线性回归分析数据表
简单线性回归

6.98020
15
a 224 (6.98020) 14.7 21.77393
15
15
Yˆ 21.77393 6.9802 X
除了图中所示两变量呈直线关系外,一 般还假定每个 X 对应 Y 的总体为正态分布, 各个正态分布的总体方差相等且各次观测 相互独立。这样,公式(12-2)中的 Yˆ 实际 上是 X 所对应 Y 的总体均数 Y |X 的一个样本 估计值,称为回归方程 的预测值(predicted value),而 a 、 b 分别为 和 的样本估计。
均数YY 是固定的,所以这部分变异由 Yˆi 的大小不同引起。
当 X 被引入回归以后,正是由于Xi 的不同导致了 Yˆi a bXi 不同,所以SS回 反映了在 Y 的总变异中可以用 X 与 Y 的直线关系解释的那部分变异。
b 离 0 越远,X 对 Y 的影响越大,SS回 就越大,说明 回归效果越好。
lXX
(X X )2
a Y bX
式 中 lXY 为 X 与 Y 的 离 均 差 乘 积 和 :
lXY
(X
X
)(Y
Y
)
XY
(
X
)( n
Y
)
本例:n=15 ΣX=14.7 ΣX2=14.81
ΣY=224 ΣXY=216.7 ΣY2=3368
216.7 (14.7)(224)
b
15 14.81 (14.7)2
儿子身高(Y,英寸)与父亲身高(X, 英寸)存在线性关
系:Yˆ 33.73 0.516 X 。
也即高个子父代的子代在成年之后的身高平均来 说不是更高,而是稍矮于其父代水平,而矮个子父代的子 代的平均身高不是更矮,而是稍高于其父代水平。Galton 将这种趋向于种族稳定的现象称之“回归”
线性回归分析ppt课件

21
多元回归分析中的其他问题 u变量筛选问题 Ø向前筛选策略
解释变量不断进入回归方程的过程,首先选择与被解释变量具有最高 线性相关系数的变量进入方程,并进行各种检验;其次在剩余的变量中挑 选与解释变量偏相关系数最高并通过检验的变量进入回归方程。 Ø向后筛选策略
变量不断剔除出回归方程的过程,首先所有变量全部引入回归方程并 检验,然后在回归系数显著性检验不显著的一个或多个变量中,剔除t检验 值最小的变量。 Ø逐步筛选策略
合准则。
最小二乘法将偏差距离定义为离差平方和,即
n
Q( 0, 1, p) ( yi E( yi ))2
i 1
最小二乘估计就是寻找参数β0
、β1、…
βp的估计
值β̂0 、β ̂1、… β ̂p,使式(1)达到极小。通过
求极值原理(偏导为零)和解方程组,可求得估计值,
SPSS将自动完成。
每个解释变量进 入方程后引起的 判定系数的变化 量和F值的变化 量(偏F统计量)
输出个解释变量 和被解释变量的 均值、标准差、 相关系数矩阵及 单侧检验概率值
输出判定系数、 调整的判定系数、 回归方程的标准 误、回归方程显 著性检验的方差 分析表
输出方程中各解 释变量与被解释 变量之间的简单 相关、偏相关系 数和部分相关
30
n回归分析的其他操作
Ø选项
DW值
输出标准化残差 绝对值大于等于 3(默认)的样 本数据的相关信 息
多重共线性分 析: 输出各解释变 量的容忍度、 方差膨胀因子、
特征值、条件 指标、方差 比例等
31
n回归分析的其他操作
Ø选项
•标准化预测值 •标准化残差 •剔除残差 •调整的预测值 •学生化残差 •剔除学生化残差
利用EXCEL函数LINEST进行统计学中的回归分析

