最新模式识别复习要点和参考习题
模式识别复习题分解

模式识别复习题分解《模式识别》试题库⼀、基本概念题1.1 模式识别的三⼤核⼼问题是:、、。
1.2、模式分布为团状时,选⽤聚类算法较好。
1.3 欧式距离具有。
马式距离具有。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性1.4 描述模式相似的测度有:。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度1.5 利⽤两类⽅法处理多类问题的技术途径有:(1);(2);(3)。
其中最常⽤的是第个技术途径。
1.6 判别函数的正负和数值⼤⼩在分类中的意义是:,。
1.7 感知器算法。
(1)只适⽤于线性可分的情况;(2)线性可分、不可分都适⽤。
1.8 积累位势函数法的判别界⾯⼀般为。
(1)线性界⾯;(2)⾮线性界⾯。
1.9 基于距离的类别可分性判据有:。
(1)1[]w BTr S S-(2)BWSS(3)BW B+1.10 作为统计判别问题的模式分类,在()情况下,可使⽤聂曼-⽪尔逊判决准则。
1.11 确定性模式⾮线形分类的势函数法中,位势函数K(x,x k)与积累位势函数K(x)的关系为()。
1.12 ⽤作确定性模式⾮线形分类的势函数法,通常,两个n维向量x和x k的函数K(x,x k)若同时满⾜下列三个条件,都可作为势函数。
①();②();③ K(x,x k )是光滑函数,且是x 和x k 之间距离的单调下降函数。
1.13 散度J ij 越⼤,说明ωi 类模式与ωj 类模式的分布()。
当ωi 类模式与ωj 类模式的分布相同时,J ij =()。
1.14 若⽤Parzen 窗法估计模式的类概率密度函数,窗⼝尺⼨h1过⼩可能产⽣的问题是(),h1过⼤可能产⽣的问题是()。
1.15 信息熵可以作为⼀种可分性判据的原因是:。
1.16作为统计判别问题的模式分类,在()条件下,最⼩损失判决规则与最⼩错误判决规则是等价的。
1.17 随机变量l(x ρ)=p( x ρ|ω1)/p( x ρ|ω2),l( x ρ)⼜称似然⽐,则E {l( x ρ)|ω2}=()。
模式识别复习题分解

《模式识别》试题库一、基本概念题1.1 模式识别的三大核心问题是:、、。
1.2、模式分布为团状时,选用聚类算法较好。
1.3 欧式距离具有。
马式距离具有。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性1.4 描述模式相似的测度有:。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度1.5 利用两类方法处理多类问题的技术途径有:(1);(2);(3)。
其中最常用的是第个技术途径。
1.6 判别函数的正负和数值大小在分类中的意义是:,。
1.7 感知器算法。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
1.8 积累位势函数法的判别界面一般为。
(1)线性界面;(2)非线性界面。
1.9 基于距离的类别可分性判据有:。
(1)1[]w BTr S S-(2)BWSS(3)BW BSS S+1.10 作为统计判别问题的模式分类,在()情况下,可使用聂曼-皮尔逊判决准则。
1.11 确定性模式非线形分类的势函数法中,位势函数K(x,x k)与积累位势函数K(x)的关系为()。
1.12 用作确定性模式非线形分类的势函数法,通常,两个n维向量x和x k的函数K(x,x k)若同时满足下列三个条件,都可作为势函数。
①();②( ); ③ K(x,x k )是光滑函数,且是x 和x k 之间距离的单调下降函数。
1.13 散度J ij 越大,说明ωi 类模式与ωj 类模式的分布( )。
当ωi 类模式与ωj 类模式的分布相同时,J ij =( )。
1.14 若用Parzen 窗法估计模式的类概率密度函数,窗口尺寸h1过小可能产生的问题是( ),h1过大可能产生的问题是( )。
1.15 信息熵可以作为一种可分性判据的原因是: 。
1.16作为统计判别问题的模式分类,在( )条件下,最小损失判决规则与最小错误判决规则是等价的。
1.17 随机变量l(x )=p( x |ω1)/p( x |ω2),l( x )又称似然比,则E {l( x )|ω2}=( )。
人工智能模式识别技术练习(习题卷1)

人工智能模式识别技术练习(习题卷1)第1部分:单项选择题,共45题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]可视化技术中的平行坐标又称为( )A)散点图B)脸谱图C)树形图D)轮廓图答案:D解析:2.[单选题]描述事物的基本元素,称为( )A)事元B)物元C)关系元D)信息元答案:B解析:3.[单选题]下面不属于层次聚类法的是( )A)类平均法B)最短距离法C)K均值法D)方差平方和法答案:C解析:4.[单选题]核函数方法是一系列先进( )数据处理技术的总称。
A)离散B)连续C)线性D)非线性答案:D解析:5.[单选题]下面哪个网络模型是最典型的反馈网络模型?( )A)BP神经网络B)RBF神经网络C)CPN网络D)Hopfield网络答案:D解析:6.[单选题]粗糙集所处理的数据必须是( )的。
答案:B解析:7.[单选题]模糊聚类分析是通过( )来实现的。
A)模糊相似关系B)模糊等价关系C)模糊对称关系D)模糊传递关系答案:B解析:8.[单选题]模糊系统是建立在( )基础上的。
