Data Service-创建一个时间维度表
数据仓库公共时间维表的设计_范文模板及概述

数据仓库公共时间维表的设计范文模板及概述引言部分的内容如下:1.1 概述数据仓库在现代企业中扮演着重要的角色,它能够从各个业务系统中提取、整合和分析数据,为企业决策提供有力支持。
然而,在数据仓库中进行时间相关的分析和报表展示时,时间维度的设计十分关键。
本文将重点讨论数据仓库公共时间维表的设计,探讨其原则、实施步骤以及使用方法与场景应用。
1.2 文章结构本文将按照以下结构进行论述:首先,在“2. 数据仓库公共时间维表的设计”部分将介绍数据仓库公共时间维表的概念和设计原则;接着,在“3. 数据仓库公共时间维表的实施步骤”部分将详细阐述如何确定时间范围和粒度,并构建和填充时间维度表;然后,在“4. 数据仓库公共时间维表的使用方法与场景应用”部分将探讨如何应用这些时间维度表进行时间相关分析、多维分析以及查询优化技巧等方面;最后,在“5. 结论与总结”部分对数据仓库公共时间维表设计的重要性和未来发展趋势进行总结和展望。
1.3 目的本文旨在全面介绍数据仓库公共时间维表的设计,帮助读者深入了解如何设计和应用这些时间维度表,以便更好地利用数据仓库进行时间相关的分析、报表展示和多维分析。
通过本文的学习,读者将能够掌握时间维度设计的基本原则和实施步骤,并能够灵活运用这些技巧解决实际业务中的时间相关问题。
2. 数据仓库公共时间维表的设计2.1 什么是数据仓库公共时间维表数据仓库公共时间维表是指在数据仓库中用于存储和管理时间相关信息的一个特殊的维度表。
它是一个独立的时间维度,与其他事实表进行关联,在数据分析和报告生成过程中发挥重要作用。
2.2 设计原则和考虑因素在设计数据仓库公共时间维表时,需要考虑以下几个原则和因素:2.2.1 统一标准:为了保证数据仓库中各个事实表对时间的定义和使用保持一致性,应该采用统一的标准来设计时间维度。
这样可以使得不同业务流程之间的数据分析结果可比较,提高整体分析准确性。
2.2.2 粒度灵活:根据业务需求,可以根据年、季度、月、周、日等不同粒度来设计维度。
PowerBI建立维度表常用的几种方式

PowerBI建立维度表常用的几种方式使用Power BI应摆脱单张表的思维,不建议在一张大宽表的基础上分析,最好先建立数据模型,而一个优秀的数据模型离不开合适的维度表。
维度也就是分析的角度,比如从日期的角度分析,模型中最好有个日期维度表;从产品角度分析,模型中应该有个产品维度表。
建立维度表的好处是,可以对每个维度单独控制,按业务需求进行分组筛选,这样才可以更方便更灵活地实现各种动态分析。
如果源数据只有一个大而平的明细表,并没有各种维度表,那么在分析之前,最好先构造维度表,以下面这个简单的明细表为例:这个明细表中有日期、产品、部门和业务员字段,如果需要从这些角度对销售情况进行分析,就要建相应的维度表,下面来看看利用DAX生成维度表的几种方式。
从表中提取一列作为维度表对于产品维度表,就可以利用VALUES函数从明细表中,提取产品名称的不重复列表来实现。
产品表 = VALUES('明细表'[产品名称])从表中提取多列作为维度表如果有部分维度之间是有对应关系的,那么就不要分开为多个独立的维度表,而应该整合为一个维度表。
比如上表中的部门和业务员字段,所属部门只算是业务员的一个属性,不用单独作为一张维度表,应把这两个字段整合到一个业务员维度表中。
从表中提取多列作为维度表可以用SUMMARIZE函数来实现。
业务员表=SUMMARIZE( '明细表', '明细表'[销售部门],'明细表'[业务员])关于SUMMARIZE函数的用法可参考:SUMMARIZE:值得你花30分钟来了解的函数!从多个表提取列作为维度表如果有两个明细表,除了上面的明细表,还有个明细表2,分别有一部分明细数据:并且两个明细表中的产品并不是完全重叠,需要从这两个表中提取产品维度放在一起,才是一个完整的产品表,那么就可以这样建产品表:产品表 =DISTINCT(UNION(VALUES('明细表'[产品名称]),VALUES('明细表2'[产品名称])))这个公式的逻辑是,先用VALUES函数分别提取两个明细表的产品名称,然后用UNION函数将它们合并起来,最后利用DISTINCT函数进行去重,就得到了一个完整不重复的产品列表。
Druid配置

Druid 配置Ingestion Spec (摄取规范)Apache Druid ingestion spec 由三个部分组成: {"dataSchema" : {...}, "ioConfig" : {...}, "tuningConfig" : {...} }字段 类型 描述是否必须dataSchema JSON Object 指定传入数据的Schema 。
所有Ingestion Spec都可以共享相同的dataSchema 。
是ioConfigJSON Object指定数据的来源和去向。
此对象将随摄取方法而变化。
是tuningConfigJSONObject指定如何调整各种摄取参数。
此对象将随摄取方法而变化。
否DataSchema以下是一个dataSchema 的示例: "dataSchema" : {"dataSource" : "wikipedia", "parser" : { "type" : "string", "parseSpec" : { "format" : "json", "timestampSpec" : { "column" : "timestamp", "format" : "auto" },"dimensionsSpec" : { "dimensions": ["page", "language","user", "unpatrolled", "newPage", "robot", "anonymous", "namespace", "continent", "country", "region","city",{"type": "long", "name": "countryNum" },{"type": "float", "name": "userLatitude" },{"type": "float", "name": "userLongitude" }], "dimensionExclusions" : [], "spatialDimensions" : [] }}},"metricsSpec" : [{"type" : "count","name" : "count"}, {"type" : "doubleSum", "name" : "added", "fieldName" : "added"}, {"type" : "doubleSum", "name" : "deleted", "fieldName" : "deleted"}, {"type" : "doubleSum", "name" : "delta", "fieldName" : "delta"}],"granularitySpec" : { "segmentGranularity" : "DAY", "queryGranularity" : "NONE", "intervals" : [ "2013-08-31/2013-09-01" ] },"transformSpec" : null}字段类型描述是否必须dataSource String 摄取数据源的名称。
SQLServer建立日期维度表
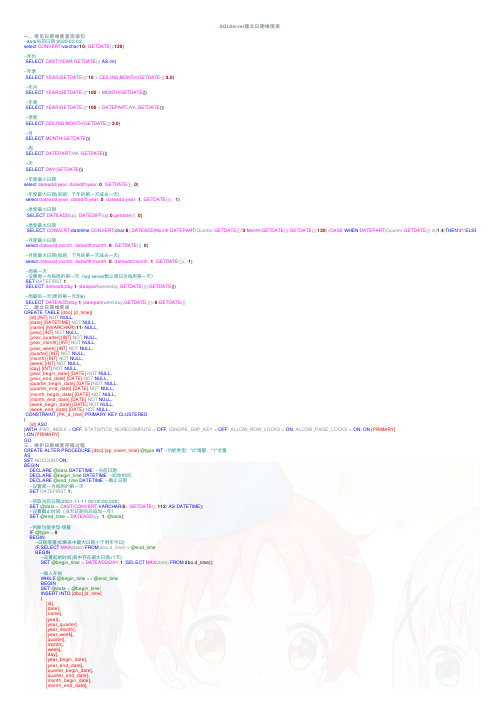
SQLServer建⽴⽇期维度表⼀、常见⽇期维度查询语句--data当前⽇期 2020-02-02select CONVERT(varchar(10),GETDATE(),120)--年份SELECT CAST(YEAR(GETDATE()) AS int)--年季SELECT YEAR(GETDATE())*10+CEILING(MONTH(GETDATE())/3.0)--年⽉SELECT YEAR(GETDATE())*100+MONTH(GETDATE())--年周SELECT YEAR(GETDATE())*100+DATEPART(WK,GETDATE())--季度SELECT CEILING(MONTH(GETDATE())/3.0)--⽉SELECT MONTH(GETDATE())--周SELECT DATEPART(WK,GETDATE())--天SELECT DAY(GETDATE())--年度最⼩⽇期select dateadd(year, datediff(year, 0, GETDATE()), 0)--年度最⼤⽇期(思路:下年的第⼀天减去⼀天)select dateadd(year, datediff(year, 0, dateadd(year, 1, GETDATE())), -1)--季度最⼩⽇期SELECT DATEADD(qq, DATEDIFF(qq,0,getdate()), 0)--季度最⼤⽇期SELECT CONVERT(datetime,CONVERT(char(8),DATEADD(Month,DATEPART(Quarter,GETDATE())*3-Month(GETDATE()),GETDATE()),120)+CASE WHEN DATEPART(Quarter,GETDATE()) in(1,4)THEN'31'ELSE'30 --⽉度最⼩⽇期select dateadd(month, datediff(month, 0, GETDATE()), 0)--⽉度最⼤⽇期(思路:下⽉的第⼀天减去⼀天)select dateadd(month, datediff(month, 0, dateadd(month, 1, GETDATE())), -1)--周第⼀天--设置周⼀为每周的第⼀天(sql server默认周⽇为每周第⼀天)SET DATEFIRST 1SELECT dateadd(day,1-(datepart(weekday,GETDATE())),GETDATE())--周最后⼀天(周的第⼀天加6)SELECT DATEADD(day,1-(datepart(weekday,GETDATE()))+6,GETDATE())⼆、建⽴⽇期维度表CREATE TABLE[dbo].[d_time]([id][INT]NOT NULL,[date][DATETIME]NOT NULL,[name][NVARCHAR](11) NULL,[year][INT]NOT NULL,[year_quarter][INT]NOT NULL,[year_month][INT]NOT NULL,[year_week][INT]NOT NULL,[quarter][INT]NOT NULL,[month][INT]NOT NULL,[week][INT]NOT NULL,[day][INT]NOT NULL,[year_begin_date][DATE]NOT NULL,[year_end_date][DATE]NOT NULL,[quarter_begin_date][DATE]NOT NULL,[quarter_end_date][DATE]NOT NULL,[month_begin_date][DATE]NOT NULL,[month_end_date][DATE]NOT NULL,[week_begin_date][DATE]NOT NULL,[week_end_date][DATE]NOT NULL,CONSTRAINT[PK_d_time]PRIMARY KEY CLUSTERED([id]ASC)WITH (PAD_INDEX =OFF, STATISTICS_NORECOMPUTE =OFF, IGNORE_DUP_KEY =OFF, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) ON[PRIMARY]) ON[PRIMARY]GO三、维护⽇期维度存储过程CREATE ALTER PROCEDURE[dbo].