LRU是Least Recently Used最近最少使用算法
lru近似淘汰算法

lru近似淘汰算法1.引言1.1 概述近似淘汰算法是一种用于缓存管理的重要技术,其中最受欢迎和广泛使用的算法之一就是LRU(Least Recently Used)算法。
LRU算法的基本原理是根据最近使用的时间来决定何时淘汰掉缓存中的数据。
在计算机科学领域,缓存是一种用于存储临时数据的高速存储器。
由于其读写速度快、响应时间低等特点,缓存被广泛应用于各种系统中,如操作系统、数据库系统和网络应用等。
然而,缓存的大小是有限的,所以当缓存已满时,就需要采取一种淘汰策略来替换掉一部分旧的数据,以便为新的数据腾出空间。
LRU算法的思想是,当需要淘汰数据时,选择最近最久未使用的数据进行替换。
其基本操作是通过维护一个用于排序访问顺序的链表或者双向队列来实现的。
每当访问一个数据时,该数据就会被移动到链表的头部或者队列的头部,以表示这是最近被使用的数据。
当需要淘汰数据时,只需要将链表或者队列的尾部数据替换掉即可。
LRU近似淘汰算法相比于其他淘汰策略具有一些独特的优势。
首先,LRU算法能够充分利用最近的访问模式,因此能够相对准确地判断哪些数据是频繁访问的。
其次,LRU算法具有较高的缓存命中率,即能够更有效地将经常访问的数据保留在缓存中,从而提高系统的性能和响应速度。
另外,LRU算法的实现相对简单,容易理解和调试,因此广泛应用于实际系统中。
综上所述,本文将对LRU近似淘汰算法进行详细的介绍和探讨。
首先,将解释LRU算法的原理和基本操作。
然后,将探讨LRU近似淘汰算法相比其他淘汰策略的优势和适用性。
最后,将总结该算法的重要性和应用前景。
通过对LRU近似淘汰算法的深入理解,我们能够更好地应用该算法来提升系统的性能和效率。
文章结构部分的内容可以按照以下方式来撰写:1.2 文章结构本文将按照以下结构来展开介绍LRU近似淘汰算法:第一部分为引言,旨在概述本文的背景和目的。
首先,我们将对LRU 算法进行简要介绍,阐述其原理和应用场景。
cache的lru 算法和plru算法

cache的lru 算法和plru算法LRU(Least Recently Used)算法和PLRU(Pseudo-Least Recently Used)算法是常用于缓存系统中的两种替换策略。
缓存是计算机系统中的重要组成部分,它用于临时存储常用数据,以提高系统的性能和响应速度。
LRU算法和PLRU算法能够有效地管理缓存中的数据,优化缓存的使用和替换,从而提高系统的效率。
LRU算法是一种基于时间局部性原理的替换策略。
它的基本思想是,当需要替换缓存中的数据时,选择最近最少使用的数据进行替换。
具体实现方式是通过维护一个访问时间的队列,每当数据被访问时,将其移动到队列的末尾。
当缓存满时,将队列头部的数据替换出去。
这样,最近最少使用的数据就会被优先替换,从而保证了缓存中的数据都是被频繁访问的。
然而,LRU算法的实现需要维护一个访问时间队列,当缓存的大小较大时,这个队列会占用较大的内存空间。
为了解决这个问题,PLRU算法应运而生。
PLRU算法是一种基于二叉树的替换策略,它通过使用多个位来表示缓存中数据的访问情况。
具体来说,PLRU 算法将缓存中的数据按照二叉树的形式组织起来,每个节点代表一个数据块。
当需要替换数据时,PLRU算法会根据节点的位状态来确定替换的路径,最终找到最久未被访问的数据进行替换。
相比于LRU算法,PLRU算法的优势在于它不需要维护一个访问时间队列,从而减少了内存开销。
而且,PLRU算法的查询和更新操作都可以在O(1)的时间复杂度内完成,具有较高的效率。
然而,PLRU算法的实现相对复杂,需要使用位运算等技术,对硬件的要求较高。
在实际应用中,选择LRU算法还是PLRU算法需要根据具体的场景和需求来决定。
如果缓存的大小较小,内存开销不是主要问题,那么可以选择LRU算法。
而如果缓存的大小较大,对内存的消耗比较敏感,那么可以选择PLRU算法。
另外,还可以根据实际情况结合两种算法的优点,设计出更加高效的替换策略。
LRU和LFU的区别和使用场景

