模式识别课程报告2.0
2021年模式识别实验报告
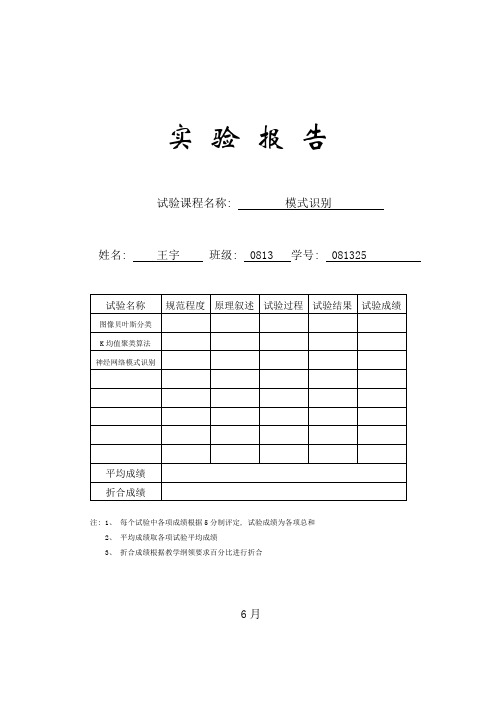
实验报告试验课程名称: 模式识别姓名: 王宇班级: 0813 学号: 081325注: 1、每个试验中各项成绩根据5分制评定, 试验成绩为各项总和2、平均成绩取各项试验平均成绩3、折合成绩根据教学纲领要求百分比进行折合6月试验一、 图像贝叶斯分类一、 试验目将模式识别方法与图像处理技术相结合, 掌握利用最小错分概率贝叶斯分类器进行图像分类基础方法, 经过试验加深对基础概念了解。
二、 试验仪器设备及软件 HP D538、 MATLAB 三、 试验原理 概念:阈值化分割算法是计算机视觉中常见算法, 对灰度图象阈值分割就是先确定一个处于图像灰度取值范围内灰度阈值, 然后将图像中每个像素灰度值与这个阈值相比较。
并依据比较结果将对应像素划分为两类, 灰度值大于阈值像素划分为一类, 小于阈值划分为另一类, 等于阈值可任意划分到两类中任何一类。
最常见模型可描述以下: 假设图像由含有单峰灰度分布目标和背景组成, 处于目标和背景内部相邻像素间灰度值是高度相关, 但处于目标和背景交界处两边像素灰度值有较大差异, 此时, 图像灰度直方图基础上可看作是由分别对应于目标和背景两个单峰直方图混合组成。
而且这两个分布应大小靠近, 且均值足够远, 方差足够小, 这种情况下直方图展现较显著双峰。
类似地, 假如图像中包含多个单峰灰度目标, 则直方图可能展现较显著多峰。
上述图像模型只是理想情况, 有时图像中目标和背景灰度值有部分交错。
这时如用全局阈值进行分割肯定会产生一定误差。
分割误差包含将目标分为背景和将背景分为目标两大类。
实际应用中应尽可能减小错误分割概率, 常见一个方法为选择最优阈值。
这里所谓最优阈值, 就是指能使误分割概率最小分割阈值。
图像直方图能够看成是对灰度值概率分布密度函数一个近似。
如一幅图像中只包含目标和背景两类灰度区域, 那么直方图所代表灰度值概率密度函数能够表示为目标和背景两类灰度值概率密度函数加权和。
假如概率密度函数形式已知, 就有可能计算出使目标和背景两类误分割概率最小最优阈值。
模式识别与智能系统概论课程报告

课程报告一、人工智能与模式识别的研究已有多年,但似乎公认的观点认为它仍然非常困难。
在查阅文献或网络的基础上,试对你所熟悉的任一方向(如人像识别、语音识别、字符识别、自然语言理解、无人驾驶等等)的发展状况进行描述。
并设想如果你将从事该方向的研究,你打算如何着手,以建立有效的理论和方法;或者你认为现在的理论和方法有何缺陷,有什么办法来进行改进?(10分)语音识别属于感知智能,而让机器从简单的识别语音到理解语音,则上升到了认知智能层面,机器的自然语言理解能力如何,也成为了其是否有智慧的标志,而自然语言理解正是目前难点。
总结目前语音识别的发展现状,dnn、rnn、lstm和cnn算是语音识别中几个比较主流的方向。
长短时记忆网络可以说是目前语音识别应用最广泛的一种结构,这种网络能够对语音的长时相关性进行建模,从而提高识别正确率。
双向LSTM网络可以获得更好的性能,但同时也存在训练复杂度高、解码时延高的问题,尤其在工业界的实时识别系统中很难应用。
语音识别发展现状面临窘境:1)噪声鲁棒性:做声环境下的鲁棒语音识别一直是语音识别大规模应用的主要绊脚石,我们如何在一些噪声场景比较大的情况下,比如说我们的马路、咖啡厅,公共汽车,飞机场,以及会议室,大巴上等等,使得得到很高的识别精度,这是非常具有挑战性的。
环境感知的深度模型以及神经网络的快速自适应方法,它使得我们一般的深度模型可以对环境进行一个实时的感知和自适应调整,来提高实现系统性能,就像人耳一样。
另外我们也将极深卷积神经网络用于抗噪的语音识别得到巨大的系统性能的提升。
2)多类复杂性:过去的大部分语音识别系统的设计主要是针对一些单一环境、单一场景下进行设计的,如何做多类别复杂场景下的通用的语音识别是非常困难的,比如说在Youtube或者BBC上的一些数据,可以来自各种各样的语境和场景,有新闻广播、新闻采访、音乐会、访谈、电影等等。
3)低数据资源与多语言:目前大部分语音识别的研究和应用,主要是基于一些大语种,比如说英语、汉语、阿拉伯语和法语等等,我们知道世界上一共有6900多种语言,如何快速的实现一套基于任何语言的语言识别系统是非常困难的,它也具有重大的战略意义。
关于学习了解模式识别技术报告

