统计学常用公式
(完整版)统计学公式大全

(完整版)统计学公式大全统计学公式大全本文档旨在提供统计学领域常用的公式大全,便于大家在研究和实践中进行参考和应用。
描述统计学公式中心趋势度量1. 平均数(Mean):$\bar{x} =\frac{{\sum_{i=1}^{n}x_i}}{n}$2. 中位数(Median):若数据个数为奇数,中位数为排序后的中间值;若数据个数为偶数,中位数为排序后的中间两个值的平均值。
3. 众数(Mode):出现频率最高的数值。
离散趋势度量1. 方差(Variance):$Var(x) = \frac{{\sum_{i=1}^{n}(x_i - \bar{x})^2}}{n}$2. 标准差(Standard Deviation):$SD(x) = \sqrt{Var(x)}$3. 极差(Range):$Range(x) = \max(x) - \min(x)$分布形状度量1. 偏度(Skewness):$\text{Skewness} =\frac{{\sum_{i=1}^{n}(x_i - \bar{x})^3}}{n \cdot SD(x)^3}$2. 峰度(Kurtosis):$\text{Kurtosis} =\frac{{\sum_{i=1}^{n}(x_i - \bar{x})^4}}{n \cdot SD(x)^4}$ 推断统计学公式参数估计1. 样本均值的抽样分布标准差(Standard Error of the Mean):$SE(\bar{x}) = \frac{{SD(x)}}{\sqrt{n}}$2. 双侧置信区间公式(Confidence Interval):$\bar{x} \pm Z\cdot SE(\bar{x})$3. 样本比例的抽样分布标准差(Standard Error of Proportion):$SE(p) = \sqrt{\frac{{p(1-p)}}{n}}$4. 双侧置信区间公式(Confidence Interval):$p \pm Z \cdotSE(p)$假设检验1. 样本均值和总体均值的差异(t检验):$t = \frac{{\bar{x} -\mu}}{{SE(\bar{x})}}$2. 双侧拒绝域临界值(t分布):$t_{\text{critical}} = \pmt_{\alpha/2, df}$3. 样本比例和总体比例的差异(z检验):$z = \frac{{\hat{p} - p}}{{SE(p)}}$4. 双侧拒绝域临界值(z分布):$z_{\text{critical}} = \pmz_{\alpha/2}$回归分析公式简单线性回归模型1. 回归方程(Simple Linear Regression):$y = \beta_0 +\beta_1x + \epsilon$2. 线性预测公式(Simple Linear Regression):$\hat{y} =\hat{\beta}_0 + \hat{\beta}_1x$3. 斯皮尔曼秩相关系数(Spearman's Rank Correlation Coefficient):$r_s = 1 - \frac{6\sum d_i^2}{n(n^2 - 1)}$4. 相关系数的显著性检验(t检验):$t = \frac{r}{\sqrt{\frac{1 - r^2}{n-2}}}$结论本文档列举了统计学领域常用的公式,包括描述统计学中的中心趋势度量、离散趋势度量和分布形状度量,推断统计学中的参数估计和假设检验,以及回归分析中的简单线性回归模型等相关公式。
统计学常用公式

统计学常用公式统计学是一门研究数据收集、分析、解释和表达的科学。
在统计学中,有许多常用的公式被广泛应用于数据处理和推断分析。
本文将介绍一些统计学常用公式,并对其进行说明和用途解释。
一、描述统计学公式1. 平均值(Mean)平均值是一组数据的总和除以数据的个数,即:$\bar{X} = \frac{X_1 + X_2 + \cdots + X_n}{n}$其中,$\bar{X}$表示平均值,$X_i$表示第i个数据,n表示数据的个数。
2. 中位数(Median)中位数是将一组数据按照大小排列后,处于中间位置的数值。
当数据个数为奇数时,中位数即为排列后正中间的数;当数据个数为偶数时,中位数为排列后中间两个数的平均值。
3. 众数(Mode)众数是一组数据中出现频率最高的数值。
4. 标准差(Standard Deviation)标准差衡量数据的离散程度,其计算公式为:$SD = \sqrt{\frac{(X_1 -\bar{X})^2 + (X_2 -\bar{X})^2 + \cdots + (X_n -\bar{X})^2}{n-1}}$5. 方差(Variance)方差是标准差的平方,即:$Var = SD^2$6. 百分位数(Percentile)百分位数是指一组数据中某个特定百分比处的数值。
比如,第25百分位数是将一组数据从小到大排列后,处于前25%位置的数值。
二、概率与统计公式1. 随机变量期望(Expectation)随机变量期望是描述随机变量平均值的指标,也称为均值。
对于离散型随机变量X,其期望计算公式为:$E(X) = \sum_{i=1}^{n} X_i \cdot P(X_i)$对于连续型随机变量X,其期望计算公式为:$E(X) = \int_{-\infty}^{\infty} x \cdot f(x)dx$其中,$X_i$表示随机变量X的取值,$P(X_i)$表示对应取值的概率,$f(x)$表示X的概率密度函数。
统计学公式汇总

