神经网络中的反向传播法算法推导及matlab代码实现_20170527
神经网络中的反向传播算法分析与优化

神经网络中的反向传播算法分析与优化神经网络是近年来备受关注的一个领域,其在图像识别、语音识别、自然语言处理、智能机器人等领域有着广泛的应用。
其中,反向传播算法是神经网络训练中最常用的方法之一。
本文将对反向传播算法进行分析,并提出一些优化思路。
一、反向传播算法简介反向传播算法(Backpropagation Algorithm)是一种神经网络的学习算法,它的主要思想是通过误差反向传播来更新每一个权值。
具体来说,对于一个输人样本(input),神经网络先进行前向传播(forward propagation),计算出每一个节点的输出值;然后利用误差反向传播(back propagation of error)算法,计算每一个连接的误差,并根据误差大小更新每一个连接的权值,最终使得网络对输人样本的输出结果更加接近期望结果。
反向传播算法可以分为两个阶段:前向传播和误差反向传播。
前向传播即为输入层到隐层和隐层到输出层的计算,隐层与输出层的计算公式如下:第 j 个输出层节点的输出值为:$$O_j=f(\sum\limits_{i=1}^n w_{ji}O_i)$$其中,$f$ 为激活函数,$w_{ji}$ 是连接权重,$O_i$ 是输入层或者隐层的输出值。
误差函数采用均方误差(MSE)或交叉熵(Cross-entropy)。
均方误差定义为:$$E=\frac{1}{2}\sum\limits_{k=1}^n(y_k-\hat{y}_k)^2$$其中,$n$ 是输出节点数,$y_k$ 是期望输出,$\hat{y}_k$ 是神经网络的输出。
交叉熵定义为:$$E=-\sum\limits_{k=1}^n y_k\log\hat{y}_k+(1-y_k)\log(1-\hat{y}_k)$$误差反向传播算法的具体步骤如下:1. 小批量随机采样训练集;2. 前向传播,计算每个节点的输出值,得到整个网络的输出值;3. 根据误差函数,计算整个网络的误差;4. 求出每个节点的误差,即计算偏导数$\frac{\partial E}{\partial O_j}$;5. 根据链式法则,求出每个连接的误差,即计算偏导数$\frac{\partial E}{\partial w_{ji}}$;6. 利用梯度下降法,更新每个连接的权值,有公式$w_{ji}\leftarrow w_{ji}-\eta\frac{\partial E}{\partial w_{ji}}$,其中$\eta$为学习率。
基于matlab的卷积神经网络(CNN)讲解及代码

基于matlab的卷积神经网络(CNN)讲解及代码转载自:/walegahaha/article/details/516030401.经典反向传播算法公式详细推导2.卷积神经网络(CNN)反向传播算法公式详细推导网上有很多关于CNN的教程讲解,在这里我们抛开长篇大论,只针对代码来谈。
本文用的是matlab编写的deeplearning toolbox,包括NN、CNN、DBN、SAE、CAE。
在这里我们感谢作者编写了这样一个简单易懂,适用于新手学习的代码。
由于本文直接针对代码,这就要求读者有一定的CNN基础,可以参考Lecun的Gradient-Based Learning Applied to Document Recognition和tornadomeet的博文首先把Toolbox下载下来,解压缩到某位置。
然后打开Matlab,把文件夹内的util和data利用Set Path添加至路径中。
接着打开tests 文件夹的test_example_CNN.m。
最后在文件夹CNN中运行该代码。
下面是test_example_CNN.m中的代码及注释,比较简单。
load mnist_uint8; %读取数据% 把图像的灰度值变成0~1,因为本代码采用的是sigmoid激活函数train_x = double(reshape(train_x',28,28,60000))/255;test_x = double(reshape(test_x',28,28,10000))/255;train_y = double(train_y');test_y = double(test_y');%% 卷积网络的结构为 6c-2s-12c-2s% 1 epoch 会运行大约200s,错误率大约为11%。
而100 epochs 的错误率大约为1.2%。
rand('state',0) %指定状态使每次运行产生的随机结果相同yers = {struct('type', 'i') % 输入层struct('type', 'c', 'outputmaps', 6, 'kernelsize', 5) % 卷积层struct('type', 's', 'scale', 2) % pooling层struct('type', 'c', 'outputmaps', 12, 'kernelsize', 5) % 卷积层struct('type', 's', 'scale', 2) % pooling层};opts.alpha = 1; % 梯度下降的步长opts.batchsize = 50; % 每次批处理50张图opts.numepochs = 1; % 所有图片循环处理一次cnn = cnnsetup(cnn, train_x, train_y); % 初始化CNNcnn = cnntrain(cnn, train_x, train_y, opts); % 训练CNN [er, bad] = cnntest(cnn, test_x, test_y); % 测试CNN%plot mean squared errorfigure; plot(cnn.rL);assert(er<0.12, 'Too big error');•1•2•3•4•5•6•7•8•9•10•11•12•13•14•15•16•17•18•19•20•21•22•23•24•25•26•27•28•29•30•31•32•33•34下面是cnnsetup.m中的代码及注释。
神经网络之反向传播算法(BP)公式推导(超详细)

神经⽹络之反向传播算法(BP)公式推导(超详细)反向传播算法详细推导反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是⼀种与最优化⽅法(如梯度下降法)结合使⽤的,⽤来训练⼈⼯神经⽹络的常见⽅法。
该⽅法对⽹络中所有权重计算损失函数的梯度。
这个梯度会反馈给最优化⽅法,⽤来更新权值以最⼩化损失函数。
在神经⽹络上执⾏梯度下降法的主要算法。
该算法会先按前向传播⽅式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的⽅式计算损失函数值相对于每个参数的偏导数。
我们将以全连接层,激活函数采⽤Sigmoid函数,误差函数为Softmax+MSE损失函数的神经⽹络为例,推导其梯度传播⽅式。
准备⼯作1、Sigmoid 函数的导数回顾sigmoid函数的表达式:\sigma(x) = \frac{1}{1+e^{-x}}其导数为:\frac{d}{dx}\sigma(x) = \frac{d}{dx} \left(\frac{1}{1+e^{-x}} \right)= \frac{e^{-x}}{(1+e^{-x})^2}= \frac{(1 + e^{-x})-1}{(1+e^{-x})^2}=\frac{1+e^{-x}}{(1+e^{-x})^2} - \left(\frac{1}{1+e^{-x}}\right)^2= \sigma(x) - \sigma(x)^2= \sigma(1-\sigma)可以看到,Sigmoid函数的导数表达式最终可以表达为激活函数的输出值的简单运算,利⽤这⼀性质,在神经⽹络的梯度计算中,通过缓存每层的 Sigmoid 函数输出值,即可在需要的时候计算出其导数。
Sigmoid 函数导数的实现:import numpy as np # 导⼊ numpydef sigmoid(x): # sigmoid 函数return 1 / (1 + np.exp(-x))def derivative(x): # sigmoid 导数的计算return sigmoid(x)*(1-sigmoid(x))2、均⽅差函数梯度均⽅差损失函数表达式为:L = \frac{1}{2}\sum_{k=1}^{K}(y_k-o_k)^2其中y_k为真实值,o_k为输出值。
神经网络中的反向传播算法

