非抢占式优先级
非抢占式优先级调度算法

非抢占式优先级调度算法1. 简介非抢占式优先级调度算法是一种常用的进程调度算法,它根据进程的优先级来确定调度顺序。
在该算法中,每个进程被分配一个优先级,优先级高的进程会先被调度执行,而优先级低的进程则会被延后执行。
2. 算法原理非抢占式优先级调度算法的原理相对简单,主要包括以下几个步骤:1.初始化:为每个进程分配一个优先级,并将它们按照优先级的高低进行排序。
2.调度:根据优先级高低,依次选择优先级最高的进程进行执行,直到所有进程执行完毕。
3.更新优先级:在每个时间片结束后,根据一定的策略更新进程的优先级,以保证公平性和避免饥饿现象。
3. 算法实现3.1 进程优先级的确定进程优先级的确定可以根据进程的特性和重要程度来进行评估。
一般来说,重要性较高的进程应该被赋予较高的优先级,以确保其能够及时得到执行。
在具体实现中,可以根据进程的类型、紧急程度、资源需求等因素来确定优先级的权重。
3.2 进程调度顺序的确定在非抢占式优先级调度算法中,进程的调度顺序是根据优先级来确定的。
优先级高的进程会先被调度执行,而优先级低的进程则会被延后执行。
在实际实现中,可以使用一个优先队列来存储待调度的进程,每次选择优先级最高的进程进行执行。
3.3 进程优先级的更新为了保证公平性和避免饥饿现象,进程的优先级需要定期更新。
更新的策略可以根据具体需求来确定,常见的策略包括:•时间片轮转:每个进程执行一个时间片后,降低其优先级,使其他进程有机会得到执行。
•动态优先级调整:根据进程的运行状态和资源使用情况,动态调整进程的优先级,以平衡系统的整体性能。
4. 算法特点非抢占式优先级调度算法具有以下特点:1.简单易实现:算法原理简单,易于理解和实现。
2.公平性:优先级较低的进程也能够得到执行的机会,避免了饥饿现象的发生。
3.灵活性:可以根据具体需求选择不同的优先级更新策略,以适应不同的应用场景。
5. 应用场景非抢占式优先级调度算法适用于以下场景:1.实时系统:对于实时性要求较高的系统,可以根据任务的紧急程度来确定优先级,确保高优先级任务能够及时得到执行。
五章处理机管理CPUScheduling

调度期Dispatch Latency
事件
响应事件
中断 处理
调度周期
调度
时实进 程执行
对实时系统的要求
提供必要的调度信息
进程的就绪时间 进程开始执行截止时间和完成执行截止时间 进程处理所需时间 进程的资源要求 进程优先级
调度方式 具有快速响应外部中断的能力
实时调度算法
Real-Time Scheduling
2.多处理机操作系统的分类
本节所介绍的多处理机操作系统是指那些用来并行执 行用户的几个程序,以提高系统的吞吐率;或 并行操作 以提高系统可靠性的多处理操作系统。这种系统由共享公 共内存和外设的n(n>1)个 CPU组成。
从概念上说,在多处理机系统中的各进程的行为与在 单机系统下的行为相同。因此,对多处理机操作系统的要 求与对多道程序的批处理系统没有太多的区别。但是,多 处理环境下,进程可在各处理机间进行透明迁移,从而, 由进程上下文切换等带来的系统开销将使得多处理机操作 系统的复杂度大大增加。另外,由于多处理机系统并行地 执行用户的几个程序(进程),这又带来了多处理机条件 下的并发执行问题。
Performance
q large FIFO q small q must be large with respect to context switch,
otherwise overhead is too high.
Example of RR with Time Slice= 1 时间片为1时的例子
If there are n processes in the ready queue and the time slice is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once. No process waits more than (n-1)q time units.
优先级调算法

优先级调算法优先级调度算法是一种操作系统中常见的调度策略,它通过为每个任务分配不同的优先级来确定下一个应该执行的任务。
本文将介绍优先级调度算法的基本概念、特点及应用场景。
一、基本概念优先级调度算法是一种非抢占式调度策略,即在任务执行过程中,不会被其他任务抢占资源。
每个任务都被分配一个优先级,优先级越高的任务越先执行。
在优先级调度算法中,每个任务都可以通过提高或降低优先级来调整执行顺序。
二、特点1. 非抢占式调度策略优先级调度算法不会抢占正在执行的任务,因此可以避免一些不必要的冲突和竞争。
2. 高优先级任务优先执行高优先级的任务会先执行,可以保证紧急任务尽早得到执行,提高系统的响应速度。
3. 可以动态调整优先级优先级调度算法可以根据任务的实时情况动态调整优先级,以适应不同的应用场景。
三、应用场景1. 实时系统对于实时系统,对任务的响应速度要求非常高,因此优先级调度算法可以保证紧急任务尽快被执行。
2. 多任务处理系统在多任务处理系统中,需要对各个任务进行调度,以保证系统的高效运行。
优先级调度算法可以根据任务的优先级来确定下一个应该执行的任务,避免系统资源的浪费。
3. 多用户系统在多用户系统中,需要对各个用户的任务进行调度,以保证公平性和效率。
优先级调度算法可以根据用户的优先级来调度任务,保证每个用户都能够得到一定的资源分配。
四、总结优先级调度算法是一种常见的操作系统调度策略,它通过为每个任务分配不同的优先级来确定下一个应该执行的任务。
优先级调度算法具有非抢占式调度、高优先级任务优先执行、可以动态调整优先级等特点,常用于实时系统、多任务处理系统和多用户系统中。
优先权调度算法的类型

