总体分布的正态性检验
总结正态性检验的几种方法

总结正态性检验的几种方法1.1 正态性检验方法1)偏度系数样本的偏度系数(记为1g )的计算公式为()2331331(1)(2)(1)(2)n ii n n g x x n n s n n s μ==-=----∑, 其中s 为标准差,3μ为样本的3阶中心距,即()3311n i i x x n μ==-∑。
偏度系数是刻画数据的对称性指标,关于均值对称的数据其偏度系数为0,右侧更分散的数据偏度系数为正,左侧更分散的数据偏度系数为负。
(2)峰度系数样本的峰度系数(记为2g ),计算公式为()242412244(1)(1)3(1)(2)(3)(2)(3)(1)(1)3(1)(2)(3)(2)(3)n i i n n n g x x n n n s n n n n n n n n s n n μ=+-=-------+-=------∑,其中s 为标准差,4μ为样本的3阶中心距,即()4411n i i x x n μ==-∑。
当数据的总体分布为正态分布时,峰度系数近似为0,;当分布为正态分布的尾部更分散时,峰度系数为正;否则为负。
当峰度系数为正时,两侧极端数据较多,当峰度系数为负时,两侧极端数据较少。
(3)QQ 图QQ 图可以帮助我们鉴别样本的分布是否近似于某种类型的分布。
现假设总体为正态分布()2,N μσ,对于样本12,,,n x x x L ,其顺序统计量是(1)(2)(),,,n x x x L 。
设()x Φ为标准正态分布()0,1N 的分布函数,1()x -Φ是反函数,对应正态分布的QQ 图是由以下的点 1()0.375,,1,2,,0.25i i x i n n -⎛⎫-⎛⎫Φ= ⎪ ⎪+⎝⎭⎝⎭L , 构成的散点图,若样本数据近似为正态分布,在QQ 图上这些点近似地在直线上y x σμ=+,附近,此直线的斜率是标准差σ,截距式均值,μ,所以利用正态QQ 图可以做直观的正态性检验。
R语言学习系列25-K-S分布检验与正态性检验

23。
K—S分布检验与正态性检验(一)假设检验1. 什么是假设检验?实际中,我们只能得到抽取的样本(部分)的统计结果,要进一步推断总体(全部)的特征,但是这种推断必然有可能犯错,犯错的概率为多少时应该接受这种推断呢?为此,统计学家就开发了一些统计方法进行统计检定,通过把所得到的统计检定值,与统计学家树立了一些随机变量的概率分布进行对比,我们可以知道在百分之多少的机遇下会得到目前的结果。
倘若经比较后发现,涌现这结果的机率很少,即是说,是在时机很少、很罕有的情况下才出现;那我们便可以有信念地说,这不是巧合,该推断结果是具有统计学上的意义的。
否则,就是推断结果不具有统计学意义。
2. 假设检验的基本思想——小概率反证法思想小概率思想是指小概率事件(P<α, α=0.05或0.01)在一次试验中基本上不会发生。
反证法思想是先提出原假设(H0),再用适当的统计方法确定假设成立的可能性(P值)大小,如可能性小(P≤α),则认为原假设不成立,若可能性大,则还不能认为备择假设(H1)成立。
3. 原假设与备择假设原假设与备择假设是完备且相互独立的事件组,一般,原假设(H0)——研究者想收集证据予以反对的假设;备择假设(H1)—-研究者想收集证据予以支持的假设;假设检验的P值,就是在H0为真时,观察到的差异来源于抽样误差的可能性大小。
假设检验判断方法有:临界值法、P值检验法.四、假设检验分类及步骤(以t检验为例)1. 双侧检验I. 原假设H0:μ=μ0, 备择假设H1:μ≠μ0;Ⅱ。
根据样本数据计算出统计量t的观察值t0;Ⅲ. P值= P{|t| ≥|t0|} = t0的双侧尾部的面积;Ⅳ. 若P值≤α(在双尾部分),则在显著水平α下拒绝H0;若P值〉α,则在显著水平α下接受H0;注意:α为临界值,看P值在不在阴影部分(拒绝域),空白部分为接受域。
2. 左侧检验I。
原假设H0:μ≥μ0, 备择假设H1:μ<μ0;Ⅱ。
正态性检验的几种常用的方法

作者简介 : 周洪伟 (9 8 ) 男 , 17 一 , 江苏南京 人 , 士 , 师 , 究方 向 : 硕 讲 研 概率 统计 , 金融 数学 , 复杂 网络. m i h zo 12 E a :w hu 2 @ l
y ho c m . n a o. o c
一
1 — 3
12 正 态 分 布 的 数 字 特 征 .
:
/ x 4
() 6
引理 4 若 X~ g, r) 则 = , N( o , 0 卢 =3 定义 4 若 随机变量 的分 布 函数 F ) ( 可表示 为 :
F )=( ) 1 ( 1一 F ( )+ ( ) ( ≤ <1 0 )
() 7
() 8
其中F( 为正态分布N g, ) . ) ( 的分布函数,: ) F ( 为正态分布 N g o ) ( ,r 的分布函数, ; 则称 的分布
引 理l若,~ (,。,( 为X 分 函 则F ) f 1 X Nt o)F ) 的 布 数, ( = xr
、 u ,
() 2
由引理可知 , 任何正态分布都可以通过标准正态分布表示.
收 稿 日期 :0 1— 0— 8 2 1 1 0 修 回 日期 :02— 3— 0 2 1 0 2
定义 2 把 三 阶 中心 矩除 以标准 差 的立 方得 到 的标准化 的三阶 中心矩称 为 随机变 量 的偏 度 , 为 , 记
即 卢= () 以方 差 的平方 得到 的标 准化 的四 阶中心矩 称为 随机 变量 的峰度 , 为 , 记 即
21 0 2年 5月
南 京 晓 庄 学 院 学 报
J RNAL OF N OU ANJNG AO HU I XI Z ANG VER IY UNI ST
总体分布的正态性检验

