JPG图片文件结构分析
JPG文件结构

JPG文件结构JPEG文件由八个部分组成,每个部分的标记字节为两个,首字节固定为:0xFF,当然,准许在其前面再填充多个0xFF,以最后一个为准。
下面为各部分的名称和第二个标记字节的数值,用ultraedit的16进制搜索功能可找到各部分的起始位置,在嵌入式系统中可用类似的数值匹配法定位。
一、图像开始SOI(Start of Image)标记,数值0xD8二、APP0标记(Marker),数值0xE01、APP0长度(length) 2byte2、标识符(identifier) 5byte3、版本号(version) 2byte4、X和Y的密度单位(units=0:无单位;units=1:点数/英寸;units=2:点数/厘米) 1byte5、X方向像素密度(X density) 2byte6、Y方向像素密度(Y density) 2byte7、缩略图水平像素数目(thumbnail horizontal pixels) 1byte8、缩略图垂直像素数目(thumbnail vertical pixels) 1byte9、缩略图RGB位图(thumbnail RGB bitmap),由前面的数值决定,取值3n,n为缩略图总像素3n byte三、APPn标记(Markers),其中n=1~15,数值对应0xE1~0xEF1、APPn长度(length)2、应用细节信息(application specific information)四、一个或者多个量化表DQT(difine quantization table),数值0xDB1、量化表长度(quantization table length)2、量化表数目(quantization table number)3、量化表(quantization table)五、帧图像开始SOF0(Start of Frame),数值0xC01、帧开始长度(start of frame length)2、精度(precision),每个颜色分量每个像素的位数(bits per pixel per color component)3、图像高度(image height)4、图像宽度(image width)5、颜色分量数(number of color components)6、对每个颜色分量(for each component)包括:ID、垂直方向的样本因子(vertical sample factor)、水平方向的样本因子(horizontal sample factor) 、量化表号(quantization table#)六、一个或者多个霍夫曼表DHT(Difine Huffman Table),数值0xC41、霍夫曼表的长度(Huffman table length)2、类型、AC或者DC(Type, AC or DC)3、索引(Index)4、位表(bits table)5、值表(value table)七、扫描开始SOS(Start of Scan),数值0xDA1、扫描开始长度(start of scan length)2、颜色分量数(number of color components)3、每个颜色分量包括:ID、交流系数表号(AC table #)、直流系数表号(DC table #)4、压缩图像数据(compressed image data)八、图像结束EOI(End of Image),数值0xD9。
JPEGExifTIFF格式解读(1):JEPG图片压缩与存储原理分析

JPEGExifTIFF格式解读(1):JEPG图⽚压缩与存储原理分析JPEG⽂件简介JPEG的全称是JointPhotographicExpertsGroup(联合图像专家⼩组),它是⼀种常⽤的图像存储格式, jpg/jpeg是24位的图像⽂件格式,也是⼀种⾼效率的压缩格式,⽂件格式是JPEG(联合图像专家组)标准的产物,该图像压缩标准是国际电信联盟(International Telecommunication Union,ITU)、国际标准化组织(International Organization for Standardization,ISO)和国际电⼯委员会(International Electrotechnical Commission,IEC)共同制定。
JPEG标准正式地称为ISO/IEC IS(国际标准)10918-1:连续⾊调静态图像数字压缩和编码(Digital Compression and Coding of Continuous-tone Still Images)和ITU-T建议T.81。
JPEG是第⼀个国际图像压缩标准,⽤于连续⾊调静态图像(即包括灰度图像和彩⾊图像),其最初⽬的是使⽤64Kbps的通信线路传输720×576 分辨率压缩后的图像。
通过损失极少的分辨率,可以将图像所需存储量减少⾄原⼤⼩的10%。
由于其⾼效的压缩效率和标准化要求,⽬前已⼴泛⽤于彩⾊传真、静⽌图像、电话会议、印刷及新闻图⽚的传送上。
但那些被删除的资料⽆法在解压时还原,所以* .jpg/.jpeg ⽂件并不适合放⼤观看,输出成印刷品时品质也会受到影响。
JPEG⽂件格式JPEG的⽂件格式⼀般有两种⽂件扩展名:.jpg和.jpeg,这两种扩展名的实质是相同的,我们可以把.jpg的⽂件改名为.jpeg,⽽对⽂件本⾝不会有任何影响。
严格来讲,JPEG的⽂件扩展名应该为.jpeg,由于DOS时代的8.3⽂件名命名原则,就使⽤了.jpg的扩展名,这种情况类似于.htm和.html的区别。
