二叉树前序、中序、后序遍历相互求法
前序遍历和后续遍历

首先明确:一颗二叉树的前序遍历=根节点+左子树前序遍历+右子树前序遍历
一颗二叉树的中序遍历=左子树中序遍历+根节点+右子树中序遍历
那么从前序遍历中取第一个点,就是根节点,知道了根节点,就可以找到中序遍历中跟节点的位置,那么就可以在中序遍历中找到左子树和右子树。
首先,我们看看前序、中序、后序遍历的特性:
前序遍历:
1.访问根节点
2.前序遍历左子树
3.前序遍历右子树
中序遍历:
1.中序遍历左子树
2.访问根节点
3.中序遍历右子树
后序遍历:
1.后序遍历左子树
2.后序遍历右子树
3.访问根节点
好了,先说说用前序遍历和中序遍历求后序遍历
假设前序遍历为adbgcefh, 中序遍历为dgbaechf
前序遍历是先访问根节点,然后再访问子树的,而中序遍历则先访问左子树再访问根节点
那么把前序的a 取出来,然后查找a 在中序遍历中的位置就得到dgb a echf
那么我们就知道dgb 是左子树echf 是右子树,因为数量要吻合
所以前序中相应的dbg 是左子树cefh 是右子树
然后就变成了一个递归的过程,具体代码如下:
而已知后序遍历和中序遍历求前序遍历的过程差不多,但由于后序遍历是最后才访问根节点的所以要从后开始搜索,例如上面的例子,后序遍历为gbdehfca,中序遍历为dgbaechf
后序遍历中的最后一个元素是根节点,a,然后查找中序中a的位置
把中序遍历分成dgb a echf,而因为节点个数要对应
后序遍历分为gbd ehfc a,gbd为左子树,ehfc为右子树,这样又可以递归计算了
其他一些附带的代码上面已经有,这里就不重复贴了,具体代码如下:。
二叉树遍历(前序、中序、后序、层次、广度优先、深度优先遍历)

⼆叉树遍历(前序、中序、后序、层次、⼴度优先、深度优先遍历)⽬录转载:⼆叉树概念⼆叉树是⼀种⾮常重要的数据结构,⾮常多其他数据结构都是基于⼆叉树的基础演变⽽来的。
对于⼆叉树,有深度遍历和⼴度遍历,深度遍历有前序、中序以及后序三种遍历⽅法,⼴度遍历即我们寻常所说的层次遍历。
由于树的定义本⾝就是递归定义,因此採⽤递归的⽅法去实现树的三种遍历不仅easy理解并且代码⾮常简洁,⽽对于⼴度遍历来说,须要其他数据结构的⽀撑。
⽐⽅堆了。
所以。
对于⼀段代码来说,可读性有时候要⽐代码本⾝的效率要重要的多。
四种基本的遍历思想前序遍历:根结点 ---> 左⼦树 ---> 右⼦树中序遍历:左⼦树---> 根结点 ---> 右⼦树后序遍历:左⼦树 ---> 右⼦树 ---> 根结点层次遍历:仅仅需按层次遍历就可以⽐如。
求以下⼆叉树的各种遍历前序遍历:1 2 4 5 7 8 3 6中序遍历:4 2 7 5 8 1 3 6后序遍历:4 7 8 5 2 6 3 1层次遍历:1 2 3 4 5 6 7 8⼀、前序遍历1)依据上⽂提到的遍历思路:根结点 ---> 左⼦树 ---> 右⼦树,⾮常easy写出递归版本号:public void preOrderTraverse1(TreeNode root) {if (root != null) {System.out.print(root.val+" ");preOrderTraverse1(root.left);preOrderTraverse1(root.right);}}2)如今讨论⾮递归的版本号:依据前序遍历的顺序,优先訪问根结点。
然后在訪问左⼦树和右⼦树。
所以。
对于随意结点node。
第⼀部分即直接訪问之,之后在推断左⼦树是否为空,不为空时即反复上⾯的步骤,直到其为空。
若为空。
则须要訪问右⼦树。
注意。
在訪问过左孩⼦之后。
二叉树前中后序遍历做题技巧

二叉树前中后序遍历做题技巧在计算机科学中,二叉树是一种重要的数据结构,而前序、中序和后序遍历则是二叉树遍历的三种主要方式。
下面将分别对这三种遍历方式进行解析,并提供一些解题技巧。
1.理解遍历顺序前序遍历顺序是:根节点->左子树->右子树中序遍历顺序是:左子树->根节点->右子树后序遍历顺序是:左子树->右子树->根节点理解每种遍历顺序是解题的基础。
2.使用递归或迭代二叉树的遍历可以通过递归或迭代实现。
在递归中,每个节点的处理函数会调用其左右子节点的处理函数。
在迭代中,可以使用栈来模拟递归过程。
3.辨析指针指向在递归或迭代中,需要正确处理指针的指向。
在递归中,通常使用全局变量或函数参数传递指针。
在迭代中,需要使用栈或其他数据结构保存指针。
4.学会断点续传在处理大规模数据时,为了避免内存溢出,可以采用断点续传的方式。
即在遍历过程中,将中间结果保存在文件中,下次遍历时从文件中读取上一次的结果,继续遍历。
5.识别循环和终止条件在遍历二叉树时,要识别是否存在循环,并确定终止条件。
循环可以通过深度优先搜索(DFS)或广度优先搜索(BFS)避免。
终止条件通常为达到叶子节点或达到某个深度限制。
6.考虑边界情况在处理二叉树遍历问题时,要考虑边界情况。
例如,对于空二叉树,需要进行特殊处理。
又如,在处理二叉搜索树时,需要考虑节点值的最小和最大边界。
7.优化空间使用在遍历二叉树时,需要优化空间使用。
例如,可以使用in-place排序来避免额外的空间开销。
此外,可以使用懒加载技术来延迟加载子节点,从而减少内存占用。
8.验证答案正确性最后,验证答案的正确性是至关重要的。
可以通过检查输出是否符合预期、是否满足题目的限制条件等方法来验证答案的正确性。
如果可能的话,也可以使用自动化测试工具进行验证。
二叉树遍历(前中后序遍历,三种方式)

