深度优先遍历算法伪代码
2.1 算法的概念及描述 同步练习 2024-2025学年高中信息技术浙教版(2019)必修一

2.1 算法的概念及描述一、选择题1.算法的特征包括下列哪几项。
()A.有穷性B.复杂性C.可行性D.确定性2.在深度优先搜索中,我们首先访问一个节点,然后尽可能深地搜索其子节点,直到无法继续为止。
然后回溯到上一个节点,继续搜索其它子节点。
这种搜索策略的一个主要特点是它会深入探索任何一个分支。
请问,这种搜索策略通常用于解决哪类问题()A.寻找最短路径问题B.解决迷宫问题C.拓扑排序问题D.寻找最大公约数问题3.下列关于算法描述,正确的是()A.一个算法的执行步骤可以是无限的B.一个完整算法必须要有输入C.一个完整算法必须要有输出D.算法只能用流程图表示4.符号运算中的“蕴含”关系通常用哪个符号表示()A.∧B.∧C.→D.↔5.计算圆面积的算法可描述为∧输入圆半径r ,∧计算圆面积s=,∧输出结果s ,∧结束,这个算法属于()A.枚举算法B.排序算法C.递归算法D.解析算法6.计算机解决问题的步骤和方法是()A.编程B.分析C.算法D.抽象建模7.有关算法理解错误的是()A.算法必须要有数据的输出B.算法是计算机解决某一问题的方法,且需要使用某种方法进行精确地描述C.解决某一个实际问题的算法可以有无限个步骤D.算法的步骤不能出现歧义8.“洗衣机的洗衣流程”情境问题,洗衣机模拟人洗衣的过程,自动执行洗衣程序,节省了大量的人力,这主要归功于由算法控制的机器设备。
算法指在有限步骤内解决问题所使用的方法,从下图2的“洗涤算法”中,可以看出算法具有的特征是()图1图2A.无穷性B.单一性C.确定性D.繁琐性9.第一年有一头小母牛,每头小母牛从出生第四年起,每年生一头小母牛,按此规律,第10年时有()头母牛。
A.13B.15C.19D.2810.i=3:s=1/(i-3) 无法执行,原因是它违反了算法特征中的()A.有穷性B.唯一性C.可行性D.确定性11.某算法部分流程图如图所示,在流程图空白处填入一组代码,使输出结果sum与表达式“2-4+6-8+…-100”值相同的是()A.∧i=i+1 ∧k=-k*2B.∧k=-k ∧i=i+2C.∧i=i+2 ∧k=-k D.∧k=-k*2 ∧i=i+212.下列问题无法用算法具体描述的是()A.求所有自然数中5的倍数之和B.计算一元二次方程的根C.百鸡百钱问题D.随机产生10个50以内的自然数并按降序排列13.下列关于流程图描述算法说法正确的是()A.流程图直观易懂,但容易产生二义性B.流程图描述算法不直观、不清晰C.流程图必须包含一个判断框D.流程图中无须填写程序代码14.某算法流程图如下图所示,若输入k的值为5,以下说法正确的是()A.程序运行结束后,s的值是2B.循环体共执行了5次C.程序结束后,t的值为-1D.表达式i<k执行了5次15.下列关于“洗涤算法”的描述,错误的是()A.洗涤算法中的每一步洗衣机都能理解并正确执行,体现了算法的确定性B.洗衣任务完成,蜂鸣器发出鸣叫声,蜂鸣器鸣叫是一种输出C.洗衣机能在有限的时间里完成洗衣任务,体现了算法的有穷性D.在“快洗”模式中,进水时间、洗涤次数等都属于输入二、填空题16.为了确保算法的正确性,我们通常需要对算法进行,以验证其是否满足预期的功能要求。
迷宫问题算法

迷宫问题算法一、引言迷宫问题是一个经典的算法问题,对于寻找路径的算法有着广泛的应用。
迷宫是一个由通路和墙壁组成的结构,从起点出发,要找到通往终点的路径。
迷宫问题算法主要解决的是如何找到一条从起点到终点的最短路径。
二、DFS(深度优先搜索)算法深度优先搜索算法是迷宫问题求解中最常用的算法之一。
其基本思想是从起点开始,沿着一个方向不断向前走,当走到无法继续前进的位置时,回退到上一个位置,选择另一个方向继续前进,直到找到终点或者无路可走为止。
1. 算法步骤1.初始化一个空栈,并将起点入栈。
2.当栈不为空时,取出栈顶元素作为当前位置。
3.如果当前位置是终点,则返回找到的路径。
4.如果当前位置是墙壁或者已经访问过的位置,则回退到上一个位置。
5.如果当前位置是通路且未访问过,则将其加入路径中,并将其邻居位置入栈。
6.重复步骤2-5,直到找到终点或者栈为空。
2. 算法实现伪代码以下为DFS算法的实现伪代码:procedure DFS(maze, start, end):stack := empty stackpath := empty listvisited := empty setstack.push(start)while stack is not empty docurrent := stack.pop()if current == end thenreturn pathif current is wall or visited.contains(current) thencontinuepath.append(current)visited.add(current)for each neighbor in getNeighbors(current) dostack.push(neighbor)return "No path found"三、BFS(广度优先搜索)算法广度优先搜索算法也是解决迷宫问题的常用算法之一。
计算机基础自学算法伪代码

栈是一种后进先出的数据结构,递归算法可以利 用栈的特点实现,如斐波那契数列等。
数据结构与算法的选择原则
问题需求
01
根据问题的需求选择合适的数据结构和算法,以满足时间复杂
度和空间复杂度的要求。
数据特点
02
根据数据的特性选择合适的数据结构,如处理大量数据时选择
合适的数据存储方式。
实际应用场景
不同的数据结构适用于不同类型 的问题,选择合适的数据结构能 够更好地解决问题。
常见数据结构与算法的结合使用