[sp_insert_time]@type INT--功能类型:"0"增量,"1"全量ASSET NOCOUNT ON;BEGINDECLARE@data DATETIME; --当前⽇期DECLARE@begin_time DATETIME; --起始时间DECLARE@end_time DATETIME; --截⽌⽇期--设置周⼀为每周的第⼀天SET DATEFIRST 1;--获取当前⽇期(2021-11-11 00:00:00.000)SET@data=CAST(CONVERT(VARCHAR(8), GETDATE(), 112) AS DATETIME);--设置截⽌时间(当天⽇期向后追加⼀年)SET@end_time=DATEADD(yy, 1, @data);--判断功能类型-增量IF@type=0BEGIN--⽇期增量(如果表中最⼤⽇期⼩于明年今⽇)IF(SELECT MAX(date) FROM dbo.d_time) <@end_timeBEGIN--设置起始时间(表中存在最⼤⽇期+1天)SET@begin_time=DATEADD(DAY,1,(SELECT MAX(date) FROM dbo.d_time));--插⼊开始WHILE@begin_time<=@end_timeBEGINSET@data=@begin_time;INSERT INTO[dbo].[d_time]([id],[date],[name],[year],[year_quarter],[year_month],[year_week],[quarter],[month],[week],[day],[year_begin_date],[year_end_date],[quarter_begin_date],[quarter_end_date],[month_begin_date],[month_end_date],[week_begin_date],[week_begin_date],[week_end_date])VALUES(cast(CONVERT(varchar(12),@data,112) AS INT ),CONVERT(varchar(10),@data,120),CAST(YEAR(@data) AS VARCHAR)+'年'+RIGHT((100+MONTH(@data)),2)+'⽉'+RIGHT(100+DAY(@data),2)+'⽇',CAST(YEAR(@data) AS int),YEAR(@data)*10+CEILING(MONTH(@data)/3.0),YEAR(@data)*100+MONTH(@data),YEAR(@data)*100+DATEPART(WK,@data),CEILING(MONTH(@data)/3.0),MONTH(@data),DATEPART(WK,@data),DAY(@data),dateadd(year, datediff(year, 0, @data), 0),dateadd(year, datediff(year, 0, dateadd(year, 1, @data)), -1),DATEADD(qq, DATEDIFF(qq,0,getdate()), 0),CONVERT(datetime,CONVERT(char(8),DATEADD(Month,DATEPART(Quarter,@data)*3-Month(@data),@data),120)+CASE WHEN DATEPART(Quarter,@data) in(1,4)THEN'31'ELSE'30'END) ,dateadd(month, datediff(month, 0, @data), 0),dateadd(month, datediff(month, 0, dateadd(month, 1, @data)), -1),dateadd(day,1-(datepart(weekday,@data)),@data),DATEADD(day,1-(datepart(weekday,@data))+6,@data));SET@begin_time=DATEADD(DAY, 1, @begin_time);END;END;END;----判断功能类型-全量IF@type=1BEGIN--全量前清空⽇期维度表TRUNCATE TABLE[dbo].[d_time]--先插⼊⼀条null数据BEGINSET@data='1900-01-01 00:00:00.000';INSERT INTO[dbo].[d_time]([id],[date],[name],[year],[year_quarter],[year_month],[year_week],[quarter],[month],[week],[day],[year_begin_date],[year_end_date],[quarter_begin_date],[quarter_end_date],[month_begin_date],[month_end_date],[week_begin_date],[week_end_date])VALUES(cast(CONVERT(varchar(12),@data,112) AS INT ),CONVERT(varchar(10),@data,120),CAST(YEAR(@data) AS VARCHAR)+'年'+RIGHT((100+MONTH(@data)),2)+'⽉'+RIGHT(100+DAY(@data),2)+'⽇',CAST(YEAR(@data) AS int),YEAR(@data)*10+CEILING(MONTH(@data)/3.0),YEAR(@data)*100+MONTH(@data),YEAR(@data)*100+DATEPART(WK,@data),CEILING(MONTH(@data)/3.0),MONTH(@data),DATEPART(WK,@data),DAY(@data),dateadd(year, datediff(year, 0, @data), 0),dateadd(year, datediff(year, 0, dateadd(year, 1, @data)), -1),DATEADD(qq, DATEDIFF(qq,0,getdate()), 0),CONVERT(datetime,CONVERT(char(8),DATEADD(Month,DATEPART(Quarter,@data)*3-Month(@data),@data),120)+CASE WHEN DATEPART(Quarter,@data) in(1,4)THEN'31'ELSE'30'END) ,dateadd(month, datediff(month, 0, @data), 0),dateadd(month, datediff(month, 0, dateadd(month, 1, @data)), -1),dateadd(day,1-(datepart(weekday,@data)),@data),DATEADD(day,1-(datepart(weekday,@data))+6,@data));END--正式数据插⼊开始SET@begin_time='2018-01-01 00:00:00.000';WHILE@begin_time<DATEADD(DAY, 1, @end_time)BEGINSET@data=@begin_time;--插⼊开始INSERT INTO[dbo].[d_time]([id],[date],[name],[year],[year_quarter],[year_month],[year_week],[quarter],[month],[week],[day],[year_begin_date],[year_end_date],[quarter_begin_date],[quarter_end_date],[month_begin_date],[month_end_date],[week_begin_date],[week_end_date])VALUES(cast(CONVERT(varchar(12),@data,112) AS INT ),CONVERT(varchar(10),@data,120),CAST(YEAR(@data) AS VARCHAR)+'年'+RIGHT((100+MONTH(@data)),2)+'⽉'+RIGHT(100+DAY(@data),2)+'⽇',CAST(YEAR(@data) AS int),YEAR(@data)*10+CEILING(MONTH(@data)/3.0),YEAR(@data)*100+MONTH(@data),YEAR(@data)*100+DATEPART(WK,@data),CEILING(MONTH(@data)/3.0),MONTH(@data),DATEPART(WK,@data),DAY(@data),dateadd(year, datediff(year, 0, @data), 0),dateadd(year, datediff(year, 0, dateadd(year, 1, @data)), -1),DATEADD(qq, DATEDIFF(qq,0,getdate()), 0),CONVERT(datetime,CONVERT(char(8),DATEADD(Month,DATEPART(Quarter,@data)*3-Month(@data),@data),120)+CASE WHEN DATEPART(Quarter,@data) in(1,4)THEN'31'ELSE'30'END) ,dateadd(month, datediff(month, 0, @data), 0),dateadd(month, datediff(month, 0, dateadd(month, 1, @data)), -1),dateadd(day,1-(datepart(weekday,@data)),@data),DATEADD(day,1-(datepart(weekday,@data))+6,@data));SET@begin_time=DATEADD(DAY, 1, @begin_time);END;END;END;View Code。
数据分析系统—用户操作手册范本

数据分析系统—用户操作手册范本数据分析系统操作手册一、前言1.1 编写目的本操作手册编写的目的是为了帮助用户更好地使用数据分析系统,提高工作效率。
1.2 读者对象本操作手册适用于所有使用数据分析系统的用户,包括但不限于数据分析师、市场营销人员等。
二、系统综述2.1 系统架构数据分析系统采用分布式架构,由前端界面、后端服务器、数据库等多个模块组成。
其中,前端界面采用响应式设计,兼容主流浏览器。
2.1.1 系统浏览器兼容数据分析系统支持主流浏览器,包括但不限于Chrome、Firefox、Safari等。
三、功能说明数据分析系统提供多项功能,包括数据导入、数据清洗、数据可视化等。
用户可以根据自己的需求选择相应的功能进行操作。
其中,数据可视化功能支持多种图表类型,如折线图、柱状图、饼图等,用户可以根据需要选择合适的图表类型进行展示。