关于了解学习模式识别技术报告谈起模式识别,我们首先想到的是人工智能。
模式识别是人工智能的一个分支,是电脑应用内容的一部分。
要想了解学习模式识别,首先要懂得人工智能。
第一篇人工智能什么是人工智能呢?人工智能主要用人工的方法和技术,模仿,延伸和扩展人的智能,实现机器智能。
人工智能的长期目标是实现到达人类智力水平的人工智能。
〔摘自《人工智能》史忠植编著,第一章绪论〕简单来说就是使机器拥有类人行为方法,类人思维方法和理性行为方法。
让机器像人一样拥有自主思维的能力,拥有人的生存技能,甚至在某方面超过人类,用所拥有的技能,更好的为人类服务,解放人类的双手。
简单了解了人工智能的概念,接下来将介绍人工智能的起源与发展历史。
说到历史,很多人可能有点不大相信。
人类对智能机器的梦想和追求可以追溯到三千多年前。
也许你会有疑问,三千多年前,人类文明发展都不算成熟,怎么可能会有人对机器有概念。
当然,那时候的机器并非现在的机器概念。
在我国,早在西周时代〔公元前1066~公元前771年〕,就流传有关巧匠偃师献给周穆王艺伎的故事。
东汉〔公元25~公元220年〕张衡发明的指南车是世界上最早的机器人雏形。
〔摘自《人工智能》史忠植编著,第一章绪论〕现在你也许已经笑掉大牙了。
那样一个简易工具竟然说是机器人雏形。
但是事实就是这样,现在对机器人的概念依旧模糊,有些人觉得机器人必须先有像人一样的外形。
其次是有人一样的思维。
这个描述是没有错的,但是有点片面了,只顾及到字面意思了。
机器人的概念是自动执行工作的机器装置。
所以机器可以自动执行工作都叫机器人。
在国外也有案例:古希腊斯吉塔拉人亚里士多德〔公元前384年~公元前322年〕的《工具论》,为形式逻辑奠定了基础。
布尔创立的逻辑代数系统,用符号语言描述了思维活动中推理的基本法则,被后世称为“布尔代数”。
这些理论基础对人工智能的创立发挥了重要作用。
〔摘自《人工智能》史忠植编著,第一章绪论〕人工智能的发展历史,可大致分为孕育期,形成期,基于知识的系统,神经网络的复兴和智能体的兴起。
神经网络与模式识别课程报告

神经网络与模式识别课程报告卷积神经网络(CNN)算法研究摘要随着信息技术的迅速发展,验证码作为一种安全验证手段广泛应用于网络平台。
然而,复杂的验证码对自动识别技术提出了挑战。
近年来,深度学习特别是卷积神经网络(CNN)在图像识别领域显示出了强大的能力。
本研究旨在探索利用CNN算法进行验证码识别的可能性和有效性。
通过设计并实现一个基于CNN的验证码识别系统,本研究评估了不同训练策略及数据增强技术对验证码识别准确率的影响。
关键词:验证码识别;卷积神经网络;深度学习;图像处理;目录摘要 .......................................................................................... I I第1章概要设计 (1)第2章程序整体设计说明 (4)第3章程序运行效果 (15)第4章设计中遇到的重点及难点 (18)第5章本次设计存在不足与改良方案 (18)结论 (20)参考文献 (21)第1章概要设计1.1 设计目的人工神经网络是深度学习之母。
随着深度学习技术的兴起及其在阿尔法围棋程序等实际应用的精彩表现,神经网络已经广泛地应用于图像的分割和对象的识别、分类问题中。
伴随人工神经网络的发展,神经网络在模式识别领域中起着越来越重要的作用。
通过本课程的学习,让大家从算法的视角,掌握神经网络与模式识别这两个彼此紧密联系的人工智能分支中的基础理论、问题、思路与方法,并理解神经网络与模式识别的研究前沿。
1.2 选题验证码(CAPTCHA)是一种常见的用于区分人类和机器的技术,常用于网站、APP用户登陆时输入一些数字或字符以验证其身份。
本文将介绍如何使用卷积神经网络(CNN)来识别常见的字符验证码。
选择使用卷积神经网络(CNN)用于验证码识别方向的原因有以下几点:1. 强大的图像处理能力:CNN是一种特别适用于处理图像数据的深度学习模型。
它具有多层结构,可以自动学习和提取图像中的特征,如边缘、纹理和形状等。
模式识别课程报告

