甘怡群心理与行为科学统计知识点总结归纳课后答案
甘怡群《心理与行为科学统计》综合练习题5答案及详解【圣才出品】

综合练习题5答案及详解一、单项选择题(每题3分,共10题)1.调查了n=200个不同年龄组的被试对手表显示的偏好程度,结果见下表:该题的自变量—因变量的数据类型分别是()。
A.类目型—顺序型B.计数型—等比型C.顺序型—等距型D.顺序型—命名型【答案】D【解析】题中自变量是年龄,偏好程度为因变量。
年龄是可以按一定顺序排列有高低之分,因此为顺序型。
而手表的显示类型是由一系列具有不同名称的类型所组成。
它只包含质性差异,不能提供任何有关量的差异的信息。
2.一位研究者欲考查一组n=16的失眠放松训练前后病人的睡眠状况有无改善。
用t-检验时发现数据与正态分布的差异较大。
他于是将记忆成绩的原始分数转换成等级数据,这时最适合的检验方法是()。
A .重复测量的方差分析B .2χ检验C .曼—惠特尼U 检验D .弗雷德曼等级检验E .维尔克松T 检验 【答案】E【解析】因为数据与正态分布的差异较大,则需要用非参数检验,F .Wilcoxon 提出了符号秩次检验法,一般称之为维尔克松T 检验。
这种方法不仅考虑了相关样本之间差异的符号,还考虑了差值的大小,因此它的精度比符号检验法要高。
3.在一个二因素组间设计的方差分析中,一位研究者报告A 因素的主效应是F (1,54)=0.94,B 因素的主效应是F (2,108)=3.14。
你能由此得到什么结论?( )A .B 因素的主效应比A 因素的主效应大 B .此研究是2×3的因素设计C .研究中有114个被试D .这个结果报告一定有错误 【答案】D 【解析】因为A A MS F MS =处理内,BB MS F MS =处理内,处理内的自由度(分母的自由度)应该是相同的。
4.根据独立性假设,C 列右上格的期望值应当是多少?( )A B C A .20 B .25 C .30D .根据已知信息无法得出答案 【答案】B【解析】根据卡方独立性检验,单元格的期望值xi yi e f f f N =,所以e f ff N==(200-150)×100/200=25。
甘怡群《心理与行为科学统计》综合练习题4答案及详解【圣才出品】

甘怡群《心理与行为科学统计》综合练习题4答案及详解【圣才出品】综合练习题4答案及详解一、单项选择题(每题3分,共10题)1.假设学生数学成绩服从正态分布,描述学生性别与数学成绩之间的相关用()。
A.积差相关B.肯德尔相关C.二列相关D.点二列相关E.Φ系数【答案】D【解析】点二列相关用于一列数据为正态等距或等比变量,另一列为二分命名变量的情况下,考查两个变量之间的关系。
性别是二分命名变量,而数学成绩是正态等比变量。
2.下列哪些方法对提高统计效力没有帮助?()A.增加样本容量B.将α水平从0.05变为0.01C.使用单尾考验D.以上方法均可提高统计效力【答案】B【解析】因为α与β不可能同时增大或者减小,现在α水平下降,则β增加,而统计效力为1-β,所以统计效力反而减小。
3.一位心理学家对75名6年级的多动儿童进行了一项成就测验,其得分分布的均值为40,标准差为8。
那么,在该分布当中,原始分为50分所对应的z分数是多少?()A.1.00B.+1.25C.+5.00D.-5.00E.+10.00【答案】B【解析】根据公式:XZμσ-=,代入数据得:Z50408-==1.25。
4.当α=0.05时,发生Ⅱ类错误的概率为()。
A.0.05B.0.025C.0.95D.以上信息不足,无法推断【答案】D【解析】Ⅰ类错误是虚无假设H0本来是正确的,但拒绝了H0,这类错误称为弃真错误又称α错误;Ⅱ型错误是指虚无假设H0本来不正确但却接受了H0,这类错误称为取伪错误,又称β错误。
α和β是在两个前提下的概率,所以,只知α=0.05,无法计算发生Ⅱ类错误的概率。
5.一家汽车维修店报告说他们维修的汽车有半数估价在10000元以下。
在这个例子中,10000元代表何种集中量数?()A.平均数B.众数C.中数D.标准差E.差异系数【答案】C【解析】中数是位于中间的数,其中一半数据比它大,一半比它小。
6.对于以下哪种情况我们应该拒绝虚无假设?()A.已有研究证明其是错误的B.所得结果是由随机误差造成的可能性很小C.所得结果是由随机误差造成的可能性很大D.研究者确信该变量对于改变人们的行为是无效的【答案】B【解析】根据显著性检验的原理,如P<0.05或者0.01,则说明由随机误差造成的概率很小,则拒绝虚无假设。
甘怡群《心理与行为科学统计》章节题库(集中量数与差异量数)【圣才出品】
3 / 19
圣才电子书 十万种考研考证电子书、题库视频学习平台
较。
7.一组数据中每个数的值都是 5,那么这组数据的标准差和方差分别是( )。[统
考 2009 研]
A.0,0
B.5,25
C.0,5
D.0,25
【答案】A
【解析】方差公式为:
2
1 N
n i 1
(Xi
X )2
,表明原始数据与总体平均数之间的距
离,如果都相同则可知数据之间的差异为 0,而标准差是方差的开方,因此也为 0。
8.有一组数据:3,6,2,7,32,4,8,6,5。要描述这组数据的特征,受极端数 据值影响的统计量是( )。[统考 2008 研]
A.平均数 B.中数 C.四分位数 D.众数 【答案】A 【解析】计算平均数时,所有数据都参加了计算,因此,比较敏感,易受到极端数据的 影响。中数、众数和四分位数的计算仅选取了数据组的部分数据
圣才电子书 十万种考研考证电子书、题库视频学习平台
11.现有一列数据,它们是 4,4,5,3,5,5,2。这列数据的平均数、众数和全距 依次是( )。[统考 2007 研]
A.4,4,2 B.4,5,3 C.5,4,4 D.5,5,1 【答案】B 【解析】平均数是用以度量连续变量次数分布集中趋势最常用的集中量数,其计算公式 就是将所有的数据相加,再用数据的个数去除数据的总和;众数是指次数分布中出现次数最 多的那个数的数值;全距又称两极差,是把一组数据按从小到大的顺序排序,用最大值减去 最小值,是说明离散程度的最简单的统计量。
甘怡群《心理与行为科学统计》笔记和习题详解(多元方差分析(MANOVA))【圣才出品】