1 2 3
数组与排序算法
数组是一种常见的数据结构,排序算法如冒泡排 序、插入排序等可以在数组上实现。
链表与图算法
链表适用于需要频繁插入和删除节点的场景,图 算法如广度优先搜索、深度优先搜索等可以在链 表上实现。
计算机基础自学算法 伪代码
目录
• 算法概述 • 基础算法 • 数据结构与算法关系 • 算法优化与复杂度分析 • 实践案例
01
算法概述
算法的定义与特性
定义
算法是一组明确的、有序的、有 限的步骤,用于解决某一问题或 完成某项任务。
特性
有穷性、确定性、可行性、输入 和输出。
算法的表示方法
自然语言
用文字描述算法步骤。
数成正比。
02
线性时间复杂度
算法的时间复杂度为O(n),表示算 法执行时间与输入规模n成正比。
04
多项式时间复杂度
算法的时间复杂度为O(n^k),其中 k为常数,表示算法执行时间与输
入规模n的k次方成正比。
空间复杂度分析
线性空间复杂度
算法的空间复杂度为O(n),表示算法所需 额外空间与输入规模n成正比。
算法设计与分析部分算法伪代码

第三章 蛮力法1.选择排序SelectionSort(A[0..n-1])for i=0 to n-2 domin=ifor j=i+1 to n-1 doif A[j]<A[min]min=jswap A[i] and A[min]2.冒泡排序BubbleSort(A[0..n-1])// 输入:数组A,数组中的元素属于某偏序集// 输出:按升序排列的数组Afor i=0 to n-2 dofor j=0 to n-2-i doif A[j+1]<A[j] swap A[j] and A[j+1]3.改进的冒泡算法ALGORITHM BubbleSortImproved( A[0,…,n –1] )// 冒泡排序算法的改进// 输入:数组A,数组中的元素属于某偏序集// 输出:按升序排列的数组Afor i ← 0 to n – 2 doflag ← Truefor j ← 0 to n – 2 – i doif A[j+1] < A[j]swap(A[j], A[j+1])flag ← False// 如果在某一轮的比较中没有交换,则flag为True,算法结束returnif flag = True4. 顺序查找算法算法 SwquentialSearch2(A[0...n],k)//顺序查找算法的实现,它用了查找键来作限位器//输入:一个n个元素的数组A和一个查找键K//输出:第一个值等于K的元素的位置,如果找不到这样的元素就返回 -1A[n]<--ki<--0while A[i]!=K doi<--i+1if i<n return iElse return -15. 蛮力字符串匹配算法 BruteForceStringMatch(T[0...n-1],P[0...m-1])//该算法实现了蛮力字符串匹配代表一段文本//输入:一个n个字符的数组T[0...n-1]// 一个m个字符的数组P[0..m-1]代表一个模式//输出:如果查找成功的话,返回文本的第一个匹配字串中第一个字符的位置, // 否则返回-1For i<--0 to n-m doj<--0While j<m and P[j]=T[i+j]doj<--i+1If j=m return ireturn -1合并排序最差Θ(nlog2n)快速排序最优Θ(nlog2n)最差Θ(n2)平均Θ(1.38nlog2n)选择排序 Θ(n2)冒泡排序 Θ(n2)插入排序最差Θ(n2)最优 Θ(n)平均 Θ(n2)第四章 分治法合并排序算法 MergeSort(A[0..n-1] )排序 // 递归调用mergesort来对数组 A[0...n-1]// 输入:一个可排序数组A[0..n-1]// 输出:非降序排列的数组A[0..n-1]if n > 1n/2 -1]copy A[0.. n/2 -1] to B[0..n/2 -1]copy A[ n/2 ..n-1] to C[0..MergeSort( B )MergeSort( C )Merge( B,C,A )两个数组合并的算法算法 Merge(B[0..p-1],C[0..q-1],A[0..p+q-1])//将两个有序数组合并成一个有序的数组和C[0...q-1]//输入:两个有序数组B[0...p-1]//输出:A[0..p+q-1]中已经有序存放了B和C中的元素 i=0,j=0,k=0;while i<p and j<q do≤C[j]if B[i]A[k]=B[i], i=i+1elseA[k]=C[j], j=j+1k=k+1if i=pcopy C[j..q-1] to A[k..p+q-1]elsecopy B[i..p-1] to A[0..p+q-1]快速排序算法QuickSort(A[l..r])// 使用快速排序法对序列或者子序列排序或者序列本身A[0..n-1]// 输入:子序列A[l..r]// 输出:非递减序列Aif l < rs ← Partition( A[l..r] )QuickSort( A[l..s-1] )QuickSort( A[s+1..r] )//s是中轴元素/基准点,是数组分区位置的标志实现分区的算法Partition( A[l..r] )// 输入:子数组A[l..r]// 输出:分裂点/基准点pivot的位置p ← A[l]i ← l; j ← r+1repeat≥ prepeat i ←i + 1until A[i]≤ prepeat j ← j – 1 until A[j]swap( A[i], A[j] )≥ juntil iswap( A[i], A[j] )swap( A[l], A[j] )return j折半查找BinarySearch( A[0..n-1], k )// 输入:已排序大小为n的序列A,待搜索对象k// 输出:如果搜索成功,则返回k的位置,否则返回-1 l=0,r=n-1;While l≤rmid= (l+r)/2if k = A[mid] return midelse if k < A[mid] r=m-1else l=m+1return -1Strassen矩阵Strassen方法M1=A11(B12-B22)M2=(A11+A12)B22M3=(A21+A22)B11M4=A22(B21-B11)M5=(A11+A22)(B11+B22)M6=(A12-A22)(B21+B22)M7=(A11-A21)(B11+B12)第五章 减治法插入排序ALGORITHM InsertionSort( A[0..n-1] )// 对给定序列进行直接插入排序// 输入:大小为n的无序序列A// 输出:按非递减排列的序列Afor i ← 1 to n-1 dotemp ← A[i]j ← i-1while j ≥ 0 and A[j] > temp doA[j+1] ← A[j]j ← j –1A[j+1] ←temp深度优先查找算法 BFS(G)//实现给定图的深度优先查找遍历//输入:图G=<V,E>//输出:图G的顶点,按照被DFS遍历第一次访问到的先后次序,用连续的整数标记,将V中的每个顶点标记为0,表示还“未访问”count =0//记录这是第几个访问的节点标记为 unvisitedmark each vertex with 0//∈ V dofor each vertex vif v is marked with 0dfs(v)dfs(v)//递归访问所有和v相连接的未访问顶点,然后按照全局变量count的值//根据遇到它们的先后顺序,给它们附上相应的数字count = count + 1mark v with countv dofor each vertexw adjacent toif w is marked with 0dfs(w)广度优先BFS(G)/实现给定图的深度优先查找遍历//输入:图G=<V,E>//输出:图G的顶点,按照被BFS遍历第一次访问到的先后次序,用连续的整数标记,将V中的每个顶点标记为0,表示还“未访问”count =0mark each vertex with 0for each vertex v∈ V dobfs(v)bfs(v)//递归访问所有和v相连接的未访问顶点,然后按照全局变量count的值//根据遇到它们的先后顺序,给它们附上相应的数字count = count + 1mark v with countinitialize queue with vwhile queue is not empty doa = front of queuefor each vertex w adjacent to a doif w is marked with 0count = count + 1mark w with countadd w to the end of the queueremove a from the front of the queue拓扑排序第六章 变治法Gauss消去法GaussElimination(A[1..n], b[1..n])// 输入:系数矩阵A及常数项 b// 输出:方程组的增广矩阵等价的上三角矩阵for i=1 to n doA[i][n+1] =b[i]for j= i+1 to n dofor k = i to n+1 do– A[i][k]*A[j][i]/A[i][i]A[j][k] = A[j][k]堆排序堆排序主要包括两个步骤:对于给定的数组构造相应的堆。
《算法概论》-伪代码

目录算法概论 (1)序言 (1)第一章 (2)乘法 (2)除法 (2)两数的最大公因数 (2)扩展 (2)RSA (3)第二章:分治算法 (3)整数相乘的分治算法 (3)递推式 (3)2.3合并排序 (3)第三章图的分解 (4)3.2.1寻找从给定顶点出发的所有可达顶点 (4)3.2.2 深度优先搜索 (4)第四章 (4)4.2、广度优先搜索 (4)4.4.1、dijkstra最短路径算法 (5)4.6.1、含有负边 (5)Bellman-Ford算法 (6)4.7、有向无环图的最短路径 (6)第五章贪心算法 (6)5.1 最小生成树 (6)算法概论序言Fibonacci数列:死板的算法:function Fib1(n)If n=0:return 0If n=1:return 1Return fib1(n-1)+fib1(n-2)(递归,很多计算是重复的,不必要)合理的算法:functionFib2(n)If n=0:return 0Create an array f[0…n]f[0]=0,f[1]=1fori=2…n:f[i]=f[i-1] + f[i-2]return f[n](随时存储中间计算结果,之后直接调用)大O符号:若存在常数c>0,使得f(n)<=c*g(n)成立,则f=O(g)。
f增长的速度慢于g。