JPEG原理详细

JPEG原理详细JPEG 是 Joint Photographic Experts Group 的缩写,即 ISO 和 IEC 联合图像专家组,负责静态图像压缩标准的制定,这个专家组开发的算法就被称为 JPEG 算法,并且已经成为了大家通用的标准,即 JPEG 标准。
JPEG 压缩是有损压缩,但这个损失的部分是人的视觉不容易察觉到的部分,它充分利用了人眼对计算机色彩中的高频信息部分不敏感的特点,来大大节省了需要处理的数据信息。
人眼对构成图像的不同频率成分具有不同的敏感度,这个是由人眼的视觉生理特性所决定的。
如人的眼睛含有对亮度敏感的柱状细胞1.8亿个,含有对色彩敏感的椎状细胞0.08亿个,由于柱状细胞的数量远大于椎状细胞,所以眼睛对亮度的敏感程度要大于对色彩的敏感程度。
总体来说,一个原始图像信息,要对其进行 JPEG 编码,过程分两大步: 1、去除视觉上的多余信息,即空间冗余度 2、去除数据本身的多余信息,即结构(静态)冗余度 1、去除视觉上的多余信息 当你拿到一个原始未经处理的图像,是由各种色彩组成的,即在一个平面上,有各种色彩,而这个平面是由水平和垂直方向上的很多点组成的。
实际上,每个点的色彩,也即计算机能表示的每个像素点的色彩,能分解成红、绿、蓝,即 RGB 三元色来表示,即这三种颜色的一定比例的混合就能得到一个实际的色彩值。
所以,实际上,这个平面的图像,可以理解为除了水平 X 和垂直 Y 以外,还有一个色彩值的 Z 的三维的系统。
Z 代表了三元色中各个分支 R/G/B 的混合时所占的具体数值大小,每个像素的 RGB 的混合值可能都有所不同,各个值有大有小,但临近的两个点的 R/G/B 三个值会比较接近。
由于这个原始图像是由很多个独立的像素点组成的,也就是说它们都是分散的,离散的。
比如有些图像的尺寸为640X480,就表示水平有640个像素点,垂直有480个像素点。
从上面的内容,我们可以知道两个相邻的点,会有很多的色彩是很接近的,那么如何能在最后得到的图片中,尽量少得记录这些不需要的数据,也即达到了压缩的效果。
jpg原理

jpg原理
JPG是一种常用的图像压缩格式,其原理是基于离散余弦变换(Discrete Cosine Transform, DCT)和量化(Quantization)技术。
首先,JPG将图像分为8×8的小块,对每个小块进行DCT变换。
DCT变换可以将图像的空域信息转换成频域信息,使得大部分图像信息压缩在低频系数中,而高频系数则表示图像细节。
通过DCT变换,我们可以得到一个8×8的矩阵,其中各个元素代表该频域上的频率分量强度。
接下来,JPG将DCT后的矩阵进行量化。
量化的目的是通过舍弃高频部分的细节信息来减少数据量,从而实现图像压缩。
在量化过程中,JPG使用了一个量化表,其中存储了用于量化不同频率分量的量化系数。
量化表的设计是JPEG标准的重要部分,不同的量化表可以用于不同的应用场景,以平衡压缩比和图像质量。
最后,JPG对量化后的矩阵进行熵编码。
熵编码是一种无损压缩算法,它利用字符出现的频率来构建编码表,将出现频率较高的字符用较短的二进制码表示,而出现频率较低的字符用较长的二进制码表示。
熵编码可以进一步压缩数据量,提高压缩比。
解码时,JPG会反向进行熵解码、逆量化和逆DCT处理,最终恢复出原始的图像数据。
总之,JPG图像的压缩原理是通过DCT变换将图像转换为频域信息,然后进行量化和熵编码来减少数据量。
解码时,通过逆向的过程将压缩后的数据恢复为原始图像。
JPG文件结构分析

JPG文件结构分析JPG(Joint Photographic Experts Group)是一种常见的图像文件格式,以其高压缩比和图像质量而闻名。
在本文中,将对JPG文件的结构进行分析。
1.文件头:JPG文件头部包含固定的标识符,用于识别文件类型。
通常,JPG文件的文件头为16个字节,其中包括"FFD8"的起始标志。
2.数据段:JPG文件的数据段是由多个标记组成的。
每个标记都由两个字节的起始标志"FF"和一个标记标识符组成。
标记标识符指示了将要跟随的数据类型或操作。
数据段中常见的标记包括APP0、DQT、SOF0、DHT、SOS等。
其中,APP0标记包含一些额外的信息,如JFIF(JPEG文件交换格式)版本号和文件创作的设备。
DQT(量化表定义)标记包含了量化表,这些表用于调整图像的颜色分辨率。
SOF0(帧头)标记包含了图像的宽度、高度以及色彩模式等信息。
DHT(霍夫曼表定义)标记包含了JPEG压缩算法所使用的霍夫曼编码表。
SOS(扫描开始)标记表示图像的实际数据开始。
3.图像数据:JPG文件的图像数据是压缩后的二进制流。
图像数据通常由几个扫描组成,每个扫描都由一个起始标记和相应的数据组成。
扫描包含的数据进行了特殊的编码处理,以实现高压缩比。
压缩算法主要包括离散余弦变换和霍夫曼编码。
在离散余弦变换中,图像被划分成8x8的块,每个块进行离散余弦变换,然后进行量化。
量化后的数据通过霍夫曼编码进行压缩。
4.文件尾:JPG文件尾部由一个16位的结束标记"FFD9"组成,用于表示图像数据的结束。
在JPG文件结构中,数据段是最重要的部分。
它包含了图像的所有信息,包括压缩参数、颜色信息和压缩后的图像数据。
图像数据经过JPEG压缩算法,可以有效地减小文件大小,并保持较高的图像质量。
总结起来,JPG文件的结构包括文件头、数据段、图像数据和文件尾。
数据段是JPG文件最重要的部分,包含了图像的所有信息和压缩后的图像数据。
JPEG文件格式简单分析.

