统计数据的描述
统计学之数据的描述

数据的特征
任何一组计量数据都有两个重要的特征:
中心值
(典型值)
围绕中心值
(典型值)的变
动幅度
数据的标记
如果我们进行一系列的观察,得到 个数,我们可以使用简单的记号标注数据,这样对数据统计与分析大有帮助。
我们可以将数据按如下方式进行标注:
1 , 2 , 3 , … …
标准差:s = 2 =
1
σ=1
−1
2ቤተ መጻሕፍቲ ባይዱ
2
− ҧ
2
和的特性
ҧ
平均数和标准差适合概括没有异类点、完全对称的直方图。如右图所示。
5
8
9
13
200
中位数为:9,平均数为:47
此时用平均数不能体现总
体毕业生的薪资水平,扭
曲了毕业生的平均薪资
异类点(极
端数值)
变动度的测量
变动度是描述数据偏离中心值有多远的量。
例如:调查学校7个学生的体重,恰好都是145斤,那
如果学生重量轻重不一,如下图所示。
就根本没有变动度,用直方图表示会很窄。如下图所
举例:随机调查某大学毕业生中5个人薪资水平,数据如下:
学号
B0034
A0003
B0020
D1005
C0096
薪资(K)
5
8
9
13
10
中位数为:9,平均数为:9
如果随机调查某大学毕业生中5个人薪资水平,其中C0096号同学薪资为200K,则:
学号
B0034
A0003
B0020
D1005
C0096
薪资(K)
示。
直方图将会变宽
统计描述与统计推断

统计描述与统计推断统计的主要工作就是对统计数据进行统计描述和统计推断。
统计描述是统计分析的最基本内容,是指应用统计指标、统计表、统计图等方法,对资料的数量特征及其分布规律进行测定和描述;而统计推断是指通过抽样等方式进行样本估计总体特征的过程,包括参数估计和假设检验两项内容。
(一)统计描述1.计量资料的统计描述计量资料的统计描述主要通过编制频数分布表、计算集中趋势指标和离散趁势指标以及统计图表来进行。
(1)集中趋势。
指频数表中频数分布表现为频数向某一位置集中的趋势。
集中趋势的描述指标:1)算术平均数。
直接法:x为观察值,n为个数加权法又称频数表法,适用于频数表资料,当观察例数较多时用。
f为各组段的频数。
2)几何平均数(geometric mean)。
几何平均数用符号G表示。
用于反映一组经对数转换后呈对称分布的变量值在数学上的平均水平。
直接法:加权法又称频数表法,当观察例数n较大时,可先编制频数分布表,用此法算几何平均数:3)百分位数(percentile )与中位数(median )。
百分位数是一种位置坐标,用符号x P 表示常用的百分位数有 2.5P 、5P 、50P 、75P 、95P 、97.5P 等,其中25P 、50P 、75P 又称为四分位数。
百分位数常用于描述一组观察值在某百分位置上的水平,多个百分位结合使用,可更全面地描述资料的分布特征。
中位数是一个特定的百分位数即50P ,用符号M 表示。
把一组观察值按从小到大(或从大到小)的次序排列,位置居于最中央的那个数据就是中位数。
中位数也是反映频数分布集中位置的统计指标,但它只由所处中间位置的部分变量值计算所得,不能反映所有数值的变化,故中位数缺乏敏感性。
中位数理论上可以用于任何分布类型的资料,但实践中常用于偏态分布资料和分布两端无确定值的资料。
其计算方法有直接法和频数表法两种。
直接法:当观察例数n 不大时,此法常用,先将观察值按大小次序排列,选用下列公式求M 。
统计学原理(第二章)

数据的计量和类型
一、数据的计量尺度 4.定比尺度:又称为比例尺度或是比较水平, 是对事物之间比值的一种测度,它是最高层 次的测量,可用于参数和非参数统计推断。 它是与定距尺度属于同一层次的一种计量尺 度,但其功能比定距尺度更强一些。
在日常生活中,大多数情况下使用的都是 定比尺度。例如,年龄、收入、某地区每年的 失业人数、罪犯人数等。
数值数据的描述
一、数值数据的 分组
为什么要进行数据的分组?
