第4章串-2
第四章串A

(1)初始化ClearString(S):初始化串S(串S存 在,将S清为空串)。 (2)StrAssign(&T,char):生成串。
(3)StrCopy(&T,S):串复制(将串S复制到串T)。5
第4 章 串
(4)Concat(&T,s1,s2):串联接(用T返回S1,S2 联接而成的新串)。 (5)求串长StrLength(S):返回S串的元素个数, 即S串的长度。 (6)串比较StrCompare(S,T) (7)求子串SubString(&Sub,S,pos,len): 返回s串的第pos个字符起始的长度为len的子串。 (8)插入运算SetInsert(&S,T,pos):把串t的 值插入到串s的第pos个字符之后。 (9)删除运算StrDelte(&S,pos,len):将串s
可能出现如下三种情况: a. S1长度+S2长度<=T长度,则S1+S2可以完整放入T中; b. S1长度+S2长度>T长度,则S1完整放入,S2放入一部 分; c. S1长度=T长度,则S1完整放入,S2不能放入。 注意:各串长度数据放入该串的 0 单中。(如图4.1示)
11
第4 章 串
两串联结的C语言程序 (算法4.2)
{ int i; orderstribg *r ;
printf(“ r1=%s,r2=%s\n”,r1.vec,r2.vec);
if (r1.len+r2.len>m0) printf(“上溢出\n”) ; /* 若两串长度之和大于m0,则进行溢出处理*/
12
第4 章 串
else { for (i=0; i<r1.len; i++) r.vec[i]=r1.vec[i]; for (i=0; i<r2.len;i++) /*将串r2传r */ r.vec[r1.len+ i ]= r2.vec[i]; r.vec[r1.len+ i ]=“\0” ; /*最后一个位置赋给\0 */ r.len=r1.len+r2.len; } return(r); } /*r串长度等于两串长度之和*/ /*将串r1传给r */
第四章 二元关系-4th-zhou-2

16/43
偏序集合与哈斯图
在哈斯图中,用小圈表示每个元素。如果有x, y P , 且x≤y和x≠y ,则把表示x的小圈画在表示y的小圈之 下。如果y盖覆x,则在x和y之间画上一条直线。如 果x≤y和x≠y ,但是y不盖覆x,则不能把x和y直接用 直线连结起来,而是要经过P的一个或多个元素把 它们连结起来。这样,所有的边的方向都是自下朝 上,故可略去边上的全部箭头表示。
24 36
12
6
2
3
19/43
偏序集合与哈斯图
P( X ) 的元素间 P( X ) 是它的幂集。 例:设集合X={a,b}, 的偏序关系≤是包含关系 。试画出 P( X ), 的哈斯 图。
注意:对于给定偏序集合来说,其哈斯图不是唯一 的。由 P, 的哈斯图,可以求得其对偶 P, 的哈 斯图.只需把它的哈斯图反转180◦即可,使得原来 是顶部的结点变成底部上各结点。
ቤተ መጻሕፍቲ ባይዱ
P( X )中的偏 例:设集合X={a,b,c}, P( X )是它的幂集。 序关系≤是包含关系 。试画出 P( X ), 的哈斯图, 并指出 P( X ) 的子集的上界和下界。
第四章 二元关系
1/43
回顾
• 关系的闭包 • 集合的划分和覆盖 • 等价关系
– 等价模数 – 等价类
2/43
四、次序关系
次序关系是集合中的可传递关系,它能提供一种比 较集合各元素的手段。 定义:设R是集合P中的二元关系.如果R是自反的、 反对称的和可传递的,亦即有
(a) (x)( x P xRx) (b) (x)(y)( x P y P xRy yRx x y ) (c) (x)(y)(z )( x P y P z P xRy yRz xRz )
第4章串(String)(2)专题知识讲座

BF算法旳基本思想图解 本趟匹配开始位置
主串S 模式T
回溯 i
si
…
tj
j 回溯
……
25
BF算法用伪代码 : 1. 在串S和串T中设比较旳起始下标i和j; 2. 循环直到S中所剩字符个数不大于T旳长度或T旳
全部字符均比较完 2.1 假如S[i]=T[j],继续比较S和T旳下一种字符; 2.2 不然将i和j回溯(j=0, i为此次比较旳最初字符 旳下一种字符旳下标),准备下一趟比较; 3. 假如T中全部字符均比较完,则匹配成功,返回 匹配旳起始比较下标;不然,匹配失败,返回0;
4
二、串旳抽象数据类型
数据集合:串旳数据集合能够表达为字符序列 s0,s1, ……,sn-1,每
个数据元素旳数据类型为字符类型。
操作集合:
(1)初始化串 Initiate(S)
(2)赋值
Assign( S, T)
(3)求串长度 strLength( S )
(4)比较
Compare( S, T)
(5)插入
13
2、顺序串旳紧缩存储方式
以字节为单位顺序存储字符串旳每个字符,根据机器字旳 长度,紧缩存储措施尽量地将多种字符存储在一种字中。 对于字符串s =“data structures”,非紧缩存储方式下字 符串s旳顺序存储构造如下:(假设字长为4)
14
2、串旳链式存储构造
它分为单字符结点和块链两种。
18
b.链串
(1)链串赋值
void strassign(linkstring *s, char t[])
{
int k=0; linkstring *r,*p;
s = (linkstring *)malloc(sizeof(linkstring)); s->data = ‘#’; r=s; while (t[k]!=‘\0’) { p=(linkstring *) malloc(sizeof(linkstring));
数据结构-数据结构题库