模式识别实验报告学生姓名:班学号:指导老师:机械与电子信息学院2014年 6月基于K-means算法的改进算法方法一:层次K均值聚类算法在聚类之前,传统的K均值算法需要指定聚类的样本数,由于样本初始分布不一致,有的聚类样本可能含有很多数据,但数据分布相对集中,而有的样本集却含有较少数据,但数据分布相对分散。
因此,即使是根据样本数目选择聚类个数,依然可能导致聚类结果中同一类样本差异过大或者不同类样本差异过小的问题,无法得到满意的聚类结果。
结合空间中的层次结构而提出的一种改进的层次K均值聚类算法。
该方法通过初步聚类,判断是否达到理想结果,从而决定是否继续进行更细层次的聚类,如此迭代执行,生成一棵层次型K均值聚类树,在该树形结构上可以自动地选择聚类的个数。
标准数据集上的实验结果表明,与传统的K均值聚类方法相比,提出的改进的层次聚类方法的确能够取得较优秀的聚类效果。
设X = {x1,x2,…,xi,…,xn }为n个Rd 空间的数据。
改进的层次结构的K均值聚类方法(Hierarchical K means)通过动态地判断样本集X当前聚类是否合适,从而决定是否进行下一更细层次上的聚类,这样得到的最终聚类个数一定可以保证聚类测度函数保持一个较小的值。
具体的基于层次结构的K均值算法:步骤1 选择包含n个数据对象的样本集X = {x1,x2,…,xi,…,xn},设定初始聚类个数k1,初始化聚类目标函数J (0) =0.01,聚类迭代次数t初始化为1,首先随机选择k1个聚类中心。
步骤2 衡量每个样本xi (i = 1,2,…,n)与每个类中心cj ( j = 1,2,…,k)之间的距离,并将xi归为与其最相似的类中心所属的类,并计算当前聚类后的类测度函数值J (1) 。
步骤3 进行更细层次的聚类,具体步骤如下:步骤3.1 根据式(5)选择类半径最大的类及其类心ci :ri = max ||xj - ci||,j = 1,2,…,ni且xj属于Xj(5)步骤3.2 根据距离公式(1)选择该类中距离类ci最远的样本点xi1,然后选择该类中距离xi1最远的样本点xi2。
最新中国地质大学-模式识别实习报告

《模式识别》上机实习报告学号:班级序号:姓名:指导老师:中国地质大学(武汉)信息工程学院遥感系2017年4月一、用贝叶斯估计做二类分类【问题描述】利用贝叶斯估计将某地区的遥感图像数据做二类分类,将图像中的裸土和水田加以区分,并使用envi classic的color mapping工具将分类好的图像加以颜色。
【模型方法】与分布有关的统计分类方法主要有最大似然/ 贝叶斯分类。
最大似然分类是图像处理中最常用的一种监督分类方法,它利用了遥感数据的统计特征,假定各类的分布函数为正态分布,在多变量空间中形成椭圆或椭球分布,也就是和中个方向上散布情况不同,按正态分布规律用最大似然判别规则进行判决,得到较高准确率的分类结果。
否则,用平行六面体或最小距离分类效果会更好。
【方案设计】(1)确定需要分类的地区和使用的波段和特征分类数,检查所用各波段或特征分量是否相互已经位置配准;(2)根据已掌握的典型地区的地面情况,在图像上选择训练区;(3)计算参数,根据选出的各类训练区的图像数据,计算和确定先验概率;(4)分类,将训练区以外的图像像元逐个逐类代入公式,对于每个像元,分几类就计算几次,最后比较大小,选择最大值得出类别;(5)产生分类图,给每一类别规定一个值,如果分10 类,就定每一类分别为1 ,2 ……10 ,分类后的像元值便用类别值代替,最后得到的分类图像就是专题图像. 由于最大灰阶值等于类别数,在监视器上显示时需要给各类加上不同的彩色;(6)检验结果,如果分类中错误较多,需要重新选择训练区再作以上各步,直到结果满意为止。
【结果讨论】优点:(1)生成式模型,通过计算概率来进行分类,可以用来处理多分类问题,(2)对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法也比较简单。
缺点:(1)对输入数据的表达形式很敏感。
(2)需要计算先验概率,分类决策存在错误率。
局部区域:精度评价步骤:(1)首先需要将外部程序生成的分类文件转化为ENVI可以识别的分类图,方法如下:Envi打开图像->Tools->Color Mapping->Density Slice->Set default numer of ran ges(设置为聚类数目)->Applydefault ranges->output ranges to class image(2)对分类结果进行合并与命名(3)从参考影像(高分辨率影像)上选取ROI并命名,方法:Envi打开图像->Tools->Region of Interest->ROI Tools(4)将ROI文件与分类图像相关联,方法:Basic Tools->Region of Interest->Reconcile ROIs Parameters->输入参考影像->输入分类影像(5)Classification->Post Classification->Confusion Matrix->Using Groun d Truth ROIs二、用Fisher估计做二类分类【问题描述】利用Fisher估计将某地区的遥感图像数据做二类分类,将图像中的裸土和水田加以区分,并使用envi classic的color mapping工具将分类好的图像加以颜色。
研究生模式识别课程汇报

