合肥工业大学数据结构试验报告
合肥工业大学数据结构试验一实验报告

计算机与信息学院数据结构实验报告专业班级学生姓名及学号课程教学班号任课教师实验指导教师实验地点2015 ~2016 学年第 2 学期说明实验报告是关于实验教学内容、过程及效果的记录和总结,因此,应注意以下事项和要求:1.每个实验单元在4页的篇幅内完成一份报告。
“实验单元”指按照实验指导书规定的实验内容。
若篇幅不够,可另附纸。
2、各实验的预习部分的内容是进入实验室做实验的必要条件,请按要求做好预习。
3.实验报告要求:书写工整规范,语言表达清楚,数据和程序真实。
理论联系实际,认真分析实验中出现的问题与现象,总结经验。
4.参加实验的每位同学应独立完成实验报告的撰写,其中程序或相关的设计图纸也可以采用打印等方式粘贴到报告中。
严禁抄袭或拷贝,否则,一经查实,按作弊论取,并取消理论课考试资格。
5.实验报告作为评定实验成绩的依据。
实验序号及名称:实验一单链表实验实验时间∶ 2016年 5 月二、实验内容与步骤(过程及数据记录):<1>求链表中第i个结点的指针(函数),若不存在,则返回NULL。
实验测试数据基本要求:第一组数据:链表长度n≥10,i分别为5,n,0,n+1,n+2第二组数据:链表长度n=0,i分别为0,2node* list::address(int i){n ode *p = head->next;i nt n = 1;w hile (n != i&&p != NULL){p = p->next;n++;}i f (p!=NULL) return p;e lse return NULL;}第一组数据第二组数据<2>在第i个结点前插入值为x的结点。
实验测试数据基本要求:第一组数据:链表长度n≥10,x=100, i分别为5,n,n+1,0,1,n+2第二组数据:链表长度n=0,x=100,i=5errorcode list::insert(const int i, const int x){n ode *p;p = head;i nt n = 1;w hile (n != i&&p != NULL){p = p->next;n++;}i f (i<1 || i>length() + 1) return rangeerror;n ode *s = new node;s->data = x;s->next = p->next;p->next = s;c ount++;r eturn success;}<3>删除链表中第i个元素结点。
数据结构实验报告2篇

数据结构实验报告数据结构实验报告精选2篇(一)实验目的:1. 熟悉数据结构的基本概念和基本操作;2. 掌握线性表、栈、队列、链表等经典数据结构的实现方法;3. 掌握数据结构在实际问题中的应用。
实验内容:本次实验主要包括以下几个部分:1. 线性表的实现方法,包括顺序表和链表,分别使用数组和链表来实现线性表的基本操作;2. 栈的实现方法,包括顺序栈和链式栈,分别使用数组和链表来实现栈的基本操作;3. 队列的实现方法,包括顺序队列和链式队列,分别使用数组和链表来实现队列的基本操作;4. 链表的实现方法,包括单链表、双链表和循环链表,分别使用指针链、双向链和循环链来实现链表的基本操作;5. 综合应用,使用各种数据结构来解决实际问题,例如使用栈来实现括号匹配、使用队列来实现马铃薯游戏等。
实验步骤及结果:1. 线性表的实现方法:a) 顺序表的基本操作:创建表、插入元素、删除元素、查找元素等;b) 链表的基本操作:插入节点、删除节点、查找节点等;c) 比较顺序表和链表的优缺点,分析适用场景。
结果:通过实验,确认了顺序表适用于频繁查找元素的情况,而链表适用于频繁插入和删除节点的情况。
2. 栈的实现方法:a) 顺序栈的基本操作:进栈、出栈、判空、判满等;b) 链式栈的基本操作:进栈、出栈、判空、判满等。
结果:通过实验,掌握了栈的基本操作,并了解了栈的特性和应用场景,例如括号匹配。
3. 队列的实现方法:a) 顺序队列的基本操作:入队、出队、判空、判满等;b) 链式队列的基本操作:入队、出队、判空、判满等。
结果:通过实验,掌握了队列的基本操作,并了解了队列的特性和应用场景,例如马铃薯游戏。
4. 链表的实现方法:a) 单链表的基本操作:插入节点、删除节点、查找节点等;b) 双链表的基本操作:插入节点、删除节点、查找节点等;c) 循环链表的基本操作:插入节点、删除节点、查找节点等。
结果:通过实验,掌握了链表的基本操作,并了解了链表的特性和应用场景。
数据结构课程实验报告