品质数据的描述
某电脑公司50名销售代表某季度电脑销售量按从小 到大排序如下表:
107 108 108 110 112 112 113 114 115 117 117 117 118 118 118 119 120 120 121 122 122 122 122 123 123 123 123 124 124 124 125 125 126 126 126 127 127 128 128 129 130 131 133 133 134 134 135 139 139 139
204 80.00% 105 41.17%
235 92.16% 51 20%
255 100% 20 7.84%
— 100% —
品质数据的描述
二、品质数据的 图示 1.条形图:是用宽度相同的条形的高度或长 短来表示数据变动的图形,横置的称为带形 图,纵置的称为柱形图(直方图)。
柱形图(直方图)
120 100 80 60 40 20
定类变量、定序变量、 数值型变量(离散变量、连续变量)
第二节 品质数据的描述
一、品质数据的描述 二、数据的类型品质数据的图示 三、品质数据的分布特征描述
品质数据的描述
一、品质数据的 描述 1.频数:是落在某一特定类别(或组)中的 数据的个数。把各个类别及其相应的频数全 部列出来则形成频数分布。
统计学原理数据的描述(1)

目 录 2.1 数据的收集 2.2 数据的整理 2.3 数据的描述 2.4 数据的计算机处理
1.1 统计数据的搜集
数据资料是经济管理和工商企业管理决策的基础。 数据资料是经济管理和工商企业管理决策的基础。 占有一定的资料是研究的基础。 占有一定的资料是研究的基础。 根据统计研究任务要求, 根据统计研究任务要求,采用科学的调查方式和方 法搜集资料,是保证统计质量的基本环节、 法搜集资料,是保证统计质量的基本环节、统计分 析的前提。 析的前提。 只有搞好统计调查, 只有搞好统计调查,才能保证统计工作达到对于客 观事物规律性的认识。并从而预测未来, 观事物规律性的认识。并从而预测未来,统计资料 还是制定政策的依据, 还是制定政策的依据,并据此检查和监督政策的贯 彻执行情况。 彻执行情况。
联邦储备局
预算编制办公室 商务部
二手数据的特点与注意问题
搜集容易, 搜集容易,采集成本低 作用广泛 • 分析所要研究的问题 • 提供研究问题的背景 • 帮助研究者更好地定义问题 • 寻找研究问题的思路和途径 搜集二手资料在研究中应优先考虑 数据是谁搜集的? 数据是谁搜集的?
可信度评估
为什么目的而搜集的? 为什么目的而搜集的? 数据是怎样搜集的? 数据是怎样搜集的? 什么时候搜集的? 什么时候搜集的?
4.调查的分类 调查的分类
调查可以从不同角度进行分类: 调查可以从不同角度进行分类: 按调查内容和性质划分, 一、按调查内容和性质划分,分为有关部门组织的专项调 市场调查和科学研究调查等。 查、市场调查和科学研究调查等。 从调查对象的范围来划分, 二、从调查对象的范围来划分,可以分为全面调查和非全 面调查。 面调查。 三、从调查是否重复来划分,可分为一次性调查和经常性 从调查是否重复来划分, 调查。 调查。 按组织方式, 四、按组织方式,可分为统计报表和专门调查 统计报表是按照统一规定的表式要求,自上而下地统一 统计报表是按照统一规定的表式要求 自上而下地统一 布置、自下而上地统一提供统计资料的组织方式。 布置、自下而上地统一提供统计资料的组织方式。 专门调查是为研究某些专门问题,由进行调查的单位专 专门调查是为研究某些专门问题 由进行调查的单位专 门组织的调查,这种调查属一次性调查 如人口普查、 这种调查属一次性调查, 门组织的调查 这种调查属一次性调查,如人口普查、劳 动力调查、科技普查等。 动力调查、科技普查等。
描述性统计报告范文

描述性统计报告范文1. 引言此次统计报告旨在对某公司销售数据进行描述性统计分析,以便更好地了解公司的销售情况并提供决策支持。
本报告将从多个维度对销售数据进行分析,包括销售额、销售数量、产品分类等方面。
2. 数据来源本报告所使用的数据来自某公司近一年的销售记录,包括每个产品的销售额、销售数量以及所属的产品分类。
数据完整、准确,可用于对公司销售情况进行全面分析。
3. 销售金额统计首先,对销售金额进行统计分析。
我们计算了每个产品的销售总额以及销售额的平均值、中位数、最大值和最小值,并绘制了销售金额的直方图和箱线图。
销售总额为X万,平均每个产品的销售额为Y万,中位数为Z万。