神经网络中的反向传播算法神经网络是一种模仿人脑神经元工作原理的计算模型,具有自主学习和适应能力,已经成为人工智能领域的前沿技术。
然而,神经网络的训练过程需要大量的数据和时间,常常考验着研究人员的耐心和智慧。
其中最重要的一个算法就是反向传播算法,本文将从以下几个方面进行探讨。
一、神经网络的基本结构及工作原理神经网络是由大量人工神经元构成的,每个神经元接收来自其他神经元的输入信号,通过非线性函数(如sigmoid函数)进行加权求和,并生成一个输出信号。
神经网络通常由输入层、隐藏层和输出层组成,其中输入层通过传递输入信号激活隐藏层,隐藏层通过传递激活后的信号影响输出层。
每层神经元都会有一组权重,用于控制输入信号在这一层中的传播和计算。
而反向传播算法就是通过不断调整神经元间相关的权重,来最小化神经网络对训练数据的误差。
二、反向传播算法的基本思想反向传播算法主要分为两部分:前向传播和反向误差传播。
在前向传播过程中,输入信号会经过各个神经元的加权求和和激活函数处理,计算得到网络的输出。
而在反向误差传播过程中,首先计算网络输出误差,然后分别计算每个神经元权重对误差的贡献,最后反向传回网络,以此来更新权重。
三、反向传播算法的实现过程对于一个有n个训练样本的神经网络,我们需要不断迭代调整权重,达到优化网络的目的。
具体步骤如下:1. 首先将训练数据输入到神经网络中,得到网络输出。
2. 根据网络输出和实际标签计算误差,由于常用的误差函数是均方误差函数,所以误差可以通过网络输出与样本标签的差值平方和来计算。
3. 反向计算误差对每个神经元的输出的贡献,然后再根据误差对该神经元相应权重的贡献来计算梯度下降也就是权重的变化量。
4. 根据得到的梯度下降值,更新每个神经元的权重。
(注意反向传播需要使用到链式法则,要将误差从输出层传递回隐藏层和输入层)5. 重复步骤1到4,直到误差满足收敛条件或者达到预设的最大迭代次数。
四、反向传播算法的优化反向传播算法是一种经典的训练神经网络的方法,但是也有一些需要注意的问题。
神经网络——前向传播与反向传播公式推导

神经⽹络——前向传播与反向传播公式推导概述对于⼀个最原⽣的神经⽹络来说,BP反向传播是整个传播中的重点和核⼼,也是机器学习中的⼀个⼊门算法。
下⾯将以逻辑回归的分类问题为例,从最简单的单个神经元开始引⼊算法,逐步拓展到神经⽹络中,包括BP链式求导、前向传播和反向传播的向量化。
最后利⽤Python语⾔实现⼀个原始的神经⽹络结构作为练习。
需了解的预备知识:代价函数、逻辑回归、线性代数、多元函数微分参考:《ML-AndrewNg》神经元单个神经元是最简单的神经⽹络,仅有⼀层输⼊,⼀个输出。
【前向传播】\[z={{w}_{1}}\cdot {{x}_{1}}+{{w}_{2}}\cdot {{x}_{2}}+{{w}_{3}}\cdot {{x}_{3}}+b=\left[ \begin{matrix} {{w}_{1}} & {{w}_{2}} & {{w}_{3}} \\\end{matrix} \right]\left[ \begin{matrix} {{x}_{1}} \\ {{x}_{2}} \\ {{x}_{3}} \\ \end{matrix} \right]+b \]若激活函数为sigmoid函数,则\[\hat{y}=a =sigmoid(z) \]【代价函数】\[J(W,b)=-[y\log (a)+(1-y)\log (1-a)] \]【计算delta】\[deleta=a-y=\hat{y}-y \]【计算偏导数】\[\frac{\partial J}{\partial w}=\frac{\partial J}{\partial a}\cdot \frac{\partial a}{\partial z}=-(\frac{y}{a}+\frac{y-1}{1-a})a(a-1)=(a-y)x^T=(\hat{y}-y)x^T \]\[\frac{\partial J}{\partial b}=\frac{\partial J}{\partial a}\cdot \frac{\partial a}{\partial z}\cdot \frac{\partial z}{\partial b}=a-y=\hat{y}-y \]【更新权重】\[w = w-\alpha*\frac{\partial J}{\partial w} \]\[b = b-\alpha*\frac{\partial J}{\partial b} \]拓展到神经⽹络假设⽹络结构如上图所⽰,输⼊特征为2个,输出为⼀个三分类,隐藏层单元数均为4,数据如列表中所⽰,共20条。
BP(BackPropagation)反向传播神经网络介绍及公式推导
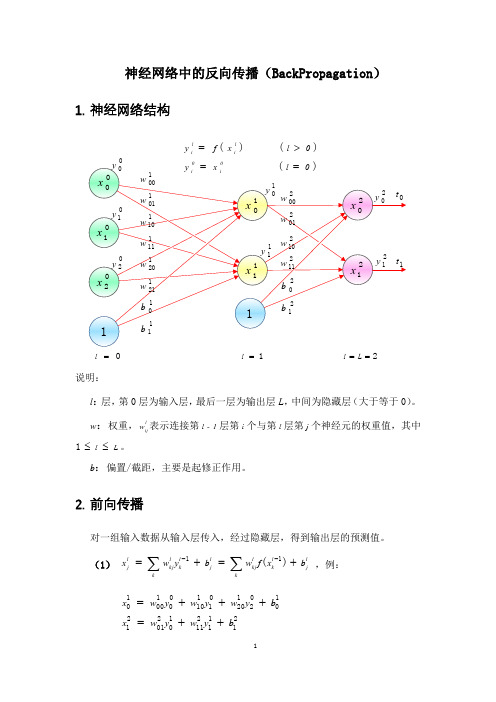
5. 链式法则
如果函数 u (t )及 v (t )都在 t 点可导,复合函数 z f(u,v)在对应点(u,v)具 有连续偏导数,z 在对应 t 点可导,则其导数可用下列公式计算:
dz z du z dv dt u dt v dt
6. 神经元误差
定义 l 层的第 i 个神经元上的误差为 il 即: (7)
5
附:激活函数
非线性: 当激活函数是线性的时候,一个两层的神经网络就可以逼近基 本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即 f(x)=x) ,就不满足这个性质了,而且如果 MLP 使用的是恒等激活函数, 那么其实整个网络跟单层神经网络是等价的。 可微性: 当优化方法是基于梯度的时候,这个性质是必须的。 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。 f(x)≈x: 当激活函数满足这个性质的时候, 如果参数的初始化是 random 的很小的值, 那么神经网络的训练将会很高效; 如果不满足这个性质, 那 么就需要很用心的去设置初始值。 输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方 法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数 的输出是 无限 的时候, 模型的训练会更加高效, 不过在这种情况小, 一 般需要更小的 learning rate.
l i
j
l 1 E x j x lj 1 xil
j
x lj 1 x
l i
jl 1 ,其中 l L
将公式(1) x j
l 1
w
k
l 1 l kj k
y blj 1
w
k
l 1 kj
f( xkl ) blj 1 ,对 x i 的求导
反向传播算法代码

