数学建模选修课第二次作业
《第三章 数学建模活动(二)》试卷及答案_高中数学必修_北师大版_2024-2025学年

《第三章数学建模活动(二)》试卷(答案在后面)一、单选题(本大题有8小题,每小题5分,共40分)1、某工厂生产一批产品,原计划每天生产100件,10天完成。
后来由于提高效率,每天多生产了20件,实际用了8天完成。
设提高效率后每天生产的件数为x件,那么x的值是:A、60B、80C、100D、1202、在解决实际问题时,建立数学模型的一般步骤不包括以下哪一项?()A. 确定问题背景和目标B. 收集和整理数据C. 建立数学模型D. 进行实验验证3、某工厂生产一批产品,已知生产这种产品需要原材料A和B,其中原材料A的用量与原材料B的用量成比例。
若生产100个产品需要原材料A和原材料B分别为10kg 和20kg,那么生产200个产品需要原材料A和原材料B分别为多少kg?A、20kg和40kgB、30kg和60kgC、40kg和80kgD、50kg和100kg4、在解决数学建模问题时,以下哪项步骤是错误的?A、明确问题背景和目标B、建立数学模型C、收集和分析数据D、求解数学模型,得到结果但不进行验证5、某工厂计划生产一批产品,已知生产这批产品需要投入的原材料费用为3000元,人工费用为1000元,其他费用为500元。
如果每件产品的利润为10元,要使得利润总额达到10000元,至少需要生产多少件产品?A. 500件B. 1000件C. 1500件D. 2000件6、在解决数学建模问题时,以下哪种方法不是常用的策略?()A、建立数学模型B、分析模型,提出假设C、进行数据收集和整理D、进行数学推导,得出结论7、某市为了改善交通状况,计划在一条长为10公里的主干道上增设若干个公交站点。
根据交通流量分析,每两个站点之间的平均距离不宜小于1公里也不宜大于2公里。
如果这条主干道的起点和终点都设有一个站点,那么最多可以设置多少个站点?最少可以设置多少个站点?A. 最多11个站点,最少6个站点B. 最多12个站点,最少5个站点C. 最多11个站点,最少5个站点D. 最多10个站点,最少6个站点8、下列关于函数模型y=ae^(bx)+c(a、b、c为常数,且a>0,b≠0)的说法中,正确的是:A. 当a=1,b=0,c=0时,该函数表示一个常数函数B. 当a=1,b=1,c=0时,该函数表示一个指数函数C. 当a=1,b=0,c=1时,该函数表示一个一次函数D. 当a=1,b=-1,c=1时,该函数表示一个二次函数二、多选题(本大题有3小题,每小题6分,共18分)1、以下哪些选项属于数学建模的基本步骤?()A. 提出问题B. 收集数据C. 建立模型D. 求解模型E. 验证模型F. 模型应用2、某工厂为了提高产品质量,计划对生产流程进行优化。
山东大学数学建模选修答案

数学建模作业:学院:计算机科学与技术班级:学号:1.在区域x∈[-2,2],y∈[-2,3]绘制函数z=exp^(-x2-y2)曲面图与等值线图。
解:曲面图如下:>> x=-2:0.5:2;>> y=-2:0.5:3;>> [X,Y]=meshgrid(x,y);>> Z=exp(-X.^2-``Y.^2);>> mesh(X,Y,Z)>>等值线图如下:>> x=-2:0.5:2;>> y=-2:0.5:3;>> [X,Y]=meshgrid(x,y);>> Z=exp(-X.^2-Y.^2);>> mesh(X,Y,Z)>> surf(X,Y,Z)>> surf(X,Y,Z)>> contour(X,Y,Z)>>2.已知一组观测数据,如表1所示.(1)试用差值方法绘制出x ∈[-2,4.9]区间的光滑曲线,并比较各种差值算法的优劣.(2)试用最小二乘多项式拟合的方法拟合表中的数据,选择一个能较好拟合数据点的多项式的阶次,给出相应多项式的系数和偏差平方和.(3)若表中数据满足正态分布函数222/)(21)(σμπσ--=x e x y .试用最小二乘非线性拟合的方法求出分布参数σμ,值,并利用锁求参数值绘制拟合曲线,观察拟合效果.解:(1)分别用最领近插值,分段线性插值(缺省值),分段三次样条插值,保形分段三次插值方法绘制在x ∈[-2,4.9]的光滑曲线,图形如下:样条插值效果最好,其次线性插值,最近点插值效果最差,在这里效果好像不太明显。
最近点插值优点就是速度快,线性插值速度稍微慢一点,但效果好不少。
所以线性插值是个不错的折中方法。
样条插值,它的目的是试图让插值的曲线显得更平滑,为了这个目的,它们不得不利用到周围若干围的点,不过计算显然要比前两种大许多。
第二次数学建模作业
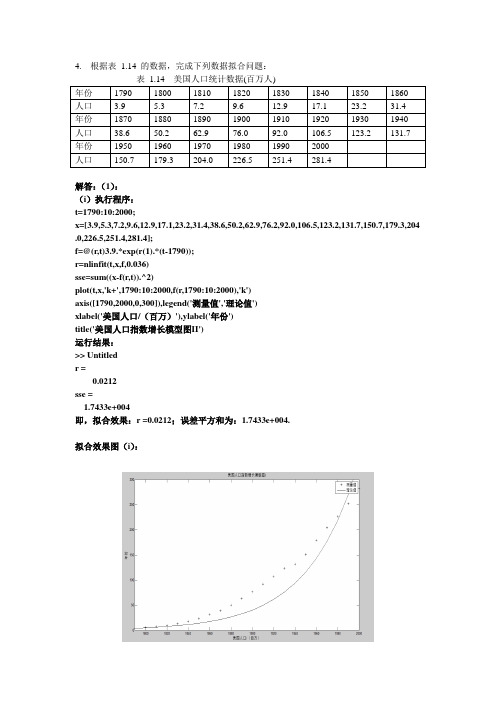
4. 根据表1.14 的数据,完成下列数据拟合问题:年份1790 1800 1810 1820 1830 1840 1850 1860 人口 3.9 5.3 7.2 9.6 12.9 17.1 23.2 31.4年份1870 1880 1890 1900 1910 1920 1930 1940 人口38.6 50.2 62.9 76.0 92.0 106.5 123.2 131.7 年份1950 1960 1970 1980 1990 2000人口150.7 179.3 204.0 226.5 251.4 281.4解答:(1):(i)执行程序:t=1790:10:2000;x=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204 .0,226.5,251.4,281.4];f=@(r,t)3.9.*exp(r(1).*(t-1790));r=nlinfit(t,x,f,0.036)sse=sum((x-f(r,t)).^2)plot(t,x,'k+',1790:10:2000,f(r,1790:10:2000),'k')axis([1790,2000,0,300]),legend('测量值','理论值')xlabel('美国人口/(百万)'),ylabel('年份')title('美国人口指数增长模型图II')运行结果:>> Untitledr =0.0212sse =1.7433e+004即,拟合效果:r =0.0212;误差平方和为:1.7433e+004.拟合效果图(i):(ii)由表1.14我们知道,当t=1800时,有5)101(0≈+r x ,所以我们可以猜测,r=0.1,x =2.5.对待定参数0x ,r 进行数据拟合同时进行绘图,其程序如下:t=1790:10:2000;x=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];f=@(r,t)r(1).*exp(r(2).*(t-1790)); r0=[2.5,0.1]; r=nlinfit(t,x,f,r0) sse=sum((x-f(r,t)).^2)plot(t,x,'k+',1790:1:2000,f(r,1790:1:2000),'k')axis([1790,2000,0,300]),legend('测量值','理论值',2) xlabel('美国人口/(百万)'),ylabel('年份') title('美国人口指数增长模型图II')命令窗口显示的计算的结果如下: >> Untitled r =15.0005 0.0142 sse =2.2657e+003即我们知道,拟合结果为:r=r(2)= 0.0142, 0x =r(1)= 15.0005;误差平方和为:2.2657e+003. 拟合效果图(ii ):(iii)由表1.14我们知道,当t=1900时,有()76)-t 1900101(00≈+r x ,所以我们可以猜测,r=0.03,x =19, 0t =1800.对待定参数0t ,0x ,r 进行数据拟合同时进行绘图,其程序如下:t=1790:10:2000;x=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];f=@(r,t)r(1).*exp(r(2).*(t-r(3))); r0=[19,0.03,1800]; r=nlinfit(t,x,f,r0) sse=sum((x-f(r,t)).^2)plot(t,x,'k+',1790:1:2000,f(r,1790:1:2000),'k')axis([1790,2000,0,300]),legend('测量值','理论值',2) xlabel('美国人口/(百万)'),ylabel('年份') title('美国人口指数增长模型图III')命令窗口显示的计算的结果如下:>> UntitledWarning: The Jacobian at the solution is ill-conditioned, and some model parameters may not be estimated well (they are not identifiable). Use caution in making predictions. > In nlinfit at 224 In Untitled at 5 r =1.0e+003 *0.0159 0.0000 1.7939 sse =2.2657e+003即,拟合效果:r =0,0x =7.9,0t =1742.5;误差平方和为:2.2657e+003我们由MATLAB9给出的警告信息,知道这个拟合存在病态条件,所以数据可能拟合的不太好。