统计学公式汇总统计学是研究数据收集、分析、解释和预测的一门学科。
在统计学中,有许多重要的公式被广泛应用于数据的处理和分析过程中。
本文将汇总一些常见的统计学公式,并简要介绍其应用场景和使用方法。
1. 均值(Mean)均值是统计学中最常用的概念之一,用于衡量一组数据的集中趋势。
对于一个样本集合,均值可以通过将所有观测值相加,然后除以样本容量来计算。
其数学公式如下:均值= ∑(观测值) / 样本容量2. 方差(Variance)方差是用于衡量一组数据的离散程度的指标。
方差越大,表示数据的离散程度越高;方差越小,表示数据的离散程度越低。
方差的计算公式如下:方差= ∑((观测值-均值)^2) / 样本容量3. 标准差(Standard Deviation)标准差是方差的平方根,用于衡量数据的离散程度,并且具有和原始数据相同的单位。
标准差的计算公式如下:标准差 = 方差的平方根4. 相关系数(Correlation Coefficient)相关系数用于衡量两组变量之间的线性关系强度和方向。
相关系数的取值范围在-1到1之间,其中-1表示完全的负相关,1表示完全的正相关,0表示无相关。
相关系数的计算公式如下:r = Cov(X,Y) / (σX * σY)5. 回归方程(Regression Equation)回归方程用于建立一个或多个自变量与因变量之间的线性关系。
回归方程的一般形式为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y表示因变量,X1、X2、...、Xn表示自变量,β0、β1、β2、...、βn表示回归系数,ε表示模型的误差项。
6. 样本容量和置信水平(Sample Size and Confidence Level)在统计学中,样本容量和置信水平是决定实验或调查结果可靠性的重要因素。
样本容量是指从总体中抽取的样本大小,而置信水平是指对总体参数的估计值的信任程度。
统计学公式总结

统计学公式总结统计学是一门关于收集、分析、解释和表达数据的科学。
它通过具体的数学模型和公式来描述和理解数据中的规律和关系。
在统计学中,有许多重要的公式被广泛应用于各种数据处理和分析的情况。
本文将会总结一些常见和重要的统计学公式。
1. 均数公式:均数是一组数据的平均值,用于反映一组数据的中心位置。
计算均数的公式是:mean = sum(data) / n其中,data表示数据集,n表示数据的个数,sum表示求和。
2. 中位数公式:中位数是将一组数据按照大小排列后,位于中间位置的数值。
计算中位数的公式有两种情况:- 当数据集的个数n为奇数时,中位数的公式是:median = data[(n+1)/2]- 当数据集的个数n为偶数时,中位数的公式是:median = (data[n/2] + data[(n/2)+1]) / 23. 众数公式:众数指一组数据中出现频率最高的数值。
计算众数的公式是:mode = value with maximum frequency4. 方差公式:方差是一组数据与其均值之间差异的平方的平均值。
方差可以用于衡量数据的离散程度,公式如下:variance = sum((data - mean)^2) / n5. 标准差公式:标准差是方差的正平方根,用于衡量数据集的离散程度。
标准差的公式是:standard deviation = sqrt(variance)6. 协方差公式:协方差用于衡量两个变量之间的相关性。
协方差的公式为:covariance = sum((X - mean_X) * (Y - mean_Y)) / n其中,X和Y表示两个变量,mean_X和mean_Y表示X和Y的均值,n表示变量的个数。
7. 相关系数公式:相关系数用于衡量两个变量之间的线性相关性,其取值范围为-1到1。
相关系数的公式是:correlation = covariance / (std_X * std_Y)其中,std_X和std_Y表示X和Y的标准差。
统计学主要计算公式

统计学主要计算公式统计学是研究数据收集、整理、分析、解释和呈现的科学。
在统计学中,有许多重要的计算公式被广泛应用于统计分析和推断,以下是一些常见的计算公式:1.平均值:平均值是一组数据的总和除以数据的数量。
公式:平均值=总和/数据数量2.中位数:中位数是一组有序数据中的中间值,将数据从小到大排列,若数据的数量为奇数,则中位数为中间的数值;若数据的数量为偶数,则中位数为中间两个数值的平均值。
3.众数:众数是一组数据中出现最频繁的值。
4.方差:方差是一组数据与其平均值的差的平方的平均值。
公式: 方差= (∑(xi-平均值)^2) / 数据数量5.标准差:标准差是方差的平方根,用于衡量一组数据的离散程度。
公式:标准差=√方差6.相关系数:用于衡量两个变量之间线性相关程度的统计量。
公式: r = Cov(X,Y) / (SD(X) * SD(Y))其中,Cov(X,Y)表示X和Y的协方差,SD(X)和SD(Y)分别表示X和Y的标准差。
7.正态分布概率密度函数:正态分布是统计学中最重要的分布之一,其概率密度函数可以描述随机变量的分布。
公式:f(x)=(1/(σ*√(2π)))*e^(-(x-μ)^2/(2σ^2))其中,μ表示均值,σ表示标准差,e表示自然常数。
8.合并概率公式:用于计算多个事件同时发生的概率。
公式:P(A∩B)=P(A)*P(B,A)其中,P(A)表示A事件发生的概率,P(B,A)表示在A事件发生的条件下B事件发生的概率。
9.条件概率公式:用于计算在已知其中一事件发生的条件下另一事件发生的概率。
公式:P(A,B)=P(A∩B)/P(B)其中,P(A,B)表示在B事件发生的条件下A事件发生的概率。
10.抽样误差公式:用于计算样本估计值与总体参数之间的误差。
公式:误差=Z*(标准误差)其中,Z表示置信水平对应的标准正态分布的分位数,标准误差表示样本估计的标准差。
这些计算公式是统计学中非常重要的工具,用于帮助我们理解和解释数据的特征和关系。
统计学公式

