网络丢包经典分析案例
VOLTE丢包率专题分析
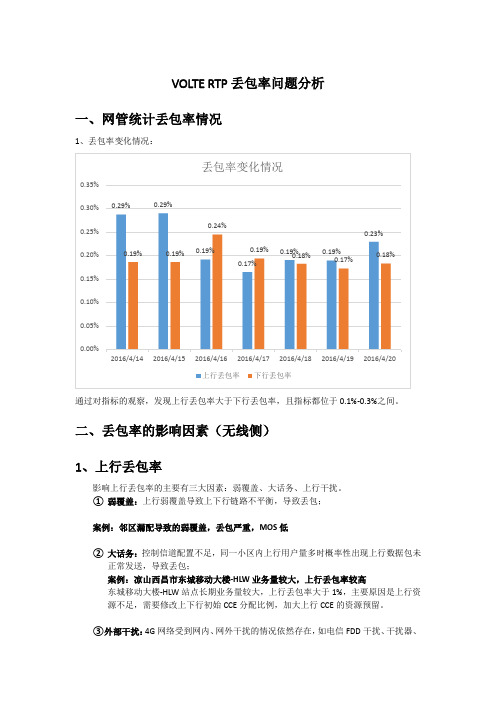
VOLTE RTP丢包率问题分析一、网管统计丢包率情况1、丢包率变化情况:通过对指标的观察,发现上行丢包率大于下行丢包率,且指标都位于0.1%-0.3%之间。
二、丢包率的影响因素(无线侧)1、上行丢包率影响上行丢包率的主要有三大因素:弱覆盖、大话务、上行干扰。
①弱覆盖:上行弱覆盖导致上下行链路不平衡,导致丢包;案例:邻区漏配导致的弱覆盖,丢包严重,MOS低②大话务:控制信道配置不足,同一小区内上行用户量多时概率性出现上行数据包未正常发送,导致丢包;案例:凉山西昌市东城移动大楼-HLW业务量较大,上行丢包率较高东城移动大楼-HLW站点长期业务量较大,上行丢包率大于1%,主要原因是上行资源不足,需要修改上下行初始CCE分配比例,加大上行CCE的资源预留。
③外部干扰:4G网络受到网内、网外干扰的情况依然存在,如电信FDD干扰、干扰器、站点GPS故障等,导致丢包。
案例:上行干扰导致上行丢包严重,造成掉话问题描述UE在芙蓉路由北往南移动,主叫占用东坡区红星路玫瑰园-HLH-2(RSRP:-77.56dBm SINR:26.9dB)在16:55:29.181完成呼叫,发起BYE REQUEST请求;被叫占用相同小区(RSRP:-80.75dBm SINR:23.5dB)在此时未收到网络侧下发的BYE REQUEST,在16:55:32.105主动发起BYE REQUEST,系统记为一次掉话。
问题分析主叫在通话完成以后上发BYE REQUEST,基站侧未收到,被叫主动发起BYE REQUEST,系统记为掉话。
查看主被叫信令,发现在挂机时刻UE重复发送BYE REQUEST消息和BYE OK 消息,基站侧也重复下发BYE REQUEST给主叫,此时上行BLER非常高,达到70%-80%,上行链路质量非常差;通过查询当时的干扰信息,发现该路段附近存在较大的上行干扰:(参考此时段共站共覆盖TDS小区“SMSNR1:红星路玫瑰园_2”干扰信号)问题结论该路段存在较强的外部干扰,需对干扰源进行定位,排除干扰。
案例-某局PING网关丢包分析、解决方案
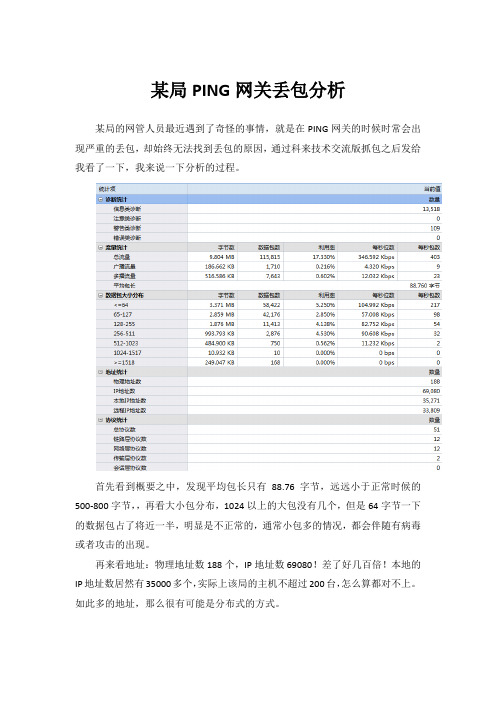
某局PING网关丢包分析某局的网管人员最近遇到了奇怪的事情,就是在PING网关的时候时常会出现严重的丢包,却始终无法找到丢包的原因,通过科来技术交流版抓包之后发给我看了一下,我来说一下分析的过程。
首先看到概要之中,发现平均包长只有88.76字节,远远小于正常时候的500-800字节,,再看大小包分布,1024以上的大包没有几个,但是64字节一下的数据包占了将近一半,明显是不正常的,通常小包多的情况,都会伴随有病毒或者攻击的出现。
再来看地址:物理地址数188个,IP地址数69080!差了好几百倍!本地的IP地址数居然有35000多个,实际上该局的主机不超过200台,怎么算都对不上。
如此多的地址,那么很有可能是分布式的方式。
再往下看,找到大概的原因了:TCP同步发送高达28161次,但是同步确认发送只有可怜的668个,难道是有蠕虫!我们可以进一步进行分析。
DNS查询也高达864次,却没有回应。
打开安全分析界面,来初步确定TCP同步发送的源头在哪儿。
发现了172.16.20.3、21.7、21.224、22.217、22.220、22.71、22.218这几台疑似中了蠕虫病毒,再回到全面分析内,进行取证。
拿20.3来进行观察:发现了,20.3在不停地使用随机端口对各主机的445端口进行TCP SYN包的发送,每次都只有发送2个数据包,没有回应。
这也就导致了大量的TCP SYN包和大量的IP地址的出现。
通过对数据包的解码发现,基本上所有的数据包都是有同步位的数据包。
由此证明,该机中了蠕虫病毒,需要及时查杀。
类似的,在其他几台主机上也发现了蠕虫病毒。
这些蠕虫病毒大量的发包,导致了网络的拥塞,使得用户体验就是网速很慢,表现出来的症状就是PING网关大量丢包。
经过查杀病毒之后,丢包现象没有再出现。
然后我们来查看DNS的查询的异常。
将协议定位到DNS上,我们再来查看数据包:发现172.16.21.15一直在查询的主机,怀疑是中了木马,需要到本机上进行进一步的查杀工作。
4G优化案例:VOLTE丢包率指标优化提升案例

VoLTE丢包率指标优化提升案例XXXX年XX月目录一、问题描述 (3)1、高丢包定义: (3)2、丢包影响 (3)3、影响丢包的因素 (3)4、XX电信VoLTE丢包率总体情况 (4)二、分析过程 (5)1、VoLTE参数核查 (5)2、高干扰小区情况分析 (5)3、TTIBundling特性功能优化提升 (7)三、解决措施 (10)1、实施方案 (10)2、优化效果 (11)四、经验总结 (15)VoLTE丢包率指标优化提升案例XX【摘要】随着电信网络LTE用户不断提升,VoLTE承载语音越来越重要,随着VoLTE用户增长,VoLTE各项指标出现不同程度的波动。
XXVoLTE上下行丢包率全省排名靠后,影响用户感知,需重点优化。
【关键字】LTE用户、 VoLTE、丢包率【业务类别】优化方法、参数优化一、问题描述1、高丢包定义:VoLTE上行高丢包小区(语音):>5%且小区QCI为1的DRB业务PDCP SDU上行期望收到的总包数>1000。
VoLTE下行高丢包小区(语音):>5%且小区QCI为1的DRB业务PDCP SDU下行发送的包数>1000。
