概率论与数理统计第七章。
概率论与数理统计复习7章

( n − 1) S 2 ( n − 1) S 2 = 1 − α 即P 2 <σ2 < 2 χα 2 ( n − 1) χ1−α 2 ( n − 1) ( n − 1) S 2 ( n − 1) S 2 置信区间为: 2 , χα 2 ( n − 1) χ12−α 2 ( n − 1)
则有:E ( X v ) = µv (θ1 , θ 2 ,⋯ , θ k ) 其v阶样本矩是:Av = 1 ∑ X iv n i =1
n
估计的未知参数,假定总体X 的k阶原点矩E ( X k ) 存在,
µ θ , θ ,⋯ , θ = A k 1 1 1 2 µ2 θ1, θ 2 ,⋯ , θ k = A2 用样本矩作为总体矩的估计,即令: ⋮ µ θ , θ ,⋯ , θ = A k k k 1 2 ɵ ɵ ˆ 解此方程即得 (θ1 , θ 2 ,⋯ , θ k )的一个矩估计量 θ 1 , θ 2 ,⋯ , θ k
+∞
−∞
xf ( x ) dx = ∫ θ x θ dx =
1 0
令E ( X ) = X ⇒
θ +1
θ
ˆ = X ⇒θ =
( )
X 1− X
θ +1
2
θ
7.2极大似然估计法
极大似然估计法: 设总体X 的概率密度为f ( x,θ ) (或分布率p( x,θ )),θ = (θ1 ,θ 2 ,⋯ ,θ k ) 为 未知参数,θ ∈ Θ, Θ为参数空间,即θ的取值范围。设 ( x1 , x2 ,⋯ , xn ) 是 样本 ( X 1 , X 2 ,⋯ , X n )的一个观察值:
i =1 n
概率论与数理统计第7章参数估计PPT课件

a1(1, ,k )=v1
1 f1(v1, ,vk )
假定方程组a2(1, ,k ) v2 ,则可求出2 f2(v1, ,vk )
ak (1, ,k ) vk
k fk (v1, ,vk )
则x1 xn为X的样本值时,可用样本值的j阶原点矩Aj估计vj,其中
Aj
1 n
n i1
xij ( j
L(x1, ,xn;ˆ)maxL(x1, ,xn;),则称ˆ(x1, ,xn)为
的一种参数估计方法 .
它首先是由德国数学家
高斯在1821年提出的 ,然而, 这个方法常归功于英国统
Gauss
计学家费歇(Fisher) . 费歇在1922年重新发现了
这一方法,并首先研究了这
种方法的一些性质 .
Fisher
10
极大似然估计是在已知总体分布形式的情形下的 点估计。
极大似然估计的基本思路:根据样本的具体情况
注:估计量为样本的函数,样本不同,估计量不 同。
常用估计量构造法:矩估计法、极大似然估计法。
4
7.1.1 矩估计法
矩估计法是通过参数与总体矩的关系,解出参数, 并用样本矩替代总体矩而得到的参数估计方法。 (由大数定理可知样本矩依概率收敛于总体矩, 且许多分布所含参数都是矩的函数)
下面我们考虑总体为连续型随机变量的情况:
n
它是的函数,记为L(x1, , xn; ) f (xi , ), i 1
并称其为似然函数,记为L( )。
注:似然函数的概念并不仅限于连续随机变量 ,
对于离散型随机变量,用 P {Xx}p(x,)
替代f ( x, )
即可。
14
设总体X的分布形式已知,且只含一个未知参数,
《概率论与数理统计》第七章假设检验.

《概率论与数理统计》第七章假设检验.第七章假设检验学习⽬标知识⽬标:理解假设检验的基本概念⼩概率原理;掌握假设检验的⽅法和步骤。
能⼒⽬标:能够作正态总体均值、⽐例的假设检验和两个正态总体的均值、⽐例之差的假设检验。
参数估计和假设检验是统计推断的两种形式,它们都是利⽤样本对总体进⾏某种推断,然⽽推断的⾓度不同。
参数估计是通过样本统计量来推断总体未知参数的取值范围,以及作出结论的可靠程度,总体参数在估计前是未知的。
⽽在假设检验中,则是预先对总体参数的取值提出⼀个假设,然后利⽤样本数据检验这个假设是否成⽴,如果成⽴,我们就接受这个假设,如果不成⽴就拒绝原假设。
当然由于样本的随机性,这种推断只能具有⼀定的可靠性。
本章介绍假设检验的基本概念,以及假设检验的⼀般步骤,然后重点介绍常⽤的参数检验⽅法。
由于篇幅的限制,⾮参数假设检验在这⾥就不作介绍了。
第⼀节假设检验的⼀般问题关键词:参数假设;检验统计量;接受域与拒绝域;假设检验的两类错误⼀、假设检验的基本概念(⼀)原假设和备择假设为了对假设检验的基本概念有⼀个直观的认识,不妨先看下⾯的例⼦。
例7.1 某⼚⽣产⼀种⽇光灯管,其寿命X 服从正态分布)200 ,(2µN ,从过去的⽣产经验看,灯管的平均寿命为1550=µ⼩时,。
现在采⽤新⼯艺后,在所⽣产的新灯管中抽取25只,测其平均寿命为1650⼩时。
问采⽤新⼯艺后,灯管的寿命是否有显著提⾼?这是⼀个均值的检验问题。
灯管的寿命有没有显著变化呢?这有两种可能:⼀种是没有什么变化。
即新⼯艺对均值没有影响,采⽤新⼯艺后,X 仍然服从)200 ,1550(2N 。
另⼀种情况可能是,新⼯艺的确使均值发⽣了显著性变化。
这样,1650=X 和15500=µ之间的差异就只能认为是采⽤新⼯艺的关系。
究竟是哪种情况与实际情况相符合,这需要作检验。
假如给定显著性⽔平05.0=α。
在上⾯的例⼦中,我们可以把涉及到的两种情况⽤统计假设的形式表⽰出来。
概率论与数理统计-参数估计

第七章 参数估计
例:
引言
设总体 X 是服从参数为 的指数分布,其中参数
未 知 ,
0 .X1 ,,
X
是总体
n
X
的一个样本,
我们的任务是根据样本,来估计 的取值,从
而估计总体的分布.
这 是 一 个 参 数 估 计 问 题.
第七章 参数估计
§1 点估计 §2 估计量的评选标准 §3 区间估计
第七章 参数估计 §1 点估计
2
令
A1
A2
, (
2
1)
.
第七章 参数估计
例6(续)
解此方程组,得
§1 点估计
ˆ
A1 2 A2 A12
,
ˆ
A2
A1 A12
.
ˆ X 2 ,
即
B2
ˆ X .
B2
其中 B2
1 n
n i 1
Xi X
2 为样本的二阶中心矩.
第七章 参数估计(第二十二讲) 三、 极大似然法
§1 点估计
1
第七章 参数估计
例6(续)
EX 2 x 2 f
x dx x 2
x 1e x dx
0
§1 点估计
2 2 x ( e 2)1 x dx
2 0 2
2 2
1 2
1
2
因此有
EX
,
EX
2
1 .
⑵ 在不引起混淆的情况下,我们统称估计量
与估计值为未知参数 的估计.
第七章 参数估计
二、 矩估计法
§1 点估计
设X为连续型随机变量,其概率密度为
f ( x;1 ,, k ), X为离散型随机变量,其分布列为
《概率论与数理统计》7

未知参数 , ,, 的函数.分别令
12
k
L(1,,k ) 0,(i 1,2,...,k)
或令
i
ln L(1,,k ) 0,(i 1,2,...,k)
i
由此方程组可解得参数 i 的极大似然估计值 ˆi.
例5 设X~b(1,p), X1, X2 , …,Xn是来自X的一个样本,
求参数 p 的最大似然估计量.
解 E( X ) ,E( X 2 ) D( X ) [E( X )]2 2 2
由矩估计法,
【注】
X
1
n
n i 1
X
2 i
2
2
ˆ X ,
ˆ
2
1 n
n i 1
(Xi
X )2
对任何总体,总体均值与方差的矩估计量都不变.
➢常见分布的参数矩估计量
(1)若总体X~b(1, p), 则未知参数 p 的矩估计量为
7-1
第七章
参数估计
统计 推断
的 基本 问题
7-2
参数估 计问题
(第七章)
点估计 区间估 计
假设检 验问题 (第八章)
什么是参数估计?
参数是刻画总体某方面概率特性的数量.
当此数量未知时,从总体抽出一个样本, 用某种方法对这个未知参数进行估计就 是参数估计.
例如,X ~N ( , 2),
若, 2未知, 通过构造样本的函数, 给出
k = k(A1, A2 , …, A k)
用i 作为i的估计量------矩估计量.
例1 设总体X服从[a,b]上的均匀分布,a,b未知,
X1, X2 , …,Xn为来自总体X的样本,试求a,b的 矩估计量.
解 E(X ) a b , D(X ) (b a)2
《概率论与数理统计》第七章

n
n
ln xi
(4)的极大似然估计量为:ˆ
n
n2 i1
lnX
i
2
i1
第七章 参数估计 ‹#›
例 9 设X~b(1,p), X1,X2,…,Xn是来自X的一个样本, 试求参数p的最大似然估计量
解: 设x1, x2,, xn,是相应于样本X1,X2,…,Xn 的一个样本值,X
的分布律为:
(3)以样本各阶矩A1, ,Ak代替总体各阶矩1,
得各参数的矩估计
ˆi gi(A1, ,Ak ), i 1, , k
, k,
第七章 参数估计 ‹#›
注意:
在实际应用时,为求解方便,也可以用
中心矩 i 代替原点矩i,相应地以样本中心矩Bi 估计 i.
(二)最大似然估计法
最(极)大似然估计的原理介绍
第七章
参数估计
目录/Contents
第1章 随机事件与 2 概率
§ 1 点估计
§3
估计量的评选标准
第七章 参数估计 ‹#›
问题的提出:
在实际进行统计时,有不少总体的(我们关心的某 确定指标)概率分布是已知的。比如
例 1 产品寿命服从的分布
X~
f
(
x)
1
x
e
x0
0
其他
但其中有参数是未知的: θ
n
似然函数 L f xi , 。 i 1
, xn ,
极大似然原理:L(ˆ( x1 ,
,
xn
))
max
L(
).
计算简化方法:
在求L 的最大值时,通常转换为求:lnL 的最大值,
lnL 称为对数似然函数.
利用
概率论与数理统计课后习题答案 第七章