3
xi x 4 n(n 1) 3(n 1) 2 ( ) . s (n 1)(n 2)(n 3) (n 2)(n 3)
2
统计学公式
二、概率分布
一、度量事件发生的可能性:
1.事件 A 发生的概率: P ( A) 二、随机变量的概率分布:
统计学公式
一、用统计量描述数据
一、水平的度量:
x x2 x3 1.简单平均数: x 1 n
xn
X
i 1
n
i
n
.
k
M f M 2 f2 M k fk 2.加权平均数: x 1 1 f1 f 2 f k
M
i 1
i i
f
n
.(如果原始数据被分成 k 组,各
2
E2
.
四、假设检验
一、一个总体参数的检验
1.大样本的检验
(1)在大样本的情况下,样本均值的抽样分布近似服从正态分布,其抽样标准差为 /
2
n.
采用正态分布的检验统计量.设假设的总体均值为 0 ,当总体方差 已知时,总体均值检验 的统计量为: z
x 0
/ n
.
(2)当总体方差 未知时,可以采用样本方差 s 来代替,此时总体均值检验的统计量为:
组的组中值分别用 M1,M 2, ,M k 表示,各组的频数分别用 f1,f 2, ,f k 表示,则得到 样本平均数计算公式)
x n 1 2 3.中位数( M e ) : Me 1 x n x n 1 2 2 2
n
p ;
(1 )
统计学常用公式

统计学常用公式统计学是一门研究数据收集、整理、分析和解释的学科。
在统计学中,公式是非常重要的工具,用于计算和推导各种统计指标和结果。
下面是一些统计学中常用的公式,它们可以帮助我们理解和应用统计学的基本概念和方法。
1. 数据的中心趋势度量在统计分析中,我们经常需要了解数据的中心趋势,即数据的集中程度或平均水平。
以下是几个常用的中心趋势度量公式:- 平均值(Mean):一组数据中所有观测值的总和除以观测值的个数。
- 中位数(Median):将一组数据按照大小排序,位于中间位置的观测值。
- 众数(Mode):出现次数最多的观测值。
- 加权平均值(Weighted Mean):将每个观测值乘以相应的权重,然后求和并除以总的权重和。
2. 数据的离散程度度量除了了解数据集中在哪里,我们还需要了解数据的离散程度,即数据分散的程度。
以下是几个常用的离散程度度量公式:- 方差(Variance):一组数据与其平均值之差的平方的平均值。
- 标准差(Standard Deviation):方差的算术平方根。
- 平均绝对偏差(Mean Absolute Deviation):一组数据与其平均值之差的绝对值的平均值。
3. 数据的相关性度量在统计分析中,我们常常需要了解两个或多个变量之间的相关性。
以下是几个常用的相关性度量公式:- 协方差(Covariance):一组数据中两个变量之间的协方差。
协方差的正负表示两个变量是正相关还是负相关。
- 相关系数(Correlation Coefficient):协方差除以两个变量各自的标准差的乘积。
相关系数的取值范围为-1到1,越接近-1或1表示相关性越强。
4. 抽样误差估计在统计学中,我们通常只能对样本数据进行分析,从而推断总体的特征。
以下是几个常用的抽样误差估计公式:- 样本标准差(Sample Standard Deviation):类似于总体标准差,但在计算时使用样本数据。
- 样本均值(Sample Mean):类似于总体均值,但在计算时使用样本数据。
统计学原理常用公式

