Hadoop常见错误总结
Hadoop集群常见错误收集

这里将自己在初识hadoop过程中遇到的一些错误做一个简单总结:(一)启动hadoop集群时易出现的错误:1. 错误现象:.NoRouteToHostException: No route to host.原因:master服务器上的防火墙没有关闭。
解决方法:在master上关闭防火墙: chkconfig iptables off.2. 错误现象:org.apache.hadoop.ipc.RPC: Server at JMN/10.22.1.203:9000 not available yet. /* JMN/10.22.1.203 是hadoop集群当中master的主机名/ip */ 原因:/etc/hosts中的文件被自动篡改。
解决方法: 将/etc/hosts 文件按配置文件要求改回来。
3. 错误现象:Too many fetch-failures.原因:结点间的连通不够全面。
解决方法:1)检查/etc/hosts要求本机ip对应服务器名,并且包含所有的服务器ip和服务器名。
2)检查.ssh/authorized_keys要求包含所有服务器(包括其自身)的public key。
(二)在hadoop集群的master中用命令运行例子易出现的故障:1. 错误现象:ng.OutOfMemoryError: Java heap space.原因:JVM内存不够。
解决方法:修改mapred-site.xml中mapred.child.java.opts属性的值,其默认值是-Xmx200m 可根据需要适当增大该值。
2. 错误现象:could only be replicated to 0 nodes, instead of 1解决方法:在NameNode上执行命令:hadoop namenode –format重新格式化HDFS,在格式化之前,需要将你NameNode上所配置的.dir这一namenode用来存放NameNode 持久存储名字空间及事务日志的本地文件系统路径删除,同时将各DataNode 上的dfs.data.dir的路径DataNode存放块数据的本地文件系统路径的目录也删除。
Hadoop集群断电后出现的问题及解决办法

Hadoop集群断电后,重新启动集群,就会报错,无法启动起来了。
一、查看各节点,具体的问题描述如下:1. 各节点之间无法通信,ping 集群各自节点在最后一次集群正常的时候的IP地址时,出现了unreacable的提示2. 启动集群的时候会报如下错误:3. ping节点自己的主机名和其他节点的主机名时提示no route to host,同时ssh 主机名的时候也会提示no route to host,截图如下:二、进入网络相关的路径和查看相关的文件发现的问题:1. 进入到/etc/sysconfig/network-scripts/目录下,发现了多了一个文件ifcfg-eth0.bak文件,而且通过setup命令来配置时,会发现Network Configuration——>Edit Devices也多了一个eth0.bak的设备。
2. 其他的一些现象暂时忘记了三、解决方案1. 进入到/etc/sysconfig/network-scripts/目录,删除ifcfg-eth0.bak2. 通过setup命令或者直接修改文件的方法,重新配置IP地址,配置IP地址前,我们会发现一个有趣的现象,之前Hadoop集群上自己的IP地址在断电后也丢了,变成了DHCP的自动IP了。
配置完毕之后,再次启动集群,发现集群仍然无法正常启动,依然报错,no route to host。
3. 配置完IP地址之后,发现集群个节点之间可以通过Ip地址ping通了,但是ssh主机名的时候,依然报错,还是报no route to host,而ssh 主机IP地址的时候,则能正常登录。
于是检查/etc/hosts文件,发现ip地址与主机名映射的时候竟然是上次集群正常运行的时候之前配置的数据,然后将主机名和IP地址改过来之后。
发现ssh还是不能正常进行远程登录。
后来重新配置了ssh免密码登录,配置之前,我把原来生成的文件都删除了。
hadoop常见问题

