浙江工商大学数据仓库与数据挖掘以及试卷真题回忆
《数据挖掘》试题与答案(2021年整理精品文档)

《数据挖掘》试题与答案编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(《数据挖掘》试题与答案)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为《数据挖掘》试题与答案的全部内容。
一、解答题(满分30分,每小题5分)1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。
知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。
流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。
2. 时间序列数据挖掘的方法有哪些,请详细阐述之时间序列数据挖掘的方法有:1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。
例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。
2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值.若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。
数据库应用期末考试试题(A卷)(包括答案)
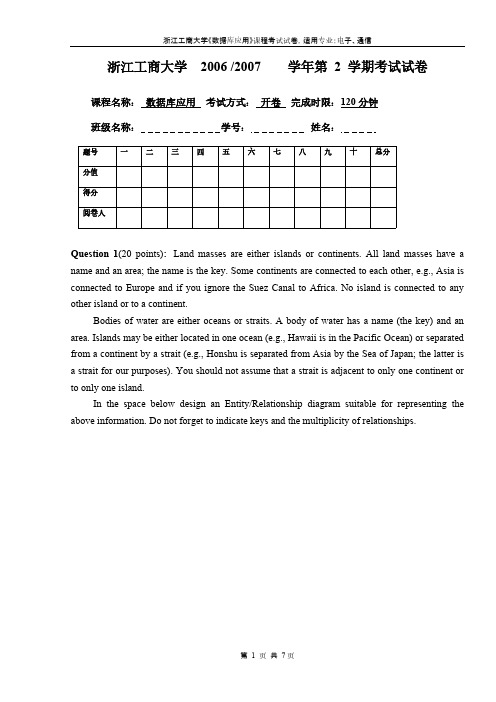
浙江工商大学2006 /2007 学年第 2 学期考试试卷课程名称:数据库应用考试方式:开卷完成时限:120分钟班级名称:学号:姓名:题号一二三四五六七八九十总分分值得分阅卷人Question 1(20 points):Land masses are either islands or continents. All land masses have a name and an area; the name is the key. Some continents are connected to each other, e.g., Asia is connected to Europe and if you ignore the Suez Canal to Africa. No island is connected to any other island or to a continent.Bodies of water are either oceans or straits. A body of water has a name (the key) and an area. Islands may be either located in one ocean (e.g., Hawaii is in the Pacific Ocean) or separated from a continent by a strait (e.g., Honshu is separated from Asia by the Sea of Japan; the latter is a strait for our purposes). You should not assume that a strait is adjacent to only one continent or to only one island.In the space below design an Entity/Relationship diagram suitable for representing the above information. Do not forget to indicate keys and the multiplicity of relationships.Question 2:In this exercises we shall write queries in various languages about our running “beer” example database:Beers (name, manf)Bars (name, addr, license)Drinkers (name, addr, phone)Likes (drinker, beer)Sells (bar, beer, price)Frequents (drinker, bar)This question is devoted to SQL queries, database modifications and declarations. Write the following in standard SQL being as succinct as possible.a) Find the name and address of all drinkers who frequent Joes Bar and like some beer that JoesBar sells. Do not print any drinker more than once. (10 Points)b) Delete from Drinkers all drinkers in the 0571(Hangzhou) area code. You may assume thatphone numbers are represented by character strings of the form ‘(xxxx) yyyyzzzz’, where xxxx is the area code. (10 Points)c) Find for each price (that appears in Sells), the number of bars that server at least one beer atthat price. (10 Points)d) Insert into Bars (with default values for addr and license) all those bars that are mentionedin Frequents but not in Bars. (10 Points)Question 3:Q1: SELECT aFROM RWHERE R.b > ALL(SELECT c FROM S);Q2: SELECT aFROM RWHERE R.b > ANY(SELECT c FROM S);(a) Q1 and Q2 produce the same answer.(b) The answer to Q1 is always contained in the answer to Q2.(c) The answer to Q2 is always contained in the answer to Q1.(d) Q1 and Q2 produce different answers.The answer is (d)I threatened to put this on the exam, and here it is problem #1. In general, ALL is a more stringent requirement than ANY, so we expect that Q1 is contained in Q2. However, if SELECT c FROM S is empty, then it is impossible to satisfy ANY, while ALL is trivially satisfied. Then, Q2 is contained in Q1. Since both containments could be proper, the queries are different.Question 4: In the following, R is a relation with schema R (a, b). The result of each sequence of modifications is the value of R at the end.Q1: UPDATE R SET b =3 WHERE b = 2;Q2: INSERT INTO RSELECT a, 3 FROM R WHERE b = 2;DELETE FROM R WHERE b = 2;(a) Q1 and Q2 produce the same answer.