第七章参数估计
概率论第七章 第1节

根据样本概率最大原则,m的估计值为3。
最大似然估计法原理
一般地,不仿设总体X是离散型分布X~p(x,θ),如果 X1,X2,…,Xn是来自这个总体的一个随机样本,x1,x2,…,xn 是这个随机样本的样本值,则这个样本发生的概率为:
记这个概率为θ的函数:
16
最大似然估计法原理
如果在一次抽样中样本值x1,x2,…,xn出现了,我们就认为 它之所以出现是因为它发生的概率最大导致的。因此我们 就选择能使这个概率最大的那个θ作为θ的估计值,这就 是极大似然估计法。 “样本值概率最大原则”
矩估计法理论依据
命题2:设总体X的l=1,2,…,k阶矩存在即E(Xl)=μk,则l阶样 本矩A1,A2,…,Ak的连续函数g(A1,A2,…,Ak)也依概率收敛于总 体矩的连续函数即
根据这两个命题,我们使用如下方法来进行矩估计: (1)用样本矩A1,A2,…,Ak来估计总体矩; (2)用样本矩的连续函数g(A1,A2,…,Ak)来估计总体矩的连续 函数g(μ1,μ2,…,μk)。
砍掉充分小的dxi,记这 个概率为θ的函数:
30
连续型总体中参数 θ的似然函数!
最大似然估计值 最大似然估计量
怎样求最大值点?
基于此通常先取对数,再求最大值点。
化成求 对数似 然函数 的最大 值点!
如果对数似然函数二阶可导,并且概率 密度函数是单峰函数,则驻点就是最大 值点!通过求一阶导数能得驻点:
第七章 参数估计
1、什么是参数估计? 当总体的分布类型已知,但其中仍有未知参数。比如总体 X服从参数μ,σ2的正态分布,但μ,σ2未知。但是我们 能根据来自总体X的一个简单随机样本X1,X2,…,Xn通过适 当的方法对这些未知参数进行估计,得到它的一个近似值 或近似区间。 2、参数估计有哪些形式? (1)点估计:矩估计法、极大似然估计法。 (2)区间估计:正态总体下区间估计法。
概率论与数理统计第7章参数估计PPT课件

a1(1, ,k )=v1
1 f1(v1, ,vk )
假定方程组a2(1, ,k ) v2 ,则可求出2 f2(v1, ,vk )
ak (1, ,k ) vk
k fk (v1, ,vk )
则x1 xn为X的样本值时,可用样本值的j阶原点矩Aj估计vj,其中
Aj
1 n
n i1
xij ( j
L(x1, ,xn;ˆ)maxL(x1, ,xn;),则称ˆ(x1, ,xn)为
的一种参数估计方法 .
它首先是由德国数学家
高斯在1821年提出的 ,然而, 这个方法常归功于英国统
Gauss
计学家费歇(Fisher) . 费歇在1922年重新发现了
这一方法,并首先研究了这
种方法的一些性质 .
Fisher
10
极大似然估计是在已知总体分布形式的情形下的 点估计。
极大似然估计的基本思路:根据样本的具体情况
注:估计量为样本的函数,样本不同,估计量不 同。
常用估计量构造法:矩估计法、极大似然估计法。
4
7.1.1 矩估计法
矩估计法是通过参数与总体矩的关系,解出参数, 并用样本矩替代总体矩而得到的参数估计方法。 (由大数定理可知样本矩依概率收敛于总体矩, 且许多分布所含参数都是矩的函数)
下面我们考虑总体为连续型随机变量的情况:
n
它是的函数,记为L(x1, , xn; ) f (xi , ), i 1
并称其为似然函数,记为L( )。
注:似然函数的概念并不仅限于连续随机变量 ,
对于离散型随机变量,用 P {Xx}p(x,)
替代f ( x, )
即可。
14
设总体X的分布形式已知,且只含一个未知参数,
第七章 参数估计

第三节 总体均数估计
估计总体平均数的步骤: 估计总体平均数的步骤: X与S 1、 计算样本 2、 计算 σ X 3、 确定置信水平或显著性水平并查表 4、计算置信区间 5、解释总体平均数的置信区间
一、正态估计法 , σ2已知 、
1、前题条件: 、前题条件:
总体正态, n不论大小 总体正态, n不论大小
点估计与区间估计的比较
定义: 定义
直接以样本统计量(数轴上的一个点) 点估计 :直接以样本统计量(数轴上的一个点) 作为总体参数的估计值
区间估计:按一定概率要求, 区间估计:按一定概率要求,根据样本统计量估 计总体参数可能落入的范围的一种统计方法。 计总体参数可能落入的范围的一种统计方法。也 就是说整体参数所落的有把握的范围 整体参数所落的有把握的范围。 就是说整体参数所落的有把握的范围。
D=0.95时 时
75.7 ≤ µ ≤ 81.3
5、解释:用样本1估计,总体的平均数落在 、解释:用样本1估计, 73.6-82.4之间的可能性为95%, 之间的可能性为95% 73.6-82.4之间的可能性为95%,超出这一范 围的可能性为5% 5%。 围的可能性为5%。 用样本2估计,总体的平均数落在76.7 80.3之 76.7用样本2估计,总体的平均数落在76.7-80.3之 间的可能性为95% 落在75.7 81.3的可能性为 95%, 75.7间的可能性为95%,落在75.7-81.3的可能性为 99%。 99%
X ± 2.58σ X
置信限:就是总体参数所落区间的上下界限。 置信限:就是总体参数所落区间的上下界限。即
X − 1.96σ X ≤ µ ≤ X + 1.96σ X
置信下限 置信上限
标准误
标准误(中心极限定理 ) 标准误(中心极限定理3)
概率论 第七章 参数估计

