线性回归推导及实例
贝叶斯线性回归的推导与应用

贝叶斯线性回归的推导与应用贝叶斯线性回归是一种基于贝叶斯统计学原理的回归模型。
它通过引入先验分布和后验分布来对线性回归进行建模,从而得到更准确的预测结果。
本文将对贝叶斯线性回归的推导过程和应用进行详细介绍。
一、推导1. 线性回归模型线性回归模型假设自变量x与因变量y之间存在线性关系,可以表示为:y = wx + b + ε其中,w是权重(系数),b是常数项,ε是误差项,服从均值为0、方差为σ^2的正态分布。
2. 先验分布贝叶斯线性回归引入先验分布来描述权重w和常数项b的不确定性。
假设先验分布为正态分布:p(w, b) = N(w|w0, V0) * N(b|b0, V0)其中,w0和b0为先验分布的均值,V0为先验分布的协方差矩阵。
3. 后验分布根据贝叶斯定理,后验分布可以表示为:p(w, b | D) = p(D | w, b) * p(w, b) / p(D)其中,D为已观测到的数据集。
4. 最大后验估计为了估计后验分布中的参数,我们采用最大后验估计(MAP)方法。
MAP估计等价于最小化负对数后验估计:(w*, b*) = argmin(-log(p(w, b | D)))根据先验和似然分布的定义,可以推导出MAP估计的目标函数为:L(w, b) = -log(p(D | w, b)) - log(p(w, b))具体推导过程较为复杂,这里不做详细介绍。
5. 参数更新为了最小化目标函数,我们可以使用梯度下降法进行参数更新。
根据目标函数的梯度,可以得到参数的更新规则为:w_new = w_old - α * (∂L/∂w)b_new = b_old - α * (∂L/∂b)其中,α为学习率。
二、应用贝叶斯线性回归在实际问题中具有广泛的应用。
以下以一个房价预测的案例来说明其应用过程。
假设我们有一组已知的房屋面积x和对应的售价y的数据,我们希望通过贝叶斯线性回归来预测未知房屋的售价。
1. 数据准备将已知的房屋面积x和售价y作为训练数据,构建数据集D。
线性回归方程推导

线性回归方程推导线性回归之最小二乘法推导及python实现线性回归、加权线性回归及岭回归的原理和公式推导- 线性回归- 加权线性回归机器学习相关的博文相信已经很多了,作为机器学习的一枚菜鸟,写这篇博文不在于标新立异,而在于分享学习,同时也是对自己研究生生涯的总结和归纳,好好地把研究生的尾巴收好。
想着比起出去毕业旅行,在实验室总结一下自己的所学,所想,所感应该更有意义吧。
(其实也想出去玩,但是老板要求再出一篇文章,那只好和毕业旅行拜拜了,所以趁机写个系列吧,反正后面的时间应该就是文章+博客的双重循环了,其实也是挺美的哈)学习机器学习的小心得:脑袋中一定要有矩阵、向量的概念,这一点非常重要,因为我们现在处理的数据是多维的数据,所以可能无法非常直观的来表述我们的数据,所以大脑中一定要有这样的概念。
然后就是Coding再Coding,这一点自己也没做好啦,惭愧。
线性回归回归的目的就是对给定的数据预测出正确的目标值,分类的目的是对给定的数据预测出正确的类标,要注意区分这两个概念,其实我在刚接触机器学习的时候经常把这两个概念弄混。
那么,对于线性回归,就是实现对给定数据目标值的预测过程。
那么对于给定的训练数据X=[x#x2192;1,x#x2192;2,#x2026;,x#x2192;m]T"role="presentation" style="position: relative;">X=[x? 1,x? 2, (x) m]TX=[x→1,x→2,…,x→m]TX = [vec{x}_1, vec{x}_2, dots, vec{x}_m]^{T},其中x#x2192;i={xi1,xi2,xi3,#x2026;,xin}T" role="presentation" style="position: relative;">x? i={xi1,xi2,xi3,…,xin}Tx→i={xi1,xi2,xi3,…,xin}Tvec{x}_i = {x_{i1}, x_{i2}, x_{i3}, dots, x_{in}}^{T}。
线 性 回 归 方 程 推 导

线性回归——正规方程推导过程线性回归——正规方程推导过程我们知道线性回归中除了利用梯度下降算法来求最优解之外,还可以通过正规方程的形式来求解。
首先看到我们的线性回归模型:f(xi)=wTxif(x_i)=w^Tx_if(xi?)=wTxi?其中w=(w0w1.wn)w=begin{pmatrix}w_0w_1.w_nend{pmatrix}w=?w0?w1?. wn?,xi=(x0x1.xn)x_i=begin{pmatrix}x_0x_1.x_nend{pmatrix}xi?=?x0 x1.xn,m表示样本数,n是特征数。
然后我们的代价函数(这里使用均方误差):J(w)=∑i=1m(f(xi)?yi)2J(w)=sum_{i=1}^m(f(x_i)-y_i)^2J(w) =i=1∑m?(f(xi?)?yi?)2接着把我的代价函数写成向量的形式:J(w)=(Xw?y)T(Xw?y)J(w)=(Xw-y)^T(Xw-y)J(w)=(Xw?y)T(Xw?y) 其中X=(1x11x12?x1n1x21x22?x2n?1xm1xm2?xmn)X=begin{pmatrix}1 x_{11} x_{12} cdots x_{1n}1 x_{21} x_{22} cdots x_{2n}vdots vdots vdots ddots vdots1 x_{m1} x_{m2} cdots x_{mn}end{pmatrix}X=?11?1?x11?x21?xm1?x12?x22?xm2?x1n?x2n?xmn?最后我们对w进行求导,等于0,即求出最优解。
在求导之前,先补充一下线性代数中矩阵的知识:1.左分配率:A(B+C)=AB+ACA(B+C) = AB+ACA(B+C)=AB+AC;右分配率:(B+C)A=BA+CA(B+C)A = BA + CA(B+C)A=BA+CA2.转置和逆:(AT)?1=(A?1)T(A^T)^{-1}=(A^{-1})^T(AT)?1=(A?1)T,(AT)T=A(A^T)^T=A(AT)T=A3.矩阵转置的运算规律:(A+B)T=AT+BT(A+B)^T=A^T+B^T(A+B)T=AT+BT;(AB)T=BTAT(AB)^T=B^TA^T(AB)T=BTAT然后介绍一下常用的矩阵求导公式:1.δXTAXδX=(A+AT)Xfrac{delta X^TAX}{delta X}=(A+A^T)XδXδXTAX?=(A+AT)X2.δAXδX=ATfrac{delta AX}{delta X}=A^TδXδAX?=AT3.δXTAδX=Afrac{delta X^TA}{delta X}=AδXδXTA?=A然后我们来看一下求导的过程:1.展开原函数,利用上面的定理J(w)=(Xw?y)T(Xw?y)=((Xw)T?yT)(Xw?y)=wTXTXw?wTXTy?yTXw+yT yJ(w)=(Xw-y)^T(Xw-y)=((Xw)^T-y^T)(Xw-y)=w^TX^TXw-w^TX^Ty-y^TXw+y^TyJ(w)=(Xw?y)T(Xw?y)=((Xw)T?yT)(Xw?y)=wTXTXw?wTXTy?yT Xw+yTy2.求导,化简得,δJ(w)δw=(XTX+(XTX)T)w?XTy?(yTX)T=0?2XTXw?2XTy=0?XTXw=X Ty?w=(XXT)?1XTyfrac{delta J(w)}{delta w}=(X^TX+(X^TX)^T)w-X^Ty-(y^TX)^T=0implies2X^TXw-2X^Ty=0implies X^TXw=X^Tyimplies w=(XX^T)^{-1}X^TyδwδJ(w)?=(XTX+(XTX)T)w?XTy?(yTX)T=0?2XTX w?2XTy=0?XTXw=XTy?w=(XXT)?1XTy最后补充一下关于矩阵求导的一些知识,不懂可以查阅:矩阵求导、几种重要的矩阵及常用的矩阵求导公式这次接着一元线性回归继续介绍多元线性回归,同样还是参靠周志华老师的《机器学习》,把其中我一开始学习时花了较大精力弄通的推导环节详细叙述一下。
线性回归方程推导

