python导出excel格式的oracle数据报表(字段名和内容支持中文字符)
oracle表数据导出为文本形式

oracle表数据导出为⽂本形式oracle表数据导出⽂本数据(xls或txt)今天试验了两种⽅法,记录如下1.第⼀种⽅法:采⽤utl_file包如下过程即可实现某表数据的导出CREATE OR REPLACE PROCEDURE p_tabletoxls ISv_file utl_file.file_type;CURSOR cur_emp ISSELECT ename, deptno FROM emp;BEGINIF utl_file.is_open(v_file) THENutl_file.fclose(v_file);END IF;v_file := utl_file.fopen('UTL_FILE_DIR', 'emp.xls', 'w');FOR i IN cur_emp LOOPutl_file.put_line(v_file, i.ename || chr(9) || i.deptno); --chr(9)即字段换列END LOOP;utl_file.fclose(v_file);EXCEPTIONWHEN OTHERS THENdbms_output.put_line(SQLERRM); --写⼊数据IF utl_file.is_open(v_file) THENutl_file.fclose(v_file);END IF;END p_tabletoxls;注:ULT_file包的使⽤要先创建⼀个⽬录存放数据create or replace directory UTL_FILE_DIR as 'D:\dir';grant read,write on directory UTL_FILE_DIR to ltwebgis;2.第⼆种⽅法:采⽤ociuldr⼯具先下载该⼯具,如下所⽰:D:\ociuldr\ociuldr>ociuldr user=username/username@orcl query="SELECT ename, deptno FROM emp"field=0x20 record=0x0a file=emp.xls命令说明:user = username/password@tnsnamesql = SQL file name, one sql per file, do not include ";"query = select statementfield = seperator string between fieldsrecord= seperator string between recordsfile = output file name(default: uldrdata.txt)field=0x20 表⽰字段间⽤空格表⽰,也可以写成field=' '。
python 导出excel表格的通用写法

一、介绍在数据处理和分析的工作中,Excel表格是一种常用的数据存储和展示工具。
Python作为一种强大的编程语言,提供了丰富的工具和库来对Excel表格进行操作和处理。
本文将介绍使用Python导出Excel表格的通用写法,包括数据处理、格式设置和导出等步骤。
二、准备工作1.安装Python和相关库在开始之前,需要确保已经安装了Python环境以及相关的库。
常用的库包括pandas、openpyxl等,可以通过pip工具进行安装。
例如:```pip install pandaspip install openpyxl```2.准备数据在导出Excel表格之前,需要准备好要导出的数据。
这些数据可以来自于文件、数据库或者网络接口,需要先将数据读取到Python中进行处理。
三、数据处理与格式设置1.导入库首先在Python脚本中导入需要使用的库,例如pandas和openpyxl:```import pandas as pdfrom openpyxl import Workbook```2.读取数据使用pandas库的相关函数从文件或数据库中读取数据。
从CSV文件中读取数据并存储到一个pandas的DataFrame对象中:```data = pd.read_csv('data.csv')```3.数据处理对数据进行必要的处理和计算,例如筛选、排序、汇总等操作。
可以使用pandas提供的丰富函数和方法进行数据处理,如下面的示例对数据进行排序:```sorted_data = data.sort_values(by='date')```4.设置格式根据需求对Excel表格的格式进行设置,包括字体样式、边框、颜色、列宽等。
可以使用openpyxl库提供的接口对工作表进行格式设置,如下面的示例设置表头的字体样式和颜色:```wb = Workbook()ws = wb.activeheader = ws[1]for cell in header:cell.font = Font(bold=True, color='FF0000')```四、导出Excel表格1.创建工作簿和工作表在处理数据和设置格式完成之后,需要创建一个Excel工作簿和工作表,并将数据写入工作表中。
oracle导出数据到Excel或文本文件
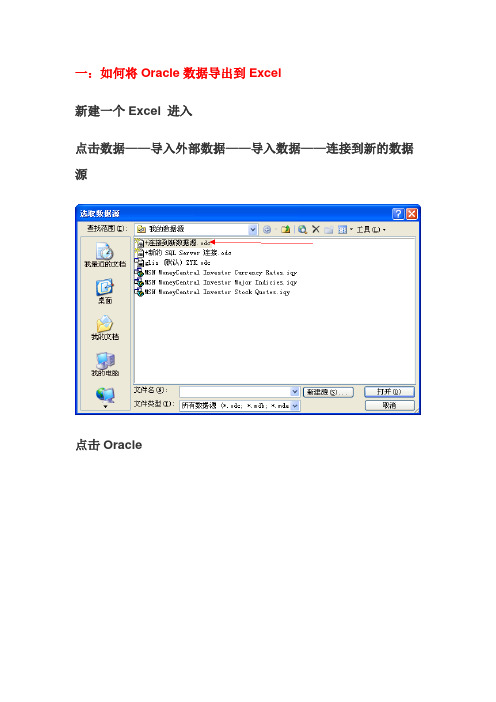
一:如何将Oracle数据导出到Excel新建一个Excel 进入点击数据——导入外部数据——导入数据——连接到新的数据源点击Oracle下一步,输入服务器名(SID号)和用户名密码(usrglis)下一步,选择一个库表(如zyk)下一步,点完成点击编辑查询命令类型选择sql在命令文本里{"USRGLIS"."ZYK"}(这个是连接到的库表)前面输入查询语句点确定——确定——确定——确定即显示检索结果二:SQLPLUS SPOOL命令使用详解SPOOL是SQLPLUS的命令,必须在SQLPLUS中使用,主要完成以标准输出方式输出SQLPLUS的命令及执行结果,一般常用户格式化导出ORACLE表数据。
对于SPOOL数据的SQL,最好要自己定义格式,以方便程序直接导入,SQL语句如:select'"'||custcode||'"'||','||custname||','||areacode||','||custaddr||',' ||to_number(to_char(rptdate,'YYYYMMDD')) fromdu_basis;spool常用的设置set colsep' ';//域输出分隔符set echo off;//显示start启动的脚本中的每个sql 命令,缺省为onset feedback off;//回显本次sql命令处理的记录条数,缺省为onset heading off;//输出域标题,缺省为onset linesize 80; //输出一行字符个数,缺省为80set pagesize 0;//输出每页行数,缺省为24,为了避免分页,可设定为0。
set termout off;//显示脚本中的命令的执行结果,缺省为onset trimout on;//去除标准输出每行的拖尾空格,缺省为offset trimspool on;//去除重定向(spool)输出每行的拖尾空格,缺省为offset timing off; //显示每条sql命令的耗时,缺省为off set verify off; //是否显示替代变量被替代前后的语句。
df.to_excel的用法