数据统计处理基本命令
Matlab相关命令
– 最值:max(x), min(x) • (1) max(X):返回向量X的最大值,如果X中包含复数元素,则按模取最大值。 • (2) max(A):返回一个行向量,向量的第i个元素是矩阵A的第i列上的最大值。 • (3) [Y,U]=max(A):返回行向量Y和U,Y向量记录A的每列的最大值,U向量记录 每列最大值的行号。
数据统计处理基本命令
Matlab相关命令
– 累加和与累乘积 在MATLAB中,使用cumsum和cumprod函数能方便地求得向量和矩阵元素的累加和与累乘
积向量,函数的调用格式为: • cumsum(X):返回向量X累加和向量。
• cumprod(X):返回向量X累乘积向量。
• cumsum(A):返回一个矩阵,其第i列是A的第i列的累加和向量。
函数名称 normpdf chi2pdf
表 概概率率密密度度函函数数(pdf)
函数说明
调用格式
正态分布
Y=normpdf (X, MU, SIGMA)
2ቤተ መጻሕፍቲ ባይዱ分布
Y=chi2pdf (X, N)
tpdf
t 分布
fpdf
F 分布
Y=tpdf (X, N) Y=fpdf (X, N1, N2)
注意: Y=normpdf (X, MU, SIGMA)的 SIGMA 是指标准差 , 而非 2 .
D n mF a (x ) x F n (x )
何谓正态性检验

何谓正态性检验,如何进行检验正态性检验(Normality test) 是一种特殊的假设检验,其原假设为:H 0:总体为正态分布正态性检验即是检验一批观测值(或对观测值进行函数变换后的数据)或一批随机数是否来自正态总体。
这是当基于正态性假定进行统计分析时,如果怀疑总体分布的正态性,应进行正态性检验。
但当有充分理论依据或根据以往的信息可确认总体为正态分布时,不必进行正态性检验。
z 有方向检验当在备择假设中仅指总体的偏度偏离正态分布的峰度,并且有明确的偏离方向时,检验称为有方向的检验。
特别当总体的偏度和峰度都偏离正态分布的偏度和峰度时,检验称为多方向的检验。
z 无方向检验当备择假设为H 1,总体不服从正态分布时,检验为无方向的检验。
检验方法由于有方向检验在实际检验中使用较少,故在此不作详细的介绍。
当不存在关于正态分布偏离的形式的实质性的信息时,推荐使用无方向检验。
GB/T4882-2001中删去了以前在无方向检验中常用的D 检验法。
代入以爱波斯—普里(EPPS-Pulley )检验法。
保留了使用较多的W 检验法,即夏皮洛—威克尔(Shapiro-Wilk )检验。
当8n 50≤≤时可以利用,小样本(n<8)对偏离正态分布的检验不太有效。
这种常用的无方向检验,由于实验室中一般检测的次数有限,所以它适于实验室测试数据的正态性检验。
它的实施步骤如下:(1) 将观测值按非降次序排列成:(1)(2)(3)()......n x x x x ≤≤≤(2) 按公式:2(1)()12()1()[]()L k n k k k n k k W x x W x x α+−==⎧⎫−⎨⎬⎩⎭=−∑∑ 计算统计量W 的值。
其中n 为偶数时,2n L =;n 为奇数时,12n L −=。
(3) 根据α和n 查GB/T 4882的表11得出W 的p 分位数p α。
(4) 判断:若W<p α,则拒绝H 0,否则不拒绝H 0。
7-2正态总体参数的检验

一、单个正态总体均值的检验 二、两个正态总体均值差的检验 三、正态总体方差的检验
同上节) 标准要求长度是32.5毫米 毫米. 例2(同上节 某工厂生产的一种螺钉 标准要求长度是 同上节 某工厂生产的一种螺钉,标准要求长度是 毫米
实际生产的产品,其长度 假定服从正态分布N( σ 未知, 实际生产的产品,其长度X 假定服从正态分布 µ,σ2 ) ,σ2 未知, 现从该厂生产的一批产品中抽取6件 得尺寸数据如下: 现从该厂生产的一批产品中抽取 件, 得尺寸数据如下
(1)与(4); (2)与(5)的拒绝域形式相同 与 的拒绝域形式相同. 与 的拒绝域形式相同
一、单个正态总体均值的检验
是来自N( σ 的样本 的样本, 设x1,…,xn是来自 µ,σ2)的样本 关于µ的三种检验问题是 (µ0是个已知数 是个已知数)
(1) H0 : µ ≤ µ0 vs H1 : µ > µ0 (2) H0 : µ ≥ µ0 vs H1 : µ < µ0 (3) H0 : µ = µ0 vs H1 : µ ≠ µ0
对于检验问题 对于检验问题
(2) H0 : µ ≥ µ0 vs H1 : µ < µ0
x − µ0
仍选用u统计量 u = 选用 统计量 相应的拒绝域的形式为: 相应的拒绝域的形式为
取显著性水平为α 取显著性水平为α,使c满足 P 0 (u ≤ c) = α 满足 µ
由于μ = μ 0时,u ~ N(0,1),故 c = uα,如图 故 , 因此拒绝域为: 因此拒绝域为 或等价地: 或等价地 φ(x)
检 H0 : µ = µ0 vs H1 : µ ≠ µ0 验
x − µ0 s/ n
接受域为: 接受域为
正态性检验

