多表连接处理查询结果
MybatisPlus多表连接查询的问题及解决方案

MybatisPlus多表连接查询的问题及解决⽅案⽬录⼀、序⾔(⼀)背景内容(⼆)场景说明(三)前期准备⼆、⼀对⼀查询(⼀)查询单条记录(⼆)查询多条记录三、⼀对多查询(⼆)查询多条记录(三)查询多条记录(分页)四、多对多查询(⼀)查询单条记录五、总结与拓展(⼀)总结(⼆)拓展⼀、序⾔(⼀)背景内容软件应⽤技术架构中DAO层最常见的选型组件为MyBatis,熟悉MyBatis的朋友都清楚,曾⼏何时MyBatis是多么的风光,使⽤XML⽂件解决了复杂的数据库访问的难题。
时⾄今⽇,曾经的屠龙者终成恶龙,以XML⽂件为基础的数据库访问技术变得臃肿、复杂,维护难度直线上升。
MybatisPlus对常见的数据库访问进⾏了封装,访问数据库⼤⼤减少了XML⽂件的依赖,开发者从臃肿的XML⽂件中获得了较⼤限度的解脱。
MybatisPlus官⽅并没有提供多表连接查询的通⽤解决⽅案,然⽽连接查询是相当普遍的需求。
解决连接查询有两种需求,⼀种是继续使⽤MyBatis提供XML⽂件解决⽅式;另⼀种本⽂提供的解决⽅案。
事实上笔者强烈推荐彻底告别通过XML访问数据库,并不断探索新式更加友好、更加⾃然的解决⽅式,现分享最新的MybatisPlus技术的研究成果。
(⼆)场景说明为了说明连接查询的关系,这⾥以学⽣、课程及其关系为⽰例。
(三)前期准备此部分需要读者掌握以下内容:Lambda 表达式、特别是⽅法引⽤;函数式接⼝;流式运算等等,否则理解起来会有些吃⼒。
实体类与 Vo 的映射关系,作者创造性的引⼊特别构造器,合理利⽤继承关系,极⼤的⽅便了开发者完成实体类向 Vo 的转换。
空指针异常忽略不处理,借助类实现,详情移步查看。
⼆、⼀对⼀查询⼀对⼀查询最典型的应⽤场景是将id替换成name,⽐如将userId替换成userName。
(⼀)查询单条记录查询单条记录是指返回值仅有⼀条记录,通常是以唯⼀索引作为条件的返回查询结果。
1、⽰例代码/*** 查询单个学⽣信息(⼀个学⽣对应⼀个部门)*/public UserVo getOneUser(Integer userId) {LambdaQueryWrapper<User> wrapper = mbdaQuery(User.class).eq(User::getUserId, userId);// 先查询⽤户信息User user = userMapper.selectOne(wrapper);// 转化为VoUserVo userVo = Optional.ofNullable(user).map(UserVo::new).orElse(null);// 从其它表查询信息再封装到VoOptional.ofNullable(userVo).ifPresent(this::addDetpNameInfo);return userVo;}附属表信息补充/*** 补充部门名称信息*/private void addDetpNameInfo(UserVo userVo) {LambdaQueryWrapper<Dept> wrapper = mbdaQuery(Dept.class).eq(Dept::getDeptId, userVo.getDeptId());Dept dept = deptMapper.selectOne(wrapper);Optional.ofNullable(dept).ifPresent(e -> userVo.setDeptName(e.getDeptName()));}2、理论分析查询单个实体共分为两个步骤:根据条件查询主表数据(需处理空指针异常);封装 Vo 并查询附属表数据。
sql:多表连接查询

sql:多表连接查询主要分为内连接、外连接。
外连接⼜分left outer join、right outer join、full outer join。
区别如下:1. INNER JOIN只返回同时存在于两张表的⾏数据,由于students表的class_id包含1,2,3,classes表的id包含1,2,3,4,所以,INNER JOIN根据条件s.class_id = c.id返回的结果集仅包含1,2,3。
2. RIGHT OUTER JOIN返回右表都存在的⾏。
如果某⼀⾏仅在右表存在,那么结果集就会以NULL填充剩下的字段。
3. LEFT OUTER JOIN则返回左表都存在的⾏。
如果我们给students表增加⼀⾏,并添加class_id=5,由于classes表并不存在id=5的⾏,所以,LEFT OUTER JOIN的结果会增加⼀⾏,对应的class_name是NULL:内连接inner join写法:select s.id,,s.classid from tbl_stu s inner join tbl_class c on s.classid = c.id1. 先确定主表,仍然使⽤FROM <表1>的语法;2. 再确定需要连接的表,使⽤INNER JOIN <表2>的语法;3. 然后确定连接条件,使⽤ON <条件...>,这⾥的条件是s.class_id = c.id,表⽰students表的class_id列与classes表的id列相同的⾏需要连接;4. 可选:加上WHERE⼦句、ORDER BY等⼦句。
假设查询语句是:SELECT ... FROM tableA JOIN tableB ON tableA.column1 = tableB.column2;我们把tableA看作左表,把tableB看成右表,那么INNER JOIN是选出两张表都存在的记录:LEFT OUTER JOIN是选出左表存在的记录:RIGHT OUTER JOIN是选出右表存在的记录:FULL OUTER JOIN则是选出左右表都存在的记录:JOIN查询需要先确定主表,然后把另⼀个表的数据“附加”到结果集上;INNER JOIN是最常⽤的⼀种JOIN查询,它的语法是SELECT ... FROM <表1> INNER JOIN <表2> ON <条件...>;JOIN查询仍然可以使⽤WHERE条件和ORDER BY排序。
MySQL多表查询合并结果unionall,内连接查询

