【思维导图】summary_of_knowledge_atlas-数据结构知识点总结
人工智能导论-第2章 逻辑推理3 - 知识图谱

目标谓词只有一个正例ℎ(David, Mike)。
反例在知识图谱中一般不会显式给出,但可从知
识图谱中构造出来。如从知识图谱中已经知道
(David, James)成立,则ℎ(David,
James)可作为目标谓词的一个反例,记为
ෞ− = 0
NA
(, )
ෞ+ = 1
ෞ− = 2
0.74
e(, )
ෞ+ = 0
ෞ− = 1
NA
(, )
ෞ+ =
ෞ− =
1.32
e(, )
ෞ+ = 0
ෞ− =0
NA
e(, )
ෞ+ = 0
ෞ− = 0
ෞ+ = 1
ෞ− = 3
0.32
(, )
ෞ+ = 0
ෞ− = 1
NA
(, )
ෞ+ = 0
ෞ− = 1
NA
(, )
ෞ+ = 0
ෞ− = 0
NA
(, )
ෞ+ = 0
ෞ− = 0
NA
(, )
ෞ+ = 1
ෞ− = 3
0.32
(, )
ෞ+ = 0
ෞ− = 1
NA
(, )
ෞ+ = 0
ෞ− = 1
NA
(, )
ෞ+ = 0
哈工大知识图谱(KnowledgeGraph)课程概述
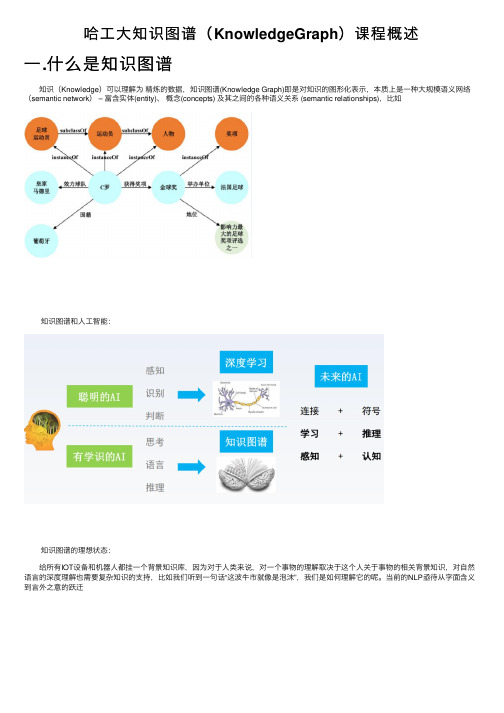
1.知 识 图 谱 中 的 概 念
实体 (entity):现实世界中可区分、可识别的事物或概念。 ➢ 客观对象:人物、地点、机构 ➢ 抽象事件:电影、奖项、赛事 关系 (relation):实体和实体之间的语义关联。 事实 (fact):陈述两个实体之间关系的断言,通常表示为 (head entity, relation, tail entity) 三元组形式。
四 .实体识别
1.信 息 抽 取
概念:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息, 并形成结构化数据输出的文本处理技术
主要任务:实体识别与抽取,关系抽取,时间抽取,实体消歧
2.命 名 实 体 识 别 ( Named Entity Recognition, 简 称 NER)
定义:狭义地讲,命名实体指现实世界中具体或抽象的实体 , 如人(张三)、机构(哈尔滨工业大学)、地点等,通常用唯一的标志符(专 有名称)表示。
Ontology(本体):通过对概念的严格定义和概念与概念之间的关系来确定概念的精确含义,表示共同认可的、可共享的知识,对于 ontology来说,author,creator和writer是同一个 概念,而doctor在大学和医院分别表示的是两个概念。因 此在语义网中,ontology具有非常 重要的地位,是解决语义层次上Web信息共享和交换的基础。简单理解就是某个领域关于自身和相关关系的描述
2.知 识 图 谱 的 特 性
知识图谱不太专注于对知识框架的定义,而专注于如何以工程的方式,从文本中自动抽取或依靠众包的方式获取并 组建广泛的、具有平铺结 构的知识实例,最后再要求使用 它的方式具有容错、模糊匹配等机制。 知识图谱的真正魅力在于其图结构,可以在知识图谱上运行搜索、 随机游走、网络流等大规模图算法,使知识图谱与图论、概率图等碰撞出火花。
1.通俗易懂解释知识图谱(KnowledgeGraph)