Hadoop上机作业1.hadoop的官方网址是?/2.Apache基金是什么?Apache软件基金会(也就是Apache Software Foundation,简称为ASF),是专门为支持开源软件项目而办的一个非盈利性组织。
在它所支持的Apache项目与子项目中,所发行的软件产品都遵循Apache许可证(Apache License)。
3.Apache Hadoop 是什么?Apache Hadoop是一个软件平台,可以让你很容易地开发和运行处理海量数据的应用。
Hadoop是MapReduce的开源实现,它使用了Hadoop分布式文件系统(HDFS)。
MapReduce将应用切分为许多小任务块去执行。
出于保证可靠性的考虑,HDFS会为数据块创建多个副本,并放置在群的计算节点中,MapReduce就在数据副本存放的地方进行处理对于一个大文件,hadoop把它切割成一个个大小为64Mblock。
这些block是以普通文件的形式存储在各个节点上的。
默认情况下,每个block都会有3个副本。
通过此种方式,来达到数据安全。
就算一台机器down掉,系统能够检测,自动选择一个新的节点复制一份。
在hadoop中,有一个master node和多个data node。
客户端执行查询之类的操作,只需与master node(也就是平时所说的元数据服务器)交互,获得需要的文件操作信息,然后与data node通信,进行实际数据的传输。
master(比如down掉)在启动时,通过重新执行原先的操作来构建文件系统的结构树。
由于结构树是在内存中直接存在的,因此查询操作效率很高。
4.什么叫大数据?简言之,从各种各样类型的数据中,快速获得有价值信息的能力,就是大数据技术。
明白这一点至关重要,也正是这一点促使该技术具备走向众多企业的潜力。
大数据的4个“V”,或者说特点有四个层面:第一,数据体量巨大。
从TB级别,跃升到PB级别;第二,数据类型繁多。
[大数据运维]第28讲:Hadoop平台常见故障汇总以及操作系统性能调优
![[大数据运维]第28讲:Hadoop平台常见故障汇总以及操作系统性能调优](https://img.taocdn.com/s3/m/28f36061b94ae45c3b3567ec102de2bd9605dea2.png)
[⼤数据运维]第28讲:Hadoop平台常见故障汇总以及操作系统性能调优第28讲:Hadoop 平台常见故障汇总以及操作系统性能调优⾼俊峰(南⾮蚂蚁)Hadoop ⽇常运维问题及其解决⽅法1.如何下线⼀个 datanode 节点?当⼀个 datanode 节点所在的服务器故障或者将要退役时,你需要在 Hadoop 中下线这个节点,下线⼀个 datanode 节点的过程如下。
(1)修改 hdfs-site.xml ⽂件如下选项,找到 namenode 节点配置⽂件 /etc/hadoop/conf/hdfs-site.xml:<property><name>dfs.hosts.exclude</name><value>/etc/hadoop/conf/hosts-exclude</value></property>(2)修改 hosts-exclude ⽂件执⾏如下操作,在 hosts-exclude 中添加需要下线的 datanode 主机名:vi /etc/hadoop/conf/hosts-exclude172.16.213.188(3)刷新配置在 namenode 上以 hadoop ⽤户执⾏下⾯命令,刷新 hadoop 配置:[hadoop@namenodemaster ~]$hdfs dfsadmin -refreshNodes(4)检查是否完成下线执⾏如下命令,检查下线是否完成:[hadoop@namenodemaster ~]$hdfs dfsadmin -report也可以通过 NameNode 的 50070 端⼝访问 Web 界⾯,查看 HDFS 状态,需要重点关注退役的节点数,以及复制的块数和进度。
2.某个 datanode 节点磁盘坏掉怎么办?如果某个 datanode 节点的磁盘出现故障,那么该节点将不能进⾏写⼊操作,并导致 datanode 进程退出,针对这个问题,你可以如下解决:⾸先,在故障节点上查看 /etc/hadoop/conf/hdfs-site.xml ⽂件中对应的 dfs.datanode.data.dir 参数设置,去掉故障磁盘对应的⽬录挂载点;然后,在故障节点上查看 /etc/hadoop/conf/yarn-site.xml ⽂件中对应的 yarn.nodemanager.local-dirs 参数设置,去掉故障磁盘对应的⽬录挂载点;最后,重启该节点的 DataNode 服务和 NodeManager 服务即可。
hadoop错误汇集

保存后,重新执行start-dfs.sh脚本,然后执行jps就能看到NameNode、DataNode等你想看到的东西了:
2、执行start-dfs.sh脚本启动Hadoop 0.20.2 HDFS时出现如下错误:
7、MapReduce操作HBase出现如下错误:
Exception in thread "main" ng.NoClassDefFoundError: org/apache/hadoop/hbase/HBaseConfiguration
Exception in thread "main" ng.NoClassDefFoundError: org/apache/zookeeper/KeeperException
3、上传本地文件到HDFS上时出现如下错误:
WARN hdfs.DFSClient: DataStreamer Exception: org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /user/root/input01/file01 could only be replicated to 0 nodes, instead of 1
需要注意的是,安装过程中至少需要选择devel和shell这两个包。
5、Run on Hadoop编译程序时,出现如下错误:
WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String)
Hadoop常见错误和处理方式_光环大数据Hadoop培训