线性回归方程推导sklearn - 线性回归(正规方程与梯度下降)一: 线性回归方程线性回归(英语:linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。
这种函数是一个或多个称为回归系数的模型参数的线性组合。
只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归在线性回归中,数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。
这些模型被叫做线性模型。
最常用的线性回归建模是给定X值的y的条件均值是X的仿射函数。
不太一般的情况,线性回归模型可以是一个中位数或一些其他的给定X的条件下y的条件分布的分位数作为X的线性函数表示。
像所有形式的回归分析一样,线性回归也把焦点放在给定X值的y的条件概率分布,而不是X 和y的联合概率分布(多元分析领域)。
线性回归有很多实际用途。
分为以下两大类:如果目标是预测或者映射,线性回归可以用来对观测数据集的和X的值拟合出一个预测模型。
当完成这样一个模型以后,对于一个新增的X值,在没有给定与它相配对的y的情况下,可以用这个拟合过的模型预测出一个y给定一个变量y和一些变量X1X1.,XpXp{displaystyleX_{1}}X_1.,{displaystyle X_{p}}X_pX1?X1?.,Xp?Xp?,这些变量有可能与y相关,线性回归分析可以用来量化y与Xj之间相关性的强度,评估出与y不相关的,XjXj{displaystyle X_{j}}X_jXj?Xj?并识别出哪些XjXj{displaystyle X_{j}}X_jXj?Xj?的子集包含了关于y的冗余信息。
使用sklearn线性回归模型(jupyter)这里我们以波士顿的房价数据来进行使用分析(一): 导入sklearnimport numpy as np# 线性回归,拟合方程,求解系数, 一次幂# 线性方程:直来直去,不拐弯from sklearn.linear_model import LinearRegression# 导入数据集from sklearn import datasets# 导入数据分离的方法(获取数据后,一部分数据用来让回归模型学习,另一部分用来预测)from sklearn.model_selection import train_test_split(二): 获取波士顿房价数据# 获取的数据是numpy,ndarray类型data = datasets.load_boston()# 该数据内有完整的影响房价的因素和完整的房价信息,本次实验就是将数据分为两部分, 一部分用来训练模型,另一部分用来预测,最后将预测出来的数据和已有的完整信息进行对比,判断该模型是否适用于这组房价数据data # 查看data的数据结构data.feature_names # 查看影响房价的属性名# x是属性,特征,未知数X = data['data']X.shape # 运行结果是(506, 13), 506表示样本是506个, 每个样本采集了13个属性特征;13个属性,需要构建构建了13元一次方程# y 是房价的估值y = data['target']# X, y = datasets.load_boston(True) 获取到X, y的值和以上的一样(三): 使用模型进行预测X_train, X_test, y_train, y_test = train_test_split(X, y) # 将数据进行分离(默认是3:1); train_test_split(X, y)函数会随机打乱顺序display(X_train.shape, X_test.shape) # (379, 13) ; (127, 13) # 声明算法linear = LinearRegression()# 训练模型linear.fit(X_train, y_train) # X_train, y_train是之前分离出来用来训练模型的数据y_ = linear.predict(X_test).round(1) # X_test是影响房价的因素,该预测模型能根据影响房价的因素预测剩余部分的房价# 预估数据和实际数据比较print(y_)print(y_test)经过估计数据和实际数据对比,说明算法模型适用于数据(四): 自建方程预测数据与使用线性模型得到的数据对比假设波士顿的房价数据符合线性回归的特性,则我们可以通过构建线性方程来预测波士顿剩余部分的房价信息根据一次线性回归方程: f(X)=Xw+bf(X) = Xw+bf(X)=Xw+b 可推导得出: f(X)=w1x1+W2x2+.+w13x13+b f(X) = w_1x_1+W_2x_2+.+w_{13}x_{13}+bf(X)=w1?x1?+W2?x2?+.+w13?x13?+b (有13个影响房价的因素)代码如下:# 通过训练模型,可从模型中得出系数ww_ = linear.coef_# 通过训练模型,可从模型中得出截距bb_ = linear.intercept_# 自建方程def fun(w_, b_, X):return np.dot(X, w_)+b_# 调用方程得到预估的房价信息fun(w_, b_, X_test).round(1) # round(1)保留一位小数array([31.3, 13.4, 28.6, 20.5, 20.4, 19.4, 32.2, 24. , 25.8, 29.5,24.5,25.2, 31.9, 8.2, 20.9, 29.3, 22.3, 35.2, 16.4, 18.5, 30.8, 41.1, 16.2, 13.7, 17.7, 23.8, 7.8, 12. , 20.5, 15.3, 29.3, 26.8, 31.8, 26. , 30.4, 39.2, 25.3, 40.7, 11.6, 27.3, 16.7, 18.8, 19.5, 19.9, 20.7, 22.8, 17.4, 21.6, 23.3, 30. , 25.2, 23.7, 34.2, 18.2, 33.5, 16. , 28.3, 14.1, 24.2, 16.2, 16.7, 23.5, 16. , 21.4, 21.8, 28.2,25.7, 31.2, 18.8, 26.4, 28.3, 21.9, 27.5, 27.1, 27.1, 15. , 26. ,26.3, 13.2, 13.3, 26.1, 20.5, 16.8, 24.3, 36.6, 21.4, 8.3, 27.8,3.6, 19.2, 27.5, 33.6, 28.4, 34.3, 28.2, 13.3, 18. , 23.5, 30.4,32.9, 23.7, 30.5, 19.8, 19.5, 18.7, 30.9, 36.3, 8. , 18.2, 13.9, 15. , 26.4, 24. , 30.2, 20. , 5.6, 21.4, 22.9, 17.6, 32.8, 22.1, 32.6, 20.9, 19.3, 23.1, 21. , 21.5])# 使用sklesrn中的线性模型得到的预估房价信息linear.predict(X_test).round(1)array([31.3, 13.4, 28.6, 20.5, 20.4, 19.4, 32.2, 24. , 25.8, 29.5,24.5,25.2, 31.9, 8.2, 20.9, 29.3, 22.3, 35.2, 16.4, 18.5, 30.8, 41.1, 16.2, 13.7, 17.7, 23.8, 7.8, 12. , 20.5, 15.3, 29.3, 26.8, 31.8, 26. , 30.4, 39.2, 25.3, 40.7, 11.6, 27.3, 16.7, 18.8, 19.5, 19.9, 20.7, 22.8, 17.4, 21.6, 23.3, 30. , 25.2, 23.7, 34.2, 18.2, 33.5, 16. , 28.3, 14.1, 24.2, 16.2, 16.7, 23.5, 16. , 21.4, 21.8, 28.2,25.7, 31.2, 18.8, 26.4, 28.3, 21.9, 27.5, 27.1, 27.1, 15. , 26. ,26.3, 13.2, 13.3, 26.1, 20.5, 16.8, 24.3, 36.6, 21.4, 8.3, 27.8,3.6, 19.2, 27.5, 33.6, 28.4, 34.3, 28.2, 13.3, 18. , 23.5, 30.4,32.9, 23.7, 30.5, 19.8, 19.5, 18.7, 30.9, 36.3, 8. , 18.2, 13.9, 15. , 26.4, 24. , 30.2, 20. , 5.6, 21.4, 22.9, 17.6, 32.8, 22.1,32.6, 20.9, 19.3, 23.1, 21. , 21.5])通过自建模型获取预估数据与使用模型获取预估数据进行比较,两组数据完全一致;(五): 使用线性回归,求解斜率和截距根据最小二乘法: min?w∣∣Xw?y∣∣22min_{w}||Xw-y||_2^2wmin?∣∣Xw?y∣∣22? 推到得出公式: w=(XTX)?1XTyw = (X^TX)^{-1}X^Tyw=(XTX)?1XTy 以上公式只能求出w,我们可以先求出w再计算出b;但此处我们有更简单的方法:根据线性回归方程f(x)=w1x1+w2x2+b f(x) = w_1x_1+w_2x_2+bf(x)=w1?x1?+w2?x2?+b 我们可以将方程中的b 看成是w3x30w_3x_3^0w3?x30?,所以可得: f(x)=w1x11+w2x21+w3x30f(x) = w_1x_1^1+w_2x_2^1+w_3x_3^0f(x)=w1?x11?+w2?x21?+w3?x3 0?代码如下:import numpy as npfrom sklearn.linear_model import LinearRegressionfrom sklearn import datasetsX, y = datasets.load_boston(True)linear = LinearRegression()linear.fit(X,y)w_ = linear.coef_b_ = linear.intercept_# 向X中插入一列全是1的数据(任何数的0次方都是1)X = np.concatenate([X, np.ones(shape = (506, 1))], axis=1) # 根据最小二乘法的推导公式:w和b的值为(最后一个值是b) w = ((np.linalg.inv(X.T.dot(X))).dot(X.T)).dot(y)# 以上w的写法过于装逼,所以分解为:# A = X.T.dot(X) 求X和转置后的X的内积(公式中的XTX)# B = np.linalg.inv(A) 求A的逆矩阵(公式中的-1次方)# C = B.dot(X.T) 求以上矩阵和X的转置矩阵的内积(公式中的XT) # w = C.dot(y) 与y求内积,得出w和b运行结果:array([-1.08011358e-01, 4.64204584e-02, 2.05586264e-02, 2.68673382e+00,-1.77666112e+01, 3.80986521e+00, 6.92224640e-04, -1.47556685e+00,3.06049479e-01, -1.23345939e-02, -9.52747232e-01,9.31168327e-03,-5.24758378e-01, 3.64594884e+01])print(b_)运行结果:36.45948838509001扩展一: 最小二乘法和向量范数min?w∣∣Xw?y∣∣22min_{w}||Xw-y||_2^2wmi n?∣∣Xw?y∣∣22?右上角的2是平方右下角的2是向量2范数竖线内的表达式是向量根据最小二乘法的公式, 推导得出w=(XTX)?1XTyw = (X^TX)^{-1}X^Tyw=(XTX)?1XTy向量的1-范数(表示各个元素的绝对值的和)∣∣X∣∣1=∑i=1n∣xi∣||X||_1 = sumlimits_{i=1}^n |x_i|∣∣X∣∣1?=i=1∑n?∣xi?∣向量的2-范数(表示每个元素的平方和再开平方)∣∣X∣∣2=∑i=1nxi2||X||_2 = sqrt{suml imits_{i=1}^n x_i^2}∣∣X∣∣2?=i=1∑n?xi2?向量的无穷范数(所有向量元素绝对值中的最大值)∣∣X∣∣∞=max?1≥i≤n∣Xi∣||X||_{infty} = maxlimits_{1 geq i leq n}|X_i|∣∣X∣∣∞?=1≥i≤nmax?∣Xi?∣扩展二: 导数, 偏导数对函数f(x)=x2+3x+8f(x) = x^2+3x+8f(x)=x2+3x+8 求导得: f(x)′=2x+3f(x)' = 2x+3f(x)′=2x+3求导规则:参数求导为0参数乘变量求导为常数变量的次方求导: xyx^yxy求导为yxy?1yx^{y-1}yxy?1复合函数求导:$$(x^2-x)^2$$求导: 先将括号看成一个整体求导, 结果再乘以括号内的求导结果$$2(x^2-x)(2x-1)$$有多个变量得函数求导:对函数: f(x,y)=x2+xy+y2f(x, y) = x^2+xy+y^2f(x,y)=x2+xy+y2 求导:求导规则: 多变量函数只能针对某一个变量求导,此时将其他变量看成常数将x看成常数a: fa(y)=a2+ay+y2f_a(y) = a^2+ay+y^2fa?(y)=a2+ay+y2求导得:fa′(y)=a+2yf_a'(y) = a+2yfa′?(y)=a+2y故求导得: ?f?y(x,y)=x+2yfrac{partial f}{partial y}(x,y)=x+2y?y?f?(x,y)=x+2y实现线性回归的两种方式:正规方程梯度下降二: 正规方程(一): 损失函数最小二乘法:min?w∣∣Xw?y∣∣22minlimits_{w}||Xw-y||_2^2wmin?∣∣Xw?y∣∣22?当X和y都是常数时,按照向量2范数将上面的最小二乘法解开:f(w)=(Xw?y)2f(w)=(Xw-y)^2f(w)=(Xw?y)2将X,y替换成常数a,bf(w)=(aw?b)2f(w)=(aw-b)^2f(w)=(aw?b)2f(w)=a2w2?2abw+b2f(w)=a^2w^2 - 2abw + b^2f(w)=a2w2?2abw+b2 ?由于最小二乘法方程的函数值都是大雨或等于0的,所以此时得到一个开口向上的抛物线(一元二次方程)此时的f(w)f(w)f(w)就是损失函数,在此时求该函数的导数(抛物线函数顶点的导数为0)就能得到该函数的最小值,也就是最小损失f′(w)=2a2w?2ab=0f'(w)=2a^2w-2ab=0f′(w)=2a2w?2ab=0(二): 矩阵常用求导公式X的转置矩阵对X矩阵求导, 求解出来是单位矩阵dXTdX=Ifrac{dX^T}{dX} = IdXdXT?=IdXdXT=Ifrac{dX}{dX^T} = IdXTdX?=IX的转置矩阵和一个常数矩阵相乘再对X矩阵求导, 求解出来就是改常数矩阵dXTAdX=Afrac{dX^TA}{dX} = AdXdXTA?=AdAXdX=ATfrac{dAX}{dX} = A^TdXdAX?=ATdXAdX=ATfrac{dXA}{dX} = A^TdXdXA?=ATdAXdXT=Afrac{dAX}{dX^T} = AdXTdAX?=A(三): 正规方程矩阵推导过程此时X,w,y都是矩阵1: 公式化简1: 最小二乘法:f(w)=∣∣Xw?y∣∣22f(w) = ||Xw-y||_2^2f(w)=∣∣Xw?y∣∣22?2: 向量2范数:∣∣X∣∣2=∑i=1nxi2||X||_2 = sqrt{sumlimits_{i = 1}^nx_i^2}∣∣X∣∣2?=i=1∑n?xi2?3: 将向量2范数的公式带入到最小二乘法中得:f(w)=((Xw?y)2)2f(w)=(sqrt{(Xw-y)^2})^2f(w)=((Xw?y)2?)2f(w)=(Xw?y)2f(w)=(Xw-y)^2f(w)=(Xw?y)2由于X, w, y都是矩阵, 运算后还是矩阵; 矩阵得乘法是一个矩阵得行和另一个矩阵得列相乘; 所以矩阵的平方就是该矩阵乘以他本身的转置矩阵f(w)=(Xw?y)T(Xw?y)f(w)=(Xw-y)^T(Xw-y)f(w)=(Xw?y)T(Xw?y) 注意: 整体转置变成每个元素都转置时,若是有乘法, 则相乘的两个矩阵要交换位置; 如下所示!f(w)=(wTXT?yT)(Xw?y)f(w)=(w^TX^T-y^T)(Xw-y)f(w)=(wTXT?yT)(Xw ?y)f(w)=wTXTXw?wTXTy?yTXw+yTyf(w)=w^TX^TXw-w^TX^Ty-y^TXw+y^Tyf( w)=wTXTXw?wTXTy?yTXw+yTy 注意: 若想交换两个相乘的矩阵在算式中的位置,则交换之后双方都需要转置一次; 如下所示!f(w)=wTXTXw?(XTy)T(wT)T?yTXw+yTyf(w)=w^TX^TXw-(X^Ty)^T(w^T)^ T-y^TXw+y^Tyf(w)=wTXTXw?(XTy)T(wT)T?yTXw+yTyf(w)=wTXTXw?yTXw?yTXw+yTyf(w)=w^TX^TXw-y^TXw-y^TXw+y^Tyf(w)= wTXTXw?yTXw?yTXw+yTyf(w)=wTXTXw?2yTXw+yTyf(w) = w^TX^TXw - 2y^TXw + y^Ty f(w)=wTXTXw?2yTXw+yTyf(w)=wTXTXw?2yTXw+yTyf(w) = w^TX^TXw - 2y^TXw + y^Ty f(w)=wTXTXw?2yTXw+yTy这里 yTyy^TyyTy 是常数求导后为02yTXw2y^TXw2yTXw 求导:d(2yTX)wdw=(2yTX)T=2XT(yT)T=2XTyfrac{d(2y^TX)w}{dw}= (2y^TX)^T=2X^T(y^T)^T=2X^Tydwd(2yTX)w?=(2yTX)T=2XT(yT)T=2XTy wTXTXww^TX^TXwwTXTXw求导:dwTXTXwdw=d(wTXTX)wdw+dwT(XTXw)dw=(wTXTX)T+XTXw=XT(XT)T(wT)T+XTXw=2XTXwfrac{dw^TX^TXw}{dw}=frac{d(w^TX^TX)w}{dw} +frac{dw^T(X^TXw)}{dw}=(w^TX^TX)^T+X^TXw=X^T(X^T)^T(w^T)^T +X^TXw=2X^TXwdwdwTXTXw?=dwd(wTXTX)w?+dwdwT(XTXw)?=(wTXTX)T+XTXw=X T(XT)T(wT)T+XT Xw=2XTXwf′(w)=2XTXw?2XTyf'(w) = 2X^TXw - 2X^Tyf′(w)=2XTXw?2XTy令f′(w)=0f'(w)=0f′(w)=0,则:2XTXw?2XTy=02X^TXw - 2X^Ty = 02XTXw?2XTy=0XTXw=XTyX^TXw=X^TyXTXw=XTy矩阵运算没有除法,可以用逆矩阵实现除法的效果等式两边同时乘以XTXX^TXXTX的逆矩阵(XTX)?1(X^TX)^{-1}(XTX)?1 (XTX)?1(XTX)w=(XTX)?1XTy(X^TX)^{-1}(X^TX)w=(X^TX)^{-1}X^Ty(X TX)?1(XTX)w=(XTX)?1XTy Iw=(XTX)?1XTyIw=(X^TX)^{-1}X^TyIw=(XTX)?1XTy I是单位矩阵得到正规方程:w=(XTX)?1XTyw=(X^TX)^{-1}X^Tyw=(XTX)?1XTy(四): 数据挖掘实例(预测2020年淘宝双十一交易额)import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionX = np.arange(2009, 2020) # 年份X = X -2008 # 年份数值太大,差别不明显y = np.array([0.5, 9.36, 52, 191, 350, 571, 912, 1207, 1682, 2135, 2684]) # 09年到19年的交易额假设X和y之间是一元三次的关系(按照前几年的数据走势提出的假设)f(x)=w1x+w2x2+w3x3+bf(x)=w_1x+w_2x^2+w_3x^3+bf(x) =w1?x+w2?x2 +w3?x3+bf(x)=w0x0+w1x1+w2x2+w3x3f(x)=w_0x^0+w_1x^1+w_2x^ 2+w_3x^3f(x) =w0?x0+w1?x1+w2?x2+w3?x3# X_oo = np.concatenate([a,a]) # 横着级联X_train = np.c_[X**0, X**1, X**2, X**3] # 竖着级联array([[ 1, 1, 1, 1],[ 1, 2, 4, 8],[ 1, 3, 9, 27],[ 1, 4, 16, 64],[ 1, 5, 25, 125],[ 1, 6, 36, 216],[ 1, 7, 49, 343],[ 1, 8, 64, 512],[ 1, 9, 81, 729],[ 1, 10, 100, 1000],[ 1, 11, 121, 1331]], dtype=int32)linear = LinearRegression(fit_intercept=False) # 声明算法; fit_intercept=False将截距设置为0, w0就是截距linear.fit(X_train, y) # 训练w_ = linear.coef_print(linear.coef_.round(2)) # 获取系数print(linear.intercept_) # 获取截距[ 58.77 -84.06 27.95 0.13]可以得到方程:f(x)=58.77?84.06x+27.95x2+0.13x3f(x)=58.77-84.06x+27.95x^2+0 .13x^3f(x)=58.77?84.06x+27.95x2+0.13x3X_test = np.linspace(0,12,126) # 线性分割(将0,12之间分成126分)等差数列包含1和12X_test = np.c_[X_test**0, X_test**1, X_test**2, X_test**3] # 和训练数据保持一致y_ = linear.predict(X_test) # 使用模型预测plt.plot(np.linspace(0,12,126), y_, color='g') # 绘制预测方程曲线plt.scatter(np.arange(1,12), y, color='red') # 绘制每年的真实销量# 定义函数fun = lambda x : w_[0] + w_[1]*x + w_[2]*x**2 + w_[-1]*x**3 '''3294.2775757576132'''三: 梯度下降梯度下降法的基本思想可以类比为一个下山的过程。
线性回归方程公式推导过程