LRU和LFU的区别和使⽤场景以下的讨论实现都是奔着O(1)时间复杂度LRULRU(Least recently used,最近最少使⽤)算法根据数据的历史访问记录来进⾏淘汰数据,其核⼼思想是“如果数据最近被访问过,那么将来被访问的⼏率也更⾼”。
LRU 总体上是这样的,最近使⽤的放在前边(最左边),最近没⽤的放到后边(最右边),来了⼀个新的数,如果内存满了,把旧的数淘汰掉(最右边),那位了⽅便移动数据,我们肯定不能考虑⽤数组,呼之欲出,就是使⽤链表了,解决⽅案:链表(处理新⽼关系)+ 哈希(查询在不在),LRU 缓存算法的核⼼数据结构就是哈希链表,双向链表和哈希表的结合体。
这个数据结构长这样:1、通常会⽤来做缓存的算法当缓存被填满时,它应该删除最近最少使⽤的项⽬。
1.JDK⾃带的LinkHashMap实现public class LRUCache{int capacity;Map<Integer, Integer> map;public LRUCache(int capacity) {this.capacity = capacity;map = new LinkedHashMap<>();}public int get(int key) {if (!map.containsKey(key)) {return -1;}// 先删除旧的位置,再放⼊新位置Integer value = map.remove(key);map.put(key, value);return value;}public void put(int key, int value) {if (map.containsKey(key)) {map.remove(key);map.put(key, value);return;}map.put(key, value);// 超出capacity,删除最久没⽤的,利⽤迭代器删除第⼀个if (map.size() > capacity) {map.remove(map.entrySet().iterator().next().getKey());}}}View Code2.Map+双向联表实现package com.mashibing.leetcode.link;import java.util.HashMap;import java.util.Map;public class LRUCache3HeadTail {private int capacity;private Map<Integer, ListNode> map; //key->nodeprivate ListNode head; // dummy headprivate ListNode tail; // dummy tailpublic LRUCache3HeadTail(int capacity) {this.capacity = capacity;map = new HashMap<>();head = new ListNode(-1, -1);tail = new ListNode(-1, -1);head.next = tail;tail.pre = head;}public int get(int key) {if (!map.containsKey(key)) {return -1;}ListNode node = map.get(key);// 先删除该节点,再接到头部node.pre.next = node.next;node.next.pre = node.pre;moveToHead(node);return node.val;}public void put(int key, int value) {// 直接调⽤这边的get⽅法,如果存在,它会在get内部被移动到尾巴,不⽤再移动⼀遍,直接修改值即可if (get(key) != -1) {map.get(key).val = value;return;}// 若不存在,new⼀个出来,如果超出容量,把尾去掉ListNode node = new ListNode(key, value);map.put(key, node);moveToHead(node);if (map.size() > capacity) {map.remove(tail.pre.key);tail.pre = tail.pre.pre;tail.pre.next = tail;}}// 把节点移动到头部private void moveToHead(ListNode node) {node.next = head.next;head.next = node;node.next.pre = node;node.pre = head;}// 定义双向链表节点private class ListNode {int key;int val;ListNode pre;ListNode next;public ListNode(int key, int val) {this.key = key;this.val = val;pre = null;next = null;}}}View Code2、也可以作为负载均衡的算法每次使⽤了每个节点的时候,就将该节点放置在最后⾯(做缓存时放在前⾯),这样就保证每次使⽤的节点都是最近最久没有使⽤过的节点。
lru 页面置换算法

LRU 页面置换算法1. 简介LRU(Least Recently Used)页面置换算法是一种常用的操作系统内存管理算法,用于在内存不足时决定哪些页面应该被置换出去以腾出空间给新的页面。
LRU算法基于一个简单的原则:最近最少使用的页面应该被置换。
在计算机系统中,内存是有限的资源,而运行程序所需的内存可能超过可用内存大小。
当系统发现没有足够的空闲内存来加载新页面时,就需要选择一些已经在内存中的页面进行替换。
LRU算法就是为了解决这个问题而设计的。
2. 原理LRU算法基于一个简单的思想:如果一个页面最近被访问过,那么它将来可能会再次被访问。
相反,如果一个页面很久没有被访问过,那么它将来可能不会再次被访问。
根据这个思想,LRU算法将最近最少使用的页面置换出去。
具体实现上,可以使用一个数据结构来记录每个页面最近一次被访问的时间戳。
当需要替换一页时,选择时间戳最早(即最久未访问)的页面进行替换即可。
3. 实现方式LRU算法的实现可以基于多种数据结构,下面介绍两种常见的实现方式。
3.1 使用链表一种简单的实现方式是使用一个双向链表来记录页面的访问顺序。
链表头部表示最近访问过的页面,链表尾部表示最久未被访问过的页面。
每当一个页面被访问时,将其从原位置移动到链表头部。
当需要替换一页时,选择链表尾部的页面进行替换。
这种实现方式的时间复杂度为O(1),但空间复杂度较高,为O(n),其中n为内存中可用页面数。
class Node:def __init__(self, key, value):self.key = keyself.value = valueself.prev = Noneself.next = Noneclass LRUCache:def __init__(self, capacity):self.capacity = capacityself.cache = {}self.head = Node(0, 0)self.tail = Node(0, 0)self.head.next = self.tailself.tail.prev = self.headdef get(self, key):if key in self.cache:node = self.cache[key]self._remove(node)self._add(node)return node.valueelse:return -1def put(self, key, value):if key in self.cache:node = self.cache[key]node.value = valueself._remove(node)self._add(node)else:if len(self.cache) >= self.capacity:del self.cache[self.tail.prev.key] self._remove(self.tail.prev)node = Node(key, value)self.cache[key] = nodeself._add(node)def _remove(self, node):prev = node.prevnext = node.nextprev.next = nextnext.prev = prevdef _add(self, node):head_next = self.head.nextself.head.next = nodenode.prev = self.headnode.next = head_nexthead_next.prev = node3.2 使用哈希表和双向链表另一种实现方式是使用一个哈希表和一个双向链表。
伪lru替换算法 -回复