2、丢包影响丢包对VoLTE语音质量的影响较大,当丢包率大于10%时,已不能接受,而在丢包率为5%时,基本可以接受。
因此,要求IP承载网的丢包率小于5%。
VoLTE丢包率是MOS值的一个重要影响因素,严重的丢包影响通话质量,甚至导致掉话,导致用户感知降低。
3、影响丢包的因素影响VoLTE丢包的因素有故障告警、无线环境、大话务、传输、核心网、参数等多因素,详细如下:针对VoLTE丢包可进行关联分析的指标有:无线环境包括TA占比、MR弱覆盖、干扰、RRC重建、切换、邻区漏配等;容量包括:PRB利用率、单板利用率、CCE利用率、小区用户数等;4、XX电信VoLTE丢包率总体情况XXVoLTE丢包率指标排名仍相对靠后,为痛点难点,需重点优化。
PING大包丢包网络故障分析案例解决方案

PING大包丢包网络故障分析案例解决方案网络故障是在使用网络过程中经常会出现的问题,其中大包丢包是一种常见的网络故障。
大包丢包指的是在网络传输过程中,发生了传输较大包的数据丢失的情况。
接下来我将进行一个关于大包丢包的网络故障分析案例,并提供相应的解决方案。
案例分析:公司A部门反馈在办公网络中使用视频会议时,经常出现画面卡顿和断流的问题。
在进行网络故障排查的过程中,发现了存在大包丢包的情况。
问题分析:大包丢包会导致网络传输不稳定,影响视频会议等带宽需求较高的应用。
造成大包丢包的原因主要有以下几点:1.网络拥塞:当网络带宽使用过高时,可能会造成网络拥塞,从而引发大包丢包问题。
2.路由器配置错误:路由器可能会存在配置错误,导致无法正确转发大包数据,从而引发大包丢包问题。
3.网络设备故障:路由器、交换机等网络设备可能存在故障,导致无法有效处理网络数据,从而引发大包丢包问题。
解决方案:针对以上问题,可以采取以下解决方案:1.网络监控与优化:通过网络监控工具对网络流量进行实时监控,及时发现网络拥塞问题。
在网络拥塞时,可以考虑对网络带宽进行扩容,以保证网络的稳定性。
2.检查路由器配置:对路由器进行检查,确保其配置正确。
可以参考厂商提供的配置文档,根据网络需求合理设置路由器参数。
同时,也可以考虑升级路由器固件,以确保设备的正常工作。
3.检查网络设备故障:定期对网络设备进行巡检,发现故障及时进行修复或更换。
例如,使用专业的网络测试工具对路由器、交换机等设备进行故障检测,确保其正常运行。
4.优化网络拓扑:对网络拓扑结构进行优化,确保网络中的数据传输路径短且流畅。
通过优化网络拓扑,可以减少数据传输的时延,从而降低大包丢包的发生概率。
5.加强网络安全:网络安全问题也可能导致大包丢包问题。
加强网络安全措施,防范网络攻击与入侵。
例如,使用防火墙、入侵检测系统等安全设备,对网络数据进行过滤和监测。
总结:大包丢包是一种常见的网络故障,可能会对网络传输稳定性产生严重影响。
经典案例-杭长高铁VoLTE业务吞字与丢包研究
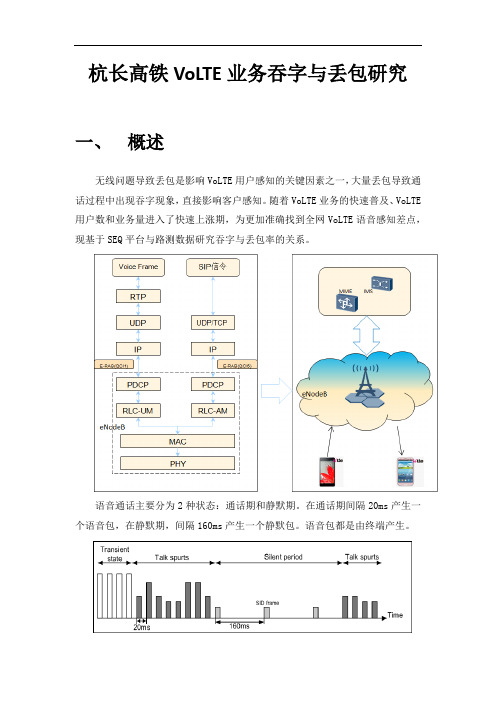
杭长高铁VoLTE业务吞字与丢包研究一、概述无线问题导致丢包是影响VoLTE用户感知的关键因素之一,大量丢包导致通话过程中出现吞字现象,直接影响客户感知。
随着VoLTE业务的快速普及、VoLTE 用户数和业务量进入了快速上涨期,为更加准确找到全网VoLTE语音感知差点,现基于SEQ平台与路测数据研究吞字与丢包率的关系。
语音通话主要分为2种状态:通话期和静默期。
在通话期间隔20ms产生一个语音包,在静默期,间隔160ms产生一个静默包。
语音包都是由终端产生。
二、研究方法2.1吞字数据分析数据来源:路测测试线路:高铁杭长线测试方式:MOS盒打分录音,人工辨别吞字2.1.1吞字点和MOS对应关系:提取本次杭长测试中所有吞字采样点撒散点图如下,可以看出取数的74个吞字点MOS分都在4分以下,MOS在4分以上没有吞字。
2.1.2吞字点丢包率及时延的关系:探寻丢包和吞字感知的之间的联系,通过吞字测试记录吞字/卡顿时间点,结合测试用户丢包分析,得出吞字点的MOS和丢包率和丢包时延之间的关系。
1、吞字点的MOS和丢包率的关系:随着丢包率的提升,MOS分下降明显。
丢包率在10%以内,MOS分在3-4之间;当吞字点的丢包率超过10%以上,MOS均小于3.5。
取采样点吞字点{丢包率在10%以内,MOS>3分}细化作图,作出趋势图可以看出,当丢包率超过3%时,MOS分低于3.5分。
2、吞字点MOS和丢包时延之间的关系:可以看出MOS>3.5分的时候,POLQA Avg Delay时延基本在200ms以内,MOS<3.5分的时候,POLQA Avg Delay时延在200ms以上。
2.1.3大数据绘制丢包和MOS之间的关系:根据鼎力MOS大量测试结果,得出每8秒钟的MOS值和丢包率之间的关系,再通过MOS区间各取100个采样点得出如下关系图:从图中可以看出MOS分和丢包率的关系,MOS>4.0时,没有高丢包采样点。
医院局域网丢包实例解析

故障 的再次 发生或能即时有效地处理此类故障
1 网 络 丢 包 的 定 义
当 网 络 中发 生 故 障 时 .我们 经 常 使 用 的 用 于 检 查
一
了. 这种故障一般容易发现和解决 。 另一种情况就不太
好 解 决 了 . 际工 作 中 . 们 经 常会 碰 到 八根 网 线 中有 实 我 根 通 过 测 线 器 测 下来 没 有 信 号 .于 是 就 在 连 接 电脑
22 网线过 长或 网线 质 量 影 响 网络 性 能 .