统计学原理常用公式1.样本均值公式:样本均值是用来估计总体均值的一种方法,公式为:\bar{x} = \frac{{\sum_{i=1}^n x_i}}{n}\]其中,\(\bar{x}\) 是样本均值,\(x_i\) 是第 \(i\) 个观察值,\(n\) 是样本容量。
2.样本方差公式:样本方差是用来估计总体方差的一种方法,公式为:s^2 = \frac{{\sum_{i=1}^n (x_i - \bar{x})^2}}{n-1}\]其中,\(s^2\) 是样本方差,\(x_i\) 是第 \(i\) 个观察值,\(\bar{x}\) 是样本均值,\(n\) 是样本容量。
计算样本方差时使用的是无偏估计公式。
3.标准差公式:标准差是样本方差的平方根,公式为:s = \sqrt{s^2}\]其中,\(s\)是样本标准差。
4.离差平方和公式:离差平方和是指每个观察值与均值之差的平方的总和,公式为:\sum_{i=1}^n (x_i - \bar{x})^2\]5.切比雪夫不等式:切比雪夫不等式给出了随机变量与其均值之间的关系,公式为:P(,X-\mu,\geq k\sigma) \leq \frac{1}{k^2}\]其中,\(X\) 是随机变量,\(\mu\) 是均值,\(\sigma\) 是标准差,\(k\) 是大于零的常数。
6.二项分布的期望值和方差公式:二项分布用于描述在\(n\)次独立重复试验中成功的次数的概率分布。
其期望值和方差分别为:E(X) = np\]Var(X) = np(1-p)\]其中,\(X\)是二项分布随机变量,\(n\)是试验次数,\(p\)是单次试验成功的概率。
7.正态分布的概率密度函数和累积分布函数公式:正态分布描述了大部分自然现象中的连续性随机变量的分布。
f(x) = \frac{1}{{\sqrt{2\pi}\sigma}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]F(x) = \frac{1}{2}\left[1 + \text{erf}\left(\frac{x -\mu}{\sqrt{2}\sigma}\right)\right]\]其中,\(x\) 是正态分布的随机变量,\(\mu\) 是均值,\(\sigma\) 是标准差,\(\text{erf}\) 是误差函数。
统计学公式大全
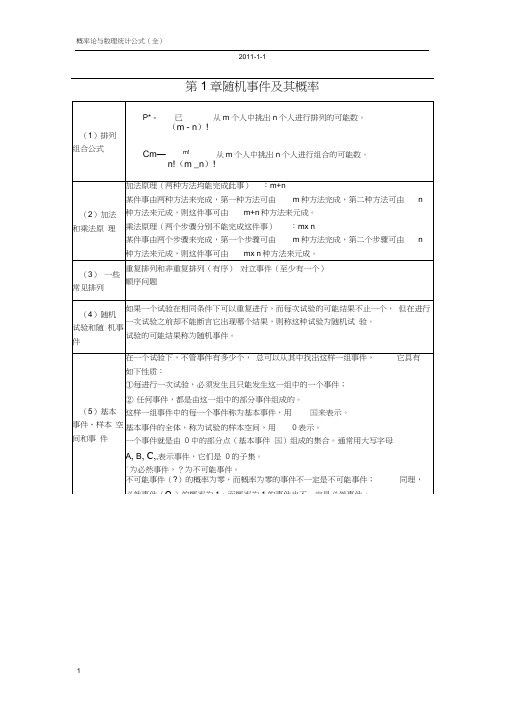
第1章随机事件及其概率第二章随机变量及其分布指数分布正态分布f (x)二0,x :: 0其中’0,则称随机变量X服从参数为’的指数分布。
X的分布函数为F(x)二1-e—'x0, x<0。
记住积分公式:■box n e」dx = n!设随机变量X的密度函数为1 . .2 --------------------------------- --------------------f(x)=^^^e 2口,—旳C X W+P,J2兀◎其中"、二0为常数,则称随机变量X服从参数为2 的正态分布或高斯(Gauss)分布,记为X〜N(.L,;-)。
f(x)具有如下性质:f(x)的图形是关于x i对称的;2°当x八I时,f(J —为最大值;^'2ncr的分布函数为dt1°若X〜N(1,JF(x)l2=x ?-e参数"、二=1时的正态分布称为标准正态分布,记为X ~ N(0,1)1其密度函数记为(【2二°",八::::,分布函数为1 x t2::J(x)e. 2心:,J(x)是不可求积函数,其函数值,已编制成表可供查用。
口1①(-x)= 1-①(x)且①(0)=—2X A如果X 〜N (丄,二),贝V ~ N (0,1)。
F x 耳、(2dt。
第三章二维随机变量及其分布如果二维随机向量'(X ,Y )的所有可能取值为至多可列 个有序对(x,y ),则称匕为离散型随机量。
设.=(X ,Y )的所有可能取值为(x ,y j )(i, j =1,2,…), 且事件{ =(x i , y j )}的概率为p j,,称P {(X,Y)=&,y j )}二P j (i,j =1,2,)为.=(X ,Y )的分布律或称为 X 和Y 的联合分布律。
联合分布有时也用下面的概率分布表来表示:这里p j 具有下面两个性质:(1) p j > 0 (i,j=1,2,,); (2) 二二 p ij =1.i j(1 )联合 离散型 分布概率论与数理统计公式(全)2011-1-1若X1,X2, , X m X m+1, , %相互独立,h,g为连续函数,则: h(X1,X2, , X m)和g (X m+1, , X n)相互独立。
统计学常用公式总结

心理统计常用公式总结1 、组数 K(总体分布为正态)( N 为数据个数, K 取近似整数)2 、算术平均数3 、中数4 、众数5 、加权平均数,其中 W i 为权数,其中为各小组的平均数, n i 为各小组人数6 、几何平均数,其中 n 为数据个数, X i 为数据的值7 、调和平均数8 、方差与标准差,其中9 、变异系数,其中 S 为标准差, M 为平均数10 、标准分数,其中 X 为原始数据,为平均数, S 为标准差11 、全距R=最大数-最小数12 、平均差13 、四分差,其中 L b 为该四分点所在组的精确下限, F b 为该四分点所在组以下的累加次数,和为该四分点所在组的次数, i 为组距, N 为数据个数14 、积差相关基本公式:,其中N 为成对数据的数目, S x 、 S y 分别为 X 和 Y 的标准差变形:差法公式:用估计平均数计算:用相关表计算:15 、斯皮尔曼等级相关,其中 D 为各对偶等级之差直接用等级序数计算:,其中 R X 、 R Y 分别为二变量各等级数有相同等级时:16 、肯德尔等级相关有相同等级:17 、点二列相关,其中是两个二分变量对偶的连续变量的平均数, p 、 q 是二分变量各自所占的比率, p+q=1 , S t 是连续变量的标准差18 、二列相关,其中 S T 与是连续变量的标准差与平均数, y 为 P 的正态曲线的高度19 、多系列相关,其中 P i 为每系列的次数比率, y 1 为每一名义变量下限的正态曲线高度,y h 为每一名义变量上线的正态曲线高度,为每一名义变量对偶的连续变量的平均数, S t 为连续变量的标准差20 、总体为正态,σ 2 已知:21 、总体为正态,σ 2 未知:22 、23 、24 、。
统计学公式总结

简单平均差(未分组数据)平均差越大说明数据的离散程度越大.反之.
加权平均差(分组数据)
简单样本方差(未分组数据)P99
加权样本方差(分组数据)
简单样本标准方差(未分组数据)
加权样本标准差(分组数据)
标准分数 (变量值与其平均数的离差除以标准差后的值。)
离散系数(变异系数)是一组数据的标准差与其相应的平均数之比..离散系数大,数据的离散程度大.反之..它们是成正比的.
( s标准差,x平均数)
(二)抽样分布主要公式
总体均值的置信区间(正态总体, 已知)P183
注意P184例题
总体均值的置信区间(未知, 大样本)P183
总体均值的置信区间(正态总体, 未知, 小样本)
总体比例的置信区间P187( 注意P187.192例题)
估计总体均值时的样本容量P201(注意P202例题)
估计总体比例时的样本容量(三)假来自检验一个总体参数的检验
总体均值的检验
(大样本检验方法的总结)
假设
双侧检验
左侧检验
右侧检验
假设形式
H0:=
H1 :(
H1:
H0 :(
H1 :<
H1:<
H0 :(
H1 :>
H1:>
统计量
已知
( 未知:
拒绝域
(小样本检验方法的总结)
假设
双侧检验
左侧检验
右侧检验
假设形式
H0:=
H1 :(
H1:
H0:(
H1 :<
H1:<
H0 :(
H1 :>
H1:>
统计学原理公式