优先权调度算法的类型
1.非抢占式优先权调度算法:
非抢占式优先权调度算法是指一旦一个进程开始执行,其他进程无法抢占其CPU资源,直到该进程完成或主动释放CPU。
这种类型的优先权调度算法具有简单和易于实现的特点,但容易导致饥饿问题,即一些低优先级的进程可能永远无法执行。
2.抢占式优先权调度算法:
抢占式优先权调度算法允许进程在执行过程中被其他优先级更高的进程抢占CPU资源。
这种类型的优先权调度算法可以有效解决饥饿问题,但实现相对复杂,需要考虑进程状态保存和恢复的问题。
3.静态优先权调度算法:
静态优先权调度算法是在进程创建时就给予每个进程一个优先级,之后不再改变。
这种类型的优先权调度算法适用于优先级相对固定、难以变化的场景。
但是,静态优先权调度算法可能导致低优先级进程无法获得足够的CPU使用时间。
4.动态优先权调度算法:
动态优先权调度算法是根据一定规则和策略不断调整进程的优先级。
这种类型的优先权调度算法可以根据进程的行为和状态来调整优先级,有助于提高系统的性能和公平性。
5.多级队列优先权调度算法:
多级队列优先权调度算法将进程按优先级划分为多个队列,每个队列拥有不同的优先级范围。
进程首先进入最高优先级队列,只有在该队列中
没有可运行的进程时,才会调度下一个优先级较低的队列。
这种类型的优先权调度算法可以根据不同的优先级范围进行调度,提高系统的资源利用率和响应速度。
综上所述,优先权调度算法可以根据是否抢占、是否静态、是否动态以及是否多级队列来进行划分。
不同类型的优先权调度算法在不同的场景下有各自的优势和适用性,选择合适的算法可以提高系统的性能和用户体验。
非抢占式优先级算法例题

非抢占式优先级算法例题一、引言在计算机操作系统中,进程调度算法是核心部分,它负责合理地分配系统资源,使得各个进程能够高效地运行。
非抢占式优先级算法是进程调度算法中的一种,本文将详细介绍非抢占式优先级算法的基本概念、实例以及其在实际应用中的优缺点。
二、非抢占式优先级算法的基本概念1.定义非抢占式优先级算法是一种进程调度算法,其基本思想是:较高优先级的进程在等待较低优先级进程执行完毕后,才接过进程控制权执行。
2.特点非抢占式优先级算法具有以下特点:(1)较高优先级的进程不会被较低优先级的进程中断,必须等待较低优先级的进程执行完毕后才能执行。
(2)较低优先级的进程在执行过程中,如果有更高优先级的进程到来,也不会被抢占,必须等待当前进程执行完毕后,才能执行更高优先级的进程。
三、非抢占式优先级算法实例1.实例描述假设有一个进程P1,优先级为3;进程P2,优先级为2;进程P3,优先级为1。
现在三个进程同时启动,请根据非抢占式优先级算法进行调度。
2.算法实现根据非抢占式优先级算法,进程调度顺序应为:P1(优先级3)→ P2(优先级2)→ P3(优先级1)。
3.实例分析在这个例子中,进程P1优先级最高,首先执行。
当P1执行完毕后,进程P2优先级次之,接着执行。
同理,当P2执行完毕后,进程P3优先级最低,最后执行。
这种调度顺序保证了高优先级进程优先得到执行,符合非抢占式优先级算法的特点。
四、非抢占式优先级算法在实际应用中的优缺点1.优点非抢占式优先级算法的优点主要有:(1)保证了高优先级进程在低优先级进程之前得到执行,符合人们的认知习惯,易于理解和接受。
(2)在某些场景下,可以避免高优先级进程被低优先级进程频繁中断,提高系统性能。
2.缺点非抢占式优先级算法的缺点主要有:(1)低优先级进程可能会长时间占用系统资源,导致高优先级进程无法及时执行,影响系统响应速度。
(2)当高优先级进程数量较多时,低优先级进程可能长时间无法执行,导致系统资源浪费。
非抢占式优先级调度算法

非抢占式优先级调度算法
非抢占式优先级调度算法(Non-Preemptive Priority Scheduling Algorithm)是一种用于处理进程调度的算法。
该算法根据进
程的优先级来决定执行顺序,高优先级的进程先执行,低优先级的进程后执行。
与抢占式优先级调度算法不同的是,非抢占式优先级调度算法不会中断正在执行的进程,直到该进程完成或者发生某种阻塞事件。
非抢占式优先级调度算法的实现流程如下:
1. 每个进程都有一个优先级值,通常是一个整数,数值越小表示优先级越高。
2. 在算法开始前,根据每个进程的优先级值对进程进行排序,将优先级最高的进程排在最前面。
3. 从排序后的进程列表中选择优先级最高的进程开始执行。
4. 执行该进程直到完成或者发生某种阻塞事件。
5. 如果进程完成,从进程列表中移除该进程,继续选择下一个优先级最高的进程执行。
6. 如果进程发生某种阻塞事件,暂停该进程的执行,执行其他可以执行的进程,直到该进程的阻塞事件解除。
7. 重复步骤3到步骤6,直到所有进程都执行完毕。
非抢占式优先级调度算法的特点是简单且容易实现,适用于一些实时系统或者对响应时间要求较高的应用场景。
但是该算法存在优先级反转的问题,即优先级较低的进程可能因为被优先级较高的进程阻塞而无法执行,从而影响整个系统的性能。
为了解决这个问题,可以引入优先级继承或者优先级反转的机制。
非抢占式优先级算法