(b) The answer to Q1 is always contained in the answer to Q2.(c) The answer to Q2 is always contained in the answer to Q1.(d) Q1 and Q2 produce different answers.The Answer is (a)Each of these modifications has the effect of replacing every tuple of the form (a,3) for some a by the tuple (a,2). If such a tuple appears more than once in R, the count is preserved as well.Question 5: In this question R(x) is the schema of relation R.Q1: SELECT xFROM R rrWHERE NOT EXISTS(SELECT * FROM R WHERE x >rr.x);Q2: SELECT MAX(x) FROM R.(a) Q1 and Q2 produce the same answer.(b) The answer to Q1 is always contained in the answer to Q2.(c) The answer to Q2 is always contained in the answer to Q1.(d) Q1 and Q2 produce different answers.The Answer is (c)Q1 produces the largest element of R as many times as it appears in R. Q2 produces the same element, but only once.Question 6 (5 points): Suppose we have an SQL relation declared byCREATE TABLE Foo(name VARCHAR(50) PRIMARY KEY,salary INT CHECK(salary <=(SELECT AVG(salary) FROM Foo)));Initially, the Contents of Foo is:name salary‘Sally’1,000‘Joe’2,000‘Sue’3,000We now execute the following sequence of modifications:INSERT INTO Foo VALUES (‘Fred’, 1200);UPDATE Foo SET salary =2000 WHERE name =’Sue’;INSERT INTO Foo VALUES (‘Sally’,1300);DELETE FROM Foo WHERE name = ‘Joe’;At the end of these statements, the sum of the salaries over all the tuples then in Foo is:(a) 5,200(b) 6,200(c) 6,500(d) 7,200The Answer is (a).The last problem also fooled a lot of people. I suspect you were calculating averages so fiercely that you forgot to check for a primary-key violation. The sequence of events is as follows:●The insert of Fred succeeds, because his salary is less than the currentaverage of 2,000. The new average salary is 1,800, and the total is7,200.●The update of Sue's salary is rejected because it is higher than theaverage.●The insertion of a tuple for Sally is rejected because there is alreadya tuple with the key value 'Sally'.●The deletion of Joe's tuple succeeds; neither of the constraints on Fooaffects a deletion. The total salary is decreased by Joe's 2,000 salary, to 5,200Question 7: Consider the following E/R diagram:If A has 100 entities, B has 1000 entities, and C has 10 entities, what is the maximum number of triples of entities that could be in the relationship set for R?(a) 100(b) 1000(c) 100,000(d) 1,000,000The Answer is (B)The stronger of the conditions represented by the arrows is that for a given A entity and C entity, there is a unique B entity. Since there are only 1000 possible A-C pairs, there cannot be more than this number of tuples. However, we could also have 1000 triples in the relationship set. Suppose the A values are 0-99, and the C values are 0-9. Let the associated B value be 10*A+C. Then all B values from 0 to 999 appear exactly once, so A and BB surely determine at most one CQuestion 8: Suppose R (a, b) contains the tuples {(1, 2),(3,4)} and S(b, c) contains thetuples{(2,5),(2,6),(7,8)}. The natural outerjoin of R and S contains how many tuples?