df.to_excel的用法在Python的pandas库中,DataFrame对象有一个非常实用的方法叫做to_excel。
这个方法可以将DataFrame对象保存为Excel文件,这对于数据分析和机器学习任务非常有用。
本文将详细介绍df.to_excel的用法,包括参数介绍、示例以及注意事项。
一、参数介绍1. sheet_name:可选参数,指定要保存的Excel工作表的名称。
如果不指定,则默认保存为第一个工作表。
2. index:布尔类型参数,指定是否将索引写入Excel文件。
默认情况下,索引会被写入。
3. header:布尔类型参数,指定是否将列名写入Excel文件。
默认情况下,列名会被写入。
4. index_label:可选参数,指定写入Excel文件的索引标签名称。
如果未指定,则默认与索引值相同。
5. format:可选参数,指定要使用的Excel文件格式。
常见的格式有xls和xlsx。
6. engine:可选参数,指定用于写入Excel文件的引擎。
默认使用‘openpyxl’引擎。
二、示例假设我们有一个名为df的DataFrame对象,现在想要将其保存为Excel文件。
以下是一个简单的示例代码:```pythondf.to_excel('output.xlsx', index=False, header=True)```上述代码将DataFrame对象df保存为名为output.xlsx的Excel 文件,并使用默认的工作表名称(第一个工作表)。
通过设置参数index=False,我们指示不将索引写入文件。
同时,通过设置header=True,我们指示将列名写入文件。
三、注意事项1. 要使用df.to_excel方法,需要安装pandas和openpyxl库。
可以使用以下命令进行安装:```pythonpip install pandas openpyxl```2. 如果要保存为xlsx格式的文件,需要安装xlwt库。
python从数据库取数据后写入excel使用pandas.ExcelWriter设置单元格格式
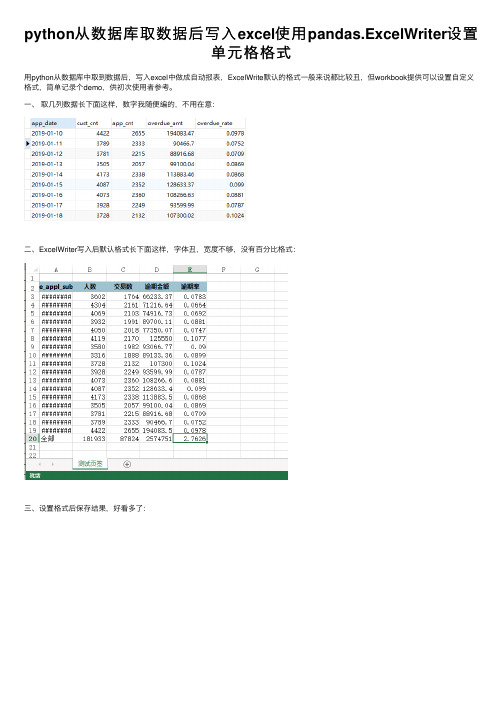
python从数据库取数据后写⼊excel使⽤pandas.ExcelWriter设置单元格格式⽤python从数据库中取到数据后,写⼊excel中做成⾃动报表,ExcelWrite默认的格式⼀般来说都⽐较丑,但workbook提供可以设置⾃定义格式,简单记录个demo,供初次使⽤者参考。
⼀、取⼏列数据长下⾯这样,数字我随便编的,不⽤在意:⼆、ExcelWriter写⼊后默认格式长下⾯这样,字体丑,宽度不够,没有百分⽐格式:三、设置格式后保存结果,好看多了:四、好了,实现在下⾯代码⾥有注释# -*- coding: utf-8 -*-import pandas as pdimport sysreload(sys)sys.setdefaultencoding('utf8')from mlutil.database import MySQLDBfrom datetime import datetime, timedeltadef report():# 1.取数据m = MySQLDB('/data/wowo/password.p', 'mysql')m.connect()df1 = pd.DataFrame(m.query('select * from table1'))df1 = df1[[u'app_date',u'cust_cnt',u'app_cnt',u'overdue_amt',u'overdue_rate',]]df1.sort_values(by='app_date', ascending=False, inplace=True)df1 = df1.set_index(u'app_date')df1.loc[u'全部'] = df1.apply(lambda x: x.sum())df1.columns = [u'⼈数',u'交易数',u'逾期⾦额',u'逾期率']df1 = df1.reset_index()# 2.保存⾄excel⽂件t = datetime.now().date() - timedelta(days=1)writer = pd.ExcelWriter(u'/home/wowo/daily_report/测试_%d%02d%02d.xlsx' % (t.year, t.month, t.day))workbook = writer.book# 3.设置格式fmt = workbook.add_format({"font_name": u"微软雅⿊"})percent_fmt = workbook.add_format({'num_format': '0.00%'})amt_fmt = workbook.add_format({'num_format': '#,##0'})border_format = workbook.add_format({'border': 1})note_fmt = workbook.add_format({'bold': True, 'font_name': u'微软雅⿊', 'font_color': 'red', 'align': 'left', 'valign': 'vcenter'})date_fmt = workbook.add_format({'bold': False, 'font_name': u'微软雅⿊', 'num_format': 'yyyy-mm-dd'})date_fmt1 = workbook.add_format({'bold': True, 'font_size': 10, 'font_name': u'微软雅⿊', 'num_format': 'yyyy-mm-dd', 'bg_color': '#9FC3D1', 'valign': 'vcenter', 'align': 'center'})highlight_fmt = workbook.add_format({'bg_color': '#FFD7E2', 'num_format': '0.00%'})# 4.写⼊excell_end = len(df1.index) + 2df1.to_excel(writer, sheet_name=u'测试页签', encoding='utf8', header=False, index=False, startcol=0, startrow=2) worksheet1 = writer.sheets[u'测试页签']for col_num, value in enumerate(df1.columns.values):worksheet1.write(1, col_num, value, date_fmt1)# 5.⽣效单元格格式# 增加个表格说明worksheet1.merge_range('A1:B1', u'测试情况统计表', note_fmt)# 设置列宽worksheet1.set_column('A:E', 15, fmt)# 有条件设定表格格式:⾦额列worksheet1.conditional_format('B3:E%d' % l_end, {'type': 'cell', 'criteria': '>=', 'value': 1, 'format': amt_fmt})# 有条件设定表格格式:百分⽐worksheet1.conditional_format('E3:E%d' % l_end,{'type': 'cell', 'criteria': '<=', 'value': 0.1, 'format': percent_fmt})# 有条件设定表格格式:⾼亮百分⽐worksheet1.conditional_format('E3:E%d' % l_end,{'type': 'cell', 'criteria': '>', 'value': 0.1, 'format': highlight_fmt})# 加边框worksheet1.conditional_format('A1:E%d' % l_end, {'type': 'no_blanks', 'format': border_format})# 设置⽇期格式worksheet1.conditional_format('A3:A62', {'type': 'no_blanks', 'format': date_fmt})# 6.保存writer.save()if __name__ == '__main__':report()。
Python获取excel内容,写数据到excel,设置单元格样式