⼆叉树遍历(前中后序遍历,三种⽅式)⽬录刷题中碰到⼆叉树的遍历,就查找了⼆叉树遍历的⼏种思路,在此做个总结。
对应的LeetCode题⽬如下:,,,接下来以前序遍历来说明三种解法的思想,后⾯中序和后续直接给出代码。
⾸先定义⼆叉树的数据结构如下://Definition for a binary tree node.struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode(int x) : val(x), left(NULL), right(NULL) {}};前序遍历,顺序是“根-左-右”。
使⽤递归实现:递归的思想很简单就是我们每次访问根节点后就递归访问其左节点,左节点访问结束后再递归的访问右节点。
代码如下:class Solution {public:vector<int> preorderTraversal(TreeNode* root) {if(root == NULL) return {};vector<int> res;helper(root,res);return res;}void helper(TreeNode *root, vector<int> &res){res.push_back(root->val);if(root->left) helper(root->left, res);if(root->right) helper(root->right, res);}};使⽤辅助栈迭代实现:算法为:先把根节点push到辅助栈中,然后循环检测栈是否为空,若不空,则取出栈顶元素,保存值到vector中,之后由于需要想访问左⼦节点,所以我们在将根节点的⼦节点⼊栈时要先经右节点⼊栈,再将左节点⼊栈,这样出栈时就会先判断左⼦节点。
代码如下:class Solution {public:vector<int> preorderTraversal(TreeNode* root) {if(root == NULL) return {};vector<int> res;stack<TreeNode*> st;st.push(root);while(!st.empty()){//将根节点出栈放⼊结果集中TreeNode *t = st.top();st.pop();res.push_back(t->val);//先⼊栈右节点,后左节点if(t->right) st.push(t->right);if(t->left) st.push(t->left);}return res;}};Morris Traversal⽅法具体的详细解释可以参考如下链接:这种解法可以实现O(N)的时间复杂度和O(1)的空间复杂度。
c语言二叉树的先序,中序,后序遍历
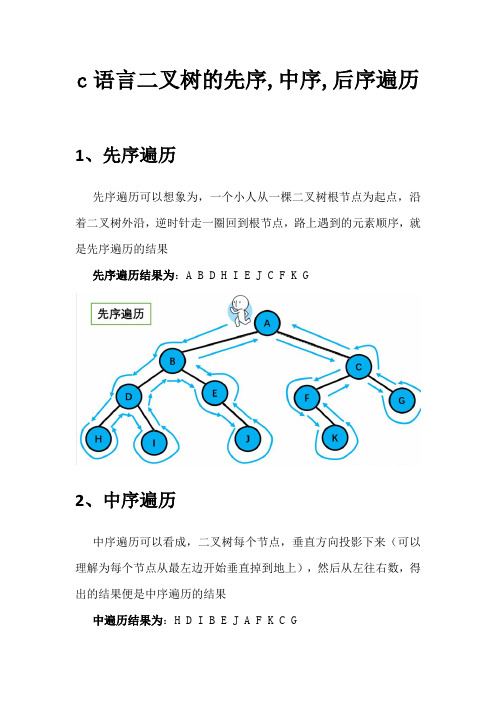
c语言二叉树的先序,中序,后序遍历1、先序遍历先序遍历可以想象为,一个小人从一棵二叉树根节点为起点,沿着二叉树外沿,逆时针走一圈回到根节点,路上遇到的元素顺序,就是先序遍历的结果先序遍历结果为:A B D H I E J C F K G2、中序遍历中序遍历可以看成,二叉树每个节点,垂直方向投影下来(可以理解为每个节点从最左边开始垂直掉到地上),然后从左往右数,得出的结果便是中序遍历的结果中遍历结果为:H D I B E J A F K C G3、后序遍历后序遍历就像是剪葡萄,我们要把一串葡萄剪成一颗一颗的。
还记得我上面提到先序遍历绕圈的路线么?(不记得翻上面理解)就是围着树的外围绕一圈,如果发现一剪刀就能剪下的葡萄(必须是一颗葡萄)(也就是葡萄要一个一个掉下来,不能一口气掉超过1个这样),就把它剪下来,组成的就是后序遍历了。
后序遍历中,根节点默认最后面后序遍历结果:H I D J E B K F G C A4、口诀先序遍历:先根再左再右中序遍历:先左再根再右后序遍历:先左再右再根这里的根,指的是每个分叉子树(左右子树的根节点)根节点,并不只是最开始头顶的根节点,需要灵活思考理解5、代码展示#include<stdio.h>#include<stdlib.h>typedef struct Tree{int data; // 存放数据域struct Tree *lchild; // 遍历左子树指针struct Tree *rchild; // 遍历右子树指针}Tree,*BitTree;BitTree CreateLink(){int data;int temp;BitTree T;scanf("%d",&data); // 输入数据temp=getchar(); // 吸收空格if(data == -1){ // 输入-1 代表此节点下子树不存数据,也就是不继续递归创建return NULL;}else{T = (BitTree)malloc(sizeof(Tree)); // 分配内存空间T->data = data; // 把当前输入的数据存入当前节点指针的数据域中printf("请输入%d的左子树: ",data);T->lchild = CreateLink(); // 开始递归创建左子树printf("请输入%d的右子树: ",data);T->rchild = CreateLink(); // 开始到上一级节点的右边递归创建左右子树return T; // 返回根节点}}// 先序遍历void ShowXianXu(BitTree T) // 先序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}printf("%d ",T->data);ShowXianXu(T->lchild); // 递归遍历左子树ShowXianXu(T->rchild); // 递归遍历右子树}// 中序遍历void ShowZhongXu(BitTree T) // 先序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}ShowZhongXu(T->lchild); // 递归遍历左子树printf("%d ",T->data);ShowZhongXu(T->rchild); // 递归遍历右子树}// 后序遍历void ShowHouXu(BitTree T) // 后序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}ShowHouXu(T->lchild); // 递归遍历左子树ShowHouXu(T->rchild); // 递归遍历右子树printf("%d ",T->data);}int main(){BitTree S;printf("请输入第一个节点的数据:\n");S = CreateLink(); // 接受创建二叉树完成的根节点printf("先序遍历结果: \n");ShowXianXu(S); // 先序遍历二叉树printf("\n中序遍历结果: \n");ShowZhongXu(S); // 中序遍历二叉树printf("\n后序遍历结果: \n");ShowHouXu(S); // 后序遍历二叉树return 0;}。
前序后序中序详细讲解