第一章绪论一.单项选择题1.数据对象是指______。
A. 描述客观事物且由计算机处理的数值、字符等符号的总称B. 数据的基本单位C. 性质相同的数据元素的集合D. 相互之间存在一种或多种特定关系的数据元素的集合2.在数据结构中,数据的基本单位是_________。
A. 数据项B. 数据类型C. 数据元素D. 数据变量3.数据结构中数据元素之间的逻辑关系被称为______。
A. 数据的存储结构B. 数据的基本操作C. 程序的算法D. 数据的逻辑结构4.在数据结构中,与所使用计算机无关的是数据的_______。
A. 存储结构B. 逻辑和物理结构C. 逻辑结构D. 物理结构5.在链式存储结构中,数据之间的关系是通过________体现的。
A. 数据在内存的相对位置B. 指示数据元素的指针C. 数据的存储地址D. 指针6.在定义ADT时,除数据对象和数据关系外,还需说明_______。
A. 数据元素B. 算法C. 基本操作D. 数据项7.计算算法的时间复杂度是属于一种_______。
A. 事前统计的方法B. 事前分析估算的方法C. 事后统计的方法D. 事后分析估算的方法8.在对算法的时间复杂度进行估计的时候,下列最佳的时间复杂度是_______。
A. n2B. nlognC. nD. logn9.设使用某算法对n个元素进行处理,所需的时间是T(n)=100nlog2n+200n+2000,则该算法的渐近时间复杂度为_______。
A. O(1)B. O(n)C. O(200n)D. O(nlog2n)10.有如下递归函数fact(a),其时间复杂度为_________。
int fact(int a){if(n==0)retrun 1;elsereturn(n*fact(n-1));}A. O(n)B. O(n2)C. O(n3)D. O(n4)11.线性表若采用链式存储结构时,要求内存中可用存储单元的地址_______。
第4章 串

4.2.1 定长顺序存储表示 串的连接算法
第4章 串
Status Concat(SString S1, SString S2, SString &T) { // 用T返回由S1和S2联接而成的新串。若未截断, 则返回TRUE,否则FALSE。 ………………. else if (S1[0] <MAXSTRSIZE) { // 截断 T[1..S1[0]] = S1[1..S1[0]]; T[S1[0]+1…MAXSTRLEN] = S2[1…MAXSTRLEN-S1[0]]; T[0] = MAXSTRLEN; uncut = FALSE; }
第4章 串
字符串本身就是一个线性表,可以用链表存储。 如果每个结点存储一个字符,如采用32位地
址,字符按8位记,则存储密度是多少?
存储密度 = 数据元素所占存储位 实际分配的存储位 8 =20% 40
21
存储密度 =
4.2.3 串的块链存储表示 链表存储字符串的讨论
第4章 串
结论:采用普通链表存储字符串,存储密度非常 低,浪费空间严重。 解决办法:一个结点存储多个字符。这就是串的 块链存储。
5
4.1 串类型的定义 串与一般线性表的区别
第4章 串
(1) 串数据对象约束为字符集。
(2) 基本操作的对象不同,线性表以“单个元素”
为操作对象;串以“串的整体”为操作对象,操作的 一般都是子串。
6
4.1 串类型的定义 串的ADT定义 ADT String {
第4章 串
数据对象:D={ ai |ai∈CharacterSet,i=1,2,...,n, n≥0 } 数据关系: R1={ < ai-1, ai > | ai-1, ai ∈D, i=2,...,n } 基本操作: } ADT String
第4章 串

第4章串4.1选择题1.下面关于串的的叙述中,哪一个是不正确的?()A)串是字符的有限序列B)空串是由空格构成的串C)模式匹配是串的一种重要运算D)串既可以采用顺序存储,也可以采用链式存储【答案】B【解析】空串是不含任何字符的串,即空串的长度是零。
空格串是由空格组成的串,其长度等于空格的个数。
2.设有两个串p和q,其中q是p的子串,求q在p中首次出现的位置的算法称为()A)求子串B)联接C)匹配D)求串长【答案】C3.若串s="software",其子串个数是()A)8 B)37 C)36 D)9【答案】C【解析】s的长度为8,长度为8的子串有1个,长度为7的子串有2个,长度为6的子串有3个,长度为5的子串有4个,…,长度为1的子串有8个,共有(1+8)*8/2=36个。
4.串的长度是指()A)串中所含不同字母的个数B)串中所含字符的个数C)串中所含不同字符的个数D)串中所含非空格字符的个数【答案】B5.若串S1="ABCDEFG",S2="9898",S3="###",S4="012345",则执行concat(replace(S1,substr(S1,length(S2),length(S3)),S3),substr(S4,index(S2, '8'),length(S2)))其结果为()A)ABC###G0123 B)ABCD###2345C)ABC###G2345 D)ABC###G1234【答案】D【解析】函数concat(x,y)返回x和y的连接串,substr(s,i,j)返回串s的从序号i的字符开始的j个字符组成的子串,length(s)返回串s的长度。
replase(s,t,v)用v替换s中出现的所有与t相等的子串,index(s,t,i)当s中存在与t值相同的子串时,返回它在s中的第i个字符之后第一次出现的位置。
汇编语言程序设计(第四版)第4章【课后答案】【精选】