另外,数据分析系统还支持数据导出功能,用户可以将分析结果导出为Excel或CSV格式的文件,方便后续处理和分享。
3、系统操作3.1、服务器监控服务器监控模块主要用于对服务器的性能进行监控。
用户可以通过该模块查看服务器的CPU、内存、磁盘等资源的使用情况,以及网络流量的情况。
同时,用户还可以设置自定义的监控项,以满足不同的监控需求。
3.2、日志源配置日志源配置模块主要用于对各类设备的日志进行采集。
用户可以通过该模块对设备进行配置,包括设备的IP地址、登录账号、密码等信息。
同时,用户还可以设置采集规则,以满足不同的采集需求。
3.3、日志查询与搜索日志查询与搜索模块主要用于对采集到的日志进行查询和搜索。
用户可以通过该模块对日志进行检索,以满足不同的查询需求。
同时,用户还可以设置查询条件,以进一步精确查询结果。
3.4、告警功能告警功能模块主要用于对采集到的日志进行告警。
用户可以通过该模块设置告警规则,以满足不同的告警需求。
同时,用户还可以设置告警方式,包括邮件、短信等方式。
3.5、系统管理系统管理模块主要用于对系统进行管理。
数仓 时间分区对应关系

数仓时间分区对应关系在数仓建设中,时间分区是一个非常重要的概念。
它可以帮助我们有效地组织和管理海量数据,满足不同业务场景对数据查询的需求。
本文将对数仓时间分区对应关系进行详细解析,帮助大家更好地理解这一概念。
一、时间分区概念概述时间分区,顾名思义,就是将数据按照时间维度进行划分。
在数仓中,通常将一个时间段内的数据存储在一个特定的区域,称为一个时间分区。
时间分区可以是一个月、一个季度、一年或者其他任意时间周期。
通过时间分区,我们可以方便地对不同时期的数据进行分别管理和查询。
二、时间分区对应关系在数仓中,时间分区对应关系主要包括以下几个方面:1.数据表命名:为了便于识别,时间分区表的命名通常包含时间周期信息,如“销售数据202101”、“订单数据2021Q3”等。
2.数据存储:根据时间分区,将数据存储在不同的文件夹或者数据库表中。
这样可以方便地对特定时间区的数据进行查询和分析。
3.数据集成:在数仓中,不同时间分区的数据需要进行集成,以便进行跨时间段的数据分析和对比。
数据集成通常采用ETL工具进行,将不同时间分区的数据导入到一个统一的数据模型中。
4.数据分区策略:针对不同时间分区的数据,可以采用不同的分区策略。
如按月分区,可以将每个月的数据单独存储;按季度分区,则将每个季度的数据存储在一起。
分区策略的选择需要根据业务需求和数据量来确定。
5.查询优化:为了提高查询效率,数仓需要针对时间分区进行优化。
如建立分区索引、使用分区函数等方法,以便在查询时快速定位到特定时间区的数据。
三、时间分区优势1.提高数据存储效率:通过时间分区,可以将相似时间期的数据存储在一起,减少数据冗余,提高数据存储效率。
2.便于数据查询和分析:时间分区使得我们可以快速定位到特定时间区的数据,方便进行数据查询和分析。
3.支持海量数据处理:随着数据量的不断增长,时间分区可以帮助我们更好地组织数据,支持高效的数据处理和分析。
4.有利于数据维护:通过时间分区,可以方便地对过期数据进行清理和维护,确保数仓数据的准确性和实时性。
(完整)实验二:Analysis Service
实验二名称:OLAP分析实验二目的:了解Analysis Services项目的创建过程,掌握对数据进行分析、处理的方法;能熟练运用OLAP技术对数据仓库中的大量数据进行复杂、有效的分析处理,并将结果以直观的形式提供给决策分析人员,从而实现对决策的支持。
实验二内容:以数据仓库为应用平台运用OLAP技术,创建新的Analysis Services项目。
对数据仓库中的大量数据进行复杂、有效的分析处理,并能将结果以直观的形式呈现出来。
实验二过程:下面简要介绍一下SQL Server 2005中OLAP的使用步骤:一.创建新的Analysis Services项目1。
单击“开始”,指向“所有程序”,再指向Microsoft SQL Server 2005,再单击SQL Server Business Intelligence Development Studio,打开Microsoft Visual Studio 2005开发环境.2。
在Visual Studio的“文件”菜单上,指向“新建”,再单击“项目”。
3.在“新建项目"对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“Analysis Services项目”。
4.将项目名称更改为Analysis Services Tutorial1,这也将更改解决方案名称,然后单击“确定”。
(如图1。
1)图1.1至此,在同样名为Analysis Services Tutorial1的新解决方案中基于Analysis Services项目模板成功创建了Analysis Services Tutorial1项目。
二.定义新的数据源1.在Microsoft Visual Studio 2005开发环境中,打开解决方案资源管理器,右键单击“数据源”,然后单击“新建数据源”,将打开数据源向导.(如图2.1)图2.12。
在“欢迎使用数据源向导”页上,单击“下一步”.3。
实用的计算机词汇大全

实用的计算机词汇大全电脑,又称计算机,是机械的一种,现在使用的越来越多。
接下来小编为大家整理了实用的计算机词汇大全,希望对你有帮助哦!实用的计算机词汇大全一:action 操作active statement 活动语句active voice 主动语态ActiveX Data Objects ActiveX 数据对象ActiveX Data Objects (Multidimensional) (ADO MD) ActiveX 数据对象(多维)(ADO MD)ad hoc connector name 特殊连接器名称add-in 加载项adjective phrasing 形容词句式ADO ADOADO MD ADO MDadverb 副词aggregate function 聚合函数aggregate query 聚合查询aggregation 聚合aggregation prefix 聚合前缀aggregation wrapper 聚合包装alert 警报alias 别名aliasing 命名别名All member "全部"成员American National Standards Institute (ANSI) 美国国家标准学会 (ANSI)Analysis server 分析服务器ancestor 祖先annotational property 批注属性anonymous subscription 匿名订阅ANSI ANSIANSI to OEM conversion ANSI 到 OEM 转换API APIAPI server cursor API 服务器游标application programming interface (API) 应用程序接口 (API) application role 应用程序角色archive file 存档文件article 项目atomic 原子的attribute 特性authentication 身份验证authorization 授权automatic recovery 自动恢复autonomy 独立axis 轴backup 备份backup device 备份设备backup file 备份文件backup media 备份媒体backup set 备份集balanced hierarchy 均衡层次结构base data type 基本数据类型base table 基表batch 批处理bcp files bcp 文件bcp utility bcp 实用工具bigint data type bigint 数据类型binary data type binary 数据类型binary large object 二进制大对象binding 绑定bit data type bit 数据类型bitwise operation 按位运算BLOB BLOBblocks 块Boolean 布尔型browse mode 浏览模式built-in functions 内置函数business rules 业务规则cache aging 高速缓存老化数据清除calculated column 计算列calculated field 计算字段calculated member 计算所得成员calculation condition 计算条件calculation formula 计算公式calculation pass 计算传递calculation subcube 计算子多维数据集call-level interface (CLI) 调用级接口 (CLI) candidate key 候选键cascading delete 级联删除cascading update 级联更新case 事例case key 事例键case set 事例集cell 单元cellset 单元集certificate 证书change script 更改脚本changing dimension 可更改维度char data type char 数据类型character format 字符格式character set 字符集CHECK constraints CHECK 约束checkpoint 检查点child 子代classification 分类clause 子句client application 客户端应用程序client cursor 客户端游标clustered index 聚集索引clustering 聚集code page 代码页collation 排序规则column 列column filter 列筛选column-level collation 列级排序规则column-level constraint 列级约束COM COMcommand relationship 命令关系commit 提交comparative form 比较级Component Object Model (COM) 组件对象模型 (COM) composite index 组合索引composite key 组合键computed column 计算列COM-structured storage file COM 结构化存储文件concatenation 串联concurrency 并发conjunction 连词connection 连接constant 常量constraint 约束continuation media 延续媒体control-break report 控制中断报表control-of-flow language 控制流语言correlated subquery 相关子查询CPU busy CPU 忙crosstab query 交叉表查询cube 多维数据集cube file 多维数据集文件cube role 多维数据集角色cursor 游标cursor data type cursor 数据类型cursor library 游标库custom rollup 自定义汇总custom rule 自定义规则data block 数据块data connection 数据连接Data Control Language (DCL) 数据控制语言 (DCL)data definition 数据定义data definition language (DDL) 数据定义语言 (DDL) data dictionary 数据字典data dictionary view 数据字典视图data explosion 数据爆炸data file 