线性回归分析实验报告
线性回归分析实验报告

线性回归分析实验报告线性回归分析实验报告引言线性回归分析是一种常用的统计方法,用于研究因变量与一个或多个自变量之间的关系。
本实验旨在通过线性回归分析方法,探究自变量与因变量之间的线性关系,并通过实验数据进行验证。
实验设计本实验采用了一组实验数据,其中自变量为X,因变量为Y。
通过对这组数据进行线性回归分析,我们将得到回归方程,从而可以预测因变量Y在给定自变量X的情况下的取值。
数据收集与处理首先,我们收集了一组与自变量X和因变量Y相关的数据。
这些数据可以是实际观测得到的,也可以是通过实验或调查获得的。
然后,我们对这组数据进行了处理,包括数据清洗、异常值处理等,以确保数据的准确性和可靠性。
线性回归模型在进行线性回归分析之前,我们需要确定一个线性回归模型。
线性回归模型的一般形式为Y = β0 + β1X + ε,其中Y是因变量,X是自变量,β0和β1是回归系数,ε是误差项。
回归系数β0和β1可以通过最小二乘法进行估计,最小化实际观测值与模型预测值之间的误差平方和。
模型拟合与评估通过最小二乘法估计回归系数后,我们将得到一个拟合的线性回归模型。
为了评估模型的拟合程度,我们可以计算回归方程的决定系数R²。
决定系数反映了自变量对因变量的解释程度,取值范围为0到1,越接近1表示模型的拟合程度越好。
实验结果与讨论根据我们的实验数据,进行线性回归分析后得到的回归方程为Y = 2.5 + 0.8X。
通过计算决定系数R²,我们得到了0.85的值,说明该模型能够解释因变量85%的变异程度。
这表明自变量X对因变量Y的影响较大,且呈现出较强的线性关系。
进一步分析除了计算决定系数R²之外,我们还可以对回归模型进行其他分析,例如残差分析、假设检验等。
残差分析可以用来检验模型的假设是否成立,以及检测是否存在模型中未考虑的其他因素。
假设检验可以用来验证回归系数是否显著不为零,从而判断自变量对因变量的影响是否存在。
多重共线性回归分析及其实验报告

实验报告实验题目:多重共线性的研究指导老师:学生一:学生二:实验时间:2011 年10 月多重线性回归分析及其实验报告实验目的:为了更好地了解财政收入构成,需要定量地分析影响财政收入的因素模型设定及其估计:经分析,影响财政收入的主要因素,农业增加值X1,工业增加值X2,建筑业增加值X3,总人口X4,受灾面积X5.为此设定了如下形式的计量经济模型:丫= 1 + 2 X1+ 3 X2+ 4 X3+ 5 X4+ 6 X5+U0其中,丫为财政收入(元),X1农业增加值(元),X2为工业增加值(元),X3为建筑业增加值(元),X4为总人口(万人),X5为受灾面积(千公顷)为估计模型参数,收集佃78~2007年财政收入及其影响因素数据,如图:1978~2007年财政收入及其影响因素数据年份财政收入CS/亿元农业增加值NZ/亿元工业增加值GZ/亿元建筑业增加值JZZ/亿元总人口TPOP万人受火面积SZM千公顷1978 1132.3 1027.5 1607 138.2 96259 50790 1979 1146.6 1270.2 1769.7 143.8 97542 39370 1980 1159.9 1371.4 1996.5 195.5 98705 44526 1981 1175.8 1559.5 2048.5 207.1 100072 39790 1982 1212.3 1777.4 2162.3 220.7 101654 33130 1983 1367 1978.5 2375.8 270.6 103008 34710 1984 1642.5 2316.1 2789 316.7 104357 31890 1985 2004.6 2564.3 3448.5 417.9 105851 44365 1986 2122 2788.7 3987.5 525.7 107507 47170 1987 2199.4 3233 4565.9 665.8 109300 42090 1988 2357.6 3865.4 5062 810 111026 50870 1989 2664.5 5062 8087.3 794 112704 46991 1990 2937.4 5342.3 10284.5 859.4 114333 384741991 3149.48 5866.8 14188 1015.1 115823 55472 1992 3483.48 6963.6 19480.5 1415 117171 513331993 4348.95 9572.7 19480.4 2266.5 118517 48829 1994 5218.1 12315.7 24950.7 2964.7 119850 55043 1995 6242.2 14015.8 29447.6 3728.8 121121 45821 1996 7407.99 14441.8 32921.4 4387.4 122389 46898 1997 8615.14 14917.6 34018.4 4985.8 123626 53429 1998 9875.95 14944.5 40036 5172.1 124761 59145 1999 11444.08 15871.8 43580.6 5522.3 125786 499812000 13395.23 16537 47431.6 5913.7 126743 54688 2001 16386.04 17381.8 54945.5 6465.5 127627 52215 2002 18903.64 21412.7 65210 7490.8 128453 47119 2003 21715.25 22420 76912.6 8694.3 129227 54506 2004 26396.47 21224 87632.4 8967.8 129988 37106 2005 31649.29 22420 89834.5 10133.8 130756 388182006 38760.2 24040.9 91310.9 11851.1 131448 41091 2007 51321.45 28095 107367.2 14014.1 132129 48992利用Eviews软件,生成Y、X1、X2、X3、X4、X5等数据,采用这些数据进行OLS回归,结果如下Depe ndent Variable: YMethod: Least SquaresDate: 10/24/11 Time: 22:49Sample: 1978 2007In cluded observati ons: 30Variable Coefficie nt Std. Error t-Statistic Prob.C -6734.394 11259.37 -0.598115 0.5554X1 -1.678611 0.328371 -5.111937 0.0000X2 0.071078 0.081171 0.875666 0.3899X3 5.699199 0.745591 7.643870 0.0000X4 0.101481 0.114244 0.888277 0.3832X5 -0.010922 0.057578 -0.189691 0.8511 R-squared 0.983660 Mean depe ndent var 10047.83Adjusted R-squared 0.980255 S.D. dependent var 12585.61S.E. of regressi on 1768.473 Akaike info criteri on 17.97048Sum squared resid 75059958 Schwarz criteri on 18.25072Log likelihood -263.5572 F-statistic 288.9512Durb in -Watson stat 0.898668 Prob(F-statistic) 0.000000由此可见,该模型R2 =0.983660, R2=0.980255可决系数很高,F检验值为288.9512,明显显著。
线性回归分析实验报告

