spss统计分析及应用教程 6课件
合集下载
spss统计分析及应用教程基本统计分析PPT课件

第43页/共74页
(4) 在“探索”对话框中 点击“统计量(S)”按钮, 选择“探索:统计量”对话 框中的系统默认设置,如图 所示。
第44页/共74页
(5)在“探索”对话框中 点击“绘制(T)”按钮, 选择“探索:图”对话框中 的默认系统设置,如图所示。
第45页/共74页
在“探索”对话框中点击 “选项(O)”按钮,选择 “探索:选项”对话框中的 默认系统设置,如图所示。
第24页/共74页
实验二 频数分析
• 实验目的
• 了解变量取值(数据)的分布情况; • 判断样本的代表性及抽样的系统偏差; • 学习运用频数分析方法解决实际问题。
第25页/共74页
• 知识准备
• 频数是同一数据或同一事件出现的次数。频数分 析可以用来考察数据值的分布状况,即变量取值
的分布情况,使研究者对所研究随机变量的变化
(4)在“频率(F)”对话框中点击 “图表(C)”按钮,打开“频率:图 表”对话框,在“图表类型”下的选 项中选择“条形图(B)”,在“图表 值”下面的选项中选择选择系统默认 设置“频率(F)” ,点击“继续”按 钮,返回“频率(F)”对话框。
第31页/共74页
(5)在“频率(F)”对话框中,单击“确定”按钮,提交系 统运行。得到各部门职工人数统计的频数表和条形图。
第8页/共74页
准备知识
描述统计
数据描述统计是对数据进行基 本分析,从总体上把握数据分布基 本特征的统计方法。通常用均值( 及标准误)、中位数和众数描述数 据的集中趋势,用标准差、方差和 全距(及最大值和最小值)描述数 据的离散性,用峰度、偏度和分位 数描述数据的分布情况。
第9页/共74页
实验一 描述性统计
第2页/共74页
(4) 在“探索”对话框中 点击“统计量(S)”按钮, 选择“探索:统计量”对话 框中的系统默认设置,如图 所示。
第44页/共74页
(5)在“探索”对话框中 点击“绘制(T)”按钮, 选择“探索:图”对话框中 的默认系统设置,如图所示。
第45页/共74页
在“探索”对话框中点击 “选项(O)”按钮,选择 “探索:选项”对话框中的 默认系统设置,如图所示。
第24页/共74页
实验二 频数分析
• 实验目的
• 了解变量取值(数据)的分布情况; • 判断样本的代表性及抽样的系统偏差; • 学习运用频数分析方法解决实际问题。
第25页/共74页
• 知识准备
• 频数是同一数据或同一事件出现的次数。频数分 析可以用来考察数据值的分布状况,即变量取值
的分布情况,使研究者对所研究随机变量的变化
(4)在“频率(F)”对话框中点击 “图表(C)”按钮,打开“频率:图 表”对话框,在“图表类型”下的选 项中选择“条形图(B)”,在“图表 值”下面的选项中选择选择系统默认 设置“频率(F)” ,点击“继续”按 钮,返回“频率(F)”对话框。
第31页/共74页
(5)在“频率(F)”对话框中,单击“确定”按钮,提交系 统运行。得到各部门职工人数统计的频数表和条形图。
第8页/共74页
准备知识
描述统计
数据描述统计是对数据进行基 本分析,从总体上把握数据分布基 本特征的统计方法。通常用均值( 及标准误)、中位数和众数描述数 据的集中趋势,用标准差、方差和 全距(及最大值和最小值)描述数 据的离散性,用峰度、偏度和分位 数描述数据的分布情况。
第9页/共74页
实验一 描述性统计
第2页/共74页
数据统计分析及方法SPSS教程完整版ppt

(3)单击右下角的“uesr prompts”按钮,添加对程序的 交互分析界面。
(4)单击“Browse”按钮制定结 果保存路径,单击“export options”按钮还可以制定结果保 存格式。
1.2.4 spss的四种输出结果
1、表格格式 2、文本格式 3、标准图与交互图 4、结果的保存和导出
Frequencies,
Employment Category
Valid
Clerical Custodial Manager Total
Frequency 363 27 84 474
Percent 76.6 5.7 17.7
100.0
Valid Percent 76.6 5.7 17.7
100.0
窗口标签
状态栏
显示区滚动条
Variable View表用来定义和修改变量的名称、类型及其他属性,如图所示。
如果输入变量名后回车,将给出变量的默认属性。如果不定义变量的 属性,直接输入数据,系统将默认变量Var00001,Var00002等。
在Variable View表中,每一行描述一个变量,依次是: Name:变量名。变量名必须以字母、汉字及@开头,总长度不超过8个字 符,共容纳4个汉字或8个英文字母,英文字母不区别大小写,最后一个字 符不能是句号。 Type:变量类型。变量类型有8 种,最常用的是Numeric数值型变量。其 它常用的类型有:String字符型,Date日期型,Comma逗号型(隔3位数加 一个逗号)等。 Width:变量所占的宽度。 Decimals:小数点后位数。 Label:变量标签。关于变量涵义的详细说明。 Values:变量值标签。关于变量各个取值的涵义说明。 Missing:缺失值的处理方式。 Columns:变量在Date View 中所显示的列宽(默认列宽为8)。 Align:数据对齐格式(默认为右对齐)。 Measure:数据的测度方式。系统给出名义尺度、定序尺度和等间距尺度 三种(默认为等间距尺度)。
(4)单击“Browse”按钮制定结 果保存路径,单击“export options”按钮还可以制定结果保 存格式。
1.2.4 spss的四种输出结果
1、表格格式 2、文本格式 3、标准图与交互图 4、结果的保存和导出
