Linux实时内存数据库eXtremeDB性能
内存数据库介绍

常用内存数据库介绍(一)博客分类:内存数据库数据结构Oracle企业应用网络应用设计模式(注:部分资料直接来源于Internet)1. 内存数据库简介1.1 概念一、什么是内存数据库传统的数据库管理系统把所有数据都放在磁盘上进行管理,所以称做磁盘数据库(DRDB:Disk-Resident Database)。
磁盘数据库需要频繁地访问磁盘来进行数据的操作,由于对磁盘读写数据的操作一方面要进行磁头的机械移动,另一方面受到系统调用(通常通过CPU中断完成,受到CPU时钟周期的制约)时间的影响,当数据量很大,操作频繁且复杂时,就会暴露出很多问题。
近年来,内存容量不断提高,价格不断下跌,操作系统已经可以支持更大的地址空间(计算机进入了64位时代),同时对数据库系统实时响应能力要求日益提高,充分利用内存技术提升数据库性能成为一个热点。
在数据库技术中,目前主要有两种方法来使用大量的内存。
一种是在传统的数据库中,增大缓冲池,将一个事务所涉及的数据都放在缓冲池中,组织成相应的数据结构来进行查询和更新处理,也就是常说的共享内存技术,这种方法优化的主要目标是最小化磁盘访问。
另一种就是内存数据库(MMDB:Main Memory Database,也叫主存数据库)技术,就是干脆重新设计一种数据库管理系统,对查询处理、并发控制与恢复的算法和数据结构进行重新设计,以更有效地使用CPU周期和内存,这种技术近乎把整个数据库放进内存中,因而会产生一些根本性的变化。
两种技术的区别如下表:内存数据库系统带来的优越性能不仅仅在于对内存读写比对磁盘读写快上,更重要的是,从根本上抛弃了磁盘数据管理的许多传统方式,基于全部数据都在内存中管理进行了新的体系结构的设计,并且在数据缓存、快速算法、并行操作方面也进行了相应的改进,从而使数据处理速度一般比传统数据库的数据处理速度快很多,一般都在10倍以上,理想情况甚至可以达到1000倍。
而使用共享内存技术的实时系统和使用内存数据库相比有很多不足,由于优化的目标仍然集中在最小化磁盘访问上,很难满足完整的数据库管理的要求,设计的非标准化和软件的专用性造成可伸缩性、可用性和系统的效率都非常低,对于快速部署和简化维护都是不利的。
关系数据库、内存数据库、实时数据库的简单比较
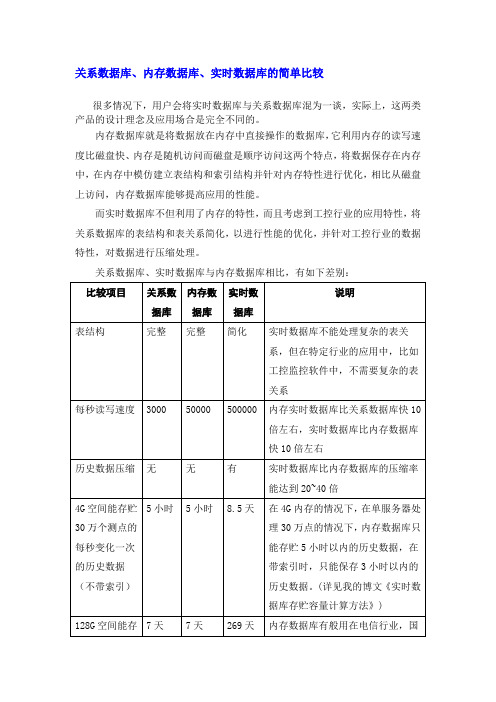
关系数据库、内存数据库、实时数据库的简单比较很多情况下,用户会将实时数据库与关系数据库混为一谈,实际上,这两类产品的设计理念及应用场合是完全不同的。
内存数据库就是将数据放在内存中直接操作的数据库,它利用内存的读写速度比磁盘快、内存是随机访问而磁盘是顺序访问这两个特点,将数据保存在内存中,在内存中模仿建立表结构和索引结构并针对内存特性进行优化,相比从磁盘上访问,内存数据库能够提高应用的性能。
而实时数据库不但利用了内存的特性,而且考虑到工控行业的应用特性,将关系数据库的表结构和表关系简化,以进行性能的优化,并针对工控行业的数据特性,对数据进行压缩处理。
关系数据库、实时数据库与内存数据库相比,有如下差别:从以上的表格可以看出,内存数据库与关系数据库相比,速度快10-20倍左右,且具有与关系数据库类似的完整表结构,因此在电信业处理大量实时事务业务时经常用到,它也可以应用在工控行业,比如,在很多电力行业SCADA软件中,都包含了一个小型的内存数据库系统(但不是真正意义上的内存数据库),但是,在超大型SCADA软件中,它仍不能满足需求,因为它性能比实时数据库慢10倍,且不能解决历史数据存贮的问题,还存在因为掉电导致大量数据丢失的风险。
以上的比较,指标并不全面,也并不是说,实时数据库一定比关系数据库和内存数据库好,只能说,需要针对不同应用的不同需求,做出综合决策,选择最适合自己需要的数据库产品。
最后,列举一些典型的内存数据库产品:■ Oracle TimesTenOracle TimesTen是Oracle从TimesTen公司收购的一个内存优化的关系数据库,它为应用程序提供了实时企业和行业(例如电信、资本市场和国防)所需的即时响应性和非常高的吞吐量。
Oracle TimesTen可作为高速缓存或嵌入式数据库被部署在应用程序层中,它利用标准的 SQL 接口对完全位于物理内存中的数据存储区进行操作。
■ AltibaseAltibase是一个在事务优先的环境中提供高性能和高可用性的软件解决方案。
查看Linux系统内存、CPU、磁盘使用率和详细信息

