层次分析法程序代码
层次分析法概述

一、层次分析法概述层次分析法是美国运筹学家Saaty教授于二十世纪80年代提出的一种实用的多方案或多目标的决策方法。
其主要特征是,它合理地将定性与定量的决策结合起来,按照思维、心理的规律把决策过程层次化、数量化。
问题该方法自1982年被介绍到我国以来,以其定性与定量相结合地处理各种决策因素的特点,以及其系统灵活简洁的优点,迅速地在我国社会经济各个领域内,如能源系统分析、城市规划、经济管理、科研评价等,得到了广泛的重视和应用。
二、层次分析法的基本思路:------先分解后综合的系统思想整理和综合人们的主观判断,使定性分析与定量分析有机结合,实现定量化决策。
首先将所要分析的问题层次化,根据问题的性质和要达到的总目标,将问题分解成不同的组成因素,按照因素间的相互关系及隶属关系,将因素按不同层次聚集组合,形成一个多层分析结构模型,最终归结为最低层(方案、措施、指标等)相对于最高层(总目标)相对重要程度的权值或相对优劣次序的问题。
三、层次分析法的用途举例例如,某人准备选购一台电冰箱,他对市场上的6种不同类型的电冰箱进行了解后,在决定买那一款式是,往往不是直接进行比较,因为存在许多不可比的因素,而是选取一些中间指标进行考察。
例如电冰箱的容量、制冷级别、价格、型式、耗电量、外界信誉、售后服务等。
然后再考虑各种型号冰箱在上述各中间标准下的优劣排序。
借助这种排序,最终作出选购决策。
在决策时,由于6种电冰箱对于每个中间标准的优劣排序一般是不一致的,因此,决策者首先要对这7个标准的重要度作一个估计,给出一种排序,然后把6种冰箱分别对每一个标准的排序权重找出来,最后把这些信息数据综合,得到针对总目标即购买电冰箱的排序权重。
有了这个权重向量,决策就很容易了。
四、层次分析法应用的程序运用AHP法进行决策时,需要经历以下4个步骤:1、建立系统的递阶层次结构;2、构造两两比较判断矩阵;(正互反矩阵)3、针对某一个标准,计算各备选元素的权重;4、计算当前一层元素关于总目标的排序权重。
java求矩阵的特征值和特征向量(AHP层次分析法计算权重)(附源代码)

java求矩阵的特征值和特征向量(AHP层次分析法计算权重)(附源代码) 这几天做一个项目,需要用到求矩阵的特征值特征向量。
我c++学的不好,所以就去网站找了很多java的源代码,来实现这个功能。
很多都不完善,甚至是不准确。
所以自己参考写了一个。
这个用于我一个朋友的毕业设计。
结果肯定正确。
话不多说,贴源代码!import java.math.BigDecimal;import java.util.Arrays;/*** AHP层次分析法计算权重** @since jdk1.6* @author 刘兴* @version 1.0* @date 2012.05.25**/public class AHPComputeWeight {/*** @param args*/public static void main(String[] args) {/** a为N*N矩阵*///double[][] a= {{1,1,1},{1,1,1},{1,1,1}};double[][] a ={{1,3,5},{2,3,1,},{4,7,3}};//double[][] a = {{1 ,1/5, 1/3},{5, 1, 1},{3,1,1}};//double[][] a ={{1, 1/2, 2, 1},{2, 1, 3, 4},{1/2 ,1/3, 1, 1},{1 ,1/4, 1, 1}};//double[][] a = {{1 ,0.5, 0.5},{2 ,1, 1},{2 ,1, 1}};//double[][] a = {{1, 1/4, 1/3, 1},{4, 1 ,3 ,5},{3, 1/3, 1, 4},{1, 1/5, 1/4, 1}};// double[][] a= {{1,2,3,5},{0.5,1,2,3},{0.33,0.5,1,2},{0.2,0.33,0.5,1}};int N = a[0].length;double[] weight = new double[N];AHPComputeWeight instance = AHPComputeWeight.getInstance();instance.weight(a, weight, N);System.out.println(Arrays.toString(weight));}// 单例private static final AHPComputeWeight acw = new AHPComputeWeight();// 平均随机一致性指针private double[] RI = { 0.00, 0.00, 0.58, 0.90, 1.12, 1.21, 1.32, 1.41,1.45, 1.49 };// 随机一致性比率private double CR = 0.0;// 最大特征值private double lamta = 0.0;/*** 私有构造*/private AHPComputeWeight() {}/*** 返回单例** @return*/public static AHPComputeWeight getInstance() { return acw;}/*** 计算权重** @param a* @param weight* @param N*/public void weight(double[][] a, double[] weight, int N) { // 初始向量Wkdouble[] w0 = new double[N];for (int i = 0; i < N; i++) {w0[i] = 1.0 / N;}// 一般向量W(k+1)double[] w1 = new double[N];// W(k+1)的归一化向量double[] w2 = new double[N];double sum = 1.0;double d = 1.0;// 误差double delt = 0.00001;while (d > delt) {d = 0.0;sum = 0;// 获取向量int index = 0;for (int j = 0; j < N; j++) {double t = 0.0;for (int l = 0; l < N; l++)t += a[j][l] * w0[l];// w1[j] = a[j][0] * w0[0] + a[j][1] * w0[1] + a[j][2] * w0[2];w1[j] = t;sum += w1[j];}// 向量归一化for (int k = 0; k < N; k++) {w2[k] = w1[k] / sum;// 最大差值d = Math.max(Math.abs(w2[k] - w0[k]), d);// 用于下次迭代使用w0[k] = w2[k];}}// 计算矩阵最大特征值lamta,CI,RIlamta = 0.0;for (int k = 0; k < N; k++) {lamta += w1[k] / (N * w0[k]);}double CI = (lamta - N) / (N - 1);if (RI[N - 1] != 0) {CR = CI / RI[N - 1];}// 四舍五入处理lamta = round(lamta, 3);CI = Math.abs(round(CI, 3));CR = Math.abs(round(CR, 3));for (int i = 0; i < N; i++) {w0[i] = round(w0[i], 4);w1[i] = round(w1[i], 4);w2[i] = round(w2[i], 4);}// 控制台打印输出System.out.println("lamta=" + lamta);System.out.println("CI=" + CI);System.out.println("CR=" + CR);// 控制台打印权重System.out.println("w0[]=");for (int i = 0; i < N; i++) {System.out.print(w0[i] + " ");}System.out.println("");System.out.println("w1[]=");for (int i = 0; i < N; i++) {System.out.print(w1[i] + " ");}System.out.println("");System.out.println("w2[]=");for (int i = 0; i < N; i++) {weight[i] = w2[i];System.out.print(w2[i] + " ");}System.out.println("");}/*** 四舍五入** @param v* @param scale* @return*/public double round(double v, int scale) {if (scale < 0) {throw new IllegalArgumentException("The scale must be a positive integer or zero");}BigDecimal b = new BigDecimal(Double.toString(v));BigDecimal one = new BigDecimal("1");return b.divide(one, scale, BigDecimal.ROUND_HALF_UP).doubleV alue();}/*** 返回随机一致性比率** @return*/public double getCR() {return CR;}}。
财务层次分析法(AHP)应用