MySQL多表查询合并结果unionall,内连接查询MySQL多表查询合并结果和内连接查询1、使⽤union和union all合并两个查询结果:select 字段名 from tablename1 union select 字段名 from tablename2;注意这个操作必须保证两张表字段相同,字段数据类型也相同,再针对结果统⼀排序操作等。
另外,使⽤union的时候会去除重复(相同)的记录?,⽽union all则不会。
create table table_newselect * from(SELECT * FROM DB.table1union allSELECT * FROM DB.table2) as tgroup by key1,key2 collate utf8_binorder by key1,key2;1. 在数据库查询中,默认是不区分⼤⼩写的。
那如何让查询结果区分⼤⼩写呢?collate utf8_bin放在like前后都可以。
2. select * from user where name like "A\%B%" collate utf8_bin;或者 select * from user where name collate utf8_bin like "A\%B%" ;注:下边的⼏个连接查询涉及到笛卡尔积的概念,即如果存在两张表,第⼀张记录数为n条,另⼀张表的记录数为m条,那么笛卡尔积得出的记录数就是n*m条;如果第⼀张表的字段数为a个,另⼀张的字段数为b个,则笛卡尔积得出的字段数就是a+b个。
2、使⽤natural join⾃然连接:前提是两张表有相同的字段:(这个操作会去掉重复的字段)对于这个查询,我的理解是:保留这两张表中关联字段(例如这⾥的depart_id)都存在的数据,去掉只有⼀个表中有的:如上述内容中,company中有四条数据,⽽emp中有7条,结果不论哪个放前边都只出来六条,因为company中depart_id为4的,emp中没有,⽽emp中depart_id为5的,company中⼜没有。
sql多表查询语句案例

sql多表查询语句案例
当涉及到多表查询时,可以使用 SQL 的 JOIN 语句将多个表连接起来,并
根据指定的条件进行筛选和聚合操作。
下面是一个示例的 SQL 多表查询语句,它展示了如何将多个表连接起来并执行查询:
```sql
SELECT , ,
FROM table1 A
JOIN table2 B ON =
JOIN table3 C ON =
WHERE = 'value'
AND = 'value'
AND = 'value';
```
在这个示例中,我们使用了三个表:table1、table2 和 table3。
通过 JOIN 语句将它们连接起来,并根据指定的条件进行筛选。
在 SELECT 子句中,我们选择了需要查询的列,并使用表别名(A、B、C)来引用这些列。
在WHERE 子句中,我们指定了筛选条件,限制查询结果只返回满足条件的行。
请注意,这只是一个示例查询语句,具体的表名、列名和条件需要根据实际情况进行调整。
在实际应用中,多表查询语句的编写需要根据具体的业务需求和数据结构进行设计。
多表关联查询语句

多表关联查询语句多表关联查询是数据库中常用的一种查询方式,它可以通过关联多个表来获取更加复杂的查询结果。
下面将列举一些常见的多表关联查询语句,以及它们的应用场景。
1. 内连接查询:SELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column;这种查询会返回两个表中满足连接条件的数据行,适用于需要同时查询两个表中的数据的场景。
2. 左连接查询:SELECT * FROM table1 LEFT JOIN table2 ON table1.column = table2.column;左连接查询会返回左表中所有的数据行,以及满足连接条件的右表数据行,适用于需要查询左表的所有数据,并根据连接条件获取右表数据的场景。
3. 右连接查询:SELECT * FROM table1 RIGHT JOIN table2 ON table1.column = table2.column;右连接查询会返回右表中所有的数据行,以及满足连接条件的左表数据行,适用于需要查询右表的所有数据,并根据连接条件获取左表数据的场景。
4. 外连接查询:SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.column = table2.column;外连接查询会返回两个表中所有的数据行,无论是否满足连接条件,适用于需要查询两个表中的所有数据的场景。
5. 自连接查询:SELECT * FROM table1 t1 INNER JOIN table1 t2 ON t1.column = t2.column;自连接查询是指将同一个表作为两个不同的表进行连接查询,适用于需要查询同一个表中不同行之间的关系的场景。
6. 多表连接查询:SELECT * FROM table1 INNER JOIN table2 ON table1.column1 = table2.column1 INNER JOIN table3 ON table2.column2 = table3.column2;多表连接查询可以连接多个表,通过多个连接条件获取多个表中的数据行,适用于需要查询多个表之间复杂关系的场景。
多表查询的方法

多表查询的方法
多表查询是指在查询中同时涉及多张表,有时候需要将多张表之间的数据进行关联,以便获取更全面准确的数据结果。
实现多表查询的方法如下:
1.使用JOIN操作符:通过JOIN操作符可以将多张表中的数据连接起来,根据关联字段进行匹配。
JOIN操作符分为多种类型,包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
2.使用子查询:可以在FROM子句中使用子查询,将子查询的结
果作为主查询的一个表参与查询,实现多表查询的效果。
3.使用UNION操作符:如果需要在多张表中查询相同的数据结构,可以使用UNION操作符将多个SELECT语句的结果合并成一个结果集。
4.使用视图:可以将多张表的数据通过视图进行整合,并且在查询时只需要调用视图即可,不需要直接操作多张表,实现了更好的数据隔离。
以上是实现多表查询的主要方法,需要根据实际情况选择合适的方法,以便获取更准确全面的数据结果。
- 1 -。
使用MySQL进行跨表查询的方法

使用MySQL进行跨表查询的方法在进行数据库开发和数据处理的过程中,经常会遇到需要查询多个数据表之间关联信息的情况,这就是跨表查询。
MySQL作为一种常用的关系型数据库管理系统,提供了多种灵活的方法来实现跨表查询。
本文将介绍一些常用的方法和技巧,帮助读者更好地应对这类问题。
一、使用JOIN语句关联多个数据表JOIN是最常见也是最常用的方法之一,通过它可以将多个数据表以某种关联条件进行连接,然后将符合条件的结果返回。
在MySQL中,JOIN语句有几种不同的形式,包括INNER JOIN、LEFT JOIN、RIGHT JOIN等,可以根据实际需要来选择合适的形式。
例如,我们有两个数据表,一个是学生表,包含学生的学号和姓名等信息;另一个是成绩表,包含学生的学号和对应科目的成绩。
我们想要查询出每个学生的姓名和对应的数学成绩,可以使用如下语句:```SELECT s.姓名, c.数学成绩FROM 学生表 sJOIN 成绩表 cON s.学号 = c.学号```这里通过ON关键字指定了学生表和成绩表之间的关联条件,即学生表的学号字段等于成绩表的学号字段。
这样,查询结果将会返回每个学生的姓名和对应的数学成绩。
二、使用子查询进行跨表查询除了使用JOIN语句外,还可以使用子查询的方法进行跨表查询。
子查询是指将一个查询嵌套在另一个查询中,可以将内部查询的结果作为外部查询的条件或者返回结果。
在跨表查询中,可以使用子查询来获取一个数据表的部分数据,然后将其作为另一个查询的条件进行进一步的筛选或匹配。
例如,我们有一个订单表和一个商品表,想要查询出所有已经下单但尚未发货的商品信息。
可以使用如下语句:```SELECT *FROM 商品表WHERE 商品编号 IN (SELECT 商品编号 FROM 订单表 WHERE 状态 = '下单') ```这里将内部查询的结果作为外部查询的条件,即在商品表中筛选出那些商品编号在订单表中状态为下单的记录。
sql语句去除重复记录(多表连接的查询)