线性回归方程公式推导过程公式是数学题目的解题关键,那么线性回归方程公式推导过程是什么呢?下面是由小编为大家整理的“线性回归方程公式推导过程”,仅供参考,欢迎大家阅读。
线性回归方程公式推导过程假设线性回归方程为: y=ax+b (1),a,b为回归系数,要用观测数据(x1,x2,...,xn和y1,y2,...,yn)确定之。
为此构造Q(a,b)=Σ(i=1->n)[yi-(axi+b)]^2 (2),使Q(a,b)取最小值的a,b为所求。
令:∂Q/∂a= 2Σ(i=1->n)[yi-(axi+b)](-xi)= 0 (3),∂Q/∂b= 2Σ(i=1->n)[yi-(axi+b)] = 0 (4),根据(3)、(4)解出a ,b就确定了回归方程(1):a Σ (Xi)² +b Σ Xi = Σ Xi Yi (5);a Σ Xi +b n = Σ Yi (6);由(5)(6)解出a,b便是。
//这一步就省略了。
拓展阅读:线性回归方程的分析方法分析按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
线性回归方程的例题求解用最小二乘法估计参数b,设服从正态分布,分别求对a、b的偏导数并令它们等于零,得方程组解得。
其中,且为观测值的样本方差.线性方程称为关于的线性回归方程,称为回归系数,对应的直线称为回归直线.顺便指出,将来还需用到,其中为观测值的样本方差。
先求x,y的平均值。
利用公式求解:b=把x,y的平均数带入a=y-bx。
求出a=是总的公式y=bx+a线性回归方程y=bx+a过定点。
(x为xi的平均数,y为yi的平均数)。
线 性 回 归 方 程 推 导

线性回归算法推导线性回归之最小二乘法推导及python实现前言线性模型基本形式模型评估寻找最优解python实现最小二乘法本文章为个人的学习笔记。
学习书籍《机器学习》(周志华著,俗称西瓜书)。
线性模型基本形式首先是最基本的线性模型:f(x)=w1x1+w2x2+w3x3+.+wnxn+bf( textbf{x} )=w_1x_1+w_2x_2+w_3x_3+.+w_nx_n+bf(x)=w1?x1?+w 2?x2?+w3?x3?+.+wn?xn?+b化简成向量形式f(x)=xw+bf( textbf{x})= textbf{x}textbf{w} +b f(x)=xw+bf(x)≈yf( textbf{x})approx yf(x)≈y其中x=(x1,x2,x3.,xn)textbf{x}=(x_1,x_2,x_3.,x_n)x=(x1?,x2?,x3?. ,xn?),xix_ixi? 代表xtextbf{x}x的第i个属性。
而w=(w1;w2;w3;.;wn)textbf{w}=(w_1;w_2;w_3;.;w_n)w=(w1?;w2?;w3 ;.;wn)对应于 xtextbf{x}x 不同属性的系数。
其中yyy代表了数据xtextbf{x}x的真实情况,而f(x)f(bf{x})f(x)得到的是对xtextbf{x}x的预测值,我们通过(y,x)(y,textbf{x})(y,x)对模型进行训练,力求通过线性模型f(x)f(bf{x})f(x)来对yyy未知的数据进行预测。
为了计算方便,令:x=(x1,x2,x3.,xn,1)textbf{x}=(x_1,x_2,x_3.,x_n,1)x=(x1?,x 2?,x3?.,xn?,1)w=(w1;w2;w3;.;wn;b)textbf{w}=(w_1;w_2;w_3;.;w _n;b)w=(w1?;w2?;w3?;.;wn?;b)线性模型就写成如下形式:f(x)=wxf( textbf{x})= textbf{w} textbf{x} f(x)=wx模型评估线性回归的目标就是要找到一个最合适的模型来使得预测的准确度最大化。
高中数学:线性回归方程