非抢占式优先级算法
非抢占式优先级算法是一种非抢占式,也就是说一个任务不会阻塞另一个任务,这里会使用先到先服务的原则。
在非抢占式优先级算法中,每个任务都会拥有自己的优先级,而系统会优先处理优先级最高的任务,同优先级的任务则根据先到先服务原则按序处理。
因为每个任务都不会被阻塞,所有无论任务的响应时间为多少,都能尽快响应。
优点:
1. 保证任务的公平性,每个任务都有相同的改进处理机会;
2. 不会出现饥饿现象,任务的优先级会根据用户需求而改变;
3. 高效灵活,执行效率很高,能在限定时间内执行完所有任务。
缺点:
1. 无法有效的控制状态转移,任务转移的效率低,需要大量的资源消耗;
2. 后到的任务不能得到任何优先级报酬,容易出现“老虎放大熊”的情况;
3. 可能发生失常,如果没有及时的处理,系统会占用大量的资源运行而无任何显著的改善,使整个系统变慢甚至失控。
非抢占式优先级调度算法

非抢占式优先级调度算法非抢占式优先级调度算法是一种常见的进程调度算法。
在该算法中,每个进程都被赋予一个优先级,优先级越高的进程被优先调度执行,优先级较低的进程被暂时放置在队列中等待执行。
非抢占式优先级调度算法的主要思想是通过不断选择优先级最高的进程来满足进程的优先级需求,从而提高系统的响应速度和执行效率。
该算法旨在保证高优先级进程的快速响应,同时尽可能减少低优先级进程的等待时间。
非抢占式优先级调度算法的实现可以采用两个主要的数据结构:就绪队列和阻塞队列。
就绪队列存储所有已经就绪并且等待执行的进程,而阻塞队列存储正在等待某种资源而无法执行的进程。
当一个进程完成执行或者进入阻塞状态时,算法从就绪队列中选择下一个优先级最高的进程进行执行。
非抢占式优先级调度算法的优点是可以充分利用系统的资源,并根据进程的优先级进行合理的调度。
同时,该算法实现简单,适用于多种操作系统和硬件平台。
然而,该算法也存在一些缺点。
首先,进程的优先级需要提前设定,这可能会导致一些优先级设置不当的问题。
其次,当一个优先级较高的进程一直处于运行状态时,可能会导致低优先级进程长时间等待,出现饥饿现象。
为了解决非抢占式优先级调度算法的一些缺点,可以采用动态优先级调度算法。
在动态优先级调度算法中,调度器会根据进程的运行情况和系统的负载情况动态地调整进程的优先级。
当一个进程运行时间过长或者频繁发生阻塞时,其优先级会逐渐降低,以便给其他进程提供更多的执行机会。
反之,进程的优先级也会随着运行时长的增加而提高,以保证长时间未执行的进程得到合理调度。
总之,非抢占式优先级调度算法是一种常见的进程调度算法,用于根据进程的优先级进行合理的调度。
该算法简单易实现,适用于多种操作系统和硬件平台。
然而,该算法也存在一些缺点,可以通过引入动态优先级调度算法来解决。
非抢占式高优先级调度算法

/*非抢占式高优先级调度算法(优先数越大级别越高)算法思想:在按进程达到时间由小到大的顺序输入进程信息后,先对其优先数进行排列,将最先到达的进程的到达时间设为开始时间,计算结束时间,然后对后面到达的时间与该进程的结束时间进行比较,如若小于该进程的结束时间,记录进程的个数,再对其优先数逐个进行比较,将优先数最大的提到前面,每次进程结束都要进行比较,得到执行序列,在依次输出结果*/#include<stdio.h>#define MAX 100struct hrfs{char name[10];float arrvitetime;float starttime;float servietime;float finishtime;int priority;//优先数int order;//进程执行次序int run_flag;//标记进程状态};hrfs p[MAX];int count;//排列到达时间//按到达时间与优先数计算执行序列void HRfs(){float temp_time=0;int i=0,j;int k,temp_count;int max_priority;max_priority=p[i].priority;j=1;while((j<count)&&(p[i].arrvitetime==p[j].arrvitetime)){if(p[j].priority>p[i].priority){max_priority=p[j].priority;i=j;}j++;}k=i;p[k].starttime=p[k].arrvitetime;//开始时间=达到时间p[k].finishtime=p[k].starttime+p[k].servietime;p[k].run_flag=1;temp_time=p[k].finishtime;p[k].order=1;temp_count=1;while(temp_count<count){max_priority=0;for(j=0;j<count;j++){//判断到达时间是否小于上一个进程的结束时间并且非处在运行状态if((p[j].arrvitetime<=temp_time)&&(!p[j].run_flag))//判断进程优先数是否大于最大优先数,如果大于,就将其值赋给max_priorityif(p[j].priority>max_priority){max_priority=p[j].priority;k=j;}}p[k].starttime=temp_time;p[k].finishtime=p[k].starttime+p[k].servietime;p[k].run_flag=1;temp_time=p[k].finishtime;temp_count++;p[k].order=temp_count;}}void input(){int i;printf("\n请输入进程名到达时间运行时间优先数,例如:a 0 100 1\n");for(i=0;i<count;i++){printf("进程%d的信息:",i+1);scanf("%s%f%f%d",p[i].name,&p[i].arrvitetime,&p[i].servietime,&p[i].priority);p[i].starttime=0;p[i].finishtime=0;p[i].order=0;p[i].run_flag=0;}}void print(){int i;float turn_round_time=0,f1,w=0;float right_turn_round_time;printf("\n-------------------------------进程完成信息------------------------------------\n");printf("进程名优先级达到时间运行时间开始时间结束时间周转时间带权周转时间运行次序\n");for(i=0;i<count;i++){f1=p[i].finishtime-p[i].arrvitetime;turn_round_time+=f1;right_turn_round_time=f1/p[i].servietime;w+=(f1/p[i].servietime);printf("%s %5d %10.2f %8.2f %8.2f %8.2f %8.2f %8.2f %8d\n",p[i].name,p[i].priority,p[i].a rrvitetime,p[i].servietime,p[i].starttime,p[i].finishtime,f1,right_turn_round_time,p[i].order);}printf("平均周转时间=%5.2f\n",turn_round_time/count);printf("平均带权周转时间=%5.2f\n",w/count);}void main(){printf("---------------------------非抢占式高优先级调度算法----------------------------\n");printf("进程个数:");scanf("%d",&count);input();HRfs();print();}。
非抢占式优先级算法例题