反向传播算法代码反向传播算法(Backpropagation Algorithm)是深度学习中常用的一种神经网络训练算法,用于优化神经网络的参数。
下面是反向传播算法的代码实现:首先,我们需要定义一些函数,包括神经网络前向传播函数和误差函数(均方差误差函数):```pythonimport numpy as npdef sigmoid(x):return 1 / (1 + np.exp(-x))def relu(x):return np.maximum(0, x)def forward_propagation(X, W1, b1, W2, b2):Z1 = np.dot(X, W1) + b1A1 = relu(Z1)Z2 = np.dot(A1, W2) + b2A2 = sigmoid(Z2)return Z1, A1, Z2, A2def compute_cost(A2, Y):m = Y.shape[0]cost = (-1/m) * np.sum(Y * np.log(A2) + (1 - Y) *np.log(1 - A2))cost = np.squeeze(cost)return cost```下面是反向传播算法的代码实现:```pythondef backward_propagation(X, Y, Z1, A1, Z2, A2, W1, W2, b1,m = Y.shape[0]dZ2 = A2 - YdW2 = (1/m) * np.dot(A1.T, dZ2)db2 = (1/m) * np.sum(dZ2, axis=0, keepdims=True)dA1 = np.dot(dZ2, W2.T)dZ1 = np.multiply(dA1, np.int64(A1 > 0))dW1 = (1/m) * np.dot(X.T, dZ1)db1 = (1/m) * np.sum(dZ1, axis=0, keepdims=True)gradients = {"dW1": dW1,"db1": db1,"dW2": dW2,"db2": db2}return gradients```最后,我们使用梯度下降算法来更新神经网络参数:```pythondef update_parameters(W1, b1, W2, b2, gradients, learning_rate):dW1 = gradients["dW1"]db1 = gradients["db1"]dW2 = gradients["dW2"]db2 = gradients["db2"]W1 = W1 - learning_rate * dW1b1 = b1 - learning_rate * db1W2 = W2 - learning_rate * dW2b2 = b2 - learning_rate * db2parameters = {"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parameters```通过以上代码,我们可以实现反向传播算法来训练神经网络,优化网络参数,从而能够更好地进行分类或回归任务。
神经网络前向传播和反向传播公式详细推导

神经⽹络前向传播和反向传播公式详细推导神经⽹络的前向传播和反向传播公式详细推导本篇博客是对Michael Nielsen 所著的《Neural Network and Deep Learning 》第2章内容的解读,有兴趣的朋友可以直接阅读原⽂。
对神经⽹络有些了解的⼈可能都知道,神经⽹络其实就是⼀个输⼊到输出的映射函数:,函数的系数就是我们所要训练的⽹络参数,只要函数系数确定下来,对于任何输⼊我们就能得到⼀个与之对应的输出,⾄于是否符合我们预期,这就属于如何提⾼模型性能⽅⾯的问题了,本⽂不做讨论。
那么问题来了,现在我们⼿中只有训练集的输⼊和输出,我们应该如何调整⽹络参数使⽹络实际的输出与训练集的尽可能接近? 在开始正式讲解之前,让我们先对反向传播过程有⼀个直观上的印象。
反向传播算法的核⼼是代价函数对⽹络中参数(各层的权重和偏置)的偏导表达式。
这些表达式描述了代价函数值随权重或偏置变化⽽变化的程度。
到这⾥,BP 算法的思路就很容易理解了:如果当前代价函数值距离预期值较远,那么我们通过调整和的值使新的代价函数值更接近预期值(和预期值相差越⼤,则和调整的幅度就越⼤)。
⼀直重复该过程,直到最终的代价函数值在误差范围内,则算法停⽌。
BP 算法可以告诉我们神经⽹络在每次迭代中,⽹络的参数是如何变化的,理解这个过程对于我们分析⽹络性能或优化过程是⾮常有帮助的,所以还是尽可能搞透这个点。
我也是之前⼤致看过,然后发现看⼀些进阶知识还是需要BP 的推导过程作为⽀撑,所以才重新整理出这么⼀篇博客。
前向传播过程 在开始反向传播之前,先提⼀下前向传播过程,即⽹络如何根据输⼊得到输出的。
这个很容易理解,粗略看⼀下即可,这⾥主要是为了统⼀后⾯的符号表达。
记为第层第个神经元到第层第个神经元的权重,为第层第个神经元的偏置,为第层第个神经元的激活值(激活函数的输出)。
不难看出,的值取决于上⼀层神经元的激活:将上式重写为矩阵形式:为了⽅便表⽰,记为了⽅便表⽰,记为每⼀层的权重输⼊,为每⼀层的权重输⼊,式则变为。
神经网络中的反向传播算法详解

神经网络中的反向传播算法详解神经网络是一种模拟人脑神经元网络结构的计算模型,它通过学习和调整权重来实现对输入数据的分类和预测。
而神经网络中的反向传播算法则是实现这一目标的重要工具。
本文将详细解析神经网络中的反向传播算法,包括其原理、步骤和应用。
一、反向传播算法的原理神经网络中的反向传播算法基于梯度下降法,通过计算损失函数对网络中各个权重的偏导数来更新权重。
其核心思想是将输出误差从网络的输出层向输入层进行传播,并根据误差的梯度来调整网络中的权重,以最小化损失函数。
二、反向传播算法的步骤反向传播算法的具体步骤如下:1. 前向传播:将输入数据通过神经网络的各个层,得到输出结果。
2. 计算损失函数:将网络的输出结果与真实值进行比较,计算损失函数的值。
3. 反向传播:从输出层开始,计算损失函数对网络中每个权重的偏导数。
4. 权重更新:根据偏导数的值和学习率,更新网络中的权重。
5. 重复以上步骤:重复执行前向传播、损失函数计算、反向传播和权重更新,直到达到预设的停止条件。
三、反向传播算法的应用反向传播算法在神经网络中的应用非常广泛,以下是几个典型的应用场景:1. 图像分类:神经网络可以通过反向传播算法学习到图像的特征,从而实现对图像的分类。
2. 语音识别:通过训练神经网络,利用反向传播算法,可以实现对语音信号的识别和转录。
3. 自然语言处理:神经网络可以通过反向传播算法学习到文本的语义和语法信息,从而实现对文本的处理和理解。
4. 推荐系统:利用神经网络和反向传播算法,可以根据用户的历史行为和偏好,实现个性化的推荐。
四、反向传播算法的改进虽然反向传播算法在神经网络中得到了广泛应用,但它也存在一些问题,如容易陷入局部最优解、计算量大等。
为了克服这些问题,研究者们提出了许多改进的方法,如随机梯度下降法、正则化、批量归一化等。
五、结语神经网络中的反向传播算法是实现网络训练和权重调整的关键步骤。
通过前向传播和反向传播的结合,神经网络可以通过学习和调整权重,实现对输入数据的分类和预测。
神经网络的正反向传播算法推导

