实验三MD算法方案与实现
MDI5算法简介及主要实现

MD5算法简介及其实现Abstract:With the abroad application of computer technology, more and more people have been depending on the information systems, the research of data encryptiontechnology has been paid more and more attention by people as well. Data security is not only need in the military, political and the diplomatic, but also everywhere in science, technology research and development, trade and so on. Cryptology technique is the core of safeguarding information security, and digital signature is always companioned with Hash functions, which is a kernel of modern Cryptography. MD5 is a typical Hash encryption technique which is quite popular.The paper mainly gives detail discussion of the MD5 encryption algorithms principle and its realization.Keywords:MD5 digital signature摘要:随着计算机在社会各个领域的广泛应用,人们对信息系统的依赖程度越来越高,数据加密技术的研究也越来越受到人们重视,数据安全保密问题己不仅仅出于军事、政治和外交上的需要,科学技术的研究和发展及商业等方面,无一不与数据安全息息相关。
计算机仿真实验报告-实验三

一、实验内容:实验三 利用欧拉法、梯形数法和二阶显式Adams 法对RLC 串联电路的仿真1前向欧拉法状态方程:Du CX y Bu AX X m +=+=+•1 然后根据前向欧拉法(其中h 为步长)•++=m m m hX X X 1即可得到系统的差分方程2后向欧拉法根据前向欧拉法得到的系统状态方程,结合后向欧拉法(其中h 为步长)•+++=11m m m hX X X 即可得到系统的差分方程3梯形法由前面的系统状态方程,结合梯形法)(211+••+++=m m m m X X h X X 即可得到系统的差分方程4二阶显式Adams 方法由前面的状态方程,结合二阶显式Adams 方法)51623(12211--++-+=m m m m m F F F h X X 即可得到系统的差分方程但是二阶显式Adams 法不能自起步,要使方程起步,需要知道开始的三个值,但是我们只知道第一个值。
经过分析后,二阶显式Adams 方法精度是二阶的,而梯形法精度也是二阶的,因此我们可以先借助梯形法得到输出的前三个值,以达到起步的目的,然后借助上面得到的差分方程对其进行求解。
二、实验波形:下图为前向欧拉法、后向欧拉法、梯形法、二阶显式Adams 方法的系统差分方程得到相应的输出波形:图1 h=410 时四种方法的输出波形图2 h=56-⨯时四种方法的输出波形10图3 h=510-时四种方法的输出波形图4 h=610-时四种方法的输出波形三、实验分析:由输出波形可以看到各种方法的特点(在图中蓝色线均表示连续系统模型的实际输出波形,红色线表示在对应方法下系统的输出波形。
):1前向欧拉法和二阶显式Adams方法对步长的要求很强。
步长太大,最后的到的结果不是绝对收敛,而是发散。
在小步长下才显得收敛,这也从另一方面验证,步长越小,截断误差越小;2步长不能太小,太小的步长相应的舍入误差和累积误差也会增大;3前向欧拉法也可称为显式欧拉法,后向欧拉法也可称为隐式欧拉法,可以看到,后向欧拉法的稳定域要比前向欧拉法大,计算精度也要高一些。
蒙特卡罗算法实验报告

蒙特卡洛算法
开发者:
开发时间:
版本号:
蒙特卡洛算法可理解为通过大量实验,模拟实际行为,来收集统计数据。本例中,算法随机产生一系列点,模拟这些点落在如下图所示的正方形区域内的情况。其几何解释如下
图1
如图1所示,正方形边长为1,左下顶点与原点重合,两边分别与x,y轴重合。曲线为1/4圆弧,圆心位于原点,与正方形左下定点重合,半径为1。正方形面积S1=1,圆弧内面积S2= 。算法模拟大量点随机落在此正方形区域内,落在圆弧内的点的数量(n2)与点的总数(n1)的比例与面积成正比关系。即
40.696
40.706
40.695
40.694
表3
图5
如图4图5所示,对同一计算量,串行算法每次运行时间相差较小,而并行算法则相差明显。因此,通过分析源代码可得出以下结论:
程序所用的rand()函数在同一时间只允许一个处理器调用,当两个处理器都需调用rand()函数时,后调用的将被挂起,等待另一个处理器运行完毕。两线程在就绪和执行态之间不断变化,浪费了大量CPU时间,因此对同一运算量,并行程序运行时间反而比串行程序慢,而且线程状态转换次数范围为[0,n],平均为 次,因此,相比于串行程序的无状态转换,并行算法的运行时间才会有如此大的波动。
示例见附件Serial.c
三、
3.1
算法步骤:
1、确定需要产生的点的个数n,参与运行的处理器数m;
2、对每一个处理器,生成两个随机数x,y,范围[0,1];
3、判断两个随机数x,y是否满足 ;
4、若满足,则变量COUNTi++;
5、重复步骤2-4,直至每个处理器均生成n/m个随机点;
6、收集COUNTi的值,并累加至变量COUNT中,此即为随机点落在圆弧内的数量;
实验三最短路径的算法(离散数学实验报告)