L( ) max L( )
称^为
的极大似然估计(MLE).
求极大似然估计(MLE)的一般步骤是:
(1) 由总体分布导出样本的联合概率分布 (或联合密度);
(2) 把样本联合概率分布(或联合密度)中自变 量看成已知常数,而把参数 看作自变量, 得到似然函数L( );
(3) 求似然函数L( ) 的最大值点(常常转化 为求ln L( )的最大值点) ,即 的MLE;
1. 将待估参数表示为总体矩的连续函数 2. 用样本矩替代总体矩,从而得到待估参
数的估计量。
四. 最大似然估计(极大似然法)
在总体分布类型已知条件下使用的一种 参数估计方法 .
首先由德国数学家高斯在1821年提出。 英国统计学家费歇1922年重新发现此
方法,并首先研究了此方法的一些性质 .
例:某位同学与一位猎人一起外出打猎.一只 野兔从前方窜过 . 一声枪响,野兔应声倒下 .
p值 P(Y=0) P(Y=1) P( Y=2) P(Y=3) 0.7 0.027 0.189 0.441 0.343 0.3 0.343 0.441 0.189 0.027
应如何估计p?
若:只知0<p<1, 实测记录是 Y=k
(0 ≤ k≤ n), 如何估计p 呢?
注意到
P(Y k) Cnk pk (1 p)nk = f (p)
第七章 参数估计
参数估计是利用从总体抽样得到的信息 估计总体的某些参数或参数的某些函数.
仅估 计一 个或 几个 参数.
估计新生儿的体重
估计废品率
估计降雨量
估计湖中鱼数
…
…
参数估计问题的一般提法:
设总体的分布函数为 F(x, ),其中为未 知参数 (可以是向量).从该总体抽样,得样本
第七章 参数估计

第七章 参数估计
1、正态总体、方差已知或非正态总体,大样本 当总体服从正态分布且方差已知时,或者总体不是正态分布但是大样本时,样本 均值的抽样分布均为正态分布,其数学期望为总体均值u,方差为Ϭ2/n。而样本均 值经过标准化以后的随机变量则服从标准正态分布,即 Z=(x-u)/(Ϭ/n0.5)~N(0,1) 根据上式和正态分布的性质可以得出总体均值u在1-α置信水平下的置信区间为: xα+是(-)事Z(α先/2)所(Ϭ确/n定0.5的)。而其一中个,概x率+Z值(α/2,) (Ϭ也/n称0.为5)为风置险信值上,限是,总x体-Z均(α/2值) (Ϭ不/包n0.含5)为在置置信信下区限间,的 概是率估;计1总- 体α称均为值置时信的水估平计,误Z差(α/。2) 是标准正态分布右侧面积为α/2的z值;Z(α/2) (Ϭ/n0.5) 也即是说,总体均值的置信区间由两个部分构成:点估计值和描述估计量精度的 +(-)值,这个+(-)值称为估计误差。
第七章 参数估计
在区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间。
其中,区间的最小值称为置信下限,最大值称为置信上限。
由于统计学家在某种程度上确信这个区间会包含真正的总体参数,所以给它取名 为置信区间。原因是:如果抽取了许多不同的样本,比如说抽取100个样本,根据 每一个样本构造了一个置信区间,这样,由100个样本构造的总体参数的100个置 信区间中,有95%的区间包含了总体参数的真值,而5%则没有包含,则95%这个值 称为置信水平。一般,如果将构造置信区间的步骤重复多次,置信区间中包含总 体参数真值的次数所占的比例称为置信水平,也称为置信度或置信系数。
自然使用估计效果最好的那种估计量。什么样的估计量才算一个好的估计量呢? 统计学家给出了评价估计量的一些标准,主要包括以下几个:
第七章-参数估计