伪lru替换算法-回复伪LRU替换算法是一种用于在计算机操作系统中管理页面置换的算法。
LRU是“最近最久未使用”(Least Recently Used)的缩写,伪LRU则是一种近似于LRU的替换算法。
本文将详细解释伪LRU替换算法的原理和步骤,以及它在操作系统中的应用。
一、算法原理伪LRU替换算法是基于页面访问模式的思想设计的。
它模拟了LRU算法中的页面置换过程,但是通过使用一种更加高效的数据结构来实现,以减少算法的时间复杂度。
在LRU算法中,每个页面都有一个时间戳,表示它最后一次被访问的时间。
当需要替换页面时,算法会选择时间戳最久远的页面进行置换。
然而,为了实现这一功能,需要维护页面的访问时间戳,并且在每次访问页面时更新这个时间戳,这样算法的时间复杂度较高。
伪LRU算法通过使用二叉树来代替时间戳,来降低时间复杂度。
二叉树的每个节点都代表一个页面,通过比较节点的数值来判断页面是否为最近使用的页面。
根节点代表最近使用的页面,左子节点代表较旧的页面,右子节点代表更旧的页面。
当需要替换页面时,算法将选择树的最深的路径,并将该页面替换掉。
根据这个逻辑,伪LRU算法在维护树的过程中,只需要比较树的节点,不需要维护时间戳,从而减少了时间复杂度。
二、算法步骤伪LRU替换算法的步骤如下:1. 初始化:为每个页面分配一个二叉树节点,并初始化树的叶子节点为空。
2. 页面访问:当有页面被访问时,算法将按照以下步骤进行操作:a. 如果页面已经在树中,将该页面对应的节点标记为最近使用,然后转到步骤d。
b. 如果页面不在树中,需要进行页面置换。
首先,找到树中最深的非叶子节点的子路径。
这个子路径上的节点都是连续被访问的页面,而且这个子路径的深度大于等于树的高度的一半。
在这个子路径中,如果左子节点的深度大于右子节点的深度,将页面替换为左子节点所代表的页面,否则替换为右子节点。
然后将新访问的页面的节点标记为最近使用,转到步骤d。
lru页面置换算法例题详解

lru页面置换算法例题详解LRU(Least Recently Used)页面置换算法是一种常用的内存管理算法,其基本思想是:当内存空间不足时,优先淘汰最近最少使用的页面。
下面是一个LRU页面置换算法的详细例子:假设我们有3个物理块,当前内存中已经装入了页面1、页面2和页面3。
现在,我们按照顺序依次访问页面4、页面3、页面2、页面1、页面4、页面3、页面5和页面4,我们需要使用LRU算法来决定哪些页面应该被淘汰。
步骤1:装入页面4。
此时内存中有页面1、页面2、页面3和页面4,下一次访问时,将页面4标记为最近使用。
步骤2:访问页面3。
由于页面3在内存中,将其标记为最近使用。
步骤3:访问页面2。
同样,页面2也在内存中,将其标记为最近使用。
步骤4:访问页面1,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面3。
因此,将页面1装入内存中,并标记为最近使用,同时将页面3淘汰。
步骤5:访问页面4,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面2。
因此,将页面4装入内存中,并标记为最近使用,同时将页面2淘汰。
步骤6:访问页面3,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面1。
因此,将页面3装入内存中,并标记为最近使用,同时将页面1淘汰。
步骤7:访问页面5,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面1。
因此,将页面5装入内存中,并标记为最近使用,同时将页面1淘汰。
在上述过程中,我们按照LRU算法依次淘汰了页面3、页面2、页面1和页面1,最终实现了页面的置换。
缓存淘汰算法之FIFO

缓存淘汰算法之FIFO前段时间去⽹易⾯试,被这个问题卡住,先做总结如下:常⽤缓存淘汰算法FIFO类:First In First Out,先进先出。
判断被存储的时间,离⽬前最远的数据优先被淘汰。
LRU类:Least Recently Used,最近最少使⽤。
判断最近被使⽤的时间,⽬前最远的数据优先被淘汰。
LFU类:Least Frequently Used,最不经常使⽤。
在⼀段时间内,数据被使⽤次数最少的,优先被淘汰。
FIFO类先进先出※ FIFO原理:按照“先进先出(First In,First Out)”的原理淘汰数据实现:1. 新访问的数据插⼊FIFO队列尾部,数据在FIFO队列中顺序移动;2. 淘汰FIFO队列头部的数据;特点:>> 命中率命中率很低,因为命中率太低,实际应⽤中基本上不会采⽤。
>> 复杂度简单>> 代价实现代价很⼩※ Second Chance原理: FIFO改进版,如果被淘汰的数据之前被访问过,则给其第⼆次机会(Second Chance)实现:每个数据会增加⼀个访问标志位,⽤于标识此数据放⼊缓存队列后是否被再次访问过。
如上图,A是FIFO队列中最旧的数据,且其放⼊队列后没有被再次访问,则A被⽴刻淘汰;否则如果放⼊队列后被访问过,则将A移到FIFO 队列头,并且将访问标志位清除。
如果所有的数据都被访问过,则经过⼀次循环后就会按照FIFO的原则淘汰数据。
特点:>> 命中率命中率⽐FIFO⾼。
>> 复杂度与FIFO相⽐,需要记录数据的访问标志位,且需要将数据移动>> 代价实现代价⽐FIFO⾼※ Clock原理: Clock是Second Chance的改进版,通过⼀个环形队列,避免将数据在FIFO队列中移动实现:l 当前指针指向C,如果C被访问过,则清除C的访问标志,并将指针指向D;l 如果C没有被访问过,则将新数据插⼊到C的位置,将指针指向D。
sru和lru定义

