机器学习 —— 概率图模型(推理:消息传递算法)
概率图模型的推理方法详解(Ⅰ)

概率图模型的推理方法详解概率图模型是一种用图来表示随机变量之间依赖关系的数学模型。
它通过图的节点表示随机变量,边表示随机变量之间的依赖关系,可以用来描述各种复杂的现实世界问题。
概率图模型包括了贝叶斯网络和马尔可夫网络两种主要类型,它们都可以用来进行推理,即根据已知的信息来推断未知的变量。
在本文中,将详细介绍概率图模型的推理方法,包括贝叶斯网络和马尔可夫网络的推理算法。
一、概率图模型概率图模型是一种用图来表示随机变量之间依赖关系的数学模型。
它通过图的节点表示随机变量,边表示随机变量之间的依赖关系,可以用来描述各种复杂的现实世界问题。
概率图模型包括了贝叶斯网络和马尔可夫网络两种主要类型。
贝叶斯网络是一种有向图模型,用来表示变量之间的因果关系;马尔可夫网络是一种无向图模型,用来表示变量之间的相关关系。
概率图模型可以用来进行概率推理,即根据已知的信息来推断未知的变量。
二、贝叶斯网络的推理方法在贝叶斯网络中,每个节点表示一个随机变量,每条有向边表示一个因果关系。
贝叶斯网络的推理方法主要分为两种:精确推理和近似推理。
1. 精确推理精确推理是指通过精确的计算来得到准确的推理结果。
常用的精确推理算法包括变量消去算法和团树传播算法。
变量消去算法通过逐步消去变量来计算联合概率分布,但是对于大型网络来说计算复杂度很高。
团树传播算法通过将网络转化为一个树状结构来简化计算,提高了计算效率。
2. 近似推理近似推理是指通过近似的方法来得到推理结果。
常用的近似推理算法包括马尔科夫链蒙特卡洛算法和变分推断算法。
马尔科夫链蒙特卡洛算法通过构建马尔科夫链来进行抽样计算,得到近似的概率分布。
变分推断算法通过将概率分布近似为一个简化的分布来简化计算,得到近似的推理结果。
三、马尔可夫网络的推理方法在马尔可夫网络中,每个节点表示一个随机变量,每条无向边表示两个变量之间的相关关系。
马尔可夫网络的推理方法主要分为两种:精确推理和近似推理。
1. 精确推理精确推理是指通过精确的计算来得到准确的推理结果。
概率图模型的推理方法详解(六)

概率图模型的推理方法详解概率图模型是一种用于描述随机变量之间关系的工具,它能够有效地表示变量之间的依赖关系,并且可以用于进行推理和预测。
在实际应用中,概率图模型广泛应用于机器学习、人工智能、自然语言处理等领域。
本文将详细介绍概率图模型的推理方法,包括贝叶斯网络和马尔科夫随机场两种主要类型的概率图模型,以及它们的推理算法。
1. 贝叶斯网络贝叶斯网络是一种用有向无环图表示的概率图模型,它描述了变量之间的因果关系。
在贝叶斯网络中,每个节点表示一个随机变量,节点之间的有向边表示了变量之间的依赖关系。
贝叶斯网络中的概率分布可以由条件概率表来表示,每个节点的条件概率表描述了该节点在给定其父节点的取值情况下的概率分布。
在进行推理时,我们常常需要计算给定一些证据的情况下,某些变量的后验概率分布。
这可以通过贝叶斯网络的条件概率分布和贝叶斯定理来实现。
具体来说,给定一些证据变量的取值,我们可以通过贝叶斯网络的条件概率表计算出其他变量的后验概率分布。
除了基本的推理方法外,贝叶斯网络还可以通过变量消除、置信传播等方法进行推理。
其中,变量消除是一种常用的推理算法,它通过对变量进行消除来计算目标变量的概率分布。
置信传播算法则是一种用于处理概率传播的通用算法,可以有效地进行推理和预测。
2. 马尔科夫随机场马尔科夫随机场是一种用无向图表示的概率图模型,它描述了变量之间的联合概率分布。
在马尔科夫随机场中,每个节点表示一个随机变量,边表示了变量之间的依赖关系。
不同于贝叶斯网络的有向图结构,马尔科夫随机场的无向图结构表示了变量之间的无向关系。
在进行推理时,我们常常需要计算给定一些证据的情况下,某些变量的后验概率分布。
这可以通过马尔科夫随机场的联合概率分布和条件随机场来实现。
具体来说,给定一些证据变量的取值,我们可以通过条件随机场计算出其他变量的后验概率分布。
除了基本的推理方法外,马尔科夫随机场还可以通过信念传播算法进行推理。
信念传播算法是一种用于计算概率分布的通用算法,可以有效地进行推理和预测。
机器学习 —— 概率图模型(推理:连续时间模型)
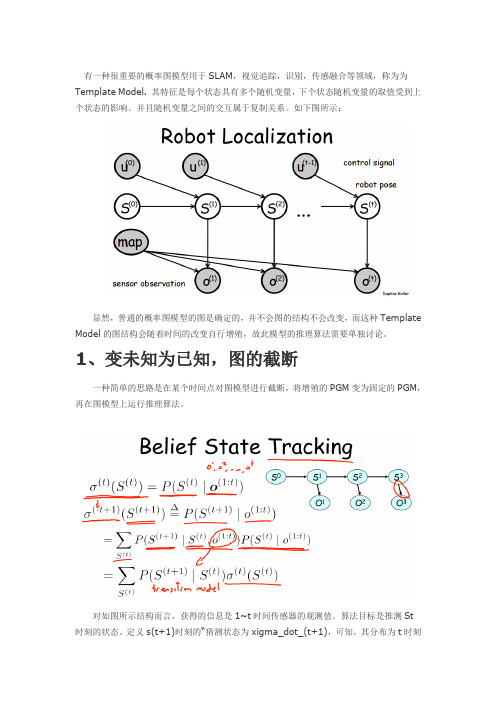
有一种很重要的概率图模型用于SLAM,视觉追踪,识别,传感融合等领域,称为为Template Model. 其特征是每个状态具有多个随机变量,下个状态随机变量的取值受到上个状态的影响。
并且随机变量之间的交互属于复制关系。
如下图所示:
显然,普通的概率图模型的图是确定的,并不会图的结构不会改变,而这种Template Model的图结构会随着时间的改变自行增殖,故此模型的推理算法需要单独讨论。
1、变未知为已知,图的截断
一种简单的思路是在某个时间点对图模型进行截断,将增殖的PGM变为固定的PGM,再在图模型上运行推理算法。
对如图所示结构而言,获得的信息是1~t时间传感器的观测值。
算法目标是推测St
时刻的状态。
定义s(t+1)时刻的“猜测状态为xigma_dot_(t+1),可知,其分布为t时刻
状态的和。
也就是t时刻取值的线性组合。
在给定t+1时刻的观测时,s(t+1)可表达为下式:
s(t+1)真正的值实际上和t+1时刻的观测,对t+1时刻的猜测,以及分母——对t+1时刻观测量的猜测有关。
分母实际上是一个跟状态无关的常数,最后求不同状态S取值比例的时候分母是可以忽略的。
所以重要的是分子。
分子和两个量有关,第一个是观测模型,第二个是t+1时刻状态猜测量。
而状态猜测量是线性组合,每次计算都可以直接带入上次结果。
所以,这种结构的Template Model算起来并不会非常困难。
概率图模型及其在机器学习中的应用