数学建模第二次作业

《数学建模》第二次作业一、填空题:一、一个连通图能够一笔画出的充分必要条件是( ).二、如图是一个邮路,邮递员从邮局A 动身走遍所有长方形街路后再返回邮局.若每一个小长方形街路的边长横向均为1km ,纵向均为2km ,则他至少要走( )km..3、设某种物资有两个产地21,A A ,其产量别离为10、20,两个销地21,B B 的销量相等均为15。
若是从任意产地到任意销地的单位运价都相等为,a 则最优运输方案与运价具有 两个特点。
4、设开始时的人口数为0x ,时刻t 的人口数为)(t x ,若人口增加率是常数r ,那麽人口增加问题的马尔萨斯模型应为 .五、设开始时的人口数为0x ,时刻t 的人口数为)(t x ,若允许的最大人口数为m x ,人口增加率由sx r x r -=)(表示,则人口增加问题的逻辑斯蒂克模型为 .二、分析判断题:一、从下面不太明确的叙述中肯定要研究的问题,需要哪些数据资料(至少列举3个),要做些甚麽建模的具体的前期工作(至少列举3个) ,成立何种数学模型:一座高层办公楼有四部电梯,早晨上班时刻超级拥堵,该如何解决。
二、一条公路交通不太拥堵,以至人们养成“冲过”马路的适应,不肯意走临近的“斑马线”。
交管部门不允许任意横穿马路,为方便行人,预备在一些特殊地址增设“斑马线”,以便让行人能够穿越马路。
那末“选择设置斑马线的地址”这一问题应该考虑哪些因素?试至少列出3种。
3、地方公安部门想明白,当紧急事故发生时,人群从一个建筑物中撤离所需要的时刻,假设有足够的安全通道.若指挥者想尽可能多且快地将人群撤离,应制定甚麽样的疏散计划.请就那个计划指出至少三个相关因素,并利用数学符号表示。
4、作为经济模型的一部份,若产量的转变率与生产量和需求量之差成正比,且需求量中一部份是常数,另一部份与产量成正比,那麽相应的微分方程模型是甚麽?五、某种疾病每一年新发生1000例,患者中有一半昔时可治愈.若2000年末时有1200个病人,到2005年将会出现甚麽结果?有人说,无论多少年过去,患者人数只是趋向2000人,但不会达到2000人,试判断那个说法的正确性。
数学建模选修大作业

中华女子学院成绩2014 — 2015学年第二学期期末考试(论文类)论文题目数学建模算法之蒙特卡罗算法课程代码 01课程名称数学建模学号 9姓名陈可心院系计算机系专业计算机科学与技术考试时间 2015年5月27日一、数学建模十大算法1、蒙特卡罗算法该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,是比赛时必用的方法。
接下来本文将着重介绍这一算法。
2、数据拟合、参数估计、插值等数据处理算法比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具。
3、线性规划、整数规划、多元规划、二次规划等规划类问题建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo软件实现。
这个也是我们数学建模选修课时主要介绍的问题,所以对这方面比较熟悉,也了解了Lindo、Lingo软件的基本用法。
4、图论算法这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,上学期数据结构课程以及离散数学课程中都有介绍。
它提供了对很多问题都很有效的一种简单而系统的建模方式。
5、动态规划、回溯搜索、分治算法、分支定界等计算机算法这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。
7、网格算法和穷举法网格算法和穷举法都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。
8、一些连续离散化方法很多问题都是实际来的,数据可以是连续的,而计算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。
【VIP专享】《数学建模》选修课班第1-4次作业

【VIP专享】《数学建模》选修课班第1-4次作业《数学建模》选修课班第1-4次作业第1次作业1. 什么是数学建模?答:当需要从定量的角度分析和研究一个实际问题时,人们就要在深入调查研究、了解对象信息、作出简化假设、分析内在规律等工作的基础上,用数学的符号和语言,把它表述为数学式子,也就是数学模型,然后用通过计算得到的模型结果来解释实际问题,并接受实际的检验。
数学建模是构造刻划客观事物原型的数学模型并用析究和解决实际问题的种方法。
运用这种科学方法,建模者必须从实际问题出发,遵循“实践――认识――实践”的辨证唯物主义认识规律,紧紧围绕着建模的目的,运用观察力、想象力和逻辑思维,对问题进行抽象、简化,反复探索、逐步完善,直到构造出一个能够用于分析、研究和解决实际问题的数学模型。
因此,数学建模不仅仅是一种定量解决实际问题的科学方法,而且还是一种从无到有的创新活动过程。
当代计算机的发展和广泛应用,使得数学模型的方法如虎添翼,加速了数学向各个学科的渗透,产生了众多的边缘学科。
当今几乎所有重要的学科,只要在其名称前面或后面加上“数学”或“计算”二字,就成了现有的一种国际学术杂志名称。
这表明各学科正在利用数学方法和数学成果来加速本学科的发展。
就连计算机本身的产生和进步也是强烈地依赖于数学科学的发展,而计算机软件技术说到底也是数学技术。
简单地来说,就是对于一个现实对象,为了一个特定的目的,根据其内在规律,作出必要的简化假设,运用适当的数得到一个数学结构。
2 数学建模的基本步骤有哪些?答:数学建模的基本方法 1.模型准备。
2模型假设。
3.模型求解,4模型分析5模型验证(2——5之间进行循环)6模型应用一、数学建模题目1·以社会,经济,管理,环境,自然现象等现代科学中出现的新问题为背景,一般都有一个比较确切的现实问题。
2·给出若干假设条件:1.只有过程、规则等定性假设;2.给出若干实测或统计数据;3.给出若干参数或图形等。
多种类型的回归模型
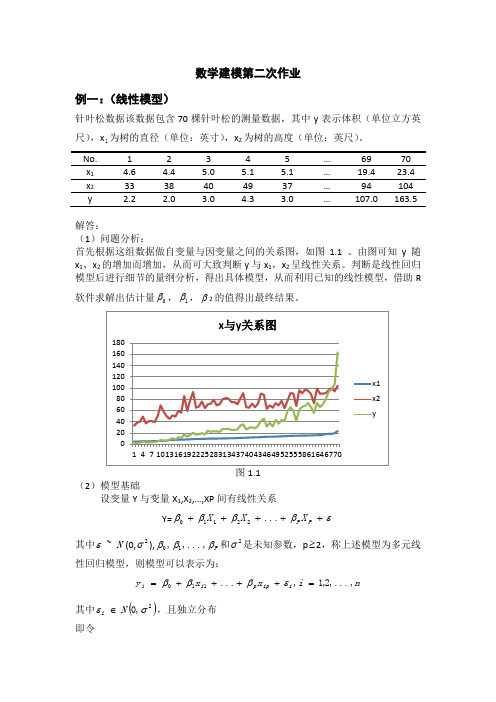
数学建模第二次作业例一:(线性模型)针叶松数据该数据包含70棵针叶松的测量数据,其中y 表示体积(单位立方英尺),x 1为树的直径(单位:英寸),x 2为树的高度(单位:英尺)。
x 1 4.6 4.4 5.0 5.1 5.1 … 19.4 23.4 x 2 33 38 40 49 37 … 94 104 解答:(1)问题分析:首先根据这组数据做自变量与因变量之间的关系图,如图1.1 。
由图可知y 随x 1、x 2的增加而增加,从而可大致判断y 与x 1,x 2呈线性关系。
判断是线性回归模型后进行细节的量纲分析,得出具体模型,从而利用已知的线性模型,借助R 软件求解出估计量0β,1β,β2的值得出最终结果。
图1.1(2)模型基础设变量Y 与变量X 1,X 2,…,XP 间有线性关系Y=εββββ+++++P P X X X (22110)其中N ~ε(0,2σ),P βββ,...,,10和2σ是未知参数,p ≥2,称上述模型为多元线性回归模型,则模型可以表示为:n i x x y i ip p i i ,...,2,1,...110=++++=εβββ其中()2,0σεN i ∈,且独立分布 即令⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n y y y y 21,⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=p ββββ 10,⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=np n n p p x x x x x x x x x X ...1...1 (12)12222111211,⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n εεεε 21则多元线性回归模型可表示为εβ+=X Y ,其中Y 是由响应变量构成的n 维向量,X 是n ⨯(p+1)阶设计矩阵,β是p+1维向量,并且满足E (ε)=0,Var (ε)=2σI n与一元线性回归类似,求参数β的估计值βˆ,就是求最小二乘函数 Q (β)=()()ββX y X y T--达到最小的β的值。