sru和lru定义SRU和LRU是两种常用的缓存替换策略,它们在计算机系统中的应用非常广泛。
下面我将以人类的视角,生动地描述这两种策略的原理和应用。
SRU(Set Random Update)是一种基于随机替换的缓存替换策略。
它的原理很简单,当缓存空间已满且需要替换时,SRU会随机选择一个缓存块进行替换。
这种策略的好处是简单高效,由于随机选择,每个缓存块都有被替换的机会,从而避免了某些数据频繁被替换的问题。
然而,SRU也存在一些问题,比如可能会导致缓存中的热数据被替换,影响访问性能。
LRU(Least Recently Used)是一种基于最近最少使用的缓存替换策略。
它的原理是根据数据的访问历史记录来确定替换的对象。
具体来说,当缓存空间已满且需要替换时,LRU会选择最近最少被访问的数据进行替换。
这种策略的好处是可以充分利用缓存空间,保留最常使用的数据,提高访问性能。
然而,LRU也存在一些问题,比如需要维护一个访问历史记录的数据结构,增加了额外的开销。
SRU和LRU在实际应用中有不同的场景。
SRU适用于对数据访问顺序没有特定要求的场景,比如缓存一些静态资源文件。
由于数据的访问顺序不受限制,随机替换可以有效地避免缓存中的热数据被替换。
而LRU适用于对数据访问顺序有严格要求的场景,比如缓存一些频繁访问的数据。
通过记录数据的访问历史,LRU可以尽量保留最常使用的数据,提高系统的响应速度。
SRU和LRU是两种常用的缓存替换策略,它们在实际应用中有不同的优势和适用场景。
选择合适的替换策略可以提高系统的性能和效率。
无论是随机替换还是基于最近最少使用的替换,都是为了更好地利用缓存资源,提供更好的用户体验。
在实际应用中,我们可以根据具体的需求和场景选择合适的策略,以达到最佳的效果。
cache缓存淘汰算法--LRU算法
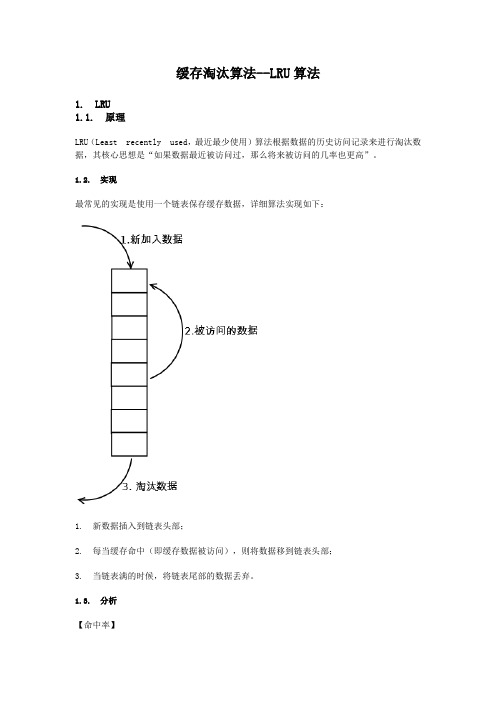
缓存淘汰算法--LRU算法1. LRU1.1. 原理LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:1. 新数据插入到链表头部;2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析【命中率】当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】实现简单。
【代价】命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
2. LRU-K2.1. 原理LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。
LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
只有当数据的访问次数达到K次的时候,才将数据放入缓存。
当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
详细实现如下:1. 数据第一次被访问,加入到访问历史列表;2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;4. 缓存数据队列中被再次访问后,重新排序;5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
LRU算法原理解析

LRU算法原理解析LRU是Least Recently Used的缩写,即最近最少使⽤,常⽤于页⾯置换算法,是为虚拟页式存储管理服务的。
现代操作系统提供了⼀种对主存的抽象概念虚拟内存,来对主存进⾏更好地管理。
他将主存看成是⼀个存储在磁盘上的地址空间的⾼速缓存,在主存中只保存活动区域,并根据需要在主存和磁盘之间来回传送数据。
虚拟内存被组织为存放在磁盘上的N个连续的字节组成的数组,每个字节都有唯⼀的虚拟地址,作为到数组的索引。
虚拟内存被分割为⼤⼩固定的数据块虚拟页(Virtual Page,VP),这些数据块作为主存和磁盘之间的传输单元。
类似地,物理内存被分割为物理页(Physical Page,PP)。
虚拟内存使⽤页表来记录和判断⼀个虚拟页是否缓存在物理内存中:如上图所⽰,当CPU访问虚拟页VP3时,发现VP3并未缓存在物理内存之中,这称之为缺页,现在需要将VP3从磁盘复制到物理内存中,但在此之前,为了保持原有空间的⼤⼩,需要在物理内存中选择⼀个牺牲页,将其复制到磁盘中,这称之为交换或者页⾯调度,图中的牺牲页为VP4。
把哪个页⾯调出去可以达到调动尽量少的⽬的?最好是每次调换出的页⾯是所有内存页⾯中最迟将被使⽤的——这可以最⼤限度的推迟页⾯调换,这种算法,被称为理想页⾯置换算法,但这种算法很难完美达到。
为了尽量减少与理想算法的差距,产⽣了各种精妙的算法,LRU算法便是其中⼀个。
LRU原理LRU 算法的设计原则是:如果⼀个数据在最近⼀段时间没有被访问到,那么在将来它被访问的可能性也很⼩。
也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
根据所⽰,假定系统为某进程分配了3个物理块,进程运⾏时的页⾯⾛向为 7 0 1 2 0 3 0 4,开始时3个物理块均为空,那么LRU算法是如下⼯作的:基于哈希表和双向链表的LRU算法实现如果要⾃⼰实现⼀个LRU算法,可以⽤哈希表加双向链表实现:设计思路是,使⽤哈希表存储 key,值为链表中的节点,节点中存储值,双向链表来记录节点的顺序,头部为最近访问节点。
操作系统lru算法