一
般而言 . 五类以上网线 质量有保 障 , 传输距 离能
达到 10 . 0 米 如果采用 劣质杂牌 网线 . 信号 传输 会衰减 很厉 害 , 的在六 十米左右信号 就不稳定 。 有 当然 . 如果 用 了好的 网线 .终端 到交换 机的距 离最好 也不要超过 10米川 0 。我院一礼堂就 出现过 因距离太长而发生信号
络 管 理人 员 的 一 大 挑 战 . 网管 人 员应 当具 备 处理 这 种 网络 丢 包故 障 的 能 力 列 举 工 作 中遇
到 的 几 种 丢 包案 例 . 结 出故 障 解 决 的 经 验 与 心 得 . 望 能 够提 高 大 家 的分 析 能 力 和 解 决 总 希
此 类 网 络 故 障 的 能 力
网卡那头 .将没信号 的那根 与闲置有信 号的某根对调
一
下 ,我们都知道实 际数据信息 只用 了其 中的 12和 、
3 6两 对 线 , 时 , 忘 了 , 入交 换 机 的那 头 也 要 同样 、 这 别 插
对调一下线序才能 正常连 网 . 可以将交换机那 头 . 也 和 墙 上的模块两头对调 。当然 ,最好是从交换机 到配线 架 , 到墙上 的模 块和 到终 端 电脑 的跳线 , 再 逐一排查 .
诊断网络设备异常丢包故障分析
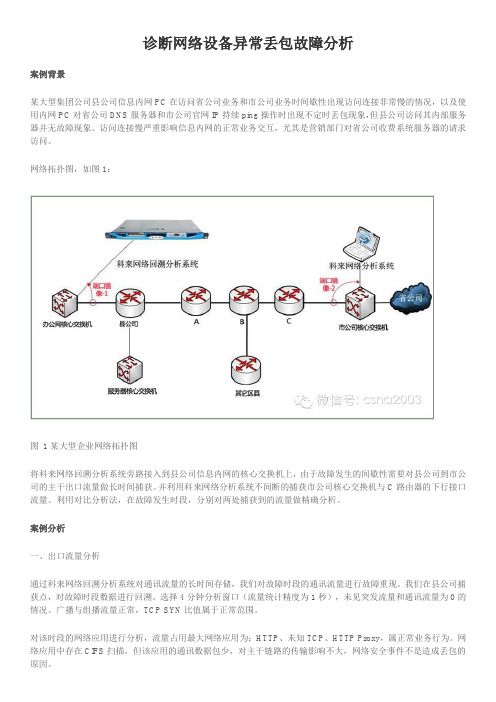
诊断网络设备异常丢包故障分析案例背景某大型集团公司县公司信息内网PC在访问省公司业务和市公司业务时间歇性出现访问连接非常慢的情况,以及使用内网PC对省公司DNS服务器和市公司官网IP持续ping操作时出现不定时丢包现象,但县公司访问其内部服务器并无故障现象。
访问连接慢严重影响信息内网的正常业务交互,尤其是营销部门对省公司收费系统服务器的请求访问。
网络拓扑图,如图1:图1某大型企业网络拓扑图将科来网络回溯分析系统旁路接入到县公司信息内网的核心交换机上,由于故障发生的间歇性需要对县公司到市公司的主干出口流量做长时间捕获。
并利用科来网络分析系统不间断的捕获市公司核心交换机与C路由器的下行接口流量。
利用对比分析法,在故障发生时段,分别对两处捕获到的流量做精确分析。
案例分析一、出口流量分析通过科来网络回溯分析系统对通讯流量的长时间存储,我们对故障时段的通讯流量进行故障重现。
我们在县公司捕获点,对故障时段数据进行回溯。
选择4分钟分析窗口(流量统计精度为1秒),未见突发流量和通讯流量为0的情况。
广播与组播流量正常,TCP SYN比值属于正常范围。
对该时段的网络应用进行分析,流量占用最大网络应用为:HTTP、未知TCP、HTTP Proxy,属正常业务行为。
网络应用中存在CIFS扫描,但该应用的通讯数据包少,对主干链路的传输影响不大,网络安全事件不是造成丢包的原因。
对县公司访问关键业务标准应用监控梳理,网络链路传输质量良好,排除链路拥塞造成丢包现象。
但客户端访问10.176.X.X服务器的TCP会话中存在98次TCP重传,上行重传次数为97次。
大量的TCP重传造成会话延迟确认,严重影响会话质量。
TCP重传大部分发生在上行,说明丢包位置在县公司到省公司之间。
二、TCP会话解码对应用请求的TCP会话进行解码以确定访问延迟的具体原因。
选取故障时段,县公司信息内网PC主机10.178.x.x 访问10.176.X.X的应用通讯流量,客户端10.178.x.x使用2487端口访问10.176.x.x的TCP 80端口,网络链路传输质量良好,无链路拥塞。
核心网链路丢包引起通话质量差处理案例

核心网链路丢包引起通话质量差问题的分析和处理案例摘要:2月11日,天长市许多用户向当地局方工作人员反映使用c网手机时无论主被叫语音质量均较差,排查完无线侧设备故障后,发现问题基站均归属同一BHS,最终与核心网工程师配合将问题定位在核心网链路丢包引起的,及时处理后改善了用户使用感知关键字:CDMA BPH 丢包误码 call shutdown 47 语音质量差【故障现象】:2月11日,天长区域内许多用户向当地局方工作人员反映使用c网手机时无论主被叫语音质量均较差,通话时收听到对方的声音总是断断续续的;【告警信息】:通过OMP网管查看用户申告较多的县城及铜城等地基站,未发现任何告警信息;【原因分析】:1、网管指标性能分析:当天障碍现象表征最明显的基站是RCS565天长中行基站,该站覆盖范围较广,话务量较高,障碍出现当天该站2扇区出现了分集告警,底噪输出值较高,如下图:底噪抬升除与天馈系统内部隐性故障相关以外与外部干扰的影响关联性也很大,因天长中行基站下问题现象较严重,网优人员在确认底噪异常告警后立即前往天长县城处理天长中行2扇区底噪异常问题,并排查外部干扰源;由于天长电信局位于天长中行1扇区覆盖范围内,处理问题初期,我们曾将1扇区CBR板件关闭,1扇区CBR板件关闭后,现场进行拨打测试,通话效果有一定改善,所以造成了一种属于单站硬件干扰引起的假象;上图标记处即为天长市电信局位置然而在1扇区关闭后查看网管内基站其他两个扇区的话统指标发现,掉话次数也非常高,而且越来越多的地方有用户反映同样的障碍情况,所以问题并不只是因为1个扇区的影响而产生的,需要针对高掉话次数的具体掉话类型进行分析;首先查看了RCS565基站的当天ROP信息,发现一种call shutdown类型为47的系统掉话所占比例较大,数据与语音相加合计有81次,具体ASSERT CODE说明有两种21590和21740;使用OMP网管内的ropsearch.sct脚本搜索11号当天出现过call shutdown 47类型的所有基站信息及之前一天记录以确定影响范围及具体开始出现的时间,分析输出发现存在以下问题:1)2月10日全天ROP内无该类型系统掉话出现,2月11日首次出现,且最早一次产生于凌晨3时15分,出现扇区为来安半塔基站2扇区;2)除天长市区中行基站外,有用户申告反映的天长汊涧、铜城等基站也有较多次数的call shutdown47产生,也说明了出现语音质量问题的区域和这种新出现的掉话类型是有一定关联的;3)问题基站空间位置上是零散的,所以产生同样的系统掉话类型且反复出现的原因说明他们在网络结构内部存在一定的逻辑相关性,或者从属于同一个网元,AP、SM等;4)出现call shutdown47的基站全部是来安县、天长市基站,其它县、市均未发现,出现频率与基站话务量相关,问题最严重基站就是天长中行基站,而来安县并未有大面积使用感知恶化情况申告;callshutdown47汇总.xlsx至此无线侧原因已基本排除,需进一步弄清call