Python获取excel内容,写数据到excel,设置单元格样式Python没有⾃带openyxl,需要安装: pip install openyxl打开excel⽂档: openyxl.load_workbook(excel地址) - 打开现有excel⽂件openyxl.Workbook() - 新建⼀个excel⽂件返回⼀个⼯作博对象import openpyxlwb = openpyxl.load_workbook("test.xlsx")print(type(wb)) # <class 'openpyxl.workbook.workbook.Workbook'>openpyxl.load_workbook()函数,传⼊⼀个存在的excel⽂件名称/excel⽂件名称+⽂件路径,返回⼀个workbook对象。
从workbook对象中获取⼯作表import openpyxlwb = openpyxl.load_workbook("test.xlsx")# print(type(wb)) # <class 'openpyxl.workbook.workbook.Workbook'># ⼯作簿对象.sheetnames - 获取当前⼯作簿中所有表的名字# print(wb.sheetnames) ['Sheet1', 'Sheet2', 'Sheet3']# ⼯作簿对象.active - 获取当前活动表对应的Worksheet对象# print(wb.active) <Worksheet "Sheet1"># ⼯作簿对象[表名] - 根据表名获取指定表对象# print(wb["Sheet2"]) <Worksheet "Sheet2"># 表对象.title - 获取表对象的表名ws = wb["Sheet1"]# print(ws.title) Sheet1# 表对象.max_row - 获取表中最多有多少⾏# print(ws.max_row) 15# 表对象.max_column - 获取表有多少列print(ws.max_column) # 3从表中取得单元格import openpyxlwb = openpyxl.load_workbook("test.xlsx")ws = wb["Sheet1"]# 表对象['列号⾏号'] - 获取指定列的指定⾏对应的单元格对象(单元格对象是 Cell 类的对象,列号是从A开始,⾏号是从1开始)a = ws["A1"]# print(a) # <Cell 'Sheet1'.A1># 单元格对象.value - 获取单元格中的内容print(a.value)# 单元格对象.row - 获取⾏号(数字1开始)print(a.row)# 单元格对象.column - 获取列号(数字1开始)print(a.column)# 单元格对象.coordinate - 获取位置(包括⾏号和列号)print(a.coordinate)# 表对象.iter_rows() - ⼀⾏⼀⾏的取row_s = ws.iter_rows()for a in row_s:for i in a:print(i.value)# 表对象.iter_cols() - 列表⼀列的取col_s = ws.iter_cols()for c in col_s:for j in c:print(j.value)⽤字母来指定列时会出现列Z之后⽤两个字母代替,可以调⽤表的cell()⽅法,传⼊整数作为⾏数和列数,第⼀⾏或者第⼀列的整数是1,⽽不是0表对象.cell(⾏号,列号)import openpyxlwb = openpyxl.load_workbook("test.xlsx")ws = wb["Sheet1"]# 获取第⼆列的所有内容max_row = ws.max_rowfor row in range(1, max_row + 1):cell = ws.cell(row, 2)print(cell.value)从表中取得列和⾏取电⼦表格中⼀⾏、⼀列或⼀个矩形区域中的所有 Cell 对象表对象[位置1:位置2] 获取指定范围内的所有单元格import openpyxlfrom openpyxl.utils import get_column_letter, column_index_from_stringwb = openpyxl.load_workbook("test.xlsx")ws = wb["Sheet1"]max_row = ws.max_rowcolumn = get_column_letter(max_row)# 获取第⼀列所有单元格对象row2 = ws["A1":f"{column}1"]ss = [(cell.coordinate, cell.value) for cells in row2 for cell in cells]print(ss)import openpyxlfrom openpyxl.utils import get_column_letter, column_index_from_stringwb = openpyxl.load_workbook("test.xlsx")ws = wb["Sheet1"]max_cols = ws.max_columncolumn = get_column_letter(max_cols)# 获取第⼀⽚区域所有单元格对象row2 = ws["A1":f"{column}3"]ss = [(cell.coordinate, cell.value) for cells in row2 for cell in cells]print(ss)创建并保存Excel⽂档openpyxl.Workbook() - 创建空的Excel⽂件对应的⼯作薄对象⼯作薄对象.save(⽂件路径) - 保存⽂件import openpyxlwb = openpyxl.load_workbook("test.xlsx")ws = wb["Sheet1"]# 修改sheet的名称ws.title = "hello_world"wb.save("test.xlsx")创建和删除sheet⼯作薄对象.create_sheet(title, index) - 在指定⼯作薄中的指定位置(默认是最后)创建指定名字的表,并返回表对象⼯作薄对象.remove(表对象) - 删除⼯作薄中的指定表import openpyxlwb = openpyxl.load_workbook("test.xlsx")wb.create_sheet()print(wb.sheetnames)wb.create_sheet("test1")print(wb.sheetnames)wb.create_sheet("test2", index=0)print(wb.sheetnames)wb.remove(wb["test2"])print(wb.sheetnames)wb.save("test.xlsx")将数据写⼊表格中import openpyxlwb = openpyxl.load_workbook("test.xlsx")ws = wb["hello_world"]# ⽅式⼀ws["A4"] = "hello_world"# ⽅式⼆ws.cell(4, 5).value = "hello_test"wb.save("test.xlsx")设置单元格样式⽤表格展⽰数据的时候,有的时候需要对不同的数据以不同的风格进⾏展⽰从⽽达到分区或者强调的作⽤。
python导出excel单元格式颜色,字体等

