【泰迪杯】通用论坛正文提取
EC-Lab software 中文操作手册

目
录
1. 介绍 ............................................................................................................................................. 6 2. EC-Lab 软件:设置.................................................................................................................... 7 2.1 开始程序............................................................................................................................ 7 2.2 EC-Lab 软件准备和运行实验 ........................................................................................... 9 2.2.1 EC-Lab 主界面 ...................................................................................................... 9 2.2.1.1 设置工具栏 .................................................................................................. 9
鲁棒特征提取与行为识别

图5 聚类结果 示例 图 ( 1】
图8 人脸表 情数据
3 7 I ——
—
—
—
—
—
—
—
—
—
2 0 1 3 年第1 l 期 \
、 — —~ — — 一 — — — — ~ …
— — ~
3 . 1使用S V M分类器的结果
如果参数 选择为卷窗 口大小 5 x5 × 5 ,盯= 6 , T=7 . 9 3 , m=0 . 9我们 的正确率如表 l 所示。
2 0 1 3 年第1 l g q
至此 ,我们就 根据 计算 出的反应 大小提 取所 需要的特 征 点 ,这些 特征 点周 围的像素所 组成 的立方体像 素窗 口就是我 们识 别 的关 键 。提 取的方 式只要不违背 我们所定 义 的响应公
式 的原则 ,选择反应计算结果大的点即可。
图7 聚类结果示例 图 ( 2)
可以很容看到 ,这 组分类结果更加不理想。 所 以,我们需 要 一种合 理 的原则 来选 定初 始 聚类 中心。 K — me a n s 算法 的缺陷主要来 自初始 聚类 中心选 择的过于密集 , 因此 我们希望选择 相距较 远 的初 始聚类 中心,换句话 说 ,我
类中心距离之和最大的点 , 并纳入初始聚类中心。
3 ) 重复 2 ) ,直至初始聚类中心选满为止 。
利用 K — me a n s 算法对所有的立方体像素窗 口进行 聚类 获
取特征字典 。单个视频数 据样本会 被压缩成一 个维度 和聚类
中心个数 相同的 向量,其 中每一维代 表该样本包 含特征字典
1 )适当选择 e个类的初始中心 ;
2 )在第 k次迭 代中,对任意一 个样本 ,求其 到 e 个 中心
华瑞科 TH2883 系列说明书

V1.1目录第1章概述 ............................................................................... 1-11.1引言1-11.2使用条件...................................................................................................................1-31.2.1电源.......................................................................................................................1-31.2.2环境温度与湿度 ....................................................................................................1-31.2.3预热.......................................................................................................................1-31.3体积与重量...............................................................................................................1-3第2章基本技术指标 ................................................................. 2-12.1技术指标...................................................................................................................2-12.2比较方法说明 ...........................................................................................................2-22.2.1面积比较 ...............................................................................................................2-22.2.2面积差比较............................................................................................................2-22.2.3电晕放电比较........................................................................................................2-32.2.4相位差比较............................................................................................................2-3第3章面板说明及显示说明....................................................... 3-13.1前面板说明...............................................................................................................3-13.2后面板说明...............................................................................................................3-23.3基本显示区域说明....................................................................................................3-3第4章测量显示键[DISP]说明.................................................... 4-14.1测量显示界面 ...........................................................................................................4-14.2测量显示界面的符号约定 ........................................................................................4-14.3测量显示界面主菜单下软键说明 .............................................................................4-14.3.1显示设置 ...............................................................................................................4-24.3.2比较设置 ...............................................................................................................4-24.3.3测量功能 ...............................................................................................................4-34.3.4辅助功能 ...............................................................................................................4-34.3.5统计功能 ...............................................................................................................4-44.3.6修改.......................................................................................................................4-4第5章测量设置键[SETUP]说明................................................. 5-15.1测量设置界面符号约定 ............................................................................................5-15.2测量设置界面 ...........................................................................................................5-15.2.1步骤(Step).........................................................................................................5-25.2.2模式(Mode).......................................................................................................5-25.2.3 CH1-CH8(TH2883S8-5),CH1-CH4(TH2883S4-5)通道配置..................................5-35.2.4采样速率(Samp)-模式选择为普通模式时可设置 .............................................5-35.2.5测试脉冲(Test Imp)-模式选择为普通模式时可设置.........................................5-35.2.6消磁脉冲(Erase Imp)-模式选择为普通模式时可设置.......................................5-35.2.7电压调整(Volt ADJ)-模式选择为普通模式时可设置 ........................................5-35.2.8起始电压(Start Volt)-模式选择为破坏模式时可设置........................................5-45.2.9终止电压(End Volt)-模式选择为破坏模式时可设置.........................................5-45.2.10电压步进(Volt Step)-模式选择为破坏模式时可设置 ......................................5-45.2.11比较器(Comparator)........................................................................................5-45.2.12位置(Position)(面积,面积差,电晕)..........................................................5-55.2.13位置(Position)(相位差) ................................................................................5-55.2.14差值(Limit)(面积,面积差,相位差)..........................................................5-55.2.15差值(Limit)(电晕)........................................................................................5-55.3波形设置界面 ...........................................................................................................5-65.3.1步骤(Step).........................................................................................................5-65.3.2模式(Mode).......................................................................................................5-75.3.3标波名()-模式选择为标准采样时有效...............................................5-85.3.4步骤名(StepNO.)-模式选择为标波复制和对比测试时有效..............................5-85.4内部文件界面 ...........................................................................................................5-85.5外部文件界面 ......................................................................................................... 