X 0
• 2.有效性
• 当总体参数的无偏估计不止一个统计量时,无偏
估计变异小者有效性高,变异大者有效性低,即 方差越小越好。
9 0.286 9 0.286 2 23.6 1.73
0.11 2 1.49
• 【例7-7】
• n=31,sn-1=5问的0.95置信区间?
• 解:先求方差的置信区间,当df=30,查χ2表,
2 0.025 47
2 0.975 16.8
2 30 52 30 5 2 47 16.8
正态分布,即Z0.05/2=1.96。
5 0.635 2 31
• 0.95的置信区间为:
5 1.96 0.635 5 1.96 0.635
3.76 6.24
• 二、方差的区间估计
• 根据χ2分布:
2
X X
2
2
2 2 n 1 sn ns 1
第七章 参数估计
思 考
• 例8-1:从某市随机抽取小学三年级学生50名,测 得平均身高为 140cm ,标准差 4 。试问该市小学 三年级学生的平均身高大约是多少?
例8-2:某教师用韦氏成人智力量表测80 名高三学生,M=105。试估计该校高三 学生智商平均数大约为多少?
什么是参数估计
当在研究中从样本获得一组数据后,如何通过 这组数据信息,对总体特征进行估计,也就是 如何从局部结果推论总体的情况,称为总体参 数估计。 • 参数估计: 样本 统计量
• 【例7-2】
• 有一个49名学生的班级,某学科历年考试成绩的
概率论与数理统计-参数估计

第七章 参数估计
例:
引言
设总体 X 是服从参数为 的指数分布,其中参数
未 知 ,
0 .X1 ,,
X
是总体
n
X
的一个样本,
我们的任务是根据样本,来估计 的取值,从
而估计总体的分布.
这 是 一 个 参 数 估 计 问 题.
第七章 参数估计
§1 点估计 §2 估计量的评选标准 §3 区间估计
第七章 参数估计 §1 点估计
2
令
A1
A2
, (
2
1)
.
第七章 参数估计
例6(续)
解此方程组,得
§1 点估计
ˆ
A1 2 A2 A12
,
ˆ
A2
A1 A12
.
ˆ X 2 ,
即
B2
ˆ X .
B2
其中 B2
1 n
n i 1
Xi X
2 为样本的二阶中心矩.
第七章 参数估计(第二十二讲) 三、 极大似然法
§1 点估计
1
第七章 参数估计
例6(续)
EX 2 x 2 f
x dx x 2
x 1e x dx
0
§1 点估计
2 2 x ( e 2)1 x dx
2 0 2
2 2
1 2
1
2
因此有
EX
,
EX
2
1 .
⑵ 在不引起混淆的情况下,我们统称估计量
与估计值为未知参数 的估计.
第七章 参数估计
二、 矩估计法
§1 点估计
设X为连续型随机变量,其概率密度为
f ( x;1 ,, k ), X为离散型随机变量,其分布列为
统计学第七章、第八章课后题答案

统计学复习笔记第七章 参数估计一、 思考题1. 解释估计量和估计值在参数估计中,用来估计总体参数的统计量称为估计量。
估计量也是随机变量。
如样本均值,样本比例、样本方差等。
根据一个具体的样本计算出来的估计量的数值称为估计值。
2. 简述评价估计量好坏的标准(1)无偏性:是指估计量抽样分布的期望值等于被估计的总体参数。
(2)有效性:是指估计量的方差尽可能小。
对同一总体参数的两个无偏估计量,有更小方差的估计量更有效。
(3)一致性:是指随着样本量的增大,点估计量的值越来越接近被估总体的参数。
3. 怎样理解置信区间在区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间。
置信区间的论述是由区间和置信度两部分组成。
有些新闻媒体报道一些调查结果只给出百分比和误差(即置信区间),并不说明置信度,也不给出被调查的人数,这是不负责的表现。
因为降低置信度可以使置信区间变窄(显得“精确”),有误导读者之嫌。
在公布调查结果时给出被调查人数是负责任的表现。
这样则可以由此推算出置信度(由后面给出的公式),反之亦然。
4. 解释95%的置信区间的含义是什么置信区间95%仅仅描述用来构造该区间上下界的统计量(是随机的)覆盖总体参数的概率。
也就是说,无穷次重复抽样所得到的所有区间中有95%(的区间)包含参数。
不要认为由某一样本数据得到总体参数的某一个95%置信区间,就以为该区间以0.95的概率覆盖总体参数。
5. 简述样本量与置信水平、总体方差、估计误差的关系。
1. 估计总体均值时样本量n 为2. 样本量n 与置信水平1-α、总体方差、估计误差E 之间的关系为 其中: 2222α2222)(E z n σα=n z E σα2=▪ 与置信水平成正比,在其他条件不变的情况下,置信水平越大,所需要的样本量越大;▪ 与总体方差成正比,总体的差异越大,所要求的样本量也越大;▪ 与与总体方差成正比,样本量与估计误差的平方成反比,即可以接受的估计误差的平方越大,所需的样本量越小。
07心理统计学-第七章 参数估计

