基于差分演化算法的软子空间聚类
差分进化算法

差分进化算法简介差分进化算法是一种优化算法,源于遗传算法,通过模拟生物进化的过程来解决优化问题。
它不同于传统的遗传算法,是基于个体间的差异性来实现优化的。
差分进化算法的原理差分进化算法的基本原理是通过在候选解向量上进行简单算术运算来生成新的解向量,并通过比较这些解向量的适应度来更新种群。
差分进化算法包括三个关键步骤:1. 初始化种群: 初始种群是随机生成的一组解向量。
2. 变异操作: 通过选择多个解向量,并对它们进行简单算术运算来产生新的解向量。
3. 交叉和选择: 通过比较原解向量和新解向量的适应度来决定是否更新种群。
差分进化算法的优势1.不需要求导: 差分进化算法不需要求解目标函数的梯度,适用于解决非线性、非光滑和高维优化问题。
2.全局最优: 由于其能够维持种群的多样性,因此差分进化算法往往可以找到全局最优解。
3.较少参数设置: 差分进化算法相对于其他优化算法来说,参数配置相对较少,并且对初始参数不敏感。
差分进化算法的应用差分进化算法被广泛应用于各种领域,包括工程优化、机器学习、信号处理等。
1. 工程优化: 在电力系统、通信网络、管道设计等领域,差分进化算法被用来优化系统设计和参数。
2. 机器学习: 在神经网络训练、特征选择、模型调优等方面,差分进化算法常用于搜索最优解。
3. 信号处理: 在图像处理、语音识别、生物信息学等领域,差分进化算法被应用于信号处理和数据分析。
结论差分进化算法作为一种优化算法,通过模拟生物进化的过程,能够有效地解决各种优化问题。
其独特的优势使其在工程、机器学习、信号处理等领域广泛应用。
未来随着算法的不断改进和扩展,差分进化算法将发挥更大的作用,为解决复杂问题提供新的解决方案。
参考文献1.Storn, R., & Price, K. (1997). Differential evolution—a simple and efficient heuristic for global optimization over continuous spaces. Journal of global optimization, 11(4), 341-359.2.Das, S., & Suganthan, P. N. (2011). Differential evolution: a survey of the state-of-the-art. IEEE Transactions on evolutionary computation, 15(1), 4-31.。
差分进化算法及应用研究

湖南大学硕士学位论文差分进化算法及应用研究姓名:吴亮红申请学位级别:硕士专业:控制理论与控制工程指导教师:王耀南20070310硕士学位论文摘要论文首先介绍了智能优化算法的产生对现代优化技术的重要影响,阐述了智能优化算法的研究和发展对现代优化技术和工程实践应用的必要性,归纳总结了智能优化算法的主要特点,简要介绍了智能优化算法的主要研究内容及应用领域。
对差分进化算法的原理进行了详细的介绍,给出了差分进化算法的伪代码。
针对混合整数非线性规划问题的特点,在差分进化算法的变异操作中加入取整运算,提出了一种适合于求解各种混合整数非线性规划问题的改进差分进化算法。
同时,采用时变交叉概率因子的方法以提高算法的全局搜索能力和收敛速率。
用四个典型测试函数进行了实验研究,实验结果表明,改进的差分进化算法用于求解混合整数非线性规划问题时收敛速度快,精度高,鲁棒性强。
采用非固定多段映射罚函数法处理问题的约束条件,提出了一种用改进差分进化算法求解非线性约束优化问题的新方法。
结合差分进化算法两种不同变异方式的特点,引入模拟退火策略,使算法在搜索的初始阶段有较强的全局搜索能力,而在后阶段有较强的局部搜索能力,以提高算法的全局收敛性和收敛速率。
用几个典型Benchmarks函数进行了测试,实验结果表明,该方法全局搜索能力强,鲁棒性好,精度高,收敛速度快,是一种求解非线性约束优化问题的有效方法。
为保持所求得的多目标优化问题Pareto最优解的多样性,提出了一种精英保留和根据目标函数值进行排序的多目标优化差分进化算法。
对排序策略中目标函数的选择方式进行了分析和比较,并提出了一种确定进化过程中求得的精英解是否进入Pareto最优解集的阈值确定方法。
用多个经典测试函数进行了实验分析,并与NSGA-Ⅱ算法进行了比较。
实验结果表明,本文方法收敛到问题的Pareto前沿效果良好,获得解的散布范围广,能有效保持所求得的Pareto最优解的多样性。
差分进化算法精品PPT课件

引言
开始
根据实际问题进行编码 设置参数
生成初始种群
计算个体适应值
是否满足进 化终止条件
是
算法结束, 输出最优个体
一般演化算法的过程
问题
遗传操作, 生成新种群
否
1、遗传操作象 ✓ 种群中所有个体 ✓ 种群中部分个体 2、遗传操作顺序 ✓ 重叠 ✓ 非重叠 3、新种群重组方式
DE的改进方法
为了提高DE的寻优能力、加快收敛速度、 克服启发式算法常见的早熟收敛现象,许多学 者对DE算法进行改进:
▪ 控制参数的改进。 ▪ 差分策略的改进。 ▪ 选择策略的改进。 ▪ 种群重构 ▪ 混合算法。
DE的改进方法---多种扩展模式
DE算法的多种变形形式常用符号DE /x/y/ z 以 示区分,其中:
开开开开开
基本原理
求解非线性函数f (x 1, x 2, ⋯, x n)的最小值问题, x i满足:
xi t xi,1 t , xi,2 t , , xi,n t
i 1, 2, , M ; t 1, 2, tmax.
令xi 是t 第t代的第i个染色体, 则
xiLj xij xiUj j 1, 2, n
行变异操作;
▪ :一般在[ 0, 2 ]之间选择, 通常取0. 5;
▪ CR:一般在[ 0, 1 ]之间选择, 比较好的选择应在0. 3 左右,
CR 大些收敛速度会加快, 但易发生早熟现象。
差异演化算法的优缺点
和其它进化算法相比, 差异演化具有以下优点:
▪ 差异演化在求解非凸、多峰、非线性函数优化问题表 现极强的稳健性。
基于差分粒子群和模糊聚类的彩色图像分割算法