β的最小二乘估计()y X X X T T 1ˆ-=β从而得到经验回归方程P P X X Y βββˆˆˆˆ11+++=(3)问题求解:由于体积与长度的量纲不一致,为了使等式两边量纲统一,首先利用excel 软件对数据进行预处理,即对y 进行三次开方的处理。
街道清扫路线设计--欧拉模型

for(int j=0;j<6;j++) for(int k=0;k<6;k++) for(int l=0;l<6;l++) for(int m=0;m<6;m++) for(int n=0;n<6;n++) {
if(i!=j&&i!=k&&i!=l&&i!=m&&i!=n&&j!=k&&j!=l&&j!=m&&j!=n&&k!=l&&k!=m&&k!=n&&l!=m& &l!=n&&m!=n&&a[0][i]+a[1][j]+a[2][k]+a[3][l]+a[4][m]+a[5][n]<=80)
本模型中只考虑了一辆清洁车,最后计算出来的时间接近一个工作日,清扫街区的时间 跨度过长,不利于城市整体面貌的展现,而考虑更多的清洁车同时进行清扫任务必然会缩短 时间,提高工作效率,所以建立“具有多个清洁车辆的清扫路径问题”是具有实际意义的。 这时,就需要根据图论理论,将图 4 中的街区 Euler 图分解成弧不交的回路的并。然后每一 条回路的清扫任务由一辆清洁车承担,多辆清洁车同时工作。
当取方案(4)时,得到最佳组对如下,用虚线表示相应的最短路,如图 4(d)。
3 → 4,6 → 5,8 → 9,11 → 7,12 → 1,14 → 13
(a) (b)
(c)
(d) 图4 第三步,图 4 中的(a)(b)(c)(d)四个图都是 Euler 图,虚线表示附加边,它是开空 车的路程。根据图论中的相关理论,Euler 图中必存在包含所有弧的有向闭迹。于是,回到 实际问题中来,清洁车从任意街道交点出发,必能沿着某一条路径扫完所有的街道,最终回 到起始点。
数学建模(2)第二次作业word版
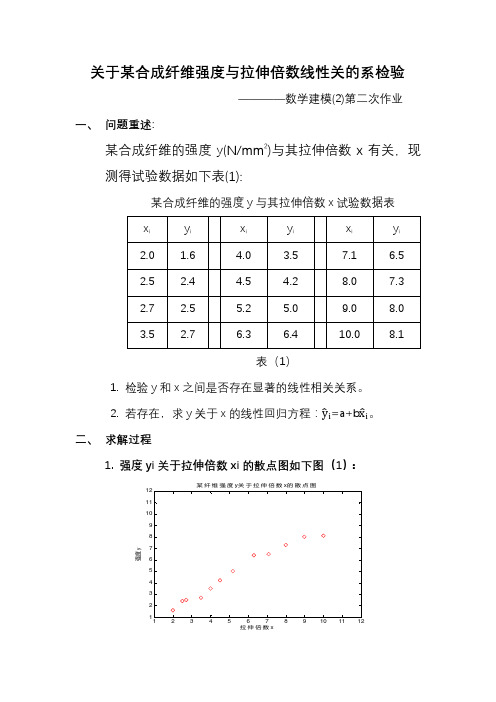
关于某合成纤维强度与拉伸倍数线性关的系检验————数学建模(2)第二次作业一、问题重述:某合成纤维的强度y(N/mm2)与其拉伸倍数x有关,现测得试验数据如下表(1):某合成纤维的强度y与其拉伸倍数x试验数据表表(1)1.检验y和x之间是否存在显著的线性相关关系。
2.若存在,求y关于x的线性回归方程:y i=a+b x i。
二、求解过程1.强度yi关于拉伸倍数xi的散点图如下图(1):图(1)2.样本相关系数计算 (1).计算公式r =nΣxy −ΣxΣynΣx 22nΣy 22(2)计算结果r =12∗382.17−3771.3612∗428.18−64.802∗ 12∗342.86−58.202=0.9859(3)结果分析r >0.8,说明该合成纤维强度y 与拉伸倍数x 成高度线性正相关关系。
2. 回归方程求解 (1).计算公式β1 =n ∑x i y i n i =1− ∑X i n i =1 ∑y i ni =1n x i2ni =1−∑x i n i =12某纤维强度y 关于拉伸倍数x 的散点图拉伸倍数x强度yβ 0=y −β1x (2).计算结果β 1= 12∗382.17−3771.3612∗428.18−64.802=0.8675β0=4.85−0.8675∗5.40=0.1655 (3).回归方程y i =0.1655+0.8675xi (4).回归前后图像对比图(2)回归系数β1=0.8675,表示拉伸倍数每增加一倍,该合成纤维强度增加0.08675。
三、 线性关系检验(1).提出假设123456789101112该纤维强度y 关于拉伸倍数x 的散点图及其线性回归方程拉伸倍数x强度yH0:β1=0线性关系不显著(2).计算检验统计量FF=SSR/1SSE/(n−2)= MSRMSE~F(1,n-2)F =58.89505/11.695902/(12−2)=347.2786(3).显著性水平α=0.05,根据分子自由度1和分母自由度12-2找出临界值Fα=4.965(4).F>Fα,拒绝H0,线性关系显著。
《模型作业设计方案-2023-2024学年高中通用技术苏教版》

《模型》作业设计方案第一课时一、课程背景:《模型》是一门重要的数学课程,通过本课程的进修,同砚将能够精通数学建模的基本原理和方法,培育解决实际问题的能力,提高数学分析和运算能力。
二、教学目标:1. 了解数学建模的观点和分类。
2. 精通数学建模的基本流程和方法。
3. 学会运用数学建模解决实际问题。
4. 培育数学思维和创新能力。
三、教学内容:1. 数学建模的基本观点和原理。
2. 数学建模的分类和应用领域。
3. 数学建模的基本流程:问题分析、模型建立、模型求解、模型评判。
4. 常用数学工具:微积分、线性代数、概率论等。
四、教学方法:1. 理论讲授:老师讲解数学建模的基本观点和方法。
2. 实例分析:老师引导同砚分析实际问题,并建立相应的数学模型。
3. 小组谈论:同砚分组谈论和解决数学建模问题,培育团队合作和解决问题的能力。
4. 实践操作:同砚利用计算机软件进行模型求解和分析,加深对数学建模的理解。
五、作业设计:1. 第一次作业:选择一个实际问题,分析问题背景和需求,提出初步的建模思路。
2. 第二次作业:建立数学模型并进行求解,分析模型的优缺点,提出改进方案。
3. 第三次作业:撰写数学建模报告,包括问题描述、模型建立、模型求解和结果分析。
六、评判方式:1. 作业评分:依据作业的完成状况和质量评定同砚的效果,包括模型的建立和求解过程。
2. 口头答辩:要求同砚在教室上对自己的建模过程和结果进行口头陈述,以检验其理解和表达能力。
3. 终期考核:通过期末考试考查同砚对数学建模的整体精通状况,包括理论知识和实际应用能力。
七、教学资源:1. 教材:《数学建模导论》2. 计算机软件:MATLAB、R、Python等3. 网络资源:公开的数学建模案例和教学视频八、实施规划:1. 第一周:介绍数学建模的观点和分类。
2. 第二周:讲解数学建模的基本流程和方法。
3. 第三周:同砚选择问题并分析,筹办第一次作业。
4. 第四周:同砚建立数学模型并进行求解,筹办第二次作业。
数学建模第二次作业(章绍辉版)
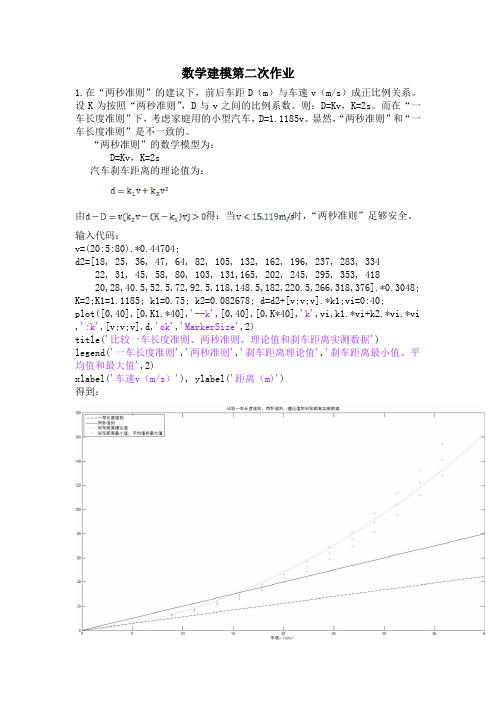
数学建模第二次作业1.在“两秒准则”的建议下,前后车距D(m)与车速v(m/s)成正比例关系。
设K为按照“两秒准则”,D与v之间的比例系数。
则:D=Kv,K=2s。
而在“一车长度准则”下,考虑家庭用的小型汽车,D=1.1185v。
显然,“两秒准则”和“一车长度准则”是不一致的。
“两秒准则”的数学模型为:D=Kv,K=2s汽车刹车距离的理论值为:由得:当时,“两秒准则”足够安全。
输入代码:v=(20:5:80).*0.44704;d2=[18, 25, 36, 47, 64, 82, 105, 132, 162, 196, 237, 283, 33422, 31, 45, 58, 80, 103, 131,165, 202, 245, 295, 353, 41820,28,40.5,52.5,72,92.5,118,148.5,182,220.5,266,318,376].*0.3048; K=2;K1=1.1185; k1=0.75; k2=0.082678; d=d2+[v;v;v].*k1;vi=0:40;plot([0,40],[0,K1.*40],'--k',[0,40],[0,K*40],'k',vi,k1.*vi+k2.*vi.*vi,':k',[v;v;v],d,'ok','MarkerSize',2)title('比较一车长度准则、两秒准则、理论值和刹车距离实测数据')legend('一车长度准则','两秒准则','刹车距离理论值','刹车距离最小值、平均值和最大值',2)xlabel('车速v(m/s)'), ylabel('距离(m)')得到:由上图也可以看出当车速超过15米每秒时,“两秒准则”不安全。
北京工业大学数学建模作业汇总

第一次作业数学建模入门1.冷却定律与破案按照Newton冷却定律,温度为T的物体在温度为To (To<T)的环境中冷却的速度与温差T-To成正比。
你能用该定律确定张某是否是下面案件中的犯罪嫌疑人。
某公安局于晚上7时30分发现一具女尸,当晚8时20分法医测得尸体温度为32.6℃,一小时后,尸体被抬走时又测得尸体温度为31.4℃,,已知室温在几个小时内均为21.1℃,由案情分析得知张某是此案的主要犯罪嫌疑人,但张某矢口否认,并有证人说:“下午张某一直在办公室,下午5时打一个电话后才离开办公室”。