研究生模式识别课程汇报模式识别是一门研究如何将输入数据划分到不同类别的学科。
它在许多领域都有广泛应用,如计算机视觉、自然语言处理、生物信息学等。
本次汇报将介绍研究生模式识别课程的主要内容和学习成果。
一、课程内容:1. 绪论:介绍模式识别的基本概念、任务和应用领域。
2. 模式分类:包括最近邻法、朴素贝叶斯法、决策树、支持向量机等分类算法的原理和应用。
3. 特征选择和降维:介绍特征选择和降维的方法,如主成分分析、线性判别分析等。
4. 聚类分析:介绍聚类分析的基本概念和常用算法,如K-means聚类、层次聚类等。
5. 神经网络:介绍人工神经网络的基本结构和学习算法。
二、学习成果:1. 掌握了模式识别的基本概念和任务。
2. 理解了各种分类算法的原理和应用。
3. 熟悉了常用的特征选择和降维方法。
4. 理解了聚类分析的原理和应用。
5. 熟悉了神经网络的基本结构和学习算法。
三、实际应用案例:本课程还结合了实际应用案例,学生们通过实践项目掌握了模式识别在计算机视觉、自然语言处理等领域的应用方法。
1. 计算机视觉:通过图像特征提取和分类,实现物体识别和图像分类任务。
2. 自然语言处理:通过文本特征提取和分类,实现文本情感分析和文本分类任务。
通过这些实际应用案例的实践,学生们更好地理解了模式识别的实际应用,并提高了解决实际问题的能力。
总结:通过本研究生模式识别课程的学习,学生们深入了解了模式识别的基本概念、分类算法、特征选择和降维方法、聚类分析以及神经网络等内容。
通过实践项目的推动,学生们在实际应用中掌握了模式识别的方法,并提高了解决实际问题的能力。
模式识别的报告(1)

模式识别实验报告(2)姓名:某某某班号:075113学号:2011100xxxx指导老师:马丽基于kNN算法的遥感图像分类一、目标:1. 掌握KNN算法原理2. 用MATLAB实现kNN算法,并进行结果分析二、算法分析:所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
kNN方法在类别决策时,只与极少量的相邻样本有关。
由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
三、实验内容:1.利用所有带标记的数据作为train数据,调用KNN分类函数KNN_Cla()对整个图像进行分类,得到整个图像的分类结果图。
2.随机在所有带标记的数据中选择train和test数据(50%train数据,50%test 数据)然后进行kNN分类。
随机选择10次,计算总体分类精度OA,然后求平均结果,作为最终对算法的评价。
K值依次选择1,3,5,7,9,11,分别用这6种K的取值进行kNN算法,得到每种K值下的总体分类精度OA,然后进行比较。
分类结果:四、数据介绍:zy3sample1:资源三号卫星遥感图,Img为读入遥感图生成的400*400*4矩阵。
xy3roi:ROI数据,GT为读入ROI生成的400*400矩阵。
INP_200:INP高光谱数据145*145*200。
92A V3GT_cls:ROI数据45*145。
五、实验程序:function [result,OA]=knn_classifier(X_train,Y_train,X_test,Y_test,options)%% 实现KNN分类% 输入参数% X_train : N*D% Y_train : 1*N% X_test : N*D% 输出参数% result :N*1% OA :精确度for k=1:len%一次处理1个点len=length(X_test);d=Euclidian_distance(X_train,X_test(k,:);%计算所有待分类点到所有训练点的距离[D,n]=sort(d);ind=n(1:option.K);%找到所有距离中最小的K个距离for k=1:len%一次处理1个点C(k)=length(find(Y_train(ind)==k);endindc=find(max(C));result(k)=indc(1);end;error=length(find(result'~=Y_test));%求出差错率OA=1-error/len;六、实验结果:zy3sample数据KNN分类结果(K=1):不同k值下的OA变化曲线图:七、心得体会:这次的程序主要是弄懂KNN 算法的思想就可以画出流程图其实最主要的就是搞清楚中间迭代部分的写法。
模式识别课程报告

考察报告一、人工智能与模式识别的研究已有多年,但似乎公认的观点认为它仍然非常困难。
在查阅文献或网络的基础上,试对你所熟悉的任一方向(如人像识别、语音识别、字符识别、自然语言理解、无人驾驶等等)的发展状况进行描述。
并设想如果你将从事该方向的研究,你打算如何着手,以建立有效的理论和方法;或者你认为现在的理论和方法有何缺陷,有什么办法来进行改进?(10分)回答:人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。
用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行识别的一系列相关技术。
其的识别内容包括三个部分:(1)人脸检测(2)人脸跟踪(3)人脸对比;人脸识别系统主要包括四个组成部分,分别为:人脸图像采集及检测、人脸图像预处理、人脸图像特征提取以及匹配与识别。
目前人脸识别的主要用途为识别身份,其主要产品有数码相机中的人脸自动对焦和笑脸快门技术、门禁系统、身份辨识、网络应用和娱乐应用等。
我认为现在的人脸识别技术还存在的问题是:时不时会人脸识别系统会将人识别成另外一个长相类似的人,有识别不清和识别错误的问题存在。
在理论上这是由于人脸作为生物特征带来的困难,还需要大量的数据来进一步改进识别的精确度,理论上是十分麻烦的,此外还存在着人脸结构相似带来的问题以及人脸易变性的技术问题。
改进方法有:提高算法的精确性以及在采集的时候对同一个人的不同表情进行采集,尽量扩大采集范围。
二、论述建立专家系统的一般步骤。
回答:(1)知识工程师首先通过与专家进行对话获取专家知识。
(2)将知识编码至知识库中(3)专家评估系统并返回意见给知识工程师(4)循环直至系统性能为专家所满意。
三、查阅统计模式识别的相关文献,论述一种统计模式识别方法、具体实现过程及其应用情况,给出所参考的文献。
(10分)回答:贝叶斯分类器模式识别的目的就是要将一个物体(由它的特征表示)判别为它所属的某一类。
模式识别学习报告(团队)