习题 7.2 1. 证明样本均值 是总体均值
证:
的相合估计
由定理
知 是 的相合估计
2. 证明样本的 k 阶矩
是总体 阶矩
证:
的相合估计量
3. 设总体 (1)
(2)
是
的相合估计
为其样品 试证下述三个估计量
(3)
都是 的无偏估计,并求出每一估计量的方差,问哪个方差最小? 证:
都是 的无偏估计
故 的方差最小.
大?(附
)
解: (1) 的置信度为 的置信区间为
(2) 的置信度为 故区间长度为
的置信区间为
解得
四、某大学从来自 A,B 两市的新生中分别随机抽取 5 名与 6 名新生,测其身高(单位:厘米)后,算的
.假设两市新生身高分别服从正态分布:
,
其中 未知 试求
的置信度为 0.95 的置信区间.(附:
解:
.从该车床加工的零件中随机抽取
4 个,测得长度分别为:12.6,13.4,12.8,13.2.
试求: (1)样本方差 ;(2)总体方差 的置信度为 95%的置信区间.
(附:
解: (1)
(2) 置信度 的置信区间为
三、设总体
抽取样本
为样本均值
(1) 已知
求 的置信度为 的置信区间
(2) 已知
问 要使 的置信度为 的置信区间长度不超过 ,样本容量 n 至少应取多
施磷肥的
620 570 650 600 630 580 570 600 600 580
设不施磷肥亩产和施磷肥亩产均服从正态分布,其方差相同.试对施磷肥平均亩产与不施磷肥平均
亩产之差作区间估计(
).
解:
查表知
概率论和数理统计(第三学期)第7章数理统计的基本概念

n i1
i
1 n
n
Ei
i1
D
D 1 n
n i 1
i
1 n2
n
Di
i 1
2
n
2
S~ 1 n
n i 1
i
2
1 n
n i 1
i2 2i
2
1 n
n
i2
i 1
2
n
i
i 1
n
2
1 n
n
i2
i 1
2
2
2
1 n
n
i2
i 1
2
E S~2
E
1 n
n
i2
i 1
23
.209
2
2 0.95
20
10
.851
当自由度n 45时,可用下面近似公式去求2 n:
x2 n
1 2
u
2
2n 1
例3
求
2 0.05
60 .
解
2 0.05
60
1 2
u0.05
2
2 60 1
1 1.645
2
119 78.798
2
3、t分布的上侧分位点
对于给定的α(0<α<1),使
2
e
xi 2 2
2
(2
) e 2
n 2
1
2 2
n i1
xi 2
在数理统计中,总体的分布往往是未知的,需 要通过样本找到一个分布来近似代替总体分布。
§7.3 分布的估计
频率分布 例 某炼钢厂生产的钢由于各种因素的影响,各炉
钢的含硅量可以看作是一个随机变量,现记录了 120炉钢的含硅量百分数,求出这个样本的频数分 布与频率分布。
概率论与数理统计教程第七章答案

.第七章假设检验7.1设总体J〜N(4Q2),其中参数4, /为未知,试指出下面统计假设中哪些是简洁假设,哪些是复合假设:(1) W o: // = 0, σ = 1 ;(2) W o√∕ = O, σ>l5(3) ∕70:// <3, σ = 1 ;(4) % :0< 〃 <3 ;(5)W o :// = 0.解:(1)是简洁假设,其余位复合假设7.2设配么,…,25取自正态总体息(19),其中参数〃未知,无是子样均值,如对检验问题“0 :〃 = 〃o, M :4工从)取检验的拒绝域:c = {(x1,x2,∙∙∙,x25)r∣x-χ∕0∖≥c},试打算常数c ,使检验的显著性水平为0. 05_ Q解:由于J〜N(〃,9),故J~N(",二)在打。
成立的条件下,一/3 5cP o(∖ξ-^∖≥c) = P(∖ξ-μJ^∖≥-)=2 1-Φ(y) =0.05Φ(-) = 0.975,-= 1.96,所以c=L176°3 37. 3 设子样。
,乙,…,25取自正态总体,cr:已知,对假设检验%邛=μ0, H2> /J。
,取临界域c = {(X[,w,…,4):片>9)},(1)求此检验犯第一类错误概率为α时,犯其次类错误的概率夕,并争论它们之间的关系;(2)设〃o=0∙05, σ~=0. 004, a =0.05, n=9,求"=0.65 时不犯其次类错误的概率。
解:(1)在儿成立的条件下,F~N(∕o,军),此时a = P^ξ≥c^ = P0< σo σo )所以,包二为册=4_,,由此式解出c°=窄4f+为% ∖∣n在H∣成立的条件下,W ~ N",啊 ,此时nS = %<c°) = AI。
气L =①(^^~品)二①匹%=①(2δξ^历σoA∣-σ+A)-A-------------- y∕n)。
东华大学《概率论与数理统计》课件 第七章 假设检验

1. 2为已知, 关于的检验(U 检验 )
在上节中讨论过正态总体 N ( , 2 ) 当 2为已知时, 关于 = 0的检验问题 :
假设检验 H0 : = 0 , H1 : 0 ;
我们引入统计量U
=
− 0 0
,则U服从N(0,1)
n
对于给定的检验水平 (0 1)
由标准正态分布分位数定义知,
~
N (0,1),
由标准正态分布分位点的定义得 k = u1− / 2 ,
当 x − 0 / n
u1− / 2时, 拒绝H0 ,
x − 0 / n
u1− / 2时,
接受H0.
假设检验过程如下:
在实例中若取定 = 0.05, 则 k = u1− / 2 = u0.975 = 1.96, 又已知 n = 9, = 0.015, 由样本算得 x = 0.511, 即有 x − 0 = 2.2 1.96,
临界点为 − u1− / 2及u1− / 2.
3. 两类错误及记号
假设检验是根据样本的信息并依据小概率原
理,作出接受还是拒绝H0的判断。由于样本具有 随机性,因而假设检验所作出的结论有可能是错
误的. 这种错误有两类:
(1) 当原假设H0为真, 观察值却落入拒绝域, 而 作出了拒绝H0的判断, 称做第一类错误, 又叫弃
设 1,2, ,n 为来自总体 的样本,
因为 2 未知, 不能利用 − 0 来确定拒绝域. / n
因为 Sn*2 是 2 的无偏估计, 故用 Sn* 来取代 ,
即采用 T = − 0 来作为检验统计量.
Sn* / n
当H0为真时,
− 0 ~ t(n −1),
Sn* / n
由t分布分位数的定义知
概率论与数理统计课件第7章参数估计

一、矩估计
4
A B
一、矩估计 例1
5
01
OPTION
02
OPTION
一、矩估计 解
6
一、矩估计
7
一、矩估计
8
解(1)
一、矩估计
9
解(2)
一、矩估计 例3
10
一、矩估计 解
11
一、矩估计
12
关于矩估计量有下列结论:
一、矩估计
13
例4
解
一、矩估计
14
01
OPTION
02
OPTION
一、无偏性 定义1
51
ˆ lim E θ 如果 n+ X1 ,
, X n θ
一、无偏性
52
例1
试求 1 3 2
解
(1)由矩估计定义可知
一、无偏性
53
故
一、无偏性
54
一、无偏性 例2
55
一、无偏性
56
解
一、无偏性 定理 1
57
则有
因此, 样本均值是总体均值的无偏估计, 样本
二、极大似然估计
48
极大似然估计求解
似然函数 对数似然求导法
直接法
49
目录/Contents
7.1 7.2
点估计 点估计的优良性评判标 准 置信区间 单正态总体下未知参数的置信区间 两个正态总体下未知参数的置信区间
7.3
7.4 7.5
50
目录/Contents
7.2
点估计的优良性评判标准 一、无偏性 二、有效性 三、相合性
置信区间
69
置信区间
70
置信区间
《概率论与数理统计》课件 第七章 随机变量的数字特征

i 1,2, , 如果 xi pi , 则称 i 1 E( X ) xi pi 为随机变量X的数学期望; i 1
或称为该分布的数学期望,简称期望或均值.
(2)设连续随机变量X的密度函数为p( x),
如果
+
x p( x)dx ,
则称
-
E( X ) xp( x)dx 为随机变量X的数学期望.
5
例2.求二项分布B(n, p)的数学期望.
P(X
k)
n!
k!n
k !
pk
(1
p)nk ,k
1, 2,
, n.
n
解:EX kP{ X k}
k0
n
k
k0
n!
k!n
k !
pk
(1
p)nk
n
np
k 1
k
n 1! 1!n
pk1
k!
(1
p)nk
np[ p (1 p)]n1 np.
特别地,若X服从0 1分布,则EX p.
6
例3. 求泊松分布P( )的数学期望.
注:P( X k) k e , k 1, 2, .
k!
解:EX k k e e
k1
e
k1
k0 k !
k1 k 1 !
k1 k 1 !
ee
e x 1 x 1 x2 1 xn [这里,x ]
当 a 450时,平均收益EY 最大.
28
第二节 方差与标准差
29
引例
比较随机变量X、Y 的期望
X3 4 5 Y1 4 7 P 0.1 0.8 0.1 P 0.4 0.2 0.4
01 2 3 4 5 67
概率论与数理统计第7章参数估计习题及答案

概率论与数理统计第7章参数估计习题及答案第7章参数估计 ----点估计⼀、填空题1、设总体X 服从⼆项分布),(p N B ,10<计量=pXN. 2、设总体)p ,1(B ~X,其中未知参数 01<则 p 的矩估计为_∑=n 1i i X n 1_,样本的似然函数为_ii X 1n1i X )p 1(p -=-∏__。
3、设 12,,,n X X X 是来⾃总体 ),(N ~X 2σµ的样本,则有关于 µ及σ2的似然函数212(,,;,)n L X X X µσ=_2i 2)X (21n1i e21µ-σ-=∏σπ__。
⼆、计算题1、设总体X 具有分布密度(;)(1),01f x x x ααα=+<<,其中1->α是未知参数,n X X X ,,21为⼀个样本,试求参数α的矩估计和极⼤似然估计.解:因?++=+=101α2α1α102++=++=+|a x 令2α1α++==??)(X X EXX --=∴112α为α的矩估计因似然函数1212(,,;)(1)()n n n L x x x x x x ααα=+∑=++=∴ni i X n L 1α1αln )ln(ln ,由∑==++=??ni i X nL 101ααln ln 得,α的极⼤似量估计量为)ln (?∑=+-=ni iXn11α2、设总体X 服从指数分布 ,0()0,x e x f x λλ-?>=??其他,n X X X ,,21是来⾃X 的样本,(1)求未知参数λ的矩估计;(2)求λ的极⼤似然估计.解:(1)由于1()E X λ=,令11X Xλλ=?=i x nn L x x x eλλ=-∑=111ln ln ln 0nii ni ni ii L n x d L n n x d xλλλλλ====-=-=?=∑∑∑故λ的极⼤似然估计仍为1X。
概率论与数理统计PDF版课件7-2

. 的一个合理解释. 但注意,并不要求包含真实值的区
间正好%,只要是大约%就是合理地,比如也可以.
第七章参数估计 §7.2 区间估计
求置信区间的步骤
=
, ⋯ , ,
(1)找一个与未知参数有关的统计量
11 0.248
3.816
第七章参数估计 §7.2 区间估计
注1 上述求解或 的置信区间时,我们选取的点估计
都是矩估计量或者最大似然估计量. 事实上,我们也可以用
贝叶斯估计量来构造置信区间.详细内容参考本章“重要补
充及扩展问题”的第五节(见教材P220)
注2 上述利用枢轴量进行区间估计的时候都要求总体服
从正态分布. 但实际中,我们考虑的总体经常不服从正态分
布. 这种情况下的区间估计采用的是大样本区间估计. 详细
内容参考本章“重要补充及扩展问题”的第六节(见教材
P220)
第七章参数估计 §7.2 区间估计
三、两个正态总体的区间估计
设 , ⋯ , 为来自正态总体 ∼ , 的简单随机
1. 当 和 已知时,求 − 的置信区间
ഥ−
ഥ 作为总体均值差 − 的点估计;
(1)选取样本均值差
X − Y − ( 1 − 2 )
(2)构造枢轴量
~ N ( 0,1) ;
2
2
(
)
1
n1
(3)选取 = − = Τ ;
+
2
n2
(4) − 的 − 的置信区间
.
n
n
2
2
第七章参数估计 §7.2 区间估计
例3( 见教材P213) 假设 轮胎的寿 命服从正 态分布
概率论与数理统计(叶慈南 刘锡平 科学出版社)第7章 参数估计教程