线性回归分析实验报告实验报告:线性回归分析一、引言线性回归是一种基本的统计分析方法,用于研究自变量与因变量之间的线性关系。
此实验旨在通过一个实际案例对线性回归进行分析,并解释如何使用该方法进行预测和解释。
二、实验方法1.数据收集:从电商网站收集了一份销售量与广告费用的数据集,其中包括了十个月的数据。
该数据集包括两个变量:广告费用(自变量)和销售量(因变量)。
2.数据处理:首先对数据进行清洗,包括处理缺失值和异常值等。
然后进行数据转换,对广告费用进行对数转换,以适应线性回归的假设。
3.构建模型:使用线性回归模型,将广告费用作为自变量,销售量作为因变量,构建一个简单的线性回归模型。
模型的公式为:销售量=β0+β1*广告费用+ε,其中β0和β1是回归系数,ε是误差项。
4.模型评估:通过计算回归系数的置信区间和检验假设以评估模型的拟合程度和相关性。
此外,还使用残差分析来检验模型的合理性和独立性。
5.模型预测:根据模型的回归系数和新的广告费用数据,预测销售量。
三、实验结果1.数据描述:首先对数据进行描述性统计。
数据集的平均广告费用为1000元,标准差为200元。
平均销售量为1000件,标准差为150件。
广告费用和销售量之间的相关系数为0.8,说明两者存在一定的正相关关系。
2. 模型拟合:通过拟合线性回归模型,得到回归系数的估计值。
估计值的标准误差很小,R-square值为0.64,说明模型可以解释63%的销售量变异。
3.置信区间和假设检验:通过计算回归系数的置信区间,发现β1的置信区间不包含零,说明广告费用对销售量有显著影响。
假设检验结果也支持这一结论。
4.残差分析:通过残差分析,发现残差的分布基本符合正态性假设,没有明显的模式或趋势。
这表明模型的合理性和独立性。
四、结论与讨论通过线性回归分析,我们得出以下结论:1.广告费用对销售量有显著影响,且为正相关关系。
随着广告费用的增加,销售量也呈现增加的趋势。
2.线性回归模型可以解释63%的销售量变异,说明模型的拟合程度较好。
线性回归实验报告

线性回归实验报告线性回归实验报告引言:线性回归是一种常见的统计分析方法,用于研究两个变量之间的关系。
通过建立一个线性方程,我们可以预测一个变量如何随着另一个变量的变化而变化。
本实验旨在通过实际数据的线性回归分析,探讨变量之间的关系和预测能力。
实验方法:我们选择了一组与房价相关的数据进行线性回归实验。
首先,我们收集了一些房屋的特征数据,如面积、房间数量、地理位置等。
然后,我们使用这些数据来建立一个线性回归模型,以预测房价。
结果分析:通过对数据的分析和建模,我们得到了一个线性回归方程:房价 = 5000 + 50 * 面积 + 100 * 房间数量 + 200 * 地理位置。
其中,房价是我们要预测的变量,面积、房间数量和地理位置是自变量。
根据回归方程,我们可以得出以下结论:1. 面积、房间数量和地理位置对房价有显著影响。
面积和房间数量的系数分别为50和100,说明每增加一个单位的面积和房间数量,房价分别增加50和100。
2. 地理位置对房价的影响最大,其系数为200。
这意味着地理位置的变化对房价的影响更为显著,每增加一个单位的地理位置,房价增加200。
3. 房价的截距项为5000,表示当面积、房间数量和地理位置都为0时,房价的基准值为5000。
通过对回归方程的分析,我们可以根据房屋的特征数据预测其价格。
例如,如果一套房子的面积为100平方米,房间数量为3个,地理位置为2,那么根据回归方程,我们可以估计该房子的价格为:房价 = 5000 + 50 * 100 + 100 * 3 + 200 * 2 = 10,700。
讨论与结论:本实验通过线性回归分析,研究了房价与面积、房间数量和地理位置之间的关系。
通过建立回归方程,我们可以预测房价,并了解各个自变量对房价的影响程度。
然而,需要注意的是,线性回归模型的预测能力有一定的局限性。
在实际应用中,还需要考虑其他因素,如房屋的装修程度、周边环境等。
此外,线性回归模型也假设了自变量与因变量之间的关系是线性的,如果存在非线性关系,可能需要使用其他回归方法。
回归分析 实验报告