1.通俗易懂解释知识图谱(KnowledgeGraph)1. 前⾔从⼀开始的Google搜索,到现在的聊天机器⼈、⼤数据风控、证券投资、智能医疗、⾃适应教育、推荐系统,⽆⼀不跟知识图谱相关。
它在技术领域的热度也在逐年上升。
本⽂以通俗易懂的⽅式来讲解知识图谱相关的知识、尤其对从零开始搭建知识图谱过程当中需要经历的步骤以及每个阶段需要考虑的问题都给予了⽐较详细的解释。
知识图谱( Knowledge Graph)的概念由⾕歌2012年正式提出,旨在实现更智能的搜索引擎,并且于2013年以后开始在学术界和业界普及。
⽬前,随着智能信息服务应⽤的不断发展,知识图谱已被⼴泛应⽤于智能搜索、智能问答、个性化推荐、情报分析、反欺诈等领域。
另外,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并且形成⼀套Web语义知识库。
知识图谱以其强⼤的语义处理能⼒与开放互联能⼒,可为万维⽹上的知识互联奠定扎实的基础,使Web 3.0提出的“知识之⽹”愿景成为了可能。
2. 知识图谱定义知识图谱:是结构化的语义知识库,⽤于迅速描述物理世界中的概念及其相互关系。
知识图谱通过对错综复杂的⽂档的数据进⾏有效的加⼯、处理、整合,转化为简单、清晰的“实体,关系,实体”的三元组,最后聚合⼤量知识,从⽽实现知识的快速响应和推理。
知识图谱有⾃顶向下和⾃底向上两种构建⽅式。
所谓⾃顶向下构建是借助百科类⽹站等结构化数据源,从⾼质量数据中提取本体和模式信息,加⼊到知识库中;所谓⾃底向上构建,则是借助⼀定的技术⼿段,从公开采集的数据中提取出资源模式,选择其中置信度较⾼的新模式,经⼈⼯审核之后,加⼊到知识库中。
看⼀张简单的知识图谱:如图所⽰,你可以看到,如果两个节点之间存在关系,他们就会被⼀条⽆向边连接在⼀起,那么这个节点,我们就称为实体(Entity),它们之间的这条边,我们就称为关系(Relationship)。
aai09知识发现和数据挖掘1高级人工智能史忠植

2019/11/13
高级人工智能 史忠植
25
2019/11/13
高级人工智能 史忠植
26
2019/11/13
高级人工智能 史忠植
27
2019/11/13
高级人工智能 史忠植
28
2019/11/13
高级人工智能 史忠植
29
关联规则发现注意的问题
充分理解数据 目标明确 数据准备工作要做好 选取适当的最小的支持度和可信度 很好地理解关联规则
第九章 知识发现和数据挖掘
数据库中知识发现
史忠植 中科院计算所
2019/11/13
高级人工智能 史忠植
1
知识发现 关联规则 数据仓库 知识发现工具
2019/11/13
高级人工智能 史忠植
2
知识发现
知识发现是指从数据集中抽取和精炼新的模式。 范围非常广泛:经济、工业、农业、军事、社会 数据的形态多样化:数字、符号、图形、图像、声音 数据组织各不相同:结构化、半结构化和非结构 发现的知识可以表示成各种形式
2019/11/13
高级人工智能 史忠植
30
关联规则发现使用步骤
连接数据,做数据准备 给定最小支持度和最小可信度,利用知识发 现工具提供的算法发现关联规则 可视化显示、理解、评估关联规则
2019/11/13
高级人工智能 史忠植
31
关联规则在保险业务中的应用
最小支持度1%,最小可信度为50%
成的,内容相对稳定的、不同时间的数据集合,用以 支持经营管理中的决策制定过程。
2019/11/13
高级人工智能 史忠植
37
数据仓库的特征(1)
数据仓库中的数据是面向主题的
知识图谱-基础概念梳理