从直方图和箱线图可以看出销售金额分布大致呈正态分布,大多数产品的销售额集中在中位数附近,但也存在一些销售额较高的产品。
4. 销售数量统计其次,对销售数量进行统计分析。
我们计算了每个产品的销售总数量以及销售数量的平均值、中位数、最大值和最小值,并绘制了销售数量的直方图和箱线图。
销售总数量为N个,平均每个产品的销售数量为M个,中位数为P个。
从直方图和箱线图可以看出销售数量分布相对均匀,大部分产品的销售数量在中位数附近。
5. 产品分类分析除了对销售金额和销售数量的统计分析外,我们还对产品分类进行了分析。
首先,我们列举了所有产品分类以及每个分类下的产品数量。
然后,我们计算了每个分类的销售总额和销售数量,并绘制了销售金额和销售数量的条形图。
从条形图可以清晰地看出不同分类产品的销售情况。
例如,分类A的销售总额最高,而分类B的销售总额最低。
此外,分类C的销售数量最多,而分类D的销售数量最少。
6. 结论通过对销售数据的描述性统计分析,我们可以得出以下结论:•公司的销售总额为X万,平均每个产品的销售额为Y万。
•销售金额的分布大致呈正态分布,多数产品销售额集中在中位数附近。
•公司的销售总数量为N个,平均每个产品的销售数量为M个。
•销售数量相对均匀分布,大部分产品的销售数量集中在中位数附近。
统计学之统计数据的描述

则必然取2,而不能取其他
离散系数
离散系数
(coefficient of variation)
1. 标准差与其相应的均值之比 2.对数据相对离散程度的测度 3.消除了数据水平高低和计量单位的影
响
4v.用 较于对不同组别数v据s 离散程xs度的比
【 例 】某管理局抽查了所属的8家企业 ,其产品销售数据如表。试比较产品销售 额与销售利润的离散程度
累积的收入百分比
绝对公平线
A B
累积的人口百分比
基尼系数
1. 20世纪初意大利经济学家基尼(G. Gini)根据
洛伦茨曲线给出了衡收入分配平均程度的指
标 基尼系数=
A
A B
2. A表示实际收入曲线与绝对平均线之间的面积 3. B表示实际收入曲线与绝对不平均线之间的面
积
A B
• 如果A=0,则基尼系数=0,表示收入绝对 平均
一般用x表示变量;用f表示频数(次数) 。
2.1.3 次数分配图
分组数据—直方图和折线图
Excel
用直方形的宽度和高度来表示次数分 布的图形。
绘制直方图时,横轴表示各组组限, 纵轴表示次数(一般标在左方)和比 率(或频率,一般标在右方)。
分组数据的图示
我一眼就看 出来了,销 售量在170~ 180之间的天 数最多!
1. 一组数据中可以自由取值的数据的个数
2. 当样本数据的个数为 n 时,若样本均值x 确定后,只有n-1个数据可以自由取值,其
中必有一个数据则不能自由取值
3.
例如,样
x3=9,则
本有
x
3个数值,即
= 5。当 x
x=1=52,确x定2=4后,,x
1
统计调查数据的收集整理与描述

统计调查数据的收集整理与描述引言统计调查是一种重要的研究方法,通过对数据的收集、整理和描述来揭示问题的本质和规律。
本文将介绍统计调查数据的收集、整理和描述的基本步骤和技巧,帮助读者更好地进行统计调查研究。
数据的收集数据的收集是统计调查的第一步,它决定了后续分析的可靠性和准确性。
数据的收集可以通过多种方式进行,包括问卷调查、实地观察、实验设计等。
问卷调查问卷调查是一种常用的数据收集方法,通过向被调查者发放问卷,收集他们的观点、态度、行为等信息。
在进行问卷调查时,需要注意以下几点:•设计合理的问卷:问卷应该具有良好的结构和逻辑,问题应该清晰明了,避免使用含混或引导性的问题。
•确定合适的样本:样本的选择要具有代表性,能够反映出总体的特征。
可以通过随机抽样或分层抽样等方法来获得样本。
•提高回收率:回收率是衡量问卷调查成功与否的重要指标。
可以通过提供奖励、提高问卷的可读性等方式来提高回收率。
实地观察实地观察是通过直接观察被研究对象的行为和环境来收集数据。
在进行实地观察时,需要注意以下几点:•制定观察方案:明确观察对象、观察的时间和地点,制定观察表格或记录表,确保观察的准确性和全面性。
•实施观察:根据观察方案进行实地观察,记录被观察对象的行为、态度和环境等信息。
•提高观察的客观性:观察者应该尽量客观公正地进行观察,避免主观偏见的干扰。
实验设计实验设计是一种控制变量的方法,通过对实验组和对照组的比较来获取数据。
在进行实验设计时,需要注意以下几点:•确定实验目的:明确实验的目的和研究的问题,根据目的选择适当的实验设计方法。
•设计合理的实验组和对照组:实验组和对照组应该具有相似的特性,只在某一变量上存在差异,以便进行比较。
