先行进位加法器课件
数字逻辑 第三章 加法器.ppt

四位二进制并行加法器
三、四位二进制并加法器的外部特性和逻辑符号 1.外部特性
图中,A4、A3、A2、A1 ------- 二进制被加数; B4、B3、 B2、B1 ------- 二进制加数; F4、 F3、 F2、 F1 ------相加产生的和数; C0 --------------------来自低位的进位输入; FC4 -------------------向高位的进位输出。
a3b1
+) 乘积 Z5 a3b2 Z4 a2b2 Z3
a2b1
a1b2 Z2
a1b1
Z1
因为: ☆1位二进制数乘法 法则和逻辑“与”运算法 则相同,“积”项aibj(i =1,2,3;j=1,2)可用 两输入与门实现。 ☆对部分积求和可用 并行加法器实现。 所以:该乘法运算电 路可由6个两输入与门和1 b2 个4位二进制并行加法器构 成。逻辑电路图如右图所 示。
四位二进制并行加法器
实现给定功能的逻辑电路图如下图所示。 1) 输入端A4、A3、A2、 A1输入8421码;
2) 而从另一输入端B4、 B3、B2、B1输入二进 制数0011; 3) 进位输入端C0接上“0”;
4) 可从输出端F4、F3、F2、 F1得到与输入8421码对
应的余3码。
四位二进制并行加法器
Z5 Z4 Z3 Z 2 Z1
F4 F3 F2 F 1 FC4 T 693 C0
0
A4 A3 A2 A1
B4 B 3 B2 B1
&
&
&
&
&
&
b1
a3
a2
a1 0 a 3
a2
a1
FA4
F3 C3
FA3
F2
先行进位加法器的名词解释

先行进位加法器的名词解释先行进位加法器(Carry Lookahead Adder,CLA)是一种高速的二进制加法器,在计算机的数字电路中得到广泛应用。
它通过提前计算进位信号,实现了快速的加法运算,极大地提高了计算速度。
先行进位加法器的工作原理基于二进制加法的规律。
在二进制加法中,每一位的运算结果由两个输入位和进位信号决定。
如果只有两个输入位,那么进位信号则是根据相加的结果判断的,并且需要等待结果出来后才能计算。
而先行进位加法器通过提前计算进位信号,将加法的计算和进位信号的生成分离开来,大大缩短了计算时间。
先行进位加法器的一个重要组成部分是生成器和传递器。
生成器(G)用来判断两个输入位是否都为1,如果是,则生成进位信号;否则,不生成进位信号。
传递器(P)则是判断两个输入位中是否有一个或两个位都为1,如果是,则传递进位信号;否则,不传递进位信号。
通过这样的组合,可以得到一个高效的进位信号生成和传递机制。
先行进位加法器的优势在于其快速的计算速度和高效的硬件实现。
不需要等待结果的同时,可以并行地计算多个位的运算,并通过树状结构组合起来,进一步减小了延迟。
在图像处理、语音识别、数据压缩等需要大量运算的应用领域,先行进位加法器是不可或缺的重要组件。
然而,先行进位加法器也存在一些不足之处。
首先,它的硬件实现较为复杂,需要大量的逻辑门和电路,占用更多的面积和功耗。
其次,随着位数的增加,进位信号的生成和传递的延迟也会增大,加法器的性能将会受到限制。
因此,在对于大规模的计算,可以考虑使用其他更加高级的加法器结构。
总的来说,先行进位加法器是一种高速的二进制加法器,通过提前计算进位信号,实现了快速的加法运算。
它在计算机的数字电路中得到广泛应用,具有较高的效率和性能。
随着科技的发展,我们期待更加先进的加法器结构的涌现,为计算领域带来更大的突破。
第2章 加法器

应用于四个4位先行进位加法器,则有:
Cm1=Gm1+Pm1C0 Cm2=Gm2+Pm2Cm1 = Gm2+ Pm2Gm1 + Pm2 Pm1C0
Cm3=Gm3+Pm3Cm2 = Gm3+ Pm3Gm2 + Pm3Pm2Gm1+ Pm3 Pm2 Pm1C0
Cm4=Gm4+Pm4Cm3 = Gm4+ Pm4Gm3 + Pm4Pm3Gm2+ Pm4Pm3Pm2 Gm1+ Pm4Pm3Pm2P m1C0
