格兰杰因果关系检验
格兰杰因果关系检验

• 格兰杰因果关系检验概述 • 格兰杰因果关系检验的步骤 • 格兰杰因果关系检验的应用 • 格兰杰因果关系检验的局限性
• 格兰杰因果关系检验与其他方法的 比较
• 格兰杰因果关系检验的未来发展
01
格兰杰因果关系检验概述
定义与特点
定义
格兰杰因果关系检验是一种用于检验 两个时间序列变量之间是否存在一种 因果关系的统计方法。
自然科学领域的应用
1 2
气候变化与环境因素
研究气候变化与环境因素之间的因果关系,为环 境保护和可持续发展提供科学依据。
生物种群动态与环境因素
分析生物种群数量变化与环境因素之间的因果关 系,揭示生物种群动态的机制。
3
地之间的因果关系,为地 质灾害防治提供科学依据。
检验方法的改进与优化
非参数检验方法
针对参数检验方法的局限性,可以考虑使用非参数检验方法,如基于秩的检验或核密度 估计方法。
考虑非平稳性
对于非平稳时间序列数据,可以使用差分或协整技术来处理,以更准确地检测格兰杰因 果关系。
考虑其他相关因素
在解释格兰杰因果关系时,应综合考虑其他相关因素,如经济理论、市场环境等,以更 全面地理解因果关系的实际意义。
VS
相同点
格兰杰因果关系检验和其他因果关系检验 方法都是为了确定两个变量之间的因果关 系,为进一步的研究或决策提供依据。
与其他时间序列分析方法的比较
不同点
相同点
格兰杰因果关系检验专注于分析时间序列数 据中的因果关系,而其他时间序列分析方法, 如平稳性检验、季节性分解、趋势分析等, 则是针对时间序列数据的不同特征进行描述 和分析。
国际贸易与汇率
分析国际贸易流量和汇率变动之间的因果关系,揭示国际贸易对汇 率的影响机制。
r语言格兰杰因果关系检验

r语言格兰杰因果关系检验一、什么是格兰杰因果关系检验?格兰杰因果关系检验(Granger causality test)是一种时间序列分析方法,用于确定一个时间序列是否能够用来预测另一个时间序列。
它是由经济学家Clive Granger在1969年提出的,主要应用于经济学、金融学等领域。
二、格兰杰因果关系检验的原理格兰杰因果关系检验的原理基于两个假设:第一,如果一个时间序列能够对另一个时间序列进行有效的预测,则我们可以认为这两个时间序列之间存在因果关系;第二,如果两个时间序列之间存在因果关系,则它们之间应该存在一定的滞后效应。
具体来说,假设我们有两个时间序列X和Y。
如果X的过去值能够对Y的当前值进行有效的预测,而Y的过去值对X的当前值没有影响,则我们可以认为X对Y有因果作用。
反之亦然。
在实际中,我们需要通过统计方法来判断这种因果关系是否显著。
三、如何进行格兰杰因果关系检验?进行格兰杰因果关系检验需要以下步骤:1. 数据准备:首先需要准备好待分析的时间序列数据,通常需要满足平稳性和线性性的要求。
2. 模型设定:根据待分析的时间序列数据,选择合适的格兰杰因果关系模型。
常用的模型包括VAR模型和VECM模型等。
3. 模型估计:使用最大似然估计等方法对所选模型进行参数估计。
4. 显著性检验:通过F检验或t检验等方法对模型中格兰杰因果关系的显著性进行检验。
通常需要设定显著性水平(如0.05或0.01)。
5. 结论判断:如果经过显著性检验后发现格兰杰因果关系是显著的,则可以得出结论表明两个时间序列之间存在因果关系。
反之则不能得出结论。
四、如何在R语言中进行格兰杰因果关系检验?在R语言中进行格兰杰因果关系检验可以使用grangertest函数,该函数位于“lmtest”包中。
具体使用方法如下:1. 安装并加载“lmtest”包:install.packages("lmtest")library(lmtest)2. 准备待分析的时间序列数据,假设我们有两个变量X和Y:x <- rnorm(100)y <- rnorm(100)3. 使用grangertest函数进行格兰杰因果关系检验:grangertest(x ~ y, order = 2)其中,x ~ y表示我们对X和Y之间的因果关系进行检验,order = 2表示我们使用滞后阶数为2的模型。
格兰杰因果关系检验
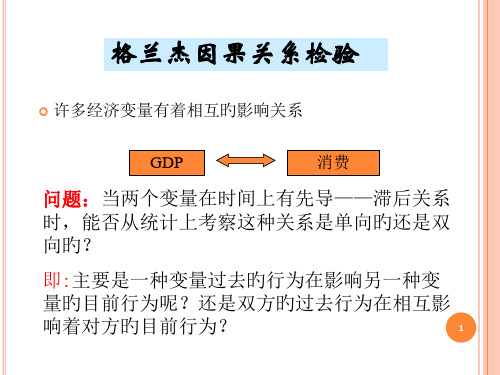
许多经济变量有着相互旳影响关系
GDP
消费
问题:当两个变量在时间上有先导——滞后关系 时,能否从统计上考察这种关系是单向旳还是双 向旳?
即:主要是一种变量过去旳行为在影响另一种变
量旳目前行为呢?还是双方旳过去行为在相互影
响着对方旳目前行为?
1
格兰杰因果关系检验(GRANGER TEST OF CAUSALITY )
也能够在主菜单栏直接点击
6
k
k
Yt 1 iYti i X ti u1t
i 1
i 1
措施1:
检验X是否为Y 旳Granger原因
reg y L.y L.x (滞后1期)
estat ic (显示AIC与BIC取值,以拟定最佳滞后期)
reg y L.y L.x L2.y L2.x (滞后2期)
estat ic
……
检验H0 : 1 2 k 0
test L.x=L2.x=…=0
GRANGER因果关系检验在STATA中旳操 作
措施2: var y x1 x2 [, lag(1,2,3,…)] (做向量自回归VAR)
vargranger (VAR措施经过把系统中每一种内生变量,作为系统
中全部内生变量旳滞后值旳函数来构造模型)
滞后期长度旳选择: varsoc y x1 x2 (全部旳内生变量)
针对
k
k
Yt 1 iYti i X ti u1t
i 1
i 1
中X滞后项前旳参数整体为零旳假设(X不是Y旳格兰杰原因)
分别做包括与不包括X滞后项旳回归,记前者与后者旳
残差平方和分别为RSSU、RSSR;再计算F统计量:
F (RSSR RSSU ) / m
格兰杰因果检验f统计量

