搜索引擎系统需求分析说明书
网站规划(需求分析)说明书

第一章网站规划(需求分析)说明书1—1 概述本网站系统利用电子商务的各种特点和优势,改变传统销售方式,将网络销售形成一种崭新的商业模式,建立一个有时尚气息的电子商店.服务对象为时尚女性,目的是为她们提供方便的网上购物环境和服务,让他她们体验乐趣。
本系统提供会员注册、会员更改忘记的密码、会员修改个人资料、商品展示、按价格和类别搜索产品并显示商品详情、信息订阅、购物车、查询显示当天所订购物品、按顾客意愿删除订单、客户留言等功能。
另外,本系统还为后台管理者提供数据库以便管理会员信息、网站商品信息、会员/访客订阅信息、会员/访客留言信息等。
1-2 功能需求本网站系统具备会员管理、商品展示、商品管理、产品搜索、信息订阅、购物车、客户留言等功能。
其中,会员管理功能具有用户注册、会员登录、会员身份验证、会员更改忘记的密码、会员修改个人资料的子功能;商品展示具有按产品的不同显示商品详细信息的功能;产品搜索具有按价格和类别搜索并显示商品部分信息的子功能;购物车具有将客户所购物品放入购物车、查询显示当天所订购物品、按顾客意愿删除订单的子功能;客户留言具有让会员或者访客在浏览本网站、购买本网站商品的同时对网站提出建议或疑问的功能;信息订阅具有让会员或访客能根据意愿订阅或退订信息的功能.第二章设计说明书2-1 环境说明本系统所使用的硬件配置:一般的计算机硬件配置.本系统所使用的软件配置:操作系统为Microsoft Windows 2000 Server;数据库管理系统为Microsoft SQL Server 2000;网页设计工具为Macromedia Dreamweaver MX 2004;图像处理工具为Adobe Photoshop 7。
0和Macromedia Fireworks MX 2004;动画制作工具为Macromedia Flash MX 2004;浏览器使用1024*768分辩率、IE6.0以上,IIS 5。
需求分析说明书(模板)

需求分析说明书(模板) XXX系统需求分析说明书XXX系统需求分析说明书编号:XXXXXXX版本:1.0作者:审批:日期:日期:XXX系统需求分析说明书状态修订人修改日期版本备注XXX系统需求分析说明书目录11.11.21.31.44.14.24.34.44.54.655.1XXX体系需求阐发说明书5.2 5.31.1目的1.2范围1.3读者对象1.4术语与缩写解释缩写、术语解释XXX系统需求分析说明书系统管理员对人员信息进行统一管理,主要负责人员信息管理,包括人员的用户分配,人员的增加,帐户冻结,另外负责体系的优化和日常维护。
表12产品介绍与开发背景3产品意义4产品的功能性需求4.1系统划分系统功能划分如下:4.2用户脚色划分XXX系统需求分析说明书4.3登录登录体系管理员图3用户登录用例编号UC001说明用户输入登录信息,如用户名和暗码,以体系承认脚色身份进入本体系。
角色登录的信息。
信息用户名密码类型不少于6位,最多20位的字符不少于6位,最多20位的字符表2描绘用于登录系统的用户名用于登录身份考证的暗码登录确认用户通过在浏览器中输入用户的用户名和暗码,由背景体系收集输入的信息,并进行核实比较确认。
对应的事件流内容用例编号用例名称用例说明参与者前置条件后置条件UC001用户登录用户登录系统系统用户系统有效用户用户所输入的信息与后台系统数据库表中所保存的信息一致1.用户输入用户名、暗码,点击提交2.系统验证用户名和密码3.验证成功,系统跳转到主页说明基本路径XXX系统需求分析说明书扩展路径1.用户输入的登录信息的用户名无效2.体系提示输入正确格式的用户名信息3.用户输入的密码无效4.系统提示输入正确的密码信息表3活动图输入用户名和密码点击登录否登录信息考证是否通过是登录成功图4用户登录活动图4.4注销注销登录系统管理员图5注销用例图U003说明已登录用户,点击“注销”按钮安全退出系统。
对应的事件流XXX系统需求分析说明书内容用例编号用例名称用例说明介入者前置条件后置条件基本路径UC003用户注销说明用户在体系中注销已登录用户用户已经成功登录系统系统注销掉当前登录状态下的用户1.用户点击注销功能按钮2.系统注销掉当前登录的用户3.注销成功,系统跳转到系统登录页面扩展路径无表4用例图点击注销按钮注销成功,调至登录页图6注销活动图4.5点窜暗码修改密码系统管理员图7点窜暗码用例编号UC004说明用户输入密码信息,如旧密码和两次密码一致的新密码,系统验证旧密码正确之后,再根据新密码进行密码的修改。
基于Lucene的搜索引擎系统设计与实现说明书