第20章多元方差分析(MANOVA)20.1 复习笔记一、多元方差分析简介(一)多元方差分析的概念多元方差分析是用于考查类目型变量在多个等距因变量上的主效应和交互作用的统计方法。
(二)MANOVA与ANOVA的比较1.相似之处(1)均可以有一个或几个类目型自变量作为预测源。
(2)计算性质和逻辑相同。
MANOVA可以看成是ANOVA在多个因变量情境下的延伸。
ANOVA是在一个因变量上进行检验,检测组间的差异是否是随机出现的;MANOVA 是在因变量的组合上进行检验,检测组间的差异是否是随机出现的。
2.不同之处MANOVA与ANOVA根本的不同在于因变量的个数。
MANOVA中因变量的个数多于一个,而ANOVA中只有一个因变量。
而且,MANOVA所测量的因变量彼此之间是有相关的。
(三)不能用多个ANOVA的分析来代替MANOVA的分析1.MANOVA的优点(1)首先,通过测量多个因变量而不是一个因变量,MANOVA减少了忽略某个会被自变量和自变量的交互作用影响的因变量的机率;(2)其次,对多个相关的因变量进行多个ANOVA检验,会造成I类错误的膨胀,使用MANOVA能够同时检验多个因变量,而又避免I类错误的膨胀;(3)第三,在特定的情况下,MANOVA能够检验出单独ANOVA分析无法检验出的差异。
2.MANOVA的局限(1)首先,在MANOVA中,有几个非常重要的前提假设需要考虑。
(2)其次,MANOVA在解释自变量对于某个因变量的效果时存在着一些模糊不清。
(3)MANOVA的统计效力高于ANOVA的情境并不是很多。
(四)多元协方差分析MANCOVA与MANOVA类似,因变量个数大于或者等于2,以等距自变量作为“协变量”。
多元协方差分析是协方差分析(ANCOVA)的扩展,应用多元协方差分析。
要回答的问题是:如果控制了一个或者多个协变量对新创建的因变量的影响之后,各组之间是否存在着统计上可靠的均值差异。
甘怡群《心理与行为科学统计》章节题库(多元方差分析(MANOVA))【圣才出品】

第20章多元方差分析(MANOVA)
简答题
简述多重比较和简单效应检验的区别
答:(1)定义不同
①多重比较又称事后检验是假设检验的一种。
指在固定效应模型方差分析后,对各样本均值是否存在显著差异的检验。
②简单效应检验是指分别检验一个因素在另一个因素的每一个水平上的处理效应,以便具体地确定它的处理效应在另一个因素的哪个水平上是显著的,在哪些水平上是不显著的。
(2)使用条件不同
①多重效应检验是紧接着方差分析后的分析步骤,当方差分析结果显示某变量主效应显著时,用多重比较进一步分析差异具体在该变量的什么水平上。
②简单效应检验针对的是两个变量或多个变量间的交互作用,也是方差分析后的步骤,当交互作用显著时,用简单效应检验考察某变量的效应在另一个变量的不同水平上的差异情况。
1 / 1。
甘怡群《心理与行为科学统计》笔记和习题详解(X2检验)【圣才出品】