实验三最短路径的算法(离散数学实验报告)实验3:最短路径算法⼀、实验⽬的通过本实验的学习,理解Floyd(弗洛伊得)最短路径算法的思想⼆、实验内容⽤C语⾔编程实现求赋权图中任意两点间最短路径的Floyd算法,并能对给定的两结点⾃动求出最短路径三、实验原理、⽅法和⼿段1、Floyd算法的原理定义:Dk[i,j] 表⽰赋权图中从结点vi出发仅通过v0,v1,┉,vk-1中的某些结点到达vj的最短路径的长度,若从vi到vj没有仅通过v0,v1,┉,vk-1 的路径,则D[i,j]=∝即D-1[i,j] 表⽰赋权图中从结点vi到vj的边的长度,若没有从结点vi到vj的边,则D[i,j]=∝D0[i,j] 表⽰赋权图中从结点vi到vj的”最短”路径的长度, 这条路上除了可能有v0外没有其它结点D1[i,j] 表⽰赋权图中从结点vi到vj的”最短”路径的长度, 这条路上除了可能有v0,v1外没有其它结点┉┉┉根据此定义,D k[i,j]=min{ D k-1[i,j] , D k-1[i,k-1]+D k-1[k-1,j] }定义:path[i,j]表⽰从结点vi到vj的“最短”路径上vi的后继结点四、实验要求要求输出每对结点之间的最短路径长度以及其最短路径五、实验步骤(⼀)算法描述Step 1 初始化有向图的成本邻矩阵D、路径矩阵path若从结点vi到vj有边,则D[i,j]= vi到vj的边的长度,path[i,j]= i;否则D[i,j]=∝,path[i,j]=-1Step 2 刷新D、path 对k=1,2,┉n 重复Step 3和Step 4Step 3 刷新⾏对i=1,2,┉n 重复Step 4Step 4 刷新Mij 对j=1,2,┉n若D k-1[i,k]+D k-1[k,j][结束循环][结束Step 3循环][结束Step 2循环]Step 5 退出(⼆)程序框图参考主程序框图其中,打印最短路径中间结点调⽤递归函数dist(),其框图如下,其中fist,end是当前有向边的起点和终点dist(int first, int end)七、测试⽤例:1、输⼊成本邻接矩阵:D :06380532290141003210∝∝∝∝V V V V V V V V (其中∝可⽤某个⾜够⼤的数据值代替,⽐如100)可得最短路径矩阵:P :131132122211111010103210--------V V V V V V V V以及各顶点之间的最短路径和最短路径长度:从V0到V1的最短路径长度为:1 ;最短路径为:V0→V1 从V0到V2的最短路径长度为:9 ;最短路径为:V0→V1→V3→V2 从V0到V3的最短路径长度为:3 ;最短路径为:V0→V1→V3 从V1到V0的最短路径长度为:11;最短路径为:V1→V3→V2→V0从V1到V2的最短路径长度为:8 ;最短路径为:V1→V3→V2 从V1到V3的最短路径长度为:2 ;最短路径为:V1→V3 从V2到V0的最短路径长度为:3 ;最短路径为:V2→V0 从V2到V1的最短路径长度为:4 ;最短路径为:V2→V0→V1 从V2到V3的最短路径长度为:6 ;最短路径为:V2→V0→V1→V3 从V3到V0的最短路径长度为:9 ;最短路径为:V3→V2→V0 从V3到V1的最短路径长度为:10;最短路径为:V3→V2→V0→V1 从V3到V2的最短路径长度为:6 ;最短路径为:V3→V2 参考程序: #include #define INFINITY 100 #define Max 10int a[Max][Max],P[Max][Max]; main() {void Print_Flod(int d);int i,j,k,D=4;printf("请输⼊成本邻接矩阵:\n");for(i=0;ifor(j=0;j{scanf("%d",&a[i][j]);}for(i=0;ifor(j=0;j{if(a[i][j]>0&& a[i][j]elseP[i][j]=-1;}for(k=0;kfor(i=0;ifor(j=0;jif (a[i][k]+a[k][j]{a[i][j]=a[i][k]+a[k][j];P[i][j]=k;}Print_Flod(D);}void Print_Flod(int d){void dist(int first,int end);int i,j;for(i=0;ifor(j=0;jif(i!=j){ printf("from V%d to V%d: ",i,j); dist(i,j);printf("V%d",j);printf(" (The length is: %d)\n",a[i][j]); }}void dist(int first,int end){ int x;x=P[first][end];if(x!=first){ dist(first,x); dist(x,end); }else printf("V%d->",x);}输出结果:。
MD模拟在新材料研究中的应用

MD模拟在新材料研究中的应用MD模拟,在物理、化学与材料科学中被广泛应用,是分子动力学模拟的缩写。
它通过模拟原子、分子等粒子在其相互作用力下的运动过程,探索材料结构与动力学性质。
MD模拟的成功归功于计算机技术的不断发展,尤其是高性能计算机和云计算。
MD 模拟为材料研究提供了一种全新的手段,它可以同实验相结合,更快地理解材料的行为,并提出预测和优化新材料的方案。
在本文中,我们将探讨MD模拟在新材料研究中的应用。
一、理解材料的结构与性质MD模拟是一种原子层次的数值计算方法,因此可以捕捉材料中原子和分子的行为。
通过该方法,我们可以计算材料的结构、形态以及有关材料的化学物理特征。
这些信息提供了材料研究的基础,例如晶体结构、电荷转移、电学性质、热学性质、机械性能、光学性质等。
MD模拟可以通过改变温度、压力、化学反应和外界环境等因素,来探索材料不同填充状态下的性质,从而发现材料中潜在的性能。
生成更好的结构、提高性能和确定制造过程可能需要的良好了解材料行为的基本知识。
这是MD模拟的优势之一。
二、预测新材料的性质借助MD模拟,研究人员可以探究具有不同的化学组成的化合物的电学、热学和机械属性。
这有助于开发更好的新材料以满足不同需求。
通过预测的物质属性,研究人员可以在不必测试的情况下比较不同材料的性能。
这防止了更多实验的进行并节省了大量的时间和资源。
虽然实验室测量是不可避免的,但MD模拟可以提供有关材料性能的有价值的信息,这是在难以实现的实验条件的情况下尤其重要。
此外,预测性能突出的新材料还可以在应用领域中广泛使用,例如电池材料、半导体材料、太阳能电池等。
三、创建分子机器人系统MD模拟可以帮助科学家研究分子机器人的运作,从而设计更好的分子机械系统。
科学家可以通过构建分子块、计算其行为来深入研究分子机器人的机制。
通过MD模拟,可以了解这些机器人如何在不同外部条件下运作,以及他们如何与其他分子交互以完成其任务。
这些机器人可以用作可编程分子集合,例如分子存储、分子计算等。
动力学模拟计算方法探究

动力学模拟计算方法探究动力学模拟计算方法(Molecular Dynamics Simulation,以下简称MD)是一种利用计算机对分子运动进行模拟的方法。
它可以在原子和分子水平上揭示材料或生物分子的动态性质。
MD方法广泛应用于物理学、化学、材料科学、生物学等领域。
MD方法的基本原理是根据牛顿力学模拟粒子间相互作用。
模拟系统中每个原子或分子的位置和速度都是由牛顿方程决定的。
通过揭示这些微观运动,我们可以了解更多关于分子结构、运动和相互作用的信息。
MD方法的具体步骤包括建立模型、设定初始条件、进行能量最小化和长时间动力学模拟。
建立模型需要确定分子的种类、数量、分子间力场等。
设定初始条件需要给每个原子或分子分配初始位置和速度。
能量最小化是为了使模拟系统处于一个平衡状态,避免模拟过程中分子浮动太大。
长时间动力学模拟是模拟分子在一段时间内的运动轨迹。
MD方法的优点在于可以模拟现实中很难或不可能观察到的物理和化学现象。
例如,MD方法可以模拟蛋白质分子的折叠过程,以及纳米材料的力学性质等。
同时,MD方法还可以为实验提供预测信息,缩短实验的周期和成本。
除了在基础研究中的应用外,MD方法也在工业生产过程中得到广泛应用。
例如,MD方法可以帮助设计材料的性质,提高材料的稳定性和生产效率。
同时,MD方法也可以帮助设计新的药物和生物分子,为药物研发和生物医学领域的重大疾病提供治疗方案。
然而,MD方法也存在一些局限性。
一方面,模拟系统必须是孤立的,没有外界干扰,这对一些材料和生物物质来说是不可行的。
另一方面,MD方法需要极高的计算能力和存储资源,计算成本也比较高。
为了弥补这些局限性,近年来出现了许多改进MD方法的技术。
例如,Monte Carlo方法可用于处理超过百万级别的分子,Metropolis-Coupled Monte Carlo方法可用于处理高度非均匀和外部约束系统,快速多极子算法(Fast Multipole Method)可用于处理大型电动力学模拟等。
MD5算法原理及代码实现