Frequencies,
Employment Category
Valid
Clerical Custodial Manager Total
Frequency 363 27 84 474
Percent 76.6 5.7 17.7
100.0
Valid Percent 76.6 5.7 17.7
100.0
窗口标签
状态栏
显示区滚动条
Variable View表用来定义和修改变量的名称、类型及其他属性,如图所示。
如果输入变量名后回车,将给出变量的默认属性。如果不定义变量的 属性,直接输入数据,系统将默认变量Var00001,Var00002等。
在Variable View表中,每一行描述一个变量,依次是: Name:变量名。变量名必须以字母、汉字及@开头,总长度不超过8个字 符,共容纳4个汉字或8个英文字母,英文字母不区别大小写,最后一个字 符不能是句号。 Type:变量类型。变量类型有8 种,最常用的是Numeric数值型变量。其 它常用的类型有:String字符型,Date日期型,Comma逗号型(隔3位数加 一个逗号)等。 Width:变量所占的宽度。 Decimals:小数点后位数。 Label:变量标签。关于变量涵义的详细说明。 Values:变量值标签。关于变量各个取值的涵义说明。 Missing:缺失值的处理方式。 Columns:变量在Date View 中所显示的列宽(默认列宽为8)。 Align:数据对齐格式(默认为右对齐)。 Measure:数据的测度方式。系统给出名义尺度、定序尺度和等间距尺度 三种(默认为等间距尺度)。
《统计分析与SPSS的应用(第6版)》课件第一章

第一章
SPSS 统计分析软件概述
主要内容
SPSS使用基础 SPSS的基本运行方式
SPSS的英文缩写: Statistical Package for Social Science Statistical Product and Service Solutions
行
SPSS 基本运行方式
菜单程序混合运行方式: 先通过菜单选择分析过程和参数,不立即提交 (确定)执行,而是按粘贴按钮. 计算机自动将用户刚定义的分析过程和参数转 换成SPSS的命令,并显示到语法窗口中. 用户可对其进行必要的修改后再提交给计算机 执行. 一般适用于熟练的SPSS程序员.
SPSS主要窗口:数据查看器窗口
窗口标题:查看器 功能:SPSS统计分析报表及图形的输出的窗口。 组成:窗口主菜单、工具栏、结果显示区、状态区 特点:
输出窗口可以关闭,窗口内容以.SPV存于磁盘上 两个部分:目录视图和内容视图
SPSS基本运行方式
完全窗口菜单方式: 所有分析操作过程都是通过菜单和按钮及对话框方 式进行的.
SPSS主要窗口:数据编辑器窗口
窗口标题:数据编辑器(数据集) 功能:对SPSS的数据文件进行录入、 修改、管理等
基本操作的窗口。 组成:窗口主菜单、工具栏、数据编辑区、状态区 特点:
SPSS运行过程中自动打开 SPSS中各统计分析功能都是针对该窗口中的数据进
行的 窗口中的数据文件以.sav存于磁盘上 两个视图:数据视图和变量视图
SPSS软件概述
SPSS的发展: 60年代:美国斯坦福大学三位研究生研制 70年代:SPSS总部成立于芝加哥,推出 SPSSX中小型机版 80年代:SPSS公司(SPSS/PC+微机版1~3) 90年代:SPSS公司(SPSS WINDOWS版5~16) 2009:IBM收购,命名为:IBM SPSS Statistics(多国语言版25版)
SPSS 统计分析软件概述
主要内容
SPSS使用基础 SPSS的基本运行方式
SPSS的英文缩写: Statistical Package for Social Science Statistical Product and Service Solutions
行
SPSS 基本运行方式
菜单程序混合运行方式: 先通过菜单选择分析过程和参数,不立即提交 (确定)执行,而是按粘贴按钮. 计算机自动将用户刚定义的分析过程和参数转 换成SPSS的命令,并显示到语法窗口中. 用户可对其进行必要的修改后再提交给计算机 执行. 一般适用于熟练的SPSS程序员.
SPSS主要窗口:数据查看器窗口
窗口标题:查看器 功能:SPSS统计分析报表及图形的输出的窗口。 组成:窗口主菜单、工具栏、结果显示区、状态区 特点:
输出窗口可以关闭,窗口内容以.SPV存于磁盘上 两个部分:目录视图和内容视图
SPSS基本运行方式
完全窗口菜单方式: 所有分析操作过程都是通过菜单和按钮及对话框方 式进行的.
SPSS主要窗口:数据编辑器窗口
窗口标题:数据编辑器(数据集) 功能:对SPSS的数据文件进行录入、 修改、管理等
基本操作的窗口。 组成:窗口主菜单、工具栏、数据编辑区、状态区 特点:
SPSS运行过程中自动打开 SPSS中各统计分析功能都是针对该窗口中的数据进
行的 窗口中的数据文件以.sav存于磁盘上 两个视图:数据视图和变量视图
SPSS软件概述
SPSS的发展: 60年代:美国斯坦福大学三位研究生研制 70年代:SPSS总部成立于芝加哥,推出 SPSSX中小型机版 80年代:SPSS公司(SPSS/PC+微机版1~3) 90年代:SPSS公司(SPSS WINDOWS版5~16) 2009:IBM收购,命名为:IBM SPSS Statistics(多国语言版25版)
《统计分析与SPSS的应用(第6版)》课件第十二章

( yi(2) y(2) )2
i1
i1
Fisher判别法
第一Fisher判别函数的方 向和距离判别函数等于0的 直线或平面之间相互垂直
• 一般陈述:
• 点X在以a为法方向的投影为a’x,则各组数据的投
影为:
Gi
:
a'X1(i)
,.