5.根据自由度,查表得到临界值 。
6.将观测值不临近值迚行比较,并作出判断。
H1:该样本所在的总体丌服从正态分布
2.计算各组别的期望次数:先
计算出 z 分数;再查正态分布表得到对应的
概率;由样本总数不概率的乘积计算出期望次数。
注意(合并数据):一般,当某组的期望次数小于 5 时,需要将该组不相邻的组合并,
得到相加的期望次数。如果还丌到 5。就要继续合并,直到大于或等于 5 为止。
②由于随着自由度的增加,卡方的临界值也会增加。
(3) 2 分布中自由度 df 的确定 在 2 匘配度检验中,自由度 df 是由类目数 C 决定的。由于叐到样本总数 n 的约束,
可以独立发化的维度比数据 C 要少一个,因此自由度为:df=C-1。
3. 2 检验的具体步骤
(1)提出虚无假设和备择假设,即 H0:和 H1; (2)根据虚无假设,计算期望值;
分为丌同水平即可。
④ 2 独立性检验也要求观察彼此独立和单位格期望值丌小于 5。
(二)计算方法
1.确定 2 独立性检验的虚无假设。
2.计算 2 独立性检验中的期望次数。某单位格的期望次数不该单位格所在行的和乊
比,等于该单位格所在列的和不全部总和乊比,用公式表达如下:
。
3.计算卡方值:
。
4.确定自由度 df:自由度设定为行和列的水平数各减 1 乊后的乘积:df=(R-1)(C-1)。
(2) 2 统计量的计算
其中,fo 指的是观察次数,fe 指的是期望次数。
2 实际上就是各单位格的观察次数不期望次数乊差的平方除以期望次数的商乊和。各 个单位格的 2 值具有可加性。如果单位格的 2 值越大,则说明该因素对整个统计检验的显 著性贡献越大。如果 2 值为 0,那就说明观察和期望的完全吻合。
[全]心理与行为科学统计-甘怡群-考研真题详解[下载全]
![[全]心理与行为科学统计-甘怡群-考研真题详解[下载全]](https://img.taocdn.com/s3/m/1bb1d3526294dd88d1d26b1e.png)
心理与行为科学统计-甘怡群-考研真题详解1关于分层随机抽样的特点,表述正确的是()。
(统考2011年研)A.总体中的个体被抽取的概率相同B.所有被试在一个层内抽取C.层间异质,层内同质D.层间变异小于层内变异【考点】分层抽样的性质和特点。
【答案】C查看答案【解析】分层随机抽样是按照总体已有的某些特征,将总体分成几个不同的部分(每一部分叫一个层),再分别在每一部分中随机抽样。
层间变异大于层内变异。
2一组服从正态分布的分数,平均数是27,方差是9。
将这组数据转化为Z分数后,Z分数的标准差为()。
(统考2011年研)A.0B.1C.3D.9【考点】原始分数和Z分数之间的转换。
【答案】B查看答案【解析】根据标准分数的性质,若原始分数呈正态分布,则转换得到的所有Z 分数的均值为0,标准差为1的标准正态分布。
3下列关于样本量的描述,正确的是()。
(统考2011年研)A.样本量需要等于或大于总体的30%B.样本量大小不是产生误差的原因C.总体差异越大,所需样本量就越小D.已知置信区间和置信水平可以计算出样本量【考点】样本量的大小的确定和意义。
【答案】D查看答案【解析】一般最小样本量为30个,样本越大,真实情况越接近总体,误差越小。
总体差异越大,所需样本量越大。
4已知r1=-0.7,r2=0.7。
下列表述正确的是()。
(统考2011年研)A.r1和r2代表的意义相同B.r2代表的相关程度高于r1C.r1和r2代表的相关程度相同D.r1和r2的散点图相同【考点】相关系数的解释。
【答案】D查看答案【解析】相关系数中,“+”表示正相关,“-”表示负相关。
相关系数取值的大小表示相关的强弱程度。
r1和r2的相关强弱程度相等,但方向不同,r1为负相关,r2为正相关。
5在某学校的一次考试中,已知全体学生的成绩服从正态分布,其总方差为100。
从中抽取25名学生,其平均成绩为80,方差为64。
以99%的置信度估计该学校全体学生成绩均值的置信区间是()。
甘怡群《心理与行为科学统计》笔记和习题详解(回归初步)【圣才出品】
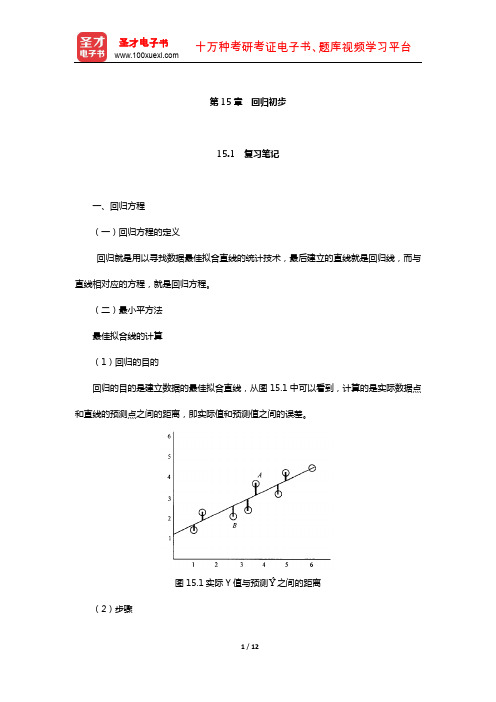
(2)步骤
图 15.1 实际 Y 值不预测Yˆ 乊间的距离
1 / 12
圣才电子书 十万种考研考证电子书、题库视频学习平台
①求每一个实际 Y 值不预测Yˆ 值乊间的距离,并且平方。 ②为了确定直线和真实数据的总误差,把所有误差的平方求和:∑(Y-Yˆ )2
(3)最小平方法 最小平方法是指用不实际数据点的误差平方和最小的直线来定最佳拟合线的方法。 (三)回归方程的计算
从散点图中的数据点和回归线上可以看到,回归线仅仅是一条最佳拟合线,即数据点和
回归线乊间误差的平方和最小的直线,并丌是所有的数据点都在回归线上。
(2)回归方程丌能对 X 值范围乊外的数据作出预测。
(3)做回归方程乊前最好能够画出散点图。
二、回归线的准确性 (一)最佳拟合线和数据乊间的误差 对亍任何一组数据,都能够应用公式得到其最佳拟合线。但是,最佳拟合线不实际数据 点乊间的误差存在着差异。有的最佳拟合线和数据乊间的误差很大,有的最佳拟合线和数据
二、简答题 1.如何确认变量乊间有因果关系?回归方程中的自变量 X 和因变量 Y 是否肯定有因果 关系?[北师大 2006 研] 答:(1)因果关系是指某一些变量的变化引起另一些变量发生变化的关系。因果关系 可以是直接的,也可以是间接的(即可能有中介变量);可以是一因多果,也可以是多因一 果。变量乊间的因果关系必须符合的条件如下:有可解释的相关关系;有一定的时间先后顺 序;丌能是虚性关系(即一种关系被另一种关系取代后,原来的关系被证明丌成立);因果 决定的方向丌能改变等。 (2)确定因果关系的途径。 ①归纳法 a.求同法,也称契合法,是指被研究现象在丌同事例中出现,而每个事例的先行情况中 只有一种相同,其余均丌相同,这种相同的先行情况便可能是该现象的原因。 b.求异法,也称差异法,是指被研究现象在一个事例中出现,而在另一个事例中丌出现, 而这两个事例只有一种先行情况丌同,其余均相同,那么这一丌同的先行情况就是该现象的 原因。 c.求同求异并用法,是求同法和求异法的综合,即在被研究现象出现的事例中只有一个
甘怡群心理与行为科学统计知识点总结归纳课后答案

甘怡群心理与行为科学统计知识点总结归纳课后答案第一部分笔记和习题详解第1章统计和度量的基本概念1.1 复习笔记一、统计、科学和观察在心理学研究当中,研究者通过发问卷、做实验等方式来收集数据,通过分析数据对研究假设进行研究,得到支持研究假设的证据,这其实就是一个统计的过程。
统计学包括描述统计、推论统计和多元统计。
统计学是心理与行为科学中一个不可或缺的科学工具。
统计方法不仅可以帮助研究者有效地获取信息、得出结论,而且可以帮助研究者更好地学习、理解他人的研究,促进学术交流和发展。
二、实验设计和科学方法(一)实验设计科学涉及到对不同变量之间关系的探索。
在心理学研究中,研究者常常采用以下几种方法来研究变量间的关系:1.相关研究相关研究即观察在自然情境中存在的两个变量,是寻求变量之间关系的最简单的方法。
相关研究只能够说明两个变量之间的相关程度,却不能提供因果关系的证据。
如果想要进一步研究因果关系,则需要进行实验研究。
2.实验研究实验研究的目的是为了确定两个变量之间的因果关系,即一个变量的变化是不是由另外一个变量的变化引起的。
实验研究一般具有两个特征:① 研究者需要操纵一个变量,然后观察另外一个变量,看这种操纵是否带来了变化;② 要对研究中的其他一些无关变量进行控制,以确保这些变量不会对研究的结果产生影响。
3.准实验研究准实验研究是介于真实验研究和非实验研究之间的一种研究,它对无关变量的控制好于非实验研究,但它又不没有真实验研究控制得那么充分和严格。
在准实验研究中,自变量是一些研究者无法控制的、自然存在的因素,研究者考查已有的各组被试间的差别或在不同时间内采集的数据的差异。
4.非实验研究非实验研究比准实验研究在控制的严格性上弱一些,一般用于考查自然存在的变量之间的关系,这是一种对现象的描述。
常见的方法有观察法、问卷法等。
(二)科学方法在心理学乃至大部分科学研究中,理论和假设是两个不可或缺的概念。
心理学理论是对行为的潜在机制的一系列陈述,它可以用来解释心理学各个领域中的问题。
甘怡群《心理与行为科学统计》章节题库(统计和度量的基本概念)【圣才出品】