sql语句去除重复记录(多表连接的查询)--处理表重复记录(查询和删除)/******************************************************************************************************************************************************1、Num、Name相同的重复值记录,没有⼤⼩关系只保留⼀条2、Name相同,ID有⼤⼩关系时,保留⼤或⼩其中⼀个记录******************************************************************************************************************************************************/--1、⽤于查询重复处理记录(如果列没有⼤⼩关系时2000⽤⽣成⾃增列和临时表处理,SQL2005⽤row_number函数处理)--> --> ⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table#TGoCreate table#T([ID] int,[Name] nvarchar(1),[Memo] nvarchar(2))Insert#Tselect1,N'A',N'A1'union allselect2,N'A',N'A2'union allselect3,N'A',N'A3'union allselect4,N'B',N'B1'union allselect5,N'B',N'B2'Go--I、Name相同ID最⼩的记录(推荐⽤1,2,3),⽅法3在SQl05时,效率⾼于1、2⽅法1:Select* from#T a where not exists(select1 from#T where Name= and ID<a.ID)⽅法2:select a.* from#T a join(select min(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID⽅法3:select* from#T a where ID=(select min(ID) from#T where Name=)⽅法4:select a.* from#T a join#T b on = and a.ID>=b.ID group by a.ID,,a.Memo having count(1)=1⽅法5:select* from#T a group by ID,Name,Memo having ID=(select min(ID)from#T where Name=)⽅法6:select* from#T a where(select count(1) from#T where Name= and ID<a.ID)=0⽅法7:select* from#T a where ID=(select top1 ID from#T where Name= order by ID)⽅法8:select* from#T a where ID!>all(select ID from#T where Name=)⽅法9(注:ID为唯⼀时可⽤):select* from#T a where ID in(select min(ID) from#T group by Name)--SQL2005:⽅法10:select ID,Name,Memo from(select*,min(ID)over(partition by Name) as MinID from#T a)T where ID=MinID⽅法11:select ID,Name,Memo from(select*,row_number()over(partition by Name order by ID) as MinID from#T a)T where MinID=1⽣成结果:/*ID Name Memo----------- ---- ----1 A A14 B B1(2 ⾏受影响)*/--II、Name相同ID最⼤的记录,与min相反:⽅法1:Select* from#T a where not exists(select1 from#T where Name= and ID>a.ID)⽅法2:select a.* from#T a join(select max(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID order by ID⽅法3:select* from#T a where ID=(select max(ID) from#T where Name=) order by ID⽅法4:select a.* from#T a join#T b on = and a.ID<=b.ID group by a.ID,,a.Memo having count(1)=1⽅法5:select* from#T a group by ID,Name,Memo having ID=(select max(ID)from#T where Name=)⽅法6:select* from#T a where(select count(1) from#T where Name= and ID>a.ID)=0⽅法7:select* from#T a where ID=(select top1 ID from#T where Name= order by ID desc)⽅法8:select* from#T a where ID!<all(select ID from#T where Name=)⽅法9(注:ID为唯⼀时可⽤):select* from#T a where ID in(select max(ID) from#T group by Name)--SQL2005:⽅法10:select ID,Name,Memo from(select*,max(ID)over(partition by Name) as MinID from#T a)T where ID=MinID⽅法11:select ID,Name,Memo from(select*,row_number()over(partition by Name order by ID desc) as MinID from#T a)T where MinID=1⽣成结果2:/*ID Name Memo----------- ---- ----3 A A35 B B2(2 ⾏受影响)*/--2、删除重复记录有⼤⼩关系时,保留⼤或⼩其中⼀个记录--> --> ⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table#TGoCreate table#T([ID] int,[Name] nvarchar(1),[Memo] nvarchar(2))Insert#Tselect1,N'A',N'A1'union allselect2,N'A',N'A2'union allselect3,N'A',N'A3'union allselect4,N'B',N'B1'union allselect5,N'B',N'B2'Go--I、Name相同ID最⼩的记录(推荐⽤1,2,3),保留最⼩⼀条⽅法1:delete a from#T a where exists(select1 from#T where Name= and ID<a.ID)⽅法2:delete a from#T a left join(select min(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID where b.Id is null⽅法3:delete a from#T a where ID not in(select min(ID) from#T where Name=)⽅法4(注:ID为唯⼀时可⽤):delete a from#T a where ID not in(select min(ID)from#T group by Name)⽅法5:delete a from#T a where(select count(1) from#T where Name= and ID<a.ID)>0⽅法6:delete a from#T a where ID<>(select top1 ID from#T where Name= order by ID)⽅法7:delete a from#T a where ID>any(select ID from#T where Name=)select* from#T⽣成结果:/*ID Name Memo----------- ---- ----1 A A14 B B1(2 ⾏受影响)*/--II、Name相同ID保留最⼤的⼀条记录:⽅法1:delete a from#T a where exists(select1 from#T where Name= and ID>a.ID)⽅法2:delete a from#T a left join(select max(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID where b.Id is null⽅法3:delete a from#T a where ID not in(select max(ID) from#T where Name=)⽅法4(注:ID为唯⼀时可⽤):delete a from#T a where ID not in(select max(ID)from#T group by Name)⽅法5:delete a from#T a where(select count(1) from#T where Name= and ID>a.ID)>0⽅法6:delete a from#T a where ID<>(select top1 ID from#T where Name= order by ID desc)⽅法7:delete a from#T a where ID<any(select ID from#T where Name=)select* from#T/*ID Name Memo----------- ---- ----3 A A35 B B2(2 ⾏受影响)*/--3、删除重复记录没有⼤⼩关系时,处理重复值--> --> ⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table#TGoCreate table#T([Num] int,[Name] nvarchar(1))Insert#Tselect1,N'A'union allselect1,N'A'union allselect1,N'A'union allselect2,N'B'union allselect2,N'B'Go⽅法1:if object_id('Tempdb..#') is not nulldrop table#Select distinct* into# from#T--排除重复记录结果集⽣成临时表#truncate table#T--清空表insert#T select* from# --把临时表#插⼊到表#T中--查看结果select* from#T/*Num Name----------- ----1 A2 B(2 ⾏受影响)*/--重新执⾏测试数据后⽤⽅法2⽅法2:alter table#T add ID int identity--新增标识列godelete a from#T a where exists(select1 from#T where Num=a.Num and Name= and ID>a.ID)--只保留⼀条记录goalter table#T drop column ID--删除标识列--查看结果select* from#T/*Num Name----------- ----1 A2 B(2 ⾏受影响)*/--重新执⾏测试数据后⽤⽅法3⽅法3:declare Roy_Cursor cursor local forselect count(1)-1,Num,Name from#T group by Num,Name having count(1)>1declare@con int,@Num int,@Name nvarchar(1)open Roy_Cursorfetch next from Roy_Cursor into@con,@Num,@Namewhile @@Fetch_status=0beginset rowcount @con;delete#T where Num=@Num and Name=@Nameset rowcount 0;fetch next from Roy_Cursor into@con,@Num,@Nameendclose Roy_Cursordeallocate Roy_Cursor--查看结果select* from#T /*Num Name ----------- ----1 A2 B(2 ⾏受影响)*/。
SQL多表连接查询(具体实例)