正态性检验安德森-达令检验、柯尔莫哥洛夫-斯米诺夫检验、雅克-贝拉检验、偏度检验、峰度检验、爱泼斯-普利检验、夏皮洛-威尔克检验。
有些统计方法只适用于正态分布或近似正态分布资料,如用均数和标准差描述资料的集中或离散情况,用正态分布法确定正常值范围及用t检验两均数间相差是否显著等,因此在用这些方法前,需考虑进行正态性检验。
正态分布的特征是对称和正态峰。
分布对称时众数和均数密合,若均数-众数>0,称正偏态。
因为有少数变量值很大,使曲线右侧尾部拖得很长,故又称右偏态;若均数-众数<0称负偏态。
因为有少数变量值很小,使曲线左侧尾部拖得很长,故又称左偏态,见图7.1(a)。
正态曲线的峰度叫正态峰,见图7.1(b)中的虚线,离均数近的或很远的变量值都较正态峰的多的称尖峭峰,离均数近或很远变量值都较正态峰的少的称平阔峰。
图7.1频数分布的偏度和峰度正态性检验的方法有两类。
一类对偏度、峰度只用一个指标综合检验,另一类是对两者各用一个指标检验,前者有W法、D法、正态概率纸法等,后者有动差法亦称矩法。
现仅将W法与动差法分述于下;1.W法此法宜用于小样本资料的正态性检验,尤其是n≤50时,检验步骤如下;(1)将n个变量值Xi从小至大排队编秩。
X1<X2<……<XN< p>见表7.5第(1)栏,表中第(2)、第(3)栏是变量值,第(2)栏由上而下从小至大排列,第(3)栏由下而上从小至大排列。
第(4)栏是第(3)栏与第(2)栏之差。
(2)由附表5按n查出ain系数列入表7.5第(5)栏,由于当n为奇数时,对应于中位数秩次的ain为0,所以中位数只列出,不参加计算。
第(6)栏是第(5)栏与第(4)栏的乘积。
(3)按式(7.8)计算W值(7.8)式中分子的∑,当n是偶数时,为的缩写,当n是奇数时为的缩写,表7.5 第(6)栏的合计平方后即为分子。
分母按原始资料计算。
(4)查附表6得P值,作出推断结论,按n查得W(n,α),α是检验前指定的检验水准,若W>W(n,α)则在α水准上按受H0,资料来自正态分布总体,或服从正态分布;若W≤W(n,α),则在α水准上拒绝H0,接受H1,资料非正态。
第四讲:正态性检验和方差齐性检验
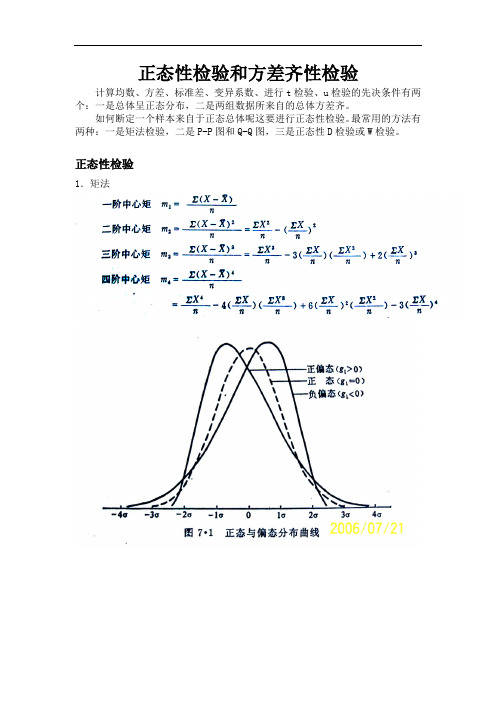
正态性检验和方差齐性检验计算均数、方差、标准差、变异系数、进行t检验、u检验的先决条件有两个:一是总体呈正态分布,二是两组数据所来自的总体方差齐。
如何断定一个样本来自于正态总体呢这要进行正态性检验。
最常用的方法有两种:一是矩法检验,二是P-P图和Q-Q图,三是正态性D检验或W检验。
正态性检验1.矩法2.P-P图/Q-Q图PP图和QQ图原理一样,都是用图形来大致检测数据是否服从某种分布的。
以PP图为例,横坐标是某检验分布的概率值,纵坐标是观测数据的经验分布的概率值(谁作横坐标谁作纵坐标无所谓)。
如果数据服从检验分布,那么图形画出来应该是一条直线(对角线);至于QQ图,只不过把概率换成了分位点而已。
红细胞数组中值频数累计频数累计频率概率单位420- 430 2 2440- 450 4 6460- 470 7 13480- 490 16 29500- 510 20 49520- 530 25 74540- 550 24 98560- 570 22 120580- 590 16 136600- 610 2 138620- 630 5 143640-660 650 1 14487654324005006007003.正态性D 检验 正态性W 检验Shapiro-Wilk 即正态性W 检验统计量。
Kolmogorov-Smirnov test 的原理是寻找最大距离(Distance ), 所以常称为D 法。
当N≤2000时正态性检验用Shapiro-Wilk 统计量,N>2000时用Kolmogorov D 统计量。
∑∑-+-=nx x n x n i D i/)(]2/)1([24W=[∑a in (X a-i+1-X i )]2 /∑(X -X )2方差齐性检验2221S S F =111-=n ν 122-=n ν。
正态性检验几种方法