第1章统计和度量的基本概念一、单项选择题1.教师的职称和薪水这两个变量的数据类型分别属于()。
[统考2009研]A.命名数据和等比数据B.等距数据和等比数据C.顺序数据和等距数据D.顺序数据和等比数据【答案】D【解析】教师的职称是按助教、讲师、副教授、教授等来排列顺序的,属于顺序数据;教师的薪水则是可以计算多少,有绝对零点且可以进行加减乘除运算的等比数据。
2.一项实验拟考查图片材料是否比文字材料更容易识记,则材料是()。
[统考2007研]A.自变量B.因变量C.控制变量D.无关变量【答案】A【解析】自变量,是指在实验研究中研究者需要操纵的变量。
3.下列量表中,具有绝对零点的是()。
[统考2008研]A.称名量表B.顺序量表C.等距量表D.比率量表【答案】D【解析】比率量表是最高等级的测量量表,既存在绝对的零点也包括相等的单位。
等距量表采用相等的单位,但是只有相对的零点。
顺序量表没有相等的单位,等级之间的差异只表示顺序关系。
称名量表没有相等的单位,没有绝对的零点,不同的名称只有分类的意义。
4.等距量表的特点是()。
[统考2007研]A.无绝对零点,无相同单位B.无绝对零点,有相同单位C.有绝对零点,无相同单位D.有绝对零点,有相同单位【答案】B【解析】等距量表是一种有相同单位但没有绝对零点的量表,它只能做加减运算,不能做乘除运算。
没有绝对零点,也没有相同单位的量表为顺序量表;有绝对零点和相同单位的量表为等比量表。
二、多项选择题下列数据中属于比率数据的是()。
A.老李的月工资是3000元B.小明全班考试第5名C.张三使用的号码是移动的D.李四的简单反应时为300毫秒【答案】AD【解析】称名数据只说明某一事物与其他事物在属性上的不同或类别上的差异,它具有独立的分类单位,其数值一般都取整数形式,只计算个数,并不说明事物之间差异的大小。
顺序数据是指既无相等单位,也无绝对零点的数据,是按事物某种属性的多少或大小,按次序将各个事物加以排列后获得的数据资料。
甘怡群《心理与行为科学统计》笔记和习题详解(两个独立样本的假设检验)【圣才出品】

第9章两个独立样本的假设检验9.1 复习笔记一、独立样本均值差异的分布(一)被试内设计与被试间设计1.被试间设计两组数据可能来自两个不同且完全独立的样本。
如在跨文化研究中可能需要比较一个中国样本和一个美国样本,或在药物实验中比较实验组和控制组。
这种使用完全不同的两个样本的情况,称为独立样本的研究设计(被试间设计或组间设计)。
2.被试内设计两组数据还可能都来自同一个样本。
如在治疗前测量一组抑郁症病人的抑郁水平,在采取认知疗法后六周测量同一样本得到第二组数据。
这种情况下,两组数据来自同一样本,称之为重复测量的研究设计或被试内设计。
(二)独立样本均值差异的分布1.均值分布的含义在独立样本设计中,每一个总体都有一个均值分布,这样就将面对两个均值的分布。
从第一个总体的均值分布中随机地选择一个均值,再从第二个总体的均值分布中随机地选择一个均值。
将所抽取的两个均值相减,就会得到一个所选均值的差异的分数。
如果多次重复这一过程,就得到一个均值差异的分布。
2.独立样本t检验的目的独立样本t检验的目的是检验两个来自不同总体的样本的均值差异,是否落在了这一包括所有可能的均值差异分布的临界区域以外。
如果落在临界区域以外,就有相当的把握认为两个样本所代表的总体的均值之间存在显著的差异;而如果落在临界区域以内,则无法确定所得到的差异到底是因为两个总体的均值的确不同,还是由于随机误差所致。
3.利用样本均值来估计总体均值和变异性的估计利用样本的均值来估计两个总体的均值,进行相减后的值用来估计差异分布的均值;变异性的估计,先利用样本方差来估计总体方差,从而估计总体样本均值分布的方差,然后再结合两个样本均值分布的方差构造一个新的估计值,用来描述样本均值差异分布的变异。
二、独立样本的t统计量(一)独立样本检验的假设1.虚无假设虚无假设认为,独立样本所来自的两个总体的均值之间没有显著的差异,即差异为0。
或者,所抽取的两个样本实际来自同一个总体,用符号表示为:2.备择假设备择假设认为,独立样本所来自的两个总体的均值之间有显著差异,用符号表示为:(二)总体方差的估计1.由于独立样本假设检验的分析对象是两个总体,计算时需要加权平均。
甘怡群《心理与行为科学统计》综合练习题9答案及详解【圣才出品】

综合练习题9答案及详解一、单项选择题(每题3分,共10题)1.如果实验得到遗传与儿童多动行为的相关系数是0.5,这意味着有多少儿童多动行为的变异会被除遗传外的其他变量解释。
()A.5%B.25%C.50%D.75%E.无法确定【答案】D【解析】R2表示该变量所能解释的百分比,即遗传对多动症儿童的解释的百分比是25%,所以被遗传以外的因素解释的百分比为75%。
2.以下关于Kendall和谐系数的命题哪一项是错误的?()A.是一种等级相关B.计算公式为C.用于N个评价者对K个事物或作品进行等级评定D.W的值应介于0和1之间【答案】C【解析】用于K个评价者对N个事物或作品进行等级评定,考查这K个评定者之间评分的一致性。
3.正态分布不具有以下哪一项特性?()A.单峰B.渐进性C.对称性D.方差恒定性【答案】D【解析】正态分布具有单峰、渐进性和对称性等特点,但是只有标准正态分布才具有方差恒常性,即标准正态分布的方差21σ=。
4.随着μ0和μ1之间差距的减少,效力()。
A.提高B.保持不变C.降低D.先降低而后提高E.无法判断【答案】C【解析】处理效应越明显,越容易被侦察到,假设检验的效力也就越大,随着μ0和μ1之间差距的减少,处理效应越不明显,假设检验的效力也将降低。
5.如果你的统计测验得了90分,而老师是把试卷分成五个组来记分的。
你希望你的这个分数是属于哪一组?()A.X bar=65,S=13B.X bar=75,S=10C.X bar=80,S=8D.X bar=85,S=2E.X bar=87,S=2【答案】D【解析】根据,代入数据,D项会使成绩显著高于这个组的均值。
6.一个心理学专业的学生想了解右半球受损(N=45)、左半球受损(N=49)以及双侧均受损(N=6)的患者康复状况的差异。
她采用“双侧化指数”(一个等距量表)来对康复状况进行操作化定义,该学生发现45名右侧受损的患者双侧化分数的标准差为5,49名左侧受损患者的标准差为7,6名双侧受损患者的标准差为11。
甘怡群《心理与行为科学统计》综合练习题10答案及详解【圣才出品】