MD5算法原理及代码实现MD5(Message Digest Algorithm 5)是一种被广泛使用的消息摘要算法,它是MD家族中的第五个版本。
MD5算法能将任意长度的输入数据转换为一个128位(16字节)的散列值,通常表示为32个十六进制数。
1. 填充(Padding):为了使输入消息的位数对512求余数等于448,填充是必要的。
例如,如果输入消息的位数是L,填充后的消息长度为K* 512 + 448,其中K是一个非负整数。
填充后的消息被分为512位(64字节)的块。
2. 初始化(Initialization):算法对四个32位的缓冲区A、B、C、D进行初始化,通常初始化为常量。
这些缓冲区用于保存中间计算结果。
3. 循环(Iteration):通过进行四轮循环的操作,将每个512位的块以及前一个块的连续散列结果作为输入,产生新的散列结果。
每轮循环包括四个步骤:数据的复制、数据的变换、数据的交换以及数据的加法。
4. 输出(Output):将最后一轮循环的输出结果根据顺序连接起来,形成128位的散列值。
下面是一个简单的MD5算法的代码示例,使用Python语言实现:```pythonimport hashlibdef md5(message):md5_hash = hashlib.md5md5_hash.update(message.encode('utf-8'))return md5_hash.hexdigest#测试message = "Hello, world!"md5_value = md5(message)print("MD5 hash value:", md5_value)```在上述代码中,我们首先导入了Python标准库中的hashlib模块,该模块提供了MD5算法的实现。
然后,我们定义了一个名为md5的函数,它接受一个字符串形式的消息作为输入,并返回该消息的MD5散列值。
算法设计算法实验报告(3篇)

第1篇一、实验目的本次实验旨在通过实际操作,加深对算法设计方法、基本思想、基本步骤和基本方法的理解与掌握。
通过具体问题的解决,提高利用课堂所学知识解决实际问题的能力,并培养综合应用所学知识解决复杂问题的能力。
二、实验内容1. 实验一:排序算法分析- 实验内容:分析比较冒泡排序、选择排序、插入排序、快速排序、归并排序等基本排序算法的效率。
- 实验步骤:1. 编写各排序算法的C++实现。
2. 使用随机生成的不同规模的数据集进行测试。
3. 记录并比较各算法的运行时间。
4. 分析不同排序算法的时间复杂度和空间复杂度。
2. 实验二:背包问题- 实验内容:使用贪心算法、回溯法、分支限界法解决0-1背包问题。
- 实验步骤:1. 编写贪心算法、回溯法和分支限界法的C++实现。
2. 使用标准测试数据集进行测试。
3. 对比分析三种算法的执行时间和求解质量。
3. 实验三:矩阵链乘问题- 实验内容:使用动态规划算法解决矩阵链乘问题。
- 实验步骤:1. 编写动态规划算法的C++实现。
2. 使用不同规模的矩阵链乘实例进行测试。
3. 分析算法的时间复杂度和空间复杂度。
4. 实验四:旅行商问题- 实验内容:使用遗传算法解决旅行商问题。
- 实验步骤:1. 设计遗传算法的参数,如种群大小、交叉率、变异率等。
2. 编写遗传算法的C++实现。
3. 使用标准测试数据集进行测试。
4. 分析算法的收敛速度和求解质量。
三、实验结果与分析1. 排序算法分析- 通过实验,我们验证了快速排序在平均情况下具有最佳的性能,其时间复杂度为O(nlogn),优于其他排序算法。
- 冒泡排序、选择排序和插入排序在数据规模较大时效率较低,不适合实际应用。
2. 背包问题- 贪心算法虽然简单,但在某些情况下无法得到最优解。
- 回溯法能够找到最优解,但计算量较大,时间复杂度较高。
- 分支限界法结合了贪心算法和回溯法的特点,能够在保证解质量的同时,降低计算量。
3. 矩阵链乘问题- 动态规划算法能够有效解决矩阵链乘问题,时间复杂度为O(n^3),空间复杂度为O(n^2)。
MD5算法的设计与实现

MD5算法的设计与实现MD5(Message Digest Algorithm 5)是一种常用的哈希算法,用于对任意长度的数据进行加密和校验。
MD5算法由美国密码学家罗纳德·李维斯特(Ronald Rivest)于1991年提出,目前仍广泛应用于数据完整性校验、密码存储等领域。
1.不可逆性:MD5算法是单向的,无法通过哈希值逆向推导出原始数据。
这意味着即使知道哈希值,也无法还原出原始数据。
2.高度离散性:MD5算法对输入数据的任意细微更改都会产生完全不同的哈希值。
这意味着即使数据只有一点点改变,其哈希值也会完全不同。
3.快速性:MD5算法的计算速度相对较快,能够在短时间内对大量数据进行哈希计算。
1.填充数据:对输入数据进行填充,使其长度恰好为512的倍数。
填充时,在数据末尾添加一个1,后面补0至满足长度要求。
2.填充长度:将填充后的数据长度(以比特位为单位)表示为64位二进制数,并添加到填充数据的末尾。
3.初始化状态:定义四个32位的寄存器A、B、C、D,并初始化为特定的常量值。
4.分组处理:将填充后的数据分成若干个512位的分组,每次处理一个分组。
5.循环操作:对每个分组进行四轮循环操作,每轮操作包括四个步骤。
a.F函数:根据当前轮数选择不同的非线性函数,并将寄存器A、B、C、D的值传入。
b.G函数:根据当前轮数选择不同的线性函数,并将寄存器A、B、C、D的值传入。
c.H函数:根据当前轮数选择不同的线性函数,并将寄存器A、B、C、D的值传入。
d.I函数:根据当前轮数选择不同的线性函数,并将寄存器A、B、C、D的值传入。
6.更新寄存器:根据循环操作的结果更新寄存器A、B、C、D的值。
7.输出结果:将最终的寄存器值按顺序连接起来,得到128位的哈希值。
1.碰撞攻击:由于MD5算法的哈希值只有128位,因此存在不同的输入数据生成相同的哈希值的可能性,这被称为碰撞。
攻击者可以通过特定的方法找到两个不同的输入数据,生成相同的哈希值,从而绕过数据完整性校验。
化合物MD模拟计算方法的研究与应用

化合物MD模拟计算方法的研究与应用随着计算机技术和软件的发展,分子动力学模拟(Molecular Dynamics,MD)计算方法在材料科学、生命科学等领域中得到了广泛应用。
在化学化工领域中,MD模拟被用于研究材料的结构、性质以及反应机制等问题。
本文将从化合物MD模拟计算方法的研究和应用两个方面来探讨这一方法在化学领域中的价值。
一、化合物MD模拟计算方法的研究MD模拟的本质是通过数值计算模拟粒子之间的相互作用,以得到材料的结构和性质等信息。
而化合物MD模拟是将MD模拟运用于化合物的研究中。
首先,化合物MD模拟研究需要建立能够准确描述化学键、原子位置以及分子间相互作用等信息的模型。
目前,常用的模型包括力场(force field)和量子化学方法(Quantum Chemistry,QC)。
力场方法采用原子-分子相互作用势能函数来模拟材料的分子结构和动力学。
力场方法具有计算速度快、适用范围广、精度可控等优点,已成为化合物MD模拟的重要方法。
而量子化学方法是基于量子力学理论的计算方法,其结果更加准确,但计算复杂度很大,适用范围也相对有限。
因此,一般情况下,研究者会根据材料类型和实际需要,选择适当的模型来进行化合物MD模拟研究。
其次,化合物MD模拟研究需要建立物理学上合理的计算模拟条件。
这些条件包括温度、压力、体积等因素。
相应的计算方法包括NVT系综(恒定温度、体积和粒子数)、NPT系综(恒定温度、压力、体积和粒子数)等。
最后,化合物MD模拟还需要合理的计算算法。
常见的算法包括Verlet算法、Leapfrog算法、Predictor-Corrector算法等。
这些算法的核心都是基于牛顿力学方程,根据系统的初始状态推演出随时间变化的物理学过程。
二、化合物MD模拟计算方法的应用化合物MD模拟计算方法已被应用于多个领域。
1. 化学反应机制研究化学反应机制研究是MD模拟在化学领域中的重要应用之一。
通过模拟反应物分子在化学反应中的电子结构、化学键变化和反应动力学等信息,可以获得反应机制、反应速率常数等信息。
实验3 M文件及程序设计实验