正态性检验的几种方法一、引言正态分布是自然界中一种最常见的也是最重要的分布。
因此,人们在实际使用统计分析时,总是乐于正态假定,但该假定是否成立,牵涉到正态性检验。
目前,正态性检验主要有三类方法:一是计算综合统计量,如动差法、Shapiro-Wilk 法(W 检验)、D ’Agostino 法(D 检验)、Shapiro-Francia 法(W ’检验)。
二是正态分布的拟合优度检验,如2χ检验、对数似然比检验、Kolmogorov-Smirov 检验。
三是图示法(正态概率图Normal Probability plot),如分位数图(Quantile Quantile plot ,简称QQ 图)、百分位数(Percent Percent plot ,简称PP 图)和稳定化概率图(Stablized Probability plot ,简称SP 图)等。
而本文从不同角度出发介绍正态性检验的几种常见的方法,并且就各种方法作了优劣比较,还进行了应用。
二、正态分布2.1 正态分布的概念定义1若随机变量X 的密度函数为()()()+∞∞-∈=--,,21222x e x f x σμπσ其中μ和σ为参数,且()0,,>+∞∞-∈σμ则称X 服从参数为μ和σ的正态分布,记为()2,~σμN X 。
另我们称1,0==σμ的正态分布为标准正态分布,记为()1,0~N X ,标准正态分布随机变量的密度函数和分布函数分别用()x ϕ和()x Φ表示。
引理1 若()2,~σμN X ,()x F 为X 的分布函数,则()⎪⎭⎫⎝⎛-Φ=σμx x F由引理可知,任何正态分布都可以通过标准正态分布表示。
2.2 正态分布的数字特征引理2 若()2,~σμN X ,则()()2,σμ==x D x E 引理3 若()2,~σμN X ,则X 的n 阶中心距为()()N k kn k k n kn ∈⎩⎨⎧=-+==2,!!1212,02σμ定义2 若随机变量的分布函数()x F 可表示为:()()()()x F x F x F 211εε+-= ()10<≤ε其中()x F 1为正态分布()21,σμN 的分布函数,()x F 2为正态分布()22,σμN 的分布函数,则称X 的分布为混合正态分布。
正态性检验 方法简介

正态性检验方法简介一、 Anderson-Darling 检验Anderson —Darling 检验(简称A-D 检验)是一种拟合检验,此检验是将样本数据的经验累积分布函数与假设数据呈正态分布时期望的分布进行比较,如果差异足够大,该检验将否定总体呈正态分布的原假设。
样本数据的经验累积分布函数与理论累积分布函数之间的差异可通过两种分布之间的二次AD 距离进行衡量,若二次AD 距离小于置信水平下的临界值,则可认为样本数据来源于正态分布。
Anderson-Darling 检验的计算步骤如下:1. 提出假设:样本数据服从正态分布:0H ;分布不服从正态样本数据:0H ; 2. 计算统计量2A ,其计算步骤为:➢ 首先将样本数据按照从小到大的顺序进行排序并编号,排在第i 位的数据为i x ;➢ 其次进行样本数据的标准化,计算公式如下:Sxx Y i i -=(式1-1) 其中,x 为所有样本数据的平均值,S 为所有样本数据的标准差。
➢ 接着计算)(i Y F ,计算公式为)()(i i Y Y F φ=(式1-2)其中,其中φ为标准正态分布函数,可查表获得。
➢ 最后A 2值,计算公式如下:[]{})(1ln )(ln )12(1112i N iNi YF Y F i NN A -+=-+---=∑(式1-3)其中,N 为样本总个数,i 为样本序号3. 计算判定统计量2'A ,计算公式为:)25.275.01(222'NN A A ++= (式1-4)4. 查找临界值:根据给定的显著性水平α,查《Anderson-Darling 临界值表》,得到临界值2'αA ;5. 作出判定:若2'A ≥2'αA ,则在α水平上,拒绝0H ,即认为样本数据不服从正态分布;若2'A <2'αA ,则不能拒绝0H ,即认为样本数据服从正态分布。
例1. 采用Anderson-Darling 判断表1中的数据是否符合正态分布。
SPSS统计分析1:正态分布检验