非抢占式优先级算法例题摘要:1.非抢占式优先级算法的基本概念2.非抢占式优先级算法的实现过程3.非抢占式优先级算法的应用场景4.非抢占式优先级算法的优缺点5.实例分析:非抢占式优先级算法在进程调度中的应用正文:一、非抢占式优先级算法的基本概念非抢占式优先级算法是一种操作系统中的进程调度算法,其主要特点是较高优先级的进程只有在较低优先级进程完成后才能获得CPU资源。
在这种算法中,进程的优先级是根据其到达时间、执行时间、截止时间等因素进行排序的。
二、非抢占式优先级算法的实现过程1.按照进程到达时间从小到大顺序输入进程信息。
2.对进程的优先级进行排序。
3.依次执行优先级最高的进程,直到完成或遇到阻塞。
4.当进程阻塞或完成时,重新评估剩余进程的优先级,并调整执行顺序。
三、非抢占式优先级算法的应用场景非抢占式优先级算法主要应用于需要考虑进程优先级的场景,例如操作系统、嵌入式系统等。
在这些系统中,进程的执行顺序对系统性能和资源利用率有很大影响,因此采用非抢占式优先级算法可以确保高优先级进程优先获得资源,提高系统的运行效率。
四、非抢占式优先级算法的优缺点优点:1.优先级高的进程能够获得优先执行,符合实时性和紧急性的需求。
2.算法实现简单,易于理解和管理。
缺点:1.低优先级进程可能会长时间得不到执行,导致系统响应速度较慢。
2.高优先级进程执行过程中,低优先级进程无法抢占资源,可能导致资源浪费。
五、实例分析:非抢占式优先级算法在进程调度中的应用以进程调度为例,假设有三个进程P1、P2、P3,它们的优先级分别为1、2、3,到达时间分别为1、2、3。
按照非抢占式优先级算法,进程执行顺序为P1、P2、P3。
在此过程中,P1优先执行,P2在P1完成后执行,P3在P2完成后执行。
总之,非抢占式优先级算法是一种实用的进程调度算法,在实际应用中需要根据具体场景权衡优先级和响应速度之间的关系。
非抢占式优先级调度算法

非抢占式优先级调度算法摘要:一、引言二、非抢占式优先级调度算法的定义及原理三、非抢占式优先级调度算法的应用场景四、非抢占式优先级调度算法的优缺点五、发展趋势与展望六、总结正文:一、引言在计算机系统中,进程调度是操作系统核心部分的重要组成部分。
非抢占式优先级调度算法是进程调度中的一种经典算法,它根据进程的优先级进行调度,确保高优先级的进程优先获得CPU资源。
本文将对非抢占式优先级调度算法进行详细介绍,包括其定义、原理、应用场景、优缺点以及发展趋势与展望。
二、非抢占式优先级调度算法的定义及原理非抢占式优先级调度算法是一种进程调度策略,其主要特点是高优先级的进程优先执行,低优先级的进程在有空闲CPU资源时才执行。
在该算法中,进程的优先级分为静态优先级和动态优先级两种。
静态优先级在进程创建时确定,动态优先级则根据进程运行过程中的需求进行调整。
非抢占式优先级调度算法的原理如下:1.操作系统维护一个进程优先级队列,队列中的进程按照优先级从高到低排列。
2.当CPU空闲时,从队列头部取出一个进程执行。
3.若高优先级进程正在执行,低优先级进程到达就绪状态,也不能抢占CPU资源,必须等待高优先级进程执行完毕后才能执行。
4.进程执行过程中,若优先级发生变化,可以根据新的优先级调整队列顺序。
三、非抢占式优先级调度算法的应用场景非抢占式优先级调度算法适用于对优先级要求较高的场景,例如实时操作系统、嵌入式系统等。
在这些系统中,实时性、可靠性要求较高,需要确保关键进程能够及时执行。
非抢占式优先级调度算法能够满足这些需求,提高系统的运行效率。
四、非抢占式优先级调度算法的优缺点优点:1.实时性较好,能确保高优先级进程及时执行。
2.资源利用率较高,低优先级进程在有空闲资源时可以执行。
3.实现简单,易于理解和管理。
缺点:1.可能导致低优先级进程长时间得不到执行,影响系统性能。
2.高优先级进程执行过程中,低优先级进程不能及时响应,可能导致实时性下降。
非抢占式优先级调度算法代码