实验三 M 文件及程序设计实验一、实验目的1. 掌握M 文件与M 函数的编写与应用;2. 掌握if 语句、switch 语句的使用;3. 掌握利用for 语句、while 语句实现循环结构的方法二、实验内容1.创建一个函数文件, 建立如下函数⎩⎨⎧<+-≥++=00),(2222y x y x y x y x y x fx,y 由键盘赋值,采用调用方法计算f 值,试编写程序(M 文件),并以x=6,y= -3及x= -6,y=3二种情况运行,写出运行结果。
x=input('input x=');y=input('input y=');if x+y>=0fun=x^2+y^2elsefun=x^2-y^2end>> numb1input x=6input y=-3fun =45>> numb1input x=-6input y=3fun =272. 已知一元函数323220y x x x =+++,编写程序求23(1)y (2)y (3)y ++ function y=y(x)y=3*x^3+2*x^2+x+20;end>> y(1)+y(2)^2+y(3)^3ans =18187903. 已知23120(x)201312x x f x x x x +-≤<⎧⎪=+≤<⎨⎪+≤≤⎩,计算f(-1),f(0.5),f(1.5)的值function f=f(x) if x>=-2&x<0f=x+1;elseif x>=0&x<1 f=x^2+2;elseif x>=1&x<=2 f=x^3+3;end>> f(-1)ans =>> f(0.5)ans =2.2500>> f(1.5)ans =6.37504. 分别用for循环语句、while循环语句求100! 和100i i=∑clearresult=1;for i=1:100result=result*i;endresult>> expresult =9.3326e+157clearresult=0;for i=1:100result=result+i;endresult>> expresult =5050clearresult=1;i=0;while i<100i=i+1;result=result*i;endresult>> expresult =9.3326e+157clearresult=0;i=0;while i<100i=i+1;result=result+i;endresult>> expresult =50505. 若一个三位整数的各位数字的立方和等于该数本身,则称该整数为水仙花数,例如333153=1+5+3,153就是个水仙花数,编程序计算出所有的水仙花数。
密码学MD实验分析报告

密码学MD实验报告作者: 日期:实验四:密码学MD5实验报告import java.io.File;import java.io.Filel nputStream;import java.io .10 Exceptio n;import java. ni o.MappedByteBufer;import java .ni o.cha nn els.FileCha nn el;import java.security.MessageDigest;import java.security.NoSuchAlgorithmExceptio n;import java.util.Sca nner;public class EXEMD5 {/*设置MD5值输出为16进制(从0到F)*/protected static char hexDigits [] = { '0', '1',2, 3, 4,'5', 6, 7: 8,9,'A', 'B', C, 'D', 'E', 'F'};/*获取MD5算法,并判断是否存在MD5算法(判断是否正确导入了加密库)*/protected static MessageDigest messagedigest = null ;static {try {messagedigest = MessageDigest. get In sta nee ("MD5");} eateh (NoSuchAlgorithmException e) {e.pri ntStackTrace();}}/*计算文件(包括EXE文件)MD5值的算法*/public static String getFileMD5String(File file) throws IOException{ FileInputStream in = new FileInputStream(file);FileCha nnel ch =i n.getCha nn el();MappedByteBuffer byteBuffer=ch.m ap(FileCha nn el.M apMode. READ_ONLY, 0, file.le ngth());messagedigest .update(byteBuffer);return bufferToHex (messagedigest .digest());}/*将字节数组转换为字符串类型*/private static String bufferToHex( byte bytes[]){return bufferToHex (bytes, 0,bytes.length);/*将字节数组从第m位元素到第n位元素的部分转换成字符串类型*/ private static String bufferToHex( byte bytes[], int m, int n){StringBuffer stringbuffer = new StringBuffer(2 * n);int k = m + n;for (int l = =m; l< k; I++) {appendHexPair (bytes[l], stringbuffer);}return stri ngbuffer.toStri ng();}private static void appendHexPair( byte bt, StringBuffer stringbuffer) { char cO = hexDigits [(bt& OxfO) >> 4];char cl = hexDigits [bt& Oxf];stri ngbuffer.appe nd(cO);stri ngbuffer.appe nd(c1);}£j^SI@Javsdoc 百明S 揑制台S3u已蜒止=EXEMD5 ( 1 ] [Jav^ 应用程序]C:\Program Fi le s\J a va1^ re7\b!ri\j^vaw.请选择你要计算MO 511的应用程序交件!【1 】erase・exe 【2】hello^exe2【运行结果】选择的文件是该文件MD5倩计茸MD5用时hello <exeCDC47D670159EEF60916CA03A9D4A007 14.303954sf)实验结果分析我们不难发现,这两个EXE文件虽然内容不同,但是MD5值却是相同的!MD5用于确保信息传输完整一致。
masm实验3 实验报告
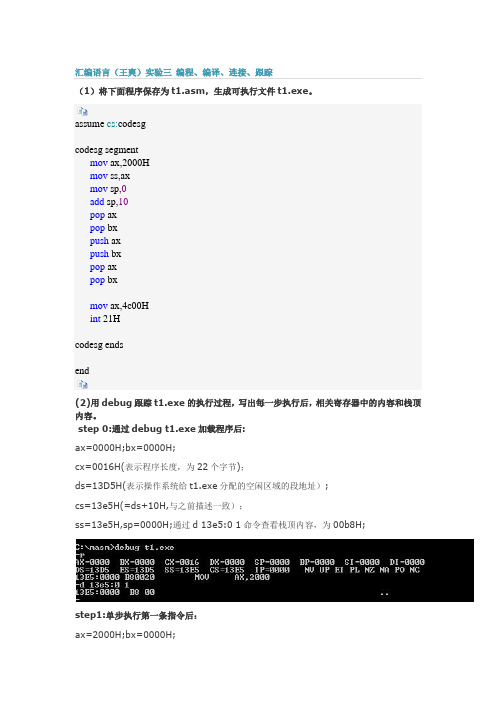
(1)将下面程序保存为t1.asm,生成可执行文件t1.exe。
assume cs:codesgcodesg segmentmov ax,2000Hmov ss,axmov sp,0add sp,10pop axpop bxpush axpush bxpop axpop bxmov ax,4c00Hint 21Hcodesg endsend(2)用debug跟踪t1.exe的执行过程,写出每一步执行后,相关寄存器中的内容和栈顶内容。
step 0:通过debug t1.exe加载程序后:ax=0000H;bx=0000H;cx=0016H(表示程序长度,为22个字节);ds=13D5H(表示操作系统给t1.exe分配的空闲区域的段地址);cs=13e5H(=ds+10H,与之前描述一致);ss=13e5H,sp=0000H;通过d 13e5:0 1命令查看栈顶内容,为00b8H;step1:单步执行第一条指令后:ax=2000H;bx=0000H;其余cx,ds,cs,ss,sp均不变;此时栈顶内容理应不变,查看依旧为00b8H;step2:单步执行第二条指令后,自动连带执行第三条指令:ax=2000H;bx=0000H;其余cx,ds,cs均不变;ss和sp被重置,栈顶指向:2000:0,查看栈顶内容,为:0ff1H;step3:单步执行第四条指令后:ax=2000H;bx=0000H;其余cx,ds,cs,ss均不变;sp被重置,栈顶指向:2000:0a,查看栈顶内容,为:615fH;step4:单步执行第五条指令后:ax=615fH(与上一步所得一致);bx=0000H;其余cx,ds,cs,ss均不变;sp=sp+2,栈顶指向:2000:0c,查看栈顶内容,为:0DF0H;----------因重新debug,导致前后ax不一致-----------step5:单步执行第六条指令后:ax=13e5H;bx=0DF0H(与上一步所得一致);其余cx,ds,cs,ss均不变;sp=sp+2,栈顶指向:2000:0E,查看栈顶内容,为:0B16H;step6:单步执行第七条指令后:ax=13e5H;bx=0DF0H;其余cx,ds,cs,ss均不变;sp=sp-2,栈顶指向:2000:0C,查看栈顶内容,为:13E5H (与AX一致);step7:单步执行第八条指令后:ax,bx,cx,ds,cs,ss均不变;sp=sp-2,栈顶指向:2000:0A,查看栈顶内容,为:0DF0H (与BX一致);step8:单步执行第九条指令后:ax=0DF0H(与上步查看一致);bx,cx,ds,cs,ss均不变;sp=sp+2,栈顶指向:2000:0C,查看栈顶内容,为:13E5H;step9:单步执行第十条指令后:bx=13E5H(与上步查看一致);ax,cx,ds,cs,ss均不变;sp=sp+2,栈顶指向:2000:0E,查看栈顶内容,为:0B16H;(3)PSP头两个字节为CD 20,用debug加载t1.exe.查看PSP内容:PSP区域地址范围为:ds:0~ds:ff.分类: 汇编语言。
D ma 实验报告