•
11、现今,每个人都在谈论着创意,坦白讲,我害怕我们会假创意之名犯下一切过失。21.8.2419:21:3719:21Aug-2124-Aug-21
•
12、在购买时,你可以用任何语言;但在销售时,你必须使用购买者的语言。19:21:3719:21:3719:21Tuesday, August 24, 2021
实现?首先将所要分析的问题层次化根据问题的性质和要达到的总目标将问题分解成不同的组成因素按照因素间的相互关系及隶属关系将因素按不同层次聚集组合形成一个多层分析结构模型最终归结为最低层方案措施指标等相对于最高层总目标相对重要程度的权值或相对优劣次序的问题
层次分析法(AHP)应用简介
• 一、层次分析法概述 • 二、层次分析法的基本思路 • 三、层次分析法的用途举例 • 四、层次分析法应用的程序 • 五、应用层次分析法的注意事项 • 六、层次分析法应用实例
一、层次分析法概述
• 层次分析法是美国运筹学家Saaty教授于二 十世纪80年代提出的一种实用的多方案或多目 标的决策方法。其主要特征是,它合理地将定 性与定量的决策结合起来,按照思维、心理的 规律把决策过程层次化、数量化。问题该方法 自1982年被介绍到我国以来,以其定性与定量 相结合地处理各种决策因素的特点,以及其系 统灵活简洁的优点,迅速地在我国社会经济各 个领域内,如能源系统分析、城市规划、经济 管理、科研评价等,得到了广泛的重视和应用。
(2)规范列平均法(和法)
• 计算判断矩阵A各行各个元素mi的和;
• 将A的各行元素的和进行归一化;
• 该向量即为所求权重向量。
(3)计算矩阵A的最大特征值max
– 对于任意的i=1,2,…,n, 式中为向量AW 的第i个元素
层次分析法判断矩阵求权值以及一致性检验程序

function [w,CR]=mycom(A,m,RI)[x,lumda]=eig(A);r=abs(sum(lumda));n=find(r==max(r));max_lumda_A=lumda(n,n);max_x_A=x(:,n);w=A/sum(A);CR=(max_lumda_A-m)/(m-1)/RI;end本matlab程序用于层次分析法中计算判断矩阵给出的权值已经进行一致性检验。
其中A为判断矩阵,不同的标度和评定A将不同。
m为A的维数RI为判断矩阵的平均随机一致性指标:根据m的不同值不同。
当CR<0.1时符合一致性检验,判断矩阵构造合理。
下面是层次分析法的简介,以及判断矩阵构造方法。
一.层次分析法的含义层次分析法(The analytic hierarchy process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂(T.L.Saaty)正式提出。
它是一种定性和定量相结合的、系统化、层次化的分析方法。
由于它在处理复杂的决策问题上的实用性和有效性,很快在世界范围得到重视。
它的应用已遍及经济计划和管理、能源政策和分配、行为科学、军事指挥、运输、农业、教育、人才、医疗和环境等领域。
二.层次分析法的基本思路与人对一个复杂的决策问题的思维、判断过程大体上是一样的。
(1)层次分析法的原理层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后得用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递阶归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。
这里所谓“优先权重”是一种相对的量度,它表明各备择方案在某一特点的评价准则或子目标,标下优越程度的相对量度,以及各子目标对上一层目标而言重要程度的相对量度。
层次分析法比较适合于具有分层交错评价指标的目标系统,而且目标值又难于定量描述的决策问题。
层次分析法的

层次分析法的
层次分析法(AHP)是一种科学方法,它利用人的主观思维来做一些复杂的决策问题。
它
将一个复杂的主题分解成若干子问题,每个子问题都会有一个回答,最后通过计算机程序计算出最优的解决方案。
它的基本步骤是分析、估算、比较、定分。
首先,在分析阶段,研究人员要分析出影响决策的重要因素,并将它们有序地列出来。
层
次分析法有两个重要层次:目标层次和属性层次。
研究者会列出所有可能的目标和属性,
并且试图建立各个层次之间的关系。
接着,在估算阶段,研究者需要使用解释性分析方法来估算每个属性层次上层与下层之间
的重要程度。
比如,研究者可以询问不同的专家对属性层次的重要程度,或使用实验数据
来确定。
然后,在比较阶段,研究者需要比较两个不同属性的重要程度。
具体的方法是通过专家给
出的“比较矩阵”来计算,这个矩阵会表明两个属性层次的相对重要性。
最后,在定分阶段,研究者需要对每个属性给出一个最终分数,这个分数反映出所有调查
者对每个属性重要程度的结论。
然后研究者就可以获得最优的解决方案,也就是最重要的
属性及其相应的分数。
层次分析法可以严格控制复杂的决策问题,它利用专家的经验和主观判断和定量分析来权衡决策属性之间的关系,最大限度地减少决策不确定性。
它在决策分析领域使用十分广泛,十分有效果。
层次分析法判断矩阵求权值以及一致性检验程序

function [w,CR]=mycom(A,m,RI)[x,lumda]=eig(A);r=abs(sum(lumda));n=find(r==max(r));max_lumda_A=lumda(n,n);max_x_A=x(:,n);w=A/sum(A);CR=(max_lumda_A-m)/(m-1)/RI;end本matlab程序用于层次分析法中计算判断矩阵给出的权值已经进行一致性检验。
其中A为判断矩阵,不同的标度和评定A将不同。
m为A的维数RI为判断矩阵的平均随机一致性指标:根据m的不同值不同。
当CR<0.1时符合一致性检验,判断矩阵构造合理。
下面是层次分析法的简介,以及判断矩阵构造方法。
一.层次分析法的含义层次分析法(The analytic hierarchy process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂(T.L.Saaty)正式提出。
它是一种定性和定量相结合的、系统化、层次化的分析方法。
由于它在处理复杂的决策问题上的实用性和有效性,很快在世界范围得到重视。
它的应用已遍及经济计划和管理、能源政策和分配、行为科学、军事指挥、运输、农业、教育、人才、医疗和环境等领域。
二.层次分析法的基本思路与人对一个复杂的决策问题的思维、判断过程大体上是一样的。
(1)层次分析法的原理层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后得用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递阶归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。
这里所谓“优先权重”是一种相对的量度,它表明各备择方案在某一特点的评价准则或子目标,标下优越程度的相对量度,以及各子目标对上一层目标而言重要程度的相对量度。
层次分析法比较适合于具有分层交错评价指标的目标系统,而且目标值又难于定量描述的决策问题。
使用Matlab程序实现层次分析法(AHP)的简捷算法