查看Linux系统内存、CPU、磁盘使⽤率和详细信息⼀、查看内存占⽤1、free# free -m以MB为单位显⽰内存使⽤情况[root@localhost ~]# free -mtotal used free shared buff/cache availableMem: 118521250866841019349873Swap: 601506015# free -h以GB为单位显⽰内存使⽤情况[root@localhost ~]# free -htotal used free shared buff/cache availableMem: 11G 1.2G 8.5G 410M 1.9G 9.6GSwap: 5.9G 0B 5.9G# free -t以总和的形式查询内存的使⽤信息[root@localhost ~]# free -ttotal used free shared buff/cache availableMem: 1213733212853448870628420268198136010105740Swap: 616038006160380Total: 18297712128534415031008# free -s 5周期性的查询内存使⽤信息每5秒执⾏⼀次命令[root@localhost ~]# free -s 5total used free shared buff/cache availableMem: 1213733212807968875008420268198152810110136Swap: 616038006160380解释:Mem:内存的使⽤情况总览表(物理内存)Swap:虚拟内存。
即可以把数据存放在硬盘上的数据shared:共享内存,即和普通⽤户共享的物理内存值buffers:⽤于存放要输出到disk(块设备)的数据的cached:存放从disk上读出的数据total:机器总的物理内存used:⽤掉的内存free:空闲的物理内存注:物理内存(total)=系统看到的⽤掉的内存(used)+系统看到空闲的内存(free)2、查看某个pid的物理内存使⽤情况# cat /proc/PID/status | grep VmRSS[root@localhost ~]# pidof nginx2732727326[root@localhost ~]#[root@localhost ~]# cat /proc/27327/status | grep VmRSSVmRSS: 2652 kB[root@localhost ~]#[root@localhost ~]# cat /proc/27326/status | grep VmRSSVmRSS: 1264 kB[root@localhost ~]#[root@localhost ~]# pidof java1973[root@localhost ~]# cat /proc/1973/status | grep VmRSSVmRSS: 1166852 kB由上⾯可知,nginx服务进程的两个pid所占物理内存为"2652+1264=3916k"3、查看本机所有进程的内存占⽐之和# cat mem_per.sh[root@localhost ~]# cat mem_per.sh#!/bin/bashps auxw|awk '{if (NR>1){print $4}}' > /opt/mem_listawk '{MEM_PER+=$1}END{print MEM_PER}' /opt/mem_list[root@localhost ~]#[root@localhost ~]# chmod755 mem_per.sh[root@localhost ~]#[root@localhost ~]# sh mem_per.sh64.4[root@localhost ~]#脚本配置解释:ps -auxw|awk '{print $3}' 表⽰列出本机所有进程的cpu利⽤率情况,结果中第⼀⾏带"%CPU"字符ps -auxw|awk '{print $4}' 表⽰列出本机所有进程的内存利⽤率情况,结果中第⼀⾏带"%MEM"字符ps auxw|awk '{if (NR>1){print $4}} 表⽰将"ps auxw"结果中的第⼀⾏过滤(NR>1)掉,然后打印第4⾏⼆、查看CPU使⽤情况1、toptop后键⼊P看⼀下谁占⽤最⼤# top -d 5周期性的查询CPU使⽤信息每5秒刷新⼀次top - 02:37:55 up 4 min, 1 user, load average: 0.02, 0.10, 0.05Tasks: 355 total, 1 running, 354 sleeping, 0 stopped, 0 zombie%Cpu(s): 3.0 us, 2.8 sy, 0.0 ni, 94.2id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st# us:表⽰⽤户空间程序的cpu使⽤率(没有通过nice调度)# sy:表⽰系统空间的cpu使⽤率,主要是内核程序。
Linux服务器性能查看分析调优

Linux服务器性能查看分析调优⼀ linux服务器性能查看1.1 cpu性能查看1、查看物理cpu个数:cat /proc/cpuinfo |grep "physical id"|sort|uniq|wc -l2、查看每个物理cpu中的core个数:cat /proc/cpuinfo |grep "cpu cores"|wc -l3、逻辑cpu的个数:cat /proc/cpuinfo |grep "processor"|wc -l物理cpu个数*核数=逻辑cpu个数(不⽀持超线程技术的情况下)1.2 内存查看1、查看内存使⽤情况:#free -mtotal used free shared buffers cachedMem: 3949 2519 1430 0 189 1619-/+ buffers/cache: 710 3239Swap: 3576 0 3576total:内存总数used:已经使⽤的内存数free:空闲内存数shared:多个进程共享的内存总额- buffers/cache:(已⽤)的内存数,即used-buffers-cached+ buffers/cache:(可⽤)的内存数,即free+buffers+cachedBuffer Cache⽤于针对磁盘块的读写;Page Cache⽤于针对⽂件inode的读写,这些Cache能有效地缩短I/O系统调⽤的时间。
对操作系统来说free/used是系统可⽤/占⽤的内存;对应⽤程序来说-/+ buffers/cache是可⽤/占⽤内存,因为buffers/cache很快就会被使⽤。
我们⼯作时候应该从应⽤⾓度来看。
1.3 硬盘查看1、查看硬盘及分区信息:fdisk -l2、查看⽂件系统的磁盘空间占⽤情况:df -h3、查看硬盘的I/O性能(每隔⼀秒显⽰⼀次,显⽰5次):iostat -x 1 5iostat是含在套装systat中的,可以⽤yum -y install systat来安装。
Linux高级存储性能调优使用SSD和NVMe

Linux高级存储性能调优使用SSD和NVMe 随着科技的不断进步,存储技术也在不断地发展和创新。
固态硬盘(Solid State Drive,简称SSD)和非易失性内存(Non-Volatile Memory Express,简称NVMe)作为高效的存储解决方案,已经逐渐被广泛应用于各种领域。
在Linux系统中,使用SSD和NVMe进行高级存储性能调优可以显著提升系统的响应速度和效率。
本文将介绍Linux下如何利用SSD和NVMe进行高级存储性能调优的方法和技巧。
一、使用I/O调度程序在Linux中,可以通过选择合适的I/O调度程序来优化存储性能。
传统的I/O调度程序如CFQ、Deadline和Noop已经无法适应SSD和NVMe的高性能需求。
为此,Linux内核引入了新的I/O调度程序BFQ (Budget Fair Queueing)和KYBER,这两者对于SSD和NVMe的性能优化效果更好。
BFQ是一种基于权重的I/O调度程序,它可以根据应用程序的优先级和权重来调度磁盘访问,以最大化整体系统性能。
KYBER则是一种基于队列的I/O调度程序,通过减小队列深度和引入最小延迟来减少I/O的等待时间。
二、启用TRIM和DiscardTRIM和Discard是SSD和NVMe存储中的常用技术,用于优化垃圾回收和擦除操作。
TRIM命令可以通知SSD和NVMe存储设备哪些数据已经被删除,从而加速垃圾回收和写入操作。
为了启用TRIM功能,我们需要在Linux系统中开启相关的支持。
首先,我们需要确认文件系统支持TRIM功能。
常见的文件系统如ext4、XFS和Btrfs都支持TRIM。
然后,使用以下命令查看SSD和NVMe设备是否支持TRIM:$ sudo hdparm -I /dev/sda如果输出中包含“TRIM supported”字样,则表示该设备支持TRIM 功能。
接下来,在/etc/fstab文件中添加以下行以启用TRIM:/dev/sda / ext4 discard,noatime 0 1最后,使用以下命令重新挂载文件系统:$ sudo mount -o remount /三、开启存储多队列和中断分配SSD和NVMe技术的出现,使得存储设备具备了更高的I/O处理能力。
Linux 服务器的那些性能参数指标
Linux 服务器的那些性能参数指标一个基于 Linux 操作系统的服务器运行的同时,也会表征出各种各样参数信息。
通常来说运维人员、系统管理员会对这些数据会极为敏感,但是这些参数对于开发者来说也十分重要,尤其当你的程序非正常工作的时候,这些蛛丝马迹往往会帮助快速定位跟踪问题。
这里只是一些简单的工具查看系统的相关参数,当然很多工具也是通过分析加工/proc、/sys 下的数据来工作的,而那些更加细致、专业的性能监测和调优,可能还需要更加专业的工具(perf、systemtap 等)和技术才能完成哦。
毕竟来说,系统性能监控本身就是个大学问。
一、CPU和内存类1.1top➜ ~ top第一行后面的三个值是系统在之前 1、5、15 的平均负载,也可以看出系统负载是上升、平稳、下降的趋势,当这个值超过 CPU 可执行单元的数目,则表示 CPU 的性能已经饱和成为瓶颈了。
第二行统计了系统的任务状态信息。
running 很自然不必多说,包括正在 CPU 上运行的和将要被调度运行的;sleeping 通常是等待事件(比如 IO 操作)完成的任务,细分可以包括 interruptible 和 uninterruptible 的类型;stopped 是一些被暂停的任务,通常发送 SIGSTOP 或者对一个前台任务操作 Ctrl-Z 可以将其暂停;zombie 僵尸任务,虽然进程终止资源会被自动回收,但是含有退出任务的 task descriptor 需要父进程访问后才能释放,这种进程显示为defunct 状态,无论是因为父进程提前退出还是未 wait 调用,出现这种进程都应该格外注意程序是否设计有误。
第三行 CPU 占用率根据类型有以下几种情况:∙(us) user:CPU 在低 nice 值(高优先级)用户态所占用的时间(nice<=0)。
正常情况下只要服务器不是很闲,那么大部分的 CPU 时间应该都在此执行这类程序∙(sy) system:CPU 处于内核态所占用的时间,操作系统通过系统调用(system call)从用户态陷入内核态,以执行特定的服务;通常情况下该值会比较小,但是当服务器执行的 IO 比较密集的时候,该值会比较大∙(ni) nice:CPU 在高 nice 值(低优先级)用户态以低优先级运行占用的时间(nice>0)。
eXtremeDB微秒级实时数据库简介