湖南文理学院实验报告书课程:三维动画设计姓名:谢江花专业:教育技术学班级:教育09101班学号:指导教师:肖芳实验一:三维模型的创建姓名:谢江花学号:时间: 1—4周一、实验目的通过本实验的学习,使学生掌握利用掌握利用软件开发工具进行三维模型的创建的基本方法。
二、实验设备和仪器多媒体计算机、网络环境及相关软件三、实验内容及要求(1) 利用3DSMAX三维创建命令创建三维模型。
(2) 在3DSMAX利用二维平面图创建三维模型。
(3)导入其他三维软件工具创建的三维模型。
四、实验原理及步骤实验原理:利用3DSMAX2010的造型命令和编辑功能创建三维模型。
实验步骤:一、地面透视图→创建几何体→标准基本体→平面,参数如右图图示如下二、墙透视图→创建几何体→扩展基本体→L-Ext参数如右图与地面对齐(Alt+A):1、首先,当前对象对目标对象XYZ三个方向中心对中心→应用2、Z轴方向最小对最大→应用→确定(下图)三、天花板透视图→选择地面→镜像→Z轴方向偏移100,复制四、床板透视图→创建几何体→扩展基本体→切角长方体参数如右图五、床头1、左视图→创建几何体→扩展基本体→切角圆柱体(边数24以上,一定要记得切片)参数如右图2、床头与床板进行对齐X轴方向最大对最大,Y轴方向中心对中心,Z轴方向最小对最大六、床头柜1、透视图→创建几何体→扩展基本体→切角长方体参数如右图2、床头柜与床板进行对齐:X轴最大对最大,Y轴最大对最小3、原地复制一个床头柜,与床板对齐:Y轴最小对最大4、将新绘制的两个床头柜附加到床组合中:选中两个床头柜→成组→附加→选中床组合七、将床组合移到墙角处选择捕捉开关右键点击→点选边捕捉→打开捕捉开关(S)→顶视图或前视图将床组合移至墙角,如果此时Y轴或Z轴方向位置变动,再以Alt+A的方式对齐一下八、将床组合隐藏命令面板→显示→隐藏→隐藏选定对象九、衣柜1、透视图→创建几何体→扩展基本体→切角长方体参数如右图2、将衣柜移至墙角处:激活顶视图→打开边捕捉开关3、将衣柜复制三组,同样以边捕捉的方式与墙对齐,将边捕捉关闭4、选中四组衣柜,透视图中再与地面对齐一下5、将衣柜冻结:命令面板→显示→冻结→冻结选定对象(我的电脑上将冻结颜色设成黄色,便于观察),如下图右键点击角度捕捉标志→将角度设为45°→打开角度捕捉开关(A)→E旋转,将灯头旋转180°与天花板对齐,Z轴方向最大对最大最终效果图如下:五、使用注意事项1、模型的质量。
分子动力学模拟的原理和方法

分子动力学模拟的原理和方法分子动力学模拟(Molecular Dynamics Simulation, 简称MD)是一种将牛顿力学应用到分子层面的模拟技术,可以模拟原子和分子之间的相互作用、热力学性质、结构和动力学行为等。
MD模拟可以帮助化学、物理、生物和材料科学等领域深入了解宏观现象的微观机制,如蛋白质折叠、物质传输、材料制备等,被广泛应用于科学研究和技术开发之中。
本文将简要介绍MD模拟的原理和方法。
一、MD模拟的基本原理MD模拟从每个原子的初始位置和速度开始,通过求解牛顿方程(F=ma)来模拟系统在时间上的演化。
在MD模拟中,系统通过使用多体势能函数对原子间的相互作用进行建模,而势能函数通常由经验势和量子化学手段得到。
在物理意义上,势能函数体现了系统的稳定性、结构性质和动力学行为。
通过构建适当的势能函数,MD模拟可以模拟系统在不同温度、压力和配位数等条件下的热力学性质。
MD模拟中的牛顿运动方程可以写成如下形式:m_i d^2r_i /dt^2 = -∇_i U,其中m_i是第i个原子的质量,r_i是它的坐标,U是总势能。
这里d^2 /dt^2表示双重时间导数,即加速度。
∇_i表示关于i号原子的拉普拉斯算子。
通过牛顿方程,我们可以获得系统中每个原子的位置和速度,并通过使用数值积分方法对它们进行离散化计算。
MD模拟的基本步骤包括:1. 构建系统模型:包括化学结构、粒子数、初始位置、速度等2. 选择适当的势能函数:包括经验势和量子化学势等,并进行参数化3. 进行初始的能量最小化:通过改变原子位置和速度,使系统达到稳定状态4. 进行温度和压力的控制:可以通过Berendsen热浴、Nose-Hoover热浴、Andersen热浴等方法对系统进行控制5. 进行时间演化:通过数值积分方法对牛顿方程进行求解,计算原子的位置和速度6. 计算系统的热力学属性:包括温度、压力、能量、速度和位移等。
二、MD模拟的方法MD模拟方法主要可以分为两类,即粒子动力学模拟(Particle Dynamics Simulation, PDS)和基于能量的最小化算法(Energy Minimization Algorithm, EMA)。
实验三_实现Tomasulo算法模拟器