犯错误的概率,常用α(或p)表示。则1-α为置信 度。(显著性水平越高表示的是α值越小,即犯错误的可
能性越低) α为预先设定的临界点,常用的如.05、.01、.001;p 为检验计算所得的实际(犯错误)概率。
第一节 点估计、区间估计与标准误
三、区间估计与标准误
3、区间估计的原理与标准误
转换成比率为
p
n
p, SE p
n
pq n
同理可得公式7-17。自习[例7-12、例7-13]
1、从某地区抽样调查400人,得到每月人均文化消费为 160元。已知该地区文化消费的总体标准差为40元。试 问该地区的每月人均文化消费额。(α=.05,总体呈正态
分布)
2、上题中总体方差未知,已知Sn-1=44元。 3、已知某中学一次数学考试成绩的分布为正态分布,总 体标准差为5。从总体中随机抽取16名学生,计算得平 均数为81、标准差为Sn=6。试问该次考试中全体考生成 绩平均数的95%置信区间。 4、上题中总体方差未知,样本容量改为17人。 5、假定智商服从正态分布。随机抽取10名我班学生测 得智商分别为98、102、105、105、109、111、117、 123、124、126(可计算得M=112,Sn≈9.4),试以95% 的置信区间估计我班全体的智商平均数。 返回
值表,求tα /2(df)。
5、计算置信区间CI。
σ2已知,区间为M-Zα /2 SE <μ< M+Zα /2 SE;
σ2未知,区间为M-tα /2(df)SE <μ< M+tα /2(df)SE。
6、对置信区间进行解释。
二、σ2已知,对μ的区间估计(Z分布,例7-1 & 2) 三、σ2未知,对μ的区间估计(t分布,例7-3 & 4)
统计学 第七章 参数估计

[
]
2 χα (n) (n)的α 分位数,记为k≜ n k≜
抽样分布
(3)性质 • 若X服从χ2 (n),则均值E(X)=n ,方差 D(X) =2n 。 • χ2分布具有可加性。若 X1,X2相互独立,
X1~ χ2(n1) ,X2~χ2(n2)
则(X1+X2)~χ2(n1+n2) • 当n→∞时,χ2分布渐进于正态分布
σ
2
~ χ (n −1)
2
第三节两个总体参数的区 间估计(112页)
• • • • • • • 一、两个总体均值之差的区间估计 (一)两个总体均值之差的估计:独立样本 大样本:近似于正态分布 小样本: (1)两个总体的方差均已知,近似于正态分布 (2)两个总体的方差均未知但相等,近似于t分布 (3)两个服从正态分布的总体的方差均未知且不等, 但样本容量相等,近似于t分布 • (4)两个总体的方差均未知且不等,样本容量也不 等,近似于t分布,自由度为V
• 解:求(3)的计算步骤: • ①求样本指标:
x =1000小时
σ=50 (小时)
µ x=
σ
n
=
50 100
=(小时) 5
• ②根据给定的F(t)=95%,查概率表得t=1.96。 • ③根据∆x=t×µx=1.96×5=9.8,计算总体平均耐 用时间的上、下限: x − ∆ x=1000-9.8=990.(小时) 2 • 下限 x +∆ x=1000+9.8=1009 .(小时) 8 • 上限 • 所以,以95%的概率保证程度估计该批产品的平均耐 用时间在990.2~1009.8小时之间。
f (x;θ ) 其中 θ
或概率密度为
是未知参数。 是未知参数。
如何求极大似然估 计量呢? 计量呢?
数理统计 第七章-参数估计

休息
结束
2. 最大似然法
是在总体类型已知条件下使用的一 种参数估计方法 。 它首先是由德国数学家高斯在1821 年提出的 ,费歇在1922年重新发现了这 一方法,并首先研究了这 种方法的一些 性质 。
休息 结束
最大似然法的基本思想:
已发生的事件具有最大概率。
休息
结束
先看一个简单例子: 在军训时,某位同学与一位教官同 时射击,而在靶纸上只留下一个弹孔。 如果要你推测,是谁打中的呢? 你会如何想呢?
max f ( xi , )
i 1
n
休息
结束
X 假设X 为连续型总体: f ( x; )
( X 1 , , X n ) 为子样
( x1 , , xn ) 为子样观察值。
已发生的事件为:
x x ,X {{X 11 1x, X 1 nx1 ,n } , xn x X n xn } x
休息
结束
ˆ
1 n ( X i X )2 n i 1
1 n ˆ X ( X i X )2 n i 1
休息
结束
矩法的优点是简单易行,并不需要 事先知道总体是什么分布 。 缺点是,当总体类型已知时,没有 充分利用分布提供的信息 . 一般场合下, 矩估计量不具有唯一性 。
( 1 )x , 0 x 1 f( x) 0, 其它
1
其中 1 是未知参数,
X1,X2,…,Xn是取自X的样本,求参数 的矩估计. 解:
1 E( X ) x( 1 )x dx
0
( 1 )
从 中解得
1
0
x
1
概率论与数理统计第7章参数估计习题及答案