估计 θ ,故称这种估计为点估计.
5 6
,σ 2未知,
… 随机抽查100个婴儿 得100个体重数据 10,7,6,6.5,5,5.2, …
而全部信息就由这100个数组成. 据此,我们应如何估计 和 σ 呢?
我们知道,服从正态分布N ( , σ 2 )的r.v. X , E ( X ) = , 由大数定律, 样本体重的平均值 1 → ∑ X i P n i =1 自然想到把样本体重的平均值作为总体平均 体重的一个估计. X= 用样本体重的均值 X估计 , 类似地,用样本体重的方差 S 2估计 σ 2 . 1 n 1 n 2 X = ∑ Xi, S = ∑ ( X i X )2 n 1 i =1 n i =1
(一)矩估计法
基本思想:用样本矩估计总体矩
(二)最大似然估计法
基本思想:
15
16
最大似然估计法 (最大似然法)
它首先是由德国数学家 高斯在1821年提出的 , 然而,这个方法常归功于 英国统计学家费希尔(Fisher) . 费希尔在1922年重新发现了 这一方法,并首先研究了这 种 方法的一些性质 . Fisher
1. 矩估计法 2. 最大似然法 3. 最小二乘法 4. 贝叶斯方法 ……
(一) 矩估计法(简称"矩法")
它是基于一种简单的"替换"思想 建立起来的一种估计方法 . 英国统计学家 K. 皮尔逊 最早提出的 . 基本思想: 用样本矩估计总体矩 . 理论依据: 大数定律
Ak = 1 n k P ∑ X i → k = E ( X k ) n i =1
4
在参数估计问题中,假定总体分布 形式已知,未知的仅仅是一个或几个 参数.
《概率论与数理统计》课件第七章 参数估计

03
若存在, 是否惟一?
添加标题
1
2
3
4
5
6
对于同一个未知参数,不同的方法得到的估计量可能不同,于是提出问题
应该选用哪一种估计量? 用何标准来评价一个估计量的好坏?
常用标准
(1)无偏性
(3)一致性
(2)有效性
7.2 估计量的评选标准
无偏性
一致性
有效性
一 、无偏性
定义1 设 是未知参数θ的估计量
09
则称 有效.
10
比
11
例4 设 X1, X2, …, Xn 是X 的一个样本,
添加标题
问那个估计量最有效?
添加标题
解 ⑴
添加标题
由于
添加标题
验证
添加标题
都是
添加标题
的无偏估计.
都是总体均值
的无偏估计量.
故
D
C
A
B
因为
所以
更有效.
例5 设总体 X 的概率密度为
关于一致性的两个常用结论
1. 样本 k 阶矩是总体 k 阶矩的一致性估计量.
是 的一致估计量.
由大数定律证明
用切比雪夫不 等式证明
似然函数为
其中
解得参数θ和μ的矩估计量为
2
时
3
令
1
当
6
,故
5
,表明L是μ的严格递增函数,又
4
第二个似然方程求不出θ的估计值,观察
添加标题
所以当
01
添加标题
从而参数θ和μ的最大似然估计值分别为
03
添加标题
时L 取到最大值
02
添加标题
概率论与数理统计(茆诗松)第二版课后第七章习题参考答案