..,
a X' (i) ni
,
i
1,2,...,k
x1,x2…为包 含p个元素 的列向量
W ( X ) ( X X )' 1( X (1) X (2) )
(X X )'a a'(X X )
判别函数为线性函数
单个判别变量时:判别函数等于0表示点X与两
类总中心重合(σ12 = σ22)
G2
G1
W(X)>0,则:X∈G1
如果W(X)<0,则:X∈G2
如果W(X)=0,则待判
距离判别法的特点
特点: 直观 若两类别的均值无显著差异,错判概率高
问题: 多个总体的均值是否存在显著差异 多个总体的协差阵是否存在显著差异
多个总体的均值检验:H0:(1)=…= (k) 单变量x均值检验中组间离差平方和与组内离差平 方和:
多变量的均值检验中计算平方和(p=2为例)
根据距离最近的原则,距离哪个中心近,则属于 哪个类
例:设(1), (2), (1), (2)分别为G1和G2的均值向量 和协差阵,则点X到Gi的距离定义为平方马氏距离为:
D2(X,Gi ) (X μ(i))'( (i))1(X μ(i)) i 1,2
u未知时用样本均值 替代
为什么采用马氏距离
为什么采用马氏距离
《SPSS数据分析与应用》第6章 聚类分析

• 在这一步中样本4(客户编号为: K100390 ) 和 样 本 5 ( 客 户 编 号 为 : K100450 ) 相 似 度 达 到 阈 值 , 聚 为 一 类 。
• 当纵坐标为13时,15个样本被12个白色 间隙分隔为13类。
系统聚类的结果解读
冰柱图聚类进程(最后一步)
依次类推,直到将15个样本全部 聚为一类,在15个样本之间没有 白色间隙,表示系统聚类结束。
• 测度观测点之间“亲疏”程度的方法与K-means聚类相同。 • 观测点与小类、小类与小类之间“亲疏”程度的测度,常用的方法有以下几种:
(1)重心法 (2)最近邻元素法 (3)组间平均联接法 (4)组间平均联接法 (5)离差平方和法
系统聚类的基本操作
第一步:用SPSS打开数据文件“移动通信客户_样本15.sav”。 第二步:在菜单栏中选择【分析(A)】→【描述统计(E)】→【描述(D)】,在弹出的 “描述”对话框的左下 角勾选【将标准化值另存为变量(Z)】,将已有的 6 个连续性变量都选到【变量(V)】列表框中,单击【确定】 按钮。
第四步:在“K均值聚类分析”对话框中单击右上角的【迭代(I)】按钮,在弹出的“K-均值聚类分析:迭代” 对话框中将【最大迭代次数(M)】修改为“50”,【收敛准则(C)】暂时不做修改。单击【继续(C)】按钮, 回到“K 均值聚类分析” 对话框。
K-Means聚类的基本操作
第五步:在“K均值聚类分析”对话框中单击右上角的【保存 (S)】按钮,在弹出的“K-均值聚类:保存新 变量”对话框中勾选【聚类成员(C)】和【与聚类中心的距离(D)】。单击【继续(C)】按钮,回到“K均 值聚类分析”对话框。
第一,如何测度样本的“亲疏程度”; 第二,如何进行聚类
K-means聚类对“亲疏程度”的测度
• 当纵坐标为13时,15个样本被12个白色 间隙分隔为13类。
系统聚类的结果解读
冰柱图聚类进程(最后一步)
依次类推,直到将15个样本全部 聚为一类,在15个样本之间没有 白色间隙,表示系统聚类结束。
• 测度观测点之间“亲疏”程度的方法与K-means聚类相同。 • 观测点与小类、小类与小类之间“亲疏”程度的测度,常用的方法有以下几种:
(1)重心法 (2)最近邻元素法 (3)组间平均联接法 (4)组间平均联接法 (5)离差平方和法
系统聚类的基本操作
第一步:用SPSS打开数据文件“移动通信客户_样本15.sav”。 第二步:在菜单栏中选择【分析(A)】→【描述统计(E)】→【描述(D)】,在弹出的 “描述”对话框的左下 角勾选【将标准化值另存为变量(Z)】,将已有的 6 个连续性变量都选到【变量(V)】列表框中,单击【确定】 按钮。
第四步:在“K均值聚类分析”对话框中单击右上角的【迭代(I)】按钮,在弹出的“K-均值聚类分析:迭代” 对话框中将【最大迭代次数(M)】修改为“50”,【收敛准则(C)】暂时不做修改。单击【继续(C)】按钮, 回到“K 均值聚类分析” 对话框。
K-Means聚类的基本操作
第五步:在“K均值聚类分析”对话框中单击右上角的【保存 (S)】按钮,在弹出的“K-均值聚类:保存新 变量”对话框中勾选【聚类成员(C)】和【与聚类中心的距离(D)】。单击【继续(C)】按钮,回到“K均 值聚类分析”对话框。
第一,如何测度样本的“亲疏程度”; 第二,如何进行聚类
K-means聚类对“亲疏程度”的测度
Spss实用统计分析PPT课件

第27页/共84页
单击Statistics按钮,打开OLAP Cubes:Statistics对话框
对话框左边的统计量清单框中,列出供选择使用的各种统计量。右边Cell Statistics框,接纳用户选择的统计量,凡选入的统计量在输出的分层报告表的 单元格里显示他们的值。
第28页/共84页
单击Title按钮,打开OLAP Cubes:Title话框
频数分析
Descriptives Statistics Descriptives…
统计描述
(描述性统计)
Explore…
数据探索
Crosstabs…
交叉表,或列联表
Compare Means