2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016)Research and implementation of search engine based on LuceneWan Pu, Wang LishaPhysics Institute, Zhaotong University,Zhaotong,Yunnan, PR ChinaPhysics InstituteZhaotong University, Zhaotong,Yunnan, PR China**************Keywords: Search engine; Lucene; web spider; Chinese word segmentationAbstract.From in-depth research on the basic principles and architecture of search engine, through secondary development for Lucene development package, this paper designs an entire search engine system framework, and realizes its core modules. This system can make up for the deficiency of the existing Lucene framework, and enhance the accuracy of the search engine system, so has higher real and commercial value.IntroductionWith the continuous expansion of network coverage and the development of network technology, the network information resources have been rapidly spread and increased. Large amounts of network information resources from all walks of life, including the information from different disciplines, different areas, different fields, different languages, very rich, and exist with text, images, audio, video, databases and other forms. Internet information has been hundreds of millions, so how to find the needed information from them has become a very important research topic in Internet technology. To help users find the information they need, the search engine came into being.Search engine is a search tool to help Internet users to query information, it is to collect, find information in the Internet with a certain strategy, and then understand, extract, organize and process the above information, thus providing users with search services, and information navigation purposes achieved. The advent of search engine for our fast, accurate and efficient access to network information resources provide great help. It is a web-based tool developed for the needs of people searching for network information, is the Internet information query navigation, and the bridge between users and network information.Principle analysis of search engineThe basic principle of search engine is to start from the existing resources, through their summary and link to determine the new information points needed to search for, and then by the relevant program search engine designed traverse these points, finally index, classify, and organize the documents on these points to the index database[1]. Logically this recursive traversal method can put all the information into the index database. When users use a search engine, enter the keywords of the content required to be found, the search program will read the information has been traversed and stored in the index database, to match with the user keyword, and then retrieve the corresponding or related information to output to the user through a certain organization method.A.Search engine system workflowA search engine to meet users needs is generally consists of information collection, informationFig.1 Search engine workflowInformation collection: web page collection obtains input from the URL database, to parse the address of a Web server in URL, establish a connection, send requests and receive data, and then store the obtained Web page data in the original page library, and from which to extract the link information to put into the page structure library, at the same time put the URL to be crawled into URL library, to ensure that the entire process is iterative, until URL library is empty[2]. Information preprocessing: after Web information collection, the preserved page information has been saved in a specific format. So the first step in this part is to index the original page, with that to provide the web page snapshot function for search engines; next Web page segmentation to the index page library, to transform each page into a set of a group of words; finally transform the mapping between Web page and index words into converse, to form inverted file, while gathering the unrepeated index words included in the Web page to be converging vocabulary; in addition, based on the structural information among Web pages to analyze the importance of the information, and then establish page meta-information. Retrieval service: the data delivered to the service stage includes index page library, inverted file and web page meta-information. Query agent to accept user input query phrase, after segmentation, retrieval from the index vocabularies and inverted file to get documents including query phrase, history log and other information, and then calculate the importance of the result set, finally sort and return to the user[3].Through the above several components, a search engine system can be built, when the user input the keywords, phrases related o the information and resources to be found, the system will traverse the program in accordance with its design search, from the Internet link address traverse pages, the results will be saved to the index database, and then process, integrate the indexed data, finally optimize of the results, according to certain priority algorithm to sort the results, and then store in the index database. When a user types a keyword the search engine will search for the matched page or data information from the index database, and in a certain way show it to the user through the user interface.B.Key technology of search engine systemA typical search engine structure generally consists of three modules: network spider, indexer, and searcher. Web spider generally first obtains URL from the URL queue to be visited, according to which get the page from Web and analyze it, to extract all of the URL links and add them to the page data URL queue to be accessed, at the same time move the visited URL to the visited URL queue[4]. Continuously repeat the above procedure. All the collected pages to be saved to store for further processing. Initially, in the URL queue only seed URL can be as a starting point the spider traverses the network, generally choose relatively large and very popular website address as a seed URL, because that such pages often have a lot of links to other pages. Web spiders use HTTP protocol to read Web pages and automatically access network resources along an HTML document hyperlink. You can use the network as a directed graph to deal with, each page as a node of it, and the page hyperlink as its directed edge. So you can takeFig.2 Web spider work principleIndexer function is to understand the searcher searched information, and extract the index entry, to be used to indicate documents and the index table to generate the documents. Generally index table uses some form of inverted list, that is, finds the corresponding documents from the index entries. Index table also may need to record the position of index entries appear in the document for indexer to calculate the adjacent or close relationship among the index entries. Indexer can use a centralized or distributed indexing algorithm[5]. The effectiveness of a search engine largely depends on the quality of index. When a user query is completed, the search engine has not real-time data retrieval on the web, and the searched data is actually the web data collected in advance. To achieve fast access to the collection page, it must be done through some sort of indexing mechanism. Page data can be represented by a series of keywords, and from the retrieval purposes they describe the content of the page. Just find the page, they can be found. Conversely, if the establishment of the page index is based on keywords, the relevant pages will be quickly retrieved. Specifically, keywords are stored in the index file, for each keyword there is a pointer list, in which each pointer directs to a page related to the keyword, and all pointer lists constitute placing file.The function of searcher is to quickly detect a document from the index database based on user query, evaluate the association of documents and queries, and then sort the results will be output, finally achieve some sort of user relevance feedback mechanism. The commonly used information retrieval models are set theory model, algebraic model, probabilistic model and hybrid model. Searcher is a module has a direct interaction with the user, and on the interface there are several implementations, the commonly used is Web mode, through these methods, the searcher receives a user query, and carries outword processing for it, finally obtains query keywords. Based on the above, the Web data matched with the query keyword will be obtained, and returned to the user after sorting[6].Search engine based on LuceneLucene is a full-text retrieval tool package based on Java, it is not a complete search application, but to provide indexing and search capabilities for applications. Currently Lucene is an open source project in the family of Apache Jakarta, also the most popular open full-text retrieval package based on Java, at present there are already many application search function is based on Lucene[7]. Lucene can establish indexing for the data with text type, so you just convert your index data format into text, Lucene will be able to index and search the document. For example, if some HTML documents, PDF documents need to be indexed, they must be first converted into text format, and then given to Lucene for indexing, next, the created index file is saved in disk or memory, finally according to the query criteria entered by the user query the index file. No specifying the format of the document to be indexed also makes Lucene is applicable for almost all of the search applications.C.Technical analysis of LuceneLucene architecture has strong object-oriented features. It first defines a platform-independent index file format, followed designs the core components of the system as abstract class, the concrete platform realization part as the achievement of the abstract class, in addition the platform-related part such as file storage is also packaged as a class, after object-oriented processing, finally a search engine system with low coupling, high efficiency, and easy secondary development is obtained. Lucene system structure is shown in figure 3.In Lucene file format, byte is the basis to define the data types, thus ensuring platform-independent, which is also the main reason for the Lucene index file format and platform independent. Lucene index consists of one or more segments, in which each segment composed by a number of documents. Document object can be treated as a virtual document: for example, a web page, an E-mail message or a text file, then you can retrieve large amounts of data. A Document object contains one or more fields with different domain name, and the field represents this document or some metadata related to it. Each field corresponds to a piece of data, and the data may be queried or retrieved in the index during the search process. The field consists of domain name and value. Term is a basic unit for the search, as field object, it includes a pair of string elements: respectively corresponding to the domain name and value. The conceptual structure of Lucene index files is shown in figure 4.Use of segments can quickly add new documents to the index through adding documents to a newly created index segment and only periodically merging with other existing paragraphs. This process increases the efficiency because that it minimizes the modification of the index file physically stored. One of the advantages of Lucene is to support incremental index. After adding a new document in the index, you can immediately search the contents of the document. Lucene supports for incremental index makes Lucene suit for the work environment of large amounts of information processing, in this environment the method of rebuilding index will look inefficient. Mapping to structure from concept, index is treated as a directory (folder), all the files contained in which are its contents, and these files are stored in group according to the different segments they belonged, the files in the same group have the same file name, different extension names. In addition there are three files, separately used to store the record of all the segments, save the record of deleted files, and control the synchronization of reading and writing, which are segments, deletable and lock files, with no extension names. Each segment contains a set of files, their file extension names are different, but the file names are all the names stored in the file segments.Lucene system structure has object-oriented feature. Developers do not need to know the internal structure and implementation of Lueene, but simply need to call application interfaces Lucene provided, and they also can extend their own needed functionality according to the actual situation. In the index, Lucene is different from the most search engines, while establishing the index create a new index file, for different update strategies, it combines the new index file with the existing index file, thus greatly improving the efficiency of the index. Lucene also have incremental indexing function, can make batch indexing, and optimize it, the incremental index with small quantities, so for large amounts of data index has obvious advantages. Lucene uses a common data structure to accept the index input, so can be flexibly adapted to a variety of data sources, such as databases, office documents, PDF documents and html documents, etc., when data indexing, only needs an appropriate parser to convert the data source into the corresponding data structure. Although Lucene has powerful search and indexing capabilities, but it is not a complete search engine, cannot collect the information of Internet pages, and in sorting have yet to be perfected[8]. The sorting of search results is very important for the search engine, usually users only take attention to the first page search engine returned, therefore, taking the pages valuable for users, with high level as the top surface of the page is an important topic of search engine study.D.Search engine based on LuceneSearch engine mainly consists of collecting, indexing, and retrieval system, while the user interface is a way to display search results for users. Web spider in the network according to a certain strategy to extract pages and recursively download the crawled pages. Indexing system for the pages the web spider have collected uses analysis system for word segmentations, then get the corresponding index entry, andfor all types of documents, uses the corresponding parser to parse the text, then index file and store it in the index database. Users input the search keyword through the user interface, and then the retrieval system will analyze it and submit it to the word segmentation system for processing, match the keywords obtained from the above processing with the words have been indexed, by specific algorithms sort the pages with same or similar keywords, finally return the search results to the user interface.The indexing mechanism in Lucene system should have analytical function, Lucene itself has the function to analyze txt, html files, and because of many Internet file formats, so in order to achieve a variety of document analysis, the corresponding search package needs to be added. Lucene analyzer consists of two parts: one part is the word segmentation device, being called Tokenizer; the other part is a filter, known as TokenFilter. A parser often consists of a word segmentation device and a plurality of filter, in which the filter is mainly used to deal with the segmented words. In the index establishment, what can be written in the index and retrieved by users are the entries. In fact, the so-called entry is the text after analyzer word segmentation and related processing. Word segmentation device through a next () method itself provided returns a primitive, segmented entry, and the filter through this method returns a filtered entry, with no segmentation function. As the filter constructor receives an instance of TokenStream, there will be two situations: first, the filter and other filters can be nested together to form a nested pipe filter structure; second, the filter can be combined with tokenizer to filter the segmented words from it. This nesting forms the core structure of Lucene analyzer.Retrieval function is the last link to achieve search engine, and the important factor to measure it in response speed and result sort. When a user enters a search keyword, the word segmentation system to analyze and cut, then the similarity calculation and matching with the morpheme vector in index database, and finally the search results successfully matched will be returned to the user. Retrieving part of the search engine system consists of Lucene search statement analysis system and search result clustering analysis system, in which the former is to understand the user input keywords, according to the reverse maximum matching algorithm for retrieve word segmentation, if the segmented results need to pause word filter, it needs to deal with the ambiguity field by using word segmentation probability, and then get the actual semantic words, establish a search term. Then, the Lucene search system query and submit the results to the clustering analysis system to analyze and process, so find high correlation pages and automatically generate pages. Finally, the analysis system will detect the similar documents from the Lucene search results.ConclusionThe rapid development of the Internet, the amount of information is increasing exponentially, but the ultimate goal is to enable users to easily access the information, this mission falls on the search engine, furthermore, how to return the needed information, web content with high quality to users, presents higher requirements and challenges to the search engine. Because that the Lucene scoring algorithm hasnot well reflected the page location information in the website, this paper designed an improved solution in index and retrieval module, which can well unite the basic points of the document, and the document location information in the website, as well as the document characteristics, to improve the accuracy of search result sorting, thereby enhancing the accuracy of the search.References[1]Monz C. Proceedings of 25th European Conference on Information Retrieval Research [c], Berlin/Heidelberg: Springer, 2003:571-579.[2]Nicholas Lester, Justin Zobel, Hugh E Williams. Efficient Online Index Maintenance for Contiguous Inverted Lists [J], Inf. Process. Manage, 2006, 42(4): 916-933.[3]George Samaras, Odysseas Papapetrou. Distributed Location Aware Web Crawling, In Proceedings of the 13th international World Wide Webconference [J], New York, USA:ACM Press, 2004: 468-469.[4]Hai Zhao, Changning Huang. Effective tag set selection in Chinese word Segmentation via conditional random field modeling [C], In: Proceedings ofPA-CL IC220.WuHan, November 123, 2006: 84-94.[5]Arvind Arasu, Jasmine Novak, Andrew Tomkins, John Tomlin. Page Rank Computation and the Structure of the WEB: Experiments and Algorithms,In Proceedings or 11th International World Wide Web Conference, 2002.[6]Giuseppe Antonio Di Lucca, Anna Rita Fasolino, Porfirio Tramontana. Reverse engineering web applications: the WARE Approach [J], Journal ofSoftware Maintenance and Evolution: Research and Practice, 2004, 11(3):15.[7]Giuseppe Pirro, Pomenico Talia. An approach to Ontology Mapping Based on the Lucene Search Engine Library[C], Proceedings of the 18thInternational Conference on Database and Expert Systems Applications, 2007, 9:156-158.[8]Laurence Hirsch, Robin Hirsch, Masoud Saeedi. Evolving Lucene Search Queries for Text Classification[C], Proceedings of the 9th AnnualConference on Genetic and Evolutionary Computation, 2007, 6(12):166.。
系统需求分析系统说明书