SPSS统计分析1:正态分布检验正态分布检验⼀、正态检验的必要性[1]当对样本是否服从正态分布存在疑虑时,应先进⾏正态检验;如果有充分的理论依据或根据以往积累的信息可以确认总体服从正态分布时,不必进⾏正态检验。
当然,在正态分布存疑的情况下,也就不能采⽤基于正态分布前提的参数检验⽅法,⽽应采⽤⾮参数检验。
⼆、图⽰法1、P-P图以样本的累计频率作为横坐标,以安装正态分布计算的相应累计概率作为纵坐标,把样本值表现为直⾓坐标系中的散点。
如果资料服从整体分布,则样本点应围绕第⼀象限的对⾓线分布。
2、Q-Q图以样本的分位数作为横坐标,以按照正态分布计算的相应分位点作为纵坐标,把样本表现为指教坐标系的散点。
如果资料服从正态分布,则样本点应该呈⼀条围绕第⼀象限对⾓线的直线。
以上两种⽅法以Q-Q图为佳,效率较⾼。
3、直⽅图判断⽅法:是否以钟形分布,同时可以选择输出正态性曲线。
4、箱式图判断⽅法:观测离群值和中位数。
5、茎叶图类似与直⽅图,但实质不同。
三、计算法1、峰度(Kurtosis)和偏度(Skewness)(1)概念解释峰度是描述总体中所有取值分布形态陡缓程度的统计量。
这个统计量需要与正态分布相⽐较,峰度为0表⽰该总体数据分布与正态分布的陡缓程度相同;峰度⼤于0表⽰该总体数据分布与正态分布相⽐较为陡峭,为尖顶峰;峰度⼩于0表⽰该总体数据分布与正态分布相⽐较为平坦,为平顶峰。
峰度的绝对值数值越⼤表⽰其分布形态的陡缓程度与正态分布的差异程度越⼤。
峰度的具体计算公式为:注:SD就是标准差σ。
峰度原始定义不减3,在SPSS中为分析⽅便减3后与0作⽐较。
偏度与峰度类似,它也是描述数据分布形态的统计量,其描述的是某总体取值分布的对称性。
这个统计量同样需要与正态分布相⽐较,偏度为0表⽰其数据分布形态与正态分布的偏斜程度相同;偏度⼤于0表⽰其数据分布形态与正态分布相⽐为正偏或右偏,即有⼀条长尾巴拖在右边,数据右端有较多的极端值;偏度⼩于0表⽰其数据分布形态与正态分布相⽐为负偏或左偏,即有⼀条长尾拖在左边,数据左端有较多的极端值。
判断正态分布的几种方法

判断正态分布的几种方法
1.直观判断法:通过观察数据分布情况,看是否呈现钟形曲线,即中央部分数据密集,两端数据逐渐稀疏。
2. 统计检验法:通过计算样本数据的偏度和峰度,以及进行正态概率图检验等方法,判断数据是否服从正态分布。
3. 图形检验法:通过绘制箱线图、散点图、直方图等图表,观察数据是否符合正态分布的特征。
4. 假设检验法:通过提出零假设和备择假设,通过显著性水平和p值等指标,来判断数据是否符合正态分布。
5. 经验法则:根据正态分布的三个标准差原则,如果样本数据中约有68%的数据集中在平均值附近,约有95%的数据集中在平均值加减两个标准差范围内,约有99.7%的数据集中在平均值加减三个标准差范围内,那么可以认为数据近似服从正态分布。
- 1 -。
正态分布总体均值的t检验统计量的推导

正态分布总体均值的t检验统计量的推导下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!正态分布总体均值的t检验统计量的推导在统计学中,t检验是一种用于比较两个样本平均值是否具有显著差异的常用方法。
第二节 正态总体参数的检验

2
9
二、两个正态总体参数的假设检验
2 设 有 两 个 相 互 独 立 的 正 态 总 体 X ~ N ( µ1,σ 1 ) ,
Y ~ N ( µ 2,σ ) , 分别抽取独立的样本 ( X1 , X2 ,⋯, Xn1 ) 和
2
µ 第六章证明, X = ( (− , ) 第六章证明,若 χ 2 ~ Nn−1σS 证明 (2) 检验统计量 2
2 2 H 下 O χ1−α / 2(n−1) 2 0 ), 2 则
x
( n − 1) S
~ χ (n −1) ,
(4) 由样本值算得
χ的值; 的值;
2
则拒绝H 否则 不能 若 χ 2 < λ1 或 χ 2 > λ2 ,则拒绝 0 ; 否则, 拒绝H 拒绝 0 .
− tα / 2 ( n − 1) O
tα / 2 (n − 1)
x
~
(4) 由样本值算得 t 的值; 的值; 则拒绝H 如果 | t |> tα 2 (n − 1) ,则拒绝 0 ; 否则, 不能拒绝H 否则 不能拒绝 0 .
5
两家生产同一类产品, 例2 两家生产同一类产品,其质量指标假定都服从正 态分布,标准规格为均值等于120.现从甲厂抽出5 120.现从甲厂抽出 态分布,标准规格为均值等于120.现从甲厂抽出5件 产品,测得其指标值为119,120,119.2,119.7,119.6; 产品,测得其指标值为119,120,119.2,119.7,119.6; 从乙厂也抽出5件产品,测得其指标值为110.5,106.3, 从乙厂也抽出5件产品,测得其指标值为110.5,106.3, 122.2,113.8,117.2。 122.2,113.8,117.2。试判断这两家厂的产品是否符 合标准. 合标准. (α = 0.05 )
正态性检验方法