概率图模型及其在机器学习中的应用机器学习是人工智能领域中的重要分支,它主要研究如何通过大量数据和学习算法构建模型,以实现自动化决策和预测。
在机器学习中,概率图模型是一种重要的工具,它可以帮助我们更好地建模和解决许多实际应用问题,包括推荐系统、自然语言处理、计算机视觉等。
一、什么是概率图模型概率图模型(Probabilistic Graphical Models,PGM)是一种用图形表示变量之间概率依赖关系的数学工具。
它的核心思想是通过变量节点和边来表示随机变量之间的联合概率分布,从而实现“图形化建模”。
概率图模型有两类:有向图模型(Directed Graphical Model,DGM)和无向图模型(Undirected Graphical Model,UGM)。
有向图模型又称贝叶斯网络(Bayesian Network,BN),它是一类有向无环图(DAG),其中结点表示随机变量,边表示变量之间的依赖关系。
无向图模型又称马尔科夫随机场(Markov Random Field,MRF),它是一个无向图,其中结点表示变量,边表示变量之间的关系。
概率图模型的优点在于可以通过图形的方式自然地表示变量之间的依赖关系,更容易理解和解释模型的含义。
而且,概率图模型能够有效地减少模型参数量,提高模型估计的准确性和效率。
二、概率图模型在机器学习中的应用概率图模型在机器学习中的应用非常广泛,下面介绍其中几个应用场景。
1.概率图模型在推荐系统中的应用推荐系统是机器学习中的一个重要研究方向,概率图模型可以帮助我们建立更精确和智能的推荐模型。
以贝叶斯网络为例,它可以用来表示用户-物品之间的依赖关系。
在一个面向物品的模型中,图中的结点表示物品,边表示商品之间的关系。
通过学习用户的历史行为数据,我们可以基于贝叶斯网络进行商品推荐,从而提高推荐准确率。
2.概率图模型在自然语言处理中的应用自然语言处理是人工智能领域中的重要研究方向,它旨在让计算机能够理解和处理人类语言。
概率图模型的推理算法并行化技巧分享(Ⅰ)