系统需求分析系统说明书系统需求分析系统说明书引言随着企业业务规模的扩大和复杂性的增加,有效的系统需求分析成为确保企业信息系统顺利开发和运行的关键环节。
本系统需求分析系统旨在提供一个全面、实用的工具,帮助企业在进行系统开发或升级时进行准确、高效的需求分析。
系统概述本系统需求分析系统采用模块化设计,主要包括以下几个模块:1、需求收集模块:用于收集用户需求和产品需求,确保需求的准确性和完整性。
2、需求分析模块:对收集到的需求进行深入分析,评估需求的可行性和优先级,确保需求的有效性和实用性。
3、需求文档生成模块:将分析后的需求生成简洁、清晰的文档,便于开发人员理解和实施。
4、需求跟踪模块:记录需求的变更和管理需求版本,确保需求的可追溯性和一致性。
5、用户管理模块:提供用户管理功能,包括用户权限设置、用户培训等,确保系统的安全性和用户的有效使用。
需求分析本系统的需求分析过程主要包括以下步骤:1、收集需求:通过访谈、问卷调查和竞品分析等方式,收集用户需求和产品需求。
2、需求筛选:对收集到的需求进行筛选,去除无效或低优先级的需求。
3、需求分类:将筛选后的需求按照功能需求、非功能需求、技术需求等进行分类。
4、需求分析:对每类需求进行深入分析,评估需求的可行性和优先级。
5、生成需求文档:将分析后的需求整理成简洁、清晰的文档,便于开发人员理解和实施。
需求分析结果经过需求分析过程,我们可以得到以下结果:1、用户需求和产品需求的优先级和数量。
2、对应的业务流程和界面设计。
3、功能模块的划分和关联关系。
4、系统性能、安全、可维护性等方面的需求。
这些结果将为后续的系统开发和实施提供准确、实用的指导。
系统测试本系统采用严格的测试流程,包括以下环节:1、单元测试:对每个独立的功能单元进行测试,确保其符合设计要求。
2、集成测试:将各个单元组合在一起进行测试,确保它们之间的协作顺畅无误。
3、性能测试:测试系统的响应速度和处理能力,确保其能够在预期的负载下正常运行。
系统需求分析系统说明书(模板)

系统需求分析系统说明书(模板)系统需求分析系统说明书(模板)1 引言1.1 系统概述说明系统的名称,并简明扼要地阐述系统的功能。
1.2 编写目的说明编写这份报告的目的,指出预期的读者。
1.3 开发背景指出待开发的软件系统的原因;行业情况;本项目的任务提出者、开发者、用户;该软件系统同其他系统或其他机构的基本的相互来往关系。
1.4 参考文献列出编写本需求时参考的文件(如经核准的计划任务书或合同、上级机关的批文等)、资料、技术标准,以及他们的作者、标题、编号、发布日期和出版单位。
1.5 术语定义列出本需求中用到的专门术语或缩略语的定义。
2 系统说明2.1 网络结构整个系统网络结构图和必要说明。
例如:图2.12.2 功能结构以图表的方式对整个系统的模块构成和功能进行描述。
例如:图2.2 3 功能需求以模块 + 功能为单位分别加以说明。
3.1 [XXXX功能名称] 例如:用户登录3.1.1 功能描述【按下列表格形式对该功能需求做详细的描述】3.1.2 页面流程描述【描述页面之间跳转流程及页面原型】3.1.3 页面定义【描述页面的元素定义】3.2 [XXXX功能名称] 例如:成绩查询3.2.1 功能描述3.2.2 页面流程描述3.2.3 页面定义4 非功能需求4.1 性能需求对页面访问响应时间、查询统计响应时间、并发用户数、在线用户数等进行说明。
4.2 网络需求对网络的类型和带宽的要求进行描述。
4.3 存储需求硬盘剩余空间容量与单位个数和每年的项目数大小相关,推荐的指标为:剩余空间容量>基础数据表300M+单位个数×100M+项目数×100M×24.4 安全需求项目所采取的数据安全保护措施,下列举例说明,具体以各自的实际项目为准。
5 运行环境5.1 硬件对硬件的最低要求和推荐标准进行说明,分为服务器和客户端。
5.2 软件对服务器和客户机的OS以及相关软件的版本等进行说明。
微博搜索引擎需求分析