cc33cc44cc22cc11gg22pp33gg33pp44gg44gg11pp22pp11先行进位产生电路cc00先行进位线路ff44cc33aa44bb44pp44gg44faff33cc22aa33bb33pp33gg33faff22cc11aa22bb22pp22gg22facc00ff11aa11bb11pp11gg11facc4444位先行进位加法器?理论上讲这种先行进位加法器可以扩充到n位字长但是当加法器位数增加时进位函数ci1会变得越来越复杂n位字长的加法器最高进位位需要一个n1位输入的或门和n1位输入的与门电路实现这给电路的实现带来了困难
• 在行波进位加法器中,进位信号的逻辑表 达式为: Ci= Gi+Pi Ci-1 • C1=G1+P1C0 • C2=G2+P2C1 • C3=G3+P3C2 • ………… • Cn=Gn+PnCn-1 可见,后一级的进位直接依赖前一级,进 位是逐级形成的,最长进位延迟时间为 2.5nty,与n成正比。可见,行波进位加法 器的加法速度比较低。
• 则当实现加法运算时,给出A→FA及B→FA 两个控制命令,则将[A]补和[B]补送到加法 器 FA 的两个输入端, FA 完成 [A] 补+ [B] 补 的加法过程,然后通过FA→A命令将加法运 算结果存入A寄存器。 • 如果实现减法运算,给出 A→FA 及 /B→FA 以及1→C0控制命令,则将[A]补和[-B]补送 到加法器FA的两个输入端,FA完成[A]补+ [-B]补的加法过程,然后通过 FA→A命令将 减法运算结果存入A寄存器。
先行进位加法器

实验四32位先行进位加法器一、功能概述串行进位加法器延时很大,每级的输出结果都要等上一级的进位到来才可以求和算出结果,这次实验对普通全加器进行改良,改良为先行进位加法器。
先行进位加法器,各级的进位彼此是独立产生,只与输入数据A,B和C_in有关,将各级间的进位级联传播给去掉了,这样就可以减小进位产生的延时。
每个等式与只有三级延迟的电路对应,第一级延迟对应进位产生信号和进位传递信号,后两级延迟对应上面的积之和。
通过这种进位方式实现的加法器称为超前进位加法器。
因为各个进位是并行产生的,所以是一种并行进位加法器。
二、实验原理1、设二进制加法器第i位为A i,B i,输出为S i,进位输入为C i,进位输出为C i+1,则有:S i=A i⊕B i⊕C i(1-1)C i+1 =A i * B i+ A i *C i+ B i*C i =A i * B i+(A i+B i)* C i(1-2)令G i = A i * B i , P i = A i+B i,则C i+1= G i+ P i *C i当A i和B i都为1时,G i = 1,产生进位C i+1 = 1当A i和B i有一个为1时,P i = 1,传递进位C i+1= C i因此G i定义为进位产生信号,P i定义为进位传递信号。
G i的优先级比P i高,也就是说:当G i = 1时(当然此时也有P i = 1),无条件产生进位,而不管C i是多少;当G i=0而P i=1时,进位输出为C i,跟C i之前的逻辑有关。
下面推导4位超前进位加法器。
设4位加数和被加数为A 和B,进位输入为C in,进位输出为C out,对于第i位的进位产生G i = A i·B i ,进位传递P i=A i+B i , i=0,1,2,3。
于是这各级进位输出,递归的展开Ci,有:C0 = C inC1=G0 + P0·C0C2=G1 + P1·C1 = G1 + P1·G0 + P1·P0▪C0C3=G2+ P2·C2= G2+ P2·G1+ P2·P1·G0+P2·P1·P0·C0C4=G3+ P3·C3= G3+ P3·G2+ P3·P2·G1+P3·P2·P1·G0 + P3·P2·P1·P0·C0 (1-3)C out=C4由此可以看出,各级的进位彼此独立产生,只与输入数据Ai、Bi和Cin有关。
先行进位加法器