(a)2(b)3(c)4(d)5Question 9: Relation R (a, b, c) currently has the following instance:{(1,2,3),(3,4,2),(2,6,1)}We make the following view definitions:CREATE VIEW V ASSELECT a*b AS d, c FROM R;CREATE VIEW W ASSELECT d, SUM(c) AS e FROM V GROUP BY d;What is the sum of all the components of all the tuples of the following query?SELECT AVG (d), e FROM W GROUP BY e;(a)10(b)17(c)23(d)28The Answer is (a) View V(d,c) consists of the tuples (2,3), (12,2), and (12,1) currently, although the view isn't materialized. Therefore, W(d,e) has the tuples (2,3) and (12,3). The query itself groups both tuples, yielding only (7,3).Question 10: In the SQL 3-valued logic, the value of expressionR.a > R.b OR R.a <=0 OR R.b>=0can be:(a)Only TRUE or FALSE(b)Only FALSE or UNKNOWN(c)Only TRUE or UNKNOWN(d)Any of TRUE_ FALSE_ or UNKNOWNThe Answer is (c), If neither R.a nor R.b are NULL, then the expression is a tautology of 2-valued logic andmust be true in either 2-valued or 3-valued logic. However, if either or both values are NULL, then the 3-valued truth value is at least unknown, and therefore cannot be false. There are, however, values that make this expression unknown, e.g., R.a = NULL and R.b = -10.Question 11: Consider the following table definition and SQL query.CREATE TABLE R (a INT PRIMARY KEY,b INT,c INT,d INT,e INT);SELECT a, MIN(b), SUM(c)FROM RWHERE b > 5GROUP BY aHAVING condition;Which of the following statements is not true?(a)The condition can be d = 5.(b)The condition can be a = sum (e).(c)The value of MIN(b) must be 6 or more.(d)None of the above. (That is, all of the above statements are true.)The Answer is (a)The rule for what attributes can appear unaggregated in a HAVING clause (outside any subqueries) is the same as for a SELECT clause: only those attributes that appear in the GROUP BY list. Attribute d is not one of those.说明:1、试卷一律采用A4纸打印,试题正文如无特殊情况均用小四号宋体,标题加粗,行间距根据具体情况自行确定。
数据仓库与数据挖掘期末试题

广西财经学院2007——2008学年第一学期《数据仓库与数据挖掘》课程期末考试试卷(A)一、名词解释(每题4分,共20分)1、数据仓库数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
2、数据挖掘数据挖掘(Data Mining),又称为数据库中的知识发现(Knowledge Discovery in Database, KDD),就是从大量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程,简单的说,数据挖掘就是从大量数据中提取或“挖掘”知识。
3、雪花模型雪花模式中某些维表是规范化的,因而把数据进一步分解到附加的表中,模式图形成了类似雪花的形状。
通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。
雪花模型增加了用户必须处理的表数量,增加了某些查询的复杂性,但同时提高了处理的灵活性,可以回答更多的商业问题,特别适合系统的逐步建设要求。
4、OLAPOLAP是联机分析处理,是使分析人员、管理人员或执行人员能够从多角度对信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。
它支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
5、决策树决策树是将训练集函数表示成树结构,通过它来近似离散值的目标函数。
这种树结构是一种有向树,它以训练集的一个属性作节点,这个属性所对应的一个值作边。
决策树一般都是自上而下的来生成的。
二、简答题(每题6分,共30分)1、企业面对海量数据,应如何具体实施数据挖掘,使之转换成可行的结果/模型?首先进行数据的预处理,主要进行数据的清洗,数据清洗,处理空缺值,数据的集成,数据的变换和数据规约。
2、请列举您使用过的各种数据仓库工具软件(包括建模工具,ETL工具,前端展现工具,OLAP Server、数据库、数据挖掘工具)和熟悉程度。
数据仓库与数据挖掘试题

09数据仓库与数据挖掘试题(最后)(总3页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--数据仓库与数据挖掘试题一、什么是数据仓库数据仓库的主要特征有哪些它与传统的关系数据库系统有什么区别二、关系模型和多维模型在数据仓库设计中各有什么优缺点?三、数据仓库上的代数操作有哪些?如何定义的,举例说明。
四、什么是知识发现,知识发现的过程包括那几个步骤五、什么是关联规则如何利用Apriori算法在给定的数据集合上找出关联规则六、什么是分类什么是聚类二者的区别是什么常用的分类和聚类方法有哪些1、数据仓库是一个面向主题的、集成的、不可更新的、随时间不断变化的数据集合,它用于支持企业或组织的决策分析处理。
数据仓库的主要特征: 面向主题的、集成的、时变的、非易失的数据仓库与数据库的区别数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。
2、关系模型先建立企业级数据仓库,再在其上开发具体的应用。
企业级数据仓库固然是我们所追求的目标,但在缺乏足够的技术力量和数据仓库建设经验的情况下,按照这种模型设计的系统建设过程长,周期长,难度大,风险大,容易失败。
这种模型的优点是信息全面、系统灵活。
由于采用了第三范式,数据存储冗余度低、数据组织结构性好、反映的业务主题能力强以及具有较好的业务扩展性等,但同时会存在大量的数据表,表之间的联系比较多,也比较复杂,跨表操作多,查询效率较低,对数据仓库系统的硬件性能要求高等问题。
另一方面,数据模式复杂,不容易理解,对于一般计算机用户来说,增加了理解数据表的困难。
多维模型降低了范式化,以分析主题为基本框架来组织数据。
数据挖掘及应用考试试题及答案