汇编语言程序设计 第四版【课后习题答案】--囮裑為檤第4章 基本汇编语言程序设计〔习题4.1〕例题4.2如果要求算术右移8位,如何修改程序。
〔解答〕思路: 首先由最高位字节向次低位字节传送……次低位字节向最低位字节传送(共7次);再判最高位字节符号位,如为0,送00h 到最高位字节;如为1,送ffh 到最高位字节。
传送可参考例题4.2,不过应从第一号字节送第零号字节,……最高位字节向次低位字节传送;也可以用循环来完成: .model small .stack 256 .dataqvar dq 1234567887654321h .code .startup mov cx,7 mov si,1again: mov al, byte ptr qvar[si] mov byte ptr qvar[si-1],al inc siloop again test al,80h jz ezzmov bl,0ffh jmp done ezz: mov bl,0done: mov byte ptr qvar[7],bl .exit 0 end〔习题4.2〕例题4.2如果要求算术左移7位,如何用移位指令实现。
〔解答〕思路:可设计外循环体为8个字节左移一次,方法是:最低位字节算术左移一次, 次低位字节至最高位字节依次带 CF 位循环左移一次(内循环共8次),外循环体控制执行7次即可。
.model small .stack 256 .dataqvar dq 1234567887654321h4 11 201628.code.startupmov dx, 7 ;外循环次数mov ax, byte ptr qvar[0] ;最低位字节送axlpp: shl ax, 1 ;最低位字节左移一次,其d7移入CF 位 mov si, 1mov cx, 7 ;内循环次数again: rcl byte ptr qvar[si], 1 ;高位字节依次左移 P50 inc siloop again dec dx jnz lpp .exit 0 .end〔习题4.3〕将AX 寄存器中的16位数连续4位分成一组,共4组,然后把这4组数分别放在AL 、BL 、CL 和DL 寄存器中。
第4章 第二节 微生物的生长

(1)稳定期出现原因 营养的消耗,特别是生长限定因子的耗尽; 营养物比例失调 有害代谢产物积累 pH值、EH值等理化条件不适
Cncnc-micro
(2)稳定期特点
①新繁殖的细菌数与衰老细胞数几乎相等,生长 速度趋向于零,总的活菌数达到最高水平 。
②细菌代谢物积累达到最高峰。
③芽孢杆菌这时开始形成芽孢。 ④这是生产收获时期。
第四章 第二节
微生物的生长
内容提要
测定微生物生长繁殖的方法 微生物的群体生长 影响微生物生长的因素
Cncnc-micro
微生物的生长:微生物在适宜的外界环境条件下,不断地吸收营
养物质并按自身的代谢方式,进行新陈代谢,如同化作用大于异 化作用,其结果是原生质的总量(包括重量、体积大小)不断地 增加称为微生物的生长。 微生物的繁殖:生物个体生长到一定阶段,通过特定方式产生新
③ 合成代谢旺盛,核糖体、酶类和ATP合成加速,易
产生各种诱导酶;
④ 对外界不良条件如pH、NaCl溶液浓度、温度和抗
生素等理化因素反应敏感。
细胞处于活跃生长中,只是分裂迟缓。 在此阶段后期,少数细胞开始分裂,曲线略有上升。
Cncnc-micro
(3)缩短延滞期的方法
接种对数生长期的菌种,采用最适菌龄 加大接种量 用与培养菌种相同组成分的培养基 通过遗传学方法改变种的遗传特性使迟缓 期缩短
生长曲线(growth curve)
Ⅰ.延滞期 Ⅱ.对数期 Ⅲ.稳定期 Ⅳ.衰亡期
细 菌 数 目 ( 个 /ml ) 对 数 Ⅰ Ⅱ
Ⅲ
总菌数 活菌数
Ⅳ
培养时间
1、延滞期(lag phase)
又称迟缓期、调整期和适应期。 指少量单细胞微生物接种到新鲜培养基 后,在开始培养的一段时间内细胞数目 不立即增加,或增加很少,生长速度接
大学《数据结构教程》(第5版) 李春葆 清华大学出版社课件第1章 绪论

edcabfg
存储结构
1)顺序存储结构 2)链式存储结构
地址 内容
地址 内容
0400 5.0
2字节 0400 5.0
2字节
0402 - 5.3
0402 0515
0515 - 5.3
例如,若T(n)=n(n+1)/2,则有 T(n)/n2=1/2+1/n, 当n∞时,T(n)/n2=1/2故它的时间复杂度为O (n2), 即T(n)与n2 数量级相同。
显然,被称做问题的基本操作的原操作应是其 重复执行次数与算法的执行时间成正比的原 操作;
多数情况下,它就是最深层循环内的语句中 的原操作,它的执行次数和包含它的语句频 度相同。
同样的数据对象,用不同的数据结构来表示, 运算效率可能有明显的差异。
程序设计的实质是对实际问题选择一个好的数 据结构,加之设计一个好的算法。而好的算法 在很大程度上取决于描述实际问题的数据结构。
1.1.2 基本概念和术语(学籍信息表)
• 数据(Data):是信息的载体,能够被计算机识别、 存储和加工处理。
++x;s+=x; } 时间复杂度为O(n)。
一重循环,其基本运算次数与问题规模 n成线性增长关系,称为线性阶,记为 O(n)
【例1-9】
for(j =1;j<=n;++j) for(k=1;k<=n;++k) {++x; s+=x;}
时间复杂度为O(n2)。 二重循环,其基本运算次数于问题规模n 成平方级增长关系,称为平方阶,记为 O(n2)。
数据结构习题