Ratio… Means…
比率统计 均值比较
(均值比较)
One-Sample T Test…
单样本T检验
Independent-Sample T Test… 独立样本T检验
Categorize Variables… Rank Cases…
Into Same Variable… Into Defferent Variable…
Automatic Recode… Create Time Series… Replace Missing Values
Run Pending Transforms
下面我们将列出所有的统计分析功能:
第12页/共84页
子菜单
用途说明
OLAP Cubes…
层分析报告
Reports(统计报告)
Case Summaries
观测量概述
Report Summaries in Rows 行概述报告
Report Summaries in Colums 列概述报告
单击Statistics按钮,打开OLAP Cubes:Statistics对话框
对话框左边的统计量清单框中,列出供选择使用的各种统计量。右边Cell Statistics框,接纳用户选择的统计量,凡选入的统计量在输出的分层报告表的 单元格里显示他们的值。
第28页/共84页
单击Title按钮,打开OLAP Cubes:Title话框
频数分析
Descriptives Statistics Descriptives…
统计描述
(描述性统计)
Explore…
数据探索
Crosstabs…
交叉表,或列联表
Compare Means
Ratio… Means…
比率统计 均值比较
(均值比较)
One-Sample T Test…
单样本T检验
Independent-Sample T Test… 独立样本T检验
Categorize Variables… Rank Cases…
Into Same Variable… Into Defferent Variable…
Automatic Recode… Create Time Series… Replace Missing Values
Run Pending Transforms
下面我们将列出所有的统计分析功能:
第12页/共84页
子菜单
用途说明
OLAP Cubes…
层分析报告
Reports(统计报告)
Case Summaries
观测量概述
Report Summaries in Rows 行概述报告
Report Summaries in Colums 列概述报告
SPSS统计分析(第6版)(高级版)教学课件SPSS 第11章 贝叶斯推断

贝叶斯统计推断概述
贝叶斯公式 贝叶斯统计学 贝叶斯统计推断中用到一些基本术语 贝叶斯统计决策中用到一些基本术语 几种常见先验条件下的后验分布
贝叶斯公式
贝叶斯统计学
由贝叶斯公式引申的关于统计推断的 系统理论和方法称为贝叶斯方法,由这种 方法得到的所有统计推断结果构成了贝叶 斯统计学的内容。
利用先验信息、总体信息、样本信息进 行统计推断的理论和方法称为贝叶斯统计 学。
贝叶斯相关样本正态分布推断分析实例计算结果1
贝叶斯相关样本正态分布推断分析实例计算结果2
贝叶斯相关样本正态分布推断分析实例计算结果3
贝叶斯相关样本正态分布推断分析实例计算结果4
当前年薪和初始年薪差异检验
贝叶斯独立样本正态分布推断分析
贝叶斯独立样本正态分布推断分析过程 贝叶斯独立样本正态分布推断分析实例
学无止境,与时俱进 再见!
“贝叶斯单因子重复量数变异数分析”对话框
“条件”对话框
贝叶斯单因素重复测量方差分析过程(续)
“贝叶斯因子”对话框
“图”对话框
贝叶斯单因素重复测量方差分析实例
【例10】 在一项记忆实验中,研究者 用随机招募了多个参与实验的被试对象, 基于4种精心设计的不同任务对每个被试 对象得到了4组测量值。假设测量值服从 正态分布。数据分析人员使用贝叶斯因子 法来评估假设,并创建一个有意义的图表 以可视化后验分布。
贝叶斯单样本泊松分布推断分析实例计算结果2
后验分布图
贝叶斯相关样本正态分布推断分析
贝叶斯相关样本正态分布推断分析过程 贝叶斯相关样本正态分布推断分析实例
贝叶斯相关样本正态分布推断分析过程
“贝叶斯相关样本推论:正态”对话框
贝叶斯相关样本正态分布推断分析实例
《统计分析与SPSS的应用(第6版)》课件第三章

分类汇总
目标:分析各分组下样本的统计特征 手段:
按指定的分组变量值对样本分组 分别计算各组中汇总变量的基本统计量 例:对比男女职工的平均年龄和平均工资
性别
年龄
奖金
男
40
1000
女
35
550
男
20
200
性别_1 男 女
年龄_1 30 35
奖金_1 600 550
原始数据
按性别变量汇总数据
分类汇总
如:nmp;(AND):并且、|(OR):或者、 ~(NOT):非
如:(nl>32) and (sr<=700) 如:(nl=32) | (sr<>700) 如: not xb=1
个案选取
目标:个案选取的意义? 手段:从现有数据中选出部分数据
按条件选取;随机选取;选取指定区间中的样本
菜单选项: 数据 -> 分类汇总
说明: 多重分组时,变量名的选择顺序。 生成的新文件名默认为:aggr.sav。可修改。 生成的新变量名默认为原变量名后加_1。可修 改 可以在新文件中存贮各分组个案数.