非抢占式优先级调度算法代码非抢占式优先级调度算法是一种常见的调度算法,它根据任务的优先级来决定任务的执行顺序,具有较好的实时性和可靠性。
本文将详细介绍非抢占式优先级调度算法的代码实现。
一、算法原理非抢占式优先级调度算法是一种静态优先级调度算法,即每个任务在运行前就确定了其优先级。
该算法通过比较各个任务的优先级,确定下一个要执行的任务,并按照其任务执行时间进行排序。
当一个任务开始执行后,直到其完成或者被阻塞才会让出CPU。
二、代码实现以下为非抢占式优先级调度算法的代码实现:```#include <stdio.h>#include <stdlib.h>#define MAX_TASKS 10 // 最大任务数#define MAX_PRIORITY 5 // 最大优先级数typedef struct {int id; // 任务IDint priority; // 任务优先级int burst_time; // 任务执行时间} Task;Task tasks[MAX_TASKS]; // 保存所有任务int n_tasks = 0; // 当前总共有多少个任务void add_task(int id, int priority, int burst_time) { if (n_tasks >= MAX_TASKS) {printf("Error: Too many tasks!\n");exit(1);}tasks[n_tasks].id = id;tasks[n_tasks].priority = priority;tasks[n_tasks].burst_time = burst_time;n_tasks++;}void sort_tasks() {int i, j;Task temp;for (i = 0; i < n_tasks - 1; i++) {for (j = i + 1; j < n_tasks; j++) {if (tasks[i].priority < tasks[j].priority) { temp = tasks[i];tasks[i] = tasks[j];tasks[j] = temp;}}}}void run_task(Task task) {printf("Task %d is running...\n", task.id); int i;for (i = 0; i < task.burst_time; i++) {// 模拟任务执行}}void schedule() {int i;for (i = 0; i < n_tasks; i++) {run_task(tasks[i]);printf("Task %d is completed.\n", tasks[i].id);}}int main() {add_task(1, 5, 10); // 添加任务1,优先级为5,执行时间为10 add_task(2, 3, 5); // 添加任务2,优先级为3,执行时间为5 add_task(3, 4, 8); // 添加任务3,优先级为4,执行时间为8sort_tasks(); // 按照优先级排序schedule(); // 进行调度return 0;}```三、代码解释1. 定义结构体Task,包含任务的ID、优先级和执行时间。
非抢占式优先级算法例题

非抢占式优先级算法例题(最新版)目录一、非抢占式优先级算法的概念及特点二、非抢占式优先级算法的例题讲解1.优先数排列2.进程执行次序计算3.标记进程状态4.输出执行序列三、非抢占式优先级算法的实际应用及优势四、总结正文一、非抢占式优先级算法的概念及特点非抢占式优先级算法是一种操作系统中的进程调度算法,它根据进程的优先级来决定进程执行的顺序。
优先级高的进程先执行,优先级相同的进程按照到达时间先后执行。
这种算法的特点是进程执行顺序确定,不会发生抢占现象。
二、非抢占式优先级算法的例题讲解以下是一个非抢占式优先级算法的例题:假设有以下五个进程:进程 1:优先级为 3,到达时间为 1进程 2:优先级为 1,到达时间为 2进程 3:优先级为 2,到达时间为 3进程 4:优先级为 4,到达时间为 4进程 5:优先级为 3,到达时间为 5按照非抢占式优先级算法,进程执行顺序如下:1.优先级为 1 的进程 2 最先到达,所以进程 2 先执行。
2.优先级为 2 的进程 3 到达,因为优先级高于进程 4,所以进程 3 开始执行。
3.优先级为 3 的进程 1 和进程 5 到达,因为进程 1 的到达时间早于进程 5,所以进程 1 开始执行。
4.优先级为 4 的进程 4 开始执行。
以此类推,直到所有进程执行完毕。
三、非抢占式优先级算法的实际应用及优势非抢占式优先级算法在实际操作系统中得到了广泛的应用,主要优势如下:1.公平性:优先级高的进程优先执行,优先级相同的进程按照到达时间先后执行,保证了进程执行的公平性。
2.稳定性:进程执行顺序确定,不会发生抢占现象,使得系统运行更加稳定。
3.简单性:算法实现简单,易于理解和维护。
四、总结非抢占式优先级算法是一种公平、稳定且简单的进程调度算法。
它根据进程的优先级和到达时间来决定进程执行的顺序,从而保证了系统的正常运行。
最短作业优先(抢占和非抢占)
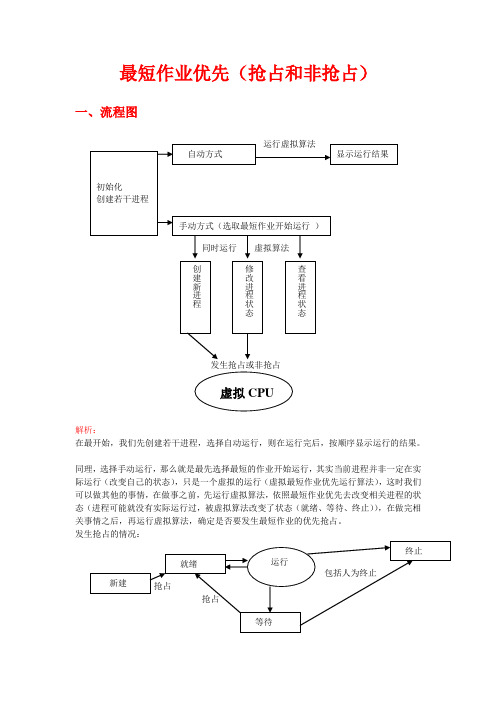
最短作业优先(抢占和非抢占)一、流程图解析:在最开始,我们先创建若干进程,选择自动运行,则在运行完后,按顺序显示运行的结果。
同理,选择手动运行,那么就是最先选择最短的作业开始运行,其实当前进程并非一定在实际运行(改变自己的状态),只是一个虚拟的运行(虚拟最短作业优先运行算法),这时我们可以做其他的事情,在做事之前,先运行虚拟算法,依照最短作业优先去改变相关进程的状态(进程可能就没有实际运行过,被虚拟算法改变了状态(就绪、等待、终止)),在做完相关事情之后,再运行虚拟算法,确定是否要发生最短作业的优先抢占。
根据以上的运行结构,我们可以在这结构的基础上,人为地设置进程状态就是改变进程状态,这时就可以发生最短作业调度的抢占和非抢占式。
我们可以进入查看进程状态,看看运行的状况,也可以进入修改进程状态,修改相关进程状态让其发生最短作业的抢占,或者进入创建进程,创建一个新的进程,这是也有可能实现最短作业优先的抢占。
二、虚拟运行算法:从进程的结构分析,进程里面有状态,到达时间(取系统时间),结束时间(取系统时间),需要运行时间,已运行时间等,我们知道第一个最短作业运行的到达时间(开始运行的时间)就是创建的时间。
在一个进程运行终止时,要设好终止的时间、改变状态等属性,这时进行进程间信息交换,终止进程的时间交给下一个要运行的进程的到达时间,这样不断下去就可以运行到最后一个进程,当发生抢占调度时,也是以上的情况运行。
先在抢占之前,就运行虚拟算法,改变相关的进程状态,发生引起抢占的事的时候就可以利用抢占来进行进程的切换。
这样就能让CPU在有工作做时就不能空闲。
直到把所有在就绪队列的进程运行完,这是CPU可以休息了,如果在CPU休息时有进程从等待进入就绪,那么CPU就要继续开工。
当我们运行完第一批输入的进程,现在CPU在空转,我们又创建了新进程,这时新进程就在创建那一刻起开始运行了,因为新进程创建好就进入了就绪的状态。
优先级 时间片轮转调度算法