操作系统lru算法LRU(Least Recently Used)算法是一种置换算法,也称为最近最少使用算法。
该算法的基本思想是每次淘汰最近最少使用(最近一段时间内没有被使用)的页面。
LRU算法的实现可以采用多种数据结构,如链表、双向链表、队列等。
下面介绍一种基于双向链表和哈希表的实现。
首先定义一个双向链表节点,包含页面的编号和指向前一个节点和后一个节点的指针。
cppstruct node {int key; 页面编号node* prev; 前驱节点node* next; 后继节点};定义一个哈希表,根据页面的编号映射到对应的链表节点,在每个节点上存储页面的内容。
cppstruct cache {unordered_map<int, node*> map; 哈希表int capacity; 缓存大小node* head; 链表头node* tail; 链表尾};具体实现LRU算法的主要操作有两个:插入新页面和淘汰页面。
插入新页面时,先判断页面是否已经在缓存中。
如果已经在缓存中,则将该节点移到链表头部,表示最近使用过;如果不在缓存中,则需要新建一个节点插入到链表头部,并将其加入哈希表。
cppvoid put(cache& c, int key, int val) {判断是否已存在于缓存中auto it = c.map.find(key);if (it != c.map.end()) {移到链表头部node* p = it->second;p->prev->next = p->next;p->next->prev = p->prev;p->next = c.head->next;p->prev = c.head;c.head->next->prev = p;c.head->next = p;更新节点的值p->val = val;} else {创建新节点node* p = new node{key, val, c.head, c.head->next};c.head->next->prev = p;c.head->next = p;添加到缓存和哈希表c.map[key] = p;如果超出缓存大小则需要淘汰if (c.map.size() > c.capacity) {node* p = c.tail->prev;p->prev->next = c.tail;c.tail->prev = p->prev;c.map.erase(p->key);delete p;}}}淘汰页面时,直接将链表尾部的节点删除,并将对应的哈希表项删除。
lru算法的实现过程,python

LRU算法是一种常用的缓存淘汰策略,LRU全称为Least Recently Used,即最近最少使用。
它的工作原理是根据数据的历史访问记录来淘汰最近最少使用的数据,以提高缓存命中率和性能。
在Python中,可以通过各种数据结构和算法来实现LRU算法,例如使用字典和双向链表来实现LRU缓存。
一、LRU算法的基本原理LRU算法是基于"最近最少使用"的原则来淘汰缓存中的数据,它维护一个按照访问时间排序的数据队列,当缓存空间不足时,会淘汰最近最少使用的数据。
LRU算法的基本原理可以用以下步骤来说明:1. 维护一个有序数据结构,用来存储缓存中的数据和访问时间。
2. 当数据被访问时,将其移动到数据结构的最前面,表示最近被使用过。
3. 当缓存空间不足时,淘汰数据结构最后面的数据,即最近最少使用的数据。
二、使用Python实现LRU算法在Python中,可以使用字典和双向链表来实现LRU算法。
其中,字典用来存储缓存数据,双向链表用来按照访问时间排序数据。
1. 使用字典存储缓存数据在Python中,可以使用字典来存储缓存数据,字典的键值对可以用来表示缓存的键和值。
例如:```cache = {}```2. 使用双向链表按照访问时间排序数据双向链表可以按照访问时间对数据进行排序,使得最近被访问过的数据在链表的最前面。
在Python中,可以使用collections模块中的OrderedDict来实现双向链表。
例如:```from collections import OrderedDict```3. 实现LRU算法的基本操作在Python中,可以通过对字典和双向链表进行操作来实现LRU算法的基本操作,包括缓存数据的存储、更新和淘汰。
以下是LRU算法的基本操作示例:(1)缓存数据的存储当缓存数据被访问时,可以将其存储到字典中,并更新双向链表的顺序。
例如:```def put(key, value):if len(cache) >= capacity:cache.popitem(last=False)cache[key] = value```(2)缓存数据的更新当缓存数据被再次访问时,可以更新其在双向链表中的顺序。
lru替换策略