数据结构课程实验报告一、实验目的数据结构是计算机科学中一门重要的基础课程,通过本次实验,旨在加深对数据结构基本概念和算法的理解,提高编程能力和解决实际问题的能力。
具体目标包括:1、掌握常见数据结构(如数组、链表、栈、队列、树、图等)的基本操作和实现方法。
2、学会运用数据结构解决实际问题,培养算法设计和分析的能力。
3、提高程序设计的规范性和可读性,培养良好的编程习惯。
二、实验环境本次实验使用的编程语言为C++,开发环境为Visual Studio 2019。
三、实验内容本次实验共包括以下几个部分:(一)线性表的实现与操作1、顺序表的实现定义一个顺序表结构体,包含数据元素数组和表的长度。
实现顺序表的初始化、插入、删除、查找等基本操作。
2、链表的实现定义链表节点结构体,包含数据域和指针域。
实现链表的创建、插入、删除、遍历等操作。
(二)栈和队列的实现与应用1、栈的实现采用顺序存储或链式存储实现栈。
实现栈的入栈、出栈、栈顶元素获取等操作,并应用于表达式求值。
2、队列的实现用循环队列或链式队列实现队列。
实现队列的入队、出队、队头元素获取等操作,应用于模拟排队系统。
(三)树的基本操作与遍历1、二叉树的实现定义二叉树节点结构体,包含数据域、左子树指针和右子树指针。
实现二叉树的创建、插入、删除节点等操作。
2、二叉树的遍历分别实现前序遍历、中序遍历和后序遍历,并输出遍历结果。
(四)图的表示与遍历1、邻接矩阵和邻接表表示图定义图的结构体,使用邻接矩阵和邻接表两种方式存储图的信息。
实现图的创建、添加边等操作。
2、图的遍历分别用深度优先搜索(DFS)和广度优先搜索(BFS)遍历图,并输出遍历序列。
四、实验步骤(一)线性表的实现与操作1、顺序表的实现首先,定义了一个结构体`SeqList` 来表示顺序表,其中包含一个整数数组`data` 用于存储数据元素,以及一个整数`length` 表示表的当前长度。
在初始化函数`InitSeqList` 中,将表的长度初始化为 0,并分配一定的存储空间给数组。
合工大数据分析报告(3篇)

第1篇一、引言随着信息技术的飞速发展,大数据已经成为推动社会进步的重要力量。
我国政府高度重视大数据产业的发展,将其列为国家战略性新兴产业。
合肥工业大学(以下简称“合工”)作为一所知名高等学府,在大数据领域有着丰富的教学、科研和实践经验。
本报告将对合工大数据发展现状进行分析,并提出相关建议。
二、合工大数据发展现状1. 教育教学(1)专业设置:合工在大数据领域设有多个相关专业,如数据科学与大数据技术、计算机科学与技术、软件工程等。
这些专业培养了大量具备大数据理论知识与实践能力的人才。
(2)课程体系:合工大数据相关课程体系完善,涵盖了数据挖掘、机器学习、数据分析、数据库技术等多个方面,为学生提供了全面的学习机会。
(3)实践教学:合工注重实践教学,通过实验室、实习基地、创新创业项目等途径,提高学生的实践能力。
2. 科研成果(1)科研项目:合工在大数据领域承担了多项国家级、省部级科研项目,如国家自然科学基金、国家重点研发计划等。
(2)学术论文:合工在大数据领域的学术论文发表数量和质量均位居国内前列,为我国大数据产业发展提供了有力支持。
(3)专利成果:合工在大数据领域拥有多项专利成果,为产业发展提供了技术保障。
3. 企业合作(1)产学研合作:合工与多家企业建立了产学研合作关系,共同开展大数据技术研究与应用。
(2)人才培养:合工为企业培养了大量大数据人才,满足了企业对人才的需求。
(3)技术服务:合工为企业提供大数据技术咨询服务,助力企业解决实际问题。
三、合工大数据发展存在的问题1. 人才培养与市场需求不匹配:虽然合工大数据专业设置较为完善,但部分课程设置与市场需求存在一定差距,导致毕业生就业面临压力。
2. 研发投入不足:相较于国外知名高校,合工在大数据领域的研发投入相对较少,影响了科研水平的提升。
3. 产业协同不足:合工与大数据企业的合作深度和广度有待提高,产业协同效应尚未充分发挥。
四、合工大数据发展建议1. 优化专业设置:根据市场需求,调整和优化大数据相关专业课程设置,提高人才培养质量。
合肥工业大学数据结构试验报告

数据结构实验报告实验三栈的实验1.实验目标(1)熟练掌握栈的顺序存储结构和链式存储结构。
(2)熟练掌握栈的有关算法设计,并在顺序栈和链栈上实现。
(3)根据具体给定的需求,合理设计并实现相关结构和算法。
2.实验内容和要求(1)顺序栈结构和运算定义,算法的实现以库文件方式实现,不得在测试主程序中直接实现;(2)实验程序有较好可读性,各运算和变量的命名直观易懂,符合软件工程要求;(3)程序有适当的注释。
3.数据结构设计(1)以结构体,类为基础,和函数调用实现各实验;4.算法设计(除书上给出的基本运算(这部分不必给出设计思想),其它实验内容要给出算法设计思想)5.运行和测试(1)各个实验运行正常,符合实验要求;(2)达到实验目的。
6.总结和心得(1)通过实验,我熟练掌握了栈的顺序存储结构和链式存储结构。
(2)通过实验,熟练掌握栈的有关算法设计,并在顺序栈和链栈上实现。
(3)通过实验,我理解线性表的真实意思,能够运用一些基本的题目。
(4)通过实验,让我了解计算机的一些机制。
(5)通过实验,我学到了很多知识,在发现问题,解决问题时,我学会了怎样处理这些问题,同时也创造许多自己的思想。
[7. 附录](源代码清单。
纸质报告不做要求。
电子报告,可直接附源文件,删除编译生成的所有文件)<1>利用顺序栈实现将10进制数转换为16进制数。
第一组数据:4第二组数据:11第三组数据:254第四组数据:1357Cpp1.cpp<2>对一个合法的数学表达式来说,其中的各大小括号“{”,“}”,“[”,“]”,“(”和“)”应是相互匹配的。
设计算法对以字符串形式读入的表达式S,判断其中的各括号是否是匹配的。
Cpp1.cpp。
数据结构 实验报告