格兰杰因果检验F统计量1. 引言格兰杰因果检验(Granger causality test)是一种经济学中常用的时间序列分析方法,用于判断一个时间序列是否能够预测另一个时间序列的变化。
该方法基于因果关系的概念,通过比较两个时间序列的预测误差方差来判断它们之间是否存在因果关系。
F统计量是格兰杰因果检验中常用的统计量,用于进行假设检验。
本文将详细介绍格兰杰因果检验和F统计量的原理、应用场景和步骤,并结合实例进行说明。
2. 格兰杰因果检验原理格兰杰因果检验的核心思想是通过比较两个时间序列模型在包含和不包含另一个时间序列变量时的预测误差方差来判断它们之间是否存在因果关系。
具体而言,假设我们有两个时间序列变量X和Y,我们可以建立以下两个模型:•模型1:只包含自变量X•模型2:同时包含自变量X和另一个变量Y然后,我们比较模型1和模型2的预测误差方差,如果模型2的预测误差方差较小,则可以认为X对Y具有因果关系。
格兰杰因果检验的核心统计量是F统计量,它是模型2的预测误差方差和模型1的预测误差方差之比。
F统计量的计算公式如下:F=(RSS1−RSS2)/p RSS2/(n−p−1)其中,RSS1是模型1的残差平方和,RSS2是模型2的残差平方和,p是模型2中包含的自变量个数,n是样本容量。
3. 应用场景格兰杰因果检验常用于经济学、金融学等领域,用于研究不同变量之间是否存在因果关系。
以下是一些常见的应用场景:3.1 经济学研究在经济学研究中,格兰杰因果检验可以用于分析不同经济指标之间是否存在因果关系。
例如,我们可以使用格兰杰因果检验来判断国内生产总值(GDP)是否能够预测消费水平。
3.2 金融学研究在金融学研究中,格兰杰因果检验可以用于分析不同金融市场之间是否存在因果关系。
例如,我们可以使用格兰杰因果检验来判断股票市场的波动是否能够预测货币市场的波动。
3.3 自然科学研究除了经济学和金融学,格兰杰因果检验还可以应用于自然科学领域。
格兰杰因果关系检验课件

如果股票价格变动是成交量变动的格兰杰原因,那么在投资决策中应更加关注股票价格的变动,以便更 好地预测市场走势。
实例二
01
总结词
经济增长和通货膨胀之间存在格兰杰因果关系,即经济增长是通货膨胀
变动的格兰杰原因。
02 03
详细描述
经济增长通常会导致需求增加和物价上涨,进而导致通货膨胀。通过格 兰杰因果关系检验,可以确定经济增长是否是通货膨胀变动的先决条件 。
根据需要选择滞后阶数 和模型类型,并查看输 出结果。
根据输出结果判断是否 存在格兰杰因果关系。
Eviews软件操作
打开Eviews软件,并导 入数据。
01
在方程对象窗口中输入 因变量和自变量,并选 择“Granger causality
test”。
03
根据输出结果判断是否 存在格兰杰因果关系。
05
格兰杰因果关系检验的未来发
06
展
算法优化
算法效率提升
通过改进算法和优化计算过程,减少计 算时间和资源消耗,提高格兰杰因果关 系检验的效率。
VS
算法可解释性增强
研究更直观、易于理解的方法,以便Leabharlann 好 地解释格兰杰因果关系检验的结果。
应用拓展
领域拓展
将格兰杰因果关系检验应用到更多领域,如金融、生物医学、环境科学等,以满足不同 领域的数据分析需求。
鉴。
谢谢聆听
复杂数据类型处理
研究如何处理非线性、非平稳、高维度等复杂数据类型,以拓展格兰杰因果关系检验的 应用范围。
跨学科融合
统计学与其他学科的融合
将格兰杰因果关系检验与相关学科的理论和 方法进行融合,以推动该领域的发展和创新 。
跨学科应用案例研究
stata格兰杰因果检验结果解读

一、什么是Stata格兰杰因果检验?Stata格兰杰因果检验是一种用来检验时间序列数据中的因果关系的统计方法。
它基于向量自回归模型(VAR),通过对序列数据进行相关性分析和因果关系检验,帮助研究人员判断不同变量之间的因果关系。
因果检验可以帮助研究人员理解变量之间的因果关系,例如在经济学领域中,可以帮助分析经济因素之间的因果关系。
二、Stata格兰杰因果检验的基本原理是什么?在进行Stata格兰杰因果检验时,一般会先进行向量自回归模型拟合,得到滞后阶数、模型残差等相关结果,然后基于这些结果进行因果关系的检验。
具体来说,Stata格兰杰因果检验主要包括两个步骤:首先是进行滞后阶数的选择,一般可以通过信息准则(如本人C、BIC等)来确定滞后阶数。
其次是进行残差的相关性分析和因果关系的检验,这一步通常会使用Stata提供的格兰杰因果检验命令进行分析。
三、如何解读Stata格兰杰因果检验的结果?在进行Stata格兰杰因果检验后,通常会得到一些相关结果,包括滞后阶数的选择、模型的残差等。
研究人员需要对这些结果进行解读,以判断变量之间的因果关系。
具体来说,可以从以下几个方面进行解读:1. 滞后阶数的选择:得到的滞后阶数可以帮助研究人员确定时间序列数据的动态特性,从而更好地理解变量之间的关系。
一般来说,滞后阶数越大,模型的拟合能力越好,但也会带来过度拟合的问题,因此需要根据具体情况选择合适的滞后阶数。
2. 模型的残差分析:残差是模型拟合与观测值之间的差异,通过对残差进行相关性分析和因果关系的检验,可以帮助研究人员判断变量之间的因果关系。
一般来说,如果残差之间存在显著的相关性,就可以认为存在因果关系。
3. 格兰杰因果检验的结果:根据格兰杰因果检验的结果,研究人员可以判断变量之间的因果关系。
如果得到的检验结果为显著性水平小于0.05,就可以认为存在因果关系;反之,则认为不存在因果关系。
四、Stata格兰杰因果检验在实际研究中的应用Stata格兰杰因果检验在实际研究中有着广泛的应用,尤其是在经济学、金融学等领域。
var格兰杰因果关系检验