摘要:这篇文章大体上介绍了JPEG文件的结构信息以及它的压缩算法和编码方式。
使读者能够对JPEG文件格式有大体上的了解。
为读者进一步进行学习JPEG文件压缩做好准备关键字:十六进制,段格式,编码一、JPEG文件格式概述:图像和动画的存储方式是一个很重要的问题。
幸好我们有了数据压缩,有了JPEG等多种压缩存储图像的文件格式,我们今天才能够拿着小小的一个存储器,却存上许多张色彩鲜艳的图片。
如果没有图像压缩算法,也许我们的多媒体时代就会晚到来许多年。
JPEG图像存储格式一个比较成熟的图像有损压缩格式,虽然一个图片经过转化为JPEG图像后,一些数据会丢失,但是,人眼是很不容易分辨出来这种差别的。
也就是说,JPEG图像存储格式既满足了人眼对色彩和分辨率的要求,又适当的去除了图像中很难被人眼所分辨出的色彩,在图像的清晰与大小中JPEG找到了一个很好的平衡点。
虽然图像转化为JPEG格式会减小很多,但是并不是文件就变得简单了,相反,JPEG文件的格式是比较复杂的。
不经过认真地分析,是不容易弄懂它的。
二、JPEG文件的存储方式:JPEG文件的格式是分为一个一个的段来存储的(但并不是全部都是段),段的多少和长度并不是一定的。
只要包含了足够的信息,该JPEG文件就能够被打开,呈现给人们。
JPEG文件的每个段都一定包含两部分一个是段的标识,它由两个字节构成:第一个字节是十六进制0xFF,第二个字节对于不同的段,这个值是不同的。
紧接着的两个字节存放的是这个段的长度(除了前面的两个字节0xFF和0xXX,X表示不确定。
他们是不算到段的长度中的)。
注意:这个长度的表示方法是按照高位在前,低位在后的,与Intel的表示方法不同。
比方说一个段的长度是0x12AB,那么它会按照0x12,0xAB的顺序存储。
但是如果按照Intel的方式:高位在后,低位在前的方式会存储成0xAB,0x12,而这样的存储方法对于JPEG是不对的。
这样的话如果一个程序不认识JPEG文件某个段,它就可以读取后两个字节,得到这个段的长度,并跳过忽略它。
JPG图片文件结构分析.docx

JPG文件结构分析2010-04-06 22:32【转自网络作者:一江秋水】一、简述JPEG是一个压缩标准,又可分为标准 JPEG、渐进式JPEG及JPEG2000三种:①标准JPEG:以24位颜色存储单个光栅图像,是与平台无关的格式,支持最高级别的压缩,不过,这种压缩是有损耗的。
此类型图片在网页下载时只能由上而下依序显示图片,直到图片资料全部下载完毕,才能看到全貌。
②渐进式 JPEG:渐进式JPG为标准JPG的改良格式,支持交错,可以在网页下载时,先呈现出图片的粗略外观后,再慢慢地呈现出完整的内容,渐进式JPG的文件比标准JPG的文件要来得小。
③JPEG2000:新一代的影像压缩法,压缩品质更好,其压缩率比标准JPEG高约30%左右,同时支持有损和无损压缩。
一个极其重要的特征在于它能实现渐进传输,即先传输图像的轮廓,然后逐步传输数据,让图像由朦胧到清晰显示。
以一幅24 位彩色图像为例,JPEG的压缩分为四个步骤:①颜色转换:在将彩色图像进行压缩之前,必须先对颜色模式进行数据转换。
转换完成之后还需要进行数据采样。
②DCT变换:是将图像信号在频率域上进行变换,分离出高频和低频信息的处理过程,然后再对图像的高频部分(即图像细节)进行压缩。
首先以象素为单位将图像划分为多个8×8的矩阵,然后对每一个矩阵作DCT 变换。
把8×8的象素矩阵变成8×8的频率系数矩阵(所谓频率就是颜色改变的速度),频率系数都是浮点数。
③量化:由于下面第四步编码过程中使用的码本都是整数,因此要对频率系数进行量化,将之转换为整数。
数据量化后,矩阵中的数据都是近似值,和原始图像数据之间有了差异,这一差异是造成图像压缩后失真的主要原因。
这一过程中,质量因子的选取至为重要。
值选得大,可以大幅度提高压缩比,但是图像质量就比较差,质量因子越小图像重建质量越好,但是压缩比越低。
④编码:编码是基于统计特性的方法。
四个步骤都完成后的JPEG文件,其基本数据结构为两大类型:“段”和经过压缩编码的图像数据。
JPEG图像数据格式简明分析

总结
总的来说,JPEG图像数据格式凭借其高压缩比、兼容性强和适用范围广等优 点,成为图像处理、数字摄影、网络传输和科学数据可视化等领域的首选格式。 然而,我们也应意识到其存在的损失细节和速度较慢等缺点。未来,随着技术的 不断发展和新的图像格式的出现,JPEG可能会面临挑战。但就目前而言,JPEG仍 然是图像处理和存储领域的重要支柱。
3、离散余弦变换:接下来,图像数据将经过离散余弦变换(DCT)。DCT将 图像的像素值从空间域转换到频域,使得图像的能量集中在一些低频区域。
4、量化和编码:在完成DCT后,JPEG算法对DCT系数进行量化,将它们转换 为更小的值。然后对这些值进行编码,以产生最终的压缩数据。编码过程中使用 的哈夫曼编码(Huffman Coding)是一种无损压缩技术,它可以根据数据的统计 特性来生成更短的编码。
%读取原始图像
%将原始图像转换为灰度图像
%对灰度图像进行DCT变换
%设定量化表
quantization_table = [16 11 10 16 24 40 51 61;
12 12 14 19 26 58 60 55;