在概率图模型的推理算法中,并行化是一种重要的技巧。
概率图模型是用来描述随机变量之间依赖关系的数学模型,在许多领域都有广泛的应用,比如自然语言处理、计算机视觉、生物信息学等。
推理算法是指利用概率图模型进行推断和预测的方法,而并行化技巧则是指利用多个处理单元同时进行计算,以提高算法的效率和性能。
概率图模型的推理算法可以分为两大类:精确推理算法和近似推理算法。
精确推理算法包括变量消去、信念传播等方法,可以得到全局最优的推断结果,但是在大规模问题上计算复杂度很高。
而近似推理算法则是通过一些近似的方法来获得局部最优的推断结果,计算复杂度相对较低,适用于大规模问题。
在并行化技巧方面,对于精确推理算法来说,变量消去是一种可以并行化的算法。
变量消去算法的基本思想是通过逐步消去概率图模型中的变量,最终得到目标变量的概率分布。
在并行化的过程中,可以将不同变量的消去过程分配给不同的处理单元进行计算,以提高算法的效率。
另外,信念传播算法也可以通过并行化技巧来加速计算过程。
信念传播算法是一种近似推理算法,通过在概率图模型中传递消息来进行推断,可以将消息传递的过程并行化,以提高算法的性能。
对于近似推理算法来说,采样算法是一种常用的方法,可以通过并行化技巧来加速计算过程。
采样算法是通过从概率分布中进行采样来进行推断,可以将不同样本的采样过程分配给不同的处理单元进行计算,以提高算法的效率。
另外,近似推理算法中的优化方法也可以通过并行化技巧来加速计算过程。
优化方法是通过迭代的方式来求解概率图模型中的参数,可以将不同迭代步骤的计算过程分配给不同的处理单元进行计算,以提高算法的性能。
总的来说,并行化技巧在概率图模型的推理算法中有着重要的作用。
通过并行化技巧,可以充分利用多个处理单元的计算能力,提高算法的效率和性能。
未来随着计算机硬件的发展和并行计算技术的进步,相信并行化技巧会在概率图模型的推理算法中发挥越来越重要的作用,为解决实际问题提供更加高效的方法。
机器学习 —— 概率图模型(推理:团树算法)
在之前的消息传递算法中,谈到了聚类图模型的一些性质。
其中就有消息不能形成闭环,否则会导致“假消息传到最后我自己都信了”。
为了解决这种问题,引入了一种称为团树(clique tree)的数据结构,树模型没有图模型中的环,所以此模型要比图模型更健壮,更容易收敛。
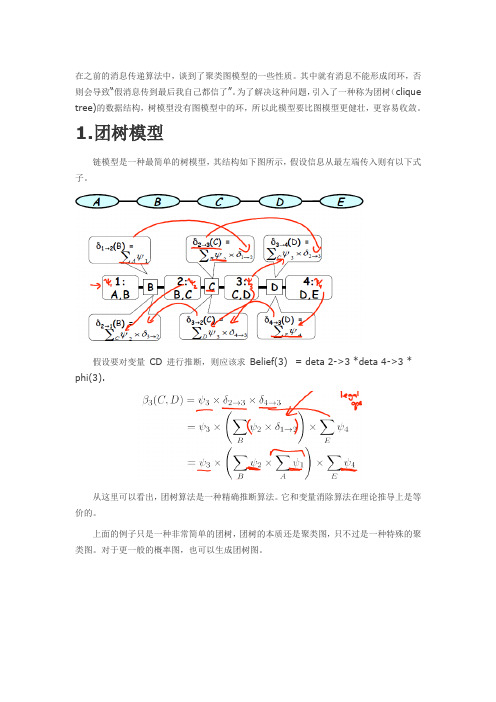
1.团树模型链模型是一种最简单的树模型,其结构如下图所示,假设信息从最左端传入则有以下式子。
假设要对变量CD 进行推断,则应该求Belief(3) = deta 2->3 *deta 4->3 * phi(3).从这里可以看出,团树算法是一种精确推断算法。
它和变量消除算法在理论推导上是等价的。
上面的例子只是一种非常简单的团树,团树的本质还是聚类图,只不过是一种特殊的聚类图。
对于更一般的概率图,也可以生成团树图。
其中,每个cluster都是变量消除诱导图中的一个最小map。
2.团树模型的计算从上面分析可知,团树模型本质上和变量消除算法还有说不清道不明的关系(团树模型也是精确推理模型)。
但是这个算法的优势在于,它可以利用消息传递机制达到收敛。
之前提过,聚类图模型中的收敛指的是消息不变。
除此之外,聚类图的本质是一种数据结构,它可以储存很多中间计算结果。
如果我们有很多变量ABCDEF,那么我们想知道P(A),则需要执行一次变量消除。
如果要计算P(B)又要执行一次变量消除。
如果中途得到了某个变量的观测,又会对算法全局产生影响。
但是使用团树模型可以巧妙的避免这些问题。
首先,一旦模型迭代收敛之后。
所有的消息都是不变的,每个消息都是可以被读取的。
每个团的belief,实际上就是未归一划的联合概率,要算单个变量的概率,只需要把其他的变量边际掉就行。
这样一来,只需要一次迭代收敛,每个变量的概率都是可算的。
并且算起来方便。
其次,如果对模型引入先验知识比如A = a 时,我们需要对D 的概率进行估计。
按照变量消除的思路又要从头来一次。
但是如果使用团树结构则不用,因为A的取值只影响deta1->2以及左向传递的消息,对右向传递的消息则毫无影响,可以保留原先对右向传递消息的计算值,只重新计算左向传递结果即可。
概率图模型的推理方法详解(十)

概率图模型的推理方法详解概率图模型是一种用于描述随机变量之间关系的数学工具,它通过图的形式表示变量之间的依赖关系,并利用概率分布来描述这些变量之间的关联。
在概率图模型中,常用的两种图结构是贝叶斯网络和马尔可夫随机场。
而推理方法则是通过已知的观测数据来计算未知变量的后验概率分布,从而进行推断和预测。
一、贝叶斯网络的推理方法贝叶斯网络是一种有向无环图,它由节点和有向边组成,每个节点表示一个随机变量,有向边表示变量之间的依赖关系。
在贝叶斯网络中,推理问题通常包括给定证据条件下计算目标变量的后验概率分布,以及对未观测变量进行预测。
常用的推理方法包括变量消去法、固定证据法和采样法。
变量消去法是一种精确推理方法,它通过对贝叶斯网络进行变量消去来计算目标变量的后验概率分布。
这种方法的优点是计算结果准确,但当网络结构复杂时,计算复杂度会很高。
固定证据法是一种近似推理方法,它通过将已知的证据变量固定,然后对目标变量进行推理。
这种方法的优点是计算速度快,但结果可能不够准确。
采样法是一种随机化推理方法,它通过蒙特卡洛采样来计算目标变量的后验概率分布。
这种方法的优点是可以处理复杂的网络结构,但计算效率较低。
二、马尔可夫随机场的推理方法马尔可夫随机场是一种无向图,它由节点和边组成,每个节点表示一个随机变量,边表示变量之间的依赖关系。
在马尔可夫随机场中,推理问题通常包括给定证据条件下计算目标变量的后验概率分布,以及对未观测变量进行预测。
常用的推理方法包括置信传播法、投影求解法和拉普拉斯近似法。
置信传播法是一种精确推理方法,它通过消息传递算法来计算目标变量的后验概率分布。
这种方法的优点是计算结果准确,但当网络结构复杂时,计算复杂度会很高。
投影求解法是一种近似推理方法,它通过对目标变量进行投影求解来计算后验概率分布。
这种方法的优点是计算速度快,但结果可能不够准确。
拉普拉斯近似法是一种随机化推理方法,它通过拉普拉斯近似来计算目标变量的后验概率分布。
概率图模型的推理算法并行化技巧分享(十)