eXtremeDB微秒级实时数据库简介eXtremeDB实时数据库是美国McObject公司于上世纪九十年代末推出的全世界第一款全内存式实时数据库,特别为高性能、低开销、稳定可靠的极速实时数据管理而设计。
eXtremeDB的性能可以达到微秒一级的惊人速度。
eXtremeDB能够达到这样惊人的极限速度,是由其对市场的独特理解、长期的行业经验、持续不断的创新精神和革命性的体系结构等一些列的因素所决定的。
内存数据库eXtremeDB将数据以程序直接使用的格式保存在主内存之中,不仅剔除了文件I/O的开销,也剔除了文件系统数据库所需的缓冲和Cache机制。
其结果是相比于磁盘数据库,其速度提高成百上千倍,以至普通PC平台的硬件条件下就可以达到每个交易1微秒甚至更小的极限速度。
嵌入式数据库eXtremeDB以链接库的形式包含在应用程序之中,其开销只有50KB~120KB。
因此,无论在嵌入式系统还是在实时系统之中,eXtremeDB都能够实现天然的嵌入。
eXtremeDB的这种天然嵌入性对实时数据管理还有更大的意义:对于应用程序而言,各个进程都可以直接访问eXtremeDB数据库,因此剔除了进程间通信,也避免了进程间通信的开销和不确定性。
并且,由于eXtremeDB数据格式是程序直接使用的格式,剔除了数据复制及数据翻译的开销,缩短了应用程序的代码执行路径。
应用定制的API应用程序对eXtremeDB数据库的操作接口是根据应用数据库设计而产生,这些动态的API剔除了通常数据库应用程序所必不可少的动态内存分配,不仅提升了数据库的实时性能,也提高了应用系统的可靠性。
跨平台的实时数据管理方案eXtremeDB对操作系统、编译器、处理器没有依赖性。
eXtremeDB可以运行在各种操作系统上,包括16位、32位及64位的嵌入式操作系统、桌面操作系统及服务器操作系统上。
eXtremeDB对平台的依赖性如此之小,以至于eXtremeDB可以运行在无操作系统的裸机上。
嵌入式linux常见评估指标介绍

嵌入式linux常见评估指标介绍在嵌入式项目预研前期阶段,我们常常需要对某个平台进行资源和性能方面的评估,以下是最常见的一些评估指标:1、内存评估系统内存空间通过free、cat /proc/meminfo或者top,查看内存情况。
一般有这样一个经验公式:应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能;20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能;应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存;$ freetotal used free shared buff/c ac heav ai lableMem: 123496 21512 75132 1132 26852 63416Swap: 0 0 0$ cat /proc/meminfoMemTotal: 123496 kB //所有可用的内存大小,物理内存减去预留位和内核使用。
系统从加电开始到引导完成,firmware/B IOS要预留一些内存,内核本身要占用一些内存,最后剩下可供内核支配的内存就是MemTotal。
这个值在系统运行期间一般是固定不变的,重启会改变。
MemFree: 75132 kB //表示系统尚未使用的内存。
MemAvailable: 63400 kB //真正的系统可用内存,系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab都有一部分可以回收,所以这部分可回收的内存加上MemFree才是系统可用的内存Buffe rs: 5644 kB //用来给块设备做缓存的内存,(文件系统的met ad ata、pages)Cached: 19040 kB //分配给文件缓冲区的内存,例如vi一个文件,就会将未保存的内容写到该缓冲区SwapCached: 0 kB //被高速缓冲存储用的交换空间(硬盘的swap)的大小Active: 20356 kB //经常使用的高速缓冲存储器页面文件大小Inactive: 12628 kB //不经常使用的高速缓冲存储器文件大小Active(anon): 9412 kB //活跃的匿名内存Inactive(anon): 20 kB //不活跃的匿名内存Active(file): 10944 kB //活跃的文件使用内存Inactive(file): 12608 kB //不活跃的文件使用内存Unevictable: 0 kB //不能被释放的内存页Mlocked: 0 kB //系统调用 mlockSwapTotal: 0 kB //交换空间总内存SwapFree: 0 kB //交换空间空闲内存Dirty: 0 kB //等待被写回到磁盘的Wri te back: 0 kB //正在被写回的AnonPages: 8300 kB //未映射页的内存/映射到用户空间的非文件页表大小Mapped: 11480 kB //映射文件内存Shmem: 1132 kB //已经被分配的共享内存KReclaimable: 2132 kB //内核内存,内存压力时内核尝试回收Slab: 8240 kB //内核数据结构缓存SReclaimable: 2132 kB //可收回slab内存SUnreclaim: 6108 kB //不可收回slab内存KernelStack: 568 kB //内核消耗的内存PageTables: 516 kB //管理内存分页的索引表的大小NFS_Unstable: 0 kB //不稳定页表的大小Bounce: 0 kB //在低端内存中分配一个临时buffer作为跳转,把位于高端内存的缓存数据复制到此处消耗的内存WritebackTmp: 0 kB //FUSE用于临时写回缓冲区的内存CommitLimit: 61748 kB //系统实际可分配内存Committed_AS: 58568 kB //系统当前已分配的内存VmallocTotal: 1048372 kB //预留的虚拟内存总量VmallocUsed: 1288 kB //已经被使用的虚拟内存VmallocChunk: 0 kB //可分配的最大的逻辑连续的虚拟内存Per cpu: 32 kB //percpu机制使用的内存2、磁盘评估获取磁盘空间$ df -hFilesystem Size Used Available Use% Mounted on /dev/root 6.0M 6.0M 0 100% /romtmpfs 60.3M 1.1M 59.2M 2% /tmp/dev/mtdblock6 23.8M 9.0M 14.8M 38% /overlay overlayfs:/overlay 23.8M 9.0M 14.8M 38% /tmpfs 512.0K 0 512.0K 0% /dev Filesystem:代表该文件系统时哪个分区,所以列出的是设备名称。
常用的嵌入式数据库的比较