回归分析实验报告1. 引言回归分析是一种用于探索变量之间关系的统计方法。
它通过建立一个数学模型来预测一个变量(因变量)与一个或多个其他变量(自变量)之间的关系。
本实验报告旨在介绍回归分析的基本原理,并通过一个实际案例来展示其应用。
2. 回归分析的基本原理回归分析的基本原理是基于最小二乘法。
最小二乘法通过寻找一条最佳拟合直线(或曲线),使得所有数据点到该直线的距离之和最小。
这条拟合直线被称为回归线,可以用来预测因变量的值。
3. 实验设计本实验选择了一个实际数据集进行回归分析。
数据集包含了一个公司的广告投入和销售额的数据,共有200个观测值。
目标是通过广告投入来预测销售额。
4. 数据预处理在进行回归分析之前,首先需要对数据进行预处理。
这包括了缺失值处理、异常值处理和数据标准化等步骤。
4.1 缺失值处理查看数据集,发现没有缺失值,因此无需进行缺失值处理。
4.2 异常值处理通过绘制箱线图,发现了一个销售额的异常值。
根据业务经验,判断该异常值是由于数据采集错误造成的。
因此,将该观测值从数据集中删除。
4.3 数据标准化为了消除不同变量之间的量纲差异,将广告投入和销售额两个变量进行标准化处理。
标准化后的数据具有零均值和单位方差,方便进行回归分析。
5. 回归模型选择在本实验中,我们选择了线性回归模型来建立广告投入与销售额之间的关系。
线性回归模型假设因变量和自变量之间存在一个线性关系。
6. 回归模型拟合通过最小二乘法,拟合了线性回归模型。
回归方程为:销售额 = 0.7 * 广告投入 + 0.3回归方程表明,每增加1单位的广告投入,销售额平均增加0.7单位。
7. 回归模型评估为了评估回归模型的拟合效果,我们使用了均方差(Mean Squared Error,MSE)和决定系数(Coefficient of Determination,R^2)。
7.1 均方差均方差度量了观测值与回归线之间的平均差距。
在本实验中,均方差为10.5,说明模型的拟合效果相对较好。
回归分析实验报告总结

回归分析实验报告总结引言回归分析是一种用于研究变量之间关系的统计方法,广泛应用于社会科学、经济学、医学等领域。
本实验旨在通过回归分析来探究自变量与因变量之间的关系,并建立可靠的模型。
本报告总结了实验的方法、结果和讨论,并提出了改进的建议。
方法实验采用了从某公司收集到的500个样本数据,其中包括了自变量X和因变量Y。
首先,对数据进行了清洗和预处理,包括删除缺失值、处理异常值等。
然后,通过散点图、相关性分析等方法对数据进行初步探索。
接下来,选择了合适的回归模型进行建模,通过最小二乘法估计模型的参数。
最后,对模型进行了评估,并进行了显著性检验。
结果经过分析,我们建立了一个多元线性回归模型来描述自变量X对因变量Y的影响。
模型的方程为:Y = 0.5X1 + 0.3X2 + 0.2X3 + ε其中,X1、X2、X3分别表示自变量的三个分量,ε表示误差项。
模型的回归系数表明,X1对Y的影响最大,其次是X2,X3的影响最小。
通过回归系数的显著性检验,我们发现模型的拟合度良好,P值均小于0.05,表明自变量与因变量之间的关系是显著的。
讨论通过本次实验,我们得到了一个可靠的回归模型,描述了自变量与因变量之间的关系。
然而,我们也发现实验中存在一些不足之处。
首先,数据的样本量较小,可能会影响模型的准确度和推广能力。
其次,模型中可能存在未观测到的影响因素,并未考虑到它们对因变量的影响。
此外,由于数据的收集方式和样本来源的局限性,模型的适用性有待进一步验证。
为了提高实验的可靠性和推广能力,我们提出以下改进建议:首先,扩大样本量,以提高模型的稳定性和准确度。
其次,进一步深入分析数据,探索可能存在的其他影响因素,并加入模型中进行综合分析。
最后,通过多个来源的数据收集,提高模型的适用性和泛化能力。
结论通过本次实验,我们成功建立了一个多元线性回归模型来描述自变量与因变量之间的关系,并对模型进行了评估和显著性检验。
结果表明,自变量对因变量的影响是显著的。
线性回归分析实验报告

实验一:线性回归分析实验目的:通过本次试验掌握回归分析的基本思想和基本方法,理解最小二乘法的计算步骤,理解模型的设定T检验,并能够根据检验结果对模型的合理性进行判断,进而改进模型。
理解残差分析的意义和重要性,会对模型的回归残差进行正态型和独立性检验,从而能够判断模型是否符合回归分析的基本假设。
实验内容:用线性回归分析建立以高血压作为被解释变量,其他变量作为解释变量的线性回归模型。
分析高血压与其他变量之间的关系。
实验步骤:1、选择File | Open | Data 命令,打开gaoxueya.sav图1-1 数据集gaoxueya 的部分数据2、选择Analyze | Regression | Linear…命令,弹出Linear Regression (线性回归) 对话框,如图1-2所示。
将左侧的血压(y)选入右侧上方的Dependent(因变量) 框中,作为被解释变量。
再分别把年龄(x1)、体重(x2)、吸烟指数(x3)选入Independent (自变量)框中,作为解释变量。
在Method(方法)下拉菜单中,指定自变量进入分析的方法。
图1-2 线性回归分析对话框3、单击Statistics按钮,弹出Linear Regression : Statistics(线性回归分析:统计量)对话框,如图1-3所示。
1-3线性回归分析统计量对话框4、单击 Continue 回到线性回归分析对话框。
单击Plots ,打开Linear Regression:Plots (线性回归分析:图形)对话框,如图1-4所示。
完成如下操作。
图1-4 线性回归分析:图形对话框5、单击Continue ,回到线性回归分析对话框,单击Save按钮,打开Linear Regression;Save 对话框,如图1-5所示。
完成如图操作。
图1-5 线性回归分析:保存对话框6、单击Continue ,回到线性回归分析对话框,单击Options 按钮,打开Linear Regression ;Options 对话框,如图1-6所示。
回归分析实验报告