指定加权变量
目标: 例:蔬菜的平均价格、男足打分
手段:指定某一变量为加权变量 例:蔬菜的平均价格
逻辑函数
range() any()
字符串函数 缺失值函数
index() length() lower() lpad() ltrim() substr()
missing() sysmis()
日期时间函数
其他函数
变量计算
(5)SPSS条件表达式:由SPSS关系运算符、逻辑运算 符、SPSS函数以及SPSS变量名组成的式子。 关系运算符: > (大于)、<(小于)、=(等于)、 ~=(不等于)、>=(大于等于)、<=(小于等于)
spss统计分析实例分析PPT课件
• 操作步骤:
• 调用命令Analyze\Descriptive Statistics \Descriptives
• 选择“人均面积”作为分析变量 • 选择必要的分析指标
• 根据户口状况对数据进行拆分(Split File) • 重新调用命令\Descriptives计算不同户口状况的
第29页/共89页
标准正态评分值,并以变量形式存入数据文件中,以便后续分析时应用。
在多元统计分析中,对均值差异较大的变量,采 用变量标准化后的数据进行分析,可以消除均值 差异带来的影响。
第31页/共89页
第11页/共89页
SPSS
频数分析
的 操 作 步 骤
1、菜单中点分析/描述统计/频率,进入频 率对话框
第12页/共89页
SPSS
的 操 作 步 骤
2、将变量选入变量 窗口,再点击统计 量,进行设置,完 成后点继续返回
第13页/共89页
SPSS
的 操 作 步 骤
2、在频率主对话框中分别进入图表和格式进 行设置,完成后点继续返回,最后点确定
• 峰度:描述变量取值分布形态陡峭程度的统计量。
• 当数据分布与标准正态分布的陡峭程度相同时,峰度值等于0;峰度大于 0表示数据的分布比标准正态分布更陡峭,为尖峰分布;峰度小于0表示 数 据 的 分 布 比 标 准 正 态 分 布 平 缓第2,5页为/共平89峰页 分 布 。
偏态
峰态
左左偏偏分分布布
Ku rto si s
7.739
Skewness
.045
Ku rto si s
.089
Descriptiv e Statistics
户口 状况 本市户口 外地户口
N
• 调用命令Analyze\Descriptive Statistics \Descriptives
• 选择“人均面积”作为分析变量 • 选择必要的分析指标
• 根据户口状况对数据进行拆分(Split File) • 重新调用命令\Descriptives计算不同户口状况的
第29页/共89页
标准正态评分值,并以变量形式存入数据文件中,以便后续分析时应用。
在多元统计分析中,对均值差异较大的变量,采 用变量标准化后的数据进行分析,可以消除均值 差异带来的影响。
第31页/共89页
第11页/共89页
SPSS
频数分析
的 操 作 步 骤
1、菜单中点分析/描述统计/频率,进入频 率对话框
第12页/共89页
SPSS
的 操 作 步 骤
2、将变量选入变量 窗口,再点击统计 量,进行设置,完 成后点继续返回
第13页/共89页
SPSS
的 操 作 步 骤
2、在频率主对话框中分别进入图表和格式进 行设置,完成后点继续返回,最后点确定
• 峰度:描述变量取值分布形态陡峭程度的统计量。
• 当数据分布与标准正态分布的陡峭程度相同时,峰度值等于0;峰度大于 0表示数据的分布比标准正态分布更陡峭,为尖峰分布;峰度小于0表示 数 据 的 分 布 比 标 准 正 态 分 布 平 缓第2,5页为/共平89峰页 分 布 。
偏态
峰态
左左偏偏分分布布
Ku rto si s
7.739
Skewness
.045
Ku rto si s
.089
Descriptiv e Statistics
户口 状况 本市户口 外地户口
N
数理统计之SPSS统计分析ppt课件

精品课件
1. 单样本T检验
检验单个变量的均值是否与给定 的常数之间存在差异。样本均数与总体 均数之间的差异显著性检验属于单一样 本T 检验。
精品课件
精品课件Байду номын сангаас
精品课件
2. 两独立样本T检验
进行独立样本T 检验,要求被比较的两个 样本彼此独立,即没有配对关系。要求样 本均来自正态总体,而且均值对于检验是 有意义的描述统计量。
常用统计量:偏度、峰度
➢ 偏度:描述变量取值分布形态对称性的统计量。
➢ 当分布为对称分布时,正负总偏差相等,偏度值等于0;当分布为不对称分布时,正负 总偏差不相等,偏度值大于0或小于0。偏度值大于0表示正偏差值大,称为正偏或右偏 ;偏度值小于0表示负偏差值大,称为负偏或左偏。偏度绝对值越大,表示数据分布形 态的偏斜程度越大。
门为该目的而设计的几个模块则集中在描述菜单中,包括:
精品课件
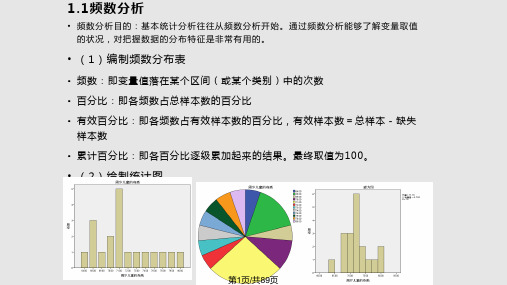
1.1 频数分析
频数分析目的:基本统计分析往往从频数分析开始。通过频数分析能 够了解变量取值的状况,对把握数据的分布特征是非常有用的。
基本任务 (1)编制频数分布表
• 频数:即变量值落在某个区间(或某个类别)中的次数 • 百分比:即各频数占总样本数的百分比 • 有效百分比:即各频数占有效样本数的百分比,有效样本数=总样本-缺失样本数 • 累计百分比:即各百分比逐级累加起来的结果。最终取值为100。
➢ 峰度:描述变量取值分布形态陡峭程度的统计量。
➢ 当数据分布与标准正态分布的陡峭程度相同时,峰度值等于0;峰度大于0表示数据的 分布比标准正态分布更陡峭,为尖峰分布;峰度小于0表示数据的分布比标准正态分布 平缓,为平峰分布。
精品课件
1.2 描述分析
(1)分析—描述统计—描述
1. 单样本T检验
检验单个变量的均值是否与给定 的常数之间存在差异。样本均数与总体 均数之间的差异显著性检验属于单一样 本T 检验。
精品课件
精品课件Байду номын сангаас
精品课件
2. 两独立样本T检验
进行独立样本T 检验,要求被比较的两个 样本彼此独立,即没有配对关系。要求样 本均来自正态总体,而且均值对于检验是 有意义的描述统计量。
常用统计量:偏度、峰度
➢ 偏度:描述变量取值分布形态对称性的统计量。
➢ 当分布为对称分布时,正负总偏差相等,偏度值等于0;当分布为不对称分布时,正负 总偏差不相等,偏度值大于0或小于0。偏度值大于0表示正偏差值大,称为正偏或右偏 ;偏度值小于0表示负偏差值大,称为负偏或左偏。偏度绝对值越大,表示数据分布形 态的偏斜程度越大。
门为该目的而设计的几个模块则集中在描述菜单中,包括:
精品课件
1.1 频数分析
频数分析目的:基本统计分析往往从频数分析开始。通过频数分析能 够了解变量取值的状况,对把握数据的分布特征是非常有用的。
基本任务 (1)编制频数分布表
• 频数:即变量值落在某个区间(或某个类别)中的次数 • 百分比:即各频数占总样本数的百分比 • 有效百分比:即各频数占有效样本数的百分比,有效样本数=总样本-缺失样本数 • 累计百分比:即各百分比逐级累加起来的结果。最终取值为100。
➢ 峰度:描述变量取值分布形态陡峭程度的统计量。
➢ 当数据分布与标准正态分布的陡峭程度相同时,峰度值等于0;峰度大于0表示数据的 分布比标准正态分布更陡峭,为尖峰分布;峰度小于0表示数据的分布比标准正态分布 平缓,为平峰分布。
精品课件
1.2 描述分析
(1)分析—描述统计—描述
《统计分析与SPSS的应用(第6版)》课件第四章

描述离散程度的统计量 标准差:表示某变量的所有变量值离散程度的统计 量。 SPSS中计算的是样本标准差 极差:最大值—最小值
计算描述统计量
描述对称程度的统计量
偏度(skewness):描述某变量分布形态的偏斜 程度和方向的统计量. 偏度为0表示对称; 大于0表示正偏差大(右偏) 小于0表示负偏差大(左偏)
第二种模式:用于多个变量基本描述统计量的对比
与频数分析相关的图形
交互作图:以制作条形图为例
计算描述统计量
目的:精确把握变量的总体分布状况,了解数据 的集中趋势、离散趋势、对称程度、陡峭程度。
基本方量
描述集中趋势的统计量 均值:表示某变量所有变量值集中趋势或平均水平 的统计量。 适用于定距数据。 特点:利用了全部数据,易受极端值的影响。
例:不同行业的人职业选择标准是否存在差异?