数据结构实验报告一、实验目的数据结构是计算机科学中非常重要的一门课程,通过本次实验,旨在加深对常见数据结构(如链表、栈、队列、树、图等)的理解和应用,提高编程能力和解决实际问题的能力。
二、实验环境本次实验使用的编程语言为C++,开发工具为Visual Studio 2019。
操作系统为 Windows 10。
三、实验内容1、链表的实现与操作创建一个单向链表,并实现插入、删除和遍历节点的功能。
对链表进行排序,如冒泡排序或插入排序。
2、栈和队列的应用用栈实现表达式求值,能够处理加、减、乘、除和括号。
利用队列实现银行排队系统的模拟,包括顾客的到达、服务和离开。
3、二叉树的遍历与操作构建一棵二叉树,并实现前序、中序和后序遍历。
进行二叉树的插入、删除节点操作。
4、图的表示与遍历用邻接矩阵和邻接表两种方式表示图。
实现图的深度优先遍历和广度优先遍历。
四、实验步骤及结果1、链表的实现与操作首先,定义了链表节点的结构体:```cppstruct ListNode {int data;ListNode next;ListNode(int x) : data(x), next(NULL) {}};```插入节点的函数:```cppvoid insertNode(ListNode& head, int val) {ListNode newNode = new ListNode(val);head = newNode;} else {ListNode curr = head;while (curr>next!= NULL) {curr = curr>next;}curr>next = newNode;}}```删除节点的函数:```cppvoid deleteNode(ListNode& head, int val) {if (head == NULL) {return;}ListNode temp = head;head = head>next;delete temp;return;}ListNode curr = head;while (curr>next!= NULL && curr>next>data!= val) {curr = curr>next;}if (curr>next!= NULL) {ListNode temp = curr>next;curr>next = curr>next>next;delete temp;}}```遍历链表的函数:```cppvoid traverseList(ListNode head) {ListNode curr = head;while (curr!= NULL) {std::cout << curr>data <<"";curr = curr>next;}std::cout << std::endl;}```对链表进行冒泡排序的函数:```cppvoid bubbleSortList(ListNode& head) {if (head == NULL || head>next == NULL) {return;}bool swapped;ListNode ptr1;ListNode lptr = NULL;do {swapped = false;ptr1 = head;while (ptr1->next!= lptr) {if (ptr1->data > ptr1->next>data) {int temp = ptr1->data;ptr1->data = ptr1->next>data;ptr1->next>data = temp;swapped = true;}ptr1 = ptr1->next;}lptr = ptr1;} while (swapped);}```测试结果:创建了一个包含 5、3、8、1、4 的链表,经过排序后,输出为 1 3 4 5 8 。
数据结构实验报告目的(3篇)