概率论与数理统计第7章参数估计习题及答案第7章参数估计 ----点估计⼀、填空题1、设总体X 服从⼆项分布),(p N B ,10<计量=pXN. 2、设总体)p ,1(B ~X,其中未知参数 01<则 p 的矩估计为_∑=n 1i i X n 1_,样本的似然函数为_ii X 1n1i X )p 1(p -=-∏__。
3、设 12,,,n X X X 是来⾃总体 ),(N ~X 2σµ的样本,则有关于 µ及σ2的似然函数212(,,;,)n L X X X µσ=_2i 2)X (21n1i e21µ-σ-=∏σπ__。
⼆、计算题1、设总体X 具有分布密度(;)(1),01f x x x ααα=+<<,其中1->α是未知参数,n X X X ,,21为⼀个样本,试求参数α的矩估计和极⼤似然估计.解:因?++=+=101α2α1α102++=++=+|a x 令2α1α++==??)(X X EXX --=∴112α为α的矩估计因似然函数1212(,,;)(1)()n n n L x x x x x x ααα=+∑=++=∴ni i X n L 1α1αln )ln(ln ,由∑==++=??ni i X nL 101ααln ln 得,α的极⼤似量估计量为)ln (?∑=+-=ni iXn11α2、设总体X 服从指数分布 ,0()0,x e x f x λλ-?>=??其他,n X X X ,,21是来⾃X 的样本,(1)求未知参数λ的矩估计;(2)求λ的极⼤似然估计.解:(1)由于1()E X λ=,令11X Xλλ=?=i x nn L x x x eλλ=-∑=111ln ln ln 0nii ni ni ii L n x d L n n x d xλλλλλ====-=-=?=∑∑∑故λ的极⼤似然估计仍为1X。
概率论第七章参数估计

概率论第七章参数估计参数估计是概率论中的一个重要概念,用于根据样本数据推断总体参数的未知值。
本文将介绍参数估计的概念、常见的估计方法以及对估计结果的评估。
一、参数估计的概念参数估计是指根据样本数据来推断总体参数的未知值。
总体是指要研究的对象的全体,参数是总体分布的特征数值,例如总体均值、总体方差等。
参数估计可以分为点估计和区间估计两种。
点估计是根据样本数据得到一个参数值的估计方法。
常见的点估计方法有最大似然估计法和矩估计法。
最大似然估计法是根据已知的样本数据,选择使得基于样本数据构建的似然函数取得最大值的参数值作为参数的估计值。
矩估计法是根据已知的样本数据,选择使得样本矩与总体矩之间的差距最小的参数值作为参数的估计值。
区间估计是指根据样本数据得到参数的一个区间估计,给出了参数取值范围的上下限。
常见的区间估计方法有置信区间法和预测区间法。
置信区间法是根据样本数据,给出参数估计值的上下限,使得该参数值落在这个区间的概率达到预先规定的置信水平。
预测区间法是根据样本数据,给出新观测值的一个区间估计,使得新观测值落在这个区间的概率达到预先规定的置信水平。
二、常见的估计方法最大似然估计法是参数估计中最常用的方法。
它是在已知样本数据的情况下,选择使得样本数据出现的概率最大的参数值作为参数的估计值。
最大似然估计法的优点是估计结果具有良好的渐进性质,但是对样本数据的要求较高,需要满足一定的充分统计条件。
矩估计法是一种简单的参数估计方法。
它是在已知样本数据的情况下,选择使得样本矩与总体矩之间的差距最小的参数值作为参数的估计值。
矩估计法的优点是计算简单,但是在一些情况下可能存在多个参数估计值。
置信区间法是一种常用的区间估计方法。
它是在已知样本数据的情况下,给出一个区间,使得参数的真值落在这个区间的概率达到预先规定的置信水平。
置信区间法的优点是提供了参数取值范围的上下限,对参数的估计结果具有一定的可信度。
预测区间法是一种用于预测新观测值的区间估计方法。
《概率论与数理统计》课件第七章 参数估计

03
若存在, 是否惟一?
添加标题
1
2
3
4
5
6
对于同一个未知参数,不同的方法得到的估计量可能不同,于是提出问题
应该选用哪一种估计量? 用何标准来评价一个估计量的好坏?
常用标准
(1)无偏性
(3)一致性
(2)有效性
7.2 估计量的评选标准
无偏性
一致性
有效性
一 、无偏性
定义1 设 是未知参数θ的估计量
09
则称 有效.
10
比
11
例4 设 X1, X2, …, Xn 是X 的一个样本,
添加标题
问那个估计量最有效?
添加标题
解 ⑴
添加标题
由于
添加标题
验证
添加标题
都是
添加标题
的无偏估计.
都是总体均值
的无偏估计量.
故
D
C
A
B
因为
所以
更有效.
例5 设总体 X 的概率密度为
关于一致性的两个常用结论
1. 样本 k 阶矩是总体 k 阶矩的一致性估计量.
是 的一致估计量.
由大数定律证明
用切比雪夫不 等式证明
似然函数为
其中
解得参数θ和μ的矩估计量为
2
时
3
令
1
当
6
,故
5
,表明L是μ的严格递增函数,又
4
第二个似然方程求不出θ的估计值,观察
添加标题
所以当
01
添加标题
从而参数θ和μ的最大似然估计值分别为
03
添加标题
时L 取到最大值
02
添加标题
第七章 参数估计