模式识别学习报告(团队)
简介
本报告是我们团队就模式识别研究所做的总结和讨论。
模式识别是一门关于如何从已知数据中提取信息并作出决策的学科。
在研究过程中,我们通过研究各种算法和技术,了解到模式识别在人工智能、机器研究等领域中的重要性并进行实践操作。
研究过程
在研究过程中,我们首先了解了模式识别的基本概念和算法,如KNN算法、朴素贝叶斯算法、决策树等。
然后我们深入研究了SVM算法和神经网络算法,掌握了它们的实现和应用场景。
在实践中,我们使用了Python编程语言和机器研究相关的第三方库,比如Scikit-learn等。
研究收获
通过研究,我们深刻认识到模式识别在人工智能、机器研究领域中的重要性,了解到各种算法和技术的应用场景和优缺点。
同时我们也发现,在实践中,数据的质量决定了模型的好坏,因此我们需要花费更多的时间来处理数据方面的问题。
团队讨论
在研究中,我们也进行了很多的团队讨论和交流。
一方面,我们优化了研究方式和效率,让研究更加有效率;另一方面我们还就机器研究的基本概念和算法的前沿发展进行了讨论,并提出了一些有趣的问题和方向。
总结
通过学习和团队讨论,我们深刻认识到了模式识别在人工智能和机器学习领域中的核心地位,并获得了实践经验和丰富的团队协作经验。
我们相信这些学习收获和经验会在今后的学习和工作中得到很好的应用。
模式识别实验报告一二.doc

信息与通信工程学院模式识别实验报告班级:姓名:学号:日期:2011年12月实验一、Bayes 分类器设计一、实验目的:1.对模式识别有一个初步的理解2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识3.理解二类分类器的设计原理二、实验条件:matlab 软件三、实验原理:最小风险贝叶斯决策可按下列步骤进行: 1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x2)利用计算出的后验概率及决策表,按下面的公式计算出采取ia ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策ka ,即()()1,min k i i aR a x R a x ==则ka 就是最小风险贝叶斯决策。
四、实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知先验概率是的曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进行分类。
模式识别实验报告

模式识别实验报告班级:电信08-1班姓名:黄**学号:********课程名称:模式识别导论实验一安装并使用模式识别工具箱一、实验目的:1.掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;2.熟练使用最小错误率贝叶斯决策器对样本分类;3.熟练使用感知准则对样本分类;4.熟练使用最小平方误差准则对样本分类;5.了解近邻法的分类过程,了解参数K值对分类性能的影响(选做);6.了解不同的特征提取方法对分类性能的影响(选做)。
二、实验内容与原理:1.安装模式识别工具箱;2.用最小错误率贝叶斯决策器对呈正态分布的两类样本分类;3.用感知准则对两类可分样本进行分类,并观测迭代次数对分类性能的影响;4.用最小平方误差准则对云状样本分类,并与贝叶斯决策器的分类结果比较;5.用近邻法对双螺旋样本分类,并观测不同的K值对分类性能的影响(选做);6.观测不同的特征提取方法对分类性能的影响(选做)。
三、实验器材(设备、元器件、软件工具、平台):1.PC机-系统最低配置512M 内存、P4 CPU;2.Matlab 仿真软件-7.0 / 7.1 / 2006a等版本的Matlab 软件。
四、实验步骤:1.安装模式识别工具箱。
并调出Classifier主界面。
2.调用XOR.mat文件,用最小错误率贝叶斯决策器对呈正态分布的两类样本分类。
3.调用Seperable.mat文件,用感知准则对两类可分样本进行分类。
4.调用Clouds.mat文件,用最小平方误差准则对两类样本进行分类。
5.调用Spiral.mat文件,用近邻法对双螺旋样本进行分类。
6.调用XOR.mat文件,用特征提取方法对分类效果的影响。
五、实验数据及结果分析:(1)Classifier主界面如下(2)最小错误率贝叶斯决策器对呈正态分布的两类样本进行分类结果如下:(3)感知准则对两类可分样本进行分类当Num of iteration=300时的情况:当Num of iteration=1000时的分类如下:(4)最小平方误差准则对两类样本进行分类结果如下:(5)近邻法对双螺旋样本进行分类,结果如下当Num of nearest neighbor=3时的情况为:当Num of nearest neighbor=12时的分类如下:(6)特征提取方法对分类结果如下当New data dimension=2时,其结果如下当New data dimension=1时,其结果如下六、实验结论:本次实验使我掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;对模式识别有了初步的了解。
模式识别报告