关 键词 : 模糊 c 均值 聚类 ; 差分粒 子群 算 法 ; 全局优 化 ; 彩 色图像 分割
中图分 类号 : T P 3 9 1 文献标 志码 : A
Fuz z y c l us t e r i n g c o l o r i ma g e s e g me nt a t i o n a l g o r i t h m ba s e d o n DEPSO
同的 色彩 空 间对 于 图像 分割 效 果 的影 响 ,尝试 在 不 同的 空 间上使 用 DE P S O— F C M 进行 图像 分
割. 实验表 明 , 该 方 法 能解 决 F C M 算 法 陷入局 部 最优 的 问题 , 在 不 同的 色彩 空 间上 都 获得 了理
想的 分割效 果.
A b s t r a c t : C o l o r i m a g e c o n t a i n s a l o t o f d a t a , t h e t r a d i t i o n a l f u z z y C - m e a n s c l u s t e i r n g a l g o r i t h m ( F C M) e a s y t o
L I U J i a n — s h e n g , QI AO S h a n g ' p i n g , K UA NG Yi - q u n
( F a c u l t y o f S c i e n c e , J i a n g x i U n i v e r s i t y o f S c i e n c e&T e c h n o l o g y , G a n z h o u 3 4 1 0 0 0 , C h i n a )
基于机器学习的子空间聚类算法研究与应用

基于机器学习的子空间聚类算法研究与应用随着数据量的不断增长,传统的聚类算法已经无法满足对大规模数据进行快速而准确的聚类的需求。
在这种情况下,基于机器学习的子空间聚类算法被提出,并且得到了广泛的研究与应用。
在传统的聚类算法中,数据点之间的距离是通过欧几里得空间中的距离来计算的。
然而,随着数据维度的增加,欧几里得空间中的距离会变得越来越稀疏,从而导致聚类算法的准确性下降。
基于机器学习的子空间聚类算法解决了这个问题。
子空间聚类算法基于假设,即数据点可以分布在低维子空间中。
因此,对于高维数据,子空间聚类算法会将其分解为多个低维子空间,并在各个子空间中进行聚类。
这种聚类方法在处理高维数据时表现极为出色。
它对空间的局部结构和复杂度作出了准确而合理的模型假设,从而对数据进行分析时能提高精度和有效性。
在子空间聚类算法中,首先需要确定子空间的维度。
传统的方法是通过人工指定维度值来实现,但这种方法需要经验和技巧,效果不稳定。
近年来,基于机器学习的自适应子空间聚类算法被提出,使实现过程更智能化。
自适应子空间聚类算法通过结合聚类结果和数据分布特征,自适应地确定每个子空间的维度。
这种方法能够使聚类结果更加准确、稳定和有效,同时能够避免人工决策的不确定性,提高计算效率。
除了自适应子空间聚类算法,还有一些其他的基于机器学习的子空间聚类算法,比如谱聚类、核聚类、对比传播聚类等。
这些算法都有着不同的适用范围和应用场景,但它们的基本思路都是相似的。
通过有效的降维和聚类方法,它们能够对高维数据进行准确、稳定、有效的聚类,为实际应用提供了有力的支持。
在实际应用中,子空间聚类算法已经被广泛地应用于网络安全、图像识别、音视频分析等领域。
例如,基于子空间聚类算法的网络异常流量检测系统、基于子空间聚类算法的人脸识别系统等。
这些应用展示了子空间聚类算法的巨大潜力和实际价值。
总之,基于机器学习的子空间聚类算法是一种有效的高维聚类方法。
通过自适应子空间聚类算法等技术手段,可以进一步提高算法的准确性、稳定性和效率。
差分进化算法介绍

1.差分进化算法背景差分进化(Differential Evolution,DE)是启发式优化算法的一种,它是基于群体差异的启发式随机搜索算法,该算法是Raincr Stom和Kenneth Price为求解切比雪夫多项式而提出的。
差分进化算法具有原理简单、受控参数少、鲁棒性强等特点。
近年来,DE在约束优化计算、聚类优化计算、非线性优化控制、神经网络优化、滤波器设计、阵列天线方向图综合及其它方面得到了广泛的应用。
差分算法的研究一直相当活跃,基于优胜劣汰自然选择的思想和简单的差分操作使差分算法在一定程度上具有自组织、自适应、自学习等特征。
它的全局寻优能力和易于实施使其在诸多应用中取得成功。
2.差分进化算法简介差分进化算法采用实数编码方式,其算法原理同遗传算法相似刚,主要包括变异、交叉和选择三个基本进化步骤。
DE算法中的选择策略通常为锦标赛选择,而交叉操作方式与遗传算法也大体相同,但在变异操作方面使用了差分策略,即:利用种群中个体间的差分向量对个体进行扰动,实现个体的变异。
与进化策略(Es)采用Gauss或Cauchy分布作为扰动向量的概率密度函数不同,DE使用的差分策略可根据种群内个体的分布自动调节差分向量(扰动向量)的大小,自适应好;DE 的变异方式,有效地利用了群体分布特性,提高了算法的搜索能力,避免了遗传算法中变异方式的不足。
3.差分进化算法适用情况差分进化算法是一种随机的并行直接搜索算法,最初的设想是用于解决切比雪夫多项式问题,后来发现差分进化算法也是解决复杂优化问题的有效技术。
它可以对非线性不可微连续空间的函数进行最小化。
目前,差分进化算法的应用和研究主要集中于连续、单目标、无约束的确定性优化问题,但是,差分进化算法在多目标、有约束、离散和噪声等复杂环境下的优化也得到了一些进展。
4.基本DE算法差分进化算法把种群中两个成员之间的加权差向量加到第三个成员上以产生新的参数向量,这一操作称为“变异”。
差分进化算法的实际应用