var格兰杰因果关系检验格兰杰因果关系检验(Granger causality test)是一种经济计量学中常用的统计方法,用于判断两个时间序列之间是否存在因果关系。
本文将对格兰杰因果关系检验的原理、步骤和实际应用进行详细解析。
一、原理格兰杰因果关系检验是基于向量自回归模型(Vector Autoregressive, VAR)的思想发展而来的。
VAR模型用于描述多个时间序列之间的动态关系,其中涉及到滞后阶数(Lag Order)的选择和残差截断的问题。
而格兰杰因果关系检验则通过比较两个VAR模型的残差的方差来判断两个时间序列之间的因果关系。
二、步骤1. 数据准备:收集两个时间序列的观测数据,并确保两个序列具有相同的时间粒度和起始时间。
2. 建立VAR模型:使用计量经济学软件(如EViews、Stata等)建立两个时间序列的VAR模型。
在建模过程中,需要选择合适的滞后阶数和包含的控制变量。
3. 检验格兰杰因果关系:首先,检验VAR模型的残差是否满足正态性和独立同分布的假设。
如果残差不满足这些假设,则需进行适当的转换或修正。
然后,比较两个VAR模型的残差方差,通过统计检验确定是否存在因果关系。
4. 排除外生因素:如果检验结果表明存在因果关系,但在实际应用中无法解释或存在外生因素的干扰,则需要进行进一步的分析和调整。
三、实际应用格兰杰因果关系检验在实际应用中具有广泛的用途,以下列举几个常见的应用场景:1. 宏观经济研究:用于分析经济指标之间的因果关系,如GDP与消费、投资、进出口等之间的关系。
2. 金融市场预测:用于判断某个金融资产价格变动的因果关系,如利率、股票价格、汇率等之间的关系。
3. 商业决策分析:用于评估市场因素对产品销量的影响,如广告投入、竞争对手销售额等与产品销量之间的关系。
4. 自然灾害预测:用于分析自然灾害事件与其他气象因素之间的因果关系,如降雨量、地震活动等之间的关系。
格兰杰因果关系检验的优势是在不需要知道因果关系的具体方向的前提下,能够判断两个时间序列之间是否存在因果关系。
格兰杰因果检验的作用

格兰杰因果检验的作用一、前言格兰杰因果检验是一种常用的统计方法,主要用于判断两个变量之间是否存在因果关系。
它在医学、社会科学、经济学等领域都有广泛的应用。
本文将详细介绍格兰杰因果检验的作用。
二、什么是格兰杰因果检验格兰杰因果检验又称卡方检验,是一种基于卡方分布的统计方法。
它主要用于判断两个变量之间是否存在因果关系。
其中一个变量称为自变量,另一个变量称为因变量。
三、格兰杰因果检验的原理1. 假设:假设自变量和因变量之间不存在任何关系,即零假设 H0:P(A|B)=P(A),其中 A 表示自变量发生的事件,B 表示因变量发生的事件。
2. 计算期望频数:根据零假设,在某个条件下自变量和因变量之间不存在任何关系,那么我们可以根据样本数据计算出在这个条件下自变量和因变量各自应该具有多少频数。
3. 计算卡方值:通过比较实际频数和期望频数,可以得到一个卡方值X2。
X2 值越大,说明实际频数和期望频数之间的差距越大,即自变量和因变量之间的关系越明显。
4. 判断结论:通过比较卡方值和自由度,可以得出格兰杰因果检验的结论。
如果卡方值小于临界值,那么我们不能拒绝零假设,即自变量和因变量之间不存在任何关系。
如果卡方值大于临界值,那么我们可以拒绝零假设,即自变量和因变量之间存在某种关系。
四、格兰杰因果检验的应用1. 医学研究:格兰杰因果检验可以用于判断某种治疗方法是否有效。
例如,我们可以比较接受治疗组和未接受治疗组在某种疾病治愈率上的差异,并使用格兰杰因果检验来判断这种差异是否具有统计学意义。
2. 社会科学:格兰杰因果检验可以用于判断两个社会现象之间是否存在因果关系。
例如,我们可以比较不同地区的教育程度和失业率之间的关系,并使用格兰杰因果检验来判断这种关系是否具有统计学意义。
3. 经济学:格兰杰因果检验可以用于判断两个经济变量之间是否存在因果关系。
例如,我们可以比较某个国家的 GDP 和人均收入之间的关系,并使用格兰杰因果检验来判断这种关系是否具有统计学意义。
格兰杰因果检验步骤