A)程序语言B)自然语言C)汇编语言D)机器语言答案:B解析:9.[单选题]在模式识别中,被观察的每个对象称为( )A)特征B)因素C)样本D)元素答案:C解析:10.[单选题]群体智能算法提供了无组织学习、自组织学习等进化学习机制,这种体现了群体智能算法的( )A)通用性B)自调节性C)智能性D)自适应性答案:C解析:11.[单选题]下面不属于遗传算法中算法规则的主要算子的是( )A)选择B)交叉C)适应D)变异答案:C解析:12.[单选题]下面不属于蚁群算法优点的是( )。
A)高并行性B)可扩充性C)不易陷入局部最优13.[单选题]只是知道系统的一些信息,而没有完全了解该系统,这种称为( )A)白箱系统B)灰箱系统C)黑箱系统D)红箱系统答案:B解析:14.[单选题]模式分类是一种______方法,模式聚类是一种_______方法。
模式识别知识重点

1、你如何理解“人工智能”以及“智能”?参考答案:人工智能是通过研制智能机器或者编制程序模拟人或者高级生物的智能行为。
智能的行为具有如下特征:感知能力、记忆与思维能力、学习与自适应能力、行为能力等,这些来自于人脑的活动结果。
2、什么是不确定推理?不确定的因素有哪些?是什么原因造成的?参考答案:从不确定的初始证据出发,通过运用不确定性的知识,最终推出具有一定不确定性但是合理的或者近乎合理的思维过程。
不确定的因素有:证据不确定(存在错误、准确性无法判定)、匹配不确定、知识(规则)不确定、合成规则不确定等。
造成不确定的原因有:主观的和客观的,例如概率的、模糊的、信息不完备、准确性无法验证等,本质上是由于人的认识的有限性。
需要解决的基本问题有:不确定性的表示和量度,不确定性匹配算法以及阈值的选择,组合证据不确定性算法,不确定性的传递算法,结论不确定性的合成等。
3、你如何理解特征空间?表示样本有哪些常见方法?参考答案:由利用某些特征描述的所有样本组成的集合称为特征空间或者样本空间,特征空间的维数是描述样本的特征数量。
描述样本的常见方法:矢量、矩阵、列表等。
4、贝叶斯决策理论中,参数估计和非参数估计有什么区别?参考答案:参数估计就是已知样本分布的概型,通过训练样本确定概型中的一些参数;非参数估计就是未知样本分布概型,利用Parzen窗等方法确定样本的概率密度分布规律。
5、线性和非线性分类器与基于贝叶斯决策理论的分类器之间是什么关系?参考答案:线性分类器与非线性分类器都属于几何分类器,是统计模式识别的一种;基于贝叶斯决策理论的分类器属于概率分类,主要是基于样本在特征空间的概率分布;利用未知样本属于已知类别的概率或者风险大小进行分类。
几何分类的理论基础是概率分类,是一种简单的处理方式,不需要求解样本的概率分布,只需要利用已知样本训练得到一些几何分界面即可。
6、无教师示范的非监督学习与聚类分析之间有何联系?有哪些常见的非监督学习方法?试简要介绍其中一种方法,并给出必要的公式。
四川大学模式识别复习要点及答案

简答题1.什么是模式与模式识别?模式:对象之间存在的规律性关系;模式识别:是研究用计算机来实现人类模式识别能力的一门学科。
/*模式:广义地说,模式是一些供模仿用的、完美无缺的标本。
本课程把所见到的具体事物称为模式,而将它们归属的类别称为模式类。
模式的直观特性:可观察性,可区分性,相似性模式识别:指对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程。
*/2.一个典型的模式识别系统主要由哪几个部分组成3.什么是后验概率?系统在某个具体的模式样本X条件下位于某种类型的概率。
4.确定线性分类器的主要步骤①采集训练样本,构成训练样本集。
样本应该具有典型性②确定一个准则J=J(w,x),能反映分类器性能,且存在权值w*使得分类器性能最优③设计求解w的最优算法,得到解向量w*5.样本集推断总体概率分布的方法6.近邻法的基本思想是什么?作为一种分段线性判别函数的极端情况,将各类中全部样本都作为代表点,这样的决策方法就是近邻法的基本思想。
7.什么是K近邻法?取未知样本x的k个近邻,看这k个近邻中多数属于哪一类,就把x归为哪一类。
7.监督学习与非监督学习的区别利用已经标定类别的样本集进行分类器设计的方法称为监督学习。
很多情况下无法预先知道样本的类别,从没有标记的样本集开始进行分类器设计,这就是非监督学习。
/*监督学习:对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习方法的训练过程是离线的。
非监督学习方法不需要单独的离线训练过程,也没有带分类号的训练数据集,一般用来对数据集进行分析。
如聚类,确定其分布的主分量等。
*/8.什么是误差平方和准则?对于一个给定的聚类,均值向量是最能代表聚类中所有样本的一个向量,也称其为聚类中心。
一个好的聚类方法应能使集合中的所有向量与这个均值向量的误差的长度平方和最小。
9.分级聚类算法的2种基本途径是什么按事物的相似性,或内在联系组织起来,组成有层次的结构,使得本质上最接近的划为一类,然后把相近的类再合并,依次类推,这就是分级聚类算法的基本思想。
模式识别复习重点总结

模式识别复习重点总结(总16页)-CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除1.什么是模式及模式识别模式识别的应用领域主要有哪些模式:存在于时间,空间中可观察的事物,具有时间或空间分布的信息; 模式识别:用计算机实现人对各种事物或现象的分析,描述,判断,识别。