使用Matlab程序实现层次分析法(AHP)的简捷算法作者:于晶来源:《科技风》2016年第16期摘要:层次分析法简便易懂,可操作性和实用性强,但是构造判断矩阵往往不容易,计算判断矩阵的特征值特别繁琐且易出错,得到的一致性检验不易调整,这些都给使用层次分析法带来困难,以往使用办公软件电子表格(Excel)的方法计算单层次排序和总层次排序,这种方法使得计算和一致性检验变得容易,文本使用Matlab程序使得计算变得更容易,也使得层次分析法在多个领域得到推广和应用。
关键词:层次分析法;Excel;matlab1 层次分析法(AHP法)的原理和解决思路层次分析法是对定性问题进行定量分析的一种简便、灵活而又实用的多准则决策方法。
它的原理是模拟人的决策过程,具有思路清晰、方法简便、适用面广、系统性强等特点。
是解决多目标、多准则、多层次复杂问题决策或者大型工程风险分析的有力工具。
层次分析法解决问题的思路就是用下一次因素的相对排序求得上一次因素的相对排序。
按照因素之间的相互影响和隶属关系将各层次因素聚类组合,形成一个递进有序的层次结构模型。
2 层次分析法的应用难点2.1合适的判断矩阵构造不易模型确定后,按照模型层次结构和模型的各因素的相对重要性,综合专家群体咨询意见,采用标度法[ 1 ],从数字1/9一9中选取恰当值,构造各层的判断矩阵,并使之尽量符合一致性检验,这一步成为问题的关键。
但实际上系统越复杂,判定矩阵的阶数就会越高,计算就会越困难。
2.2计算量大,步骤繁琐层次分析法首先要求的就是判断矩阵的最大特征值?姿max,及其正规化的特征向量w,向量w的分量wi是相应因素的单层次权值,这部分计算理论上基于线性代数知识,不用计算机也可以将其计算出来。
但实际上,当矩阵的阶数高于4阶时,人工计算就变得相当困难且易出错,如使用计算机计算,就容易得多,常用的方法有Basic语言,电子表格Excel等方法。
但计算量都有待改进。
用电子表格(Excel)实现层次分析法(AHP)的简捷计算

用电子表格(Excel)实现层次分析法(AHP)的简捷计算先锋(华南农业大学林学院,广东广州510640)摘要:传统的层次分析法算法具有构造判断矩阵不容易、计算繁多重复且易出错、一致性调整比较麻烦等缺点。
层次分析法Excel 算法利用常用的办公软件电子表格(Excel)的运算功能,设置简明易懂的计算表格和步骤,使得判断矩阵的构造、层次单排序和层次总排序的计算以及一致性检验和检验之后对判断矩阵的调整变得十分简单。
从而可以为层次分析法的学习、应用、推广和改进探讨提供方便。
关键词:层次分析法Excel1 层次分析法(AHP)的应用难点层次分析法(Analytical Hierarchy Process,简称AHP)是美国匹兹堡大学教授A.L.Saaty ,于20 世纪70 年代提出的一种系统分析方法,它综合了定性与定量分析,模拟人的决策思维过程,具有思路清晰、方法简便、适用面广、系统性强等特点,是分析多目标、多因素、多准则的复杂大系统的有力工具。
层次分析法的基本原理简单说就是用下一层次因素的相对排序来求得上一层次因素的相对排序。
应用层次分析法解决问题的思路是:首先把要解决的问题分出系列层次,即根据问题的性质和要达到的目标将问题分解为不同的组成因素,按照因素之间的相互影响和隶属关系将各层次各因素聚类组合,形成一个递阶的有序的层次结构模型;然后对模型中每一层次每一因素的相对重要性,依据人们对客观现实的判断给予定量表示(也可以先进行定性判断,再予赋值量化),再利用数学方法确定每一层次全部因素相对重要性次序的权值;最后通过综合计算各层因素相对重要性的权值,得到最低层(方案层)相对于较高层(分目标或准则层)和最高层(总目标)的相对重要性次序的组合权值,以此进行进行方案排序,作为评价和选择方案的依据。
层次分析法在多个领域得到广泛应用,但在应用中也是确实存在着不少难点。
1.1 构造一个合适的判断矩阵不容易建立层次结构模型和构造判断矩阵是层次分析法的主要基本工作,构造判断矩阵是关键之关键。
层次分析法及matlab程序

层次分析法建模层次分析法(AHP-Analytic Hierachy process)---- 多目标决策方法70 年代由美国运筹学家T·L·Satty提出的,是一种定性与定量分析相结合的多目标决策分析方法论.吸收利用行为科学的特点,是将决策者的经验判断给予量化,对目标(因素)结构复杂而且缺乏必要的数据情况下,採用此方法较为实用,是一种系统科学中,常用的一种系统分析方法,因而成为系统分析的数学工具之一。
传统的常用的研究自然科学和社会科学的方法有:机理分析方法:利用经典的数学工具分析观察的因果关系;统计分析方法:利用大量观测数据寻求统计规律,用随机数学方法描述(自然现象、社会现象)现象的规律。
基本内容:(1)多目标决策问题举例AHP建模方法(2)AHP建模方法基本步骤(3)AHP建模方法基本算法(3)AHP建模方法理论算法应用的若干问题。
参考书:1、姜启源,数学模型(第二版,第9章;第三版,第8章),高等教育出版社2、程理民等, 运筹学模型与方法教程,(第10章),清华大学出版社3、《运筹学》编写组,运筹学(修订版),第11章,第7节,清华大学出版社一、问题举例:A.大学毕业生就业选择问题获得大学毕业学位的毕业生,“双向选择”时,用人单位与毕业生都有各自的选择标准和要求。
就毕业生来说选择单位的标准和要求是多方面的,例如:①能发挥自己的才干为国家作出较好贡献(即工作岗位适合发挥专长);②工作收入较好(待遇好);③生活环境好(大城市、气候等工作条件等);④单位名声好(声誉—Reputation);⑤工作环境好(人际关系和谐等)⑥发展晋升(promote,promotion)机会多(如新单位或单位发展有后劲)等。
问题:现在有多个用人单位可供他选择,因此,他面临多种选择和决策,问题是他将如何作出决策和选择?——或者说他将用什么方法将可供选择的工作单位排序?工作选择贡献收入发展声誉工作环境生活环境B.假期旅游地点选择暑假有3个旅游胜地可供选择.例如:1P :苏州杭州,2P 北戴河,3P 桂林,到底到哪个地方去旅游最好?要作出决策和选择。
AHP(层次分析法)附Python示例代码(觉得还可以的,帮忙点个赞,谢谢)