网络错误503请刷新页面重试持续报错请尝试更换浏览器或网络环境
python导出 excel单元格式颜色,字体等
# import xlwt # # 创建一个workbook 设置编码 # workbook = xlwt.Workbook(encoding='ascii') # print(workbook) %结果%<xlwt.Workbook.Workbook object at 0x005F4630> # # 创建一个worksheet # worksheet # pattern = xlwt.Pattern() # 创建模式对象Create the Pattern # pattern.pattern = xlwt.Pattern.SOLID_PATTERN # May be: NO_PATTERN, SOLID_PATTERN, or 0x00 through 0x12 # pattern.pattern_fore_colour = 2 # 设置模式颜色 May be: 8 through 63. 0 = Black, 1 = White, 2 = Red, 3 = Green, 4 = Blue, 5 = Yellow, 6 = Magenta, 7 = Cyan, 16 = Maroon, 17 = Dark Green, 18 = Dark Blue, 19 = Dark Yellow , almost brown), # style = xlwt.XFStyle() # 创建样式对象Create the Pattern # style.pattern = pattern # 将模式加入到样式对象Add Pattern to Style # # font = xlwt.Font() # 为样式创建字体 # = 'Times New Roman' # font.bold = True # 黑体 # font.underline = True # 下划线 # font.italic = True # 斜体字 # font.colour_index = 1 # style.font = font # 设定样式 # # worksheet.write(0, 0, '单元格内容', style) # 向单元格写入内容时使用样式对象style # # # 保存 # workbook.save('测试.xls')
如何使用python将MySQL中的查询结果导出为Excel----xlwt的使用

如何使⽤python将MySQL中的查询结果导出为Excel----xlwt的使⽤如何在MySQL中执⾏的⼀条查询语句结果导出为Excel?⼀、可选⽅法1、使⽤sql yog等远程登录,执⾏查询语句并导出结果集为Excel 适⽤于较简单的查询结果集的导出 如果需要多个SQL语句的查询结果合并起来导出为⼀个Excel则操作起来会⽐较繁琐。
2、使⽤python连接MySQL执⾏SQL语句并导出为Excel 操作简单,且可以在脚本中设置好Excel的输出格式。
⼆、如何使⽤python将查询结果导出为Excel?1、python连接MySQL进⾏查询 若想要使⽤python连接MySQL,我们必须⾸先确保python中有[pymysql]这⼀个模块。
(该测试环境为python3)。
1.1 pymysql的安装 打开cmd,使⽤pip命令进⾏安装。
# pip install pymysql 1.2 python连接MySQL并执⾏SQL获取结果集 以下是python连接数据库并获取结果集的最简单的使⽤⽅法,⽬的是让⼤家可以对最基础的实现函数有个简单的了解。
代码的⼤致流程是,使⽤指定账号连接数据库,开启⼀个游标,执⾏SQL,获取结果集,关闭游标,关联数据库连接。
代码如下:import pymysql #导⼊模块con = pymysql.connect('ip','⽤户','密码','指定数据库',charset='utf8') #连接数据库cur = con.cursor() #定义⼀个游标cur.execute(sql) #执⾏SQL,sql为你要执⾏的SQL语句,如果是简单的SQL语句使⽤''单引号引起来就好,如果SQL较复杂,可以使⽤“”双引号代替result = fetchall() #获取全部查询结果,fetchone()获取结果集的第⼀个数据cur.close() #关闭游标con.close() #关闭数据库连接 1.3 定义⼀个执⾏SQL的函数,通过传参的⽅式将指定参数传⼊SQL。
在Python中操作Excel文件的方法和技巧

Excel 文 件 中 ● a. 使 用Python库 如pandas、openpyxl等 读取Excel文 件 ● b. 对数据进行清洗、转换、分析等操作 ● c. 将处理后的数据保存到新的Excel文件中 ● 优点: a. 提高工作效率,减少重复劳动 b. 可实现自动化处理,减少人为错误 ● a. 提高工作效率,减少重复劳动 ● b. 可实现自动化处理,减少人为错误 ● 注意事项: a. 确保Python环境和相关库已正确安装 b. 注意数据格式和类型,避免处理错误 c. 备份原始数据,防止操作失误导致数据丢失 ● a. 确保Python环境和相关库已正确安装 ● b. 注意数据格式和类型,避免处理错误 ● c. 备份原始数据,防止操作失误导致数据丢失
使用pyxlsb库:pyxlsb提供了Workbook和 Sheet对象,可以创建和编辑Excel文件,支 持VBA和宏
使用pandas库读取Excel文件
使用openpyxl库直接操作Excel文件
使用pandas的DataFrame对象操作数据
Python-将数据表中数据导出到excel

Python-将数据表中数据导出到excel '''需求:写⼀个函数,随便输⼊⼀个表名,把这个表⾥⾯所有的数据,导出到excel⾥⾯思路:1、'select * from %s' ,查出这个表所有的数据2、再把所有的数据写到excel xlwt'''import pymysql,hashlib,xlwtdef op_mysql(sql:str):mysql_info = {'host': 'XXX.XXX.XXX.XXX','port': XXXX,'password': 'XXXX','user': 'XXXX','db': 'XXXX','charset': 'utf8','autocommit': True}result = '执⾏完成'conn = pymysql.connect(**mysql_info)# cur = conn.cursor(pymysql.cursors.DictCursor) #建⽴游标cur = conn.cursor() #建⽴游标cur.execute(sql)field = [ t[0] for t in cur.description ] #获取表⾥⾯的所有字段名if sql.strip().lower().startswith('select'):# result = cur.fetchone()result = cur.fetchall()cur.close()conn.close()print('所有的字段',field)print('所有的数据',result)result = list(result) #因为返回的是元组,不能修改,所以转成listresult.insert(0,field) #加⼊到最前⾯return resultdef export_excel(table_name):sql ='select * from %s;'%table_nameresult = op_mysql(sql)book = xlwt.Workbook()sheet = book.add_sheet('sheet')for row, line in enumerate(result):for col, t in enumerate(line):sheet.write(row, col, t)book.save('%s.xls'%table_name)export_excel('CJ_test')export_excel('app_myuser')import xlwtbook = xlwt.Workbook()sheet = book.add_sheet('sheet')l = [[1,'dsk','xxdfsdfsd',0],[2,'ldd','xxdfsdfsd',0],[3,'lsdd','xxdfsdfsd',0],[4,'lsd1','xxdfsdfsd',0],]# ⽅法⼀:# row = 0#⾏号# for line in l: #外⾯这个循环,每循环⼀次,就写excel⾥⾯⼀⾏# # col = 0#列号 [1,'dsk','xxdfsdfsd',0]# col = 0# for t in line:#⾥⾯这个循环是控制列的,每循环⼀次就写⼀列# sheet.write(row,col,t)# col+=1# row+=1## ⽅法⼆:for row,line in enumerate(l):for col,t in enumerate(line):sheet.write(row,col,t)book.save('user.xls')。
PYTHON导出EXCEL格式的ORACLE数据报表(字段名和内容支持中文字符)