第1篇一、引言数据结构是计算机科学中一个重要的基础学科,它研究如何有效地组织、存储和操作数据。
在计算机科学中,数据结构的选择直接影响到算法的效率、存储空间和程序的可维护性。
为了使学生在实际操作中更好地理解数据结构的概念、原理和应用,本实验报告旨在明确数据结构实验的目的,指导学生进行实验,并总结实验成果。
二、实验目的1. 理解数据结构的基本概念和原理通过实验,使学生深入理解数据结构的基本概念,如线性表、栈、队列、树、图等,掌握各种数据结构的定义、性质和特点。
2. 掌握数据结构的存储结构及实现方法实验过程中,使学生熟悉各种数据结构的存储结构,如顺序存储、链式存储等,并掌握相应的实现方法。
3. 培养编程能力通过实验,提高学生的编程能力,使其能够熟练运用C、C++、Java等编程语言实现各种数据结构的操作。
4. 提高算法设计能力实验过程中,要求学生根据实际问题设计合适的算法,提高其算法设计能力。
5. 培养实际应用能力通过实验,使学生将所学知识应用于实际问题,提高解决实际问题的能力。
6. 培养团队合作精神实验过程中,鼓励学生进行团队合作,共同完成实验任务,培养团队合作精神。
7. 提高实验报告撰写能力通过实验报告的撰写,使学生学会总结实验过程、分析实验结果,提高实验报告撰写能力。
三、实验内容1. 线性表实验(1)实现线性表的顺序存储和链式存储结构;(2)实现线性表的基本操作,如插入、删除、查找等;(3)比较顺序存储和链式存储的优缺点。
2. 栈和队列实验(1)实现栈和队列的顺序存储和链式存储结构;(2)实现栈和队列的基本操作,如入栈、出栈、入队、出队等;(3)比较栈和队列的特点及适用场景。
3. 树和图实验(1)实现二叉树、二叉搜索树、图等数据结构的存储结构;(2)实现树和图的基本操作,如遍历、插入、删除等;(3)比较不同树和图结构的优缺点及适用场景。
4. 查找算法实验(1)实现二分查找、顺序查找、哈希查找等查找算法;(2)比较不同查找算法的时间复杂度和空间复杂度;(3)分析查找算法在实际应用中的适用场景。
合肥工业大学计算机组成原理实验报告
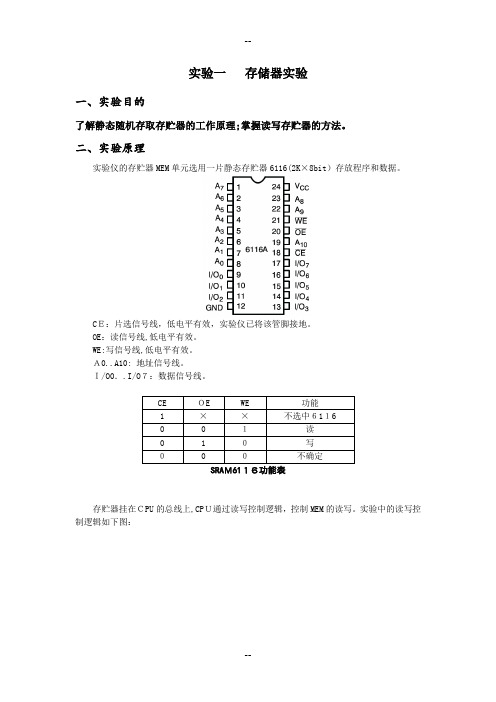
实验一存储器实验一、实验目的了解静态随机存取存贮器的工作原理;掌握读写存贮器的方法。
二、实验原理实验仪的存贮器MEM单元选用一片静态存贮器6116(2K×8bit)存放程序和数据。
CE:片选信号线,低电平有效,实验仪已将该管脚接地。
OE:读信号线,低电平有效。
WE:写信号线,低电平有效。
A0..A10: 地址信号线。
I/O0..I/O7:数据信号线。
SRAM6116功能表存贮器挂在CPU的总线上,CPU通过读写控制逻辑,控制MEM的读写。
实验中的读写控制逻辑如下图:读写控制逻辑M_nI/O用来选择对MEM还是I/O读写,M_nI/O = 1,选择存贮器MEM;M_nI/O = 0,选择I/O设备。
nRD = 0为读操作;nWR= 0为写操作。
对MEM、I/O的写脉冲宽度与T2一致;读脉冲宽度与T2+T3一致,T2、T3由CON单元提供。
存贮器实验原理图存贮器数据信号线与数据总线DBus相连;地址信号线与地址总线ABus相连,6116的高三位地址A10..A8接地,所以其实际容量为256字节。
数据总线DBus、地址总线ABus、控制总线CBus与扩展区单元相连,扩展区单元的数码管、发光二极管上显示对应的数据。
IN单元通过一片74HC245(三态门),连接到内部数据总线iDBus上,分时提供地址、数据。
MAR由锁存器(74HC574,锁存写入的地址数据)、三态门(74HC245、控制锁存器中的地址数据是否输出到地址总线上)、8个发光二极管(显示锁存器中的地址数据)组成。
T2、T3由CON单元提供,按一次CON单元的uSTEP键,时序单元发出T1信号;按一次uSTEP键,时序单元发出T2信号;按一次uSTEP键,时序单元发出T3信号;再按一次uSTEP键,时序单元又发出T1信号,……按一次STEP键,相当于按了三次uSTEP键,依次发出T1、T2、T3信号。
其余信号由开关区单元的拨动开关模拟给出,其中M_nI/O应为高(即对MEM读写操作)电平有效,nRD、nWR、wMAR、nMAROE、IN单元的nCS、nRD都是低电平有效。
合肥工业大学数据结构与算法试验报告2

数据结构实验报告实验二单链表实验1.实验目标(1)熟练掌握线性表的链式存储结构。
(2)熟练掌握单链表的有关算法设计。
(3)根据具体问题的需要,设计出合理的表示数据的顺序结构,并设计相关算法。
2.实验内容和要求(1)本次实验中的链表结构指带头结点的单链表;(2)单链表结构和运算定义,算法的实现以库文件方式实现,不得在测试主程序中直接实现;(3)实验程序有较好可读性,各运算和变量的命名直观易懂,符合软件工程要求;(4)程序有适当的注释。
3.数据结构设计(1)以结构体,类为基础,和函数调用实现各实验;4.算法设计(除书上给出的基本运算(这部分不必给出设计思想),其它实验内容要给出算法设计思想)5.运行和测试(1)各个实验运行正常,符合实验要求;(2)达到实验目的。
6.总结和心得[7. 附录](源代码清单。
纸质报告不做要求。
电子报告,可直接附源文件,删除编译生成的所有文件)<1>尾插法创建单链表,打印创建结果。
题1.cpp<2>头插法创建单链表,打印创建结果。
题2.cpp<3>销毁单链表。
题3.cpp<4>求链表长度。
题4.cpp<5>求单链表中第i个元素(函数),若不存在,报错。
题5.cpp<6>在第i个结点前插入值为x的结点。
题6.cpp<7>链表中查找元素值为x的结点,成功返回结点指针,失败报错。
题7.cpp<8>删除单链表中第i个元素结点。
题8.cpp<9>在一个递增有序的单链表L中插入一个值为x的元素,并保持其递增有序特性。
题9.cpp<10>将单链表L中的奇数项和偶数项结点分解开(元素值为奇数、偶数),分别放入新的单链表中,然后原表和新表元素同时输出到屏幕上,以便对照求解结果。
题10.cpp<11>求两个递增有序单链表L1和L2中的公共元素,放入新的单链表L3中。
HFUT 数据结构试验一预习报告