5-11第6章系统设置键[SYSTEM]说明.............................................. 6-16.1系统界面...................................................................................................................6-16.1.1显示屏亮度(Brightness) .........................................................................................6-26.1.2合格/不合格显示(Pass/Fail) ..............................................................................6-26.1.3合格报警(Pass Alarm).......................................................................................6-26.1.4不合格报警(Pass Alarm) ...................................................................................6-26.1.5按键声音(Key Sound) .......................................................................................6-26.1.6拷屏区域(Hard Copy) .......................................................................................6-26.1.7密码(Password) .................................................................................................6-36.1.8 Language .................................................................................................................6-36.1.9风格(Theme) ..........................................................................................................6-36.1.10日期(Date) ......................................................................................................6-36.1.11时间(Time)......................................................................................................6-46.2参数界面...................................................................................................................6-46.2.1波形显示(Wave Disp)........................................................................................6-46.2.2触发模式(Trig Mode)........................................................................................6-56.2.3延迟时间(Delay Time) ......................................................................................6-56.3接口界面...................................................................................................................6-56.3.1 I/O ..........................................................................................................................6-66.3.2 TH2883S RS232C接口...........................................................................................6-66.3.3 USB通讯接口 ........................................................................................................6-86.3.4 LAN通讯接口...................................................................................................... 6-116.4关于界面................................................................................................................. 6-13第7章使用指南 ........................................................................ 7-17.1按键使用...................................................................................................................7-17.1.1滚轮的使用............................................................................................................7-17.1.2显示页面切换........................................................................................................7-17.2基本测量...................................................................................................................7-17.2.1无标准测试............................................................................................................7-27.2.2标波采样测试........................................................................................................7-27.3破坏测试...................................................................................................................7-27.4技术应用...................................................................................................................7-27.4.1测试对象 ...............................................................................................................7-27.4.2判据的选择............................................................................................................7-37.4.3判据的设置............................................................................................................7-37.4.4标准的选取............................................................................................................7-47.4.5面积差图 ...............................................................................................................7-4第8章命令参考 ........................................................................ 8-18.1命令结构...................................................................................................................8-18.2符号约定与定义 .......................................................................................................8-28.3命令参考...................................................................................................................8-38.3.1 DISPlay子系统命令...............................................................................................8-38.3.2 IVOLTage子系统命令 ...........................................................................................8-68.3.3 SRATE子系统命令................................................................................................8-88.3.4 COMParator子系统命令 ........................................................................................8-88.3.5 TRIGger子系统命令 ............................................................................................ 8-148.3.6 STATistic子系统命令 .......................................................................................... 8-158.3.7 WADJust子系统命令........................................................................................... 8-158.3.8 SWAVE 子系统命令 ........................................................................................... 8-168.3.9 FETCh?子系统命令.............................................................................................. 8-178.3.10 MEASure 子系统命令........................................................................................ 8-208.3.11 ABORt 子系统命令 ........................................................................................... 8-218.3.12 MMEMory 子系统命令 ..................................................................................... 8-228.3.13 MeasSTEP 子系统命令...................................................................................... 8-238.3.14 WaveSTEP 子系统命令 ..................................................................................... 8-248.4出错信息................................................................................................................. 8-26第9章分选接口使用说明 .......................................................... 9-19.1基本信息...................................................................................................................9-19.2电气特征...................................................................................................................9-29.2.1直流隔离输出........................................................................................................9-29.2.2直流隔离输入........................................................................................................9-39.3 HNADLER接口板跳线设置 .....................................................................................9-4第10章成套与保修 ................................................................. 10-110.1成套...................................................................................................................... 10-110.2保修...................................................................................................................... 10-1第1章概述感谢您购买和使用我公司产品,在您使用本仪器前请根据说明书最后一章“成套和保修”的事项进行确认,若有不符请尽快与我公司联系,以维护您的权益。
基于MATLAB控制系统的仿真与应用毕业设计论文

毕业设计(论文)题目基于MATLAB控制系统仿真应用研究毕业设计(论文)任务书I、毕业设计(论文)题目:基于MATLAB的控制系统仿真应用研究II、毕业设计(论文)使用的原始资料(数据)及设计技术要求:原始资料:(1)MATLAB语言。
(2)控制系统基本理论。
设计技术要求:(1)采用MATLAB仿真软件建立控制系统的仿真模型,进行计算机模拟,分析整个系统的构建,比较各种控制算法的性能。
(2)利用MATLAB完善的控制系统工具箱和强大的Simulink动态仿真环境,提供用方框图进行建模的图形接口,分别介绍离散和连续系统的MATLAB和Simulink仿真。
III、毕业设计(论文)工作内容及完成时间:第01~03周:查找课题相关资料,完成开题报告,英文资料翻译。
第04~11周:掌握MATLAB语言,熟悉控制系统基本理论。
第12~15周:完成对控制系统基本模块MATLAB仿真。
第16~18周:撰写毕业论文,答辩。
Ⅳ、主要参考资料:[1] 《MATLAB在控制系统中的应用》,张静编著,电子工业出版社。
[2]《MATLAB在控制系统应用与实例》,樊京,刘叔军编著,清华大学出版社。
[3]《智能控制》,刘金琨编著,电子工业出版社。
[4]《MATLAB控制系统仿真与设计》,赵景波编著,机械工业出版社。
[5]The Mathworks,Inc.MATLAB-Mathemmatics(Cer.7).2005.信息工程系电子信息工程专业类 0882052 班学生(签名):填写日期:年月日指导教师(签名):助理指导教师(并指出所负责的部分):信息工程系(室)主任(签名):学士学位论文原创性声明本人声明,所呈交的论文是本人在导师的指导下独立完成的研究成果。
除了文中特别加以标注引用的内容外,本论文不包含法律意义上已属于他人的任何形式的研究成果,也不包含本人已用于其他学位申请的论文或成果。
对本文的研究成果作出重要贡献的个人和集体,均已在文中以明确方式表明。
辛迪控制系统SIMATIC PCS neo功能库手册说明书

5
Monitoring blocks
6
Controller blocks
7
Motor and valve blocks
8
Interlock blocks
9
Mathematical block
10
Counter blocks
11
Digital logic blocks
12
Services
13
14 TCP communication blocks
SIMATIC SIMATIC PCS neo SIMATIC Process Function Library (V3.0)
Function Manual
About this document
1
Deployment conditions
2
Basics
3
Library structure
4
Operator control blocks
CAUTION
indicates that minor personal injury can result if proper precautions are not taken.
NOTICE
indicates that property damage can result if proper precautions are not taken. If more than one degree of danger is present, the warning notice representing the highest degree of danger will be used. A notice warning of injury to persons with a safety alert symbol may also include a warning relating to property damage.