数据文件data integrity 数据完整性data lineage 数据沿袭data manipulation language (DML) 数据操作语言 (DML) data mart 数据集市data member 数据成员data modification 数据修改data pump 数据抽取data scrubbing 数据清理data source 数据源data source name (DSN) 数据源名称 (DSN)data type 数据类型data warehouse 数据仓库database 数据库database catalog 数据库目录database diagram 数据关系图database file 数据库文件database language 数据库语言database object 数据库对象database owner 数据库所有者database project 数据库工程database role 数据库角色database schema 数据库架构database script 数据库脚本data-definition query 数据定义查询dataset 数据集datetime data type datetime 数据类型DBCS DBCSDCL DCLDDL DDLdeadlock 死锁decimal data type decimal 数据类型decision support 决策支持decision tree 决策树declarative referential integrity (DRI) 声明引用完整性 (DRI)default 默认值DE**ULT constraint 默认约束default database 默认数据库default instance 默认实例default language 默认语言default member 默认成员default result set 默认结果集Delete query 删除查询delimiter 分隔符denormalize 使非规范化density 密度deny 拒绝dependencies 相关性descendant 后代destination object 目的对象device 设备dictionary entry 字典条目differential database backup 差异数据库备份dimension 维度dimension hierarchy 维度层次结构dimension table 维度表direct connect 直接连接direct object 直接对象direct response mode 直接响应模式dirty pages 脏页dirty read 脏读distribute 分发distributed query 分布式查询distribution database 分发数据库distribution retention period 分发保持期Distributor 分发服务器DML DMLdomain 域domain integrity 域完整性double-byte character set (DBCS) 双字节字符集 (DBCS) DRI DRIdrill down/drill up 深化/浅化drill through 钻取DSN DSNDSN-less connection 无 DSN 连接DTS package DTS 包DTS package template DTS 包模板dump 转储dump file 转储文件dynamic cursor 动态游标dynamic filter 动态筛选dynamic locking 动态锁定dynamic recovery 动态恢复dynamic snapshot 动态快照dynamic SQL statements 动态 SQL 语句encrypted trigger 加密触发器encryption 加密English Query English QueryEnglish Query application English Query 应用程序entity 实体entity integrity 实体完整性enumeration 枚举equijoin 同等联接error log 错误日志error state number 错误状态号escape character 转义符exclusive lock 排它锁explicit transaction 显式事务expression 表达式extended stored procedure 扩展存储过程extent 扩展fact 事实fact table 事实数据表Federal Information Processing Standard (FIPS) 联邦信息处理标准 (FIPS)fetch 提取field 字段field length 字段长度field terminator 字段终止符file 文件file DSN 文件 DSNfile storage type 文件存储类型filegroup 文件组fill factor 填充因子filter 筛选filtering 筛选FIPS FIPSfirehose cursor 流水游标firehose cursors 流水游标fixed database role 固定数据库角色fixed server role 固定服务器角色FK FKflattened interface 平展界面flattened rowset 平展行集float data type float 数据类型foreign key (FK) 外键 (FK)foreign table 外表forward-only cursor 只进游标fragmentation 碎片full outer join 完整外部联接full-text catalog 全文目录full-text enabling 全文启用full-text index 全文索引full-text query 全文查询full-text service 全文服务function 函数global default 全局默认值global properties 全局属性global rule 全局规则global subscriptions 全局订阅global variable 全局变量grant 授权granularity 粒度guest 来宾heterogeneous data 异类数据hierarchy 层次结构HOLAP HOLAPhomogeneous data 同类数据hop 跃点horizontal partitioning 水平分区HTML HTMLhuge dimension 巨型维度hybrid OLAP (HOLAP) 混合 OLAP (HOLAP)Hypertext Markup Language (HTML) 超文本标记语言 (HTML) identifier 标识符identity column 标识列identity property 标识属性idle time 空闲时间IEC IECimage data type image 数据类型immediate updating 即时更新immediate updating Subscribers 即时更新订阅服务器immediate updating subscriptions 即时更新订阅implicit transaction 隐性事务implied permission 暗示性权限incremental update 增量更新index 索引index ORing 索引或运算index page 索引页indirect object 间接宾语information model 信息模型initial media 初始化媒体initial snapshot 初始化快照inner join 内联接input member 输入成员input set 输入集input source 输入源insensitive cursor 不感知游标Insert query 插入查询Insert values query 插入值查询instance 实例int (integer) data type int (integer) 数据类型integer 整型integrated security 集成安全性integrity constraint 完整性约束intent lock 意向锁interactive structured query language (ISQL) 交互式结构化查询语言 (ISQL)interface 接口interface implication 接口含义internal identifier 内部标识符International Electrotechnical Commission (IEC) 国际电子技术委员会 (IEC)International Organization for Standardization (ISO) 国际标准化组织 (ISO)Internet-enabled 可支持 Internet 的interprocess communication (IPC) 进程间通讯 (IPC)IPC IPCirregular form 不规则形式irregular form type 不规则形式类型irregular noun 不规则名词irregular verb 不规则动词ISO ISOisolation level 隔离级别实用的计算机词汇大全二:job 作业join 联接join column 联接列join condition 联接条件join field 联接字段join filter 联接筛选join operator 联接运算符join path 联接路径join table 联接表junction table 连接表kernel 核心key 键key column 键列key range lock 键范围锁keyset-driven cursor 键集驱动游标keyword 关键字large level 大级别latency 滞后时间LCID LCIDleaf 叶leaf level 叶级leaf member 叶成员left outer join 左向外联接level 级别level hierarchy 级别层次结构library 库linked cube 链接多维数据集linked server 链接服务器linked table 链接表linking table 链接表livelock 活锁local cube 本地多维数据集local Distributor 本地分发服务器local group 本地组local login identification 本地登录标识local server 本地服务器local subscription 本地订阅local variable 局部变量locale 区域设置locale identifier (LCID) 区域设置标识符 (LCID)lock 锁lock escalation 锁升级log file 日志文件logical name 逻辑名称logical operators 逻辑运算符logical_join 逻辑联接login (account) 登录(帐户)login security mode 登录安全模式lookup table 查找表machine DSN 机器 DSNMake Table query 生成表查询many-to-many relationship 多对多关系many-to-one relationship 多对一关系MAPI MAPImaster database master 数据库master