正态性检验方法在数据分析过程中,往往需要数据服从正态分布,正态分布,也称“常态分布”,又名高斯分布,在求二项分布的渐近公式中得到。
很多方法都需要数据满足正态分布,比如方差分析、独立t检验、线性回归分析(因变量)等。
如果说没有这个前提可能会导致分析不严谨等等。
所以进行数据正态性检验很重要。
那么如何进行正态性检验?接下来进行说明。
一、检验方法SPSSAU共提供三种正态性检验的方法,分别是描述法、正态性检验以及图示法,其中图示法包括直方图以及P-P/Q-Q图。
1.1描述法理论上讲,标准正态分布偏度和峰度均为0,但现实中数据无法满足标准正态分布,因而如果峰度绝对值小于10并且偏度绝对值小于3,则说明数据虽然不是绝对正态,但基本可接受为正态分布。
从上表可以看出例子中峰度为1.160绝对值小于10,偏度为-1.084绝对值小于3。
说明数据基本可以接受为正态分布。
1.2正态性检验SPSSAU的正态性检验包括三种:正态性shapro-WiIk检验、正态性Kolmogorov-Smirnov检验和Jarque-Bera检验。
背景简单描述:调查一个班级的53名学生的身高,判断搜集的数据是否满足μ=140.79,σ=8.6的正态分布。
由于n>50,所以检验方法选择K-S检验或者J-B检验。
如果利用K-S检验进行证明,步骤如下:H0:x服从μ=140.79,σ=8.6的正态分布H1:x不服从μ=140.79,σ=8.6的正态分布附表如下:因为样本超过35,并且α=0.05,所以D约为1.36/≈0.187;相应指标首先计算K-S检验中的D统计量,计算公式如下:【D=maxleft{D^{+},D^{-}ight}】【D^{+}=left|F_{n}left(x_{(k)}ight)-F_{0}left(x_{(k)}ight)ight|】【D^{-}=left|F_{n}left(x_{(k)}ight)-F_{0}left(x_{(k-1)}ight)ight|】首先将数据按从小到大进行排序,用x进行描述,k代表次序,然后计算其标准化的数据,标准化公式为:【x^{prime}=rac{x-mu}{sigma}】接着算出每个数据的频次,并记录好累积频次,然后计算【F_{n}left(x_{(k)}ight)】,(N为累积频次),n为样本量即例子中的53。
正态分布与正态分布检验

正态分布与正态分布检验正态分布是一种常见且重要的连续型数据分布。
标准正态分布是其中一种,当μ=0,σ=1时,即为标准正态分布。
为了方便应用,常用Z分数分布来表示正态分布。
正态分布的主要特征包括:集中性、对称性和均匀变动性。
正态分布有两个参数,即均数μ和标准差σ,可记作N(μ,σ)。
在应用某些统计方法之前,需要判断数据是否服从正态分布或样本是否来自正态总体,因此需要进行正态性检验。
任何正态检验原假设都是数据服从正态分布。
正态性检验有两种方法:P-P图和Q-Q图。
P-P概率图的原理是检验样本实际累积概率分布与理论累积概率分布是否吻合。
若吻合,则散点应围绕在一条直线周围,或者实际概率与理论概率之差分布在对称于以为水平轴的带内(这种称为去势P-P图)。
P-P图常用来判断正态分布,但实际上它可以考察其他很多种分布。
Q-Q概率图的原理是检验实际分位数与理论分位数之差分布是否吻合。
若吻合,则散点应围绕在一条直线周围,或者实际分位数与理论分位数之差分布在对称于以为水平轴的带内(这种称为去势Q-Q图)。
Q是单词quantile的缩写,是分位数的意思。
Q-Q图比P-P图更加稳健一些。
构建Q-Q图的方法是先将数据值排序,然后按照公式(i–0.5)/n计算累积分布值,其中字母表示总数为n的值中的第i 个值。
累积分布图通过以比较方式绘制有序数据和累积分布值得到。
标准正态分布的绘制过程与此相同。
生成这两个累积分布图后,对与指定分位数相对应的数据值进行配对并绘制在QQ图中。
普通QQ图可以用来评估两个数据集分布的相似程度。
它的创建过程类似于正态QQ图,不同的是第二个数据集不必服从正态分布,任何数据集都可以使用。
如果两个数据集具有相同的分布,普通QQ图中的点将落在45度直线上。
峰度和偏度是用来反映频数分布曲线尖峭或扁平程度以及数据分布曲线非对称程度的指标。
它们最初是由皮尔逊用矩的概念演算而来,其中随机变量X的3阶标准矩称为偏度,4阶标准矩称为峰度。
正态性检验方法说明介绍