差分进化算法的实际应用差分进化算法(Differential Evolution,DE)是一种优化算法,最初由Storn和Price 在1995年提出。
该算法通过模拟自然选择的过程,不断优化目标函数,达到最优解。
近年来,差分进化算法在各个领域得到了广泛的应用。
差分进化算法在工程优化领域是被广泛应用的。
例如,在室内设计领域,使用差分进化算法来优化各种室内设计的元素,如家具布置、灯具设计等,优化的结果可以增强空间美感和舒适性,延长家具和设备的使用寿命,降低了设计成本。
在管道系统和化学工业中,差分进化算法也能够用来解决复杂工艺的问题。
例如,在纸浆和纸制品制造中,使用差分进化算法进行预测的生产条件,以便减少生产成本,优化生产过程;另外,差分进化算法亦被应用于工业口味的优化、生产中的卫生质量控制、物流和生产计划的优化等。
2. 差分进化算法在信号与图像处理中的应用差分进化算法在信号和图像处理中得到了广泛的应用。
例如,在图像压缩技术中,差分进化算法被用来找出最佳的图像的变换参数,包括图像的分辨率和压缩比例。
在音频信号中,差分进化算法常常与混响器和均衡器相伴。
通过差分进化算法来优化这些音频效果器的性能参数,提神音频品质,使音频的全局调整更为精准和高效。
差分进化算法在机器嗅觉领域得到了广泛的应用。
例如,食品行业使用差分进化算法来判定食品的成分。
此外,差分进化算法还在汽车领域被应用于车内高温时的臭味测量,以及疲劳驾驶时的呼吸测量。
差分进化算法在金融领域中的应用,主要是预测股票和外汇的市场行情,进行投资决策。
例如,在股票市场中,差分进化算法被用来挖掘股票与其他市场之间的关联性。
此外,差分进化算法还可以通过自动化的方式,完成对阿尔法交易策略等的优化。
结论总体来说,差分进化算法是一种强大而灵活的优化算法,涵盖了诸多领域的应用,在实际应用中所表现的效果也非常出色。
差分进化算法的发展也处于一个不断成熟和完善的过程,随着时间的推移,相信该算法在更多领域中应用的空间也会越来越广阔。
子空间聚类算法解析

子空间聚类算法解析子空间聚类算法是一种用于处理高维数据的聚类方法。
高维数据是指具有大量特征的数据,对于传统的聚类算法而言,高维数据会面临维度灾难的问题,即随着特征维度的增加,数据之间的距离会愈发稀疏,聚类效果会受到严重影响。
为了解决这个问题,子空间聚类算法引入了子空间的概念,将高维数据投影到低维子空间中进行聚类,从而降低维度灾难的影响。
子空间聚类算法主要包括两个步骤:子空间构建和聚类划分。
首先,需要构建表示数据的子空间,一般可以通过主成分分析(PCA)、因子分析等方法得到数据的主要特征子空间。
然后将数据投影到这些子空间中,得到降低维度后的数据表示。
接着,在降维后的子空间中进行聚类划分,可以使用传统的聚类算法,如k-means、DBSCAN等。
1.子空间聚类算法有较好的鲁棒性。
由于数据在子空间中被降维处理,可以过滤掉噪声和冗余特征,提高聚类的准确性和鲁棒性。
2.子空间聚类算法能够发现数据的局部和全局结构。
通过将数据投影到不同的子空间中,可以捕捉到数据在不同维度上的局部和全局结构信息。
3.子空间聚类算法能够处理特征选择问题。
由于高维数据可能存在大量冗余特征,通过子空间聚类算法可以选择数据的主要特征子空间,减少特征数量,提高聚类效果。
4.子空间聚类算法具有较好的可解释性。
子空间聚类得到的结果可以转化为可视化的形式,便于理解和解释聚类结果。
然而,子空间聚类算法也存在一些挑战和限制:1.子空间聚类算法对子空间的选择较为敏感。
不同的子空间表示方法可能得到不同的聚类结果,选择合适的子空间表示方法是一个挑战。
2.子空间聚类算法可能会受到噪声和异常值的干扰。
由于子空间构建和降维过程中,可能存在噪声和异常值的影响,导致聚类结果不准确。
3.子空间聚类算法的计算复杂度较高。
由于需要进行降维和聚类操作,计算复杂度相对较高,需要较长的计算时间。
总结来说,子空间聚类算法是一种解决高维数据聚类问题的有效方法。
通过将数据投影到低维子空间中进行聚类,能够降低高维数据的维度灾难问题,提高聚类效果。
自适应差分演化算法研究

自适应差分演化算法研究自适应差分演化算法是一种优化算法,用于解决多维非线性函数的优化问题。
相对于传统的差分演化算法,自适应差分演化算法能够更好地提高算法的鲁棒性和效率。
本文将介绍自适应差分演化算法的原理、优势、应用以及未来研究方向。
一、算法原理自适应差分演化算法是一种基于差分演化算法的高效优化算法。
其主要思想是通过自适应的方法动态地调整差分进化方程中的参数,以适应不同的函数模型。
自适应差分演化算法主要包含以下三个步骤:1.差分进化:原始种群中的每个个体都通过差分进化产生新的解向量。
2.适应度评估:根据适应度评价函数计算每个个体的适应度值。
3.选择:根据适应度值进行优胜劣汰,选择新的种群。
在自适应差分演化算法中,差分进化方程的参数需要根据函数的特点来进行调整。
常见的调整方法有自适应控制参数以及自适应策略参数。
其中,自适应控制参数是根据不同维度的信息来调整差分进化方程的参数。
而自适应策略参数则是根据算法执行过程中的表现来自适应调整差分进化方程的参数。
二、算法优势自适应差分演化算法相对于传统的差分进化算法具有以下优势:1.适应性强:自适应差分演化算法能够根据不同的函数模型自适应地调整算法的参数,从而提高算法的适应性。
2.鲁棒性强:自适应差分演化算法对于初始化种群的质量要求较低,对于噪声干扰以及非凸性函数也具有很好的鲁棒性。
3.优化效果好:自适应差分演化算法能够跳出局部最优解,并在全局搜索空间上寻找最优解。
4.计算效率高:自适应差分演化算法在计算过程中具有高度的并行性,能够有效地提高算法的计算效率。
三、算法应用自适应差分演化算法在实际应用中具有广泛的应用场景,尤其是在工程优化领域和机器学习领域具有显著优势。
下面介绍其中两个应用场景:1.工程优化:自适应差分演化算法可用于高维复杂的优化场景中,如模块化设计、自适应控制、无线网络优化等领域。
2.机器学习:自适应差分演化算法可用于训练深度神经网络、回归分析以及数据聚类等领域。
【国家自然科学基金】_子空间聚类_基金支持热词逐年推荐_【万方软件创新助手】_20140731