前序后序中序详细讲解1.引言1.1 概述在数据结构与算法中,前序、中序和后序是遍历二叉树的三种基本方式之一。
它们是一种递归和迭代算法,用于按照特定的顺序访问二叉树的所有节点。
通过遍历二叉树,我们可以获取有关树的结构和节点之间关系的重要信息。
前序遍历是指先访问根节点,然后递归地访问左子树,最后递归地访问右子树。
中序遍历是指先递归地访问左子树,然后访问根节点,最后递归地访问右子树。
后序遍历是指先递归地访问左子树,然后递归地访问右子树,最后访问根节点。
它们的不同之处在于访问根节点的时机不同。
前序遍历可以帮助我们构建二叉树的镜像,查找特定节点,或者获取树的深度等信息。
中序遍历可以帮助我们按照节点的大小顺序输出树的节点,或者查找二叉搜索树中的某个节点。
后序遍历常用于删除二叉树或者释放二叉树的内存空间。
在实际应用中,前序、中序和后序遍历算法有着广泛的应用。
它们可以用于解决树相关的问题,例如在Web开发中,树结构的遍历算法可以用于生成网页导航栏或者搜索树结构中的某个节点。
在图像处理中,前序遍历可以用于图像压缩或者图像识别。
另外,前序和后序遍历算法还可以用于表达式求值和编译原理中的语法分析等领域。
综上所述,前序、中序和后序遍历算法是遍历二叉树的重要方式,它们在解决各种与树有关的问题中扮演着关键的角色。
通过深入理解和应用这些遍历算法,我们可以更好地理解和利用二叉树的结构特性,并且能够解决更加复杂的问题。
1.2文章结构文章结构是指文章中各个部分的布局和组织方式。
一个良好的文章结构可以使读者更好地理解和理解文章的内容。
本文将详细讲解前序、中序和后序三个部分的内容和应用。
首先,本文将在引言部分概述整篇文章的内容,并介绍文章的结构和目的。
接下来,正文部分将分为三个小节,分别对前序、中序和后序进行详细讲解。
在前序讲解部分,我们将定义和解释前序的意义,并介绍前序在实际应用中的场景。
通过详细的解释和实例,读者将能更好地理解前序的概念和用途。
由前序跟中序遍历序求后序遍历序的设计与实现

(中文)由前序跟中序遍历序求后序遍历序的设计与实现(英文)The design and implementation of getting postorder traversal according to preorderand inorder traversal of a binary tree蔡智聪摘要:树的遍历问题在应用开发过程中是一个很经典且常遇到的问题,在实际工程中,经常可能需要进行某种遍历充的求解。
本文介绍如何由一棵二叉树的前序遍历序和中序遍历序来后序遍历序的设计思路与具体C++实现。
首先根据前序遍历序和中序遍历序来建立(还原)出二叉树的原型,文中详细介绍了建立(还原)树的算法及原理。
然后再用后后序遍历算法求后序遍历序(一串字符串序列)。
关键字:二叉树前序遍历序中序遍历序后序遍历序Binary –Tree ,Preorder traversal, inorder traversal, postorder traversal正文:几个术语的介绍:二叉树:在计算机科学中,二叉树是每个结点最多有两个子树的有序树。
通常子树的根被称作“左子树”(left subtree)和“右子树”(right subtree)。
前序遍历序:在对一个树进行前序遍历而得到的一个访问结点的序列。
遍历的顺序是:先父结点,然后左子树,然后右子树。
中序遍历序:在对一个树进行中序遍历而得到的一个访问结点的序列。
遍历的顺序是:先左子树,然后父结点,然后右子树。
前序遍历序:在对一个树进行前序遍历而得到的一个访问结点的序列。
遍历的顺序是:先左子树,然后右子树,然后父结点。
引言:树的遍历问题在应用开发过程中是一个很经典且常遇到的问题,在实际工程中,经常可能需要进行某种遍历充的求解。
为了描述和实现的简化,本文中以二叉树来代替为例,并将二叉树的结点抽象成一个字符来代替,在实现运用中可以自己加以灵活变通。
问题的引出:那么对于一棵给定的二叉树,如何根据前序遍历序和中序遍历序来求出后序遍历序呢?如图A:这样的一棵树的前序遍历序为:ABDGHCEIFJ中序遍历序为:GDHBAEICFJ那么如何求出后序遍历序(GHDBIEJFCA)呢?算法原理及分析:1.先建立还原二叉树。
在线索二叉树中如何求先序

1在线索二叉树中如何求先序、中序的前驱、后继,为什么后续线索二叉树是不完备的?先序前驱:若左标志为1,则左链为线索,指示其前驱;否则a) 若该结点是二叉树的根,则其前驱为空;b) 若该结点是其双亲的左孩子或是其双亲的右孩子且其双亲没有左子树,则其前驱为其双亲;c) 若该结点是其双亲的右孩子且其双亲有左子树,则其前驱为其双亲的左子树中的先序遍历列出的最后一个结点。
先序后继:若右标志为1,则右链为线索,指示其后继;否则,如果有左子树则遍历左子树第一个访问的结点,为其后继;如果没有左子树则遍历右子树第一个访问的结点,为其后继;中序前驱:若左标志为1,则左链为线索,指示其前驱;否则,遍历其左子树最后访问的结点,为其前驱中序后继:若右标志为1,则右链为线索,指示其后继;否则,遍历其右子树第一个访问的结点,为其后继后续后继:a) 若该结点是二叉树的根,则其后继为空;b) 若该结点是其双亲的右孩子或是其双亲的左孩子且其双亲没有右子树,则其后继为其双亲;c) 若该结点是其双亲的左孩子且其双亲有右子树,则其后继为其双亲的右子树中的后序遍历列出的第一个结点。
求后续后继需要知道双亲结点,而二叉链表无法找到双亲,因此不完备:5如果只想得到一个序列中前k(k>=5)个最小元素的部分排序序列,可以采用哪些排序方法,最好采用哪种排序方法?1插入、快速、归并需要全体排序不合适2起泡、简单选择、堆可以。
堆完成查找总时间:4n+klogn,起泡和简单选择总时间kn,因此堆较好。
5荷兰国旗问题分析:这个问题我们可以将这个问题视为一个数组排序问题,这个数组分为前部,中部和后部三个部分,每一个元素(红白蓝分别对应0、1、2)必属于其中之一。
由于红、白、蓝三色小球数量并不一定相同,所以这个三个区域不一定是等分的,也就是说如果我们将整个区域放在[0,1]的区域里,由于三色小球之间数量的比不同(此处假设1:2:2),可能前部为[0,0.2),中部为[0.2,0.6),后部为[0.6,1]。
已知二叉树的中序和先序序列,求后序序列