常⽤的嵌⼊式数据库的⽐较2.1 Berkeley DB 技术特点: 1. Berkeley DB是⼀个开放源代码的内嵌式数据库管理系统,能够为应⽤程序提供⾼性能的数据管理服务。
应⽤它程序员只需要调⽤⼀些简单的API就可以完成对数据的访问和管理。
(不使⽤SQL语⾔) 2. Berkeley DB为许多编程语⾔提供了实⽤的API接⼝,包括C、C++、Java、Perl、Tcl、Python和PHP等。
所有同数据库相关的操作都由Berkeley DB函数库负责统⼀完成。
3. Berkeley DB轻便灵活(Portable),可以运⾏于⼏乎所有的UNIX和Linux系统及其变种系统、Windows操作系统以及多种嵌⼊式实时操作系统之下。
Berkeley DB被链接到应⽤程序中,终端⽤户⼀般根本感觉不到有⼀个数据库系统存在。
4. Berkeley DB是可伸缩(Scalable)的,这⼀点表现在很多⽅⾯。
Database library本⾝是很精简的(少于300KB的⽂本空间),但它能够管理规模⾼达256TB的数据库。
它⽀持⾼并发度,成千上万个⽤户可同时操纵同⼀个数据库。
Berkeley DB能以⾜够⼩的空间占⽤量运⾏于有严格约束的嵌⼊式系统。
Berkeley DB在嵌⼊式应⽤中⽐关系数据库和⾯向对象数据库要好,有以下两点原因: (1)因为数据库程序库同应⽤程序在相同的地址空间中运⾏,所以数据库操作不需要进程间的通讯。
在⼀台机器的不同进程间或在⽹络中不同机器间进⾏进程通讯所花费的开销,要远远⼤于函数调⽤的开销; (2)因为Berkeley DB对所有操作都使⽤⼀组API接⼝,因此不需要对某种查询语⾔进⾏解析,也不⽤⽣成执⾏计划,⼤⼤提⾼了运⾏效。
2.2 SQLite 轻量级别数据库SQLite的主要特点: 1. ⽀持事件,不需要配置,不需要安装,也不需要管理员; 2. ⽀持⼤部分SQL92; 3. ⼀个完整的数据库保存在磁盘上⾯⼀个⽂件,同⼀个数据库⽂件可以在不同机器上⾯使⽤,最⼤⽀持数据库到2T,字符和BLOB的⽀持仅限制于可⽤内存; 4. 整个系统少于3万⾏代码,少于250KB的内存占⽤(gcc),⼤部分应⽤⽐⽬前常见的客户端/服务端的数据库快,没有其它依赖 5. 源代码开放,代码95%有较好的注释,简单易⽤的API。
常用主存数据库

常用主存数据库1.内存数据库简介传统的数据库管理系统把所有数据都放在磁盘上进行管理,所以称做磁盘数据库(DRDB:Disk-Resident Database)。
磁盘数据库需要频繁地访问磁盘来进行数据的操作,由于对磁盘读写数据的操作一方面要进行磁头的机械移动,另一方面受到系统调用(通常通过CPU中断完成,受到CPU时钟周期的制约)时间的影响,当数据量很大,操作频繁且复杂时,就会暴露出很多问题。
近年来,内存容量不断提高,价格不断下跌,操作系统已经可以支持更大的地址空间(计算机进入了64位时代),同时对数据库系统实时响应能力要求日益提高,充分利用内存技术提升数据库性能成为一个热点。
在数据库技术中,目前主要有两种方法来使用大量的内存。
一种是在传统的数据库中,增大缓冲池,将一个事务所涉及的数据都放在缓冲池中,组织成相应的数据结构来进行查询和更新处理,也就是常说的共享内存技术,这种方法优化的主要目标是最小化磁盘访问。
另一种就是内存数据库(MMDB:Main Memory Database,也叫主存数据库)技术,就是干脆重新设计一种数据库管理系统,对查询处理、并发控制与恢复的算法和数据结构进行重新设计,以更有效地使用CPU 周期和内存,这种技术近乎把整个数据库放进内存中,因而会产生一些根本性的变化。
两种技术的区别如下表:内存数据库系统带来的优越性能不仅仅在于对内存读写比对磁盘读写快上,更重要的是,从根本上抛弃了磁盘数据管理的许多传统方式,基于全部数据都在内存中管理进行了新的体系结构的设计,并且在数据缓存、快速算法、并行操作方面也进行了相应的改进,从而使数据处理速度一般比传统数据库的数据处理速度快很多,一般都在10倍以上,理想情况甚至可以达到1000倍。
而使用共享内存技术的实时系统和使用内存数据库相比有很多不足,由于优化的目标仍然集中在最小化磁盘访问上,很难满足完整的数据库管理的要求,设计的非标准化和软件的专用性造成可伸缩性、可用性和系统的效率都非常低,对于快速部署和简化维护都是不利的。
Linux中CPU与内存性能监测

Linux中CPU与内存性能监测(出处://chenleixing/article/details/46678413)在系统维护的过程中,随时可能有需要查看CPU 使用率内存使用情况的需要,尤其是涉及到JVM,程序调优的情况,并根据相应信息分析系统状况的需要。
top命令top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
运行top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式-- 用基于top 的命令,可以控制显示方式等等。
退出top 的命令为q (在top 运行中敲q 键一次)。
可以直接使用top命令后,查看%MEM的内容。
可以选择按进程查看或者按用户查看,如想查看Oracle用户的进程内存使用情况的话可以使用top -u oracle,以下为在CentOS中top命令的截图:内容解释:第一行(top):15:59:14 系统当前时刻167 days 系统启动后到现在的运作时间1 user 当前登录到系统的用户,更确切的说是登录到用户的终端数-- 同一个用户同一时间对系统多个终端的连接将被视为多个用户连接到系统,这里的用户数也将表现为终端的数目load average 当前系统负载的平均值,后面的三个值分别为1分钟前、5分钟前、15分钟前进程的平均数,一般的可以认为这个数值超过CPU 数目时,CPU 将比较吃力的负载当前系统所包含的进程第二行(Tasks):75 total 当前系统进程总数1 running 当前运行中的进程数74 sleeping 当前处于等待状态中的进程数0 stoped 被停止的系统进程数0 zombie 僵尸进程数第三行(Cpus):0.0% us 用户空间占用CPU百分比0.3% sy 内核空间占用CPU百分比0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比99.7% id 空闲CPU百分比0.0% wa 等待输入输出的CPU时间百分比0.0% hi0.0% si0.0% st第四行(Mem):1018600k total 物理内存总量798356k used 使用的物理内存总量220244k free 空闲内存总量180628k buffers 用作内核缓存的内存量Swap: 192772k total 交换区总量0k used 使用的交换区总量192772k free 空闲交换区总量123988k cached 缓冲的交换区总量第五行(Swap):表示类别同第四行(Mem),但此处反映着交换分区(Swap)的使用情况。
内存数据库eXtremeDB介绍