神经⽹络的正反向传播算法推导1 正向传播1.1 浅层神经⽹络为简单起见,先给出如下所⽰的简单神经⽹络:该⽹络只有⼀个隐藏层,隐藏层⾥有四个单元,并且只输⼊⼀个样本,该样本表⽰成⼀个三维向量,分别为为x1,x2和x3。
⽹络的输出为⼀个标量,⽤ˆy表⽰。
考虑该神经⽹络解决的问题是⼀个⼆分类的问题,把⽹络的输出解释为正样本的概率。
⽐⽅说输⼊的是⼀张图⽚(当然图⽚不可能只⽤三维向量就可以表⽰,这⾥只是举个例⼦),该神经⽹络去判断图⽚⾥⾯是否有猫,则ˆy代表该图⽚中有猫的概率。
另外,为衡量这个神经⽹络的分类表现,需要设置⼀个损失函数,针对⼆分类问题,最常⽤的损失函数是log−loss函数,该函数如下所⽰:L(y,ˆy)=−y×log(ˆy)−(1−y)×log(1−ˆy)上式只考虑⼀个样本的情况,其中y为真实值,ˆy为输出的概率。
1.1.1 单样本的前向传播我们把单个输⼊样本⽤向量表⽰为:\boldsymbol{x} = \left[ \begin{matrix} x_1 \\ x_2 \\ x_3 \end{matrix} \right] \tag{2}那么对于隐藏层中的第⼀个单元,如果不考虑激活函数,则其输出可以表⽰为:z^{[1]}_1 = \boldsymbol{w}^{[1]^T}_1\boldsymbol{x} + b^{[1]}_1 \tag{3}上式中,字母右上⾓的⽅括号中的数字代表这是神经⽹络的第⼏层,如果把输⼊层看作是第0层的话,那么这⾥的隐藏层就是第⼀层,字母的下标代表该层的第⼏个单元。
\boldsymbol{w}^{[1]}_1是权重向量,即给输⼊向量的每个元素⼀个权重,这些权重组合起来就形成了\boldsymbol{w}^{[1]}_1向量,把向量和其权重作点乘,再加上⼀个偏置标量b^{[1]}_1,就得到了该神经元的输出z^{[1]}_1。
同理可得隐藏层剩余三个单元的输出为:z^{[1]}_2 = \boldsymbol{w}^{[1]^T}_2\boldsymbol{x} + b^{[1]}_2 \tag{4}z^{[1]}_3 = \boldsymbol{w}^{[1]^T}_3\boldsymbol{x} + b^{[1]}_3 \tag{5}z^{[1]}_4 = \boldsymbol{w}^{[1]^T}_4\boldsymbol{x} + b^{[1]}_4 \tag{6}但是对于每⼀个神经单元,其输出必须有⼀个⾮线性激活函数,否则神经⽹络的输出就是输⼊向量的线性运算得到的结果,这样会⼤⼤限制神经⽹络的能⼒。
反向传播算法(过程及公式推导)

反向传播算法(过程及公式推导)⼀、反向传播的由来在我们开始DL的研究之前,需要把ANN—⼈⼯神经元⽹络以及bp算法做⼀个简单解释。
关于ANN的结构,我不再多说,⽹上有⼤量的学习资料,主要就是搞清⼀些名词:输⼊层/输⼊神经元,输出层/输出神经元,隐层/隐层神经元,权值,偏置,激活函数接下来我们需要知道ANN是怎么训练的,假设ANN⽹络已经搭建好了,在所有应⽤问题中(不管是⽹络结构,训练⼿段如何变化)我们的⽬标是不会变的,那就是⽹络的权值和偏置最终都变成⼀个最好的值,这个值可以让我们由输⼊可以得到理想的输出,于是问题就变成了y=f(x,w,b)(x是输⼊,w是权值,b为偏置,所有这些量都可以有多个,⽐如多个x1,x2,x3……最后f()就好⽐我们的⽹络它⼀定可以⽤⼀个函数来表⽰,我们不需要知道f(x)具体是怎样的函数,从⼩我们就认为只要是函数就⼀定要是可表⽰的,像f(x)=sin(x)⼀样,但是请摈弃这样的错误观念,我们只需要知道⼀系列的w和b决定了⼀个函数f(x),这个函数让我们由输⼊可以计算出合理的y)最后的⽬标就变成了尝试不同的w,b值,使得最后的y=f(x)⽆限接近我们希望得到的值t但是这个问题依然很复杂,我们把它简化⼀下,让(y-t)^2的值尽可能的⼩。
于是原先的问题化为了C(w,b)=(f(x,w,b)-t)^2取到⼀个尽可能⼩的值。
这个问题不是⼀个困难的问题,不论函数如何复杂,如果C降低到了⼀个⽆法再降低的值,那么就取到了最⼩值(假设我们不考虑局部最⼩的情况)如何下降?数学告诉我们对于⼀个多变量的函数f(a,b,c,d,……)⽽⾔,我们可以求得⼀个向量,它称作该函数的梯度,要注意的是,梯度是⼀个⽅向向量,它表⽰这个函数在该点变化率最⼤的⽅向(这个定理不详细解释了,可以在⾼等数学教材上找到)于是C(w,b)的变化量ΔC就可以表⽰成其中是该点上的微⼩变化,我们可以随意指定这些微⼩变化,只需要保证ΔC<0就可以了,但是为了更快的下降,我们为何不选在梯度⽅向上做变化呢?事实上,梯度下降的思想就是这样考虑的,我们使得从⽽保证C⼀直递减,⽽对于w来说只要每次更新即可。
神经网络中的反向传播算法

神经网络中的反向传播算法神经网络是模仿人类神经系统构造出来的一种人工智能技术。
其训练过程中使用了一种叫做反向传播算法的技术,可以从训练样本中学习,优化神经网络的权值和偏置,进而提高网络的预测能力。
本文将介绍反向传播算法的基本原理、实现细节和一些应用。
1. 基本原理反向传播算法作为常见的神经网络训练方法之一,其基本原理是将误差从输出端向输入端传递,并基于误差对网络中每个节点的权值和偏置进行调整。
其流程如下所示:- 向前传播:通过在网络中输入一个样本,从输入层开始,逐层计算神经元的输出值,一直到输出层得到最终的预测结果。
- 计算误差:将输出值与样本的真实标签进行比较,计算误差函数的值。
- 反向传播:将误差从输出端向输入端传递,一层一层计算每个节点的误差贡献,并基于误差调整每个节点的权值和偏置。
- 更新权值:根据误差调整后的权值和偏置更新网络中每个节点的参数,重新进行网络的前向传播。
2. 实现细节反向传播算法的实现有一些重要的细节需要注意。
2.1 损失函数损失函数是指网络在训练过程中需要优化的目标函数,其值反映了网络预测结果与实际结果的差距。
常见的损失函数有均方误差(MSE)和交叉熵(Cross Entropy)等。
均方误差适合用于回归问题,交叉熵适合用于分类问题。
2.2 激活函数激活函数是用于引入非线性因素的函数,其使网络得以拟合非线性的数据分布。
常见的激活函数有sigmoid、ReLU、tanh等。
激活函数应该满足连续可微、非线性和单调性等性质。
2.3 初始化权值网络中每个节点的权值和偏置需要先进行随机初始化,避免落入局部最优解。
按照高斯分布或均匀分布随机初始化可以获得更好的效果。
2.4 学习率学习率是指每次更新参数时,参数的变化量的倍率。
学习率过大容易跨越最优值;而学习率过小,则会导致训练时间过长。
因此,需要根据具体的问题和模型,进行参数调整。
3. 应用场景反向传播算法作为一种常见的神经网络训练方法,被广泛应用于图像识别、自然语言处理、预测分析等领域。
神经网络中的反向传播算法