AHP(层次分析法)附Python⽰例代码(觉得还可以的,帮忙点个赞,谢谢) AHP(层次分析法) 层次分析法(The analytic hierarchy process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂(TLsaaty)正式提出。
它是⼀种定性和定量相结合的、系统化、层次化的分析⽅法。
由于它在处理复杂的决策问题上的实⽤性和有效性,很快在世界范围得到重视。
它的应⽤已遍及经济计划和管理、能源政策和分配、⾏为科学、军事指挥、运输、农业、教育、⼈才、医疗和环境等领域。
层次分析法的基本步骤1、建⽴层次结构模型。
在深⼊分析实际问题的基础上,将有关的各个因素按照不同属性地分解成若⼲层次,同⼀层的诸因素从属于上⼀层的因素或对上层因素有影响,同时⼜⽀配下⼀层的因素或受到下层因素的作⽤。
最上层为⽬标层,通常只有1个因素,最下层通常为⽅案或对象层,中间可以有⼀个或⼏个层次,通常为准则或指标层。
当准则过多时(譬如多于9个)应进⼀步分解出⼦准则层。
2、构造成对⽐较阵。
从层次结构模型的第2层开始,对于从属于(或影响)上⼀层每个因素的同⼀层诸因素,⽤和1—9⽐较尺度构造成对⽐较阵,直到最下层。
3、计算权向量并做⼀致性检验。
对于每⼀个成对⽐较阵计算最⼤特征根及对应特征向量,利⽤⼀致性指标、随机⼀致性指标和⼀致性⽐率做⼀致性检验。
若检验通过,特征向量(归⼀化后)即为权向量:若不通过,需重新构造成对⽐较阵。
4、计算组合权向量并做组合⼀致性检验。
计算最下层对⽬标的组合权向量,并根据公式做组合⼀致性检验,若检验通过,则可按照组合权向量表⽰的结果进⾏决策,否则需要重新考虑模型或重新构造那些⼀致性⽐率较⼤的成对⽐较阵。
建⽴层次结构模型例--选拔⼲部模型 对三个⼲部候选⼈y 1、y 2、y 3,按选拔⼲部的五个标准:品德、才能、资历、年龄和群众关系,构成如下层次分析模型:假设有三个⼲部候选⼈y 1、y 2、y 3,按选拔⼲部的五个标准:品德,才能,资历,年龄和群众关系,构成如下层次分析模型构造成对⽐较矩阵⽐较第i个元素与第j个元素相对上⼀层某个因素的重要性时,使⽤数量化的相对a i j来描述。
层次分析法简介1

• • • • • • 一、层次分析法概述 二、层次分析法的基本思路 三、层次分析法的用途举例 四、层次分析法应用的程序 五、应用层次分析法的注意事项 六、层次分析法应用实例
一、层次分析法概述
•
层次分析法是美国运筹学家Saaty教授于二 十世纪80年代提出的一种实用的多方案或多目 标的决策方法。其主要特征是,它合理地将定 性与定量的决策结合起来,按照思维、心理的 规律把决策过程层次化、数量化。问题该方法 自1982年被介绍到我国以来,以其定性与定量 相结合地处理各种决策因素的特点,以及其系 统灵活简洁的优点,迅速地在我国社会经济各 个领域内,如能源系统分析、城市规划、经济 管理、科研评价等,得到了广泛的重视和应用。
• 一般而言CR愈小,判断矩阵的 一致性愈好,通常认为CR0.1时, 判断矩阵具有满意的一致性。
六、层次分析法应用实例
• 1、建立国民素质评价系统的递阶层次结构;
• 2、构造两两比较判断矩阵;(正互反矩阵) • 根据层次分析模型示意图所示,每位问卷评分 者就可以依据个人对评价指标的主观评价,进 行综合分析,对各指标之间进行两两对比之后, 然后按9分位比率排定各评价指标的相对优劣 顺序,依次构造出评价指标的判断矩阵。
三、层次分析法的用途举例
•
例如,某人准备选购一台电冰箱,他对市场上的 6种不同类型的电冰箱进行了解后,在决定买那一款式 是,往往不是直接进行比较,因为存在许多不可比的 因素,而是选取一些中间指标进行考察。例如电冰箱 的容量、制冷级别、价格、型式、耗电量、外界信誉、 售后服务等。然后再考虑各种型号冰箱在上述各中间 标准下的优劣排序。借助这种排序,最终作出选购决 策。在决策时,由于6种电冰箱对于每个中间标准的优 劣排序一般是不一致的,因此,决策者首先要对这7个 标准的重要度作一个估计,给出一种排序,然后把6种 冰箱分别对每一个标准的排序权重找出来,最后把这 些信息数据综合,得到针对总目标即购买电冰箱的排 序权重。有了这个权重向量,决策就很容易了。
python实现AHP算法的方法实例(层次分析法)