Operetta实验数据导出方法

实验数据导出方法实验数据导出有2种方式:
1.setting-Data Management-Export Data:
点击页面右上角的Setting选项,出现如下界面:
点击Data Management选项:
点击Export Data选项:
注:
Analysis Sequences: 导出.aas文件,可以导入columbus使用
Measurement index and images:导出图片结果,可以在个人电脑上用Image J软件打开。
也可以上传Columbus软件进行分析。
选择存储路径,最后点击Start。
2.setting-Data Management-Write Archive:
点击页面右上角的Setting选项,出现如下界面:
点击Data Management选项:
点击Write Archive:
点击选择框:
点击OK,则数据被选中,系统计算数据大小;选择存储路径;最后点击Start。
archive文件的生存需要一定时间,请耐心等候。
生成的archive文件,可以拷走,包含全部的原始数据,如果日后有需要,可以再用Read Archive选项读取回来。
注:可以保存所有的原始数据并带走,archive文件可以重新用harmony软件读取再次分析,但是不能直接传上Columbus 进行分析。
推荐数据存储方式:
A 若不需要保留原始数据,实验完毕请及时导出并清理自己的实验数据。
B 导出的实验数据可以上传到Columbus服务器进行分析处理。
C 若需要保留原始数据,请及时生成archive文件拷走并清理自己的实验数据。
浅析杂宝纹在明代彩瓷中的应用

031浅析杂宝纹在明代彩瓷中的应用摘要:杂宝纹是我国传统的装饰题材,其在宋代末期就已经出现;元时,多用于青花器的辅纹装饰,常以八大码的形式出现;而到了明代,除了继续沿用青花器八大码的表现形式,也逐渐发展出新的装饰形式;同时,明代彩瓷的出现和繁荣,打破了青花器成主流的单一局面,杂宝纹也不可避免的应用在明代五彩斑斓的彩瓷装饰当中;本文基于一些具有代表性的彩瓷,谈谈杂宝纹在明代彩瓷中的应用,并对其装饰形式和艺术语言进行分析。
关键词:杂宝纹;明代;彩瓷 中图分类号:J527 文献标识码:A 文章编号:1000—9892(2023)02—031—(03)Analysis on the Application of Miscellaneous Treasure Patterns of Decorative Porcelain in the Ming Dynasty 0前言 杂宝纹是我国传统陶瓷装饰中常见的一种装饰题材,可以直接理解为“多种宝物”,其在陶瓷装饰中的体现主要包含“八吉祥”和其他各种吉祥纹样。
八吉祥纹的组成元素为固定的八种佛教法器,带有着一定的宗教色彩,一般将任意运用超过两组宝物以上的纹饰都可以称为杂宝纹。
它们在陶瓷装饰应用以及演变的长河,逐渐摆脱其自然固有的政治或者宗教色彩,既独立运用,又产生穿插结合。
回望我国陶瓷的发展历程,在经历了宋元黄金时期之后,至明代,达到了又一个高峰,有了宋元陶瓷装饰进入“画花”阶段的基础,陶瓷装饰在明代有了更大的发展,出现了新的彩绘工艺,打破了青花占主流的单一局面,杂宝纹除了继续在青花上得以沿用,其在其他陶瓷彩绘工艺上也有所表现,并且其发展呈现十分繁荣的局面。
1明代彩瓷的主要品种 明代是我国陶瓷装饰工艺发展变革的重要时期之一。
在此之前,我国陶瓷的装饰大多是以施釉为主的素瓷,即便早在宋代,磁州窑就已经开始运用黑白对比的画花装饰手法进行瓷器坯体的装饰,以及在元代,青花瓷上种种精致的青白色的彩绘装饰,它们虽然都属于彩绘瓷的一种,但它们两者关于陶瓷装饰的表现仍然都属于素色的装饰。
ResultsPlus 用户指南说明书
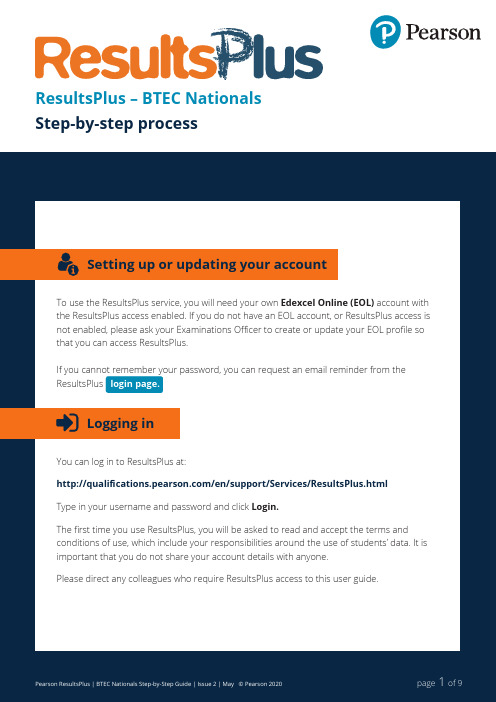
ResultsPlus – BTEC Nationals Step-by-step processStep 1 – Login to ResultsPlus using your EdexcelOnline credentialsLeave the default authentication mode as EOL (EdexcelOnline)Step 2 – If your centre has subsites, select the relevant subsite from the drop-down menu at the top of the screen where your learners are registered, e.g. 99999AStep 3 – Select the BTEC Analysis tabStep 4 – You can search for results either by Student or by Cohort .Get student resultsStep 1 – To search by Individual Student , enter the learner’s details.You can search by either the student registration numberYou can search by their personal details (e.g. forename, surname).If you enter the students’ registration number , you will be directed to their personal record.If you entered their personal details , such as a name, you will be presented with a list of all students matching your search criteria as displayed below.orStep 4Student results overview Press the VIEW tab to view a detailed breakdown of the learner’s external assessment performanceStep 3 – A breakdown of the learners’ performance will be displayed, including:•Qualification grade if certificated •Date external assessment(s) undertaken •Exam or Task based •Unit score achieved • External assessment grade achievedStep 4 – Press the VIEW tab next to the external assessment grade to view the unit performance in more detail, such as by individual questionUnit AnalysisThe top section provides an overview of the students’ details, such as:•Name •Registration number •Qualification details •Unit details •Session test undertaken • Unit mark achievedAdditionally, you will have access to a wide range of information by using the tabs to navigate between:Step 2 – Select VIEW on the student results you wish to view.• Unit analysis• Highlight report• Learning aims (which show how performance links to specific topics and skills)• Unit docs (papers, mark schemes and examiner reports)• For each question you can see the score achieved by this student and the maximum score• For most papers you will need to scroll down the page to see all scores• The percentage/performance column helps you see at a glance how well the student performed on each question• You can sort any column to quickly identify strengths and weaknesses• Pearson averages help you compare your students’ performance with all BTEC candidates• Variance helps you see quickly where your students outperformed or underperformed against Pearson averages. If the student achieved a higher average score than the BTEC average, the variance will appear green. Red indicates a score lower than theBTEC average• For subjects with learning aims reports, you can see which topic or skill was tested in that questionHighlight reportThe Highlight report screen helps you to filter question analysis to show the best and worst areas of performance for each student.• The drop-down menus allow you to select between 1 and 10 best/worst questions• You can choose whether to view a student’s best/worst questions in relation to the Pearson average, or in absolute terms• Where learning aims are available, scrolling further down the page allows you to sort the results according to a student’s best and worst skill/topic areaLearning aimsThe analysis for many BTEC qualifications includes a learning aims detail which link students’ performance on assessments to topics and skills from the specification.