SQL多表连接查询(具体实例)本⽂主要列举两张和三张表来讲述多表连接查询。
新建两张表:表1:student 截图例如以下:表2:course 截图例如以下:(此时这样建表仅仅是为了演⽰连接SQL语句。
当然实际开发中我们不会这样建表,实际开发中这两个表会有⾃⼰不同的主键。
)⼀、外连接外连接可分为:左连接、右连接、全然外连接。
1、左连接 left join 或 left outer joinSQL语句:select * from student left join course on student.ID=course.ID运⾏结果:左外连接包括left join左表所有⾏。
假设左表中某⾏在右表没有匹配。
则结果中相应⾏右表的部分所有为空(NULL).注:此时我们不能说结果的⾏数等于左表数据的⾏数。
当然此处查询结果的⾏数等于左表数据的⾏数,由于左右两表此时为⼀对⼀关系。
2、右连接 right join 或 right outer joinSQL语句:select * from student right join course on student.ID=course.ID运⾏结果:右外连接包括right join右表所有⾏,假设左表中某⾏在右表没有匹配,则结果中相应左表的部分所有为空(NULL)。
注:相同此时我们不能说结果的⾏数等于右表的⾏数。
当然此处查询结果的⾏数等于左表数据的⾏数,由于左右两表此时为⼀对⼀关系。
3、全然外连接 full join 或 full outer joinSQL语句:select * from student full join course on student.ID=course.ID运⾏结果:全然外连接包括full join左右两表中所有的⾏,假设右表中某⾏在左表中没有匹配,则结果中相应⾏右表的部分所有为空(NULL),假设左表中某⾏在右表中没有匹配,则结果中相应⾏左表的部分所有为空(NULL)。
数据库多表查询的几种方法

数据库多表查询的几种方法一个完整而高效的数据库系统必然包含多个表格,并且常常需要进行多表查询以得出完整的数据。
这里将会介绍如下几种多表查询的方法:一、嵌套查询嵌套查询是一种常用的多表查询方法,它将一次查询分成两次或多次,先查出符合某一条件的数据,再将这批数据作为新查询的条件之一。
这种方法可以应对较为复杂的查询需求,但也会造成较大的查询开销。
一般情况下,这种方法在数据量较少、需要进行复杂关联查询的时候使用。
二、联合查询联合查询是一种比较简便的多表查询方法,它可以将多个表格中的数据连接到一起查询。
在进行联合查询时,必须让每个表格的列数、列名以及列类型相同,以便于查询和展示。
三、内部连接查询内部连接查询是一种将两个或多个表格中的数据连接起来的方法。
它会将具有相同值的行合并成一个结果集,但是需要注意的是,不同的内部连接类型也会产生不同的查询结果。
常用的内部连接类型有:等值连接、非等值连接、自连接、自然连接等。
对于内部连接查询,需要注意数据表的主键和外键的对应关系,以便得到准确的查询结果。
四、外部连接查询外部连接查询是一种将两个或多个表格中的数据连接起来的方法。
外部连接查询包含左连接、右连接等不同查询类型。
这种方法是为了查询一些在另一个表中可能没有对应数据的表格数据。
在使用外部连接查询的时候,需要注意数据表的关联关系和数据源的正确性。
五、交叉连接查询交叉连接查询也叫笛卡尔积连接。
它以一张空表格为基础,将多个表格的数据组合起来,得到所有可能的数据组合。
这种查询方法会得到大量的结果,但是很少使用,因为其过于庞大的结果集很难使用。
在使用交叉连接查询时,需要注意数据表的列数和行数,以避免产生数据爆炸的情况。
以上就是多表查询的几种方法,不同的查询方法适用于不同的查询场景,在具体需求中需要选择合适的方法进行查询,以获得最佳的查询结果。
SQL的多表关联查询常用的几种方式
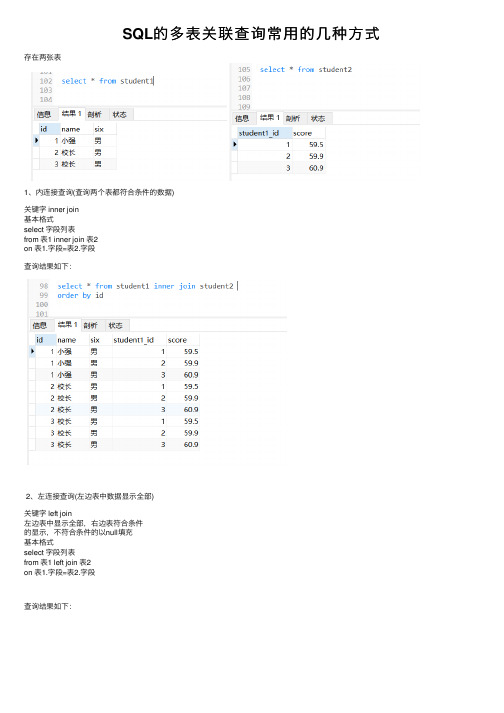
SQL的多表关联查询常⽤的⼏种⽅式存在两张表1、内连接查询(查询两个表都符合条件的数据)关键字 inner join基本格式select 字段列表from 表1 inner join 表2on 表1.字段=表2.字段查询结果如下:2、左连接查询(左边表中数据显⽰全部)关键字 left join左边表中显⽰全部,右边表符合条件的显⽰,不符合条件的以null填充基本格式select 字段列表from 表1 left join 表2on 表1.字段=表2.字段查询结果如下:3、右连接查询(右边表中数据显⽰全部)关键字 right join右表显⽰全部,左表显⽰符合条件的数据,不符合的以null填充基本格式select 字段列表from 表1 right join 表2on 表1.字段=表2.字段查询结果如下:4、union连接select * from a表 union select * from b表; //union连接(前提条件,多个关系表的表字段数⽬必须相同)举例:存在两张表,且表字段数都是两列⽤union查询结果如下:练习题:-- 查询⼀班得分在80分以上的学⽣select * from student stu LEFT JOIN class cl on stu.c_id=cl.Idwhere stu.Score>80 and cl.`Name`='⼀班'-- ⽤⼀条sql语句查询出各个班级的男⽣⼈数和平均分select count(sex) as '男⽣⼈数',avg(Score) as '平均分' from studentwhere sex='男' GROUP BY c_id查找出name中所有相同的名字select * from studentwhere Name in (SELECT name from student GROUP BY name HAVING count(name) >1)。
sql表连接查询使用方法(sql多表连接查询)