shutdown47的具体解释及产生原因和所有问题基站的关联性;2、核心侧问题分析:在确认问题可能与核心侧设备相关后第一时间联系了本地网网络操作维护中心维护C 网核心网的工作人员,确认2月11日当天核心侧设备是否出现新增告警信息等,并进一步确定问题基站内部联系;在查看数据库信息发现来安、天长基站同时归属于同一SM下,与其他各县不同,SM即为交换模块,它的作用有以下几点:基站的SM归属是根据区域来进行划分的,并在基站的cell2表里配置对应的BHS信息,实现基站和SM及BPH对应关系,来安、天长所归属的SM2下总共下挂了129个基站,出现call shutdown47告警的基站总共有34个,故判断问题可能来自于SM2内部,SM的内部网元结构如下:语音呼叫占用的MGW资源查看565基站的BHS配置,其BHS归属为2-0-2:继续查看铜城、汊涧基站BHS配置,发现也是2-0-2,使用DBsurvey命令取出了所有基站的BHS配置,并查询出有问题的34个基站的BHS配置,发现均为2-0-2,而SM2的2-0-2总共映射了35个基站,其中有34个存在异常,(唯一未出现异常的RCS925翁家集基站属省际边界基站,话务量偏低),所以更加怀疑是SM2内部隐性故障引起此次障碍;此时从核心侧得到反馈结果,C网核心网维护人员查看了MGW网管,网管无告警且没有相应历史告警记录,然后查看了7750设备,也未发现任何告警信息,将问题基站归属于同一BHS问题告知其,并请核心网工程师对SM2及2-0-2对应的BPH进行性能观察和分析;核心网工程师通过7750设备长ping对应2-0-2的BPH板卡的ip地址;发现对应0-09板卡ping时存在严重丢包问题,丢包率为9%,而1-02则正常无丢包问题,至此可以确定因SM2下挂2-0-2的BPH板卡至7750链路丢包导致其映射基站下用户出现通话感知较差、掉话等问题;【解决方法】:现网MGW的SM配置,有两个BPH服务器互为主备用,一块PHV处理器,每个SM间通过CM进行通信,并且可以进行一定资源的共享,而此次问题已确定为BPH板件至7750链路丢包引起的通话异常,为更明确问题诱因,决定将BPH服务器的主备用倒换,倒换完毕后如果现场测试使用正常,ROP里该类型系统掉话消失,则问题明确;BPH服务器之间的倒换是无缝倒换的,倒换期间并不影响业务使用,有两种倒换方式:自动倒换和人工倒换,自动倒换每天凌晨自动操作一次;在将BPH服务器人工倒换完毕后,联系现场天长局方人员进行拨打测试,无异常,使用ropsearch脚本搜索call shutdown 47,倒换完毕1小时内均为出现,观察stone表指标问题较严重的天长中行等基站指标均恢复问题;确认障碍现象恢复正常后,核心网工程师前往核心网主设备机房对原长ping存在丢包的0-09板卡与7750设备间各段连接线进行检查处理,发现一处接头网线存在一定松动,插紧检查完毕确认无告警后,重新从7750设备对该板卡进行长ping,无丢包;2月13日SM2的2-0-2BPH对应的两个服务器自动倒换后观察指标,类似异常未再出现,call shutdown 类型为47的系统掉话也没有出现,由此看出,此次天长、来安语音通话质量差、掉话问题主要是因为BPH与7750设备间一条链路丢包引起的;【经验教训或建议与总结】:1、CDMA网络的无线侧设备与核心侧网元是一个整体,无线侧问题往往只影响部分特定区域用户,而核心网的隐性故障可能影响大范围的用户使用;2、网络问题的发现往往从一个点发展到一个面的,针对大范围区域出现的问题,需排查本身设备侧问题及外部干扰问题外及时与核心网工程师配合排查核心侧隐性故障,提高问题处理效率和及时性;3、朗讯设备的掉话类型主要有两大类:lost call和call shutdown,系统侧掉话call shutdown类型较多,在系统统计到大量同一类型call shutdown掉话时,往往也表征着网络的某一环节存在着较大疏漏,在分析突发性大范围用户障碍时,及时通过ROP找到对应新增的call shutdown 类型,有助于更及时找到问题的“疑点”和“共性”;。
M9000 利用流量统计功能判断丢包问题处理案例

M9000利用流量统计功能判断丢包问题处理案例一组网:如下面示意图所示,客户反馈某业务的客户端及服务器分别部署在M9000两侧,客户端与服务器之间的来回双向流量均通过M9000处理。
二问题描述:客户反馈在日常运维中发现客户端和服务器之间存在丢包情况,希望通过M9000进行分析,判断丢包的位置。
三过程分析:M9000业务报文收发都是由接口板交换芯片处理的,因为最简单最精确的方法就是利用接口板芯片的流量统计功能,在M9000的上/下行端口的Inbound/Outbound方向下发流量统计策略,然后根据流统的结果判断在双方向上M9000是否将接收到的报文都成功转发了。
假设通过流统的结果,确认M9000在一个方向上接收到报文数和发送报文数相等,那就可以说明转发没有问题;但如果接收到的报文数大于发送报文数,就说明在M9000内部由于性能或其它原因造成了丢包,需要进行进一步的分析和排查。
四解决方法:在M9000上通过下发QoS流量统计策略,配置业务测试(常用方法为ping)来判断丢包问题。
接下来以客户端IP为10.255.255.1,服务器IP为10.255.255.3为例。
1、首先配置ACL规则及流分类,其中ACL规则要尽可能精确:#acl number 3991rule 10 permit icmp source 10.255.255.1 0 destination 10.255.255.3 0#acl number 3992rule 10 permit icmp source 10.255.255.3 0 destination 10.255.255.1 0#traffic classifier c_to_s operator andif-match acl 3991#traffic classifier s_to_c operator andif-match acl 3992#除了ACL规则以外,在流分类中还可以配置其它报文匹配条件,比如报文的VLAN ID等,用于更精确的匹配报文。
经典案例-传输CN2设备拥塞导致用户丢包速率恶化问题定位与处理
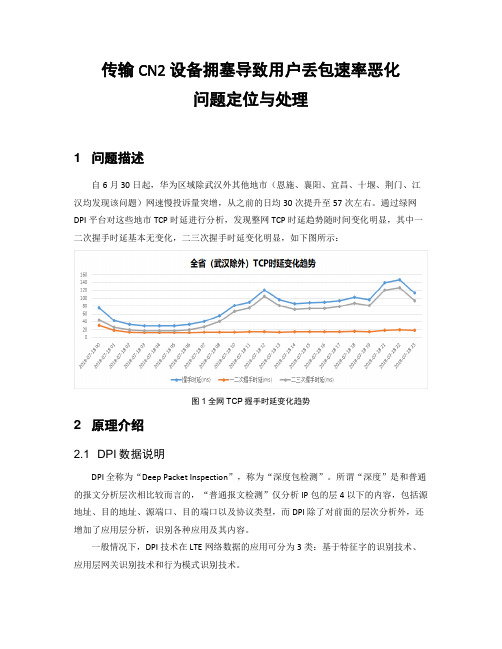
传输CN2设备拥塞导致用户丢包速率恶化问题定位与处理1 问题描述自6月30日起,华为区域除武汉外其他地市(恩施、襄阳、宜昌、十堰、荆门、江汉均发现该问题)网速慢投诉量突增,从之前的日均30次提升至57次左右。