利⽤EXCEL函数LINEST进⾏统计学中的回归分析介绍统计学中的⼀元和多元线性回归,并通过EXCEL⾃带的统计函数LINEST、INDEX进⾏⼿⼯计算,再通过EXCEL数据分析⼯具包进⾏⾃动计算。
由于很多复杂的EXCEL⾃动化程序,需要⽤到⾃动化计算,EXCEL数据分析⼯具并不适⽤⾃动计算,反⽽EXCEL统计函数是很容易实现批量⾃动计算。
所以本⽂重点介绍EXCEL统计函数的使⽤。
统计学上的线性回归原理简介回归是研究⼀个随机变量y对另⼀个(x)或⼀组(x1,x2,…,xn)变量的相依关系的统计分析⽅法。
其中y⼜叫因变量,x叫⾃变量。
简单的记忆⽅法:x是⾃⾝可以变动的,y是因为x的变化⽽变化的,就不会把⾃变量和因变量的意义搞乱。
线性回归是⾃变量与因变量之间是线性关系的回归。
⼀般来说,因变量只有⼀个,⾃变量会有⼀个或多个。
下⾯就按因变量的数量及类别为分:⼀元线性回归、多元线性回归。
⼀元线性回归⼀元线性回归是指⼀个因变量y只与⼀个⾃变量x有相关关系,通过公式可以表⽰为如下图:⼀元线性回归其中a称为斜率,b称为截距。
它的意思是当x增减⼀个单位时,y会同样增减a个单位的x,如a=2时,x增加⼀个单位,y就增加2个单位x。
通过EXCEL统计函数LINEST来实现⼀元线性回归分析,在EXCEL的A1到B10输⼊如下数据:x y1.12001.92452.536744004.555055405.966777701210使⽤LINEST线性回归函数进⾏⼿⼯计算。
LINEST函数可通过使⽤最⼩⼆乘法计算与现有数据最佳拟合的直线,来计算某直线的统计值,然后返回描述此直线的数组。
也可以将 LINEST 与其他函数结合使⽤来计算未知参数中其他类型的线性模型的统计值,包括多项式、对数、指数和幂级数。
因为此函数返回数值数组,所以必须以数组公式的形式输⼊。
LINESTLINEST(known_y’s, [known_x’s], [const], [stats])Known_y’s 必需。
数据处理及回归分析

§6 回归模型的建立
(1)一元线性回归模型
假定因变量y主要受自变量x的影响,它 们之间的简单线性回归模型如下 :
y 0 1x
0、1 为参数, 为随机误差项。
• ⑴y是x的线性函数部分加上误差项 • ⑵线性部分反映了由于x的变化而引起y的变化
对于误差项,在回归分析中有如下假设:
xy
5 200 6 300 7 750 7 700 9 750 12 012 13 860 17 000 19 372 22 500 22 750 25 900 170 094
砝码质量(Kg) 弹簧伸长位(cm)
0.00
x0
1.00
x1
2.00
x2
3.00
x3
4.00
x4
5.00
x5
6.00
x6
7.00
x7
逐项逐差法处理
X1 X1 X 0 X 2 X 2 X1 ...... X 7 X 7 X 6
这样,弹簧的平均伸长量为:
X ( X1X0 )( X2 X1)...( X7 X63.00
4.00
电学元件伏安特性曲线
U (V)
错在哪里?
P(×105Pa)
1.6000
图3
1.2000
0.8000
0.4000
o
图纸使用不当。 实际作图时, 坐标原点的读 数可以不从零 开始。
t(℃)
20.00 40.00 60.00 80.00 100.00 120.00 140.00
(2)相关分析可以不必确定变量中哪 个是自变量,哪个是因变量,其所涉及的 变量可以都是随机变量。而回归分析则必 须事先研究确定具有相关关系的变量中哪 个为自变量,哪个为因变量。
利用Excel进行线性回归分析

利用Excel进行线性回归分析————————————————————————————————作者: ————————————————————————————————日期:ﻩ文档内容1.利用Excel进行一元线性回归分析2. 利用Excel进行多元线性回归分析1.利用Excel进行一元线性回归分析第一步,录入数据以连续10年最大积雪深度和灌溉面积关系数据为例予以说明。
录入结果见下图(图1)。
图1第二步,作散点图如图2所示,选中数据(包括自变量和因变量),点击“图表向导”图标;或者在“插入”菜单中打开“图表(H)”。
图表向导的图标为。
选中数据后,数据变为蓝色(图2)。
图2点击“图表向导”以后,弹出如下对话框(图3):图3在左边一栏中选中“XY散点图”,点击“完成”按钮,立即出现散点图的原始形式(图4):灌溉面积y(千亩)01020304050600102030灌溉面积y(千亩)图4第三步,回归观察散点图,判断点列分布是否具有线性趋势。
只有当数据具有线性分布特征时,才能采用线性回归分析方法。
从图中可以看出,本例数据具有线性分布趋势,可以进行线性回归。
回归的步骤如下:1. 首先,打开“工具”下拉菜单,可见数据分析选项(见图5):图5用鼠标双击“数据分析”选项,弹出“数据分析”对话框(图6):图62.然后,选择“回归”,确定,弹出如下选项表(图7):图7进行如下选择:X 、Y 值的输入区域(B1:B11,C1:C11),标志,置信度(95%),新工作表组,残差,线性拟合图(图8-1)。
或者:X 、Y 值的输入区域(B2:B11,C2:C11),置信度(95%),新工作表组,残差,线性拟合图(图8-2)。
注意:选中数据“标志”和不选“标志”,X 、Y 值的输入区域是不一样的:前者包括数据标志:最大积雪深度x (米) 灌溉面积y (千亩)后者不包括。
这一点务请注意(图8)。
图8-1包括数据“标志”图8-2不包括数据“标志”3.再后,确定,取得回归结果(图9)。
SPSS实现一元线性回归分析实例