Hadoop常见错误和处理方式_光环大数据Hadoop培训mysql版本,必须是MYSQL5.1。
查询办法mysqladminversion在建立hive数据库的时候,最好是:createdatabasehive;oozie的数据库,同样:createdatabaseoozie;hadoop采集的字符集问题。
修改/etc/sysconfig/i18n更改字符集为en_US.UTF-8重启机器生效。
重启机器的指令为:在root下敲入如下指令:sync;sync;init6修改mapreduce。
在gateway/性能下修改:MapReduce子Java基础选项、Map任务Java选项库、Reduce 任务Java选项库全部配置成-Xmx4294967296在TASKTRACKER/性能下修改:MapReduce子Java基础选项、Map任务Java选项库、Reduce 任务Java选项库全部配置成-Xmx4294967296必须关注各个任务的详细情况当出现如下的错误的时候,请及时的将下载的进程数调小。
vi/home/boco/oozie_wy/config/lte/mro/ftp/807101.xml将max_thread由原来的6个调整为3个,或者协调厂家加大FTP的最大线程数。
stderrlogs:.ftp.FTPConnectionClosedException:FTPresponse421received.Serv erclosedconnection..ftp.FTP.__getReply(FTP.java:363).ftp.FTP.__getReply(FTP.java:290).ftp.FTP.connectAction(FTP.java:396).ftp.FTPClient.connectAction(FTPClient.java:796).SocketClient.connect(SocketClient.java:172).SocketClient.connect(SocketClient.java:192).SocketClient.connect(SocketClient.java:285)atcom.boco.wangyou.utils.Ftp.connectServer(Ftp.java:550)atcom.boco.wangyou.lte.mro.ftp.tools.FindFileThread.run(FindFileThread.java:67)登录ftp服务器【10.140.177.149】失败,FTP服务器无法打开!.ftp.FTPConnectionClosedException:FTPresponse421received.Serv erclosedconnection..ftp.FTP.__getReply(FTP.java:363).ftp.FTP.__getReply(FTP.java:290).ftp.FTP.connectAction(FTP.java:396).ftp.FTPClient.connectAction(FTPClient.java:796).SocketClient.connect(SocketClient.java:172).SocketClient.connect(SocketClient.java:192).SocketClient.connect(SocketClient.java:285)atcom.boco.wangyou.utils.Ftp.connectServer(Ftp.java:550)atcom.boco.wangyou.lte.mro.ftp.tools.FindFileThread.run(FindFileThread.java:67)登录ftp服务器【10.140.177.149】失败,FTP服务器无法打开!.ftp.FTPConnectionClosedException:FTPresponse421received.Serv erclosedconnection..ftp.FTP.__getReply(FTP.java:363).ftp.FTP.__getReply(FTP.java:290).ftp.FTP.connectAction(FTP.java:396).ftp.FTPClient.connectAction(FTPClient.java:796).SocketClient.connect(SocketClient.java:172).SocketClient.connect(SocketClient.java:192)TASKTRACKER和HDFS组的问题发现部分地方在安装的时候,将所有的机器分组的问题。
上传文件到Hadoop失败的原因分析及解决方法

Java Web 上传文件到Hadoop失败的原因分析及解决方法1. 问题描述:Eclipse中开发Java Web程序,使用Hadoop-Core JAR包中的Java API,上传文件到Hadoop HDFS文件系统中,上传提示成功,但是在Hadoop集群中通过“hadoop fs –ls /xxx”命令却无法查看到相应的上传文件。
2. 问题原因分析:其实,本次文件上传并未成功!在Tomcat中观察运行结果,会发现已经出现了Exception “org.apache.hadoop.security.AccessControlException:org.apache.hadoop.security.AccessControlException: Permission denied: user=bikun,access=WRITE, inode="/user":user:supergroup:drwxr-xr-x”!!得到的教训:在编写Java Web程序时,应该多使用“try , catch”语句,在运行Java Web 程序中,需要多观察Tomcat的输出结果!从上段提示中可以看出,提示“security.AccessControlException”(访问控制异常),导致的结果是“Permission denied”(许可被拒绝),因为“user=bikun, access=WRITE”(当前用户名为“bikun”,他想“写文件”),但是当前文件夹的主人是“user”(“ inode="/user":user:supergroup”),并且访问控制位是“rwxr-xr-x”(即文件所有者“user”是可读写执行“rwx”,所在组“supergroup”是可读可执行“r-x”,其它用户是可读可执行“r-x”)。
看到此处,原因已经明朗:因为除了“user”用户之外,其它用户不能写!而当前用户“bikun”却想上传(写)一个文件到“user”目录,违反了访问控制规则,导致抛出“security.AccessControlException”(访问控制异常)。
HadoopYARN常见问题以及解决方案