第一章乘法:functionMultiply(x,y)If y=0:return 0z=multiply(x,y/2)//向下取整If y is even: //even---偶数return 2zelse:return x+2z除法:functionDivide(x,y)If x=0: return (q,r)=(0,0)(q,r)=divide( x/2 ,y) //向下取整q=2*q,r=2*rif x is odd:r=r+1if r>=y :r=r-y,q=q+1return (q,r)p22两数的最大公因数:function Euclid(a,b)if b=0: return areturn Euclid(b,a mod b)扩展:function extended-Euclide(a,b)if b=0: return (1,0,a)(x1,y1,d)=extended-Euclide(b,a mod b)retrun (y1,x1-a/b*y1,d)RSA:(X^e)^d ==X mod Nd=e^-1 mod(p-1)(q-1)N=pq第二章:分治算法整数相乘的分治算法:function multiply(x,y)input:n-bit positive integers x and youtput:their productif n=1:return xyxl,xr=leftmost n/2_^ ,rightmost n/2_v bits of x // _^表示向上取整,_v表示向下取整yl,yr=leftmost n/2_^ ,rightmost n/2_v bits of yp1=multiply(xl,yl)p2=multiply(xr,yr)p3=multiply(xl+xr,yl+yr)return p1*p2+(p3-p1-p2)*2^(n/2)+p22.2递推式:T(n)={ O(nd):d>logba|| O(n d *log n) :d=log b a|| O(n^(log b a)): d<log b a}2.3合并排序function mergersort(a[1…n])if n>1:return merge(mergesort( a[1…n/2]), a[n/2+1…n]))else:return afunction merge(x[1…k], y[1…L] )if k=0: return y[1…L]if L=0: return x[1…k]if x[1]<=y[1]:return x[1]&merge(x[2…k],y[1…L])else:return y[1]&merge( x[1…k], y[2…L] )第三章图的分解3.2.1寻找从给定顶点出发的所有可达顶点:procedure explore(G,v)input:G=(V,E) is a graph; v ∈Voutput:visited(u) is set to true for all nodes u reachable from vvisited(v)=trueprevisit(v)for each edge(v,u)∈E:if not visited(u):explore(u)postvisit(v)3.2.2 深度优先搜索:proceduredfs(G)for all v ∈V:visited(v)=falsefor all v∈V:if not visited(v):explore(v)线性化序列:对图深度优先搜索,取post的降序序列。
计算机学科专业基础综合数据结构-图(二)_真题-无答案

计算机学科专业基础综合数据结构-图(二)(总分100,考试时间90分钟)一、单项选择题(下列每题给出的4个选项中,只有一个最符合试题要求)1. 具有6个顶点的无向图至少应有______条边才能确保是一个连通图。
A.5 B.6 C.7 D.82. 设G是一个非连通无向图,有15条边,则该图至少有______个顶点。
A.5 B.6 C.7 D.83. 下列关于无向连通图特性的叙述中,正确的是______。
①所有顶点的度之和为偶数②边数大于顶点个数减1③至少有一个顶点的度为1A.只有① B.只有② C.①和② D.①和③4. 对于具有n(n>1)个顶点的强连通图,其有向边的条数至少是______。
A.n+1B.nC.n-1D.n-25. 下列有关图的说法中正确的是______。
A.在图结构中,顶点不可以没有任何前驱和后继 B.具有n个顶点的无向图最多有n(n-1)条边,最少有n-1条边 C.在无向图中,边的条数是结点度数之和 D.在有向图中,各顶点的入度之和等于各顶点的出度之和6. 对于一个具有n个顶点和e条边的无向图,若采用邻接矩阵表示,则该矩阵大小是______,矩阵中非零元素的个数是2e。
A.n B.(n-1)2 C.n-1 D.n27. 无向图的邻接矩阵是一个______。
A.对称矩阵 B.零矩阵 C.上三角矩阵 D.对角矩阵8. 从邻接矩阵可知,该图共有______个顶点。
如果是有向图,该图共有4条有向边;如果是无向图,则共有2条边。
A.9 B.3 C.6 D.1 E.5 F.4 G.2 H.09. 下列说法中正确的是______。
A.一个图的邻接矩阵表示是唯一的,邻接表表示也唯一 B.一个图的邻接矩阵表示是唯一的,邻接表表示不唯一 C.一个图的邻接矩阵表示不唯一,邻接表表示唯一 D.一个图的邻接矩阵表示不唯一,邻接表表示也不唯一10. 用邻接表存储图所用的空间大小______。
A.与图的顶点数和边数都有关 B.只与图的边数有关 C.只与图的顶点数有关 D.与边数的二次方有关11. 采用邻接表存储的图的深度优先搜索算法类似于二叉树的______,广度优先搜索算法类似于二叉树的层次序遍历。
大数据(单选)第三章

大数据(单选)第三章1. 1.设某顺序表中第一个元素的地址是se(下标从1开始),每个结点占m个单元,则第i个结点的地址为( )。
[单选题]A、 se+(i-1)×m(正确答案)B、 se+(i+1)×mC、 se+i×mD、 se-i×m2. 2.()是一种选优搜索法,又称为试探法,按选优条件向前搜索,以达到目标。
但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择。
[单选题]A、回溯法(正确答案)B、递归法C、分而治之法D、演绎法3. 3.在常用的问题解决方法中,一一列举出问题所有可能的解,并逐一检验每个可能解,采纳问题的真正解,抛弃非真正解的方法,我们称之为( )。