统计学原理公式统计学是一门研究数据收集、分析、解释和呈现的学科,它在各个领域都有着广泛的应用。
在统计学中,公式是非常重要的工具,它们可以帮助我们理解数据的规律,进行数据分析和推断。
本文将介绍一些统计学原理中常用的公式,帮助读者更好地理解统计学的基本概念和原理。
1. 样本均值公式。
样本均值是统计学中最基本的概念之一,它表示了一组数据的平均水平。
样本均值的计算公式如下:\[ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i \]其中,\( \bar{x} \) 表示样本均值,\( n \) 表示样本容量,\( x_i \) 表示第 \( i \) 个观测值。
通过样本均值公式,我们可以快速计算出一组数据的平均值,从而对数据的集中趋势有一个直观的认识。
2. 样本方差公式。
样本方差是衡量一组数据离散程度的指标,它表示了数据点与样本均值之间的差异程度。
样本方差的计算公式如下:\[ s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i \bar{x})^2 \]其中,\( s^2 \) 表示样本方差,\( n \) 表示样本容量,\( x_i \) 表示第 \( i \) 个观测值,\( \bar{x} \) 表示样本均值。
样本方差公式可以帮助我们衡量数据的离散程度,从而对数据的分布情况有一个直观的了解。
3. 样本标准差公式。
样本标准差是样本方差的平方根,它也是衡量数据离散程度的重要指标。
样本标准差的计算公式如下:\[ s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i \bar{x})^2} \]其中,\( s \) 表示样本标准差,其他符号的含义与样本方差公式相同。
样本标准差公式可以帮助我们更直观地理解数据的离散程度,它是许多统计推断和假设检验的基础。
4. 正态分布概率密度函数。
正态分布是统计学中最重要的概率分布之一,它具有许多重要的性质和应用。
统计学计算公式大全

统计学计算公式大全统计学是数学中一个重要的分支,它利用分析数据,抽象出具有相似特征的概念,研究其变化规律、发展趋势,为决策提供重要的依据。
统计学涉及的范畴较广,涉及统计数据的收集、分析处理、描述抽象、模型建立、推理预测等数学计算技术,其中重要的组成部分就是计算公式,下面就是统计学计算公式大全。
一、抽样调查统计1、样本量的计算公式:n=N/ (1+N*e2/δ2)其中:n为样本量,N为总体量,e为期望的标准误差,δ为期望的置信度。
2、样本抽取a)取系统抽样公式:Pi=Di/n其中:Pi为抽取的概率,Di为分层抽样时的各层系统抽样量,n 为总体量。
b)层抽样公式:Di=ni/ni+N1+…+Nk其中:Di为分层抽样时的各层系统抽样量,ni为各层抽样量,N1+…+Nk为总体量。
3、数据分析a)差、方差、标准差极差X=Xmax-Xmin方差S2=G2S/(n-1)标准差S=根号[G2S/(n-1)]其中:Xmax,Xmin为所有样本数据的最大值和最小值,G1S和G2S分别为样本一阶矩和二阶矩,n为样本量。
b)值、中位数均值:X=G1S/n中位数:中位数=X((n+1)/2)其中:G1S为样本一阶矩,n为样本量。
c)分位数百分位数:Xp=(n+1)P/100其中:P为百分位数,n为样本量二、两个样本的比较1、大样本检验a) t检验t=X1-X2/S其中:X1,X2分别为样本1和样本2的均值,S为两个样本总体方差的平均值。
b) F检验F=S12/S22其中:S12,S22分别为样本1和样本2的方差。
2、小样本检验a) Z检验z=X1-X2/S其中:X1,X2分别为样本1和样本2的均值,S为样本1和样本2的总体标准差的平方根。
b)2检验χ2=∑[(Oi-Ei)2/Ei]其中:Oi,Ei分别为样本的实际频数和期望频数。
三、数据回归分析1、回归分析公式Y=a+bX其中:Y,X分别为回归变量,a,b分别为回归系数。
统计学原理重要公式

统计学原理重要公式1.样本均值公式:样本均值是样本数据的总和除以样本的大小。
它的公式是:$$ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i $$其中,n是样本的大小,xi是第i个观测值。
2.总体均值公式:总体均值是从总体中取得的全部样本数据的总和除以总体的大小。
它的公式是:$$ \mu = \frac{1}{N} \sum_{i=1}^{N} x_i $$其中,N是总体的大小,xi是第i个观测值。
3.样本方差公式:样本方差是样本数据与样本均值差的平方和的平均值。
它的公式是:$$ s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2 $$其中,n是样本的大小,xi是第i个观测值,$ \bar{x} $是样本均值。
4.总体方差公式:总体方差是总体数据与总体均值差的平方和的平均值。
它的公式是:$$ \sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 $$其中,N是总体的大小,xi是第i个观测值,$ \mu $是总体均值。
5.样本标准差公式:样本标准差是样本方差的平方根。
它的公式是:$$ s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2} $$其中,n是样本的大小,xi是第i个观测值,$ \bar{x} $是样本均值。
6.总体标准差公式:总体标准差是总体方差的平方根。
它的公式是:$$ \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2} $$其中,N是总体的大小,xi是第i个观测值,$ \mu $是总体均值。
7.样本比例公式:样本比例是样本中具有一些特征的观测值的比例。
$$ p = \frac{x}{n} $$其中,n是样本的大小,x是具有特征的观测值的数量。
统计学重要公式