sql表连接查询使⽤⽅法(sql多表连接查询)实际的项⽬,存在多张表的关联关系。
不可能在⼀张表⾥⾯就能检索出所有数据。
如果没有表连接的话,那么我们就需要⾮常多的操作。
⽐如需要从A表找出限制性的条件来从B表中检索数据。
不但需要分多表来操作,⽽且效率也不⾼。
⽐如书中的例⼦:复制代码代码如下:SELECT FIdFROM T_CustomerWHERE FName='MIKE'这个SQL语句返回2,也就是姓名为MIKE 的客户的FId值为2,这样就可以到T_Order中检索FCustomerId等于2 的记录:复制代码代码如下:SELECT FNumber,FPriceFROM T_OrderWHERE FCustomerId=2下⾯我们详细来看看表连接。
表连接有多种不同的类型,有交叉连接(CROSS JOIN)、内连接(INNER JOIN)、外连接(OUTTER JOIN)。
(1)内连接(INNER JOIN):内连接组合两张表,并且只获取满⾜两表连接条件的数据。
复制代码代码如下:SELECT o.FId,o.FNumber,o.FPrice,c.FId,c.FName,c .FAgeFROM T_Order o JOIN T_Customer cON o.FCustomerId= c.FId注:在⼤多数数据库系统中,INNER JOIN中的INNER是可选的,INNER JOIN 是默认的连接⽅式。
在使⽤表连接的时候可以不局限于只连接两张表,因为有很多情况下需要联系许多表。
例如,T_Order表同时还需要连接T_Customer和T_OrderType两张表才能检索到所需要的信息,编写如下SQL语句即可:复制代码代码如下:SELECT o.FId,o.FNumber,o.FPrice,c.FId,c.FName,c .FAgeFROM T_Order o JOIN T_Customer cON o.FCustomerId= c.FIdINNER JOIN T_OrderTypeON T_Order.FTypeId= T_OrderType.FId(2)交叉连接(CROSS JOIN):交叉连接所有涉及的表中的所有记录都包含在结果集中。
多表联查的sql语句

多表联查的sql语句多表联查的SQL语句是一种常用的数据库查询语句,它可以让我们在多个数据库表中提取数据。
它不仅可以实现跨表的查询,而且可以返回更加准确和有意义的查询结果。
要理解多表联查的SQL语句,我们首先需要知道它的定义。
SQL 中的多表联查是指将多个SQL查询语句组合在一起,用来从几个(或更多)表中获得所需的数据。
多表联查可以使用SELECT子句来执行,它有许多类型,比如内连接,外连接,自连接,UNION等。
接下来我们来看一下,如何使用多表联查的SQL语句来查询数据库。
主要有两种方法:第一种方法是使用JOIN子句,用来从两个(或更多)表中提取数据。
例如,我们可以使用内连接来实现:SELECT *FROM table1INNER JOIN table2ON table1.field1 = table2.field2;上面的语句用于从两个表(table1和table2)中的匹配的字段(field1和field2)中提取数据。
我们也可以使用外连接,用来从一个表中提取与另一个表中不匹配的数据:SELECT *FROM table1LEFT OUTER JOIN table2ON table1.field1 = table2.field2;此外,我们还可以使用自连接,它在SQL中是一个非常强大的工具,可以让我们在一个表中搜索匹配的行和列:SELECT *FROM table1 t1INNER JOIN table1 t2ON t1.field1 = t2.field2;第二种方法是使用UNION子句来合并多个查询的结果,它可以让我们对多个表的数据进行分析和统计,而无需进行多次查询:SELECT field1, field2FROM table1UNIONSELECT field1, field2FROM table2;在使用UNION前,我们需要确保每个查询返回的字段数量、类型和顺序是相同的。
总之,多表联查的SQL语句是SQL Server中重要的查询工具,它可以让我们从多个数据库表中提取数据,并分析统计多个表的数据。
postgresql多表连接查询groupby用法