[单选题]A、算法B、解析算法C、归纳法D、枚举法(正确答案)4. 4.算法是对解题过程的精确描述,目前表示算法的工具主要有自然语言、流程图、伪代码和()等。
[单选题]A、程序设计语言(正确答案)B、汇编语言C、机器语言D、人工智能语言5. 5.以下叙述中,错误的是()。
[单选题]A、算法就是求解问题的方法和步骤B、算法可以用中文来描述C、算法必须在有限步内完成D、一个算法可以没有输出(正确答案)6. 6.造成下面三段论推理错误的原因是()。
所有的鸟都会飞 ,鸵鸟是鸟 ,所以鸵鸟会飞 [单选题]A、大前提(正确答案)B、小前提C、结论D、都不是7. 7.有A、,B两个充满水的杯子和一个空杯C,假设A、B、C三个杯的容量是相等的,现要求将A,B两个杯中的水互换,下面算法中正确的是()。
(B←A 表示将A中的水到入B中,其它类似) [单选题]A、B←A,A←B,C←AB、B←A,C←B,A←CC、C←A,A←B,B←C(正确答案)D、B←A,C←B,A←C8. 8.问题解决的过程大致可以划分为若干个阶段,其中首先要做的是()。
[单选题]A、总结评价B、分析问题C、提出假设D、发现问题(正确答案)9. 9.问题虽然有简单或复杂、具体或抽象之分,但每个问题都包含三个基本成分()。
基于Profile信息的连续性分析算法及其优化

作码的 WH R 结点 ,从其对 应的符号表 中获得元素大小、 IL 数组或指针名称 ,从操作码可 以获得其存取类型 ,每次数据 引用插桩对总插桩次数加 l 并 对该类 型的插桩计数加 1 作 , ,
图 3 w i 结构及 插桩位置示意 hr l
—
f r a hkdi o e c i n wn
kd / is / wn的 孩 子 结 点
一
级 ,这 些表示之 间通过 whrlw r i e 函数进 行翻译 降到 下一 层 lo 级表示 。 在编译框架 内,本文方法为获取循 环内数据 引用的连 续 性信息选择在循环优化(NO 模块之前进行插桩 ,如 图 3所 L ) 示 。插桩的位置不同 , 再结合 whr c hr f i2、w i2 模块在不同的 l l
[ srclOnte aio Opn 4c mplr a wok tip pr rp ssa loi m i a lmeth o t u u frn e n ls Abta t s f e6 o i  ̄ me r,hs a e o oe nag rh whc cni e n ecni o seeec ayi hb s e p t h mp t n r a s
图论之 Tarjan及其应用
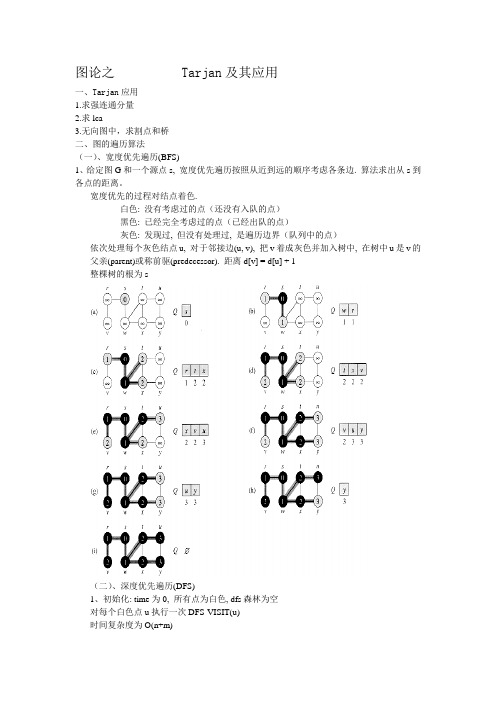
图论之 Tarjan及其应用一、Tarjan应用1.求强连通分量2.求lca3.无向图中,求割点和桥二、图的遍历算法(一)、宽度优先遍历(BFS)1、给定图G和一个源点s, 宽度优先遍历按照从近到远的顺序考虑各条边. 算法求出从s到各点的距离。
宽度优先的过程对结点着色.白色: 没有考虑过的点(还没有入队的点)黑色: 已经完全考虑过的点(已经出队的点)灰色: 发现过, 但没有处理过, 是遍历边界(队列中的点)依次处理每个灰色结点u, 对于邻接边(u, v), 把v着成灰色并加入树中, 在树中u是v的父亲(parent)或称前驱(predecessor). 距离d[v] = d[u] + 1整棵树的根为s(二)、深度优先遍历(DFS)1、初始化: time为0, 所有点为白色, dfs森林为空对每个白色点u执行一次DFS-VISIT(u)时间复杂度为O(n+m)2、伪代码三、DFS树的性质1、括号结构性质对于任意结点对(u, v), 考虑区间[d[u], f[u]]和[d[v], f[v]], 以下三个性质恰有一个成立: 完全分离u的区间完全包含在v的区间内, 则在dfs树上u是v的后代v的区间完全包含在u的区间内, 则在dfs树上v是u的后代2、定理(嵌套区间定理):在DFS森林中v是u的后代当且仅当d[u]<d[v]<f[v]<f[u], 即区间包含关系. 由区间性质立即得到。
四、边的分类1、一条边(u, v)可以按如下规则分类树边(Tree Edges, T): v通过边(u, v)发现后向边(Back Edges, B): u是v的后代前向边(Forward Edges, F): v是u的后代交叉边(Cross Edges, C): 其他边,可以连接同一个DFS树中没有后代关系的两个结点, 也可以连接不同DFS树中的结点。
判断后代关系可以借助定理12、算法当(u, v)第一次被遍历, 考虑v的颜色白色, (u,v)为T边灰色, (u,v)为B边(只有它的祖先是灰色)黑色: (u,v)为F边或C边. 此时需要进一步判断d[u]<d[v]: F边(v是u的后代, 因此为F边)d[u]>d[v]: C边(v早就被发现了, 为另一DFS树中)时间复杂度: O(n+m)定理: 无向图只有T边和B边(易证)3、实现细节if (d[v] == -1) dfs(v); //树边, 递归遍历else if (f[v] == -1) show(“B”); //后向边else if (d[v] > d[u]) show(“F”); // 前向边else show(“C”); // 交叉边注:d(入栈时间戳)和f 数组(出栈时间戳)的初值均为-1, 方便了判断四、强连通图1、在有向图G 中,如果两点互相可达,则称这两个点强连通,如果G 中任意两点互相可达,则称G 是强连通图。
中国地图四色染色问题

中国地图四色染色问题一、问题描述将中国地图用四种不同的颜色红、蓝、绿、黄来染色,要求相邻的省份染色不同,有多少种不同的方案?二、问题分析本文将中国地图的34个省、直辖市、自治区、以及特别行政区转化为图论中的图模型。