14 13 16 24 40 57 69 56;
14 17 22 29 51 87 80 62;
参考内容
JPEG静态图像压缩算法是一种重要的数字图像处理技术,它通过去除图像中 的冗余信息来减小图像的文件大小,从而方便了图像的存储和传输。JPEG算法采 用了一种基于离散余弦变换(DCT)的压缩方法,将图像数据转化为一种更有效 的表示形式,从而实现了图像的压缩。
JPEG算法主要由以下几个步骤构成:
组成结构
JPEG图像数据格式的组成结构包括三个主要部分:头部、图像部分和尾部。 头部包含关于图像的一些基本信息,如文件号、量化表、色彩空间等。图像部分 是实际的图像数据,包括经DCT变换和量化的像素值。尾部包含一些附加信息, 如压缩方法、图像大小等。
JPG图片文件结构分析

JPG文件结构分析2010-04-06 22:32【转自网络 作者:一 江秋水】一、简述JPEG是一个压缩标准,又可分为标准 JPEG、渐进式JPEG及JPEG2000三种:①标准JPEG:以24位颜色存储单个光栅图像,是与平台无关的格式,支持最高级 别的压缩,不过,这种压缩是有损耗的。
此类型图片在网页下载时只能由上而下依序显示图片,直到图片资料全部下载完毕,才能看到全貌。
②渐进式 JPEG:渐进式JPG为标准JPG的改良格式,支持交错,可以在网页下载时,先呈现出图片的粗略外观后,再慢慢地呈现出完整的内容,渐进式JPG的文件 比标准JPG的文件要来得小。
③JPEG2000:新一代的影像压缩法,压缩品质更好,其压缩率比标准JPEG高约30%左右,同时支持有损 和无损压缩。
一个极其重要的特征在于它能实现渐进传输,即先传输图像的轮廓,然后逐步传输数据,让图像由朦胧到清晰显示。
以一幅24 位彩色图像为例,JPEG的压缩分为四个步骤:①颜色转换:在将彩色图像进行压缩之前,必须先对颜色模式进行数据转换。
转换完成之后 还需要进行数据采样。
②DCT 变换:是将图像信号在频率域上进行变换,分离出高频和低频信息的处理过程,然后再对图像的高频部分(即图像细 节)进行压缩。
首先以象素为单位将图像划分为多个8×8的矩阵,然后对每一个矩阵作DCT 变换。
把8×8的象素矩阵变成8×8的频率系数矩阵(所谓频率 就是颜色改变的速度),频率系数都是浮点数。
③量化:由于下面第四步编码过程中使用的码本都是整数,因此要对频率系数进行量化,将之转换为整 数。
数据量化后,矩阵中的数据都是近似值,和原始图像数据之间有了差异,这一差异是造成图像压缩后失真的主要原因。
这一过程中,质量因子的选取至为重要。
值选得大,可以大幅度提高压缩比,但是图像质量就比较差,质量因子越小图像重建质量越好,但是压缩比越低。
④编码:编码是基于统计特性的方 法。
JPEG文件结构
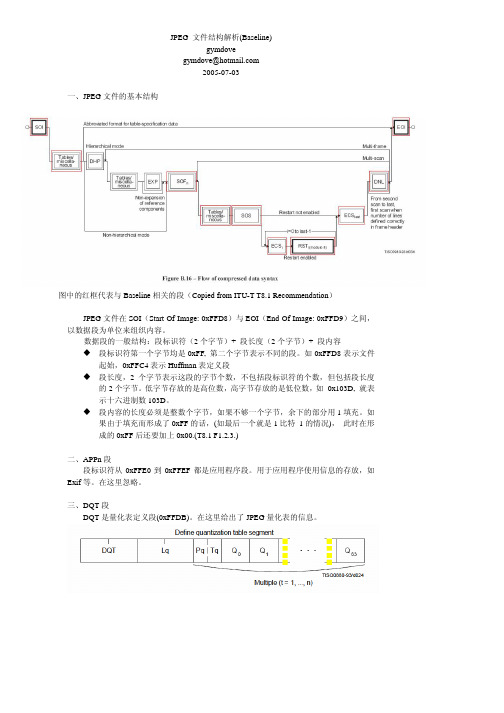
JPEG 文件结构解析(Baseline)gymdovegymdove@2005-07-03一、JPEG文件的基本结构图中的红框代表与Baseline相关的段(Copied from ITU-T T8.1 Recommendation)JPEG文件在SOI(Start Of Image: 0xFFD8)与EOI(End Of Image: 0xFFD9)之间,以数据段为单位来组织内容。
数据段的一般结构:段标识符(2个字节)+ 段长度(2个字节)+ 段内容段标识符第一个字节均是0xFF, 第二个字节表示不同的段。
如0xFFD8表示文件起始,0xFFC4表示Huffman表定义段段长度,2个字节表示这段的字节个数,不包括段标识符的个数,但包括段长度的2个字节。
低字节存放的是高位数,高字节存放的是低位数,如 0x103D, 就表示十六进制数103D。
段内容的长度必须是整数个字节,如果不够一个字节,余下的部分用1填充。
如果由于填充而形成了0xFF的话,(如最后一个就是1比特1的情况),此时在形成的0xFF后还要加上0x00.(T8.1 F1.2.3.)二、APPn段段标识符从0xFFE0到0xFFEF都是应用程序段。
用于应用程序使用信息的存放,如Exif等。
在这里忽略。
三、DQT段DQT是量化表定义段(0xFFDB)。
在这里给出了JPEG量化表的信息。
图量化表结构DQT: 0xFFDB,量化表段标识符,2个字节L q:段长度, 2个字节P q:半字节,量化表元素精度。
0表示每个量化表的值为8比特, 1表示为16比特T q:半字节,量化表编号。
通常为0-3Q :量化值,通常为一个字节,根据量化精度不同而不同。
量化值按Zig-Zag的顺序排列注: 从Pq到Q63为一个完整的量化表。
一个量化表段可包含一个或多个量化表。