数据挖掘及应用考试试题及答案一、选择题(每题2分,共20分)1. 以下哪项不属于数据挖掘的主要任务?A. 分类B. 聚类C. 关联规则挖掘D. 数据清洗答案:D2. 数据挖掘中,以下哪项技术不属于关联规则挖掘的方法?A. Apriori算法B. FP-growth算法C. ID3算法D. 决策树算法答案:C3. 以下哪个算法不属于聚类算法?A. K-means算法B. DBSCAN算法C. Apriori算法D. 层次聚类算法答案:C4. 数据挖掘中,以下哪个属性类型不适合进行关联规则挖掘?A. 连续型属性B. 离散型属性C. 二进制属性D. 有序属性答案:A5. 数据挖掘中,以下哪个评估指标用于衡量分类模型的性能?A. 准确率B. 精确度C. 召回率D. 所有以上选项答案:D二、填空题(每题3分,共30分)6. 数据挖掘的目的是从大量数据中挖掘出有价值的________和________。
答案:知识;模式7. 数据挖掘的主要任务包括分类、聚类、关联规则挖掘和________。
答案:预测分析8. Apriori算法中,最小支持度(min_support)和最小置信度(min_confidence)是两个重要的参数,它们分别用于控制________和________。
答案:频繁项集;强规则9. 在K-means聚类算法中,聚类结果的好坏取决于________和________。
答案:初始聚类中心;迭代次数10. 数据挖掘中,决策树算法的构建过程主要包括________、________和________三个步骤。
答案:选择最佳分割属性;生成子节点;剪枝三、判断题(每题2分,共20分)11. 数据挖掘是数据库技术的一个延伸,它的目的是从大量数据中提取有价值的信息。
()答案:√12. 数据挖掘过程中,数据清洗是必不可少的步骤,用于提高数据质量。
()答案:√13. 数据挖掘中,分类和聚类是两个不同的任务,分类需要训练集,而聚类不需要。
数据仓库与数据挖掘考试试题

一、填空题(15分)1。
数据仓库的特点分别是面向主题、集成、相对稳定、反映历史变化。
2。
元数据是描述数据仓库内数据的结构和建立方法的数据。
根据元数据用途的不同可将元数据分为技术元数据和业务元数据两类。
3。
OLAP技术多维分析过程中,多维分析操作包括切片、切块、钻取、旋转等。
4。
基于依赖型数据集市和操作型数据存储的数据仓库体系结构常常被称为“中心和辐射”架构,其中企业级数据仓库是中心,源数据系统和数据集市在输入和输出范围的两端。
5。
ODS实际上是一个集成的、面向主题的、可更新的、当前值的、企业级的、详细的数据库,也叫运营数据存储。
二、多项选择题(10分)6。
在数据挖掘的分析方法中,直接数据挖掘包括(ACD)A 分类B 关联C 估值D 预言7.数据仓库的数据ETL过程中,ETL软件的主要功能包括(ABC)A 数据抽取B 数据转换C 数据加载D 数据稽核8.数据分类的评价准则包括( ABCD )A 精确度B 查全率和查准率C F-MeasureD 几何均值9。
层次聚类方法包括( BC )A 划分聚类方法B 凝聚型层次聚类方法C 分解型层次聚类方法D 基于密度聚类方法10。
贝叶斯网络由两部分组成,分别是( A D )A 网络结构B 先验概率C 后验概率D 条件概率表三、计算题(30分)11。
一个食品连锁店每周的事务记录如下表所示,其中每一条事务表示在一项收款机业务中卖出的项目,假定sup min=40%,conf min=40%,使用Apriori算法计算生成的关联规则,标明每趟数据库扫描时的候选集和大项目集。
(15分)解:(1)由I={面包、果冻、花生酱、牛奶、啤酒}的所有项目直接产生1—候选C1,计算其支持度,取出支持度小于sup min的项集,形成1-频繁集L1,如下表所示:(2)组合连接L1中的各项目,产生2-候选集C2,计算其支持度,取出支持度小于sup min的项集,形成2-频繁集L2,如下表所示:至此,所有频繁集都被找到,算法结束,所以,confidence({面包}→{花生酱})=(4/5)/(3/5)=4/3〉 conf minconfidence({花生酱}→{面包})=(3/5)/(4/5)=3/4〉 conf min所以,关联规则{面包}→{花生酱}、{ 花生酱}→{面包}均是强关联规则。
数据仓库与数据挖掘技术-试题答案

数据仓库与数据挖掘技术答案一、简答1.为什么需要对数据进行预处理?数据预处理主要包括哪些工作(需要对数据进行哪些方面预处理)?(1)现实世界的数据是杂乱的,数据多了什么问题会出现。
数据库极易受到噪音数据(包含错误或孤立点)、遗漏数据(有些感兴趣的属性缺少属性值或仅包含聚集数据)和不一致数据(在编码或者命名上存在差异)的侵扰,因为数据库太大,常常多达几G或更多。
进行数据预处理,提高数据质量,从而提高挖掘结果质量。
(2)数据预处理主要包括:数据清理:去除数据中的噪音、纠正不一致;数据集成:将数据由多个源合并成一致的数据存储,如数据仓库或数据方;数据交换:规范化或聚集可以改进涉及距离度量的挖掘算法精度和有效性;数据归约:通过聚集、删除冗余特征或聚类等方法来压缩数据。
数据离散化:属于数据归约的一部分,通过概念分层和数据的离散化来规约数据,对数字型数据特别重要。
2. 什么叫有监督学习?什么叫无监督学习?) 是通过发现数据属性和类别属性之间的关联模式,并通监督学习(Supervised learning或归纳过利用这些模式来预测未知数据实例的类别属性。
监督学习又称为分类Classification。
学习Inductive Learning无监督学习(Unsupervised learning)即聚类技术。
在一些应用中,数据的类别属性是缺失的,用户希望通过浏览数据来发现其的某些内在结构。
聚类就是发现这种内在结构的技术。
3.什么是数据仓库的星形模式?它与雪花模式有何不同?雪花模式与星形模式不同在于:雪花模式的维表可能是规范化形式,以便减少冗余。
这种表易于维护,并节省存储空间,因为当维结构作为列包含在内时,大维表可能非常大。
然而,与巨大的事实表相比,这种空间的节省可以忽略。
此外,由于执行查询更多的连接操作,雪花结构可能降低浏览的性能。
这样系统的性能可能受影响。
因此,在数据仓库设计中,雪花模式不如星形模式流行。
二、写出伪代码三答:(1)所有频繁项集为:[E,K,O] [K,M] [K,Y] (2) 关联规则:[O]->[E,K] 1.0[E,O] -> [K] 1.0[K,O] -> [E] 1.01.0[M] -> [K][Y] -> [K] 1.0答:a)决策树表示一种树型结构,它由它的分来对该类型对象依靠属性进行分类。
《数据仓库与数据挖掘》课程练习题

《数据仓库与数据挖掘》课程练习题1、定义以下数据挖掘功能:特征化,区分,关联,分类,预测,聚类和演变分析。
同时,使用你熟悉的现实生活中的数据库,给出每种数据挖掘功能的例子。
2、假定数据仓库包含4个维date,spectator,location和game,2个度量count和charge。
其中charge是观众在给定的日期观看节目的付费。
观众可以是学生、成年人或老人,每类观众有不同的收费标准。
(a)画出该数据仓库的星型模式图;(b)由基本方体[date,spectator,location,game]开始,为列出2000年学生观众在GM-Place的总付费,应当执行哪些OLAP 操作?(c)对于数据仓库,位图索引是有用的。
以该数据立方体为例,简略讨论使用位图索引结构的优点和问题。
3、假定用于分析的数据包含属性age。
数据元组中age的值如下(按递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70,现在使用按箱平均值平滑对以上数据进行平滑,箱的深度是3。
请给出你求解的步骤和结果。
4、使用习题4给出的age数据,回答以下问题:(a)使用最小-最大规范化,将age值35转换到[0.0,1.0]区间;(b)使用z-score规范化转换age 值35,其中age的标准差为12.94年;(c)使用小数定标规范化转换age值35;(d)指出对于给定的数据,你愿意使用哪种方法。
陈述你的理由。
5、用例子图解如下属性子集选择过程:(a)逐步向前选择;(b)逐步向后删除;(c)逐步向前选择和逐步向后删除的结合。
数据仓库与数据挖掘 复习题

数据仓库与数据挖掘教程期末复习题1、数据挖掘来源于机器学习。
2、数据仓库是面向主题的、集成的、稳定的、不同时间的数据集合,用于支持经营管理中决策制定过程。
3、元数据描述了数据仓库的数据和环境,遍及数据仓库的所有方面,是整个数据仓库的核心。