2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
推荐指数 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
k-means算法 dna微阵列数据 ap聚类
53 d-s证据理论 54 clique
推荐指数 4 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
科研热词 子空间聚类 聚类分析 聚类 数据挖掘 支持向量机 多类分类 高雏指标 高维数据索引 高维数据 高光谱 频繁模式 非线性建模 遥感 逆系统方法 辨识 谱聚类 聚类算法 聚类树 联合基尼值 网格划分 线性判别分析 粗糙集 类别保留投影 相对熵 相似兴趣子空间 目标检测 热工过程 模糊规则 模糊c均值聚类 模拟电路 核方法 最优聚类中心 最优变换 故障诊断 投影寻踪 属性关系图 密度聚类 子空间 基因表达数据 基于内容图像检索 图像分割 可视化 可信子空间 加速遗传算法 加权ls-svm 分解聚类 分类属性 农业综合生产力 亚像素目标 二又树 k均值聚类 fp.树
基于粒子群优化算法的模糊聚类分析

\ \ \
、
竺
基 于粒子群优 化算 法 的模糊 聚 类分析
周 洪 斌 1 , 2
(. 1 沙洲 职业工 学院 , 张家港 2 5 0 2 苏州 大学计 算机科学 与技 术学 院 , 16 0; . 苏州 2 5 0 10 6)
摘 要 : 提 出 一 种 基 于 模 糊 C一均 值 算 法 和 粒 子 群 优 化 算 法 的 混 合 聚 类 算 法 , 算 法 利 用 粒 子 群 该 优 化 算 法 全 局 寻 优 的 特 点 . 效 地 克 服 了模 糊 c一均 值 算 法 对 初 始 值 敏 感 、 陷入 局 部 有 易 最 优 的 缺 点 。 实 验 表 明 , 算 法 具 备 良好 的 聚 类 效 果 。 该 关 键 词 :模 糊 聚 类 ;K一均 值 算 法 ;模 糊 c一 值 算 法 ;粒 子 群 优 化 算 法 均
通 常在算 法执行 时给 出一 个 固定 的最大 迭代次数 。
2 模 糊 C一 值 算 法 均
21 模 糊 集 简 介 .
K一 值 算 法 是 一 种 硬 划 分 . 把 每 个 待 辨 识 的 对 均 它
类是一 个很有 意义 的研究 方 向
1 K 均 值 算 法 一
R 空间 中 的聚类 问题 可描 述 为 :对于 给定 的 n w 个 点 . 照 它 们 之 间 的 相 似 性 划 分 为 K个 ( 事 先 给 按 K 集合 。令 S f。 :… ,n 表 n个 点构 成 的集 合 , =x, , X 代 x ) 现 定) G , 2… , 代 表 K个 划 分 后 的 集 合 , 满 足 : 。G , 则 代
( at l S am pi i t n P O) 是 P rce w r O t z i ,S i m ao 19 年 由 95 K n ey和 E eh r 在 鸟 群 、 群 和 人 类 社 会 的 行 为 en d b rat 鱼
【国家自然科学基金】_改进差分进化算法_基金支持热词逐年推荐_【万方软件创新助手】_20140801

科研热词 差分进化 差分进化算法 小生境 密度聚类 高速工业平缝机 预防性维修 非线性参数估计 重油热解 适应度 进化策略 补料优化 约束优化问题 精英策略 稀布阵列 种群多样性 混沌迁移算子 模拟退火 有限时间区间 早熟收敛 方向图 性能优化 广义差分进化算法 实根 多项式方程 多目标进化算法(cde) 多目标优化问题 多目标优化 圆形阵列 发酵 参数反演 单纯形加速算子 单纯形 勾线机构 全局优化 停滞 优进策略 代数方程 二分之一规则
53 54 55 56
全局最优解 优化 仿真 iir数字滤波器设计
推荐指数 7 5 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
推荐指数 8 3 3 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
子空间聚类概述

子空间聚类概述
子空间聚类是一种在高维数据中发现隐含的低维子空间结构的聚类方法。
与传统的聚类算法不同,子空间聚类考虑到了数据在不同的属性子空间中可能具有不同的聚类结构。
它将数据投影到不同的子空间中进行聚类分析,以发现数据在各个子空间中的聚类特征。
子空间聚类算法通常具有以下步骤:
1. 子空间选择:选择要进行聚类的属性子空间。
可以通过特征选择、主成分分析等方法来选择合适的子空间。
2. 子空间投影:将数据投影到选择的子空间中,得到在每个子空间中的投影结果。
3. 聚类分析:在每个子空间中使用传统的聚类算法(如
k-means、DBSCAN等)进行聚类分析,得到每个子空间中的聚类结果。
4. 融合聚类结果:将各个子空间中的聚类结果进行融合,得到最终的聚类结果。
子空间聚类的优势在于可以处理高维数据中存在的低维子空间结构,能够更好地挖掘数据的潜在模式和关联信息。
它适用于许多领域,如图像处理、文本挖掘、生物信息学等。
然而,子空间聚类也面临着一些挑战,如选择合适的子空间、处理噪音和异常值等问题,需要根据具体应用场景进行算法选择和参数调优。
子空间聚类算法解析

右图是识别子空间聚类的示意图在由年龄和 工资两维构成的原始空间中没有密集区域,但是在 其由工资一维构成的子空间中,存在两个密集区域 , 形 成 两 个 类 ( 1000≤ 工 资 ≤ 3000 和 5000≤ 工 资 ≤6000)而在由年龄一维构成的子空间中没有密集 区域,不形成任何聚类。
具体而言,对于给定的数据集 X {x1, x2,, xN } RD ,人们希望利用软子空v间i 聚类算法得到 C 个聚类中心V {vi,1 i C} 定义 uij 表示第 j 个样本x j 属于第 i 个聚类中心 的模糊隶属度,则 U 表示整个数据集的模糊隶属度矩阵 U {uij |1 i C,1 j N} 。同时,为了更好地发现各个 数据簇相应的子空间结构,软子空间聚类算法在聚类过程中对每个数据簇的全部特征都赋 予一个特征加权系数。
自底向上子空间聚类算法
自底向上子空间聚类算法一般是基于网格密度,采用自底向上搜索策略进行的子空间聚类 算法。它先将原始特征空间分成若干个网格,再以落到某网格中样本点的概率表示该子空 间的密度情况。对于密度超过一定阈值的子空间作为密集单元进行保留,而对非密集的子 空间进行舍弃。
经典的自底向上子空间聚类方法有最早的静态网格聚类算法CLIQUE、利用熵理论作为密 度度量的 ENCLUS 方法,以及后来提出的通过动态查找策略,得到更加稳定划分结果的 子空间聚类算法:MAFIA和 DOC等
法的性能。
根据特征选择算法评估方法的不同,特征选择可以大致分为以下三类:
基于深度学习的子空间聚类算法优化研究