第七章 假设检验习题7.11. 设X 1 , …, X n 是来自N (µ , 1) 的样本,考虑如下假设检验问题H 0:µ = 2 vs H 1:µ = 3,若检验由拒绝域为}6.2{≥=x W 确定. (1)当n = 20时求检验犯两类错误的概率;(2)如果要使得检验犯第二类错误的概率β ≤ 0.01,n 最小应取多少? (3)证明:当n → ∞ 时,α → 0,β → 0. 解:(1)犯第一类错误的概率为0037.0)68.2(168.220126.21}2|6.2{}|{0=Φ−=⎭⎬⎫⎩⎨⎧=−≥−==≥=∈=n X P X P H W X P µµα,犯第二类错误的概率为0367.0)79.1(79.120136.21}3|6.2{}|{1=−Φ=⎭⎬⎫⎩⎨⎧−=−<−==<=∉=n X P X P H W X P µµβ;(2)因01.0)4.0(4.0136.21}3|6.2{≤−Φ=⎭⎬⎫⎩⎨⎧−=−<−==<=n n n n X P X P µµβ,则99.0)4.0(≥Φn ,33.24.0≥n ,n ≥ 33.93,故n 至少为34;(3))(0)6.0(16.0126.21}2|6.2{∞→→Φ−=⎭⎬⎫⎩⎨⎧=−≥−==≥=n n n n n X P X P µµα,)(0)4.0(4.0136.21}3|6.2{∞→→−Φ=⎭⎬⎫⎩⎨⎧−=−<−==<=n n n n n X P X P µµβ. 2. 设X 1 , …, X 10是来自0-1总体b (1, p ) 的样本,考虑如下检验问题H 0:p = 0.2 vs H 1:p = 0.4,取拒绝域为}5.0{≥=x W ,求该检验犯两类错误的概率. 解:因X ~ b(1, p ),有),10(~10101p b X X i i =∑=,则0328.08.02.0}2.0|510{}2.0|5.0{}|{10510100=⋅⋅==≥==≥=∈=∑=−k k k kC p X P p X P H W X P α,6331.06.04.0}4.0|510{}4.0|5.0{}|{410101=⋅⋅==<==<=∉=∑=−k k k kC p X P p X P H W X P β.3. 设X 1 , …, X 16是来自正态总体N (µ , 4) 的样本,考虑检验问题H 0:µ = 6 vs H 1:µ ≠ 6,拒绝域取为}|6{|c x W ≥−=,试求c 使得检验的显著性水平为0.05,并求该检验在µ = 6.5处犯第二类错误的概率.解:因05.0)]2(1[22162162}6||6{|}|{0=Φ−=⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧=≥−==≥−=∈=c c c X P c X P H W X P µµα,则Φ (2c ) = 0.975,2c = 1.96,故c = 0.98;故}5.6|48.05.648.1{}5.6|98.0|6{|}|{1=<−<−==<−=∉=µµβX P X P H W X P83.0)96.2()96.0(96.01625.696.2=−Φ−Φ=⎭⎬⎫⎩⎨⎧<−<−=X P .4. 设总体为均匀分布U (0, θ ),X 1 , …, X n 是样本,考虑检验问题H 0:θ ≥ 3 vs H 1:θ < 3,拒绝域取为}5.2{)(≤=n x W ,求检验犯第一类错误的最大值α ,若要使得该最大值α 不超过0.05,n 至少应取多大?解:因均匀分布最大顺序统计量X (n ) 的密度函数为θθ<<−Ι=x nn n nx x p 01)(,则nn n n nn n n x dx nx X P H W X P ⎟⎠⎞⎜⎝⎛=====≤=∈=∫−6535.233}3|5.2{}|{5.205.201)(0θα, 要使得α ≤ 0.05,即05.065≤⎟⎠⎞⎜⎝⎛n,43.16)6/5ln(05.0ln =≥n ,故n 至少为17.5. 在假设检验问题中,若检验结果是接受原假设,则检验可能犯哪一类错误?若检验结果是拒绝原假设,则又有可能犯哪一类错误?答:若检验结果是接受原假设,当原假设为真时,是正确的决策,未犯错误;当原假设不真时,则犯了第二类错误.若检验结果是拒绝原假设,当原假设为真时,则犯了第一类错误;当原假设不真时,是正确的决策,未犯错误.6. 设X 1 , …, X 20是来自0-1总体b (1, p ) 的样本,考虑如下检验问题H 0:p = 0.2 vs H 1:p ≠ 0.2,取拒绝域为⎭⎬⎫⎩⎨⎧≤≥=∑∑==17201201i i i i x x W 或,(1)求p = 0, 0.1, 0.2, …, 0.9, 1的势并由此画出势函数的图;(2)求在p = 0.05时犯第二类错误的概率.解:(1)因X ~ b(1, p ),有),20(~201p b X i i ∑=,势函数∑∑=−=−⎟⎟⎠⎞⎜⎜⎝⎛−=⎭⎬⎫⎩⎨⎧∈=6220201)1(201)(k kk i i p p k p WX P p g , 故110201)0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k k k g ,3941.09.01.0201)1.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k kk k g , 1559.08.02.0201)2.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k k k g ,3996.07.03.0201)3.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k kk g ,7505.06.04.0201)4.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k kk g ,9424.05.05.0201)5.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k k k g , 9935.04.06.0201)6.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k k k g ,9997.03.07.0201)7.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k kk g , 999998.02.08.0201)8.0(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k kk g11.09.0201)9.0(6220≈××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k k kk g , 101201)1(6220=××⎟⎟⎠⎞⎜⎜⎝⎛−=∑=−k kk k g ; (2)在p = 0.05时犯第二类错误的概率2641.095.005.02005.0|6220201=××⎟⎟⎠⎞⎜⎜⎝⎛=⎭⎬⎫⎩⎨⎧=∉=∑∑=−=k kk i i k p W X P β. 7. 设一个单一观测的样本取自密度函数为p (x )的总体,对p (x )考虑统计假设: H 0:p 0(x ) = I 0 < x < 1 vs H 1:p 1(x ) = 2x I 0 < x < 1.若其拒绝域的形式为W = {x : x ≥ c },试确定一个c ,使得犯第一类,第二类错误的概率满足α + 2β 为最小,并求其最小值.解:当0 < c < 1时,α = P {X ∈ W | H 0} = P {X ≥ c | X ~ p 0(x )} = 1 − c ,且20112)}(~|{}H |{c xdx x p X c X P W X P c==<=∉=∫β,则2224128721161287212⎟⎠⎞⎜⎝⎛−+=⎟⎠⎞⎜⎝⎛+−+=+−=+c c c c c βα,故当41=c 时,α + 2β 为最小,其最小值为87. 8. 设X 1, X 2, …, X 30为取自柏松分布P (λ)的随机样本.(1)试给出单侧假设检验问题H 0:λ ≤ 0.1 vs H 1:λ > 0.1的显著水平α = 0.05的检验; (2)求此检验的势函数β (λ)在λ = 0.05, 0.2, 0.3, …, 0.9时的值,并据此画出β (λ)的图像.解:(1)因)30(~3021λP X X X X n +++=L ,假设H 0:λ ≤ 0.1 vs H 1:λ > 0.1, 统计量)30(~λP X n ,当H 0成立时,设)3(~P X n ,其p 分位数)3(p P 满足∑∑=−−=−≤<)3(031)3(03e !3e !3p p P k k P k k k p k 显著水平α = 0.05,可得P 1−α (3) = P 0.95 (3) = 6,右侧拒绝域}7{≥=x n W ;(2)因∑=−−=≥=∈=630e!)30(1}|7{}|{)(k k k X n P W X n P λλλλλβ, g故0001.0e !5.11)05.0(605.1=−=∑=−k k k β,3937.0e !61)2.0(606=−=∑=−k k k β,7932.0e !91)3.0(609=−=∑=−k k k β,9542.0e !121)4.0(6012=−=∑=−k k k β,9924.0e !151)5.0(6015=−=∑=−k k k β,9990.0e !181)6.0(6018=−=∑=−k k k β,9999.0e !211)7.0(6021=−=∑=−k kk β, 1e !241)8.0(6024≈−=∑=−k k k β,1e !271)9.0(6027≈−=∑=−k k k β.习题7.2说明:本节习题均采用拒绝域的形式完成,在可以计算检验的p 值时要求计算出p 值. 1. 有一批枪弹,出厂时,其初速率v ~ N (950, 1000)(单位:m /s ).经过较长时间储存,取9发进行测试,得样本值(单位:m /s )如下:914 920 910 934 953 945 912 924 940.据经验,枪弹经储存后其初速率仍服从正态分布,且标准差保持不变,问是否可认为这批枪弹的初速率有显著降低(α = 0.05)?解:设枪弹经储存后其初速率X ~ N (µ , 1000),假设H 0:µ = 950 vs H 1:µ < 950,已知σ 2,选取统计量)1,0(~N nX U σµ−=, 显著性水平α = 0.05,u 1 − α = u 0.95 = 1.645,左侧拒绝域W = {u ≤ −1.645}, 因928=x ,µ = 950,σ = 10,n = 9, 则W u ∈−=−=6.6910950928,并且检验的p 值p = P {U ≤ −6.6} = 2.0558 × 10−11 < α = 0.05,故拒绝H 0,接受H 1,即可以认为这批枪弹的初速率有显著降低. 2. 已知某炼铁厂铁水含碳量服从正态分布N (4.55, 0.1082 ).现在测定了9炉铁水,其平均含碳量为4.484,如果铁水含碳量的方差没有变化,可否认为现在生产的铁水平均含碳量仍为4.55(α = 0.05)? 解:设现在生产的铁水含碳量X ~ N (µ , 0.1082 ),假设H 0:µ = 4.55 vs H 1:µ ≠ 4.55,已知σ 2,选取统计量)1,0(~N nX U σµ−=, 显著性水平α = 0.05,u 1 − α /2 = u 0.975 = 1.96,双侧拒绝域W = {| u | ≥ 1.96}, 因484.4=x ,µ = 4.55,σ = 0.108,n = 9, 则W u ∉−=−=8333.19108.055.4484.4,并且检验的p 值p = 2P {U ≤ −1.8333} = 0.0668 > α = 0.05,β (故接受H 0,拒绝H 1,即可以认为现在生产的铁水平均含碳量仍为4.55. 3. 由经验知某零件质量X ~ N (15, 0.05 2 ) (单位:g ),技术革新后,抽出6个零件,测得质量为14.7 15.1 14.8 15.0 15.2 14.6.已知方差不变,问平均质量是否仍为15 g (取α = 0.05)?解:设技术革新后零件质量X ~ N (µ , 0.05 2 ),假设H 0:µ = 15 vs H 1:µ ≠ 15,已知σ 2,选取统计量)1,0(~N nX U σµ−=, 显著性水平α = 0.05,u 1 − α /2 = u 0.975 = 1.96,双侧拒绝域W = {| u | ≥ 1.96}, 因9.14=x ,µ = 15,σ = 0.05,n = 6, 则W u ∈−=−=8990.4605.0159.14,并且检验的p 值p = 2P {U ≤ −4.8990} = 9.6326 × 10−7 < α = 0.05,故拒绝H 0,接受H 1,即不能认为平均质量仍为15 g . 4. 化肥厂用自动包装机包装化肥,每包的质量服从正态分布,其平均质量为100 kg ,标准差为1.2 kg .某日开工后,为了确定这天包装机工作是否正常,随机抽取9袋化肥,称得质量如下:99.3 98.7 100.5 101.2 98.3 99.7 99.5 102.1 100.5.设方差稳定不变,问这一天包装机的工作是否正常(取α = 0.05)? 解:设这天包装机包装的化肥每包的质量X ~ N (µ , 1.22 ),假设H 0:µ = 100 vs H 1:µ ≠ 100,已知σ 2,选取统计量)1,0(~N nX U σµ−=, 显著性水平α = 0.05,u 1 − α /2 = u 0.975 = 1.96,双侧拒绝域W = {| u | ≥ 1.96}, 因9778.99=x ,µ = 100,σ = 1.2,n = 9, 则W u ∉−=−=0556.092.11009778.99,并且检验的p 值p = 2P {U ≤ −0.0556} = 0.9557 > α = 0.05,故接受H 0,拒绝H 1,即可以认为这一天包装机的工作正常. 5. 设需要对某正态总体的均值进行假设检验H 0:µ = 15, H 1:µ < 15.已知σ 2 = 2.5,取α = 0.05,若要求当H 1中的µ ≤ 13时犯第二类错误的概率不超过0.05,求所需的样本容量.解:设该总体X ~ N (µ , 2.5 ),假设H 0:µ = 15 vs H 1:µ < 15,已知σ 2,选取统计量)1,0(~N nX U σµ−=, 显著性水平α = 0.05,u 1 − α = u 0.95 = 1.645,左侧拒绝域W = {u ≤ −1.645}, 因µ = 15,σ 2 = 2.5,有nx u 5.215−=,当µ ≤ 13时犯第二类错误的概率为⎭⎬⎫⎩⎨⎧≤−+−>−=⎭⎬⎫⎩⎨⎧≤−>−=13|5.21565.15.213|65.15.215µµµµβn n X P n X P 05.0)2649.165.1(15.2131565.15.2≤+−Φ−=⎭⎬⎫⎩⎨⎧−+−>−≤n n nX P µ,则95.0)2649.165.1(≥+−Φn ,即65.12649.165.1≥+−n ,6089.2≥n ,n ≥ 6.8064, 故样本容量n 至少为7.6. 从一批钢管抽取10根,测得其内径(单位:mm )为:100.36 100.31 99.99 100.11 100.64 100.85 99.42 99.91 99.35 100.10.设这批钢管内直径服从正态分布N (µ , σ 2),试分别在下列条件下检验假设(α = 0.05).H 0:µ = 100 vs H 1:µ > 100.(1)已知σ = 0.5; (2)σ 未知.解:设这批钢管内直径X ~ N (µ , σ 2),假设H 0:µ = 100 vs H 1:µ > 100,(1)已知σ 2,选取统计量)1,0(~N nX U σµ−=, 显著性水平α = 0.05,u 1 − α = u 0.95 = 1.645,右侧拒绝域W = {u ≥ 1.645}, 因104.100=x ,µ = 100,σ = 0.5,n = 10, 则W u ∉=−=6578.0105.0100104.100,并且检验的p 值p = P {U ≥ 0.6578} = 0.2553 > α = 0.05,故接受H 0,拒绝H 1,即不能认为µ > 100. (2)未知σ 2,选取统计量)1(~−−=n t nS X T µ, 显著性水平α = 0.05,t 1 − α (n − 1) = t 0.95 (9) = 1.8331,右侧拒绝域W = {t ≥ 1.8331}, 因104.100=x ,µ = 100,s = 0.4760,n = 10, 则W t ∉=−=6910.0104760.0100104.100,并且检验的p 值p = P {T ≥ 0.6910} = 0.2535 > α = 0.05,故接受H 0,拒绝H 1,即不能认为µ > 100.7. 假定考生成绩服从正态分布,在某地一次数学统考中,随机抽取了36位考生的成绩,算得平均成绩为66.5分,标准差为15分,问在显著性水平0.05下,是否可以认为这次考试全体考生的平均成绩为70分?解:设这次考试考生的成绩X ~ N (µ , σ 2 ),假设H 0:µ = 70 vs H 1:µ ≠ 70,未知σ 2,选取统计量)1(~−−=n t nS X T µ, 显著性水平α = 0.05,t 1 − α /2 (n − 1) = t 0.975 (35) = 2.0301,双侧拒绝域W = {| t | ≥ 2.0301}, 因5.66=x ,µ = 70,s = 15,n = 36, 则W t ∉−=−=4.13615705.66,并且检验的p 值p = 2P {T ≤ −1.4} = 0.1703 > α = 0.05,故接受H 0,拒绝H 1,即可以认为这次考试全体考生的平均成绩为70分. 8. 一个小学校长在报纸上看到这样的报道:“这一城市的初中学生平均每周看8 h 电视.”她认为她所在学校的学生看电视的时间明显小于该数字.为此她在该校随机调查了100个学生,得知平均每周看电视的时间5.6=x h ,样本标准差为s = 2 h .问是否可以认为这位校长的看法是对的(取α = 0.05)? 解:设学生看电视的时间X ~ N (µ , σ 2 ),假设H 0:µ = 8 vs H 1:µ < 8,未知σ 2,选取统计量)1(~−−=n t nS X T µ,n = 100,大样本,有)1,0(~N n S X T &µ−=,显著性水平α = 0.05,t 1 − α (n − 1) = t 0.95 (99) ≈ u 0.95 = 1.645,左侧拒绝域W ≈ {t ≤ −1.645},因5.6=x ,µ = 8,s = 2,n = 100, 则W t ∈−=−=5.7100285.6,并且检验的p 值p = P {T ≤ −7.5} = 3.1909 × 10−14 < α = 0.05,故拒绝H 0,接受H 1,即可以认为这位校长的看法是对的.9. 