微博搜索引擎需求分析摘要:自从微博这一事物走入我们的生活中,在短短几年的时间里迅速被人们接受,尤其是得到了年轻人的热捧。
人们通过微博可以建立密友圈进行互动,可以把握最新的热点新闻资讯,也可以看到一些轻松诙谐的小故事、图片,在学习工作的压力之余,极大的丰富了我们的精神生活。
不知不觉人们养成了在微博上搜索的习惯。
我知道这种不自觉养成的习惯必然与我们的需求和搜索意图密切相关,微博的特点是实时性强,支持多平台的用户体验,极为方便快捷,这刚好能满足人们的需求。
关键词:JSP MySQL Hibernate Struts1 AJAX javascript 微博搜索引擎网络蜘蛛1引言Java Web,是基于B / S模式(Brower/Server),用Java技术来解决相关web互联网领域的技术总和。
web包括:web服务器和web客户端两部分。
Java在web的应用框架很多,如JSP、 AJAX、 XML、 Struts1、 Struts12、 JQuery、 Hibernate、 Spring、Flex、 JPA 等。
本系统主要用到了JSP、 AJAX、 XML、 Struts11、Hibernate。
其中,JSP(Java Server Pages)是由Sun Microsystems公司倡导、许多公司参与一起建立的一种动态网页技术标准;AJAX是使用客户端脚本与Web服务器交换数据的Web应用开发方法;XML是可扩展标记语言(Extensible Markup Language, XML) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言;Struts11 是Apache软件基金会(ASF)赞助的一个开放源代码的项目;Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了对象封装,使得Java程序员可以使用对象编程思维来操纵数据库。
搜索引擎对用户的需求分析

用户需求分析分为两个方面,一个是搜索词分析,另外一个是用户搜索意图分析,通过搜索词的分析可以返回一个可能是用户需求的结果列表,通过用户搜索意图的分析并对搜索结果进行调整,可以获得此用户更加想要的结果列表。
搜索词分析:用户向搜索引擎提交一个查询后,搜索引擎会首先判断用户提交的搜索词类型是普通文本搜索、普通文本带有高级指令的搜索还是纯高级指令的搜索。
这三类搜索词汇搜索引擎会分别进行不同的索引匹配。
首先我们先了解什么是纯高级指令搜索,年少有一篇文章就是专门讲高级指令的,大家可以直接点击SEO优化中一些高级搜索指令这篇文章进行了解,这里年少就不细讲了。
普通文本搜索:搜索引擎就会和处理网页内容一样先进行分词,去除停止词等处理,如果用户输入明显错误的字,搜索引擎还会依次进行矫正(注意:必须是错误汉字和矫正后的汉字是同一拼音,否则搜索引擎不会强制矫正)普通文本带高级指令的搜索:这个一般搜索引擎首先会根据高级指令限定搜索范围,然后根据用户提交的文本搜索词,在限定范围内容进行检索和排名。
搜索意图分析如果用户搜索一些比较宽泛的关键词时,如果只根据关键词本身,搜索引擎可能并不知道用户想要获取的是什么内容,这个时候搜索引擎就会尝试性的分析用户的搜索意图。
比如说:“刘亦菲”,这个时候,搜索引擎并不知道用户是想要搜刘亦非的电影还是图片还是音乐了,这个时候,搜索引擎就会触发搜索引擎的整合功能,把刘亦菲的相关且不同方向的内容同时呈现出来,让用户自由选择,这样也可以保证在搜索结果的首页就能满足用户的需求。
根据统计分析用户搜索该关键词的关注内容比率,搜索引擎也会调整这些内容的排名。
有的时候当用户搜索一些通用词汇的时候,搜索引擎会尝试参考用户所处地域的信息,返回可能是用户最需要的当地的相关信息。
例如在武汉搜索饭店和在北京搜索饭店,得到的搜索结果首页一般都是当地“武汉信息”、“北京信息”。
因为此类关键词一般都是在寻找本地信息。
这也是搜索引擎分析用户搜索意图后对常规关键词的匹配搜索结果的改进。
系统需求分析系统说明书(模板)

系统需求分析系统说明书1、引言本章主要介绍本文档的目的、范围、定义和缩略词。
1.1 目的本文档旨在对系统的需求进行分析和说明,明确系统的功能、性能、可靠性、安全性等方面的需求,为系统的开发和实施提供指导。
1.2 范围本文档适用于系统的需求分析阶段,并覆盖系统的所有功能和功能扩展。
1.3 定义本文档中使用的术语和定义应与相关文档和标准一致。
1.4 缩略词在本文档中使用的缩略词及其定义如下:- CRM:客户关系管理- ERP:企业资源计划2、系统概述本章主要介绍系统的背景和目标,以及对系统的总体描述和功能。
2.1 背景在这里描述系统的背景信息,如为什么需要该系统以及当前的业务痛点。
2.2 目标明确系统的主要目标,包括提高效率、降低成本、提升用户体验等。
2.3 总体描述对系统进行整体描述,包括系统的角色、主要功能模块和关键业务流程。
2.4 功能描述系统的主要功能模块和子功能。
3、需求分析本章主要详细说明系统的需求,包括功能需求、性能需求、可靠性需求、安全性需求等。
3.1 功能需求和描述系统的各项功能需求,包括用户管理、订单管理、客户服务等。
3.2 性能需求说明系统在各方面的性能要求,如响应时间、并发处理能力、数据容量等。
3.3 可靠性需求描述系统的可靠性要求,如可用性、容错性、恢复性等。
3.4 安全性需求明确系统的安全性要求,包括数据安全、用户认证等。
4、系统设计本章主要介绍系统的设计方案,包括架构设计、数据库设计、界面设计等。
4.1 架构设计描述系统的总体架构设计,包括分层结构、模块划分等。
4.2 数据库设计说明系统的数据库设计,包括数据表结构、关系定义和索引设计等。
4.3 界面设计描述系统的用户界面设计,包括界面布局、样式和交互设计等。
5、接口设计本章主要详细说明系统的接口设计,包括与外部系统的接口、与用户的接口等。
5.1 外部系统接口说明系统与其他外部系统的接口设计,包括数据交换格式、接口协议、安全认证等。
KWIC索引系统需求说明书

目录1引言 (2)1.1编写目的 (2)1.2背景 (2)1.3定义 (2)1.3.1 参考资料 (2)1.3.2 术语 (2)2任务概述 (3)2.1目标 (3)2.2用户的特点 (3)3假定和约束 (3)4需求规定 (3)4.1软件功能说明 (3)4.1.1功能说明 (3)4.1.2索引数据输入(编号:SRS-KWIC-01) (3)4.1.3索引数据行(编号:SRS-KWIC-02) (4)4.1.4索引数据循环移位(编号:SRS-KWIC-03) (5)4.1.5索引款目行(编号:SRS-KWIC-04) (5)4.1.6索引款目排序(编号:SRS-KWIC-05) (6)4.1.7索引款目输出(编号:SRS-KWIC-06) (6)4.2对性能的规定——灵活性 (7)4.3对功能的一般性规定 (7)4.4输入输出要求 (7)4.5对安全性的要求 (8)4.6其他专门性要求 (8)5运行环境规定 (8)5.1设备 (8)5.2支持软件 (8)5.3程序运行方式 (8)5.4开发成本 (8)5.5尚需解决的问题 (9)1引言1.1编写目的本需求报告为使客户与开发小组成员就系统需求达成一致。
1.2背景1)待开发的软件系统的名称为“KWIC索引系统”;2)KWIC索引的出现是现代科学技术的发展和科技文献急剧增长的产物,本系统简单实现了文字的索引的功能。
3)本项目的任务提出者是“南华大学科学与计算机学院软件工程系”,开发者为“旗舰开发小组”,用户为南华大学学生。
1.3定义1.3.1 参考资料编写本报告时查阅的Intenet上杂志、专业著作、技术标准以及他们的网址:1.3.2 术语1)KWIC:Key Word In Context,又称上下文关键词索引,是二次文献的辅助索引,是最早的机编索引,首先应用于1960年美国化学文摘社创办的《化学题录》,由早年在ACM的Paper提出这一问题。
题内关键词索引的标目在款目的中部,左右均为该标目的上下文,索引款目按位于款目中部作为标目的关键词的字顺排列。
系统需求分析说明书(模板)