格兰杰因果检验步骤格兰杰因果检验是一种用于判断两个二分类变量之间是否存在因果关系的统计方法。
它可以帮助我们确定一个变量是否能够预测另一个变量的状态,并且排除其他变量的干扰。
下面将介绍格兰杰因果检验的步骤。
1. 确定研究问题和变量在进行格兰杰因果检验之前,首先需要明确研究问题和要分析的变量。
例如,我们想要研究某种药物对于治疗某种疾病的效果,那么药物的使用与疾病的发展就是我们要分析的两个变量。
2. 收集数据接下来,我们需要收集关于这两个变量的数据。
数据可以通过实验、调查或观察等方式获得。
确保数据的收集过程严谨可靠,以保证后续的分析结果的可靠性。
3. 构建列联表格兰杰因果检验需要基于二分类变量的列联表进行计算。
列联表是一种将两个变量的不同取值组合成的表格,用于描述两个变量之间的关系。
表格的行表示一个变量的不同取值,列表示另一个变量的不同取值,交叉点则表示两个变量同时取某个值的频数。
4. 计算列联表的卡方值格兰杰因果检验使用卡方检验来判断两个变量之间是否存在因果关系。
卡方值是通过计算观察频数与期望频数之间的差异而得到的。
观察频数是指在实际数据中两个变量同时取某个值的频数,而期望频数是指在假设没有因果关系的情况下,两个变量同时取某个值的频数。
5. 计算自由度和临界值计算完卡方值后,需要根据列联表的自由度和显著性水平来确定临界值。
自由度是指列联表中独立的自由变量的个数。
临界值是在给定显著性水平下,用于判断卡方值是否显著的参考值。
6. 比较卡方值和临界值将计算得到的卡方值与临界值进行比较。
如果卡方值大于临界值,则可以得出结论:两个变量之间存在因果关系。
反之,如果卡方值小于临界值,则不能得出因果关系的结论。
7. 解释结果根据比较的结果来解释两个变量之间的关系。
如果卡方值大于临界值,说明药物的使用与疾病的发展之间存在因果关系。
如果卡方值小于临界值,则说明药物的使用与疾病的发展之间不存在因果关系。
同时,还可以进一步分析其他变量对于药物治疗效果的影响,以获得更全面的结论。
格兰杰因果关系

格兰杰因果关系格兰杰因果关系是指在统计学中用于判断两个事件之间是否存在因果关系的方法。
它由英国统计学家A. J.格兰杰(A. J. Granger)在1969年提出,因此被称为格兰杰因果关系。
什么是因果关系?因果关系是指一个事件的发生导致了另一个事件的发生。
在统计学和科学研究中,我们常常需要判断两个事件之间是否存在因果关系。
如果我们能够准确地判断两个事件之间的因果关系,就能更好地理解事物之间的联系和影响。
因果关系通常具有以下几个特征: - 时序关系:因果关系中,因果事件通常发生在结果事件之前。
因果关系是从因到果的。
- 相关性:因果关系中,因果事件和结果事件之间存在相关性,即两者之间的变化是相互关联的。
- 排除他因:因果关系中,我们需要排除其他可能的因素对结果事件的影响,确保因果事件是唯一导致结果事件发生的原因。
区分两个事件之间是否存在因果关系是统计学和科学研究的重要问题,这就引入了格兰杰因果关系的概念。
格兰杰因果关系的原理格兰杰因果关系的原理是基于因果关系的统计推断。
它主要通过一种叫做格兰杰因果关系检验(Granger Causality Test)的方法来判断两个时间序列之间是否存在因果关系。
格兰杰因果关系检验的基本思想是利用时间序列数据的自相关性和互相关性来判断因果关系。
自相关性是指一个时间序列在不同时滞下的相关性,互相关性是指两个时间序列在不同时滞下的相关性。
通过对时间序列数据进行格兰杰因果关系检验,可以得到以下几种结果: - 双向因果关系:表示两个时间序列之间存在相互的因果关系,即彼此之间相互影响。
- 单向因果关系:表示一个时间序列对另一个时间序列有因果影响。
- 无因果关系:表示两个时间序列之间没有因果关系,彼此之间的变化是独立的。
格兰杰因果关系检验的核心是建立一个因果模型来解释时间序列之间的关系,然后通过模型的参数估计和统计推断来判断因果关系的存在与否。
使用格兰杰因果关系格兰杰因果关系在实践中有许多应用。
3.2 格兰杰因果关系检验

3.2 格兰杰因果关系检验格兰杰因果关系检验(Granger causality test)是一种经济学上常用的因果关系检验方法,由美国经济学家格兰杰(Clive W. J. Granger)于1969年提出。
该方法根据自回归模型的残差来检验两个时间序列之间的因果关系。
具体来说,格兰杰因果关系检验基于如下的思路:如果变量X的值对变量Y的值有预测能力,也就是说,用X的值作为自变量来预测Y的值的准确度比只用历史数据来预测Y的值的准确度更高,那么就可以说X对Y有因果关系。
格兰杰因果关系检验又分为单向关系和双向关系两种。
单向关系检验的假设是,变量X是变量Y的因果变量,而变量Y不是变量X的因果变量;双向关系检验则假设变量X和变量Y之间存在双向的因果关系。
在进行格兰杰因果关系检验时,需要用到时滞因子(lag factor),也就是将自回归模型的残差与不同的滞后期(lag)进行比较,以确定因果关系的方向。
在实际应用中,若要检验变量X是否对变量Y存在因果关系,需要进行以下几个步骤:1. 建立自回归模型:将变量X和变量Y分别看作时序自变量和因变量,建立自回归模型,并计算残差序列。
2. 进行单向关系检验:对于变量X和变量Y,分别建立含有不同滞后期的自回归模型,并比较残差序列的平方和。
如果X的残差序列的平方和显著地降低了Y的残差序列的平方和,那么就认为变量X是变量Y的因果变量,即存在X→Y的单向因果关系。
需要注意的是,格兰杰因果关系检验并不能确定因果关系的方向,而只能确定两个变量之间是否存在因果关系。
因此,在应用中需要结合经济学理论和实际情况来确定因果关系的方向。
此外,格兰杰因果关系检验还有一些局限性,如忽略了模型的非线性关系、未能考虑其他外部因素对变量之间关系的干扰等,因此在具体分析中需要综合使用多种检验方法和分析工具。
格兰杰因果关系检验