a
2
b
X
2 (a,b)
a2
ab b2 3
1 n
n i 1
X
2 i
解方程组得aˆ X
3 n
n i1
(Xi
X )2 ,bˆ
X
3 n
n i1
(Xi
X )2
练习1
设总体X
~
e(),
X
1
,
X
2
,...,
X
是来自该
n
总体的一组样本,求的矩估计。
2 总体X的概率密度为f (x, )
1
L L
0, 0,
2
L 0,
s
1
ln L ln L
0, 0,
2
lnL 0,
s
解方程组求解出ˆ1, ˆ2 , ,ˆs .
例1.设总体X ~ N(, 2 ), 但, 2均未知,设X1, X2 ,Xn 是来自该总体的一组样本, 求, 2的极大似然估计.
2
)2
2
(3)似然方程
ln L
1
2
n
(Xi
i 1
)
0
ln L
2
n 2
1
2
1
2 4
n
(Xi
i 1
)2
0
(4)解方程组得 X ,
第七章__参数估计

三、区间估计与标准误
㈠区间估计的定义 是根据样本统计量,利用抽样分布的原理,在一定的
可靠程度上,估计出总体参数所在的范围,即以数 轴上的一段距离表示未知参数可能落入的范围。 ㈡置信区间与显著性水平 ⑴置信区间:也称置信间距,指在一定可靠程度上,总体参
数所在的区域距离或区域长度。
⑵置信界限(临界值):置信区间的上下两端点值。 ⑶显著性水平:指估计总体参数落在某一区间时,可能犯错
⑶区间估计的原理是样本分布理论。在计算区间估计值解释估 计的正确概率时,依据的是该样本统计量的分布规律及样本 分布的标准误。样本分布可提供概率解释,而标准误的大小 决定区间估计的长度。一般情况下,加大样本容量可使标准 误变小。
当总体方差已知时,样本平均数的分布为正态分布或
渐近正态分布,此时,样本平均数的平均数uX u, 平均数的离散程度即平均数分布的标准差(简称
例4
解:由题意知,其总体方差未知,但其总体分布为正态分布,
则此样本均数的分布服从t分布, 可以依t分布对总平 均身高μ进行估计。
SEX
S 4.8 0.81; df n 1 36 1 35 n 1 35
查t值表可知 : t0.05 230 2.042;t0.01 230 2.75
例2 已知某区15 岁男生立定跳远的方差 为 436.8cm ,现从该区抽取58名15岁男生, 测得该组男生立定跳远的平均数为198.4cm, 试求该区15岁男生立定跳远平均成绩的95%和 99%的置信区间。
例2
解:由题意知:由于样本容量(n=58)大于30 ,
该样本的抽样分布为渐进正态分布。
SEX
因此, 的95%的置信区间为 :
82 2.0211.12 82 2.0211.12
概率论与数理统计第七章参数估计
例1. 设总体X的数学期望和方差分别是μ,
σ2 ,求μ , σ2的矩估计量。
E(X )
E( X 2 ) D( X ) [EX ]2 2 2
(3) 写出方程 ln L 0
i1
若方程有解,
求出L(θ)的最大值点 ˆ(x1,x2,..x.n,)
于 是 ˆ ˆ ( X 1 , X 2 , . . . , X n ) 即 为 的 极 大 似 然 估 计 量
例2. 设总体X服从参数λ>0的泊松分布,求 参数λ的极大似然估计量。
例3. 已知某产品的不合格率为p,有简单随机样本 X1 ,X2 ,…, Xn,求p的极大似然估计量。 若抽取100件产品,发现10件次品,试估计p.
ˆ(x1,x2,..x.n,),使得
L (ˆ) m a x L (), (或 L (ˆ) s u p L ())
则 称 ˆ ( x 1 ,x 2 , . . . ,x n ) 为 的 极 大 似 然 估 计 值
称 ˆ ( X 1 ,X 2 ,...,X n ) 为 极 大 似 然 估 计 量
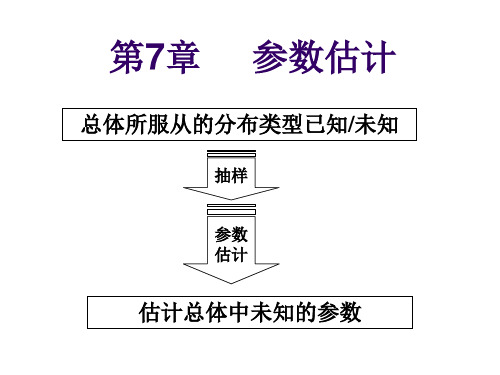
第7章 参数估计
总体所服从的分布类型已知/未知
抽样
参数 估计
估计总体中未知的参数
参数估计 参数估计问题是利用从总体抽样得到的信息
来估计总体的某些参数. 估计新生儿的体重
估计废品率
估计湖中鱼数
§7.1
点估计
设有一个统计总体,总体的分布函数
为 F(x, ),其中为未知参数 (可以是向量) .
概率论第7章