模式识别的应用领域:(1)字符识别;(2) 医疗诊断;(3)遥感; (4)指纹识别 脸形识别;(5)检测污染分析,大气,水源,环境监测; (6)自动检测;(7 )语声识别,机器翻译,电话号码自动查询,侦听,机器故障判断;(8)军事应用。
2.模式识别系统的基本组成是什么(1) 信息的获取:是通过传感器,将光或声音等信息转化为电信息;(2) 预处理:包括A\D,二值化,图象的平滑,变换,增强,恢复,滤波等, 主要指图象处理;(3) 特征抽取和选择:在测量空间的原始数据通过变换获得在特征空间最能反映分类本质的特征;(4) 分类器设计:分类器设计的主要功能是通过训练确定判决规则,使按此类判决规则分类时,错误率最低。
把这些判决规则建成标准库;(5) 分类决策:在特征空间中对被识别对象进行分类。
3.模式识别的基本问题有哪些(1)模式(样本)表示方法:(a )向量表示;(b )矩阵表示;(c )几何表示;(4)基元(链码)表示;(2)模式类的紧致性:模式识别的要求:满足紧致集,才能很好地分类;如果不满足紧致集,就要采取变换的方法,满足紧致集(3)相似与分类;(a)两个样本x i ,x j 之间的相似度量满足以下要求: ① 应为非负值② 样本本身相似性度量应最大 ③ 度量应满足对称性④ 在满足紧致性的条件下,相似性应该是点间距离的 单调函数(b)用各种距离表示相似性(4)特征的生成:特征包括:(a)低层特征;(b)中层特征;(c)高层特征 (5) 数据的标准化:(a)极差标准化;(b)方差标准化4.线性判别方法(1)两类:二维及多维判别函数,判别边界,判别规则二维情况:(a )判别函数: ( ) (b )判别边界:(c )判别规则:n 维情况:(a )判别函数: 也可表示为: 32211)(w x w x w x g ++=为坐标向量为参数,21,x x w 12211......)(+++++=n n n w x w x w x w x g X W x g T =)(为增值模式向量。
模式识别习题及答案-精品资料

第一章绪论1 •什么是模式?具体事物所具有的信息。
模式所指的不是事物本身,而是我们从事物中获得的—信息__。
2. 模式识别的定义? 让计算机来判断事物。
3. 模式识别系统主要由哪些部分组成? 数据获取一预处理一特征提取与选择一分类器设计/分类决策。
第二章贝叶斯决策理论P ( W 2 ) / p ( w 1 ) _,贝V X1. 最小错误率贝叶斯决策过程?答:已知先验概率,类条件概率。
利用贝叶斯公式 得到后验概率。
根据后验概率大小进行决策分析。
2 .最小错误率贝叶斯分类器设计过程?答:根据训练数据求出先验概率P ( W i ), i类条件概率分布p ( x | W i ), i 1 , 2 利用贝叶斯公式得到后验概率P (W i | x)P(X | W j )P(W j )j 1如果输入待测样本 X ,计算X 的后验概率根据后验概率大小进行分类决策分析。
3. 最小错误率贝叶斯决策规则有哪几种常用的表示形式?决策规则的不同形式(董点)C1^ 如vr, | JV ) = max 戶(vr ] WJ A * U vtvEQ 如杲尹a H ; )2^(ir, ) = max |沪0輕』),则x e HpCx |=尸4 "J"匕< 4) 如!4i= — 1IL | /( JV )] = — 111 戸(兀 | w”. ) -+- 11111r a4. 贝叶斯决策为什么称为最小错误率贝叶斯决策?答:最小错误率Bayes 决策使得每个观测值下的条件错误率最小因而保证了 (平均)错误率最小。
Bayes 决策是最优决策:即,能使决策错误率最小。
5 .贝叶斯决策是 由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利用这 个概率进行决策。
6.利用乘法法则和全概率公式证明贝叶斯公式p(AB) p(A|B)p(B) p(B|A)p(A)P (A」B )答:m所以推出贝叶斯公式p(B) p(B|Aj)p(Aj)j 17. 朴素贝叶斯方法的条件独立D (1P (x | W i ) P(W i )i i入)2P(x | W j ) P (w j )j 11 ,2P (x | W i )P(W i )如果 I (x)P(B |A i )P(AJ P ( B ) P ( B | A i ) P ( A i ) 7MP ( B | A j ) P ( A j )2假设是( P(x| 3 i) =P(x1, x2, …,xn | co i)19.=P(x1|3 i) P(x2| 3 i)…P(xn| 3 i))8•怎样利用朴素贝叶斯方法获得各个属性的类条件概率分布?答:假设各属性独立,P(x| 3 i) =P(x1, x2, …,xn |3 i) = P(x1| 3 i) P(x2| 3 i)P(xn| 3 i)后验概率:P( 3 i|x) = P( 3 i) P(x1|3 i) P(x2| 3 i)…P(xn| 3 i)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值方 差,最后得到类条件概率分布。
模式识别复习

第一、二章1. 模式识别概念、方法?概念:就是要用机器去完成人类智能中通过视觉听觉触觉等感官去识别外界环境的自然信息的这些工作。