数学与计算机学院课程名称: 模式识别题目: 决策树-基于手写数据实现任课老师: 王晓明年级专业: 2011级计算机科学与技术姓名: 游在雨城学号: 312011*********时间:2013 年11月20日目录一决策树介绍 (2)1决策树算法的历史与发展: (2)2决策树算法的主要思想: (2)二决策树ID3算法描述 (4)1 ID3属性选择: (4)2 ID3实例 (4)三ID3算法C++实现-基于手写数据实现 (9)1 数据读入 (9)1 手写数据的产生: (9)2 手写数据的识别过程: (9)2 算法运行结果 (10)四总结和心得 (15)五附录——核心算法的主要源代码 (16)参考文献 (23)决策树一决策树介绍1决策树算法的历史与发展:决策树算法是一种逼近离散函数值的方法。
它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。
本质上决策树是通过一系列规则对数据进行分类的过程。
决策树方法最早产生于上世纪60年代,到70年代末。
由J Ross Quinlan提出了ID3算法,此算法的目的在于减少树的深度。
但是忽略了叶子数目的研究。
C4.5算法在ID3算法的基础上进行了改进,对于预测变量的缺值处理、剪枝技术、派生规则等方面作了较大改进,既适合于分类问题,又适合于回归问题。
1960’s:Hunt的完全搜索决策树方法(CLS)对概念学习建模。
1970后期:Quinlan发明用信息增益作为启发策略的ID3方法,从样本中学习构造专家系统同时,Breiman和Friedman开发的CART(分类与回归树)方法类似于ID3。
1980’s:对噪声、连续属性、数据缺失、改善分割条件等进行研究。
1993:Quinlan的改进决策树归纳包(C4.5),目前被普遍采用。
2决策树算法的主要思想:决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法。
模式识别技术实验报告

模式识别技术实验报告本实验旨在探讨模式识别技术在计算机视觉领域的应用与效果。
模式识别技术是一种人工智能技术,通过对数据进行分析、学习和推理,识别其中的模式并进行分类、识别或预测。
在本实验中,我们将利用机器学习算法和图像处理技术,对图像数据进行模式识别实验,以验证该技术的准确度和可靠性。
实验一:图像分类首先,我们将使用卷积神经网络(CNN)模型对手写数字数据集进行分类实验。
该数据集包含大量手写数字图片,我们将训练CNN模型来识别并分类这些数字。
通过调整模型的参数和训练次数,我们可以得到不同准确度的模型,并通过混淆矩阵等评估指标来评估模型的性能和效果。
实验二:人脸识别其次,我们将利用人脸数据集进行人脸识别实验。
通过特征提取和比对算法,我们可以识别不同人脸之间的相似性和差异性。
在实验过程中,我们将测试不同算法在人脸识别任务上的表现,比较它们的准确度和速度,探讨模式识别技术在人脸识别领域的应用潜力。
实验三:异常检测最后,我们将进行异常检测实验,使用模式识别技术来识别图像数据中的异常点或异常模式。
通过训练异常检测模型,我们可以发现数据中的异常情况,从而做出相应的处理和调整。
本实验将验证模式识别技术在异常检测领域的有效性和实用性。
结论通过以上实验,我们对模式识别技术在计算机视觉领域的应用进行了初步探索和验证。
模式识别技术在图像分类、人脸识别和异常检测等任务中展现出了良好的性能和准确度,具有广泛的应用前景和发展空间。
未来,我们将进一步深入研究和实践,探索模式识别技术在更多领域的应用,推动人工智能技术的发展和创新。
【字数:414】。
模式识别课程报告

模式识别课程报告什么是模式识别引用Anil K. Jain的话对模式识别下定义:Pattern recognition is the study of how machines can observe the environment, learn to distinguish patterns of interest from their background, and make sound and reasonable decisions about the categories of the patterns.什么是 Pattern 呢,Watanabe defines a pattern “as opposite of achaos; it is an entity, vaguely defined, that could be given a name.”比如说一张指纹图片,一个手写的文字,一张人脸,一个说话的信号,这些都可以说是一种模式。
识别在现实生活中是时时刻刻发生的,识别就是再认知(Re-Cognition),识别主要做的是相似和分类的问题,按先验知识的分类,可以把识别分为有监督的学习和没有监督的学习,下面主要介绍的支持向量机就是属于一种有监督的学习。
模式识别与统计学、人工智能、机器学习、运筹学等有着很大的联系,而且各行各业的工作者都在做着识别的工作,一个模式识别系统主要有三部分组成:数据获取和预处理,数据表达和决策。
模式识别的研究主要集中在两方面,一是研究生物体( 包括人)是如何感知对象的,二是在给定的任务下,如何用计算机实现模式识别的理论和方法。
前者是生理学家、心理学家、生物学家、神经生理学家的研究内容,属于认知科学的范畴;后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力,已经取得了系统的研究成果。
模式识别的方法介绍:模式识别方法(Pattern Recognition Method)是一种借助于计算机对信息进行处理、判决分类的数学统计方法。
模式识别实验报告哈工程

一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。
模式识别实验报告2_贝叶斯分类实验_实验报告(例)

end
plot(1:23,t2,'b','LineWidth',3);
%下面是bayesian_fun函数
functionf=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10- (x'*W2*x+w2'*x+w20);
%f=bayesian_fun.m
function f=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10 - (x'*W2*x+w2'*x+w20);
w10=-1/2 * u1'*S1tinv*u1 - 1/2 *log(det(S1t)) + log(pw1);
w20=-1/2 * u2'*S2tinv*u2 - 1/2 *log(det(S2t)) + log(pw2);
t2=[]
fort1=1:23
tt2 = fsolve('bayesian_fun',5,[],t1,W1,W2,w1,w2,w10,w20);
'LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0 1 0],...
'MarkerSize',10)
模式识别学习报告(团队)