3、递归求解树。将左子树和右子树分别看成一棵二叉树,重复1、2、3步,直到所有的节点完成定位。
二、已知二叉树的后序序列和中序序列,求解树。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct Node /*树结点类型*/
{
int info; /*数据域*/
struct Node* parent; /*父结点*/
struct Node* lchild; /*左孩子结点*/
4、在后序序列LH中最后出现的元素为H,H|L|D|B|EK|A|FCG
5、在后序序列KE中最后出现的元素为E,H|L|D|B|E|K|A|FCG
5、在后序序列FGC中最后出现的元素为C,H|L|D|B|E|K|A|F|C|G
6、所有元素都已经定位,二叉树求解完成。
A
/ \
B C
/ \ / \
D E F G
post_order(root->rchild);
printf("%d ",root->info);
}
}
int main(void)
{
PNode *root;
int pre[50]={1,2,4,8,10,5,9,3,6,7};
int in[ 50]={8,10,4,2,5,9,1,6,3,7} ;
1、确定树的根。树根是当前树中所有元素在后序遍历中最后出现的元素。
二叉树的遍历【NOIP2001普及组】洛谷P1030求先序排列

⼆叉树的遍历【NOIP2001普及组】洛⾕P1030求先序排列题⽬链接模板题先讲⼀下⼆叉树的遍历⼆叉树的遍历分类性质求法分为三类:1. 先序遍历(PreOrder):根节点→左⼦树→右⼦树2. 中序遍历(InOrder):左⼦树→根节点→右⼦树3. 后序遍历(PostOrder):左⼦树→右⼦树→根节点我们可知:**序遍历实际上是指根节点的位置⽆论哪种遍历顺序,左⼦树都在右⼦树的前⾯在前序遍历中,第⼀个点是根节点在后序遍历中,最后⼀个点是根节点例如这样⼀个⼆叉树:它的先序遍历:A--B--D--E--X--C--F--Y--Z它的中序遍历:D--B--X--E--A--Y--F--Z--C它的后序遍历:D--X--E--B--Y--Z--F--C--A求后序遍历⽤到递归的思想,求整个⼆叉树的后序遍历就是求每个⼦树的后序遍历,最后连接起来即可。
1 #include<iostream>2using namespace std;3string z,q;4int len,cnt;5void PostOrder(int l,int r){//求中序遍历中l到r这个⼦树的后序遍历6if(l>r) return; //边界条件7int i;8char ans=q[cnt++]; //先序遍历的第⼀个是根节点9for(i=l;i<=r;i++){10if(z[i]==ans) break;//找到根节点在中序遍历中的位置11 }12 PostOrder(l,i-1); //递归左⼦树13 PostOrder(i+1,r); //递归右⼦树14 cout<<ans; //注意后序遍历是左右根的顺序,所以最后输出根15 }16int main()17 {18 cin>>z>>q; //z是中序遍历,q是先序遍历19 len=z.length()-1;20 PostOrder(0,z.length()-1);//⼀开始是整个⼦树21return0;22 }求先序遍历这⽐求后序遍历稍微有些复杂,需要保留根节点,即:PreOrder(左端点,右端点,根节点)。
二叉树的遍历PPT-课件

4 、二叉树的创建算法
利用二叉树前序遍历的结果可以非常方便地生成给定的
二叉树,具体做法是:将第一个输入的结点作为二叉树的 根结点,后继输入的结点序列是二叉树左子树前序遍历的 结果,由它们生成二叉树的左子树;再接下来输入的结点 序列为二叉树右子树前序遍历的结果,应该由它们生成二 叉树的右子树;而由二叉树左子树前序遍历的结果生成二 叉树的左子树和由二叉树右子树前序遍历的结果生成二叉 树的右子树的过程均与由整棵二叉树的前序遍历结果生成 该二叉树的过程完全相同,只是所处理的对象范围不同, 于是完全可以使用递归方式加以实现。
void createbintree(bintree *t) { char ch; if ((ch=getchar())==' ') *t=NULL; else { *t=(bintnode *)malloc(sizeof(bintnode)); /*生成二叉树的根结点*/ (*t)->data=ch; createbintree(&(*t)->lchild); /*递归实现左子树的建立*/ createbintree(&(*t)->rchild); /*递归实现右子树的建立*/ }
if (s.top>-1) { t=s.data[s.top]; s.tag[s.top]=1; t=t->rchild; }
else t=NULL; }
}
7.5 二叉树其它运算的实现
由于二叉树本身的定义是递归的,因此关于二叉树的许多 问题或运算采用递归方式实现非常地简单和自然。 1、二叉树的查找locate(t,x)
(1)对一棵二叉树中序遍历时,若我们将二叉树严
格地按左子树的所有结点位于根结点的左侧,右子树的所
吉林省专升本数据结构习题——二叉树的遍历和构造