通过绿网DPI平台对这些地市TCP时延进行分析,发现整网TCP时延趋势随时间变化明显,其中一二次握手时延基本无变化,二三次握手时延变化明显,如下图所示:图1全网TCP握手时延变化趋势2 原理介绍2.1 DPI数据说明DPI 全称为“Deep Packet Inspection”,称为“深度包检测”。
所谓“深度”是和普通的报文分析层次相比较而言的,“普通报文检测”仅分析IP包的层4 以下的内容,包括源地址、目的地址、源端口、目的端口以及协议类型,而DPI 除了对前面的层次分析外,还增加了应用层分析,识别各种应用及其内容。
一般情况下,DPI技术在LTE网络数据的应用可分为3类:基于特征字的识别技术、应用层网关识别技术和行为模式识别技术。
基于特征字的识别技术:现阶段DPI数据解析中最主要的DPI技术,其原理就是不同的业务或应用通常有特殊的“指纹”,这些指纹可能是特定的字符串或者比特流,例如URL就是典型的特征字,依此可以确定该用户业务流承载的具体应用和业务类型;应用层网关识别技术:部分业务的业务流和控制流是分开的,从业务流中无法找到相应的特征字,所有特征信息及控制流与业务流的关联信息都存在于控制流中,,和这种情况下就使用应用层网关识别技术,其实就是控制流识别技术,受限识别出控制流,从控制流信息中提取出业务流信息,再基于此对业务流进行识别。
使用应用层网关识别技术进行包检测的典型协议就是FTP协议。
行为模式识别技术:基于对对终端已经实施的行为的分析,判断出用户正在进行的动作或者即将实施的动作。
通常用于无法根据特征字判断的业务的识别。
比如路测仪表模拟生成业务流和普通的业务流从内容上看是完全一致的,只有通过对用户行为的分析,才能够准确的识别出路测业务行为。
网络丢包经典分析案例
网络丢包,请离我远去1 网络丢包-烦恼网络是多种设备的集合体,一个较为完善的网络除去网络终端大量的客户机以外,有众多的设备穿插集中,包括二层交换机、三层交换机、DSLAM、BAS、路由器、服务器、存储设备等。
而涉及到的网络协议、技术更为繁杂,要维护这么庞大以及技术复杂的网络,很多时候是雾里看花,总是看不清楚问题的实质,尤其是网络丢包问题,让多少网络专家为之彻夜难眠却又束手无策。
本案例汇集了经常遇到的网络丢包案例,希望这些小的案例能够为我们的日常网络维护提供一些启发。
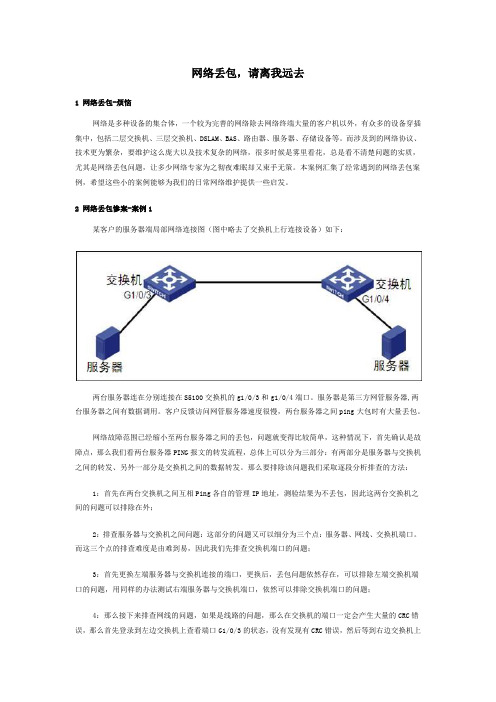
2 网络丢包惨案-案例1某客户的服务器端局部网络连接图(图中略去了交换机上行连接设备)如下:两台服务器连在分别连接在S5100交换机的g1/0/3和g1/0/4端口。
服务器是第三方网管服务器,两台服务器之间有数据调用。
客户反馈访问网管服务器速度很慢,两台服务器之间ping大包时有大量丢包。
网络故障范围已经缩小至两台服务器之间的丢包,问题就变得比较简单,这种情况下,首先确认是故障点,那么我们看两台服务器PING报文的转发流程,总体上可以分为三部分:有两部分是服务器与交换机之间的转发、另外一部分是交换机之间的数据转发。
那么要排除该问题我们采取逐段分析排查的方法:1:首先在两台交换机之间互相Ping各自的管理IP地址,测验结果为不丢包,因此这两台交换机之间的问题可以排除在外;2:排查服务器与交换机之间问题:这部分的问题又可以细分为三个点:服务器、网线、交换机端口。
而这三个点的排查难度是由难到易,因此我们先排查交换机端口的问题;3:首先更换左端服务器与交换机连接的端口,更换后,丢包问题依然存在,可以排除左端交换机端口的问题,用同样的办法测试右端服务器与交换机端口,依然可以排除交换机端口的问题;4:那么接下来排查网线的问题,如果是线路的问题,那么在交换机的端口一定会产生大量的CRC错误,那么首先登录到左边交换机上查看端口G1/0/3的状态,没有发现有CRC错误,然后等到右边交换机上查看端口G1/0/4的状态,发现端口有大量CRC错误,而且CRC错误包的数量还在增长,因此初步怀疑该接口下的网线有问题,于是更换一条生产发货的网线更换后,丢包问题解决。
网络丢包分析案例解决方案

网络丢包分析案例解决方案网络丢包是指在数据传输过程中,部分数据包未能正常到达目的地。
网络丢包可能导致数据传输速度变慢、网络连接中断以及影响用户体验等问题。
本文将针对网络丢包分析一个案例,并提出解决方案。
案例分析:假设一个中小型企业,拥有自己的局域网和接入互联网的路由器,由于最近网络丢包问题频发,导致员工在办公过程中遇到了困难。
为了解决这个问题,我们需要进行以下步骤:1.判断丢包情况:首先,需要确定是否存在网络丢包问题。
可以通过ping命令检测网络丢包率。
在命令提示符中输入ping目标IP,可以观察到ping的结果,如果出现丢包,则说明存在丢包问题。
2.排除硬件故障:网络丢包问题可能是由于硬件故障引起的。
首先,需要确保路由器和交换机没有故障。
可以尝试更换网络设备进行排错。
3.检查网络拓扑结构:网络拓扑结构可能导致丢包问题。
过多的中转、线路负载不均衡等都可能导致丢包。
需要检查路由器、交换机和服务器的连接情况,确保没有物理障碍。
4.调整MTU和MSS:最大传输单元(MTU)和最大报文段长度(MSS)是数据包大小的两个参数。
过大的MTU或MSS可能导致网络丢包。
可以通过调整这两个参数,减小数据包的大小,以提高网络稳定性。
5.网络流量管理:网络流量过大可能导致网络拥堵和丢包。
可以限制特定应用程序的带宽使用,或者调整路由器的流量控制策略,以减少网络拥堵和丢包。
6.升级网络设备固件:网络设备的固件可能存在漏洞,导致网络丢包。
可以升级网络设备的固件,以修复已知的漏洞,并提高网络性能。
解决方案:针对上述分析结果,我们提出以下解决方案:1.网络设备故障:更换或修复故障的网络设备,确保网络设备正常运行。
2.优化网络拓扑结构:根据实际情况重新设计网络拓扑结构,减少中转节点,确保网络连接稳定。
3.调整MTU和MSS:根据网络情况调整MTU和MSS的参数,保证数据包大小合适。
4.网络流量管理:使用流量管理工具进行网络流量监控和控制,合理分配网络带宽资源,减少网络拥堵。
PING大包丢包网络故障分析案例、解决方案
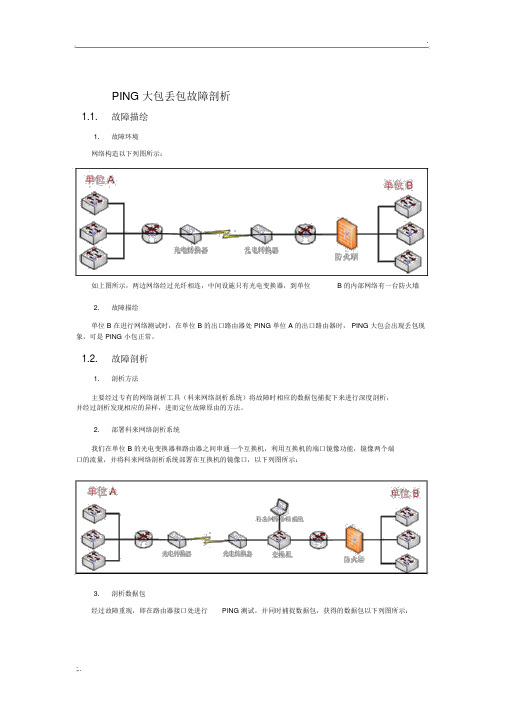
PING 大包丢包故障剖析1.1.故障描绘1.故障环境网络构造以下列图所示:如上图所示,两边网络经过光纤相连,中间设施只有光电变换器,到单位 B 的内部网络有一台防火墙2.故障描绘单位 B 在进行网络测试时,在单位 B 的出口路由器处 PING 单位 A 的出口路由器时, PING 大包会出现丢包现象,可是 PING 小包正常。