在 PostgreSQL 中进行多表连接查询并使用 GROUP BY 子句时,您通常会涉及到多个表之间的关联以及对结果进行分组聚合。
以下是一个详细的解答,涵盖了PostgreSQL 多表连接查询和 GROUP BY 的用法。
假设我们有两个表:orders和order_items,它们之间通过order_id字段进行关联。
orders表包含订单的基本信息,而order_items表包含订单中的各个商品项。
创建示例表格
首先,我们创建这两个示例表格:
多表连接查询与 GROUP BY
现在,我们将执行一个多表连接查询,然后使用 GROUP BY 对结果进行分组。
此查询中的关键点如下:
•使用JOIN子句将orders表和order_items表连接起来,关联条件是o.order_id = oi.order_id。
•使用GROUP BY子句将结果按照订单的基本信息分组,这里使用了o.order_id, o.customer_id, o.order_date。
•使用聚合函数SUM计算每个订单的总数量和总金额。
这个查询的结果将显示每个订单的基本信息,总数量和总金额。
请注意,GROUP BY 子句中的列是 SELECT 子句中未使用聚合函数的列,而聚合函数应用于其他列。
这是 SQL 中 GROUP BY 的一般规则。
mysql连接查询-多表连接查询

多表连接查询mysql多表查询详解: 交叉连接、内连接、外链接、左连接、右连接、联合查询、全连接MYSQL-连接查询:# 连接查询:把多张表进行记录的连接(按照某个条件进行数据的拼接)# 分类1,内链接2,外连接# 左外# 右外3,自然连接4,交叉连接MYSQL-内链接:# inner join (inner关键字可以省略) [inner join比left join快]# 从左表中取出每一条记录,与右表中的所有记录进行匹配# 匹配必须是某个条件,在左表和右表中相同【公共部分】,才会保留结果.否则,不保留# 基本语法SELECT * FROM [左表] innder join [右表] on [左表].[字段]=[右表].[字段];# 内连接,可以没有on,那么系统会保留所有的结果,没错.又是传说中的笛卡尔积# '还可以使用where代替on,但是效率没有on高'如上例子:排他性:A,B表中至少有1个匹配时,才返回行。
两表的【交集】SQL语句如下:select ,B.address from Ainner join Bon A.id = B.A_id查询结果为:name address张北京王上海inner join 内连接等价于下面的sql:SELECT , B.addressFROM A, BWHERE A.id = B.A_idMYSQL-外连接:1,左外# outer join(并没有outer这个关键字)【通俗:就是2张表,查左表满足条件的所有以及右表中含有左表条件的数据,where (右表条件)..is not null显示不为null的数据】左外连接: 包含左边表的全部行(不管右边的表中是否存在与它们匹配的行),以及右边表中全部匹配的行。
# 以某张表为主,取出里面的所有记录.每条与另外一张表.不管能不能匹配上条件.最终都会保留.如果不能匹配,那么其他表的字段都置空# left join (left join 是left outer join的简写)# 基本语法SELECT...FROM[左表]LEFT JOIN[右表]ON[条件]# 会把左边所有的数据都显示出来,如果右表没有匹配的数据.以null显示e:SELECT * from a_table a LEFT JOIN b_table b on a.a_id = b.b_id (where b_id is not NULL);2,右外【通俗:就是2张表,查右表满足条件的所有以及左表中含有右表条件的数据,where (左表条件)..is not null显示不为null的数据】右外连接: 包含右边表的全部行(不管左边的表中是否存在与它们匹配的行),以及左边表中全部匹配的行# right join# 基本语法SELECT...FROM[左表]RIGHT JOIN[右表]ON[条件]# 会把右表所有的数据都显示出来,如果左表没有匹配的数据.以null显示e:SELECT * from a_table a RIGHT JOIN b_table b on a.a_id = b.b_id (where a_id is not NULL);MYSQL-自然连接:# natural join# MYSQL方言,其他数据库不一定有# '自动的匹配连接条件',但是.不怎么建议使用.是以'字段名称作为匹配模式'# 基本语法SELECT ...FROM [表1] natural join [表2];//内连接* 自动使用同名字段作为连接条件,结果中会合并该字段SELECT ...FROM [表1] left natural join [表2];//左外自然连接SELECT ...FROM [表1] right natural join [表2];//右外自然连接MYSQL-交叉连接:# cross join# 从一张表中循环取出每一条记录,每条记录都去另外一张表进行匹配.而且匹配一定保留(没有条件匹配不带条件where...)# 而连接本身字段就会增加(保留) -- 笛卡尔积(笛卡尔是没有意义的,【尽量要避免】)# 存在的价值:保证连接这种结构的完整性而已.# 基本语法SELECT * from [左表] cross join [右表];== select * from [左表],[右表];select * from emp cross join dept;# 也可以加上条件select *from emp ecross joindept don e.deptno=d.deptno ;【两表连接如果要避免返回笛卡尔积,必须确保至少一方表是唯一的,否则在能查到记录的情况下,不论哪一种连接方式一定会返回笛卡尔积记录集的。
SQL多表连接查询

sql 语法:inner join on, left join on, right join on 详细使用方法。
1.理论只要两个表的公共字段有匹配值,就将这两个表中的记录组合起来。
个人理解:以一个共同的字段求两个表中符合要求的交集,并将每个表符合要求的记录以共同的字段为牵引合并起来。
语法select * FROM table1 INNER JOIN table2 ON table1 . field1 compopr table2 . field2INNER JOIN 操作包含以下部分:部分说明 table1,table2 要组合其中的记录的表的名称。
field1,field2 要联接的字段的名称。
如果它们不是数字,则这些字段的数据类型必须相同,并且包含同类数据,但是,它们不必具有相同的名称。
compopr任何关系比较运算符:“=”、“<”、“>”、“<=”、“>=”或者“<>”。
说明可以在任何 FROM 子句中使用 INNER JOIN 操作。
这是最常用的联接类型。
只要两个表的公共字段上存在相匹配的值,Inner 联接就会组合这些表中的记录。
可以将 INNER JOIN 用于 Departments 及 Employees 表,以选择出每个部门的所有雇员。
而要选择所有部分(即使某些部门中并没有被分配雇员)或者所有雇员(即使某些雇员没有分配到任何部门),则可以通过 LEFT JOIN 或者 RIGHT JOIN 操作来创建外部联接。
如果试图联接包含备注或 OLE 对象数据的字段,将发生错误。
可以联接任何两个相似类型的数字字段。
例如,可以联接自动编号和长整型字段,因为它们均是相似类型。
然而,不能联接单精度型和双精度型类型字段。
下例展示了如何通过 CategoryID 字段联接 Categories 和 Products 表:SELECT CategoryName, ProductNameFROM Categories INNER JOIN ProductsON Categories.CategoryID = Products.CategoryID;在前面的示例中,CategoryID 是被联接字段,但是它不包含在查询输出中,因为它不包含在SELECT 语句中。
多表查询sql语句