数据结构试验报告试验一 单链表试验1、试验目的(1)理解线性表的链式存储结构(2)熟练掌握动态链表结构及有关算法设计。
(3)根据具体问题的需要,设计出合理的表示数据的链表结构,并设计相关算法。
二、实验环境:Windows xp Dev C++三、实验内容:(1)编写链表类,实现基本的操作。
(2)实现以下功能:求链表中第i个结点的指针(函数);在第i个结点前插入值为x的结点;删除链表中第i个元素结点;在一个递增有序的链表L中插入一个值为x的元素,并保持其递增有序特性;将单链表L中的奇数项和偶数项结点分解开,并分别连成一个带头结点的单链表,然后再将这两个新链表同时输出在屏幕上,并保留原链表的显示结果;将单链表L中的奇数项和偶数项结点分解开,并分别连成一个带头结点的单链表,然后再将这两个新链表同时输出在屏幕上,并保留原链表的显示结果;求两个递增有序链表L1和L2中的公共元素,并以同样方式连接成链表L3。
四、试验准备(1)类结构:错误代码(枚举)enum error_code{sucess=0,overflow=1,downflow=2,rangeerror=3};节点(结构体)template <class Element_type> struct node{Element_type data;node *next;};链表类template <class Element_type>class List{public:List();//构造函数~List();//析构函数bool empty()const;//判断函数是否为空,空则返回trueerror_code show()const;//输出链表内容int length()const;//链表长度error_code get_element(const int i,Element_type &x)const;//取出第i个位置的值并赋给xnode<Element_type>* locate(const Element_type x)const;//返回值为x 的节点地址node<Element_type>* locate_node(const int i)const;//返回第i个节点的地址node<Element_type>* return_top()const;//返回链表的首节点error_code insert(const int i ,const Element_type x);//在第i个位置插入值为x的节点error_code insert(const Element_type x);//按顺序插入值为x的节点 error_code delete_element(const int i);删除第i个位置的节点error_code clear();//置为空private:node<Element_type> *top;};5、试验过程(1)具体实现:一些辅助函数:(2)试验目标的程序实现:<1>求链表中第i个结点的指针(函数),若不存在,则返回NULL。
数据结构实验报告

数据结构实验报告数据结构实验报告1.实验目的1.1 理解数据结构的基本概念和原理1.2 掌握数据结构的常用算法和操作方法1.3 培养编写高效数据结构代码的能力2.实验背景2.1 数据结构的定义和分类2.2 数据结构的应用领域和重要性3.实验内容3.1 实验一:线性表的操作3.1.1 线性表的定义和基本操作3.1.2 实现顺序存储结构和链式存储结构的线性表 3.1.3 比较顺序存储结构和链式存储结构的优缺点3.2 实验二:栈和队列的实现3.2.1 栈的定义和基本操作3.2.2 队列的定义和基本操作3.2.3 比较栈和队列的应用场景和特点3.3 实验三:树的操作3.3.1 树的定义和基本概念3.3.2 实现二叉树的遍历和插入操作3.3.3 比较不同类型的树的存储结构和算法效率3.4 实验四:图的遍历和最短路径算法3.4.1 图的定义和基本概念3.4.2 实现深度优先搜索和广度优先搜索算法3.4.3 实现最短路径算法(例如Dijkstra算法)4.实验步骤4.1 实验一的步骤及代码实现4.2 实验二的步骤及代码实现4.3 实验三的步骤及代码实现4.4 实验四的步骤及代码实现5.实验结果与分析5.1 实验一的结果和分析5.2 实验二的结果和分析5.3 实验三的结果和分析5.4 实验四的结果和分析6.实验总结6.1 实验心得体会6.2 实验中存在的问题及解决方案6.3 对数据结构的理解和应用展望7.附件实验所使用的源代码、运行截图等相关附件。
8.法律名词及注释8.1 数据结构:指计算机中数据的存储方式和组织形式。
8.2 线性表:一种数据结构,其中的元素按照顺序排列。
8.3 栈:一种特殊的线性表,只能在一端进行插入和删除操作。
8.4 队列:一种特殊的线性表,按照先进先出的顺序进行插入和删除操作。
8.5 树:一种非线性的数据结构,由节点和边组成。
8.6 图:一种非线性的数据结构,由顶点和边组成。
数据库实验报告

数据库实验报告合肥工业大学实验报告一课程名称:数据库系统原理及应用学号:20095382 姓名:魏泽民专业班级:电子商务09-1班指导教师:马华伟二零一一年十月一、实验目的:(1)熟练掌握数据更新语句,灵活地操作插入数据、修改数据和删除数据;(2)熟练掌握关系数据库中的完整性概念的应用;(3)了解数据录入的方法和过程。
(4)掌握单表查询的基本方法;(5)掌握连接查询的基本方法;(6)熟练掌握以下练习,并进行以下各类查询:①选择表中的若干列、查询全部列、查询经过计算的值;②选择表中的若干元组,即消除取值重复的行与查询满足指定条件的元组(包括:比较大小、确定范围、确定集合、字符匹配、涉及空值和多种条件查询);③对查询结果排序;④使用集函数;⑤对查询结果分组(7)熟练掌握以下练习,并进行下列各类连接查询:①等值与非等值连接查询;②自身连接;③外连接;④复合条件连接;(8)掌握嵌套查询的基本方法;(9)掌握集合查询的基本方法;(10)熟练掌握查询视图操作(11)熟练掌握更新视图操作(12)熟练关系的完整性概念,领会视图的用途(13)练习以下各类查询:①带有IN谓词的子查询;②带有比较运算符的子查询;③带有ANY或ALL谓词的子查询;④带有EXISTS谓词的子查询;⑤视图查询与更新操作;二、实验要求:(1)为了便于程序正确性测试,需要对自己建立起来的数据表录入一些模拟数据(模拟数据是指符合数据格式要求的假数据),然后按照教材中结构化查询语言SQL章节例题和习题自己组织SQL语句:(2)设计的SQL程序应该涵盖数据更新操作的全部内容不,包括插入、修改、删除;(3)综合运用SQL语句实现数据插入、修改、删除等操作的综合运用能力。
(4)按照SQL语言编程要求,实现各类查询和检索操作;(5)利用后台的SQL平台环境,编程验证数据库的控制保护功能。
(6)将查询视图命令等价改写为对数据表的查询操作命令,利用SQL编程设计完成并进行效率分析。
数据结构 实验报告