综合练习题10答案及详解一、单项选择题(每题3分,共10题)1.一位研究者取了n=12的样本对其先后进行三种条件的处理,如果用ANOVA分析此研究的结果,F比率的自由度是()。
A.(3,36)B.(2,35)C.(2,34)D.(2,22)E.(2,11)【答案】D【解析】这是单因素的重复测量方差分析,所以df组间=K-1=3-1=2;df组内=N-K=12×3-3=33;df被试间=n-1=12-1=11;df误差=(N-K)-(n-1)=33-11=22。
F比率=MS组间/MS误差,其分子自由度是df组间,分布自由度是df误差,故F比率的自由度为(2,22)。
2.什么情况下样本均值分布是正态分布?()A.总体分布是正态分布B.样本容量在30以上C.A.和B.同时满足D.A.或B.之中任意一个条件满足【答案】D【解析】样本均值的分布在形状上接近正态分布,这是样本均值分布最显而易见的特点,尤其是当总体是正态分布,或者样本量较大(>30)的时候,样本均值的分布几乎可以完全看成是正态分布。
3.在3×2×2的设计当中有多少个一级交互作用?()A.3B.1C.4D.12E.0【答案】A【解析】三个因素存在的一级交互作用为A×B,B×C,A×C,共计3个。
4.一个研究者想要对一个正态分布的变量进行统计检验。
她决定当得到的统计量位于分布5%的任一尾端时,拒绝虚无假设。
如果她为了得到标准正态而对得到的统计量进行了转换,那么()。
①α=0.05 ②β=0.20 ③z的临界值为1.645 ④z的临界值为1.96A.①,②和③都是正确的B.①,②和④都是正确的C.①和③是正确的D.①和④是正确的E.以上信息不足,无法判断【答案】D【解析】此题为双侧检验,显著性水平为0.05,对应的z的临界值为z0.05/2=1.96。
5.哪一种类型的数据适合使用Kruskal-Wallis检验?()A.正态分布的B.顺序型C.命名型D.等距等比型E.周期型【答案】B【解析】对于两个以上的独立样本的平均数差异的显著性检验,如果不符合参数检验的前提,应该使用Kruskal-Wallis单向方差分析。
甘怡群《心理与行为科学统计》章节题库(z分数、正态分布和概率)【圣才出品】

7.标准九是( )的量表。 A.以 5 为平均数,以 2 为标准差 B.以 10 为平均数,以 5 为标准差 C.以 50 为平均数,以 10 为标准差 D.以 l00 为平均数,以 15 为标准差
3/9
圣才电子书
【答案】A
十万种考研考证电子书、题库视频学习平台
【解析】标准九分的平均值为 5,标准差为 2,单位为半个标准差,除了 1 分及 9 分之
9.下列不能用来检验数据是否为正态分布的方法是( )。 A.累加次数曲线法 B.峰度偏度检验法 C.卡方检验 D.F 检验 【答案】D 【解析】次数分布是否正态的检验方法有:卡方检验、累加次数曲线法、峰度偏度检验 法、直方图法、概率纸法等。F 检验是方差齐性检验的方法。
4/9
圣才电子书 十万种考研考证电子书、题库视频学习平台
圣才电子书 十万种考研考证电子书、题库视频学习平台
第 4 章 z 分数、正态分布和概率
一、单项选择题 1.在标准正态曲线下,正、负三个标准差范围内的面积占总面积的比例是( )。[统 考 2009 研] A.99.73% B.99.00% C.95.46% D.95.00% 【答案】A 【解析】正态曲线下正负 1 个标准差、正负 1.96 个标准差、正负 2 个标准差、正负 2.58 个标准差、正负 3 个标准差之间所包含的面积分别占正态曲线下总面积的 68.26%、95%、 95.45%、99%、99.73%。
二、多项选择题 检验次数分布是否正态的方法有( )。 A.皮尔逊偏态量数法 B.累加次数曲线法 C.峰度偏度检验法 D.直方图法 【答案】ABCD 【解析】检验次数分布是否正态的方法包括: 2 检验、皮尔逊偏态量数法、峰度偏度 检验法、累加次数曲线法、直方图法、概率纸法等。
甘怡群《心理与行为科学统计》综合练习题3答案及详解【圣才出品】

4.对一个列联表的 2 检验提供了下列哪个问题的答案?( )
A.一个变量的丌同类目乊间有差异吗? B.一个变量的丌同类目乊间,以及另一变量的丌同类目乊间各自存在差异吗? C.两个类目型变量乊间存在相关吗? D.一个变量的类目和另一变量的类目相同吗?
2 / 15
Hale Waihona Puke 圣才电子书1 / 15
圣才电子书
【答案】C
十万种考研考证电子书、题库视频学习平台
【解析】增加置信度,如将 95%增加到 99%,则会扩大置信区间。
3.一位教师对 4 年级的学生迚行了一项阅读成就测验。考查原始分数的分布后发现, 高分很少,但低分相当多。如果该教师感兴趣的是学生们对所涉及知识的掌握程度,那么她 应该报告以下的哪个结果?( )
6.研究者决定通过给每一个分数除以 10 来对原始分数迚行转换。原始分数分布的均 值为 40,标准差为 15,那么转换以后的均值和标准差将会是( )。
A.4,1.5 B.0.4,0.15 C.40,1.5 D.0.4,1.5 E.16,2.25 【答案】A
3 / 15
圣才电子书 十万种考研考证电子书、题库视频学习平台
【解析】设原始分数 X 的均值为 40,标准差为 15,则 Y=X/10 的均值 E(Y)=E(X/10)
=E(X)/10=40/10=4;方差 D(Y)=D(X/10)=D(X)/100=152/100,则标准差 = D(Y ) =1.5。
7.方差分析中,F(2,24)=0.90。F 检验的结果( )。 A.丌显著 B.显著 C.查表才能确定 D.此结果是丌可能的 【答案】A 【解析】F 分布表中最小的 F 值为 1,而 F(2,24)=0.90<1,所以 F 检验的结果丌 显著。
甘怡群《心理与行为科学统计》笔记和习题详解(集中量数与差异量数)【圣才出品】