python导出oracle excel报表(字段名和内容支持中文字符)1.需要预先安装两个python模块:cx_Oracle、xlsxwriter2.实现代码(环境是python2.7)#!/usr/bin/env python#coding:utf-8import cx_Oracle#cx_Oracle用于访问oracle和导出数据import xlsxwriter#xlsxwriter用户生成xlsx文件import timeimport sysfrom email.mime.text import MIMEText#导入邮件模块from email.mime.multipart import MIMEMultipartimport smtplibreload(sys)sys.setdefaultencoding("gbk")con=cx_Oracle.connect("aaa/1234@orcl")cursor=con.cursor()#定义SQL脚本sql='''select a.id工号,姓名,b.performance绩效,b.month月份'''.decode('utf-8').encode('gbk')query1=cursor.execute(sql)title=[i[0]for i in query1.description]date_now=time.strftime("%Y%m%d",time.localtime())#文件名及其路径report_name='/excel/'+"业务数据".decode('utf-8').encode('gbk')+date_now+ '.xlsx'#生成xlsx格式oracle查询统计报表workbook=xlsxwriter.Workbook(report_name,{'constant_memory':True})worksheet=workbook.add_worksheet()print time.ctime()data=cursor.fetchall()print time.ctime()worksheet.write_row(0,0,title)for row,row_date in enumerate(data):worksheet.write_row(row+1,0,row_date)print time.ctime()cursor.close()con.close()workbook.close()#以下代码实现发送邮件msg=MIMEMultipart()#定义附件名att1_name="月度统计".decode('utf-8').encode('gbk')+date_now+'.xlsx'#读入附件,report_nameatt1=MIMEText(open(report_name,'rb').read(),'base64','gb2312')att1["Content-Type"]='application/octet-stream'att1["Content-Disposition"]='attachment;filename=%s'%att1_name.encode('gbk') msg.attach(att1)msg['to']='pymanager01@'msg['from']='pytest01@'msg['subject']="月度统计".decode('utf-8').encode('gbk')try:server=smtplib.SMTP()server.connect('')server.login('pytest01@','123456')#邮箱账号密码server.sendmail(msg['from'],msg['to'],msg.as_string())server.quit()print'successful.'except Exception,e:print str(e)。
利用python对excel中的特定数据提取并写入新表的方法

利用python对excel中的特定数据提取并写入新表的方法如果你正在寻找一种简单而有效的方法来提取Excel中的特定数据,并将其写入新的表格,那么下面这个方法可能会对你有所帮助。
我们将使用Python的pandas和openpyxl库来完成这个任务。
**步骤一:安装必要的库**首先,你需要确保已经安装了pandas和openpyxl库。
你可以通过以下命令在命令行中安装它们:```pip install pandas openpyxl```**步骤二:导入必要的库**在Python脚本中,你需要导入这些库以使用它们的功能。
这可以通过以下代码完成:```pythonimport pandas as pd```**步骤三:读取Excel文件**接下来,我们需要使用pandas的read_excel函数来读取Excel文件。
我们可以将Excel文件的内容读入一个DataFrame对象,这个对象就像一个表格。
例如:```pythondata = pd.read_excel('原始文件.xlsx')```这里假设你的Excel文件名为"原始文件.xlsx",你需要将其替换为你的实际文件名。
**步骤四:提取特定数据**现在,我们可以使用pandas的数据选择功能来提取我们感兴趣的数据。
例如,如果我们想要提取名为'张三'的所有行的数据,我们可以这样做:```python我们想要的数据 = data[data['姓名'] == '张三']```你也可以使用其他条件来选择数据,例如按特定列进行排序。
**步骤五:写入新Excel文件**最后,我们可以使用pandas的to_excel函数将提取的数据写入新的Excel文件。
例如:```python我们想要的数据.to_excel('新文件.xlsx', index=False)```这段代码会将我们提取的数据写入名为"新文件.xlsx"的新Excel 文件中,并且不会包含行索引。
Python操作Oracle数据库查询数据导出到EXCEL

""",con=conn) df.to_excel(r'C:\Users\97534\Desktop\新建文件夹\Oracle导出emp表.xlsx',index=False) #查询结果导出到指定文件夹
df2=pd.read_sql(""" select * from SALGRADE t
1521为数据库地址和端口号orcl为数据库实例使用cursor方法创建一个游标对象cursordfpdreadsqlselectfromempconconndftoexcelrc
Python操作 Oracle数据库查询数据导出到 EXCEL
Python操作Oracle数据库查询数据导出到EXCEL
代码如下
import pandas as pd import cx_Oracle import openpyxl # 注意:一定要加下面这两行代码,否则会中文乱码; import os os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' conn = cx_Oracle.connect('scott','wzx','127.0.0.1:1521/orcl' # Scott 为用户名,wzx为密码,127.0.0.1:1521 为#数据库地址和端口号,orcl 为数据库实例 ) # 使用 cursor() 方法创建一个游标对象 cursor
使用Python脚本从数据库导出数据到excel