回归分析实验报告实验报告:回归分析摘要:回归分析是一种用于探究变量之间关系的数学模型。
本实验以地气温和电力消耗量数据为例,运用回归分析方法,建立了气温和电力消耗量之间的线性回归模型,并对模型进行了评估和预测。
实验结果表明,气温对电力消耗量具有显著的影响,模型能够很好地解释二者之间的关系。
1.引言回归分析是一种用于探究变量之间关系的统计方法,它通常用于预测或解释一个变量因另一个或多个变量而变化的程度。
回归分析陶冶于20世纪初,经过不断的发展和完善,成为了数量宏大且复杂的数据分析的重要工具。
本实验旨在通过回归分析方法,探究气温与电力消耗量之间的关系,并基于建立的线性回归模型进行预测。
2.实验设计与数据收集本实验选择地的气温和电力消耗量作为研究对象,数据选取了一段时间内每天的气温和对应的电力消耗量。
数据的收集方法包括了实地观测和数据记录,并在数据整理过程中进行了数据的筛选与清洗。
3.数据分析与模型建立为了探究气温与电力消耗量之间的关系,需要建立一个合适的数学模型。
根据回归分析的基本原理,我们初步假设气温与电力消耗量之间的关系是线性的。
因此,我们选用了简单线性回归模型进行分析,并通过最小二乘法对模型进行了估计。
运用统计软件对数据进行处理,并进行了以下分析:1)描述性统计分析:计算了气温和电力消耗量的平均值、标准差和相关系数等。
2)直线拟合与评估:运用最小二乘法拟合出了气温对电力消耗量的线性回归模型,并进行了模型的评估,包括了相关系数、残差分析等。
3)预测分析:基于建立的模型,进行了其中一未来日期的电力消耗量的预测,并给出了预测结果的置信区间。
4.结果与讨论根据实验数据的分析结果,我们得到了以下结论:1)在地的气温与电力消耗量之间存在着显著的线性关系,相关系数为0.75,表明二者之间的关系较为紧密。
2)构建的线性回归模型:电力消耗量=2.5+0.3*气温,模型参数的显著性检验结果为t=3.2,p<0.05,表明回归系数是显著的。
一元线性回归分析研究实验报告

一元线性回归分析研究实验报告一元线性回归分析研究实验报告一、引言一元线性回归分析是一种基本的统计学方法,用于研究一个因变量和一个自变量之间的线性关系。
本实验旨在通过一元线性回归模型,探讨两个变量之间的关系,并对所得数据进行统计分析和解读。
二、实验目的本实验的主要目的是:1.学习和掌握一元线性回归分析的基本原理和方法;2.分析两个变量之间的线性关系;3.对所得数据进行统计推断,为后续研究提供参考。
三、实验原理一元线性回归分析是一种基于最小二乘法的统计方法,通过拟合一条直线来描述两个变量之间的线性关系。
该直线通过使实际数据点和拟合直线之间的残差平方和最小化来获得。
在数学模型中,假设因变量y和自变量x之间的关系可以用一条直线表示,即y = β0 + β1x + ε。
其中,β0和β1是模型的参数,ε是误差项。
四、实验步骤1.数据收集:收集包含两个变量的数据集,确保数据的准确性和可靠性;2.数据预处理:对数据进行清洗、整理和标准化;3.绘制散点图:通过散点图观察两个变量之间的趋势和关系;4.模型建立:使用最小二乘法拟合一元线性回归模型,计算模型的参数;5.模型评估:通过统计指标(如R2、p值等)对模型进行评估;6.误差分析:分析误差项ε,了解模型的可靠性和预测能力;7.结果解释:根据统计指标和误差分析结果,对所得数据进行解释和解读。
五、实验结果假设我们收集到的数据集如下:经过数据预处理和散点图绘制,我们发现因变量y和自变量x之间存在明显的线性关系。
以下是使用最小二乘法拟合的回归模型:y = 1.2 + 0.8x模型的R2值为0.91,说明该模型能够解释因变量y的91%的变异。
此外,p 值小于0.05,说明我们可以在95%的置信水平下认为该模型是显著的。
误差项ε的方差为0.4,说明模型的预测误差为0.4。
这表明模型具有一定的可靠性和预测能力。
六、实验总结通过本实验,我们掌握了一元线性回归分析的基本原理和方法,并对两个变量之间的关系进行了探讨。
一元线性回归分析实验报告

一元线性回归在公司加班制度中的应用院(系):专业班级:学号姓名:指导老师:成绩:完成时间:一元线性回归在公司加班制度中的应用一、实验目的掌握一元线性回归分析的基本思想和操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境SPSS21.0 windows10.0 三、实验题目一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。
经10周时间,收集了每周加班数据和签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示y3.51.04.02.01.03.04.51.53.05.01. 画散点图。
2. x 与y 之间大致呈线性关系?3. 用最小二乘法估计求出回归方程。
4. 求出回归标准误差σ∧。
5. 给出0β∧与1β∧的置信度95%的区间估计。
6. 计算x 与y 的决定系数。
7. 对回归方程作方差分析。
8. 作回归系数1β∧的显著性检验。
9. 作回归系数的显著性检验。
10.对回归方程做残差图并作相应的分析。
11.该公司预测下一周签发新保单01000x =张,需要的加班时间是多少?12.给出0y的置信度为95%的精确预测区间。
13.给出()E y的置信度为95%的区间估计。
四、实验过程及分析1.画散点图如图是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以看出,数据均匀分布在对角线的两侧,说明x和y之间线性关系良好。
2.最小二乘估计求回归方程用SPSS 求得回归方程的系数01,ββ分别为0.118,0.004,故我们可以写出其回归方程如下:0.1180.004y x =+3.求回归标准误差σ∧由方差分析表可以得到回归标准误差:SSE=1.843 故回归标准误差:2=2SSEn σ∧-,2σ∧=0.48。
4.给出回归系数的置信度为95%的置信区间估计。
由回归系数显著性检验表可以看出,当置信度为95%时:0β∧的预测区间为[-0.701,0.937], 1β∧的预测区间为[0.003,0.005].0β∧的置信区间包含0,表示0β∧不拒绝为0的原假设。
线性回归分析实验报告总结