SPSS实现一元线性回归分析实例2009-12-14 15:311、准备原始数据。
为研究某一大都市报开设周日版的可行性,获得了34种报纸的平日和周日的发行量信息(以千为单位)。
数据如图1所示。
SPSS17.0图12、判断是否存在线性关系。
制作直观散点图:(1)SPSS:菜单Analyze/Regression/linear Regression,如图2所示:图2 (2)打开对话框如图3图3图3中,Dependent是因变量,Independent是自变量,分别将左栏中的sunday选入因变量,daily选入自变量,newspaper作为标识标签选入case labels.(3)点击图3对话框中的plots按钮,如图4所示:图4将因变量DEPENTENT 选入Y:,自变量 ZPRED 选入X: continue 返回上级对话框。
单击主对话框OK.便生成散点图如图5所示:图5从以上散点图可看出,二者变量之间关系趋势呈线性关系。
2、回归方程菜单Analyze/Regression/linear Regression,在图3对话框的右边单击statistics如图6所示:图6regression coefficient回归系数,estimates估计值,confidence intervals level:95%置信区间,model fit拟合模型。
点击continue返回主对话框,单击OK.结果如图7、图8所示:图7图7中第一个图是变量的输入与输出,从图下的提示可知所有变量均输入与输出,没有遗漏。
图7中的第二图是模型总和R值,R平方值,R调整后的平方值,及标准误。
图8图8中第一图为方差统计图,包括回归平方和,自由度,方程检验F值及P值。
图8第二图为回归参数图,从图中可知,constant为回归方程截距,即13.836,回归系数为1.340,标准误分别为:35.804和0.071,及t检验值和95%的置信区间的最大值和最小值。
线性回归分析

一元线性回归分析1.理论回归分析是通过试验和观测来寻找变量之间关系的一种统计分析方法。
主要目的在于了解自变量与因变量之间的数量关系。
采用普通最小二乘法进行回归系数的探索,对于一元线性回归模型,设(X1,Y1),(X2,Y2),…,(X n,Y n)是取至总体(X,Y)的一组样本。
对于平面中的这n个点,可以使用无数条曲线来拟合。
要求样本回归函数尽可能好地拟合这组值。
综合起来看,这条直线处于样本数据的中心位置最合理。
由此得回归方程:y=β0+β1x+ε其中Y为因变量,X为解释变量(即自变量),ε为随机扰动项,β0,β1为标准化的偏斜率系数,也叫做回归系数。
ε需要满足以下4个条件:1.数据满足近似正态性:服从正态分布的随机变量。
2.无偏态性:∑(εi)=03.同方差齐性:所有的εi 的方差相同,同时也说明εi与自变量、因变量之间都是相互独立的。
4.独立性:εi 之间相互独立,且满足COV(εi,εj)=0(i≠j)。
最小二乘法的原则是以“残差平方和最小”确定直线位置。
用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。
最常用的是普通最小二乘法(OLS):所选择的回归模型应该使所有观察值的残差平方和达到最小。
线性回归分析根据已有样本的观测值,寻求β0,β1的合理估计值^β0,^β1,对样本中的每个x i,由一元线性回归方程可以确定一个关于y i的估计值^y i=^β0+^β1x i,称为Y关于x的线性回归方程或者经验回归公式。
^β0=y-x^β1,^β1=L xy/L xx,其中L xx=J12−x2,L xy=J1−xy,x=1J1 ,y=1J1 。
再通过回归方程的检验:首先计算SST=SSR+SSE=J1^y−y 2+J1−^y2。
其中SST为总体平方和,代表原始数据所反映的总偏差大小;SSR为回归平方和(可解释误差),由自变量引起的偏差,放映X的重要程度;SSE为剩余平方和(不可解释误差),由试验误差以及其他未加控制因子引起的偏差,放映了试验误差及其他随机因素对试验结果的影响。
;2运用EXCEL、SPSS进行相关分析和线性、非线性回归分析