模式识别学习报告(团队)简介该报告旨在总结我们团队在模式识别研究中的成果和收获。
模式识别是一门重要的学科,它涉及到从数据中识别和分类出模式和结构。
通过研究模式识别,我们可以更好地理解和处理各种数据,并应用到实际问题中。
研究内容我们团队在研究模式识别时,主要涉及以下内容:1. 模式识别算法:我们研究了各种常用的模式识别算法,包括K近邻算法、支持向量机、决策树等。
通过研究这些算法,我们可以根据不同的数据和问题选择合适的方法进行模式识别。
2. 特征提取和选择:在模式识别中,选择合适的特征对于识别和分类模式至关重要。
我们研究了特征提取和选择的方法,包括主成分分析、线性判别分析等,可以帮助我们从原始数据中提取重要的特征。
3. 模型评估和选择:为了评估和选择模式识别模型的性能,我们研究了各种评估指标和方法,包括准确率、召回率、F1分数等。
通过合适的评估方法,我们可以选择最合适的模型来应对具体问题。
研究成果通过团队研究,我们取得了以下成果:1. 理论知识的掌握:我们对模式识别的基本概念和原理有了较为深入的了解,并能够灵活运用于实际问题中。
2. 算法实现和编程能力的提升:我们通过实践练,掌握了常用模式识别算法的实现方法,并在编程中加深了对算法的理解。
3. 团队合作和沟通能力的提高:在研究过程中,我们通过合作完成了多个小组项目,提高了团队合作和沟通的能力。
总结通过研究模式识别,我们不仅增加了对数据的理解和处理能力,还提高了团队合作和沟通的能力。
模式识别是一个不断发展和应用的领域,我们将继续深入研究,并将所学知识应用到实际问题中,为社会发展做出更大的贡献。
参考[1] 孙建华. 模式识别与机器研究[M]. 清华大学出版社, 2019.[2] Bishop, C. M. (2006). Pattern recognition and machine learning. Springer Science & Business Media.。
中南大学模式识别课程设计报告

