,y的位置C. 按照现在画笔状态,将画笔移动到坐标为x,y的位置D. 将目前原点移动到x,y的位置答案解析:C19. print(6+8/2)输出的结果是() [单选题] *A. 7B. 10.0(正确答案)C. 10D. 6+8/2答案解析:B20. a="python3",print(2 * a)的结果是() [单选题] *A. python6B. python2C. python2python3D. python3python3(正确答案)答案解析:D21. 下列Python变量的使用正确的是?() [单选题] *A. 2a = 4B. my$ = 4C. class = 4;D.A = 4;(正确答案)答案解析:D22. 下列的哪个编程工具是Python自带的编程工具?() [单选题] *A. ipythonB. Visual Studio CodeC. JupyterNotebookD. IDLE(正确答案)答案解析:D23. 下面哪个命令是逆时针旋转90度?() [单选题] *A. turtle.right(90)B. turtle.left(90)(正确答案)C. turtle.goto(0,90)D. turtle.goto(90,0)答案解析:B24. Python中的除法是用哪个符号表示的?() [单选题] *A. *B. xC. /(正确答案)D. #答案解析:C25. 以下哪个后缀名为Python源码文件的后缀名?() [单选题] *A. .exe;B. .py;(正确答案)C. .sb3;D. .pip;答案解析:B26. 下列程序哪个是画一个三角形?() [单选题] *A. turtle.forward(100)turtle.left(120)turtle.forward(100)turtle.right(60)turtle.backward(100)(正确答案)B. turtle.forward(100)turtle.left(60)turtle.forward(100)turtle.right(60)turtle.backward(10 0)C. turtle.forward(100)turtle.left(120)turtle.forward(100)turtle.right(60)turtle.forward(100 )D. turtle.forward(100)turtle.left(120)turtle.forward(100)turtle.right(120)turtle.forward(10 0)答案解析:A27. 关于Python的表述,下列不正确的是?() [单选题] *A. Python是一种解释型程序设计语言;B. Python是一种面对对象型程序设计语言;C. Python是一种动态数据类型程序设计语言;D. Python是一种编译型程序设计语言。
pythonupdate函数

pythonupdate函数Python 是一种高级编程语言,因为它具有简单易懂、易学易用、面向对象、可扩展等优点而成为了程序员们的首选。
Python 的代码也很容易阅读和编写,因此它被全世界范围内的开发者广泛使用,并且还是科学计算、Web 开发等领域的必备工具。
Python 的开发社区很活跃,并且它有一个广泛的库生态圈,这意味着可以方便地获取、使用和共享代码。
这也是 Python 能够一直保持更新的重要原因之一。
为了更好地理解 Python 处于不断变化的状态,我们需要了解 Python 的更新机制。
在 Python 中,函数是一种非常重要的代码片段。
在这篇文章中,我们将重点介绍Python 中的 update 函数。
一、Python 的 update 函数在 Python 中,字典是一种非常重要的数据结构,它允许用户存储键值对。
update 函数是字典类中的一个内置函数,在一些应用场景中它非常有用。
update 函数的作用是将另一个字典中的键值对插入到当前字典中,或者用另一个字典中的键值对更新当前字典中的键值对。
以下是 Python 中 update 函数的基本语法:```dict.update(other_dict)```其中 dict 是需要更新的字典,other_dict 是另一个需要合并的字典。
该函数将会把 other_dict 中的所有键值对都插入或更新到字典 dict 中。
需要注意的是,如果 other_dict 中的键在 dict 中已经存在,则其他字典中的键值对将覆盖 dict 中已经存在的键值对。
下面是一些示例代码,说明 update 函数如何使用。
二、Python 的 update 函数示例示例 1:使用 update 函数将另一个字典中的键值对插入到当前字典中```dict1 = {'a': 1, 'b': 2}dict2 = {'c': 3, 'd': 4}dict1.update(dict2)print(dict1)```输出结果:```{'a': 1, 'b': 2, 'c': 3, 'd': 4}```在这个例子中,字典 dict1 包含键 'a' 和 'b',字典 dict2 包含键 'c' 和 'd'。
python常用库collections源码浅析

python常⽤库collections源码浅析前述:collections是python⽐较常⽤的库了,主要提供了⼀些⽐较常⽤的数据结构,其次为⽤户编写⾃⼰的python结构提供基类,不⽤list dict这些是因为cpython的原因,这些数据结构经常会⾛cpython的后门,不是纯python实现,还有就是⼤部分轮⼦原理不算难,其实研究研究对⾃⼰还是有好处的数据结构1__all__ = ['deque', 'defaultdict', 'namedtuple', 'UserDict', 'UserList',2'UserString', 'Counter', 'OrderedDict', 'ChainMap']34# For backwards compatibility, continue to make the collections ABCs5# available through the collections module.6from _collections_abc import *7import _collections_abc8__all__ += _collections_abc.__all__910from operator import itemgetter as _itemgetter, eq as _eq11from keyword import iskeyword as _iskeyword12import sys as _sys13import heapq as _heapq14from _weakref import proxy as _proxy15from itertools import repeat as _repeat, chain as _chain, starmap as _starmap16from reprlib import recursive_repr as _recursive_reprall⾥⾯就是所有的数据结构,这⾥不单独详解⽤法了,user前缀的是提供来做接⼝便利⽤户实现⾃⼰的数据结构,其他的是有特殊⽤途的数据结构⼤量使⽤了运算符重载,所以引⼊eq这些模块,⼜⽐如引⼊heapq堆实现Counter的功能1 collections包含了⼀些特殊的容器,针对Python内置的容器,例如list、dict、set和tuple,提供了另⼀种选择;23 namedtuple,可以创建包含名称的tuple;45 deque,类似于list的容器,可以快速的在队列头部和尾部添加、删除元素;6双端队列,⽀持从两端添加和删除元素。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