• Learning aims allow you to see how your students performed on topic or skill areas.• Topics and skills are arranged in a tree-structure. You can click on headings to see more detail, or contract the view to just see the main topics.• For each topic or skill, you can see how many marks your student scored and the maximum number of marks available.• Pearson averages and variance help you to see how your students have performed in relation to other learners.Accessing external assessment documentsThe Unit docs tab provides access to downloadable pdf versions of examination papers, lead examiner feedback and mark schemes.Click on the document that you wish to access to download it straight to your computer.Get whole cohort resultsCohort paper analysis allows you to analyse your whole cohort’s performance for a particular external test.Step 1 – To search by a Cohort, use the calendar to select the month and year in which the test was undertaken and press SEARCH.You will be presented with a list of all qualifications and units for your centre for the session you have selected.Cohort analysis works in the same way as that for an individual student and provides similar information, such as date, assessment type, score, etc.The number (e.g. 4) within the Students column indicates how many students are within the cohort. You can view a list of the students within any specific cohort by pressingthis number.Step 2 – Press the VIEW tab next to the external assessment unit to view a breakdownof the cohort unit performance.The top section provides a breakdown by number of students and grade achieved.Move the cursor over the grade bar to display the number of students who achieved thevarious grades.As with individual student analysis, you will have access to a wide range of information byusing the tabs to navigate between:• Unit analysis• Highlight report• Learning aims (which show how performance links to specific topics and skills)• Unit docs (papers, mark schemes and examiner reports)9。
中标麒麟高可用集群软件(龙芯版)V7.0 产品白皮书说明书

中标软件有限公司
目录
目录
目录 ...................................................................................................................................................i 前言 ..................................................................................................................................................v 内容指南 ........................................................................................................................................vii 中标麒麟高可用集群产品介绍....................................................................................................... 9 1 概述 ............................................................................................................................................ 11
第 i 页 / 共 54 页
通用论坛正文提取》赛题解读

第五届泰迪杯数据挖掘挑战赛竞赛——《通用论坛正文提取》赛题解读互动派科技-苏淦数说故事团队题目背景:1.数据爆炸•每半年产生的数据,即以往数据总量之和2.互联网数据价值巨大•舆情分析 (事件、活动 )•社会调查 (企业、品牌、产品、人群)•决策支撑 (营销、生产、渠道)3.面临挑战•海量数据挖掘需要海量的抓取、存储、计算能力•但是:真正的有效信息分散在半结构化的HTML页面中、提取成本高数说故事Q: 对于任意提供的BBS类型的网页(或url),获取其HTML源码内容,设计一个能够智能地提取该页面主贴、所有回帖的算法,自动提取该页面的所有主贴和回帖的下列核心字段:●用户名●标题(回帖若无可为空)●帖子内容●帖子的发布日期规则:1.不依赖于特定网站、或网页模板2.简化场景,只考虑对静态HTML的渲染后的结果进行提取•降低对Ajax、js动态生成页面的处理难度作品回顾 & 企业收获:1.集思广益—“好犀利”●效果好的参赛作品,虽然不依赖“特定网站”模板,本质还是离不开“规则库”的构建●企业从参赛作品里面,看到了很多构建“规则库”的新花样,或者对这个方法论的数学证明。
2. 抛砖引玉—“求简历”●做数据采集类的赛题比较少见,提取数据这个话题看似简单,但是要做到“通用”却很难,实际考虑场景更加复杂●大数据行业对海量的互联网数据的高效抓取和提取需求很大,越来越多人开始重视互联网数据的综合运用,这方面的人才需求也较大(快到碗里来~~ )3.企业代表—“棒棒哒”●荣幸地能作为企业代表之一参与到“泰迪杯”全国数据挖掘竞赛里面。
景德镇陶瓷非物质文化遗产的传承与发展路径研究

景德镇陶瓷非物质文化遗产的传承与发展路径研究摘要:作为世界瓷都,景德镇以精湛的传统手工制瓷技艺和绝伦的瓷器产品闻名于世。
景德镇陶瓷非遗不只是文化遗存,更是这座以瓷立市的城镇不断进步的缩影。
本文从当前景德镇陶瓷非遗保护的现状出发,探讨了制约景德镇陶瓷非遗传承与发展的因素,并从加大对陶瓷非遗的保护力度、加强专业化队伍建设、创新传播媒介和传播形式及打造手工制瓷非遗品牌等视角提出对策,以此加强景德镇陶瓷文化资源的传承与发展。
关键词:陶瓷非物质文化遗产;手工制瓷技艺;陶瓷文化中图分类号:J527 文献标识码:A 文章编号:1000—9892(2023) 04—084—(03)Studies on the Inheritance and Development of Jingdezhen Ceramic Intangible Cultural Heritage0引言各民族或社群世代相传、并作为文化遗产有机组成部分的各种传统文化表现形式,以及相关的工具、工艺品或场所等实物,统称为非物质文化遗产。
非物质文化遗产的传承与发展对人类文明意义非凡,对于不同国家和民族的多样性、独特性和地域性的文化保护和传播尤为重要[1]。
作为世界瓷都,景德镇以精湛的传统手工制瓷技艺和绝伦的瓷器产品闻名于世。
千百年来,陶瓷文化在景德镇不断发展、创新与传承,孕育了景德镇特色的陶瓷非物质文化遗产。
2019年,景德镇获批国家陶瓷文化传承创新试验区,如何把景德镇建设成为国家陶瓷文化保护传承创新基地,使其能够传承和延续历史悠久的陶瓷非遗文化,提炼和打造“瓷都”不同寻常且丰富多彩的历史价值、文化价值和旅游价值,已成为日益迫切的任务。
1景德镇陶瓷非遗现状考古资料显示,景德镇及周边地区从晚唐开始制作瓷器,宋代生产出精美的青白瓷而崭露头角,元代生产的青花瓷一枝独秀,到明清时期随着专为皇家烧瓷的御窑厂设立和陶瓷出口贸易的兴盛,景德镇逐渐成为中国乃至全球制瓷中心,享有“瓷都”美誉[2]。
TransPort Digi Debug.txt 提取指南说明书