行业PPT模板:www.1p pt.co m/ hang ye / PPT素材下载:/sucai/ PPT图表下载:www.1p pt.co m/ tubiao/ PPT教程: /powerpoint/ Excel教程:www.1ppt.c om/excel/ PPT课件下载:www.1p pt.co m/ kejian/ 试卷下载:www.1ppt.c om/shiti /
(3.11)
用这组方程实现的逻辑电路称作N位的先行进位部件。从上述公式可知,这个N位 加法器的各位进位输出信号仅由进位产生函数G与进位传递函数P以及最低位进位 C0决定。而Gi 和Pi只与本位的Ai和Bi有关,即Gi和Pi的形成是同时的,因此各级进 位输出Ci也是同时形成的。这种同时形成各种进位的方法称为并行进位或先行进 位。对应于N=4的CLA电路如图3.8所示。
3.7(b)所示。这些进位的线路也可用下列方程表示:
C1 G0 C0P0
C2 G1 C1P1 G1 G0P1 C0P0P1
C3 G2 C2 P2 G2 G1P2 G0P1P2 C0P0 P1P2 Ck1 G k G k1Pk G k2 Pk1Pk G0P1P2 Pk C0P0P1 Pk Cn G n1 G n2 Pn1 C0度化
基于otsu阈值分割对 图像按像素信息分割
用sobel算子提 取图像边缘信息
用sobel算子提 取图像边缘信息
用种子填充算法得
到连通域及连通域 相关的形态学信息
用霍夫变换检测 圆形
综合形态学信息和 圆形“车轮”信息检 测出车辆的大致位 置进行图像分割
设计过程:
行业PPT模板:www.1p pt.co m/ hang ye / PPT素材下载:/sucai/ PPT图表下载:www.1p pt.co m/ tubiao/ PPT教程: /powerpoint/ Excel教程:www.1ppt.c om/excel/ PPT课件下载:www.1p pt.co m/ kejian/ 试卷下载:www.1ppt.c om/shiti /
先行进位加法器共26页文档

•
26、我们像鹰一样,生来就是自由的 ,但是 为了生 存,我 们不得 不为自 己编织 一个笼 子,然 后把自 己关在 里面。 ——博 莱索
•
27、法律如果不讲道理,即使延续时 间再长 ,也还 是没有பைடு நூலகம்制约力 的。— —爱·科 克
•
28、好法律是由坏风俗创造出来的。 ——马 克罗维 乌斯
•
29、在一切能够接受法律支配的人类 的状态 中,哪 里没有 法律, 那里就 没有自 由。— —洛克
•
30、风俗可以造就法律,也可以废除 法律。 ——塞·约翰逊
先行进位加法器
1、最灵繁的人也看不见自己的背脊。——非洲 2、最困难的事情就是认识自己。——希腊 3、有勇气承担命运这才是英雄好汉。——黑塞 4、与肝胆人共事,无字句处读书。——周恩来 5、阅读使人充实,会谈使人敏捷,写作使人精确。——培根
组内并行,组间串行

组内并行,组间串行完成进位的时间图如下: 进位延迟时间为8T
ty 8
6 4 2 C16 C12 C8 C4 C1 C0 Ci
CLA加法器由“进位生成/传递部件”、“CLA部件”和“求和部件”构成。
延迟时间: 先行进位部件: 2T x 4 = 8T 进位产生/传播部件:3T 求和部件:3T 单级先行进位加法器的总延迟时间: t = 8T+ 3T + 3T = 14T
单级先行进位加法器逻辑图以16位加法器为例将其分为4组每个小组4位各组内采用4位并行进位加法器组间采用串行进位方式这样就构成了组内并行组间串行进位加法器
组内并行,组间串行进4001
4位先行(并行)进位部件
C1=G0+P0C0 C2=G1+P1C1=G1+P1G0+P1P0C0 C3=G2+P2C2=G2+P2G1+P2P1G0+P2P1P0C0 C4=G3+P3C3=G3+P3G2+P3P2G1+P3P2P1G0+P3P2P1P0C0 各位的进位均不依赖于低位的进位,可以同时产生。 若不考虑Pi的形成时间,从C0→C4的最长延迟时间仅为 2ty。 通常把实现上述逻辑的电路称为4位先行进位部件。