系统需求分析说明书目录1 产品概述 (4)1.1 目标&意义 (4)1.2 领域知识 (4)1.3 思维导图 (4)1.4 业务流程图 (5)2 功能范围 (7)2.1 功能名称 (7)2.1.1 功能说明 (7)2.1.2 用例说明 (7)2.1.3 操作流程 (9)2.1.4 界面原型 (11)2.1.5 对应字段 (11)2.1.6 相关规则 (12)3 词汇表 (12)4 非功能需求 (12)4.1 规则变更需求 (12)4.2 产品服务需求 (12)4.3 帮助需求 (12)4.4 安全性需求 (12)4.5 上线实现需求 (3)5 上线时间安排表 (12)1产品概述说明:<简单描述项目的背景、意义、目的、目标等,描述领域知识>1.1目标&意义项目目标:完整保存教师信息;简化教师管理流程;提高相关部门工作效率;建立合理系统功能。
项目意义:保证每学期开班的正常进行建立有效的教师管理机制按照统一规则计算工资,保证教师待遇、奖金的公平公正性有效提高师资管理相关部门的工作效率,优化工作流程1.2领域知识说明:<包括:项目涉及到的业务背景、业务知识、业务词汇解释。
>项目类似于人力资源管理系统,主要信息管理、考勤、工资、合同、排名、访谈几个角度管理和利用教师信息为实际工作服务。
涉及工资核算、考勤制度。
1.3思维导图<整个产品功能思维导图><整个产品涉及业务的整个流程图>2功能范围<主要功能描述>2.1教师入职2.1.1功能说明<描述功能的作用>新录入老师的信息管理入职老师审批专职老师转正审批审批记录查询2.1.2用例说明<编写业务用例,即按照真实的用户业务划分用例,记录人机交互过程,完成用例描述><<uses>>系统表格 1教师入职用例图2.1.2.1用例图_新增教师用例 2-1 2.1.3操作流程<描述该部分功能的业务流程>2.1.3.1转正审批流程表格 2转正审批流程2.1.4界面原型<粘贴所有跟该功能相关的界面原型>2.1.4.1教师管理-教师查询表格 3教师管理-教师查询2.1.5对应字段<描述页面上相关字段,而不是操作字段>2.1.5.1基本信息表2.1.6相关规则<描述跟系统实现相关的业务规则>3词汇表<定义系统中的词汇,解释词汇含义,整个文档统一词汇名称> 4非功能需求4.1规则变更需求可能变更的系统规则4.2产品服务需求产品设计需要提供的附加人为服务4.3帮助需求需要提供的帮助信息4.4安全性需求需要提供的安全性信息5上线时间安排表分解项目任务,制定上线时间欢迎您的下载,资料仅供参考!致力为企业和个人提供合同协议,策划案计划书,学习资料等等打造全网一站式需求。
搜索引擎软件使用说明书
搜索引擎软件使用说明书1 软件概述1.1 编写目的随着计算机产业的迅猛发展,搜索引擎也应运而生。
用户直接获得自己想要的信息其实是很简单,但是面对着简单的搜索框,很多用户都只是了解大概,要想了解的更彻底关键在于学会怎么来用。
为了用户能够更快更方便的获得想要的信息,本人针对自己开发的搜索引擎包特编写了使用说明书。
1.2 搜索引擎介绍1.2.1 搜索引擎定义搜索引擎主要用于帮助互联网用户查询信息的搜索工具,它以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织及处理,并且能为用户提供检索服务,从而起到信息导航的目的因此,搜索引擎是用来在网上找资料的工具。
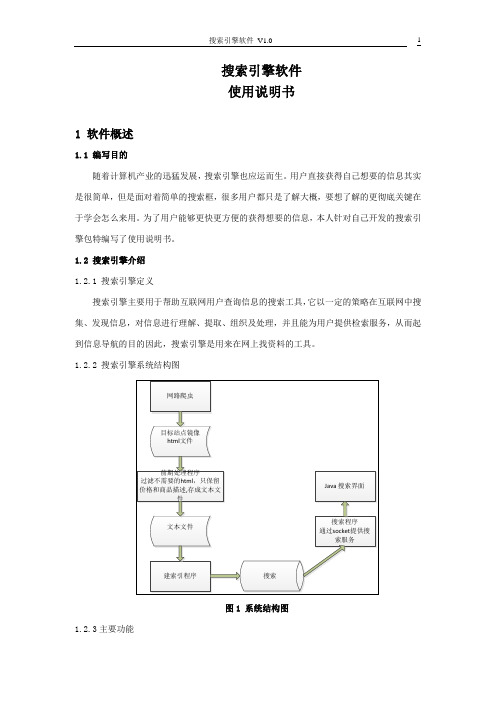
1.2.2 搜索引擎系统结构图1.2.3主要功能本人开发的搜索引擎主要是进行信息检索,从而返回检索结果。
搜索引擎将用户所产生的一些信息列入了排序因素中,具有对各大商城的网站进行抓取、建立索引、搜索比价的功能。
它是网络营销中最重要的组成部分,是向终端客户传递信息的重要环节。
搜索界面如下图:1.2.4 主要特点1.2.4.1 快速地为搜索文件建立索引,支持追加,重建,和不同编码的搜索文件。
1.2.4.2 搜索引擎支持关键字搜索,与或非逻辑搜索,支持按需返回搜索结果。
1.2.4.3 web服务器能快速连接搜索引擎,支持用户的多样化搜索,并展示搜索结果。
2 如何编译fts1. aclocal2. automake --add-missing3. autoconf4. ./configure5. make编译成功以后,在../src/目录下,有index.exe, search.exe 和shutdown.exe。
2.1 index.exeindex.exe是对网络爬虫抓来的网页建立索引,-D源目录,-d索引目录,-R重建索引(只在第一次用),-c 国标或台湾$ ./index -D /cygdrive/c/tf/src/ -d /cygdrive/c/tf/trg -R -c GB2312Start indexing ...Indexing /cygdrive/c/tf/src/Copy of baima.t4i# of Files Processed : 1# of Files Indexed : 1Total Data Processed : 136.242 KB.Average Processing Rate : 45.4141 KBps.Total Time Used : 3 seconds.Total Processor Time Used : 2.875 seconds.CPU Usage : 95.8333%2.2 search.exeSearch.exe 会在已建立的索引上运行一个socket服务器,可以接收多个搜索请求,默认听在端口30001。
搜索引擎使用分析报告

搜索引擎使用分析报告1. 引言本文档旨在分析搜索引擎的使用情况,并提供相关数据和见解,以便了解用户在搜索引擎上的行为和偏好。
搜索引擎作为我们日常生活中常用的工具之一,可以帮助我们在海量信息中快速找到所需的内容。
通过分析用户在搜索引擎上的行为,我们可以更好地理解用户需求,为网站优化和营销提供指导。
2. 数据收集方法为了获取搜索引擎的使用数据,我们采用了以下方法:•用户调查问卷:我们设计了一份调查问卷,在线收集用户在搜索引擎上的使用情况和偏好。
通过问卷收集的数据可以提供用户自述的信息和观点。
•访问日志分析:我们收集了一定时间范围内的搜索引擎访问日志,并进行了数据清洗和整理。
通过分析访问日志,我们可以了解用户搜索的关键词、访问时间、页面停留时间等指标。
3. 用户调查结果在用户调查中,我们收集了500份有效问卷,并进行了数据分析和统计。
以下是一些主要结果的概述:•搜索引擎使用频率:近80%的受访者表示每天都使用搜索引擎,其中超过一半的人使用频率达到每天多次。
•搜索引擎选择偏好:超过70%的受访者表示他们最常使用的搜索引擎是谷歌,其次是百度和必应。
•搜索关键词类型:大约50%的受访者表示他们主要使用搜索引擎进行信息检索,25%的人主要使用搜索引擎寻找产品或服务,其他人主要用于娱乐和学习。
•搜索结果点击率:约60%的受访者表示他们通常只点击搜索结果的前一页,只有20%的人会查看更多的搜索结果页面。
•搜索偏好设置:大多数受访者(约70%)表示他们会根据个人需求调整搜索引擎的搜索结果排序方式,例如按时间、相关性或评分排序。
4. 访问日志分析结果通过对搜索引擎访问日志的分析,我们得到了以下结论:•热门搜索关键词:在收集的访问日志中,一些热门搜索关键词包括旅游、健康、科技、时尚等。
这些领域的搜索需求较高。
•搜索峰值时间:根据访问日志的时间戳数据,我们可以看到搜索引擎的访问在工作日的上午和下午较为集中,而在周末和假期时间段搜索量相对较低。
大连理工大学搜索引擎与文本挖掘课程设计需求报告 - 搭建小型搜索引擎