神经网络中的反向传播算法是一种非常常见的训练神经网络的方法。
通过它,神经网络可以根据输入和输出之间的关系调整权重,从而达到更准确的预测结果。
本文将对反向传播算法进行详细概述,包括反向传播算法的基本原理、算法的实现步骤以及在神经网络中的应用。
一、反向传播算法的基本原理反向传播算法本质上是一个优化算法。
在神经网络中,我们希望通过调整权重来实现输入与输出之间的最佳拟合。
在这个问题中,我们需要找到一个能够最小化损失函数的权重实现。
其中,损失函数是我们希望优化的目标函数,它描述了输入和输出之间的误差。
通过不断地调整权重,我们可以最小化损失函数,从而得到最优解。
反向传播算法使用梯度下降方法来最小化损失函数。
在这个问题中,梯度是指损失函数关于权重的导数。
我们希望通过不断地移动权重,来寻找损失函数的最小值。
在这个过程中,我们需要计算每个权重的梯度,然后调整它们的值。
二、算法的实现步骤反向传播算法是一个迭代算法,它通过不断地调整权重来逐步逼近最优解。
算法的实现可以大体分为以下几个步骤:1.正向传播(forward propagation):对于给定的输入,我们首先执行正向传播操作,通过一系列的计算过程来得到预测输出。
2.计算误差(compute error):使用预测的输出和实际的输出之间的误差来计算损失函数。
3.反向传播(backward propagation):对于每个权重,我们计算梯度,并使用它们来调整权重的值。
4.重复以上步骤:不断重复以上步骤,直到损失函数的值降至最小。
三、在神经网络中的应用反向传播算法是神经网络中最常用的训练算法之一。
在图像识别、语音识别、自然语言处理等领域中,它已经被广泛应用。
在现代深度学习领域中,反向传播算法是构建各种深度学习模型的基础。
例如,在卷积神经网络(CNN)中,卷积层和池化层之间的连接使用的就是反向传播算法。
通过这个过程,CNN可以根据输入图像中的特征自动分配权重,从而实现识别目标。
matlab 空间的bp算法

matlab 空间的bp算法Matlab是一种广泛应用于科学和工程领域的高级编程语言和环境。
它具有丰富的功能和强大的工具,使得在空间数据分析和处理方面非常有用。
在本文中,我们将重点探讨Matlab中的空间反向传播(backpropagation)算法及其应用。
本文将一步一步回答,帮助读者理解这个算法的原理和实现细节。
第一步:理解反向传播算法反向传播算法是一种在人工神经网络中常用的训练算法。
它通过计算损失函数对网络参数的梯度,来不断更新参数以优化网络的性能。
在空间数据处理中,反向传播算法可以用于训练和优化卷积神经网络(CNN),这是一种能够有效学习和识别空间模式的神经网络结构。
第二步:了解卷积神经网络卷积神经网络是一种特殊的神经网络结构,其主要用于处理和分析空间数据,比如图像、语音、文本等。
它通过多层神经元节点的组织和连接来实现非线性特征的提取和模式的学习。
在Matlab中,我们可以使用深度学习工具箱来构建和训练卷积神经网络。
第三步:准备数据集在进行反向传播算法之前,我们需要准备好需要处理的空间数据集。
例如,如果我们想要训练一个图像分类器,我们需要准备一个包含图像和对应标签的数据集。
这个数据集可以在Matlab中表示为一个数据数组和一个标签数组。
第四步:构建卷积神经网络模型在Matlab中,我们可以使用深度学习工具箱来构建卷积神经网络模型。
我们可以选择不同的网络结构和层类型来满足特定的任务需求。
例如,我们可以使用卷积层来提取图像的空间特征,然后使用池化层来减小特征图的尺寸,并使用全连接层来实现分类或回归任务。
在构建模型时,我们还需要设置模型的参数,如学习率、迭代次数等。
第五步:定义损失函数在训练神经网络时,我们需要定义一个损失函数来衡量模型预测结果和实际标签之间的差异。
常见的损失函数包括均方误差(MSE)、交叉熵损失函数等。
选择合适的损失函数取决于任务的性质和目标。
第六步:进行训练和优化在完成模型构建和损失函数定义后,我们可以使用反向传播算法对模型进行训练和优化。
神经网络之反向传播算法实现