基于深度学习的子空间聚类算法优化研究随着数据时代的到来,大数据处理成为了现代社会信息技术发展的必经之路。
其中数据挖掘、机器学习等技术的兴起,为数据处理的效率和准确性提供了有力保障。
聚类算法作为数据挖掘的重要手段之一,在数据处理和应用中具有较为重要的地位。
子空间聚类算法作为聚类算法的一种,具有诸多优点。
与传统的聚类算法相比,子空间聚类算法可以有效解决高维数据处理中的维数诅咒问题。
而深度学习则是近年来兴起的一种强大的机器学习技术,其优点在于可以自动特征提取和表征学习。
本文旨在探讨如何基于深度学习来进行子空间聚类算法优化研究。
一、子空间聚类算法的发展历程子空间聚类算法最早出现在1998年,最初是用于模式识别和图像处理中。
从那时起,随着数据结构复杂性的增加,子空间聚类算法也逐渐被应用于不同的领域。
在传统的聚类算法中,每个数据点都被看作是一个“整体”,而在子空间聚类算法中,数据被表示为一个子空间。
这种算法可以将数据点分割为不同的子空间,进而对子空间内进行聚类。
这使得算法能够更加准确地处理高维数据,而高维数据处理却是传统聚类算法的弱点。
二、深度学习在子空间聚类算法中的应用深度学习作为一种带有层次化结构的机器学习模型,其最大的优势在于可以自动从数据中提取特征。
在子空间聚类算法中,深度学习可以实现子空间特征提取、子空间重建和子空间聚类三个过程的优化。
1、子空间特征提取在传统的子空间聚类算法中,通常采用PCA或LDA等技术来降维。
然而,这些技术容易受到线性化的影响,并且不够灵活。
相比之下,深度学习可以根据数据的特点来自适应地提取空间特征,进一步优化数据降维的效果。
2、子空间重建子空间重建是子空间聚类算法中一个非常重要的过程。
深度学习可以帮助我们更好地实现子空间重建。
具体而言,在使用深度学习之前,通常采用经典的线性代数技术,如奇异值分解或QR分解来实现子空间重建。
而基于深度学习的子空间重建可以有更高的拟合度,并且具有较好的自适应性。
自适应差分演化算法研究

自适应差分演化算法研究自适应差分演化算法(Adaptive Differential Evolution, ADE)是一种用于解决优化问题的进化算法,它结合了差分进化算法(Differential Evolution, DE)和自适应性的特点,能够有效地应对复杂和多变的优化问题。
本文将从算法原理、研究现状和应用等方面对自适应差分演化算法进行深入的介绍和分析。
一、算法原理自适应差分演化算法是基于差分进化算法的基础上进行优化的一种算法。
差分进化算法是一种基于种群的全局最优化算法,通过不断迭代寻找适应度函数的最小值或最大值。
其基本原理是通过对种群中个体进行变异、交叉和选择操作,来搜索最优解。
而自适应差分演化算法在差分进化算法的基础上引入了自适应性的概念,能够自动调整算法参数以适应优化问题的变化。
自适应差分演化算法中的基本操作包括变异、交叉和选择。
进行变异操作时,每个个体都会被随机选择出三个不同的个体,然后根据一定的变异策略对这三个个体进行变异操作,得到一个新的个体。
接着,进行交叉操作时,将变异后的个体与原始个体进行交叉操作,生成一个子代个体。
通过比较子代个体与原始个体的适应度大小,选择适应度更高的个体作为下一代的种群。
在自适应差分演化算法中,自适应性主要体现在算法参数的自适应调整上。
通过对算法参数进行自适应调整,可以使得算法在不同优化问题上表现更加稳健和高效。
自适应差分演化算法通过自适应地调整变异因子、交叉概率和种群大小等参数,以适应优化问题的不同特性和要求,从而提高算法的搜索能力和收敛速度。
二、研究现状自适应差分演化算法自提出以来,得到了广泛的研究和应用。
研究者们通过对算法的改进和优化,使自适应差分演化算法在各个领域都取得了显著的成绩。
研究者们针对自适应差分演化算法的局部搜索能力进行了改进。
由于差分进化算法容易陷入局部最优解,导致算法的收敛速度变慢。
为了克服这一问题,研究者们提出了一系列的局部搜索策略,如重启策略、自适应权重策略等,使得自适应差分演化算法在解决复杂优化问题时有了更好的性能。
子空间算法

子空间算法1. 介绍子空间算法(Subspace Algorithm)是一种用于数据挖掘和聚类的机器学习算法。
它的核心思想是通过发现数据的子空间结构来进行特征选择和聚类分析。
子空间是指数据中的一个子集,它具有一定的维度和特征。
子空间算法可以应用于各种领域,如图像处理、文本挖掘、生物信息学等。
它可以帮助我们从海量的数据中提取有用的信息,发现隐藏在数据背后的规律和模式。
2. 原理子空间算法的原理基于以下几个关键概念:2.1 子空间子空间是指数据的一个子集,它是原始数据的一个投影或降维。
子空间可以是低维的,也可以是高维的。
子空间的维度决定了数据的特征数。
2.2 特征选择特征选择是指从原始数据中选择最重要的特征。
子空间算法通过计算特征的重要性来选择最优的特征子集。
常用的特征选择方法包括相关性分析、信息增益和卡方检验等。
2.3 聚类分析聚类分析是指将相似的数据点分组到一起形成簇的过程。
子空间算法通过在每个子空间中进行聚类分析来发现数据的潜在结构和模式。
2.4 子空间聚类子空间聚类是指在多个子空间中进行聚类分析。
子空间算法通过将数据分别投影到不同的子空间中来进行聚类。
这种方法可以更好地捕捉数据的不同特征和属性。
3. 算法步骤子空间算法的核心步骤包括特征选择和聚类分析。
下面是子空间算法的一般步骤:3.1 数据预处理首先,需要对原始数据进行预处理,包括数据清洗、缺失值处理和数据标准化等。
这些步骤可以帮助提高数据的质量和准确性。
3.2 特征选择接下来,需要进行特征选择,选择最重要的特征子集。
可以使用相关性分析、信息增益和卡方检验等方法进行特征选择。
选择的特征应该具有较高的相关性和区分度。
3.3 子空间构建然后,需要构建子空间,将数据投影到不同的子空间中。
可以使用主成分分析(PCA)和线性判别分析(LDA)等方法进行子空间构建。
子空间的维度可以根据需要进行调整。
3.4 子空间聚类最后,需要在每个子空间中进行聚类分析。
基于高斯采样和随机采样聚类的差分演化算法