X Y
S
X
S
Y
L
X X
=
∑ (X
n i = 1
i
X
)
2
=
∑
n
X
2 i
i = 1
i = 1
L
X Y
=
∑ (X
n i = 1
i
X
) (Y
2
i
Y
)= ∑
n 2 i
X
X
n
i = 1
i
Y
i = 1
i
Y
i = 1
i
i
n
L
Y Y
=
∑ (Y
n
X
=
∑
i = 1
i
Y
)
=
n
∑
Y
i
n
Y
∑
Y n
i = 1
i
,
n
X n
=
∑
k
(
i=1
fi ei ei :
)
2
,df = k 1
=
i
×
j
:
=
∑ ∑
i j
(f
ij
e ij e ij
)
2
,df =
(R
1 ) (C 1 )
值均本样的理处个j第 差方本样的理处个j第
: X
t
验检
: X
j
=
∑
n n
j
j
X n
j
i=1
ij
, X 1
: S X
2 j
=
∑ (X
i=1
ij
j
45.两 个 总 体 比 率 之 差 的 区 间 估 计 : 大 样 本 n1 p1 , n1 (1 p1 ), n 2 p 2 , n 2 (1 p 2 ) ≥ 5时 , ) ) ( p1 p 2 ) ± Z α S p1 p2
统计学公式

(一)频数分布中变量数列相关公式1、全距=最大标志值-最小标志值2、组距=各组最大标志值(上限) -各组最小标志值(下限) =全距÷组数3、组数、组距确定的斯特杰斯经验公式:4、重合式(指相邻两组中,前一组的上限和后一组的下限数值重合)组距=上限-下限组中值=(上限+下限)÷2 =下限+组距/2=上限-组距/25、不重合式(指前一组的上限与后一组的下限,两值紧密相连而不相重复)组距=下组下限-本组下限=本组上限-前组上限 组中值=(本组下限+下一组下限) ÷2 =本组下限+组距/2 =下组下限-组距/2 6、闭口式分组的组中值求法:(二)综合指标相关公式<1>相对指标之计划完成相对数1.(分子分母位子不能换)超额完成(或未完成)绝对数=实际完成数-计划数 2 . 短期检查:(1)产量、产值增长百分数:1 3.3lg max min 1 3.3lg :max min n N R X X d n N n N d R X X =+-==+组数,:总体单位数,:组距,:全距:最大变量值,:最小变量值2下限上限下限或 2组的下限组的上限组中值-+=+=100%计划完成数实际完成数计划完成相对数⨯=%100%%100%%100⨯++=计划增长实际增长计划完成相对数(2)产品成本降低百分数3.中长期检查(1) 水平法(注意提前完成时的相关问题)(2)累计法4.执行进度检查<2>相对指标之结构相对数<3>相对指标之比例相对数<4>相对指标之比较相对数<5>相对指标之强度相对数(注意与平均数的区别)%100%%100%%100⨯--=计划规定降低实际降低计划完成相对数%100⨯=计划期末年应达水平计划期末年实达水平计划完成相对数100%=⨯计划期内各年累计完成数同期计划规定的累计数计划完成相对数%100⨯=本期计划数成数计划期内某月止累计完计划执行进度%100⨯=总体的数值总体某部分的数值结构相对数同一总体另一部分数值总体中某一部分数值比例相对数=%100)()(⨯=同一现象数值单位另一地区某一现象数值单位某地区比较相对数另一现象数值某一现象数值强度相对数=<6>相对指标之动态相对数<7>平均指标之算术平均数nx ∑=x (简单算术平均)∑∑=fxf x (加权算术平均)<8>平均指标之调和平均数(注意其应用条件)∑∑==xn nx H 111(简单调和平均)∑∑∑∑==fx f ff x H 111(加权调和平均)<9>平均指标之几何平均数(简单几何平均)(加权几何平均)<10>平均指标之众数 (1)上限公式(2 %100⨯=基期数值报告期数值动态相对数注:U 为众数所在组组距的上限,L 为众数所在组组距的下限,f 为众数所在组的次数,f-1 为众数所在组前一组次数, f+1 为众数所在组后一组次数,i 为组距。
统计学公式