量化表的例子:FF DB 00 84 00 01 03 03 04 03 03 05 04 04 04 05 05 05 06 07 0D 09 08 07 07 08 10 0B 0C 0A 0D 13 11 14 14 13 11 12 12 15 18 1E 1A 15 16 1C 17 12 12 1A 24 1A 1C 1F 20 22 22 22 14 19 25 28 25 21 27 1E 21 22 20 01 01 05 05 07 06 07 0E 08 08 0E 1C 13 10 13 1C 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20FF DB : Define quantization table marker00 84 : Lq,Quantization table definition length00 : [Pq|Tq]Q0-Q63:01 03 03 04 03 03 05 04 04 04 05 05 05 06 07 0D 09 08 07 07 08 10 0B 0C 0A 0D 13 11 14 14 13 11 12 12 15 18 1E 1A 15 16 1C 17 12 12 1A 24 1A 1C 1F 20 22 22 22 14 19 25 28 25 21 27 1E 21 22 20 01 : [Pq|Tq]Q0-Q63:01 05 05 07 06 07 0E 08 08 0E 1C 13 10 13 1C 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20四、DHT段图哈夫曼表段结构DHT : 哈夫曼表段标识符,0xFFC4,2字节。
JPEG图像格式详解

JPEG图像格式详解JPEG 压缩简介-------------1. 色彩模型JPEG 的图片使用的是 YCrCb 颜色模型, 而不是计算机上最常用的 RGB. 关于色彩模型, 这里不多阐述. 只是说明, YCrCb 模型更适合图形压缩. 因为人眼对图片上的亮度 Y 的变化远比色度 C 的变化敏感. 我们完全可以每个点保存一个 8bit 的亮度值, 每 2x2 个点保存一个 Cr Cb 值, 而图象在肉眼中的感觉不会起太大的变化. 所以, 原来用 RGB 模型, 4 个点需要 4x3=12 字节. 而现在仅需要 4+2=6 字节; 平均每个点占 12bit. 当然 JPEG 格式里允许每个点的 C 值都记录下来; 不过 MPEG 里都是按 12bit 一个点来存放的, 我们简写为 YUV12.[R G B] -> [Y Cb Cr] 转换-------------------------(R,G,B 都是 8bit unsigned)| Y | | 0.299 0.587 0.114 | | R | | 0 || Cb | = |- 0.1687 - 0.3313 0.5 | * | G | + |128|| Cr | | 0.5 - 0.4187 - 0.0813| | B | |128|Y = 0.299*R + 0.587*G + 0.114*B (亮度)Cb = - 0.1687*R - 0.3313*G + 0.5 *B + 128Cr = 0.5 *R - 0.4187*G - 0.0813*B + 128[Y,Cb,Cr] -> [R,G,B] 转换-------------------------R = Y + 1.402 *(Cr-128)G = Y - 0.34414*(Cb-128) - 0.71414*(Cr-128)B = Y + 1.772 *(Cb-128)一般, C 值 (包括 Cb Cr) 应该是一个有符号的数字, 但这里被处理过了, 方法是加上了 128. JPEG 里的数据都是无符号 8bit 的.2. DCT (离散余弦变换)JPEG 里, 要对数据压缩, 先要做一次 DCT 变换. DCT 变换的原理, 涉及到数学知识, 这里我们不必深究. 反正和傅立叶变换(学过高数的都知道) 是差不多了. 经过这个变换, 就把图片里点和点间的规律呈现出来了, 更方便压缩.JPEG 里是对每 8x8个点为一个单位处理的. 所以如果原始图片的长宽不是 8 的倍数, 都需要先补成 8的倍数, 好一块块的处理. 另外, 记得刚才我说的 Cr Cb 都是 2x2 记录一次吗? 所以大多数情况, 是要补成 16x16 的整数块.按从左到右, 从上到下的次序排列 (和我们写字的次序一样). JPEG 里是对 Y Cr Cb 分别做 DCT 变换的. 这里进行 DCT 变换的 Y, Cr, Cb 值的范围都是 -128~127. (Y 被减去 128)JPEG 编码时使用的是 Forward DCT (FDCT) 解码时使用的 Inverse DCT (IDCT)下面给出公式:FDCT:7 7 2*x+1 2*y+1F(u,v) = alpha(u)*alpha(v)* sum sum f(x,y) * cos (------- *u*PI)* cos (------ *v*PI) x=0 y=0 16 16u,v = 0,1,...,7{ 1/sqrt(8) (u==0)alpha(u) = {{ 1/2 (u!=0)IDCT:7 7 2*x+1 2*y+1f(x,y) = sum sum alpha(u)*alpha(v)*F(u,v)*cos (------- *u*PI)* cos (------ *v*PI) u=0 v=0 16 16x,y=0,1 (7)这个步骤很花时间, 另外有种 AA&N 优化算法, 大家可以去 inet 自己找一下.在 Intel 主页上可以找到 AA&N IDCT 的 MMX 优化代码. ( Intel 主页上的代码,输入数据为 12.4 的定点数, 输入矩阵需要转置 90 度)3. 