基于高斯采样和随机采样聚类的差分演化算法差分演化算法 (Differential Evolution, DE) 是一种优化算法,其主要思想是通过高效的策略在参数空间中寻找最优解。
差分演化算法采用了高斯采样和随机采样的聚类技术,使得算法具有更好的收敛性和能力。
高斯采样是一种常用的随机数生成方法,从高斯分布中采样得到的随机数具有对称性和平滑性,适用于连续型参数优化。
高斯采样的核心思想是根据均值和方差生成服从高斯分布的随机数。
在差分演化算法中,高斯采样被用于生成候选解,以便在过程中进行参数更新和优化。
随机采样聚类是一种基于采样和聚类的优化技术,它通过对参数空间进行随机采样,并将采样结果进行聚类分析,得到一组候选解。
随机采样的目的是使得算法具有更好的探索性,通过在整个参数空间范围内进行采样,可以避免陷入局部最优解。
聚类分析则是将采样的结果进行聚类,找出一组相似性较高的解作为优化的候选解。
这种方法能够较好地保持全局和局部优化的平衡。
在差分演化算法中,高斯采样和随机采样聚类被结合起来,形成了一种强大的策略。
具体而言,算法首先通过高斯采样生成初始种群的候选解,然后利用随机采样聚类技术对这些候选解进行优化。
聚类结果中的质心将作为新的种群个体,用于下一代的演化。
这样,在过程中就可以实现全局和局部优化的有效平衡。
差分演化算法基于高斯采样和随机采样聚类的优点有以下几个方面:1.高斯采样能够提供更好的效果。
由于高斯分布具有对称性和平滑性,使用高斯采样能够更充分地探索整个参数空间,从而提高效率。
2.随机采样聚类能够提供更好的优化效果。
通过将采样结果进行聚类分析,可以找到一组相似性较高的解作为优化的候选解。
这种方法能够在保持全局的同时,更好地进行局部优化。
3.高斯采样和随机采样聚类的结合能够提供更好的策略。
将高斯采样和随机采样聚类相结合,能够实现全局和局部优化的平衡,从而提高算法的收敛性和能力。
总之,基于高斯采样和随机采样聚类的差分演化算法是一种有效的优化算法,它通过结合高斯采样和随机采样聚类的优点,实现了更好的策略。
【国家自然科学基金】_k-均值聚类算法_基金支持热词逐年推荐_【万方软件创新助手】_20140801
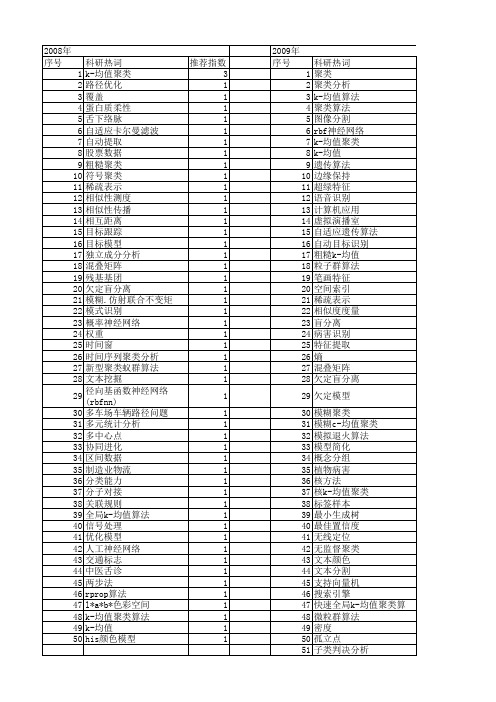
科研热词 推荐指数 k-均值聚类 3 路径优化 1 覆盖 1 蛋白质柔性 1 舌下络脉 1 自适应卡尔曼滤波 1 自动提取 1 股票数据 1 粗糙聚类 1 符号聚类 1 稀疏表示 1 相似性测度 1 相似性传播 1 相互距离 1 目标跟踪 1 目标模型 1 独立成分分析 1 混叠矩阵 1 残基基团 1 欠定盲分离 1 模糊.仿射联合不变矩 1 模式识别 1 概率神经网络 1 权重 1 时间窗 1 时间序列聚类分析 1 新型聚类蚁群算法 1 文本挖掘 1 径向基函数神经网络(rbfnn) 1 多车场车辆路径问题 1 多元统计分析 1 多中心点 1 协同进化 1 区间数据 1 制造业物流 1 分类能力 1 分子对接 1 关联规则 1 全局k-均值算法 1 信号处理 1 优化模型 1 人工神经网络 1 交通标志 1 中医舌诊 1 两步法 1 rprop算法 1 l*a*b*色彩空间 1 k-均值聚类算法 1 k-均值 1 his颜色模型 1
科研热词 聚类分析 遗传算法 k-均值聚类 差分演化算法 k-均值聚类算法 k-均值算法 k-均值 马尔可夫随机场(mrf) 进化优化 超分辨率(sr) 谱聚类 调度 蚁群算法 舌质舌苔分割 舌诊 自适应技术 自然语言处理 聚类算法 聚类有效性指标 聚类数 聚类中心初始化 聚类 群体层次分析法 组合优化 粗糙集 空间一致特性 知识转移 相容函数 混合性能指标 模糊聚类 模拟退火算法 权核k-均值 最小支撑树 日侧冕状极光 文本聚类 改进的仿射传播聚类 批处理机 快速全局k-均值 基因表达数据分析 图像分割 参数初始化 初始聚类中心 全局k-均值 免疫优势克隆算法 供应商管理库存 交互 t混合模型 k中心点法 k-均值聚类法 k-means算法 hsi gabor特征
一种基于差分演化的K-medoids聚类算法