概率图模型(Probabilistic Graphical Models, PGM)是一种描述随机变量之间关系的数学模型,它在机器学习、人工智能等领域有着广泛的应用。
在构建概率图模型时,一个重要的问题是如何进行推理,即通过已知的变量值来推断未知变量的概率分布。
由于概率图模型通常包含大量的变量和复杂的依赖关系,因此需要高效的推理算法来处理。
在实际应用中,处理大规模概率图模型的推理问题是非常具有挑战性的。
传统的推理算法往往面临着计算复杂度高、运行时间长的问题。
为了解决这一难题,研究者们提出了各种并行化技巧,以提高推理算法的效率。
本文将介绍一些常见的概率图模型推理算法并行化技巧,希望能为相关领域的研究者和从业者提供一些启发。
### 一、并行化技巧概述在进行概率图模型的推理时,常用的算法包括变量消去、信念传播、马尔可夫链蒙特卡洛等。
这些算法往往需要进行大量的概率计算和变量更新,因此可以通过并行化技巧来提高运行效率。
常见的并行化技巧包括并行化算法设计、多核并行计算、分布式计算等。
### 二、并行化算法设计在设计概率图模型的推理算法时,可以从算法本身入手,通过并行化技巧来提高算法的效率。
例如,在变量消去算法中,可以将不依赖于彼此的变量分组,并行进行计算和更新,从而加快算法的运行速度。
此外,还可以利用GPU等硬件加速技术,将部分计算任务转移到GPU上进行并行计算,以提高运行效率。
### 三、多核并行计算多核并行计算是一种常见的并行化技巧,通过利用多核处理器的并行计算能力,将计算任务分配给多个核心同时进行处理。
在概率图模型的推理算法中,可以利用多核并行计算来加速概率计算和变量更新过程。
通过合理设计并行任务的划分和调度策略,可以充分利用多核处理器的计算能力,提高算法的运行效率。
### 四、分布式计算随着大数据技术的发展,分布式计算已经成为处理大规模数据的重要技术手段。
在概率图模型的推理中,可以将概率计算和变量更新任务分布到多台计算机上进行并行处理,以提高算法的运行效率。
深度学习-概率图模型

无向图模型
量函数,Z 是配分函数。
《神经网络与深度学习》
22
Illustration: Image De-Noising (1)
Original Image
Noisy Image
《神经网络与深度学习》
23
Illustration: Image De-Noising (2)
18
无向图的马尔可夫性
《神经网络与深度学习》
19
团(Clique)
团:一个全连通子图,即团内的所有节点之间都连边。
共有7个团
《神经网络与深度学习》
20
Hammersley-Clifford定理
无向图的联合概率可以分解为一系列定义在最大团上的非负函数的乘积形式。
《神经网络与深度学习》
21
引集合T
process)是一组随机变量 的集合,其中t属于一个索引
可以定义在时间域或者空间域。
在随机过程中,马尔可夫性质(Markov
property)是指一个随机过程在给定现在
状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。
《神经网络与深度学习》
70
马尔可夫链
离散时间的马尔可夫过程也称为马尔可夫链(Markov
《神经网络与深度学习》
9
条件独立性
在贝叶斯网络中,如果两个节点是直接连接的,它们肯定是非条件独立的,是
直接因果关系。
父节点是“因”,子节点是“果”。
如果两个节点不是直接连接的,但是它们之间有一条经过其他节点的路径连接
互连接,它们之间的条件独立性就比较复杂。
《神经网络与深度学习》
10
常见的有向图模型
《神经网络与深度学习》
概率图模型的推理方法详解

概率图模型是一种用来描述变量之间关系的数学模型,其应用涉及到很多领域,如机器学习、计算机视觉、自然语言处理等。
而概率图模型的推理方法则是指对于给定模型和观测数据,如何计算未观测变量的后验分布。
在本文中,我们将详细介绍概率图模型的推理方法,包括贝叶斯网络和马尔可夫随机场两种常见的概率图模型。
概率图模型的推理方法可以分为两大类:精确推理和近似推理。
精确推理是指通过准确地计算出后验分布来进行推理;而近似推理则是指通过一定的近似计算方法来得到后验分布的近似值。
下面分别介绍这两种推理方法在贝叶斯网络和马尔可夫随机场中的应用。
首先,我们来讨论贝叶斯网络中的推理方法。
贝叶斯网络是一种用有向无环图来表示变量之间依赖关系的概率图模型。
在贝叶斯网络中,我们通常关心的是给定观测数据,如何计算未观测变量的后验分布。
在这里,精确推理方法主要有变量消去法和团树算法两种。
变量消去法是一种递归计算边际分布的方法,通过对变量进行消去来计算目标变量的边际分布;而团树算法则是一种基于图的消息传递算法,通过在图上进行消息传递来计算目标变量的边际分布。
另外,近似推理方法中的采样方法也常用于贝叶斯网络的推理,如马尔可夫链蒙特卡洛法和变分推理方法等。
接下来,我们来讨论马尔可夫随机场中的推理方法。
马尔可夫随机场是一种用无向图来表示变量之间关系的概率图模型。
在马尔可夫随机场中,我们通常关心的是给定观测数据,如何计算未观测变量的后验分布。
在这里,精确推理方法主要有信念传播算法和变量消去法两种。
信念传播算法是一种基于图的消息传递算法,通过在图上进行消息传递来计算目标变量的边际分布;而变量消去法则是一种递归计算边际分布的方法,通过对变量进行消去来计算目标变量的边际分布。
另外,近似推理方法中的采样方法也常用于马尔可夫随机场的推理,如马尔可夫链蒙特卡洛法和变分推理方法等。
总之,概率图模型的推理方法是概率图模型研究的核心内容之一。
通过对概率图模型的推理方法进行深入的了解,我们可以更好地理解概率图模型的基本原理,从而更好地应用概率图模型到实际问题中。
机器学习——概率图模型(推理:MAP)