神经⽹络之反向传播算法实现1 神经⽹络模型以下⾯神经⽹络模型为例,说明神经⽹络中正向传播和反向传播过程及代码实现1.1 正向传播(1)输⼊层神经元i1,i2,输⼊层到隐藏层处理过程HiddenNeth1=w1i1+w2i2+b1HiddenNeth2=w3i1+w4i2+b1h1=sigmoid(HiddenNeth1)h2=sigmoid(HiddenNeth2)(2)隐藏层:神经元h1,h2,隐藏层到输出层处理过程OutputNeto1=w5h1+w6h2OutputNeto2=w7h1+w8h2o1=sigmoid(OutputNeto1)o2=sigmoid(OutputNeto2)1.2 反向传播反向传播是根据每次前向传播得到的误差来评估每个神经⽹络层中的权重对其的影响程度,再根据链式规则和梯度下降对权重进⾏更新的过程,下⾯以对更新权重w5和w1为例进⾏说明totalo1表⽰参考值0.01totalo2参考值0.991.2.1 更新权重w_5∂totalo1∂w5=∂totalo1∂o1∗∂o1∂outputneto1∗∂outputneto1∂w5其中:∂totalo1∂o1=∂12(totalo1−o1)2∂o1=−(totalo1−o1)∂o1∂outputneto1=o1(1−o1)∂outputneto1∂w5=h1则:∂totalo1∂w5=−(totalo1−o1)o1(1−o1)h1更新w_5的值:w5new=w5−learningrate∗∂totalo1∂w51.2.2 更新权重w_1求w1的偏导与求w5偏导唯⼀的区别在于,w1的值影响了o1和o2,所以∂total ∂w1=∂totalol∂w1+∂totalo2∂w1接下来的求导思路和上⾯⼀样:∂totalol ∂w1=∂totalol∂h1∗∂h1∂hiddenneth1∗∂hiddenneth1∂w1∂total∂w1=−(totalo1−o1)o1(1−o1)w5∗h1(1−h1)i1+−(totalo2−o2)o2(1−o2)w7∗h1(1−h1)i1更新w_1的值:w1new=w1−learningrate∗∂total ∂w12. 代码实现正向和⽅向传播算法import randomimport mathclass NeuralNetwork:learning_rate = 0.5def __init__(self,input_num,hidden_num,output_num,input_hidden_weights=None,input_hidden_bias=None,hidden_output_weights=None,hidden_output_bias=None): self.input_num = input_num# 构建掩藏层self.hidden_layer = NeuralLayer(hidden_num,input_hidden_bias)# 构建输出层self.output_layer = NeuralLayer(output_num,hidden_output_bias)# 初始化输⼊层到隐藏层权重self.init_input_to_hidden_weights(input_hidden_weights)# 初始化隐藏层到输出层权重self.init_hidden_to_output_weights(hidden_output_weights)def init_input_to_hidden_weights(self,weights):weight_num = 0for i_num in range(len(self.hidden_layer.neurons)):for o_num in range(self.input_num):if weights is None:self.hidden_layer.neurons[i_num].weights.append(random.random())else:self.hidden_layer.neurons[i_num].weights.append(weights[weight_num])weight_num += 1def init_hidden_to_output_weights(self,weights):weight_num = 0for i_num in range(len(self.output_layer.neurons)):for o_num in range(len(self.hidden_layer.neurons)):if weights is None:self.output_layer.neurons[i_num].weights.append(random.random())else:self.output_layer.neurons[i_num].weights.append(weights[weight_num])weight_num += 1def inspect(self):print('..................')print('input inspect:',[i for i in self.inputs])print('..................')print('hidden inspect:')self.hidden_layer.inspect()print('..................')print('output inspect:')self.output_layer.inspect()print('..................')def forward(self,inputs):hidden_layer_outout = self.hidden_layer.forward(inputs)print('hidden_layer_outout',hidden_layer_outout)ouput_layer_ouput = self.output_layer.forward(hidden_layer_outout)print('ouput_layer_ouput',ouput_layer_ouput)return ouput_layer_ouputdef train(self,x,y):ouput_layer_ouput = self.forward(x)# 求total / neto的偏导total_o_pd = [0] * len(self.output_layer.neurons)for o in range(len(self.output_layer.neurons)):total_o_pd[o] = self.output_layer.neurons[o].calculate_total_net_pd(y[o])# 求total / h的偏导 = total.1 / h的偏导 + total.2 / h的偏导total_neth_pd = [0] * len(self.hidden_layer.neurons)for h in range(len(self.hidden_layer.neurons)):total_h_pd = 0for o in range(len(self.output_layer.neurons)):total_h_pd += total_o_pd[o] * self.hidden_layer.neurons[h].weights[o]total_neth_pd[h] = total_h_pd * self.output_layer.neurons[h].calculate_output_net_pd()# 更新输出层神经元权重for o in range(len(self.output_layer.neurons)):for ho_w in range(len(self.output_layer.neurons[o].weights)):ho_w_gradient = total_o_pd[o] * self.output_layer.neurons[o].calculate_net_linear_pd(ho_w) self.output_layer.neurons[o].weights[ho_w] -= self.learning_rate * ho_w_gradient# 更新隐藏层神经元权重for h in range(len(self.hidden_layer.neurons)):for ih_w in range(len(self.hidden_layer.neurons[h].weights)):ih_w_gradient = total_neth_pd[h] * self.hidden_layer.neurons[h].calculate_net_linear_pd(ih_w) self.hidden_layer.neurons[h].weights[ih_w] -= self.learning_rate * ih_w_gradientdef calculate_total_error(self, training_sets):total_error = 0for t in range(len(training_sets)):training_inputs, training_outputs = training_sets[t]self.forward(training_inputs)for o in range(len(training_outputs)):total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o])return total_errorclass NeuralLayer:def __init__(self,neural_num,bias):self.bias = bias if bias else random.random()self.neurons = []for i in range(neural_num):self.neurons.append(Neuron(self.bias))def inspect(self):print('weights:',[neuron.weights for neuron in self.neurons])print('bias:',[neuron.bias for neuron in self.neurons])def get_output(self,inputs):outputs = []for neuron in self.neurons:outputs.append(neuron.output)return outputsdef forward(self,inputs):outputs = []for neuron in self.neurons:outputs.append(neuron.calculate_output(inputs))return outputsclass Neuron:def __init__(self,bias):self.bias = biasself.weights = []def calculate_output(self,inputs):self.inputs = inputstotal_net_outputs = self.calculate_total_net_output()self.output = self.sigmoid(total_net_outputs)return self.outputdef calculate_total_net_output(self):total = 0for i in range(len(self.inputs)):total += self.inputs[i] * self.weights[i]return total + self.biasdef sigmoid(self,total_net_input):return 1 / (1 + math.exp(-total_net_input))def calculate_total_output_pd(self,total_output):return -(total_output - self.output)def calculate_output_net_pd(self):return self.output * (1 - self.output)def calculate_total_net_pd(self,total_output):return self.calculate_total_output_pd(total_output) * self.calculate_output_net_pd()def calculate_net_linear_pd(self,index):return self.inputs[index]def calculate_error(self, target_output):return 0.5 * (target_output - self.output) ** 2nn = NeuralNetwork(2, 2, 2, input_hidden_weights=[0.15, 0.2, 0.25, 0.3], input_hidden_bias=0.35, hidden_output_weights=[0.4, 0.45, 0.5, 0.55], hidden_output_bias=0.6)for i in range(10000):nn.train([0.05, 0.1], [0.01, 0.99])print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.99]]]), 9))hidden_layer_outout [0.5932699921071872, 0.596884378259767]ouput_layer_ouput [0.7513650695523157, 0.7729284653214625]hidden_layer_outout [0.5932662857458805, 0.5968782561589732]ouput_layer_ouput [0.7420894573166411, 0.775286681791022]迭代1次误差0.291028391hidden_layer_outout [0.5932662857458805, 0.5968782561589732]ouput_layer_ouput [0.7420894573166411, 0.775286681791022]hidden_layer_outout [0.5932623797502049, 0.5968720205376407]ouput_layer_ouput [0.7324789213021788, 0.7775850216973027]迭代2次误差 0.283547957hidden_layer_outout [0.5932623797502049, 0.5968720205376407]ouput_layer_ouput [0.7324789213021788, 0.7775850216973027]hidden_layer_outout [0.5932582778661456, 0.5968656853189723]ouput_layer_ouput [0.7225410209751278, 0.7798256906644981]迭代3次误差 0.275943973hidden_layer_outout [0.5932582778661456, 0.5968656853189723]ouput_layer_ouput [0.7225410209751278, 0.7798256906644981]hidden_layer_outout [0.5932539857457403, 0.5968592652405116]ouput_layer_ouput [0.7122866732919141, 0.7820107943242337]迭代4次误差0.268233041.........hidden_layer_outout [0.5930355856011269, 0.5965960242813179]ouput_layer_ouput [0.016365976874939202, 0.9836751989707726]hidden_layer_outout [0.5930355857116121, 0.5965960243868048]ouput_layer_ouput [0.016365393177895763, 0.9836757760229975]迭代10000次误差 4.0257e-05迭代10000次后结果:hidden_layer_outout [0.5930355856011269, 0.5965960242813179]ouput_layer_ouput [0.016365976874939202, 0.9836751989707726]hidden_layer_outout [0.5930355857116121, 0.5965960243868048]ouput_layer_ouput [0.016365393177895763, 0.9836757760229975]迭代10000次误差 4.0257e-05Processing math: 100%。
神经网络中的反向传播法算法推导及matlab代码实现_20170527