《计量地理学》实验指导§2 运用EXCEL、SPSS进行相关分析和线性、非线性回归分析回归分析是处理两个及两个以上变量间线性依存关系的统计方法。
可以通过软件EXCEL 和SPSS实现。
一、利用EXCEL软件实现回归分析以第4章习题2为例,运用EXCEL进行回归分析。
首先在菜单中选择工具==>加载宏,把“分析工具库”和“规划求解”加载上。
然后在“工具”菜单中将出现“数据分析”选项。
点击“数据分析”中的“回归”,将出现对话框如下图1所示。
图1 回归界面【输入】用以选择进行回归分析的自变量和因变量。
在“Y值输入区域”内输入B7:B11,在“X值输入区域”输入A7:A11,如果是多元线性回归,则X值的输入区就是除Y变量以外的全部解释变量“标志”;置信度水平为95%,输出结果选择在一张新的工作表中;“残差分析”,并绘制回归拟合图,点击“确定”即得到残差表。
【输出选项】用于指定输出结果要显示的内容,包括是否需要残差表及图,参差的正态分布图等。
输出结果解释图 2 回归结果显示回归结果分为三部分:(1)回归统计:包括R^2 及调整后的R^2、标准误差和观测值个数(2)方差分析:包括回归平方和、残差平方和总离差平方和以及它们的自由度、均方差和F通机量(3)回归方程的截距、自变量的系数以及它们的t统计值、95%的上下限值图3 残差与子变量之间的散点图图4 预测值与实际值散点图同样,如果在“数据分析”中点击“相关系数”,可以对多个变量进行相关系数的计算。
二、.利用SPSS软件实现回归分析在SPSS软件中,同样可以简单的实现回归分析,因为回归分析包含了线性回归与曲线拟合两部分内容,首先来看线性回归分析过程(LINEAR)(一)线性回归分析过程(LINEAR)例如,课本中数据,把降水量(P)看作因变量,把纬度(Y)看作自变量,在平面直角坐标系中作出散点图,发现它们之间呈线性相关关系,因此,可以用一元线性回归方程近似地描述它们之间的数量关系。
一元线性回归分析例题

SPSS一元线性回归分析例题(体检数据中的体重和肺活量的分析)某单位对12名女工进行体检,体检项目包括体重(kg)和肺活量(L),数据如下:X(体重:kg) 42.00 42.00 46.00 46.00 46.00 50.0050.00 50.00 52.00 52.00 58.00 58.00Y(肺活量:L) 2.55 2.20 2.75 2.40 2.80 2.813.41 3.10 3.46 2.85 3.50 3.00用x表示体重,y表示肺活量,建立数据文件。
利用一元线性回归分析描述其关系。
基本操作提示:Step 1 建立数据文件,并打开该数据文件。
Step 2 选择菜单Analyz e→Regressio n→Linear,打开主对话框。
在“Dependent”(因变量)列表框中选择变量“肺活量”,作为线性回归分析的被解释变量;在“Independent”(自变量)列表框中选择变量“体重”,作为解释变量。
Step 3 单击“Statistics”按钮,在打开的对话框中,依次选择“Estimates”(显示回归系数的估计值)、“Confidence intervals”、“Model fit”(模型拟合)、“Descriptives”、“Casewise diagnostic”(个案诊断)和“All Cases”选项。
选择完毕后,单击“Continue”按钮,返回主对话框。
Step 4 单击“Plots”(图形)按钮,在打开的主对话框中,选择“DEPENDENT”(因变量)作为y轴变量,“*ZPRED”(标准化预测值)作为x轴变量;并在“Standardized Residual Plots”(标准化残差图)中选择“Histogram”(直方图)和“Normal probabilityplot”(正态概率图,即P-P图)选项。
选择完毕后,单击“Continue”按钮,返回主对话框。
Step 5 单击“Save”(保存)按钮,在打开的主对话框中,在“Predicted Values”(预测值)选项区域中选择“Unstandardized”和“S. E. ofmean predictions”(预测值均数的标准误差)选项;“PredictionIntervals”(预测区间)选项区域中选择“Mean”和“Individual”选项;“Residuals”(残差)选项区域中选择“Unstandardized”选项。
广义线性回归分析

(二) 假设条件满足后,再进行协方差分析: 【SAS 程序】 proc glm;
class drug; model y=drug x; lsmeans drug / pdiff; run; 【SAS 输出结果】 General Linear Models Procedure Class Level Information Class Levels Values DRUG 3 A D F Number of observations in data set = 30
(3) 检验线性相关性的结果:(H0: 线性无关,H1:线性相关) (4) A组:F=11.23,df=(1,8),p=0.0101 (5) D组:F=39.24,df=(1,8),p=0.0002 (6) F组:F= 6.21,df=(1,8),p=0.0374 (7) --------说明三个组上 y 与 x 均近似呈线性关系。 (4) 检验平行性的结果:(H0: 斜率相等) (5) F= 0.59,df=(2,24),p=0.560, (6) --------说明三条直线近似平行。
第一节 广义线性模型分析的概念
广义线性模型分析是将方差分析和回归分 析的基本原理结合起来,用来分析连续型 因变量与任意型自变量之间各种关系的一 种统计分析方法。
其意义是使得方差分析和回归分析的实用 性和准确性得到进一步提高。
两个典型的广义线性模型分析方法
协方差分析
含有数值型自变量 的方差分析
广义线性回归分析
协方差分析在医学中的应用
1)借助协方差分析来排除非处理因素的干扰,从而 准确地估计处理因素的试验效应。
Excel数据分析:相关系数、协方差、回归的案例演示「超详细!!」