单级先行进位加法器逻辑图
以16位加法器为例,将其分为4组,每个小 组4位,各组内采用4位并行进位加法器, 组间采用串行进位方式,这样就构成了组 内并行,组间串行进位加法器。
S16~S13 S12~S9 S8 ~ S5 S4 ~ S1
C16
4位CLA 加法器
C12
4位CLA 加法器
C8
课件:第三章 计算机的算术运算加减法

G4 P4
G3 P3
S 16~S 13
S 12~S 9
G2 P2 S 8~S 5
G1 P1 S 4~S 1
BCLA
C12
BCLA
C8
BCLA
C4
BCLA
C0
加法器
加法器
加法器
加法器
A 16~A 13
A 12~A 9
B 16~B 13
B 12~B 9
A 8~A 5 B 8~B 5
A 4~A 1 B 4~B 1
再经过2ty后,才能产生第2、3、4小组内的C5~C7、C9~C11、 C13~C15。
以典型的四位ALU芯片(SN74181)为例介绍ALU的结 构及应用。
得[x+y]补=0.0110,x+y=+0.0110
[例2]X=-11001,Y=-00011,求X+Y=? 解:[x]补=1,00111,[y]补=1,11101
[x]补 = 1,00111 +)[y]补 = 1,11101 [x+y]补 =1 1,00100
丢掉
验算:
x=-11001=(-25)10 Y=(-3)10 X+Y=(-28)10 =(-11100)2
S 8~S 5
S 4~S 1
C16
4位C L A
C12
4位C L A
C8
4位C L A
C4
4位C L A
C0
加法器
加法器
加法器
加法器
A 1 6~A 1 3
A 1 2~A 9
B 1 6~B 1 3
B 1 2~B 9
A 8~A 5
B 8~B 5
A 4~A 1
《加法器及运算》PPT课件

+ P12P11P10P9CⅡ
PⅢ
所以 CⅢ = GⅢ + PⅢ CⅡ
精选PPT
13
4)第4组进位逻辑式
组内: C13 = G13 + P13CⅢ C14 = G14 + P14G13 + P14P13CⅢ C15 = G15 + P15G14 + P15P14G13 + P15P14P13CⅢ
组间:
精选PPT
11
2)第2组进位逻辑式
组内: C5 = G5 + P5CI C6 = G6 + P6G5 + P6P5CI C7 = G7 + P7G6 + P7P6G5 + P7P6P5CI
组间:
GⅡ
C8 = G8 + P8G7 + P8P7G6 + P8P7P6G5
+ P8P7P6P5CI
PⅡ
所以 CⅡ = GⅡ + PⅡCI
例. 求(X – Y)补
1) X= 4 X补=0 0100 Y= –5 Y补=1 1011
2) X= –4 X补=1 1100 Y= 5 Y补=0 0101
4位并行进位链 4位选择器 1个控制门
原始进位 Cn
进位输出
Cn+4 G、P
构成组间串行进位 构成组间并行进位
精选PPT
23
2. 运算功能 Ci
⊕ Fi
16种算术运算功能,16种逻辑运算功能
列于表2-5(P50)。
例1. S3S2S1S0 Xi ⊕ Yi F(M=1)F(M=0)
0 0 0 0 1 Ai
C16 16 8 C12 16 8 C8 16
数电实验丨多路复用器-进位加法器-先行进位加法器

数字电路与逻辑设计实验二一、实验目的1.熟悉多路复用器、加法器的工作原理。
2.学会使用VHDL语言设计多路复用器、加法器。
3.掌握generic的使用,设计n-1多路复用器。
4.兼顾速度与成本,设计行波加法器和先行进位加法器。
二、实验内容1.用VHDL语言设计8重3-1多路复用器;2.用VHDL语言设计n-1多路复用器,调用该n-1多路复用器定制为8-1多路复用器。
53.用VHDL语言设计4位行波进位加法器。
4.用VHDL语言设计4位先行进位加法器。
第一部分:8重3-1多路复用器①实验方法1、实验方法采用基于FPGA进行数字逻辑电路设计的方法。
采用的软件工具是Quartus II。