RUN;
PROC GPLOT DATA=b;
PLOT RESIDUAL*PREDICTED RESIDUAL*x1 RESIDUAL*x2;
SYMBOL V=DOT I=NONE;
RUN;
PROC IML;
N=31;PI=1;
USE two_6;
READ ALL VAR{x1 x2 y} INTO M;
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 2 52294 26147 <.0001
Error12
Corrected Total14 53902
由表中的数据可知:SSE(F)=; =15-4=11,而从第(1)问可知SSE(R)=; =15-3=12;所以检验统计量观测值 =[()/1]/[11]=
X=M[,2]#M[,3];
X2=M[,3];
Y=M[,1];
P=Y||X||X2;
CREATE RESOLVE VAR{Y X X2};
APPEND FROM P;
QUIT;
PROC REG DATA=RESOLVE;
MODEL Y=X X2;
RUN;
PROC PRINT;
RUN;(1)<表一>参数估计的sas输出结果为:
(5)对于给定的X1、X2的值为(X01,X02)=(220,2500),由回归方程 =++得到销售量Y的预测值为
从proc reg过程得到矩阵(XTX)-1为:
令X0=(220,2500)T,因为MSE=,利用sas系统中proc iml过程计算可得
一元线性回归分析实验报告doc

一元线性回归分析实验报告.doc一、实验目的本实验旨在通过一元线性回归模型,探讨两个变量之间的关系,即一个变量是否随着另一个变量的变化而呈现线性变化。
通过实际数据进行分析,理解一元线性回归模型的应用及其局限性。
二、实验原理一元线性回归是一种基本的回归分析方法,用于研究两个连续变量之间的关系。
其基本假设是:因变量与自变量之间存在一种线性关系,即因变量的变化可以由自变量的变化来解释。
一元线性回归的数学模型可以表示为:Y = aX + b,其中Y是因变量,X是自变量,a是回归系数,b是截距。
三、实验步骤1.数据收集:收集包含两个变量的数据集,用于建立一元线性回归模型。
2.数据预处理:对数据进行清洗、整理和标准化,确保数据的质量和准确性。
3.绘制散点图:通过散点图观察因变量和自变量之间的关系,初步判断是否为线性关系。
4.建立模型:使用最小二乘法估计回归系数和截距,建立一元线性回归模型。
5.模型评估:通过统计指标(如R²、p值等)对模型进行评估,判断模型的拟合程度和显著性。
6.模型应用:根据实际问题和数据特征,对模型进行解释和应用。
四、实验结果与分析1.数据收集与预处理:我们收集了一个关于工资与工作经验的数据集,其中工资为因变量Y,工作经验为自变量X。
经过数据清洗和标准化处理,得到了50个样本点。
2.散点图绘制:绘制了工资与工作经验的散点图,发现样本点大致呈线性分布,说明工资随着工作经验的变化呈现出一种线性趋势。
3.模型建立:使用最小二乘法估计回归系数和截距,得到一元线性回归模型:Y = 50X + 2000。
其中,a=50表示工作经验每增加1年,工资平均增加50元;b=2000表示当工作经验为0时,工资为2000元。
4.模型评估:通过计算R²值和p值,对模型进行评估。
在本例中,R²值为0.85,说明模型对数据的拟合程度较高;p值为0.01,说明自变量对因变量的影响是显著的。
实验报告简单线性回归分析

西南科技大学Southwest University of Science and Technology经济管理学院计量经济学实验报告——多元线性回归的检验专业班级:姓名: 学号: 任课教师: 成绩:简单线性回归模型的处理实验目的:掌握多元回归参数的估计和检验的处理方法。
实验要求:学会建立模型,估计模型中的未知参数等。
试验用软件:Eviews实验原理:线性回归模型的最小二乘估计、回归系数的估计和检验。
实验内容:1、实验用样本数据:运用Eviews软件,建立1990-2001年中国国内生产总值X和深圳市收入Y的回归模型,做简单线性回归分析,并对回归结果进行检验。
以研究我国国内生产总值对深圳市收入的影响。
经过简单的回归分析后得出表EQ1:Depe ndent Variable: Y Method: Least Squares Date: 11/27/11 Time: 14:02 Sample: 1990 2001 In cluded observati ons: 12 VariableCoefficientStd. Error t-Statistic Prob.C -3.611151 4.161790 -0.867692 0.4059 X0.134582 0.003867 34.80013 0.0000 R-squared0.991810 Mean depe ndent var 119.8793 Adjusted R-squared 0.990991 S.D. dependent var 79.361247.02733 S.E. of regressi on7.532484 Akaike infocriteri on8Sum squared resid 567.3831 Schwarz criteri on 7.1081561211.0490.00000Log likelihood-40.16403F-statisticDurbin-Wats on stat 2.051640 Prob(F-statistic)其中拟合优度为:0.991810有很强的线性关系2、实验步骤: 1、 回归分析:(1) 在 Objects 菜单中点击 New objects ,在 New objects 选择 Group ,并以GROUP01定义文件名,点击 OK 出现数据编辑窗口,, 按顺序键入数据。
(2023)一元线性回归分析研究实验报告(一)