设在木材中抽出100根,测其小头直径,得到样本平均数2.11=x cm ,样本标准差为s = 2.6 cm ,问该批木材小头的平均直径能否认为不低于12 cm (取α = 0.05)? 解:设该批木材小头的直径X ~ N (µ , σ 2 ),假设H 0:µ = 12 vs H 1:µ < 12,未知σ 2,选取统计量)1(~−−=n t n S X T µ,n = 100,大样本,有)1,0(~N nS X T &µ−=, 显著性水平α = 0.05,t 1 − α (n − 1) = t 0.95 (99) ≈ u 0.95 = 1.645,左侧拒绝域W ≈ {t ≤ −1.645},因2.11=x ,µ = 12,s = 2.6,n = 100, 则W t ∈−=−=0769.31006.2122.11,并且检验的p 值p = P {T ≤ −3.0769} = 0.0010 < α = 0.05,故拒绝H 0,接受H 1,即不能认为这批木材小头的平均直径不低于12 cm .10.考察一鱼塘中鱼的含汞量,随机地取10条鱼测得各条鱼的含汞量(单位:mg )为:0.8 1.6 0.9 0.8 1.2 0.4 0.7 1.0 1.2 1.1.设鱼的含汞量服从正态分布N (µ , σ 2),试检验假设H 0:µ = 1.2 vs H 1:µ > 1.2(取α = 0.10). 解:设鱼的含汞量X ~ N (µ , σ 2 ),假设H 0:µ = 1.2 vs H 1:µ > 1.2,未知σ 2,选取统计量)1(~−−=n t nSX T µ,显著性水平α = 0.1,t 1 − α (n − 1) = t 0.9 (9) = 1.3830,右侧拒绝域W = {t ≥ 1.3830}, 因97.0=x ,µ = 1.2,s = 0.3302,n = 10, 则W t ∉−=−=2030.2103302.02.197.0,并且检验的p 值p = P {T ≥ −2.2030} = 0.9725 > α = 0.10,故接受H 0,拒绝H 1,即不能认为µ > 1.2 . 11.如果一个矩形的宽度w 与长度l 的比618.0)15(21≈−=l w ,这样的矩形称为黄金矩形.下面列出某工艺品工厂随机取的20个矩形宽度与长度的比值.0.693 0.749 0.654 0.670 0.662 0.672 0.615 0.606 0.690 0.628 0.668 0.611 0.606 0.609 0.553 0.570 0.844 0.576 0.933 0.630.设这一工厂生产的矩形的宽度与长度的比值总体服从正态分布,其均值为µ ,试检验假设(取α = 0.05)H 0:µ = 0.618 vs H 1:µ ≠ 0.618.解:设这一工厂生产的矩形的宽度与长度的比值X ~ N (µ , σ 2 ),假设H 0:µ = 0.618 vs H 1:µ ≠ 0.618,未知σ 2,选取统计量)1(~−−=n t nS X T µ, 显著性水平α = 0.05,t 1 − α /2 (n − 1) = t 0.975 (19) = 2.0930,双侧拒绝域W = {| t | ≥ 2.0930},因6620.0=x ,µ = 0.618,s = 0.0918,n = 20, 则W t ∈=−=1422.2200918.0618.06620.0,并且检验的p 值p = 2P {T ≥ 2.1422} = 0.0453 < α = 0.05,故拒绝H 0,接受H 1,即不能认为µ = 0.618.12.下面给出两种型号的计算器充电以后所能使用的时间(h )的观测值型号A 5.5 5.6 6.3 4.6 5.3 5.0 6.2 5.8 5.1 5.2 5.9;型号B 3.8 4.3 4.2 4.0 4.9 4.5 5.2 4.8 4.5 3.9 3.7 4.6.设两样本独立且数据所属的两总体的密度函数至多差一个平移量.试问能否认为型号A 的计算器平均使用时间明显比型号B 来得长(取α = 0.01)?解:设两种型号的计算器充电以后所能使用的时间分别为),(~211σµN X ,),(~222σµN Y ,且2221σσ=,假设H 0:µ 1 = µ 2 vs H 1:µ 1 > µ 2,未知2221,σσ,但2221σσ=,选取统计量)2(~112121−++−=n n t n n S YX T w ,显著性水平α = 0.01,t 1 − α (n 1 + n 2 − 2) = t 0.99 (21) = 2.5176,右侧拒绝域W = {t ≥ 2.5176}, 因5.5=x ,3667.4=y ,s x = 0.5235,s y = 0.4677,n 1 = 11,n 2 = 12,4951.0214677.0115235.0102)1()1(22212221=×+×=−+−+−=n n s n s n s yx w ,则W t ∈=+×−=4844.51211114951.03667.45.5,并且检验的p 值p = P {T ≥ 5.4844} = 9.6391 × 10 −6 < α = 0.01,故拒绝H 0,接受H 1,即可以认为型号A 的计算器平均使用时间明显比型号B 来得长.13.从某锌矿的东、西两支矿脉中,各抽取样本容量分别为9与8的样本进行测试,得样本含锌平均数及样本方差如下:东支:1337.0,230.0211==s x ;西支:1736.0,269.0222==s x .若东、西两支矿脉的含锌量都服从正态分布且方差相同,问东、西两支矿脉含锌量的平均值是否可以看作一样(取α = 0.05)?解:设东、西两支矿脉的含锌量分别为),(~211σµN X ,),(~222σµN Y ,且2221σσ=,假设H 0:µ 1 = µ 2 vs H 1:µ 1 ≠ µ 2,未知2221,σσ,但2221σσ=,选取统计量)2(~11212121−++−=n n t n n S X X T w,显著性水平α = 0.05,t 1 − α /2 (n 1 + n 2 − 2) = t 0.975 (15) = 2.1314,双侧拒绝域W = {| t | ≥ 2.1314},因1736.0,269.0,1337.0,230.0222211====s x s x ,n 1 = 9,n 2 = 8,3903.0151736.071337.082)1()1(21222211=×+×=−+−+−=n n s n s n s w ,则W t ∉−=+×−=2056.081913903.0269.0230.0,并且检验的p 值p = 2P {T ≤ −0.2056} = 0.8399 > α = 0.05, 故接受H 0,拒绝H 1,即可以认为东、西两支矿脉含锌量的平均值是一样的.14.在针织品漂白工艺过程中,要考察温度对针织品断裂强力(主要质量指标)的影响.为了比较70°C与80°C 的影响有无差别,在这两个温度下,分别重复做了8次试验,得数据如下(单位:N ):70°C 时的强力:20.5 18.8 19.8 20.9 21.5 19.5 21.0 21.2, 80°C 时的强力:17.7 20.3 20.0 18.8 19.0 20.1 20.0 19.1.根据经验,温度对针织品断裂强力的波动没有影响.问在70°C 时的平均断裂强力与80°C 时的平均断裂强力间是否有显著差别?(假设断裂强力服从正态分布,α = 0.05)解:设在70°C 和80°C 时的断裂强力分别为),(~211σµN X ,),(~222σµN Y ,且2221σσ=,假设H 0:µ 1 = µ 2 vs H 1:µ 1 ≠ µ 2,未知2221,σσ,但2221σσ=,选取统计量)2(~112121−++−=n n t n n S Y X T w,显著性水平α = 0.05,t 1 − α /2 (n 1 + n 2 − 2) = t 0.975 (14) = 2.1448,双侧拒绝域W = {| t | ≥ 2.1448}, 因4.20=x ,375.19=y ,s x = 0.9411,s y = 0.8876,n 1 = 8,n 2 = 8,9148.0148876.079411.072)1()1(22212221=×+×=−+−+−=n n s n s n s yx w ,则W t ∈=+×−=2410.281819148.0375.194.20,并且检验的p 值p = 2P {T ≥ 2.2410} = 0.0418 < α = 0.05, 故拒绝H 0,接受H 1,即可以认为70°C 时的平均断裂强力与80°C 时的平均断裂强力间有显著差别. 15.一药厂生产一种新的止痛片,厂方希望验证服用新药片后至开始起作用的时间间隔较原有止痛片至少缩短一半,因此厂方提出需检验假设H 0:µ 1 = 2µ 2 vs H 1:µ 1 > 2µ 2.此处µ 1 , µ 2分别是服用原有止痛片和服用新止痛片后至开始起作用的时间间隔的总体的均值.设两总体均为正态分布且方差分别为已知值2221,σσ,现分别在两总体中取一样本X 1 , …, X n 和Y 1 , …, Y m ,设两个样本独立.试给出上述假设检验问题的检验统计量及拒绝域.解:设服用原有止痛片和新止痛片后至开始起作用的时间间隔分别为),(~211σµN X ,),(~222σµN Y ,因X 1 , …, X n 和Y 1 , …, Y m 分别X 和Y 为来自的样本,且两个样本独立,则),(~211n N X σµ,,(~222mN Y σµ,且X 与Y 独立,有4,2(~2222121m n N Y X σσµµ+−−, 标准化,得)1,0(~4)2()2(222121N mnY X σσµµ+−−−,假设H 0:µ 1 = 2µ 2 vs H 1:µ 1 > 2µ 2,已知2221,σσ,选取统计量)1,0(~422221N mnYX U σσ+−=,显著性水平α ,右侧拒绝域W = {u ≥ u 1 − α}.16.对冷却到−0.72°C 的样品用A 、B 两种测量方法测量其融化到0°C 时的潜热,数据如下:方法A :79.98 80.04 80.02 80.04 80.03 80.03 80.04 79.97 80.05 80.03 80.02 80.0080.02,方法B :80.02 79.94 79.98 79.97 80.03 79.95 79.97 79.97.假设它们服从正态分布,方差相等,试检验:两种测量方法的平均性能是否相等?(取α = 0.05).解:设用A 、B 两种测量方法测量的潜热分别为),(~211σµN X ,),(~222σµN Y ,且2221σσ=,假设H 0:µ1 = µ2 vs H 1:µ1 ≠ µ2,未知2221,σσ,但2221σσ=,选取统计量)2(~112121−++−=n n t n n S YX T w ,显著性水平α = 0.05,t 1−α /2 (n 1 + n 2 − 2) = t 0.975 (19) = 2.0930,双侧拒绝域W = {| t | ≥ 2.0930}, 因0208.80=x ,9787.79=y ,s x = 0.0240,s y = 0.0.314,n 1 = 8,n 2 = 8,0269.0190314.070240.0122)1()1(22212221=×+×=−+−+−=n n s n s n s yx w ,则W t ∈=+×−=4722.3811310269.09787.790208.80,并且检验的p 值p = 2P {T ≥ 3.4722} = 0.0026 < α = 0.05,故拒绝H 0,接受H 1,可以认为两种测量方法的平均性能不相等.17.为了比较测定活水中氯气含量的两种方法,特在各种场合收集到8个污水样本,每个水样均用这两种方法测定氯气含量(单位:mg /l ),具体数据如下:水样号 方法一(x ) 方法二(y ) 差(d = x − y ) 1 0.36 0.39 −0.03 2 1.35 0.84 0.51 3 2.56 1.76 0.80 4 3.92 3.35 0.57 5 5.35 4.69 0.66 6 8.33 7.70 0.63 7 10.70 10.52 0.18 8 10.91 10.92 −0.01设总体为正态分布,试比较两种测定方法是否有显著差异.请写出检验的p 值和结论(取α = 0.05).解:设用这两种测定方法测定的氯气含量之差为),(~2d d N Y X D σµ−=,成对数据检验,假设H 0:µ d = 0 vs H 1:µ d ≠ 0,未知2d σ,选取统计量)1(~−=n t nS D T d,显著水平α = 0.05,t 1−α /2 (n − 1) = t 0.975 (7) = 2.3646,双侧拒绝域W = {| t | ≥ 2.3646}, 因4138.0=d ,s d = 0.3210,n = 8, 则W t ∈==6461.383210.04138.0,并且检验的p 值p = 2P {T ≥ 3.6461} = 0.0082 < α = 0.05,故拒绝H 0,接受H 1,可以认为两种测定方法有显著差异.18.一工厂的;两个化验室每天同时从工厂的冷却水取样,测量水中的含气量(10−6)一次,下面是7天的记录:室甲:1.15 1.86 0.75 1.82 1.14 1.65 1.90, 室乙:1.00 1.90 0.90 1.80 1.20 1.70 1.95.设每对数据的差d i = x i − y i (i = 1, 2, …, 7)来自正态总体,问两化验室测定结果之间有无显著差异?(α = 0.01)解:设两个化验室测定的含气量数据之差为),(~2d d N Y X D σµ−=,成对数据检验,假设H 0:µ d = 0 vs H 1:µ d ≠ 0,未知2d σ,选取统计量)1(~−=n t nS D T d,显著水平α = 0.01,t 1−α /2 (n − 1) = t 0.995 (6) = 3.7074,双侧拒绝域W = {| t | ≥ 3.7074}, 因0257.0−=d ,s d = 0.0922,n = 7, 则W t ∉−=−=7375.070922.00257.0,并且检验的p 值p = 2P {T ≤ −0.7375} = 0.4886 > α = 0.05,故接受H 0,拒绝H 1,可以认为两化验室测定结果之间没有显著差异.19.为比较正常成年男女所含红血球的差异,对某地区156名成年男性进行测量,其红血球的样本均值为465.13(104/mm 3),样本方差为54.802;对该地区74名成年女性进行测量,其红血球的样本均值为422.16,样本方差为49.202.试检验:该地区正常成年男女所含红血球的平均值是否有差异?(取α = 0.05)解:设该地区正常成年男女所含红血球分别为),(~211σµN X ,),(~222σµN Y ,假设H 0:µ1 = µ2 vs H 1:µ1 ≠ µ2,未知2221,σσ,大样本场合,选取统计量)1,0(~2212N n S n SY X U yx&+−=,显著水平α = 0.05,u 1−α /2 = u 0.975 = 1.96,双侧拒绝域W = {| t | ≥ 1.96},因222220.49,16.422,80.54,13.465====y x s y s x ,n 1 = 156,n 2 = 74,则W u ∈=+−=9611.57420.4915680.5416.42213.46522,并且检验的p 值p = 2P {U ≥ 5.9611} = 2.5055 × 10−9 < α = 0.05,故拒绝H 0,接受H 1,可以认为该地区正常成年男女所含红血球的平均值有差异.20.为比较不同季节出生的女婴体重的方差,从去年12月和6月出生的女婴中分别随机地抽取6名及10名,测其体重如下(单位:g ):12月:3520 2960 2560 2960 3260 3960,6月:3220 3220 3760 3000 2920 3740 3060 3080 2940 3060.假定新生女婴体重服从正态分布,问新生女婴体重的方差是否是冬季的比夏季的小(取α = 0.05)?解:设12月和6月出生的女婴体重分别为),(~211σµN X ,),(~222σµN Y ,假设H 0:2221σσ= vs H 1:2221σσ<,选取统计量)1,1(~2122−−=n n F S S F yx,显著水平α = 0.05,21.077.41)5,9(1)9,5()1,1(95.005.021====−−F F n n F α,左侧拒绝域W = { f ≤ 0.21},因225960.491=x s ,225217.306=y s ,则W f ∉==5721.25217.3065960.49122,并且检验的p 值p = P {F ≤ 2.5721} = 0.8967 > α = 0.05,故接受H 0,拒绝H 1,新生女婴体重的方差冬季的不比夏季的小.21.已知维尼纶纤度在正常条件下服从正态分布,且标准差为0.048.从某天产品中抽取5根纤维,测得其纤度为1.32 1.55 1.36 1.40 1.44问这一天纤度的总体标准差是否正常(取α = 0.05)?解:设这一天维尼纶纤度X ~ N (µ , σ 2),假设H 0:σ 2 = 0.0482 vs H 1:σ 2 ≠ 0.0482,选取统计量)1(~)1(2222−−=n S n χσχ,显著性水平α = 0.05,4844.0)4()1(2025.022/==−χχαn ,1433.11)4()1(2975.022/1==−−χχαn ,双侧拒绝域W = {χ 2 ≤ 0.4844或χ 2 ≥ 11.1433}, 因σ 2 = 0.0482,s 2 = 0.08822,n = 5,则W ∈=×=5069.13048.00882.04222χ,并且检验的p 值p = 2P {χ 2 ≥ 13.5069} = 0.0181 < α = 0.05, 故拒绝H 0,接受H 1,即可以认为这一天纤度的总体方差不正常.22.某电工器材厂生产一种保险丝.测量其熔化时间,依通常情况方差为400,今从某天产品中抽取容量为25的样本,测量其熔化时间并计算得24.62=x ,s 2 = 404.77,问这天保险丝熔化时间分散度与通常有无显著差异(取α = 0.05,假定熔化时间服从正态分布)? 