统计学114个公式1.组距=本组上限-本组下限(不包括上.下限的数字)2.间断式分组组距: 组距=本组上限-前组上限3.组距=本组下限-前组下限4.组距=本组上限-本组下限+15.开口组中值:组中值=(上限+下限)/2 缺下限:上限- —————— =组中值6.缺上限:下限- ————— =组中值 7.d=R/n(R 为总体全距,n 为组数,d 为组距) 8.N=1+3.322lgN N 为组数,N 为总体容量9. 简单算术平均数X = (X 1+X 2 +X 3 +…+X n )/n(可简记为X =ΣX n /n )10.加权算术平均数X=(X 1f 1+X 2f 2+…+ X k f k )/ (f 1+f 2+…+f k )=ΣX i f i /Σf i (可简记为 X=ΣX i f i /Σf i )11. 算术平均数的数学性质(1)各变量值与算术平均数的离差之和等于零,即:相邻组组距2 相邻组组距 2=0(对于简单算术平均数) 或=0(对于加权算术平均数)12.(2)各变量值与算术平均数的离差平方之和为最小值,即: Σ(x i -x)2 =最小值 或Σ(x i -x)2≤Σ(x i -x 0)2 (只有当x = x 0 时,等号成立) 13. 简单调和平均数 H =km /(m/x 1+m/x 2+…+m/x k )=k /Σ(1/x i )可简记为:H = k /Σ(1/x i )14.加权调和平均数H =(m 1+m 2+…+m k )/(m 1/x 1+m 2/x 2+…+m k /x k )=Σm i /Σ(m i /x i )(可简记为:H =Σm i /Σ(m i /x i )。
)15. 简单几何平均数 G = n √x 1.x 2.x 3…x n = n √∏x i (可简记为G = n √∏x i )16. 加权几何平均数 G = Σfi √x 1 f1.x 2 f2.x 3 f3…x n fk= Σfi √∏x fi i(可简记为G =Σfi √∏x fi i ) 17. 算术平均数、调和平均数和几何平均数的数学关系 幂平均数的定义是:x t = t √Σx t /n 当t=1时,幂平均数就是算术平均数; 当=-1时,幂平均数就是调和平均数;当趋向于0时,幂平均数的极限形式就是几何平均数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
公式一1. 众数【MODE 】(1) 未分组数据或单变量值分组数据众数的计算未分组数据或单变量值分组数据的众数就是出现次数最多的变量值。
(2) 组距分组数据众数的计算对于组距分组数据,先找出出现次数最多的变量值所在组,即为众数所在组,再根据下面的公式计算计算众数的近似值。
下限公式: 1012M =L++i ∆⨯∆∆ 式中:0M 表示众数;L 表示众数的下线;1∆表示众数组次数与上一组次数之差;2∆表示众数组次数与下一组次数之差;i 表示众数组的组距。
上限公式:2012M =U-+i ∆⨯∆∆ 式中:U 表示众数组的上限。
2.中位数【MEDIAN 】(1)未分组数据中中位数的计算根据未分组数据计算中位数时,要先对数据进行排序,然后确定中位数的位置。
设一组数据按从小到大排序后为12N X X X ,,…,,中位数e M ,为则有:e N+M =X1()2当N 为奇数e N N +1221M =X +X 2⎛⎫⎛⎫ ⎪ ⎪⎝⎭⎝⎭⎧⎫⎪⎪⎨⎬⎪⎪⎩⎭当N 为偶数(2)分组数据中位数的计算分组数据中位数的计算时,要先根据公式N / 2 确定中位数的位置,并确定中位数所在的组,然后采用下面的公式计算中位数的近似值:N=1m-1e m-S 2M =L+ii fd f ⨯∑式中:e M 表示中位数;L 表示中位数所在组的下限;m-1S 表示中位数所在组以下各组的累计次数;m f 表示中位数所在组的次数;d 表示中位数所在组的组距。
3.均值的计算【AVERAGE 】(1)未经分组均值的计算未经分组数据均值的计算公式为: 112n ++==nii x x x x x n n=∑…(2)分组数据均值计算分组数据均值的计算公式为: 11221121+++==+ki ik k i k kii x f x f x f x f x f f f f==+∑∑L L +4.几何平均数【GEOMEAN 】几何平均数是N 个变量值乘积的N 次方根,计算公式为:式中:G 表示几何平均数;∏表示连乘符号。
5.调和平均数【HARMEAN 】调和平均数是对变量的倒数求平均,然后再取倒数而得到的平均数,它有简单调和平均数与加权调和平均数两种计算形式。
简单调和平均数: 211H==111+++nini n n x x x x =∑1…加权调和平均数: 21211211m m +m ++m H==m m m m +++n i ni n i nn ii x x x x ==∑∑…… 式中:H 表示调和平均数。
6.极差【Range 】极差也称全距,是一组数据的最大值与最小值之差,即 ()()R=max -min i i x x式中:R 表示极差;()max i x 和()min i x 分别表示一组数据的最大值与最小值。
7.平均差【Mean Deviation 】平均差是各标志值与其平均数的绝对离差的算术平均。
(1) 根据未分组资料的计算公式: 1-AD=ini x xn=∑(2) 根据分组资料的计算公式: 11-AD=inii nii x xf f==∑∑式中:AD 表示平均差8.方差【Variance 】和标准差【Standard Deviation 】方差是各变量值与其均值离差平方的平均数。
要求掌握方差和标准差的计算方法。
未分组数据方差的计算公式为: ()221ni x x nσ=-=∑分组数据方差的计算公式为: ()2211i nii nii x xf fσ==-=∑∑式中:2σ表示方差。
方差的平方根即为标准差,其相应的计算公式为:未分组数据:σ=分组数据:σ=式中:σ表示标准差。
9.离散系数离散系数通常是就标准差来计算的,因此,也称为标准差系数,它是一组数据的标准差与其相应的均值之比,是测度数据离散程度的相对指标。
其计算公式为: V xσσ=式中:V σ表示离散系数。
10.偏态【SKEW 】偏态是对分布偏斜方向及程度的测度。
利用众数、中位数和均值之间的关系就可以判断分布是左偏还是右偏。
显然,判别偏态的方向并不困难,但要测度偏斜的程度就需要计算偏态系数了。