神经网络中的反向传播法算法推导及matlab代码实现最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进行补充,但是补充的又是错的,难怪觉得有问题。
反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。
如果不想看公式,可以直接把数值带进去,实际的计算一下,体会一下这个过程之后再来推导公式,这样就会觉得很容易了。
说到神经网络,大家看到这个图应该不陌生:这是典型的三层神经网络的基本构成,Layer L1是输入层,Layer L2是隐含层,Layer L3是隐含层,我们现在手里有一堆数据{x1,x2,x3,...,xn},输出也是一堆数据{y1,y2,y3,...,yn},现在要他们在隐含层做某种变换,让你把数据灌进去后得到你期望的输出。
如果你希望你的输出和原始输入一样,那么就是最常见的自编码模型(Auto-Encoder)。
可能有人会问,为什么要输入输出都一样呢?有什么用啊?其实应用挺广的,在图像识别,文本分类等等都会用到,我会专门再写一篇Auto-Encoder的文章来说明,包括一些变种之类的。
如果你的输出和原始输入不一样,那么就是很常见的人工神经网络了,相当于让原始数据通过一个映射来得到我们想要的输出数据,也就是我们今天要讲的话题。
本文直接举一个例子,带入数值演示反向传播法的过程,公式的推导等到下次写Auto-Encoder的时候再写,其实也很简单,感兴趣的同学可以自己推导下试试:)(注:本文假设你已经懂得基本的神经网络构成,如果完全不懂,可以参考Poll写的笔记:[Mechine Learning & Algorithm] 神经网络基础)假设,你有这样一个网络层:第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
机器学习之五:神经网络、反向传播算法推导

机器学习之五:神经⽹络、反向传播算法推导⼀、逻辑回归的局限在逻辑回归⼀节中,使⽤逻辑回归的多分类,实现了识别20*20的图⽚上的数字。
但所使⽤的是⼀个⼀阶的模型,并没有使⽤多项式,为什么?可以设想⼀下,在原有400个特征的数据样本中,增加⼆次、三次、四次多项式,会是什么情形?很显然,训练样本的特征数量将会拔⾼多个数量级,⽽且,更重要的,要在⼀个式⼦中拟合这么多的特征,其难度是⾮常⼤的,可能⽆法收敛到⼀个⽐较理想的状态。
也就是说,逻辑回归没法提供很复杂的模型。
因为其本质上是⼀个线性的分类器,擅长解决的是线性可分的问题。
那么⾮线性可分问题,要怎么解决?解决思路如果有⼀种⽅法,将⾮线性可分问题先进⾏特征提取,变为接近线性可分,那么再应⽤⼀次逻辑回归,是否就能解决⾮线性问题了?这便是神经⽹络的思想。
⼆、神经⽹络1、结构神经⽹络的结构,如下图所⽰上⾯是⼀个最简单的模型,分为三层:输⼊层、隐藏层、输出层。
其中,隐藏层可以是多层结构,通过扩展隐藏层的结构,可以构建更得杂的模型,例如下⾯的模型:每⼀层的输出,皆是下⼀层的输出,层层连接⽽成,形成⼀个⽹络。
⽹络中的节点,称为神经元。
每个神经元,其实就是进⾏⼀次类似逻辑回归的运算(之所以说是"类似",是因为可以使⽤逻辑回归,也有别的算法代替,但可以使⽤逻逻回归来理解它的运算机理)。
根据上⾯前⾔中的分析,显然,隐藏层是进⾏特征的提取,⽽输出层,其实就是进⾏逻辑回归。
为何说隐藏层是进⾏特征提取?为⽅便理解,这⾥假设所有神经元执⾏逻辑回归。
⼀次逻辑回归,可以将平⾯⼀分为⼆。
神经⽹络中,执⾏的是 N 多个逻辑回归,那么可以将平⾯切割为 N 多个区域,这些区域最后由输出层进⾏综合后做为结果。
matlab 反向传播训练

matlab 反向传播训练反向传播算法是深度学习中常用的训练方法之一,它通过利用链式法则来计算模型参数的梯度,并根据梯度更新模型参数。
本文将介绍反向传播算法的基本原理和实现过程,并给出一个基于MATLAB 的反向传播训练的示例。
一、反向传播算法的原理反向传播算法是一种基于梯度下降的优化算法,它通过计算损失函数对模型参数的梯度,从而实现模型的训练。
具体而言,反向传播算法通过利用链式法则来计算每个模型参数对损失函数的偏导数,并根据梯度的方向来更新模型参数,以使损失函数的值逐步减小。
反向传播算法的基本原理可以简要概括为以下几个步骤:1. 前向传播:将输入样本通过神经网络前向计算,得到模型的输出结果。
2. 计算损失函数:根据模型的输出结果和真实标签,计算损失函数的值。
3. 反向传播:根据损失函数,利用链式法则计算每个模型参数对损失函数的偏导数。
4. 参数更新:根据梯度的方向,使用梯度下降法更新模型参数,使损失函数的值逐步减小。
5. 重复上述步骤,直到达到指定的训练轮数或达到收敛条件。
二、反向传播算法的实现下面以一个简单的神经网络为例,介绍如何利用MATLAB实现反向传播算法的训练过程。
假设我们要训练一个二分类模型,输入样本为2维向量,输出为0或1。
我们可以定义一个包含一个隐藏层的神经网络,其中隐藏层有4个神经元。
我们需要定义模型的结构和参数。
在MATLAB中,我们可以使用神经网络工具箱来定义和训练神经网络模型。
具体而言,我们可以使用`feedforwardnet`函数来创建一个前馈神经网络模型,然后使用`train`函数来训练模型。
接下来,我们需要准备训练数据。
假设我们有1000个训练样本,可以使用`rand`函数生成随机的样本数据和标签。
然后,我们可以使用`train`函数来训练模型。
在训练过程中,我们可以指定训练参数,如学习率、训练轮数等。
训练完成后,我们可以使用`sim`函数来对新样本进行预测。
我们可以使用测试数据来评估模型的性能,如准确率、精确率、召回率等指标。
反向传播算法