( 2 )
情况 :
cP仍然与它原先所属 的聚类 的中心点距离最 短 , P仍 ) 则 将 属于原先的聚类 , 如图 1 c 所示 , () 如用 0 代替 0 , 据 … 数 对象 p的代价不变。 d 在所有 聚类 的中心点 中, ) P与 0 … 的距离 最短 , P将 则
ME NG n ,L e ,L U Ja — u “ SHIS a 。 Yi g UO K I in h a hu ng
,
( .ntueo o p t & C mmui t nE gnei bIstto l tcl I omai n ier g, .ntue a Istt fC m ue i r o nc i nier g, .ntuefEe r a & n r tnE gne n cIstto ao n i ci f o i i f t nE gne n i n ier g,C agh n e i Si c o i h nsaU ir t o c ne& Tcnlg , h nsa4 0 1 v syf e eh ooy C agh 114,C ia hn )
制 ; 爽 ( 9 3 ) 男 , 东定 陶人 , 士研 究 生 , 要 研 究方 向为 交通 运 输 规 划 与 管 理 . 石 18 . , 山 应 用 研 究
第2 9卷
:
』: n ≤衄 。( b i )P ) mr ( ( m ‘
(
其 中: n ()~U 0, ] r dj a [ 1 之间 的均匀分 布随 机数 ; 为 [ , ] P 0 1 之 间的交叉概率 ;nr ) { , , D} rb( 为 12 …, 之问的随机量。 经过变异交叉得到新种群 的个体 t , 即
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
期 1 0
毕 志 升 等 基 于 差 分 演 化 算 法 的 软 子 空 间 聚 类 :
2 1 1 7
( ) 化 新 目 标 函 数 和 搜 索 子 空 间 中 的 聚 类 类 别 的 样 本 往 往 与 不 同 的 属 性 子 集 子 空 间 相 关 因 优 这 是 第 一 . . , 基 于 的 软 子 空 间 聚 类 算 法 实 验 表 明 新 的 目 , , 而 受 到 冗 余 和 不 相 关 属 性 的 影 响 传 统 的 聚 类 算 法 个 D E . [ ] 2 标 函 数 和 复 合 差 分 演 化 算 法 的 引 入 有 效 地 提 高 了 软 无 法 有 效 解 决 高 维 数 据 集 上 的 聚 类 问 题. 为 了 解 决 空 间 聚 类 算 法 的 性 能 新 算 法 较 已 有 软 子 空 间 聚 . , 上 述 问 题 国 内 外 学 者 提 出 了 各 种 特 征 转 换 和 特 征 选 子 [ ] 3 算 法 有 明 显 优 势 . 择 的 方 法 子 空 间 聚 类 就 是 其 中 一 个 重 要 分 支 , . 类 ; 本 文 第 节 介 绍 软 子 空 间 聚 类 算 法 的 现 状 第 2 子 空 间 聚 类 是 一 种 寻 找 隐 藏 在 不 同 低 维 子 空 间 [ ] 4 , 节 介 绍 新 的 目 标 函 数 和 新 的 隶 属 度 计 算 方 法 并 ,3 中 的 聚 类 的 技 术. 它 将 数 据 样 本 划 分 成 簇 的 同 时 ; 出 新 算 法 第 节 通 过 实 验 验 证 新 算 法 的 D E S C 4 , 搜 索 各 个 簇 所 在 的 子 空 间 在 每 一 个 簇 中 各 个 属 性 提 . ; 能 第 节 是 本 文 结 论 5 . , 被 赋 予 不 同 的 权 值 用 于 度 量 属 性 与 簇 的 相 关 性 子 性 . 空 间 就 是 这 样 一 个 加 权 的 属 性 空 间 根 据 加 权 方 法 . 相 关 工 作 , : 的 不 同 子 空 间 聚 类 可 分 为 两 大 类 硬 子 空 间 聚 类 和2 [ ] 5 , 软 子 空 间 聚 类. 在 硬 子 空 间 聚 类 中 属 性 权 值 为 0 [ ] , 记 为 聚 类 中 心 矩 阵 记 录 每 个 簇 的 犣 = 狕 ; , 或 而 在 软 子 空 间 聚 类 中 属 性 依 据 其 与 簇 的 相 关 犆 × 犇 犻 犽 1 ; [ ] , 为 权 值 矩 阵 记 录 每 个 簇 的 心 位 置 [ , ] , 区 间 上 的 权 值 权 值 越 大 属 性 与 中 程 度 被 赋 予 犠 = 狑 0 1 . 犻 犽 犆 × 犇 , ; [ ] , 簇 的 相 关 性 越 高 相 比 硬 子 空 间 聚 类 软 子 空 间 聚 类 属 为 划 分 矩 阵 记 录 每 个 样 本 性 权 值 . 犝 = 狌 犻 犆 × 犖 犼 , , , 不 仅 反 映 了 属 性 与 簇 是 否 相 关 各 个 簇 的 隶 属 度 而 且 反 映 了 各 个 相 对 其 中 为 聚 类 数 为 样 本 总 . 犆 犖 , 为 样 本 的 维 数 关 属 性 在 相 关 程 度 上 的 差 异 数 . 犇 . 子 空 间 聚 类 算 法 能 有 效 减 少 冗 余 和 不 相 关 属 性 : 软 子 空 间 聚 类 算 法 的 分 类 方 法 很 多 例 如 按 加 . , 对 聚 类 过 程 的 干 扰 从 而 提 高 高 维 数 据 集 上 的 聚 类 权 方 式 可 分 为 熵 加 权 软 子 空 间 聚 类 算 法 和 模 糊 加 权 [ ] 6 [ ] 文 献 对 子 空 间 聚 类 算 法 有 详 细 介 绍 本 文 软 效 果 子 空 间 聚 类 算 法; 按 权 值 计 算 与 聚 类 过 程 的 结 . 6 . 仅 关 注 软 子 空 间 聚 类 算 法 型 软 子 空 间 聚 类 算 法 和 合 方 式 可 分 为 . W r a e r[ p p ] 7 , 近 年 来 国 内 外 出 现 了 很 多 新 的 软 子 空 间 聚 类 F 型 软 子 空 间 聚 类 算 法. 本 文 根 据 软 子 空 间 聚 i l t e r [ ] 4 1 0 , 然 而 这 些 算 法 仅 关 注 于 提 出 新 的 目 标 函 类 算 法 . 算 法 的 搜 索 策 略 将 其 分 为 基 于 局 部 搜 索 策 略 的 软 , ( , 数 在 搜 索 策 略 上 它 们 普 遍 采 用 与 均 值 空 间 聚 类 算 法 和 基 于 全 局 搜 索 策 略 的 软 子 空 间 聚 . 