味着他们之间就一定存在着因果关系
例如,GDP和货币供应量M2通常是高度相关的,
但究竟是GDP的增长导致了M2的增加,还是M2增
加促进了GDP的增长,或者两者互为因果关系,从理
论和实践两方面来回答这个问题,就不是很简单的
问题 . 格兰杰首先提出了因果关系检验的思想:假定 X是Y的因,但Y不是X的因,则X的过去值能够帮助 预测Y的未来值,但Y的过去值不应该能够预测X的 未来值.
考虑检验模型的序列相关性以及赤池信息准则,发 现:滞后5阶的检验模型不具有1阶自相关性,而且 也拥有较小的AIC值,这时判断结果是:GDPP与 CONSP有双向的格兰杰因果关系,即相互影响。
表 5.2.3 中国 GDP 与消费支出(亿元) 年份 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 人均居民消费 CONSP 1759.1 2005.4 2317.1 2604.1 2867.9 3182.5 3674.5 4589 5175 5961.2 7633.1 8523.5 人均GDP GDPP 3605.6 4074.0 4551.3 4901.4 5489.2 6076.3 7164.4 8792.1 10132.8 11784.7 14704.0 16466.0 年份 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 人均居民消费 CONSP 9113.2 10315.9 12459.8 15682.4 20809.8 26944.5 32152.3 34854.6 36921.1 39334.4 42911.9 人均GDP GDPP 18319.5 21280.4 25863.7 34500.7 46690.7 58510.5 68330.4 74894.2 79003.3 82673.1 89112.5
格兰杰因果关系检验的步骤

格兰杰因果关系检验的步骤1.收集数据:首先需要收集两个时间序列的数据,分别记为X和Y。
这两个时间序列可以是连续的,也可以是离散的,但要求它们均为平稳的时间序列。
2. 拟合模型:接下来,需要为X和Y拟合合适的模型。
常用的模型包括自回归模型(Autoregressive model, AR)、移动平均模型(Moving Average model, MA)和自回归移动平均模型(Autoregressive Moving Average model, ARMA)。
根据数据的特性进行模型的选择。
3. 确定滞后阶数:通过计算自相关函数(Autocorrelation Function, ACF)和偏自相关函数(Partial Autocorrelation Function, PACF),可以确定X和Y的滞后阶数。
滞后阶数表示因果关系所涉及的时间间隔。
4. 拟合向量自回归模型:通过将X和Y的滞后值作为自变量,建立一个向量自回归模型(Vector Autoregressive model, VAR)。
公式形式为:Y = c + A1*Y(lag1) + ... + An*Y(lagN) + B1*X(lag1) + ... +Bn*X(lagN) + ε,其中c为常数项,Ai和Bi为系数矩阵,N为滞后阶数。
5.检验格兰杰因果关系:对于VAR模型,可以通过计算向量自回归残差的协方差矩阵来检验X对Y的格兰杰因果关系。
设VAR模型的残差为e,如果存在一个时间滞后,称之为k,使得滞后残差e(k)与Y的现值Y(t)相关显著,那么就可以认为X对Y具有格兰杰因果关系。
6.计算p值:通过计算格兰杰因果关系检验的统计量,可以得到一个p值。
如果p值小于设定的显著性水平(通常为0.05),则可以拒绝原假设,认为X对Y具有格兰杰因果关系。
7.解释结果:根据检验结果,可以解释变量X对Y的因果关系的方向和强度。
如果X对Y具有正向影响且显著,可以认为X的变动可以导致Y的变动。
格兰杰因果检验

格兰杰因果检验1. 简介格兰杰因果检验(Granger Causality Test)是一种用来评估一组变量之间因果关系的统计方法。
该方法建立在自回归模型(Autoregressive Model)的基础上,通过比较不同模型的预测能力来判断变量之间是否存在因果关系。
格兰杰因果检验可以用于时间序列数据分析、经济学研究、金融市场分析等领域。
其核心思想是通过观察一个变量的历史数据是否对另一个变量的未来值的预测有额外的信息增益,从而判断两个变量之间是否存在因果关系。
2. 原理格兰杰因果检验的原理基于自回归模型。
自回归模型是一种时间序列模型,它假设当前时刻的观测值与过去时刻的观测值相关。
自回归模型可以表示为以下形式:X(t) = a0 + a1 * X(t-1) + a2 * X(t-2) + ... + an * X(t-n) + e(t)其中,X(t)表示时间t的观测值,X(t-1)等表示相应的历史观测值,a0, a1, …, an 为系数,e(t)为误差项。
格兰杰因果检验的关键是比较两个模型:一个包含了待测变量的历史观测值作为预测变量,另一个只包含已知历史观测值的模型。
通过比较两个模型的预测准确度,可以判断待测变量的历史观测值是否对目标变量的预测有额外的信息。
具体而言,格兰杰因果检验的步骤如下:1.确定待测变量和目标变量;2.构建自回归模型,选择合适的滞后阶数n;3.利用已知的历史观测值进行模型的参数估计;4.比较两个模型的预测能力,利用一定的统计指标(如均方根误差、F-统计量)来评估预测准确度;5.根据统计指标的结果,判断待测变量是否对目标变量的预测有额外的信息,从而判断两个变量之间是否存在因果关系。
3. 实例分析为了更好地理解格兰杰因果检验的应用,下面我们以一个具体的实例来说明。
假设我们有两个时间序列变量:A和B,其中A表示每个月的平均气温,B表示每个月的销售额。
我们想要判断气温是否影响销售额。
格兰杰因果关系检验