Quick Note 24 Extracting the debug.txt file from a TransPortDigi Technical SupportFebruary 20161Introduction (3)2Version (4)3FTP method (5)3.1FTP Using FileZilla FTP Client (5)3.2FTP using Firefox web browser (5)3.3FTP Using Internet Explorer web browser (6)4HTTP (WEB interface) method (8)4.1Using Directory Listings (8)5Using “Execute a command” (9)6Using Windows Telnet CLIENT (10)7Using PuTTY (14)The debug.txt output is particularly useful because it collates technical and configuration information about the router in a single file or output stream. Digi technical support will frequently request thisfile/output to aid in troubleshooting.If the debug.txt file is not present, then it will not be possible to extract the file; the TransPort firmware may need to be updated.This guide details the different methods and steps involved in extracting the debug.txt file from a TransPort.The HTTP (web interface) method is generally recommended, as it only requires a web browser. In case the TransPort’s web interface is inaccessible, alternative methods, su ch as FTP and Telnet, are offered. NOTE: Local Ethernet IP addresses are used in these example s. Depending on the TransPort’s configuration, the mobile IP address can also be used.3.1FTP Using FileZilla FTP ClientMake an FTP connection to the TransPort and “drag” the debug.txt file to the PC’s hard drive.3.2FTP using Firefox web browserMake an FTP connection by typing the IP address of the TransPort prefixed with “ftp://”,for example, ftp://192.168.1.1 (the default Ethernet IP address is used here)Enter the login details for the TransPort and click “OK”.Right click the “debug.txt” file, click “Save Link As”, and then save the file somewhere convenient.3.3FTP Using Internet Explorer web browserMake an FTP connection by typing the IP address of the TransPort prefixed with “ftp://”, for example, ftp://192.168.1.1 (the default Ethernet IP address is used here)Enter the login details for the TransPort and click “Log on”.Right click the “debug.txt” file, click “Save target as”, and then save the file somewhere convenient.4.1Using Directory ListingsFrom the TransPort web interface, navigate to Administration - File Management > FLASH DirectoryRight click the “debug.txt” file, click “Save link as”, and then save the file somewhere convenient. NOTE: The Chrome web browser is used in this example. In other browsers, the menu option may be slightly different. For example, Internet Explorer says “Save target as”.From the TransPort web interface, navigate to Administration - Execute a commandEnter the following command:type debug.txtClick the ‘Execute’ button.Wait a few seconds for the data to populate below.Look for “[ENDCFG]” and then “OK” at the very bottom to confirm that no data is missing.Copy and paste the data in a text editor such as Microsoft Notepad.NOTE:The debug.txt file is quite large, so it may be necessary to increase the scroll back buffer in telnet to make it large enough to capture the full file.Do this as follows:Click on the C:\ icon and select “Properties”.Next click “Layout” and set the Screen Buffer Size Height to its maximum.C lick “OK”.Next, Telnet to the TransPort’s IP address.Enter the username and password when prompted.Once connected, issue the following command:type debug.txtThis is a small excerpt from the output, which will be a large file.To copy the file, right-click on the page and select “Mark” from the drop-down menu then starting at the bottom of the page highlight the text and hit “enter”.Paste the data in a text editor such as Microsoft Notepad.PuTTY.exe is a free terminal emulator that can be used to Telnet or SSH to a TransPort to obtain the debug.txt file.Setup PuTTY to log “all session output”and specify a location (“c:\” for example) to save the log file:Input the IP address of the TransPort, select either Telnet or SSH, and then click “Open”:Type “type debug.txt” then hit Enter:The “[ENDCFG]” and “OK” entries confirm that no data is missing:PuTTY may now be closed. The resulting putty.log file should contain the debug.txt output.。
湛博特(Z-Bot)力量抽取杆(Power Draw Bar)说明书

The premier source of tooling, parts, and accessories for bench top machinists. The Z-Bot Power Draw BarThe Z-bot Power Draw Bar for mini mills is designed to work with the popular Tormach tooling system. This system employs an R8 or MT3 collet which remains in the spindle and accepts a ¾” straight shank undercut tool holder. It is designed for a high degree of repeatability and is particularly suited to CNC milling. However, it can also be used as a manual quick change tool system to great effect. The Tormach system is further enhanced by the use of a power draw bar which minimizes tool change time and effort. Driven by a shop compressor, and installed in less than an hour, the Z-bot Power Draw Bar brings a new level of convenience to milling and tool changing. Although a manual system, the Z-Bot Draw Bar can be easily upgraded to serve as a computer controlled component of the Z-Bot Automatic Tool Changing System for Tormach tooling by replacing the manual air valve with automatic solenoid controls.For more information on the Tormach Tooling System, visit /TormachZ-bot Power Draw Bar incorporates a stack of Belleville spring washers that preload the drawbar into the tightened position. The force of the Belleville spring washers draws the collet into the spindle and retains the tool holder.To release the tool holder, air from the compressor is directed through a four way valve to a double acting air cylinder. When the control handle is pushed downward, the air