从办公室到案发现场步行需要5分钟,问张某是否能被排除在犯罪嫌疑人之外?解答:首先,牛顿冷却定律为温度为T(t)的物体在温度的环境中冷却的速度与温度差成正比。
所以,得出微分方程 ( ,K为比例常数。
任意时刻t,物体的温度为 ,C为常数根据已知条件,记晚上8时20分为t=0时刻,T(0)=32.6℃,T(1)=31.4℃,=21.1℃:求解函数得,k=-0.11,C=11.5,即假定人的正常体温为37℃,代入公式得t-2.95小时, 即遇害时间为8.33-2.95=5.38≈5时23分。
张某在5时离开办公室,步行需要5分钟到达案发地点,所以张某不能排除作案嫌疑。
2.锻炼想象力、洞察力和判断力的问题(1)某人早8时从山下旅店出发沿一条山路上山,下午5时到达山顶并留宿,次日8时沿同一条路径下山,下午5时回到旅店。
该人必在两天中的同一是可经过路径中的同一地点,为什么?解答:令:A(t)表示此人第一天上山时t时刻离山脚的路程;B(t)表示此人第二天下山时t时刻离山脚的路程。
假设山顶到山下的总路程为S,由已知条件可知:A(8)=0,A(17)= SB(8)= S,B(17)=0令:C(t)= A(t)- B(t);则C(8)=-S,C(17)= S;由于C(t)为连续函数,由零点定理推出结论:在t=[8,17]中间,至少存在一点 t 使C(t)= A(t)- B(t)=0;即A(t)= B(t),可证明这人必在两天中的同一时刻经过路径中的同一地点。
数学建模选修课第二次作业

数学建模作业一、回答以下问题1.什么是数学模型?答:所谓数学模型,是指针对或参照现实世界中某类事物系统的主要特征、主要关系,经过简化与抽象,用形式化的数学语言概括或近似地加以表述的一种数学结构.一般表现为数理逻辑的逻辑表达式、各种数学方程(如代数方程、微分方程、积分方程等)及反映量与量之间相互关系的图形、表格等形式.它或者能解释特定现象的现实状态,或者能预测对象的未来状态,或者能提供处理对象的最优决策与控制.好的数学模型应具备可靠性和可解性(也叫适用性)两方面的特性:可靠性指在允许的误差范围内,能反映出该系统有关特性的内在联系;可解性指易于数学处理与计算.数学模型方法将复杂的研究对象简单化、抽象化,撇开对象的一些具体特征,减少其参数,只抽取其主要量、量的变化及量与量之间的相互关系,在“纯粹”的形态上进行研究,突出主要矛盾,忽略次要矛盾,用数学语言刻画出客观对象量的规律性,简洁明了地描述现实原形,揭示出其本质的规律,并在对模型修正、求解的基础上使原问题得以解决.可以说,数学模型是对现实原形的一种理想化处理是一个科学的抽象过程,因而具有高度的抽象性与形式化特征.这一特征使其成为一种经典的数学方法,并随着科学技术的数学化趋势,超越数学范畴,广泛地应用于自然2013数学建模选修课第二次作业科学、工程技术和社会科学的一切领域.。
2.数学模型是如何分类的?答:用字母、数字和其他数学符号构成的等式或不等式,或用图表、图像、框图、数理逻辑等来描述系统的特征及其内部联系或与外界联系的模型。
它是真实系统的一种抽象。
数学模型是研究和掌握系统运动规律的有力工具,它是分析、设计、预报或预测、控制实际系统的基础。
3.建立数学模型一般应遵循什么原则?答:模型假设是整个建模的起点,是模型建立的基础,不同的人对同一事物的认识因其角度及深度不一致而产生不同的假设条件,从而导致不同的模型建立恰当进行模型假设是极为重要的。
同时模型假设和模型建立是一个不易分离的整体过程。
第二次作业饮酒驾车问题数学建模

dw = − kw dt w(0) = w0
其中 k 为吸收速率常数,解得: w( t) = w0 e− kT 时,由于经过时间间隔 T,又第二次饮酒,饮入量为 w0 ,所以 t=T 时
w(T ) = w0 + w0 e − kt
同理:当 t=2T 时,前两次酒精残余为: ( w0 + w0 e − kT )e − kT 并且当 t = 2T 时,又第三次饮酒,饮酒量仍为 w0 ,所以,
在前面就设好喝酒瓶数 n 比较方便)
问题一: (喝一瓶酒故参数 f/V 应代为 51.35) 下午六点检时测, t=6 时代入: w(6)= 19(mg/100ml) w(6)<20,即下午六点时没有检测出为饮酒驾车。 再次喝酒时,体内有酒精残余,有一个值为 19 的初始值, 凌晨两点再次检测时, t=8 代入: y(8)=27(mq/ml) 酒精含量 y(8)>20,因此大李被认定为饮酒驾车。
数学建模作业二:
饮酒驾车问题分析
一、 一次性饮酒的模型:
假设: 1 .酒精转移的速率与出发处酒精浓度成正比; 2 .过程为酒精从胃到体液到体外; 3. 酒精在血液与体液中含量相同; 4 在很短时间内饮酒,认为是一次性饮入,中间的时间差不计; 5.不考虑个体差异。
t为饮酒时间, y1 (t ) 为 t 时刻人体消化的酒精量, y2 (t ) 为 t 时刻人体的酒精
这样考虑 1.假设饮酒周期固定; 2.假设每次饮酒量也一定; 3.假设为一次性饮入; 4. 酒精浓度消除率为常数; 5.不考虑个体差异。 设 w(t ) 表式 t 时刻酒精在人体内的浓度, w(0) 表示 t=0 时饮入酒精量在体 内浓度, y (0) 表示饮入酒精量,T 表示周期,V 为体液体积,k 为酒精浓度消除 率。 饮酒后体内酒精的浓度逐渐降低, 酒精浓度消除率与饮酒量成线性比, 则有:
数学建模第二次作业(3)(精编文档).doc

【最新整理,下载后即可编辑】数学建模任意两个城市之间的最廉价路线参与人员信息:2012 年 6 月 6 日一、问题提出某公司在六个城市C1、C2、C3、C4、C5、C6中都有分公司,从Ci到Cj的直达航班票价由下述矩阵的第i行、第j列元素给出(∞表示无直达航班),该公司想算出一张任意两个城市之间最廉价路线表,试做出这样的表来。
0 50 ∞40 25 1050 0 15 20 ∞25∞15 0 10 20 ∞40 20 10 0 10 2525 ∞20 10 0 5510 25 ∞25 55 0二、问题分析若网络中的每条边都有一个数值(长度、成本、时间等),则找出两节点(通常是源节点和阱节点)之间总权和最小的路径就是最短路问题。
最短路问题是网络理论解决的典型问题之一,可用来解决管路铺设、线路安装、厂区布局和设备更新等实际问题。
最短路问题,我们通常归属为三类:单源最短路径问题、确定起点终点的最短路径问题、全局最短路径问题———求图中所有的最短路径。
题中要求算出一张任意城市间的最廉价路线表,属于全局最短路问题,并且使得该公司总经理能够与各个子公司之间自由往返。
(此两点为主要约束条件)Floyd 算法,具体原理如下:(1) 我们确定本题为全局最短路问题,并采用求距离矩阵的方法根据路线及票价表建立带权矩阵W ,并把带权邻接矩阵我w 作为距离矩阵的初始值,即(0)(0)()ij v v D d W ⨯==(2)求路径矩阵的方法在建立距离矩阵的同时可建立路径矩阵R ,()ij v v R r ⨯=,ij r 的含义是从i v 到j v 的最短路径要经过点号为ij r 的点。
(3)查找最短路径的方法若()1v ij r p =,则点1p 是点i 到j 的最短距离的中间点,然后用同样的方法再分头查找。
三、 模型假设: 1.各城市间的飞机线路固定不变2.各城市间飞机线路的票价不改变3.忽略乘客除票价以外的各项开销费用4.不考虑雷雨云、低云、大风、雷暴、冰雹等主要天气因素对飞行的影响。
数学建模选修课作业2012
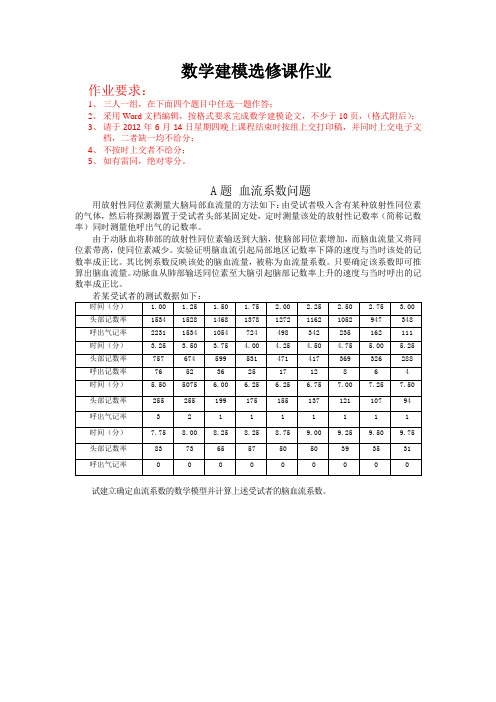
数学建模选修课作业作业要求:1、三人一组,在下面四个题目中任选一题作答;2、采用Word文档编辑,按格式要求完成数学建模论文,不少于10页,(格式附后);3、请于2012年6月14日星期四晚上课程结束时按组上交打印稿,并同时上交电子文档,二者缺一均不给分;4、不按时上交者不给分;5、如有雷同,绝对零分。
A题血流系数问题用放射性同位素测量大脑局部血流量的方法如下:由受试者吸入含有某种放射性同位素的气体,然后将探测器置于受试者头部某固定处,定时测量该处的放射性记数率(简称记数率)同时测量他呼出气的记数率。
由于动脉血将肺部的放射性同位素输送到大脑,使脑部同位素增加,而脑血流量又将同位素带离,使同位素减少。
实验证明脑血流引起局部地区记数率下降的速度与当时该处的记数率成正比。
其比例系数反映该处的脑血流量,被称为血流量系数。
只要确定该系数即可推算出脑血流量。
动脉血从肺部输送同位素至大脑引起脑部记数率上升的速度与当时呼出的记数率成正比。
试建立确定血流系数的数学模型并计算上述受试者的脑血流系数。
B 题 摩托车选购问题你已经去过几家主要的摩托车商店,基本确定将从三种车型中选购一种。
你选择的标准主要有:价格、耗油量大小、舒适程度和外表美观情况。