2、实验步骤1、新建,编写源代码。
(1).选择保存项和芯片类型:【File】-【new project wizard】-【next】(设置文件路径+设置project name为multiplexer_3_to_1_st)-【next】(设置文件名multiplexer_3_to_1_st.vhd—在【add】)-【properties】(type=AHDL)-【next】(family=FLEX10K;name=EPF10K10TI144-4)-【next】-【finish】(2).新建:【file】-【new】(第二个AHDL File)-【OK】2、根据题意,写好源代码并保存文件。
3、编译与调试。
确定源代码文件为当前工程文件,点击【processing】-【start compilation】进行文件编译,编译成功。
4、波形仿真及验证。
新建一个vector waveform file。
按照程序所述插入S、I0-I2、Y五个八维向量节点(S、I0-I2为输入节点,Y为输出节点)。
(操作为:右击-【insert】-【insert node or bus】-【node finder】(pins=all;【list】)-【>>】-【ok】-【ok】)。
带进位位的加法指令精品PPT课件

• 用移位操作代替乘除法可提高运算速度
例:前例中计算 x×10。
(1)采用乘法指令:
MOV BL,10
MUL BL
共需70~77个T周期。
(2)采用移位和加法指令:
SAL AL,1
; 2T
MOV AH,AL
; 2T
SAL AL,1
; 2T
SAL AL,1
; 2T
ADD AL,AH
; 3T
只需11个T周期,仅相当于乘法的1/7。
SAL mem/reg, CL
1
;移位位数>1时 ;移位位数=1时
12
移位指令执行的操作如下图所示:
最高位 CF
最低位 0
(a)算术/逻辑左移 SAL/SHL
最高位 CF
最低位
最高位
CF 0
最低位
(b)算术右移 SAR
(c)逻辑右移 SHR
非循环移位指令功能示意图
13
➢算术移位——把操作数看做有符号数;
;(DI)←串偏移地址 ;(CX)←串长度 ;搜索关键字=’E’ ;从低地址到高地址进行搜索 ;若未找到, 继续搜索 ;找到, 转至FOUND ;串中无’E’,(DL)←’N’ ;转至DONE ;指针回退 ;ADDR←’E’的地址
3.3.3 逻辑运算和移位指令
1.逻辑运算指令(与/或/异或/非)
2. ● 运算规则:按位操作,无进/借位 3. ● 对标志位的影响(除NOT指令外):
CF OF SF ZF PF AF 0 0 * * * 无定义
根据运算结果设置 注意: 非指令NOT对标志无影响
1
表 4 – 3 逻辑运算类指令
2
29
⒉串比较指令CMPSB / CMPSW
组合逻辑电路—加法器(电子技术课件)
例. 用74283构成将8421BCD码转换为余3码的码制转换电路 。
8421码
0000 0001 0010
+0011 +0011 +0011
余3码
0011 0100 0101
8421码输入 0011
A3 A2 A1 A0 B3 B2 B1 B0
CCO
O
S3
74283 S2 S1 S0
C–1 0
余3码输出
A B Ci Co AB + ABCi + ABCi
AB + (A B)Ci
A
A B A B Ci S
B
AB CO
CO ( A B)Ci
Ci
≥1 Co
A S B Ci C I C O CO
任务一:加法器
加法器的应用
全加器真值表
AB C SC 0 0 00 0 0 0 11 0 0 1 01 0 0 1 101 1 0 01 0 1 0 10 1 1 1 00 1 1 1 11 1
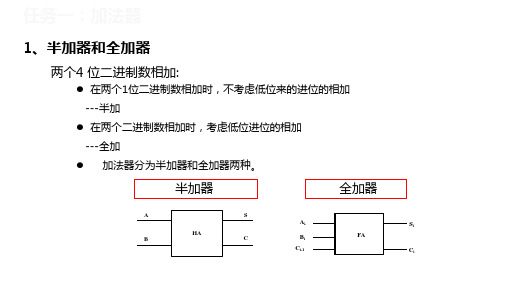
➢ 不考虑低位进位,将两个1位二进制数A、B相加的器件。
• 半加器的真值表 • 逻辑表达式
S AB+ AB C = AB
如用与非门实现最少要几个门?