高中数学:线性回归方程一、推导2个样本点的线性回归方程例1、设有两个点A(x1,y1),B(x2,y2),用最小二乘法推导其线性回归方程并进行分析。
解:由最小二乘法,设,则样本点到该直线的“距离之和”为从而可知:当时,b有最小值。
将代入“距离和”计算式中,视其为关于b的二次函数,再用配方法,可知:此时直线方程为:设AB中点为M,则上述线性回归方程为可以看出,由两个样本点推导的线性回归方程即为过这两点的直线方程。
这和我们的认识是一致的:对两个样本点,最好的拟合直线就是过这两点的直线。
上面我们是用最小二乘法对有两个样本点的线性回归直线方程进行了直接推导,主要是分别对关于a和b的二次函数进行研究,由配方法求其最值及所需条件。
实际上,由线性回归系数计算公式:可得到线性回归方程为设AB中点为M,则上述线性回归方程为。
二、求回归直线方程例2、在硝酸钠的溶解试验中,测得在不同温度下,溶解于100份水中的硝酸钠份数的数据如下0 4 10 15 21 29 36 51 6866.7 71.0 76.3 80.6 85.7 92.9 99.4 113.6 125.1描出散点图并求其回归直线方程.解:建立坐标系,绘出散点图如下:由散点图可以看出:两组数据呈线性相关性。
设回归直线方程为:由回归系数计算公式:可求得:b=0.87,a=67.52,从而回归直线方程为:y=0.87x+67.52。
三、综合应用例3、假设关于某设备的使用年限x和所支出的维修费用y(万元)有如下统计资料:(1)求回归直线方程;(2)估计使用10年时,维修费用约是多少?解:(1)设回归直线方程为:(2)将x = 10代入回归直线方程可得y = 12.38,即使用10年时的维修费用大约是12.38万元。
线性回归案例

线性回归案例线性回归是统计学中一种常见的建模方法,用于研究自变量和因变量之间的关系。
在本文中,我们将通过一个实际的案例来介绍线性回归的应用和分析过程。
假设我们是一家房地产公司的数据分析师,公司希望了解房屋的售价与其面积之间的关系,以便更好地定价和销售房屋。
我们收集了一些房屋的数据,包括房屋的面积和售价,现在我们将利用线性回归模型来分析这些数据。
首先,我们需要对数据进行可视化分析,以便更直观地了解变量之间的关系。
我们可以绘制散点图来展现房屋面积与售价之间的关系,通过观察散点图,我们可以大致判断出是否存在线性关系,并初步了解数据的分布情况。
接下来,我们可以利用线性回归模型来拟合数据,建立房屋面积与售价之间的数学模型。
线性回归模型的数学表达式为,Y = β0 + β1X + ε,其中Y表示因变量(售价),X表示自变量(面积),β0和β1分别表示截距和斜率,ε表示误差。
通过拟合线性回归模型,我们可以得到最优的截距和斜率的估计值,从而建立起房屋面积与售价之间的线性关系。
同时,我们还可以利用拟合的模型对房屋售价进行预测,从而帮助公司更好地制定定价策略。
除了建立模型和进行预测,我们还需要对模型的拟合效果进行评估。
常用的评估指标包括均方误差(MSE)、决定系数(R-squared)等,这些指标可以帮助我们判断模型的拟合程度和预测精度,从而更好地理解房屋面积与售价之间的关系。
最后,我们需要对线性回归模型的结果进行解释和分析,从统计学的角度来解释房屋面积对售价的影响程度。
通过对模型结果的解释,我们可以为公司提供更深入的市场分析和房屋定价建议,从而更好地满足客户的需求。
通过以上实例,我们可以看到线性回归在实际数据分析中的应用和重要性。
通过建立数学模型、进行预测和评估,线性回归可以帮助我们更好地理解变量之间的关系,为决策提供更有力的支持。
希望本文的案例分析能够帮助读者更好地理解线性回归的应用和分析过程,为实际工作中的数据分析提供一些启发和帮助。
多元线性回归模型的案例讲解
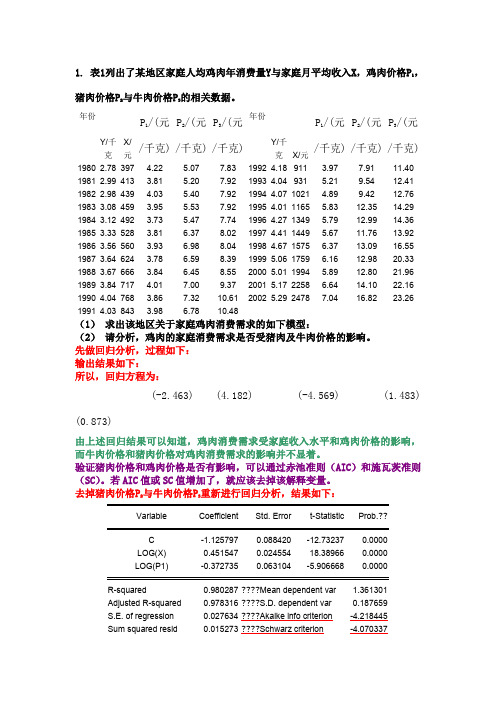
1. 表1列出了某地区家庭人均鸡肉年消费量Y与家庭月平均收入X,鸡肉价格P1,猪肉价格P2与牛肉价格P3的相关数据。
年份Y/千克X/元P1/(元/千克)P2/(元/千克)P3/(元/千克)年份Y/千克X/元P1/(元/千克)P2/(元/千克)P3/(元/千克)1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.401981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.411982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.761983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.291984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.361985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.921986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.551987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.331988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.961989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.161990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.261991 4.03 843 3.98 6.78 10.48(1)求出该地区关于家庭鸡肉消费需求的如下模型:(2)请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。
线 性 回 归 方 程 推 导