getchar();
gets(chars);
break;
case'3':
ByeBye();
default:
cout<<"BadInput!Tryagain:";
boolSpecialCharacters;
};
Flagsflags={false,false,false,false};//使用全局标志来简化程序实现
boolUserDefined;
charchars[MaxCharNum];//全局数组
charpass[MaxPassLen];
<<"1.AllNumbers(0to9)"<<endl
<<"2.AllSmallLetters(atoz)"<<endl
<<"3.AllCapitalLetters(AtoZ)"<<endl
<<"4.AllPrintedSpecialCharacters"<<endl<<endl
voidGuide();//提供选择,并设置相应标志
voidBuild();//生成字典
voidGetPass(intstrlen,intpasslen,intnow,ofstream&fout);//递归函数,生成定长密码
voidAdvanced();//提供高级功能的选择菜单
voidAddPrefix();//添加前缀
<<" "
<<"Blog:"<<endl;
Label:
charchoice;
cout<<endl
<<"Pleaseselectoneofthefollows:"<<endl
<<"1.Makeadictionary"<<endl
cin>>maxpasslen;
intlen;
chartmp;
if(UserDefined==true){
len=strlen(chars);
for(inti=1;i<len;i++){
for(intj=0;j<i;j++){
if(chars[i]==chars[j]){ 来自err=true; }
}
}while(err);
break;
case'2':
UserDefined=true;
cout<<endl
<<"Pleaseenterallthecharactersthatyouselect(lessthan"<<MaxCharNum<<"):"
gotoLabel;
break;
case'2':
ByeBye();
default:
cout<<"BadInput!Tryagain:";
}
}while(choice<'1'||choice>'2');
case'2':
flags.SmallLetters=true;break;
case'3':
flags.CapitalLetters=true;break;
case'4':
flags.SpecialCharacters=true;break;
case'':
break;
default:
cout<<"BadInput!Tryagain:";
cout<<"BadInput!Tryagain:";
}
}while(choice<'1'||choice>'3');
cout<<endl
<<"Pleaseselectoneofthefollows:"<<endl
voidAddSuffix();//添加后缀
voidJoin();//合并字典
voidFilter();//过滤重复密码
voidByeBye();//退出程序运行
voidmain(){
cout<<endl
<<" "
<<"Welcometo7dicV1.0"<<endl
<<"Pleaseenteryourchoice(1to3):";
charchoice;
do{
cin>>choice;
switch(choice){
case'1':
cout<<endl
<<"Pleaseselectcharactersneeded:"<<endl
<<" "
<<"Codebychris7"<<endl
<<" "
<<"Fineshedat2005-8-21"<<endl
<<" "
<<"E-mail:[email]technevol@[/email]"<<endl
chars[i]=chars[len-1];
chars[len-1]='\0';
len--;
i--;
}
}
}
}
else{
len=0;
}
voidGuide(){
cout<<endl
<<"Pleaseselectonemodel:"<<endl
<<"1.GuideModel"<<endl
<<"er-definedModel"<<endl
<<"3.Exit"<<endl<<endl
for(tmp=':';tmp<'A';tmp++)chars[len++]=tmp;
for(tmp='[';tmp<'a';tmp++)chars[len++]=tmp;
for(tmp='{';tmp<='~';tmp++)chars[len++]=tmp;
}
}while(choice<'1'||choice>'3');
}
voidBuild(){
intmaxpasslen;
cout<<endl
<<"Pleaseenterthemaximumlenthofthepassword:";
[原创]一个简单的字典工具(C++源码)
文章标题:[原创]一个简单的字典工具(C++源码)顶部 chris7 发布于:2005-08-2216:06 [楼主][原创]一个简单的字典工具(C++源码)
文章作者:chris7
信息来源:邪恶八进制信息安全团队技术论坛
目前实现的主要功能:
1.制作字典
<<"2.Advancedtools"<<endl
<<"3.Exit"<<endl<<endl
<<"Pleaseenteryourchoice(1to3):";
do{
cin>>choice;
switch(choice){
case'1':
Guide();
Build();
break;
case'2':
Advanced();
break;
case'3':
ByeBye();
default:
err=false;
for(i=0;i<strlen(nums);i++){
if(err==true)break;