经反复思考比较,构造了它们之间的成对比较矩阵⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=13151131517155118731A 三种车型(记为a ,b ,c )关于价格、耗油量、舒适程度及你对它们表观喜欢程度的成对比较矩阵为(价格) (耗油量) c b a c b ac b a ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡121312121321 c b a ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡171271521511(舒适程度) (外表)c b a c b ac b a ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡1411411531 c b a ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡17131715311 试建立模型解决下面问题:(1)根据上述矩阵可以看出四项标准在你心目中的比重是不同的,请按由重到轻的顺序将它们排出。
数学建模第二章作业答案章绍辉

习题2作业讲评1. 继续考虑2.2节的“汽车刹车距离”案例,请问“两秒准则”和“一车长度准则”一样吗?“两秒准则”是否足够安全?对于安全车距,你有没有更好的建议?(“两秒准则”,即后车司机从前车经过某一标志开始,默数2秒之后到达同一标志,而不管车速如何.刹车距离与车速的经验公式20.750.082678d v v =+,速度单位为m/s ,距离单位为m )解答(1)“两秒准则”表明前后车距与车速成正比例关系. 引入以下符号:D ~ 前后车距(m );v ~ 车速(m/s );于是“两秒准则”的数学模型为22D K v v ==. 与“一车长度准则”相比是否一样,依赖于一车长度的选取.比较20.750.082678d v v =+与2D v =,得:()0.082678 1.25d D v v -=-所以当15.12 m/s v <(约合54.43 km/h )时,有d<D ,即前后车距大于刹车距离的理论值,可认为足够安全;当15.12 m/s v >时,有d>D ,即前后车距小于刹车距离的理论值,不够安全. 也就是说,“两秒准则”适用于车速不算很快的情况.另外,还可以通过绘图直观的解释“两秒准则”够不够安全. 用以下MATLAB 程序把刹车距离实测数据和“两秒准则”都画在同一幅图中(图1).v=(20:5:80).*0.44704;d2=[18,25,36,47,64,82,105,132,162,196,237,283,334 22,31,45,58,80,103,131,165,202,245,295,353,418 20,28,40.5,52.5,72,92.5,118,148.5,182,220.5,266,318,376]; d2=0.3048.*d2;k1=0.75;k2=0.082678;K2=2; d1=[v;v;v].*k1; d=d1+d2;plot([0,40],[0,K2*40],'k') hold onplot(0:40,polyval([k2,k1,0],0:40),':k') plot([v;v;v],d,'ok','MarkerSize',2)title('比较刹车距离实测数据、理论值和两秒准则') legend('两秒准则','刹车距离理论值',...'刹车距离的最小值、平均值和最大值',2) xlabel('车速v (m/s )') ylabel('距离(m )') hold off510152025303540020406080100120140160180比较刹车距离实测数据、理论值和两秒准则车速v (m/s )距离(m )图1(2)用最大刹车距离除以车速,得到最大刹车距离所需要的尾随时间(表1),并以尾随时间为依据,提出更安全的“t秒准则”(表2)——后车司机根据车速快慢的范围,从前车经过某一标志开始,默数t秒钟之后到达同一标志.v=(20:5:80).*0.44704;d2=[18,25,36,47,64,82,105,132,162,196,237,283,33422,31,45,58,80,103,131,165,202,245,295,353,41820,28,40.5,52.5,72,92.5,118,148.5,182,220.5,266,318,376];d2=0.3048.*d2;k1=0.75;k2=0.082678;d=d2+[v;v;v].*k1;vi=0:40;plot([0,10*0.44704],[0,10*0.44704],'k',...vi,k1.*vi+k2.*vi.*vi,'k:',...[v;v;v],d,'ok','MarkerSize',2)legend('t 秒准则','刹车距离理论值',...'刹车距离的最小值、平均值和最大值',2)hold onplot([10,35]*0.44704,2*[10,35]*0.44704,'k',...[35,60]*0.44704,3*[35,60]*0.44704,'k',... [60,75]*0.44704,4*[60,75]*0.44704,'k') title('t 秒准则,刹车距离的模型和数据') xlabel('车速v (m/s )') ylabel('距离(m )') hold off510152025303540020406080100120140160180车速v (m/s )距离(m )t 秒准则,刹车距离的模型和数据图24. 继续考虑2.3节“生猪出售时机”案例,假设在第t 天的生猪出售的市场价格(元/公斤)为2()(0)p t p gt ht =-+(1)其中h 为价格的平稳率,取h =0.0002. 其它模型假设和参数取值保持不变.(1) 试比较(1)式与(2.3.1)式,解释新的假设和原来的假设的区别与联系;(2)在新的假设下求解最佳出售时机和多赚的纯利润; (3)作灵敏度分析,分别考虑h 对最佳出售时机和多赚的纯利润的影响;(4)讨论模型关于价格假设的强健性. 解答一(用MATLAB 数值计算)(1)比较(1)式与(2.3.1)式,(1)式表明价格先降后升,(2.3.1)式假设价格匀速下降,(1)式更接近实际(图3). 两个假设都满足(0)p g '=-,在最佳出售时机附近误差微小(图4). 绘图的程序p=@(t)12-0.08*t+0.0002*t.^2; figure(1) n=400;plot([0,n],[12,12-0.08*n],'k:',... 0:.1:n,p(0:.1:n),'k') axis([0,400,0,20])title('模型假设(1)式与(2.3.1)式的比较')legend('p(0) - g t (1)式',... 'p(0) - g t + h t^2 (2.3.1)式') xlabel('t (天)')ylabel('p (元/公斤) ') figure(2) n=20;plot([0,n],[12,12-0.08*n],'k:',... 0:.1:n,p(0:.1:n),'k')title('模型假设(1)式与(2.3.1)式的比较')legend('p(0) - g t (1)式',... 'p(0) - g t + h t^2 (2.3.1)式')xlabel('t (天)'), ylabel('p (元/公斤) ')50100150200250300350400024********161820模型假设(1)式与(2.3.1)式的比较t (天)p (元/公斤)图3246810121416182010.410.610.81111.211.411.611.812模型假设(1)式与(2.3.1)式的比较t (天)p (元/公斤)图4(2)在(1)式和(2.3.1)式组成的假设下,多赚的纯利润为()()23()(0)(0)(0)Q t rp gw c t hw gr t hrt =--+-+保留h ,代入其他具体数值,得()32()900.08 1.6Q t ht h t t =+-+令()2()31800.16 1.60Q t ht h t '=+-+=解得生猪出售时机为130t =-(舍去负根)多赚的纯利润为()321111900.08 1.6Q ht h t t =+-+.代入h =0.0002,得113.829t =天,110.798Q =元.或者用MATLAB 函数fminbnd 计算,脚本如下: C=@(t)3.2*t; w=@(t)90+t;p=@(t,h)12-0.08*t+h*t.^2;Q=@(t,h)p(t,h).