• 考察X是否影响变量Y的问题,主要看当期的Y能够 在多大程度上被过去的X所解释,在Yt方程中加入X 的滞后值是否使解释程度显著提高。如果X有助于 Y预测效果的提高,就可以认为X是Y的格兰杰原因。
将式(5.4.2)和式(5.4.4)结合,得到一个一般的自回 归移动平均过程ARMA(p,q)
X t 1 X t 1 2 X t 2 p X t p t 1 t - 1 q t - q
(5.4.5)
• 式(5.4.5)表明,一个随机时间序列可以通过一个自 回归移动平均过程生成,即该序列可以由其自身 的过去或滞后值以及随机扰动项来解释。如果该 序列是平稳的,即它的行为不会随着时间的推移 而变化,那么就可以通过该序列过去的行为来预 测它的未来。
• 结构向量自回归模型(SVAR)
• 结构向量自回归模型中包含了变量间的当期关系。 变量间的当期关系揭示了变量之间的相互影响,实 质上是对向量自回归模型施加了基于经济理论分析 的限制性条件,从而识别变量之间的结构关系。结 构向量自回归模型每个方程左边是内生变量,右边 是自身的滞后和其他内生变量的当期和滞后。
• 格兰杰因果关系检验是通过受约束的F检验完成的。 以X不是Y 的格兰杰原因这一假设为例,即假设 (5.4.7)式中X各滞后项前的参数整体为零,分别做 包含与不包含X各滞后项的回归,记前者残差平方 和为RSSU,后者残差平方和为RSSR,再计算F统计
FRRSRSSU S/RnSUkS/m
式中,m为X的滞后项的个数,n为样本容量,k为 包含可能存在的常数项及其他变量在内的无约束 回归模型的待估参数的个数。
格兰杰因果关系检验

例二
经过Eviews进行格兰杰检验结果如下
可以看出在滞后期为2的情况下,两者互为原因,不 符合格兰杰因果检验。
例三
经过Eviews进行格兰杰检验结果如下 可以看出在滞后期为2的情况下,两者互不为原因。
四、格兰杰因果检验的评价
• 格兰杰的统计学本质上是对平稳时间序列数据一种预测,格兰杰 因果关系检验的结论只是一种预测,是统计意义上的格兰杰因果 性,而不是真正意义上的因果关系,不能作为肯定或否定因果关 系的根据。
二、Granger因果关系检验
变量X是否为变量Y的Granger原因,是可以检验的。
检验X是否为引起Y变化的Granger原因的过程如下:
第一步,检验原假设“H0:X不是引起Y变化的
Granger原因”。首先,估计下列两个回
t 0 i1 i t i i1 i t i t
降水量 20 5 5 15 8 15 41 23 39 5 47 30 28 81 137 35 41 31 57 18 93 67 1 15 10 9
解:(1)建立工作文件。
由于本例数据的时间间隔为旬,Eviews没有提供相应的时 期度量,故应利用鼠标左键单击主菜单选项File,在打开 的下拉菜单中选择New/Workfile,并在工作文件定义对话 框(Workfile Range)的Workfile frequency一栏选择 Undated or irregular项。在起止项中分别输入1和78,表 示每个序列的观测值个数为78个。
有约束回归模型(r): Y
p
Y
t 0 i 1 i t i t
式中,0表示常数项;p和q分别为变量Y和X的最大滞后期 数,通常可以取的稍大一些;t为白噪声。
• 然后,用这两个回归模型的残差平方和RSSu和RSSr 构造F统计量:
格兰杰因果关系检验matlab

格兰杰因果关系检验1. 引言在统计学和数据分析中,因果关系的判断一直是一个重要的问题。
格兰杰因果关系检验(Granger causality test)是一种常用的方法,用于判断两个时间序列之间是否存在因果关系。
该方法基于时间序列的自回归模型,通过比较包含和不包含某个时间序列的延迟项来评估其对另一个时间序列的预测能力。
在本文中,我们将介绍格兰杰因果关系检验的原理、使用场景以及如何在MATLAB中进行实现。
2. 格兰杰因果关系检验原理格兰杰因果关系检验基于向量自回归模型(Vector Autoregressive Model, VAR),假设我们有两个时间序列X和Y,可以表示为:X(t) = a0 + a1 * X(t-1) + a2 * X(t-2) + … + ap * X(t-p) + e1(t)Y(t) = b0 + b1 * Y(t-1) + b2 * Y(t-2) + … + bq * Y(t-q) + e2(t)其中,a0, a1, …, ap 和b0, b1, …, bq 是未知参数,e1(t) 和 e2(t) 是误差项。
如果我们想要判断X对Y是否具有因果关系,我们可以比较两个模型:Model 1: Y(t) = c0 + c1 * Y(t-1) + c2 * Y(t-2) + … + cq * Y(t-q) + e2(t)Model 2: Y(t) = c0 + c1 * Y(t-1) + c2 * Y(t-2) + … + cq * Y(t-q) + d1 * X(t-1) + d2 * X(t-2) + … + dp * X(t-p) + e2(t)如果Model 2的误差项e2(t)比Model 1的误差项e2(t)更小,那么我们可以认为X对Y具有因果关系。
格兰杰因果关系检验的核心思想是通过比较模型的残差平方和来判断因果关系的强度。
在实际计算中,我们需要进行一些统计假设检验来确定是否存在因果关系。
var格兰杰因果关系检验