python实现AHP算法的⽅法实例(层次分析法)⼀、层次分析法原理层次分析法(Analytic Hierarchy Process,AHP)由美国运筹学家托马斯·塞蒂(T. L. Saaty)于20世纪70年代中期提出,⽤于确定评价模型中各评价因⼦/准则的权重,进⼀步选择最优⽅案。
该⽅法仍具有较强的主观性,判断/⽐较矩阵的构造在⼀定程度上是拍脑门决定的,⼀致性检验只是检验拍脑门有没有⾃相⽭盾得太离谱。
相关的理论参考可见:⼆、代码实现需要借助Python的numpy矩阵运算包,代码最后⽤了⼀个b1矩阵进⾏了调试,相关代码如下,具体的实现流程已经⽤详细的注释标明,各位⼩伙伴有疑问的欢迎留⾔和我⼀起讨论。
import numpy as npclass AHP:"""相关信息的传⼊和准备"""def __init__(self, array):## 记录矩阵相关信息self.array = array## 记录矩阵⼤⼩self.n = array.shape[0]# 初始化RI值,⽤于⼀致性检验self.RI_list = [0, 0, 0.52, 0.89, 1.12, 1.26, 1.36, 1.41, 1.46, 1.49, 1.52, 1.54, 1.56, 1.58,1.59]# 矩阵的特征值和特征向量self.eig_val, self.eig_vector = np.linalg.eig(self.array)# 矩阵的最⼤特征值self.max_eig_val = np.max(self.eig_val)# 矩阵最⼤特征值对应的特征向量self.max_eig_vector = self.eig_vector[:, np.argmax(self.eig_val)].real# 矩阵的⼀致性指标CIself.CI_val = (self.max_eig_val - self.n) / (self.n - 1)# 矩阵的⼀致性⽐例CRself.CR_val = self.CI_val / (self.RI_list[self.n - 1])"""⼀致性判断"""def test_consist(self):# 打印矩阵的⼀致性指标CI和⼀致性⽐例CRprint("判断矩阵的CI值为:" + str(self.CI_val))print("判断矩阵的CR值为:" + str(self.CR_val))# 进⾏⼀致性检验判断if self.n == 2: # 当只有两个⼦因素的情况print("仅包含两个⼦因素,不存在⼀致性问题")else:if self.CR_val < 0.1: # CR值⼩于0.1,可以通过⼀致性检验print("判断矩阵的CR值为" + str(self.CR_val) + ",通过⼀致性检验")return Trueelse: # CR值⼤于0.1, ⼀致性检验不通过print("判断矩阵的CR值为" + str(self.CR_val) + "未通过⼀致性检验")return False"""算术平均法求权重"""def cal_weight_by_arithmetic_method(self):# 求矩阵的每列的和col_sum = np.sum(self.array, axis=0)# 将判断矩阵按照列归⼀化array_normed = self.array / col_sum# 计算权重向量array_weight = np.sum(array_normed, axis=1) / self.n# 打印权重向量print("算术平均法计算得到的权重向量为:\n", array_weight)# 返回权重向量的值return array_weight"""⼏何平均法求权重"""def cal_weight__by_geometric_method(self):# 求矩阵的每列的积col_product = np.product(self.array, axis=0)# 将得到的积向量的每个分量进⾏开n次⽅array_power = np.power(col_product, 1 / self.n)# 将列向量归⼀化array_weight = array_power / np.sum(array_power)# 打印权重向量print("⼏何平均法计算得到的权重向量为:\n", array_weight)# 返回权重向量的值return array_weight"""特征值法求权重"""def cal_weight__by_eigenvalue_method(self):# 将矩阵最⼤特征值对应的特征向量进⾏归⼀化处理就得到了权重array_weight = self.max_eig_vector / np.sum(self.max_eig_vector)# 打印权重向量print("特征值法计算得到的权重向量为:\n", array_weight)# 返回权重向量的值return array_weightif __name__ == "__main__":# 给出判断矩阵b = np.array([[1, 1 / 3, 1 / 8], [3, 1, 1 / 3], [8, 3, 1]])# 算术平均法求权重weight1 = AHP(b).cal_weight_by_arithmetic_method()# ⼏何平均法求权重weight2 = AHP(b).cal_weight__by_geometric_method()# 特征值法求权重weight3 = AHP(b).cal_weight__by_eigenvalue_method()总结到此这篇关于python实现AHP算法(层次分析法)的⽂章就介绍到这了,更多相关python AHP算法(层次分析法)内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
层次分析法程序代码
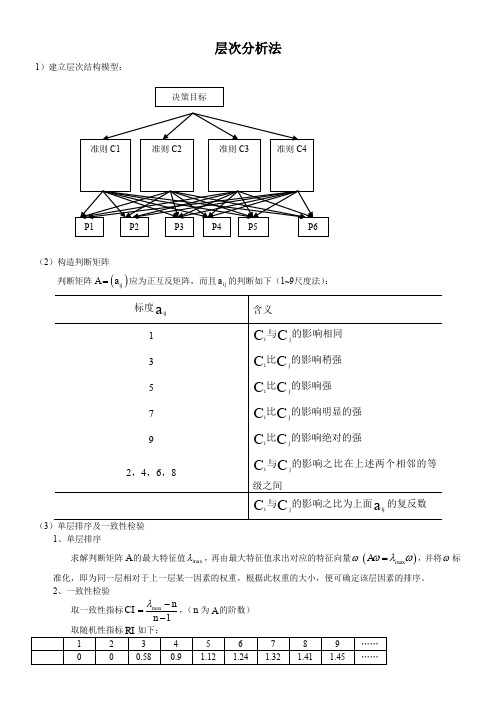
层次分析法1)建立层次结构模型:(2)构造判断矩阵判断矩阵()ij A a =应为正互反矩阵,而且ij a 的判断如下(1~9尺度法):(3)单层排序及一致性检验1、单层排序求解判断矩阵A 的最大特征值max λ,再由最大特征值求出对应的特征向量ω()max A ωλω=,并将ω标准化,即为同一层相对于上一层某一因素的权重,根据此权重的大小,便可确定该层因素的排序。
2、一致性检验取一致性指标max 1nCI n λ-=-,(n 为A 的阶数)令CICR RI=,若0.1CR <,则认为A 具有一致性。
否则,需要对A 进行调整,直到具有满意的一致性为止。
(4)层次总排序及一致性检验假定准则层12,,,n C C C 排序完成,其权重分别为12,,,n a a a ,方案层P 包含m 个方案:12,,,m P P P 。
其相对于上一层的()1,2,,j C j n =对方案层P 中的m 个方案进行单层排序,其排序权重记为12,,,j j mj b b b()1,2,,j n =,则方案层P 中第i 个方案Pi 的总排序权重为1nj ij j a b =∑,见下表:从而确定层的排序。
例:纯文本文件txt3.txt 中的数据格式如下:1 1 1 4 1 1/2 1 1 2 4 1 1/2 1 1/2 1 53 1/2 1/4 1/4 1/5 1 1/3 1/3 1 1 1/3 3 1 1 2 2 2 3 3 1 1 1/4 1/2 4 1 3 2 1/3 1 1 1/4 1/5 4 1 1/2 5 2 1 1 3 1/3 1/3 1 1/7 3 7 1 1 1/3 5 3 1 7 1/5 1/7 1 1 1 7 1 1 7 1/7 1/7 1 1 7 9 1/7 1 1 1/9 1 1 matlab 程序:>> fid=fopen('txt3.txt','r');n1=6;n2=3;a=[];for i=1:n1tmp=str2num(fgetl(fid));a=[a;tmp]; %读准则层判断矩阵endfor i=1:n1str1=char(['b',int2str(i),'=[];']);str2=char(['b',int2str(i),'=[b',int2str(i),';tmp];']); eval(str1);for j=1:n2tmp=str2num(fgetl(fid));eval(str2); %读方案层的判断矩阵endendri=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45]; %一致性指标[x,y]=eig(a);lamda=max(diag(y));num=find(diag(y)==lamda);w0=x(:,num)/sum(x(:,num));cr0=(lamda-n1)/(n1-1)/ri(n1)for i=1:n1[x,y]=eig(eval(char(['b',int2str(i)])));lamda=max(diag(y));num=find(diag(y)==lamda);w1(:,i)=x(:,num)/sum(x(:,num));cr1(i)=(lamda-n2)/(n2-1)/ri(n2);endcr1, ts=w1*w0, cr=cr1*w0。
层次分析法中高阶平均随机一致性指标(RI)的计算