方法:统计方法,句法方法,模糊方法,人工神经网络法,人工智能法2. 模式识别系统的组成,简述各部分的作用?数据获取:通过测量、采样和量化获取数据的过程 预处理:去出噪声,加强有用的信息,复原退化现象 特征提取和选择:得到最能反映分类本质的特征分类决策:就是在特征空间中用统计方法把被识别对象归为某一类别3.相似性度量有哪几种方法?(我找不到,要不你找找?)4.最常见的贝叶斯决策规则?分类?以两类模式(w1和w2 )为例,根据Bayes 公式:1(|)()(|)(|)()i i i j j j P x w P w P w x P x w P w =×=×å即利用Bayes 公式将先验概率转化为后验概率。
①基于最小错误概率的Bayes 决策规则为:• 若P(w1|x)>P(w2|x),则x ∈w1 ;反之则x ∈w2 • 或P(wi|x)=maxP(wj|x) ,则x ∈wi (i=1,2)②基于最小风险的贝叶斯决策如果1,...,(|)(|)mini aR a x R a x ==则 a=ak (即应采取的决策为ak )(或述为x ∈wk)③最小和最大决策5.N-P 决策推导过程令 2)(ε=e P 下,求 (1eP 的极小值。
即:()0P e ε-=⎫⎬约束条件:条件极值如下(求极小值)目标函数采用Lagrange 乘子法,构造Lagrange 函数为:其中λ是Lagrange 乘子,目的是求 γ 的极小值。
(即λ为一待定常数)。
将p1(e)与p2(e)的表达式代入 上式。
]))|([)|(01221εωλωγ-+=⎰⎰dx x P dx x P R R化简后 dx x P x P dx R ⎰-+-=1120)]|()|([)1(ωωλλεγ上式中λ是Lagrange 乘子,而R1是变量,这样γ的极小值问题就是要选择R1和R2的边界(边界点为t )问题了,即求R1使γ取极小值。
模式识别练习题及答案.docx

1=填空题1、模式识别系统的基本构成单元包括:模式采集、特征选择与提取和模式分类。
2、统计模式识别中描述模式的方法一般使用特征矢量;句法模式识别中模式描述方法一般有串、树、网。
3、影响层次聚类算法结果的主要因素有计算模式距离的测度、聚类准则、类间距离门限、预定的类别数目。
4、线性判别函数的正负和数值大小的几何意义是正(负)表示样本点位于判别界面法向量指向的正(负)半空间中;绝对值正比于样本点到判别界面的距离。
5、感知器算法丄。
(1 )只适用于线性可分的情况;(2)线性可分、不可分都适用。
6、在统计模式分类问题中,聂曼-皮尔逊判决准则主要用于某一种判决错误较另一种判决错误更为重愛情况;最小最大判别准则主要用于先验概率未知的情况。
7、“特征个数越多越有利于分类”这种说法正确吗?错误。
特征选择的主要目的是从n个特征中选出最有利于分类的的m个特征(m<n),以降低特征维数。
一般在可分性判据对特征个数具有单调性和(C n m»n )的条件下,可以使用分支定界法以减少计算量。
& 散度Jij越大,说明。
类模式与3j类模式的分布差别越大;当3类模式与(Oj类模式的分布相同时,Jij=_O_.选择题1、影响聚类算法结果的主要因素有(BCD ).A.已知类别的样本质量B.分类准则C.特征选取D.模式相似性测度2、模式识别中,马式距离较之于欧式距离的优点是(CD )。
A.平移不变性B.旋转不变性C.尺度不变性D.考虑了模式的分布3、影响基本K-均值算法的主要因素有(DAB )。
A.样本输入顺序B.模式相似性测度C.聚类准则D.初始类中心的选取4、在统计模式分类问题中,当先验概率未知时,可以使用(BD )。
A.最小损失准则B.最小最大损失准则C.最小误判概率准则D.N-P判决5、散度环是根据(C )构造的可分性判据。
A.先验概率B.后验概率C.类概率密度D.信息燔E.几何距离6、如果以特征向量的相关系数作为模式相似性测度,则影响聚类算法结果的主要因素有(B C )。
(完整版)《模式识别》知识重点总结与计算题,推荐文档

0.影响聚类结果的主要因素有那些?(2)证明马氏距离是平移不变的、非奇异线性变换不变的。
答:(1)分类准则,模式相似性测度,特征量的选择,量纲。
1.监督学习与非监督学习的区别:监督学习方法用来对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习方法的训练过程是离线的。
非监督学习方法不需要单独的离线训练过程,也没有带分类号(标号)的训练数据集,一般用来对数据集进行分析,如聚类,确定其分布的主分量等。
(实例:道路图)就道路图像的分割而言,监督学习方法则先在训练用图像中获取道路象素与非道路象素集,进行分类器设计,然后用所设计的分类器对道路图像进行分割。
使用非监督学习方法,则依据道路路面象素与非道路象素之间的聚类分析进行聚类运算,以实现道路图像的分割。
2.动态聚类是指对当前聚类通过迭代运算改善聚类; 分级聚类则是将样本个体,按相似度标准合并,随着相似度要求的降低实现合并。
3. 线性分类器三种最优准则: Fisher准则:根据两类样本一般类内密集, 类间分离的特点,寻找线性分类器最佳的法线向量方向,使两类样本在该方向上的投影满足类内尽可能密集,类间尽可能分开。
该种度量通过类内离散矩阵Sw和类间离散矩阵Sb实现。
感知准则函数:准则函数以使错分类样本到分界面距离之和最小为原则。
其优点是通过错分类样本提供的信息对分类器函数进行修正,这种准则是人工神经元网络多层感知器的基础。
支持向量机:基本思想是在两类线性可分条件下,所设计的分类器界面使两类之间的间隔为最大, 它的基本出发点是使期望泛化风险尽可能小。
一、试问“模式”与“模式类”的含义。