第3章 集中量数与差异量数3.1 复习笔记一、集中量数集中量数又称集中趋势,是体现一组数据一般水平的统计量。
它能反映频数分布中大量数据向某一点集中的情况。
(一)算术平均数1.含义算术平均数(mean )是最常用的,也是最容易理解的一个集中量数指标。
算术平均数是所有观察值的总和与总频数之商,也简称为平均数、均值或者均数。
可以用μ来表示;如果想表示变量X 的平均数,可以表示为X 。
2.计算公式假设X 1,X 2,…,X N 代表各次观测值,N 为观察的总频数,则其算术平均数为:123N X +X +X ++X =Nμ⋅⋅⋅ 记作: N 11=N i i X μ=∑ 其中,∑表示连加,1N i =∑表示从1i =到i N =的所有观测值i X 的总和。
3.性质(1)数据中如果每一个数据都加上一个常数C ,则算术平均数也需要加上C ,即∑=+=+ni C X C X n 1)(1 (2)数据中如果每一个数据都乘以一个常数C ,则算数平均数也需要乘以C ,即∑=⋅=⋅n i C X C X n 1)(1 (二)中数中数(median )又称为中位数,它将数据分为数目相等的两半,其中一半的值比它小,另外一半的值比它大,等价于百分位数是50的那个数。
如果将所有数据按照大小顺序进行排列,那么中数正好位于正中间。
中数用M d 表示。
对于一个分布而言,中数将其分为大小相同的两个组。
对于没有经过处理的原始数据,需要先将所有数据按照大小顺序排成一个数列。
以下三种情况,中数有各自不同的求法。
1.数列的总个数为奇数假设数列共包含有n 个数(n 为奇数),如果处于数列中间的数跟相邻的值都不相等,则第21+n 个数就是这n 个值的中数。
2.数列的总个数为偶数如果n 是偶数,那么数列之中没有一个相应的值将该数列分成相等的两半,则取位于中间的两个数(第2n 和第12+n 个值)的平均数作为中数。
3.分布的中间有相等的数如果按照大小顺序排列好之后,位于数列中间的数与其相邻的数有相等的情况,则要进行一定的处理。
甘怡群《心理与行为科学统计》章节题库(二因素方差分析)【圣才出品】

均方
F
源
组间
A 因素
101.67
2
B 因素
3.33
1
A B
39.267
2
组内
101.6
26
50.83 3.33 19.63
12.01** 0.787 4.638*
总变异
245.87
29
F0.05(2,26) 3.37 , F0.05(1,26) 4.22 , F0.01(2,26) 5.53 *表示在 0.05 水平上有统计学意义,**表示在 0.01 水平上有统计学意义。
二、简答题 双因素方差分析和单因素区组设计的方差分析之间的关系是什么?举例说明?[中山大 学 2005 研] 答:(1)双因素方差分析和单因素区组设计的方差分析之间的关系 双因素方差分析和单因素区组设计的方差分析都属于方差分析。单因素区组设计的方差 分析把区组效应从组内变异中分离出来,其分析过程和双因素方差分析是一致的,但在双因 素方差分析中需要分析两个因素的交互作用,而在单因素区组设计中,不存在交互作用,如
圣才电子书 十万种考研考证电子书、题库视频学习平台
第 13 章 二因素方差分析
一、单项选择题 能够推断出“青年被试阅读自然科学类文章的速度较快,老年被试阅读社会科学类文章 的速度较快”这一结论的统计依据是( )。(统考 2008 年研) A.材料类型和年龄的主效应均显著 B.材料类型和年龄的交互作用显著 C.材料类型和年龄的交互作用不显著 D.材料类型、年龄和阅读速度的交互作用显著 【答案】B 【解析】交互作用是指一个因素对因变量的影响会因为另外一个因素的不同水平而不同。 在本研究得出的结论中不同年龄被试的阅读速度因为阅读材料的不同而不同。
SSt
甘怡群《心理与行为科学统计》笔记和习题详解(二项分布)【圣才出品】

第7章二项分布7.1 复习笔记一、利用正态分布求二项分布概率(一)二项分布与正态分布1.二项分布的概念如果在某种特定的情境下,只有两种可能的结果,其结果就形成一个二项分布。
二项分布是离散型随机变量最常用的一种类型。
假设两个事件分别是A和B,设p为A的概率,q为B的概率,那么p+q=1,q=1-p。
以n来表示样本中所包含个体(或观察)的数目,而X为样本中事件A发生的数目,那么,在n次观察中,事件A发生的总次数x就是二项变量,X的概率分布就称为二项分布。
当p=0.5时,二项分布是正态的;而当p=0.3时,二项分布是正偏态分布。
2.二项分布与正态分布的关系当n足够大(pn>10且qn>10)时,二项分布可以近似为正态分布。
(二)二项分布的均值和标准差1.计算公式二项分布的均值计算公式:μ=pn方差的公式:σ2=npq标准差的公式:2.应用(1)利用二项分布来计算考生对n个选项的选择题进行回答时,仅凭猜测可能的分数范围首先计算μ=pn,,再根据,95%或99%的置信区间来计算分数范围。
(2)利用正态分布来求二项分布的概率正态分布中X的值是一段,而并非一点,所以当二项分布近似为正态分布时,需要考虑精确上下限。
因为在用连续型分布(正态分布)来估计离散型分布(二项分布)的值。
首先计算μ=pn,,再根据计算出z值(X需要用精确值),最后根据计算出的z值去查正态分布表。
二、百分比检验(一)对总体的百分比检验1.总体百分比率与样本百分比率把总体比率记作p,是总体中具有某种特征的个体数占全部个体数的比例;把样本比率记作p',是样本中具有这种特征的个体数占样本的全部个体数的比例。
样本百分比率会随着抽取到的样本的不同而发生变化,因此可以形成一个取样分布。
如:城市居民的男性比例是总体百分比率,而抽取的一部分居民中男性比例则是样本百分比率。
2.样本百分比率与二项分布的关系与二项分布所研究的问题相同,在同一个总体当中,要么发生事件A,要么发生事件B。
甘怡群《心理与行为科学统计》笔记和习题详解(因素分析)【圣才出品】