比 未 能 穷 尽 的 不 足 ,对 判 断 矩 阵 做 一 致 性 检 验 ,成 为 不 可 或 缺 的 环 节 [6]。
在 对 判 断 矩 阵 进 行 一 致 性 检 验 时 ,要 使 用 平 均 随 机 一 致 性 指标(RI)参与计算[7]。一般而言,对于低阶判断矩阵(阶数 N! 15),其 平 均 随 机 一 致 性 指 标 可 以 查 表 得 到 ;但 对 于 高 阶 判 断 矩 阵(阶数 N>15),平均随机一致性指标的值就无法直接获取了[8]。 该 文 提 出 的 算 法 ,正 是 解 决 了 两 两 比 较 判 断 矩 阵 中 高 阶 平 均 随 机 一 致 性 指 标(RI)的 计 算 问 题 。
1 引言
层 次 分 析 法(Anaiytic Hierarchy Process,简 称 AHP)是 20 世 纪 70 年 代 由 Thomas Saaty 提 出 的 一 种 定 性 问 题 定 量 化 的 行之有效的方法[3]。AHP 的应用范围十分广泛,涉及军事指挥、 经 济 分 析 和 计 划 、行 为 科 学 、管 理 信 息 系 统 、运 筹 学 方 法 评 价 和 教育等许多领域。
(2 Computer Dep.,USTC,Hefei 230027)
Abstract: To anaiyze and soive probiems with Anaiytic Hierarchy Process needs a check on the consistency of a matrix coming from a two -two comparison [1].Usuaiiy peopie can hardiy get the vaiue of High -Ranked R.I.immediateiy through consuiting reiated tabies,and as a resuit,it hinders a mass of appiications of Anaiytic Hierarchy Process[2].0n the basis of a thorough anaiysis of Anaiytic Hierarchy Process,the aigorithm to caicuiate out the vaiue of High-Ranked R I according to the definition of R I is offered in the paper.The program of the aigorithm under windows using deiphi 6.0 is provided as weii.The aigorithm has been successfuiiy appiied to a project of the inteiiigent decision system in the knowiedge innovation of Chinese Academy of Sciences.
层次分析法简介

• 一般而言CR愈小,判断矩阵的 一致性愈好,通常认为CR≤0.1时, 判断矩阵具有满意的一致性。
3、针对某一个标准,计算各备选元素的权重; • 关于判断矩阵权重计算的方法有两种,即几何 平均法(根法)和规范列平均法(和法)。 • (1)几何平均法(根法) • 计算判断矩阵A各行各个元素mi的乘积; • 计算mi的n次方根; • 对向量进行归一化处理; • 该向量即为所求权重向量。
(2)规范列平均法(和法)
六、层次分析法应用实例
• 1、建立国民素质评价系统的递阶层次结构 建立国民素质评价系统的递阶层次结构; 建立国民素质评价系统的递阶层次结构 • 2、构造两两比较判断矩阵;(正互反矩阵) • 根据层次分析模型示意图所示,每位问卷评分 者就可以依据个人对评价指标的主观评价,进 行综合分析,对各指标之间进行两两对比之后, 然后按9分位比率排定各评价指标的相对优劣 顺序,依次构造出评价指标的判断矩阵。
三、层次6种不同类型的电冰箱进行了解后,在决定买那一款式 是,往往不是直接进行比较,因为存在许多不可比的 因素,而是选取一些中间指标进行考察。例如电冰箱 的容量、制冷级别、价格、型式、耗电量、外界信誉、 售后服务等。然后再考虑各种型号冰箱在上述各中间 标准下的优劣排序。借助这种排序,最终作出选购决 策。在决策时,由于6种电冰箱对于每个中间标准的优 劣排序一般是不一致的,因此,决策者首先要对这7个 标准的重要度作一个估计,给出一种排序,然后把6种 冰箱分别对每一个标准的排序权重找出来,最后把这 些信息数据综合,得到针对总目标即购买电冰箱的排 序权重。有了这个权重向量,决策就很容易了。
• 计算判断矩阵A各行各个元素mi的和;
• 将A的各行元素的和进行归一化;
• 该向量即为所求权重向量。
matlab-层次分析法一致性