Hadoop YARN常见问题以及解决方案导读:本文汇总了几个hadoop yarn中常见问题以及解决方案,注意,本文介绍解决方案适用于hadoop 2.2.0以及以上版本。
(1)默认情况下,各个节点的负载不均衡(任务数目不同),有的节点很多任务在跑,有的没有任务,怎样让各个节点任务数目尽可能均衡呢?本文汇总了几个hadoop yarn中常见问题以及解决方案,注意,本文介绍解决方案适用于hadoop 2.2.0以及以上版本。
(1)默认情况下,各个节点的负载不均衡(任务数目不同),有的节点很多任务在跑,有的没有任务,怎样让各个节点任务数目尽可能均衡呢?答:默认情况下,资源调度器处于批调度模式下,即一个心跳会尽可能多的分配任务,这样,优先发送心跳过来的节点将会把任务领光(前提:任务数目远小于集群可以同时运行的任务数量),为了避免该情况发生,可以按照以下说明配置参数:如果采用的是fair scheduler,可在yarn-site.xml中,将参数yarn.scheduler.fair.max.assign设置为1(默认是-1,)如果采用的是capacity scheduler(默认调度器),则不能配置,目前该调度器不带负载均衡之类的功能。
当然,从hadoop集群利用率角度看,该问题不算问题,因为一般情况下,用户任务数目要远远大于集群的并发处理能力的,也就是说,通常情况下,集群时刻处于忙碌状态,没有节点一直空闲着。
(2)某个节点上任务数目太多,资源利用率太高,怎么控制一个节点上的任务数目?答:一个节点上运行的任务数目主要由两个因素决定,一个是NodeManager可使用的资源总量,一个是单个任务的资源需求量,比如一个 NodeManager上可用资源为8 GB内存,8 cpu,单个任务资源需求量为1 GB内存,1cpu,则该节点最多运行8个任务。
NodeManager上可用资源是由管理员在配置文件yarn-site.xml中配置的,相关参数如下:yarn.nodemanager.resource.memory-mb:总的可用物理内存量,默认是8096yarn.nodemanager.resource.cpu-vcores:总的可用CPU数目,默认是8对于MapReduce而言,每个作业的任务资源量可通过以下参数设置:mapreduce.map.memory.mb:物理内存量,默认是1024mapreduce.map.cpu.vcores:CPU数目,默认是1注:以上这些配置属性的详细介绍可参考文章:Hadoop YARN配置参数剖析(1)—RM与NM相关参数。
hadoop配置及运行过程中遇到的问题及解决方案

1. ssh报端口22打不开的错误通常是因为sshd服务没有打开,从管理——>服务中将sshd服务打开。
2. Cygwin配置ssh时遇到的关于connection closed的问题。
配置无密码访问后,执行“ssh localhost”命令,报”connection closed”的错误。
该错误需要修改服务属性,找到Cygwin sshd服务,右键属性——>登陆——>此账户——>高级——>立即查找,找到当前用户,确定,回到登陆界面,输入密码,确定,然后重启服务。
如果重启时遇到服务无法启动的错误,可以重新执行“ssh-host-config”。
3. ssh远程访问其他机器时无法访问,输密码也不行当前遇到的该问题是由于两台机器上的用户名不一致造成的,当前机器会以当前用户名去访问远程机器,远程机器上可能没有该账户。
解决方案是在”.ssh”目录下创建一个config文件,不用后缀,在里面添加如下内容:Host 远程机器IPUser 远程机器用户名有多台远程机器,则为每一台都添加2上面两行。
4. hdfs 报连接不到端口的错误一般是namenode的问题,format一下namenode就可以解决这个问题。
5. had oop hdfs端口问题网上大多选用9000端口,基本上都认为是选用一个没有占用的端口就可以。
在我们这次配置中遇到了问题,报与默认的8020端口不一致的错误。
解决方案就是把端口换成8020。
在Ubuntu下配置时好像没有遇到过类似问题,不知道是不是因为在windows下的原因?这个需要进一步验证。
6. 诡异的添加新节点失败问题系统运行后,新加一台机器,添加步骤:在slaves中,将新机器IP地址加上,在新机器上通过bin/hadoop-daemon.sh start datanode 启动新机器的datanode进程,结果该节点不能在系统中出现。
后经过多次重新启动集群,甚至删除原集群重新format namenode都不行。
【推荐下载】Hadoop错误之namenode宕机的数据恢复

Hadoop 错误之namenode 宕机的数据恢复2018/01/09 200 情景再现:在修复hadoop 集群某一个datanode 无法启动的问题时,搜到有一个答案说要删除hdfs-site.xml 中dfs.data.dir 属性所配置的目录,再重新单独启动该datanode 即可;问题就出在这个误删除上,当时是在namenode 的hadoop/hdfs/目录下,然后就执行了一个可怕的命令rm -rf datarm -rf name #存储namenode 永久性元数据目录当时还不知道删除这个的可怕,以为只是误删除了普通数据而已,然后再转到datanode 下再次执行删除,再启动datanode 后就正常了,jps 查看各项服务均已正常启动然后晚上在执行一个job 时,报错了,说目录不存在,到此我才意识到是我之前到误删导致到这个错误,当时把datanode 节点调试成功后也没试试执行一个job 验证hadoop 环境到正确性。
然后我就手动建了一个日志说找不到到目录,重启后报错namenode is not formatted,就是说需要格式化namenode 才行,到这里就傻眼了,格式化容易,可集群上几个t 的数据可能就没了,这很阔怕。
解决历程:首先重启集群,发现除了namenode 外其他均成功启动,这个时候使用hdfs dfs -ls / 这样的命令去查看hdfs 文件系统,是无法查看的,应该是报错被拒绝。
我们去查看192.168.1.148:50070/dfshealth.html#tab-datanode 这个目录,发现是无法访问了,然后再去查看每个数据节点的使用量,使用命令df -lh 发现几个节点的使用量都不是为0,就是说集群的数据并没有被删除,还有恢复的可能,然后看到了几篇hadoop 数据恢复的文章1,hadoop 主节点(NameNode)备份策略以及恢复方法2,hadoop 集群崩溃恢复记录3,模拟namenode 宕机:数据块损坏,该如何修复还有一篇介绍数据存储的文章4,hadoop HDFS 存储原理以下是正确的解决方案,耗时一天一夜,首先在本地伪分布式环境测试成功,然后移到集群环境中成功解决:1、存在一个正常的hadoop 环境,hdfs 上存在多个文件及文件夹2、删除name 目录3、stop-all.sh 4、执行namenode 格式化操作。
Hadoop记录-hadoop集群常见问题汇总