eXtremeDB:多线程、多进程支持
常规内存中创建多线程eXtremeDB 共享内存中创建多进程eXtremeDB
eXtremeDB:各种数据类型支持
整数、实数、字符、字符串 Blob、数组、Vector
Vector:单字段嵌套表
日期、时间、AutoID、Ref
ref相当于常规数据库的外键
结构
eXtremeDB: 为各行各业的实时数据管理而在
全世界数千家用户采用 eXtremeDB管理实时数据
eXtremeDB:微秒级实时数据库
数据库建立在主内存中, 程序可以直接使用,数据 库操作的速度以微秒计 静态内存分配及定制的 API缩短了代码执行路径, 既加快的时间反应性能, 更提高系统强壮性 应用程序直接以库的形 式使用eXtremeDB,剔除 了进程间通信的开销
安全的实时数据管理
eXtremeDB提供API save()/load()数据库影 像 NVRAM中建立内存库 eXtremeLog提供交易一 级的数据安全保障机制 eXtremeDB Fusion:内 存/磁盘混合数据库 eXtremeHA多模式容灾
加载
保存
保存
加载
安全的实时数据管理:NVRAM 支持
驻留交易
一个eXtremeDB节点上驻留 易,其它节点调用驻留交易, 快速访问eXtremeDB
eXtremeSQL Server Engine
一个节点创建SQL Server Engine, 其它节点作为 Client访eXtremeDB
ODBC
通过eXtremeSQL之ODBC接口访 问本地和远程eXtremeDB数据库
uint4 string Table-2 oid S_ID
[linux下查看cpu内存硬盘等硬件信息的方法]linuxcpu内存硬盘
![[linux下查看cpu内存硬盘等硬件信息的方法]linuxcpu内存硬盘](https://img.taocdn.com/s3/m/f3b8aa0e78563c1ec5da50e2524de518964bd356.png)
[linux下查看cpu内存硬盘等硬件信息的方法]linuxcpu内存硬盘linux下查看cpu内存、硬盘等硬件信息的方法一、linuxCPU大小其实应该通过PhysicalProcessorID来区分单核和双核。
而PhysicalProcessorID可以从cpuinfo或者dmesg中找到.flags如果有ht说明支持超线程技术判断物理CPU的个数可以查看physicalid的值,相同则为同一个物理CPU可以看到上面,这台机器有两个双核的CPU,ID分别是0和3,大小是2.8G。
二、内存大小uname-a#查看内核/操作系统/CPU信息的linux系统信息命令head-n1/etc/issue#查看操作系统版本,是数字1不是字母Lcat/proc/cpuinfo#查看CPU信息的linux系统信息命令hostname#查看计算机名的linux系统信息命令lspci-tv#列出所有PCI设备lsusb-tv#列出所有USB设备的linux 系统信息命令lsmod#列出加载的内核模块env#查看环境变量资源free-m#查看内存使用量和交换区使用量df-h#查看各分区使用情况du-sh#查看指定目录的大小grepMemTotal/proc/meminfo#查看内存总量cat/proc/loadavg#查看系统负载磁盘和分区mount|column-t#查看挂接的分区状态fdisk-l#查看所有分区swapon-s#查看所有交换分区hdparm-i/dev/hda#查看磁盘参数(仅适用于IDE设备)dmesg|grepIDE#查看启动时IDE设备检测状况网络ifconfig#查看所有网络接口的属性iptables-L#查看防火墙设置route-n#查看路由表netstat-lntp#查看所有监听端口netstat-antp#查看所有已经建立的连接netstat-s#查看网络统计信息进程ps-ef#查看所有进程top#实时显示进程状态用户w#查看活动用户id#查看指定用户信息last#查看用户登录日志cut-d:-f1/etc/passwd#查看系统所有用户cut-d:-f1/etc/group#查看系统所有组crontab-l#查看当前用户的计划任务服务chkconfig–list#列出所有系统服务chkconfig–list|grepon#列出所有启动的系统服务程序rpm-qa#查看所有安装的软件包cat/proc/cpuinfo:查看CPU相关参数的linux系统命令cat/proc/partitions:查看linux硬盘和分区信息的系统信息命令cat/proc/meminfo:查看linux系统内存信息的linux系统命令cat/proc/version:查看版本,类似uname-rcat/proc/ioports:查看设备io端口cat/proc/interrupts:查看中断cat/proc/pci:查看pci设备的信息cat/proc/swaps:查看所有swap分区的信息看了“linux下查看cpu内存、硬盘等硬件信息的方法”还想看:1.Linux系统如何查看cpu和内存信息2.Linux下查看CPU型号,内存大小,硬盘空间命令3.Linux中查看CPU的信息的方法是什么4.Linux怎么查看cpu内存系统参数5.linux中怎么查看硬件信息。
数据库性能报告

数据库性能报告1. 引言数据库是现代软件系统的核心组件之一,其性能对于系统的稳定运行和用户体验至关重要。
本报告旨在评估当前系统中数据库的性能,并提供改进建议。
2. 环境介绍在开始性能评估之前,我们首先介绍使用的数据库环境。
本次评估使用的是MySQL数据库,版本为8.0。
数据库运行在一台Linux服务器上,具有4核心CPU 和16GB内存。
数据库中存储了大约100万条数据,并且承载了系统的所有核心功能。
3. 性能指标评估数据库性能时,我们关注以下主要指标:3.1 响应时间响应时间是衡量用户请求在数据库上执行所需时间的指标。
较低的响应时间意味着更快的数据库性能,有利于提升用户体验。
3.2 吞吐量吞吐量表示数据库在单位时间内能够处理的请求数量。
较高的吞吐量意味着数据库可以更快地处理更多用户请求,提高系统的并发性能。
3.3 并发性能并发性能是指数据库在同时处理多个请求时的表现。
较高的并发性能意味着数据库可以更好地处理大量并发请求,降低系统响应时间的波动性。
4. 性能评估结果通过对数据库进行性能评估,我们得到以下结果:4.1 响应时间在评估期间,数据库的平均响应时间为200毫秒。
我们注意到在高峰期时,响应时间会有轻微增加,但整体上仍然在可接受范围内。
4.2 吞吐量数据库的吞吐量平均为每秒处理150个请求。
在高峰期,吞吐量会略有下降,但整体上仍然能够满足系统需求。
4.3 并发性能数据库表现出较好的并发性能,能够同时处理50个并发请求而不受到明显的性能影响。
在高负载情况下,数据库的并发性能会略微下降,但仍然能够保持相对稳定。
5. 性能问题与建议在评估期间,我们发现了一些潜在的性能问题,并提出以下改进建议:5.1 索引优化数据库中部分查询语句的执行时间较长,通过分析我们认为这是由于缺乏适当的索引所致。
建议对查询频率较高的字段进行索引优化,以提升查询性能。
5.2 查询调优某些查询语句的执行时间过长,可能是由于查询语句的逻辑不够优化导致的。
Linux系统数据库性能监控与分析

Linux系统数据库性能监控与分析随着科技的不断进步,数据库在企业和组织的信息管理中发挥着至关重要的作用。
随着数据库规模的不断扩大和复杂性的增加,保证数据库的高性能运行变得尤为重要。
本文将介绍Linux系统中数据库的性能监控与分析的相关内容,旨在帮助读者更好地了解和掌握监控和分析Linux数据库性能的方法和技巧。
一、性能监控的重要性数据库作为企业和组织中最重要的数据存储和处理工具,其性能直接影响到整个系统的运行效率和稳定性。
因此,及时监控和分析数据库的性能指标是非常重要的。
通过性能监控,可以实时了解数据库在不同时间段的负载情况、资源利用率、响应时间等指标,便于及时发现问题并进行优化和调整,以保证数据库能够以高效稳定的方式运行。
二、性能监控工具的选择在Linux系统中,有许多性能监控工具可供选择,其中一些是开源的且广泛应用的。
以下是一些常用的性能监控工具:1. SAR:系统活动报告(System Activity Reporter)是Linux系统中自带的一个监控工具,可用于收集和分析系统的各种性能指标,如CPU使用率、内存使用情况、网络流量等。
通过SAR,可以快速了解系统的整体运行情况,帮助发现潜在的性能瓶颈。
2. iostat:iostat是一个用于监控Linux系统IO性能的工具,可以提供各个硬盘分区的读写情况、IO等待时间、平均响应时间等指标,帮助发现磁盘IO问题。
3. vmstat:vmstat是一个用于监控Linux系统内存和CPU性能的工具,可以提供内存使用情况、虚拟内存情况、CPU上下文切换次数等指标,帮助发现内存和CPU相关的性能问题。
4. top:top是一个用于实时监控Linux系统进程和系统资源利用率的工具,可以提供各个进程的CPU使用率、内存使用情况等指标,以及系统整体的负载情况,帮助发现进程相关的性能问题。
以上这些工具只是其中的一部分,选择适合自己需求的工具,结合实际情况进行监控和分析。
第 9 章 嵌入式数据库程序设计