用了两周左右的时间,我编写了网络分析法(The Analytic Network Process,ANP)的Matlab源代码(将在下面给出),主要针对王莲芬老师的《网络分析法(ANP)的理论与算法》中的内部依存的递阶层次结构,而且假设N = 4 的情形,所以如果要使用该程序,需要作修改,如果你不想改,我可以帮忙!ANP是美国匹兹堡大学的T.L.Saaty 教授于1996年提出了一种适应非独立的递阶层次结构的决策方法,它是在网络分析法(AHP)基础上发展而形成的一种新的实用决策方法。
其关键步骤有以下几个:1 确定因素,并建立网络层和控制层模型。
2 创建比较矩阵。
3 按照指标类型针对每列进行规范化。
4 求出每个比较矩阵的最大特征值和对应的特征向量。
5 一致性检验。
如果不满足,则调整相应的比较矩阵中的元素。
6 将各个特征向量单位化(归一化),组成判断矩阵。
7 将控制层的判断矩阵和网络层的判断矩阵相乘,得到加权超矩阵。
8 将加权超矩阵单位化(归一化),求其K次幂收敛时的矩阵。
其中第j列就是网络层中各元素对于元素j的极限排序向量。
% 第一个函数% 矩阵归一化(单位化)% Unitize 函数开始function Matrix_Unitize = Unitize(Matrix)[line,colume] = size(Matrix);for j = 1:1:columefa = 0;for i = 1:1:linefa = fa + Matrix(i,j);endsum(j) = fa;endfor j = 1:1:columefor i = 1:1:lineMatrix_Unitize(i,j) = Matrix(i,j) / sum(j);endend% Unitize 函数结束% 第二个函数% 求一个方阵的最大特征值及其对应的特征向量% MAX_EigenV 函数开始function [Max_Eigenvector,Max_Eigenvalue] = Max_EigenV(Matrix)[line,colume] = size(Matrix);if line ~= columemessage = '矩阵不是方阵,无法求解最大特征值及其对应的特征向量';disp(message);return;end[Eigenvector Eigenvalue] = eigs(Matrix);Max_Eigenvalue = Eigenvalue(1);for i=1:1:lineMax_Eigenvector(i) = Eigenvector(i,1);end% MAX_EigenV 函数结束% 第三个函数(此函数我没有用)% 根据给定的指标类型对矩阵的列进行规范化% Standardize 函数开始function Matrix_Standardize = Standardize(Matrix, IndexType)% a 是需要规范化的矩阵% IndexType 是该矩阵各列的指标类型数组% IndexType(j) = 1 a 的第j 列是效益型指标% IndexType(j) = 0 a 的第j 列是成本型指标[m n] = size(Matrix);MAX = max(Matrix);MIN = min(Matrix);d = MAX - MIN;for j=1:1:nfor i=1:1:mif IndexType(j) == 1 % 效益型指标规范化Matrix_Standardize(i,j) = (Matrix(i,j) - MIN(j)) / d(j);elseif IndexType(j) == 0 % 成本型指标规范化Matrix_Standardize(i,j) = (MAX(j) - Matrix(i,j)) / d(j);endendend% Standardize 函数结束% 第四个函数% 读取一个格式化文件中所有矩阵,连接成归一化的判断矩阵% 计算最大特征值对应的特征向量,进行一致性检验,构造判断矩阵.% version 2.0% 矩阵文件的(*.txt)格式要求(共4条)% 1 空格开头的行,回车行,注释行(见第3条)在读取时都会被忽略.%% 2 每个矩阵要有维数(Dimension)和序号(Sequence),其次序可以颠倒,但是不能缺项,% 且关键字及其取值要各占一行(共4行,中间可以有空格行或空行),但关键字行尾不能有空格.%% 3 竖线"|"是注释标记,要独自占一行,但是不要在有效的矩阵元素行之后加竖线.%% 4 矩阵的元素只能用空格分开,每个元素后都可以跟空格,且空格的数量可以是任意多个. % 但是,需要强调的是,每一行第一个元素的前面不能有空格(参照第1条)!% JudgementMatrix 函数开始function [judge_matrix_unitize,flag] = JudgementMatrix(fid)judge_matrix = 0;judge_matrix_unitize = 0;flag = 0; % 判断矩阵构造成功的标志LineData = IgnoreLine(fid); % 跳到第一行有效的数据Count = 0; % 矩阵计数器Flag1 = 0; % 是否读取矩阵序号的开关Flag2 = 0; % 是否读取矩阵列数的开关Flag3 = 0; % 是否读取矩阵行数的开关Sequence = 0; % 矩阵的序号Dimension = 0; % 矩阵的阶DCount = 0; % 同一文件中每个矩阵的阶数下标LastCount = 0; % 同一文件中上一个矩阵的阶数下标while( feof(fid) == 0 )if strcmp(LineData, 'Sequence')LineData = IgnoreLine(fid);if LineData == -1warning('已经到了文件末尾,无数据可读取!');flag = -1;return;endSequence = str2num(LineData);Flag1 = Flag1 + 1;elseif strcmp(LineData, 'Dimension')LineData = IgnoreLine(fid);if LineData == -1warning('已经到了文件末尾,无数据可读取!');flag = -1;return;endDCount = DCount + 1;Dimension(DCount) = str2num(LineData);LastCount = DCount-1;if LastCount > 0 && Dimension(DCount) ~= Dimension(LastCount) flag = -1;warning('矩阵的维数不等,比较矩阵弄错了吧!');endFlag2 = Flag2 + 1;endif ( Flag1 > 1 || Flag2 > 1 )if Flag1 > 1c = num2str(Sequence);c = strcat('第',c);message = strcat(c, '个矩阵的上一个矩阵没有设置维数关键字"Dimension"!');flag = -1;warning(message);return;elseif Flag2 > 1c = num2str(Sequence);c = strcat('第',c);message = strcat(c, '个矩阵的上一个矩阵没有设置序号关键字"Sequence"!');warning(message);flag = -1;return;endelseif ( Flag1 == 0 && Flag2 ==0 )warning('没有发现矩阵的序号或行数或列数关键字!请参考文件格式要求!');flag = -1;return;elseif ( Flag1 == 1 && Flag2 == 1 )Matrix = 0;% 为了读分数矩阵,逐行读取再变为数值类型for i = 1:1:Dimension(DCount)LineData = IgnoreLine(fid);if LineData == -1warning('已经到了文件末尾,无数据可读取!');flag = -1;judge_matrix_unitize = Unitize(Matrix);return;endDoubleLine = str2num(LineData);[line_DoubleLine,colume_DoubleLine] = size(DoubleLine);if colume_DoubleLine ~= Dimension(DCount)flag = -1;endfor j = 1:1:colume_DoubleLineMatrix(i,j) = DoubleLine(j);endendif flag == -1judge_matrix_unitize = Unitize(Matrix);return;endif isreal(Matrix)Count = Count + 1;if Sequence ~= Countc = num2str(Sequence);c = strcat('文件中编号为',c);message = strcat(c,'的矩阵的序号没有按照顺序排列!');warning(message);end% 最大特征值及其对应的特征向量[vector_lmd_max,lmd_max(Count)] = MaxEV(Matrix);for j = 1:1:Dimension(DCount)judge_matrix(Count,j) = vector_lmd_max(j);end% 一致性检验CI(Count) = 0; % 一致性指标% 当矩阵的阶数n < 3 时,判断矩阵永远具有完全一致性。
层次分析法判断矩阵求权值以及一致性检验程序