Hadoop记录-hadoop集群常见问题汇总【问题1】HBase Shell:ERROR: org.apache.hadoop.hbase.c.ServerNotRunningYetException: Server is not running yet原因:hadoop处于safe modehadoop dfsadmin -safemode get 查看hadoop当前启动状态是否为safe modehadoop dfsadmin -safemode leave 退出【问题2】Rowkey设计问题现象打开HBase的Web端,发现HBase下⾯各个RegionServer的请求数量⾮常不均匀,第⼀个想到的就是HBase的热点问题,上⾯是HBase下某张表的region请求分布情况,从中我们明显可以看到,部分region的请求数量为0,⽽部分的请求数量可以上百万,这是⼀个典型的热点问题。
原因HBase出现热点问题的主要原因⽆⾮就是rowkey设计的合理性,像上⾯这种问题,如果rowkey设计得不好,很容易出现,⽐如:⽤时间戳⽣成rowkey,由于时间戳在⼀段时间内都是连续的,导致在不同的时间段,访问都集中在⼏个RegionServer 上,从⽽造成热点问题。
解决知道了问题的原因,对症下药即可,联系应⽤修改rowkey规则,使rowkey数据随机均匀分布建议对于HBase来说,rowkey的范围划定了RegionServer,每⼀段rowkey区间对应⼀个RegionServer,我们要保证每段时间内的rowkey访问都是均匀的,所以我们在设计的时候,尽量要以hash或者md5等开头来组织rowkey【问题3】Region重分布现象HBase的集群是在不断扩展的,分布式系统的最⼤好处除了性能外,不停服横向扩展也是其中之⼀,扩展过程中有⼀个问题:每次扩展的机器的配置是不⼀样的,⼀般,后⾯新加⼊的机器性能会⽐⽼的机器好,但是后⾯加⼊的机器经常被分配很少的region,这样就造成了资源分布不均匀,随之⽽来的就是性能上的损失每台RegionServer上的请求极为不均匀,多的好⼏千,少的只有⼏⼗原因资源分配不均匀,造成部分机器压⼒较⼤,部分机器负载较低,并且部分Region过⼤过热,导致请求相对较集中。
Hadoop安装遇到的各种异常及解决办法

at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:218)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:660)
Hadoop安装遇到的各种异常及解决办法
异常一:
2014-03-13 11:10:23,665 INFO org.apache.Hadoop.ipc.Client: Retrying connect to server: Linux-hadoop-38/10.10.208.38:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2014-03-13 11:10:32,676 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: Linux-hadoop-38/10.10.208.38:9000. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
Hadoop中数据乱序问题解决方案分享