反向传播算法是人工神经网络的一种重要算法,它通过计算每个神经元的误差,从输出层向输入层反向传播,以更新网络权值,从而使神经网络学习和适应输入数据的规律。
本文将从的基本原理、算法实现、常见问题及优化等方面进行讲述。
一、的基本原理是一种有监督学习的算法,它需要一些已知输出值的训练数据,通过不断调整网络的权值,使网络的输出尽可能接近于期望输出。
的基本原理可以分为两个部分,即误差计算和权值更新。
1. 误差计算误差计算是指在神经网络输出预测结果与实际输出结果之间计算误差,从而确定网络的训练效果。
误差计算可以使用不同的方法,如均方误差、交叉熵等。
在中,使用均方误差的方法进行误差计算。
均方误差的计算公式如下:$E = \frac{1}{2}\sum_{i=1}^{n}(y_i-o_i)^2$其中,$E$为均方误差,$n$为输出节点数,$y_i$为期望输出值,$o_i$为实际输出值。
计算出均方误差后,就可以根据误差反向传播更新神经网络的权值。
2. 权值更新权值更新是指在误差计算的基础上,通过反向传播更新神经网络的权值,使它们逐渐趋近于最优值。
在中,使用梯度下降法进行权值更新。
梯度下降法的基本思想是沿着误差曲面的反方向,以学习率为步长逐渐逼近误差函数局部极小值点的方向,直到找到最优解。
梯度下降法可以表述为以下公式:$w_{ij}^{new} = w_{ij}^{old} -\alpha\frac{\delta E}{\deltaw_{ij}}$其中,$w_{ij}^{new}$为更新后的权值,$w_{ij}^{old}$为更新前的权值,$\alpha$为学习率,$\frac{\delta E}{\delta w_{ij}}$为误差对权值的偏导数。
二、的实现的具体实现分为前向传播和反向传播两个步骤。
1. 前向传播前向传播是指从输入层到输出层按顺序计算每一层的输出值。
具体实现时,需要完成以下步骤:(1)将输入值送入输入层,并计算输入层到隐藏层的输出值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
神经网络中的反向传播法算法推导及matlab代码实现
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进行补充,但是补充的又是错的,难怪觉得有问题。
反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。
如果不想看公式,可以直接把数值带进去,实际的计算一下,体会一下这个过程之后再来推导公式,这样就会觉得很容易了。
说到神经网络,大家看到这个图应该不陌生:
这是典型的三层神经网络的基本构成,Layer L1是输入层,Layer L2是隐含层,Layer L3是隐含层,我们现在手里有一堆数据{x1,x2,x3,...,xn},输出也是一堆数据{y1,y2,y3,...,yn},现在要他们在隐含层做某种变换,让你把数据灌进去后得到你期望的输出。
如果你希望你的输出和原始输入一样,那么就是最常见的自编码模型(Auto-Encoder)。
可能有人会问,为什么要输入输出都一样呢?有什么用啊?其实应用挺广的,在图像识别,文本分类等等都会用到,我会专门再写一篇Auto-Encoder的文章来说明,包括一些变种之类的。
如果你的输出和原始输入不一样,那么就是很常见的人工神经网络了,相当于让原始数据通过一个映射来得到我们想要的输出数据,也就是我们今天要讲的话题。
本文直接举一个例子,带入数值演示反向传播法的过程,公式的推导等到下次写Auto-Encoder的时候再写,其实也很简单,感兴趣的同学可以自己推导下试试:)(注:本文假设你已经懂得基本的神经网络构成,如果完全不懂,可以参考Poll写的笔记:[Mechine Learning & Algorithm] 神经网络基础)
假设,你有这样一个网络层:
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
现在对他们赋上初值,如下图:
其中,输入数据 i1=0.05,i2=0.10;
输出数据o1=0.01,o2=0.99;
初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播
1.输入层---->隐含层:
计算神经元h1的输入加权和:
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
同理,可计算出神经元h2的输出o2:
2.隐含层---->输出层:
计算输出层神经元o1和o2的值:
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
1.计算总误差
总误差:(square error)
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
2.隐含层---->输出层的权值更新:
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)
下面的图可以更直观的看清楚误差是怎样反向传播的:
现在我们来分别计算每个式子的值:
计算:
计算:
(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)计算:
最后三者相乘:
这样我们就计算出整体误差E(total)对w5的偏导值。
回过头来再看看上面的公式,我们发现:
为了表达方便,用来表示输出层的误差:
因此,整体误差E(total)对w5的偏导公式可以写成:
如果输出层误差计为负的话,也可以写成:
最后我们来更新w5的值:
(其中,是学习速率,这里我们取0.5)
同理,可更新w6,w7,w8:
3.隐含层---->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---
->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
计算:
先计算:
同理,计算出:
两者相加得到总值:
再计算:
再计算:
最后,三者相乘:
为了简化公式,用sigma(h1)表示隐含层单元h1的误差:
最后,更新w1的权值:
同理,额可更新w2,w3,w4的权值:
这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。
迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99]),证明效果还是不错的。
88888888888888888888888888888888888888888888888888888888888888
clear all
clc
close all
i1=0.05; i2=0.10;
o1=0.01; o2=0.99;
w1=0.15; w2=0.20; w3=0.25; w4=0.30; b1=0.35;
w5=0.40; w6=0.45; w7=0.50; w8=0.55; b2=0.6;
% alpha=38.9
% epoch=6000;
alpha=0.5
epoch=10000;
for k=1:epoch
% forward:hidden layers
net_h1=w1*i1+w2*i2+b1*1;
out_h1=1/(1+exp(-net_h1));
net_h2=w3*i1+w4*i2+b1*1;
out_h2=1/(1+exp(-net_h2));
%forward:output layer
net_o1=w5*out_h1+w6*out_h2+b2*1;
net_o2=w7*out_h1+w8*out_h2+b2*1;
out_o1=1/(1+exp(-net_o1));
out_o2=1/(1+exp(-net_o2));
% cost function
E_total(k)=((out_o1-o1)^2+(out_o2-o2)^2)/2;
% backward: output layer
dE_dw5=-(o1-out_o1)*out_o1*(1-out_o1)*out_h1;
dE_dw6=-(o1-out_o1)*out_o1*(1-out_o1)*out_h2;
dE_dw7=-(o2-out_o2)*out_o2*(1-out_o2)*out_h1;
dE_dw8=-(o2-out_o2)*out_o2*(1-out_o2)*out_h2;
% backward: hidden layer
dE_douto1=-(o1-out_o1);
douto1_dneto1=out_o1*(1-out_o1);
% dEo1_douth1=-(o1-out_o1)*out_o1*(1-out_o1)
dEo1_dneto1=dE_douto1*douto1_dneto1;
dEo1_douth1=dEo1_dneto1*w5;
dEo1_douth2=dEo1_dneto1*w6;
dE_douto2=-(o2-out_o2);
douto2_dneto2=out_o2*(1-out_o2);
% dEo1_douth1=-(o1-out_o1)*out_o1*(1-out_o1)
dEo2_dneto2=dE_douto2*douto2_dneto2;
dEo2_douth1=dEo2_dneto2*w7;
dEo2_douth2=dEo2_dneto2*w8;
dE_dw1=(dEo1_douth1+dEo2_douth1)*out_h1*(1-out_h1)*i1; dE_dw2=(dEo1_douth1+dEo2_douth1)*out_h1*(1-out_h1)*i2; dE_dw3=(dEo1_douth2+dEo2_douth2)*out_h2*(1-out_h2)*i1; dE_dw4=(dEo1_douth2+dEo2_douth2)*out_h2*(1-out_h2)*i2;
w1=w1-alpha*dE_dw1;
w2=w2-alpha*dE_dw2;
w3=w3-alpha*dE_dw3;
w4=w4-alpha*dE_dw4;
w5=w5-alpha*dE_dw5;
w6=w6-alpha*dE_dw6;
w7=w7-alpha*dE_dw7;
w8=w8-alpha*dE_dw8;
end
v_E_total_k=E_total(k)
plot(E_total)。