数据结构实验报告数据结构实验报告一、引言数据结构是计算机科学中非常重要的一门课程,它涉及到数据的存储、组织和管理等方面。
通过实验学习,我们可以更好地理解和掌握不同的数据结构,提升我们在编程中解决实际问题的能力。
二、实验目的本次实验的主要目的是通过实际操作,加深对数据结构的理解,学习并掌握不同数据结构的特点和应用场景,提高编程能力。
三、实验内容1. 实验环境的搭建在开始实验之前,我们需要搭建相应的实验环境。
首先,我们选择合适的集成开发环境(IDE),如Eclipse或IntelliJ IDEA,并安装好Java Development Kit(JDK)。
然后,根据实验要求,下载并安装相应的数据结构库或框架。
2. 实验一:线性表线性表是最基本且最常用的数据结构之一,它可以用于存储一系列具有相同数据类型的元素。
实验中,我们需要实现一个线性表的基本操作,包括插入、删除、查找、修改等。
3. 实验二:栈和队列栈和队列是两种常用的数据结构,它们都是线性表的衍生结构,但在操作上有一些特殊的限制。
实验中,我们需要实现栈和队列的基本操作,并比较它们在不同场景下的优劣。
4. 实验三:树和二叉树树是一种非线性的数据结构,它以分层的方式存储数据。
二叉树是树的一种特殊情况,其中每个节点最多只有两个子节点。
实验中,我们需要实现树和二叉树的构建和遍历算法,并掌握它们在实际问题中的应用。
5. 实验四:图图是一种非线性的数据结构,由节点和边组成。
实验中,我们需要实现图的构建和遍历算法,并应用它们解决实际的图相关问题。
四、实验结果与分析通过实验,我们得到了以下结果和分析:1. 在线性表实验中,我们成功实现了插入、删除、查找和修改等基本操作,并验证了其正确性和效率。
2. 在栈和队列实验中,我们对比了它们在不同场景下的应用,发现栈适用于后进先出(LIFO)的情况,而队列适用于先进先出(FIFO)的情况。
3. 在树和二叉树实验中,我们掌握了树和二叉树的构建和遍历算法,并应用它们解决了一些实际问题,如树形结构的存储和搜索。
合肥工业大学数据结构试验一实验报告
计算机与信息学院数据结构实验报告专业班级学生姓名及学号课程教学班号任课教师实验指导教师实验地点2015 ~2016 学年第 2 学期说明实验报告是关于实验教学内容、过程及效果的记录和总结,因此,应注意以下事项和要求:1.每个实验单元在4页的篇幅内完成一份报告。
“实验单元”指按照实验指导书规定的实验内容。
若篇幅不够,可另附纸。
2、各实验的预习部分的内容是进入实验室做实验的必要条件,请按要求做好预习。
3.实验报告要求:书写工整规范,语言表达清楚,数据和程序真实。
理论联系实际,认真分析实验中出现的问题与现象,总结经验。
4.参加实验的每位同学应独立完成实验报告的撰写,其中程序或相关的设计图纸也可以采用打印等方式粘贴到报告中。
严禁抄袭或拷贝,否则,一经查实,按作弊论取,并取消理论课考试资格。
5.实验报告作为评定实验成绩的依据。
实验序号及名称:实验一单链表实验实验时间∶ 2016年 5 月二、实验内容与步骤(过程及数据记录):<1>求链表中第i个结点的指针(函数),若不存在,则返回NULL。
实验测试数据基本要求:第一组数据:链表长度n≥10,i分别为5,n,0,n+1,n+2第二组数据:链表长度n=0,i分别为0,2node* list::address(int i){n ode *p = head->next;i nt n = 1;w hile (n != i&&p != NULL){p = p->next;n++;}i f (p!=NULL) return p;e lse return NULL;}第一组数据第二组数据<2>在第i个结点前插入值为x的结点。
实验测试数据基本要求:第一组数据:链表长度n≥10,x=100, i分别为5,n,n+1,0,1,n+2第二组数据:链表长度n=0,x=100,i=5errorcode list::insert(const int i, const int x){n ode *p;p = head;i nt n = 1;w hile (n != i&&p != NULL){p = p->next;n++;}i f (i<1 || i>length() + 1) return rangeerror;n ode *s = new node;s->data = x;s->next = p->next;p->next = s;c ount++;r eturn success;}<3>删除链表中第i个元素结点。
数据结构课程实验报告