第9 章嵌入式数据库程序设计随着数据存储的快速发展,数据库应用的范围更加深入和具体。
那些仅适用于PC机、体积庞大、延时较长的数据库技术已不能满足针对性较强的嵌入式系统开发的需求。
而且随着嵌入式系统的内存和各种永久存储介质容量都在不断增加,嵌入式系统内数据处理量会不断增加,那么大量的数据如何处理问题变得非常现实。
一种全新的数据库产品——嵌入式数据库系统应运而生。
9.1 嵌入式数据库概述9.1.1 嵌入式数据库的内涵数据库的目标是实现对数据的存储、检索等功能。
传统的数据库产品除提供了基本的查询、添加、删除等功能外,也提供了很多高级特性,如触发器、存储过程、数据备份恢复等。
但实际上用到这些高级功能的时候并不多,应用中频繁用到的还是数据库的基本功能。
于是,在一些特殊的应用场合,传统的数据库就显得过于臃肿了。
在这种情况下,嵌入式数据库开始崭露头角。
嵌入式数据库是一种具备了基本数据库特性的数据文件,它与传统数据库的区别是:嵌入式数据库采用程序方式直接驱动,而传统数据库则采用引擎响应方式驱动。
嵌入式数据库的体积通常都很小,这使得嵌入式数据库常常应用在移动设备上。
由于性能卓越,所以在高性能的应用上也经常见到嵌入式数据库的身影。
嵌入式数据库的名称来自其独特的运行模式。
这种数据库嵌入到了应用程序进程中,消除了与客户机服务器配置相关的开销。
嵌入式数据库实际上是轻量级的,在运行时,它们需要较少的内存。
它们是使用精简代码编写的,对于嵌入式设备,其速度更快,效果更理想。
嵌入式运行模式允许嵌入式数据库通过 SQL 来轻松管理应用程序数据,而不依靠原始的文本文件。
嵌入式数据库还提供零配置运行模式,这样可以启用其中一个并运行一个快照。
在嵌入式系统中,对数据库的操作具有定时限制的特性,因而把应用于嵌入式系统的数据库系统称为嵌入式数据库系统或嵌入式实时数据库系统(ERTDBS)。
9.1.2 嵌入式数据库的特征嵌入式数据库和我们现在常见的企业级数据库有很大的区别。
linux下查看系统CPU内存硬盘使用情况

linux下查看系统CPU内存硬盘使用情况linux下查看系统CPU内存硬盘使用情况用'top -i' 看看有多少进程处于Running 状态,可能系统存在内存或I/O 瓶颈,用free 看看系统内存使用情况,swap 是否被占用很多,用iostat 看看I/O 负载情况...还有一种办法是ps -ef | sort -k7 ,将进程按运行时间排序,看哪个进程消耗的cpu时间最多。
top:主要参数d:指定更新的间隔,以秒计算。
q:没有任何延迟的更新。
如果使用者有超级用户,则top命令将会以最高的优先序执行。
c:显示进程完整的路径与名称。
S:累积模式,会将己完成或消失的子行程的CPU时间累积起来。
s:安全模式。
i:不显示任何闲置(Idle)或无用(Zombie)的行程。
n:显示更新的次数,完成后将会退出to显示参数:PID(Process ID):进程标示号。
USER:进程所有者的用户名。
PR:进程的优先级别。
NI:进程的优先级别数值。
VIRT:进程占用的虚拟内存值。
RES:进程占用的物理内存值。
SHR:进程使用的共享内存值。
S:进程的状态,其中S表示休眠,R表示正在运行,Z 表示僵死状态,N表示该进程优先值是负数。
%CPU:该进程占用的CPU使用率。
%MEM:该进程占用的物理内存和总内存的百分比。
TIME+:该进程启动后占用的总的CPU时间。
Command:进程启动的启动命令名称,如果这一行显示不下,进程会有一个完整的命令行。
top命令使用过程中,还可以使用一些交互的命令来完成其它参数的功能。
这些命令是通过快捷键启动的。
:立刻刷新。
P:根据CPU使用大小进行排序。
T:根据时间、累计时间排序。
q:退出top命令。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据使用内存大小进行排序。
W:将当前设置写入~/.toprc文件中。
这是写top配置文件的推荐方法。
Linux中CPU与内存性能监测
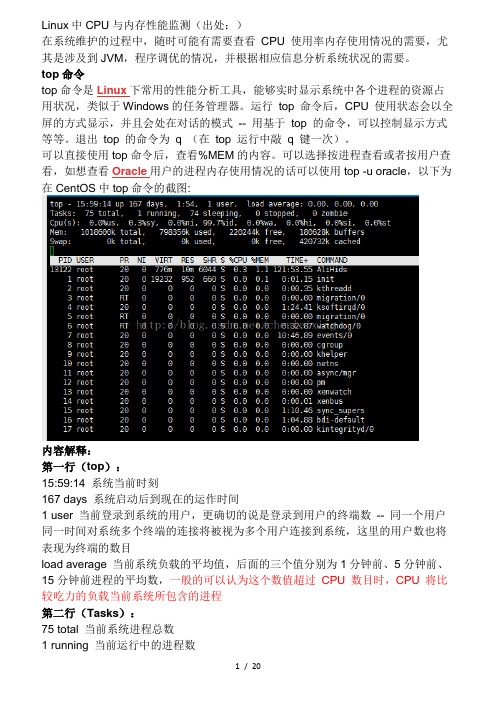
Linux中CPU与内存性能监测(出处:)在系统维护的过程中,随时可能有需要查看CPU 使用率内存使用情况的需要,尤其是涉及到JVM,程序调优的情况,并根据相应信息分析系统状况的需要。
top命令top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
运行top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式-- 用基于top 的命令,可以控制显示方式等等。
退出top 的命令为q (在top 运行中敲q 键一次)。
可以直接使用top命令后,查看%MEM的内容。
可以选择按进程查看或者按用户查看,如想查看Oracle用户的进程内存使用情况的话可以使用top -u oracle,以下为在CentOS中top命令的截图:内容解释:第一行(top):15:59:14 系统当前时刻167 days 系统启动后到现在的运作时间1 user 当前登录到系统的用户,更确切的说是登录到用户的终端数-- 同一个用户同一时间对系统多个终端的连接将被视为多个用户连接到系统,这里的用户数也将表现为终端的数目load average 当前系统负载的平均值,后面的三个值分别为1分钟前、5分钟前、15分钟前进程的平均数,一般的可以认为这个数值超过CPU 数目时,CPU 将比较吃力的负载当前系统所包含的进程第二行(Tasks):75 total 当前系统进程总数1 running 当前运行中的进程数74 sleeping 当前处于等待状态中的进程数0 stoped 被停止的系统进程数0 zombie 僵尸进程数第三行(Cpus):0.0% us 用户空间占用CPU百分比0.3% sy 内核空间占用CPU百分比0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比99.7% id 空闲CPU百分比0.0% wa 等待输入输出的CPU时间百分比0.0% hi0.0% si0.0% st第四行(Mem):1018600k total 物理内存总量798356k used 使用的物理内存总量220244k free 空闲内存总量180628k buffers 用作内核缓存的内存量Swap: 192772k total 交换区总量0k used 使用的交换区总量192772k free 空闲交换区总量123988k cached 缓冲的交换区总量第五行(Swap):表示类别同第四行(Mem),但此处反映着交换分区(Swap)的使用情况。
linux系统性能指标总结