知识图谱-基础概念梳理计算机专业刚⼊坑知识图谱,我⼤概是这种状态:这⾥主要是为了开发时看懂需求,所以不做深⼊了解。
不过没办法- -从概念开始慢慢来吧。
1. 什么是知识图谱:知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显⽰知识发展进程与结构关系的⼀系列各种不同的图形,⽤可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显⽰知识及它们之间的相互联系。
个⼈理解就是展⽰复杂知识资源相互联系的⼀图形结构2. RDF:资源描述框架(Resource Description Framework)(知识表⽰的⼀种⽅式)知识图谱是展⽰资源相互联系的结构,所以⾸先要能描述资源,以及资源的联系。
然后通过各种处理来发现其中的直接关系(我们⽤RDF已经存储的)和可能的隐藏关系(推导出来的)。
最简单的应⽤:你淘宝搜个卫⽣⼱,然后淘宝知识图谱⾥:卫⽣⼱是⼤姨妈的 “需要” 属性之⼀,⼤姨妈的其他 “需要” 属性还包含了:绿⾖汤,卫⽣棉,热⽔壶。
然后你第⼆天就发现你的淘宝主页上各种暖⽔壶,卫⽣棉,绿⾖汤。
或者:特朗普是美国总统,特朗普是房地产商 -》美国总统是⼀个房地产商然后进⼀步推导出别的隐藏关系。
资源(Resource):所有以RDF表⽰法来描述的东西都叫做资源,它可能是⼀个⽹站,可能是⼀个⽹页,可能只是⽹页中的某个部分,甚⾄是不存在于⽹络的东西,如纸本⽂献、器物、⼈等。
在RDF中,资源是以统⼀资源标识(URI,Uniform Resource Indentifiers)来命名,统⼀资源定位器(URL,Uniform Resource Locators)、统⼀资源名称(URN,Uniform Resource Names)都是URI的⼦集。
属性(Properties):属性是⽤来描述资源的特定特征或关系,每⼀个属性都有特定的意义,⽤来定义它的属性值(Value)和它所描述的资源形态,以及和其它属性的关系。
知识图谱技术原理介绍

知识图谱技术原理介绍近两年来,随着Linking Open Data1等项目的全面展开,语义Web数据源的数量激增,大量RDF数据被发布。
互联网正从仅包含网页和网页之间超链接的文档万维网(Document Web)转变成包含大量描述各种实体和实体之间丰富关系的数据万维网(Data Web)。
在这个背景下,Google、百度和搜狗等搜索引擎公司纷纷以此为基础构建知识图谱,分别为Knowledge Graph、知心和知立方,来改进搜索质量,从而拉开了语义搜索的序幕。
下面我将从以下几个方面来介绍知识图谱:知识图谱的表示和在搜索中的展现形式,知识图谱的构建和知识图谱在搜索中的应用等,从而让大家有机会了解其内部的技术实现和各种挑战。
知识图谱的表示和在搜索中的展现形式正如Google的辛格博士在介绍知识图谱时提到的:“The world is not made of strings , but is made of things.”,知识图谱旨在描述真实世界中存在的各种实体或概念。
其中,每个实体或概念用一个全局唯一确定的ID来标识,称为它们的标识符(identifier)。
每个属性-值对(attribute-value pair,又称A VP)用来刻画实体的内在特性,而关系(relation)用来连接两个实体,刻画它们之间的关联。
知识图谱亦可被看作是一张巨大的图,图中的节点表示实体或概念,而图中的边则由属性或关系构成。
上述图模型可用W3C提出的资源描述框架RDF2或属性图(property graph)3来表示。
知识图谱率先由Google提出,以提高其搜索的质量。
为了更好地理解知识图谱,我们先来看一下其在搜索中的展现形式,即知识卡片(又称Knowledge Card)。
知识卡片旨在为用户提供更多与搜索内容相关的信息。
更具体地说,知识卡片为用户查询中所包含的实体或返回的答案提供详细的结构化摘要。
从某种意义来说,它是特定于查询(query specific)的知识图谱。
中文知识图谱体系获取与服务