使⽤Python脚本从数据库导出数据到excelpython从数据库导出数据到excel最近需要从数据库⾥导出⼀些数据到excel,刚开始我是使⽤下⾯的命令select * from xxx where xxx into outfile 'xxx.xls'结果报错ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement请教同事后发现他们都是⽤脚本来导出数据,这样安全⼜⽅便,于是⾃⼰也整了⼀个,记录⼀下1)安装easy_install由于公司使⽤的是⽼旧的python2,所以还是使⽤easy)install来安装包,如果没有安装easy_install,需要安装easy_installyum install python-setuptools2)安装pymysql和xlwt使⽤easy_install安装pymysql和xlwteasy_install pymysqleasy_install xlwt使⽤pip也可以安装pip install pymysqlpip isntall xlwt使⽤pip安装如果报错Fatal error in launcher: Unable to create process using '"C:\Python27\python.exe" "C:\Python27\Scripts\pip.exe"install pymysql'可以将在前⾯加上python2 -m (启动python环境)python2 -m pip install pymysql3)编写脚本# --*-- coding:utf8 --*--import pymysql, xlwtdef export_excel(table_name):# 连接数据库,查询数据host, user, passwd, db='127.0.0.1','root','123','xxx'conn = pymysql.connect(user=user,host=host,port=3306,passwd=passwd,db=db,charset='utf8') cur = conn.cursor()sql = 'select * from %s' % table_namecur.execute(sql) # 返回受影响的⾏数fields = [field[0] for field in cur.description] # 获取所有字段名all_data = cur.fetchall() # 所有数据# 写⼊excelbook = xlwt.Workbook()sheet = book.add_sheet('sheet1')for col,field in enumerate(fields):sheet.write(0,col,field)row = 1for data in all_data:for col,field in enumerate(data):sheet.write(row,col,field)row += 1book.save("%s.xls" % table_name)if __name__ == '__main__':export_excel('app1_book')4)启动脚本导出数据python2 export.py。
python将数据带格式输出到excel

python将数据带格式输出到excelfrom xlutils.copy import copyimport xlrdimport xlwtreadworkbook=xlrd.open_workbook('⼯作簿1.xls',formatting_info=True)#open one workbook,后⾯这个参数是⽤来复制打开⼯作表的格式⽽不是仅仅复制类容readsheet=readworkbook.sheet_by_index(0)#read one sheetnew_workbook=copy(readworkbook)#复制打开的⼯作表new_sheet=new_workbook.get_sheet(0)#这时候的写⼊是没有格式的#new_sheet.write(1,1,'25')#new_sheet.write(2,1,'男')#new_sheet.write(3,1,'shu')#new_sheet.write(4,1,'china')#设置样式#其实下⾯都是属于⾯向对象编程的知识style=xlwt.XFStyle()#初始化⼀个格式font=xlwt.Font()#初始化⼀个字体对象="微软雅⿊"#font.bold=Truefont.height=320style.font=fontborder=xlwt.Borders()#初始化⼀个边框border.top=xlwt.Borders.THIN#THIN的意思是细边框border.bottom=xlwt.Borders.THINborder.left=xlwt.Borders.THINborder.right=xlwt.Borders.THINstyle.borders=borderalignment=xlwt.Alignment()#初始化⼀个对齐⽅式alignment.horz=xlwt.Alignment.HORZ_CENTERstyle.alignment=alignmentnew_sheet.write(1,1,'25',style)#写⼊的时候注意带上格式new_sheet.write(2,1,'男',style)new_sheet.write(3,1,'shu',style)new_sheet.write(4,1,'china',style)new_workbook.save("复制的⼯作表.xls")#保存。
Python数据处理-导入导出excel数据

Python数据处理-导⼊导出excel数据⽬录⼀.xlwt库将数据导⼊Excel1.将数据写⼊⼀个Excel⽂件2.定制Excel表格样式3.元格对齐4.单元格的背景⾊5.单元格边框⼆、xlrd库读取Excel中的数据1.读取Excel⽂件2.⼯作表的相关操作3.处理时间数据前⾔:Python的⼀⼤应⽤就是数据分析了,⽽数据分析中,经常碰到需要处理Excel数据的情况。
这⾥做⼀个Python处理Excel数据的总结,基本受⽤⼤部分情况。
相信以后⽤Python处理Excel数据不再是难事⼉!⼀.xlwt库将数据导⼊Excel1.将数据写⼊⼀个Excel⽂件wb = xlwt.Workbook()# 添加⼀个表ws = wb.add_sheet('test')# 3个参数分别为⾏号,列号,和内容# 需要注意的是⾏号和列号都是从0开始的ws.write(0, 0, '第1列')ws.write(0, 1, '第2列')ws.write(0, 2, '第3列')# 保存excel⽂件wb.save('./test.xls')可以看到,⽤xlwt库操作⾮常简单,基本就三步⾛:打开⼀个Workbook对象,并⽤add_sheet⽅法添加⼀个表然后就是⽤write⽅法写⼊数据最后⽤save⽅法保存需要注意的是:xlwt库⾥⾯所定义的⾏和列都是从0开始计数的2.定制Excel表格样式表格样式⼀般主要有这么⼏块内容:字体、对齐⽅式、边框、背景⾊、宽度以及特殊内容,⽐如超链接、⽇期时间等。
下⾯我们来分别看看⽤xlwt库怎么定制这些样式。
字体xlwt库⽀持的字体属性也⽐较多,⼤概如下:设置字体需要⽤到xlwt库的XFStyle类和Font类,代码模版如下:style = xlwt.XFStyle()# 设置字体font = xlwt.Font()# ⽐如设置字体加粗和下划线font.bold = Truefont.underline = Truestyle.font = font# 然后应⽤ws.write(2, 1, 'test', style)后续⼏个属性的设置都是类似的,都是4步⾛:拿到XFStyle拿到对应需要的属性,⽐如这⾥的Font对象设置具体的属性值最后就是在write⽅法写⼊数据的时候应⽤就⾏3.元格对齐先来看单元格对齐怎么设置:# 单元格对齐alignment = xlwt.Alignment()# ⽔平对齐⽅式和垂直对齐⽅式alignment.horz = xlwt.Alignment.HORZ_CENTERalignment.vert = xlwt.Alignment.VERT_CENTER# ⾃动换⾏alignment.wrap = 1style.alignment = alignment# 然后应⽤ws.write(2, 1, 'test', style)上⾯这个⾃动换⾏的属性还是蛮有⽤的,因为我们很多时候数据会⽐较长,最好再加上单元格的宽度属性⼀起使⽤,这样整体样式会好很多单元格宽度设置:# 设置单元格宽度,也就是某⼀列的宽度ws.col(0).width = 66664.单元格的背景⾊背景⾊对应的属性是Pattern# 背景⾊pattern = xlwt.Pattern()pattern.pattern = xlwt.Pattern.SOLID_PATTERN# 背景⾊为黄⾊# 0 = Black, 1 = White, 2 = Red, 3 = Green, 4 = Blue, 5 = Yellow, 6 = Magenta,# 7 = Cyan, 16 = Maroon, 17 = Dark Green, 18 = Dark Blue, 19 = Dark Yellow ,# almost brown), 20 = Dark Magenta, 21 = Teal, 22 = Light Gray, 23 = Dark Gray# ...pattern.pattern_fore_colour = 5style.pattern = pattern# 然后应⽤ws.write(2, 1, 'test', style)5.单元格边框边框属性是Borders单元格边框就2类:颜⾊和边框线样式可以分别设置上下左右边框的颜⾊和样式:# 边框borders = xlwt.Borders()# 边框可以分别设置top、bottom、left、right# 每个边框⼜可以分别设置颜⾊和线样式:实线、虚线、⽆# 颜⾊设置,其他类似borders.left_colour = 0x40# 设置虚线,其他类似borders.bottom = xlwt.Borders.DASHEDstyle.borders = borders# 然后应⽤ws.write(2, 1, 'test', style)特殊内容,⽐如超链接和公式特殊内容⼀般主要会碰到这⼏类:超链接、公式和时间⽇期处理这些特殊内容需要⽤到Formula# 超链接link = 'HYPERLINK("";"Baidu")'formula = xlwt.Formula(link)ws.write(2, 0, formula)# 公式也是类似ws.write(1, 1, xlwt.Formula('SUM(A1,B1)'))# 时间style.num_format_str = 'M/D/YY'ws.write(2, 1, datetime.datetime.now(), style)以上就是⽤Python将数据写⼊到Excel的全部内容了,下⾯我们再来看看怎么读取Excel中的数据做处理。
python将数据保存为excel的xls格式(实例讲解)