重排列 DCT 结果DCT 将一个 8x8 的数组变换成另一个 8x8 的数组. 但是内存里所有数据都是线形存放的, 如果我们一行行的存放这 64 个数字, 每行的结尾的点和下行开始的点就没有什么关系, 所以 JPEG 规定按如下次序整理 64 个数字.0, 1, 5, 6,14,15,27,28,2, 4, 7,13,16,26,29,42,3, 8,12,17,25,30,41,43,9,11,18,24,31,40,44,53,10,19,23,32,39,45,52,54,20,22,33,38,46,51,55,60,21,34,37,47,50,56,59,61,35,36,48,49,57,58,62,63这样数列里的相邻点在图片上也是相邻的了.4. 量化对于前面得到的 64 个空间频率振幅值, 我们将对它们作幅度分层量化操作.方法就是分别除以量化表里对应值并四舍五入.for (i = 0 ; i<=63; i++ )vector[i] = (int) (vector[i] / quantization_table[i] + 0.5)下面有张 JPEG 标准量化表. (按上面同样的弯曲次序排列)16 11 10 16 24 40 51 6112 12 14 19 26 58 60 5514 13 16 24 40 57 69 5614 17 22 29 51 87 80 6218 22 37 56 68 109 103 7724 35 55 64 81 104 113 9249 64 78 87 103 121 120 10172 92 95 98 112 100 103 99这张表依据心理视觉阀制作, 对 8bit 的亮度和色度的图象的处理效果不错.当然我们可以使用任意的量化表. 量化表是定义在 jpeg 的 DQT 标记后. 一般为 Y 值定义一个, 为 C 值定义一个.量化表是控制 JPEG 压缩比的关键. 这个步骤除掉了一些高频量, 损失了很高细节. 但事实上人眼对高空间频率远没有低频敏感.所以处理后的视觉损失很小.另一个重要原因是所有的图片的点与点之间会有一个色彩过渡的过程. 大量的图象信息被包含在低空间频率中. 经过量化处理后, 在高空间频率段, 将出现大量连续的零.注意, 量化后的数据有可能超过 2 byte 有符号整数的处理范围.5. 0 RLE 编码现在我们矢量中有许多连续的 0. 我们可以使用 RLE 来压缩掉这些 0. 这里我们将跳过第一个矢量 (后面将解释为什么) 因为它的编码比较特别. 假设有一组矢量(64 个的后 63 个) 是57,45,0,0,0,0,23,0,-30,-16,0,0,1,0,0,0, 0 , 0 ,0 , 0,..,0经过 RLE 压缩后就是(0,57) ; (0,45) ; (4,23) ; (1,-30) ; (0,-16) ; (2,1) ; EOBEOB 是一个结束标记, 表示后面都是 0 了. 实际上, 我们用 (0,0) 表示 EOB但是, 如果这组数字不以 0 结束, 那么就不需要 EOB.另外需要注意的是, 由于后面 huffman 编码的要求, 每组数字前一个表示 0 的数量的必须是 4 bit, 就是说, 只能是 0~15, 所以, 如果有这么一组数字:57, 十八个0, 3, 0, 0, 0, 0, 2, 三十三个0, 895, EOB我们实际这样编码:(0,57) ; (15,0) (2,3) ; (4,2) ; (15,0) (15,0) (1,895) , (0,0)注意 (15,0) 表示了 16 个连续的 0.6. huffman 编码为了提高储存效率, JPEG 里并不直接保存数值, 而是将数值按位数分成 16 组:数值组实际保存值0 0 --1,1 1 0,1-3,-2,2,3 2 00,01,10,11-7,-6,-5,-4,4,5,6,7 3 000,001,010,011,100,101,110,111-15,..,-8,8,..,15 4 0000,..,0111,1000,..,1111-31,..,-16,16,..,31 5 00000,..,01111,10000,..,11111-63,..,-32,32,..,63 6 .-127,..,-64,64,..,127 7 .-255,..,-128,128,..,255 8 .-511,..,-256,256,..,511 9 .-1023,..,-512,512,..,1023 10 .-2047,..,-1024,1024,..,2047 11 .-4095,..,-2048,2048,..,4095 12 .-8191,..,-4096,4096,..,8191 13 .-16383,..,-8192,8192,..,16383 14 .-32767,..,-16384,16384,..,32767 15 .还是来看前面的例子:(0,57) ; (0,45) ; (4,23) ; (1,-30) ; (0,-8) ; (2,1) ; (0,0)只处理每对数右边的那个:57 是第 6 组的, 实际保存值为 111001 , 所以被编码为 (6,111001)45 , 同样的操作, 编码为 (6,101101)23 -> (5,10111)-30 -> (5,00001)-8 -> (4,0111)1 -> (1,1)前面的那串数字就变成了:(0,6), 111001 ; (0,6), 101101 ; (4,5), 10111; (1,5), 00001; (0,4) , 0111 ;(2,1), 1 ; (0,0)括号里的数值正好合成一个字节. 