吉林省专升本数据结构习题、参考答案及解析——二叉树的遍历和构造1、已知一棵二叉树如下图所示,请写出该二叉树的前序、中序、后序、层序遍历序列。
参考答案前序遍历:ABDCEFGH中序遍历:BDACGFHE后序遍历:DBGHFECA层序遍历:ABCDEFGH解析:前序遍历是D(根)L(左子树)R(右子树)的顺序,左右子树也需要进行前序遍历。
中序遍历是LDR顺序,后序遍历是LRD顺序。
层序遍历是从上层到下层同层之间从左到右的顺序进行遍历。
2、已知一棵二叉树的前序和中序遍历序列分别是ABCDEFH和BCAEDFH,构造该二叉树,并写出后序遍历序列。
参考答案后序遍历序列:CBEHFDA解析: 1)、前序遍历的顺序是DLR,所以序列的第一个结点是根结点。
2)、中序遍历的顺序是LDR,在前序确定了根结点的情况下,中序序列能区分左右子树。
3)、左右子树的构造方法重复1、2即可。
3、已知一棵二叉树的中序和后序遍历序列分别是ACBEFDG和CFEGDBA,构造该二叉树,并写出前序遍历序列。
参考答案前序遍历:ABCDEFG解析:后序和中序构造二叉树的方法参考前序和中序构造二叉树的方法。
后序遍历LRD顺序,确定序列的最后一个元素是根结点,再用中序分左右子树。
4、已知一棵表达式树的前序遍历序列和中序遍历序列分别是-*+abcd和a+b*c-d。
构造该表达式树,并写出后序遍历序列。
参考答案后序遍历:ab+c*d-解析:表达式树的分支结点应该是+-*/这类运算符,而叶子结点放abcd这些操作数。
在一些题目中会出现重复使用的运算符,通过这个性质就能区分出正确的表达式树。
5、已知一棵表达式树的中序遍历序列和后序遍历序列分别是a+b*c-d+e/f和ab+c*de+f/-。
构造该表达式树,并写出前序遍历序列。
前序遍历:-*+abc/+def。
二叉树前序和中序遍历求后序 表格法

二叉树前序和中序遍历求后序表格法1.概述二叉树是计算机科学中常见的数据结构,它可以用来表示树形结构的数据。
在二叉树的遍历中,前序遍历、中序遍历和后序遍历是三种重要的遍历方式。
本文将介绍如何通过前序遍历和中序遍历的结果来求出二叉树的后序遍历结果,以及如何使用表格法来进行求解。
2.二叉树遍历的概念在二叉树中,前序遍历指的是首先访问根节点,然后再递归地前序遍历左子树和右子树;中序遍历指的是先递归地中序遍历左子树,然后访问根节点,最后再递归地中序遍历右子树;后序遍历指的是先递归地后序遍历左子树和右子树,最后再访问根节点。
在本文中,我们将讨论如何通过前序遍历和中序遍历的结果来求出后序遍历的结果。
3.二叉树的定义我们需要了解二叉树的定义。
二叉树是一种树形结构,它的每个节点最多有两个子节点,分别为左子节点和右子节点。
对于任意一个节点,它的左子树和右子树也分别是二叉树。
如果一个节点没有左子树或者右子树,我们称其为叶子节点。
二叉树一般用递归的方式来定义,并且可以通过链式存储结构或者顺序存储结构来实现。
4.二叉树前序和中序遍历求后序接下来,我们将介绍如何通过二叉树的前序遍历和中序遍历结果来求出后序遍历的结果。
4.1 基本思路我们知道前序遍历的顺序是根节点、左子树、右子树,中序遍历的顺序是左子树、根节点、右子树。
假设我们已经知道了二叉树的前序遍历序列和中序遍历序列,那么我们可以通过这两个序列来确定二叉树的结构。
具体地,我们可以通过前序遍历序列找到根节点,然后在中序遍历序列中找到该根节点的位置,这样就可以确定左子树和右子树的中序遍历序列。
再根据左子树和右子树的节点数目,我们可以在前序遍历序列中确定左子树和右子树的前序遍历序列。
我们可以递归地对左子树和右子树进行求解,直到最终得到二叉树的后序遍历序列。
4.2 具体步骤具体地,通过前序遍历序列和中序遍历序列求后序遍历序列的步骤如下:1)在前序遍历序列中找到根节点2)在中序遍历序列中找到根节点的位置,确定左子树和右子树的中序遍历序列3)计算左子树和右子树的节点数目,确定左子树和右子树的前序遍历序列4)递归地对左子树和右子树进行求解5)最终得到二叉树的后序遍历序列4.3 表格法求解除了上述的基本思路和具体步骤外,我们还可以通过表格法来求解二叉树的后序遍历序列。
前序序列和后续序列确定二叉树

前序序列和后续序列确定⼆叉树⼆叉树:已知前序与后序建树那么我们换⼀种思考⽅式,我们先来看看先序与后序序列的排布规律。
以下⾯这棵树来举例:其先序序列为: 1 2 3 4 6 7 5后序序列为:2 6 7 4 5 3 1⾸先我们要知道:先序序列遍历顺序是:根结点-左⼦树-右⼦树后序序列遍历顺序是:左⼦树-右⼦树-根结点很明显,我们可以看出结点在先、后序列中的排布有以下这些特征:【1】、在先序序列中,根结点在⼦树中的结点前⾯,在后序序列中,根结点在⼦树中的结点后⾯。
【2】、以任⼀节点为根结点时,其⼦树在先序后序序列中排布都是先左⼦树后右⼦树,⽽根结点排在最后。
那么,反过来思考,已知这个先序与后序序列所确定的树是唯⼀的吗?进⼀步推⼴:怎么通过先序与后序序列判断是否存在唯⼀的树呢?现在,我们来⼀步步分析已知先序与后序的建树过程:①、根据特征【1】可知:根结点为先序序列第⼀个节点以及后序序列最后⼀个结点,因此根结点为1。
②、先序序列中第⼆个结点为2,其在后序序列中的位置是第⼀个,那么根据特征【2】我们可以知道结点2是没有⼦树的,⽽且结点2要么在根结点的左⼦树,要么在右⼦树。
假设结点2在右⼦树,那么由特征【2】可知根结点1没有左⼦树,⽽且先序序列中结点2后⾯的结点全部为结点2的⼦树上的结点。
再看后序序列,由特征【2】可知,结点2后⾯的结点不可能是其⼦树上的结点。
因此,假设显然与已知⽭盾。
这样,我们⼜知道结点2是结点1的左孩⼦,且结点2没有⼦结点。
③、先序序列第三个位置上的结点为3,该结点在后序序列中排倒数第⼆个。
由②可知,结点3必然是根结点1的右孩⼦。
④、先序序列第四个位置上的结点为4,该结点在后序序列中排第四个。
因为结点4在先序序列中排在结点3后⾯,⼜因为结点3是根结点1的右孩⼦,所以结点4只可能在结点3的⼦树上。
结点3的⼦树可能出现的情况是:只有左⼦树,只有右⼦树,左右⼦树都有。
因为在后序序列中,结点4左边是结点6、7,右边是结点5。
已知二叉树的先序遍历序列和中序遍历序列,求其后序遍历序列