Hadoop中数据乱序问题解决方案分享在大数据时代,Hadoop已成为处理海量数据的首选工具。
然而,随着数据规模的不断增大,Hadoop面临着一个严重的问题——数据乱序。
数据乱序会导致计算节点之间的数据倾斜,进而影响作业的执行效率。
本文将分享一些解决Hadoop 中数据乱序问题的方案。
一、背景介绍Hadoop是一个分布式计算框架,它将海量数据分散存储在多台机器上,并通过MapReduce模型实现并行处理。
在MapReduce过程中,数据会被切分成多个数据块,然后分配给不同的计算节点进行处理。
然而,由于数据的特性和分布情况的不均匀性,导致计算节点之间的数据倾斜,从而导致作业执行效率低下。
二、数据倾斜的原因1. 数据分布不均匀:数据在不同的分区中分布不均匀,导致某些计算节点负载过重。
2. 数据键值冲突:在进行数据分组时,由于数据键值的冲突,导致某些计算节点处理的数据量过大。
三、解决方案1. 采用Combiner函数:Combiner函数可以在Map阶段进行局部聚合,减少数据量的传输。
通过使用Combiner函数,可以减少计算节点之间的数据传输量,从而减轻数据倾斜的问题。
2. 重新划分数据分区:通过重新划分数据分区,可以使得数据在不同的计算节点上分布更加均匀。
可以根据数据的特性和分布情况,采用不同的划分策略,如范围划分、哈希划分等。
3. 动态调整任务数量:根据作业的执行情况,动态调整任务的数量,以实现负载均衡。
通过监控作业的执行情况,可以根据计算节点的负载情况,动态调整任务的数量,从而减轻数据倾斜的问题。
4. 采用随机前缀技术:在进行数据分组时,可以采用随机前缀技术,将数据键值加上一个随机前缀,从而减少数据键值冲突的概率。
通过引入随机前缀,可以将数据分散到不同的计算节点上,减轻数据倾斜的问题。
5. 采用二次排序技术:在进行数据分组时,可以采用二次排序技术,对数据进行二次排序。
通过二次排序,可以将相同的键值放在相邻的位置,从而减少数据键值冲突的概率,减轻数据倾斜的问题。
Hadoop开发过程中所遇到的那些坑
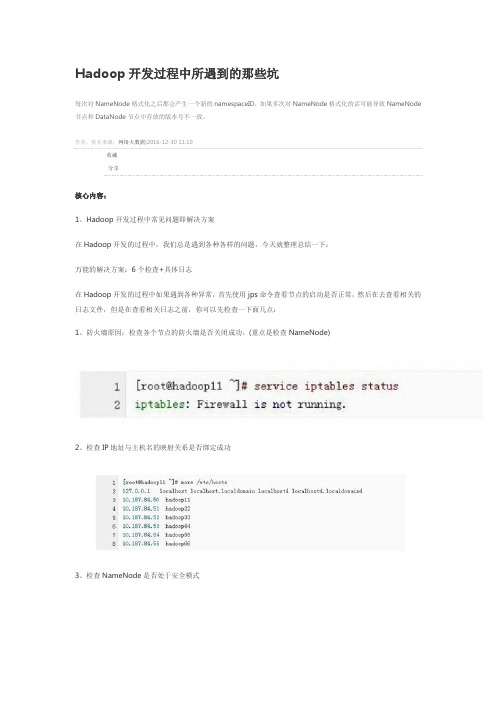
Hadoop开发过程中所遇到的那些坑每次对NameNode格式化之后都会产生一个新的namespaceID,如果多次对NameNode格式化的话可能导致NameNode节点和DataNode节点中存放的版本号不一致。
作者:佚名来源:网络大数据|2016-12-30 11:10收藏分享核心内容:1、Hadoop开发过程中常见问题即解决方案在Hadoop开发的过程中,我们总是遇到各种各样的问题,今天就整理总结一下:万能的解决方案:6个检查+具体日志在Hadoop开发的过程中如果遇到各种异常,首先使用jps命令查看节点的启动是否正常,然后在去查看相关的日志文件,但是在查看相关日志之前,你可以先检查一下面几点:1、防火墙原因:检查各个节点的防火墙是否关闭成功。
(重点是检查NameNode)2、检查IP地址与主机名的映射关系是否绑定成功3、检查NameNode是否处于安全模式4、检查NameNode是否已经进行了格式化处理5、检查配置文件的配置是否成功6、检查NameNode节点和DataNode节点中存放的namespaceID的版本号是否相同好的,当我们查看完上述6点之后如果还没有解决问题,那我们再去查看相关的日志文件即可。
OK,到现在为止我在给大家介绍一下在开发过程中经常遇到的几个异常问题:1、启动hadoop时没有NameNode的可能原因这个问题对于Hadoop的初学者是经常遇到的,之所以出现这个问题,可能有3点原因:1)、NameNode没有进行格式化处理(6个检查以包括)先删除hadoop.tmp.dir所对应的目录(即logs和tmp),然后对NameNode进行格式化处理2)、检查IP地址与主机名的映射关系是否绑定成功(6个检查以包括)3)、检查配置文件的配置是否成功(6个检查以包括),重点是hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml和slaves。
hadoop一些常见报错的解决方式

hadoop⼀些常见报错的解决⽅式Failed to set setXIncludeAware(true) for parser遇到此问题通常是jar包冲突的问题。
⼀种情况是我们向java的lib⽂件夹加⼊我们⾃⼰的jar包导致hadoop引⽤jar包的冲突。
解决⽅式就是删除我们⾃⼰向系统加⼊的jar包,⼜⼀次配置。
将⾃⼰的jar包或者外部jar放⼊系统⽂件夹会在编译程序时带来⽅便,可是这不是⼀种好习惯,我们应该通过改动CLASSPATH的⽅式指定jar包路径。
Cannot lock storage /tmp/hadoop-root/dfs/name. The directory isalready locked这个错误通常是我们在某次配置失败后。
hadoop创建该⽂件夹,锁定之后失败退出造成的。
解决⽅式就是删除tmp⽂件夹下hadoop创建的相关⽂件夹。
然后⼜⼀次配置。
localhost Name or service not known在配置hadoop单节点环境时。
须要利⽤ssh登录localhost。
假设依照⽹上的⽅式配置之后还是不能正确登录localhost,并报上述错误,能够检查/etc/sysconfig/network和 /etc/hosts下的localhost名字是否⼀致。
有时在某个⽂件⾥localhost是凝视掉的。
ls: Cannot access .: No such file or directory.当在hadoop中执⾏ls命令时常会出现这个错误,这个错误是指hdfs⽂件系统中当前⽂件夹为空,并⾮指本地⽂件系统中当前⽂件夹为空。
当我们使⽤hdfs⽂件系统时,会默认进⼊/user/username下,这个⽂件夹不存在于本地⽂件系统,⽽是由hdfs内部管理的⼀个⽂件夹。
当我们第⼀次使⽤ls命令时,/user/username下是空的。
所以会提⽰上述错误。
当我们加⼊新的⽂件之后就不再报该错。
hadoop单点故障的产生