线性回归之最小二乘法线性回归Linear Regression——线性回归是机器学习中有监督机器学习下的一种简单的回归算法。
分为一元线性回归(简单线性回归)和多元线性回归,其中一元线性回归是多元线性回归的一种特殊情况,我们主要讨论多元线性回归如果因变量和自变量之间的关系满足线性关系(自变量的最高幂为一次),那么我们可以用线性回归模型来拟合因变量与自变量之间的关系.简单线性回归的公式如下:y^=ax+b hat y=ax+by^?=ax+b多元线性回归的公式如下:y^=θTx hat y= theta^T x y^?=θTx上式中的θthetaθ为系数矩阵,x为单个多元样本.由训练集中的样本数据来求得系数矩阵,求解的结果就是线性回归模型,预测样本带入x就能获得预测值y^hat yy^?,求解系数矩阵的具体公式接下来会推导.推导过程推导总似然函数假设线性回归公式为y^=θxhat y= theta xy^?=θx.真实值y与预测值y^hat yy^?之间必然有误差?=y^?yepsilon=haty-y?=y^?y,按照中心极限定理(见知识储备),我们可以假定?epsilon?服从正态分布,正态分布的概率密度公式为:ρ(x)=1σ2πe?(x?μ)22σ2rho (x)=frac {1}{sigmasqrt{2pi}}e^{-frac{(x-mu)^2}{2sigma^2}}ρ(x)=σ2π1e2σ2(x?μ)2?为了模型的准确性,我们希望?epsilon?的值越小越好,所以正态分布的期望μmuμ为0.概率函数需要由概率密度函数求积分,计算太复杂,但是概率函数和概率密度函数呈正相关,当概率密度函数求得最大值时概率函数也在此时能得到最大值,因此之后会用概率密度函数代替概率函数做计算.我们就得到了单个样本的误差似然函数(μ=0,σmu=0,sigmaμ=0,σ为某个定值):ρ(?)=1σ2πe?(?0)22σ2rho (epsilon)=frac {1}{sigmasqrt{2pi}}e^{-frac{(epsilon-0)^2}{2sigma^2}}ρ(?)=σ2π?1?e?2σ2(?0)2?而一组样本的误差总似然函数即为:Lθ(?1,?,?m)=f(?1,?,?m∣μ,σ2)L_theta(epsilon_1,cdots,e psilon_m)=f(epsilon_1,cdots,epsilon_m|mu,sigma^2)Lθ?(?1?,? ,?m?)=f(?1?,?,?m?∣μ,σ2)因为我们假定了?epsilon?服从正态分布,也就是说样本之间互相独立,所以我们可以把上式写成连乘的形式:f(?1,?,?m∣μ,σ2)=f(?1∣μ,σ2)?f(?m∣μ,σ2)f(epsilon_1,cdots,epsilon_m|mu,sigma^2)=f(epsilon_1|mu,sigma^2)*cdots *f(epsilon_m|mu,sigma^2)f(?1?,?,?m?∣μ,σ2)=f(?1?∣μ,σ2)?f(?m?∣μ,σ2) Lθ(?1,?,?m)=∏i=1mf(?i∣μ,σ2)=∏i=1m1σ2πe?(?i?0)22σ2L_theta(epsilon_1,cdots,epsilon_m)=prod^m_{i=1}f(epsilon _i|mu,sigma^2)=prod^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(epsilon_i-0)^2}{2sigma^2}}Lθ? (?1?,?,?m?)=i=1∏m?f(?i?∣μ,σ2)=i=1∏m?σ2π?1?e?2σ2(?i?0)2?在线性回归中,误差函数可以写为如下形式:i=∣yiy^i∣=∣yiθTxi∣epsilon_i=|y_i-haty_i|=|y_i-theta^Tx_i|?i?=∣yi?y^?i?∣=∣yi?θTxi?∣最后可以得到在正态分布假设下的总似然估计函数如下:Lθ(?1,?,?m)=∏i=1m1σ2πe?(?i?0)22σ2=∏i=1m1σ2πe?(yi θTxi)22σ2L_theta(epsilon_1,cdots,epsilon_m)=prod^m_{i=1} frac{1}{sigmasqrt{2pi}}e^{-frac{(epsilon_i-0)^2}{2sigma^2}}=pro d^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}L θ?(?1?,?,?m?)=i=1∏m?σ2π?1?e?2σ2(?i?0)2?=i=1∏m?σ2π?1 e2σ2(yi?θTxi?)2?推导损失函数按照最大总似然的数学思想(见知识储备),我们可以试着去求总似然的最大值.遇到连乘符号的时候,一般思路是对两边做对数运算(见知识储备),获得对数总似然函数:l(θ)=loge(Lθ(?1,?,?m))=loge(∏i=1m1σ2πe?(yi?θTxi)22σ2)l(theta)=log_e(L_theta(epsilon_1,cdots,epsilon_m))=log_ e(prod^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}) l(θ)=loge?(Lθ?(?1?,?,?m?))=loge?(i=1∏m?σ2π?1?e?2σ2(yi θTxi?)2?)l(θ)=loge(∏i=1m1σ2πe?(yi?θTxi)22σ2)=∑i=1mloge1σ2πexp(?(yi?θTxi)22σ2)=mloge1σ2π?12σ2∑i=1m(yi?θTxi)2l (theta) = log_e(prod^m_{i=1}frac {1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}) = sum_{i=1}^mlog_efrac {1}{sigmasqrt{2pi}}exp({-frac{(y_i-theta^Tx_i)^2}{2sigma^2} })=mlog_efrac{1}{sigmasqrt{2pi}}-frac{1}{2sigma^2}sum^m_{i= 1}(y^i-theta^Tx^i)^2l(θ)=loge?(i=1∏m?σ2π?1?e?2σ2(yi?θTxi?)2?)=i=1∑m?loge?σ2π?1?exp(?2σ2(yi?θTxi?)2?)=mloge?σ2π?1?2σ21?i=1∑m?(yi?θTxi)2前部分是一个常数,后部分越小那么总似然值越大,后部分则称之为损失函数,则有损失函数的公式J(θ)J(theta)J(θ):J(θ)=12∑i=1m(yi?θTxi)2=12∑i=1m(yi?hθ(xi))2=12∑i=1m (hθ(xi)?yi)2J(theta)=frac{1}{2}sum^m_{i=1}(y^i-theta^Tx^i)^2=frac{1}{2} sum^m_{i=1}(y^i-h_theta(x^i))^2=frac{1}{2}sum^m_{i=1}(h_the ta(x^i)-y^i)^2J(θ)=21?i=1∑m?(yi?θTxi)2=21?i=1∑m?(yi?hθ?(xi))2=21?i=1∑m?(hθ?(xi)?yi)2解析方法求解线性回归要求的总似然最大,需要使得损失函数最小,我们可以对损失函数求导.首先对损失函数做进一步推导:J(θ)=12∑i=1m(hθ(xi)?yi)2=12(Xθ?y)T(Xθ?y)J(theta)=fr ac{1}{2}sum^m_{i=1}(h_theta(x^i)-y^i)^2=frac{1}{2}(Xtheta-y )^T(Xtheta-y)J(θ)=21?i=1∑m?(hθ?(xi)?yi)2=21?(Xθ?y)T(Xθy)注意上式中的X是一组样本形成的样本矩阵,θthetaθ是系数向量,y也是样本真实值形成的矩阵,这一步转换不能理解的话可以试着把12(Xθ?y)T(Xθ?y)frac{1}{2}(Xtheta-y)^T(Xtheta-y)21?(Xθ?y) T(Xθ?y)带入值展开试试.J(θ)=12∑i=1m(hθ(xi)?yi)2=12(Xθ?y)T(Xθ?y)=12((Xθ)T? yT)(Xθ?y)=12(θTXT?yT)(Xθ?y)=12(θTXTXθ?yTXθ?θTXTy+yTy)J(theta)=frac{1}{2}sum^m_{i=1}(h_theta(x^i)-y^i)^2=frac{1} {2}(Xtheta-y)^T(Xtheta-y)=frac{1}{2}((Xtheta)^T-y^T)(Xtheta -y)=frac{1}{2}(theta^TX^T-y^T)(Xtheta-y)=frac{1}{2}(theta^T X^TXtheta-y^TXtheta-theta^TX^Ty+y^Ty)J(θ)=21?i=1∑m?(hθ?( xi)?yi)2=21?(Xθ?y)T(Xθ?y)=21?((Xθ)T?yT)(Xθ?y)=21?(θTXT yT)(Xθ?y)=21?(θTXTXθ?yTXθ?θTXTy+yTy)根据黑塞矩阵可以判断出J(θ)J(theta)J(θ)是凸函数,即J(θ)J(theta)J(θ)的对θthetaθ的导数为零时可以求得J(θ)J(theta)J(θ)的最小值.J(θ)?θ=12(2XTXθ?(yTX)T?XTy)=12(2XTXθ?XTy?XTy)=XTXθXTyfrac{partialJ(theta)}{partialtheta}=frac{1}{2}(2X^TXtheta-(y^TX)^T-X^Ty )=frac{1}{2}(2X^TXtheta-X^Ty-X^Ty)=X^TXtheta-X^Ty?θ?J(θ)? =21?(2XTXθ?(yTX)T?XTy)=21?(2XTXθ?XTy?XTy)=XTXθ?XTy 当上式等于零时可以求得损失函数最小时对应的θthetaθ,即我们最终想要获得的系数矩阵:XTXθ?XTy=0XTXθ=XTy((XTX)?1XTX)θ=(XTX)?1XTyEθ=(XTX)?1 XTyθ=(XTX)?1XTyX^TXtheta-X^Ty=0X^TXtheta=X^Ty((X^TX)^{-1}X^TX)theta=(X^TX)^{-1}X^TyEtheta=(X^TX)^{-1}X^Tytheta=(X^TX)^{-1}X^TyXTXθ?XTy=0XT Xθ=XTy((XTX)?1XTX)θ=(XTX)?1XTyEθ=(XTX)?1XTyθ=(XTX)?1XTy (顺便附上一元线性回归的系数解析解公式:θ=∑i=1m(xi?x ̄)(yi?y ̄)∑i=1m(xi?x  ̄)2theta=frac{sum^m_{i=1}(x_i-overline{x})(y_i-overline{y} )}{sum^m_{i=1}(x_i-overline{x})^2}θ=∑i=1m?(xi?x)2∑i=1m?( xi?x)(yi?y?)?)简单实现import numpy as npimport matplotlib.pyplot as plt# 随机创建训练集,X中有一列全为'1'作为截距项X = 2 * np.random.rand(100, 1)y = 5 + 4 * X + np.random.randn(100, 1)X = np.c_[np.ones((100,1)),X]# 按上面获得的解析解来求得系数矩阵thetatheta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)# 打印结果print(theta)# 测试部分X_test = np.array([[0],X_test = np.c_[(np.ones((2, 1))), X_test]print(X_test)y_predict = X_test.dot(theta)print(y_predict)plt.plot(X_test[:,-1], y_predict, 'r-')plt.axis([0, 2, 0, 15])plt.show()sklearn实现import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegression X = 2 * np.random.rand(100, 1)y = 5 + 4 * X + np.random.randn(100, 1)X = np.c_[np.ones((100,1)),X]# 新建线性回归模型model = LinearRegression(fit_intercept=False)# 代入训练集数据做训练model.fit(X,y)# 打印训练结果print(model.intercept_,model.coef_)X_test = np.array([[0],X_test = np.c_[(np.ones((2, 1))), X_test]print(X_test)y_predict =model.predict(X_test)print(y_predict)plt.plot(X_test[:,-1], y_predict, 'r-')plt.axis([0, 2, 0, 15])plt.show()使用解析解的公式来求得地模型是最准确的.计算量非常大,这会使得求解耗时极多,因此我们一般用的都是梯度下降法求解.知识储备距离公式机器学习中常见的距离公式 - WingPig - 博客园中心极限定理是讨论随机变量序列部分和分布渐近于正态分布的一类定理。
线性回归计算方法及公式PPT课件

(y = ax + b)
解释
其中(y)是因变量,(a)是斜率,(x)是自变量,(b)是截距。
实例二:多元线性回归分析
总结词
多个自变量的线性关系
详细描述
多元线性回归分析研究因变量与多个自变量之间的线性关 系。通过引入多个自变量,可以更全面地描述因变量的变 化规律。
公式
(y = a_1x_1 + a_2x_2 + ... + a_nx_n + b)
加权最小二乘法的公式
加权最小二乘法的公式是:(ŷ=β₀+β₁x₁+β₂x₂+...+βₙxₙ)其中,(w_i)是加权因 子,用于对不同观测值赋予不同的权重。
加权最小二乘法适用于数据存在异方差性的情况,通过给不同观测值赋予不同的 权重,能够更好地拟合数据。
主成分回归的公式
主成分回归的公式是:(ŷ=β₀+β₁z₁+β₂z₂+...+βₙzₙ)其中, (z_i)是主成分得分,通过对原始自变量进行线性变换得到。
误差项独立同分布
误差项被假设是相互独立的,并且具有相 同的分布(通常是正态分布)。
误差项无系统偏差
自变量无多重共线性
误差项被假设没有系统偏差,即它们不随 着自变量或因变量的值而变化。
自变量之间被假设没有多重共线性,即它 们是独立的或相关性很低。
02
线性回归模型
模型建立
确定因变量和自变量
首先需要确定研究的因变量和自变量, 以便建立线性回归模型。
以提供更稳定和准确的估 计。
(y = (X^T X + lambda I)^{1}X^T y)
其中(y)是因变量,(X)是自变量 矩阵,(lambda)是正则化参数
线性回归数学推导

线性回归数学推导⼀、数学基础似然函数概率(probability):描述已知参数时的随机变量的输出结果;似然函数(likelihood):⽤来描述已知随机变量输出结果时,未知参数的可能取值。
\[L(\theta | x) = f(x | \theta) \]似然函数和密度函数是完全不同的两个数学对象,前者是关于\(\theta\)的函数,后者是关于\(x\)的函数。
⾼斯分布数学期望(mean):试验中,每次可能结果的概率乘以其结果的总和。
(伯努利)⼤数定律:当试验次数⾜够多时,事件发⽣的频率⽆穷接近于该事件发⽣的概率。
伯努利试验:设试验E只可能有两种结果:“A”和“⾮A”n重伯努利试验:将E独⽴的重复地进⾏n次,则称这⼀穿重复的独⽴试验为n重伯努利试验⼆项分布(伯努利分布):将⼀伯努利试验重复了n次,在这n次试验中成功次数k,k为随机变量,称为⼆次随机变量,其分布称为⼆项分布\[P(X = k) = C_n^kp^k(1-p)^{n-k} , k = 1,2,...,n \]正态分布:⼜称“⾼斯分布”\[f(x) = \frac 1 {\sqrt{2 \pi }\sigma} e ^ {- \frac {(x^2-\mu^2)} {2\sigma^2}} \]对数公式\[\log AB = \log A + \log B \]矩阵计算矩阵转置:⾏变列,列变⾏。
矩阵乘法:A的列数必须与B的⾏数相等\[A = \left[ \begin{matrix} a & b & c \end{matrix} \right] \\\\ B = \left[ \begin{matrix} e & f & g \end{matrix} \right] \\\\ A^T B = ae + bf + cg \]矩阵求导\[\frac {d( { x ^ T A X } )} {d(x)} = 2Ax \\\\ \frac {d( { x ^ T A } )} {d(x)} = A \\\\ \frac {d( { A x} )} {d(x)} = {A ^ T} \]⼆、推导线性回归公式\[y = wx + b \]当存在多个特征参数的时候,不同的特征参数对⽬标函数值有不同的权重参数。
多元线性回归公式推导及R语言实现