正态性检验方法简介一、 Anderson-Darling 检验Anderson —Darling 检验(简称A-D 检验)是一种拟合检验,此检验是将样本数据的经验累积分布函数与假设数据呈正态分布时期望的分布进行比较,如果差异足够大,该检验将否定总体呈正态分布的原假设。
样本数据的经验累积分布函数与理论累积分布函数之间的差异可通过两种分布之间的二次AD 距离进行衡量,若二次AD 距离小于置信水平下的临界值,则可认为样本数据来源于正态分布。
Anderson-Darling 检验的计算步骤如下:1. 提出假设:样本数据服从正态分布:0H ;分布不服从正态样本数据:0H ; 2. 计算统计量2A ,其计算步骤为:➢ 首先将样本数据按照从小到大的顺序进行排序并编号,排在第i 位的数据为i x ;➢ 其次进行样本数据的标准化,计算公式如下:Sxx Y i i -=(式1-1) 其中,x 为所有样本数据的平均值,S 为所有样本数据的标准差。
➢ 接着计算)(i Y F ,计算公式为)()(i i Y Y F φ=(式1-2)其中,其中φ为标准正态分布函数,可查表获得。
➢ 最后A 2值,计算公式如下:[]{})(1ln )(ln )12(1112i N iNi YF Y F i NN A -+=-+---=∑(式1-3)其中,N 为样本总个数,i 为样本序号3. 计算判定统计量2'A ,计算公式为:)25.275.01(222'NN A A ++= (式1-4) 4. 查找临界值:根据给定的显著性水平α,查《Anderson-Darling 临界值表》,得到临界值2'αA ;5. 作出判定:若2'A ≥2'αA ,则在α水平上,拒绝0H ,即认为样本数据不服从正态分布;若2'A <2'αA ,则不能拒绝0H ,即认为样本数据服从正态分布。
例1. 采用Anderson-Darling 判断表1中的数据是否符合正态分布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Matlab相关命令
数据统计处理基本命令
– 相关系数
MATLAB提供了corrcoef函数,可以求出数据的相关系数矩阵。 corrcoef函数的调用格式为: • corrcoef(X):返回从矩阵X形成的一个相关系数矩阵。此相关系数矩 阵的大小与矩阵X一样。它把矩阵X的每列作为一个变量,然后求它 们的相关系数。 • corrcoef(X,Y):在这里,X,Y是向量,它们与corrcoef([X,Y])的作用一 样。
Matlab相关命令
数据统计处理基本命令
– 排序
MATLAB中对向量X是排序函数是sort(X),函数返回一个对X中的元素 按升序排列的新向量。
sort函数也可以对矩阵A的各列或各行重新排序,其调用 格式为: [Y,I]=sort(A,dim)
其中dim指明对A的列还是行进行排序。若dim=1,则按列排;若dim=2, 则按行排。Y是排序后的矩阵,而I记录Y中的元素在A中位置。
Matlab相关命令
数据统计处理基本命令
– 求和: • (1) sum(X),返回向量X各元素的和。 • (2) sum(A) ,返回一个行向量,其第i个元素是 A的第i列的元素和。 • (3)sum(A,dim) ,当dim为1时,该函数等同于sum(A);当dim为 2时,返回一个列向量,其第i个元素是A的第i行的各元素之和。 – 乘积: • (1) prod(X) ,返回向量X各元素的乘积。 • (2) prod (A) , 返回一个行向量,其第i个元素是A的第i列元素的 乘积。 • (3) prod(A,dim) ,当dim为1时,该函数等同于prod(A);当dim 为2时,返回一个列向量,其第i个元素是A的第i行的各元素之乘积。
• 当随机变量X服从正态分布时
v1 0, v2 3
若X服从正态分布,当n充分大时
G1 G2 B3 6(n 2) ~ N (0, ) 3/2 B2 (n 1)(n 2)
Bk E{( X E( X ))k }, k 2, 3, 4
B4 6 24n(n 2)(n 3) ~ N (3 , ) 2 2 B2 n 1 (n 1) (n 3)(n 5)
• 随机变量X的偏度和峰度指的是X的标准化变量的 三阶矩和四阶矩:
X E( X ) 3 E ( X E ( X )) 3 v1 E[( ) ] ( D( X )) 3/2 D( X ) X E( X ) 4 E ( X E ( X )) 4 v2 E[( ) ] ( D( X )) 2 D( X )
Matlab相关命令
数据统计处理基本命令
– 累加和与累乘积 在MATLAB中,使用cumsum和cumprod函数能方便地求得向量和矩 阵元素的累加和与累乘积向量,函数的调用格式为: • cumsum(X):返回向量X累加和向量。 • cumprod(X):返回向量X累乘积向量。 • cumsum(A):返回一个矩阵,其第i列是A的第i列的累加和向量。 • cumprod(A):返回一个矩阵,其第i列是A的第i列的累乘积向量。 • cumsum(A,dim):当dim为1时,该函数等同于cumsum(A);当 dim为2时,返回一个矩阵,其第i行是A的第i行的累加和向量。 • cumprod(A,dim):当dim为1时,该函数等同于cumprod(A);当 dim为2时,返回一个向量,其第i行是A的第i行的累乘积向量。
• 3.用样本容量n和显著水平a查出临界值Dna; • 4.通过Dn与Dna的比较做出判断,若Dn<Dna,则认 为拟合是满意的即接收H0。
x
• K-s检验只能做标准正态分布的检验,所以, 用该方法检验前先将数据中心化Z = ZSCORE(X) ,然后再对Z进行检验。
正态性方法比较