多表查询SQL语句多表查询是指在SQL中同时涉及到多个表的查询操作。
通过多表查询,我们可以根据不同表之间的关联关系,获取更加丰富的数据结果,以满足实际需求。
本文将介绍常用的多表查询SQL语句。
内连接查询内连接查询是指通过两个或多个表中共有的字段进行连接,将两个或多个表中的数据进行匹配,返回满足条件的结果集。
语法格式SELECT 列名 FROM 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段;示例假设我们有两个表:表1和表2,它们都包含字段id和姓名。
我们想获取这两个表中id字段相等的记录。
SELECT 表1.姓名, 表2.姓名FROM 表1INNER JOIN 表2ON 表1.id = 表2.id;左连接查询左连接查询是指通过左边的表主动取出所有记录,并根据共同的字段与右边的表进行关联,返回满足条件的结果集。
如果右边的表没有匹配到对应的记录,则以NULL填充。
语法格式SELECT 列名 FROM 表1 LEFT JOIN 表2 ON 表1.字段 = 表2.字段;示例假设我们有两个表:表1和表2,它们都包含字段id和姓名。
我们希望获取左表表1中的所有记录以及与之匹配的右表表2中的记录。
SELECT 表1.姓名, 表2.姓名FROM 表1LEFT JOIN 表2ON 表1.id = 表2.id;右连接查询右连接查询与左连接查询相反,通过右边的表主动取出所有记录,并根据共同的字段与左边的表进行关联,返回满足条件的结果集。
如果左边的表没有匹配到对应的记录,则以NULL填充。
语法格式SELECT 列名 FROM 表1 RIGHT JOIN 表2 ON 表1.字段 = 表2.字段;示例假设我们有两个表:表1和表2,它们都包含字段id和姓名。
我们希望获取右表表2中的所有记录以及与之匹配的左表表1中的记录。
SELECT 表1.姓名, 表2.姓名FROM 表1RIGHT JOIN 表2ON 表1.id = 表2.id;全连接查询全连接查询是指返回两个表之间所有的匹配和非匹配记录。
超过3个表的联合查询sql写法

超过3个表的联合查询sql写法在SQL中,联合查询是指从多个表中检索数据并将它们组合在一起的操作。
当需要查询的数据分布在多个表中时,联合查询可以帮助我们获取所需的结果。
下面将介绍超过3个表的联合查询的SQL写法。
SQL联合查询使用UNION关键字将多个SELECT语句的结果组合在一起。
每个SELECT语句都可以来自不同的表,但是它们的列数和数据类型必须匹配。
以下是超过3个表的联合查询的SQL写法示例:```SELECT 列名1, 列名2, 列名3FROM 表名1JOIN 表名2 ON 表名1.列名 = 表名2.列名JOIN 表名3 ON 表名2.列名 = 表名3.列名JOIN 表名4 ON 表名3.列名 = 表名4.列名WHERE 条件;```在上述示例中,我们使用了JOIN关键字来连接多个表。
JOIN关键字用于将两个或多个表中的行连接在一起,基于它们之间的共同列。
通过使用多个JOIN语句,我们可以连接超过3个表。
在每个JOIN语句中,我们使用ON关键字指定连接条件。
连接条件是指两个表之间用于匹配行的列。
在示例中,我们使用了多个JOIN语句来连接表名1、表名2、表名3和表名4,并通过列名进行连接。
在WHERE子句中,我们可以添加额外的条件来筛选所需的数据。
条件可以基于表中的列或其他条件进行过滤。
需要注意的是,联合查询的结果集将包含所有满足条件的行,并且会自动去重。
如果需要保留重复的行,可以使用UNION ALL关键字。
以上是超过3个表的联合查询的SQL写法示例。
通过使用JOIN关键字和连接条件,我们可以在SQL中进行复杂的联合查询,以获取所需的结果。
sql多表关联查询语句

sql多表关联查询语句SQL多表关联查询语句是指通过一系列SQL语句来实现数据库表之间的连接。
在SQL语句中,一般使用JOIN来实现多个表之间的关联查询,即在某个查询中将多个表的数据组合在一起来查询符合条件的记录。
关联查询能够有效的解决数据库表之间的关系,从而更好的进行查询。
1. JOIN查询语句JOIN查询语句是一种查询多个表的SQL语句,是将多个表的数据作为一个整体,根据指定的条件将两个或更多的表之间的记录连接起来的一种技术。
根据JOIN的类型不同,可以将其分为内连接、左外连接、右外连接和全外连接。
(1)内连接内连接也叫做等值连接,是指表的两个字段之间的比较,满足条件的数据才会显示。
使用内连接时,只有当两个表中的某一字段相等时,才能够进行查询。
(2)左外连接左外连接是用于查询两个或者多个表中存在相同字段的全部记录,以及不存在该字段的表中的记录。
将指定条件查询作为左表,另一张表作为右表,以左表为准将两张表进行关联,以便可以查看全部记录。
(3)右外连接右外连接与左外连接类似,其主要思想也是将两张表作为两个集合,分别以其中的一张表作为准,以另一张表中的字段与之进行连接,然后将全部记录进行查询。
(4)全外连接全外连接又称为全连接,它的作用是针对两张表中的指定条件,查找两张表由于字段不同出现的记录。
它是将两张表按照指定条件进行横向连接,并将结果集中所有匹配的记录显示出来。
2. UNION语句UNION语句是一种查询多个表的SQL语句,是指将多个查询结果集合起来,显示为一个结果集的一种技术。
它的主要作用是将两个或更多的查询结果连接起来,并将结果中相同的行组合在一起,以便进行分析。
UNION语句的执行原则是,以查询结果中首次出现的列做为显示。
3. INTERSECT语句INTERSECT语句也称为交集查询语句,是指将数据库中存放的多种表之间的信息进行比较,取出其中并集部分数据的一种查询技术。
它是用来检索某一表中存在,而不存在另一表中的信息。
Yii2中多表关联查询(join、joinwith)