•控制变量:除了要比较的变量外,其他变量应该尽可能保持一致,避免对实验结果的干扰。
数据的整理数据的整理是对收集到的原始数据进行加工和整理,使其更加便于分析和描述。
数据的整理包括数据清洗、数据编码和数据归纳等步骤。
统计学 第2章 统计数据的描述
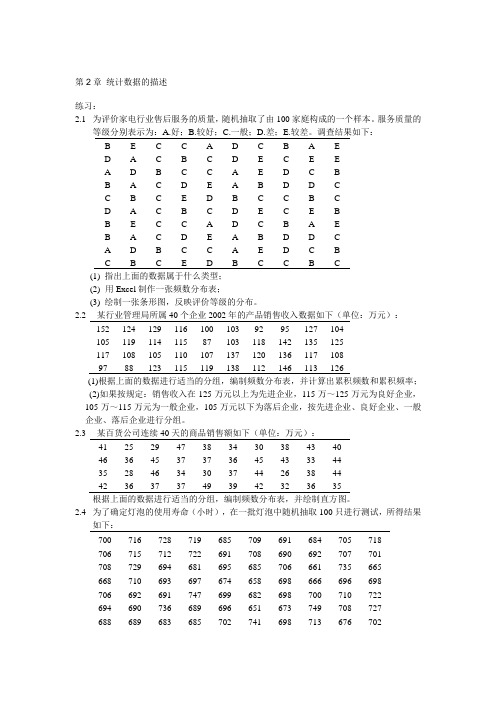
第2章统计数据的描述练习:2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):152 124 129 116 100 103 92 95 127 104105 119 114 115 87 103 118 142 135 125117 108 105 110 107 137 120 136 117 10897 88 123 115 119 138 112 146 113 126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
2.3某百货公司连续40天的商品销售额如下(单位:万元):41 25 29 47 38 34 30 38 43 4046 36 45 37 37 36 45 43 33 4435 28 46 34 30 37 44 26 38 4442 36 37 37 49 39 42 32 36 35根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5. 选用哪一个测度值来反映数据的集中趋势,要根据所掌握 的数据的类型来确定
均值
1. 集中趋势的测度值之一 2. 最常用的测度值 3. 一组数据的均衡点所在 4. 易受极端值的影响 5. 用于数值型数据,不能用于分类数据
Mo=不满意
(三)数值型分组数据的众数
(要点及计算公式)
1. 众数的值与相邻两组频数的分布有关
2. 相邻两组的频数相等时,众数组的组中值
即为众数
Mo
3. 相邻两组的频数不相等时,众数采用下
列近似公式计算
M0
L (f
f f1 f1) ( f
f1)
i
Mo
4. 该公式假定众数组的频数在众数组内均匀分布
商品广告
112 0.560 56.0
服务广告
51
0.255 25.5
金融广告
9
0.045
4.5
房地产广告
16
0.080
8.0
招生招聘广告 10
0.050
5.0
其他广告
2
0.010
1.0
合计
200
1
100
解:这里的变量为“ 广告类型”,这是个 分类变量,不同类型 的广告就是变量值。 我们看到,在所调查 的200人当中,关注商 品广告的人数最多, 为112人,占总被调查 人数的56%,因此众 数为“商品广告”这 一类别,即
—
50
XiFi 322.5 562.5 940.0 1715.0 1275.0 795.0 550.0
6160.0
加权算术平均数公式转化:
先计算权重
x x1 f 1x2 f2 ... xn fn f 1 f2 ... fn
xi fi fi
xi
fi fi
计算P65表3与表4
算术平均数的几何性质
例题:
表4-1 按零件数分组
105~110 110~115 115~120 120~125 125~130 130~135 135~140
合计
某车间50名工人日加工零件均值计算表
组中值(Xi) 107.5 112.5 117.5 122.5 127.5 132.5 137.5
频数(Fi) 3 5 8 14 10 6 4
众数
(众数的不唯一性)
无众数 原始数据: 10 5 9 12 6 8
一个众数 原始数据:
659855
多于一个众数 原始数据: 25 28 28 36 42 42
(一)分类数据的众数(来自例)【例】根据下表数据,计算众数
表3-1 某城市居民关注广告类型的频数分布 广告类型 人数(人) 比例 频率(%)
Mo=商品广告
(二)顺序数据的众数
(算例)
【例】根据下表的数据,计算众数
甲城市家庭对住房状况评价的频数分布
回答类别
甲城市 户数 (户) 百分比 (%)
非常不满意
24
8
不满意
108
36
一般
93
31
满意
45
15
非常满意
30
10
合计
300
100.0
解:这里的数据为定
序数据。变量为“回 答类别”。甲城市中 对住房表示不满意的 户数最多,为108户 ,因此众数为“不满 意”这一类别,即
N
GM N X1 X 2 ... X N N Xi i 1
加权几何平均数:
GM
f
X f1 1
X f2 2
...