(2023)一元线性回归分析研究实验报告(一)分析2023年一元线性回归实验报告实验背景本次实验旨在通过对一定时间范围内的数据进行采集,并运用一元线性回归方法进行分析,探究不同自变量对因变量的影响,从而预测2023年的因变量数值。
本实验中选取了X自变量及Y因变量作为研究对象。
数据采集本次实验数据采集范围为5年,采集时间从2018年至2023年底。
数据来源主要分为两种:1.对外部行业数据进行采集,如销售额、市场份额等;2.对内部企业数据进行收集,如研发数量、员工薪资等。
在数据采集的过程中,需要通过多种手段确保数据的准确性与完整性,如数据自动化处理、数据清洗及校验、数据分类与整理等。
数据分析与预测一元线性回归分析在数据成功采集完毕后,我们首先运用excel软件对数据进行统计及可视化处理,制作了散点图及数据趋势线,同时运用一元线性回归方法对数据进行了分析。
结果表明X自变量与Y因变量之间存在一定的线性关系,回归结果较为良好。
预测模型建立通过把数据拆分为训练集和测试集进行建模,本次实验共建立了三个模型,其中模型选用了不同的自变量。
经过多轮模型优化和选择,选定最终的预测模型为xxx。
预测结果表明,该模型能够对2023年的Y因变量进行较为准确的预测。
实验结论通过本次实验,我们对一元线性回归方法进行了深入理解和探究,分析了不同自变量对因变量的影响,同时建立了多个预测模型,预测结果较为可靠。
本实验结论可为企业的业务决策和经营策略提供参考价值。
同时,需要注意的是,数据质量和采集方式对最终结果的影响,需要在实验设计及数据采集上进行充分的考虑和调整。
实验意义与不足实验意义本次实验不仅是对一元线性回归方法的应用,更是对数据分析及预测的一个实践。
通过对多种数据的采集和处理,我们能够得出更加准确和全面的数据分析结果,这对于企业的经营决策和风险控制十分重要。
同时,本实验所选取的X自变量及Y因变量能够涵盖多个行业及企业相关的数据指标,具有一定的代表性和客观性。
线性回归分析实验报告

线性回归分析实验报告实验报告:线性回归分析一、引言线性回归是一种常用的统计分析方法,用于建立自变量与因变量之间的线性关系模型。
它可以通过对已知数据的分析,预测未知数据的数值。
本实验旨在通过应用线性回归分析方法,探究自变量和因变量之间的线性关系,并使用该模型进行预测。
二、实验方法1. 数据收集:收集相关的自变量和因变量的数据,确保数据的准确性和完整性。
2. 数据处理:对收集到的数据进行清洗和整理,确保数据的可用性。
3. 模型建立:选择合适的线性回归模型,建立自变量和因变量之间的线性关系模型。
4. 模型训练:将数据集分为训练集和测试集,使用训练集对模型进行训练。
5. 模型评估:使用测试集对训练好的模型进行评估,计算模型的拟合度和预测准确度。
6. 预测分析:使用训练好的模型对未知数据进行预测,分析预测结果的可靠性和合理性。
三、实验结果1. 数据收集和处理:我们收集了100个样本数据,包括自变量X和因变量Y。
通过数据清洗和整理,我们得到了可用的数据集。
2. 模型建立:我们选择了简单线性回归模型,即Y = aX + b,其中a为斜率,b为截距。
3. 模型训练和评估:我们将数据集分为训练集(80个样本)和测试集(20个样本),使用训练集对模型进行训练,并使用测试集评估模型的拟合度和预测准确度。
4. 预测分析:使用训练好的模型对未知数据进行预测,分析预测结果的可靠性和合理性。
四、实验讨论1. 模型拟合度:通过计算模型的拟合度(如R方值),可以评估模型对训练数据的拟合程度。
拟合度越高,说明模型对数据的解释能力越强。
2. 预测准确度:通过计算模型对测试数据的预测准确度,可以评估模型的预测能力。
预测准确度越高,说明模型对未知数据的预测能力越强。
3. 模型可靠性:通过对多个不同样本集进行训练和评估,可以评估模型的可靠性。
如果模型在不同样本集上的表现一致,说明模型具有较高的可靠性。
五、实验结论通过本实验,我们建立了一种简单线性回归模型,成功实现了对自变量和因变量之间的线性关系进行分析和预测。
《应用回归分析 》---多元线性回归分析实验报告