hadoop单点故障的产生Hadoop是一个开源的分布式计算框架,用于存储和处理大规模数据。
然而,由于其分布式的特性,Hadoop也存在单点故障的问题。
本文将从几个方面探讨Hadoop单点故障的产生原因及解决方法。
Hadoop集群的主节点是整个系统的控制中心,负责调度任务、分配资源以及监控集群的状态。
因此,主节点的故障将导致整个集群的不可用。
主节点故障可能由于硬件故障、软件异常或者网络问题等原因引起。
例如,主节点的服务器硬盘发生故障,导致主节点无法启动。
为了解决这个问题,可以使用冗余主节点的方式,即在集群中添加一个备用的主节点,当主节点发生故障时,备用主节点会自动接管其职责。
Hadoop的分布式文件系统HDFS是Hadoop的核心组件之一,用于存储大量的数据。
然而,由于HDFS的设计特点,存在单点故障的风险。
HDFS的单点故障主要体现在NameNode节点上,它负责管理文件系统的命名空间和数据块的元数据。
如果NameNode 节点发生故障,将导致整个HDFS不可用。
为了解决这个问题,可以使用NameNode的冗余备份方式。
具体来说,可以设置一个Standby NameNode节点,它会监控主NameNode的状态,一旦主NameNode发生故障,Standby NameNode会接管其职责,确保HDFS的高可用性。
Hadoop的资源调度框架YARN也存在单点故障的问题。
YARN的单点故障主要体现在ResourceManager节点上,它负责整个集群的资源调度和任务分配。
如果ResourceManager节点发生故障,将导致整个集群无法正常工作。
为了解决这个问题,可以使用ResourceManager的高可用模式。
具体来说,可以设置一个Standby ResourceManager节点,它会监控主ResourceManager的状态,一旦主ResourceManager发生故障,Standby ResourceManager会接管其职责,确保YARN的高可用性。
hadoop中namenode启动不成功的问题