第一章 绪论练习一1、 设有数据逻辑结构为Data-Structure = (D,S),其中D={d 1, d 2, …, d 9},S={r},r={< d 1,d 3>, < d 1, d 8>,< d 2, d 3>, <d 2, d 4>, <d 2, d 5>, <d 3, d 9>,<d 5, d 6>,<d 8, d 9>,<d 9, d 7>,<d 4,d 6>,<d 4, d 7>},画出这个逻辑结构的图示,对于关系r ,那些结点是起始结点,那些结点是终端结点?2、 设n 为整数,试确定下列各程序中前置以@语句的频度(1) FOR (i=1;i<=n;i++){FOR (j=1;j<=i;j++){FOR (k=1;k<=j;k++) @ x+=delta; } }(2) X=91;y=100;WHILE (y>0){@ if (x>100) {x-=10;y--;} else x++; }3、 按增长率由小到大的顺序排列下列各函数:,log,log,,!,,,,)34(,)32(,)23(,22223100nn n n n n n n n n n nnnn n n n 2log22222,log),(loglog ,log4、设有以下三个函数:f(n)=21n 4+ n 2+1000, g(n)=15 n 4 +500n 3 h(n)=5000 n 3.5+nlogn判断下列断言正确与否: (1) f(n)是O(g(n)); (2) h(n)是O(f(n)); (3) g(n)是O(h(n)); (4) h(n)是 O(n 3.5) (5) h(n)是 O(nlogn) 5、试用数学归纳法证明:(1)∑=+--=ni n i x x x 01)1/()1( )且(01≥≠n x (2)∑==-ni n i 12)12()(1≥n 6、试写一算法自大到小依次输出顺序读入的三个整数X 、Y 、Z 的值。
大学物理上 第4章 流体-2

作业:15页,T6-T81Q S =∆=常量v 2211v v S S ∆∆+=常量=++221v ρρgh p常量=++221v ρρgh p •• ghB 2=v221221122p ρρ+=+v v 常量=++221v ρρgh p 实例: 喷雾器、水流抽气机、内燃机中汽化器S 2v 2=S 1v 15ABCA p 大C p 大B p 小p <p 021p =v ρv 2=0p p gh ρ'=+(3) 组合皮托管28Pitot tube on a helicopter to measureairspeed Close ‐up of a Pitot tube, showing the stagnation pressure hole and two of the five static circumferential pressure holes.1+ p1. 实验:甘油在竖直圆管中的分层流动分析11甘油、血液⋯理想流体:绝对不可压缩;完全没有黏性⇒较大的黏性黏性与哪些因素有关?第2节黏性流体的运动Motion of Viscous Fluid✶创造了用水银压力计测量狗主动脉血压的方法✶建立了黏滞流动的泊肃叶公式泊肃叶(Poiseuille,1778‐1869)法国医生及生理学家血压测量✶1733年英国牧师黑尔斯(R.S.Hales,1677-1761)完成最早的血压测量。
✶1828年,泊肃叶设计出了“U”形汞压力计。
✶1856年医生们开始用这种方法测量人的血压。
✶1896年,意大利医生罗克西首创了将袖带与血压计连接起来测量血压的方法。
16212()8p p R Lη-=max21v v =2212()(4p p R r Lη-=-v )rv248f LR Rη⇒=π只决定与管的长度、半径和流体的黏度。
+ + 412()8R p p Q Lηπ-=S 1SS 2vf R R生活小常识:为什么自来水龙头开大了以后,水流就变得不透明了?层流湍流20着色水水龙头清水层流状态23湍流会发声,层流不会发声。
第4章:局域网--2csmacd

k值
1
r取值范围
[0,1]
延迟时间T
T = r*B
2
3 4 11 12
2
3 4 10 10
[0,1,2,3]
[0,1,…7] [0,1,…15] ……… [0,1,…210-1] [0,1,…210-1] ………
T = r*B
T = r*B T = r*B T = r*B T = r*B
16
停止传送
36
地址解析协议ARP
1.为什么需要地址解析?
AD
37
地址解析协议ARP
为什么需要地址解析?
237.196.7.78 1A-2F-BB-76-09-AD
A
237.196.7.23
237.196.7.14
B
A
LAN
A
71-65-F7-2B-08-53
58-23-D7-FA-20-B0
0C-C4-11-6F-E3-98 237.196.7.88
多用户竞争单信道使用权 发送方发送数据前不进行载波侦听,不考虑其他用户 是否在发送,导致冲突概率大 无线通信距离长,传播时延>>传输时延,不便于侦听, 发送完后仍然可能发生冲突 信道利用率低,仅为18%
ALOHA协议的改进--分槽ALOHA ALOHA协议信道利用率低的原因
发送方在发送前没有也不便于进行侦听
传输率固定时网络跨距越大最小帧长度就应越大网络跨距固定时传输率越高最小帧长度就应越大62在一个采用csmacd协议的网络中传输介质是一根完整的电缆传输速率为1gbps电缆中的信号传播速度是200000kms若最小数据帧长度减少800比特则最远的两个站点之间的距离至少需要增加80mc减少160md减少80m63以太网的发展随着以太网的传输速度不断提高以太网的mac子层变化很小仍保留着传统的帧格式介质访问控制方法
算法与数据结构考研试题精析(第二版)第4章串答案概要

第四章串一、选择题1.B 2.E 3.C 4.A5.C6.A7.1D 7.2F 8.B注9.D 10.B注:子串的定义是:串中随意个连续的字符构成的子序列,并规定空串是随意串的子串,随意串是其自己的子串。
若字符串长度为n(n>0),长为n的子串有1个,长为n-1的子串有2个,长为n-2的子串有3个,,,,长为1的子串有n个。
因为空串是任何串的子串,所以此题的答案为:8*(8+1)/2+1=37。
应选B。
但某些教科书上以为“空串是随意串的子串”无心义,所以以为选C。
为防止考试中的二意性,编者以为第9题出得好。
二、判断题1.√2.√3.√三.填空题1.(1)由空格字符(ASCII值32)所构成的字符串(2)空格个数23.随意个连续的字符构成的子序列4.5 5.O(m+n) 6.011223127.010104218.(1)模式般配(2)模式串.字符9.(1)其数据元素都是字符(2)次序储存(3)和链式储存(4)串的长度相等且两串中对应地点的字符也相等10.两串的长度相等且两串中对应地点的字符也相等。
11.’xyxyxywwy’12.*s++=*t++或(*s++=*t++)!=‘\0’13.(1)chars[] (2)j++ (3)i>=j14.[题目剖析]此题算法采纳次序储存构造求串s和串t的最大公共子串。
串s 用i指针(1<=i<=s.len)。
t串用j指针(1<=j<=t.len)。
算法思想是对每个i(1<=i<=s.len,即程序中第一个WHILE循环),来求从i开始的连续字符串与从j(1<=j<=t.len,即程序中第二个WHILE循环)开始的连续字符串的最大般配。
程序中第三个(即最内层)的WHILE循环,是当s中某字符(s[i])与t中某字符(t[j])相等时,求出局部公共子串。
若该子串长度大于已求出的最长公共子串(初始为0),则最长公共子串的长度要改正。
《数据结构》填空作业题(答案)