解:设这天保险丝熔化时间分散度X ~ N (µ , σ 2),假设H 0:σ 2 = 400 vs H 1:σ 2 ≠ 400,选取统计量)1(~)1(2222−−=n S n χσχ,显著性水平α = 0.05,4012.12)24()1(2025.022/==−χχαn ,3641.39)24()1(2975.022/1==−−χχαn ,双侧拒绝域W = {χ 2 ≤ 12.4012或χ 2 ≥ 39.3641}, 因σ 2 = 400,s 2 = 404.77,n = 25,则W ∉=×=2862.2440077.404242χ,并且检验的p 值p = 2P {χ 2 ≥ 24.2862} = 0.8907 > α = 0.05,故接受H 0,拒绝H 1,即可以认为这天保险丝熔化时间分散度与通常没有显著差异. 23.某种导线的质量标准要求其电阻的标准差不得超过0.005(Ω).今在一批导线中随机抽取样品9根,测得样本标准差s = 0.007(Ω),设总体为正态分布.问在显著水平α = 0.05下,能否认为这批导线的标准差显著地偏大?解:设这批导线的电阻X ~ N (µ , σ 2),假设H 0:σ 2 = 0.005 2 vs H 1:σ 2 > 0.005 2,选取统计量)1(~)1(2222−−=n S n χσχ,显著性水平α = 0.05,5073.15)8()1(295.021==−−χχαn ,右侧拒绝域W = {χ 2 ≥ 15.5073},因σ 2 = 0.005 2,s 2 = 0.007 2,n = 9,则W ∈=×=68.15005.0007.08222χ,并且检验的p 值p = P {χ 2 ≥ 15.68} = 0.0472 < α = 0.05, 故拒绝H 0,接受H 1,即可以认为这批导线的标准差显著地偏大.24.两台车床生产同一种滚珠,滚珠直径服从正态分布.从中分别抽取8个和9个产品,测得其直径为甲车床:15.0 14.5 15.2 15.5 14.8 15.1 15.2 14.8;乙车床:15.2 15.0 14.8 15.2 15.0 15.0 14.8 15.1 14.8.比较两台车床生产的滚珠直径的方差是否有明显差异(取α = 0.05).解:设两台车床生产的滚珠直径分别为),(~211σµN X ,),(~222σµN Y ,假设H 0:2221σσ= vs H 1:2221σσ≠,选取统计量)1,1(~2122−−=n n F S S F yx,显著性水平α = 0.05,2041.09.41)7,8(1)8,7()1,1(975.0025.0212/====−−F F n n F α,F 1 − α /2 (n 1 − 1, n 2 − 1) = F 0.975 (7, 8) = 4.53,双侧拒绝域W = {F ≤ 0.2041或F ≥ 4.53},因223091.0=x s ,221616.0=y s ,则W F ∉==6591.31616.03091.022,并且检验的p 值p = 2P {F ≥ 3.6591} = 0.0892 > α = 0.05,故接受H 0,拒绝H 1,即可以认为两台车床生产的滚珠直径的方差没有明显差异. 25.有两台机器生产金属部件,分别在两台机器所生产的部件中各取一容量为m = 14和n = 12的样本,测得部件质量的样本方差分别为46.1521=s ,66.922=s ,设两样本相互独立,试在显著性水平α = 0.05下检验假设H 0:2221σσ= vs H 1:2221σσ>.解:设两台机器生产金属部件质量分别为),(~211σµN X ,),(~222σµN Y ,假设H 0:2221σσ= vs H 1:2221σσ>,选取统计量)1,1(~2221−−=n m F S S F ,显著性水平α = 0.05,F 1 − α (m − 1, n − 1) = F 0.95 (13, 11) = 2.7614,右侧拒绝域W = {F ≥ 2.7614},因46.1521=s ,66.922=s ,则W F ∉==6004.166.946.15,并且检验的p 值p = P {F ≥ 1.6004} = 0.2206 > α = 0.05, 故接受H 0,拒绝H 1,即可以认为2221σσ=.26.测得两批电子器件的样品的电阻(单位:Ω)为A 批(x ) 0.140 0.138 0.143 0.142 0.144 0.137;B 批(y ) 0.135 0.140 0.142 0.136 0.138 0.140.设这两批器材的电阻值分别服从),(211σµN ,),(222σµN ,且两样本独立.(1)试检验两个总体的方差是否相等(取α = 0.05)? (2)试检验两个总体的均值是否相等(取α = 0.05)?解:设两批电子器件样品的电阻分别为),(~211σµN X ,),(~222σµN Y ,(1)假设H 0:2221σσ= vs H 1:2221σσ≠,选取统计量)1,1(~2122−−=n n F S S F yx,显著性水平α = 0.05,1399.015.71)5,5(1)5,5()1,1(975.0025.0212/====−−F F n n F α,F 1 − α /2 (n 1 − 1, n 2 − 1) = F 0.975 (5, 5) = 7.15,双侧拒绝域W = {F ≤ 0.1399或F ≥ 7.15},因22002805.0=x s ,22002665.0=y s ,则W F ∉==1080.1002665.0002805.022,并且检验的p 值p = 2P {F ≥ 1.1080} = 0.9131 > α = 0.05, 故接受H 0,拒绝H 1,即可以认为两个总体的方差相等; (2)假设H 0:µ 1 = µ 2 vs H 1:µ 1 ≠ µ 2,未知2221,σσ,但2221σσ=,选取统计量)2(~112121−++−=n n t n n S YX T w ,显著性水平α = 0.05,t 1 − α /2 (n 1 + n 2 − 2) = t 0.975 (10) = 2.2281,双侧拒绝域W = {| t | ≥ 2.2281}, 因1407.0=x ,1385.0=y ,s x = 0.002805,s y = 0.002665,n 1 = 6,n 2 = 6,002736.010002665.05002805.052)1()1(22212221=×+×=−+−+−=n n s n s n s yx w ,则W t ∉=+×−=3718.16161002736.01385.01407.0,并且检验的p 值p = 2P {T ≥ 1.3718} = 0.2001 > α = 0.05, 故接受H 0,拒绝H 1,即可以认为两个总体的均值相等.27.某厂使用两种不同的原料生产同一类型产品,随机选取使用原料A 生产的样品22件,测得平均质量为2.36(kg ),样本标准差为0.57(kg ).取使用原料B 生产的样品24件,测得平均质量为2.55(kg ),样本标准差为0.48(kg ).设产品质量服从正态分布,两个样本独立.问能否认为使用原料B 生产的产品质量较使用原料A 显著大(取α = 0.05)?解:设两种原料生产的产品质量分别为),(~211σµN X ,),(~222σµN Y ,假设H 0:µ 1 = µ 2 vs H 1:µ 1 < µ 2 ,未知2221,σσ,大样本,选取统计量)1,0(~2212N n S n SY X U yx&+−=,显著性水平α = 0.05,u 1 − α = u 0.95 = 1.645,左侧拒绝域W ≈ {u ≤ −1.645}, 因36.2=x ,55.2=y ,s x = 0.57,s y = 0.48,n 1 = 22,n 2 = 24, 有W u ∉−=+−=2171.12448.02257.055.236.222,并且检验的p 值p = P {U ≤ −1.2171} = 0.1118 > α = 0.05,故接受H 0,拒绝H 1,即可以认为使用原料B 生产的产品质量较使用原料A 不是显著大.习题7.31. 从一批服从指数分布的产品中抽取10个进行寿命测试,观测值如下(单位:h ): 1643 1629 426 132 1522 432 1759 1074 528 283根据这批数据能否认为其平均寿命不低于1100 h (取α = 0.05)? 解:设这批产品的寿命X ~ Exp (1/θ ),假设H 0:θ = 1100 vs H 1:θ < 1100,选取统计量)2(~222n Xn χθχ=,显著性水平α = 0.05,8508.10)20()2(205.02==χχαn ,左侧拒绝域W = {χ 2 ≤ 10.8508},因8.942=x ,n = 10,θ = 1100,则W ∉=××=1418.1711008.9421022χ,并且检验的p 值p = P {χ 2 ≤ 17.1418} = 0.3563 > α = 0.05,故接受H 0,拒绝H 1,即可以认为其平均寿命不低于1100 h .2. 某厂一种元件平均使用寿命为1200 h ,偏低,现厂里进行技术革新,革新后任选8个元件进行寿命试验,测得寿命数据如下:2686 2001 2082 792 1660 4105 1416 2089假定元件寿命服从指数分布,取α = 0.05,问革新后元件的平均寿命是否有明显提高? 解:设革新后元件的寿命X ~ Exp (1/θ ),假设H 0:θ = 1200 vs H 1:θ > 1200,选取统计量)2(~222n Xn χθχ=,显著性水平α = 0.05,2962.26)16()2(295.021==−χχαn ,右侧拒绝域W = {χ 2 ≥ 26.2962},因875.2103=x ,n = 8,θ = 1200,则W ∈=××=0517.281200875.2103822χ,并且检验的p 值p = P {χ 2 ≥ 28.0517} = 0.0312 < α = 0.05,故拒绝H 0,接受H 1,即可以认为革新后元件的平均寿命有明显提高.3. 有人称某地成年人中大学毕业生比例不低于30%,为检验之,随机调查该地15名成年人,发现有3名大学毕业生,取α = 0.05,问该人看法是否成立?并给出检验的p 值.解:设该地n 名成年人中大学毕业生人数为∑==ni i X X n 1,有),(~p n b X n ,假设H 0:p = 0.3 vs H 1:p < 0.3, 选取统计量),(~p n b X n ,显著性水平α = 0.05,n = 15,p = 0.3, 有1268.07.03.005.00353.07.03.021515101515=⋅⋅<<=⋅⋅∑∑=−=−k k k kk kkkC C ,左侧拒绝域}1{≤=x n W ,因W x n ∉=3,并且检验的p 值2969.07.03.0}3{31515=⋅⋅=≤=∑=−k k k kC X n P p ,故接受H 0,拒绝H 1,即可以认为该人看法成立.4. 某大学随机调查120名男同学,发现有50人非常喜欢看武侠小说,而随机调查的85名女同学中有23人喜欢,用大样本检验方法在α = 0.05下确认:男女同学在喜爱武侠小说方面有无显著差异?并给出检验的p 值. 解:设n 1名男同学中有∑==111n i i X X n 人喜欢看武侠小说,n 2名女同学中有∑==212n j j Y Y n 人喜欢看武侠小说,有),(~111p n B X n ,),(~222p n B Y n ,大样本,有⎟⎟⎠⎞⎜⎜⎝⎛−1111)1(,~n p p p N X &,⎟⎟⎠⎞⎜⎜⎝⎛−2222)1(,~n p p p N Y &, 则⎟⎟⎠⎞⎜⎜⎝⎛−+−−−22211121)1()1(,~n p p n p p p p N Y X &,即)1,0(~)1()1()()(22211121N n p p n p p p p Y X &−+−−−−,当p 1 = p 2 = p 但未知时,此时用总频率2121ˆn n Yn X n p++=作为p 的点估计替换p ,在大样本场合,有)1,0(~11)ˆ1(ˆ21N n n p pY X U &+−−=,假设H 0:p 1 = p 2 vs H 1:p 1 ≠ p 2, 大样本,选取统计量)1,0(~11)ˆ1(ˆ21N n n p pY X U &+−−=,显著性水平α = 0.05,u 1 − α /2 = u 0.975 = 1.96,双侧拒绝域W = {| u | ≥ 1.96},因n 1 = 120,n 2 = 85,501=x n ,232=y n ,有3561.0851202350ˆ2121=++=++=n n y n x n p,则W u ∈=+−×−=1519.28511201)3561.01(3561.0852312050,并且检验的p 值p = 2P {U ≥ 2.1519} = 0.0314 < α = 0.05,故拒绝H 0,接受H 1,可以认为男女同学在喜爱武侠小说方面有显著差异.5. 假定电话总机在单位时间内接到的呼叫次数服从泊松分布,现观测了40个单位时间,接到的呼叫次数如下:0 2 3 2 3 2 1 0 2 2 1 2 2 1 3 1 1 4 1 1 5 1 2 2 3 3 1 3 1 3 4 0 6 1 1 1 4 0 1 3.在显著性水平0.05下能否认为单位时间内平均呼叫次数不低于2.5次?并给出检验的p 值. 解:设电话总机在单位时间内接到的呼叫次数X ~ P(λ),有)(~1λn P X X n ni i ∑==,大样本,有)1,0(~N nX n n X n &λλλλ−=−,假设H 0:λ = 2.5 vs H 1:λ < 2.5, 大样本,选取统计量)1,0(~N nX U &λλ−=, 显著性水平α = 0.05,u 1 − α = u 0.95 = 1.645,左侧拒绝域W = {u ≤ −1.645}, 因975.1=x ,n = 40,λ = 2.5, 则W u ∈−=−=1.2405.25.2975.1,并且检验的p 值p = P {U ≤ −2.1} = 0.0179 < α = 0.05,故拒绝H 0,接受H 1,不能认为单位时间内平均呼叫次数不低于2.5次;6. 通常每平方米某种布上的疵点数服从泊松分布,现观测该种布100 m 2,发现有126个疵点,在显著性水平0.05下能否认为该种布每平方米上平均疵点数不超过1个?并给出检验的p 值. 解:设每平方米该种布上的疵点数X ~ P(λ),有)(~1λn P X X n ni i ∑==,大样本,有)1,0(~N nX n n X n &λλλλ−=−,假设H 0:λ = 1 vs H 1:λ > 1, 大样本,选取统计量)1,0(~N nX U &λλ−=,显著性水平α = 0.05,u 1 − α = u 0.95 = 1.645,右侧拒绝域W = {u ≥ 1.645},因26.1=x ,n = 100,λ = 1, 则W u ∈=−=6.21001126.1,并且检验的p 值p = P {U ≥ 2.6} = 0.0047 < α = 0.05, 故拒绝H 0,接受H 1,不能认为该种布每平方米上平均疵点数不超过1个; 7. 某厂的一批电子产品,其寿命T 服从指数分布,其密度函数为p (t ; θ ) = θ −1exp{− t /θ } I t > 0,从以往生产情况知平均寿命θ = 2000 h .为检验当日生产是否稳定,任取10件产品进行寿命试验,到全部失效时停止.试验得失效寿命数据之和为30200.试在显著性水平α = 0.05下检验假设H 0:θ = 2000 vs H 1:θ ≠ 2000.解:假设H 0:θ = 2000 vs H 1:θ ≠ 2000,选取统计量)2(~222n Xn χθχ=,显著性水平α = 0.05,5908.9)20()2(2025.022/==χχαn ,1696.34)20()2(2975.022/1==−χχαn ,双侧拒绝域W = {χ 2 ≤ 9.5908或χ 2 ≥ 34.1696},因30201030200==x ,n = 10,θ = 2000, 则W ∉=××=20.30200030201022χ,并且检验的p 值p = P {χ 2 ≥ 30.20} = 0.0667 > α = 0.05,故接受H 0,拒绝H 1,即可以认为其平均寿命等于2000 h . 8. 设X 1, X 2, …, X n 为取自两点分布b (1, p )的随机样本.(1)试求单侧假设检验问题H 0:p ≤ 0.01 vs H 1:p > 0.01的显著水平α = 0.05的检验; (2)若要这个检验在p = 0.08时犯第二类错误的概率不超过0.10,样本容量n 应为多大? 解:(1)假设H 0:p = 0.01 vs H 1:p > 0.01,若为小样本,选取统计量),(~1p n b X X n ni i ∑==,显著性水平α = 0.05,p = 0.01,取⎭⎬⎫⎩⎨⎧≥⋅⋅=⎭⎬⎫⎩⎨⎧≤⋅⋅=∑∑−=−=−95.099.001.0min 05.099.001.0min 102c k k n k k n n c k kn k k n C C c ,当n ≤ 5时,c 2 = 1;当6 ≤ n ≤ 35时,c 2 = 2;当36 ≤ n ≤ 82时,c 2 = 3;当83 ≤ n ≤ 137时,c 2 = 4; 右侧拒绝域}{2c x n W ≥=, 根据x n ,作出决策; 若为大样本,选取统计量)1,0(~)1(N np p pX U &−−=,显著性水平α = 0.05,u 1 − α = u 0.95 = 1.645,右侧拒绝域W = {u ≥ 1.645}, 计算u ,作出决策;(2)在p = 0.08时,)08.0,(~1n b X X n ni i ∑==,则犯第二类错误的概率10.092.008.0}08.0|{}08.0|{1022≤⋅⋅==<==∉=∑−=−c k k n k kn C p c X n P p W X n P β,当n ≤ 5时,c 2 = 1,β = 0.92n ≥ 0.6591;当6 ≤ n ≤ 35时,c 2 = 2,2184.092.008.01≥⋅⋅=∑=−k k n k kn C β;当36 ≤ n ≤ 82时,c 2 = 3, 若n = 64,1050.092.008.02=⋅⋅=∑=−k kn kknC β;若n = 65,0991.092.008.02=⋅⋅=∑=−k k n k kn C β;故n ≥ 65.9. 有一批电子产品共50台,产销双方协商同意找出一个检验方案,使得当次品率p ≤ p 0 = 0.04时拒绝的概率不超过0.05,而当p > p 1 = 0.30时,接受的概率不超过0.1,请你帮助找出适当的检验方案. 解:设这批电子产品中的次品数为∑==ni i X X n 1,有),(~p n b X n ,假设H 0:p = 0.04 vs H 1:p > 0.04, 小样本,选取统计量),(~p n b X n , 显著性水平α = 0.05,p = 0.04,。
概率论与数理统计第七章