EXCEL 中偏态系数的计算公式为: ()()31--1-2i ni x x nn n s =⎡⎤⎢⎥⎣⎦∑11.峰值【KURT 】EXCEL 中峰值系数的计算公式为:()()()()()()()421-13112313in i x x n n n n n n s n n =⎧⎫+-⎛⎫⎪⎪-⎨⎬ ⎪-----⎝⎭⎪⎪⎩⎭∑ 式中:s 表示样本标准差。
公式二1.均值估计(1)样本均值的标准差样本均值的标准差,即为样本均值的标准误差,又称为样本均值的抽样平均误差,它反映的是所有可能样本的均值与总体均值的平均差异程度,反映了所有可能样本的实际抽样误差水平。
样本均值的抽样平均误差计算公式为:重复抽样方式: ()x σ==不重复抽样方式: ()x σ=通常情况下,当N 很大时,(N-1)几乎等于N ,样本均值的抽样平均误差的计算公式也可简化为:()x σ=在公式中,σ是总体标准差。
但实际计算时,所研究总体的标准差通常是未知的,在大样本的情况下,通常用样本标准差S 代替。
(2)大样本均值的极限误差 ()x Z x ασ∆= (3)大样本下总体均值的区间估计总体均值的置信度为(1α-)的置信区间:()()22x z x x z x αασμσ-≤≤+ 即22x z x z ααμ-≤≤+(4)总体方差未知,小样本正态总体均值的区间估计总体均值的置信度为(1α-)的置信区间:()()22x t x x t x αασμσ-≤≤+即22x t x t ααμ-≤≤+ 2.比例估计(1)样本比例的抽样平均误差样本比例的抽样平均误差为:重复抽样下: ()p σ=上式中,p 应为总体比例,实际计算时通常用样本比例p 代替。
不重复抽样下: ()p σ=≈(2)样本比例的抽样极限误差()2P Z p ασ∆=(3)总体比率的区间估计总体比例P 的置信度为(1α-)的置信区间为:P P p p p -∆≤≤+∆即 ()()22p Z p p p Z p αασσ-≤≤+3. 总体均值检验(1) 单一总体均值检验①正态总体(总体方差已知)或大样本均值检验检验统计量Z 为:x Z =②正态总体(总体方差未知)小样本均值检验检验统计量t 为:x t =(2) 两个总体的均值检验①两个正态总体均值检验——两个总体方差已知或大样本Z 检验统计量为:-x x Z μμ--=大样本下对两个总体均值进行检验时,在总体标准差未知的情况下,可用样本标准差代替总体标准差进行计算,检验统计量不变。
②两个正态总体均值检验(小样本)——两个总体方差未知但相等T 检验统计量为:-x x Z μμ--=p s =其中: ()122111111i n i s x x n ==--∑; ()222221211i n i s x x n ==--∑4. 总体比例检验(1) 单一总体的比例检验Z 检验统计量:Z =(2) 两个总体比例的检验检验的统计量为:Z =其中:112212ˆˆˆn pn p pn n +=+,ˆp为当12p p =时1p 和2p 的联合估计值。
5. 总体方差假设检验(1) 单一正态总体方差的假设检验检验统计量为: ()2221n s χσ-= 其中:()2211i ni x xs n =-=-∑为2σ的估计量。
(2) 两个正态总体的方差假设检验检验统计量为: 2212F s s =其中: ()1221111i n i x xs n =-=-∑; ()2221221i n i x xs n =-=-∑。
公式三1.单因素方差分析设总体共分为k 种处理进行观察,第j 种处理试验了容量为j n 的样本。
(1) 计算各项离差平方和在单因素方差分析中,需要计算的离差平方和有3个,它们分别是总离差平方和,误差项离差平方和以及水平项离差平方和。
总离差平方和,用SST (Sum of Squares for T otal )代表:()211jn kij i j SST x x ===-∑∑式中:x 表示全部样本观测值的总均值。
其计算公式为:ij x x n =∑∑误差离差平方和,用SSE (Sum of Squares for Error )代表:()211j n kij j i j SSE x x ===-∑∑ 式中:j x 表示第j 种水平的样本均值,1j n iji j j x x n ==∑水平项离差平方和。
为了后面叙述方便,可以把单因素方差分析中的因素称为A 。
于是水平项离差平方和可以用SSA (Sum of Squares for Factor A )表示。
SSA 的计算公式为: ()211j n k j i j SSA x x ===-∑∑(2) 计算平均平方用离差平方和除以自由度即可得到平均平方和(Mean Square )。
对SST 来说,其自由度为(n-1);对SSA 来说,其自由度为(r-1),这里r 表示水平的个数;对SSE 来说,其自由度为(n-r )。
与离差平方和一样,SST 、SSA 、SSE 之间的自由度也存在着如下的关系:n-1=(r-1)+(n-r )对于SSA ,其平均平方MSA (组间均方差)为: 1SSA MSA r =- 对于SSE ,其平均平方MSE (组内均方差)为: SSE MSE n r =- (3) 检验统计量F MSA F MSE=2.两因素方差分析设两个因素A 、B 分别有k 个水平和n 个水平,共进行nk 次试验。
(1) 计算各项离差平方和在两因素方差分析中,需要计算的离差平方和有4个,它们分别是总离差平方和,误差项离差平方和以及水平A 、B 项离差平方和。
总离差平方和,用SST (Sum of Squares for Total )代表: ()2ij SST x x =-∑∑ 式中:x 表示全部样本观察值的总均值,其计算公式为: 111n kij i j x x nk ===∑∑ 水平项离差平方和可以分别用SSA (Sum of Squares for Factor A )和SSB (Sum of Squares for Factor B )表示。
SSA 的计算公式为: ()211n k j i j SSA x x •===-∑∑式中: 11n j ij i x x n •==∑ SSB 的计算公式为: ()211n k i i j SSB x x •===-∑∑式中: 11k i ij j x x k •==∑ 误差离差平方和,用SSE (Sum of Squares for Error )代表:()211n k ij i j i j SSE x x x x ••===--+∑∑(2) 计算平均平方用离差平方和除以自由度即可得到平均平方和(Mean Square )。