优先级调度算法和时间片轮转调度算法是两种不同的操作系统进程或任务调度算法。
下面我将分别解释这两种算法:
1. 优先级调度算法:
优先级调度算法是一种非抢占式的调度算法,在这种算法中,每个进程被赋予一个优先级,调度器总是选择优先级最高的进程来执行。
如果多个进程具有相同的优先级,则可以按照FCFS (先进先出)的方式进行调度。
这种算法的优点是简单且易于实现,但可能导致某些进程长时间得不到执行,因此公平性较差。
2. 时间片轮转调度算法:
时间片轮转调度算法是一种抢占式的调度算法,在这种算法中,每个进程被分配一个时间片,当进程在执行过程中用完时间片后,调度器将剥夺该进程的CPU并分配给下一个等待的进程。
如果一个进程在时间片用完之前阻塞或完成,调度器将进行特殊处理。
这种算法的优点是公平性较好,每个进程都有机会获得执行,但实现起来相对复杂。
优先级调度算法和时间片轮转调度算法各有优缺点,适用于不
同的场景。
在实际应用中,操作系统通常会根据具体需求选择适合的调度算法。
非抢占式优先级调度算法

非抢占式优先级调度算法(最新版)目录一、非抢占式优先级调度算法概述二、非抢占式优先级调度算法的工作原理三、非抢占式优先级调度算法的例子四、非抢占式优先级调度算法的优点与不足五、结论正文一、非抢占式优先级调度算法概述非抢占式优先级调度算法是一种操作系统中用于进程调度的算法。
在这种算法中,进程根据分配给它们的优先级编号进行调度。
一旦进程被安排好了,它就会运行直到完成。
通常,优先级数越低,进程的优先级越高。
二、非抢占式优先级调度算法的工作原理非抢占式优先级调度算法的工作原理是,操作系统会根据进程的优先级编号来安排执行顺序。
优先级编号越低的进程,执行顺序越靠前。
在进程执行过程中,如果还有其他优先级更低的进程到达,那么操作系统会立即停止当前进程的执行,转而执行优先级更低的进程。
三、非抢占式优先级调度算法的例子为了更好地理解非抢占式优先级调度算法,我们可以通过一个例子来进行说明。
假设有 7 个进程,它们的优先级编号分别为 1、2、3、4、5、6、7。
根据非抢占式优先级调度算法,进程的执行顺序如下:1.进程 P1(优先级 2)在时间 0 到达,立即执行。
2.进程 P2(优先级 1)和进程 P3(优先级 3)同时到达,由于 P2的优先级高于 P3,所以操作系统先执行 P2,再执行 P3。
3.进程 P4(优先级 4)到达,由于其优先级低于 P3,所以 P4 在 P3 之后执行。
4.进程 P5(优先级 5)、进程 P6(优先级 6)和进程 P7(优先级 7)同时到达,由于它们的优先级都低于 P4,所以它们的执行顺序按照到达时间先后进行。
四、非抢占式优先级调度算法的优点与不足非抢占式优先级调度算法的优点是简单易懂,优先级设置合理时可以保证系统资源得到有效利用。
然而,它也存在一些不足,例如可能导致低优先级进程长时间等待高优先级进程完成,从而导致系统响应速度变慢。
五、结论非抢占式优先级调度算法是一种简单的进程调度算法,具有一定的优点,但同时也存在不足。
非抢占式多级反馈队列调度算法

非抢占式多级反馈队列调度算法非抢占式多级反馈队列调度算法是一种常用的进程调度算法,也是操作系统领域中非常经典和重要的一个概念。
在操作系统中,进程调度是指操作系统对进程进行选择和分配处理器的过程,而多级反馈队列调度算法是其中一种常见的调度策略。
一、多级反馈队列调度算法的基本原理1.1 多级反馈队列的设置多级反馈队列调度算法通过设置多个队列,每个队列具有不同的优先级,来实现对进程的调度。
一般来说,优先级高的队列具有更高的调度优先级,而优先级低的队列具有较低的调度优先级。
当一个进程到达系统时,首先被放入最高优先级的队列中,如果在一个时间片内没有执行完毕,则将其移动到优先级稍低的队列中,以此类推,直到进程执行完毕或者被放入最低优先级的队列中。
1.2 时间片的设定在多级反馈队列调度算法中,不同队列具有不同的时间片大小,一般来说,优先级高的队列具有较短的时间片,而优先级低的队列具有较长的时间片。
这样设计的好处是,能够兼顾高优先级进程的及时响应和低优先级进程的长时间执行。
1.3 调度策略多级反馈队列调度算法的核心在于其调度策略。
一般来说,即使在同一优先级的队列中,也采用先来先服务的策略,即按照进程到达的顺序进行调度。
而在不同优先级的队列之间,则按照各自的调度策略来执行。
二、多级反馈队列调度算法的实现在实际的操作系统中,多级反馈队列调度算法的实现需要考虑诸多因素。
首先是如何设置各个队列的优先级和时间片大小,需要根据具体的系统特点和需求来进行调整。
其次是如何具体实现调度策略,包括进程的进入队列和离开队列的条件、时间片的划分和分配等细节问题。
针对不同的操作系统,可能会有不同的实现方式和优化方法。
三、对非抢占式多级反馈队列调度算法的个人理解和观点在我看来,非抢占式多级反馈队列调度算法是一种非常灵活和高效的调度策略。
它能够兼顾到各个进程的优先级和执行时间,既能够保证高优先级进程的及时响应,又能够充分利用处理器资源,提高系统的整体吞吐量。
操作系统中的多核处理器调度算法比较