• 知识服务
– Semantic Parsing – 知识推理
谢谢
规则所产生的训练语料规模: Top1+无最近邻 12.8 MB Top1+最近邻 12.8 MB Top5+无最近邻 25.4 MB Top5+最近邻 25.4 MB
在大数据环境下,细致的处理不再重要 训练语料量的增加比训练语料质的提升更为重要
知识服务
已有的知识服务:检索与问答
基于知识图谱的检索或问答的核 心问题:Semantic Parsing
Solution:建立框架?
• 是否需要建立知识体系的框架
– 已有的体系框架
• GeoNames/DBpedia Ontology/TexonConcept Ontology • KOS/
– 的翻译和扩展
• 体系覆盖度不足,局限于英文 • 细致化不足
– 百科知识描述体系的制订
Types
Chinese English
2000 1985 1984 2007 2007 2007
Manual
Common Sense Knowledge
Automatic
Common Sense Knowledge + Factual Knowledge
Crowding Sourcing
知识工程:三个层面问题
– 构建知识图谱不需要正确识别每个句子中的实体关系 – 充分利用网络数据的冗余特性
• 根据数据源、文本信息结构的置信度进行投票
• 中文 vs. 英文
– 中文文本缺乏严格的句法信息
• Yao Ming was born in 1980. • 姚明,1980,上海人,篮球运动员…….
知识图谱———— 机器学习基础

• 它目前是人工智能的核心,是使计算机具有智能的根本途径,其应用 遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎
机器学习
机器学习主要是研究如何使计算机从给定的数据中学习规律,即从观测数据 (样本)中寻找规律,并利用学习到的规律(模型)对未知或无法观测的数据 进行预测。目前,主流的机器学习算法是基于统计的方法,也叫统计机器学习
损失函数
Hinge 损失函数 对于两类分类问题,假设 y 和 f (x,θ ) 的取值为 {−1,+1}。Hinge 损失函数(Hinge Loss Function)的定义如下:
L ( y, f ( x,θ )) = max (0,1− yf ( x,θ ))
= 1− yf ( x,θ ) +
过拟合 overfitting
训练集
开发集
测试集
机器学习问题类型
回归(Regression) y 是连续值(实数或连续整数),f (x) 的输出也是连续值。 这种类型的问题就是回归问题。对于所有已知或未知的 (x, y),使得 f (x,θ ) 和 y 尽可能地一致。损函数通常定义为平方误差。
分类(Classification) y 是离散的类别标记(符号),就是分类问题。损失 函数有一般用 0-1 损失函数或负对数似然函数等。在分类问题中,通过学习 得到的决策函数 f (x,θ ) 也叫分类器。
结构风险最小化原则
为了解决过拟合问题,一般在经验风险最小化的原则上加参数的正则化(Regularization), 也叫结构风险最小化原则(Structure Risk Minimization)。
第七章 知识图谱

之间的关系(实体的命名、称谓、英文 名等)以及词汇之间的关系(同义关系、 反义关系、缩略词关系、上下位词关系 等)。例如,(“Plato”,中文名,柏 拉图)、(赵匡胤,庙号,宋太祖)、 (妻子,同义,老婆)。
(4)常识知识
常识是人类通过身体与世界交互而积累
的经验与知识,是人们在交流时无须言明就 能理解的知识。例如,我们都知道鸟有翅膀、 鸟能飞等;又如,如果X 是一个人,则X要么 是男人要么是女人。常识知识的获取是构建 知识图谱时的一大难点。
知识表示学习主要是面向知识图谱中的
实体和关系进行表示学习,使用建模方法将 实体和向量表示在低维稠密向量空间中,然 后进行计算和推理。
知识是人类在认识和改造客观世界的过程 中总结出的客观事实、概念、定理和公理的 集合。知识具有不同的分类方式,例如,按 照知识的作用范围可分为常识性知识与领域 性知识。知识表示是将现实世界中存在的知 识转换成计算机可识别和处理的内容,是一 种描述知识的数据结构,用于对知识的描述 或约定。
实体抽取的方法主要有基于规则与词典的方法、 基于机器学习的方法以及面向开放域的抽取方法。
关系抽取
关系抽取的目标是抽取语料中命名实体的语义关 系。实体抽取技术会在原始的语料上标记一些命名 实体。为了形成知识结构,还需要从中抽取命名实 体间的关联信息,从而利用这些信息将离散的命名 实体连接起来,这就是关系抽取技术。
象看本质,准确地捕捉到用户的真实意图,并依此来进行搜索,从而更准确地向用户返回 最符合其需求的搜索结果。 (8)知识库问答系统在回答用户问题时,需要正确理解用户所提出的自然语言问题,抽取其 中的关键语义信息,然后在已有单个或多个知识库中通过检索、推理等手段获取答案并返 回给用户。
知识图谱总结规律(热门4篇)