4、Codd将数据分析模型分为四类:绝对模型、解释模型、思考模型和公式化。
5、数据立方体是在所有可能组合的维上进行分组聚集运算的总和。
6、数据质量是数据仓库的成败关键。
7、概括分析是探索者分析过程的第一步。
8、数据仓库的物理模型设计是对逻辑模型设计的数据模型确定物理存储结构和存取方法。
9、自组织网络以ART模型、Kohonen模型为代表,用于聚类。
10、预测是利用历史数据找出变化规律,建立模型,并用此模型来预测未来数据的种类、特征等。
11、调和数据是存储在企业级数据仓库和操作型数据存储中的数据。
12、SQL、SERVER SSAS提供了所有业务数据的同意整合试图,可以作为传统报表和数据挖掘、在线分析处理、关键性能指示器记分卡的基础。
13、数据仓库的概念模型通常采用信息包图法来进行设计。
14、关联规则(关联规则的定义)的经典算法包括()算法。
15、分类器设计阶段包含划分数据集、分类器构造、分类器测试。
16、雪花模型是对星型模式维表的进一步层次化和规范化来消除冗余的数据。
17、数据处理通常分成两大类:联机事务处理和联机分析处理(英文缩写)。
18、数据抽取的两个常见类型是静态抽取和增量抽取。
19、维度表一般由主键、分类层次和描述属性组成。
20、ROLAP是基于关系数据库的OLAP实现,而MOLAP是基于多维数据结构组织的OLAP实现。
21、数据仓库按照其开发过程,其关键环节包括数据抽取、数据存储、数据管理和数据表现等到。
22、KDD是数据集中识别出有效的、新颖的、潜在有用的、以及最终可理解的模式的高级处理过程。
23、遗传算法中的基本要素(P27):问题编码;初始群体的设宴设定;适应值函数的设计;遗传操作设计;控制参数设定;24、数据集市数据集市是指具有特定应用的数据仓库主针对某个具有应用战略意义的应用或者具体部门级的应用,支持用户利用已有的数据获得重要竞争优势或者找到进入市场的具体解决方案。
1213年第2学期《数据挖掘与知识发现》期末考试试卷及答案

1213年第2学期《数据挖掘与知识发现》期末考试试卷及答案12/13年第2学期《数据挖掘与知识发现》期末考试试卷及答案一、什么是数据挖掘?什么是数据仓库?并简述数据挖掘的步骤。
(20分)数据挖掘是从大量数据中提取或发现(挖掘)知识的过程。
数据仓库是面向主题的、集成的、稳定的、不同时间的数据集合,用于支持经营管理中的决策制定过程。
步骤:1)数据清理(消除噪声或不一致数据)2)数据集成(多种数据源可以组合在一起)3 )数据选择(从数据库中检索与分析任务相关的数据)4 )数据变换(数据变换或统一成适合挖掘的形式,如通过汇总或聚集操作)5)数据挖掘(基本步骤,使用智能方法提取数据模式)6)模式评估(根据某种兴趣度度量,识别表示知识的真正有趣的模式;)7)知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)二、元数据的定义是什么?元数据包括哪些内容?(20分)元数据是关于数据的数据。
在数据仓库中,元数据是定义仓库对象的数据。
元数据包括:数据仓库结构的描述,包括仓库模式、视图、维、分层结构、导出数据的定义,以及数据集市的位置和内容。
操作元数据,包括数据血统(移植数据的历史和它所使用的变换序列)、数据流通(主动的、档案的或净化的)、管理信息(仓库使用统计量、错误报告和审计跟踪)。
汇总算法,包括度量和维定义算法,数据所处粒度、划分、主题领域、聚集、汇总、预定义的查询和报告。
由操作环境到数据仓库的映射,包括源数据库和它们的内容,网间连接程序描述,数据划分,数据提取、清理、转换规则和缺省值,数据刷新和净化规则,安全(用户授权和存取控制)。
关于系统性能的数据,刷新、更新定时和调度的规则与更新周期,改善数据存取和检索性能的索引和配置。
商务元数据,包括商务术语和定义,数据拥有者信息和收费策略。
三、在O L A P中,如何使用概念分层?请解释多维数据模型中的OLAP上卷下钻切片切块和转轴操作。
(20分)在多维数据模型中,数据组织成多维,每维包含由概念分层定义的多个抽象层。
数据挖掘考试题库——2024年整理

1.何谓数据挖掘?它有哪些方面的功能?从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程称为数据挖掘。
相关的名称有知识发现、数据分析、数据融合、决策支持等。
数据挖掘的功能包括:概念描述、关联分析、分类与预测、聚类分析、趋势分析、孤立点分析以及偏差分析等。
2.何谓粒度?它对数据仓库有什么影响?按粒度组织数据的方式有哪些?粒度是指数据仓库的数据单位中保存数据细化或综合程度的级别。
粒度影响存放在数据仓库中的数据量的大小,同时影响数据仓库所能回答查询问题的细节程度。
按粒度组织数据的方式主要有:1简单堆积结构2轮转综合结构3简单直接结构4连续结构3.简述数据仓库设计的三级模型及其基本内容。
概念模型设计是在较高的抽象层次上的设计,其主要内容包括:界定系统边界和确定主要的主题域。
逻辑模型设计的主要内容包括:分析主题域、确定粒度层次划分、确定数据分割策略、定义关系模式、定义记录系统。
物理数据模型设计的主要内容包括:确定数据存储结构、确定数据存放位置、确定存储分配以及确定索引策略等。
在物理数据模型设计时主要考虑的因素有:I/O存取时间、空间利用率和维护代价等。
提高性能的主要措施有划分粒度、数据分割、合并表、建立数据序列、引入冗余、生成导出数据、建立广义索引等。
4.在数据挖掘之前为什么要对原始数据进行预处理?原始业务数据来自多个数据库或数据仓库,它们的结构和规则可能是不同的,这将导致原始数据非常的杂乱、不可用,即使在同一个数据库中,也可能存在重复的和不完整的数据信息,为了使这些数据能够符合数据挖掘的要求,提高效率和得到清晰的结果,必须进行数据的预处理。
为数据挖掘算法提供完整、干净、准确、有针对性的数据,减少算法的计算量,提高挖掘效率和准确程度。
5.简述数据预处理方法和内容。
1数据清洗:包括填充空缺值,识别孤立点,去掉噪声和无关数据。
2数据集成:将多个数据源中的数据结合起来存放在一个一致的数据存储中。
2022年浙江工商大学数据科学与大数据技术专业《数据库系统原理》科目期末试卷A(有答案)

2022年浙江工商大学数据科学与大数据技术专业《数据库系统原理》科目期末试卷A(有答案)一、填空题1、在一个关系R中,若每个数据项都是不可再分割的,那么R一定属于______。
2、在SQL语言中,为了数据库的安全性,设置了对数据的存取进行控制的语句,对用户授权使用____________语句,收回所授的权限使用____________语句。
3、数据库内的数据是______的,只要有业务发生,数据就会更新,而数据仓库则是______的历史数据,只能定期添加和刷新。
4、完整性约束条件作用的对象有属性、______和______三种。
5、对于非规范化的模式,经过转变为1NF,______,将1NF经过转变为2NF,______,将2NF 经过转变为3NF______。
6、数据仓库是______、______、______、______的数据集合,支持管理的决策过程。
7、视图是一个虚表,它是从______导出的表。
在数据库中,只存放视图的______,不存放视图对应的______。
8、有两种基本类型的锁,它们是______和______。
9、从外部视图到子模式的数据结构的转换是由______________实现;模式与子模式之间的映象是由______________实现;存储模式与数据物理组织之间的映象是由______________实现。
10、如图所示的关系R的候选码为;R中的函数依赖有;R属于范式。
一个关系R二、判断题11、连接是数据库最耗时的操作。
()12、在一个关系中,不同的列可以对应同一个域,但必须具有不同的列名。
()13、在SELECT语句中,需要对分组情况满足的条件进行判断时,应使用WHERE子句。
()14、在数据库恢复中,对已完成的事务进行撤销处理。
()15、可以用UNION将两个查询结果合并为一个查询结果。
()16、有了外模式/模式映象,可以保证数据和应用程序之间的物理独立性。
()17、视图是可以更新的。
数据仓库与数据挖掘,DBMS题库考试大纲和答案.