A
半加器的真值表
=1
S
A
B
BA
B
S
C
0000
1010
& C=AB
0110
1101
• 逻辑图
任务一:加法器
(2) 全加器(Full Adder)
全加器能进行加数、被加数和低位来的进位信号相加,并根据求和结果给出
余 3 码输出
A3 B3 A2 B2 A1 B1 A0 B0
逻辑电路的设计加法器PPT课件
请同学们思考以下两个问题:
1、各位上的运算有何不同之处?
2、只考虑某一位数相加,用逻辑电路实现,分别有几个 输入端和输出端?
——加法器
加法器
加法运算的基本规则:
(1)逢二进一。 (2)最低位是两个数最低位的叠加,不需
考虑进位。 (3)其余各位都是三个数相加,包括加数
例2:利用四位全加器实现四位全减器。
两个多位数相减,可以用补码相加来实现。
A-B=A+B补=A+B反+1
差
A4A3A2A1 N4N3N2N1
借位 1
S4
S3
S2
C4
S1 C0
A4A3A2A1 N4N3N2N1 1 “1”
A4 A3 A2 A1 B4 B3 B2 B1
被减数
1 1 11
• 由于4位二进制数相加是逢十六进一,而 8421码相加是逢十进一,用4位全加器构成 8421码加法器时,必须解决“逢十六进一 变成逢十进一”的问题。
“逢十六进一变成逢十进一”
6+7=13
加
6修正
非法码
8+9=17
加6
需要加6修正情况:①:和在10—15之间,② :有进位Co。
•BCD(8421)码加法器电路设计
Bn
Cn
Cn-1
F3
F2
F1
F0
加法器
C3
C0
B3 A3 B2 A2
B1 A1 B0 A0
74LS83
加法器(5)
多位加法器
串行进位加法器 并行进位加法器
例:四位串行进位加法器
先行进位加法器课件

实验四32位先行进位加法器一、功能概述串行进位加法器延时很大,每级的输出结果都要等上一级的进位到来才可以求和算出结果,这次实验对普通全加器进行改良,改良为先行进位加法器。
先行进位加法器,各级的进位彼此是独立产生,只与输入数据A,B 和C_in有关,将各级间的进位级联传播给去掉了,这样就可以减小进位产生的延时。
每个等式与只有三级延迟的电路对应,第一级延迟对应进位产生信号和进位传递信号,后两级延迟对应上面的积之和。
通过这种进位方式实现的加法器称为超前进位加法器。
因为各个进位是并行产生的,所以是一种并行进位加法器。
二、实验原理1、设二进制加法器第i位为A i,B i,输出为S i,进位输入为C i,进位输出为C i+1,则有:S i=A i⊕B i⊕C i(1-1)C i+1 =A i * B i+ A i *C i+ B i*C i =A i * B i+(A i+B i)* C i(1-2)令G i = A i * B i , P i = A i+B i,则C i+1= G i+ P i *C i当A i和B i都为1时,G i = 1,产生进位C i+1 = 1当A i和B i有一个为1时,P i = 1,传递进位C i+1= C i因此G i定义为进位产生信号,P i定义为进位传递信号。
G i的优先级比P i高,也就是说:当G i = 1时(当然此时也有P i = 1),无条件产生进位,而不管C i是多少;当G i=0而P i=1时,进位输出为C i,跟C i之前的逻辑有关。
下面推导4位超前进位加法器。
设4位加数和被加数为A和B,进位输入为C in,进位输出为C out,对于第i位的进位产生G i = A i·B i,进位传递P i=A i+B i , i=0,1,2,3。
于是这各级进位输出,递归的展开Ci,有:C0 = C inC1=G0 + P0·C0C2=G1 + P1·C1 = G1 + P1·G0 + P1·P0▪C0C3=G2 + P2·C2 = G2 + P2·G1 + P2·P1·G0 + P2·P1·P0·C0C4=G3 + P3·C3 = G3 + P3·G2 + P3·P2·G1 + P3·P2·P1·G0 + P3·P2·P1·P0·C0 (1-3)C out=C4由此可以看出,各级的进位彼此独立产生,只与输入数据Ai、Bi和Cin有关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验四32位先行进位加法器一、功能概述串行进位加法器延时很大,每级的输出结果都要等上一级的进位到来才可以求和算出结果,这次实验对普通全加器进行改良,改良为先行进位加法器。
先行进位加法器,各级的进位彼此是独立产生,只与输入数据A,B 和C_in有关,将各级间的进位级联传播给去掉了,这样就可以减小进位产生的延时。
每个等式与只有三级延迟的电路对应,第一级延迟对应进位产生信号和进位传递信号,后两级延迟对应上面的积之和。
通过这种进位方式实现的加法器称为超前进位加法器。