definition site 主定义位置master file 主文件master site 主位置MDX MDXmeasure 度量值measurement 度量media description 媒体描述media family 媒体家族media header 媒体首部media name 媒体名称media set 媒体集member 成员member delegation 成员委派member group 成员组member key column 成员键列member name column 成员名列member property 成员属性member variable 成员变量memo 备注merge 合并merge replication 合并复制message number 消息编号name phrasing 名称句式named instance 命名实例named pipe 命名管道named set 命名集naming relationship 命名关系native format 本机格式nchar data type nchar 数据类型nested query 嵌套查询nested table 嵌套表Net-Library Net-Library nickname 别名niladic functions niladic 函数noise word 干扰词nonclustered index 非聚集索引nonleaf 非叶nonleaf member 非叶成员nonrepeatable read 不可重复读取normalization rules 规范化规则noun 名词ntext data type ntext 数据类型NULL NULLnullability 为空性numeric expression 数值表达式nvarchar data type nvarchar 数据类型object 对象object dependencies 对象相关性object identifier 对象标识符object owner 对象所有者object permission 对象权限object variable 对象变量ODBC ODBCODBC data source ODBC 数据源ODBC driver ODBC 驱动程序ODS ODSOIM OIMOLAP OLAPOLE Automation controller OLE 自动化控制器OLE Automation objects OLE 自动化对象OLE Automation server OLE 自动化服务器OLE DB OLE DBOLE DB consumer OLE DB 使用者OLE DB for OLAP 用于 OLAP 的 OLE DBOLE DB provider OLE DB? 提供程序OLTP OLTPone-to-many relationship 一对多关系one-to-one relationship 一对一关系online analytical processing (OLAP) 联机分析处理 (OLAP)online redo log 联机重做日志online transaction processing (OLTP) 联机事务处理 (OLTP)Open Data Services (ODS) 开放式数据服务 (ODS)Open Database Connectivity (ODBC) 开放式数据库连接(ODBC)Open Information Model (OIM) 开放信息模型 (OIM)optimize synchronization 优化同步optimizer 优化程序ordered set 有序集origin object 起始对象outer join 外联接overfitting 过适page 页page split 页拆分parent 父代partition 分区partitioning 分区parts of speech 词性pass order 传递顺序passive voice 被动语态pass-through query 直接传递查询pass-through statement 直接传递语句persistence 持续性phantom 幻像phrase 短语phrasing 句式physical name 物理名称physical reads 物理读取pivot 数据透视PK PKposition 位置positioned update 定位更新possessive case 所有格precision 精度predicate 谓词prediction 预测prefix characters 前缀字符prefix length 前缀长度prefix search 前缀搜索preposition 介词preposition phrasing 介词句式primary dimension table 主维度表primary key (PK) 主键 (PK)primary table 主表private dimension 专用维度procedure cache 过程缓存process 处理producer 发生器project 工程pronoun 代词proper noun 专有名词property 属性property pages 属性页provider 提供程序proximity search 近似搜索publication 发布publication database 发布数据库publication retention period 发布保持期published data 已发布数据Publisher 发布服务器publishing server publishing server publishing table 发布表pubs database pubs 数据库pull subscription 请求订阅push subscription 强制订阅query optimizer 查询优化器question 问题Question Builder 问题生成器question file (.eqq) 问题文件 (.eqq)question template 问题模板queue 队列root servers / 根服务器round robin / 循环提示器Routemon utility / Routemon 实用程序router / 路由器routing / 路由Routing Information Protocol over IPX, RIPX / 在 IPX 上的路由信息协议routing link / 路由链接routing-link cost / 路由链接成本routing protocol / 路由协议旘routing services / 路由服务RPC, remote procedure call / 远程过程调用RR, resource record / 资源记录Rrset, resource record set / 资源记录集RS-232-C standard / RS-232-C 标准RSA 一个认证安全机构RSL, registry size limit / 注册表大小限制RSVP, Resource Reservation Protocol / 资源保留协议RTP, Rea / ime Transport Protocol / 实时传输协议S/MIME, Secure Multipurpose Internet Mail Extensions / 安全多用途网际邮件扩展协议SACL, system access control list / 系统访问控制列表safe mode / 安全模式safe mode with command prompt / 命令提示符下的安全模式safe mode with networking / 联网安全模式SAM, security account manager / 安全帐户管理器SAM account name / SAM 帐户名saturation / 饱和度SBM, subnet bandwidth management / 子网带宽管理scalability / 可伸缩性scavenging / 清理schema / 架构schema master / 架构主机scope / 作用域scope of influence / 影响的作用域screen fonts / 屏幕字体screen resolution / 屏幕分辨率screen saver / 屏幕保护程序SCSI, small computer system interface / 小型计算机系统接口SDP, Standard Description Protocol / 标准描述协议second-level domains / 二级域secondary master / 辅助主机secret key encryption / 密钥加密sector / 扇区Secure Hash Algorithm, SHA-1 / 安全散列算法Secure Multipurpose Internet Mail Extensions, S/MIME / 安全多用途网际邮件扩展协议Secure Sockets Layer, SSL / 安全套接字层security / 安全性security account manager,SAM / 安全帐户管理器security descriptor / 安全描述security group / 安全组security host / 安全主机security ID,SID / 安全 IDsecurity identifier / 安全标识符security log / 安全日志security principal / 安全主体security principal name / 安全主体名称See Files / 查看文件See Folders / 查看文件夹seed router / 种子路由器Serial Line Internet Protocol, SLIP / 串行线路网际协议serial port / 串行端口server / 服务器server application / 服务器应用程序server cluster / 服务器群集server zone / 服务器区域service / 服务Service Profile Identifier, SPID / 服务配置文件标识符service (SRV) resource record / 服务 (SRV) 资源记录service ticket / 服务票据service-centric / 服务屏幕字体Services for Macintosh (now called AppleTalk network integration) / Macintosh 服务(现在称为AppleTalk 网络集成)session / 会话session concentration / 会话集中度set-by-caller callback / 由呼叫者设置的回叫SHA-1, Secure Hash Algorithm / 安全散列算法share / 共享shared folder / 共享文件夹shared folder permissions / 共享文件夹权限shared network directory / 共享网络目录shared printer / 共享打印机shared resource / 共享资源short name / 短名称shortcut / 快捷方式SID, security ID / 安全 IDsignaling protocol / 信号协议signature PKI / 签名 PKISimple