其中每个省、市、自治区、特别行政区用图中的一个结点表示,两个结点间联通仅当两个板块接壤。
则问题转化为图论中的染色问题。
由于海南、台湾省不与其它任何省份相邻,所以如果除海南、台湾外如果有n种染色方法,那么加上海南和台湾省后,有4*4*n种染色方法。
下面考虑除海南和台湾后的32个结点的染色方法。
三、中国地图染色方法采用分开海南和台湾省的分析方法,一方面的原因是除海南和台湾后的32个结点,可以组成一个联通图,因为海南省和台湾省不和任何其它省份邻接。
另一方面,我们建立一个联通图模型后,染色问题可以用深度优先遍历算法DFS,或者广度优先遍历算法BFS来解决,由于该方法的时间复杂度较高,属于暴力法,少考虑两个省份可以减少计算机处理此问题的时间。
本文采用DFS算法来解决这个染色问题。
3.1 DFS算法简介DFS算法是图的一种图的深度遍历算法,即按照往深的地方遍历一个图,若到一个分支的尽头,则原路返回到最近一个未被遍历的结点,继续深度遍历。
DFS遍历的具体步骤可为下:1)标记图中所有结点为“未访问”标记。
2)输出起始结点,并标记为“访问”标记3)起始结点入栈4)若栈为空,程序结束;若栈不为空,取栈顶元素,若该元素存在未被访问的邻接顶点,则输出一个邻接顶点,并置为“访问”状态,入栈;否则,该元素退出栈顶。
3.2 染色问题中的DFS算法设计我们先对任一结点染色,然后用DFS从该结点出发,遍历该图,遍历的下一结点颜色染为与之相邻的结点不同的颜色即可。
如果该结点无法染色则回到上一个结点重新染色,直到所有的结点都被染色即可。
最后统计染色种数。
染色问题的算法伪代码可以描述如下:color_DFS(当前染色结点):for i in 所有颜色{ while j的已染色邻接点if 结点j相邻接点被染成i颜色标记并breakif 未被标记{当前结点染为i色if 当前结点为最后一个结点endelsecolor_DFS(next)}}3.3 数据结构设计为了实现DFS染色算法,我们需要设计相应的数据结构。
深度优先遍历算法和广度优先遍历算法实验小结

深度优先遍历算法和广度优先遍历算法实验小结一、引言在计算机科学领域,图的遍历是一种基本的算法操作。
深度优先遍历算法(Depth First Search,DFS)和广度优先遍历算法(Breadth First Search,BFS)是两种常用的图遍历算法。
它们在解决图的连通性和可达性等问题上具有重要的应用价值。
本文将从理论基础、算法原理、实验设计和实验结果等方面对深度优先遍历算法和广度优先遍历算法进行实验小结。
二、深度优先遍历算法深度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,沿着一条路径一直向前直到不能再继续前进为止,然后退回到上一个节点,尝试下一个节点,直到遍历完整个图。
深度优先遍历算法通常使用栈来实现。
以下是深度优先遍历算法的伪代码:1. 创建一个栈并将起始节点压入栈中2. 将起始节点标记为已访问3. 当栈不为空时,执行以下步骤:a. 弹出栈顶节点,并访问该节点b. 将该节点尚未访问的邻居节点压入栈中,并标记为已访问4. 重复步骤3,直到栈为空三、广度优先遍历算法广度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,先访问起始节点的所有相邻节点,然后再依次访问这些相邻节点的相邻节点,依次类推,直到遍历完整个图。
广度优先遍历算法通常使用队列来实现。
以下是广度优先遍历算法的伪代码:1. 创建一个队列并将起始节点入队2. 将起始节点标记为已访问3. 当队列不为空时,执行以下步骤:a. 出队一个节点,并访问该节点b. 将该节点尚未访问的邻居节点入队,并标记为已访问4. 重复步骤3,直到队列为空四、实验设计本次实验旨在通过编程实现深度优先遍历算法和广度优先遍历算法,并通过对比它们在不同图结构下的遍历效果,验证其算法的正确性和有效性。
具体实验设计如下:1. 实验工具:使用Python编程语言实现深度优先遍历算法和广度优先遍历算法2. 实验数据:设计多组图结构数据,包括树、稠密图、稀疏图等3. 实验环境:在相同的硬件环境下运行实验程序,确保实验结果的可比性4. 实验步骤:编写程序实现深度优先遍历算法和广度优先遍历算法,进行多次实验并记录实验结果5. 实验指标:记录每种算法的遍历路径、遍历时间和空间复杂度等指标,进行对比分析五、实验结果在不同图结构下,经过多次实验,分别记录了深度优先遍历算法和广度优先遍历算法的实验结果。
深度优先搜索算法

深度优先搜索算法深度优先搜索算法是一种经典的算法,它在计算机科学领域中被广泛应用。
深度优先搜索算法通过沿着一个分支尽可能的往下搜索,直到搜索到所有分支的末端后,返回上一层节点,再继续往下搜索其它分支。
在搜索过程中,深度优先搜索算法采用递归的方式进行,它的工作原理与树的先序遍历算法相似。
本文将介绍深度优先搜索算法的基本原理、应用场景、实现方式及其优缺点等内容。
一、深度优先搜索算法的基本原理深度优先搜索算法是一种基于贪心法的搜索算法,它的目标是在搜索过程中尽可能的向下搜索,直到遇到死路或者找到了目标节点。
当搜索到一个节点时,首先将该节点标记为已访问。
然后从它的相邻节点中选择一个未被访问过的节点继续搜索。
如果没有未被访问过的节点,就返回到前一个节点,从该节点的其它相邻节点开始继续搜索。
这样不断地递归下去,直到搜索到目标节点或者搜索完所有的节点。
深度优先搜索算法的实现方式通常是通过递归函数的方式进行。
假设我们要搜索一棵树,从根节点开始进行深度优先搜索。