11.数据仓库的设计方法与操作型环境中系统设计采用的系统生命周期法有什么不同?12.举例说明多维分析操作(切片、切块、旋转)的含义是什么?切片和切块(slice and dice)在多维数组的某一维选定一个维成员的动作称为切片。
在多维数组的某一维上选定某一区间的维成员的动作称为切块旋转是改变一个报告或页面显示的维方向,以用户容易理解的角度来观察数据13.数据挖掘的步骤是什么?确定挖掘对象,准备数据,建立模型,数据挖掘,结果分析,知识应用阶段14.简要说明数据仓库环境中元数据的内容。
元数据(Meta Data)——“关于数据的数据”,是指在数据仓库建设过程中产生的有关数据源定义、目标定义、转换规则等关键数据,是定义数据仓库对象的数据。
如传统数据库中的数据字典就是一种元数据。
15.企业的数据库体系化环境的四个层次是什么?它们之间的关系是什么?数据库的体系化环境,是在一个企业或组织内部,由各面向应用的OLTP数据库及各级面向主题的数据仓库所组成的完整的数据环境四层体系化环境:操作型环境——OLTP,全局级——数据仓库,部门级——局部仓库,个人级——个人仓库,用于启发式的分析16.简要说明数据仓库设计的步骤。
数据仓库的设计可以分为以下几个步骤:◆明确主题◆概念模型设计所要完成的工作:界定系统边界,确定主要的主题域及其内容◆技术准备工作这一阶段的工作包括:技术评估,技术环境准备。
形成技术评估报告、软硬件配置方案、系统(软、硬件)总体设计方案。
◆逻辑模型设计进行的工作主要:分析主题域,确定当前要装载的主题确定粒度层次划分确定数据分割策略关系模式定义◆物理模型设计这一步所做的工作:确定数据的存储结构 ---RAID技术确定索引策略——B树索引位图索引等确定数据存放位置——磁带磁盘等确定存储分配优化◆数据仓库生成通过专用的数据抽取工具或者通过自行编程实现数据抽取、转换和装载。
◆数据仓库运行与维护建立DSS应用,使用数据仓库理解需求,调整和完善系统,维护数据仓库。
数据仓库与数据挖掘试题

《数据仓库与数据挖掘试题》一、判断题(每小题1分,计30分,答题时每5个答案写在一起)1.数据库作为数据资源用于管理业务中的信息分析处理。
(X)2.数据库的查询不是指对记录级数据的查询,而是指对分析要求的查询。
(X)3.关系数据库是二维数据(平面),多维数据库是空间立体数据。
(v)4.数据进入数据仓库之前,必须经过加工与集成。
(V)5.OLAP使用的是当前数据;OLTP使用的是历史数据。
(V)6.对数据仓库操作不明确,操作数据量少。
(X)7.数据集市实现难度超过数据仓库。
(X)8.OLAP使用的数据经常更新;OLTP使用的数据不更新,但周期性刷新。
(X)9.数据集市可升级到完整的数据仓库。
(V)10.数据库中存放的数据基本上是保存当前综合数据。
(X)11.OLAP可以应分析人员的要求快速、灵活地进行大数据量的复杂处理。
(V)12.OLAP支持复杂的决策分析操作,侧重对分析人员和高层管理人员的决策支持。
(V)13.OLTP的事务处理量大,处理内容比较简单但重复率高。
(V)14.数据仓库的用户有两类:信息使用者和探索者。
(V)15.对数据库的操作比较明确,操作数据量大。
(X)16.数据库用于事务处理,数据仓库用于决策分析。
(V)17.信息使用者以一种可预测的、重发性的方式使用数据仓库平台。
(V)18.OLAP一次处理的数据量大;OLTP一次性处理的数据量小。
(V)19.OLTP每次操作的数据量不大且多为当前的数据。
(V )20.数据仓库系统由数据仓库(DW)、仓库管理和分析工具三部分组成。
(V)21.随着业务的变化,数据仓库中的数据会随时更新。
(X)22.数据集市的规模比数据仓库更大。
(X)23.数据集市具有更详细的、预先存储在数据仓库的数据。
(V)24.不同维值的组合及其对应的度量值构成了不同的查询和分析。
(V)25.OLAP使用细节性数据,OLTP使用综合性数据。
(X)26.数据集市由企业管理和维护。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、数据仓库的定义:数据仓库就是面向主题的、集成的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程。
数据仓库特征:数据仓库是将原始的操作数据进行各种处理并转换成综合信息,提供功能强大的分析工具对这些信息进行多方位的分析以帮助企业领导做出更符合业务发展规律的决策。
2、数据仓库与数据库的相同点与不同点:3、数据仓库的重要特性:面向主题性、集成性、时变性、非易失性、集合性和支持决策作用。
4、数据挖掘的定义:从技术角度看,数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的,但又是潜在有用的信息和知识的过程。