Excel数据分析:相关系数、协方差、回归的案例演示「超详细!!」文末领取【旅游行业数据报告】1相关系数1. 相关系数的概念著名统计学家卡尔·皮尔逊设计了统计指标——相关系数(Correlation coefficient)。
相关系数是用以反映变量之间相关关系密切程度的统计指标。
相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。
依据相关现象之间的不同特征,其统计指标的名称有所不同。
如将反映两变量间线性相关关系的统计指标称为相关系数(相关系数的平方称为判定系数);将反映两变量间曲线相关关系的统计指标称为非线性相关系数、非线性判定系数;将反映多元线性相关关系的统计指标称为复相关系数、复判定系数等。
相关系数的计算公式为:复相关系数(multiple correlation coefficient):反映一个因变量与一组自变量(两个或两个以上)之间相关程度的指标。
它是包含所有变量在内的相关系数。
它可利用单相关系数和偏相关系数求得。
其计算公式为:当只有两个变量时,复相关系数就等于单相关系数。
Excel中的相关系数工具是单相关系数。
2. 相关系数工具的使用CORREL 和 PEARSON 工作表函数均可计算两个测量值变量之间的相关系数,条件是每种变量的测量值都是对N 个对象进行观测所得到的。
(丢失任何对象的任何观测值都会导致在分析中忽略该对象。
)相关系数分析工具特别适合于当N 个对象中的每个对象都有两个以上的测量值变量的情况。
它提供一张输出表(相关矩阵),其中显示了应用于每个可能的测量值变量对的 CORREL(或 PEARSON)值。
与协方差一样,相关系数是描述两个测量值变量之间的离散程度的指标。
与协方差的不同之处在于,相关系数是成比例的,因此它的值与这两个测量值变量的表示单位无关。
(例如,如果两个测量值变量为重量和高度,当重量单位从磅换算成千克时,相关系数的值并不改变。
方差分析 线性回归

1 线性回归1.1 原理分析要研究最大积雪深度x与灌溉面积y之间的关系,测试得到近10年的数据如下表:使用线性回归的方法可以估计x与y之间的线性关系。
线性回归方程式:对应的估计方程式为线性回归完成的任务是,依据观测数据集(x1,y1),(x2,y2),...,(xn,yn)使用线性拟合估计回归方程中的参数a和b。
a,b都为估计结果,原方程中的真实值一般用α和β表示。
为什么要做这种拟合呢?答案是:为了预测。
比如根据前期的股票数据拟合得到股票的变化趋势(当然股票的变化可就不是这么简单的线性关系了)。
线性回归的拟合过程使用最小二乘法,最小二乘法的原理是:选择a,b的值,使得残差的平方和最小。
为什么是平方和最小,不是绝对值的和?答案是,绝对值也可以,但是,绝对值进行代数运算没有平方那样的方便,4次方又显得太复杂,数学中这种“转化化归”的思路表现得是那么的优美!残差平方和Q,求最小,方法有很多。
代数方法是求导,还有一些运筹学优化的方法(梯度下降、牛顿法),这里只需要使用求导就OK了,为表示方便,引入一些符号,最终估计参数a与b的结果是:自此,针对前面的例子,只要将观测数据带入上面表达式即可计算得到拟合之后的a和b。
不妨试一试?从线性函数的角度,b表示的拟合直线的斜率,不考虑数学的严谨性,从应用的角度,结果的b可以看成是离散点的斜率,表示变化趋势,b的绝对值越大,表示数据的变化越快。
线性回归的估计方法存在误差,误差的大小通过Q衡量。
1.2 误差分析考虑获取观测数据的实验中存在其它的影响因素,将这些因素全部考虑到e~N(0,δ^2)中,回归方程重写为y = a + bx + e由此计算估计量a与b的方差结果为,a与b的方差不仅与δ和x的波动大小有关,而且还与观察数据的个数有关。
在设计观测实验时,x的取值越分散,估计ab的误差就越小,数据量越大,估计量b的效果越好。
这也许能为设计实验搜集数据提供某些指导。
1.3 拟合优度检验及统计量拟合优度检验模型对样本观测值的拟合程度,其方法是构造一个可以表征拟合程度的指标,称为统计量,统计量是样本的函数。
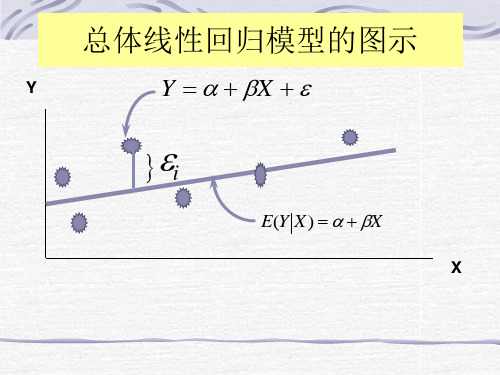
总体线性回归模型的图示
公式:
样本可决系数
Y
Y
2
Y
Y
2
r 2
2
1
Y Y
2
Y Y
a Y b XY nY 2 Y 2 nY 2
相关系数---- 可决系数的平方根
r r2
nXY XY
=
nX2 X2 nY2 Y2
=0.8257
经调整的可决系数
ra2dj 1
YY2 n2
2
YY n1
=0.6419
SY .12k
(Y Y )2
n (k 1)
e2 n k 1
估计标准误它的平方数是总体随机
误差
的方差
2 Y .12k
的无偏估计量。
复可决系数
R2Y12k
(Y Y )2 1
(Y Y )2
(Y Y )2 (Y Y )2
经调整的
复可决系数 R2Y12k(adj) 1
(Y Y )2 /[n (k 1)] 1 S 2Y12k
Y tn2S E(Y / X 0 ) Y tn2 S
Y
Y
因变量特定值 Y0 的点估计
Y0 Y a bX 0
因变量特定值 Y0 的区间估计
Y t n2 Y0 E(Y / X 0 ) Y tn2 Y0
式中 Y0 y.x
1 1 n
( X 0 X )2 X 2 nX 2
Model 1
R
R Square
.951a
.904
Adjusted R Square
.876
a. Pred ict ors: (Con stant), 次 数 , 距 离
Std. Error of the
Esti ma te .573
用Excel做线性回归分析报告