Mail Transfer Protocol, SMTP / 简单邮件传输协议Simple Network Management Protocol, SNMP / 简单网络管理协议Simple TCP/IP Services / 简单 TCP/IP 服务simple volume / 简单卷Single Instance Store, SIS / 零备份存储single sign-on / 单一登录SIS, Single Instance Store / 零备份存储site / 站点Site Se4 6 b d a; y; 站点服务器 ILS 服务SLIP, Serial Line Internet Protocol / 串行线路网际协议small computer system interface, SCSI / 小型计算机系统接口smart card / 智能卡smart card reader / 智能卡读取器SMTP, Simple Mail Transfer Protocol / 简单邮件传输协议snap-in / 管理单元SNMP, Simple Network Management Protocol / 简单网络管理协议SOA (start-of-authority) resource record / SOA(颁发机构开始)资源记录software decoder / 软件解码器source document.nbsp/ 源文档source journaling / 源日志spanned volume / 跨区卷sparse file / 稀疏文件special access permissions / 特殊访问权限SPID, Service Profile Identifier / 服务配置文件标识符split horizon / 水平拆分splitting / 拆分spooler / 后台打印程序spooling / 后台打印SRV (service) resource record / SRV(服务)资源记录SSL, Secure Sockets Layer / 安全套接字层stand-alone server / 独立服务器Standard Description Protocol, SDP / 标准描述协议start-of-authority (SOA) resource record / 颁发机构开始 (SOA) 资源记录startup environment / 启动环境static dialog box / 静态对话框static load balancing / 静态负载平衡static routes / 静态路由status area / 状态区域status bar / 状态栏STOP error / STOP 错误storage-class resource / 存储类资源strict RFC checking / 严格的 RFC 检查string / 字符串stripe set / 带区集stripe set with parity / 带有奇偶校验的带区集striped volume / 带区卷subdomain / 子域subkey / 子项subnet bandwidth management, SBM / 子网带宽管理subtree / 子树superscope / 超级作用域SVC, switched virtual circuit / 交换虚电路swap file / 交换文件switch type / 交换类型switched circuit / 交换电路switched virtual circuit, SVC / 交换虚电路switching hub / 交换集线器symmetric encryption / 对称加密system access control list, SACL / 系统访问控制列表system default profile d driver /system disk / 系统盘system files / 系统文件System menu / 系统菜单system partition / 系统分区system policy / 系统策略system queue / 系统队列System State / 系统状态system variables / 系统变量system volume / 系统卷systemroot / 系统根Systems Management Server / 系统管桨服务器SYSVOLtag / 标记TAPI, Telephony API / 电话 APItarget journaling / 目标日志taskbar / 任务栏taskbar button / 任务栏按钮TCP/IP, Transmission Control Protocol/Internet Protocol / 传输控制协议/网际协议Telephony API, TAPI / 电话 APItelephony switch / 电话交换Terminal Services / 终端服务Terminal Services Licensing / 终端服务授权terminate-and-stay-resident (TSR) program / 终止并驻留内存(TSR) 程序test queue / 测试队列text box / 文本框TFTP, Trivial File Transfer Protocol / 简单文件传输协议TGS, ticket-granting service / 票据授予服务TGT, ticket-granting ticket / 票据授予票据Thread Count / 线程数thumbnail / 缩略图ticket / 票据ticket-granting service, TGS / 票据授予服务ticket-granting ticket, TGT / 票据授予票据time slice / 时间片time stamp / 时间戳time-out error / 超时错误Time-To-Live, TTL / 活动时间title bar / 标题鯅TLS, Transport Layer Security / 传输层安全top-level domains / 顶级域topological database / 拓扑数据库topology / 拓扑touch-tone dialing / 按键式拨号trace log / 追踪日志transaction / 事务处理transaction dead-letter queue / 事务处理死信队列transactional message / 事务处理消息transitive trust / 可传递信任Transmission Control Protocol/Internet Protocol, TCP/IP / 传输控制协议/网际协议transmitting station ID (TSID) string / 传输站 ID (TSID) 字符串Transport Layer Security, TLS / 传输层安全trap / 陷阱tree view / 树视图triggered update / 触发更新Trivial File Transfer Protocol, TFTP / 简单文件传输协议Trojan horse / 特洛伊木马TrueType fonts / TrueType 字体trust relationship / 信任关系TSID (transmitting station ID) string / 传输站 ID 字符串TSR (terminate-and-stay-resident) program / 终止并驻留内存程序TTL, Time-To-Live / 生存时间tunnel / 隧道tunnel server / 隧道服务器two-way trust / 双向信任Type 1 fonts / Type 1 字体UAM, user authentication module / 用户身份验证模块UBR, unspecified bit rate / 未指定的传输率UCS, Unicode Character System / Unicode 字符系统UDP, User Datagram Protocol / 用户数据报协议unallocatelimit / / 未分配的空间UNC (Universal Naming Convention) name / 通用命名规则名称UNI, user network interface / 用户网络接口unicast / 单播UnicodeUnicode Character System, UCS / Unicode 字符系统Unicode Transmission format 8, UTF-8 / Unicode 传输格式 8 uninstall / 卸载universal group / 通用组Universal Naming Convention (UNC) name / 通用命名规则名称universal serial bus, USB / 通用串行总线unspecified bit rate, UBR / 未指定的传输率upcasing / 大写转换upgrade / 升级UPS, uninterruptible power supply / 不间断电源UPS service / UPS 服务USB, universal serial bus / 通用串行总线user account / 用户帐户user authentication module, UAM / 用户身份验证模块user class / 用户类User Datagram Protocol, UDP / 用户数据报协议user name / 用户名user network interface, UNI / 用户网络接口USER object / USER 对象user password / 用户密码user principal name / 用户主体名称user principal name suffix / 用户主体名称后缀user profile / 用户配置文件user rights / 用户权限user rights policy / 用户权限策略Users / 用户UTF-8, Unicode Transmission format 8 / Unicode 传输格式 8 validation / 验证value entry / 值项variable / 变量variable bit rate, VBR / 可变传输率VBR, variable bit rate / 可变传输率VCI, virtual channel identifier / 虚拟信道标识符VDM, virtual DOS machine / 虚拟 DOS 机vector / 矢量vector fonts / 矢量字体vendor class / 供应商类别video codec / 视频?解码virtual channel identifier, VCI / 虚拟信道标识符virtual container / 虚拟容器virtual DOS machine / 虚拟 DOS 机器(VDM)virtual IP address / 虚拟 IP 地址virtual link / 虚拟链接virtual local area network, VLAN / 虚拟局域网virtual memory / 虚拟内存Virtual Memory Size / 虚拟内存大菆virtual network / 虚拟网络virtual path identifier, VPI / 虚拟路径标识符virtual printer memory / 虚拟打印机内存virtual private network, / 虚拟专用网络virtual server / 虚拟服务器virus / 病毒VLAN, virtual local area network / 虚拟局域网VoIP, Voice over Internet Protocol / 通过 IP 协议的语音volume / 卷volume password / 卷密码。