1.2.故障剖析1.剖析方法主要经过专有的网络剖析工具(科来网络剖析系统)将故障时相应的数据包捕捉下来进行深度剖析,并经过剖析发现相应的异样,进而定位故障原由的方法。
2.部署科来网络剖析系统我们在单位 B 的光电变换器和路由器之间串通一个互换机,利用互换机的端口镜像功能,镜像两个端口的流量,并将科来网络剖析系统部署在互换机的镜像口,以下列图所示:3.剖析数据包经过故障重现,即在路由器接口处进行PING 测试,并同时捕捉数据包,获得的数据包以下列图所示:如上图所示,我们在使用大包PING 对端时,对端返回了一个超时的数据包,查察它详细的数据包解码,以下列图:造成该故障的原由是因为,我们在网络中传输大包时,因为网络中“最大传输单元”的限制,大数据包会发生疏片,当分片数据包都抵达目的端时会发生重组,一旦有一个分片丢掉就会造成数据报重组超时,因此会发送超时的差错提示。
4.剖析结论我们在进行 PING 测试时,数据包只经过了光电变换器和中间链路,因此造成该故障的原由就是光电变换器或中间链路丢包造成的。
1.3.总结当我们在剖析数据包时,发现通讯的数据包中有异样的数据包,那么我们就需要关注它是何种应用的数据包,经过剖析异样的数据包能够帮助我们迅速的找到故障原由,进而解决故障。
经典案例_VoLTE上行丢包率优化思路及解决方案

VOLTE上行丢包率优化思路及解决方案目录1问题分析 (1)1.1V oLTE网管丢包率指标定义 (1)1.2上行丢包原理 (2)1.3丢包优化流程与思路 (2)2分场景优化 (5)2.1覆盖类场景优化 (5)2.1.1VOLTE上行覆盖增强 (5)2.1.2天馈调整及功率优化 (6)2.2高话务场景优化 (7)2.2.1PDCCH CCE初始比例优化 (7)2.2.2ROHC功能开启 (8)2.3上行干扰场景优化 (11)2.3.1基于干扰的动态功控 (11)2.4频繁切换场景优化 (13)2.5其他功能及参数优化 (15)2.5.1PDCP层参数优化 (15)2.5.2RLC重排序定时器 (16)2.5.3包聚合关闭 (16)3总结 (19)【摘要】随着VOLTE业务的快速普及,VOLTE用户数和业务量都进入了快速上涨期,用户对语音质量要求越来越高,单通、吞字、双不通等严重影响用户感知,制约着4G业务的发展。
其中“空口丢包”和“基站丢包”指标可有效表征VOLTE 语音感知,减少“空口丢包”和“基站丢包”是VOLTE语音质量优化提升的重要方向。
本文将对Volte上行QCI1丢包率优化展开全面论述。
【关键词】全面商用、QCI1上行丢包率、语音质量1问题分析1.1VoLTE网管丢包率指标定义1.2上行丢包原理VOLTE高清语音编码速率为23.85kbps,终端每20ms生成一个VOLTE语音包(使用RTP实时流媒体协议传输),再加上UDP包头、IP包头、在应用层最终打包成IP包进行传输。
在无线空口,按照协议IP包进一步被转换成PDCP包,PDCP 包就是空口传输的有效数据,PDCP包在终端和基站间传输异常会导致应用层RTP 包的丢失,从而引起语音感知差。
eNodeB的PDCP层接收语音包时如果检测到语音包的SN号不连续,则认为出现丢包。
上行丢包主要原因:1)大TA/PHR受限、SR漏检、DCI漏检、RLC分段过多、上行调度不及时(上图① )会导致UE PDCP层丢弃定时器超时丢包;2)空口传输质量(上图② )差,MAC层多次传输错误后,失败导致丢包;3)配置的PDCP层discard timer过小,SR周期过大存在UE得不到及时调度,导致PDCP超时丢包。
精品案例_传输丢包引起的VoLTE丢包案例

传输丢包引起的VoLTE丢包案例目录一、问题描述 (3)二、分析过程 (4)三、解决措施 (4)四、经验总结 (5)传输丢包引起的VoLTE丢包案例【摘要】黄山屯溪区城区RCU拉网测试时发现Volte MOS质量差问题,数据显示无线环境良好,基站侧无告警,联系传输侧核查发现传输侧输入光功率过低,安排传输人员紧急排障后问题解决。
告警不仅存在于基站侧,也可能存在传输侧,所以在优化过程中需要对告警因素考虑其中。
【关键字】MOS值、丢包、误码【业务类别】优化方法、VoLTE一、问题描述黄山屯溪区城区RCU拉网测试时发现Volte MOS质量差问题,测试车辆行驶至滨江东路时,主叫UE占用HS-市区-喜来登酒店-HFTA-448842-54(PCI:40)信号RSRP=-66.44dbm左右,SINR=21.8db左右,无线环境良好,丢包率、误块率偏高且MOS值差。
二、分析过程从测试UE的RSRP以及SINR看无线环境良好,不存在无线方面的原因。
通过U2000网管进行告警查询,结果无告警,对现场多轮DT测试仍出现同样问题,排除终端问题,疑似设备存在隐形故障或者是传输方面问题。
下一步协调传输侧进行排查。
通知传输方核查,传输方反馈:与基站对接的PTN设备一切正常,没有告警;最后无线侧通过ping核心网用户面IP地址发现存在83.3%左右的丢包现象,PING查询脚本如下:PING:SN=7,SRCIP="7.183.53.22",DSTIP="192.168.0.49",CONTPING=DISABLE,APPTIF=NO;PING结果:三、解决措施通过传输方面通过逐级排查,确认为HS-市区-喜来登酒店1端口输入光功率过低(显示21.2dBm,参考值14.1dBm),安排传输人员紧急排障后问题解决。
效果验证:调整后上行丢包率从7.34%改善0.16%,MOS值从3.2左右提升至4.23左右,问题得到解决,复测图层如下:四、经验总结由于告警不仅存在于基站侧,也可能存在传输侧,所以在优化过程中需要对告警因素考虑其中,在问题优化处理起来更高效,网络保障更有力,才能实现未来Volte业务商用后的全面领先。
经典案例-基于劣化原因处理VoLTE高丢包(推荐)

基于劣化原因处理VOTE高丢包目录基于劣化原因处理VOTE高丢包 (1)1概述 (3)1.1背景 (3)2VOLTE高丢包原因分析 (3)3高丢包小区劣化原因的定义和识别 (4)3.1基于劣化原因的优化方法 (5)4、基于劣化场景的VOLTE丢包小区参数优化总结 (19)【摘要】本文针对弱覆盖、干扰、切换差、大话务等造成VoLTE高丢包的4大类主要原因,分别从分原因处理高丢包小区、利用质量切换和功控调优等策略提升网络级指标、运用新功能针对性改善特性区域指标等方面,开展VoLTE丢包分析和优化,根据优化成果,总结了VoLTE 丢包优化方法,以供日常丢包优化工作中使用,提高优化效果和处理效率。
【关键词】VOLTE弱符干扰切换差大话务高丢包1 概述1.1背景VoLTE是基于IMS的语音业务。