用Excel做线性回归分析报告1. 引言1.1 主题背景介绍在当今数据分析日益普及的大背景下,Excel作为一款广泛使用的电子表格软件,凭借其强大的数据处理和计算能力,成为了众多行业和领域中不可或缺的工具。
线性回归作为统计学中最基础也是应用最广泛的预测模型之一,其在Excel中的实现和应用,极大地便利了各类研究和决策过程。
通过对Excel线性回归分析的深入研究,可以帮助我们更好地理解数据间的内在联系,为决策提供科学依据。
1.2 研究目的和意义本次研究的目的是通过Excel实现线性回归分析的全过程,探索其在实际数据中的应用效果。
研究意义主要体现在以下几个方面:1.提高数据处理效率:通过掌握Excel线性回归分析,可以快速处理大量数据,提高工作效率。
2.辅助决策制定:利用线性回归模型,可以为企业或个人提供更为准确的数据预测,辅助决策的制定。
3.普及统计知识:Excel线性回归分析的普及有助于提升公众对统计学基本概念的理解和认识。
1.3 研究方法概述本研究主要采用以下方法:•文献调研:收集和整理线性回归相关理论知识,以及Excel进行线性回归分析的实操步骤。
•数据实践:选取合适的数据集,使用Excel进行实际操作,包括数据清洗、模型建立、求解以及结果分析等。
•模型评估与优化:结合实际应用场景,对建立的模型进行评估和优化,确保分析结果的准确性和可靠性。
2. Excel线性回归分析基本概念2.1 线性回归的定义与原理线性回归是统计学中最基础也是应用最广泛的预测模型之一,它主要用于描述两个或两个以上变量之间的线性关系。
其基本原理是通过历史数据,寻找一个或多个自变量(解释变量)与因变量(响应变量)之间的最佳线性关系表达式。
简单线性回归涉及一个自变量和一个因变量,其模型可以表示为:[ Y = _0 + _1X + ]其中,( Y )代表因变量,( X )代表自变量,( _0 )是截距项,表示当( X = 0 )时( Y )的期望值,( _1 )是斜率,表示( X )每变化一个单位时( Y )的平均变化量,( )是误差项,表示模型未能解释的随机变异。
基于Excel的地理数据分析多元线性回归分析
基于Excel 的地理数据分析多元线性回归分析多元线性回归分析是一元线性回归分析的推广,或者说一元线性回归分析是多元线性回归分析的特例。
掌握了一元线性回归分析,就不能学习多元线性回归分析方法了。
利用Excel 进行多元线性回归与一元线性回归的过程大体相似,操作上有些细节方面的微妙差别。
不过,对于多元线性回归,统计检验的内容相对复杂。
下面以一个简单的实例予以说明。
【例】某省工业产值、农业产值、固定资产投资对运输业产值的影响分析。
通过产值的回归模型,探索影响交通运输业的主要因素。
我们想要搞清楚的是,在工业、农业和固定资产投资等方面,究竟是哪些因素直接影响运输业的发展。
数据来源于李一智主编的《经济预测技术》。
原始数据来源不详。
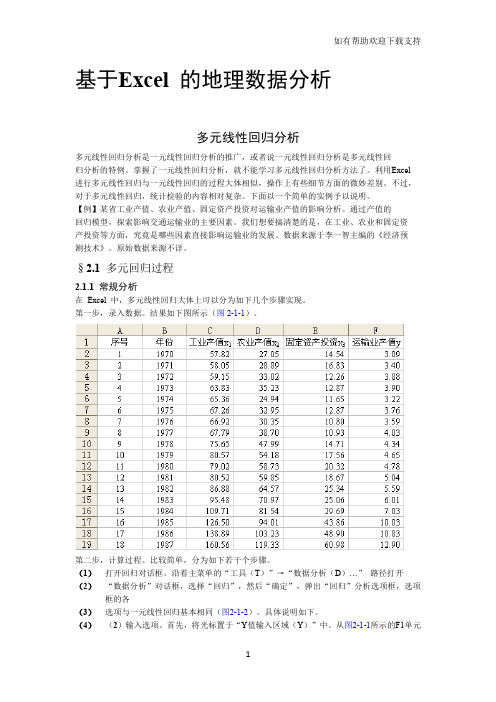
§2.1 多元回归过程2.1.1 常规分析在Excel 中,多元线性回归大体上可以分为如下几个步骤实现。
第一步,录入数据。
结果如下图所示(图2-1-1)。
第二步,计算过程。
比较简单,分为如下若干个步骤。
(1)打开回归对话框。
沿着主菜单的“工具(T)”→“数据分析(D)…”路径打开(2)“数据分析”对话框,选择“回归”,然后“确定”,弹出“回归”分析选项框,选项框的各(3)选项与一元线性回归基本相同(图2-1-2)。
具体说明如下。
(4)(2)输入选项。
首先,将光标置于“Y值输入区域(Y)”中。
从图2-1-1所示的F1单元(5)格起,至F19止,选中用作因变量全部数据连同标志,这时“Y值输入区域(Y)”的数据区域(6)中立即出现“$F$1:$F$19”。
然后,将光标置于“X值输入区域(X)”中。
从图2-1-1所示的C1单元格起,至E19止,选中用作自变量全部数据连同标志,这时“X值输入区域(X)”中立即出现“$C$1:$E$19”——当然,也可以直接在“X值输入区域(X)”中手动输入地址为“$C$1:$E$19”的单元格范围。
注意,与一元线性回归的设置一样,这里数据范围包括数据标志“工业产值x1”、“农业产值x2”、“固定资产投资x3”和“运输业产值y”。
线性回归分析