数据结构课程实验报告数据结构课程实验报告引言:数据结构是计算机科学中非常重要的一门课程,它研究了数据的组织、存储和管理方法。
在数据结构课程中,我们学习了各种数据结构的原理和应用,并通过实验来加深对这些概念的理解。
本文将对我在数据结构课程中的实验进行总结和分析。
实验一:线性表的实现与应用在这个实验中,我们学习了线性表这种基本的数据结构,并实现了线性表的顺序存储和链式存储两种方式。
通过实验,我深刻理解了线性表的插入、删除和查找等操作的实现原理,并掌握了如何根据具体应用场景选择合适的存储方式。
实验二:栈和队列的实现与应用栈和队列是两种常见的数据结构,它们分别具有后进先出和先进先出的特点。
在这个实验中,我们通过实现栈和队列的操作,加深了对它们的理解。
同时,我们还学习了如何利用栈和队列解决实际问题,比如迷宫求解和中缀表达式转后缀表达式等。
实验三:树的实现与应用树是一种重要的非线性数据结构,它具有层次结构和递归定义的特点。
在这个实验中,我们学习了二叉树和二叉搜索树的实现和应用。
通过实验,我掌握了二叉树的遍历方法,了解了二叉搜索树的特性,并学会了如何利用二叉搜索树实现排序算法。
实验四:图的实现与应用图是一种复杂的非线性数据结构,它由节点和边组成,用于表示事物之间的关系。
在这个实验中,我们学习了图的邻接矩阵和邻接表两种存储方式,并实现了图的深度优先搜索和广度优先搜索算法。
通过实验,我深入理解了图的遍历方法和最短路径算法,并学会了如何利用图解决实际问题,比如社交网络分析和地图导航等。
实验五:排序算法的实现与比较排序算法是数据结构中非常重要的一部分,它用于将一组无序的数据按照某种规则进行排列。
在这个实验中,我们实现了常见的排序算法,比如冒泡排序、插入排序、选择排序和快速排序等,并通过实验比较了它们的性能差异。
通过实验,我深入理解了排序算法的原理和实现细节,并了解了如何根据具体情况选择合适的排序算法。
结论:通过这些实验,我对数据结构的原理和应用有了更深入的理解。
数据结构实验总结报告

数据结构实验总结报告数据结构实验总结报告⼀、调试过程中遇到哪些问题?(1)在⼆叉树的调试中,从⼴义表⽣成⼆叉树的模块花了较多时间调试。
由于⼀开始设计的⼴义表的字符串表⽰没有思考清晰,处理只有⼀个孩⼦的节点时发⽣了混乱。
调试之初不以为是设计的问题,从⽽在代码上花了不少时间调试。
⽬前的设计是:Tree = Identifier(Node,Node)Node = Identifier | () | TreeIdentifier = ASCII Character例⼦:a(b((),f),c(d,e))这样便消除了歧义,保证只有⼀个孩⼦的节点和叶节点的处理中不存在问题。
(2)Huffman树的调试花了较长时间。
Huffman编码本⾝并不难处理,⿇烦的是输⼊输出。
①Huffman编码后的⽂件是按位存储的,因此需要位运算。
②⽂件结尾要刷新缓冲区,这⾥容易引发边界错误。
在实际编程时,⾸先编写了屏幕输⼊输出(⽤0、1表⽰⼆进制位)的版本,然后再加⼊⼆进制⽂件的读写模块。
主要调试时间在后者。
⼆、要让演⽰版压缩程序具有实⽤性,哪些地⽅有待改进?(1)压缩⽂件的最后⼀字节问题。
压缩⽂件的最后⼀字节不⼀定对齐到字节边界,因此可能有⼏个多余的0,⽽这些多余的0可能恰好构成⼀个Huffman编码。
解码程序⽆法获知这个编码是否属于源⽂件的⼀部分。
因此有的⽂件解压后末尾可能出现⼀个多余的字节。
解决⽅案:①在压缩⽂件头部写⼊源⽂件的总长度(字节数)。
需要四个字节来存储这个信息(假定⽂件长度不超过4GB)。
②增加第257个字符(在⼀个字节的0~255之外)⽤于EOF。
对于较长的⽂件,会造成较⼤的损耗。
③在压缩⽂件头写⼊源⽂件的总长度%256的值,需要⼀个字节。
由于最后⼀个字节存在或不存在会影响⽂件总长%256的值,因此可以根据这个值判断整个压缩⽂件的最后⼀字节末尾的0是否在源⽂件中存在。
(2)压缩程序的效率问题。
在编写压缩解压程序时①编写了屏幕输⼊输出的版本②将输⼊输出语句⽤位运算封装成⼀次⼀个字节的⽂件输⼊输出版本③为提⾼输⼊输出效率,减少系统调⽤次数,增加了8KB的输⼊输出缓存窗⼝这样⼀来,每写⼀位⼆进制位,就要在内部进⾏两次函数调⽤。
合肥工业大学计算机体系结构实验报告