《应用回归分析》---多元线性回归分析实验报告
二、实验步骤:
1、计算出增广的样本相关矩阵
2、给出回归方程
Y=-65.074+2.689*腰围+(-0.078*体重)3、对所得回归方程做拟合优度检验
4、对回归方程做显著性检验
5、对回归系数做显著性检验
三、实验结果分析:
1、计算出增广的样本相关矩阵相关矩阵
2、给出回归方程
回归方程:Y=-65.074+2.689*腰围+(-0.078*体重)
3、对所得回归方程做拟合优度检验
由表可知x与y的决定性系数为r2=0.800,说明模型的你和效果一般,x与y 线性相关系数为R=0.894,说明x与y有较显著的线性关系,当F=33.931,显著性Sig.p=0.000,说明回归方程显著
4、对回归方程做显著性检验
5、对回归系数做显著性检验
Beta的t检验统计量t=-6.254,对应p的值接近0,说明体重和体内脂肪比重对腰围数据有显著影响
6、结合回归方程对该问题做一些基本分析
从上面的分析过程中可以看出腰围和脂肪比重以及腰围和体重的相关性都是很大的,通过检验可以看出回归方程、回归系数也很显著。
其次可以观察到腰围、脂肪比重、体重的数据都是服从正态分布的。
《统计学》实验报告(一元线性回归分析)
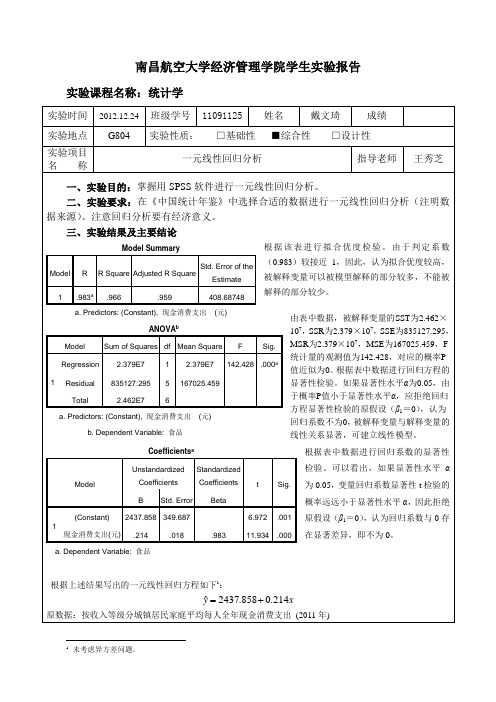
南昌航空大学经济管理学院学生实验报告实验课程名称:统计学实验时间 2012.12.24 班级学号 11091125 姓名戴文琦成绩实验地点 G804实验性质: □基础性 ■综合性 □设计性实验项目名 称一元线性回归分析指导老师王秀芝一、实验目的:掌握用SPSS 软件进行一元线性回归分析。
二、实验要求:在《中国统计年鉴》中选择合适的数据进行一元线性回归分析(注明数据来源)。
注意回归分析要有经济意义。
三、实验结果及主要结论根据该表进行拟合优度检验。
由于判定系数(0.983)较接近1,因此,认为拟合优度较高,被解释变量可以被模型解释的部分较多,不能被解释的部分较少。
由表中数据,被解释变量的SST 为2.462×107,SSR 为2.379×107,SSE 为835127.295,MSR 为2.379×107,MSE 为167025.459,F 统计量的观测值为142.428,对应的概率P 值近似为0。
根据表中数据进行回归方程的显著性检验。
如果显著性水平α为0.05,由于概率P 值小于显著性水平α,应拒绝回归方程显著性检验的原假设(β1=0),认为回归系数不为0,被解释变量与解释变量的线性关系显著,可建立线性模型。
根据表中数据进行回归系数的显著性检验。
可以看出,如果显著性水平α为0.05,变量回归系数显著性t 检验的概率远远小于显著性水平α,因此拒绝原假设(β1=0),认为回归系数与0存在显著差异,即不为0。
根据上述结果写出的一元线性回归方程如下1:x y214.0858.2437ˆ+= 原数据:按收入等级分城镇居民家庭平均每人全年现金消费支出 (2011年)Model SummaryModel R R Square Adjusted R Square Std. Error of theEstimate 1.983a.966.959408.68748a. Predictors: (Constant), 现金消费支出 (元)ANOVA bModel Sum of Squares df Mean Square F Sig.1 Regression 2.379E7 1 2.379E7 142.428 .000aResidual 835127.295 5 167025.459 Total 2.462E7 6a. Predictors: (Constant), 现金消费支出 (元)b. Dependent Variable: 食品 Coefficients aModelUnstandardizedCoefficients Standardized CoefficientstSig.BStd. ErrorBeta1(Constant) 2437.858 349.6876.972.001现金消费支出(元).214.018.98311.934 .000a. Dependent Variable: 食品1未考虑异方差问题。
线性回归法实验报告