5、数据挖掘与数据仓库的关系:●数据挖掘是数据仓库发展的必然结果:数据挖掘可以看作是联机分析处理的高级阶段。
●数据仓库为数据挖掘提供应用基础总之,数据仓库为数据挖掘提供了更广阔的活动空间。
数据仓库完成数据的收集、集成、存储和管理工作,数据挖掘面对的是经初步加工的数据,使得数据挖掘更能专注于知识的发现。
6、数据仓库的体系结构:数据仓库系统是由数据源、数据仓库的数据存储、数据仓库的应用工具和可视化用户界面组成。
7、主题数据是数据仓库的核心数据,一般以多维数据模型的形式存储在数据仓库中。
8、在数据仓库中涉及数据存储包括以下几种:数据源、主题数据、数据准备区和查询服务数据。
9、数据集市定义:数据集市一般是为满足某个业务部门进行分析决策的需求而建立的,我们可以将数据集市理解为部门级的数据仓库,数据仓库是数据集市的集合。
如果一个数据集市不依赖于中央数据仓库,则这个数据集市为独立数据集市。
10、元数据的定义:元数据就是关于数据的数据。
元数据是任何信息处理环境的一个重要组成部分。
元数据描述了数据仓库的数据和环境,并使得用户能够更方便地使用数据仓库中的数据进行各种分析,辅助决策。
11、元数据的主要两种作用:元数据进行数据仓库的管理和通过元数据来使用数据仓库。
用于对元数据进行管理的元数据称为管理元数据,而帮助我们使用数据仓库的元数据又称作用户元数据。
12、元数据的分类:根据元数据的内容我们将其分为四类:数据源元数据、预处理数据源元数据、数据仓库主题数据元数据、查询服务元数据。
13、数据仓库的数据模型:●概念模型:多维数据模型是一种能够清楚地表达分析领域的数据模型。
实体关系模型注重的是数据的结构,而多维数据模型注重的是数据的含义。
数据仓库的概念模型一般采用多维数据模型来建模。
在多维数据模型中,包含两种建模要素:观察事物的角度和观察得到的事实数据,前者被称作维度,后者被称作事实。
一个分析领域或主题表达为由多个维度和一组事实数据构成的一个星型模型。
●一个数据仓库通常包含多个主题,其概念模型也就由多个星型模型组成。
●14、数据仓库中的粒度是指数据仓库的数据单位中保存数据的细化或综合程度的级别。
越是详细的数据,粒度级别就越小;越是概括的的数据,粒度级别就越大。
判断:粒度问题是设计数据仓库的一个非常重要的方面,它既是一个逻辑设计的问题,也是一个物理设计的问题。
15、数据分割是把大的数据集划分成多个较小的数据集,并分散到多个物理单元中进行存储,使它们能独立的被处理。
粒度的划分和数据的分割对数据仓库的设计和实现有重大的影响。
16、确定粒度大小的一般原则:●如果数据仓库的空间很有限的话,为了节省存储空间,宜采用大粒度集表示数据。
●如果追求数据仓库能够回答的问题类型的能力,要求能够回答非常具体的问题,那么使用较小的粒度级别。
●如果想要减轻服务器的负担,提高查询性能,则采用较大的数据集粒度。
●如果没有存储空间的限制,则可以在一个数据仓库中采用多重粒度级别,既存储多粒度级别的数据,也存储高粒度级别的数据,以同时获得高的查询效率和查询能力。
17、数据仓库的建设应该以建立部门级的数据集市为出发点,同时统观全局,使建立的数据集市成为整个企业数据仓库的逻辑子集。
从而由多个数据集市集成企业级的数据仓库。
为了实施这种数据仓库建设的思想,提出了一种总线型的数据仓库结构,称之为数据仓库的总线型结构。
这种数据仓库结构的核心思想是使用统一的维和统一的事实来构造数据仓库的总线。
18、统一的维是指该维可以在数据集市中共享,且不论它与哪个事实表相连接,维的含义都是完全相同的。
19、统一的事实是指一个事实数据,比如销售额,如果在多个数据集市中出现,则该事实数据必须是一致的。
20、在数据仓库管理中,最关键的是对数据的管理。
21、休眠数据的管理数据仓库管理的第一块基本内容。
22、数据仓库管理的三个基本内容:(1)休眠数据的管理;(2)元数据的管理;(3)数据清理。
23、休眠数据是那些存在与数据仓库中、当前并不使用的、将来也很少使用或者根本就不会使用的数据。
休眠数据会以多种方式进入数据仓库,我们在识别和处理它们之前需要理解它们的进入方式。
造成这些休眠数据在数据仓库中存在的原因至少有四种:●由于概括表格的创建●由于错误估计实际上所需要的历史数据的年限●由于随着时间的推移,需求的现实性逐渐明显●由于坚持让详细数据驻留在数据仓库中24、休眠数据的处理:查找休眠数据、删除休眠数据、选择删除的数据、确定访问可能性。
我们认为数据仓库中包含25%到50%的休眠数据时,数据仓库的结构也许比较适当。
25、(必考填空)数据管理中最重要的一步是协调分布在多种数据仓库中的元数据,而建立企业级的中心知识库则是实现元数据管理的基本途径和关键。