已知⼆叉树的先序遍历序列和中序遍历序列,求其后序遍历序列2018.1.19 Fri已知⼆叉树的先序遍历序列和中序遍历序列,求其后序遍历序列例:先序遍历:ABDGCEFH中序遍历:DGBAECHF解:⾸先要先知道各种遍历⽅式的规则:先序遍历(先根遍历、前序遍历):1. 访问根结点2. 遍历左⼦树3. 遍历右⼦树中序遍历(中根遍历):1. 遍历左⼦树2. 访问根结点3. 遍历右⼦树后序遍历(后根遍历):1. 遍历左⼦树2. 遍历右⼦树3. 访问根结点且⽆论哪种遍历,左右⼦树仍然遵循该遍历规则。
若没有左⼦结点或右⼦结点(即不是满⼆叉树,如图2)则输出⼀个空代替⼀下就好,然后继续遍历。
例如图⼆中后序遍历为:BOA,即BA。
因为先序遍历是先访问根节点,所以A⼀定是根节点。
因此可以进⾏如下拆分:先序遍历:A BDGCEFH中序遍历:DGB A ECHF⼜因为中序遍历的顺序是:左⼦树,根节点,右⼦树,所以再拆 先序遍历:A BDG CEFH中序遍历:DGB A ECHF然后同理看BDG树先序遍历:B DG中序遍历:DG B得到B是A的左⼦结点。
同理看DG树: 先序遍历:D G中序遍历:D G得到D是B的左⼦结点, G是D的右⼦结点。
(因为如果G是左⼦结点的话中序遍历是GD)。
得到了左⼦树。
右⼦树同理:先序遍历:C E FH 中序遍历:E C HF得到C是A的右⼦结点,E是C的左⼦结点。
先序遍历:F H 中序遍历:H F得到F是C的右⼦结点,H是F的左⼦结点。
得到右⼦树。
得到如图1的⼆叉树。
然后得到后序遍历:GDBEHFCA。
二叉树的各种算法

二叉树的各种算法1.二叉树的前序遍历算法:前序遍历是指先访问根节点,再访问左子树,最后访问右子树的遍历顺序。
具体算法如下:-如果二叉树为空,则直接返回。
-访问根节点,并输出或进行其他操作。
-递归地前序遍历左子树。
-递归地前序遍历右子树。
2.二叉树的中序遍历算法:中序遍历是指先访问左子树,再访问根节点,最后访问右子树的遍历顺序。
具体算法如下:-如果二叉树为空,则直接返回。
-递归地中序遍历左子树。
-访问根节点,并输出或进行其他操作。
-递归地中序遍历右子树。
3.二叉树的后序遍历算法:后序遍历是指先访问左子树,再访问右子树,最后访问根节点的遍历顺序。
具体算法如下:-如果二叉树为空,则直接返回。
-递归地后序遍历左子树。
-递归地后序遍历右子树。
-访问根节点,并输出或进行其他操作。
4.二叉树的层序遍历算法:层序遍历是按照从上到下、从左到右的顺序逐层遍历二叉树的节点。
具体算法如下:-如果二叉树为空,则直接返回。
-创建一个队列,将根节点入队。
-循环执行以下步骤,直到队列为空:-出队并访问当前节点,并输出或进行其他操作。
-若当前节点的左子节点不为空,则将左子节点入队。
-若当前节点的右子节点不为空,则将右子节点入队。
5.二叉树的深度算法:二叉树的深度是指从根节点到叶节点的最长路径的节点数。
具体算法如下:-如果二叉树为空,则深度为0。
-否则,递归地计算左子树的深度和右子树的深度,然后取较大的值加上根节点的深度作为二叉树的深度。
6.二叉树的查找算法:二叉树的查找可以使用前序、中序或后序遍历来完成。
具体算法如下:-如果二叉树为空,则返回空。
-如果当前节点的值等于目标值,则返回当前节点。
-否则,先在左子树中递归查找,如果找到则返回找到的节点。
-如果左子树中未找到,则在右子树中递归查找,如果找到则返回找到的节点。
-如果左右子树中都未找到,则返回空。
7.二叉树的插入算法:二叉树的插入可以使用递归或循环来实现。
具体算法如下:-如果二叉树为空,则创建一个新节点作为根节点,并返回根节点。
二叉树的遍历有三种方式

二叉树的遍历有三种方式,如下:(1)前序遍历(DLR),首先访问根结点,然后遍历左子树,最后遍历右子树。
简记根-左-右。
(2)中序遍历(LDR),首先遍历左子树,然后访问根结点,最后遍历右子树。
简记左-根-右。
(3)后序遍历(LRD),首先遍历左子树,然后遍历右子树,最后访问根结点。
简记左-右-根。
例1:如上图所示的二叉树,若按前序遍历,则其输出序列为。
若按中序遍历,则其输出序列为。
若按后序遍历,则其输出序列为。
前序:根A,A的左子树B,B的左子树没有,看右子树,为D,所以A-B-D。
再来看A的右子树,根C,左子树E,E的左子树F,E的右子树G,G的左子树为H,没有了结束。
连起来为C-E-F-G-H,最后结果为ABDCEFGH中序:先访问根的左子树,B没有左子树,其有右子树D,D无左子树,下面访问树的根A,连起来是BDA。
再访问根的右子树,C的左子树的左子树是F,F的根E,E的右子树有左子树是H,再从H出发找到G,到此C的左子树结束,找到根C,无右子树,结束。
连起来是FEHGC, 中序结果连起来是BDAFEHGC 后序:B无左子树,有右子树D,再到根B。
再看右子树,最下面的左子树是F,其根的右子树的左子树是H,再到H的根G,再到G的根E,E的根C无右子树了,直接到C,这时再和B找它们其有的根A,所以连起来是DBFHGECA例2:有下列二叉树,对此二叉树前序遍历的结果为()。
A)ACBEDGFH B)ABDGCEHFC)HGFEDCBA D)ABCDEFGH解析:先根A,左子树先根B,B无左子树,其右子树,先根D,在左子树G,连起来是ABDG。
A的右子树,先根C,C左子树E,E无左子树,有右子树为H,C的右子树只有F,连起来是CEHF。
整个连起来是B答案ABDGCEHF。
例3:已知二叉树后序遍历是DABEC,中序遍历序列是DEBAC,它的前序遍历序列是( ) 。
A)CEDBA B)ACBED C)DECAB D)DEABC解析:由后序遍历可知,C为根结点,由中序遍历可知,C左边的是左子树含DEBA,C右边无结点,知根结点无右子树。
二叉树的先序,中序,后序遍历的递归写法