实验一主板架构的测试一、实验目的及要求了解Internet系列主板的基本构架二、实验设备(环境)及要求多核计算机,windows os ,CPU-Z,GPU-Z。
三、实验内容与步骤1.执行计算机硬件检测程序CPU-Z,GPU-Z;2.记录所用计算机的CPU ID号,Cache大小,指令集,CPU型号,电压,内存,主板,SPD和GPU等所有显示的信息;3.在任务和设备管理器中查看CPU是否为双核?四、实验结果与数据处理1.执行计算机硬件检测程序CPU-Z,GPU-Z;2.记录所用计算机的CPU ID号,Cache大小,指令集,CPU型号,电压,内存,主板,SPD和GPU等所有显示的信息;3.在任务和设备管理器中查看CPU是否为双核?在任务管理器中可以看到CPU为双核:在设备管理器中可以看到CPU为4线程:五、分析与讨论结论:对电脑的构架有的更深的了解。
1.此台电脑CPU是Inter i5,3.20GHz,三级缓存;2.从CPU-Z中的核心时钟频率可以判断计算机的性能,时钟频率越高越好;3.从任务管理器和系统属性上并不能准确的判断CPU的核数,需要用CPU-Z进行检测才能真正确定计算机的核数。
实验一熟悉WinDLX的使用一、实验目的1.熟练掌握WinDLX模拟器的操作和使用2.熟悉DLX指令集结构及其特点二、实验内容1.用WinDLX模拟器执行求阶乘程序fact.s。
这个程序说明浮点指令的使用。
该程序从标准输入读入一个整数,求其阶乘,然后将结果输出。
该程序中调用了input.s中的输入子程序,这个子程序用于读入正整数。
2.用WinDLX模拟器执行求最大公约数程序gcm.s。
该程序从标准输入读入两个整数,求他们的最大公约数,然后将结果写到标准输出。
该程序中调用了input.s中的输入子程序。
3.通过上述使用WinDLX,总结WinDLX的特点。
三、实验报告认真记录实验数据或显示结果。
如实填写实验报告。
数据结构实验报告(合工大)

数据结构实验报告实验一:栈和队列实验目的:掌握栈和队列特点、逻辑结构和存储结构熟悉对栈和队列的一些基本操作和具体的函数定义。
利用栈和队列的基本操作完成一定功能的程序。
实验任务1.给出顺序栈的类定义和函数实现,利用栈的基本操作完成十进制数N与其它d进制数的转换。
(如N=1357,d=8)实验原理:将十进制数N转换为八进制时,采用的是“除取余数法”,即每次用8除N所得的余数作为八进制数的当前个位,将相除所得的商的整数部分作为新的N值重复上述计算,直到N为0为止。
此时,将前面所得到的各余数反过来连接便得到最后的转换结果。
程序清单#include<iostream>#include<cstdlib>using namespace std;typedef int DATA_TYPE;const int MAXLEN=100;enum error_code{success,overflow,underflow};class stack{public:stack();bool empty()const;error_code get_top(DATA_TYPE &x)const;error_code push(const DATA_TYPE x);error_code pop();bool full()const;private:DATA_TYPE data[MAXLEN];int count;};stack::stack(){count=0;}bool stack::empty()const{return count==0;}error_code stack::get_top(DATA_TYPE &x)const {if(empty())return underflow;else{x=data[count-1];return success;}}error_code stack::push(const DATA_TYPE x){if(full())return overflow;else{data[count]=x;count++;}}error_code stack::pop() {if(empty())return underflow;else{count--;return success;}}bool stack::full()const {return count==MAXLEN; }void main(){stack S;int N,d;cout<<"请输入一个十进制数N和所需转换的进制d"<<endl; cin>>N>>d;if(N==0){cout<<"输出转换结果:"<<N<<endl;}while(N){(N%d);N=N/d;}cout<<"输出转换结果:"<<endl;while(!()){(N);cout<<N;();}cout<<endl;}while(!()){(x);cout<<x;();}}测试数据:N=1348 d=8运行结果:2.给出顺序队列的类定义和函数实现,并利用队列计算并打印杨辉三角的前n行的内容。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据结构实验报告
实验三栈的实验
1.实验目标
(1)熟练掌握栈的顺序存储结构和链式存储结构。
(2)熟练掌握栈的有关算法设计,并在顺序栈和链栈上实现。
(3)根据具体给定的需求,合理设计并实现相关结构和算法。
2.实验内容和要求
(1)顺序栈结构和运算定义,算法的实现以库文件方式实现,不得在测试主程序中直接实现;
(2)实验程序有较好可读性,各运算和变量的命名直观易懂,符合软件工程要求;
(3)程序有适当的注释。
3.数据结构设计
(1)以结构体,类为基础,和函数调用实现各实验;
4.算法设计
(除书上给出的基本运算(这部分不必给出设计思想),其它实验内容要给出算法设计思想)
5.运行和测试
(1)各个实验运行正常,符合实验要求;
(2)达到实验目的。
6.总结和心得
(1)通过实验,我熟练掌握了栈的顺序存储结构和链式存储结构。
(2)通过实验,熟练掌握栈的有关算法设计,并在顺序栈和链栈上实现。
(3)通过实验,我理解线性表的真实意思,能够运用一些基本的题目。
(4)通过实验,让我了解计算机的一些机制。
(5)通过实验,我学到了很多知识,在发现问题,解决问题时,我学会了怎样处理这些问题,同时也创造许多自己的思想。
[7. 附录]
(源代码清单。
纸质报告不做要求。
电子报告,可直接附源文件,删除编译生成的所有文件)
<1>利用顺序栈实现将10进制数转换为16进制数。
第一组数据:4
第二组数据:11
第三组数据:254
第四组数据:1357
Cpp1.cpp
<2>对一个合法的数学表达式来说,其中的各大小括号“{”,“}”,“[”,“]”,“(”和“)”应是相互匹配的。
设计算法对以字符串形式读入的表达式S,判断其中的各括号是否是匹配的。
Cpp1.cpp。