26、脏数据进入的四种方式:●数据源系统中的脏数据进入数据仓库●不合适的集成造成脏数据进入数据仓库●数据仓库中以前输入的数据过期●用户需求的改变或添加了对数据质量有不同要求的用户27、OLAP:联机分析处理OLTP:联机事务处理OLAM:联机分析挖掘FASMI共享多维信息的快速分析28、好的OLAP应该具有的准则:基本特性、特殊特性、报表特性、维控制特性29、OLAP的基本概念:度量值:度量值是人们观察事物的焦点维:维是人们观察事物的角度多维数据集的度量值及其关联的维的维成员构成一个多维数据集,当维数为3时,多维数据集表现为一个数据立方体。
多维数据集能支持各种各样的查询,是OLAP的核心。
每一个多维数据集都可以用一个多维数组表示。
30、虚拟维度是基于物理维度内容的逻辑维度。
31、OLAP的基本操作主要包括对多维数据进行切片、切块、旋转、钻取等分析操作。
切片操作就是在某个或某些维上选定一个属性成员,而在其他维上取一定区间的属性成员或全部属性成员来观察数据的一种分析方式。
切片就是在各个维上取一定区间的成员属性或全部成员属性来观察数据的一种分析方式。
32、钻取包含下钻和上钻/上卷操作。
下钻是从概括性的数据出发获得相应的更详细的数据,上钻则相反。
旋转即改变一个报告或页面显示的维方向。
33(解答必考)OLTP称作联机事务处理,OLAP是继OLTP之后发展起来发展起来的一种技术。
他们的区别如下:●OLAP和OLTP产生的背景和目的不同。
前者的目的是通过对现有数据进行分析处理,获得信息,支持决策;而后者的目的则是则是加速对业务数据的处理,支持企业的业务运作。
●使用的数据模型不同●使用的综合程度不同●OLAP中的数据不可更改,但需周期性的刷新;而OLTP中的数据可以更改●对数据的处理不同。
OLTP对数据进行操作型处理,一般运用SQL命令进行追加、删除、修改、简单查询等处理。
而OLAP则进行切片、切块、旋转、钻取等分析性处理。
34、在实施OLAP时,有两种实施方案可供选择:●多维联机分析处理(MOLAP),直接采用多维数据库进行联机分析处理;●关系联机分析处理(ROLAP),,采用关系数据库来存放多维数据进行联机分析处理35、MOLAP和ROLAP的特征●查询功能:MOLAP在查询性能和相应速度上要优于ROLAP●空间占用:如果所有维成员组合都存在相应度量值,MOLAP比较节省空间,反之,当大量维成员组合不存在相应度量值,MOLAP会造成空间大量浪费。
●分析查询能力:MOLAP在查询能力上要次于ROLAP如果建立功能复杂、规模较大的企业级数据仓库,则一般选择ROLAP方式;而如果是建立功能单一,小型的数据集市则宜采用MOLAP方式。
MOLAP缺点增加系统复杂度,增加系统培训与维护费用受操作系统平台中文件大小的限制,难以达到TB 级(只能10~20G)需要进行预计算,可能导致数据爆炸无法支持维的动态变化缺乏数据模型和数据访问的标准ROLAP缺点一般响应速度较慢不支持有关预计算的读写操作SQL无法完成部分计算无法完成多行的计算无法完成维之间的计算36、星型模式:一般地,我们用一张事实表和多张维表表示星型模式。
事实表在模式图中处于中心位置,存放的是业务数据,具有可加性。
维表的信息用做对事实表进行查询时的约束条件。
37、星座模式:一系列同质而不同综合程度的事实表共享一系列维度表38、雪花模式:维度层次较多,使用多个维度表来描述一个维,形成二级维表结构,可以大大减少数据冗余,节省存储空间39、KDD是基于数据库的知识发现,指的是从大型数据库中或数据仓库中提取人们感兴趣的知识,这些知识是隐含的,事先未知的,易被理解的模式。
KDD过程可分为三部分:数据准备、数据挖掘及结果的解释和评估40、数据挖掘的任务:关联分析、时序模式、聚类、分类、偏差检测及预测关联分析:用来发现关联规则,这星系模式:多个不同的事实表共享多个维度表,且维度表不完全相同时序模式:时间序列模式是用变量过去的值来预测未来的值聚类:把整个数据库分成不同的群组分类:数据挖掘应用最多的任务要属分组,分类找出描述并区分数据类或概念的模型,以便能够使用模型预测类标记未知的对象类偏差检测:在数据分析中发现很多异常情况存在于数据库中,我们可以根据这些异常情况获得很多信息。
预测:预测可以利用历史数据或数据分布依据一定的模型计算出数值数据或识别出未来分布的趋势。
41、数据挖掘与专家系统的区别(必考)数据挖掘和专家系统的共同点是它们都是利用已有的信息来帮助人们解决问题。
不同的是,数据挖掘是利用大量已存在的数据中发现人们难以用直观或手工方法发现的有用信息来进行决策支持;而专家系统则是利用专家知识和启发性知识,按一定的推理规则来帮助人们解决问题。
数据挖掘强调事实第一,而专家系统则强调经验第一;专家系统是“唯专家”,而数据挖掘是“唯数据”。
42、(填空)数据挖掘用各种方法获得知识的表现形式主要有五种:规则、决策树、知识基(浓缩数据)、网络权值和公式。
数据挖掘的信息论方法所获的知识一般表示为决策树。
43、(填空)遗传算子主要有:繁殖算子(复制、选择算子)、交叉算子(重组、配对算子)。
遗传算法是一种基于自然选择原理和自然遗传的搜索算法。