多元线性回归公式推导及R语⾔实现多元线性回归多元线性回归模型实际中有很多问题是⼀个因变量与多个⾃变量成线性相关,我们可以⽤⼀个多元线性回归⽅程来表⽰。
为了⽅便计算,我们将上式写成矩阵形式:Y = XW假设⾃变量维度为NW为⾃变量的系数,下标0 - NX为⾃变量向量或矩阵,X维度为N,为了能和W0对应,X需要在第⼀⾏插⼊⼀个全是1的列。
Y为因变量那么问题就转变成,已知样本X矩阵以及对应的因变量Y的值,求出满⾜⽅程的W,⼀般不存在⼀个W是整个样本都能满⾜⽅程,毕竟现实中的样本有很多噪声。
最⼀般的求解W的⽅式是最⼩⼆乘法。
最⼩⼆乘法我们希望求出的W是最接近线性⽅程的解的,最接近我们定义为残差平⽅和最⼩,残差的公式和残差平⽅和的公式如下:上⾯的公式⽤最⼩残差平⽅和的⽅式导出的,还有⼀种思路⽤最⼤似然的⽅式也能推导出和这个⼀样的公式,⾸先对模型进⾏⼀些假设:误差等⽅差不相⼲假设,即每个样本的误差期望为0,每个样本的误差⽅差都为相同值假设为σ误差密度函数为正态分布 e ~ N(0, σ^2)简单推导如下:由此利⽤最⼤似然原理导出了和最⼩⼆乘⼀样的公式。
最⼩⼆乘法求解⼆次函数是个凸函数,极值点就是最⼩点。
只需要求导数=0解出W即可。
模拟数据我们这⾥⽤R语⾔模拟实践⼀下,由于我们使⽤的矩阵运算,这个公式⼀元和多元都是兼容的,我们为了可视化⽅便⼀点,我们就⽤R语⾔⾃带的women数据做⼀元线性回归,和多元线性回归的⽅式基本⼀样。
women数据如下> womenheight weight1 58 1152 59 1173 60 1204 61 1235 62 1266 63 1297 64 1328 65 1359 66 13910 67 14211 68 14612 69 15013 70 15414 71 15915 72 164体重和⾝⾼具有线性关系,我们做⼀个散点图可以看出来:我们⽤最⼩⼆乘推导出来的公式计算w如下X <- cbind(rep(1, nrow(women)), women$height)X.T <- t(X)Y <- women$weightw <- solve(X.T %*% X) %*% X.T %*% Y> w[,1][1,] -87.51667[2,] 3.45000> lm.result <- lm(women$weight~women$height)> lm.resultCall:lm(formula = women$weight ~ women$height)Coefficients:(Intercept) women$height-87.52 3.45上⾯的R代码w使我们利⽤公式计算出来的,下边是R语⾔集成的线性回归函数拟合出来的,可以看出我们的计算结果是正确的,lm的只是⼩数点取了两位⽽已,将回归出来的函数画到图中看下回归的效果。
一次线性回归分析详解及推导
⼀次线性回归分析详解及推导线性回归 linear regression我们需要根据⼀个⼈的⼯作年限 来预测他的 薪酬 (我们假设⼀个⼈的薪酬只要⼯作年限有关系)。
⾸先引⼊必要的类库,并且获得trainning data 。
import tensorflow as tfimport pandas as pdimport numpy as npunrate = pd.read_csv('SD.csv')print(unrate)Year Salary0 1.0 394511 1.2 463132 1.4 378393 1.9 436334 2.1 39999.. ... ...85 12.0 10624786 12.5 11763487 12.6 11330088 13.3 12305689 13.5 122537[90 rows x 2 columns]接着,我们⽤matplotlib 绘制出⼯作年限和薪酬之间的关系的点状图,⽅便我们更加直观的感受他们之间的关系。
from matplotlib import pyplot as pltunrate = unrate.sort_values('Year')plt.scatter(unrate['Year'],unrate['Salary'])plt.show()根据上图的关系,我们可以看到:他们基本上还是成正相关的。
考虑到只有⼀维数据,我们假定存在⼀个函数,可以描述⼯作年限和薪酬之间的关系。
我们假定该函数为:ˆy=Wx +b ˆy 即为我们根据模型预测出来的数值。
ˆ(y ) 和实际数值y 之间的距离,即为我们预测的偏差值。
即:loss =n ∑i =0(y i −ˆy i)2</p>我们先随机的挑选W 和b ,并且计算⼀下loss 。
同时绘制出来预测的数值与原来的数值。
w = np.random.rand(1)b = np.random.rand(1)y_pred = (unrate['Year']*w + b)loss = np.power((unrate['Year']*w + b)-unrate['Salary'],2).sum()plt.scatter(unrate['Year'],unrate['Salary'])plt.plot(unrate['Year'],y_pred)plt.show()print(w)print(b)print(loss)[0.31944837][0.48968515]698967170603.215我们可以看到差距还是⽐较⼤的。
线性回归推导及实例

数据点基本落在一条直线附近。
这告诉我们,变量X与Y的关系大致可看作是线性关系,即它们之间的相互关系可以用线性关系来描述。
但是由于并非所有的数据点完全落在一条直线上,因此X与Y的关系并没有确切到可以唯一地由一个X值确定一个Y值的程度。
其它因素,诸如其它微量元素的含量以及测试误差等都会影响Y的测试结果。
如果我们要研究X与Y的关系,可以作线性拟合(2-1-1)我们称(2-1-1)式为回归方程,a与b是待定常数,称为回归系数。
从理论上讲,(2-1-1)式有无穷多组解,回归分析的任务是求出其最佳的线性拟合。
二、最小二乘法原理如果把用回归方程计算得到的i值(i=1,2,…n)称为回归值,那么实际测量值y i与回归值i之间存在着偏差,我们把这种偏差称为残差,记为e i(i=1,2,3,…,n)。
这样,我们就可以用残差平方和来度量测量值与回归直线的接近或偏差程度。
残差平方和定义为:(2-1-2)所谓最小二乘法,就是选择a和b使Q(a,b)最小,即用最小二乘法得到的回归直线是在所有直线中与测量值残差平方和Q最小的一条。
由(2-1-2)式可知Q是关于a,b的二次函数,所以它的最小值总是存在的。
下面讨论的a和b的求法。
三、正规方程组根据微分中求极值的方法可知,Q(a,b)取得最小值应满足(2-1-3)由(2-1-2)式,并考虑上述条件,则(2-1-4)(2-1-4)式称为正规方程组。
解这一方程组可得(2-1-5) 其中(2-1-6)(2-1-7) 式中,L xy称为xy的协方差之和,L xx称为x的平方差之和。
如果改写(2-1-1)式,可得(2-1-8) 或(2-1-9)由此可见,回归直线是通过点的,即通过由所有实验测量值的平均值组成的点。
从力学观点看,即是N个散点的重心位置。
现在我们来建立关于例1的回归关系式。
将表2-1-1的结果代入(2-1-5)式至(2-1-7)式,得出a=1231.65b=-2236.63因此,在例1中灰铸铁初生奥氏体析出温度(y)与氮含量(x)的回归关系式为y=1231.65-2236.63x四、一元线性回归的统计学原理如果X和Y都是相关的随机变量,在确定x的条件下,对应的y值并不确定,而是形成一个分布。
线 性 回 归 方 程 推 导 ( 2 0 2 0 )