需求报告——搜索引擎与文本挖掘日期:2014.10.29 目标:在理解搜索引擎原理及整体流程的基础上,通过亲自动手搭建一个完整、可运行的小型全文检索实验系统,进一步加深对搜索引擎系统底层实现的理解和掌握,熟悉搜索方面的一些经典算法和思想。
可选工具索引、检索工具:Lucene、Indri、Firtex等网页爬行器(Crawler):Weblech、Nutch Crawler、Wget、Larbin等Web服务:Tomcat、Apache等分词组件:对于中文语料来说,不能采用Lucene默认的分词器(如StandardAnalyzer等),必须引入新的、适合中文的分词器。
可以自己实现一个简单的基于最大匹配的分词程序,也可以上网下载Lucene的扩展分词组件包CJKAnalyzer(二字串方式分词),当然也可以采用第三方分词组件,如中科院ICTCLAS分词组件等。
功能要求(必须):1、利用开源的网页爬行器或者自己开发的网页爬行器,爬取一定数目的网页。
2、对网页进行必要的去噪,预处理工作。
3、采用Lucene等全文检索工具包对数据建立倒排索引,并能提供检索服务4、返回给用户的应该是一个进过相关性排序的结果列表5、不能采用Lucene默认的分词器分词,必须完成一个中文分词接口。
6、必要的预处理工作。
中文:分词、停用词过滤。
英文:大小写转化(Case insensitive)、词干化(Stemming)、停用词过滤。
7、结果高亮显示注意事项:1、中文分词可以借助现有的组件,如中科院ICTCLAS分词组建、哈工大IRLAS词法分析系统等。
这时需要做的是,根据Lucene的Analyzer接口规范将上述分词组建进行封装,使之可被索引器、搜索器等调用。
2、英文的词干化(Stemming)可以调用网上现有的算法实现,比过Porter StemmingAlgorithm算法等。
3、用户界面可以仿照Google、百度等,不要太花哨,简洁、大方即可。
搜索引擎需求分析

搜索引擎需求分析搜索引擎需求分析搜索引擎简介搜索引擎指⾃动从英特⽹搜集信息,经过⼀定整理以后,提供给⽤户进⾏查询的系统。
英特⽹上的信息浩瀚万千,⽽且毫⽆秩序,所有的信息象汪洋上的⼀个个⼩岛,⽹页链接是这些⼩岛之间纵横交错的桥梁,⽽搜索引擎,则为你绘制⼀幅⼀⽬了然的信息地图,供你随时查阅。
搜索引擎的⼯作原理?搜索引擎的⼯作原理⼤致可以分为:1、搜集信息:搜索引擎的信息搜集基本都是⾃动的。
搜索引擎利⽤称为⽹络蜘蛛(spider)的⾃动搜索机器⼈程序来连上每⼀个⽹页上的超连结。
机器⼈程序根据⽹页链到其他中的超链接,就象⽇常⽣活中所说的“⼀传⼗,⼗传百……”⼀样,从少数⼏个⽹页开始,连到数据库上所有到其他⽹页的链接。
理论上,若⽹页上有适当的超连结,机器⼈便可以遍历绝⼤部分⽹页。
2、整理信息:搜索引擎整理信息的过程称为“建⽴索引”。
搜索引擎不仅要保存搜集起来的信息,还要将它们按照⼀定的规则进⾏编排。
这样,搜索引擎根本不⽤重新翻查它所有保存的信息⽽迅速找到所要的资料。
想象⼀下,如果信息是不按任何规则地随意堆放在搜索引擎的数据库中,那么它每次找资料都得把整个资料库完全翻查⼀遍,如此⼀来再快的计算机系统也没有⽤。
3、接受查询:⽤户向搜索引擎发出查询,搜索引擎接受查询并向⽤户返回资料。
搜索引擎每时每刻都要接到来⾃⼤量⽤户的⼏乎是同时发出的查询,它按照每个⽤户的要求检查⾃⼰的索引,在极短时间内找到⽤户需要的资料,并返回给⽤户。
⽬前,搜索引擎返回主要是以⽹页链接的形式提供的,这些通过这些链接,⽤户便能到达含有⾃⼰所需资料的⽹页。
通常搜索引擎会在这些链接下提供⼀⼩段来⾃这些⽹页的摘要信息以帮助⽤户判断此⽹页是否含有⾃⼰需要的内容。
搜索引擎对⽹站的影响⼀个⽹站的命脉就是流量,⽽⽹站的流量可以分为两类。
⼀类是⾃然流量,⼀类就是通过搜索引擎⽽来的流量。
如果搜索引擎能够更多更有效的抓取⽹站内容,那么对于⽹站的好处是不⾔⽽喻的。
《基于Lucene的蒙古文搜索引擎的设计与实现》范文

《基于Lucene的蒙古文搜索引擎的设计与实现》篇一一、引言随着信息技术的飞速发展,搜索引擎已成为人们获取信息的重要工具。
在多元化的文化背景下,针对特定语种如蒙古文的搜索引擎设计显得尤为重要。
本文将详细阐述基于Lucene的蒙古文搜索引擎的设计与实现过程,包括系统需求分析、系统设计、关键技术实现及系统测试等环节。
二、系统需求分析1. 业务需求:为满足蒙古文信息检索需求,系统需支持蒙古文文本的索引、检索及优化等功能。
2. 功能需求:系统应具备高效、准确、易用的特点,支持全文检索、关键词检索、高级检索等功能。
3. 性能需求:系统应具备良好的可扩展性、稳定性和安全性,确保大规模数据下的检索性能。
三、系统设计1. 总体架构设计:系统采用分层架构,包括数据层、业务逻辑层和表示层。
数据层负责存储和管理蒙古文文本数据;业务逻辑层实现文本的索引、检索等功能;表示层负责用户界面的展示。
2. 索引设计:采用Lucene的倒排索引技术,将蒙古文文本转换为可搜索的索引格式。
同时,为提高检索效率,采用分词、词干还原等预处理技术。
3. 检索设计:支持全文检索、关键词检索、高级检索等多种检索方式,满足用户多样化的检索需求。
四、关键技术实现1. 文本预处理:对蒙古文文本进行分词、词干还原等预处理,以便后续的索引和检索操作。
2. 索引构建:采用Lucene的倒排索引技术,将预处理后的文本转换为可搜索的索引格式。
同时,为提高索引的质量和检索效率,采用多线程并行处理技术。
3. 检索算法:实现多种检索算法,如全文检索算法、关键词检索算法、基于统计的检索算法等,以满足用户的不同需求。
4. 系统界面:设计友好的用户界面,提供简洁明了的操作流程和丰富的交互方式,提高用户体验。
五、系统测试1. 功能测试:对系统的各项功能进行测试,确保系统能够正常运行并满足业务需求。
2. 性能测试:对系统的性能进行测试,包括响应时间、吞吐量、并发用户数等指标,确保系统在大规模数据下仍能保持良好的性能。
搜索引擎使用分析报告