操作系统中的多核处理器调度算法比较随着计算机技术的发展和进步,多核处理器已经成为了当今计算系统的一种主流架构。
多核处理器的使用可以显著提高计算机的性能,但同时也带来了一些新的问题,例如如何合理地调度多核处理器上的任务,以最大化系统的吞吐量和响应速度。
为了解决这个问题,操作系统中涌现出了各种不同的多核处理器调度算法。
本文将比较几种常见的多核处理器调度算法,包括抢占式和非抢占式调度,静态和动态优先级调度等。
1. 抢占式调度算法抢占式调度算法是一种可被中断的调度算法,在多核处理器上能够及时响应高优先级任务的到来,并通过抢占低优先级任务的方式将CPU资源分配给高优先级任务。
常见的抢占式调度算法有最短作业优先(SJF)、最短剩余时间优先(SRTF)和最高响应比优先(HRRN)等。
SJF算法是基于任务执行时间的短暂程度作为调度依据,总是选择执行时间最短的任务进行调度。
这种算法能够最大程度地减少任务的等待时间和响应时间,但是对于长任务可能会导致其他任务的饥饿现象。
SRTF算法是SJF算法的改进版本,它在任务到达时动态地调整任务的执行顺序。
SRTF算法会检测当前正在执行的任务的剩余执行时间,如果新来的任务的剩余执行时间比当前执行的任务短,则中断当前任务并将CPU资源分配给新任务。
通过动态调整任务的执行顺序,SRTF 算法能够更好地响应新任务,但是也会引入一定的上下文切换开销。
HRRN算法是根据任务的等待时间和执行时间比值来做出调度决策。
该算法优先选择等待时间较长且执行时间较短的任务,以保证长任务不会饥饿其他任务。
2. 非抢占式调度算法非抢占式调度算法是一种不可被中断的调度算法,在多核处理器上,任务一旦分配到某个核心上,就会一直执行直至完成。
常见的非抢占式调度算法有先来先服务(FCFS)和轮转调度(Round Robin)等。
FCFS算法按照任务到达的先后顺序进行调度,即先到达的任务先执行。
这种算法简单易懂,但是当一个长任务到达时,会导致其他任务的等待时间过长,从而影响整个系统的响应速度。
非抢占式优先级算法例题

非抢占式优先级算法是一种常见的任务调度算法,它按照任务的优先级顺序依次执行任务,直到所有任务都完成或者没有任务可执行为止。
下面是一个非抢占式优先级算法的例题,以及相应的解答。
题目描述:假设有一个任务队列,包含n个任务,每个任务的优先级不同。
任务队列按照优先级从高到低的顺序排列。
现在要求实现一个非抢占式优先级调度算法,按照优先级顺序依次执行任务,直到所有任务都完成或者没有任务可执行为止。
算法实现:1. 初始化一个循环变量i,初始值为0;2. 每次从任务队列中取出优先级最高的任务,将其加入执行队列;3. 如果执行队列为空,则循环结束;否则继续执行步骤4;4. 将执行队列的第一个任务从队列中移除,将其标记为正在执行状态;5. 当任务执行完毕后,将其从正在执行状态切换回就绪状态;6. 如果队列中还有其他任务正在执行,则继续执行步骤4;否则循环结束。
时间复杂度分析:该算法的时间复杂度取决于任务队列的大小n以及执行队列的大小。
如果任务队列中只有一组数据,则算法的时间复杂度为O(n)。
如果任务队列中的数据量很大,则可以使用哈希表等数据结构来优化算法性能。
代码实现(使用Python语言):```pythonimport queueclass Task:def __init__(self, priority, task_id):self.priority = priorityself.task_id = task_idself.status = 'READY' # 任务状态,可以设置为READY、RUNNING、DONE等self.exec_time = 0 # 任务执行时间self.next = None # 指向下一个需要执行的任务class Scheduler:def __init__(self):self.tasks = [] # 任务队列,按照优先级从高到低排列self.exec_queue = queue.PriorityQueue() # 执行队列,按照优先级从低到高排列self.task_count = 0 # 当前任务数量self.running_tasks = [] # 正在执行的任务列表def add_task(self, task):self.tasks.append(task)task.status = 'READY' # 将任务状态设置为READYself.task_count += 1if self.task_count == 1: # 第一个任务加入时,将优先级最高的任务加入执行队列self.exec_queue.put(self.tasks[0])def run(self):while self.exec_queue.qsize() > 0: # 如果执行队列中有任务可执行task = self.exec_queue.get() # 取出优先级最低的任务加入执行队列中等待执行的任务加入等待执行的队列中等待执行的队列排在最前面位置最好的工作做好了放入任务前设置next属性为下一个要执行的task准备进行任务切换完成后退出run函数其他情况下跳过本次循环或者继续运行下次循环使用异步或并发等其他机制完成更多的功能来优化调度器效率如果有并发情况可以加锁确保同时只能有一个线程在运行run函数防止出现死锁等异常情况等其他情况处理机制等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题等其他细节问题添加上述额外信息能够丰富问题内容有助于获得更加准确的答案以及详细的解决方案以及解答针对上述代码的实现分析需要先检查以下要点并确认:以下代码的实现方式是否正确是否存在代码漏洞是否存在死锁情况以及其他错误问题的分析需要考虑:由于优先级是按照顺序处理的,如果有两个或更多具有相同优先级的任务应该如何处理?此外,代码中的部分内容需要根据实际需求进行调整和修改。
短作业优先调度算法