IMS由于支持多种接入和丰富的多媒体业务,成为全IP 时代的核心网标准架构。
经历了过去几年的发展成熟后,如今IMS已经跨越裂谷,成为固定话音领域VoBB、PSTN网改的主流选择,而且也被3GPP、GSMA确定为移动语音的标准架构。
VoLTE即VoiceoverLTE,它是一种IP数据传输技术,无需2G/3G网,全部业务承载于4G网络上,可实现数据与语音业务在同一网络下的统一。
换言之,4G网络下不仅仅提供高速率的数据业务,同时还提供高质量的音视频通话,后者便需要VoLTE技术来实现。
Volte通过过程中高丢包会导致通话不清楚、断续等问题,需要对高丢包问题进行优化。
2 VOLTE高丢包原因分析通过对某地市分析日常督办VoLTE高丢包小区问题原因,主要存在4方面,分别为弱覆盖、干扰、切换问题和高话务造成的资源受限,4类问题小区占比分别达87.5%、3.55%、2.13%、1.7%。
而在TDD制式中,VoLTE上行覆盖受限和资源受限问题较突出,在分析高丢包小区时,重点需定位上行弱覆盖、上行干扰、切换及上行CCE等资源受限问题,先通过参数优化,快速降低丢包率,改善语音感知。
经典案例-VoLTE丢包弃包分析优化最佳实践总结

杭州VoLTE丢包弃包分析方法与应用最佳实践总结1 概述VoLTE高清语音编码速率为23.85kbps,终端每20ms生成一个VoLTE 语音包(使用RTP实时流媒体协议传输),再加上UDP包头、IP包头,在应用层最终打包成IP包进行传输。
在无线空口,按照协议IP包进一步被转换成PDCP包,PDCP包就是空口传输的有效数据。
PDCP包在终端和基站间传输异常会导致应用层RTP包的丢失,从而引起语音感知差。
为实现VoLTE语音包(PDCP层)在终端与基站间的正常传输,则务必保证两个关键点:1)基站(或终端)不能丢弃PDCP包。
业务高负荷、质差引发重传都会大量消耗无线资源,若基站因为缺乏有效的无线资源无法完成对PDCP包的及时调度时,基站(或终端)会主动丢弃VoLTE语音包;2)空口不能丢失PDCP包。
弱覆盖,系统内干扰,系统外干扰都会引发无线网络质差,会直接导致VoLTE语音包在无线空口传输过程中出现丢失。
3 VoLTE“感知丢包”统计及优化流程为综合表征4G无线质量和VoLTE语音感知,定义感知丢包=空口丢包+基站弃包表征小区级无线质差。
感知丢包率公式:上行感知丢包率=上行空口丢包率=上行PDCP丢包数/上行PDCP总包数下行感知丢包率=(下行PDCP丢包数+下行PDCP弃包数)/下行PDCP总包数感知丢包主要表现在上行丢包、下行空口丢包以及下行弃包三个表象上,可以通过问题分析流程图定位相关问题,如故障、干扰、资源等方面。
4 弃包丢包原理机制4.1 基站(或终端)弃包原理在基站(或终端)在空口发送PDCP SDU之前,由于容量或空口质量问题,PDCP discardtimer定时器(目前配置为100ms)超时后会发生主动弃包。
例如基站调度了序列号为1/2/3/4/5共5个包,而4/5两个包因容量受限或空口质差在100ms内没有被调度出去,基站侧根据认为超过PDCP丢弃时长而主动丢弃,下行弃包率为2/5=40%。
精品案例_VoLTE下行丢包率优化案例

阜阳VoLTE下行丢包率优化案例目录一、问题描述 (3)二、分析过程 (3)三、解决措施 (3)四、经验总结 (3)阜阳VoLTE下行丢包率优化案例【摘要】本文通过对阜阳长线局基站的丢包问题分析,经过现场测试和KPI指标分析,解决上行PUCCH干扰问题进行VolTE丢包率优化,为今后的VoLTE感知优化提供了一种思路。
【关键字】下行丢包率、DT测试【业务类别】VoLTE一、问题描述在VoLTE百日大会战中,阜阳长线局基站的2.1G小区FY-市区-长线局-HFTA-152078-137小区QCI1下行丢包率忙时达到80%,全天平均在50%左右,现场测试VolTE业务发现RTP丢包率在80%以上且频繁出现单通影响VoLTE用户感知,需要分析解决。
二、分析过程1、丢包统计方法在VoLTE的话务性能统计中,可以通过“空口丢包率”和“基站弃包率”两项指标来评估和分析VoLTE语音包在无线网络中的传输质量。
(1)空口丢包率终端或基站调度发出VoLTE语音包(PDCP层)后,由于空口质量问题导致在空口传输过程中丢失称为空口丢包。
空口丢包率=空口语音丢包数/总语音包数●上行空口丢包基站侧根据终端上发的PDCP SN序列号是否连续判断丢包的数量。
例如,终端发送了PDCP SN为1/2/3/4/5共5个包,而基站收到PDCP SN为1/2/3/5共4个包,那么基站侧统计的上行丢包率为1/5=20%。
●下行空口丢包下行语音空口丢包是基站根据终端在MAC层反馈的确认(ACK)/否认(NACK)消息进行统计的。
例如,基站向终端下发了1个PDCP 包,终端反馈否认消息表示未收到,基站再次重传,如果终端反馈确认消息,则表示终端已经收到,这个包不统计为丢包。
而如果经过多次重传终端仍然反馈否认消息,达到重传的最大次数后,基站则会统计为1个丢包。
(2)基站弃包率基站由于容量或空口质量导致无线资源受限,语音包因为在基站侧得不到及时调度,最终超过PDCP丢弃定时器而被基站丢弃的过程称为基站弃包。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
网络丢包,请离我远去
1 网络丢包-烦恼
网络是多种设备的集合体,一个较为完善的网络除去网络终端大量的客户机以外,有众多的设备穿插集中,包括二层交换机、三层交换机、DSLAM、BAS、路由器、服务器、存储设备等。
而涉及到的网络协议、技术更为繁杂,要维护这么庞大以及技术复杂的网络,很多时候是雾里看花,总是看不清楚问题的实质,尤其是网络丢包问题,让多少网络专家为之彻夜难眠却又束手无策。
本案例汇集了经常遇到的网络丢包案例,希望这些小的案例能够为我们的日常网络维护提供一些启发。
2 网络丢包惨案-案例1
某客户的服务器端局部网络连接图(图中略去了交换机上行连接设备)如下:
两台服务器连在分别连接在S5100交换机的g1/0/3和g1/0/4端口。
服务器是第三方网管服务器,两台服务器之间有数据调用。
客户反馈访问网管服务器速度很慢,两台服务器之间ping大包时有大量丢包。
网络故障范围已经缩小至两台服务器之间的丢包,问题就变得比较简单,这种情况下,首先确认是故障点,那么我们看两台服务器PING报文的转发流程,总体上可以分为三部分:有两部分是服务器与交换机之间的转发、另外一部分是交换机之间的数据转发。