MAP 是最大后验概率的缩写。
后验概率指的是当有一定观测结果的情况下,对其他随机变量进行推理。
假设随机变量的集合为X ,观察到的变量为 e, W = X-e , AP = P(W|e). 后验概率和联合概率是不同的两个概念。
事实上,后验概率更接近推理本身的“意义”,并且被越来越多的用于诊断系统中。
在医疗诊断系统中,存在包括病症,症状等许多随机变量,使用VE或者消息传递之类的推理手段确实可以获得每个随机变量的概率以及某些随机变量的联合概率(一个Scope的概率)。
但实际上,如果面对某些很少出现的症状以及对应病症,联合概率密度函数并不合适,比如病人红细胞减少的概率非常小,但红细胞减少很大几率上对应“白血病”。
如果求联合分布则会得到一个较小的概率值(因为得白血病的人本来就不多,加上有其他症状干扰),但是如果使用后验概率,则能排除此干扰。
1. 积化和的最大化最大后验概率是一种推理手段。
w = argmax P(W|e)。
W是尚未观测到的随机变量,使得此概率最大的意义是在获得某观测后,推断最可能发生了什么。
这个公式把MAP变成了一个优化问题。
P(X)实际上是一系列 P(scope)的乘积。
在取对数的情况下,积就变成了和,对数的底是可以随意选择的。
demo example 如下图所示.如果 PHI_k (Dk) 是链状分解的情况下,可以采用变量分离最大化的方式来求取其最大值。
如图所示:由变量边际类比可知,还可由消息传递的方式来计算最终结果。
实际上这里的最大值代替了边际。
利用消息传递的方式计算最大后验概率如图所示:最大化执行完毕后,得到的是各个变量的“势”,以及使得“势”最大的变量组合取值。
简而言之,就是一组推断的结果。
2. NP完备的MAP问题2.1 对应问题对应问题是在工程中经常碰到的问题。
例如多目视觉中的配准,同一个物体被不同像素观测到。
那么我们关心的两个不同的像素值各是多少。
这个像素值本质是随机变量,物体是观测量。
机器学习——概率图模型(贝叶斯网络)
机器学习——概率图模型(贝叶斯⽹络) 概率图模型(PGM)是⼀种对现实情况进⾏描述的模型。
其核⼼是条件概率,本质上是利⽤先验知识,确⽴⼀个随机变量之间的关联约束关系,最终达成⽅便求取条件概率的⽬的。
1.从现象出发---这个世界都是随机变量 这个世界都是随机变量。
第⼀,世界是未知的,是有多种可能性的。
第⼆,世界上⼀切都是相互联系的。
第三,随机变量是⼀种映射,把观测到的样本映射成数值的过程叫做随机变量。
上述三条原则给了我们以量化描述世界的⼿段,我们可以借此把⼀个抽象的问题变成⼀个数学问题。
并且借助数学⼿段,发现问题,解决问题。
世界上⼀切都是未知的,都是随机变量。
明天会有多少婴⼉降⽣武汉是随机变量,明天出⽣婴⼉的基因也是随机变量,这些孩⼦智商⾼低是随机变量,⾼考分数是随机变量,⽉薪⼏何是随机变量。
但是这些随机变量之间完全⽆关么?男孩,智商⾼,⾼考低分,⽉薪⾼的概率⼜有多少?显然,随机变量每增多⼀个,样本空间就会以指数形式爆表上涨。
我们要如何快速的计算⼀组给定随机变量观察值的概率呢?概率图给出了答案。
2.概率图---⾃带智能的模型 其实在看CRF的时候我就常常在想,基于CRF的词性分割使⽤了词相邻的信息;基于边缘检测的图像处理使⽤了像素的相邻信息;相邻信息够么?仅仅考虑相邻像素所带来的信息⾜够将⼀个观察(句⼦或图像)恢复出其本意么?没错,最丰富的关系⼀定处于相邻信息中,⽐如图像的边缘对分割的共线绝对不可磨灭,HMM词性分割也效果不错.......但是如果把不相邻的信息引⼊判断会怎样?在我苦思冥想如何引⼊不相邻信息的时候Deep Learning 和 CNN凭空出现,不得不承认设计这套东西的⼈极度聪明,利⽤下采样建⽴较远像素的联系,利⽤卷积将之前产⽣的效果累加到⽬前时刻上(卷积的本质是堆砌+变质)。
这样就把不相邻的信息给使⽤上了。
但是这样是不是唯⼀的⽅法呢?显然不是,还有⼀种不那么⾃动,却 not intractable⽅法,叫做PGM。
机器学习——概率图模型(推理:采样算法)

机器学习——概率图模型(推理:采样算法) 基于采样的推理算法利⽤的思想是概率 = ⼤样本下频率。
故在获得图模型以及CPD的基础上,通过设计采样算法模拟事件发⽣过程,即可获得⼀系列事件(联合概率质量函数)的频率,从⽽达到inference的⽬的。
1、采样的做法 使⽤采样算法对概率图模型进⾏随机变量推理的前提是已经获得CPD。
举个简单的例⼦,如果x = x1,x2,x3,x4的概率分别是a1,a2,a3,a4.则把⼀条线段分成a1,a2,a3,a4,之后使⽤Uniform采样,x落在1处,则随机变量取值为a1...依次类推,如图所⽰。
显然,采样算法中最重要的量就是采样的次数,该量会直接影响到结果的精度。
关于采样次数有以下定理: 以简单的贝叶斯模型为例,如果最终关⼼的是联合概率,条件概率,单⼀变量的概率都可以使⽤采样算法。
下图共需要设置 1+1+4+2+3 =11 个uniform采样器,最终得到N个结果组合(d0i1g1s0l1等)。
最后计算每个组合出现的频率即可获得联合概率分布。
通过边缘化则可获得单⼀变量概率。
如果是条件概率,则去除最终结果并将符合条件的取出,重新归⼀化即可。
总结可知,采样算法有以下性质: 1.精度越⾼,结果越可靠,需要的采样次数也越多。
2.所关⼼的事件发⽣的概率很⼩,则需要很⼤的采样次数才能得到较为准确的结果。
3.如果随机变量的数量很多,则采样算法会⾮常复杂。
故此算法不适⽤于随机变量很多的情况。
2、马尔科夫链与蒙特卡洛算法 马尔科夫链是⼀种时域动态模型,其描述的随机变量随着时间的推进,在不同状态上跳跃。
实际上,不同的状态是随机变量所可能的取值,相邻状态之间是相关关系。
引⼊马尔科夫链的⽬的是为了描述某些情况下,随机变量的分布⽆法⽤数学公式表达,⽽可利⽤马尔科夫链进⾏建模。
把随机变量的取值视为状态,把随机变量视为跳蚤。
马尔科夫链如下图所⽰: 显然,对于简单的马尔科夫链我们⼤致还可以猜到或者通过⽅程解出CPD,但是⼀旦变量⾮常复杂,则我们很难获得CPD了。
机器学习7-概率图模型