hadoop中namenode启动不成功的问题当你在学习和使用hadoop时,也许会遇到这样的一个问题,运行bin/start-all.sh时发现namenode没有启动,可以通过以下方法进行排查解决:翻看日志,寻找错误提示,并进行内容的改进,最后进行重启原因一:权限问题#查看日志cd /usr/local/hadoop/logs#发现权限问题,更改文件权限chown -R hadoop:hadoop /usr/local/hadoop/hdfs/*chown -R hadoop:hadoop /usr/local/hadoop/logs#重启hadoopbin/stop-all.shbin/start-all.sh原因二:tmp文件问题#创建hadoop_tmp目录sudo mkdir ~/hadoop_tmp#修改hadoop/conf目录里面的core-site.xml文件,加入以下节点<property><name>hadoop.tmp.dir</name><value>/home/user/hadoop_tmp</value><description>A base for other temporary directories.</description></property>#格式化Namenodehadoop namenode –format#启动hadoopstart-all.sh以上是hadoop namenode启动不了常见的原因,当然不排除其他原因的存在,可以尝试用这两种方式试一试!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop常见错误总结
2010-12-30 13:55
错误1:bin/hadoop dfs 不能正常启动,持续提示:
INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 0 time(s).
原因:由于 dfs 的部分文件默认保存在tmp文件夹,在系统重启时被删除。
解决:修改core-site.xml 的 hadoop.tmp.dir配置文件路径:
/home/hadoop/tmp。
错误2:hadoop出现了一些问题。
用$ bin/hadoop dfsadmin -report 测试的时候,发现dfs没有加载。
显示如下:
Configured Capacity: 0 (0 KB)
Present Capacity: 0 (0 KB)
DFS Remaining: 0 (0 KB)
DFS Used: 0 (0 KB)
DFS Used%: ?%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
查看日志:
ERROR
org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs in /home/hadoop/data: namenode namespaceID = ; datanode namespaceID =
经分析,是由于namenode namespaceID = ;和datanode namespaceID = 不一致造成原因。
修改了namenode namespaceID = 可以使用,但是重启之后,又不可以用了。
最后解决方案:删除hadoop用户下的name文件夹,data文件夹,tmp文件夹,temp文件里的内容,然后重新执行namenode命令。
重启电脑之后,正常。
错误3:File /home/hadoop/tmp/mapred/system/ could only be replicated to 0 nodes, instead of 1
出现此错误,一般发生在datanode与namenode还没有进行连接,就开始往hdfs 系统上put数据了。
稍等待一会,就可以了。
也可以使用:hadoop dfsadmin –report命令查看集群的状态。
错误4:
每次启动总有部分datanade不能去全部启动,查看日志文件,显示为:ERROR org.apache.hadoop.hdfs.server.datanode.DataNode:
.UnknownHostException: zgchen-ubutun: zgchen-ubutun at
.InetAddress.getLocalHost(InetAddress.java:1426)。
分析:这是由于datanode 找不到服务host引起的。
解决:通过查找/etc/hostname 找到hostname;比如:ubuntu。
然后找到/etc/hosts ,添加:127.0.1.1 ubuntu
错误5:
ng.OutOfMemoryError: GC overhead limit exceeded
分析:这个是JDK6新添的错误类型。
是发生在GC占用大量时间为释放很小空间的时候发生的,是一种保护机制。
解决方案是,关闭该功能,可以添加JVM的启动参数来限制使用内存: -XX:-UseGCOverheadLimit
添加位置是:mapred-site.xml 里新增项:mapred.child.java.opts 内容:
-XX:-UseGCOverheadLimit
ng.OutOfMemoryError: Java heap space
出现这种异常,明显是jvm内存不够得原因,要修改所有的datanode的jvm内存大小。
Java -Xms1024m -Xmx4096m
一般jvm的最大内存使用应该为总内存大小的一半,我们使用的8G内存,所以设置为4096m,这一值可能依旧不是最优的值。
(其实对于最好设置为真实物理内存大小的0.8)
错误6:Too many fetch-failures
Answer:
出现这个问题主要是结点间的连通不够全面。
1) 检查、/etc/hosts
要求本机ip 对应服务器名
要求要包含所有的服务器ip + 服务器名
2) 检查 .ssh/authorized_keys
要求包含所有服务器(包括其自身)的public key
错误7:处理速度特别的慢出现map很快但是reduce很慢而且反复出现reduce=0%
Answer:
结合第二点,然后修改可用内存大小。
conf/hadoop-env.sh 中的export HADOOP_HEAPSIZE=4000
错误8:能够启动datanode,但无法访问,也无法结束的错误
在重新格式化一个新的分布式文件时,需要将你NameNode上所配置的
.dir这一namenode用来存放NameNode 持久存储名字空间及事务日志的本地文件系统路径删除,同时将各DataNode上的dfs.data.dir的路径DataNode 存放块数据的本地文件系统路径的目录也删除。
如本此配置就是在NameNode上删除/home/hadoop/NameData,在DataNode上删除
/home/hadoop/DataNode1和/home/hadoop/DataNode2。
这是因为Hadoop在格式化一个新的分布式文件系统时,每个存储的名字空间都对应了建立时间的那个版本(可以查看/home/hadoop /NameData/current目录下的VERSION文件,上面记录了版本信息),在重新格式化新的分布式系统文件时,最好先删除NameData
目录。
必须删除各DataNode的dfs.data.dir。
这样才可以使namedode和datanode记录的信息版本对应。
注意:删除是个很危险的动作,不能确认的情况下不能删除!!做好删除的文件等通通备份!!
错误9:java.io.IOException: Could not obtain block: blk__1100
file=/user/hive/warehouse/src__log/src__log
出现这种情况大多是结点断了,没有连接上。
或者
mapred.tasktracker.map.tasks.maximum 的设置超过 cpu cores数目,导致出现获取不到文件。
错误10:Task Id : attempt_5_0001_m__0, Status : FAILED Error:
java.io.IOException: No space left on device
Task Id : attempt_5_0001_m__0, Status : FAILED java.io.IOException: Spill failed
磁盘空间不够,应该分析磁盘空间df -h 检查是否还存在磁盘空间。
错误11:Task Id : attempt_6_0007_m__0, Status : FAILED
org.apache.hadoop.hbase.client.RegionOfflineException: region offline: lm,,44
网上说,将/hbase删除;重启hbase后,可以正常应用了。
但是我找不到/hbase 目录,只好自己重新删除掉一些hadoop文件,重新生成文件管理系统。
还有一个可能是,配置错了/hbase/conf/hbase-env.sh的HBASE_CLASSPATH,这个默认是不配置的,所以可以不配置。
错误12:org.apache.hadoop.hbase.TableNotFoundException:
org.apache.hadoop.hbase.TableNotFoundException: lm
找不到表,hbase启动了,检查一下是否存在需要的Htable。