cylinder pushes the piston rod down, thereby moving the lever arm so that it bears on the top of the drawbar. Thelever action multiplies the force of the air cylinder to provide more than 1000 lbs of force to overcome the action of the Belleville spring washers. This action releases the Tormach tool holder. Conversely, when the control handle is moved up, the piston rod is pulled up, which allows the lever arm to clear the top of the drawbar, and the Belleville spring washers pull the tool holder tightly against the spindle.The height of the mechanism is adjusted so that the lever arm clears the top of the drawbar which allows free rotation of the spindle when milling.A silencer/flow control is installed on the “up” air valve exhaust port to assure the air cylinder does not return too violently. It is adjusted and thread locked at the factory. The “down” exhaust port has a simple air muffler as the Belleville washers slow its descent. Do not remove these air controls as it will result in shortened life of the air cylinder.Z-Bot Power Draw Bar ComponentsThe following components are included with the Z-Bot Power Draw Bar:•Power draw bar actuator mechanism •Sheet metal cover•Two stand-offs •Two ¼-20x.25 thumb screws •Four ¼-20x.5 hex bolts•Two M5 x25mm machine screwsYou must also purchase either an MT3 or R8 Z-Bot spring bar set. This will include the following: •Specially machined drawbar (either MT3 or R8)•Six Belleville spring washersTools RequiredYou must also furnish an air hose coupling or fitting for your compressed air hose with a ¼” NPT male thread.You will need the following tools to install the Z-Bot Power Draw Bar:•Electric hand drill•Screw drivers•Hex (Allen) wrenches•End wrenches•4” capacity C-clamp•Teflon plumbers thread seal tape •0.25” transfer punch or center punch •#7 drill bit•¼-20 plug tap and tap wrench •Tapping fluid•Tin snipsNomenclatureAir hoseControl handleSilencer/ flow controlAir valveAir cylinderInput portLever armThumbscrewStand-offsClevisActuator mechanismZ-Bot Spring bar (MT3or R8)Installing the Z-Bot Power Draw Bar Follow these steps to install the Z-Bot Power Draw Bar. Preliminary1.Unplug the mill’s power cord.2.Remove the two screws holding thesheet metal cover from the Z-axisfine feed linkage mechanism and setthe sheet metal cover aside. Alsoremove the two socket head capscrews holding the front block to themill head and let the linkage dangledown.3. Remove the four screws holding the cover on the plastic control box.4. Remove the three screws holding the control box to the mill head and push the control box aside. Let it hang on its cables. The control box will be reinstalled on two standoffs in the bottom holes after the draw bar is installed.5. On each side of the mill head scribe a line 0.6” below the top of the mill head casting. These lines will be used to locate the holes for the drawbar actuator assembly mounting bolts.Measure from top of spindle box castingInstall the drawbar1.Remove the appropriate Z-Bot SpringBar Assembly (R8 or MT3) from itspacking tube and remove the blueretainer tape.2.Insert the drawbar, with theBelleville washers installed, into thetop of the spindle as shown.3.Install a Tormach collet into thespindle and engage the drawbar. 4.Insert a Tormach tool holder into theTormach collet and tighten thedrawbar until it is finger tighting a wrench, tighten the drawbaragainst the spring washers anotherfull turn. This is sufficient to holdthe tool. You may need to adjust this again later when the draw bar isfitted.Install the drawbar actuator assembly1.Install an appropriate air hoseconnector or fitting for your air hoseinto the ¼ NPT air input port on theleft side of the draw bar actuatorassembly. Seal threads with Teflonplumbers tape.2.Connect an air hose to the connectoror fitting and charge the hose with atleast 95 PSI air.3.Ensure that your fingers are out ofthe mechanism of the drawbaractuator assembly. Push the blackrubber draw bar control handle up to raise the internal lever and clevis tothe up position.4.Place the drawbar actuator assembly(with the control handle raised) sothe center of the mounting holes line up with the center of the score line.5.Temporarily C-clamp the sides of thedraw bar housing to the mill head sothe mechanism is straight up anddown.6.Check the orientation of the leverarm and ensure it is in the positionshown in the illustration above.Double check that the holes arecentered on the score line. Checkthat there is clearance between thedrawbar and lever arm. The spindleshould spin without interference.Tighten the draw bar slightly, ifnecessary to allow the spindle to turn freely. Air hoseLine upClearancehereClevis in uppositionC-clamp hereing a transfer punch or centerpunch, mark the locations of theholes for the four mounting bolts.Mark the spot that is at theintersection of the line that youscribed and the center of the hole for each of the four mounting bolt holes.e a #7 (0.201”) drill bit to drill thefour mounting holes 0.5” deep.e a ¼-20 plug tap and tappingfluid to tap the four mounting holesto a depth of at least 0.4”. Clear thechips from the holes.10.Thread 1/4-20 x .5” hex screwsthrough draw bar housing into thetapped holes. Tighten the screws toclamp the draw bar housing firmly tothe mill head.11.Replace the control box using the 225mm M5 screws provided and 16mm plastic standoffs between the millhead and the box.12.Replace the control box cover usingthe four original screws.13.Reinstall the Z-axis micro feedmechanism block. Optionally, use tin snips to trim the sheet metal fromthe Z-axis fine feed mechanism cover where it overlaps the draw barhousing. Alternately, this cover maybe left off the mill. Removal and re-installation of the draw barmechanism is easier without thecover.14.Install the sheet metal cover on thedraw bar housing by threading the ¼-20 thumb screws into the air cylinderholes.Trim 2 Stand-offsCongratualtions! The Z-Bot Power Draw Bar is ready to use. It should look like this:Operating the Z-Bot Power Draw BarWARNING: Never operate the Z-Bot Power Draw Bar when the mill spindle is turning!Connect an air hose to the input port of the air valve on the actuator mechanism. Set the air pressure to a minimum of 95 psi and a maximum of 150 psi. The power draw bar will not release the tool holder without sufficient air pressure.To change a Tormach tool holder:1.Turn the spindle off and wait until it stops rotating.2.With your right hand, grasp the tool holder so it does not fall out of the collet.3.With your left hand, push the draw bar control handle down to release the tool holderfrom the Tormach collet.4.Remove the tool holder from the collet.5.Insert the new tool into the Tormach collet and push the draw bar handle up.To remove the draw bar actuator to use a non-Tormach tool:1.Turn the spindle off and wait until it stops rotating.2.Remove the four hex screws holding the draw bar actuator to the spindle head.3.Slide the draw bar actuator mechanism up and off the mill head and set it aside. There isno need to disconnect the air hose.4.Lock the spindle using the pin supplied with the mill and unscrew the drawbar from theTormach collet.5.Insert another tool holder in the spindle and tighten the draw bar against the springwashers.To replace the draw bar actuator to use Tormach tooling:1.Turn the spindle off and wait until it stops rotating.2.Lock the spindle using the pin supplied with the mill and unscrew the drawbar from thetool holder.3.Install a Tormach collet into the spindle and engage the drawbar.4.Insert a Tormach tool holder into the Tormach collet and tighten the drawbar until it isfinger tighting a wrench, tighten the drawbar against the spring washers another full turn. This issufficient to hold the tool.6.Slide the draw bar housing onto the mounting screws on the mill head and insert andtighten the hex screws.The draw bar is ready to be used again.。
竞赛管理系统的设计与实现

竞赛管理系统的设计与实现摘要随着国家教育体制的改革,竞赛活动的举办也越来越频繁,报名参赛的学生数量也是越来越多。
面对如此众多参与者信息的录入,人工采集信息的方式已经不能满足当下的需求。
竞赛信息的管理又是一份繁琐的工作,参赛者的信息量很大,而且通常不允许出现错误。
如果执行手工操作,则必须手动填写大量表格,这将使比赛管理工作又增加一个难度。
本论文所讲述的竞赛管理系统是在PyCharm环境下用Python中的Django框架和MySQL数据库来实现的,它具有检索迅速、查找方便、可靠性高、存储量大等特点。
该系统分为前端和后端两大部分,前端使用Bootstrap框架,主要实现的功能是用户的注册、登录、浏览赛事、搜索赛事、各个赛事浏览统计、报名、评审打分、排名等功能;后端主要实现的是对用户信息、赛事信息、排名信息的管理。
关键词:竞赛管理系统;PyCharm;Django;MySQLDesign and implementation of competitionmanagement systemAbstractWith the reform of the national education system, competitions are being held more and more frequently, and the number of students registering for competition is also increasing. Faced with the input of information from so many participants, the way of manually collecting information can no longer meet the current needs. The management of the competition information is another tedious task. The information of the contestants is very large, and errors are usually not allowed. If you perform manual operations, you must manually fill out a large number of forms, which will make the game management work more difficult.The competition management system described in this paper is implemented in the PyCharm environment using the Django framework and MySQL database in python.It has the characteristics of fast retrieval, convenient search, high reliability and large storage capacity. The system is divided into two parts: front-end and back-end. The front-end uses the bootstrap framework. The main functions are user registration, login, browsing events, searching events, browsing statistics of various events, registration, review scoring, ranking, etc. The main realization is the management of user information, event information, ranking information.Keywords: Competition Management System; PyCharm;Django;MySQL目录1 绪论 (3)1.1本设计的目的及意义 (3)1.2本设计在国内的发展概况及存在的问题 (3)1.3本设计应解决的主要问题 (3)2 需求分析 (4)2.1可行性需求分析 (4)2.1.1社会可行性 (4)2.1.2经济可行性 (4)2.2非功能性需求分析 (4)2.3功能性需求分析 (4)2.3.1竞赛信息管理功能 (4)2.3.2用户信息管理功能 (5)2.3.3参赛选手信息管理功能 (5)3运行环境 (5)3.1硬件环境 (5)3.2软件环境 (5)4开发技术及开发工具 (5)4.1开发技术介绍 (5)4.1.1B/S结构及其优势 (5)4.1.2web开发框架—django (6)4.1.3MTV设计模式 (7)4.2开发工具介绍 (7)4.2.1JetBrains PyCharm 2018.3.5 x64 (7)4.2.2MySQL5.7 (8)4.2.3Navicat 12 for MySQL (8)5系统概要设计 (8)5.1系统功能结构设计 (8)5.2数据库连接 (9)5.3数据库E-R图 (9)5.4数据表详细设计 (10)6系统详细设计 (12)6.1注册功能模块 (12)6.2登录功能模块 (13)6.3忘记密码功能模块 (15)6.4 浏览赛事统计并显示 (15)6.5导航条 (16)6.6赛事信息 (17)6.7赛事详细信息 (19)6.8 查询功能模块 (20)6.9 报名功能模块 (21)6.2.10名人堂模块 (21)6.2.11个人中心模块 (23)6.2.12后台管理模块 (23)7系统测试 (24)7.1测试目的 (24)7.2功能测试 (24)8结论 (28)参考文献 (28)1 绪论1.1本设计的目的及意义本设计来源于举办方对竞赛管理系统的实际需要,如果实行手工操作,在参赛人数太多时往往容易出错,但是竞赛项目是要保持公正严谨,不容许有丝毫错误发生。