层次分析法判断矩阵求权值以及一致性检验程序以下是一种基于层次分析法的判断矩阵求权值以及一致性检验的程序:第一步:确定目标和准则层首先,明确分析的目标以及需要进行比较和排序的准则。
例如,在选择旅游目的地的决策中,目标可以是选择最适合个人喜好的目的地,而准则可以包括交通便利性、旅游景点的丰富程度、美食水平等。
第二步:构建判断矩阵根据目标和准则,构建判断矩阵,矩阵的大小为n*n,其中n是准则的个数。
判断矩阵中的元素对应于两两准则之间的比较结果。
例如,对于两个准则i和j,可以使用1-9的尺度来表示它们之间的重要程度,其中1表示相同重要,9表示极端重要。
如果准则i相对于准则j更重要,则在判断矩阵的(i,j)位置上填写9、判断矩阵的对角线元素全为1,因为每个准则相对于自身的重要性是相同的。
第三步:求判断矩阵的权值利用判断矩阵求解初始权值的过程主要分为两个步骤:特征根法和一致性检验。
1.特征根法求解判断矩阵的特征值和对应的特征向量,通过特征向量的归一化,得到各个准则的权重。
2.一致性检验判断矩阵是否具有一致性,即各个准则的权重是否合理。
这里使用一致性指标CI(Consistency Index)和一致性比例CR(Consistency Ratio)来进行检验。
CR的计算公式为CR = CI/RI,其中RI是一个随着准则个数n而变化的随机一致性指数,可以在AHP的标准表格中查找。
第四步:一致性检验与调整如果CR小于一些事先设定的阈值(通常为0.1),则认为判断矩阵通过一致性检验,各个准则的权重是合理的;否则,需要对判断矩阵进行调整。
判断矩阵的调整可以通过以下步骤进行:1.计算判断矩阵的平均列向量2.计算平均列向量的加权平均向量3.计算调整后的判断矩阵4.重复进行一致性检验和调整,直至通过一致性检验为止第五步:权值的应用经过一致性检验和调整后,各个准则的权重即为最终结果。
可以将权重应用于具体的决策问题中,进行多个准则的比较和排序。
(完整版)层次分析法计算权重在matlab中的实现

信息系统分析与设计作业层次分析法确定绩效评价权重在matlab中的实现小组成员:孙高茹、王靖、李春梅、郭荣1 程序简要概述编写程序一步实现评价指标特征值lam、特征向量w以及一致性比率CR的求解。
具体的操作步骤是:首先构造评价指标,用专家评定法对指标两两打分,构建比较矩阵,继而运用编写程序实现层次分析法在MATLAB中的应用。
通过编写MATLAB程序一步实现问题求解,可以简化权重计算方法与步骤,减少工作量,从而提高人力资源管理中绩效考核的科学化电算化。
2 程序在matlab中实现的具体步骤function [w,lam,CR] = ccfx(A)%A为成对比较矩阵,返回值w为近似特征向量% lam为近似最大特征值λmax,CR为一致性比率n=length(A(:,1));a=sum(A);B=A %用B代替A做计算for j=1:n %将A的列向量归一化B(:,j)=B(:,j)./a(j);ends=B(:,1);for j=2:ns=s+B(:,j);endc=sum(s);%计算近似最大特征值λmaxw=s./c;d=A*wlam=1/n*sum((d./w));CI=(lam-n)/(n-1);%一致性指标RI=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45,1.49,1.51];%RI为随机一致性指标CR=CI/RI(n);%求一致性比率if CR>0.1disp('没有通过一致性检验');else disp('通过一致性检验');endend3 案例应用我们拟构建公司员工绩效评价分析权重,完整操作步骤如下:3.1构建的评价指标体系我们将影响员工绩效评定的指标因素分为:打卡、业绩、创新、态度与品德。
3.2专家打分,构建两两比较矩阵A =1.0000 0.5000 3.0000 4.00002.0000 1.0000 5.00003.00000.3333 0.2000 1.0000 2.00000.2500 0.3333 0.5000 1.00003.3在MATLAB中运用编写好的程序实现直接在MATLAB命令窗口中输入[w,lam,CR]=ccfx(A)继而直接得出d =1.30352.00000.51450.3926w =0.31020.46910.12420.0966lam =4.1687CR =0.0625,通过一致性检验3.4解读程序结果根据程序求解中得出的特征向量,可以得出打卡、业绩、创新以及态度品德在员工绩效评价中所占的权重分别为:0.3102、0.4691、0.1242、0.0966。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
层次分析法
1)建立层次结构模型:
(2)构造判断矩阵
判断矩阵()
ij A a =应为正互反矩阵,而且ij a 的判断如下(1~9尺度法):
(3)单层排序及一致性检验
1、单层排序
求解判断矩阵A 的最大特征值max λ,再由最大特征值求出对应的特征向量
ω()max A ωλω=,并将ω标准化,即为同一层相对于上一层某一因素的权重,根据此
权重的大小,便可确定该层因素的排序。
2、一致性检验
取一致性指标max 1
n
CI n λ-=
-,(n 为A 的阶数)
取随机性指标RI 如下:
令CR RI
=
,若0.1CR <,则认为A 具有一致性。
否则,需要对A 进行调整,直到具有满意的一致性为止。
(4)层次总排序及一致性检验
假定准则层12,,,n C C C L 排序完成,其权重分别为12,,,n a a a L ,方案层P 包含m 个方案:12,,,m P P P L 。
其相对于上一层的()1,2,,j C j n =L 对方案层P 中的m 个方案进行单层排序,其排序权重记为12,,,j j mj b b b L ()1,2,,j n =L ,则方案层P 中第i 个方案Pi 的总
排序权重为
1
n
j ij
j a b
=∑,见下表:
从而确定P层的排序。
例:
纯文本文件txt3.txt中的数据格式如下:1 1 1 4 1 1/2
1 1
2 4 1 1/2
1 1/
2 1 5
3 1/2
1/4 1/4 1/5 1 1/3 1/3
1 1 1/3 3 1 1
2 2 2
3 3 1
1 1/4 1/2
4 1 3
2 1/
3 1
1 1/4 1/5
4 1 1/2
5 2 1
1 3 1/3
1/3 1 1/7
3 7 1
1 1/3 5
3 1 7
1/5 1/7 1
1 1 7
1 1 7
1/7 1/7 1
1 7 9
1/7 1 1
1/9 1 1
matlab程序:
>> fid=fopen('txt3.txt','r');
n1=6;n2=3;
a=[];
for i=1:n1
tmp=str2num(fgetl(fid));
a=[a;tmp]; %读准则层判断矩阵
end
for i=1:n1
str1=char(['b',int2str(i),'=[];']);
str2=char(['b',int2str(i),'=[b',int2str(i),';tmp];']); eval(str1);
for j=1:n2
tmp=str2num(fgetl(fid));
eval(str2); %读方案层的判断矩阵
end
end
ri=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45]; %一致性指标[x,y]=eig(a);
lamda=max(diag(y));
num=find(diag(y)==lamda);
w0=x(:,num)/sum(x(:,num));
cr0=(lamda-n1)/(n1-1)/ri(n1)
for i=1:n1
[x,y]=eig(eval(char(['b',int2str(i)])));
lamda=max(diag(y));
num=find(diag(y)==lamda);
w1(:,i)=x(:,num)/sum(x(:,num));
cr1(i)=(lamda-n2)/(n2-1)/ri(n2);
end
cr1, ts=w1*w0, cr=cr1*w0。