累积分布函数(CDF)
基本采样法(Basic Sampling)
高斯分布:
不适用于积分及反 函数难求的分布!
Box-Muller变换
拒绝采样(Rejection Sampling)
重要性采样(Importance Sampling)
对于个变量 期望值:
,一个关于 函数 ,预测 的
很复杂,或者无法写出解析形式,但可以估算每个出
现 的概率 。要估计
可以按如下方式计算-将空间网络化
重要性采样(Importance Sampling)
直接计算
维数灾难 效率低下
有两个困难:
模型
,如何计算
算法
,以及
预测问题(又叫解码问题):给定维观特比测序
列
,以及模型 (Viterbi) ,
序列
学习问题:给定观测序列
Baum-Welch ,估计模型
参数
,使得在该模型下算观法 测序列出现的概率
最大
隐马尔可夫模型
(Hidden Markov Models)
当
马尔可夫链各状态趋于平稳,即
同时
平稳分布
Metropolis-Hastings 方法
思想:对于需要采样的一分布 ,构造一个转移矩阵为 的马
尔可夫链,使它的平稳分布恰好为
假设有一个转移矩阵
, 为容易采样的分布
通常情况下,该转移矩阵难以满足细致平稳条件
引入
使
其中:
接受率
Metropolis-Hastings 方法
晴天
阴天
下雨
机器学习——概率图模型(CPD)

机器学习——概率图模型(CPD) CPD是conditional probability distribution的缩写,翻译成中⽂叫做条件概率分布。
在概率图中,条件概率分布是⼀个⾮常重要的概念。
因为概率图研究的是随机变量之间的练习,练习就是条件,条件就要求条件概率。
对于简单的条件概率⽽⾔,我们可以⽤⼀个条件概率表来表达。
如图1所⽰。
图1 中表达的是p(g|i,d)。
幸运的是id都只有两个取值,是⼀个伯努利分布的函数。
但是如果i d 有六个取值呢?⽐如骰⼦。
那么这张表就会猛然增加到6^2那么长。
这是不科学的。
并且,常规情况下,仅考虑疾病诊断问题,如果有多种原因都会导致某个症状,那么我们要表达症状|疾病那么就会变得分成复杂,表有有2^N那么长,N是疾病的数⽬。
所以,我们需要⼀种简单的⽅法,能够简化CPD的表达,除了⽤表之外,还应该有⽐较优雅的⼿段。
1.树状CPD 很多随机变量依赖于多个随机变量,但这多个随机变量的优先级别都不⼀样。
就像找对象,⾸先要是个学⽣,然后要漂亮,最后要聪明。
这三个并不是同时要求的,所以树状结构的CPD就利⽤了这个思想,把各级“并联”变成了串联。
本来job依赖于 c L ,但是L ⼜是依赖于c 的,所以就转成了树状的CPD.特点是该有的概率都在图⾥能读出来。
但是却⼜另外指定了⼀些图⾥没有的逻辑关系。
2.⽚选CPD ⽚选CPD(Multiplexer CPD),实际上是对应⼀种情况:随机变量A⼀旦指定后,Y的取值就仅和其中⼀个⽗节点有关。
这是⼀个实际问题,⽐如天上有很多飞机,它们的速度都是随机变量(Y),塔台指定⼀架飞机观测之后,随机变量Y就只与指定的那架飞机有关。
那么条件概率就有以下表达:3.噪声或CPD 噪声或CPD(Noise OR CPD)对应的情况是:咳嗽可能由很多因素引起,这些因素的或结果是咳嗽。
咳嗽<--感冒<---受凉。
但是受凉并不⼀定会感冒,也就是说,受凉不⼀定会导致咳嗽,那么相当于受凉和感冒之间存在⼀个噪声。
概率图模型的推理方法详解(四)

概率图模型的推理方法详解概率图模型(Probabilistic Graphical Model,PGM)是一种用于描述变量之间概率关系的数学模型。
它通过图的方式来表示变量之间的依赖关系,可以分为贝叶斯网和马尔科夫网两种主要类型。
在实际应用中,我们需要对概率图模型进行推理,即通过给定的观测数据来推断未知变量的概率分布。
本文将详细介绍概率图模型的推理方法,包括精确推理、近似推理和因子图推理。
一、精确推理精确推理是指在概率图模型中通过精确计算来得到变量的后验概率分布。
其中最常用的方法是变量消去算法和团树算法。
变量消去算法通过对图模型进行变量消去操作来计算边缘概率和条件概率。
它利用了概率分布的乘法和加法规则,通过递归地将变量消去直到得到最终的概率分布。
虽然变量消去算法可以得到精确的结果,但在计算复杂度上往往随着变量数量的增加而指数级增长,因此只适用于变量较少的情况。
团树算法是一种基于图的推理方法,它将概率图模型转化为一个团树(Clique Tree),并利用团树的特性来进行推理。
团树算法在处理较大规模的概率图模型时具有较好的效率和灵活性,但也需要较为复杂的数据结构和计算过程。
二、近似推理在实际应用中,往往面临着大规模、高维度的概率图模型,精确推理方法难以满足实时性和计算复杂度的要求。
因此近似推理成为了一种重要的方法。
近似推理的核心思想是通过采样或优化的方式来逼近真实的后验概率分布。
其中最常用的方法包括蒙特卡洛方法、变分推断和期望传播算法。
蒙特卡洛方法通过生成随机样本来逼近后验概率分布,其中包括马尔科夫链蒙特卡洛(MCMC)和重要性采样等方法。
蒙特卡洛方法的优点是能够得到较为准确的近似结果,但缺点是计算量大,并且对初始参数较为敏感。
变分推断是一种通过优化的方式来逼近后验概率分布的方法,它将概率分布的表示空间限定在一个参数化的分布族中,并通过最大化似然函数或最小化KL散度来逼近真实的后验概率分布。
变分推断具有较好的计算效率和稳定性,但由于参数空间的限制,可能无法得到全局最优解。
概率图模型简明教程