如果一位姓王的先生是位老年人,试问“王先生”和“老头”谁是模式,谁是模式类?答:在模式识别学科中,就“模式”与“模式类”而言,模式类是一类事物的代表,概念或典型,而“模式”则是某一事物的具体体现,如“老头”是模式类,而王先生则是“模式”,是“老头”的具体化。
最新模式识别复习题

《模式识别》试题库一、基本概念题1.1 模式识别的三大核心问题是:、、。
1.2、模式分布为团状时,选用聚类算法较好。
1.3 欧式距离具有。
马式距离具有。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性1.4 描述模式相似的测度有:。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度1.5 利用两类方法处理多类问题的技术途径有:(1);(2);(3)。
其中最常用的是第个技术途径。
1.6 判别函数的正负和数值大小在分类中的意义是:,。
1.7 感知器算法。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
1.8 积累位势函数法的判别界面一般为。
(1)线性界面;(2)非线性界面。
1.9 基于距离的类别可分性判据有:。
(1)1[]w BTr S S-(2)BWSS(3)BW BSS S+1.10 作为统计判别问题的模式分类,在()情况下,可使用聂曼-皮尔逊判决准则。
1.11 确定性模式非线形分类的势函数法中,位势函数K(x,x k)与积累位势函数K(x)的关系为()。
1.12 用作确定性模式非线形分类的势函数法,通常,两个n维向量x和x k的函数K(x,x k)若同时满足下列三个条件,都可作为势函数。
①();②( ); ③ K(x,x k )是光滑函数,且是x 和x k 之间距离的单调下降函数。
1.13 散度J ij 越大,说明ωi 类模式与ωj 类模式的分布( )。
当ωi 类模式与ωj 类模式的分布相同时,J ij =( )。
1.14 若用Parzen 窗法估计模式的类概率密度函数,窗口尺寸h1过小可能产生的问题是( ),h1过大可能产生的问题是( )。
1.15 信息熵可以作为一种可分性判据的原因是: 。
1.16作为统计判别问题的模式分类,在( )条件下,最小损失判决规则与最小错误判决规则是等价的。
1.17 随机变量l(x )=p( x |ω1)/p( x |ω2),l( x )又称似然比,则E {l( x )|ω2}=( )。
模式识别第二版答案完整版

所以,如果 p(x|w1) p(x|w2)
>
(λ12 (λ21
− −
λ22)P (w2) ,则x λ11)P (w1)
∈
w1。反之则x
∈
w2。
• 2.7 若λ11 = λ22 = 0, λ12 = λ21,证明此时最小最大决策面是来自两类的错误率相等。
解: 最小最大决策时满足
∫
∫
(λ11 − λ22) + (λ21 − λ11) p(x|w1)dx − (λ12 − λ22) p(x|w2)dx = 0
{
}
p(x|m)
=
(2π)
1 2
σ−1
exp
− 1 (x − m)2/σ2
2
再假设m的边缘分布是正态分布,期望值是m0,方差是σm2 ,证明
p(m|x)
=
(σ3
+
σm)
1 2
1
(2π) 2 σσm
[
exp
−
1 2
σ2 + σm2 σ2σm2
( m−
σm2 x + m0σ2 )2] σ2 + σm2
5
对于(3),E{l(x)|w1} − E2{l(x)|w2} = E{l2(x)|w2} − E2{l(x)|w2} = var{l(x)|w2}
• 2.11 xj(j = 1, 2, ..., n)为n个独立随机变量,有E[xj|wi] = ijη,var[xj|wi] = i2j2σ2,计 算在λ11 = λ22 = 0 及λ12 = λ21 = 1的情况下,由贝叶斯决策引起的错误率。(中心极限 定理)
误)
P (wi|x)
=
p(x|wi)P (wi) . p(x)
模式识别复习重点总结85199

1.什么是模式及模式识别?模式识别的应用领域主要有哪些?模式:存在于时间,空间中可观察的事物,具有时间或空间分布的信息; 模式识别:用计算机实现人对各种事物或现象的分析,描述,判断,识别。
模式识别的应用领域:(1)字符识别;(2) 医疗诊断;(3)遥感; (4)指纹识别 脸形识别;(5)检测污染分析,大气,水源,环境监测;(6)自动检测;(7 )语声识别,机器翻译,电话号码自动查询,侦听,机器故障判断; (8)军事应用。
2.模式识别系统的基本组成是什么?(1) 信息的获取:是通过传感器,将光或声音等信息转化为电信息;(2) 预处理:包括A \D,二值化,图象的平滑,变换,增强,恢复,滤波等, 主要指图象处理;(3) 特征抽取和选择:在测量空间的原始数据通过变换获得在特征空间最能反映分类本质的特征;(4) 分类器设计:分类器设计的主要功能是通过训练确定判决规则,使按此类判决规则分类时,错误率最低。
把这些判决规则建成标准库; (5) 分类决策:在特征空间中对被识别对象进行分类。