98989《数据结构》填空作业题答案第1 章绪论(已校对无误)1.数据结构包括数据的逻辑结构、数据的存储结构和数据的运算三方面的内容。
2.程序包括两个内容:数据结构和算法。
3. Data Structure =(D,S)。
数据结构的形式定义为:数据结构是一个二元组:4. 数据的逻辑结构在计算机存储器内的表示,称为数据的存储结构。
5. 结构两大类。
线性结构和非线性数据的逻辑结构可以分类为6. 在图状结构中,每个结点的前驱结点数和后继结点数可以。
有多个7. 的关系。
一对多在树形结构中,数据元素之间存在8.中的标识(映象),也即数据的物理结构,指数据元素在存储结构。
计算机9.图形结构 3 种类型,树型结构和有向、和数据的逻辑结构包括线性结构树形结构。
图结构合称为非线性结构连续10. 顺序存储结构是把逻辑上相邻的结点存储在物理上的存储单元里,结点之间的逻辑关系由存储单元位置的邻接关系来体现。
任意链式存储结构是把逻辑上相邻的结点存储在物理上11. 的存储单元里,节点之间的逻辑关系由附加的指针域来体现。
12.数据的存储结构可用4 种基本的存储方法表示,它们分别是顺序存储、链式存储、索引存储和散列存储。
一的,非线性结构反映结点间的逻辑关系是一对一线性结构反映结点间的逻辑关系是13. 对多或多对多。
存储结构。
14.数据结构在物理上可分为顺序存储结构和链式方式,还给出了处理数15. 我们把每种数据结构均视为抽象类型,它不但定义了数据的表示实现方法据的。
16.数据元素可由若干个组成。
数据项复杂度。
空间复杂度和算法分析的两个主要方面是时间17.一个算法的时间复杂度是用该算法所消耗的时间的多少来度量的,一个算法的空间复杂18. 的大小来度量的。
度是用该算法在运行过程中所占用的存储空间19.算法具有如下特点:有穷性、确定性、、输入、输出。
可行性20. 对于某一类特定的问题,算法给出了解决问题的一系列操作,每一操作都有它的确切内计算出结果。
第4章 串

�
串:是一种受限制的线性表,数据元素有字符组成 4.1 串的基本概念 定义:表示形式:S="a1,a2,a3,….an"(n>=0); 定义:表示形式:S="a1,a2,a3,….an"(n>=0) n是串的长度,当N=0时,长度为0,表示空串, 是串的长度,当N=0时,长度为0 仅有一个或多个空格组成的串称为空白串,注意:空白串不等于空串 子串:串中由任意连续的字符组成的子序列称为该串的子串, 主串:包含子串的串称为主串 位置:字符在序列中的序号称为该字符在串中的位置 ,子串的首字符在主串中的序号称为子串在主串 中的位置 相等:若2个串中的对应位置的字符都相同,串的长度也相等,则2 相等:若2个串中的对应位置的字符都相同,串的长度也相等,则2个串都相等 ,如果两个串不相等 时,按他们的ASCII码区分大小 时,按他们的ASCII码区分大小 模式匹配:在S中寻找与T 模式匹配:在S中寻找与T相同的子串的过程, S称为正文,T称为模式,如果找到称为匹配成功,否 称为正文,T 则为匹配失败 基本操作: 1,串赋值 strassigh(s,t) 将一个串值t赋给串s 将一个串值t赋给串s 2,求串长度strlength(s) ,求串长度strlength(s) 求串s 求串s的长度 3,串比较strcmp(s1,s2) ,串比较strcmp(s1,s2) 如果相等,返回值0,如果s1>s2,返回值为1,如果s1<s2,则返回如果相等,返回值0,如果s1>s2,返回值为1,如果s1<s2,则返回-1 4,串复制strcopy(s,t) ,串复制strcopy(s,t) 将一个串t复制给串s 将一个串t复制给串s中 5,串连接strconcat(s1,s2) ,串连接strconcat(s1,s2) 在s1后边连接s2的串值,并返回连接够的结果 s1后边连接s2的串值,并返回连接够的结果 6,求子串substr(s,I,k) ,求子串substr(s,I,k)
第4章 串与数组 习题参考答案