后面被编码的数字表示范围是 -32767..32767.合成的字节里, 高 4 位是前续 0 的个数, 低 4 位描述了后面数字的位数.继续刚才的例子, 如果 06 的 huffman 编码为 111000 ( 06 对应 111000 为查表所得. jpeg 文件里保存了压缩时所产生的 huffman 表, 将 0~255 这 256 个 8 bits 定长数字, 对应成 1~16 bits 的不定长数值. 出现频率高的数字小于 8bits, 频率低的大于8bits,从而使整个的数据长度降低, 关于 huffman 压缩算法, 请查阅相关资料 )69 = (4,5) --- 1111111110011001 ( 注: 69=4*16+5=0x45 )21 = (1,5) --- 111111101104 = (0,4) --- 101133 = (2,1) --- 110110 = EOB = (0,0) --- 1010那么最后对于前面的例子表示的 63 个系数 (记得我们将第一个跳过了吗?) 按位流写入 JPG 文件中就是这样的:111000 111001 111000 101101 1111111110011001 10111 11111110110 00001 1011 0111 11011 1 10107. DC 的编码-----------记得刚才我们跳过了每组 64 个数据的第一个吧, DC 就是指的这个数字 (后面 63 个简称 AC) 代入前面的 FDCT 公式可以得到c(0,0) 7 7DC = F(0,0) = --------- * sum sum f(x,y) * cos 0 * cos 0 其中 c(0,0) = 1/2 4 x=0 y=01 7 7= --- * sum sum f(x,y)8 x=0 y=0即一块图象样本的平均值. 就是说, 它包含了原始 8x8 图象块里的很多能量. (通常会得到一个很大的数值)JPEG 的作者指出连续块的 DC 率之间有很紧密的联系, 因此他们决定对 8x8 块的DC 值的差别进行编码. (Y, Cb, Cr 分别有自己的 DC)Diff = DC(i) - DC(i-1)所以这一块的 DC(i) 就是: DC(i) = DC(i-1) + DiffJPG 从 0 开始对 DC 编码, 所以 DC(0)=0. 然后再将当前 Diff 值加在上一个值上得到当前值.下面再来看看上面那个例子: (记住我们保存的 DC 是和上一块 DC 的差值 Diff)例如上面例子中, Diff 是 -511, 就编码成(9, 000000000)如果 9 的 Huffman 编码是 1111110 (在 JPG 文件中, 一般有两个 Huffman 表, 一个是 DC 用, 一个是 AC 用) 那么在 JPG 文件中, DC 的 2 进制表示为1111110 000000000它将放在 63 个 AC 的前面, 上面上个例子的最终 BIT 流如下:1111110 000000000 111000 111001 111000 101101 1111111110011001 10111 11111110110 00001 1011 0111 11011 1 1010解码过程简述-------------8. 一个数据单元 Y 的解码 (其余类同)--------------------------------在整个图片解码的开始, 你需要先初始化 DC 值为 0.1) 先解码 DC:a) 取得一个 Huffman 码 (使用 Huffman DC 表)b) Huffman解码, 看看后面的数据位数 Nc) 取得 N 位, 计算 Diff 值d) DC + = Diffe) 写入 DC 值: " vector[0]=DC "2) 解码 63 个 AC:------- 循环处理每个 AC 直到 EOB 或者处理到 64 个 ACa) 取得一个 Huffman 码 (使用 Huffman AC 表)b) Huffman 解码, 得到 (前面 0 数量, 组号)[记住: 如果是(0,0) 就是 EOB 了]c) 取得 N 位(组号) 计算 ACd) 写入相应数量的 0e) 接下来写入 AC-----------------下一步的解码------------上一步我们得到了 64 个矢量. 下面我们还需要做一些解码工作:1) 反量化 64 个矢量 : "for (i=0;i<=63;i++) vector[i]*=quant[i]" (注意防止溢出)2) 重排列 64 个矢量到 8x8 的块中3) 对 8x8 的块作 IDCT对 8x8 块的 (Y,Cb,Cr) 重复上面的操作 [Huffman 解码, 步骤 1), 2), 3)]4) 将所有的 8bit 数加上 1285) 转换 YCbCr 到 RGB9. JPG 文件(Byte 级)里怎样组织图片信息-----------------------------------注意 JPEG/JFIF 文件格式使用 Motorola 格式, 而不是 Intel 格式, 就是说, 如果是一个字的话, 高字节在前, 低字节在后.JPG 文件是由一个个段 (segments) 构成的. 