短作业优先调度算法SJF算法的核心思想是最短作业先执行,这样可以最大化利用CPU资源,减少平均等待时间和作业的响应时间。
它适用于批处理系统和交互式系统。
SJF算法的实现包括两种方式:非抢占式和抢占式。
非抢占式SJF算法:在非抢占式SJF算法中,一旦CPU开始执行一个作业,它会一直执行完毕,直到作业完成或者发生I/O请求。
当一个新的作业到达时,系统会比较该作业的执行时间和当前正在执行的作业的剩余执行时间,如果新作业的执行时间较短,则优先执行新作业。
抢占式SJF算法:在抢占式SJF算法中,一旦有一个新的作业到达,并且它的执行时间比当前正在执行的作业短,操作系统会暂停当前作业的执行,将CPU分配给新作业,等新作业执行完毕后再继续执行之前的作业。
抢占式SJF算法需要操作系统具备抢占能力,即能够中断并恢复作业的执行。
SJF算法的优点是可以最大化利用CPU资源,减少平均等待时间和作业的响应时间,适用于CPU密集型的作业。
然而,SJF算法也存在一些问题和局限性:1.预测执行时间的困难:在实际系统中,很难准确预测一个作业的执行时间,因此SJF算法可能会出现误判,导致等待时间增加。
2.饥饿问题:如果有大量的短作业不断到达,长作业可能会一直等待。
这种情况称为饥饿问题,长作业可能无法获取足够的CPU时间,导致低响应性。
3.处理I/O请求的处理:SJF算法无法解决I/O请求的调度问题,因此需要结合其他算法来处理。
为了解决SJF算法存在的问题,还发展了一些改进的版本,如最短剩余时间优先算法(Shortest Remaining Time First, SRTF),该算法在抢占式的基础上,可以在作业执行过程中切换到更短的作业,以进一步减少等待时间。
总结起来,SJF算法是一种重要的进程调度算法,它按照作业的执行时间来确定优先级。
它的优点是可以最大化利用CPU资源,减少等待时间和作业响应时间。
然而,它也存在预测执行时间困难、饥饿问题和无法解决I/O请求的问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
printf("\n-------------------------------------------------------------------------------\n");
printf("\n-------------------------------调度顺序----------------------------------------\n");
p[k].order=1;
temp_count=1;
while(temp_count<count){
max_priority=0;
for(j=0;j<count;j++){
//判断到达时间是否小于上一个进程的结束时间并且非处在运行状态
if((p[j].AT<=temp_time)&&(!p[j].flag))
}p[MAX];
int count;
//排列到达时间
//按到达时间与优先数计算执行序列
void P()
{
float temp_time=0;
int i=0,j;
int k,temp_count;
int max_priority;
max_priority=p[i].priority;
j=1;
while((j<count)&&(p[i].AT==p[j].AT)){
printf("进程名优先级到达时间运行时间开始时间结束时间周转时间\n");
for(i=0;i<count;i++){
f1=p[i].fT-p[i].AT;
turn_round_time+=f1;
printf("%s %5d %10.2f %8.2f %8.2f %8.2f %8.2f \n",p[i].name,p[i].priority,p[i].AT,p[i].RT,p[i].sT,p[i].fT,f1);
}
}
p[k].sT=temp_time;
p[k].fT=p[k].sT+p[k].RT;
p[k].flag=1;
temp_time=p[k].fT;
temp_count++;
p[k].order=temp_count;
}
}
void input()
{
int i;
printf("\n-------------------------------------------------------------------------------\n");
printf("\n-----------------------------平均周转时间--------------------------------------\n");
printf("平均周转时间=%5.2f\n",turn_round_time/count);
printf("\n-------------------------------------------------------------------------------\n");
printf("\n请输入进程名到达时间运行时间优先数,例如:a 0 100 1\n");
for(i=0;i<count;i++)
{
printf("进程%d的信息:",i+1);
scanf("%s%f%f%d",p[i].name,&p[i].AT,&p[i].RT,&p[i].priority);
非抢占式优先级
#include<stdio.h>
#define MAX 10
struct Process
{
char name[10];
float AT;
float sT;
float RT;
float fT;
int priority;//优先数
int order;//进程执行次序
int flag;//标记进程状态
p[i].sT=0;
p[i].fT=0;
p[i].order=0;
p[i].flag=0;
}
}
void print()
{
int i;
float turn_round_time=0,f1;
printf("\n-------------------------------进程完成信息------------------------------------\n");
if(p[j].priority>p[i].priority){
max_priority=p[j].priority;
i=j;
}
j++;
}
k=i;
p[k].sT=p[k].AT;//开始时间=达到时间
p[k].fT=p[k].sT+p[k].RT;
p[k].flag=1;
temp_time=p[k].fT;
//判断进程优先数是否大于最大优先数,如果大于,就将其值赋给max_priority
if(p[j].priority>max_priority){
max_priority=p[j].priority;
k=j;
}ቤተ መጻሕፍቲ ባይዱ
if(p[j].AT>temp_time)
{ k=j;
temp_time=p[j].AT;
printf("进程名运行次序\n");
for(i=0;i<count;i++){
printf("%s %8d\n",p[i].name,p[i].order);
}
printf("\n-------------------------------------------------------------------------------\n");
}
}
void main()
{
printf("---------------------------非抢占式优先级调度算法----------------------------\n");
printf("进程个数(不大于10):");
scanf("%d",&count);
input();
P();
print();