*w(t)-C(t)-90*12; Qh=@(t)-Q(t,0.0002); t1=fminbnd(Qh,0,30) Q1=Q(t1,0.0002)为帮助理解,可用以下脚本绘制图5: figure(2) tp=0:250;plot(tp,Q(tp,0.0002),'k') title('纯利润Q') xlabel('t (天)') ylabel('Q (元) ')050100150200250-600-500-400-300-200-100100纯利润Qt (天)Q (元)图5(3)用以下MATLAB 脚本计算灵敏度(,)t tS t h h h ∆=∆和(,)Q QS Q h h h ∆=∆,将结果列表.结论:h 的微小变化对t 和Q 的影响都很小 Qh=@(t)-Q(t,0.0002*1.01); [tn,Qn]=fminbnd(Qh,0,30); (tn-t1)/t1/0.01 (-Qn-Q1)/Q1/0.01Qh=@(t)-Q(t,0.0002*1.05); [tn,Qn]=fminbnd(Qh,0,30); (tn-t1)/t1/0.05 (-Qn-Q1)/Q1/0.05Qh=@(t)-Q(t,0.0002*1.1); [tn,Qn]=fminbnd(Qh,0,30); (tn-t1)/t1/0.1 (-Qn-Q1)/Q1/0.1表3 数值计算最佳出售时机t 对h 的灵敏度表4 数值计算多赚的纯利润Q 对h 的灵敏度(4)市场价格是经常波动的,如果价格下跌,往往会止跌回稳,模型假设(1)式以二次函数来刻画价格止跌回升的变化趋势,如果考虑的时间段长达数月,(1)式比(2.3.1)式更接近实际(见图3),但是本问题的最佳出售时机不超过20天,(1)式与(2.3.1)式在最佳出售时机附近非常近似(见图4),(1)式导致的模型解答可以由(2.3.1)式导致的解答加上灵敏度分析所代替. 所以采用更为简单的(2.3.1)式作为假设更好.具体分析如下:由12()(,)g g t p t h -+∆=,得12(,)1g p t h g gt∆-=-, 代入h =0.0002,t =13.82852279,g =0.08,得0.034571gg∆=-. 由于(,)t g S t g t g∆∆≈,根据课本2.3节,代入(,) 5.5S t g =-,t =10,算得11.901t t +∆=,与t =13.829只相差两天.用于以上分析计算的MATLAB 脚本: dg_g=(12-p(ts,0.0002))/ts/0.08-1 10+dg_g*10*(-5.5)解答二(用MATLAB 的Symbolic Math Toolbox 的MuPAD 软件符号计算)(1)运行以下MuPAD 语句,绘得图6和图7:plot(plot::Function2d(12-0.08*t+0.0002*t^2,t=0..400), plot::Function2d(12-0.08*t,t=0..150, LineStyle=Dashed));plot(plot::Function2d(12-0.08*t+0.0002*t^2,t=0..20), plot::Function2d(12-0.08*t,t=0..20, LineStyle=Dashed),#O);(1)式表明价格先降后升,在实际当中有一定道理. 而 (2.3.1)式假设价格匀速下降. 两个假设都满足(0)p g '=-,在最佳出售时机附近误差微小.图6假设(2.3.1)式与(1)式的比较图7假设(2.3.1)式与(1)式的比较(2) 在(1)式和(2.3.1)式组成的假设下,保留h,代入其他具体数值,计算多赚的纯利润. 运行以下MuPAD语句:C:=t->32/10*t:w:=t->90+t:p:=(t,h)->12-8/100*t+h*t^2:Q:=(t,h)-->expand(w(t)*p(t,h)-C(t)-90*12); plot(plot::Function2d(Q(t,0.0002),t=0..290));算得223(2)825,905ht h h t Q t t t =+-+,绘得图8.图8(,0.0002)Q t 的图像运行以下MuPAD 语句:S:=solve(diff(Q(t,h),t),t) assuming h>0; t1:=S[1];subs(t1,h=0.0002); t2:=S[2];ts:=subs(t2,h=0.0002); Q2:=Q(t2,h);Qs:=subs(Q2,h=0.0002);由方程0Qt∂=∂,解得两根:12t t ==代入h =0.0002,得12192.8381439, 13.82852279t t ==(天). 2t 符合题意,1t 应该舍去(对应的Q 是负数). 2t 对应的多赚的纯利润为10.79837809元.(3)接着上一小题,运行以下MuPAD 语句:subs(diff(t2,h)*h/t2,h=0.0002); //t 对h 的灵敏度利用导数算得t 对h 的灵敏度:d (,)0.4124276803d t hS t h h t=⋅=.运行以下MuPAD 语句:subs(diff(Q2,h)*h/Q2,h=0.0002); //Q 对h 的灵敏度,方法一 subs(diff(Q(t,h),h)*h/Q(t,h),t=ts,h=0.0002); //Q 对h 的灵敏度,方法二,更简单用两种方法利用导数算得Q 对h 的灵敏度:d (,)0.367739025d Q hS Q h h Q=⋅=. 结论:h 的微小变化对t 2和Q 2的影响都很小. (4)同解答一5. 继续考虑第2.3节“生猪出售时机”案例,假设在第t 天的生猪体重(公斤)为()000()mt m w w w t w w w e α-=+-(2)其中0(0)90w w ==(公斤),270m w =(公斤),其它模型假设和参数取值保持不变.(1)试比较(2)式与(2.3.2)式,解释新的假设和原来的假设的区别与联系(提示:说明当α (α>0)取何值时,在t =0时可以保持(0)1w r '==;说明当t 增大时,猪的体重会如何变化).(2)在新的假设下求解最佳出售时机和多赚的纯利润. (3)参数m w 代表猪长成时的最终重量,对m w 做灵敏度分析,分别考虑m w 对最佳出售时机和多赚的纯利润的影响.(4)讨论模型关于生猪体重假设的强健性. 解答一(用MATLAB 数值计算)(1)在(2)式中,为使(0)w r '=,必须00()m m w w w w α-=. 当m w =270,0w =90时,有160α=.新假设(2)式是阻滞增长模型,假设生猪体重的增长率是体重的线性递减函数,于是体重增加的速率先快后慢,时间充分长后,体重趋于m w . 而(2.3.2)式0()w t w rt =+只假设体重匀速增加. 长时间来看,新假设比原假设更符合实际(图9). 两个假设都满足(0)w r '=,在最佳出售时机附近误差微小(图10).50100150200250300350400050100150200250300t (天)价格 p (元/公斤)模型假设(2.3.2)式与(2)式的比较图924681012141618209095100105110115t (天)价格 p (元/公斤)图10(2) 在(2.3.1)式和(2)式组成的假设下,用MATLAB 函数fminbnd 计算,可以求得生猪出售时机为t =14.434天,多赚的纯利润为Q =12.151元.(3) 编程计算(,)m m m t t S t w w w ∆=∆和(,)mm m Q QS Q w w w ∆=∆,将结果列表.表5数值计算最佳出售时机t 对m w 的灵敏性表6数值计算多赚的纯利润Q 对m w 的灵敏性结论:m w 的微小变化对t 和Q 的影响都较小.(4)模型假设(2)式导致的模型解答可以由(2.3.2)式导致的解答加上灵敏度分析所代替,所以实践中采用更为简单的(2.3.2)式作为假设即可. 具体分析过程见解答二之(4).MATLAB 脚本: %% (1) 绘图的程序w=@(t)90*270./(90+180*exp(-t/60));figure(1)n=400;plot([0,n],[90,90+n],'k:',...0:.1:n,w(0:.1:n),'k')axis([0,400,0,300])legend('p(0) - g t (2.3.2)式',... 'p(0) - g t + h^2 (2)式',4) title('模型假设(2.3.2)式与(2)式的比较') xlabel('t(天)')ylabel('价格 p(元/公斤) ')figure(2)n=20;plot([0,n],[90,90+n],'k:',...0:.1:n,w(0:.1:n),'k')legend('p(0) - g t (2.3.2)式',... 'p(0) - g t + h^2 (2)式',2) xlabel('t(天)')ylabel('价格 p(元/公斤) ')%% (2) 最佳出售时机和多赚的纯利润C=@(t)3.2*t;w=@(t,m)90*m./(90+(m-90)*exp(-t/60));p=@(t)12-0.08*t;Q=@(t,m)p(t).