Hive基础(试卷编号111)

Hive基础(试卷编号111)1.[单选题]下面哪种数据类型是不被Hive查询语言所支持的?( )A)MapB)StringC)TimeD)Array答案:C解析:2.[单选题]Hive的计算引擎是( )。
A)SparkB)MapReduceC)HDFSD)HQL答案:B解析:3.[单选题]下列不属于Hive记录中默认分隔符( )A)\nB)^AC)^BD)\r\n答案:D解析:4.[单选题]在Hive的条件语句中,关于条件A>=B理解正确的有( )A)A为null,则返回为trueB)B为null,则返回为falseC)如果A大于等于B则返回trueD)如果A小于等于B则返回true答案:C解析:5.[单选题]在Hive中,假设要删除的数据库名称为mydb1的命令正确的是( )A)drop mydb1;B)drop database if exists mydb1;C)drop schema database mydb1;D)以上命令都正确6.[单选题]Hive在处理数据时,默认的行分隔符是( )A)\tB)\nC)\bD)\a答案:B解析:7.[单选题]通过( )命令可以显示当前正在使用的数据库名称A)set mysql.cli.print.current.db=true;B)set mysql.cli.print.current.db=false;C)set hive.cli.print.current.db=true;D)set hive.cli.print.current.db=false;答案:C解析:8.[单选题]在HBase中,使用truncate命令删除表数据首先将该表状态修改为( )A)TRUEB)ableC)disableD)FALSE答案:C解析:9.[单选题]在HBase的专用过滤器中,单列排除过滤器是( )A)SingleValueExcludeFilterB)SingleColumnExcludeFilterC)SingleColumnValueExcludeFilterD)ColumnValueExcludeFilter答案:C解析:10.[单选题]按粒度大小的顺序,Hive数据被组成为数据仓库、表、( )和桶表。
高校数据分析模型方案介绍V3.0
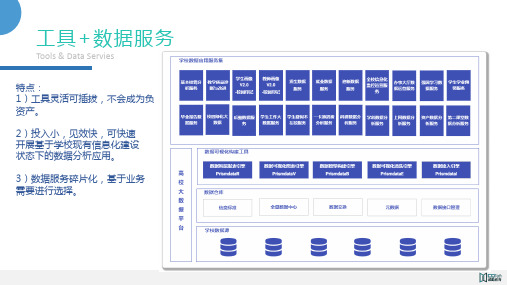
诚勤PrismData数据全产品线架构
整体架构
外部大数据 工具ET平台
PrismDataV 数据分析报告
PrismDataE 数据清洗 PrismDataC 数据计算
PrismDataI 数据接入
嵌入
内部业务系统 外部业务系统 开放API与开放平台
目标客户系统 目标数据源 跑批结果
客户系统API,跑批结果文件,Kafka消息管线,客户数据库,公网数据等数据源
南京晓庄学院-《我的大学时光》毕业生数据报告
模型05. 招生数据报告服务
——让每年全校及学院招生情况分析报告输出更加简单
学校招生数据服务
School Enrollment Data Service
1.人工处理,工作量大
2.缺少数据融合交叉
3.历史招生数据
招生数据报告
示例: 数据来源:高招网录取名单Excel 输出: 1.校级招生图表、报表:32张 2.每个二级学院:19张 共计输出:260张
2.视图随意跳转
3 不同视图间自由跳转, 按您最 舒适的方式对话数据分析结 果
扫一扫,解锁更多精彩
• 基于搜索引擎/大数据平台列式库的实时搜索 • 轻松做到亿级数据量,秒级分析响应
一端配置,多端适配
手机、大屏、实时监控、动态效果,统筹指挥、参观宣传
扫一扫,解锁更多精彩
产品技术特点
数据采集与接入
扫一扫,解锁更多精彩
数据在线清洗
扫一扫,解锁更多精彩
全可视化、自然语言建模
1
1. 分析图表构建
像聊天一样完成分析逻辑建模
零学习使用成本 无需任何IT背
景也可顺畅对话数据,实现自助
式分析
2.仪表板/商业报表构建
维度表和事实表 例子

维度表和事实表例子维度表和事实表是数据仓库中的两个重要概念,用于组织和管理数据。
维度表包含了数据的描述性属性,而事实表则包含了与这些描述性属性相关的数值性数据。
下面列举了10个维度表和事实表的例子,以帮助更好地理解这两个概念。
1. 电商维度表和事实表:- 维度表:商品维度表(包含商品ID、商品名称、商品类型等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:订单事实表(包含订单ID、商品ID、购买数量、销售金额等属性)2. 酒店维度表和事实表:- 维度表:酒店维度表(包含酒店ID、酒店名称、酒店地址等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:客房预订事实表(包含预订ID、酒店ID、客房类型、入住时间、离店时间等属性)3. 人力资源维度表和事实表:- 维度表:员工维度表(包含员工ID、员工姓名、所属部门等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:薪资事实表(包含员工ID、薪资金额、发放日期等属性)- 维度表:物流公司维度表(包含物流公司ID、物流公司名称、物流公司地址等属性)、时间维度表(包含日期、星期、月份等属性) - 事实表:运输事实表(包含物流公司ID、订单ID、运输距离、运输费用等属性)5. 医院维度表和事实表:- 维度表:医院维度表(包含医院ID、医院名称、医院地址等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:门诊事实表(包含医院ID、就诊日期、患者ID、就诊科室、就诊费用等属性)6. 学生维度表和事实表:- 维度表:学生维度表(包含学生ID、学生姓名、班级等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:考试成绩事实表(包含学生ID、考试科目、考试日期、考试成绩等属性)7. 游戏维度表和事实表:- 维度表:游戏角色维度表(包含角色ID、角色名称、角色等级等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:游戏日活跃用户事实表(包含角色ID、日期、登录次数、在线时长等属性)- 维度表:销售人员维度表(包含销售人员ID、销售人员姓名、所属区域等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:销售订单事实表(包含订单ID、销售人员ID、客户ID、销售金额等属性)9. 飞机航班维度表和事实表:- 维度表:航班维度表(包含航班号、起飞机场、到达机场等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:乘客座位预订事实表(包含航班号、日期、乘客ID、座位号等属性)10. 财务维度表和事实表:- 维度表:财务科目维度表(包含科目ID、科目名称、科目类型等属性)、时间维度表(包含日期、星期、月份等属性)- 事实表:财务报表事实表(包含科目ID、日期、金额等属性)以上是10个维度表和事实表的例子,它们分别适用于不同的领域和业务场景。
SAP DataService-中文操作手册

DataServices培训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (2)三、DS进行数据抽取模型开发的基本过程 (3)四、DS创建数据源系统和目标系统的数据存储 (3)1、Oracle数据库作为数据源系统 (3)2、ECC作为数据源系统 (4)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project和Job (5)2、导入源表的元数据到资源库 (6)3、创建Data Flow (6)4、设置源表和目标表 (7)5、手工执行Job (7)六、基于表比较的增量加载 (8)1、在Job下定义工作流 (8)2、在工作流中定义数据流 (8)3、加入Table_Comparison控件 (9)4、设置Table_Comparison控件 (9)七、基于时间戳的增量加载 (10)1、在Job下定义工作流 (10)2、定义Script控件 (10)3、定义处理新增数据的数据流和处理更新数据的数据流 (11)八、DS中常用控件介绍 (13)1、Key_Generation (13)2、Case (13)3、Merge (14)4、Validation (15)5、设置过滤器和断点 (15)九、定义Job定期执行 (16)1、登录Data Services Management Console (16)2、定义Batch Job Schedules (17)十、其他注意事项 (18)一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:◆Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行◆Designer:Designer是一个具有易于使用的图形用户界面的开发工具。
大数据开发基础(试卷编号141)

大数据开发基础(试卷编号141)1.[单选题]熵是为消除不确定性所需要获得的信息量,投掷均匀正六面体骰子的熵是:A)1比特B)2.6比特C)3.2比特D)3.8比特答案:B解析:2.[单选题]Flume 传输数据过程中,为了防止数据不丢失,使用的Channel类型是?A)Memory ChannelB)File ChanneC)JDBC ChanneD)HDES Channel答案:B解析:3.[单选题]当特征值大致相等时。
会发生的情况是()。
A)PCA将表现出色B)PCA将表现不佳C)不知道D)以上都没有答案:B解析:当所有特征向量相同时将无法选择主成分,因为在这种情况下所有主成分相等。
4.[单选题]当 Mapper 输出的相同 partition 的 kv 数据到达一个 Reducer 后,会有一个聚合的过程,即将“相同” key 的 kv 聚合到一起,其实质是利用 来对 key 进行比较。
A)GroupingComparatorB)ComparatorC)PartitionerD)GroupingPartitioner答案:A解析:5.[单选题]Hive 适合( )环境A)Hive 适合用于联机(online)事务处理B)提供实时查询功能C)适合应用在大量不可变数据的批处理作业6.[单选题]在FuisonInsight HD 中,创建Loader 作业的进行数据转换的正确步骤是?A)输入设置,转换,输出B)抽取,转换,输出C)加载,转换,输出D)加载,转换,抽取答案:A解析:7.[单选题]对数值型输出,最常见的结合策略是( )A)投票法B)平均法C)学习法D)排序法答案:B解析:8.[单选题]Jieba 的( )会把文本精确切分,不存在冗余单词。
A)匹配模式B)全模式C)精准模式D)搜索引擎模式答案:C解析:精准模式不存在冗余,而全模式存在。
9.[单选题]( )是一种建立在Hadoop之上的数据仓库架构。
维度表和事实表