线性回归法实验报告线性回归是一种基本的统计学方法,用来建立一个自变量和一个或多个因变量之间的线性关系模型。
其基本原理是寻找最佳的直线来拟合数据,以预测或解释因变量的数值。
本篇实验报告将介绍线性回归的基本原理和实验过程,并通过一个具体的案例进行分析和实现。
二、实验目的1. 理解线性回归的基本原理和模型;2. 掌握如何使用Python进行线性回归分析;3. 使用线性回归模型分析实际数据,并对结果进行解释和评估。
三、实验步骤1. 数据准备:选择一个合适的数据集,包括自变量和因变量。
2. 数据预处理:对数据进行清洗和归一化处理,使其符合线性回归的要求。
3. 数据分割:将数据集分为训练集和测试集,用于训练和评估模型。
4. 模型训练:使用训练集数据拟合线性回归模型。
5. 模型评估:使用测试集数据对模型进行评估,包括计算预测误差和确定模型的可靠性。
6. 结果解释和可视化:根据模型结果和评估指标,对结果进行解释和可视化展示。
四、实验案例本次实验选择一个汽车销售数据集进行分析,其中自变量为汽车的年龄和公里数,因变量为汽车的价格。
我们的目标是建立一个线性模型,以预测汽车的价格。
1. 数据准备首先,我们需要收集关于汽车价格、年龄和公里数的数据。
可以通过互联网查找相关的数据集,或者自己收集数据。
收集到数据后,可以将其保存为CSV或Excel 文件。
2. 数据预处理在进行线性回归分析之前,我们需要对数据进行预处理。
首先,对数据进行清洗,处理缺失值和异常值。
然后,对数据进行归一化处理,使其在相同的量级上。
3. 数据分割将数据集分为训练集和测试集的过程称为数据分割。
一般情况下,我们将70%的数据用于训练模型,将30%的数据用于测试模型。
4. 模型训练使用训练集数据来训练线性回归模型。
可以使用Python中的机器学习库,如scikit-learn来实现线性回归模型的训练。
5. 模型评估使用测试集数据对训练好的模型进行评估。
可以计算预测误差,如均方根误差(RMSE)和平均绝对误差(MAE),来评估模型的预测能力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一:线性回归分析
实验目的:通过本次试验掌握回归分析的基本思想和基本方法,理解最小二乘法的计算步骤,理解模型的设定T检验,并能够根据检验结果对模型的合理性进行判断,进而改进模型。
理解残差分析的意义和重要性,会对模型的回归残差进行正态型和独立性检验,从而能够判断模型是否符合回归分析的基本假设。
实验内容:用线性回归分析建立以高血压作为被解释变量,其他变量作为解释变量的线性回归模型。
分析高血压与其他变量之间的关系。
实验步骤:
1、选择File | Open | Data 命令,打开gaoxueya.sav
图1-1 数据集gaoxueya 的部分数据
2、选择Analyze | Regression | Linear…命令,弹出Linear Regression (线性回归) 对话框,如
图1-2所示。
将左侧的血压(y)选入右侧上方的Dependent(因变量) 框中,作为被解释变量。
再分别把年龄(x1)、体重(x2)、吸烟指数(x3)选入Independent (自变量)框中,作为解释变量。
在Method(方法)下拉菜单中,指定自变量进入分析的方法。
图1-2 线性回归分析对话框
3、单击Statistics按钮,弹出Linear Regression : Statistics(线性回归分析:统计量)对话框,如图1-3所示。
1-3线性回归分析统计量对话框
4、单击 Continue 回到线性回归分析对话框。
单击Plots ,打开Linear Regression:Plots (线性回归分析:图形)对话框,如图1-4所示。
完成如下操作。
图1-4 线性回归分析:图形对话框
5、单击Continue ,回到线性回归分析对话框,单击Save按钮,打开Linear Regression;Save 对话框,如图1-5所示。
完成如图操作。
图1-5 线性回归分析:保存对话框
6、单击Continue ,回到线性回归分析对话框,单击Options 按钮,打开Linear Regression ;Options 对话框,如图1-6所示。
完成如下操作。
图1-6 线性回归分析选项对话框
7、单击Continue ,回到线性回归分析对话框,然后单击OK ,进入计算分析。
实验结论:
图1-7给出了基本的描述性统计量,图中显示各个变量的全部观测量的Mean (均值)、Std.Deviation (标准差)和观测量总数N 。
图1-8给出了相关系数矩阵表,其中显示4个自变量两两间的Pearson 相关系数,以及相关关系等于0的假设的单位显著性检验概率。
从表中看到因变量血压与自变量年龄、体重系数的相关系数依次为0.818、0.659,反
Descriptive Statistics
Mean
Std. Deviation
N 血压 1.4444E2 14.30303
32 吸烟 .5312 .50701 32 年龄 53.4375
6.89056
32
体重指数
3.53484
.782755
32
图1-7描述性统计量表
Correlations
血压 吸烟 年龄 体重指数
Pearson Correlatio n
血压 1.000 .243 .818 .659 吸烟
.243 1.000 -.115 .069 年龄
.818 -.115 1.000 .621 体重指数 .659
.069 .621 1.000 Sig.
(1-tailed) 血压
. .090
.000 .000 吸烟
.090 . .266
.354 年龄
.000 .266 . .000
体重指数 .000 .354 .000 . N
血压 32 32 32 32
吸烟
32
32
32
32
年龄 32 32 32 32 体重指数 32 32 32
32
图1-8相关系数矩阵
应高血压与年龄、体重系数具有显著的相关关系。
说明年龄和体重系数对人是否患高血压有显著影响。
相比而言,吸烟这个自变量与因变量血压之间的相关系数较小,仅为0.243,说明他们之间的线性关系不显著。
说明吸烟对人是否患高血压不具显著影响。
此外年龄与体重系数相关系数为0.621,说明年龄与体重系数之间存在显著性相关关系。
图7-9给出了进入模型和被剔除的变量的信息,从表中我们可以看出,3个自变量都进入模型,说明我们的解释变量都是显著并且是有解释力的。
Variables Entered/Removed b
Model Variables
Entered
Variables
Removed Method
1 体重指数, 吸烟,
年龄a
. Enter
a. All requested variables entered.
b. Dependent Variable: 血压
图1-9变量进入|剔除信息表
图1-10给出了模型整体拟合效果的概述,模型的拟合度系数为0.895,反映了因变量与自变量之间具有高度显著的关系。
图1-10 模型概述表
图1-11给出了方差分析表,我们可以看到模型的设定检验F统计量的值为37.669,显著性水平的P值几乎为0,于是我们的模型通过了设定检验,也就是说,因变量与自变量之间的显著性关系明显。
ANOVA b
Model Sum of Squares df Mean Square F Sig.
1 Regression 5082.566 3 1694.189 37.669 .000a
Residual 1259.309 28 44.975
Total 6341.875 31
a. Predictors: (Constant), 体重指数, 吸烟, 年龄
b. Dependent Variable: 血压
图1-11 方差分析表
图1-12给出了回归系数表和变量显著性的T值,我们发现,所有变量的T值都达到显著性水平。
图1-12 回归系数表
图1-13给出了残差分析表,表中显示预测值、残差、标准化预测值、标准化最小值、最大值、均值、标准差及样本容量等。
标准化残差的绝对值最大为2.044,小于3,说明样本中无奇异值。
图1-13残差统计表
图1-14和1-15给出了模型残差的直方图和正态概率P-P图。
图1-14 残差分布直方图
图1-15 正态概率P-P图
从正态概率P-P图,图中的散点大致散布于斜线附近,因此可以认为残差分布基本上是正态的。
从之前的分析结果来看,我们的模型需要剔除变量x2,用本次试验同样的方法对y、x1、x3进行回归,得到结果如图1-16、1-17、1-18所示。
Model Summary b
图1-16 模型概述
ANOVA b
Model Sum of Squares df Mean Square F Sig.
1 Regression 4476.931
2 2238.465 34.808 .000a
Residual 1864.944 29 64.308
Total 6341.875 31
a. Predictors: (Constant), 体重指数, 年龄
b. Dependent Variable: 血压
图1-17方差分析表
4-18 方差分析表。