实验三实现 Tomasulo算法模拟器一、实验目的1.加深对指令级并行性及其开发的理解;2.加深对Tomasulo算法的理解;3.掌握Tomasulo算法在指令流出、执行、写结果各阶段对浮点操作指令以及load和store指令进行什么处理;4.掌握采用了Tomasulo算法的浮点处理部件的结构;5.掌握保留站的结构;6.给定被执行代码片段,对于具体某个时钟周期,能够写出保留站、指令状态表以及浮点寄存器状态表内容的变化情况。
二、实验要求设计和实现一个Tomasulo算法模拟器。
1.基本要求:针对程序中直线型代码,可乱序执行、乱序完成。
a.能够正确输出每个周期之后保留站的内容。
保留站基本信息:b.能够正确输出每个周期之后寄存器状态表的内容。
寄存器状态表基本信息:c.能够正确输出每个周期之后指令状态表的内容(指令分为浮点运算指令和load/store指令),指令状态分为流入,执行和写回。
指令状态表基本信息标志出每条指令流出、执行、写回这三个阶段所在的周期号2.较高要求:a.实现带界面的模拟器,可动态输入指令并配置相关信息(e.g指令各个状态周期数,运算部件数目),并能正确输出上述基本要求中的相关信息。
b.实现带“再定序缓冲”的Tomasula算法模拟器,支持分支指令三、实验报告1.给定指令流输入测试L.D F6, 21(R2)L.D F2, 20(R3)MUL.D F0, F2, F4SUB.D F8, F6, F2DIV.D F10, F0, F6ADD.D F6, F8, F2假设浮点功能部件的延迟时间:加减法2个周期,乘法10个周期,load/store2个周期,除法40个周期。
而指令的流入和写回为1个周期。
a.给出第5个时钟周期后保留站的内容:算法模拟器模板——保留站内容:算法模拟器个人——保留站内容:分析:第5个时钟周期流出了5条指令,其中load指令2条,mult指令1条,sub指令1条,divd指令1条。
MD算法设计(精)

d
r
算法设计
第一层
第一层:随机生成球体,球心 保证落在规定区域内。单个球 体满足下述条件: 1.球体在长方体区域内。不满 足条件的球体如1、2等删除。 2.球体之间的距离设定为r,根 据“热量”E控制。如果E较 高,则允许球体相交互穿如右 图3、4的情况,E较低则球体 之间的距离r为两球体直径, 也即不互穿(一次多少的问题 由实验决定)。 实现方法:将三维简化为二维 如右图所示。 1
d
r
1
第三层
z y 0 x 第三层球体的球心范围: 1.在X方向,球心的位置不能超出规定的区 域范围。 2.在y方向,球心的位置也不能超出规定的 区域范围。 3.在z方向,球心的位置为在z方向表示为 [2r,3r],且需要作出判断: (1)如果正下方第二层两球体之间的间 距d大于等于2r,则可以落到第二层。 (2)如果间距d小于2r,则同第二层的判 断方法相同。 (3)如果热量E值较大,可以像第一层一 样在x.y.z三个方向都考虑互穿情况。互穿 的程度由E决定。 注:第三层时已经假设第一层已经密排, 此时球体已经不会掉到第一层。所有球体 在x,y方向可以不接触,在z方向必须有 接触或互穿。以后的层一次类推。
r
2 3 4
ቤተ መጻሕፍቲ ባይዱ二层
z y 0 x 第二层:第二层球体的球心位置: 1.在X方向,球心的位置不能超出 规定的区域范围。 2.在y方向,球心的位置也不能超 出规定的区域范围。 3.在z方向,球心的位置为在z方向 表示为[r,2r],且需要作出判断: (1)如果正下方第一层两球体之 间的间距d大于等于2r,则可以落 到第一层。 (2)如果间距d小于2r,则根据 左下图模式计算1号球的球心,同 时考虑x,y方向的球体。 (3)如果热量E值较大,可以像 第一层一样在x.y.z三个方向都考 虑互穿情况。互穿的程度由E决定。
实验三MD算法方案与实现