lru替换策略LRU(Least Recently Used,最近最少使用)替换策略是计算机科学领域中使用最广泛的内存管理策略之一,它通过根据用户使用页面的频率来决定哪些页面应该由虚拟地址转换为物理地址,以达到更好的内存管理效果。
下面是LRU替换策略的具体解释:1. 典型场景:LRU替换策略是通常用于磁盘缓存或虚拟存储的替换策略。
它的目的是尽可能最大程度地利用存储媒体的空间,使空间得到更充分的利用,以便有效地提高系统性能。
2. 工作原理:LRU替换策略假设,如果某个页面最近被访问过,那么在不久的将来它也会被访问到,因此当要替换一个页面的时候,会优先替换没有被使用的页面,这样较劣质的页面在被释放后很快又能被访问到。
3. 特点:(1) 它是一种最经常使用的页面替换算法,但其最大的缺点就是可能会有一些冗余的内存换出;(2) 另外,它根据页面最近使用的情况来决定替换哪一页,因此只要页面被访问过就不会被太快替换掉,对于那些被经常使用的页面,LRU算法可以比较好地维护页面的分配,可以使系统的总体性能提高。
4. 优势:LRU替换策略具有以下几点优势:(1) 实现简单:LRU算法只需要维护一个有序的页面访问表,即能够快速定位需要换出的页面;(2) 少的缺页次数:LRU算法能够运用当前的访问表,更好地实现未来访问模式的预测,从而减少缺页次数;(3) 少的发生率:LRU算法只要快速读取内存中的访问表即可,从而使发生率降低。
总之,LRU(Least Recently Used,最近最少使用)替换策略是一种有效的内存管理策略,其优势在于简单易实现,可以降低缺页次数,同时降低发生率,使系统可以得到更有效的内存管理,获得更好的性能。
bufferpool缓存淘汰机制

bufferpool缓存淘汰机制
缓存淘汰机制是指在缓存空间不足的情况下,系统根据一定的策略选择需要淘汰的数据块,以腾出空间给新的数据块存储。
在bufferpool中,缓存淘汰机制主要有以下几种常见的策略:
1. 最近最少使用(Least Recently Used,LRU):根据数据块最近一次被访问的时间戳,选择最久未被访问的数据块进行淘汰。
2. 最不经常使用(Least Frequently Used,LFU):根据数据块被访问的频率,选择最少被访问的数据块进行淘汰。
3. 先进先出(First-In-First-Out,FIFO):根据数据块进入缓存的时间顺序,选择最早进入缓存的数据块进行淘汰。
4. 随机替换(Random Replacement):随机选择一个数据块进行淘汰,这种方法相对来说比较简单,但也可能导致淘汰了一些热数据。
5. 最佳缓存替换(Optimal Replacement):根据未来一段时间内数据块的访问模式,选择最优的数据块进行淘汰。
这种方法理论上可以取得最好的缓存效果,但由于需要准确预测未来的访问模式,实际上很难实现。
不同的淘汰策略适用于不同的应用场景和数据访问模式,选择合适的淘汰策略可以提高缓存的效率和性能。
redis的lru近似算法

Redis的LRU近似算法一、背景介绍Redis是一种开源的高性能键值对存储数据库,常用于存储和缓存数据。
在缓存应用场景中,缓存的大小是有限的,因此需要一种算法来决定哪些数据应该被保留在缓存中,以便提高缓存命中率。
LRU(Least Recently Used)是一种经典的缓存淘汰策略,即最近最少使用的数据会最先被淘汰。
然而,在现实应用中,完全按照LRU策略来淘汰缓存数据可能代价过高。
因此,Redis采用了一种近似的LRU算法来解决这个问题。
二、完全LRU算法在介绍Redis的LRU近似算法之前,先简单介绍一下完全LRU算法。
完全LRU算法需要维护一个访问顺序的链表,并且每次访问一个数据时,都将该数据移动到链表的头部。
当缓存满时,需要淘汰链表中的末尾数据。
这种算法的优点是简单直观,但缺点也显而易见:每次访问数据都需要维护链表的访问顺序,时间复杂度为O(n),其中n为缓存中的数据量,效率较低。
三、Redis的LRU近似算法为了解决完全LRU算法效率低的问题,Redis采用了一种近似的LRU算法,即Clock-Pro算法。
Clock-Pro算法引入了一个时间戳位和一个访问标志位来辅助判断数据的访问顺序。
具体算法如下:1.每个缓存数据项有两个位,一个时间戳位和一个访问标记位,初始均为0。
2.当一个数据被访问时,将时间戳位设置为当前时间,并将访问标记位置为1。
3.当需要淘汰一个数据时,从链表头开始遍历,找到第一个时间戳位为0且访问标记位为0的数据,将其淘汰。
4.如果没有找到时间戳位和访问标志位都为0的数据,则从链表头开始遍历,找到一个时间戳位为0但访问标记位为1的数据,将其淘汰,并将其访问标记位置为0。
5.如果还是没有找到,那么重复步骤4,直到找到一个数据。
这种近似LRU算法相对于完全LRU算法的优势是,每次访问数据时只需要修改两个位的状态,时间复杂度为O(1),大大提高了效率。
四、Clock-Pro算法的特点Clock-Pro算法相对于完全LRU算法来说,具有以下几个特点:1. 近似LRUClock-Pro算法是一种近似LRU算法,它通过时间戳位和访问标志位的组合来判断数据的访问顺序。
lru算法堆栈类算法 -回复