3.模式识别的基本问题有哪些?(1)模式(样本)表示方法:(a)向量表示;(b)矩阵表示;(c)几何表示;(4)基元(链码)表示;(2)模式类的紧致性:模式识别的要求:满足紧致集,才能很好地分类;如果不满足紧致集,就要采取变换的方法,满足紧致集(3)相似与分类;(a)两个样本x i ,x j 之间的相似度量满足以下要求: ① 应为非负值② 样本本身相似性度量应最大 ③ 度量应满足对称性④ 在满足紧致性的条件下,相似性应该是点间距离的 单调函数(b)用各种距离表示相似性 (4)特征的生成:特征包括:(a)低层特征;(b)中层特征;(c)高层特征 (5) 数据的标准化:(a)极差标准化;(b)方差标准化4.线性判别方法(1)两类:二维及多维判别函数,判别边界,判别规则 二维情况:(a)判别函数: ( )(b)判别边界:g(x )=0; (c)判别规则:n 维情况:(a)判别函数:也可表示为:32211)(w x w x w x g ++=为坐标向量为参数,21,x x w 12211......)(+++++=n n n w x w x w x w x g X W x g T =)(为增值权向量,T T n n w w w w W ),,...,,(121=+(b)判别边界:g1(x ) =W TX =0 (c)判别规则:(2)多类:3种判别方法(函数、边界、规则)(A )第一种情况:(a)判别函数:M 类可有M 个判别函数(b) 判别边界:ωi (i=1,2,…,n )类与其它类之间的边界由 g i(x )=0确定(c)(B)第二种情况:(a)判别函数:有 M (M _1)/2个判别平面(b) 判别边界: (c )判别规则:(C)第三种情况:(a)判别函数: (b) 判别边界:g i (x ) =gj (x ) 或g i (x ) -gj (x ) =0(c)判别规则:5.什么是模式空间及加权空间,解向量及解区? (1)模式空间:由 构成的n 维欧氏空间;(2)加权空间:以为变量构成的欧氏空间; (3)解向量:分界面为H,W 与H 正交,W称为解向量; (4)解区:解向量的变动范围称为解区。
模式识别第二版答案完整版
1. 对c类情况推广最小错误率率贝叶斯决策规则; 2. 指出此时使错误率最小等价于后验概率最大,即P (wi|x) > P (wj|x) 对一切j ̸= i
成立时,x ∈ wi。
2
模式识别(第二版)习题解答
解:对于c类情况,最小错误率贝叶斯决策规则为: 如果 P (wi|x) = max P (wj|x),则x ∈ wi。利用贝叶斯定理可以将其写成先验概率和
(2) Σ为半正定矩阵所以r(a, b) = (a − b)T Σ−1(a − b) ≥ 0,只有当a = b时,才有r(a, b) = 0。
(3) Σ−1可对角化,Σ−1 = P ΛP T
h11 h12 · · · h1d
• 2.17 若将Σ−1矩阵写为:Σ−1 = h...12
h22 ...
P (w1) P (w2)
= 0。所以判别规则为当(x−u1)T (x−u1) > (x−u2)T (x−u2)则x ∈ w1,反
之则s ∈ w2。即将x判给离它最近的ui的那个类。
[
• 2.24 在习题2.23中若Σ1 ̸= Σ2,Σ1 =
1
1
2
策规则。
1]
2
1
,Σ2
=
[ 1
−
1 2
−
1 2
] ,写出负对数似然比决
1
6
模式识别(第二版)习题解答
解:
h(x) = − ln [l(x)]
= − ln p(x|w1) + ln p(x|w2)
=
1 2 (x1
−
u1)T
Σ−1 1(x1
−
u1)
−
1 2 (x2
模式识别复习题
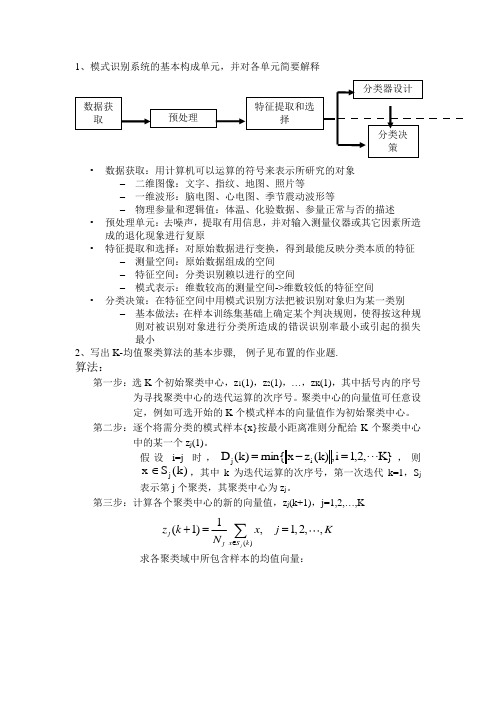
1、模式识别系统的基本构成单元,并对各单元简要解释• 数据获取:用计算机可以运算的符号来表示所研究的对象– 二维图像:文字、指纹、地图、照片等– 一维波形:脑电图、心电图、季节震动波形等– 物理参量和逻辑值:体温、化验数据、参量正常与否的描述• 预处理单元:去噪声,提取有用信息,并对输入测量仪器或其它因素所造成的退化现象进行复原• 特征提取和选择:对原始数据进行变换,得到最能反映分类本质的特征– 测量空间:原始数据组成的空间 – 特征空间:分类识别赖以进行的空间– 模式表示:维数较高的测量空间->维数较低的特征空间• 分类决策:在特征空间中用模式识别方法把被识别对象归为某一类别– 基本做法:在样本训练集基础上确定某个判决规则,使得按这种规则对被识别对象进行分类所造成的错误识别率最小或引起的损失最小2、写出K-均值聚类算法的基本步骤, 例子见布置的作业题.算法:第一步:选K 个初始聚类中心,z 1(1),z 2(1),…,z K (1),其中括号内的序号为寻找聚类中心的迭代运算的次序号。
聚类中心的向量值可任意设定,例如可选开始的K 个模式样本的向量值作为初始聚类中心。
第二步:逐个将需分类的模式样本{x}按最小距离准则分配给K 个聚类中心中的某一个z j (1)。
假设i=j 时,}K ,2,1i ,)k (z x min{)k (D i j =-=,则)k (S x j ∈,其中k 为迭代运算的次序号,第一次迭代k=1,S j 表示第j 个聚类,其聚类中心为z j 。
第三步:计算各个聚类中心的新的向量值,z j (k+1),j=1,2,…,K求各聚类域中所包含样本的均值向量:()1(1),1,2,,j j x S k jz k x j KN ∈+==∑其中N j 为第j 个聚类域S j 中所包含的样本个数。
以均值向量作为新的聚类中心,可使如下聚类准则函数最小:在这一步中要分别计算K 个聚类中的样本均值向量,所以称之为K-均值算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
复习要点绪论1、举出日常生活或技术、学术领域中应用模式识别理论解决问题的实例。