*w(t,m)-C(t)-90*12;Qh=@(t)-Q(t,270);ts=fminbnd(Qh,0,30)Qs=Q(ts,270)%% (3) 灵敏度分析Qh=@(t)-Q(t,270*1.01);[tn,Qn]=fminbnd(Qh,0,30);(tn-ts)/ts/0.01(-Qn-Qs)/Qs/0.01Qh=@(t)-Q(t,270*1.05);[tn,Qn]=fminbnd(Qh,0,30);(tn-ts)/ts/0.05(-Qn-Qs)/Qs/0.05Qh=@(t)-Q(t,270*1.1);[tn,Qn]=fminbnd(Qh,0,30);(tn-ts)/ts/0.1(-Qn-Qs)/Qs/0.1%% (4) 强健性分析dr_r=(w(ts,270)-90)/ts-110+dr_r*10*6.5解答二(用MATLAB的Symbolic Math Toolbox的MuPAD软件符号计算)(1)运行以下MuPAD 语句,算得160α=:solve(subs(diff(90*270/(90+(270-90)*E^(-a*t)),t), t=0)=1,a);运行以下MuPAD 语句,绘得图11:plot(plot::Function2d(90*270/(90+180*E^(-1/60*t)), t=0..400),plot::Function2d(90+t,t=0..180,LineStyle=Dashed), plot::Line2d([0,270],[400,270],LineStyle=Dotted),#O);运行以下MuPAD 语句,绘得图12 :plot(plot::Function2d(90*270/(90+180*E^(-1/60*t)), t=0..20),plot::Function2d(90+t,t=0..20,LineStyle=Dashed),#O);(2)式()06000()mt m w w w t w w w e -=+-是阻滞增长模型,假设生猪体重的增长率是体重的线性递减函数. 于是,体重w 是时间t 的增函数,体重增加的速率先快后慢,时间充分长后,体重趋于m w . 而(2.3.2)式0()w t w rt =+只假设体重匀速增加. 长时间来看,新假设比原假设更符合实际. 两假设都满足(0)w r '=,在最佳出售时机附近误差微小.图11假设(2.3.2)式与(2)式的比较图12假设(2.3.2)式与(2)式的比较w,代入其(2)在由(2)式和(2.3.1)式组成的假设下,保留m他具体数值,计算多赚的纯利润. 运行以下MuPAD语句:C:=t->3.2*t:w:=(t,wm)->90*wm/(90+(wm-90)*E^(-t/60)): p:=t->12-0.08*t:Q:=(t,wm)-->w(t,wm)*p(t)-C(t)-90*12;plot(plot::Function2d(Q(t,270),t=0..30));算得()()6090120.08(,) 3.210809090emm tmw tQ t w tw--=--+-,绘得图13.图13(,270)Q t的图像运行以下MuPAD语句:T:=solve(diff(Q(t,270),t),t);ts:=T[1];Qs:=Q(ts,270);可解出Q的驻点的数值解14.43357158st=(天),根据函数图像和问题的实际意义,可知这是所求的最佳出售时机,对应的多赚的纯利润为12.15129217s Q =元.(3)接着上一小题,运行以下MuPAD 语句,但是求不出当(,)m Q t w 达到最大值时t 关于m w 的函数解析式:solve(diff(Q(t,wm),t),t);运行以下MuPAD 语句:solve(diff(Q(t,wm),t),wm);可见当(,)m Q t w 达到最大值时m w 关于t 的反函数解析式却有可能求得出,只是MuPAD 给出的表达式很复杂. 其实可以按如下步骤推出m w 关于t 的反函数解析式:g1:=diff(Q(t,wm),t)=0; 算得0Q t∂=∂即: ()()260606030.0812907.2 3.209090902e 90e e m m m m t m t t w t w w w w -----=--⎛⎫++ ⎪⎝⎭观察上式,发现分母大于零,而且去分母之后,合并m w 的同类项,可以表示为m w 的二次方程:g2:=g1*((wm-90)/E^(t/60)+90)^2*25*E^(t/60); //去分母 g2:=collect(g2,wm); //合并wm 的同类项,t 当作参数2606060306060801440016200e 270327038700e e e 648000e 64800012960000e e t m m t t t t t t t w t w ⎛⎫⎛⎫--++-- ⎪ ⎪⎝⎭⎝⎭+--=运行以下MuPAD 语句,由图像(图14)可知在实际问题关心的0<t<30范围内,二次项系数608027030e tt-->:plot(plot::Function2d((270-80/E^(t/60)-3*t),t=0..100));图4 二次项系数的符号于是,运行以下MuPAD语句,解方程:S:=solve(g2,wm);MuPAD给出解的四种情况,其中第一种是二次项系数非零,正是本问题所要求的解. 但是二次方程有两个根,要检验哪一个根才是当(,)mQ t w达到最大值时mw关于t的反函数解析式.float(subs(S[1][1],t=ts));算得当st t=时,有0.8519704108mw=-,这是增根,舍去;float(subs(S[1][2],t=ts));算得当st t=时,有270mw=,这是要找的根;wms:=S[1][2]; //当Q达到最大值时wm关于t的反函数解析式float(subs(1/(diff(wms,t))*wm/t,t=ts,wm=270));//t 对wm 的灵敏度,利用反函数求导数利用反函数求导数算得t 对m w 的灵敏度:d 1(,) 3.80183985d d d m m m m m w w t S t w w w tt t=⋅=⋅=. Q 对m w 的灵敏度则比较简单,运行以下MuPAD 语句: float(subs(diff(Q(t,wm),wm)*wm/Q(t,wm),t=ts,wm=270)); //Q 对wm 的灵敏度利用导数算得Q 对m w 的灵敏度:d (,)7.786585188d m m m w Q S Q w w Q=⋅=. 结论:m w 的微小变化对t 和Q 存在一定影响,不算厉害.(4)模型假设(2)式以阻滞增长模型来刻画生猪体重的变化趋势,如果考虑的时间段长达数月,(2)式比(2.3.2)式更符合实际,但是本问题的最佳出售时机不超过20天,(2)式与(2.3.2)式在最佳出售时机附近非常近似,(2)式导致的模型解答可以由(2.3.2)式导致的解答加上灵敏度分析所代替. 所以采用更为简单的(2.3.2)式作为假设更好. 具体分析如下:由()90(,)m r r t w t w ++∆=,得(,)90m w t w r r t-∆=-, 代入270m w =,14.43357158s t t ==,r =1,得0.036565352791r r r ∆∆==. 由于(,)t r S t r t r∆∆≈,根据2.3节,代入(,) 6.5S t r =,t =10,r =1,算得12.37674793t t +∆=,与14.43357158s t =只相差两天.以上计算可以用以下MuPAD 语句实现:dr:=float((w(ts,270)-90)/ts-1);10+dr*10*6.5;。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
三、数值积分
轮船的甲板成近似半椭圆面形,为了得到甲板的面积,首先测得横向 最大相间8.534米,然后等距离的测得纵向高度,自左向右分别为 0.914,5.060,7.772,8.717,9.083,9.144,9.083,8.992,8.687,7.376,2.073米,计 算甲板的面积。
(2)运行结果:
x= Columns 1 through 11 0 5.6893 0.7112 6.4005 1.4223 7.1117 2.1335 2.8447 3.5558 4.2670 4.9782
Columns 12 through 13 7.8228 8.5340
梯形积分结果为: S= 54.6894 n=