中国高校大数据教育创新联盟

中国高校大数据教育创新联盟第一届“泰迪杯”数据分析职业技能大赛通知各有关单位:为推广我国高职院校数据分析实践教学,培养学生数据分析的应用和创新能力,增加校企交流合作和信息共享,提升我国高职院校的教学质量和企业的竞争能力,由中国产学研合作促进会指导,中国高校大数据教育创新联盟主办,广州泰迪智能科技有限公司承办,人民邮电出版社和广东省工业与应用数学学会协办的“泰迪杯”数据分析职业技能大赛(以下简称竞赛)于2018年10月举行。
竞赛目的在于以赛促学,激励学生学习数据分析的积极性,提高学生分析、解决实际问题的职业技能;以赛促教,推动数据分析技术在职业院校的推广和应用;以赛促创,通过竞赛提高学生的数据分析应用创新能力。
竞赛设立组委会,负责每年竞赛报名、拟定赛题、组织评奖、印制证书,举办全国颁奖仪式等。
2018年竞赛时间如下:报名起讫时间:2018年10月9日—11月7日A题竞赛时间:2018年11月10日 8:00:00-20:00:00B题竞赛时间:2018年11月11日 8:00:00-20:00:00视频答辩时间:2018年12月1日成绩公示时间:2018年12月5—9日最终成绩公布时间:2018年12月10日颁奖时间:2018年12月(具体时间待定)诚邀各高职院校积极参加,具体参赛要求详见大赛官网()。
附件:1.第一届“泰迪杯”数据分析职业技能大赛章程2.第一届泰迪杯数据分析职业技能大赛组委会成员中国高校大数据教育创新联盟中国产学研合作促进会创新联盟工作办公室(代章)2018年10月8日“泰迪杯”数据分析职业技能大赛章程(试行)第一条总则“泰迪杯”数据分析职业技能大赛(以下简称竞赛)是由中国产学研合作促进会指导,中国高校大数据教育创新联盟主办,广州泰迪智能科技有限公司承办,广东省工业与应用数学学会、人民邮电出版社协办的面向全国职业类院校学生的科技竞赛活动,目的在于以赛促学,激励学生学习数据分析的积极性,提高学生分析、解决实际问题的职业技能;以赛促教,推动数据分析技术在职业院校的推广和应用;以赛促创,通过竞赛提高学生的数据分析应用创新能力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
所选题目: C
综合评定成绩:评委评语:
评委签名:
通用论坛正文提取
摘要:
在如今的大数据时代,伴随着互联网和移动互联网的高速发展,在线产生的数据总量不断攀升,其所蕴含的大量信息已成为各行各业的一个重要的数据分析来源。
其中论坛类网页数量和涉及的信息越来越多,充分挖掘这类信息对社会舆论和情感分析、企业决策和政策制定等具有重要的现实意义。
而各论坛网页风格不一,如何从海量的差异论坛网页中提取有价值的信息是目前互联网数据处理一个急需解决的问题。
本次数据挖掘目标旨在根据论坛网页的特性,提出一种全新的通用论坛正文提取方法。
整个过程主要分为5个步骤:
第一步:数据的清洗。
附件中有些url存在错误,体现为三类:网页找不到、本帖被删除了以及404的错误码,针对这些网页不做正文提取的处理。
第二步:无用标签的清洗。
html网页存在部分非正文的区域,它们大多都是一些js脚本、css样式以及html注释信息,这些标签里面的内容没有价值,事先清除这些标签可以缩小正文区域的搜索范围。
第三步:关键词定位和噪声过滤。
关键词指的是时间文本。
首先利用BeautifulSoup工具查找出满足时间格式的文本,并将这些时间文本划分为目标时间和正文时间。
正文时间出现在主题帖或回复帖的正文内容中,不能帮助定位目标区域,因此将其视为噪声,做相应的过滤处理。
将过滤后的时间文本作为目标时间,生成关键词向量。
第四步:目标内容区域定位。
首先,以DOM树解析各个论坛网页,分析DOM解析树中包含关键词的节点的路径特征,寻找各路径特征的最大公共子序列,定位所有关键词节点的最近公共父亲节点。
其次,在下递归寻找目标区域,有且仅包含一个时间关键词的为目标区域,不包含时间关键词的为非目标区域。
第五步:目标内容提取。
目标内容包括作者,主题、正文和发表时间。
发表时间选取上述的关键词;主题信息通过定位<title>标签并删除相应的网站信息提取得到;针对作者和正文信息,首先划分链接文本和非链接文本,并以结构化的文本特征向量表示。
其次,在链接文本集合中,基于文本结构相似性提取作者信息;在非链接文本集合中,结合文本结构相似性和正文片段空间分布的连续性以及文本密度定位正文信息。
为了验证上述算法的鲁棒性和通用性,我们设计了三个实验,分别是:对比只含主题帖和同时包含主题帖和回复帖的网页内容提取效果;对比同类网页的内容提取效果;对比不同类型网页的内容提取效果。
实验结果表明,上述算法简单高效,内容提取准确率高,且具有很好的通用性。
关键词:网页正文提取;数据挖掘;BeautifulSoup;DOM树;文本结构相似性;通用性
Text extraction of general BBS
Abstract:
In the current period of big data, with the high-speed development of internet and mobile internet, the amount of data generated online has increased dramatically, which contained a great deal of information that has become an important data resource of most industries. The number of BBS and data rise rapidly, fully excavate this kind of information has important practical significance for public opinion and sentiment analysis, enterprise decision-making and policy-making. However, the style of BBS pages are differ, how to extract valuable information from amounts different BBS web pages is an urgent problem of the Internet data analysis.
The goal of data mining is to propose a new and general method of content extraction in BBS according to the characteristics of BBS. The whole process involved five steps: First step: data clean. There are some wrong urls in the given data, such as “can’t find the webpage”, “The webpage has been delete” or “404 error”. We do not deal with the data with these replies.
Second step: useless tags clean. HTML can be divided into object and none-object regions, non-object regions may belong to js script, css style or comment item in which the content is worthless. Thus, we delete these items in advance in order to reduce the search scope of object region.
Third step: keywords location and noise filtering. Time is considered as the keyword. We firstly find out all text meeting the time format based on BeautifulSoup, and the time is divided into two part of object time and noise time. The noise time generally exit in main text that can't help to locate object region, which should be filtered. After noise filtering, the remaining time is regard as the keyword and generate the keyword vector.
Fourth step: object region location. Firstly, use DOM tree parse every BBS website, analyze path characteristics of the tree nodes contained keyword in the DOM tree, look for the biggest public subsequence of path characteristics and locate the nearest public father node of all keywords. Secondly, search target areas in the recursive way. The area that contains a keyword is the target area, and the area that do not include the time keyword is not the object region.
Fifth step, objective content extraction. Object content includes author, title, text and publish time. The publish time choose above keyword vector. We get the title information by positioning。