r 2 SSR / SST 1 SSE / SST L2xy Lxx Lyy
❖
两个变量之间线性相关的强弱可以用相关系数r(Correlation
coefficient)度量。
❖ 相关系数(样本中 x与y的线性关系强度)计算公式如下:
❖ 统计学检验,它是利用统计学中的抽样理论来检验样本 回归方程的可靠性,具体又可分为拟合程度评价和显著 性检验。
1、拟合程度的评价
❖ 拟合程度,是指样本观察值聚集在估计回归线周围的紧密 程度。
❖ 评价拟合程度最常用的方法是测定系数或判定系数。 ❖ 对于任何观察值y总有:( y y) ( yˆ y) ( y yˆ)
当根据样本研究二个自变量x1,x2与y的关系时,则有
估计二元回归方程: yˆ b0 b1x1 b2 x2
求估计回归方程中的参数,可运用标准方程如下:
L11b1+L12b2=L1y
L12b1+L22b2=L2y b0 y b1 x1 b2 x2
例6:根据表中数据拟合因变量的二元线性回归方程。
21040
x2
4 36 64 64 144 256 400 400 484 676
2528
练习3:以下是采集到的有关女子游泳运动员的身高(英寸)和体
重(磅)的数据: a、用身高作自变量,画出散点图 b、根据散点图表明两变量之间存在什么关系? c、试着画一条穿过这些数据的直线,来近似身高和体重之间的关 系
测定系数与相关系数之间的区别
第一,二者的应用场合不同。当我们只对测量两个变量之间线性关系的 强度感兴趣时,采用相关系数;当我们想要确定最小二乘直线模型同数据符 合的程度时,应用测定系数。
《统计学》实验报告(一元线性回归分析)
南昌航空大学经济管理学院学生实验报告实验课程名称:统计学实验时间 2012.12.24 班级学号 11091125 姓名戴文琦成绩实验地点 G804实验性质: □基础性 ■综合性 □设计性实验项目名 称一元线性回归分析指导老师王秀芝一、实验目的:掌握用SPSS 软件进行一元线性回归分析。
二、实验要求:在《中国统计年鉴》中选择合适的数据进行一元线性回归分析(注明数据来源)。
注意回归分析要有经济意义。
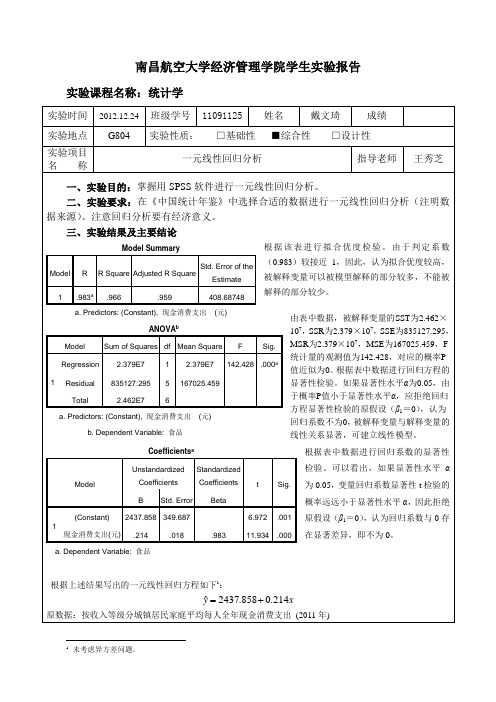
三、实验结果及主要结论根据该表进行拟合优度检验。
由于判定系数(0.983)较接近1,因此,认为拟合优度较高,被解释变量可以被模型解释的部分较多,不能被解释的部分较少。
由表中数据,被解释变量的SST 为2.462×107,SSR 为2.379×107,SSE 为835127.295,MSR 为2.379×107,MSE 为167025.459,F 统计量的观测值为142.428,对应的概率P 值近似为0。
根据表中数据进行回归方程的显著性检验。
如果显著性水平α为0.05,由于概率P 值小于显著性水平α,应拒绝回归方程显著性检验的原假设(β1=0),认为回归系数不为0,被解释变量与解释变量的线性关系显著,可建立线性模型。
根据表中数据进行回归系数的显著性检验。
可以看出,如果显著性水平α为0.05,变量回归系数显著性t 检验的概率远远小于显著性水平α,因此拒绝原假设(β1=0),认为回归系数与0存在显著差异,即不为0。
根据上述结果写出的一元线性回归方程如下1:x y214.0858.2437ˆ+= 原数据:按收入等级分城镇居民家庭平均每人全年现金消费支出 (2011年)Model SummaryModel R R Square Adjusted R Square Std. Error of theEstimate 1.983a.966.959408.68748a. Predictors: (Constant), 现金消费支出 (元)ANOVA bModel Sum of Squares df Mean Square F Sig.1 Regression 2.379E7 1 2.379E7 142.428 .000aResidual 835127.295 5 167025.459 Total 2.462E7 6a. Predictors: (Constant), 现金消费支出 (元)b. Dependent Variable: 食品 Coefficients aModelUnstandardizedCoefficients Standardized CoefficientstSig.BStd. ErrorBeta1(Constant) 2437.858 349.6876.972.001现金消费支出(元).214.018.98311.934 .000a. Dependent Variable: 食品1未考虑异方差问题。
简单线性回归分析