多元线性回归推导过程常用算法一多元线性回归详解1此次我们来学习人工智能的第一个算法:多元线性回归.文章会包含必要的数学知识回顾,大部分比较简单,数学功底好的朋友只需要浏览标题,简单了解需要哪些数学知识即可.本章主要包括以下内容数学基础知识回顾什么是多元线性回归多元线性回归的推导过程详解如何求得最优解详解数学基础知识回顾我们知道,y=ax+b这个一元一次函数的图像是一条直线.当x=0时,y=b,所以直线经过点(0,b),我们把当x=0时直线与y轴交点到x轴的距离称为直线y=ax+b图像在x轴上的截距,其实截距就是这个常数b.(有点拗口,多读两遍)截距在数学中的定义是:直线的截距分为横截距和纵截距,横截距是直线与X轴交点的横坐标,纵截距是直线与Y轴交点的纵坐标。
根据上边的例子可以看出,我们一般讨论的截距默认指纵截距.既然已知y=ax+b中b是截距,为了不考虑常数b的影响,我们让b=0,则函数变为y=ax.注意变换后表达式的图像.当a=1时,y=ax的图像是经过原点,与x轴呈45°夹角的直线(第一,三象限的角平分线),当a的值发生变化时,y=ax 的图像与x轴和y轴的夹角也都会相应变化,我们称为这条直线y=ax的倾斜程度在发生变化,又因为a是决定直线倾斜程度的唯一的量(即便b不等于0也不影响倾斜程度),那么我们就称a为直线y=ax+b的斜率.斜率在数学中的解释是表示一条直线(或曲线的切线)关于(横)坐标轴倾斜程度的量.还是y=ax+b,我们知道这个函数的图像是一条直线,每个不同的x对应着直线上一点y.那么当自变量x的值变化的时候,y值也会随之变化.数学中我们把x的变化量成为Δx,把对应的y的变化量成为Δy,自变量的变化量Δx与因变量的变化量Δy的比值称为导数.记作y'.y'=Δy-Δx常用的求导公式在这部分不涉及,我们用到一个记住一个即可.4-矩阵和向量什么是向量:向量就是一个数组.比如[1,2,3]是一个有三个元素的向量.有行向量和列向量之分,行向量就是数字横向排列:X=[1,2,3],列向量是数字竖向排列,如下图什么是矩阵:矩阵就是元素是数组的数组,也就是多维数组,比如[[1,2,3],[4,5,6]]是一个两行三列的矩阵,也叫2*3的矩阵. 行代表内层数组的个数,列代表内层数组的元素数.一个矩阵中的所有数组元素相同.5-向量的运算:一个数乘以一个向量等于这个数同向量中的每个元素相乘,结果还是一个向量.2 * [1,2,3] = [2,4,6]一个行向量乘以一个列向量,是两个向量对位相乘再相加,结果是一个实数.= 11 + 22 + 3*3 = 14附加:转置转置用数学符号T来表示,比如W向量的转置表示为.转置就是将向量或者矩阵旋转九十度.一个行向量的转置是列向量,列向量的转置是行向量.一个m*n的矩阵转置是n*m的矩阵.注:以上概念完全是为了读者能容易理解,并不严谨,若想知道上述名词的严谨解释,请自行百度.什么是多元线性回归我们知道y=ax+b是一元一次方程,y=ax1+bx2+c(1和2是角标,原谅我的懒)是二元一次方程.其中,"次"指的是未知数的最大幂数,"元"指的是表达式中未知数的个数(这里就是x的个数).那么"多元"的意思可想而知,就是表达式中x(或者叫自变量,也叫属性)有很多个.当b=0时,我们说y=ax,y和x的大小始终符合y-x=a,图像上任意一点的坐标,y值都是x值的a倍.我们把这种横纵坐标始终呈固定倍数的关系叫做"线性".线性函数的图像是一条直线.所以我们知道了多元线性回归函数的图像一定也是一条直线.现在我们知道了多元线性回归的多元和线性,而回归的概念我们在人工智能开篇(很简短,请点搜索"回归"查看概念)中有讲述,所以多元线性回归就是:用多个x(变量或属性)与结果y的关系式来描述一些散列点之间的共同特性.这些x和一个y关系的图像并不完全满足任意两点之间的关系(两点一线),但这条直线是综合所有的点,最适合描述他们共同特性的,因为他到所有点的距离之和最小也就是总体误差最小.所以多元线性回归的表达式可以写成:y= w0x0 + w1x1 + w2x2 + . + wnxn (0到n都是下标哦)我们知道y=ax+b这个线性函数中,b表示截距.我们又不能确定多元线性回归函数中预测出的回归函数图像经过原点,所以在多元线性回归函数中,需要保留一项常数为截距.所以我们规定 y= w0x0 + w1x1 + w2x2 + . + wnxn中,x0=1,这样多元线性回归函数就变成了: y= w0 + w1x1 + w2x2 + . + wnxn,w0项为截距.如果没有w0项,我们 y= w0x0 + w1x1 + w2x2 + . + wnxn就是一个由n+1个自变量所构成的图像经过原点的直线函数.那么就会导致我们一直在用一条经过原点的直线来概括描述一些散列点的分布规律.这样显然增大了局限性,造成的结果就是预测出的结果函数准确率大幅度下降.有的朋友还会纠结为什么是x0=1而不是x2,其实不管是哪个自变量等于1,我们的目的是让函数 y= w0x0 + w1x1 + w2x2 + . + wnxn编程一个包含常数项的线性函数.选取任何一个x都可以.选x0是因为他位置刚好且容易理解.多元线性回归的推导过程详解1-向量表达形式我们前边回顾了向量的概念,向量就是一个数组,就是一堆数.那么表达式y= w0x0 + w1x1 + w2x2 + . + wnxn是否可以写成两个向量相乘的形式呢?让我们来尝试一下.假设向量W= [w1,w2.wn]是行向量,向量X= [x1,x2.xn],行向量和列向量相乘的法则是对位相乘再相加, 结果是一个实数.符合我们的逾期结果等于y,所以可以将表达式写成y=W * X.但是设定两个向量一个是行向量一个是列向量又容易混淆,所以我们不如规定W和X都为列向量.所以表达式可以写成 (还是行向量)与向量X 相乘.所以最终的表达式为:y= * X,其中也经常用θ(theta的转置,t是上标)表示.此处,如果将两个表达式都设为行向量,y=W * 也是一样的,只是大家为了统一表达形式,选择第一种形式而已.2-最大似然估计最大似然估计的意思就是最大可能性估计,其内容为:如果两件事A,B 相互独立,那么A和B同时发生的概率满足公式P(A , B) = P(A) * P(B)P(x)表示事件x发生的概率.如何来理解独立呢?两件事独立是说这两件事不想关,比如我们随机抽取两个人A和B,这两个人有一个共同特性就是在同一个公司,那么抽取这两个人A和B的件事就不独立,如果A和B没有任何关系,那么这两件事就是独立的.我们使用多元线性回归的目的是总结一些不想关元素的规律,比如以前提到的散列点的表达式,这些点是随机的,所以我们认为这些点没有相关性,也就是独立的.总结不相关事件发生的规律也可以认为是总结所有事件同时发生的概率,所有事情发生的概率越大,那么我们预测到的规律就越准确.这里重复下以前我们提到的观点.回归的意思是用一条直线来概括所有点的分布规律,并不是来描述所有点的函数,因为不可能存在一条直线连接所有的散列点.所以我们计算出的值是有误差的,或者说我们回归出的这条直线是有误差的.我们回归出的这条线的目的是用来预测下一个点的位置.考虑一下,一件事情我们规律总结的不准,原因是什么?是不是因为我们观察的不够细或者说观察的维度不够多呢?当我们掷一个骰子,我们清楚的知道他掷出的高度,落地的角度,反弹的力度等等信息,那上帝视角的我们是一定可以知道他每次得到的点数的.我们观测不到所有的信息,所以我们认为每次投骰子得到的点数是不确定的,是符合一定概率的,未观测到的信息我们称为误差.一个事件已经观察到的维度发生的概率越大,那么对应的未观测到的维度发生的概率就会越小.可以说我们总结的规律就越准确.根据最大似然估计P(y) = P(x1,x2 . xn)= P(x1) * P(x2) . P(xn)当所有事情发生的概率为最大时,我们认为总结出的函数最符合这些事件的实际规律.所以我们把总结这些点的分布规律问题转变为了求得P(x1,x2 . xn)= P(x1) * P(x2) . P(xn)的发生概率最大.3-概率密度函数数学中并没有一种方法来直接求得什么情况下几个事件同时发生的概率最大.所以引用概率密度函数.首先引入一点概念:一个随机变量发生的概率符合高斯分布(也叫正太分布).此处为单纯的数学概念,记住即可.高斯分布的概率密度函数还是高斯分布.公式如下:公式中x为实际值,u为预测值.在多元线性回归中,x就是实际的y,u 就是θ * X.既然说我们要总结的事件是相互独立的,那么这里的每个事件肯定都是一个随机事件,也叫随机变量.所以我们要归纳的每个事件的发生概率都符合高斯分布.什么是概率密度函数呢?它指的就是一个事件发生的概率有多大,当事件x带入上面公式得到的值越大,证明其发生的概率也越大.需要注意,得到的并不是事件x发生的概率,而只是知道公式的值同发生的概率呈正比而已.如果将y= θT* X中的每个x带入这个公式,得到如下函数求得所有的时间发生概率最大就是求得所有的事件概率密度函数结果的乘积最大,则得到:求得最大时W的值,则总结出了所有事件符合的规律.求解过程如下(这里记住,我们求得的是什么情况下函数的值最大,并不是求得函数的解):公式中,m为样本的个数,π和σ为常数,不影响表达式的大小.所以去掉所有的常数项得到公式:因为得到的公式是一个常数减去这个公式,所以求得概率密度函数的最大值就是求得这个公式的最小值.这个公式是一个数的平方,在我国数学资料中把他叫做最小二乘公式.所以多元线性回归的本质就是最小二乘.J(w)′=2(Y?Xw)TXJ(w)^{#x27;}=2(Y-Xtextbf{w})^TXJ(w)′=2(Y?Xw )TXSystem.out.print("("+xy[0]+",");X为自变量向量或矩阵,X维度为N,为了能和W0对应,X需要在第一行插入一个全是1的列。
线性回归案例ppt课件

2003-1 -1.151 -0.331 0.299 4.085 0.188 11.919 0.004 0.078 21.492 -0.403
2003-2 0.338 -0.611 0.3 1.402 5.369 18.418 -0.669 0.167 20.456 0.211
2003-3 0.722 0.794 0.016 -2.929 0.749 -20.886 -0.733 0.327 21.532 1.085
.
回归分析的根本目的
探寻因变量同自变量之是的数量关系,为此需假设它们之间 的数量关系满足某种函数形式,而最简单最常用的函数形式 就是线性函数。
y i0 1 x i1 2 x i2 p x ip i i1,2,...n,
➢ 其中 0为常 ,j数 (j1,项 2, ,p)为第 j 个解释性变量 xij
…
…
…
…
…
…
…
…
…
…
…
2002-498 0.3 0.5 0.255 3.167 2.5 16.795 -1.419 -0.071 19.701 -0.25
2002-499 0.484 0.127 0.287 -2.593 2.473 -4.511 0.4 0.184 20.199 0.884
2002-500 0.063 -0.416 0 -1.739 2.482 -4.809 1.793 -0.009 19.747 1.017
.
预测
.
令R
2 i
为辅助回归的判定系数
则方差膨胀因子为:
VIFi
1 1 Ri2
它反映了在多大程度上第i个自变量所包含的信息
被其他自变量覆盖
• 当VIF≥10时,说明存在多重共线性。
线性回归算法原理推导
线性回归算法原理推导机器学习的有监督算法分为分类和回归两种。
回归:通过输⼊的数据,预测出⼀个值,如银⾏贷款,预测银⾏给你贷多少钱。
分类:通过输⼊的数据,得到类别。
如,根据输⼊的数据,银⾏判断是否给你贷款。
⼀、线性回归 现在这⾥有⼀个例⼦ 数据:⼯资和年龄(2个特征) ⽬标:预测银⾏会贷款给我多少钱(标签) 考虑:⼯资和年龄都会影响最终银⾏贷款的结果那么它们各⾃有多⼤的影响呢?(参数)⼯资年龄额度40002520000800030700005000283500075003350000120004085000 输⼊为⼯资和年龄,输出为银⾏贷款的额度。
那么输⼊和输出到底有什么关系呢? 假设X1,X2就是我们的两个特征(年龄,⼯资),Y是银⾏最终会借给我们多少钱 线性回归呢就是找到最合适的⼀条线(想象⼀个⾼维)来最好的拟合我们的数据点,那么这个地⽅因为⾃变量涉及两个,所以最终⽬的就是找出⼀个拟合平⾯。
那么现在继续假设θ1是年龄的参数,θ2是⼯资的参数。
那么拟合的平⾯表达式为(θ0为偏置项,θ1、θ2为权重参数): 这⾥的话总共有两个特征,那么当有n个特征的时候的表达式为(θ0对应的X0全为1):⼆、误差 真实值和预测值之间肯定是要存在差异的(⽤ε来表⽰该误差),⽽对于每个样本来说,真实值等于预测值加上误差值,公式表达为:误差ε(i)是独⽴并且具有相同的分布,并且服从均值为0⽅差为θ2的⾼斯分布(正态分布)。
独⽴:张三和李四⼀起来贷款,他俩没关系。
同分布:他俩都来得是我们假定的这家银⾏。
⾼斯分布:银⾏可能会多给,也可能会少给,但是绝⼤多数情况下这个浮动不会太⼤,极⼩情况下浮动会⽐较⼤,符合正常情况。
预测值与误差: 由于误差服从⾼斯分布: 将两个式⼦整合得到: 似然函数(什么样的参数跟我们的数据组合后(这个组合后的值就是预测值)恰好是真实值),最⼤似然估计(参数跟数据组合后恰好是真实值的概率是最⼤的),下⾯两个竖线数学符号的意思是进⾏累乘。
第五讲 线性回归