维度表示你要对数据进行分析时所用的一个量, 比如你要分析产品销售情况, 你可以选择按类别来进行分析,或按区域来分析. 这样的按..分析就构成一个维度。
前面的示例就可以有两个维度:类型和区域。
另外每个维度还可以有子维度(称为属性),例如类别可以有子类型,产品名等属性。
下面是两个常见的维度表结构:产品维度表:Prod_id, Product_Name, Category, Color, Size, Price时间维度表:TimeKey, Season, Year, Month, Date而事实表是数据聚合后依据某个维度生成的结果表。
它的结构示例如下:销售事实表:Prod_id(引用产品维度表), TimeKey(引用时间维度表), SalesAmount(销售总量,以货币计), Unit(销售量)上面的这些表就是存在于数据仓库中的。
从这里可以看出它有几个特点:1. 维度表的冗余很大,主要是因为维度一般不大(相对于事实表来说的),而维度表的冗余可以使事实表节省很多空间。
2. 事实表一般都很大,如果以普通方式查询的话,得到结果一般发的时间都不是我们可以接受的。
所以它一般要进行一些特殊处理。
如SQL Server 2005就会对事实表进行如预生成处理等。
3. 维度表的主键一般都取整型值的标志列类型,这样也是为了节省事实表的存储空间。
事实表和维度表的分界线事实表是用来存储主题的主干内容的。
以日常的工作量为例,工作量可能具有如下属性:工作日期,人员,上班时长,加班时长,工作性质,是否外勤,工作内容,审核人。
那么什么才是主干内容?很容易看出上班时长,加班时长是主干,也就是工作量主题的基本内容,那么工作日期,人员,工作性质,是否外勤,工作内容是否为主干信息呢?认真分析特征会发现,日期,人员,性质,是否外勤都是可以被分类的,例如日期有年-月-日的层次,人员也有上下级关系,外勤和正常上班也是两类上班考勤记录,而上班时长和加班时长则不具有此类意义。
date -s 用法 -回复

date -s 用法-回复关于“[date s 用法]”,我将为您提供一篇1500-2000字的文章来回答您的问题。
[date s]是一个常见的日期格式控制符,用于在Python中格式化日期和时间。
在Python中,datetime模块提供了处理日期和时间的类和函数。
通过使用该模块中的date.strftime()函数,可以将日期和时间对象格式化为指定的字符串形式。
下面我们将一步一步回答关于[date s]的用法的问题。
步骤一:导入datetime模块在使用任何与日期和时间相关的函数之前,我们需要先导入datetime模块。
在Python中,可以通过以下语句导入datetime模块:pythonfrom datetime import datetime, date步骤二:创建一个日期对象在使用[date s]进行格式化之前,我们需要先创建一个日期对象。
可以使用datetime模块中的date类来创建一个日期对象。
以下是创建日期对象的示例代码:pythondate_obj = date(2022, 11, 1)在上述示例代码中,我们创建了一个日期对象,表示2022年11月1日。
步骤三:使用[date s]进行日期格式化在步骤二中,我们创建了一个日期对象,现在我们将使用[date s]来格式化该日期对象。
以下是使用[date s]进行日期格式化的示例代码:pythonformatted_date = date_obj.strftime("Y-m-d")print(formatted_date)该示例代码将日期对象格式化为形如"2022-11-01"的字符串。
在[date s]中,"Y"表示四位数的年份,"m"表示两位数的月份,"d"表示两位数的日期。
使用这些格式化控制符,我们可以根据自己的需求格式化日期。
Hive基础(习题卷1)

Hive基础(习题卷1)说明:答案和解析在试卷最后第1部分:单项选择题,共88题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]HBase交互模式中,查看当前服务状态的命令是( )A)serviceB)servicesC)statusD)statu2.[单选题]HBase是一种“NoSQL”数据库,支持大型( )数据存储A)集中式B)集合式C)分布式D)分散式3.[单选题]HBase中的所有数据文件都存储在Hadoop HDFS上,主要有HFile格式与( )格式A)HTXTB)HLogC)HLog FileD)HFile Log4.[单选题]OLAP是什么意思( )A)联机分析处理B)单机分析处理C)联网分析处理D)事务分析处理5.[单选题]命令行界面,也就是( ),是和Hive交互的最常用的方式A)CMDB)CLIC)CMID)CLD6.[单选题]在Hive中,如果只需要结构集的部分数据,可以通过( )子句来限定返回的行数A)limitB)sortC)fromD)order7.[单选题]内部表和外部表之间可以互相转换,所使用的关键字是( )。
A)CreateB)AlterC)TruncateD)Drop8.[单选题]Hive交互Shell指执行$HIVE_HOME/bin/hive之后,交互式命令行的提示符是( )A)help>B)hive>C)user>D)cmd>9.[单选题]在HBase中,Scan类的( )方法限定返回数据的列簇A)family()B)addFamily()C)Column()D)addColumn()10.[单选题]在Hive的查询语句中,表示A和B按位取或的是( )A)A|BB)A&BC)A-BD)A~B11.[单选题]Hive将表中的数据保存到文本,并使用命令插入到employee表中的命令正确是( )A)load local inpath '/opt/data/test.txt' overwrite into table employee;B)load data inpath '/opt/data/test.txt' overwrite into table employee;C)load data local inpath '/opt/data/test.txt' into table employee;D)load data local inpath '/opt/data/test.txt' overwrite into table employee;12.[单选题]关于Hive嵌入模式说法错误的是( )。
维度建模-事实表类型

维度建模-事实表类型维度建模数仓领域中的事实表⼤致分以下三种:事务事实表,周期快照事实表,累计事实表什么是稀疏表,什么是稠密表?稀疏表:当天只有发⽣了操作才会有记录稠密表:当天没有操作也会有记录,便于下游使⽤1.事务事实表事务事实表记录的事务层⾯的事实,保存的是最原⼦的数据,也称“原⼦事实表”。
事务事实表中的数据在事务事件发⽣后产⽣,数据的粒度通常是每个事务记录⼀条记录。
⼀旦事务被提交,事实表数据被插⼊,数据就不再进⾏更改,其更新⽅式为增量更新。
由于事实表具有稀疏性质,因此只有当天数据才会进⼊当天的事实表中,相当于每个分区⾥⾯都是每天的数据,不包含之前的数据。
事务事实表的⽇期维度记录的是事务发⽣的⽇期,它记录的事实是事务活动的内容。
⽤户可以通过事务事实表对事务⾏为进⾏特别详细的分析。
为什么事务事实表具有稀疏性质?事实表⼀般围绕着度量来建⽴,当度量产⽣的时候,事实记录就⽣成了。
度量可以是销售数量、交易流⽔值、⽉末节余等数值。
如果同时⽣成多个度量值的话,我们可以在⼀个事实表中建⽴多个事实。
当我们的事实表中的事实⽐较多时,有可能多个事实不同时发⽣,如果同时⽣成的⼏率很⼩,我们称之为稀疏事实表(Sparse Facts)。
2.周期快照事实表周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每⽉、每年等等。
典型的例⼦如销售⽇快照表、库存⽇快照表等。
它统计的是间隔周期内的度量统计,如历史⾄今、⾃然年⾄今、季度⾄今等等周期快照表没有粒度的概念,取⽽代之的是周期+状态度量的组合,如历史⾄今的订单总数,其中历史⾄今是⼀个周期,订单总数是度量。
周期快照事实表的粒度是每个时间段⼀条记录,通常⽐事务事实表的粒度要粗,是在事务事实表之上建⽴的聚集表,⽐如说时间周期是1周,那么这个周期快照事实表的⼀条记录就是这⼀周的对于某个度量的统计值(我理解的)。
周期快照事实表的维度个数⽐事务事实表要少,但是记录的事实要⽐事务事实表多(为什么记录的事会⽐事务事实表表多呢?)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Data Service-创建一个时间维度表
写在前面:
本篇文章介绍利用SAP Data Service 创建一个时间维度表的过程.
准备工作:
SAP Data Service(本人使用的是4.2版本)
具体步骤:
步骤一:
建立一个项目及Batch Job
步骤二:
双击步骤一中建立的Batch Job,在右侧界面中新建一个Data Flow组件,新建方式可选择从最右侧组件列表中拖取(第三个),也可选择在右侧界面中直接右键,选择出来列表中的”ADD NEW” ,选择相应的部件即可。
新建好后双击新建的Data Flow组件,进入Data Flow 的界面
步骤三:
选择软件界面左下角第五项即Transforms,在Transforms界面中展开第一项“Data Integrator”,选择第二项“Data_Gentration”将其拖动到步骤二中展开的Data Flow界面。
步骤四:
在Data Flow界面中,双击上一步拖来的“Data_Gentration”,进入设置界面,在这一界面可以选择想要创建的时间维度表的开始和结束时间,并选择增量。
这里我选择的开始时间是2010.01.01,结束时间为2017.06.01,增量选择Daily,即按日期为增量。
根据需求还可以选择月份,年等。
步骤五:
与在SAPData Serice抽取数据到HANA一样,在Data Flow中新建一个“Query”组件,
和一个“Template Table”组件,并按图连接
步骤六:
双击“Query”组件,进入设置界面,将左侧的属性选中拖入右侧即可,根据实际情况可对右侧列表中的属性进行设置,如修改名字,设置为主键等。
设置好后,右键本J0b,选
择Excute即可,运行成功后,最简单的时间维度表即可完成。
步骤七:
因在时间维度表中只有一个日期属性一般不能满足需求,所以一般还需要添加别的属性,例如主键ID,年份,月份,周等。
此时,我们可直接在上图右侧选中行上右键,选择New Output Column ,点击后在弹出的选项中选择位置,此时可选位于当前选中行上一行还是下一行。
选中后出现下图界面,按照图中要求设置你想要添加的属性名,类型,以及是否设为主键。
步骤八:
添加主键;按照上图,我在这里添加了一个ID主键,其设置类型为int,并将其设为主键,接下来要做的是为其添加主键数据,此时在下方截图界面的最下方输入计算式,计算式写好后点击截图中红笔圈中部位验证其正确性。
此时,主键完全设置成功。
PS:此时可采用多种计算方式,这里介绍两种,一种是采用gen_row_num(),该方法产生的主键是从1开始递增排列的。
还有一种是采用julian(),该方法产生的主键是国际通用主键。
这里采用第二种。
步骤9:
设置年份(月份);同上,增加一个年份的属性,设置计算式步骤:
单击上图中的Functions 按钮,在弹出界面中选择“Data Function”,并选择year后下一步
选择input date后点击完成。
步骤十:
运行该Job,可看到运行结果为Successfully,点击下图对应表下方的放大镜可以看到所产生的时间维度表数据:。