习题四参考答案一、选择题1.下面关于串的叙述中,哪一个是不正确的?(B )A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储2.串的长度是指( A )A. 串中包含的字符个数B. 串中包含的不同字符个数C. 串中除空格以外的字符个数D. 串中包含的不同字母个数3.设有两个串p和q,其中q是p的子串,求q在p中首次出现的位置的算法称为( C )A.求子串B.联接C.模式匹配D.求串长4.设主串的长度为n,模式串的长度为m,则串匹配的KMP算法时间复杂度是( C )。
A. O(m)B. O(n)C. O(n + m)D. O(n×m)5. 串也是一种线性表,只不过( A )。
A. 数据元素均为字符B. 数据元素是子串C. 数据元素数据类型不受限制D. 表长受到限制6.设有一个10阶的对称矩阵A,采用压缩存储方式,以行序为主进行存储,a11为第一元素,其存储地址为1,每个元素占一个地址空间,则a85的地址为( B )。
A. 13B. 33C. 18D. 407. 有一个二维数组A[1..6, 0..7] ,每个数组元素用相邻的6个字节存储,存储器按字节编址,那么这个数组占用的存储空间大小是(D )个字节。
A. 48B. 96C. 252D. 2888.设有数组A[1..8,1..10],数组的每个元素占3字节,数组从内存首地址BA开始以列序为主序顺序存放,则数组元素 A[5,8]的存储首地址为( B )。
A. BA+141B. BA+180C. BA+222D. BA+2259. 稀疏矩阵的三元组存储表示方法( B )A. 实现转置操作很简单,只需将每个三元组中行下标和列下标交换即可B. 矩阵的非零元素个数和位置在操作过程中变化不大时较有效C. 是一种链式存储方法D. 比十字链表更高效10. 用十字链表表示一个稀疏矩阵,每个非零元素一般用一个含有( A )域的结点表示。
电路第4章-2(阻抗与导纳)
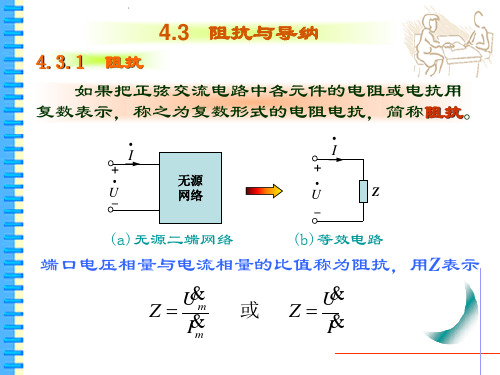
& I
R1
i2
R2
Xc
+
& U
R1
& I1
R2
& I2
XL
–
jXL - jX C
相量模型
解:
& U = 220∠10o V
1 1 1 = = = 0.2∠ − 53o S Y1 = R1 + jX L 3 + j4 5∠53o
1 1 1 Y2 = = = = 0.1∠37 o S R2 − jX C 8 − j6 10∠ − 37 o
U Um | Z |= = I Im
ϕ z = θu − θi
电压滞后电流, ϕ z < 0 电压滞后电流,容性 电压电流同相, ϕ z = 0 电压电流同相,阻性
4.3.2 用阻抗法分析串联电路
相量模型将所有元件以相量形式表示: 相量模型
C → − jX C 的阻抗
R R的阻抗
i + uR - R L - uC C (a) RLC 串联电路
Z = R + j( X L − X C )
5
1 ) = 5 + j (2 × 10 × 6 × 10 − 5 −6 2 × 10 × 0.001× 10
−3
= 5 − j 3.8 = 6.28∠ − 37.2° kΩ
ϕ z < 0 ,电路呈容性。
如果几个理想元件相串联 几个理想元件相串联时,阻抗的模和幅角 几个理想元件相串联 可由以下三角形求出:
& & I1 = Y1U = 0.2∠ − 53o × 220∠10o = 44∠ − 43o A & & I 2 = Y2U = 0.1∠37o × 220∠10o = 22∠47o A
算法与数据结构考研试题精析(第二版)第4章 串

第四章串一、选择题1.下面关于串的的叙述中,哪一个是不正确的?()【北方交通大学2001 一、5(2分)】A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储2 若串S1=‘ABCDEFG’, S2=‘9898’,S3=‘###’,S4=‘012345’,执行concat(replace(S1,substr(S1,length(S2),length(S3)),S3),subst r(S4,index(S2,‘8’),length(S2)))其结果为()【北方交通大学1999 一、5 (25/7分)】A.ABC###G0123 B.ABCD###2345 C.ABC###G2345 D.ABC###2345E.ABC###G1234 F.ABCD###1234 G.ABC###012343.设有两个串p和q,其中q是p的子串,求q在p中首次出现的位置的算法称为()A.求子串B.联接C.匹配D.求串长【北京邮电大学2000 二、4(20/8分)】【西安电子科技大学1996 一、1 (2分)】4.已知串S=‘aaab’,其Next数组值为()。
【西安电子科技大学1996 一、7 (2分)】A.0123 B.1123 C.1231 D.12115.串‘ababaaababaa’的next数组为()。
【中山大学1999 一、7】A.012345678999 B.012121111212 C.011234223456 D.01230123223456.字符串‘ababaabab’的nextval 为()A.(0,1,0,1,04,1,0,1) B.(0,1,0,1,0,2,1,0,1)C.(0,1,0,1,0,0,0,1,1) D.(0,1,0,1,0,1,0,1,1 )【北京邮电大学1999 一、1(2分)】7.模式串t=‘abcaabbcabcaabdab’,该模式串的next数组的值为(),nextval数组的值为()。
(第七讲)第4章 组合逻辑电路(2)