搜索引擎使用分析报告1. 引言随着互联网的快速发展,搜索引擎已成为人们获取信息的重要工具。
搜索引擎使用分析报告旨在分析用户在搜索引擎中的行为和偏好,从而为搜索引擎优化提供指导和建议。
2. 数据收集为了进行搜索引擎使用分析,我们收集了大量的数据。
主要数据来源包括用户搜索查询记录、点击记录、停留时间和页面浏览深度等。
这些数据将帮助我们深入了解用户在搜索引擎中的行为模式。
3. 用户搜索查询分析在搜索引擎中,用户输入关键词进行搜索。
通过分析用户搜索查询,我们可以了解用户的兴趣和需求。
例如,某些关键词的搜索频率较高,说明这些主题或问题备受用户关注。
我们可以将这些热门关键词作为搜索引擎结果的优化方向,提供更相关和有用的信息。
4. 搜索结果点击分析当用户在搜索引擎中查找信息时,他们通常会点击搜索结果列表中的某个链接。
通过分析用户的点击行为,我们可以了解用户对搜索结果的满意度和相关性。
通过识别用户点击率较高的链接,我们可以得出哪些页面或网站在特定搜索查询下是最具价值的。
这将有助于优化搜索结果,提高用户体验。
5. 用户停留时间和浏览深度分析当用户点击搜索结果链接后,他们会在打开的页面上停留一段时间并浏览页面内容。
通过分析用户停留时间和浏览深度,我们可以了解用户对页面内容的兴趣程度和满意度。
如果用户停留时间短且页面浏览深度较浅,可能意味着页面内容不够吸引人或与用户的需求不匹配。
因此,我们可以通过优化页面内容和结构,使用户花更多的时间停留并浏览更多的内容。
6. 结果优化建议基于对用户行为的分析,我们提出以下搜索引擎优化建议:6.1 提供相关的搜索结果根据用户搜索查询分析结果,我们可以确定用户关注的热门主题和问题。
因此,搜索引擎应该确保在搜索结果中提供与这些关键词相关的信息,帮助用户快速找到所需的答案。
6.2 优化搜索结果排序通过分析用户点击行为,我们可以确定哪些链接受到用户的青睐。
为了提高用户满意度,搜索引擎应该将这些受欢迎的链接排在搜索结果的前面,使用户更容易找到他们想要的信息。
如何利用互联网搜索的说明书范本

如何利用互联网搜索的说明书范本当今社会,互联网已经成为人们获取各种信息的重要途径。
而在互联网中,搜索引擎无疑是最常用的工具之一。
大部分人在使用搜索引擎时,往往是为了查找资料、解答问题或者寻找特定的商品。
但是,还有一类人群在使用互联网搜索时,专注于寻找说明书范本。
那么,如何利用互联网搜索来找到需要的说明书范本呢?首先,我们需要明确搜索的关键词。
在搜索说明书范本时,我们可以利用产品的名称和型号作为关键词进行搜索。
例如,如果我们需要一份手机的说明书范本,我们可以在搜索引擎中输入手机品牌和型号,然后加上“说明书范本”等关键词进行搜索。
这样有助于提高搜索的准确性,缩小搜索结果的范围,快速找到所需要的信息。
其次,在选择搜索引擎时,我们可选择多个不同的搜索引擎进行尝试。
虽然目前主流的搜索引擎如 Google、百度等在市场上占据主导地位,但并不代表其他搜索引擎没有价值。
不同的搜索引擎有着不同的搜索算法和数据库,有些搜索引擎可能会提供更优质的搜索结果。
因此,我们可以通过尝试不同的搜索引擎来找到适合自己需求的说明书范本。
除此之外,还可以通过一些特定的网站或平台来搜索说明书范本。
许多产品制造商会在自己的官方网站上提供产品说明书的下载,我们可以直接在制造商的官方网站上搜索所需的说明书范本。
此外,一些电子商务平台也会提供相关的服务,我们可以在这些平台上搜索并下载所需要的说明书范本。
此外,在使用互联网搜索时,我们还可以使用一些高级搜索技巧来提高搜索的效果。
例如,在搜索引擎中可以使用双引号来指定精确的搜索关键词,如将“手机型号+说明书范本”用双引号括起来进行搜索,这样可以只搜索包含完全相符的关键词的结果,提高搜索的准确性。
另外,可以使用减号符号来排除某些关键词,如“手机型号+说明书范本-售后服务”,这样可以排除掉与售后服务相关的结果,获得更加精准的搜索结果。
最后,需要注意的是,在搜索说明书范本时,我们应该注意信息的可靠性和真实性。
手机搜索引擎需求分析及设计文档

素、品牌、多媒体功能等,亦可以加入其他一些辅助性的功能选择,如蓝牙、 手写功能、收音机、可用扩展卡、红外接口、支持 JAVA、免提通话、来电防火 墙等。 2. 用户可以选择两款甚至两款以上的手机予以比较,并由系统给出比较结果,包括各 款手机的得分和排名; 3. 在查询或比较结果中,可以点击结果中的一款,以得到其详细信息,并可以看到以 下几项: (1) 用户打分情况(多少人打分,多少正分,多少负分等) (2) 著名搜索引擎的关注程度 (3) 排行榜排名情况(依赖不同手机型号,有些可能有此信息,有些可能没有) (4) 论坛中正负评价的比例(时间充裕则实现) (5) 编辑评论(时间充裕则实现) 4. 其他(有待继续讨论或开发过程中进行扩充) 三、数据结构及数据类型分析(决定数据库表如何设计) 1. 手机属性 手机属性依据不同属性而决定其取值,有些可以进行编码存储,有些则可以取绝对 数值,有些则简单的定为有无。 (1) 基本信息 颜色,上市时间,参考价,配置、网络频率,尺寸/体积,重量,屏幕种类,内屏类型, 外屏类型,通话时间,待机时间,外观样式。 (2) 主要功能 内置天线,三防功能,可换外壳,WAP 上网,中文输入,中文短信,超长短信,EMS 短信,多媒体短信,短信群发,内置震动,时钟,录音,语音拨号,语音指令,可选铃 声,和弦铃声,自编铃声,录制铃声,个性化铃声,个性化图片,情景模式,通话时间 提示,免提通话,话机通讯录,通讯录群组,通话记录,留言应答,来电防火墙,内置 游戏,动画屏保,屏幕休眠,待机图片,图形菜单,EFR-STK 支持, (3) 高级功能 无线下载,无线数据通讯,红外接口,数据线接口,手写输入,PDA 功能,支持 E-Mail, Java 扩展,支持 MP3,数码相机,动态内存,支持收音机, 支持电子书 (4) 附加功能 闹钟,日历,计算器,定时器,秒表,记事本,日程表,货币换算,世界时钟,电子名
搜索引擎需求分析