X fn n
f
N
Xf
i1
两边取对数: lg G f lg x
请计算P68,表6
f
二、分类数据:众数
众数
(概念要点)
1. 集中趋势的测度值之一 2. 出现次数最多的变量值 3. 不受极端值的影响 4. 可能没有众数或有几个众数 5. 主要用于分类数据,也可用于顺序数据 和数值型数据
Mo
【例4.1】 根据下表 数据,计 算50名工 人日加工 零件数的 众数
数值型分组数据的众数
(算例)
表3-5 某车间50名工人日加工零件数分组表
按零件数分组
频数(人)
累积频数
3
3
105~110
110~115
5
8
115~120
8
16
120~125
14
30
125~130
10
40
130~135
6
46
135~140
析
数据分布的特征
集中趋势 (位置) 离中趋势 (分散程度)
偏态和峰度 (形状)
数据分布的特征和测度
数据的特征和测度
集中趋势
均值 众数 中位数
离散程度
分布的形状
四分位差 方差 标准差 离散系数
偏态 峰度
集中趋势
(Central tendency)
1. 一组数据向其中心值靠拢的倾向和程度 2. 测度集中趋势就是寻找数据一般水平的代表值或中心值 3. 不同类型的数据用不同的集中趋势测度值
和顺序数据
一、算术平均数
计算公式:变量值之和/变量值个数
计算方法
简单算术平均数:x
x 1 x2
... n
xn
xi
n
加权算术平均数:x x1 f 1x2 f2 ... xn fn xi fi
f1 f2 ... fn
fi
(请计算P63表4-1到4-8)
如果fi 都相等,那么加权平均和简单平均 相同
4
50
合计
50
—
M0
120
14 8
(14 8) (14 10)
5 123(个)
三、顺序数据:中位数和分位数
(一)中位数
(概念要点)
1.集中趋势的测度值之一 2.排序后处于中间位置上的值
计算公式:
xp
xi fi 1 P 0 Q P
fi
PQ
计算表5,P67
几何平均数
1. 集中趋势的测度值之一 2. N 个变量值乘积的 N 次方根 3. 适用于特殊的数据:变量值本身是比率
的形式,且比率的连乘积等于末期除以 基期 4. 主要用于计算平均发展速度
几何平均数
简单几何平均数:
如果 (xi x) 0 ,那么 (xi x) f 0
如果 (xi x)2 min ,那么 (xi x)2 f min
交替标志平均数
1表示具有某种属性的单位标志值
0表示不具有某种属性的单位标志值
有某种属性的单位数所占比重P=N1/N
不具有某种属性的单位数所占比重 P=N2/N
第四章 统计数据的描述
统计数据的描述有三个方面:集 中趋势、离散程度、分布形态
第四章 统计数据的描述
第一节 集中趋势的测度 第二节 离散程度的测度 第三节 偏态与峰度的测度
学习目标
1.集中趋势各测度值的计算方法 2.集中趋势不同测度值的特点和应用场合 3.离散程度各测度值的计算方法 4.离散程度不同测度值的特点和应用场合 5.偏态与峰度测度方法 6.用Excel、SPSS描述统计量并进行分