–
制造业
服务业
物质报酬 105
45
稳定性 40
35
2乘2的列联表进行yates连续性校正:
列联表中行列变量间的关系
卡方检验的要求: 一般要求列联表中期望频数小于5的格子数不 超过20%,否则会夸大卡方值,容易得出拒绝 结论,可以合并单元格。 卡方值会受样本数的影响
•期望分布反映的是H0成立情况下的分布特征
(3)计算卡方的观测值,
优 良 中 及格 总数
得到概率P值
男 10 5
5
3
23
(4)比较显著性水平和
概率P值。小于等于则 女 8 12 4 1 25
拒绝H0,否则不能拒绝 总数 18 17 9 4 48
37.5 35.4 18.8 8.3 100
列联表中行列变量间的关系
描述连续变量分布的图形
计算描述统计量
描述对称程度的统计量
偏度(skewness):描述某变量分布形态的偏斜 程度和方向的统计量. 偏度为0表示对称; 大于0表示正偏差大(右偏) 小于0表示负偏差大(左偏)
第二种模式:用于多个变量基本描述统计量的对比
与频数分析相关的图形
交互作图:以制作条形图为例
计算描述统计量
目的:精确把握变量的总体分布状况,了解数据 的集中趋势、离散趋势、对称程度、陡峭程度。
基本方量
描述集中趋势的统计量 均值:表示某变量所有变量值集中趋势或平均水平 的统计量。 适用于定距数据。 特点:利用了全部数据,易受极端值的影响。
例:不同行业的人职业选择标准是否存在差异?
–
制造业
服务业
物质报酬 105
45
稳定性 40
35
2乘2的列联表进行yates连续性校正:
列联表中行列变量间的关系
卡方检验的要求: 一般要求列联表中期望频数小于5的格子数不 超过20%,否则会夸大卡方值,容易得出拒绝 结论,可以合并单元格。 卡方值会受样本数的影响
•期望分布反映的是H0成立情况下的分布特征
(3)计算卡方的观测值,
优 良 中 及格 总数
得到概率P值
男 10 5
5
3
23
(4)比较显著性水平和
概率P值。小于等于则 女 8 12 4 1 25
拒绝H0,否则不能拒绝 总数 18 17 9 4 48
37.5 35.4 18.8 8.3 100
列联表中行列变量间的关系
描述连续变量分布的图形
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第6章 相关和回归分析
spss统计分析及应用教程 6
第6章 相关和回归分析
• 本章学习目标
• 理解相关和回归分析的基本思想、原理与两者之间关 系;
• 明确相关和回归分析的实验目的、实验步骤和实验内 容;
• 掌握实验结果的统计分析; • 熟练使用散点图; • 相关和回归分析应用在经济管理数据分析中的应用。
统计学中,相关分析是以分析变量间的线性关系为主,是研究它们 之间线性相关密切程度一种统计方法。它是通过几个描述相关关系 的统计量来确定相关的密切程度和线性相关的方向。这些统计量包 括皮尔逊(Pearson)相关系数、斯皮尔曼(Spearman)和肯德尔 (Kendall)秩相关系数,一般用符号r来表示。
spss统计分析及应用教程 6
实验二 偏相关分析
• 实验目的
• 准确理解偏相关分析的方法原理和使用前提; • 熟练掌握偏相关分析的SPSS操作; • 了解偏相关分析在中介变量运用方法。
spss统计分析及应用教程 6
实验二 偏相关分析
• 准备知识
偏相关分析的概念
在多元相关分析中,由于其他变量的影响,Pearson相关系数 只是从表面上反映两个变量相关性,相关系数不能真正反映两 个变量间的线性相关程度,甚至会给出相关的假想。因此,在 有些场合中,简单的Pearson相关系数并不是测量相关关系的 本质性统计量。当其他变量控制后,给定的任意两个变量之间 的相关系数叫做偏相关系数。偏相关系数才是真正反映两个变 量相关关系的统计量。
spss统计分析及应用教程 6
第6章 相关和回归分析
• 相关和回归分析是分析客观事物之间相关性的数量分析方法。客观 事物之间的关系可分为函数关系和统计关系。函数关系指客观事物 之间的一一对应关系,即当一组变量取一定值时,另一变量y可以依 确定的函数取唯一确定的值。统计关系指客观事物之间的一种非一 一对应关系,即当一组变量取一定值时,另一变量y无法依确定的函 数取唯一确定的值。事物之间的函数关系比较容易分析,而事物之 间的统计关系不像函数关系那样直接。相关和回归分析正是以不同 的方式处理事物间的统计关系。 。
(1)绘制散点图,以判断两个变量之间有无线性相关趋势,
见图
spss统计分析及应用教程 6
(2)从菜单上依次选择“分析—相关—双变量(二元相关) ”命令,打开对话框,如图6-1-2所示。选择“胸围”、“肺 活量”到变量框;选择“相关系数-pearson”、“显著性检验 -双侧检验”、“标记显著性相关”。单击“确定”按钮。
spss统计分析及应用教程 6
• 准备知识
简单相关分析的概念