性能指标总结性能指标总结 (1)1. 内存子系统 (8)1.1每秒种从交换分区中读入到物理内存中的数据量: (8)1.1.1指标含义 (8)1.1.2相关知识介绍 (8)1.1.3实现工具和方法 (9)1.1.4参考文献 (9)1.2每秒种从物理内存写入交换分区的数据量: (9)1.2.1指标含义 (9)1.2.2相关知识介绍 (10)1.2.3实现工具和方法 (10)1.2.4参考文献 (11)1.3系统每秒种产生的主内存页错误数量: (11)1.3.1指标含义 (11)1.3.2相关知识介绍 (11)1.3.3实现工具和方法 (12)1.3.4参考文献 (12)1.4系统每秒种放入空闲队列的内存页数量: (12)1.4.1指标含义 (12)1.4.2相关知识介绍 (13)1.4.3实现工具和方法 (14)1.4.4参考文献 (15)1.5 kswapd进程每秒钟扫描的内存页数量: (15)1.5.1指标含义 (15)1.5.2相关知识介绍 (15)1.5.3实现工具和方法 (16)1.5.4参考文献 (17)1.6系统每秒钟直接扫描的内存页数量: (17)1.6.1指标含义 (17)1.6.2相关知识介绍 (17)1.6.3实现工具和方法 (17)1.6.4参考文献 (18)1.7每秒种被清除用来满足内存需求的内存页数: (18)1.7.1指标含义 (18)1.7.2相关知识介绍 (19)1.7.3实现工具和方法 (19)1.7.4参考文献 (20)1.8内存页使用的效率: (20)1.8.1指标含义 (20)1.8.2相关知识介绍 (20)1.8.3实现工具和方法 (21)1.8.4参考文献 (22)1.9.3实现工具和方法 (22)1.9.4参考文献 (23)1.10已经使用的物理内存量: (23)1.10.1指标含义 (23)1.10.2相关知识介绍 (23)1.10.3实现工具和方法 (24)1.10.4参考文献 (25)1.11使用的物理内存占内存总量的百分比: (25)1.11.1指标含义 (25)1.11.2相关知识介绍 (25)1.11.3实现工具和方法 (25)1.11.4参考文献 (26)1.12内核用作buffer的物理内存量: (26)1.12.1指标含义 (26)1.12.2相关知识介绍 (26)1.12.3实现工具和方法 (27)1.12.4参考文献 (27)1.13内核用来缓存数据(cache)的物理内存量: (28)1.13.1指标含义 (28)1.13.2相关知识介绍 (28)1.13.3实现工具和方法 (28)1.13.4参考文献 (29)1.14空闲的交换分区: (29)1.14.1指标含义 (29)1.14.2相关知识介绍 (29)1.14.3实现工具和方法 (30)1.14.4参考文献 (30)1.15已经使用的交换分区: (30)1.15.1指标含义 (30)1.15.2相关知识介绍 (31)1.15.3实现工具和方法 (31)1.15.4参考文献 (32)1.16使用的交换分区占交换分区总量的百分比: (32)1.16.1指标含义 (32)1.16.2相关知识介绍 (32)1.16.3实现工具和方法 (33)1.16.4参考文献 (33)1.17交换分区中的缓存容量: (34)1.17.1指标含义 (34)1.17.2相关知识介绍 (34)1.17.3实现工具和方法 (34)1.17.4参考文献 (35)1.18系统每秒钟释放的内存页数-新分配的内存页数: (35)1.18.4参考文献 (36)1.19系统每秒钟分配的buffer内存页数-释放的buffer内存页数: (36)1.19.1指标含义 (36)1.19.2相关知识介绍 (37)1.19.3实现工具和方法 (37)1.19.4参考文献 (38)1.20系统每秒钟分配的cache内存页数-释放的cache内存页数: (38)1.20.1指标含义 (38)1.20.2相关知识介绍 (38)1.20.3实现工具和方法 (39)1.20.4参考文献 (39)1.21连续读操作内存子系统带宽: (39)1.21.1指标含义 (39)1.21.2相关知识介绍 (39)1.21.3实现工具和方法 (40)1.21.4参考文献 (42)1.22连续写操作内存子系统带宽: (42)1.22.1指标含义 (42)1.22.2相关知识介绍 (42)1.22.3实现工具和方法 (42)1.22.4参考文献 (44)1.23交叉读写内存子系统带宽: (44)1.23.1指标含义 (44)1.23.2相关知识介绍 (44)1.23.3实现工具和方法 (45)1.23.4参考文献 (46)1.24初始化一大块内存区域需要的时间: (46)1.24.1指标含义 (46)1.24.2相关知识介绍 (46)1.24.3实现工具和方法 (47)1.24.4参考文献 (48)1.25拷贝一大块内存区域需要的时间: (48)1.25.1指标含义 (48)1.25.2相关知识介绍 (48)1.25.3实现工具和方法 (49)1.25.4参考文献 (50)1.26内存读写: (50)1.26.1指标含义 (50)1.26.2相关知识介绍 (50)1.26.3实现工具和方法 (51)1.26.4参考文献 (53)2. 磁盘子系统 (54)2.1 IO等待时间: (54)2.1.4参考文献 (56)2.2平均队列长度: (56)2.2.1指标含义 (56)2.2.2相关知识介绍 (57)2.2.3实现工具和方法 (57)2.2.4参考文献 (59)2.3平均等待时间: (59)2.3.1指标含义 (59)2.3.2相关知识介绍 (59)2.3.3实现工具和方法 (60)2.3.4参考文献 (62)2.4每秒传输次数: (62)2.4.1指标含义 (62)2.4.2相关知识介绍 (62)2.4.3实现工具和方法 (63)2.4.4参考文献 (64)2.5每秒块读、写个数: (65)2.5.1指标含义 (65)2.5.2相关知识介绍 (65)2.5.3实现工具和方法 (65)2.5.4参考文献 (68)2.6每秒读、写字节数: (68)2.6.1指标含义 (68)2.6.2相关知识介绍 (68)2.6.3实现工具和方法 (69)2.6.4参考文献 (74)2.7 CPU使用率: (74)2.7.1指标含义 (74)2.7.2相关知识介绍 (74)2.7.3实现工具和方法 (74)2.7.4参考文献 (79)2.8吞吐量: (79)2.8.1指标含义 (79)2.8.2相关知识介绍 (79)2.8.3实现工具和方法 (80)2.8.4参考文献 (80)2.9磁盘活动时间百分比: (81)2.9.1指标含义 (81)2.9.2相关知识介绍 (81)2.9.3实现工具和方法 (81)2.9.4参考文献 (85)2.10服务时间: (85)2.10.1指标含义 (85)2.11平均I/O 数据尺寸: (88)2.11.1指标含义 (88)2.11.2相关知识介绍 (88)2.11.3实现工具和方法 (89)2.11.4参考文献 (91)2.12平均每秒钟事务数: (91)2.12.1指标含义 (91)2.12.2相关知识介绍 (91)2.12.3实现工具和方法 (91)2.12.4参考文献 (92)2.13每秒钟读、写扇区数: (93)2.13.1指标含义 (93)2.13.2相关知识介绍 (93)2.13.3实现工具和方法 (93)2.13.4参考文献 (94)3. 进程调度与通信子系统 (95)3.1上下文切换次数: (95)3.1.1指标含义 (95)3.1.2相关知识介绍 (95)3.1.3实现工具和方法 (96)3.1.4参考文献 (97)3.2运行队列长度: (97)3.2.1指标含义 (97)3.2.2相关知识介绍 (97)3.2.3实现工具和方法 (97)3.2.4参考文献 (98)3.3 CPU利用率: (99)3.3.1指标含义 (99)3.3.2相关知识介绍 (99)3.3.3实现工具和方法 (99)3.3.4参考文献 (101)3.4中断次数: (101)3.4.1指标含义 (101)3.4.2相关知识介绍 (101)3.4.3实现工具和方法 (102)3.4.4参考文献 (103)3.5系统平均负载: (103)3.5.1指标含义 (103)3.5.2相关知识介绍 (103)3.5.3实现工具和方法 (104)3.5.4参考文献 (105)3.6单位时间内创建进程的数量: (105)3.6.1指标含义 (105)3.7系统调用开销: (107)3.7.1指标含义 (107)3.7.2相关知识介绍 (107)3.7.3实现工具和方法 (108)3.7.4参考文献 (110)3.8信号处理延时: (110)3.8.1指标含义 (110)3.8.2相关知识介绍 (110)3.8.3实现工具和方法 (111)3.8.4参考文献 (111)3.9任务调度延时: (112)3.9.1指标含义 (112)3.9.2相关知识介绍 (112)3.9.3实现工具和方法 (113)3.9.4参考文献 (113)3.10管道读写速率: (114)3.10.1指标含义 (114)3.10.2相关知识介绍 (114)3.10.3实现工具和方法 (115)3.10.4参考文献 (115)3.11计算能力: (116)3.11.1指标含义 (116)3.11.2相关知识介绍 (116)3.11.3实现工具和方法 (116)3.11.4参考文献 (117)4. 