二叉树的先序,中序,后序遍历的递归写法一、前言二叉树是数据结构中最基础、最重要的一种数据结构之一,如何遍历二叉树是每一个数据结构学习者需要掌握的技能。
本文将介绍二叉树的三种遍历方式:前序遍历、中序遍历和后序遍历,以及它们的递归写法。
二、先序遍历二叉树的先序遍历顺序是:根节点→ 左子树→ 右子树。
1.递归写法(1)基本思路先访问根节点,然后递归遍历左子树,最后递归遍历右子树。
(2)代码实现public void preOrderTraversal(TreeNode root) {if (root == null) return;System.out.println(root.val);preOrderTraversal(root.left);preOrderTraversal(root.right);}2.中序遍历二叉树的中序遍历顺序是:左子树→ 根节点→ 右子树。
1.递归写法(1)基本思路递归遍历左子树,然后访问根节点,最后递归遍历右子树。
(2)代码实现public void inOrderTraversal(TreeNode root) {if (root == null) return;inOrderTraversal(root.left);System.out.println(root.val);inOrderTraversal(root.right);}3.后序遍历二叉树的后序遍历顺序是:左子树→ 右子树→ 根节点。
1.递归写法(1)基本思路递归遍历左子树,然后递归遍历右子树,最后访问根节点。
(2)代码实现public void postOrderTraversal(TreeNode root) {if (root == null) return;postOrderTraversal(root.left);postOrderTraversal(root.right);System.out.println(root.val);}三、总结本文介绍了二叉树的三种遍历方式以及它们的递归写法。
二叉树遍历解题技巧

二叉树遍历解题技巧
二叉树遍历是指按照一定规则,依次访问二叉树的所有节点的过程。
常见的二叉树遍历有前序遍历、中序遍历和后序遍历。
以下是一些二叉树遍历解题技巧:
1. 递归遍历:递归是最直观、最简单的遍历方法。
对于一个二叉树,可以递归地遍历其左子树和右子树。
在递归的过程中,可以对节点进行相应的处理。
例如,前序遍历可以先访问根节点,然后递归遍历左子树和右子树。
2. 迭代遍历:迭代遍历可以使用栈或队列来实现。
对于前序遍历,可以使用栈来记录遍历路径。
首先将根节点入栈,然后依次弹出栈顶节点,访问该节点,并将其右子节点和左子节点分别入栈。
中序遍历和后序遍历也可以使用类似的方法,只是访问节点的顺序会有所不同。
3. Morris遍历:Morris遍历是一种空间复杂度为O(1)的二叉树遍历方法。
它利用二叉树节点的空闲指针来存储遍历下一个节点的信息,从而避免使用额外的栈或队列。
具体步骤可以参考相关算法书籍或博客。
4. 层次遍历:层次遍历是一种逐层遍历二叉树的方法。
可以使用队列来实现。
首先将根节点入队,然后依次将队首节点出队并访问,同时将其左子节点和右子节点入队。
不断重复这个过程,直到队列为空。
层次遍历可以按照从上到下、从左到右的顺序访问二叉树的节点。
除了以上技巧,还可以根据具体问题的特点来选择合适的遍历方法。
在实际解题中,可以尝试不同的遍历方法并选择效率高、代码简洁的方法。
知道前序和中序求后序的例题