lru算法堆栈类算法-回复什么是LRU算法?LRU算法,全称为“最近最少使用”(Least Recently Used)算法,是一种常用的缓存算法。
LRU算法的核心思想是,如果一个数据最近被访问或使用过,那么它以后也有很高的概率会被再次访问或使用,因此应该优先保留在缓存中。
与其他缓存算法不同,LRU算法会从缓存中淘汰最近最少被访问的数据,以便为新的数据腾出空间。
LRU算法的目的是提高缓存的命中率,从而提高系统性能。
LRU算法的实现原理是通过一个数据结构来记录缓存中数据项的访问顺序。
一般使用一个双向链表来实现,链表头表示最近使用的数据项,链表尾表示最久未使用的数据项。
每当一个数据项被访问时,它会被移到链表头,而当缓存满时,链表尾的数据项会被淘汰。
这样做的好处是,链表的头部是最热门的数据项,被频繁访问的几率较高,而链表的尾部是最冷门的数据项,被访问的几率较低。
下面一步一步来介绍LRU算法的实现过程。
步骤一:创建一个双向链表的节点类首先,我们需要创建一个双向链表的节点类,该节点类包含一个值域和两个指针,分别指向前一个节点和后一个节点。
该节点类的定义如下:javaclass Node{int key;int value;Node prev;Node next;}步骤二:创建一个哈希表来存储缓存的键值对为了使LRU算法的查找效率更高,我们需要使用一个哈希表来存储缓存的键值对。
哈希表的键用来进行快速查找,对应的值是指向双向链表节点的指针。
在Java中,我们可以使用HashMap来实现哈希表。
具体的代码如下:javaimport java.util.HashMap;class LRUCache {int capacity;HashMap<Integer, Node> map;Node head;Node tail;public LRUCache(int capacity) {this.capacity = capacity;map = new HashMap<>();head = new Node();tail = new Node();head.next = tail;tail.prev = head;}}步骤三:实现LRU算法的get操作当进行get操作时,首先需要在哈希表中查找对应的节点。
cache缓存淘汰算法--LRU算法
缓存淘汰算法--LRU算法1. LRU1.1. 原理LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:1. 新数据插入到链表头部;2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析【命中率】当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】实现简单。
【代价】命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
2. LRU-K2.1. 原理LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。
LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
只有当数据的访问次数达到K次的时候,才将数据放入缓存。
当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
详细实现如下:1. 数据第一次被访问,加入到访问历史列表;2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;4. 缓存数据队列中被再次访问后,重新排序;5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
OPT与LRU

为了尽量减少与理想算法的差距,产生了各种精妙的算法,最近最少使用页面置换算法便是其中一个。当
然,LRU算法的缺点在于实现方法的不足----效率高的硬件算法通常在大多数机器上无法多用LRU进行页面替换
2)RAND、FIFO、LRU及OPT算法
·LFU算法:最近最不常用调度算法,是根据在一段时间里页面被使用的次数选择出最少使用的页
大家要注意LRU和LFU两个算法的区别,从上边两种解决使用位都为1的方法来看,随机法接近于LRU,
第二种接近LFU,大家看看《操作系统》P76页,那写的清楚。
·OPT算法:根据未来实际使用情况将未来的近期里不用的页替换出去。这种算法是用来评价期它替
·RAND算法:用软硬件的随面数产生主存中要被替换页的页号。
·FIFO算法:选择最早装入主存的页作为被替换的页。这种算法实现方便,但不一定正确反映出程序
的局部性。
谁还记的《数据结构》的队列,哦,你对了,给你一个糖,队列就象排队买票,谁先排到队中,谁更
早滚蛋。
·LRU算法:选择近期最少访问的页作为被替换页。
LRU算法的实现 什么是LRU算法? LRU是Least Recently Used的缩写,即最近最少使用页面置换算法,是
为虚拟页式存储管理服务的。自然,达到这样一种情形的算法是最理想的了----每次调换出的页面是所有
内存页面中最迟将被使用的----这可以最大限度的推迟页面调换,这种算法,被称为理想页面置换算法。
换算法好坏的标准。不可能实现。 �
lru算法