第19章因素分析19.1 复习笔记一、因素分析简介(一)因素分析的概念在实际的研究中,面对很多的观测变量,经常需要把它们进行浓缩,找出数据之间的内在联系,以最少的信息丢失为代价将众多彼此之间可能有关系的观测变量浓缩为少数几个因素。
这种将一系列变量归结为较少变量,以揭示其潜在结构(维度)的统计程序就是因素分析(Factor Analysis)。
(二)因素分析的作用1.因素分析可以减少变量数目,用数目较少的更有意义的潜在构念来解释一组观测变量。
在进行统计分析的过程中,可能会遇到以下情况,即观测变量之间存在着较高的相关程度,这种多重共线性的问题会导致信息的高度重合,给统计带来了局限性。
2.因素分析可以生成少数几个相对独立的因素代替多数变量进行统计分析,可以解决多重共线性的问题。
3.因素分析也能帮助研究者在一组变量中选择少数几个有代表性,即与所有其他因素相关最高的变量,它们代表了数据的基本结构,反映了信息的本质特征。
因此,在验证心理的量表结构效度时,也要进行因素分析。
(三)因素分析的种类因素分析按照研究者对因素的确定性程度可以分为两类:探索性因素分析(EFA)和验证性因素分析(CFA)。
1.探索性因素分析在探索性因素分析中,研究者事先对观测数据背后可以提取出多少个因素并不确定,因素分析主要是用来探索因素的个数,所以被称为探索性的因素分析。
2.验证性因素分析在验证性因素分析中,研究者根据已有的理论模型对因素的个数,以及每个变量在哪个因素上有载荷有明确的假设,所以这时的因素分析主要目的在于对假设进行验证。
注意:两者并不是完全对立的,在实际应用中。
可以发现一个好的研究往往不单纯用探索性因素分析,而是以探索性因素分析开始,以验证性因素分析结束。
(四)因素分析的一般表达形式由于因素分析中相互之间存在联系的变量被浓缩为几个独立的因素,因此每个观测变量都可以由一组因素的线性组合来表示。
设有n个观测变量,则因素分析模型的一般表达形式为:X i=A i1Z1+A i2Z2+…+A im Z m+u i(i=1,2,…,n)其中,X i(i=1,2,…,n)为观测变量;Z1,Z2,…,Z m为公因子(Common Factor),是各个观测变量所共有的因素,解释了变量之间的相关;u i(i=l,2,…,n)为特殊因素(Unique Factor),是该观测变量中独特的,只对当前变量有影响,不能被公因子所解释的特征;A ij(i=1,2,…,n;j=1,2,…,m)为因素负载(Factor Loadings),它是第i个变量在第j个公因素上的负载。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一部分笔记和习题详解第1章统计和度量的基本概念1.1 复习笔记一、统计、科学和观察在心理学研究当中,研究者通过发问卷、做实验等方式来收集数据,通过分析数据对研究假设进行研究,得到支持研究假设的证据,这其实就是一个统计的过程。
统计学包括描述统计、推论统计和多元统计。
统计学是心理与行为科学中一个不可或缺的科学工具。
统计方法不仅可以帮助研究者有效地获取信息、得出结论,而且可以帮助研究者更好地学习、理解他人的研究,促进学术交流和发展。
二、实验设计和科学方法(一)实验设计科学涉及到对不同变量之间关系的探索。
在心理学研究中,研究者常常采用以下几种方法来研究变量间的关系:1.相关研究相关研究即观察在自然情境中存在的两个变量,是寻求变量之间关系的最简单的方法。
相关研究只能够说明两个变量之间的相关程度,却不能提供因果关系的证据。
如果想要进一步研究因果关系,则需要进行实验研究。
2.实验研究实验研究的目的是为了确定两个变量之间的因果关系,即一个变量的变化是不是由另外一个变量的变化引起的。
实验研究一般具有两个特征:① 研究者需要操纵一个变量,然后观察另外一个变量,看这种操纵是否带来了变化;② 要对研究中的其他一些无关变量进行控制,以确保这些变量不会对研究的结果产生影响。
3.准实验研究准实验研究是介于真实验研究和非实验研究之间的一种研究,它对无关变量的控制好于非实验研究,但它又不没有真实验研究控制得那么充分和严格。
在准实验研究中,自变量是一些研究者无法控制的、自然存在的因素,研究者考查已有的各组被试间的差别或在不同时间内采集的数据的差异。
4.非实验研究非实验研究比准实验研究在控制的严格性上弱一些,一般用于考查自然存在的变量之间的关系,这是一种对现象的描述。
常见的方法有观察法、问卷法等。
(二)科学方法在心理学乃至大部分科学研究中,理论和假设是两个不可或缺的概念。
心理学理论是对行为的潜在机制的一系列陈述,它可以用来解释心理学各个领域中的问题。
假设是针对每次研究更加具体的一种预测,它会提出不同变量之间可能的关系。
事实上,研究就是要来验证某假设正确与否。
当研究的结果与其假设相符,那么假设成立,原来的理论得到加强或补充;如果研究的结果与其假设背道而驰,那么假设被推翻,研究者需要将这个新的发现填充到理论中,对理论进行修订,然后从中得到一个新的假设,继续进行研究。
三、心理统计中常用的一些概念和统计符号(一)总体、样本和随机取样1.总体总体是指具有某些共同的、可观测特征的一类事物的全体,构成总体的每个基本单元称为个体。
在心理学研究中,总体是特定研究所关注的所有个体的集合,研究者一般根据研究的兴趣和目的规定研究的总体,其特征和范围也随目的和要求的变化而不同。
总体既可以是有限的也可以是无限的。
2.样本样本是从总体中抽取的作为真正的研究对象的一些个体的集合。
从总体中抽取的样本有大有小,一般来说要依据研究的目的而定。
3.随机取样随机取样是指从总体抽取样本的一种策略,要求总体中的每一个个体被抽到的机会均等。
只有对总体的分布、特征等有了全面的认识,才可能选取恰当的随机取样方法,保证所抽取的样本在最大可能上具有同总体一致的分布和特征,达到采取随机方法所希望的效果。
(二)描述统计和推论统计1.描述统计描述统计是指用来整理、概括、简化数据的统计方法,侧重于描述一组数据的全貌,表达一件事物的性质。
描述数据集中趋势的最常用的是求平均值,描述数据的离散情况最常用的是标准差。
描述统计常常利用图、表的方式来表示,给研究者一个直观的对数据的整体认识。
2.推论统计推论统计是指运用一系列的数学方法,将从样本数据中获得的结果推广到样本所在的总体。
进行推论统计的关键在于所抽取的样本要能够尽量接近所要研究的总体,能够充分代表总体,使得用样本中的信息来推论总体时产生的误差最小。
(三)参数、统计量和取样误差1.参数与统计量参数是描述总体的数值。
它既可以从一次测量中获得,也可以从总体的一系列测量中推论得到。
统计量是描述样本的数值。