实验三 MD5算法的设计与实现MD5算法及C++实现一、理论部分:1、预备知识1.1什么是数据校验通俗的说,就是为保证数据的完整性,用一种指定的算法对原始数据计算出的一个校验值。
接收方用同样的算法计算一次校验值,如果和随数据提供的校验值一样,就说明数据是完整的。
1.2最简单的检验实现方法:最简单的校验就是把原始数据和待比较数据直接进行比较,看是否完全一样这种方法是最安全最准确的。
同时也是效率最低的。
适用范围:简单的数据量极小的通讯。
应用例子:龙珠cpu在线调试工具bbug.exe。
它和龙珠cpu间通讯时,bbug发送一个字节cpu返回收到的字节,bbug确认是刚才发送字节后才继续发送下一个字节的。
1.3奇偶校验Parity Check 实现方法:在数据存储和传输中,字节中额外增加一个比特位,用来检验错误。
校验位可以通过数据位异或计算出来。
应用例子:单片机串口通讯有一模式就是8位数据通讯,另加第9位用于放校验值。
1.4 bcc异或校验法(block check character>实现方法:很多基于串口的通讯都用这种既简单又相当准确的方法。
它就是把所有数据都和一个指定的初始值<通常是0)异或一次,最后的结果就是校验值,通常把她附在通讯数据的最后一起发送出去。
接收方收到数据后自己也计算一次异或和校验值,如果和收到的校验值一致就说明收到的数据是完整的。
校验值计算的代码类似于:unsigned uCRC=0。
//校验初始值for(int i=0。
i<DataLenth。
i++> uCRC^=Data[i]。
适用范围:适用于大多数要求不高的数据通讯。
应用例子:ic卡接口通讯、很多单片机系统的串口通讯都使用。
1.5 crc循环冗余校验(Cyclic Redundancy Check> 实现方法:这是利用除法及余数的原理来进行错误检测的.将接收到的码组进行除法运算,如果除尽,则说明传输无误;如果未除尽,则表明传输出现差错。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三MD5算法的设计与实现MD5 算法及C++ 实现一、理论部分1 、预备知识1.1 什么是数据校验通俗的说,就是为保证数据的完整性,用一种指定的算法对原始数据计算出的一个校验值。
接收方用同样的算法计算一次校验值,如果和随数据提供的校验值一样,就说明数据是完整的。
1.2 最简单的检验实现方法:最简单的校验就是把原始数据和待比较数据直接进行比较,看是否完全一样这种方法是最安全最准确的。
同时也是效率最低的。
适用范围:简单的数据量极小的通讯。
应用例子:龙珠cpu在线调试工具bbug.exe。
它和龙珠cpu间通讯时,bbug发送一个字节cpu返回收到的字节,bbug确认是刚才发送字节后才继续发送下一个字节的。
1.3奇偶校验Parity Check 实现方法:在数据存储和传输中,字节中额外增加一个比特位,用来检验错误。
校验位可以通过数据位异或计算出来。
应用例子:单片机串口通讯有一模式就是8位数据通讯,另加第9位用于放校验值。
1.4bcc 异或校验法(block check character〉实现方法:很多基于串口的通讯都用这种既简单又相当准确的方法。
它就是把所有数据都和一个指定的初始值 <通常是0)异或一 次, 最后的结果就是校验值, 通常 把她附在通讯数据的最后一起发送出去。
接收方收到数据后自己也 计算一次异或和校验值, 如果和收到的校验值 致就说明收到的数据 是 宀兀整的。
校 验值 计 算 的代码 类 似 于un sig neduCRC=0 。
//校验初始 值 for(i nti=0。
ivDataLe nth。
i++>uCRC A=Data[i]。
适用范 围: 适用 于大多 数 要 求不 高的数据通讯。
应用例子:ic 卡接口通讯、很多单片机系统的串口通讯都使用。
1.5 crc循 环冗 余校 验 (CyclicRedundancy Check 〉实现方法:这是利用除法及余数的原理来进行错误检测的 .将接收到 的 码 组 进 行 除 法 运 算 ,如果除尽,贝朋明传输无误;如果未除尽,贝y 表明传输出现差 错。
crc校 验具 还 有 自 动 纠 错 能 力。
crc 检验主要有计算法和查表法两种方法,网上很多实现代码。
适用范围:CRC-12码通常用来传送6-bit 字符串。
CRC-16及CRC-CCITT 码 则 用 是 来 传 送 8-bit 字符。
CRC-32 :硬盘数据,网络传输等应用例子:rar,以太网卡芯片、MPEG 解码芯片中1.6 md5 校 验 和 数实现方法:主要有 md5和适用范围:数据比较大或要求比较高的场合。
如 据、文件校验,des 用于保密数据的校验 < 数字签名)等等应用例子:文件校验、银行系统的交易数据2 、 具 体 的 实 现 理 论 2.1算法概述MD5算法是 MD4算法的改进算法。
Ron Rivest 于1990年提出 MD4单向散列函数,MD 表示消息摘要(Message Digest 〉,对输入消息, 算法产生128位散列值。
该算法首次公布之后,Bert den Boer 和An toon Bosselaers 对算法三轮中的后两轮进行了成功的密码分析。
在一个不相关的分析结果中,Ralph MerKle 成功地攻击了前两轮。
尽 管这些攻击都没有扩展到整个算法,但 Rivest 还是改进了其算法, 结 果 就 是MD5 算 法 。
MD5算法是MD4的改进算法,它比MD4更复杂,但设计思想相似, 输入的消息可任意长,输出结果也仍为128位,特别适用于高速软件 实现,是基于32-位操作数的一些简单的位操作。
2.2算 法步 骤l 将输入消息按512-位分组,最后要填充成为512位的整数倍,且最 后一组的后64位用来填充消息长度(填充前 >。
填充方法为附一个1 在消息后,后接所要求的多个0。
这样可以确保不同消息在填充后不 相 同。
字 签 名des 算法。
md5用于大量数l由于留出64位用来表示消息长度,那么消息的长度最多可达264字节,相当于4GMG字节,文件的长度是不可能达到这么大,因此通常都是只采用64位中的低32位来表示消息长度,高32位填充0。
I初始化MD变量。
由于每轮输出128位,这128位可用下面四个32 位字A,B,C,D 来表示。
其初始值设为:A=0x01234567B=0x89ABCDEFC=0xFEDCBA98D=0x76543210I开始进入算法主循环,循环的次数是消息中512位消息分组的数目。
先将上面A、B、C、D四个变量分别复制到另外四个变量a、b、c、d中去。
主循环有四轮,每轮很相似。
每轮进行16次操作,每次操作对a、b、c、d四个变量中的三个作一次非线性函数运算,然后将所得结果加上第四个变量,消息的一个子分组和一个常数。
再将所得结果向右环移一个不定的数,并加上a,b,c或d中之一。
最后用该结果取代a,b,c 或 d 中之一。
以下是每次操作中用到的四个非线性函数< 每轮一个)。
F(X,YZ>=(X A Y> V (( X> A Z>G(X,YZ>=(X A Z> V (Y A ( Z>> H(X,Y,Z>=X ㊉Y ㊉ZI(X,Y,Z>=Y ㊉(X V ( Z>> 其中,㊉是异或,A是与,V是或,是反符号。
这些函数是这样设计的:如果X、丫和Z的对应位是独立和均匀的,那么结果的每一位也应是独立和均匀的。
函数F是按逐位方式操作:如果X,那么丫否则Z。
函数H是逐位奇偶操作符。
设Mj表示消息的第j个子分组<从0到15) ,<<<s表示循环左移s ,则四种操作为:FF(a,b,c,d,Mj,s,ti> 表示 a = b+((a+F(b,c,d>+ Mj + ti>vvvs> GG(a,b,c,d,Mj,s,ti> 表示 a = b+((a+G(b,c,d>+ Mj + ti>vvvs> HH(a,b,c,d,Mj,s,ti> 表示 a = b+((a+H(b,c,d>+ Mj + ti>vvvs>ll(a,b,c,d,Mj,s,ti> 表示 a = b+((a+I(b,c,d>+ Mj + ti>vvvs> 四轮(64 步> 结果略注:常数ti 的选择第i步中,ti是232冷bs (sin(i>>的整数部分,i的单位是弧度。
所有这些完成之后,将A,B,C,D分别加上a,b,c,d。
然后用下一分组数据继续运行算法,最后的输出是A,B,C和D的级联。
l最后得到的A,B,C,D就是输出结果,A是低位,D为高位,DCBA组2.3 成128MD5位的输出安结全果。
性Ron Rivest 概述了MD5 安全性[8]l 与MD4 相比增力口了第四轮。
l 每一步均有唯一的加法、常数。
l为减弱第二轮中函数G 的对称性从((X A Y> V (X A Z> V (Y A Z>>变为((X A Z> V (Y A ( Z>>> 。
l每一步加上了上一步的结果,引起更快的雪崩效应。
l改变了第二轮和第三轮中访问消息子分组的次序,使其形式更不相似。
I近似优化了每一轮中的循环左移位移量以实现更快的雪崩效应。
各轮的位移量互不相同。
从安全角度讲,MD5的输出为128位,若采用纯强力攻击寻找一个消息具有给定Hash值的计算困难性为2128,用每秒可实验1 000 000 000个消息的计算机需时1.07 X1022年。
若采用生日攻击法,寻找有相同Hash值的两个消息需要实验264个消息,用每秒可实验1 000 000 000个消息的计算机需时585年。
二、实现方法由于此处的文件校验用到要求比较高的场合,故采用了方法6, md5校验算法,从CodeGuru下载了一个md5校验算法的实现模块,加入自己要校验的文件名,实现完成。
下面具体描述一下实现过程:1 、创建一个简单的对话框程序;2、设置CString 类型的变量m_filename 和m_strFileChecksum 以存放要校验的文件名和校验和;3、在对话框类中创建ChecksumSelectedFilev )函数,调用md5校验和类< 附录中有其实现文件)中的GetMD5计算文件校验和。
4、使用定时器定时巡检该文件的校验和,一旦发现校验和发生变化,立刻出现提示。
三、附录<md5 算法实现的源码)以下代码实现均来自 。