答:我的本科毕设内容和以后的研究方向为重症监护病人的状态监测与预诊断,其中的第一步就是进行ICU病人的死亡率预测,与模式识别理论密切相关。
主要的任务是分析数据库的8000名ICU病人,统计分析死亡与非死亡的生理特征,用于分析预测新进ICU病人的病情状态。
按照模式识别的方法步骤,首先从数据库中采集数据,包括病人的固有信息,生理信息,事件信息等并分为死亡组和非死亡组,然后分别进行数据的预处理,剔除不正常数据,对数据进行插值并取中值进行第一次特征提取,然后利用非监督学习的方法即聚类分析进行第二次特征提取,得到训练样本集和测试样本集。
分别利用判别分析,人工神经网络,支持向量机的方法进行训练,测试,得到分类器,实验效果比传统ICU 中采用的评价预测系统好一些。
由于两组数据具有较大重叠,特征提取,即提取模式特征就变得尤为重要。
语音识别,图像识别,车牌识别,文字识别,人脸识别,通信中的信号识别;① 文字识别汉字已有数千年的历史,也是世界上使用人数最多的文字,对于中华民族灿烂文化的形成和发展有着不可磨灭的功勋。
所以在信息技术及计算机技术日益普及的今天,如何将文字方便、快速地输入到计算机中已成为影响人机接口效率的一个重要瓶颈,也关系到计算机能否真正在我过得到普及的应用。
目前,汉字输入主要分为人工键盘输入和机器自动识别输入两种。
其中人工键入速度慢而且劳动强度大;自动输入又分为汉字识别输入及语音识别输入。
从识别技术的难度来说,手写体识别的难度高于印刷体识别,而在手写体识别中,脱机手写体的难度又远远超过了联机手写体识别。
到目前为止,除了脱机手写体数字的识别已有实际应用外,汉字等文字的脱机手写体识别还处在实验室阶段。
②语音识别语音识别技术技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
近年来,在生物识别技术领域中,声纹识别技术以其独特的方便性、经济性和准确性等优势受到世人瞩目,并日益成为人们日常生活和工作中重要且普及的安验证方式。
而且利用基因算法训练连续隐马尔柯夫模型的语音识别方法现已成为语音识别的主流技术,该方法在语音识别时识别速度较快,也有较高的识别率。
③ 指纹识别我们手掌及其手指、脚、脚趾内侧表面的皮肤凹凸不平产生的纹路会形成各种各样的图案。
而这些皮肤的纹路在图案、断点和交叉点上各不相同,是唯一的。
依靠这种唯一性,就可以将一个人同他的指纹对应起来,通过比较他的指纹和预先保存的指纹进行比较,便可以验证他的真实身份。
一般的指纹分成有以下几个大的类别:环型(loop),螺旋型(whorl),弓型(arch),这样就可以将每个人的指纹分别归类,进行检索。
指纹识别基本上可分成:预处理、特征选择和模式分类几个大的步骤。
③ 遥感遥感图像识别已广泛用于农作物估产、资源勘察、气象预报和军事侦察等。
④医学诊断在癌细胞检测、X射线照片分析、血液化验、染色体分析、心电图诊断和脑电图诊断等方面,模式识别已取得了成效。
2、若要实现汽车车牌自动识别,你认为应该有哪些处理步骤?分别需要哪些模式识别方法?试用流程图予以说明。
答:汽车车牌自动识别需要有以下三大步骤:(1)获取包含车牌的彩色图像(2)实现车牌定位和获取(3)进行字符分割和识别,详细操作如流程图所示。
第一步需要建立字符库,即根据已知字符的二值图像进行处理生成特征字符库;第二步通过摄像头获取包含车牌的彩色图像,输入图像;第三步利用主成分分析法、K-L变换,MDS和KPCA等方法对车牌进行特征识别;第四步对车牌进行粗略定位和精细定位,如VMLA定位,基于边缘检测的方法,基于水平灰度变化特征的方法,基于车牌颜色特征的方法等。
第五步利用分类器确定车牌类型之后对字符进行分割,对图像进行预处理,去除铆钉,谷值分析,模板匹配,二值化投影法等第六步分割成得单个字符进行模式识别,得到每个字符,然后组合输出结果,具体的方法为统计学习或人工神经网络等。
统计决策3、最小错误率贝叶斯决策方法与最小风险贝叶斯决策方法4、正态分布下最小错误率决策与Neyman-Pearson决策方法(1)假设在某个地区的细胞识别中正常1ω和异常 2ω两类的先验概率分别为 正常状态 :1()0.9P ω=异常状态:2()0.1P ω=现有一待识的细胞,其观测值为x ,从类条件概率密度分布曲线上查得12()0.2,()0.4p x p x ω==并且已知损失系数为λ11=0,λ12=1,λ21=6,λ22=0。
试对该细胞以以下两种方法进行分类:①基于最小错误概率准则的贝叶斯判决;②基于最小风险的贝叶斯判决。
解:①基于最小错误概率准则的贝叶斯判决.),()(),()(,182.0)(1)(818.01.04.09.02.09.02.0)()()()()(211211221111用所以先验概率起很大作因为属正常细胞。
因为先计算先验概率ωωωωωωωωωωωP P x x P x P x P x P P x P P x P x P j jj>>∈∴>=-==⨯+⨯⨯==∑=②基于最小风险的贝叶斯判决作用。
较大,决策损失起决定=因类风险大。
因决策异常细胞因为条件风险:概率:由上例中计算出的后验6,)()(818.0)()(092.1)()()(182.0)(,818.0)(121211212212121121λωααωλαωλωλαωω∈∴>=======∑=x x R x R x P x R x P x P x R x P x P j j j(2)已知两个一维模式类别的类概率密度函数为⎩⎨⎧≤≤=其它 ,010 ,2)|(1x x x p ω ⎩⎨⎧≤≤-=其它, 010 , 22)|(2x x x p ω 先验概率P(ω1)=P(ω2),损失函数,λ11=λ22=0,λ12=0.6,λ21=0.4。