X1, ... ,Xn是来自总体X的独立同分布样本,分布
律或概率密度函数是f(x,q),其中q∈Q是参数,Q已知, 是q的取值范围.f (x,q)的形式已知,则有统计模型
f ( x1,θ) f ( xn ,θ) θ Q
例1 某种型号的产品N个,其合格率q未知,从中随机
抽取n个(n<<N),设Xi 是第i次抽到的样品,正品Xi=1, 否则 Xi =0,则 X1,X2,…,Xn 就是样本.总体分布为两点
分布B(0,1),参数空间为q=(0,1),则可得统计模型
n
n
xi
n xi
θ i1 (1 θ) i1
用矩估计法估计λ的值。
解 设X为灯管寿命,则
1 n
x n i1 xi 130.55
μ1
E
X
=
1 λ
μ1 m1
μ1
E
X
=
1 λ
X
λˆ 1 0.0077 X
例2 设总体X的均值μ和方差σ2 >0都存在,μ,σ2未知.
X1,…,Xn是来自 X 的样本,试求μ, σ2的矩估计量 .
矩估计量的观察值称为矩估计值 .
总体k阶中心矩 样本k阶中心矩
Vk
Bk
E[ X 1n
n i1
E( X )]k; ( Xi X )k .
例1. 设有一批灯管,其寿命服从参数为λ的指数分 布,今随机从中抽取11只,测得其寿命数据如下:
110, 184, 145, 122, 165, 143, 78, 129, 62, 130, 168
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第七章 参数估计1.[一] 随机地取8只活塞环,测得它们的直径为(以mm 计) 74.001 74.005 74.003 74.001 74.000 73.998 74.006 74.002 求总体均值μ及方差σ2的矩估计,并求样本方差S 2。
解:μ,σ2的矩估计是 6122106)(1ˆ,002.74ˆ-=⨯=-===∑ni i x X n X σμ621086.6-⨯=S 。
2.[二]设X 1,X 1,…,X n 为准总体的一个样本。
求下列各总体的密度函数或分布律中的未知参数的矩估计量。
(1)⎩⎨⎧>=+-其它,0,)()1(cx x c θx f θθ其中c >0为已知,θ>1,θ为未知参数。
(2)⎪⎩⎪⎨⎧≤≤=-.,010,)(1其它x x θx f θ其中θ>0,θ为未知参数。
(5)()p p m x p px X P x m xmx,10,,,2,1,0,)1()(<<=-==- 为未知参数。
解:(1)X θcθθc θc θc θdx x c θdx x xf X E θθcθθ=--=-===+-∞+-∞+∞-⎰⎰1,11)()(1令,得cX Xθ-=(2),1)()(10+===⎰⎰∞+∞-θθdx xθdx x xf X E θ2)1(,1X X θX θθ-==+得令(5)E (X ) = mp 令mp = X , 解得mXp=ˆ 3.[三]求上题中各未知参数的极大似然估计值和估计量。
解:(1)似然函数1211)()()(+-===∏θn θn nni ix x x c θx f θL0ln ln )(ln ,ln )1(ln )ln()(ln 11=-+=-++=∑∑==ni ini i xc n n θθd θL d x θc θn θn θL∑=-=ni icn xnθ1ln ln ˆ (解唯一故为极大似然估计量)(2)∑∏=--=-+-===ni i θn n ni ix θθnθL x x x θx f θL 112121ln )1()ln(2)(ln ,)()()(∑∑====+⋅-=ni ini ix nθxθθn θd θL d 121)ln (ˆ,0ln 2112)(ln 。
(解唯一)故为极大似然估计量。
(5)∑∑==-=-⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛===∏ni ni iix mn x n ni i p px m x m x X P p L 11)1(}{)(11,()),1ln()(ln ln )(ln 111p x mn p xp L ni i ni ini m x i--++=∑∑∑===01)(ln 11=---=∑∑==pxmn pxdpp L d ni ini i解得 mX mnxp ni i==∑=2,(解唯一)故为极大似然估计量。
4.[四(2)] 设X 1,X 1,…,X n 是来自参数为λ的泊松分布总体的一个样本,试求λ的极大似然估计量及矩估计量。
解:(1)矩估计 X ~ π (λ ),E (X )= λ,故λˆ=X 为矩估计量。
(2)极大似然估计λn n x ni i e x x x λλx P λL ni i-=∑===∏!!!);()(2111,λn x λxλL ni ini i--=∑∑==11!ln ln )(lnX λn λxλd λL d ni i==-=∑=ˆ,0)(ln 1解得为极大似然估计量。
(其中),1,0,!}{);( ====-i λi x i i x e x λx X P λx p i 5.[六] 一地质学家研究密歇根湖湖地区的岩石成分,随机地自该地区取100个样品,每个样品有10块石子,记录了每个样品中属石灰石的石子数。
假设这100次观察相互独立,并由过去经验知,它们都服从参数为n =10,P 的二项分布。
P 是该地区一块解:λ的极大似然估计值为λˆ=X =0.499 [四(1)] 设总体X 其中θ(0<θ<1)为未知参数。
已知取得了样本值x 1=1,x 2=2,x 3=1,试求θ的矩估计值和最大似然估计值。