知识图谱总结规律(热门4篇)知识图谱总结规律第1篇构成知识图谱的核心是三元组:实体(Entity)、属性(Attribute)和关系(Relation),可以表示为 <实体1,关系,实体2> 或 <实体1,属性1,属性值1>,例如:;<人工智能公司,subclass,高料技公司>基于已有的知识图谱三元组,可以推导出新的关系。
例如:<翅膀 part-of 鸟>,<麻雀kind-of 鸟>,可以推导出<翅膀 part-of 麻雀>。
知识图谱的分类通用知识图谱实际上是谷歌或者百度这样的大型的互联网公司在构建的,它主最主要是用于它的搜索引擎,它面向的是通用领域,它的用户是全部的互联网的用户,它构建常识性的知识为主,包括结构化的百科知识,它强调的更多的是一种知识的广度,对知识的深度方面不做更多的要求,它的使用者也是普通的用户。
行业知识图谱面向一个特定的领域,它的数据来源是来源于特定行业的语料,它是基于行业的数据来构建,而且要有一定的行业的深度,它强调的是更多的是深度,而不是广度,能够解决行业人员的问题,它的使用者也是这个行业内的从业人员,或是这个领域里面的专业人员来使用。
通用知识图谱和行业知识图谱,个并不是说完全互相独立的,是具有互相互补性的关系。
一方面,通用知识图谱会不断的吸纳行业或者领域知识图谱的知识,来扩充它的知识面,然后增加它的知识的广度。
同时,我们在构建一个行业知识图谱或者领域知识图谱的时候,实际上也并不是说只局限在这个领域的基本的数据,我们同时还要去通用知识图谱里面去吸纳更多的常识性的知识来作为补充,只有这样才能构成一个非常完整的行业知识图谱。
知识图谱总结规律第2篇知识图谱:是一种结构化的语义知识库,用来所描述物理世界中的概念和物理关系。
“The world is not made of strings , but is made of things.”——辛格博士,from Google.辛格尔博士对知识图谱的介绍很简短:things,not string。
什么是知识图谱(KnowledgeGraphVault)?

什么是知识图谱(KnowledgeGraphVault)?
什么是知识图谱?
知识图谱(Knowledge Graph/Vault)又称为科学知识图谱,其本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。
在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。
知识图谱是关系的最有效的表示方式。
通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。
知识图谱提供了从“关系”的角度去分析问题的能力。
知识图谱这个概念最早由Google提出,主要是用来优化现有的搜索引擎。
不同于基于关键词搜索的传统搜索引擎,知识图谱可用来更好地查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。
比如在Google的搜索框里输入Bill Gates的时候,搜索结果页面的右侧还会出现Bill Gates相关的信息比如出生年月,家庭情况等等。
知识图谱与本体
知识图谱并不是本体的替代品,它是在本体的基础上进行了丰富和扩充,这种扩充主要体现在实体(Entity)层面。
本体中突出和强调的是概念以及概念之间的关联关系,而知识图谱则是在本体的基础上,增加了更加丰富的关于实体的信息。
本体描述了知识图谱的数据模式(schema),即为知识图谱构建数据模式相当于为其建立本体。
知识图谱助力人工智能。