1、模型检验
目的在于检验模型中所有自变量系数是否全部为0,当自 变量系数不全为0时,Y与(X1,X2,„,XK)才具有某种程度 的函数关系 。 零假设及对立假设: H0: j=0, 对所有j H1: j0 ,对某些j(j=1,2,„,K) 检验统计量:
或
Yn1 Xn(k1) β(k 1)1 εn1
其中:(模型假设条件)
E( i ) 0 i = 1,, n ,各组误差项的条件平均数为0。条件平均 条件下,第i组的平均数为0。 V ( i ) 2 i = 1,, n ,误差项的条件方差均相同为 2 ,具方 2 为 Y / X X X 。 i ~ N ,误差项为正态分配。 i Cov( i , j ) 0 i j,, j = 1,, n ,任何两组误差项不相关,或协方 关或称无序列相关。 Cov( X j , i ) 0 j = 1,, k,i = 1,, n ,误差项 i 与k个自变数无关
描出散点图发现:随着收入的增加,消费“平均地说” 也在增加,且Y的条件均值均落在一根正斜率的直线上。 这条直线称为回归线。
3500 每 月 消 费 支 出 Y (元) 3000 2500 2000 1500 1000 500 0 500 1000 1500 2000 2500 3000 3500 4000
ry . x1 ,xk R 2 可证,Y与X的多重相关系数
线性回归模型的意义
考虑一元的情形,随机变量y与可控变量之间存在这样一 种关系,其均值随自变量变化而变化。
Y
* * * * * * * * * * * * * * * * * * *
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据点基本落在一条直线附近。
这告诉我们,变量X与Y的关系大致可看作是线性关系,即它们之间的相互关系可以用线性关系来描述。
但是由于并非所有的数据点完全落在一条直线上,因此X与Y的关系并没有确切到可以唯一地由一个X值确定一个Y值的程度。
其它因素,诸如其它微量元素的含量以及测试误差等都会影响Y的测试结果。
如果我们要研究X与Y的关系,可以作线性拟合(2-1-1)我们称(2-1-1)式为回归方程,a与b是待定常数,称为回归系数。
从理论上讲,(2-1-1)式有无穷多组解,回归分析的任务是求出其最佳的线性拟合。
二、最小二乘法原理如果把用回归方程计算得到的i值(i=1,2,…n)称为回归值,那么实际测量值y i与回归值i之间存在着偏差,我们把这种偏差称为残差,记为e i(i=1,2,3,…,n)。
这样,我们就可以用残差平方和来度量测量值与回归直线的接近或偏差程度。
残差平方和定义为:(2-1-2)所谓最小二乘法,就是选择a和b使Q(a,b)最小,即用最小二乘法得到的回归直线是在所有直线中与测量值残差平方和Q最小的一条。
由(2-1-2)式可知Q是关于a,b的二次函数,所以它的最小值总是存在的。
下面讨论的a和b的求法。
三、正规方程组根据微分中求极值的方法可知,Q(a,b)取得最小值应满足(2-1-3)由(2-1-2)式,并考虑上述条件,则(2-1-4)(2-1-4)式称为正规方程组。
解这一方程组可得(2-1-5) 其中(2-1-6)(2-1-7) 式中,L xy称为xy的协方差之和,L xx称为x的平方差之和。
如果改写(2-1-1)式,可得(2-1-8) 或(2-1-9) 由此可见,回归直线是通过点的,即通过由所有实验测量值的平均值组成的点。
从力学观点看,即是N个散点的重心位置。
现在我们来建立关于例1的回归关系式。
将表2-1-1的结果代入(2-1-5)式至(2-1-7)式,得出a=1231.65b=-2236.63因此,在例1中灰铸铁初生奥氏体析出温度(y)与氮含量(x)的回归关系式为y=1231.65-2236.63x四、一元线性回归的统计学原理如果X和Y都是相关的随机变量,在确定x的条件下,对应的y值并不确定,而是形成一个分布。
当X取确定的值时,Y的数学期望值也就确定了,因此Y的数学期望是x的函数,即E(Y|X=x)=f(x)(2-1-10) 这里方程f(x)称为Y对X的回归方程。
如果回归方程是线性的,则E(Y|X=x)=α+βx(2-1-11) 或Y=α+βx+ε(2-1-12) 其中ε―随机误差从样本中我们只能得到关于特征数的估计,并不能精确地求出特征数。
因此只能用f(x)的估计式来取代(2-1-11)式,用参数a和b分别作为α和β的估计量。
那么,这两个估计量是否能够满足要求呢?1. 无偏性把(x,y)的n组观测值作为一个样本,由样本只能得到总体参数α和β的估计值。
可以证明,当满足下列条件:(1)(x i,y i)是n个相互独立的观测值(2)εi是服从分布的随机变量则由最小二乘法得到的a与b分别是总体参数α和β的无偏估计,即E(a)= αE(b)=β由此可推知E()=E(y)即y是回归值在某点的数学期望值。
2. a和b的方差可以证明,当n组观测值(x i,y i)相互独立,并且D(y i)=σ2,时,a和b的方差为(2-1-13)(2-1-14)以上两式表明,a和b的方差均与x i的变动有关,x i分布越宽,则a和b的方差越小。
另外a的方差还与观测点的数量有关,数据越多,a的方差越小。
因此,为提高估计量的准确性,x i的分布应尽量宽,观测点数量应尽量多。
建立多元线性回归方程,实际上是对多元线性模型(2-2-4)进行估计,寻求估计式(2-2-3)的过程。
与一元线性回归分析相同,其基本思想是根据最小二乘原理,求解使全部观测值与回归值的残差平方和达到最小值。
由于残差平方和(2-2-5)是的非负二次式,所以它的最小值一定存在。
根据极值原理,当Q取得极值时,应满足由(2-2-5)式,即满足(2-2-6)(2-2-6)式称为正规方程组。
它可以化为以下形式(2-2-7)如果用A表示上述方程组的系数矩阵可以看出A是对称矩阵。
则有(2-2-8)式中X是多元线性回归模型中数据的结构矩阵,是结构矩阵X的转置矩阵。
(2-2-7)式右端常数项也可用矩阵D来表示即因此(2-2-7)式可写成Ab=D(2-2-10)或(2-2-11)如果A满秩(即A的行列式)那么A的逆矩阵A-1存在,则由(2-10)式和(2-11)式得的最小二乘估计为(2-2-12)也就是多元线性回归方程的回归系数。
为了计算方便往往并不先求,再求b,而是通过解线性方程组(2-2-7)来求b。
(2-2-7)是一个有p+1个未知量的线性方程组,它的第一个方程可化为(2-2-13)式中(2-2-14)将(2-2-13)式代入(2-2-7)式中的其余各方程,得(2-2-15)其中(2-2-16)将方程组(2-2-15)式用矩阵表示,则有Lb=F(2-2-17)其中于是b=L-1F(2-2-18)因此求解多元线性回归方程的系数可由(2-2-16)式先求出L,然后将其代回(2-2-17)式中求解。
求b时,可用克莱姆法则求解,也可通过高斯变换求解。
如果把b直接代入(2-2-18)式,由于要先求出L的逆矩阵,因而相对复杂一些。
例2-2-1表2-2-1为某地区土壤内含植物可给态磷(y)与土壤内所含无机磷浓度(x1)、土壤内溶于K2CO3溶液并受溴化物水解的有机磷浓度(x2)以及土壤内溶于K2CO3溶液但不溶于溴化物的有机磷(x3)的观察数据。
求y对x1,x2,x3的线性回归方程。
表2-2-1土壤含磷情况观察数据计算如下:由(2-2-16)式代入(2-2-15)式得(2-2-19)若用克莱姆法则解上述方程组,则其解为(2-2-20)其中计算得b1=1.7848,b2=-0.0834,b3=0.1611回归方程为应用克莱姆法则求解线性方程组计算量偏大,下面介绍更实用的方法——高斯消去法和消去变换。
在上一节所介绍的非线性回归分析,首先要求我们对回归方程的函数模型做出判断。
虽然在一些特定的情况下我们可以比较容易地做到这一点,但是在许多实际问题上常常会令我们不知所措。
根据高等数学知识我们知道,任何曲线可以近似地用多项式表示,所以在这种情况下我们可以用多项式进行逼近,即多项式回归分析。
一、多项式回归方法假设变量y与x的关系为p次多项式,且在x i处对y的随机误差(i=1,2,…,n)服从正态分布N(0,),则令x i1=x i, x i2=x i2,…,x ip=x i p则上述非线性的多项式模型就转化为多元线性模型,即这样我们就可以用前面介绍的多元线性回归分析的方法来解决上述问题了。
其系数矩阵、结构矩阵、常数项矩阵分别为(2-4-11)(2-4-12)(2-4-13) 回归方程系数的最小二乘估计为(2-4-14)需要说明的是,在多项式回归分析中,检验b j是否显著,实质上就是判断x的j次项x j对y是否有显著影响。
对于多元多项式回归问题,也可以化为多元线性回归问题来解决。
例如,对于(2-4-15) 令x i1=Z i1, x i2=Z i2, x i3=Z i12, x i4=Z i1Z i2, x i5=Z i22则(2-4-15)式转化为转化后就可以按照多元线性回归分析的方法解决了。
下面我们通过一个实例来进一步说明多项式回归分析方法。
一、应用举例例2-4-2某种合金中的主要成分为元素A和B,试验发现这两种元素之和与合金膨胀系数之间有一定的数量关系,试根据表2-4-3给出的试验数据找出y与x之间的回归关系。
表2-4-3例2-4-2试验数据首先画出散点图(图2-4-3)。
从散点图可以看出,y与x的关系可以用一个二次多项式来描述:i=1,2,3…,13图2-4-3例2-4-2的散点图令x i1=x i,x i2=x i2,则现在我们就可以用本篇第二章介绍的方法求出的最小二乘估计。
由表2-4-3给出的数据,求出由(2-2-16)式由此可列出二元线性方程组将这个方程组写成矩阵形式,并通过初等变换求b1,b2和系数矩阵L的逆矩阵L-1:于是b1=-13.3854b2=0.16598b0=2.3323+13.385440-0.165981603.5=271.599因此下面对回归方程作显著性检验:由(2-2-43)式S回=由(2-2-42)式S总=S残=L yy- S回=0.2572将上述结果代入表2-2-2中制成方差分析表如下:表2-4-4方差分析表查F检验表,F0。
01(2,10)=7.56, F>F0.01(2 ,10),说明回归方程是高度显著的。
下面对回归系数作显著性检验由前面的计算结果可知:b1=-13.3854b2=0.16598c11=51.125c22=7.991610-3由(2-2-54)式由(2-2-53)式检验结果说明的x一次及二次项对y都有显著影响。
Welcome To Download !!!欢迎您的下载,资料仅供参考!。