LRU算法1. 简介LRU(Least Recently Used,最近最少使用)算法是一种常用的缓存淘汰算法。
该算法根据数据的访问顺序来进行缓存淘汰,优先淘汰最近最少使用的数据,以保证缓存中始终保存着最常用的数据。
2. 算法原理LRU算法的原理很简单,在数据插入或访问时,首先查看缓存中是否存在该数据,如果存在,则将该数据移动到链表的头部;如果不存在,则将该数据插入到链表的头部。
当缓存达到容量上限时,需要淘汰最近最少使用的数据,即将链表尾部的数据删除。
基本的数据结构是双向链表,链表的头部存储的是最近访问的数据,链表的尾部存储的是最久未访问的数据。
3. 算法实现下面是一个简单的实现LRU算法的伪代码:class LRUCache:def__init__(self, capacity: int):self.capacity = capacityself.cache = {}self.count =0self.head = DoubleNode(0, 0)self.tail = DoubleNode(0, 0)self.head.next =self.tailself.tail.prev =self.headdef get(self, key: int) -> int:if key in self.cache:node =self.cache[key]self._remove(node)self._add(node)return node.valreturn-1def put(self, key: int, value: int) ->None: if key in self.cache:node =self.cache[key]self._remove(node)self.count -=1node = DoubleNode(key, value)self.cache[key] = nodeself._add(node)self.count +=1if self.count >self.capacity:node =self.tail.prevself._remove(node)self.count -=1def _add(self, node: DoubleNode) ->None:next_node =self.head.nextself.head.next = nodenode.prev =self.headnode.next = next_nodenext_node.prev = nodedef _remove(self, node: DoubleNode) ->None:prev_node = node.prevnext_node = node.nextprev_node.next = next_nodenext_node.prev = prev_nodeclass DoubleNode:def__init__(self, key: int, val: int):self.key = keyself.val = valself.prev =Noneself.next =None4. 使用示例cache = LRUCache(2) # 创建一个容量为2的缓存cache.put(1, 1) # 缓存中插入数据 (1,1)cache.put(2, 2) # 缓存中插入数据 (2,2)cache.get(1) # 返回 1cache.put(3, 3) # 缓存中插入数据 (3,3),因为缓存容量已满,所以需要淘汰 (2,2)cache.get(2) # 返回 -1,因为该数据已被淘汰cache.put(4, 4) # 缓存中插入数据 (4,4),因为缓存容量已满,所以需要淘汰 (1,1)cache.get(1) # 返回 -1,因为该数据已被淘汰cache.get(3) # 返回 3cache.get(4) # 返回 45. 算法分析•时间复杂度:LRU算法的时间复杂度是O(1),由于使用哈希表存储数据和双向链表维护数据顺序,所以对于插入、查找、删除等操作都是常数时间复杂度。
lru实现原理

lru实现原理
LRU(LeastRecentlyUsed)是一种常见的缓存淘汰策略,它的实现原理是根据数据的访问时间来判断数据的热度,将最近最少使用的数据淘汰出缓存。
具体实现时,可以使用哈希表和双向链表相结合的方式,将缓存中的数据存储在哈希表中,并使用双向链表记录数据的访问顺序。
当缓存满时,将链表尾部的数据淘汰出缓存,当有新数据访问时,将数据添加到链表头部,并更新哈希表中的对应数据。
举个例子,假设缓存大小为5,缓存中已经存储了以下数据: ```
哈希表:{1: 1, 2: 2, 3: 3, 4: 4, 5: 5}
链表顺序:1 -> 2 -> 3 -> 4 -> 5
```
此时,如果有一个新的数据6访问,由于缓存已满,需要淘汰链表尾部的数据5,更新哈希表和链表:
```
哈希表:{1: 1, 2: 2, 3: 3, 4: 4, 6: 6}
链表顺序:6 -> 1 -> 2 -> 3 -> 4
```
这样就保证了缓存中始终存储了热度较高的数据,提高了缓存的命中率,减少了缓存的淘汰次数,提高了系统的性能。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LRU是Least Recently Used最近最少使用算法。
内存管理的一种算法,对于在内存中但最近又不用的数据块(内存块)叫做LRU,Oracle会根据那些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
什么是LRU算法? LRU是Least Recently Used的缩写,即最近最少使用页面置换算法,是为虚拟页式存储管理服务的。
关于操作系统的内存管理,如何节省利用容量不大的内存为最多的进程提供资源,一直是研究的重要方向。
而内存的虚拟存储管理,是现在最通用,最成功的方式——在内存有限的情况下,扩展一部分外存作为虚拟内存,真正的内存只存储当前运行时所用得到信息。
这无疑极大地扩充了内存的功能,极大地提高了计算机的并发度。
虚拟页式存储管理,则是将进程所需空间划分为多个页面,内存中只存放当前所需页面,其余页面放入外存的管理方式。
然而,有利就有弊,虚拟页式存储管理减少了进程所需的内存空间,却也带来了运行时间变长这一缺点:进程运行过程中,不可避免地要把在外存中存放的一些信息和内存中已有的进行交换,由于外存的低速,这一步骤所花费的时间不可忽略。
因而,采取尽量好的算法以减少读取外存的次数,也是相当有意义的事情。
对于虚拟页式存储,内外存信息的替换是以页面为单位进行的——当需要一个放在外存的页面时,把它调入内存,同时为了保持原有空间的大小,还要把一个内存中页面调出至外存。
自然,这种调动越少,进程执行的效率也就越高。
那么,把哪个页面调出去可以达到调动尽量少的目的?我们需要一个算法。
自然,达到这样一种情形的算法是最理想的了——每次调换出的页面是所有内存页面中最迟将被使用的——这可以最大限度的推迟页面调换,这种算法,被称为理想页面置换算法。
可惜的是,这种算法是无法实现的。
差距
为了尽量减少与理想算法的差距,产生了各种精妙的算法,最近最少使用页面置换算法便是其中一个。
LRU算法的提出,是基于这样一个事实:在前面几条指令中使用频繁的页面很可能在后面的几条指令中频繁使用。
反过来说,已经很久没有使用的页面很可能在未来较长的一段时间内不会被用到。
这个,就是著名的局部性原理——比内存速度还要快的cache,也是基于同样的原理运行的。
因此,我们只需要在每次调换时,找到最近最少使用的那个页面调出内存。
这就是LRU算法的全部内容。
LRU在电子系统中的解释:
Line Replaceable Unit — LRU,电子系统中常采用模块化设计,这种可更换的模块单元则被叫做LRU,中文名称是“线性可更换单元”。