相关系数具有一些特性: (1)它的取值极限在-1和+1之间,即-1≤r≤+1。 (2)它具有对称性,即X与Y之间的相关系数和Y与X之间的相关系 数相同。 (3)它与原点和测度都无关,即如果定义和,其中,且c和d都是 常数,则和之间的r无异于原始变量X与Y之间的r。 (4)如果X和Y统计上独立的,则它们之间的相关系数r=0;但反过 来,r=0不等于说X和Y是独立的。 (5)它仅是线性关联的一个度量,不能用于描述非线性关系。
spss统计分析及应用教程 6
• 实验结果
胸围与肺活量相关性
spss统计分析及应用教程 6
• 实验分析
胸围与肺活量相关性
由结果表可以看出,变量间相关系数是用2*2方阵形式出现 的。每一行和每一列的两个变量对应的单元格就是这两个变 量相关分析结果,有三个数字,分别为Pearson 相关性、显 著性(双侧)、N(样本量)。如表格中黑色单元格所示。 胸围与肺活量的Pearson 相关系数为0.549,显著性检验为 0.064,样本量为12。如果单从相关系数可以看出两者是正 相关的而且具有中等相关性。但是,显著性检验0.064> 0.05,接受原假设,所以Pearson 相关系数为0.549的值没有 通过显著检验。根据这12个小样本来推断该大学一年级女生 胸围与肺活量之间的没有线性相关性。
零假 H0:设 r0
给出显著性水平ɑ,做出判断。对给定的显著性水平,与检验统 计量相对应的p值进行比较:当p值(SPSS中常用Sig值来表示) 小于显著性水平ɑ,则拒绝原假设,认为相关系数不为零。如 ɑ=0.05,P=0.01,则P<ɑ,拒绝零假设,即两个变量相关系数 r≠0,计算得到的相关系数是有意义,可以对它进行说明两个变 量之间的相关程度:反之,当p值大于显著性水平ɑ,则不能拒 绝原假设,认为相关系数为零,不能根据计算得到的相关系数来 说明两者之间相关程度。
spss统计分析及应用教程 6
• 相关系数的计算方法 斯皮尔曼和肯德尔秩相关关系
用于反映两个序次或等级变量的相关程度。计算Spearman相关数
据时,要求先对原始变量的数据排序,根据秩使用Spearman相关
系数公式进行计算。公式可为:
rs
(Ri R)(Si S) (Ri R)2(Si S)2
spss统计分析及应用教程 6
• 相关系数的计算方法 皮尔逊(Pearson)相关系数
通常,仅对刻度级(Scale)变量计算皮尔逊(Pearson)相关系数,
公式为:
rxy
(xi x)(yi y) (xi x)2 (yi y)2
其中 x ,y 分别为 x i , y(i i=1,2,…,n)的算术平均值。
式中,R
i
、S
i分别是
x
i,y
i 的秩。R 、S
分别是变量 R
i 、S
的平均值。
i
至于肯德尔秩相关系数的计算公式,此处不再列出。
spss统计分析及应用教程 6
• 关于相关系数统计意义的检验
我们通常利用样本来研究总体的特性,由于抽样误差的存在,样 本中两个变量之间的相关系数不为0,不能直接就断定总体中两 个变量间的相关系数不是0,而必须进行检验。
spss统计分析及应用教程 6
实验一 相关分析
• 实验目的
• 了解相关分析的方法原理; • 熟练掌握相关分析的SPSS操作命令; • 熟练应用三个常用相关系数的计算方法及其数据测度
要求; • 运用相关分析解决管理学实际问题的能力。
spss统计分析及应用教程 6
实验一 单一样的概念
spss统计分析及应用教程 6
实验一 相关分析
• 实验内容
• 某大学一年级12名女生的胸围(cm)、肺活量(L)身高 (m),数据见表6-1-1。试分析胸围与肺活量两个变量之 间相关关系。
spss统计分析及应用教程 6
• 表6-1-1 胸围、肺活量与身高相关数据表
spss统计分析及应用教程 6
• 实验步骤
spss统计分析及应用教程 6
第6章 相关和回归分析
• 本章学习目标
• 理解相关和回归分析的基本思想、原理与两者之间关 系;
• 明确相关和回归分析的实验目的、实验步骤和实验内 容;
• 掌握实验结果的统计分析; • 熟练使用散点图; • 相关和回归分析应用在经济管理数据分析中的应用。
统计学中,相关分析是以分析变量间的线性关系为主,是研究它们 之间线性相关密切程度一种统计方法。它是通过几个描述相关关系 的统计量来确定相关的密切程度和线性相关的方向。这些统计量包 括皮尔逊(Pearson)相关系数、斯皮尔曼(Spearman)和肯德尔 (Kendall)秩相关系数,一般用符号r来表示。
spss统计分析及应用教程 6
实验二 偏相关分析
• 实验目的
• 准确理解偏相关分析的方法原理和使用前提; • 熟练掌握偏相关分析的SPSS操作; • 了解偏相关分析在中介变量运用方法。
spss统计分析及应用教程 6
实验二 偏相关分析
• 准备知识
偏相关分析的概念
在多元相关分析中,由于其他变量的影响,Pearson相关系数 只是从表面上反映两个变量相关性,相关系数不能真正反映两 个变量间的线性相关程度,甚至会给出相关的假想。因此,在 有些场合中,简单的Pearson相关系数并不是测量相关关系的 本质性统计量。当其他变量控制后,给定的任意两个变量之间 的相关系数叫做偏相关系数。偏相关系数才是真正反映两个变 量相关关系的统计量。