Yii2中多表关联查询(join、joinwith)我们⽤实例来说明这⼀部分表结构现在有客户表、订单表、图书表、作者表,客户表Customer (id customer_name)订单表Order (id order_name customer_id book_id)图书表 (id book_name author_id)作者表 (id author_name)模型定义下⾯是这4个个模型的定义,只写出其中的关联Customer1. class Customer extends \yii\db\ActiveRecord2. {3. // 这是获取客户的订单,由上⾯我们知道这个是⼀对多的关联,⼀个客户有多个订单4. public function getOrders()5. {6. // 第⼀个参数为要关联的⼦表模型类名,7. // 第⼆个参数指定通过⼦表的customer_id,关联主表的id字段8. return $this->hasMany(Order::className(), ['customer_id' => 'id']);9. }10. }复制代码Order1. class Order extends \yii\db\ActiveRecord2. {3. // 获取订单所属⽤户4. public function getCustomer()5. {6. //同样第⼀个参数指定关联的⼦表模型类名7. //8. return $this->hasOne(Customer::className(), ['id' => 'customer_id']);9. }10.11. // 获取订单中所有图书12. public function getBooks()13. {14. //同样第⼀个参数指定关联的⼦表模型类名15. //16. return $this->hasMany(Book::className(), ['id' => 'book_id']);17. }18. }复制代码Book1. class Book extends \yii\db\ActiveRecord2. {3. // 获取图书的作者4. public function getAuthor()5. {6. //同样第⼀个参数指定关联的⼦表模型类名7. return $this->hasOne(Author::className(), ['id' => 'author_id']);8. }9. }复制代码Author1. class Autor extends \yii\db\ActiveRecord2. {3.4. }复制代码hasMany、hasOne使⽤Yii2中的表之间的关联有2种,它们⽤来指定两个模型之间的关联。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
要查询的数据存在在多个表中,需要使用这些数据,有三种方式获取
(一对多)
需要在一个实体类中封装另一个实体类的实体变量,(eg:list<另一个实体类>)一.通过表连接一次性查询所有数据
a)通过list集合获取
public List<User> queryTeacher() {//查询教师的信息
Connection conn = JdbcUtilConf.getConnection();
PreparedStatement pstm = null;
ResultSet rs = null;
String sql = "select
er_id,ername,t1.password,t1.realname,t1.department,t 1.role,c.course_id,c.course_name from (select * from t_user u inner join course_user cu on er_id = cu.u_id) t1 inner join t_course c on t1.c_id=c.course_id";
List<Course> listcourse = null;
List<User> listuser = new ArrayList<User>();
User user = null;
try {
pstm = conn.prepareStatement(sql);
rs = pstm.executeQuery();
Course c = null;
while(rs.next()){
Integer cid =
rs.getInt("course_id");
String course =
rs.getString("course_name");
c = new Course(cid,course);
if(!listuser.isEmpty()){
for(int i
=0;i<listuser.size();i++){
user = listuser.get(i);
if(user.getUserId()==rs.getInt("user_id")){
for(int j
=0;j<user.getListcourse().size();j++){
if(user.getListcourse().get(j).getCourseId()!=cid&&j==use r.getListcourse().size()-1)
user.getListcourse().add(c);
}
}else{ if(i==listuser.size()-1){
listcourse = new ArrayList<Course>();
listcourse.add(c);
user = new User(
rs.getInt("user_id"),
rs.getString("username"),
rs.getString("password"),
rs.getString("realname"),
rs.getString("department"),
rs.getString("role"),listcourse);
listuser.add(user);
}
}
}
}else{
listcourse = new ArrayList<Course>();
listcourse.add(c);
user = new User( rs.getInt("user_id"),
rs.getString("username"),
rs.getString("password"),
rs.getString("realname"),
rs.getString("department"),
rs.getString("role"),listcourse);
listuser.add(user);
}
}
} catch (SQLException e) {
System.out.println("异常位置和信息为
"+e.getMessage());
e.printStackTrace();
}finally{
JdbcUtilConf.release(rs, pstm, conn);
}
return listuser;
}
b)通过map集合获取
public List<User> findALLCourseAndTeacher() throws Exception {
Connection conn = null;
PreparedStatement pstm = null;
ResultSet rs = null;
List<User> list = new ArrayList<User>();
Map<String,User> map = new HashMap<String,User>();
try {
conn=JdbcUtil.getConn();
String sql="select * from t_user u join course_user cu on er_id = cu.u_id join t_course c on c.course_id = cu.c_id";
pstm=conn.prepareStatement(sql);
rs = pstm.executeQuery();
while(rs.next()){
if(map.containsKey(rs.getString("username"))){
Course c = new Course();
c.setCourseName(rs.getString("course_name"));
map.get(rs.getString("username")).getCourses().add(c);
}else{
User user = new User();
user.setUserId(rs.getInt("user_id"));
user.setUserName(rs.getString("username"));
user.setPassword(rs.getString("password"));
user.setRealName(rs.getString("realname"));
user.setRole(rs.getString("role"));
user.setDepartment(rs.getString("department"));
Course c = new Course();
c.setCourseName(rs.getString("course_name"));
user.getCourses().add(c);
map.put(user.getUserName(), user);
}
}
Set<String> set = map.keySet();
for (String key : set) {
list.add(map.get(key));
}
} catch (Exception e) {
e.printStackTrace();
}finally{
JdbcUtil.release(rs, pstm, conn);
}
return list;
}
二.通过两个表的连接查询到与另一个表关联的字段,返回一个查询结果(所有老师的信息),再利用这个结果中的某个字段查询另一个关系表表(每个老师的id
对应的课程),在servic层封装这两个查询结果,给一个实体类(封装其他实
体类的实体类),
三.通过不同的实体类,查询通过同一个字段(或者可以查询到相关数据的字段),通过不同的查询方法,将包含需要的信息的返回值封装到对应的对象中,在
action层进行处理,将这两个实体类封装给一个集合,将集合传递给页面,遍
历使用
eg:
Accusation acc = new
AccusationDaoServiceImpl().queryByInteractId(interactId);
Interact it = new
InteractDaoServiceImpl().queryDetailById(interactId);
list.add(it);
list.add(acc);。