那么要排除该问题我们采取逐段分析排查的方法:
1:首先在两台交换机之间互相Ping各自的管理IP地址,测验结果为不丢包,因此这两台交换机之间的问题可以排除在外;
2:排查服务器与交换机之间问题:这部分的问题又可以细分为三个点:服务器、网线、交换机端口。
而这三个点的排查难度是由难到易,因此我们先排查交换机端口的问题;
3:首先更换左端服务器与交换机连接的端口,更换后,丢包问题依然存在,可以排除左端交换机端口的问题,用同样的办法测试右端服务器与交换机端口,依然可以排除交换机端口的问题;
4:那么接下来排查网线的问题,如果是线路的问题,那么在交换机的端口一定会产生大量的CRC错误,那么首先登录到左边交换机上查看端口G1/0/3的状态,没有发现有CRC错误,然后等到右边交换机上
查看端口G1/0/4的状态,发现端口有大量CRC错误,而且CRC错误包的数量还在增长,因此初步怀疑该接口下的网线有问题,于是更换一条生产发货的网线更换后,丢包问题解决。
TIPS:做网线是网络工程师的基本技能,甚至任何一个IT卖场的售货人员都会做网线,但是网线的质量却千差万别,由网线引发的网络丢包无计其数,千里之堤毁于蚁穴,日常网络维护中不可忽视小小的网线。
而对于线路引发的丢包,如果交换机或者路由器接口上收到runts,giants,throttles,CRC,frame 等错帧而且错帧的数量在不断的增长,那么需要检查对端设备或者中间的传输链路是否存在问题;如果收到overruns等错帧,需要确定本端的链路带宽是否足够。
3网络丢包惨案-案例2
某客户全国网项目在在北京中心通过配置CPOS板卡通过拆分E1连接下面31个省中心实现省节点与中心节点的互联,某局点与中心节点连接示意图如下:
在S省节点,客户反馈访问总部的业务很慢,通过Ping检测发现网络有不规律丢包,工程师查看S 省节点路由器E1接口上有大量的CRC错误,如下:
<RT_3016_1>disp int ser 5/1。
Last clearing of counters: Never
Last 300 seconds input rate 0.00 bytes/sec, 0 bits/sec, 0.00 packets/sec
Last 300 seconds output rate 0.00 bytes/sec, 0 bits/sec, 0.00 packets/sec
Input: 57433 packets, 2314250 bytes
0 broadcasts, 0 multicasts
57338 errors, 0 runts, 0 giants
46901 CRC, 23 align errors, 0 overruns
0 dribbles, 0 aborts, 0 no buffers
10414 frame errors
Output:211 packets, 49547 bytes
0 errors, 0 underruns, 0 collisions
0 deferre
根据如上的输出信息,工程师认定是线路问题,于是客户协调运营商排查线路,但是运营商经过一个星期的艰苦卓绝的辛苦工作,非常确认线路没有问题。
运营商为了证实自己的线路没有问题,自己携带了一台新的路由器替换S省节点客户的MSR路由器,替换的结果让所有的人意外,替换后,网络不再有丢包!看起来CRC错误并不一定是线路的问题?难道问题是MSR路由器引发的?工程师仔细检查了两台设备环境的不同之处,发现最大的区别是MSR路由器接地了,而新替换的路由器没有接地而且客户机房中的光端机以及其他传输设备都没有接地,那么意味着MSR与网络中的其他设备不共地,由于电磁干扰对E1线路影响较大,因此工程师确认是接地因此的丢包问题,于是在现场将MSR路由器上的接地取消后,网络不再丢包。
TIPS:对于网络设备,最好全部共地,避免由于不共地而引起的丢包,而在雷雨较多的南方城市,接地更是强制的,而在北方地区由于气候干燥,那么静电引起的丢包或者其他问题对网扩设备影响较大;对于E1线路引发的丢包问题,一般可以从三方面着手,一是可以通过打环,二是确认E1或者CPOS的时钟设置、三是接口CRC或者是其他字段的参数设置是否一致;而如果是POS链路问题,那么要查看Pos接口的字段C2、j0以及加扰设置是否一致。
4 网络丢包惨案—案例3
某客户的对外服务办公网络通过大量二层交换机连接终端,这些终端对外提供实时服务,而所有的二层交换机都通过双上行的方式连接到核心交换机上,客户网络示意图如下:
客户的网络是局域网典型网络结构,整个网络通过STP来避免环路并实现双上行链路备份,整个网络设计合理规范,但是突然有段时间客户反馈下面的终端业务办理很慢,而且有时断时续的现象。
工程师首先明确网络现象,确认网络中所有的终端业务都受到影响,因此工程师怀疑网络中有环路导致引发广播风暴从而影响网络的正常转发。
因此工程师将处于备份状态的一台S7500下行连接业务的端口都断开,断开
后,终端业务恢复,因此可以确认为网络环路导致了业务丢包,但是依然不能具体的问题点在那里。
接下来工程师在晚上网络没业务流量的情况下,对S7500下行连接的L2交换机进行逐个排查,也即逐个将下行的L2交换机上行恢复到双上行结构同时开通过个Ping窗口对业务进行监测。
果不其然,再将某台L2交换局恢复到双上行结构时,Ping业务出现丢包现象。
工程师对该接入L2交换机的接口状态进行查看,发现两个上行端口都处于STP Forwarding状态。
这种情况下必然导致网络环路。
最后工程师确认是光模块硬件问题导致状态错误而引起STP计算错误。
TIPS:对于局域网的问题,由于局域网有大量的L2交换局、HUB以及接入很多终端,因此局域网的问题要特别注意广播风暴引发的全网振荡,而广播风暴的引发的局域网问题,可能是由于环路产生,而ARP Flooding、病毒、非法软件也都有可能引发局域网振荡,对于局域网网络问题建议如下;
à尽可能将L3网关下移,增加路由L3层次的报文处理,减少L2交换层次的连接;
à避免网络中单个VLAN下交换机或者HUB级联层次太多,减少广播风暴以及网络环路的影响;
à在接入终端服务器或者PC的交换机端口上配置STP 边缘端口、BPDU保护;
à全网部署EAD,对接入网络的用户终端强制实施企业安全策略,严格控制终端用户的网络使用行为,有效地加强用户终端的主动防御能力
5 总结
丢包的问题是网络中最常见的问题也是耗费时间最久定位时间较长的问题,以上三个案例基本上涵盖了常见的丢包问题的处理思路,我们在日常的网络维护过程中需要慢慢积累经验,也许丢包也并不那么惹人烦!。