CENTRAL SOUTH UNIVERSITY模式识别课程设计报告题目学生姓名班级学号指导教师设计时间前言1、课程设计的目的《模式识别》课程是智能科学与技术等专业教学计划中以应用为基础的一门专业课,是研究如何用机器去模拟人的视觉、听觉、触觉等感觉器官以识别外界环境的理论与方法,《模式识别》课程设计的目的是使学生掌握统计模式识别的基本分类方法的算法设计及其验证方法,通过设计性实验的训练,以提高学生设计算法及数值实验的能力,进一步提高分析问题、解决问题的能力。
通过本课程设计,学习利用监督或非监督学习方法对生活中的实际问题进行识别分类,掌握模式识别系统的基本设计思路与步骤。
2、课程设计的基本内容观察生活与环境,自选一个题目,采用一种监督或非监督学习方法对其进行分类与识别。
(贝叶斯决策、Fisher线性判别、感知准则方法、Parzen 窗法或 Kn 近邻法、K-L变换法、K-means等)。
数据源可以自选,也可以参考UCI数据集:/ml/前言---------------------------------------------------------------------------1目录---------------------------------------------------------------------------2正文---------------------------------------------------------------------------3结论---------------------------------------------------------------------------5附录---------------------------------------------------------------------------6参考文献---------------------------------------------------------------------8我们组选择用模式识别中的Fisher线性判别方法,根据身高体重数据,来进行男女判别分类的问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3 3 深度检测技术演进 5 5 讨论与致谢
2
1 卷积神经网络
R-CNN算法
Fast R-CNN
z
第一阶段
第三阶段
第二阶段
R-CNN Faster R-CNN z
3 深度检测技术演进
R-CNN算法的核心思想
深度对象检测的开山之作——R-CNN(Regions with CNN)
对每个区域通过CNN提取特征,然后接上一个分类器预测这个
3 深度检测技术演进
R-CNN算法的工作流程
1 2 3 4
候选区域生成:一张图像用SS方法生成1K~2K个候选区域
特征提取: 对每个候选区域,使用深度卷积网络提取特征(CNN) 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类 位置精修: 使用回归器精细修正候选框位置
3 深度检测技术演进
3 深度检测技术演进
深度网络提取特征
使用两个数据库: 一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类
别;
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别
和位置。
使用识别库进行预训练得到CNN(有监督预训练),而后用检测库调优 参数,最后在检测库上评测。
3 深度检测技术演进
Fast R-CNN算法
发现问题
每一个ROI由四元 组 (r,c,h,w)表示, 其中(h,w)代表 高度和宽度 introduction
解决方案
核心思路
工作流程
效果对比
Roi_pool层的作用
Roi_pool层将每个候选区域均匀分成M×N块,对每块进行max pooling操作 将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层
西南科技大学模式识别课程报告
卷积神经网络(CNN)在深度检测 方向的发展
报告人:第六组 日期:2017. 11. 7
目录 Contents 1
神经网络背景
2 卷积神经网络 44 全文总结
3 3 深度检测技术演进 5 5 讨论与致谢
2
目录 Contents
1
神经网络背景
2 卷积神经网络 44 全文总结
2 卷积神经网络
Part3 poolingБайду номын сангаас的工作方式
1. Pooling层主要的作用是下采样。 introduction 2. 通过去除Feature Map中不重要的样本,进一步减少参数数量。最常用的 方法是Max Pooling,Max Pooling实际上就是在n*n的样本中取最大值,
作为采样后的样本值。
候选框搜索阶段
采用Selective Search方法从图像中搜索出可能是物体的区域,即一 系列大小不同的矩形候选框。
由于CNN要求输入图片的大小固定,因此,需要将每个输入的候选框 缩放到固定的大小。
3 深度检测技术演进
候选框搜索阶段
两种不同的处理方法:
(1)各向异性缩放
(2)各向同性缩放
3 深度检测技术演进
Faster R-CNN算法
K个box是目标/非
生成网络 (RPN)用来代替Selective Search方法,以缩短搜寻时间。
3 深度检测技术演进 3 目标检测技术演进
Faster R-CNN算法
Faster R-CNN将一直以来分离的region proposal和CNN分类融合到 了一起,使用端到端的网络进行目标检测,无论在速度上还是精度上 都得到了不错的提高。 faster RCNN可以大致看做“区域生成网络(RPN)+fast RCNN“的 系统,且RPN网络和Fast RCNN共享卷积层特征。
3 深度检测技术演进
Fast R-CNN算法
发现问题
解决方案
核心思路
工作流程
效果对比
conclusion
Multi-task loss
将原来与网络分开的bbox regression的操作整合在了 网络内部,并设计了一个同时优化两个输出层的loss函数。
3 深度检测技术演进
Fast R-CNN算法
2.权值共享
目录 Contents
1
神经网络背景
2 卷积神经网络 44 全文总结
3 3 深度检测技术演进 5 5 讨论与致谢
2
2 卷积神经网络
Part1 卷积神经网络的层次
卷积层
+
pooling层
+
全连接层
introduction
输入一张图片,接着第一个卷积层对这幅图像进行了卷积操作, 得到了四个Feature Map,也就是我们熟悉的通过卷积变换提取到的 图像特征。
R-CNN
速度: R-CNN则采用Selective Search方法 训练集:R-CNN则采用深度网络进行特征提取
3 深度检测技术演进
Selective Search方法
Selective Search 主要思想:
1.使用一种过分割手段,将图像分割成小区域 (1k~2k 个) 2.查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复 直到整张图像合并成一个区域位置 3.输出所有曾经存在过的区域,所谓候选区域
3 3 深度检测技术演进 5 5 讨论与致谢
2
1 背景介绍
卷积神经网络的发展
卷积神经网络是近年发展起来,并引起广泛重视的一种高效识别方法。20世纪 60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发 现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神 经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多 科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的 复杂前期预处理,可以直接输入原始图像,并且相较于全连接神经网络而言参数
它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到
全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。
3 深度检测技术演进
SVM分类阶段
多个SVM级联完成分类
1 卷积神经网络
Fast R-CNN算法
Fast R-CNN
z
第一阶段
第三阶段
第二阶段
R-CNN Faster R-CNN
区域包含一个感兴趣对象的置信度,也就是说,转换成了一个图像分
类问题(类似 imagenet ),后面接的这个分类器可以是独立训练的 svm也可以是简单的softmax分类。
3 深度检测技术演进
R-CNN算法与传统方法的对比
传统方法
速度:传统的目标检测算法使用滑动窗口判断所有可能的区域。 训练集:传统的目标检测算法在区域中提取人工设定的特征
3 深度检测技术演进
Fast R-CNN算法
发现问题 分类
解决方案
核心思路
工作流程
introduction
效果对比
边框回归
类似 单层 的SPPnet
1. 在SPPnet的基础上,通过RP层输出一 个固定维度的特征,再通过softmax 统一分类,减少resize过程时间提高 处理速度。 2. 把softmax(分类)和bbox regressor(回归)放入神经网络 内部形成混合模型,提高处理精 度。
2 卷积神经网络
Part2 卷积层的工作方式
2 卷积神经网络
Part2 卷积层的工作方式
2 卷积神经网络
Part2 卷积层的工作方式
introduction
左边是图像输入,中间部分就是滤波器filter(带着一组固定 权重的神经元),不同的滤波器filter会得到不同的输出数据,
比如颜色深浅、轮廓。
A、先扩充后裁剪
B、先裁剪后扩充
3 深度检测技术演进
CNN特征提取阶段
a. 网络结构设计阶段
选用Alexnet,其特 征提取部分包含5个 卷积层、2个全连接 层。 通过这个网络训练完 毕后,最后提取特征, 每个输入候选框图片 都能得到一个n维的 特征向量。
b.网络有监督预训练阶段 无监督预训练 预训练阶段的样本不需要 人工标注数据 有监督预训练 把一个任务训练好的参数, 作为神经网络的初始值, 相比于直接采用随机初始 化的方法,精度有很大的 提高。
C. fine-tuning阶段
将selective search 获 得的候选框对预训练的 CNN模型进行微调。 假设有N类待检测物体, 将预训练阶段的CNN模 型最后一层替换,继而 在该层直接采用参数随 机初始化的方法继续 SGD训练。
3 深度检测技术演进
SVM分类阶段
SVM的主要思想可以概括为两点: 它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法 将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维 特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
2 卷积神经网络
Part4 全连接层的工作方式
在整个卷积神经网络中起到“分类器”的作用,就是将之前得到的所有特征综合起来。
1 卷积神经网络
Part5 卷积神经网络的发展 z
Fast R-CNN
第一阶段
第三阶段
第二阶段
R-CNN Faster R-CNN
目录 Contents
1
神经网络背景
2 卷积神经网络 44 全文总结
第二阶段
R-CNN
z
Faster R-CNN
3 深度检测技术演进 3 目标检测技术演进
Faster R-CNN算法
Fast R-CNN沿用SS方法获得候选区域,耗时占据了整体耗时的大部分, 且没有应用在GPU上。