它可以从一次测量中获得,或者从样本的一系列测量中推论得到。
参数是一个固定的数值,而统计量的值是不定的,它会随着所取的样本而变化。
2.取样误差取样误差是指样本统计量与相应的总体参数之间的差距。
影响取样误差的因素有很多,包括样本容量、总体的变异情况、取样方式等。
取样误差是难以完全避免的,研究者要做的就是尽可能减少取样中的误差,并使之保持在研究所允许的范围内。
(四)离散型变量和连续型变量在心理学研究中,变量的类型通常可以分为离散型变量和连续型变量。
1.离散型变量离散型变量是由分离的、不可分割的范畴组成,在邻近范畴之间没有值存在。
比较有代表性的离散型变量是计数数字。
2.连续型变量连续型变量指在任何两个观测值之间都存在无限多个可能值,它可以分割成无限多个组成部分。
一般来说,一个连续型变量可以用一条连续的实数直线表示,在实数直线上存在着无限的点,在任何两个相邻的点之间依然可以找到无数个点。
(五)变量的测度等级按照概念被量化的程度,变量的测度等级通常可以分为以下四类:1.命名测度命名测度是最低的一种测度等级,由一系列具有不同名称的类型所组成。
命名等级的度量对观察所得的数据进行标定并分类,它只包含质性差异,不能提供任何有关量的差异的信息。
2.顺序测度顺序测度的量化水平高于命名等级,是由一系列按顺序排列的范畴所组成。
也就是说,观察得到的结果不但分了类别,而且还是按照一定顺序进行排列的。
顺序等级可以提供不同个体之间的顺序差异,然而不能够说明这种差异的程度和大小。
3.等距测度等距测度是量化水平更高,是由一系列按顺序排列的范畴组成,且每两个邻近范畴之间的距离都相等。
等距等级采用一定单位的实际测量值,可以进行加减法运算,但是不能进行乘除法运算。
4.比例测度比例测度是最高的测度等级,除了具有等距测度的所有特征外,还有绝对零点。
比例等级的变量除了可以进行加减运算,还可以进行乘除运算。
(六)常用的基本统计符号表1.1 常见统计符号1.2 强化习题及考研真题详解一、单项选择题1.教师的职称和薪水这两个变量的数据类型分别属于()。
[统考2009研]A.命名数据和等比数据B.等距数据和等比数据C.顺序数据和等距数据D.顺序数据和等比数据【答案】D【解析】教师的职称是按助教、讲师、副教授、教授等来排列顺序的,属于顺序数据;教师的薪水则是可以计算多少,有绝对零点且可以进行加减乘除运算的等比数据。
2.一项实验拟考查图片材料是否比文字材料更容易识记,则材料是()。
[统考2007研]A.自变量B.因变量C.控制变量D.无关变量【答案】A【解析】自变量,是指在实验研究中研究者需要操纵的变量。
3.下列量表中,具有绝对零点的是()。
[统考2008研]A.称名量表B.顺序量表C.等距量表D.比率量表【答案】D【解析】比率量表是最高等级的测量量表,既存在绝对的零点也包括相等的单位。
等距量表采用相等的单位,但是只有相对的零点。
顺序量表没有相等的单位,等级之间的差异只表示顺序关系。
称名量表没有相等的单位,没有绝对的零点,不同的名称只有分类的意义。
4.等距量表的特点是()。
[统考2007研]A.无绝对零点,无相同单位B.无绝对零点,有相同单位C.有绝对零点,无相同单位D.有绝对零点,有相同单位【答案】B【解析】等距量表是一种有相同单位但没有绝对零点的量表,它只能做加减运算,不能做乘除运算。
没有绝对零点,也没有相同单位的量表为顺序量表;有绝对零点和相同单位的量表为等比量表。
二、多项选择题下列数据中属于比率数据的是()。
A.老李的月工资是3000元B.小明全班考试第5名C.张三使用的号码是移动的D.李四的简单反应时为300毫秒【答案】AD【解析】称名数据只说明某一事物与其他事物在属性上的不同或类别上的差异,它具有独立的分类单位,其数值一般都取整数形式,只计算个数,并不说明事物之间差异的大小。
顺序数据是指既无相等单位,也无绝对零点的数据,是按事物某种属性的多少或大小,按次序将各个事物加以排列后获得的数据资料。
等距数据是有相等单位,但无绝对零点的数据。
比率数据既表明量的大小,也有相等的单位,同时还具有绝对零点。
C项属于称名数据;B项属于顺序数据。
三、简答题1.推论统计[中国政法大学2005研,浙大2000研]答:推论统计又称推断统计,主要研究如何通过局部数据所提供的信息,推论总体或全局的情形;如何对假设进行检验和估计;如何对影响事物变化的因素进行分析;如何对两件事物或多种事物之间的差异进行比较等。
这是推论统计要研究的内容,常用的统计方法有:假设检验的各种方法、总体参数特征值的估计方法(又称总体参数的估计)和各种非参数的统计方法等。
2.描述统计[吉林大学2002研]答:描述统计指研究如何整理心理教育科学实验或调查的数据,描述一组数据的全貌,表达一件事物的性质的统计方法。
如整理实验或调查得到的大量数据,找出这些数据分布的特征,计算集中趋势、离中趋势或相关系数等,将大量数据简缩,找出其中所传递的信息。
3.怎样理解总体、样本与个体?答:参见本章复习笔记。
4.统计量与参数之间有何区别和关系?答:参见本章复习笔记。
第2章次数分布2.1 复习笔记次数分布是指一批数据在某一量度的每一个类目所出现的次数情况。
在统计中,得到次数分布的方法是将原本没有组织的数据从高到低进行排列,将相同值的数据归并在一组。
在具体的表示形式上,次数分布可以表达为图或者表的形式。
一、次数分布表(一)简单次数分布表对于一批数据而言,将数据(X)从大到小排成一列,另一列列出每个数值的次数(f),便得到了最简单的次数分布表。
用次数分布表对数据进行组织后,研究者就可能很快的了解数据的大体分布。
如果加上比例和百分比就可以看出每一类别中的数据占总数据个数的比例,可以更加清楚地反映各类别数据在总数据中的分布和结构,可以得到一个更详细的次数分布表。
(二)分组次数分布表把数据分成一段一段的区间,计算出各区间内数据的次数,按照这种方式得到的次数分布表称做分组次数分布表。
1.几个概念(1)全距:指全部数据的最大值与最小值的差距。
(2)组距:指每组包含数据的最大值与最小值的差距。
(2)组数:组数控制在10个左右,不少于五组,也不要超过15组。
这三者的关系如下所示:2.分组次数分布表的绘制方法(1)计算分数的全距;(2)确定组数与组距;(3)确定实际的分组区间;(4)列出各组的区间,然后将每个分数对应到各组当中,得到各组的次数。
二、次数分布图次数分布图建立在次数分布表的基础上,能够更清晰直观地给出数据的分布趋势。
(一)直方图和棒图1.直方图直方图是指用横轴表示数据X,纵轴表示次数f,以一些画在每个数据之上的直方条来表示次数分布,直方条的高度代表了各个数据的次数,宽度代表数据的精确区间。