• 1.经常使用的拟合优度检验和Kolmogorov-Smirnov检 验的检验功效较低,在许多计算机软件的KolmogorovSmirnov检验无论是大小样本都用大样本近似的公式,很 不精准,一般使用Shapiro-Wilk检验和Lilliefor检验。 • 2. Kolmogorov-Smirnov检验只能检验是否一个样本来 自于一个已知样本,而Lilliefor检验可以检验是否来自未 知总体。 • 3. Shapiro-Wilk检验和Lilliefor检验都是进行大小排序 后得到的,所以易受异常值的影响。 • 4. Shapiro-Wilk检验只适用于小样本场合(3n50),其 他方法的检验功效一般随样本容量的增大而增大。
Matlab相关命令
数据统计处理基本命令
类似的用法,请自己借助matlab在线 帮助功能自己了解:
– 中位数:median(x) – 标准差:std(x) – 方差:var(x) – 偏度:skewness(x) – 峰度:kurtosis(x)
常见的概率分布
二项式分布 卡方分布 指数分布 F分布 几何分布 正态分布 泊松分布 T分布 均匀分布 离散均匀分布 Binomial Chisquare Exponential F Geometric Normal Poisson T Uniform
141 147 126 140 141 150 142 148 148 140 146 149 132 137 132 144 144 142 148 142 134 138 150 142 137 135 142 144 154 149 141 148 148 143 146 142 145 140 154 152 153 147 150 149 145 137 143 149 140 146 158 135 139 144 146 142 155 143 147 143 141 149 140 158 141 146 140 143 138 137 150 144 141 131 147 142 152 140 144 136 143 146 149 145
(二)k-s检验(D检验) • 用 Fn(x)表示样本量为n的随机样本观察值 的累计分布函数,且Fn(x) =i/n(i是等于 或小于x的所有观察结果的数目,i=1, 2,…,n)。F(x)表示正态分布的累计概 率分布函数。
K-S单样本检验通过样本的累计分布函数Fn(x)和 理论分布函数F(x)的比较来做拟合优度检验。检 验统计量是F(x)与Fn(x)间的最大偏差Dn:
z /4 1.96
计算样本中心距:
1 n k Ak X i n i 1 B2 A2 A12 , B3 A3 3 A2 A1 2 A13 B4 A4 4 A1 A3 6 A2 A12 3 A14
带入观察值得
g1 0.1363, g2 3.0948
数据统计处理基本命令
Matlab相关命令
– 最值:max(x), min(x)
• (1) max(X):返回向量X的最大值,如果X中包含复数元 素,则按模取最大值。 • (2) max(A):返回一个行向量,向量的第i个元素是矩阵A 的第i列上的最大值。 • (3) [Y,U]=max(A):返回行向量Y和U,Y向量记录A的 每列的最大值,U向量记录每列最大值的行号。 • (4) max(A,[],dim):dim取1或2。dim取1时,该函数和 max(A)完全相同;dim取2时,该函数返回一个列向量,其 第i个元素是A矩阵的第i行上的最大值。
D n max F ( x) Fn ( x)
若对每一个x值来说, F(x)与Fn(x)都十分接近, 则表明实际样本的分布函数与理论分布函数的拟 合程度很高。
• 1.建立假设组: H0:Fn(x)=F(x) H1: Fn(x)≠ F(x) • 2.计算样本累计频率与理论分布累计概率的绝对差, 令最大的绝对差为Dn; Dn max F ( x ) Fn ( x ) ~ K 分布
非参数检验
正态检验法
• • • • 偏度、峰度检验法(样本容量大于100) K-s正态性检验 Lilliefor正态性检验 W检验(2<n ≤50 )
(一)偏度、峰度检验法
• 由于中心极限定理知道,正态分布随机变量是较为 广泛地存在,因此,当研究一个连续型总体时候,往 往先考察它是否服从正态分布。上面介绍的拟合检验 法虽是一般方法,但他在检验正态时,犯第二类错误 的概率较大。下面来介绍“偏度、峰度检验法”,还 有 “夏丕罗-威尔克法”也较为有效。
U1
1
G1
1
6( n 2) ( n 1)( n 2)
U1 ~ N (0, 1)
U2 G2 2
2
2 =3
6 n 1
2
24n (n 2)( n 3) ( n 1) 2 ( n 3)( n 5)
U 2 ~ N (0, 1)
H0 : X 服从正态分布 H1 : X 不服从正态分布
检验统计量:
U1
1
G1
~ N (0, 1)
U2
G2 2
2
~ N (0, 1)
H0为真,当n充分大一般说来G1与v1的偏离不应 该太大,同样G2与v2的偏离也不应该太大。取显著 水平α下, H0的拒绝域为:
| u1 | z /4 或 | u2 | z /4
例1 下面给出了84个伊特拉斯坎(Etruscan)人 男子的头颅的最大宽度(mm), 现在来画这些 数据的“频率直方图”.
• 5. 拟合优度检验和Kolmogorov-Smirnov检验 都采用实际频数和期望频数进行检验,前者既可 用于连续总体,又可用于离散总体,而 Kolmogorov-Smirnov检验只适用于连续和定量 数据。 • 6.拟合优度检验的检验结果依赖于分组,而其他 方法的检验结果与区间划分无关。 • 7.偏度和峰度检验易受异常值的影响,检验功效 就会降低。 • 8.假设检验的目的是拒绝原假设,当p值不是很大 时,应根据数据背景再作讨论。