因为各个进位是并行产生的,所以是一种并行进位加法器。
二、实验原理1、设二进制加法器第i位为A i,B i,输出为S i,进位输入为C i,进位输出为C i+1,则有:S i=A i⊕B i⊕C i(1-1)C i+1 =A i * B i+ A i *C i+ B i*C i =A i * B i+(A i+B i)* C i(1-2)令G i = A i * B i , P i = A i+B i,则C i+1= G i+ P i *C i当A i和B i都为1时,G i = 1,产生进位C i+1 = 1当A i和B i有一个为1时,P i = 1,传递进位C i+1= C i因此G i定义为进位产生信号,P i定义为进位传递信号。
G i的优先级比P i高,也就是说:当G i = 1时(当然此时也有P i = 1),无条件产生进位,而不管C i是多少;当G i=0而P i=1时,进位输出为C i,跟C i之前的逻辑有关。
下面推导4位超前进位加法器。
设4位加数和被加数为A和B,进位输入为C in,进位输出为C out,对于第i位的进位产生G i = A i·B i,进位传递P i=A i+B i , i=0,1,2,3。
于是这各级进位输出,递归的展开Ci,有:C0 = C inC1=G0 + P0·C0C2=G1 + P1·C1 = G1 + P1·G0 + P1·P0▪C0C3=G2 + P2·C2 = G2 + P2·G1 + P2·P1·G0 + P2·P1·P0·C0C4=G3 + P3·C3 = G3 + P3·G2 + P3·P2·G1 + P3·P2·P1·G0 + P3·P2·P1·P0·C0 (1-3)C out=C4由此可以看出,各级的进位彼此独立产生,只与输入数据Ai、Bi和Cin有关。
2、接口说明表1:32位超前进位加法器接口信号说明表3、结构框图三、实验方案方案一:分为两个模块:1个4位add_4和1个add_32,其中add_32调用4个add_4.首先设计4位超前进位加法器:框图如下:设计好四位的之后,开始调用四位的实现32位的。
方案二:分为五个模块:(1)计算传播值和产生值模块:pg模块(2)超前进位模块:cla模块(3)加法求和模块:sum模块(4)求和并按输出a,b,c_in分组:bit_slice模块(5)32位超前进位加法器总模块:cla_32总框图:四、验证方案:对32位的两个输入赋值:当a=32'b1000_0001_0111_1011_1101_1001_1101_1000;b=32'b0111_1000_0001_1000_1100_0111_0101_0001;c_in=1'b0;结果:s=32'b1111_1001_1001_0100_1010_0001_0010_1001;当a=32'b1000_0001_0111_1011_1101_1001_1101_1000;b=32'b0111_1000_0001_1000_1100_0111_0101_0001;c_in=1'b1;结果:s=32'b1111_1001_1001_0100_1010_0001_0010_1010;来对波形进行观察,看波形是否正确。
五、实验代码:方案一:(1)add_32模块顶层模块:(2)4位add_4模块方案二:(1)cla_32顶层模块:module cla_32(a,b,c_in,s,count );input [31:0] a,b;input c_in;output [31:0] s;output count;wire [7:0] gg,gp,gc;wire [3:0] ggg,ggp,ggc;wire gggg,gggp;bit_slice b1(.a(a[3:0]),.b(b[3:0]),.c_in(gc[0]),.s(s[3:0]),.gp(gp[0]),.gg(gg[0])); bit_slice b2(.a(a[7:4]),.b(b[7:4]),.c_in(gc[1]),.s(s[7:4]),.gp(gp[1]),.gg(gg[1])); bit_sliceb3(.a(a[11:8]),.b(b[11:8]),.c_in(gc[2]),.s(s[11:8]),.gp(gp[2]),.gg(gg[2]));bit_sliceb4(.a(a[15:12]),.b(b[15:12]),.c_in(gc[3]),.s(s[15:12]),.gp(gp[3]),.gg(gg[3])); bit_sliceb5(.a(a[19:16]),.b(b[19:16]),.c_in(gc[4]),.s(s[19:16]),.gp(gp[4]),.gg(gg[4])); bit_sliceb6(.a(a[23:20]),.b(b[