网络子系统 (118)4.1单位时间发送/接收包数量: (118)4.1.1指标含义 (118)4.1.2相关知识介绍 (118)4.1.3实现工具和方法 (119)4.1.4参考文献 (122)4.2单位时间发送/接收数据量: (122)4.2.1指标含义 (122)4.2.2相关知识介绍 (122)4.2.3实现工具和方法 (122)4.2.4参考文献 (127)4.3丢包数/丢包百分比: (127)4.3.1指标含义 (127)4.3.2相关知识介绍 (127)4.3.3实现工具和方法 (128)4.3.4参考文献 (130)4.4网络抖动: (130)4.4.1指标含义 (130)4.5每秒冲突数: (132)4.5.1指标含义 (132)4.5.2相关知识介绍 (132)4.5.3实现工具和方法 (132)4.5.4参考文献 (133)4.6网卡缓存溢出: (133)4.6.1指标含义 (133)4.6.2相关知识介绍 (133)4.6.3实现工具和方法 (134)4.6.4参考文献 (134)4.7错误帧个数: (134)4.7.1指标含义 (134)4.7.2相关知识介绍 (135)4.7.3实现工具和方法 (136)4.7.4参考文献 (136)1. 内存子系统1.1每秒种从交换分区中读入到物理内存中的数据量:1.1.1指标含义使用交换分区的情况下,系统会将当前不使用的数据从内存中转移到交换分区中,当需要这些数据时再从交换分区读入内存中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Linux实时内存数据库eXtremeDB性能
eXtremeDB内存式实时数据库是专为诸如网路通信设备、自动化产品、控制系统、医疗仪器、航空航天、机顶盒、手机及PDA等各行各业管理实时数据而设计的一种数据管理技术。
自问世以来,eXtremeDB实时数据库得到了业界的大力欢迎,在包括波音公司的Apache直升机的Longbow雷达系统、F5网路公司的路由器、中国华东电网及华电集团的电力系统、华北电力大学、电力科学研究院、创建伟业公司的呼叫中心、Genesis Microchip/Philipps/DirectTV的机顶盒、Panasonic和Simens的手机,JVC最新便携式播放器等各个领域得到了广泛的应用。
eXtremeDB实时数据库成功帮助中国监测电网状态
华东成千上万的企业及家庭用户今后将拥有更加可靠的电力供应,因为电网中将有一种新型监测系统对电力系统的运行情况进行监测,而这个系统中的实时数据管理将由McObject公司发布的eXtremeDB内存式实时数据库来完成。
这种新型的监测系统就是由电力科学研究院研制的基于PMU的发电厂就地监测系统。
这种监测系统工作在发电厂,接收PMU采集的实时数据,对电网状态、尤其是关系电网稳定性的参数进行实时监视。
这些实时数据首先保存在本地化eXtremeDB实时数据库中,然后定时保存进历史数据库,以提供安全可靠的电力传输。
这种新型监测系统接收PMU内部数据的实时采集速度高达每秒100条。
“在大型电网中,系统故障蔓延速度非常之快,旧的安全设备根本来不及监测,更勿论阻止。
而新型基于PMU的监测系统速度大大地加快了,向操作员提前发出危险警报,让操作员有充分的时间排除故障。
这样就大大提高了电网的安全性。
”电科院资深工程师许勇先生说道。
在这种新型监测系统中,eXtremeDB运行于Red Hat Linux 9之上。
eXtremeDB在管理实时数据的优点和特点:
.产品系列完整。
McObject公司实时数据管理的eXtreme家族软件产品系列为您管理实时数据提供完整的解决方案,包括eXtremeDB内存式实时数据库、
eXtremeSQL提供SQL语言访问内存数据库接口、eXtremeHA提供安全高效的数据备份、eXtremeLog为您的交易建立日志、eXtremeWS为您提供通过Web方式管理/监控实时数据。
.功能特别全。
eXtremeDB将数据保存在内存中,在内存中建立数据结构,在数据结构上提供数据库API,这些API提供了通常只有在企业数据库上才有的各种数据管理功能,如表结构、交易管理、HASH索引、树索引、OID、Autoid、引用、历史版本、事件触发等。
在eXtremeDB的表中,不仅可以支持通常的简单数据,而且可以支持结构和矢量等等复杂数据。
.性能特别高。
由于数据是保存在内存中,因此,每次插入、检索、更新数据的操作都非常快。
通常,在400MHz的处理器上一个交易的时间只有1~2微秒。
这要比静态数据管理或常规数据库的性能要高很多。
.硬件要求特别低。
eXtremeDB在使用的时候,基本开销只有50K~100K尺寸;管理数据的效率高达70%~80%。
相比而言,Oracle等商业数据库或我们自己编写的数据管理软件,效率在10%~20%左右。
以我们为Genesis Microchip做的参考设计而言,管理152K个节目信息,包括标题索引、内容索引等诸多功能的数据库,占用内存的尺寸在8~9M左右。
在我们的EPG参考设计中,如果用400MHz的处理器,检索一个节目的时间机会感觉不到。
.开发非常方便。
eXtremeDB的数据库系统以C/C++的Library的形式提供给用户,与用户的程序无缝集成在一个运行程序之中。
开发过程流畅,使用非常方便。
eXtremeDB首先是实时数据库。
在Pentium 4/2.4GMHz的台式机上,eXtremeDB的插入速度可以达到微秒一级:
Insert ……………………100000 objects: 315 milliseconds,(3 microsecs/object)
Creating tree ………………100000 objects: 271 milliseconds (2 microsecs/object)
Hash search ………………100000 searches: 63 milliseconds (0 microsecs/search)
Tree search …………………100000 searches: 271 milliseconds (2 microsecs/search)
Sequential …………………100000 searches: 30 milliseconds (0 microsecs/search)
Removing the tree ………2 milliseconds
Search/delete ………………100000 objects: 321 milliseconds (3 microsecs/object)
eXtremeDB完全工作在主内存中,不基于文件系统,减少了诸如磁盘访问、文件I/O操作、缓存同步等开销,使得eXtremeDB的存取速度提高到极限;通过数据库定义语言面向应用系统定制的API使得eXtremeDB能够面向应用最优化;事件触发、字段优先级等特色使得eXtremeDB管理实时数据时具有确定性。
eXtremeDB根据用户需求定义的API使得eXtremeDB与应用程序无缝集成。
因此,eXtremeDB不仅在系统中嵌入,而且“嵌入”在应用程序中,是一种真正的嵌入式实时数据库。
在资源紧凑的系统中,eXtremeDB基本内存开销在60K到100K左右;对于大量实时数据需管理的情形,eXtremeDB最大一表格的记录总数可以达到2,147,483,647条。
eXtremeDB直观易用的,使您在零学习周期的情况下使用它管理实时数据。
不论是VxWorks、WinCE、嵌入式Linux还是UNIX、Solaris,eXtremeDB都能出色地进行数据管理。