模型假设是整个建模的起点,是模型建立的基础,不同的人对同一事 物的认识因其角度及深度不一致而产生不同的假设条件,从而导致不同 的模型建立恰当进行模型假设是极为重要的。同时模型假设和模型建立 是一个不易分离的整体过程。 . 在进行模型假设和模型建立的过程中,我们应遵从以下两个基本原 则,并按两个基本原则的顺序进行反复的操作。 (1) 分割原则 分割成若干个独立的研究对象并说明对象间应有联系可 用图来表示对象间联系。 (2) 联系原则 构造出对象之间的联系的具体方式或细节 分割的复杂性在于不存在绝对的客观分割的标准因为任何一个分割方 式都带有一定的主观性, 分割问题不单纯是数学问题,还需要有其他学科的观点,这就构成模 型假设的复杂性。对其复杂性我们有必要作深入探讨和研究。
(3)结果分析:
开始时我用了四个不同次数多项式来进行拟合结果如第一个图,但是由 于最后要计算x=6.5,12处的值,我取了误差最小的四次多项式来进行计 算,拟合,结果如第二个图。
5、 常微分方程数值解
用预估校正Euler法,求解定解问题 求出步长为1的所有点的值,并绘制图形。
解:
(1)程序代码:
clc; clear all; f=inline('y^2-2*x/y'); xx=0:1:10; x=xx; x(1)=0; y(1)=1; h=1; n=10; fprintf('每个节点的结果为:\n\n')%%输出语句 for i=1:1:n+1 x(i+1)=x(i)+h; y(i+1)=y(i)+h*f(x(i),y(i)); xx=x(i) yy=y(i) end; fprintf('最后的结果为:\n\n')%%输出语句 m=y(n) plot(x,y,'-mo') % 绘图,原始数据+拟合曲线 xlabel('x'); ylabel('y'); title('预估校正Euler法解定解问题的曲线');
解:
(1)程序代码:
clear all; clc; x=[1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 7 8 9 10 11]; y=[4 4.6 8 8.4 9.28 9.5 9.7 9.86 10 10.2 10.32 10.30 10.24 10.18 10.00 9.40]; a=polyfit(x,y,5); % 拟合出的五次函数的系数 fprintf('运行结果为:\n\n')%%输出语句 disp('构造的二次插值多项式P2(x)为:')%%输出语句 f=poly2str(a,'x')%%将拟合后的多项式系数(双精度数组)转换为字符形 式的函数 poly2sym(a);%%将该向量转换为多项式 fprintf('x=6.5的近似值为:\n') m=polyval(a,6.5)%%用于对已经拟合后的多项式系数, fprintf('x=12的近似值为:\n') n=polyval(a,12)%%用于对已经拟合后的多项式系数, xx=linspace(min(x),max(x)); % 绘图用到的点的横坐标 yy=polyval(a,xx); % 拟合曲线的纵坐标 %subplot(2,2,4);
解:
令, 则
(1)程序代码:
clear all; clc; x=[0 pi/4 pi/2];%%计算各个插值点的x的值 y=sin(x);%%sin中一定要带括号 p=polyfit(x,y,2);%%构造二次插值多项式 f=inline('sinx');%%将sinx定义成内联函数以便使用 fprintf('运行结果为:\n\n')%%输出语句 disp('构造的二次插值多项式P2(x)为:')%%输出语句 f=poly2str(p,'x')%%将拟合后的多项式系数(双精度数组)转换为字符形 式的函数 poly2sym(p);%%将该向量转换为多项式 fprintf('sin(π/8)的近似值为:\n') m=polyval(p,pi/8)%%用于对已经拟合后的多项式系数, %%当给出某个点时求其函数值;计算插值多项式在pi/8处的值 fprintf('sin(π/8)的真实值为:\n') n=sin(pi/8) fprintf('截断误差Rn(x)为:\n')%%输出语句 R=abs(n-m)
11 辛普森积分结果为: S2 = 65.2824
(3)结果分析:
上面结果是用两种方法来进行计算的,第一个是一维线性插值,第二个 是辛普森积分,运行结果如上图,但是无法再给图像命名时再给两个图 填充颜色,原因未知。结果是第一个的结果没有第二个结果好。
四、多项式拟合
对于以下实验数据 x=(1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 7 8 9 10 11) y=(4 4.6 8 8.4 9.28 9.5 9.7 9.86 10 10.2 10.32 10.30 10.24 10.18 10.00 9.40) 给出拟合多项式,计算x=6.5,12处的值,并绘制相应曲线图。
数学建模作业
一、回答以下问题
1.什么是数学模型? 答:
所谓数学模型,是指针对或参照现实世界中某类事物系统的主要特 征、主要关系,经过简化与抽象,用形式化的数学语言概括或近似地加以 表述的一种数学结构.一般表现为数理逻辑的逻辑表达式、各种数学方 程(如代数方程、微分方程、积分方程等)及反映量与量之间相互关系的 图形、表格等形式.它或者能解释特定现象的现实状态,或者能预测对象 的未来状态,或者能提供处理对象的最优决策与控制.好的数学模型应具 备可靠性和可解性(也叫适用性)两方面的特性:可靠性指在允许的误差范 围内,能反映出该系统有关特性的内在联系;可解性指易于数学处理与计 算.数学 模型方法将复杂的研究对象简单化、抽象化,撇开对象的一些具体 特征,减少其参数,只抽取其主要量、量的变化及量与量之间的相互关系, 在“纯粹”的形态上进行研究,突出主要矛盾,忽略次要矛盾,用数学语言刻 画出客观对象量的规律性,简洁明了地描述现实原形,揭示出其本质的规 律,并在对模型修正、求解的基础上使原问题得以解决.可以说,数学模型 是对现实原形的一种理想化处理是一个科学的抽象过程,因而具有高度 的抽象性与形式化特征.这一特征使其成为一种经典的数学方法,并随着 科学技术的数学化趋势,超越数学范畴,广泛地应用于自然科学、工程技 术和社会科学的一切领域.。
4.建立数学模型一般都有什么方法? 答:
建模的一般方法: 机理分析:根据对现实对象特性的认识,分析其因果关系,找出反映内 部机理的规律,所建立的模型常有明确的物理或现实意义。 测试分析方法:将研究对象视为一个“黑箱”系统,内部机理无法直接寻 求,通过测量系统的输入输出数据,并以此为基础运用统计分析方法, 按照事先确定的准则在某一类模型中选出一个数据拟合得最好的模型。 测试分析方法也叫做系统辩识。 将这两种方法结合起来使用,即用机理分析方法建立模型的结构,用系 统测试方法来确定模型的参数,也是常用的建模方法。 在实际过程中用那一种方法建模主要是根据我们对研究对象的了解程度 和建模目的来决定建立数
5.建立数学模型的一般步骤是什么? 答:
建模的具体步骤大致如下: 1、 实际问题通过抽象、简化、假设,确定变量、参数; 2、 建立数学模型并数学、数值地求解、确定参数; 3、 用实际问题的实测数据等来检验该数学模型;
2、 多项式插值
由函数y=sin x在三点0,π/4,π/2处的函数值,构造二次插值多项式 P2(x),计算sin(π/8)的近似值,并估计截断误差。
fprintf('梯形积分结果为:\n\n')%%输出语句 x=[x,fliplr([x(1),x,x(end)])]; y=[y/2,fliplr([y(1)/2,-y/2,y(end)/2])]; subplot(1,2,1); plot(x,y,'-r')%,x0,y1,'-r') S=trapz(y1)*0.001%%积分函数 title('用梯形积分结果图'); xlabel('x'); ylabel('y'); y=[0.914,5.060,7.772,8.717,9.083,9.144,9.083,8.992,8.687,7.376,2.073]; n=length(y) x=linspace(0,8.534,n); pp=spline(x,y);%%求样条函数表达式 fprintf('辛普森积分结果为:\n\n')%%输出语句 S2=qu数值积分 %%%绘制甲板的图形 subplot('position',[200,150,900,400])%%subplot('Position',[left bottom %width height]) %figure的位置和大小,距离屏幕左边200,底部150,宽900,高400, 默认单位是像素 xx=[x,fliplr([x(1),x,x(end)])];%%把x矩阵的第1个到最后一个元素沿垂直 轴左右翻转 yy=[y/2,fliplr([y(1)/2,-y/2,y(end)/2])];%实现矩阵的左右翻转 subplot(1,2,2) plot(xx,yy) title('用辛普森积分结果图'); xlabel('x'); ylabel('y');