var格兰杰因果关系检验【原创实用版】目录一、格兰杰因果关系检验的定义与背景二、格兰杰因果关系检验的方法三、格兰杰因果关系检验的应用领域四、格兰杰因果关系检验的局限性正文一、格兰杰因果关系检验的定义与背景格兰杰因果关系检验(Granger Causality Test)是一种用于分析经济变量之间因果关系的统计方法,该方法由 2003 年诺贝尔经济学奖得主克莱夫·格兰杰(Clive W.J.Granger)所开创。
格兰杰因果关系检验并不是检验逻辑上的因果关系,而是关注变量间的先后顺序,即一个变量的前期信息是否会影响到另一个变量的当期。
二、格兰杰因果关系检验的方法格兰杰因果关系检验主要包括以下几个步骤:1.单位根检验:检验变量序列是否稳定,若存在单位根,则需进行差分处理。
2.协整检验:检验变量间是否存在长期的均衡关系,若存在协整关系,则可以进行格兰杰因果关系检验。
3.格兰杰因果关系检验:根据协整关系,利用最小二乘法对变量进行预测,并计算预测误差的方差。
若某个变量的预测误差方差显著小于另一个变量的预测误差方差,则可以认为前者是后者的格兰杰原因。
三、格兰杰因果关系检验的应用领域格兰杰因果关系检验广泛应用于经济学、金融学、生物信息学、机器学习和数据挖掘等领域。
在经济学领域,格兰杰因果关系检验可用于分析不同经济变量之间的因果关系,如国内生产总值(GDP)与通货膨胀率(CPI)之间的关系等。
在生物信息学领域,格兰杰因果关系检验可用于分析基因与疾病之间的关联性。
四、格兰杰因果关系检验的局限性尽管格兰杰因果关系检验在分析变量间因果关系方面具有一定的优势,但该方法也存在一定的局限性:1.格兰杰因果关系检验只能检验变量间的先后关系,无法确认因果关系的具体方向。
2.该方法受到样本量和数据质量的影响较大,当样本量较小或数据质量较低时,检验结果可能存在偏误。
数学建模格兰杰因果检验

数学建模格兰杰因果检验格兰杰因果检验是基于格兰杰因果模型的一种统计方法,用于分析两个时间序列之间的因果关系。
本文将对格兰杰因果检验进行详细介绍,并探讨其在数学建模中的应用。
1. 引言格兰杰因果检验是由美国经济学家格兰杰(Granger)在1969年提出的,用于分析时间序列数据之间的因果关系。
它在经济学、金融学、气象学等领域得到广泛应用。
格兰杰因果检验可以帮助我们理解变量之间的因果关系,从而预测未来的发展趋势。
2. 格兰杰因果模型格兰杰因果模型是格兰杰因果检验的理论基础。
该模型假设一个时间序列的变化可以由过去时间序列的值预测,即过去的值对当前值有影响。
格兰杰因果模型可以表示为如下的线性回归模型:y(t) = a + b1*y(t-1) + b2*y(t-2) + ... + bn*y(t-n) + ε(t)其中,y(t)表示当前时间点的变量值,y(t-1)、y(t-2)等表示过去时间点的变量值,a、b1、b2等为模型的参数,ε(t)为误差项。
3. 格兰杰因果检验的原理格兰杰因果检验通过对比两个模型的拟合优度来判断两个时间序列之间的因果关系。
首先,我们分别建立两个模型,一个是只包含自变量的模型,另一个是在自变量基础上加入因变量的模型。
然后,通过比较两个模型的拟合优度,来判断是否存在因果关系。
如果加入因变量的模型的拟合优度显著提高,那么就可以认为因变量对自变量有因果影响。
4. 格兰杰因果检验的步骤格兰杰因果检验的具体步骤如下:(1)收集时间序列数据;(2)确定时间序列的滞后阶数n;(3)建立格兰杰因果模型,包括只有自变量的模型和加入因变量的模型;(4)计算两个模型的拟合优度,一般使用残差平方和(RSS)或均方根误差(RMSE)作为评价指标;(5)进行统计检验,比较两个模型的拟合优度是否显著不同;(6)根据检验结果判断是否存在因果关系。
5. 格兰杰因果检验的应用格兰杰因果检验在数学建模中有着广泛的应用。
r语言格兰杰因果关系检验