矩估计法的具体做法如下 设总体的分布函数中含有k个未知参数 1,2, ,k 。 (1) 写出总体的前 k 阶矩μ1, μ2, , μk ,,一般是这 k 个未知参数的函数, 记为:
μi μi (θ1 , θ2 ,
θ j θ j ( μ1 , μ2 ,
(3)
, θk )
, μk )
你就会想,只发一枪便打中,猎人命中的概率一 般大于这位同学命中的概率。看来这一枪是猎人 射中的。
这个例子所作的推断已经体现了最大似然法的基 本思想 :一次试验就出现的事件有较大的概率。
718 例7.4 设总体 X 服从0-1分布, 且P {X = 1} = p, 用最大似然法求 p 的估计值。 解: 总体 X 的分布律为
以Ai分别代替上式的 可得 a , b 的矩估计量为
i , i 1, 2,
总体矩
n 3 2 2 ˆ a A 3( A A ) X ( X X ) , 1 2 1 i n i 1 n 3 ˆ 2 2 b A 3( A A ) X ( X X ) . 1 2 1 i n i 1
1. 矩估计法(简称“矩法” ) 矩法是基于一种简单的“替换”思 想建立起来的一种估计方法 。又称 数字特征法估计。 是由英国统计学家K.皮尔逊最早提出的。
1 n l 依据:(1) 样本矩 Al X i 依概率收敛于相应 n i 1 的总体矩 l , l 1, 2,.., k .
(2) 样本矩的连续函数依概率收敛于相应的总体矩 的连续函数。
解:
1
2X 1 ˆ , 由矩法, 可得α的矩估计量 1 X
矩法的优点是简单易行, 并不需要事先知道总体 是什么分布。 缺点是,当总体类型已知时,没有充分利用分布 提供的信息。一般场合下 , 矩估计量不具有唯一 性。
概率论与数理统计第七章参数估计
例1. 设总体X的数学期望和方差分别是μ,
σ2 ,求μ , σ2的矩估计量。
E(X )
E( X 2 ) D( X ) [EX ]2 2 2
(3) 写出方程 ln L 0
i1
若方程有解,
求出L(θ)的最大值点 ˆ(x1,x2,..x.n,)
于 是 ˆ ˆ ( X 1 , X 2 , . . . , X n ) 即 为 的 极 大 似 然 估 计 量
例2. 设总体X服从参数λ>0的泊松分布,求 参数λ的极大似然估计量。
例3. 已知某产品的不合格率为p,有简单随机样本 X1 ,X2 ,…, Xn,求p的极大似然估计量。 若抽取100件产品,发现10件次品,试估计p.
ˆ(x1,x2,..x.n,),使得
L (ˆ) m a x L (), (或 L (ˆ) s u p L ())
则 称 ˆ ( x 1 ,x 2 , . . . ,x n ) 为 的 极 大 似 然 估 计 值
称 ˆ ( X 1 ,X 2 ,...,X n ) 为 极 大 似 然 估 计 量
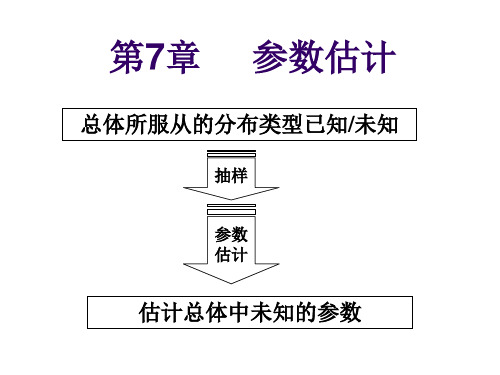
第7章 参数估计
总体所服从的分布类型已知/未知
抽样
参数 估计
估计总体中未知的参数
参数估计 参数估计问题是利用从总体抽样得到的信息
来估计总体的某些参数. 估计新生儿的体重
估计废品率
估计湖中鱼数
§7.1
点估计
设有一个统计总体,总体的分布函数
为 F(x, ),其中为未知参数 (可以是向量) .
概率论与数理统计第七章