而四选一数据选择器输出信号的表达式
Y m0 D0 m1 D1 m2 D2 m3 D3
将A、B作为地址输入变量并比较L和Y可得
D0 C、D1 C、D2 0、D3 1
38
画出如图所示的逻辑电路图。
39
4.5.3 数据分配器
数据分配器能把一个输入端信号根据需要分配给 多路输出中的某一路输出。它的作用实际上相当于 一个多个输出的单刀多掷开关。其示意图如图所示 。
13
解:对图进行分析,可知:该 图将高位片的EO接 低位片的EI。当高位片输入端无有效信号输入时, EO=0,使低位片的EI=0,则低位片可以输入信号。 当高位片有有效信号输入时,EO=1,使低位片的 EI=1,禁止低位片工作。 设13有输入信号,因13输入端为高位片的5脚, 此时对应的高位片编码A2A1A0为010、EO=1、 CS=0,低位片的EI=EO=1,所以不工作,此时对应 的低位片输出A2A1A0为111、CS=1、EO=1。所以 A3A2A1A0=0010。
16
4.4.2二进制译码器
二进制译码器通常有n个输入端,2n个输出端,并 且每一个输出端对应一个n个输入端组成的最小项。 常见的MSI集成译码器有2线-4线、3线-8线和4线-16 线译码器。
17
由真值表(P88)可得输出逻辑函数表达式:
Y0 A2 A1 A0 Y4 A2 A1 A0
Y1 A2 A1 A0
(2)由于译码器74LS138的各输出端为最小项的 非,故将上式转化为以下形式:
F ( A, B, C ) m3 m6 m7 m3 m6 m7 Y3 Y6 Y7
22
(3)由上式可画出该函数的逻辑电路图如图所示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
•
• 设定 A 是一个二维数组,如图 是一个二维数组,如图4-7(a)所示 所示
4.2.3 二维数组的向量存储结构 . .
组成数组结构的元素可以是多维的,但存 储数据元素的内存单元地址是一维的,因此, 在存储数组结构之前,需要解决将多维关系 映射到一维关系的问题,即要按某种次序将 元素排成一个线性序列。顺序存放的次序有 两种规则:
两个重要操作: 两个重要操作: ):取出的表头为非空广义表的第一 (1)取表头 )取表头Head(LS):取出的表头为非空广义表的第一 ( ): 个元素,它可能是一个原子,也可能是一个子表。 个元素,它可能是一个原子,也可能是一个子表。 ):取出的表尾为除去表头元素外 (2)取表尾 )取表尾Tail(LS):取出的表尾为除去表头元素外,由 ( ):取出的表尾为除去表头元素外, 其余元素所构成的表。 其余元素所构成的表。
4.3 .
广义表
线性表被定义为n≥0个数据元素的有限序列,表中的数据元 素具有相同结构。现在放宽这一限定,引出了广义表的概念。
4.3.1 广义表的定义 . .
广义表是线性表的推广。广义表是 个元素的有限序, 广义表是线性表的推广。广义表是n≥0个元素的有限序, 个元素的有限序 记作: 记作: LS=(a1,a2,…,an) ( , , , ) 其中LS是广义表的名称, 是它的长度 是它的长度, ( 其中 是广义表的名称,n是它的长度,ai(1≤i≤n) 是广义表的名称 ) 当广义表LS非空时,称第一个元素 为 的 当广义表 非空时,称第一个元素a1为LS的表头 非空时 ),称其余元素组成的表 (Head),称其余元素组成的表(a2,a3,…,an)为LS ),称其余元素组成的表( , , , ) 的表尾(Tail)。 )。
为便于理解,下面给出 、 、 、 、 、 六个广义表的描述 六个广义表的描述: 为便于理解,下面给出A、B、C、D、E、F六个广义表的描述:
• A=( ),表A是一个空表,它的长度为零。 ( ),表 是一个空表,它的长度为零。 是一个空表 • B=(e),表B只有一个原子 ,B的长度为 。. ),表 只有一个原子 只有一个原子e, 的长度为 的长度为1。 ( ), • C=(a,( ,c,d)),表C的长度为 ,第1个元 ( ,(b, , )), )),表 的长度为 的长度为2, ,( 个元 素为原子a, 个元素为子表(b,c,d)。 素为原子 ,第2个元素为子表 个元素为子表 。 • D=(A,B,C),表D的长度为 ,三个元素都是 ),表 的长度为 的长度为3, ( , , ), 子表,显然将子表的值代入后,则有D=(( 子表,显然将子表的值代入后,则有 (( ), ),(a,( (e),( ,( ,c,d))) ),( ,(b, , ))) • E=(a,E),这是一个递归的表,它的长度为 , ),这是一个递归的表 ( , ),这是一个递归的表,它的长度为2, E相当于一个无限的列表 (a,( , 相当于一个无限的列表E=( ,( ,(a, 相当于一个无限的列表 (a,…))) , ))) • F=(()), 是长度为 的广义表,它有一个子 (()),F是长度为 的广义表, (()), 是长度为1的广义表 且子表为空表。 表,且子表为空表。
(1)一般插入算法 )
算法的思路是:对a.data扫描一遍,扫描过程中依
次取出a.data中的每一个三元组元素,将对应的行号 和列号对换,放入b.data中。为保证b.data具有三元组 存放元素的规律,需在放入前和前面的元素按行及 列比较,插在对应位置上。
(2)transpose算法 ) 算法
× 6)为下三角矩阵, 其元素满足下列条件: Ai,j ≠ 0 (i ≥ j, 1 ≤ i, j ≤ 6) , Ai,j = 0 (i < j, 1 ≤ i, j ≤ 6) , 现将所有非0元素以行优先顺序存放在 首地址为1000的内存中,每个元素占4个 单元,计算元素A5,2的首地址。 ,
【例4-2】设矩阵A(6 例