23:20]),.c_in(gc[5]),.s(s[23:20]),.gp(gp[5]),.gg(gg[5])); bit_sliceb7(.a(a[27:24]),.b(b[27:24]),.c_in(gc[6]),.s(s[27:24]),.gp(gp[6]),.gg(gg[6])); bit_sliceb8(.a(a[31:28]),.b(b[31:28]),.c_in(gc[7]),.s(s[31:28]),.gp(gp[7]),.gg(gg[7])); clac0(.p(gp[3:0]),.g(gg[3:0]),.c_in(ggc[0]),.c(gc[3:0]),.gp(ggp[0]),.gg(ggg[0])); clac1(.p(gp[7:4]),.g(gg[7:4]),.c_in(ggc[1]),.c(gc[7:4]),.gp(ggp[1]),.gg(ggg[1])); assign ggp[3:2]=2'b11;assign ggg[3:2]=2'b00;cla c2(.p(ggp),.g(ggg),.c_in(c_in),.c(ggc),.gp(gggp),.gg(gggg));assign count=gggg|(gggp&c_in);endmodule(2)pg模块:module pg(a,b,p,g);input [3:0] a,b;output [3:0] p,g;assign p=a^b;assign g=a&b;endmodule(3)cla模块:module cla(p,g,c_in,c,gp,gg);input [3:0] p,g;input c_in;output [3:0] c;output gp,gg;function [99:0] do_cla;input [3:0] p,g;input c_in;begin:labelinteger i;reg gp,gg;reg [3:0] c;gp=p[0];gg=g[0];c[0]=c_in;for(i=1;i<4;i=i+1)begingp=gp&p[i];gg=(gg&p[i])|g[i];c[i]=(c[i-1]&p[i-1])|g[i-1];enddo_cla={c,gp,gg};endendfunctionassign {c,gp,gg}=do_cla(p,g,c_in); endmodule(4)sum模块:module sum(a,b,c,s );input [3:0] a,b,c;output [3:0] s;wire [3:0] t=a^b;assign s=t^c;endmodule(5)bit_slice模块:module bit_slice(a,b,c_in,s,gp,gg );input [3:0] a,b;input c_in;output [3:0] s;output gp,gg;wire [3:0]p,g,c;pg i1(a,b,p,g);cla i2(p,g,c_in,c,gp,gg);sum i3(a,b,c,s);endmodule(6)激励代码:module cla32_tb;// Inputsreg [31:0] a;reg [31:0] b;reg c_in;// Outputswire [31:0] s;wire count;// Instantiate the Unit Under Test (UUT)cla_32 uut (.a(a),.b(b),.c_in(c_in),.s(s),.count(count));initial begin// Initialize Inputsa = 0;b = 0;c_in = 0;// Wait 100 ns for global reset to finish#10a=32'b1000_0001_0111_1011_1101_1001_1101_1000;b=32'b0111_1000_0001_1000_1100_0111_0101_0001;c_in=1'b0;#10a=32'b1000_0001_0111_1011_1101_1001_1101_1000;b=32'b0111_1000_0001_1000_1100_0111_0101_0001;c_in=1'b1;// Add stimulus hereendendmodule六、波形图说明1、仿真波形2、结果说明对于三个输入:a=32'b1000_0001_0111_1011_1101_1001_1101_1000;b=32'b0111_1000_0001_1000_1100_0111_0101_0001;c_in=1'b0;结果与实验方案的相同,结果仿真正确.七、实验总结对于这次实验,自己在老师布置完,努力做了几个下午,不断调试才得到正确结果波形,是非常有收获的。