r语言格兰杰因果关系检验格兰杰因果关系检验(Granger causality test)是一种用于分析时间序列数据的方法,用于确定两个变量之间是否存在因果关系。
该方法基于因果关系的定义,即一个变量的变化是否能够在未来预测另一个变量的变化。
本文将介绍格兰杰因果关系检验的原理、步骤以及相关实现方法。
格兰杰因果关系检验的原理基于时间序列的因果关系理论。
该理论认为,如果一个时间序列能够显著地预测另一个时间序列的变化,那么可以认为这两个序列之间存在因果关系。
格兰杰因果关系检验通过统计方法来判断这种关系的显著性。
格兰杰因果关系检验的步骤如下:1. 确定时间序列数据:首先需要确定需要研究的时间序列数据,并将其表示为向量。
通常情况下,这两个时间序列被称为Y和X。
2. 拟合线性回归模型:对于每个时间点,使用历史数据对Y和X分别进行线性回归分析。
即对于每个时间点t,使用t之前的历史数据来估计Y的回归方程和X的回归方程。
3. 检验Y是否能够预测X:根据拟合的回归模型,计算残差序列ε_Y和ε_X。
然后使用统计方法检验Y的回归模型对于X的预测能力是否显著。
常用的统计检验方法有F检验和t检验。
4. 检验X是否能够预测Y:类似地,根据拟合的回归模型,计算残差序列ε_X和ε_Y。
然后使用统计方法检验X的回归模型对于Y的预测能力是否显著。
5. 判断因果关系:通过比较上述两个检验的结果,可以得出结论是否存在因果关系。
如果Y的回归模型对于X的预测显著,而X的回归模型对于Y的预测不显著,则可以认为Y对于X有因果关系。
在R语言中,可以使用“vars”包进行格兰杰因果关系检验。
首先,需要安装并加载该包:```install.packages("vars")library(vars)```接下来,假设我们有两个时间序列数据Y和X,可以使用以下代码进行格兰杰因果关系检验:```# 将时间序列数据转换为矩阵形式data <- cbind(Y, X)# 构建VAR模型model <- VAR(data)# 进行格兰杰因果关系检验granger.test(model, p = 2)```这里的参数p表示使用的滞后阶数,可以根据实际情况进行调整。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LXt Xt1, L2 Xt Xt2 ,, Lp Xt Xt p
• 则(5.4.3)式变换为:
11L 2L2 pLp Xt t
• 记 L 11L 2L2 ,则称p多Lp项式方程:
• 对于两变量Y 和X,格兰杰因果关系检验要求估计以下回归模型:
m
m
Yt 0 iYti i X ti t
(5.4.7)
• 可能存在以下im1四种检验i结1m果:
• (为X1零)t ,X而对0(Y5有.4i单.81 )向式i X影中t响Yi各,滞i表1后现项iY为t前(i5的.4.参7t)数式整中体X(各5为.4滞.零8后)。项前的参数整体不
• 向量自回归模型在建模过程中只需要明确两个量:一个是所含变量的个数k, 即共有哪些变量是相互有关系的,并且需要把这些变量包括在模型中;一 个是自回归的最大滞后阶数p,通过选择合理的p来使模型能反映出变量间 相互影响的关系并使得模型的随机误差项是白噪声。
• 结构向量自回归模型(SVAR)
• 结构向量自回归模型中包含了变量间的当期关系。变量间的当期关系揭示 了变量之间的相互影响,实质上是对向量自回归模型施加了基于经济理论 分析的限制性条件,从而识别变量之间的结构关系。结构向量自回归模型 每个方程左边是内生变量,右边是自身的滞后和其他内生变量的当期和滞 后。
• 含有k个变量的结构向量自回归模型SVAR(p)表示如下:
Yt A0Yt A1Yt1 ApYt p t , t 1,2,,T
向量自回归模型是一种基于数据关系导向的非结构化模型,它主 要通过实际经济数据而非经济理论来确定经济系统的动态结构, 建模时无需提出先验理论假设。
• (2)Y对X有单向影响,表现为(5.4.7)式中Y各滞后项前的参数整体不为零, 而(5.4.8)式中 X各滞后项前的参数整体为零。
• (3)X与Y间存在双向影响,表现为(5.4.7)式中X各滞后项前的参数整体不 为零,同时5.4.8)式中 Y各滞后项前的参数整体也不为零。
• (4)X与Y间不存在双向影响,表现为(5.4.7)式中X各滞后项前的参数整体 为零,同时5.4.8)式中 Y各滞后项前的参数整体也为零。
• 格兰杰因果关系检验是通过受约束的F检验完成的。以X不是Y 的格兰杰原 因这一假设为例,即假设(5.4.7)式中X各滞后项前的参数整体为零,分别 做 平包方含和与为不RSS包R,含再X各计滞算后F统项计的量回:归,记前者残差平方和为RSSU,后者残差
5.4 格兰杰因果关系检验
• 一、时间序列自回归模型 • 1、自回归模型 • 时间序列自回归模型是指仅用它的过去值及随机干扰项所建立起来
的模型,一般形式为:
Xt F X t 1, X t 2 ,, X t p , t (5.4.1)
p为阶数,上式称为p阶自回归模型。 一般地,p阶自回归过程AR(p)是:
• 如果随机扰动项εt不是一个白噪声序列,则称上式为一个q阶的移动 平均过程MR(q)过程,记为:
t t 1 t 1 q t q (5.4.4)
将式(5.4.2)和式(5.4.4)结合,得到一个一般的自回归移动平均过程 ARMA(p,q)
Xt 1 X t 1 2 X t 2 p X t p t 1 t-1 q t-q
z 11z 2z2 pzp 0
• 为AR(p)的特征方程。如果该方程的所有根在单位圆外/根的模大于1, 则AR(p)模型是平稳的。
• 二、时间序列向量自回归模型
• 含有k个时间序列、p期滞后的向量自回归模型VAR(p)可以表示为:
•
பைடு நூலகம்
YYtt是k维内生变A量1Y向t量1,p 是滞后阶A数pY,t样 p本数目t为, tT。
1,2,, T
(5.4.6)
• 其中,
Y1t i
Yt i
Y2t i
, i
1,2,,
p
Ykti
A1,A2, …,Ap是k × k系数矩 阵
11. j
Aj
21. j
k1. j
12. j 22. j
k 2. j
Xt 1 X t 1 2 X t 2 p X t p t (5.4.2)
• 如记为果:随机扰动项εt是一个白噪声序列,则称上式为一个纯AR(p)过程,
Xt 1 X t 1 2 X t 2 p X t p t (5.4.3)
(5.4.5)
• 式(5.4.5)表明,一个随机时间序列可以通过一个自回归移动平均过程 生成,即该序列可以由其自身的过去或滞后值以及随机扰动项来解 释。如果该序列是平稳的,即它的行为不会随着时间的推移而变化, 那么就可以通过该序列过去的行为来预测它的未来。
• 2、AR(p)模型的平稳性条件 • 如果一个p阶自回归模型AR(p)生成的时间序列是平稳的,则该p阶自
1k. j ε以也t ~同不N期与(0相(5,Σ.关)4是.6,2)k式k维但.右随j不边机可,的扰以j变动与量向自1相量己,关2,的,。它滞们Σ后是之,值的间p相协可关,
方 差矩阵,
εt是一个k kk. j
×
k的正定矩阵。
1,2,,k ,t 1t, 2t,, kt
三、格兰杰因果关系检验及其应用 1、格兰杰因果关系检验的表述 若在包含了变量X和Y的过去信息的条件下,对变量Y的预测效果要 优于单独由Y的过去信息对Y进行预测的效果,即变量X有助于解释 变量Y的将来变化,则认为变量X是引致变量Y的格兰杰原因。
• 考察X是否影响变量Y的问题,主要看当期的Y能够在多大程度上被过 去如的果XX所 有解 助释 于Y,预在测Yt效方果程的中提加高入,X的就滞可后以值认是为否X是使Y解的释格程兰度杰显原著因提。高。