spss统计分析及应用教程 6
第6章 相关和回归分析
• 相关和回归分析是分析客观事物之间相关性的数量分析方法。客观 事物之间的关系可分为函数关系和统计关系。函数关系指客观事物 之间的一一对应关系,即当一组变量取一定值时,另一变量y可以依 确定的函数取唯一确定的值。统计关系指客观事物之间的一种非一 一对应关系,即当一组变量取一定值时,另一变量y无法依确定的函 数取唯一确定的值。事物之间的函数关系比较容易分析,而事物之 间的统计关系不像函数关系那样直接。相关和回归分析正是以不同 的方式处理事物间的统计关系。 。
(1)绘制散点图,以判断两个变量之间有无线性相关趋势,
见图
spss统计分析及应用教程 6
(2)从菜单上依次选择“分析—相关—双变量(二元相关) ”命令,打开对话框,如图6-1-2所示。选择“胸围”、“肺 活量”到变量框;选择“相关系数-pearson”、“显著性检验 -双侧检验”、“标记显著性相关”。单击“确定”按钮。
spss统计分析及应用教程 6
• 准备知识
简单相关分析的概念
相关系数具有一些特性: (1)它的取值极限在-1和+1之间,即-1≤r≤+1。 (2)它具有对称性,即X与Y之间的相关系数和Y与X之间的相关系 数相同。 (3)它与原点和测度都无关,即如果定义和,其中,且c和d都是 常数,则和之间的r无异于原始变量X与Y之间的r。 (4)如果X和Y统计上独立的,则它们之间的相关系数r=0;但反过 来,r=0不等于说X和Y是独立的。 (5)它仅是线性关联的一个度量,不能用于描述非线性关系。
spss统计分析及应用教程 6
• 实验结果
胸围与肺活量相关性
spss统计分析及应用教程 6
• 实验分析
胸围与肺活量相关性
由结果表可以看出,变量间相关系数是用2*2方阵形式出现 的。每一行和每一列的两个变量对应的单元格就是这两个变 量相关分析结果,有三个数字,分别为Pearson 相关性、显 著性(双侧)、N(样本量)。如表格中黑色单元格所示。 胸围与肺活量的Pearson 相关系数为0.549,显著性检验为 0.064,样本量为12。如果单从相关系数可以看出两者是正 相关的而且具有中等相关性。但是,显著性检验0.064> 0.05,接受原假设,所以Pearson 相关系数为0.549的值没有 通过显著检验。根据这12个小样本来推断该大学一年级女生 胸围与肺活量之间的没有线性相关性。
零假 H0:设 r0
给出显著性水平ɑ,做出判断。对给定的显著性水平,与检验统 计量相对应的p值进行比较:当p值(SPSS中常用Sig值来表示) 小于显著性水平ɑ,则拒绝原假设,认为相关系数不为零。如 ɑ=0.05,P=0.01,则P<ɑ,拒绝零假设,即两个变量相关系数 r≠0,计算得到的相关系数是有意义,可以对它进行说明两个变 量之间的相关程度:反之,当p值大于显著性水平ɑ,则不能拒 绝原假设,认为相关系数为零,不能根据计算得到的相关系数来 说明两者之间相关程度。
spss统计分析及应用教程 6
• 相关系数的计算方法 斯皮尔曼和肯德尔秩相关关系
用于反映两个序次或等级变量的相关程度。计算Spearman相关数
据时,要求先对原始变量的数据排序,根据秩使用Spearman相关
系数公式进行计算。公式可为:
rs
(Ri R)(Si S) (Ri R)2(Si S)2
spss统计分析及应用教程 6
• 相关系数的计算方法 皮尔逊(Pearson)相关系数
通常,仅对刻度级(Scale)变量计算皮尔逊(Pearson)相关系数,
公式为:
rxy
(xi x)(yi y) (xi x)2 (yi y)2
其中 x ,y 分别为 x i , y(i i=1,2,…,n)的算术平均值。
式中,R
i
、S
i分别是
x
i,y
i 的秩。R 、S
分别是变量 R
i 、S
的平均值。
i
至于肯德尔秩相关系数的计算公式,此处不再列出。
spss统计分析及应用教程 6
• 关于相关系数统计意义的检验
我们通常利用样本来研究总体的特性,由于抽样误差的存在,样 本中两个变量之间的相关系数不为0,不能直接就断定总体中两 个变量间的相关系数不是0,而必须进行检验。
spss统计分析及应用教程 6
实验一 相关分析
• 实验目的
• 了解相关分析的方法原理; • 熟练掌握相关分析的SPSS操作命令; • 熟练应用三个常用相关系数的计算方法及其数据测度
要求; • 运用相关分析解决管理学实际问题的能力。
spss统计分析及应用教程 6
实验一 单一样的概念
spss统计分析及应用教程 6
实验一 相关分析
• 实验内容
• 某大学一年级12名女生的胸围(cm)、肺活量(L)身高 (m),数据见表6-1-1。试分析胸围与肺活量两个变量之 间相关关系。
spss统计分析及应用教程 6
• 表6-1-1 胸围、肺活量与身高相关数据表
spss统计分析及应用教程 6
• 实验步骤