搜索引擎需求分析搜索引擎简介搜索引擎指自动从英特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。
英特网上的信息浩瀚万千,而且毫无秩序,所有的信息象汪洋上的一个个小岛,网页链接是这些小岛之间纵横交错的桥梁,而搜索引擎,则为你绘制一幅一目了然的信息地图,供你随时查阅。
搜索引擎的工作原理?搜索引擎的工作原理大致可以分为:1、搜集信息:搜索引擎的信息搜集基本都是自动的。
搜索引擎利用称为网络蜘蛛(spider)的自动搜索机器人程序来连上每一个网页上的超连结。
机器人程序根据网页链到其他中的超链接,就象日常生活中所说的“一传十,十传百……”一样,从少数几个网页开始,连到数据库上所有到其他网页的链接。
理论上,若网页上有适当的超连结,机器人便可以遍历绝大部分网页。
2、整理信息:搜索引擎整理信息的过程称为“建立索引”。
搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。
这样,搜索引擎根本不用重新翻查它所有保存的信息而迅速找到所要的资料。
想象一下,如果信息是不按任何规则地随意堆放在搜索引擎的数据库中,那么它每次找资料都得把整个资料库完全翻查一遍,如此一来再快的计算机系统也没有用。
3、接受查询:用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。
搜索引擎每时每刻都要接到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。
目前,搜索引擎返回主要是以网页链接的形式提供的,这些通过这些链接,用户便能到达含有自己所需资料的网页。
通常搜索引擎会在这些链接下提供一小段来自这些网页的摘要信息以帮助用户判断此网页是否含有自己需要的内容。
搜索引擎对网站的影响一个网站的命脉就是流量,而网站的流量可以分为两类。
一类是自然流量,一类就是通过搜索引擎而来的流量。
如果搜索引擎能够更多更有效的抓取网站内容,那么对于网站的好处是不言而喻的。
所以,SEO也应运而生了。
信息检索与分析系统需求分析

专利信息检索与分析系统和英文论文信息检索与分析系统需求分析文档大连灵动科技发展有限公司2018年11月目录1任务概述22需求规定2 2.1专利信息检索与分析系统22.1.1数据导入22.1.2建立数据索引22.1.3快速搜索32.1.4高级搜索32.1.5保存检索结果42.1.6统计并生成报表42.1.7组织曾用名管理42.1.8组织曾用名替换52.1.9新组织识别与保存52.1.10组织地址维护52.1.11地域划归62.1.12矩阵分析61.2论文信息检索与分析系统62.2.1数据导入62.2.2建立索引72.2.3快速搜索72.2.4高级搜索72.2.5保存检索结果82.2.6统计并生成报表82.2.7组织曾用名管理92.2.8组织曾用名替换92.2.9新组织识别与保存92.2.10组织名称翻译与维护102.2.11地域划归102.2.12矩阵分析103工作量及报价111任务概述本工程开发两个系统——“专利信息检索与分析系统”和“英文论文信息检索与分析系统”,均为科研使用。
工程使用C#.net编写,运行于Windows系统,将采用C/S模式,即在处理程序在服务器上运行,任何一个接入服务器的客户端,只要安装了客户端软件,便可使用分析功能。
b5E2RGbCAP本工程将采用数据库和搜索引擎相结合的方式,数据库主要用来保存数据,而搜索引擎则用来做复杂条件搜索和统计。
p1EanqFDPw2需求规定2.1专利信息检索与分析系统2.1.1数据导入2.1.2建立数据索引2.1.3快速搜索2.1.4高级搜索2.1.5保存检索结果2.1.6统计并生成报表2.1.7组织曾用名管理2.1.8组织曾用名替换2.1.9新组织识别与保存2.1.10组织地址维护2.1.11地域划归2.1.12矩阵分析1.2论文信息检索与分析系统2.2.1数据导入2.2.2建立索引2.2.3快速搜索2.2.4高级搜索2.2.5保存检索结果2.2.6统计并生成报表2.2.7组织曾用名管理2.2.8组织曾用名替换2.2.9新组织识别与保存2.2.10组织名称翻译与维护2.2.11地域划归2.2.12矩阵分析3工作量及报价个人收集整理资料,仅供交流学习,勿作商业用途注:专利信息检索与分析系统的功能和论文信息检索与分析系统可以部分重用时,按0.5系数计,但是由于专利为中文检索和论文为英文检索分词原理完全不同,不可重用功能,因此这部分功能按系数1计。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
软件需求规格说明书《xxx》软件系统
目录
0. 文档介绍 (3)
0.1文档目的 (3)
0.2文档范围 (3)
0.3读者对象 (3)
指导老师、设计人员、开发人员参考 (3)
0.4参考文档 (3)
0.5术语与缩写解释 (4)
1. 需求概述 (4)
1.1系统目标 (4)
1.2用户特点 (4)
1.3功能需求 (4)
2.系统用例建模 (5)
2.1系统角色 (5)
2.2系统用例图 (5)
2.N用例规约UC N (6)
3. 软件的非功能性需求 (8)
3.1用户界面需求 (8)
3.2软硬件环境需求 (8)
3.3软件质量需求 (8)
3.N 其它需求 (9)
附录A:需求确认 (10)
0. 文档介绍
0.1 文档目的
为软件的开发者能更好的理解开发的需求,避免由于对问题认识的不清或错误理解而增加更多的开发成本。
需求分析是软件系统生存期中定义阶段的最后一个步骤。
是作为整个软件开发范围的指南,是软件开发人员开发出正确的符合用户要求的软件的重点。
0.2 文档范围
1.简易文件搜管理系统介绍
2.系统面向的用户群体
3.系统应当遵循的标准或规范
4.系统的应用范围
5.系统中的角色
6.系统的功能性需求
7.系统的非功能性需求
0.3 读者对象
客户、设计人员、开发人员参考
0.4 参考文档
《征服AJAX.LUCENE构建搜索引擎》李刚人民邮电出版社
[软件项目管理] 杨律清软件项目管理电子工业出版社 2012年1月
0.5 术语与缩写解释
1. 需求概述
1.1系统目标
当电脑用户中的电脑文档很多的时候,需要寻找某一些满足某引起具体内容的文档时,如果一个文件一个文件的方式打开地进行查找是很不方便。
本软件提供了一种通过提供关键字快速查找文件路径的方式。
此软件经过了可行性研究:技术可行、经济可行、操作可行、社会可行、1.2用户特点
所有希望通过此软件查找自己文档的用户。
1.3功能需求
系统的功能需求包括以下几个方面:
(1)索引生成模块:对用户需要查找的文件夹生成索引数据
(2)文件查找模块:用户输入关键字进行文件查找。
2.系统用例建模
2.1普通用户
提示:本软件只涉及到一种用户,使用者用户
2.2系统用例图
2.2.1生成索引文件的用例图
用户在使用本软件的时候,首先要为自己查找的文件夹里面的所有文件生成索引数据。
如图 2.2.1 所示。
图2.2.1
2.2.2利用关键字查找文件用例图
有了索引文件后,用户可以使用关键字快速地对文件进行查找,如图2.2.2 所示。
Actor_1
图2.2.2
2.3用例规约UC n
UC1:“生成索引文件”用例文档
1、用例名称:生成索引文件
2、用例标识:Use Case01
3、涉及的参与者:用户
4、描述:用户使用本软件之前必须要先生成索引文件
5、前置条件:无
6、后置条件:索引文件生成成功
7、正常事件流:下图为生成索引文件的界面图
A.用户运行此软件
B.点击“选择数据文件夹”选择用户数据文件所在的文件夹
C.确认文件夹选择正确后,点击“初始化“.
D.系统提示成功,打开索引文件夹可以查看到索引的生成。
8、备选事件流:
A.输入空信息错误提示(特定信息不能为空、格式错误、长度错误等)
UC2:“使用关键字查找文件”用例文档
1、用例名称:使用关键字查找文件
2、用例标识:Use Case-02
3、涉及的参与者:用户
4、描述:用户可以通过输入关键字的方式快速定位到自己所需要的文件
5、前置条件:索引文件正确生成
6、后置条件:显示文件路径
7、正常事件流:下图为查找文件的界面图
A.用户输入关键字
B.用户点击“开始搜索”
C.如果能查找到文件则在结果框中显示找到的文件路径
D.如果没有查找到对应的文件则在结果框中显示没有没有符合
条件的文件路径。
8、备选事件流:
A、输入空信息错误提示(特定信息不能为空、格式错误、长度错误等)
2.4、系统流程图
3. 软件的非功能性需求3.1 用户界面需求
3.2 软硬件环境需求
3.3 软件质量需求。