估计 为1.68,这是点估计.
估计在区间[1.57, 1.84]内,这是区间估计.
一、点估计概念及讨论的问题
例1 已知某地区新生婴儿的体重X~ N(,2),
, 2未知,
…
随机抽查100个婴儿
得100个体重数据
9, 7, 6, 6.5, 5, 5.2, … 而全部信息就由这100个数组成.
求:两个参数a,b的矩估计
解: 写出方 V E 程 (X a(X )r组 ) ˆˆ2
其 中uˆˆ2Xn1in1(Xi X)2
但是
E
(
X
)
Var ( X )
a
b 2 (b a)2
12
即有
(ab2ba)2 12
X
ˆ
2
由方程组求解出a,b的矩估计:
a ˆX 3 ˆ b ˆX 3 ˆ
其中 ˆ:ˆ2 n 1i n1 ( XiX)2
(4) 在最大值点的表达式中, 用样本值代入 就得参数的极大似然估计值 .
两点说明:
1、求似然函数L( ) 的最大值点,可以应
用微积分中的技巧。由于ln(x)是x的增函
数,lnL( )与L( )在 的同一值处达到 它的最大值,假定是一实数,且lnL( ) 是 的一个可微函数。通过求解所谓“似 然方程”: dlnL() 0
E(X1m)=E(X2m)==E(Xnm)= E(Xm)=am . 根据大数定律,样本原点矩Am作为 X1m,X2m, ,Xnm的算术平均值依概率收敛到均 值am=E(Xm).即:
n 1i n1Xim pE(Xm)am
例1 设总体X的概率密度为
f(x)(1)x,
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
矩法特点分析: 矩法的优点是简单易行,并不需要 事先知道总体是什么分布 . 缺点是,当总体类型已知时,没有 充分利用分布提供的信息 . 一般场合下, 矩估计量不具有唯一性 .
极大似然估计
例: 设一箱中装有若干个白色和黑色的球, 已知两种球的数目之比为3:1或1:3,现有放回 地任取3个球,有2个白球,问:白球所占的 比例p是多少?
1 ˆ 1 X X i n i 1 ˆ 2 ai X i , ( ai 1)
i 1 i 1 n n
n
一致性(相合性)
ˆ ˆ 设 n n ( X1,, X n ) 是参数 的估计量,若有 ˆ lim P(| n | ) 0 即
E( X )
由E ( X 2 ) D ( X ) [ EX ]2 2 2 可得
2 E( X 2 ) u2
X1 X n ˆ X n 1 n 1 n n 1 2 2 2 2 2 ˆ Xi X (Xi X ) S n i 1 n i 1 n
第7章
参数估计
参数估计只是参数统计分析中的一个分支,
背景:已知X~F(x, ),其中 为未知参数,
并取得总体X的一个样本 X1, X2,…, Xn 参数估计要解决的三大问题: 1. 未知参数 值的估计—点估计 矩估计,极大似然估计 2. 估计量优劣的评价标准 3. 未知参数 取值范围的估计—区间估计
E ( X ) gi (1 ,, k ), i 1,, k
i
(2)用样本i阶原点矩替换总体i阶原点矩
1 n g1 (1 , 2 ,..., k ) E ( X ) n X i , i 1 1 n 2 g 2 (1 , 2 ,..., k ) E ( X 2 ) X i , n i 1 ............ 1 n k g k (1 , 2 ,..., k ) E ( X k ) X i , n i 1
1 n ˆ n xi x i 1 1 n 2 2 ˆ ( xi x ) n i 1
ˆ X 2 n 1 2 ˆ S n
求极大似然估计量的步骤: (1) 根据f(x; θ),写出似然函数 L( ) f ( xi ; ) (2) 对似然函数取对数 ln L( ) ln f ( xi ; )
参数估计总体思路:
背景: 总体所服从的分布类型已知
抽样
构造 统计量
估计总体中未知的参数/特征等 注:参数估计可估计总体分布的某些参数 或 数字特征或与参数有关的函数g( ).
参数估计的应用 参数估计问题是利用从总体抽样得到的信息 来估计总体的某些未知参数.
估计新生儿的体重
估计废品率 估计湖中鱼数
n n
ˆ lim P(| n | ) 1
对于固定的样本观测值x1,x2,…,xn。如果有
ˆ ( x1 , x2 ,..., xn ) , 使得
ˆ ˆ L( ) max L( ), (或L( ) sup L( ))
ˆ 则称 ( x1 , x2 ,..., xn )为 的极大似然估计值
ˆ 称 ( X1 , X 2 ,..., X n )为极大似然估计量
rs ˆ ˆ g ( N ) 40 N 40 x
注意:频率估计概率,未知参数函数的估计
关于矩法估计的更一般表述:
1. 用样本矩代替总体矩,既可用
原点矩也可用中心矩。
2. 用样本矩函数代替总体矩函数 3. 用事件的频率代替事件的概率
关于矩法估计的计算技巧:
1. 单参数时用一阶原点矩
2. 双参数时用一阶原点矩和二阶中心矩
极大似然估计法
设总体X的分布律或概率密度为f(x; Ө), θ=(θ1, θ2,…, θk)是未知参数, X1,X2, …,Xn是 总体X的样本,则称X1,X2, …,Xn的联合分布 律或概率密度函数
L( x1 , x2 ,..., xn ; ) f ( xi ; )
i 1
n
为样本的似然函数,简记为L(θ)。
2
(2 ) ( 2 ) exp[
n 2
n 2
1 2 2
( xi ) 2 ]
i 1
n
n n 1 2 2 ln L( , ) ln( 2 ) ln 2 2 2 2
( xi ) 2
i 1
n
ln L 1 n 2 [ xi n ] 0 i 1 n ln L n 1 2 ( xi n ) 2 0 2 2 2 2 2( ) i 1
3(n 1) 2 ˆ 3(n 1) 2 ˆ aX S ,b X S n n
例4.某种鱼每条售价40元,鱼塘养殖户为了预 估今年鱼的收益,想了一个办法:他一次性从 湖中网出r 条鱼,做上记号后放回湖中,然后 再从湖中一次性网出s 条鱼,共发现其中有 x 条鱼有标记。至此你能给出他心中预估的收益 吗?
解:(1)矩估计
E( X )
1 xf ( x)dx x( 1) x dx 0 2
1
1 X 2
ˆ 2 X 1 1 1 X
(2)极大似然估计
L( ) ( 1) ( xi )
n i 1 n
n
(0 xi 1)
有效性
ˆ ˆ ˆ ˆ 设 1 1( X1,, X n )和 2 2 ( X1,, X n )
都是参数 的无偏估计量,若有
ˆ ˆ D(1 ) D( 2 )
则称 ˆ1 较 ˆ2 有效 .
如果对固定的n, D(ˆ1 ) min( D(ˆ)) 则称ˆ 是ˆ的有效估计。
i 1
ln L( ) n ln( 1) ln xi
d ln L( ) 令 0 d
1
n
ln xi
i 1
n
ˆ2 1
n
ln x
i 1
n
i
作业:习题7: 2, 3, 5
§7.2
评价一个估计量的好坏,不能仅仅依 据一次试验的结果,而必须由多次试验结 果来衡量 . 即确定估计量好坏必须在大量 观察的基础上从统计的意义来评价。 常用的几条标准是: 1.无偏性 2.有效性 3.一致性
(3) 解方程组,得 θi=hi (X1, X2,…, Xn) (i=1,2,…,k); 则以hi (X1, X2,…, Xn)作为θi 的估计量 ,并 称hi(X1, X2,…, Xn)为θi 的矩法估计量,而称
hi(x1, x2,…, xn) 为θi 的矩法估计值。
例1. 设总体X的数学期望和方差分别是μ, σ2 ,求μ , σ2的矩估计量。
例:两个猎人,一个老手,一个菜鸟,上 山打猎。突然窜出一只野兔,砰的一枪,命 中野兔,你会认为是哪个猎人打中了野兔?
对例1:如果只知道0<p<1,并且 实测记录是X=k (0 ≤ k≤ n),又应 如何估计p呢?
若总体分布已知,对于样本值,选取适当 的参数,使样本值出现的概率最大,这种 估计方法就是极大似然估计法。
ˆ ˆ( x1 ,, xn )
关键问题:如何构造统计量
ˆ ˆ ( X1 ,, X n )
点估计
矩估计 极大似然估计
注:这两种方法具有优良的统计性质,常用且实用
矩法
总体k阶原点矩 样本k阶原点矩
k EX
k
1 n k Ak X i n i 1
K.皮尔逊
k
例3. 已知某产品的不合格率为p,有简单随机样本 X1 ,X2 ,…, Xn,求p的极大似然估计量。 若抽取100件产品,发现10件次品,试估计p.
例4. 设X1,X2,…,Xn为取自总体X~U(a, b)的样 本, 求a, b的极大似然估计量.
例5 设X1,X2,…Xn是取自总体X的一个样本 ( 1) x , 0 x 1 X ~ f ( x) 其中 >0, 0, 其它 求 的矩估计量和极大似然估计量.
X
大数定律: nlim P (|
i 1
n
k i
n
E ( X ) | ) 1
矩估计基本思想: 1.分布函数中的未知参数和总体矩有函数关系 2.用样本矩估计(代替)总体矩 .
设总体的分布函数中含有k个未知参数 1 ,, k (1)它的前k阶原点矩都是这k个参数的函数,记为:
解:E(X)=(a+b)/2, D(X)=(b-a)2/12.
1 1 1 n ˆ ˆ E ( X ) ( a b) ( a b ) X i X 2 2 n i 1 1 1 ˆ n 1 2 2 2 ˆ D( X ) (b a) (b a) M 2 S 12 12 n
§7.1
点估计
设有一个统计总体,总体的分布函数 为 F(x, ),其中 为未知参数 ( 可以是向量) . 现从该总体抽样,得到样本 X1,X2,…,Xn 从样本出发构造适当的统计量
ˆ ˆ ( X1 ,, X n )
作为参数 的估计量,即点估计。 将样本观测值 x1,, xn 代入,得到 的估计值
无偏性
ˆ 设 ( X1,, X n )是未知参数 的估计量,若
E (ˆ)
ˆ 则称 为 的无偏估计 .
例:总体X, 已知 EX , DX 判断 , 2 的矩法估计量是否是无偏估计。
2
例2:设总体X ~ P( ), X1 ,, X n为一组样本,判断下面 估计量是否为的无偏估计。 1 n 1 n 2 2 ˆ X, ˆ ˆ 1 ( X i X ) ,3 n 1 ( X i X ) 2 n i 1 i 1