可以采用以下的伪代码:```function depthFirstSearch(node)://标记节点为已访问node.visited = true//递归搜索该节点的相邻节点for each adjacentNode in node.adjacentNodes:if adjacentNode.visited == false:depthFirstSearch(adjacentNode)```这段代码表示了深度优先搜索算法的基本思想。
在搜索过程中,首先将当前节点标记为已访问,然后递归搜索该节点的相邻节点。
如果相邻节点未被访问过,就以该节点为起点继续深度优先搜索。
通过递归函数不断往下搜索,最终遍历完整棵树。
二、深度优先搜索算法的应用场景深度优先搜索算法在计算机科学领域中有很多应用,例如图论、路径查找、迷宫和游戏等领域。
下面介绍一些具体的应用场景。
1.图论深度优先搜索算法被广泛应用于图论中。
二叉树两节点的最短距离

二叉树两节点的最短距离二叉树中两个节点的最短距离,指的是这两个节点之间经过的边的数量最少。
我们可以使用深度优先搜索(DFS)来解决这个问题。
具体的解题思路如下:1. 首先判断两个节点是否存在于树中,若其中一个节点不存在,则返回-1。
2. 如果两个节点相等,则它们之间的最短距离为0。
3. 否则,求出从根节点到这两个节点的路径长度,并分别保存在路径1和路径2中。
4. 对路径1和路径2进行遍历,找到它们的最近公共祖先节点。
假设最近公共祖先节点为LCA(Lowest Common Ancestor)。
5. 计算节点1到LCA的距离和节点2到LCA的距离,将这两个距离相加,即为节点1和节点2之间的最短距离。
下面是用伪代码表示的具体实现过程:```function findShortestDistance(root, node1, node2):if root is null or node1 is null or node2 is null:return -1if node1 == node2:return 0path1 = findPath(root, node1) # 从根节点到节点1的路径 path2 = findPath(root, node2) # 从根节点到节点2的路径if path1 is null or path2 is null:return -1lca = findLowestCommonAncestor(path1, path2) # 最近公共祖先节点distance1 = calculateDistance(path1, lca) # 节点1到最近公共祖先节点的距离distance2 = calculateDistance(path2, lca) # 节点2到最近公共祖先节点的距离return distance1 + distance2function findPath(root, target):if root is null:return nullif root == target:return [root]leftPath = findPath(root.left, target)rightPath = findPath(root.right, target)if leftPath is not null:leftPath.append(root)return leftPathif rightPath is not null:rightPath.append(root)return rightPathreturn nullfunction findLowestCommonAncestor(path1, path2):node = nullindex1 = length(path1) - 1index2 = length(path2) - 1while index1 >= 0 and index2 >= 0:if path1[index1] != path2[index2]:breaknode = path1[index1]index1 = index1 - 1index2 = index2 - 1return nodefunction calculateDistance(path, target):distance = 0for node in path:distance = distance + 1if node == target:breakreturn distance```通过以上的算法,我们可以找到二叉树中任意两个节点之间的最短距离。
算法分析与设计伪代码大全

算法分析与设计伪代码大全在此,我们提供一个算法分析与设计伪代码的实现示例,包括常用的排序算法、查找算法、图算法等。
请注意,由于字数限制,下方的示例并不会涵盖所有可能的算法伪代码。
1.排序算法1.1 冒泡排序(Bubble Sort)```procedure bubbleSort(A: array of integers)for i from 0 to length(A) - 2for j from 0 to length(A) - i - 2if A[j] > A[j + 1] thenswap A[j] and A[j + 1]end ifend forend forend procedure```1.2 选择排序(Selection Sort)```procedure selectionSort(A: array of integers) for i from 0 to length(A) - 2smallestIndex = ifor j from i + 1 to length(A) - 1if A[j] < A[smallestIndex] thensmallestIndex = jend ifend forif smallestIndex != i thenswap A[i] and A[smallestIndex]end ifend forend procedure```1.3 插入排序(Insertion Sort)```procedure insertionSort(A: array of integers) for i from 1 to length(A) - 1key = A[i]j=i-1while j >= 0 and A[j] > keyA[j+1]=A[j]j=j-1end whileA[j + 1] = keyend forend procedure```2.