1、MD5ChecksumDefines.hv 定义相关常量的头文件)//Magic in itializatio n con sta nts #defi ne MD5_ _INIT_STATE_0 0x67452301 #defi ne MD5. _INIT_STATE_1 0xefcdab89 #defi ne MD5. _INIT_STATE_2 0x98badcfe #defi ne MD5_ 」NIT_STATE_ 3 0x10325476//Con sta nts for Tran sform routi ne. #defi ne MD5_S11 7 #defi ne MD5_S12 12 #defi ne MD5_S13 17 #defi ne MD5_S14 22 #defi ne MD5_S21 5 #defi ne MD5_S22 9 #defi ne MD5_S23 14 #defi ne MD5_S24 20 #defi ne MD5_S31 4 #defi ne MD5_S32 11 #defi ne MD5_S33 16 #defi ne MD5_S34 23 #defi ne MD5_S41 6 #defi ne MD5_S42 10#defi ne MD5_S43 15 #defi ne MD5_S44 21//Tran sformatio n Con sta nts - Rou nd 1 #defi ne MD5_T01 0xd76aa478 //Tran sformatio n Con sta nt 1 #defi ne MD5_T02 0xe8c7b756 //Tran sformatio n Con sta nt 2 #defi ne MD5_T03 0x242070db //Tran sformatio n Con sta nt 3 #defi ne MD5_T04 0xc1bdceee //Tran sformatio n Con sta nt 4 #defi ne MD5_T05 0xf57c0faf //Tran sformatio n Con sta nt 5 #defi ne MD5_T06 0x4787c62a //Tran sformatio n Con sta nt 6 #defi ne MD5_T07 0xa8304613 //Tran sformatio n Con sta nt 7 #defi ne MD5_T08 0xfd469501 //Tran sformatio n Con sta nt 8 #defi ne MD5_T09 0x698098d8 //Tran sformatio n Con sta nt 9 #defi ne MD5_T10 0x8b44f7af //Tran sformatio n Con sta nt 10 #defi ne MD5_T11 0xffff5bb1 //Tra nsformatio n Con sta nt 11 #defi ne MD5_T12 0x895cd7be //Tran sformatio n Con sta nt 12 #defi ne MD5_T13 0x6b901122 //Tran sformatio n Con sta nt 13 #defi ne MD5_T14 0xfd987193 //Tra nsformatio n Con sta nt 14 #defi ne MD5_T15 0xa679438e //Tran sformatio n Con sta nt 15 #defi ne MD5_T16 0x49b40821 //Tran sformation Con sta nt 16//Tran sformatio n Con sta nts - Rou nd 2 #defi ne MD5_T17 0xf61e2562 //Tra nsformatio n Con sta nt 17 #defi ne MD5_T18 0xc040b340 //Tran sformatio n Con sta nt 18#defi ne MD5_ T19 0x265e5a51 //Tran sformatio n Con sta nt 19 #defi ne MD5_ T20 0xe9b6c7aa //Tra nsformatio n Con sta nt 20 #defi ne MD5_ _T21 0xd62f105d //Tra nsformatio n Con sta nt 21 #defi ne MD5_ T22 0x02441453 //Tran sformatio n Con sta nt 22 #defi ne MD5_ T23 0xd8a1e681 //Tran sformatio n Con sta nt 23 #defi ne MD5_ _T24 0xe7d3fbc8 //Tran sformatio n Con sta nt 24 #defi ne MD5_ T25 0x21e1cde6 //Tran sformatio n Con sta nt 25 #defi ne MD5_ T26 0xc33707d6 //Tran sformatio n Con sta nt 26 #defi ne MD5_ T27 0xf4d50d87 //Tra nsformatio n Con sta nt 27 #defi ne MD5_ T28 0x455a14ed //Tran sformatio n Con sta nt 28 #defi ne MD5_ T29 0xa9e3e905 //Tran sformatio n Con sta nt 29 #defi ne MD5_ _T30 0xfcefa3f8 //Tran sformatio n Con sta nt 30 #defi ne MD5_ _T31 0x676f02d9 //Tra nsformatio n Con sta nt 31#defi ne MD5_T32 0x8d2a4c8a //Tran sformation Con sta nt 32//Tran sformatio n Con sta nts - Rou nd 3 #defi ne MD5_T33 0xfffa3942 //Tran sformatio n Con sta nt 33 #defi ne MD5_T34 0x8771f681 //Tra nsformatio n Con sta nt 34 #defi ne MD5_T35 0x6d9d6122 //Tran sformatio n Con sta nt 35 #defi ne MD5_T36 0xfde5380c //Tran sformatio n Con sta nt 36 #defi ne MD5_T37 0xa4beea44 //Tran sformatio n Con sta nt 37 #defi ne MD5_T38 0x4bdecfa9 //Tran sformatio n Con sta nt 38 #defi ne MD5_T39 0xf6bb4b60 //Tra nsformatio n Con sta nt 39#defi ne MD5_ _T40 0xbebfbc70 //Tran sformatio n Con sta nt 40 #defi ne MD5_ T41 0x289b7ec6 //Tran sformatio n Con sta nt 41 #defi ne MD5_ _T42 0xeaa127fa //Tran sformatio n Con sta nt 42 #defi ne MD5_ _T43 0xd4ef3085 //Tra nsformatio n Con sta nt 43 #defi ne MD5_ _T44 0x04881d05 //Tran sformatio n Con sta nt 44 #defi ne MD5_ _T45 0xd9d4d039 //Tran sformatio n Con sta nt 45 #defi ne MD5_ T46 0xe6db99e5 //Tran sformatio n Con sta nt 46 #defi ne MD5_ _T47 0x1fa27cf8 //Tran sformatio n Con sta nt 47#defi ne MD5_T48 0xc4ac5665 //Tran sformatio n Con sta nt 48//Tran sformatio n Con sta nts - Rou nd 4 #defi ne MD5_T49 0xf4292244 //Tra nsformatio n Con sta nt 49 #defi ne MD5_T50 0x432aff97 //Tran sformatio n Con sta nt 50 #defi ne MD5_T51 0xab9423a7 //Tran sformatio n Con sta nt 51 #defi ne MD5_T52 0xfc93a039 //Tran sformatio n Con sta nt 52 #defi ne MD5_T53 0x655b59c3 //Tran sformatio n Con sta nt 53 #defi ne MD5_T54 0x8f0ccc92 //Tran sformatio n Con sta nt 54 #defi ne MD5_T55 0xffeff47d //Tra nsformatio n Con sta nt 55 #defi ne MD5_T56 0x85845dd1 //Tran sformatio n Con sta nt 56 #defi ne MD5_T57 0x6fa87e4f //Tran sformatio n Con sta nt 57 #defi ne MD5_T58 0xfe2ce6e0 //Tran sformatio n Con sta nt 58 #defi ne MD5_T59 0xa3014314 //Tran sformatio n Con sta nt 59#defi ne MD5_T60 0x4e0811a1 //Tran sformatio n Con sta nt 60 #defi ne MD5_ _T61 0xf7537e82 //Tra nsformatio n Con sta nt 61#defi ne MD5_ _T62 0xbd3af235 //Tra nsformatio n Con sta nt 62#defi ne MD5_ T63 0x2ad7d2bb //Tran sformatio n Con sta nt 63 #defi ne MD5_T64 0xeb86d391 //Tran sformation Con sta nt 64//Null data (except for first BY TE> used to fin alise the checksum calculati on static un sig ned char PADDING[64] = { 0x 80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0,} 。