概率图模型简明教程概率图模型(Probabilistic Graphical Models,PGMs)是一种用于描述变量之间概率关系的图模型。
它通过图的形式展现变量之间的依赖关系,帮助我们更好地理解和推断复杂的概率分布。
概率图模型在机器学习、人工智能、统计学等领域有着广泛的应用,是一种强大的建模工具。
本文将介绍概率图模型的基本概念、常见类型以及推断方法,帮助读者快速入门和理解概率图模型的核心思想。
一、概率图模型概述概率图模型是一种用图来表示随机变量之间条件独立性的概率模型。
它主要包括两类图模型:贝叶斯网络(Bayesian Network)和马尔可夫网络(Markov Network)。
贝叶斯网络使用有向无环图表示变量之间的依赖关系,每个节点表示一个随机变量,边表示变量之间的依赖关系;马尔可夫网络使用无向图表示变量之间的关系,节点表示随机变量,边表示变量之间的相关性。
概率图模型通过图的结构和参数来描述变量之间的概率关系,从而实现对复杂概率分布的建模和推断。
二、贝叶斯网络贝叶斯网络是一种有向无环图模型,用于表示变量之间的因果关系。
在贝叶斯网络中,每个节点表示一个随机变量,节点之间的有向边表示变量之间的依赖关系。
每个节点都与一个条件概率分布相关联,描述了给定其父节点的情况下该节点的条件概率分布。
贝叶斯网络可以用来表示复杂的概率分布,并进行推断和预测。
三、马尔可夫网络马尔可夫网络是一种无向图模型,用于表示变量之间的相关性。
在马尔可夫网络中,节点表示随机变量,边表示变量之间的相关性。
每个节点都与一个势函数(potential function)相关联,描述了节点之间的关系强度。
马尔可夫网络可以用来建模无向关系的复杂概率分布,通常用于图像处理、自然语言处理等领域。
四、概率图模型的推断方法推断是概率图模型中的核心问题,指的是在给定观测数据的情况下,计算未观测变量的后验概率分布。
常见的推断方法包括变量消去法、信念传播算法、马尔可夫链蒙特卡洛法等。
机器学习中的概率图模型算法研究

机器学习中的概率图模型算法研究一、引言深度学习技术的快速发展和广泛应用已经促进了机器学习研究的不断深入,涌现出越来越多的新方法和新技术。
概率图模型作为一种深度学习技术在近年来也逐渐得到了重视。
本文将探讨机器学习中的概率图模型算法研究。
二、机器学习中的概率图模型介绍概率图模型是通过图形化方式表示概率分布的一种工具。
这种图形化表示方式直观明了,可以方便地对于各种概率分布进行建模分析。
在机器学习领域,概率图模型已经被广泛应用于分析各种复杂问题。
在概率图模型中,图形结构被用于表示变量之间的关系。
图形中的节点代表随机变量,边代表随机变量之间的依赖关系。
在概率图模型中,很多算法都可以被归纳为两类:基于生成模型和基于判别模型。
三、基于生成模型的概率图模型算法基于生成模型的概率图模型算法主要包括贝叶斯网络和潜在因子分析。
1. 贝叶斯网络贝叶斯网络是一种可以有效地处理不确定性问题的概率图模型。
在此模型中,每个节点代表一个随机事件,并且节点之间的关系可以通过概率分布来表示。
贝叶斯网络的建立过程可以分为两个步骤:首先,确定需要研究的变量,然后确定它们之间的关系。
通过贝叶斯网络,我们可以进行事件之间的推断,同时也可以通过观察到的特定事件来确定其他事件的相关性。
2. 潜在因子分析在潜在因子分析中,随机变量被表示为其潜在因子的线性组合。
潜在因子通常体现了随机变量之间的更深层次的相关性。
在潜在因子分析中,重点是从观察到的数据中推导出潜在因子的值。
四、基于判别模型的概率图模型算法基于判别模型的概率图模型算法主要包括条件随机场和最大熵模型。
1. 条件随机场条件随机场是一种用于建立标签之间依赖关系的方法。
在条件随机场中,每一个标记都被视为一个随机变量。
标记之间的关系是通过一个或多个特征函数来定义的。
一旦特征函数被定义,就可以使用条件随机场来预测标签序列。
2. 最大熵模型最大熵模型是一种基于最大熵原理的建模技术,其目的是为了求解概率分布最为平均的模型。
机器学习理论与实战(十五)概率图模型03