查找算法2.1 顺序查找(Sequential Search)```function sequentialSearch(A: array of integers, target: integer): booleanfor i from 0 to length(A) - 1if A[i] = target thenreturn trueend ifend forend function```2.2 二分查找(Binary Search)```function binarySearch(A: array of integers, target: integer): booleanlow = 0high = length(A) - 1while low <= highmid = (low + high) / 2if A[mid] = target thenreturn trueelse if A[mid] < target thenlow = mid + 1elsehigh = mid - 1end ifend whileend function```3.图算法3.1 广度优先(Breadth-First Search)```procedure breadthFirstSearch(G: graph, startVertex: vertex) create empty queue Qcreate empty visited set Senqueue startVertex into Qadd startVertex to Swhile Q is not emptycurrent = dequeue Qprocess currentfor each neighbor of currentif neighbor is not in Sadd neighbor to Senqueue neighbor into Qend ifend forend whileend procedure```3.2 深度优先(Depth-First Search)```procedure depthFirstSearch(G: graph, startVertex: vertex) create empty visited set SdfsHelper(G, startVertex, S)end procedureprocedure dfsHelper(G: graph, currentVertex: vertex, visitedSet: set of vertices)add currentVertex to visitedSetprocess currentVertexfor each neighbor of currentVertexif neighbor is not in visitedSetdfsHelper(G, neighbor, visitedSet)end ifend forend procedure```这里提供的伪代码示例只是一部分常用算法的示例,你可以根据实际需要调整算法的实现。
强连通分量的三种算法

有向图中, u可达v不一定意味着v可达u. 相互可达则属于同一个强连通分量(S trongly Connected Component, SCC)最关键通用部分:强连通分量一定是图的深搜树的一个子树。
一、Kosaraju算法1. 算法思路基本思路:这个算法可以说是最容易理解,最通用的算法,其比较关键的部分是同时应用了原图G和反图GT。
(步骤1)先用对原图G进行深搜形成森林(树),(步骤2)然后任选一棵树对其进行深搜(注意这次深搜节点A能往子节点B走的要求是EAB存在于反图GT),能遍历到的顶点就是一个强连通分量。
余下部分和原来的森林一起组成一个新的森林,继续步骤2直到没有顶点为止。
改进思路:当然,基本思路实现起来是比较麻烦的(因为步骤2每次对一棵树进行深搜时,可能深搜到其他树上去,这是不允许的,强连通分量只能存在单棵树中(由开篇第一句话可知)),我们当然不这么做,我们可以巧妙的选择第二深搜选择的树的顺序,使其不可能深搜到其他树上去。
想象一下,如果步骤2是从森林里选择树,那么哪个树是不连通(对于GT来说)到其他树上的呢?就是最后遍历出来的树,它的根节点在步骤1的遍历中离开时间最晚,而且可知它也是该树中离开时间最晚的那个节点。
这给我们提供了很好的选择,在第一次深搜遍历时,记录时间i离开的顶点j,即numb[i] =j。
那么,我们每次只需找到没有找过的顶点中具有最晚离开时间的顶点直接深搜(对于GT来说)就可以了。
每次深搜都得到一个强连通分量。
隐藏性质:分析到这里,我们已经知道怎么求强连通分量了。
但是,大家有没有注意到我们在第二次深搜选择树的顺序有一个特点呢?如果在看上述思路的时候,你的脑子在思考,相信你已经知道了!!!它就是:如果我们把求出来的每个强连通分量收缩成一个点,并且用求出每个强连通分量的顺序来标记收缩后的节点,那么这个顺序其实就是强连通分量收缩成点后形成的有向无环图的拓扑序列。
为什么呢?首先,应该明确搜索后的图一定是有向无环图呢?废话,如果还有环,那么环上的顶点对应的所有原来图上的顶点构成一个强连通分量,而不是构成环上那么多点对应的独自的强连通分量了。