犽 犽 m e a n s 子 [ ] [ ] 1 1 1 2 ) , 算 法 相 似 的 算 法 结 构 通 过 在 中 加 类 算 法 两 大 类 K M K M . , 迭 代 地 优 化 目 标 函 数 值 因 2 入 计 算 权 值 的 额 外 步 骤 基 于 局 部 搜 索 策 略 的 软 子 空 间 聚 类 算 法 . . 1 此 这 类 算 法 都 保 留 了 依 赖 于 初 始 解 以 及 容 易 , 一 般 地 基 于 局 部 搜 索 策 略 的 软 子 空 间 聚 类 算 , K M 陷 入 局 部 最 优 的 缺 点 为 了 弥 补 这 些 不 足 等 , 首 先 提 出 一 个 加 权 目 标 函 数 然 后 采 用 基 于 梯 度 , . L u 法 [ ] 1 2 人 ( 通 过 引 入 全 面 学 习 的 粒 子 群 下 降 的 技 术 迭 代 地 优 化 目 标 函 数 值 最 终 收 敛 于 局 , C o m r e h e n s i v e p [ ] 1 3 , )算 部 最 优 解 C L P S O L e a r n i n P a r t i c l e S w a r m O t i m i z e r . g p 法 提 出 了 基 于 粒 子 群 算 法 的 子 空 间 聚 类 算 法 , ( , 模 糊 子 空 间 聚 类 F u z z S u b s a c e C l u s t e r i n y p g [ ] 8 ( ) 算 法是 一 个 经 典 的 软 子 空 间 聚 类 算 法 该 算 P S O V W P a r t i c l e S w a r m O t i m i z e r f o r V a r i a b l eF S C . p [ ] 1 6 ) , 此 外 的 目 标 函 数 将 原 本 对 权 ( , ) 法 模 仿 模 糊 均 值 算 W e i h t i n . P S O V W g g 犮 F u z z 犮 m e a n s F C M 法 y 值 矩 阵 的 等 式 约 束 放 松 为 界 约 束 简 化 了 算 法 的 搜 中 , 的 模 糊 隶 属 度 和 模 糊 因 子 定 义 了 模 糊 权 值 和 相 , 索 过 程 , 实 验 证 明 大 大 提 高 了 软 子 空 间 聚 应 , , 的 模 糊 因 子 并 通 过 提 出 一 个 加 权 目 标 函 数 利 用 . P S O V W 类 算 法 的 性 能 与 相 似 的 算 法 结 构 求 解 软 子 空 间 聚 类 问 题 . K M . [ ] 1 2 , 等 人 指 出 合 适 的 目 标 函 数 和 有 效 的 搜 索 : 的 目 标 函 数 如 下 L u F S C 犆 犖 犇 犆 犇 基 于 这 种 策 略 是 提 高 软 子 空 间 聚 类 算 法 性 能 的 基 础 . 2 β β ( ) 犑 = 狌 狑 - 狕 狑 ε F S C 犻 犽 0 犼 犼 犻 犽狓 犻 犽 + 犻 犽 ∑ ∑ ∑ ∑ ∑ 思 想 , ( 本 文 提 出 了 一 种 基 于 差 分 演 化 D i f f e r e n t i a l 犻 犻 犽 1 1 犽 1 1 1 = = = = = 犼 [ ] 犆 犖 1 4 , ) 算 法 的 软 子 空 间 聚 类 算 法 D E D E S C s E v o l u t i o n { , } , , ,( ) . t . 狌 0 1 狌 = 1 0 狌 犖 1 ∈ < < 犻 犻 犻 犼 犼 犼 ∑ ∑ ( ) D i f f e r e n t i a l E v o l u t i o n f o r S u b s a c e C l u s t e r i n . p g 犻 1 1 = = 犼 犇 , 首 先 我 们 设 计 了 一 个 结 合 模 糊 加 权 类 内 相 似 性 和 且 0 狑 1 狑 = 1 犻 犽 犻 犽 ∑ , 然 后 通 过 结 合 模 糊 界 约 束 权 值 矩 阵 的 新 目 标 函 数 1 犽 = . , 中 是 避 免 属 性 零 散 度 时 出 现 除 零 错 误 而 引 入 ε 0 , 隶 属 度 和 硬 隶 属 度 提 出 了 新 的 隶 属 度 计 算 方 法 最 其 . β , 常 数 是 模 糊 因 子 对 各 个 属 性 上 样 本 与 其 . 狑 后 引 入 了 一 种 有 效 的 全 局 搜 索 算 法 复 合 差 分 的 , — — — 犻 犽 β [ ] β 1 5 属 簇 中 心 的 距 离 进 行 加 权 由 于 形 式 上 与 演 化 算 法 并 运 用 该 算 法 所 ( , ), . 狑 C o m o s i t e D E C o D E 犻 犽 p
: ; : ( , , ) 、 收 稿 日 期 最 终 修 改 稿 收 到 日 期 本 课 题 得 到 国 家 自 然 科 学 基 金 广 东 省 自 然 科 学 2 0 1 2 0 6 3 0 2 0 1 2 0 8 2 0 . 6 0 8 0 5 0 2 6 6 1 0 7 0 0 7 6 6 1 0 3 3 0 1 0 广 东 省 科 技 计 划 项 目 广 州 市 珠 江 科 技 新 星 资 ( ) 、 ( , , ) 、 ( ) 基 金 S 2 0 1 1 0 2 0 0 0 1 1 8 2 2 0 0 9 B 0 9 0 3 0 0 4 5 0 2 0 1 0 A 0 4 0 3 0 3 0 0 4 2 0 1 1 B 0 4 0 2 0 0 0 0 7 2 0 1 1 J 2 2 0 0 0 9 3 助 男 年 生 博 士 研 究 生 主 要 研 究 方 向 为 数 据 挖 掘 计 算 智 能 通 信 作 者 男 毕 志 升 王 甲 海 , , , , 、 : ( ) , , . 1 9 8 3 . E m a i l b i v i c t o r m a i l . c o m . 1 9 7 7 @ g 年 生 博 士 副 教 授 主 要 研 究 方 向 为 计 算 智 能 和 数 据 挖 掘 男 年 生 博 士 教 授 博 , , , : , , , , , 印 鉴 . E m a i l w a n i a h m a i l . s s u . e d u . c n . 1 9 6 8 @ g j y , : 士 生 导 师 主 要 研 究 领 域 为 机 器 学 习 和 数 据 挖 掘 . E m a i l i s s i n m a i l . s s u . e d u . c n . @ j y y