知道前序和中序求后序的例题说到二叉树的遍历,很多人都觉得这玩意儿挺抽象的,脑袋一片懵。
不过,别急,我今天就给你们唠唠这个问题,保证你听了之后能一下子就明白,完全不迷糊。
今天要聊的题目是:知道前序和中序,怎么求后序?听上去像是一个魔法题,但其实完全不是这么复杂。
你只需要掌握一些套路,熟悉了之后,再复杂的题目也能一眼看出门道来。
好了,咱们开始吧!什么是前序遍历?说白了就是你从树的根节点开始,一路往下走。
遇到根,先拜一拜;然后去左边走,右边再说。
就像是你见到一个老朋友,先跟他说“嘿,朋友”,然后才会问他家在哪儿,再问他最近怎么样,最后再去看看他家里有没有啥好吃的。
这就是前序的套路:根,左,右。
中序遍历就是,你从左边开始,走到根节点,然后再去右边。
就像你在家里做事一样,先把左边的任务都干完,然后再去处理中心的事,最后再去右边收尾。
你有没有发现?根节点是个关键人物,前序是它先出场,接着你才能知道左边和右边分别是什么。
知道了前序和中序的规则,后序遍历自然不难了。
后序遍历是啥?简单来说,就是左边的事先做,右边的事做完再来干根节点的事。
所以,后序就是:左,右,根。
听起来是不是很简单?不过,要是你手里有前序和中序两个序列,怎么看才能推算出后序呢?这可不是个小问题,但放心,套路在这儿,你学会了就是吃定了!先看看前序和中序。
前序给你了根节点的信息,中序则告诉你根节点左右孩子的分布情况。
记住,根节点一旦确定,前序中第一个元素就是根节点。
接下来你就能根据这个根节点在中序里的位置,划分出左右子树的部分了。
就像你整理家里的书架,看到根节点位置,你马上知道哪些书是放在左边的,哪些是放右边的。
然后,咱们从左边开始干。
左子树的情况就相当于我们从左侧书架开始翻,右子树是右侧书架,前序和中序的分布会帮你划分得清清楚楚。
到这儿,你其实就差不多能把整个树的结构给搭建起来了,最后一步就是把这些子树按照后序的方式给整理出来。
左,右,根。
树的结构清楚了,后序自然就能顺利求解。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二叉树前序、中序、后序遍历相互求法今天来总结下二叉树前序、中序、后序遍历相互求法,即如果知道两个的遍历,如何求第三种遍历方法,比较笨的方法是画出来二叉树,然后根据各种遍历不同的特性来求,也可以编程求出,下面我们分别说明。
首先,我们看看前序、中序、后序遍历的特性:
前序遍历:
1.访问根节点
2.前序遍历左子树
3.前序遍历右子树
中序遍历:
1.中序遍历左子树
2.访问根节点
3.中序遍历右子树
后序遍历:
1.后序遍历左子树
2.后序遍历右子树
3.访问根节点
一、已知前序、中序遍历,求后序遍历
例:
前序遍历: GDAFEMHZ
中序遍历: ADEFGHMZ
画树求法:
第一步,根据前序遍历的特点,我们知道根结点为G
第二步,观察中序遍历ADEFGHMZ。
其中root节点G左侧的ADEF必然是root的左子树,G右侧的HMZ必然是root的右子树。
第三步,观察左子树ADEF,左子树的中的根节点必然是大树的root的leftchild。
在前序遍历中,大树的root的leftchild位于root之后,所以左子树的根节点为D。
第四步,同样的道理,root的右子树节点HMZ中的根节点也可以通过前序遍历求得。
在前序遍历中,一定是先把root和root的所有左子树节点遍历完之后才会遍历右子树,并且遍历的左子树的第一个节点就是左子树的根节点。
同理,遍历的右子树的第一个节点就是右子树的根节点。
第五步,观察发现,上面的过程是递归的。
先找到当前树的根节点,然后划分为左子树,右子树,然后进入左子树重复上面的过程,然后进入右子树重复上面的过程。
最后就可以还原一棵树了。
该步递归的过程可以简洁表达如下:
1 确定根,确定左子树,确定右子树。
2 在左子树中递归。
3 在右子树中递归。
4 打印当前根。
那么,我们可以画出这个二叉树的形状:
那么,根据后序的遍历规则,我们可以知道,后序遍历顺序为:AEFDHZMG
编程求法:(依据上面的思路,写递归程序)
1 #include <iostream>
2 #include <fstream>
3 #include <string>
4
5 struct TreeNode
6 {
7 struct TreeNode* left;
8 struct TreeNode* right;
9 char elem;
10 };
11
12 void BinaryTreeFromOrderings(char* inorder, char* preorder, int length)
13 {
14 if(length == 0)
15 {
16 //cout<<"invalid length";
17 return;
18 }
19 TreeNode* node = new TreeNode;//Noice that [new] should be written out.
20 node->elem = *preorder;
21 int rootIndex = 0;
22 for(;rootIndex < length; rootIndex++)
23 {
24 if(inorder[rootIndex] == *preorder)
25 break;
26 }
27 //Left
28 BinaryTreeFromOrderings(inorder, preorder +1, rootIndex);
29 //Right
30 BinaryTreeFromOrderings(inorder + rootIndex + 1, preorder + rootIndex + 1, length - (rootIndex + 1));
31 cout<<node->elem<<endl;
32 return;
33 }
34
35
36 int main(int argc, char* argv[])
37 {
38 printf("Hello World!\n");
39 char* pr="GDAFEMHZ";
40 char* in="ADEFGHMZ";
41
42 BinaryTreeFromOrderings(in, pr, 8);
43
44 printf("\n");
45 return 0;
46 }
输出的结果为:AEFDHZMG
二、已知中序和后序遍历,求前序遍历
依然是上面的题,这次我们只给出中序和后序遍历:
中序遍历: ADEFGHMZ
后序遍历: AEFDHZMG
画树求法:
第一步,根据后序遍历的特点,我们知道后序遍历最后一个结点即为根结点,即根结点为G。
第二步,观察中序遍历ADEFGHMZ。
其中root节点G左侧的ADEF必然是root的左子树,G右侧的HMZ必然是root的右子树。
第三步,观察左子树ADEF,左子树的中的根节点必然是大树的root的leftchild。
在前序遍历中,大树的root的leftchild位于root之后,所以左子树的根节点为D。
第四步,同样的道理,root的右子树节点HMZ中的根节点也可以通过前序遍历求得。
在前后序遍历中,一定是先把root和root的所有左子树节点遍历完之后才会遍历右子树,并且遍历的左子树的第一个节点就是左子树的根节点。
同理,遍历的右子树的第一个节点就是右子树的根节点。
第五步,观察发现,上面的过程是递归的。
先找到当前树的根节点,然后划分为左子树,右子树,然后进入左子树重复上面的过程,然后进入右子树重复上面的过程。
最后就可以还原一棵树了。
该步递归的过程可以简洁表达如下:
1 确定根,确定左子树,确定右子树。
2 在左子树中递归。
3 在右子树中递归。
4 打印当前根。
这样,我们就可以画出二叉树的形状,如上图所示,这里就不再赘述。
那么,前序遍历: GDAFEMHZ
编程求法:(并且验证我们的结果是否正确)
#include <iostream>
#include <fstream>
#include <string>
struct TreeNode
{
struct TreeNode* left;
struct TreeNode* right;
char elem;
};
TreeNode* BinaryTreeFromOrderings(char* inorder, char* aftorder, int length)
{
if(length == 0)
{
return NULL;
}
TreeNode* node = new TreeNode;//Noice that [new] should be written out.
node->elem = *(aftorder+length-1);
std::cout<<node->elem<<std::endl;
int rootIndex = 0;
for(;rootIndex < length; rootIndex++)//a variation of the loop
{
if(inorder[rootIndex] == *(aftorder+length-1))
break;
}
node->left = BinaryTreeFromOrderings(inorder, aftorder , rootIndex);
node->right = BinaryTreeFromOrderings(inorder + rootIndex + 1, aftorder + rootIndex , length - (rootIndex + 1));
return node;
}
int main(int argc, char** argv)
{
char* af="AEFDHZMG";
char* in="ADEFGHMZ";
BinaryTreeFromOrderings(in, af, 8);
printf("\n");
return 0;
}
输出结果:GDAFEMHZ。