(1)求最小平均损失Bayes 判决函数; (2)求总的误判概率P(e);解:先求先验概率:()()()()()()()()()()()()()()22112222211111||||||||ωωωωωωωωωωωωωωP x P P x P P x P x P P x P P x P P x P x P +=+=、求条件风险:()()()()()()()()x P x P x P x P x P x P x P x P ||||||||12122212122122121111ωλωλωλαωλωλωλα=+==+=期望风险要求最小,当()()x P x P ||21αα=时满足要求,即()()()()()()6.024.0)22(6.0|4.0|6.0||1122121212=⨯=-==x x x P x P P x P x P x P ωωωωωλωλ(3)对于这个两类一维问题,若这两类的类概率密度分别服从正态分布N(0,σ2)和 N(1,σ2),证明使平均决策风险最小的决策阈值为()()1212122ln 21ωλωλσP P x -=这里,假设风险函数λ11=λ22=0 。
一维正态分布:]2)([2221)(σμσπ--=x ex p解:先求先验概率:()()()()()()()()()()()()()()22112222211111||||||||ωωωωωωωωωωωωωωP x P P x P P x P x P P x P P x P P x P x P +=+=、求条件风险:()()()()()()()()x P x P x P x P x P x P x P x P ||||||||12122212122122121111ωλωλωλαωλωλωλα=+==+=期望风险要求最小,当()()x P x P ||21αα=时满足要求,即()()()()()()()()()()()()12121222212122212122122)1(1211212212121212ln 212ln 2)1(ln 2121||||2222ωλωλσσωλσωλωσπλωσπλωωλωωλωλωλσσP P x x P x P P e P e P x P P x P x P x P x x -=-=--===---两边取对数概率密度函数估计5、最大似然估计方法与贝叶斯估计方法答:最大似然估计是把待估的参数看作固定的未知量,而贝叶斯估计则是把待估的参数作为具有某种先验分布的随机变量,通过对第i 类学习样本Xi 的观察,使概率密度分布P(Xi/θ)转化为后验概率P(θ/Xi) ,再求贝叶斯估计。
(4)设以下两类模式均为正态分布 1:{(0,0)T ,(2,0)T ,(2,2)T ,(0,2)T} 2:{(4,4)T ,(6,4)T ,(6,6)T ,(4,6)T}设P( 1)= P( 2)=1/2,求该两类模式之间的Bayes 判别界面的方程,并绘出判别界面。
解:()()()()()()()()[]()()()()()()()()[]()()()()[]()()()()[]()()()()()()()()[]()()()()[]()()()()0ln ,5.00ln ,916430043340034345656545431056545656545654543134545656543191643004334003434121210103101210121210121010313410121210315,5,,1,1,5)6644(41,5)4664(411)2200(41,1)0220(4166444664,2200022021212121-2122121112111,22222222221212222221111-112212111211112222122121112222211122212121112221121121====∑∑=∑⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=∑⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=⎥⎦⎤⎢⎣⎡=∑=-+-+-+-==--+--+--+--===-+-+-+-==∑⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=∑⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=⎥⎦⎤⎢⎣⎡=∑=-+-+-+-==--+--+--+--===-+-+-+-======+++==+++==+++==+++=⎥⎦⎤⎢⎣⎡=⎥⎦⎤⎢⎣⎡=ωωωωP P P P C C C C C C C C C C C C C C C C X X X X X X X X X X X X TTTT先验概率:,,,,协方差矩阵为: ①假定二类协方差矩阵不等6-0)()0,0(018)()0,0(),(x ,),(x 0)()(lnln 21)x x ()x x (21)x x ()x x (21)()()(21121212121211222111112=+==<-====∈⇒><-+-----=-=∑∑∑∑--x x x g X x g x x x x x P P x g x g x g T T T T T T 得分界线方程为:令类。