机器学习理论与实战(⼗五)概率图模型0303 图模型推理算法这节了解⼀下概率图模型的推理算法(Inference algorithm),也就是如何求边缘概率(marginalization probability)。
推理算法分两⼤类,第⼀类是准确推理(Exact Inference),第⼆类就是近似推理(Approximate Inference)。
准确推理就是通过把分解的式⼦中的不相⼲的变量积分掉(离散的就是求和);由于有向图和⽆向图都是靠积分不相⼲变量来完成推理的,准确推理算法不区分有向图和⽆向图,这点也可以在准确推理算法:和积算法(sum-product)⾥体现出来,值得⼀提的是有向图必须是⽆环的,不然和积算法不好使⽤。
如果有向图包含了环,那就要使⽤近似推理算法来求解,近似推理算法包含处理带环的和积算法(”loopy” sum-product)和朴素均值场算法(naive mean field),下⾯就来了解下这两种推理算法的⼯作原理。
假如给⼀个⽆向图,他包含数据节点X和标签Y,它可以分解成(公式⼀)的形式:(公式⼀)有些⼈⼀开始觉得(公式⼀)很奇怪,貌似和上⼀节的⽆向图分解有点不⼀样,其实是⼀样的,稍微有点不同的是把不同的团块区分对待了,这⾥有两种团块,⽐如(公式⼀)右边第⼀项是归⼀化常量配分函数,第⼆项可能是先验概率,⽽第⼆项就可能是给定标签时样本的概率。
这⾥⽤可能这个措辞,表⽰这些势函数只是⼀个抽象的函数,他可以根据你的应⽤来变化,它就是对两种不同团块的度量。
如果X的取值状态只有两个,那么配分函数可以写成(公式⼆)的形式:(公式⼆)配分函数就是把所有变量都积分掉得到的最终的度量值,如果要求边缘概率就要通过积分掉其他变量得到的度量值除以配分函数,例如我们要求(图⼀)中的x1的边缘概率P(x1):(图⼀)要求取P(x1),我们就要积分掉x2-x6这五个变量,写成数学的形式如(公式三)所⽰:(公式三)如果你对代数分配率很熟悉,外⾯的加法符号⼤sigma可以分开写成(公式四)的样⼦:(公式四)其实(公式四)就是和积算法的雏形,因为可以很明显的看出⼜有和⼜有积。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
机器学习——概率图模型(推理:消息传递算法)
概率图模型G(V,E)由节点V和边E构成。
在之前马尔科夫模型相关的博客中,我谈到马尔科夫模型的本质是当两个人交流后,其意见(两个随机变量)同意0与不同意1的概率组合。
而势函数表达的是两个意见相同或者相左的程度。
我们搞的那么麻烦,最后想要得到的不就是每个意见正确与否(随机变量取不同值的概率)吗?与其采用解析的方法去算,去把所有其他的变量边际掉,那干脆采用模拟的方法,让这个消息传递跑起来,把系统迭代N次以后的结果拿出来分析。
这种朴素(Naive)的想法,就是Message Passing 算法。
1. 聚类图
在执行消息传递之前,我们需要指定两件事情:1.掌握消息的人有哪些,手里都有哪些消息。
2.他把这个消息告诉了谁。
为了解答这两个问题,需要从我们手里仅有的材料去构造。
P(ABCD) = P(AB)*P(BC)*P(CD)*P(DA) ------- 这里的P是未归一化的概率。
通过这个联合概率计算式,我们获得一种叫做聚类图的全新图模型。
从概率图到聚类图如下所示。
其中,聚类图中存在Cluster 和Edge. Cluster 就是掌握消息的人,Cluster 里的内容就是人所掌握的消息。
Edge 连接了两个交互消息的人,Edge上是两个人交换的消息。
当然,聚类图不仅仅是这么简单的结构。
还有更复杂的聚类图如下.
势函数表达的是两个人意见相同或者相左的程度,两个势函数相乘则会表达多个消息相同或相左的程度。
多个势函数相乘可以成为某个人的消息函数。
对于聚类图,有以下性质:
1.C(Clusters)由节点组成。
2. 边上传递的消息,是两个C的交集(必须要两个人同时知道的消息才能交流)。
3.消息函数是势函数的乘积。
总结一下:消息是随机变量,并且都是相关的。
人掌握消息之间的关系。
人和人之间可以传递消息。
我们假设消息A:明天下雨B:明天下雪C:地上有水那么人们一般都会认为
A1B1C1的可能性肯定大于A1B1C0。
而E有可能是明天有洒水车。
总之,不同的人掌握着不同的消息。
消息与消息之间会相互影响。
2.消息传递
有了消息之后,两个都知道同一件事情的人就会交流和这件事有关的内容,比如 2 会告诉1 关于C(地上有没有水)的事情,这会改变1对消息C的看法(概率)。
我们把消息传递写成以下形式。
i->j 表示消息从i 传递到j。
Sij表示被传递的消息。
通式的物理意义有以下三点:
1.消息从i 传递到j,i 会综合所有人给他说的信息(把所有的δ 相乘)
2.加上自己对消息组合的认知(把δ 相乘的结果乘以消息之间的关系)
3.去除掉不需要传递的部分(把其他变量边际掉)
以上循环一定次数后,达到某种稳定状态。
最终计算某个人对所有消息的看法Belief (所有稳态输入消息δ 乘以消息关系)
这种算法会和精确解法存在一定偏差,故此仅为一种近似算法。
3.聚类图的性质
不是随便一幅图都可以作为聚类图。
聚类图有3个基本要素:
1.每个势函数都被使用,且被使用一次。
2.聚类图中消息传递不能形成环。
3.每个消息如果存在两个知道的人,这两个人必须要有交流途径
关于第一点,势函数描述了消息之间的关系,如果漏了,则失去了消息之间的某个信息,如果重复使用,则某种关系被多余的加强了。
第二点则比较有意思,其实际上描述的是一个正反馈的情况。
假设有个人,编了一个谎话:明天会下雨。
并且把这个谎话告诉了A,然后A又告诉B,B->C,C-D。
如果恰好编这个谎话的人正好和D认识,又正好交流了明天是否会下雨的情况。
那么就“谎话到最后自己都信了”。
这就对“明天下雨”这个随机变量的概率产生较大的估计偏差。
简而言之就是,消息不能成环。
第三点要表达的是,如果甲乙两个人都知道一件事情A,那么他们一定要有交流途径,无论直接交流还是通过其他人转达,总之消息A一定要有在甲乙两人之间联通的路径。
值得注意的一点是,明天下雨A和地上有水C之间可能存在较强的相关性,就算A没有形成环,却通过C形成了环,最终也会对结果产生较大影响。
比如图中,xy强相关时,消息传递算法的表现并不好。
有一种一定能够满足上诉性质的聚类图成为Bethe Clusters Graph。
在使用消息传递算法时,优先考虑构造此聚类图。
该聚类图中有两种不同的人,一种掌握多个消息,一种掌握单种消息。
这样的聚类图一定不会存在环。
其形式如下所示:
4. 传播算法的性质
一群人交换意见,如果大家最后意见都相同了。
比如甲乙都认为明天下雨的概率是0.6,乙丙都认为明天地上有水的概率是0.7.........这种情况称为聚类图校准了。
公式表示,边际掉无关量,两个人对交流消息的看法是一致的。
意见相同还有一个说法,就是交流过程稳定,也就是说,在经过无数次迭代后,消息收敛了。
——————消息传递公式
————————δj-i 与求和无关,因为不在求和域内,故可以乘出去。
发现i,j是对称轮换的
——————————最终得出
收敛和校准是等价的
———————
———一种新的符号
————此式证明了,消息传递算法无论如何运行,初始设定都没有引入新的信息
5.总结
消息传递算法是一种朴素的模拟推断算法,用于求解随机变量的给定依赖条件下的概率。
这种算法的计算结果是有偏的,但该算法却可以大幅降低推断所需要的计算量。