实验报告1日期姓名班级一简单线性回归分析题目:设公司的每周广告费支出和每周销售额数据如下图所示:要求:(1)广告费与消费额之间是否存在显著的相关关系?(2)计算回归模型参数。
(3)回归模型能解释销售额变动的比例有多大?(4)计算D-W的统计量。
(5)如下周的广告费支出为6700元,试预测下周的消费额(取置信区间a=0.05)步骤:一在excel里输入数据:每周广告费每周消费额4100 12.505400 13.806300 14.255400 14.254800 14.504600 13.006200 14.006100 15.006400 15.757100 16.50根据上表数据画出散点图由图可知,所有点几乎在同一条直线上,由插入趋势线后的散点图可知,每周销售额和每周广告费间的函数关系为:y=0.0011x+8.3039 ;本例中R 2值为0.719,表明销售额的变动中有71.9%可用广告费通过线性回归模型加以解释,剩余的28.1%则由其余因素引起,两个变量间的线性关系显著,可以进行下一步的回归分析。
二 回归分析(1)斜率计算公式为∑∑∑∑∑--=∧22)(x n y x xy n b x ,在H1中输入n ,在K2输入斜率b ,在L2中输入n 截距公式=(10*D12-B12*C12)/(10*E12-(B12)*(B12));(2) 截距计算公式为 nx b n y a ∑∑∧∧-=,在K3输入截距a ,在L3输入公式=(C12/10-I2*B12/10);(3)y 的估计值为x b a y ∧∧∧+=,在F2输入公式=$L$3+$L $2*B2,并往下复制到F11处(4)检验线性关系的显著性可决系数222)(/)(1∑∑-∧---=y y y y R i i i ,在L4输入公式=1-SUMXMY2(C2:C11,F2:F11)/DEVSQ(C2:C11);可得719039.02=R ,在L5中输入=soqr (L4),可得相关系数R=0.847962。