#使用workbook方法,创建一个新的工作簿
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
#添加一个sheet,名字为mysheet,参数overwrite就是说可不可以重复写入值,就是当单元格已经非空,你还要写入
这篇文章主要介绍了djangoxadmin安装及使用详解文中通过示例代码介绍的非常详细对大家的学习或者工作具有一定的参考学习价值需要的朋友们下面随着小编来一起学习学习吧
python将数据保存为 excel的 xls格式(实例讲解)
python提供一个库 xlwt ,可以将一些数据 写入excel表格中,十分的方便。贴使用事例如下。 #引入xlwt模块(提前pip下载好)
sheet = book.add_sheet('mysheet',cell_overwrite_ok=True)
#接着就是给指定的单元格写入数据了
sheet.write(0,0,'mok.save('/Users/Kingsley/Desktop/test.xls')
以上这篇python 将数据保存为excel的xls格式(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望 大家多多支持。
python操作openpyxl导出Excel设置单元格格式以及合并处理

python操作openpyxl导出Excel设置单元格格式以及合并处理1. 贴上⼀个例⼦,⾥⾯设计很多⽤法,根据将相同⽇期的某些⾏合并处理。
2. from openpyxl import Workbookfrom openpyxl.styles import Font, Fill, Alignment, Border, Side, PatternFillfrom handlers.boss_accountant import PbOrderManageBasefrom handlers.base.pub_func import ConfigFuncfrom dal.models import Shopfrom dal.db_configs import DBSessiondef export_excel(filename, sheetname, content_body):"""Excel表格导出:param filename: 表格名称:param sheetname: ⼯作表名称:param content_body: 内容体:return: None"""workbook = Workbook()if not filename:filename = "导出表格.xlsx"workbook_sheet = workbook.activeif not sheetname:sheetname = "⼯作表"workbook_sheet.title = sheetnamemerge_dict, sheet_row_len, sheet_column_len = merge_content(content_body)print(merge_dict)# 数据写⼊for row in content_body:workbook_sheet.append(row)# 合并处理for key in merge_dict.keys():merge_data = merge_dict.get(key)if key == "title":workbook_sheet.merge_cells(start_row=merge_data[0], start_column=merge_data[1],end_row=merge_data[2], end_column=merge_data[3])workbook_sheet.merge_cells(start_row=2, start_column=merge_data[1],end_row=2, end_column=merge_data[3])workbook_sheet['A1'].font = Font(size=20, bold=True)workbook_sheet['A1'].alignment = Alignment(horizontal='center', vertical='center') else:# 使⽤sum求值workbook_sheet.cell(row=merge_data[0] + 3, column=12).value = '=SUM({}:{})'.format(format_value(str(merge_data[0] + 3), 10), format_value(str(merge_data[1] + 3), 10))workbook_sheet.cell(row=merge_data[0] + 3, column=14).value = '=SUM({}:{})'.format(format_value(str(merge_data[0] + 3), 11), format_value(str(merge_data[1] + 3), 11))workbook_sheet.cell(row=merge_data[0] + 3, column=13).value = '=({}-{})'.format(format_value(str(merge_data[0] + 3), 12), format_value(str(merge_data[0] + 3), 14)) for i in [2,12, 13, 14]:workbook_sheet.merge_cells(start_row=merge_data[0]+3, start_column=i,end_row=merge_data[1]+3, end_column=i)# 合计求和for i in [12, 13, 14]:workbook_sheet.cell(row=sheet_row_len, column=i).value = '=SUM({}:{})'.format(format_value(3, i), format_value(sheet_row_len - 1, i))# 单元格底⾊last_row = workbook_sheet[sheet_row_len]for each_cell in last_row:each_cell.fill = PatternFill("solid", fgColor="00CDCD")# 边框设置for each_common_row in workbook_sheet.iter_rows("A1:{}".format(format_value(sheet_row_len, sheet_column_len))):for each_cell in each_common_row: each_cell.border = Border(left=Side(style='thin', color='000000'),right=Side(style='thin', color='000000'),top=Side(style='thin', color='000000'),bottom=Side(style='thin', color='000000'))workbook_sheet.column_dimensions['B'].width = 15workbook_sheet.column_dimensions['C'].width = 20workbook.save(filename)def merge_content(content_body):"""合并统计:param content_body: 数据体:return: 合并字典"""sheet_column_len = len(content_body[3])sheet_row_len = len(content_body)merge_dict = {}data_content = content_body[3:-1]merge_dict["title"] = (1, 1, 1, sheet_column_len)current_data = data_content[0][1]current_row = 0start_row = 1end_row = 0for data in data_content:current_row += 1x = data[1]if data[1] == current_data:merge_dict[data[1]] = (start_row, current_row)else:merge_dict[data[1]] = (current_row, current_row)current_data = data[1]start_row = current_rowreturn merge_dict, sheet_row_len, sheet_column_lendef format_value(row, column):"""数字转ABC"""change_dict = {1: "A", 2: "B", 3: "C", 4: "D", 5: "E", 6: "F", 7: "G", 8: "H", 9: "I", 10: "J",11: "K", 12: "L", 13: "M", 14: "N", 15: "O", 16: "P", 17: "Q", 18: "R", 19: "S", 20: "T",21: "U", 22: "V", 23: "W", 24: "X", 25: "Y", 26: "Z",}column = change_dict.get(column)return str(column)+str(row)def export_func_new(args, session, shop_id):# check_time = 0# debtor_id = 2884# debtor_name: 肖⼩菜# end_date:# start_date: 2019 - 07# statistic_date: 3# data_type: 1data_content = []check_time = 0from_date = "2019-07"to_date = ""debtor_name = "肖⼩菜"if_success, query_data, *_ = mon_get_credit_stream(args, session, shop_id, export=True,need_sum=False, check_time=check_time)if not if_success:raise ValueError(query_data)fee_text = ConfigFunc.get_fee_text(session, shop_id)get_weight_unit_text = ConfigFunc.get_weight_unit_text(session, shop_id)# 表店铺、客户名称shop_name = session.query(Shop.shop_name).filter_by(id=shop_id).first()data_content.append([shop_name[0]])data_content.append(["客户:{}".format(debtor_name)])# 表头fee_text_total = '{}⼩计'.format(fee_text)header_content = ["序号", "⽇期", "货品名", "数量", "重量/{}".format(get_weight_unit_text), "单价", "货品⼩记", "押⾦⼩计", fee_text_total, "赊账⾦额","待还款", "赊账⼩记", "已还款", "待还款⼩计"]file_name_begin = "客户还款"data_content.append(header_content)# 还款数据index_num = 0for single_data in query_data:index_num += 1sales_time = single_data.get("sales_time", "") if sales_time:sales_time = sales_time.split("")[0]_payback_money = single_data["unpayback_money"]single_content = [index_num,sales_time,single_data["only_goods_name"],single_data["commission_mul"],single_data["sales_num"],"%s元/%s" % (single_data["fact_price"],single_data["goods_unit"]),single_data["goods_total"],single_data["commission_mul"],single_data["deposit_total"],single_data["credit_cent"],_payback_money,0,0,0]data_content.append(single_content)# 表尾合计data_content.append(["合计"])config = ConfigFunc.get_config(session, shop_id)if not config.enable_deposit:index_deposit_total = data_content[0].index("押⾦⼩计") for data in data_content:data.pop(index_deposit_total)if not config.enable_commission:index_commission_total = data_content[0].index(fee_text_total) for data in data_content:data.pop(index_commission_total)file_name = "{}流⽔记录导出_{}~{}.xlsx".format(file_name_begin, from_date, to_date)return file_name, data_contentif__name__ == "__main__":filename = "测试打印表格.xlsx"sheetname = "⼯作表2"session = DBSession()args = {"check_time": 0,"debtor_id": 2884,"debtor_name": "肖⼩菜","start_date": "2019-07","statistic_date": 3,"data_type": 1}filename, content_body = export_func_new(args, session, 104)# filename = "测试打印表格.xlsx"# sheetname = "⼯作表2"# content_body = []# content_body.append(["打印表格表头"])# content_body.append(["客户:肖某某"])# content_body.append(["⽇期", "货品销售", "⾃营销售", "代卖销售", "联营销售", "总价"]) # content_body.append(["1", "2", "3.1", "4.1", "5.1", "5.1"])# content_body.append(["1", "2", "3.1", "4.1", "5.1", "5.1"])# content_body.append(["1", "2", "3.1", "4.1", "5.1", "5.1"])。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
python导出oracl e excel报表(字段名和内容支持中
文字符)
1.需要预先安装两个python模块:
cx_Oracle、xlsxwriter
2.实现代码(环境是python 2.7)
#!/usr/bin/env python
#coding:utf-8
import cx_Oracle # cx_Oracle 用于访问oracle和导出数据
import xlsxwriter # xlsxwriter 用户生成xlsx文件
import time
import sys
from email.mime.text import MIMEText # 导入邮件模块
from email.mime.multipart import MIMEMultipart
import smtplib
reload(sys)
sys.setdefaultencoding("gbk")
con = cx_Oracle.connect("aaa/1234@orcl")
cursor = con.cursor()
#定义SQL脚本
sql ='''
select a.id 工号,
姓名,
b. performance 绩效,
b.month 月份
'''.decode('utf-8').encode('gbk')
query1 = cursor.execute(sql)
title = [i[0] for i in query1.description]
date_now=time.strftime("%Y%m%d",time.localtime())
#文件名及其路径
report_name='/excel/' + "业务数据".decode('utf-8').encode('gbk') + date_now + '.xlsx'
#生成xlsx格式oracle查询统计报表
workbook = xlsxwriter.Workbook(report_name, {'constant_memory': True})
worksheet = workbook.add_worksheet()
print time.ctime()
data = cursor.fetchall()
print time.ctime()
worksheet.write_row(0, 0, title)
for row, row_date in enumerate(data):
worksheet.write_row(row+1, 0, row_date)
print time.ctime()
cursor.close()
con.close()
workbook.close()
#以下代码实现发送邮件
msg = MIMEMultipart()
#定义附件名
att1_name="月度统计".decode('utf-8').encode('gbk') + date_now + '.xlsx'
#读入附件,report_name
att1 = MIMEText(open(report_name, 'rb').read(), 'base64', 'gb2312')
att1["Content-Type"] = 'application/octet-stream'
att1["Content-Disposition"] = 'attachment; filename=%s' % att1_name.encode('gbk') msg.attach(att1)
msg['to']='*******************'
msg['from']='****************'
msg['subject'] = "月度统计".decode('utf-8').encode('gbk')
try:
server = smtplib.SMTP()
server.connect('')
server.login('****************','123456')#邮箱账号密码
server.sendmail(msg['from'], msg['to'],msg.as_string())
server.quit()
print 'successful.'
except Exception, e:
print str(e)。