解:(1)求θ的矩估计值θθθθθθθθθX E 23)]1()][1(3[)1(3)1(221)(22-=-+-+=-+-⋅+⨯=X θX E =-=23)(令则得到θ的矩估计值为6523121323ˆ=++-=-=X θ(2)求θ的最大似然估计值 似然函数}1{}2{}1{}{)(32131======∏=X P X P X P x XP θL i i i)1(2)1(2522θθθθθθ-=⋅-⋅=ln L (θ )=ln2+5ln θ+ln(1-θ) 求导01165)(ln =--=θθd θL d得到唯一解为65ˆ=θ8.[九(1)] 设总体X ~N (μ,σ 2),X 1,X 1,…,X n 是来自X 的一个样本。
试确定常数c 使21121)(σX Xcn i i i 为∑-=+-的无偏估计。
解:由于∑∑∑-=++-=+-=+-+-=-=-11212111211121]))(()(])([])([n i i i i i n i i i n i i i X X E X X D c X X E c X X c E =∑∑-=-=++-=+=-++11112222111)12()02(])()()([n i n i i i i σn c σcEX EX X D XD c当的无偏估计为时21121)(,)1(21σ∑-=+--=n i i i X X c n c 。
[十] 设X 1,X 2, X 3, X 4是来自均值为θ的指数分布总体的样本,其中θ未知,设有估计量)(31)(6143211X X X X T +++=5)432(43212X X X X T +++=4)(43213X X X X T +++=(1)指出T 1,T 2, T 3哪几个是θ的无偏估计量; (2)在上述θ的无偏估计中指出哪一个较为有效。
解:(1)由于X i 服从均值为θ的指数分布,所以E (X i )= θ,D (X i )= θ 2,i=1,2,3,4由数学期望的性质2°,3°有θX E X E X E X E T E =+++=)]()([31)]()([61)(43211 θX E X E X E X E T E 2)](4)(3)(2)([51)(43212=+++= θX E X E X E X E T E =+++=)]()()()([41)(43213即T 1,T 2是θ的无偏估计量(2)由方差的性质2°,3°并注意到X 1,X 2, X 3, X 4独立,知243211185)]()([91)]()([361)(θX D X D X D X D T D =+++= 24321241)]()()()([161)(θX D X D X D X D T D =+++=D (T 1)> D (T 2) 所以T 2较为有效。
14.[十四] 设某种清漆的9个样品,其干燥时间(以小时计)分别为6.0 5.7 5.8 6.5 7.0 6.3 5.6 6.1 5.0。
设干燥时间总体服从正态分布N ~(μ,σ2),求μ的置信度为0.95的置信区间。
(1)若由以往经验知σ=0.6(小时)(2)若σ为未知。
解:(1)μ的置信度为0.95的置信区间为(2αz n σX ±), 计算得)392.6,608.5()96.196.00.6(,6.0,96.1,0.6025.0=⨯±===即为查表σz X(2)μ的置信度为0.95的置信区间为()1(2-±n t n SX α),计算得0.6=X ,查表t 0.025(8)=2.3060.)442.6,558.5()3060.2333.00.6(.33.064.281)(819122=⨯±=⨯=-=∑=故为i i x x S16.[十六] 随机地取某种炮弹9发做试验,得炮弹口速度的样本标准差为s=11(m/s)。
设炮口速度服从正态分布。
求这种炮弹的炮口速度的标准差σ的置信度为0.95的置信区间。
解:σ的置信度为0.95的置信区间为)1.21,4.7()18.2118,535.17118())1()1(,)1()1((2212222=⨯⨯=-----n S n n S n ααχχ 其中α=0.05, n=9查表知 180.2)8(,535.17)8(2975.02025.0==χχ19.[十九] 研究两种固体燃料火箭推进器的燃烧率。
设两者都服从正态分布,并且已知燃烧率的标准差均近似地为0.05cm/s ,取样本容量为n 1=n 2=20.得燃烧率的样本均值分别为./24,/1821s cm x s cm x ==设两样本独立,求两燃烧率总体均值差μ1-μ2的置信度为0.99的置信区间。
解:μ1-μ2的置信度为0.99的置信区间为).96.5,04.6()22005.058.22418()(2222121221--=⨯+-=+±-n n z X X σσα其中α=0.01,z 0.005=2.58,n 1=n 2=20, 24,18,05.02122221====X X σσ 20.[二十] 设两位化验员A ,B 独立地对某中聚合物含氯两用同样的方法各做10次测定,其测定值的样本方差依次为2222,.6065.0,5419.0B A B A σσS S 设==分别为A ,B 所测定的测定值总体的方差,设总体均为正态的。
设两样本独立,求方差比22B A σσ的置信度为0.95的置信区间。
解:22B A σσ的置信度为0.95的置信区间))1,1(,)1,1((21212221222-----n n FS S n n F S S αB A αB A)6065.003.45419.0,03.46065.05419.0(⨯⨯== (0.222, 3.601).其中n 1=n 2=10,α=0.05,F 0.025(9,9)=4.03, 03.41)9,9(1)9,9(025.0975.0==F F 。