三元组存储结构因以行优先存放,存在以下的规律: 三元组存储结构因以行优先存放,存在以下的规律:元组中 的第一列按行号的顺序由小到大排列, 的第一列按行号的顺序由小到大排列,元组中的第二列是列 列号在行号相同时也是由小到大排列。 号,列号在行号相同时也是由小到大排列。
【例4-3】稀疏矩阵的转置算法 例 设定b是类型定义为SPMATRIX的变量,图4-13(a)所示的是图 4-12(a)的M矩阵转置后得到的稀疏矩阵N,图4-13(b)是N矩阵 对应的三元组存储结构示意图。
算法的思路是:考虑到b.data中的行就是
a.data中的列,要想得到b.data中行号为0的三元 组元素,可对a.data扫描一遍,找出a.data中列 号为0的元素即可。
SPMATRIX transpose(SPMATRIX a) { SPMATRIX b; int p, q, col; b.m = a.n; b.n = a.m; b.t = a.t; if(a.t != 0) { q = 1; for(col = 0; col < a.n; col++) for(p = 0; p < a.t; p++) if(a.data[p].j == col) [ ] { b.data[q].j = a.data[p].i; [ ] [ ] b.data[q].i = a.data[p].j; [ ] [ ] b.data[q].v = a.data[p].v; [ ] [ ] q++; } } return b; }
• 将稀疏矩阵中的非零元素的表。三元组表是稀疏矩阵的一 称为三元组表。 种顺序存储结构。 种顺序存储结构。 • 以下的讨论中均假定三元组是按行优先的顺序 排列的。 排列的。稀疏矩阵的三元组存储的数据类型描 述如下
将稀疏矩阵中的非零元素的三元组按行优先的顺序存放在一 个一维数组中则得到一个三元组表。 个一维数组中则得到一个三元组表。三元组表是稀疏矩阵 的一种顺序存储结构,数据类型描述如下: 的一种顺序存储结构,数据类型描述如下:
从上述广义表的定义和例子可以得到广义表的下列 重要性质: 重要性质: • ⑴广义表是一种多层次的数据结构。广义表的元素 广义表是一种多层次的数据结构。 可以是单元素,也可以是子表, 可以是单元素,也可以是子表,而子表的元素还可 以是子表,以此类推…。 以是子表,以此类推 。 • ⑵广义表可以是递归的表。广义表的定义并没有限 广义表可以是递归的表。 制元素的递归,即广义表也可以是其自身的子表。 制元素的递归,即广义表也可以是其自身的子表。 例如表E就是一个递归的表 就是一个递归的表。 例如表 就是一个递归的表。 • ⑶广义表可以为其他表所共享。例如,表A、表B、 广义表可以为其他表所共享。例如, 、 、 是表D的共享子表 表C是表 的共享子表。在D中可以不必列出子表 是表 的共享子表。 中可以不必列出子表 的值,而用子表的名称来引用。 的值,而用子表的名称来引用。
先行后列顺序 先列后行顺序
先行后列顺序,或者称为行优先顺序, 先行后列顺序,或者称为行优先顺序,在PASCAL, , C语言中,数组就是按行优先顺序存储的。图4-7(a) 语言中, 语言中 数组就是按行优先顺序存储的。 的二维数组Am×n按行优先顺序 的二维数组 × 按行优先顺序
先列后行顺序,或者称为列优先顺序,在 FORTRAN语言中,数组就是按列优先顺序存储的。 语言中, 语言中 数组就是按列优先顺序存储的。 的二维数组Am×n按列优先顺序存储方式 图4-7(a)的二维数组 的二维数组 × 按列优先顺序存储方式
结论: 结论:线性表结构是数组结构的一个 特例, 特例,而数组结构又是线性表结构的 扩展。 扩展。或可理解成多维数组对应的线 性表中的数据元素本身又是一个线性 表。
4.2.2 . . •
二维数组定义及基本操作
是由下标和值组成的序对的集合。 数组是由下标和值组成的序对的集合。 在数组中,一旦给定下标, 在数组中,一旦给定下标,都存在一个与 其相对应的值,这个值就称为数组元素。 其相对应的值, 数组元素。
index(ai,j) = n (i - 1) + j
公式(1) 公式
LOC(ai,j) = LOC(a1,1) +[n×(i-1) + (j-1)]×b [ × - - ] , 公式(2) 公式
注意: 注意:在C语言中,数组下标的下界是0,因此,
如果数组元素从0下标开始存储,则地址的计算 公式(2)应改为: LOC(ai,j) = LOC(a0,0) + (n×i + j)×b 公式 公式(3) × ×
• 以上规则可以推广到多维数组:行优先顺序可 以上规则可以推广到多维数组: 规定为最右的下标优先,从右向左; 规定为最右的下标优先,从右向左;列优先顺 序规定为最左的下标优先,从左向右。 序规定为最左的下标优先,从左向右。 •对于顺序存储的数组,只要知道向量的起始地址, 对于顺序存储的数组,只要知道向量的起始地址, 对于顺序存储的数组 数组的行号数和列号数, 数组的行号数和列号数,以及每个数组元素所占用 的存储单元, 的存储单元,就可以求得给定下标的数组元素的存 储起始地址。 储起始地址。
例如: 例如: Head(B)= e ( ) Head(D)= A ( ) Head(F)=() ( ) () Tail(C)=(( ,c,d)) ((b, , )) ( ) (( Tail(E)=(E) ( ) ( ) Head(C)= a ( ) Head(E)= a ( ) Tail(B)= ( ) ( ) Tail(D)=(B,C) ( ) ( , ) Tail(F)=() ( ) ()
【例4-1】已知一个二维数组A,行下标 0 ≤ i ≤ 7,列下 例 标 0 ≤ j ≤ 9,每个元素的长度为3字节,从首地址200开始 连续存放在内存中。问: (1) 该数组元素按行优先存放,元素A7,4的起地址是多少? , (2) 该数组元素按列优先存放,元素A7,4的起地址是多少? , 解