每个段长度 <=65535. 每个段从一个标记字开始. 标记字都是 0xff 打头的, 以非 0 字节和 0xFF 结束. 例如 'FFDA' ,'FFC4', 'FFC0'. 每个标记有它特定意义, 这是由第2字节指明的. 例如, SOS (Start Of Scan = 'FFDA') 指明了你应该开始解码. 另一个标记 DQT (Define Quantization Table = 0xFFDB) 就是说它后面有 64 字节的 quantization 表在处理 JPG 文件时, 如果你碰到一个 0xFF, 而它后面的字节不是 0, 并且这个字节没有意义. 那么你遇到的 0xFF 字节必须被忽略. (一些 JPG 里, 常用用 0xFF 做某些填充用途) 如果你在做 huffman 编码时碰巧产生了一个 0xFF, 那么就用 0xFF0x00 代替. 就是说在 jpeg 图形解码时碰到 FF00 就把它当作 FF 处理.另外在 huffman 编码区域结束时, 碰到几个 bit 没有用的时候, 应该用 1 去填充. 然后后面跟 FF.下面是几个重要的标记--------------------SOI = Start Of Image = 'FFD8'这个标记只在文件开始出现一次EOI = End Of Image = 'FFD9'JPG 文件都以 FFD9 结束RSTi = FFDi ( i = 0..7) [ RST0 = FFD0, RST7=FFD7]= 复位标记通常穿插在数据流里, 我想是担心 JPG 解码出问题吧(应该配合 DRI 使用). RST 将Huffman 的解码数据流复位. DC 也重新从 0 开始计(SOS --- RST0 --- RST1 -- RST2 --......-- RST6 --- RST7 -- RST0 --...)-------10. 标记-------下面是必须处理的标记SOF0 = Start Of Frame 0 = FFC0SOS = Start Of Scan = FFDAAPP0 = it's the marker used to identify a JPG file which uses the JFIFspecification = FFE0COM = Comment = FFFEDNL = Define Number of Lines = FFDCDRI = Define Restart Interval = FFDDDQT = Define Quantization Table = FFDBDHT = Define Huffman Table = FFC411. JPG 文件中 Haffman 表的储存-----------------------------JPEG 里定义了一张表来描述 Haffman 树. 定义在 DHT 标记后面. 注意: Haffman 代码的长度限制在 16bit 内.一般一个 JPG 文件里会有 2 类 Haffman 表: 一个用于 DC 一个用于 AC (实际有 4 个表, 亮度的 DC,AC 两个, 色度的 DC,AC 两个)这张表是这样保存的:1) 16 字节:第 i 字节表示了 i 位长的 Huffman 代码的个数 (i= 1 到 16)2) 这表的长度 (字节数) = 这 16 个数字之和现在你可以想象这张表怎么存放的吧? 对应字节就是对应 Haffman 代码等价数字. 我不多解释, 这需要你先了解 Haffman 算法. 这里只举一个例子:Haffman 表的表头是 0,2,3,1,1,1,0,1,0,0,0,0,0,0,0,0就是说长度为 1 的代码没有长度为 2 的代码为 0001长度为 3 的代码是 100101110长度为 4 的代码是 1110长度为 5 的代码是 11110长度为 6 的代码是 111110长度为 7 的代码没有 (如果有一个的话应该是 1111110)长度为 8 的代码是 11111100.....后面都没有了.如果表下面的数据是45 57 29 17 23 25 34 28就是说45 = 0057 = 0129 = 10017 = 10123 = 110等等...如果你懂 Haffman 编码, 这些不难理解12. 采样系数-----------下面讲解的都是真彩 JPG 的解码, 灰度 JPG 的解码很简单, 因为图形中只有亮度信息. 而彩色图形由 (Y, Cr, Cb) 构成, 前面提到过, Y 通常是每点采样一次, 而 Cr, Cb 一般是 2x2 点采样一次, 当然也有的 JPG 是逐点采样, 或者每两点采样 (横向两点, 纵向一点) 采样系数均被定义成对比最高采样系数的相对值.一般情况 (即: Y 逐点采样, Cr Cb 每 2x2 点一次) 下: Y 有最高的采样率, 横向采样系数HY=2 纵向采样系数 VY=2; Cb 的横向采样系数 HCb=1, 纵向采样系数 VCb=1; 同样 HCr=1, VCr=1在 Jpeg 里, 8x8 个原始数据, 经过 RLE, Huffman 编码后的一串数据流称为一个Data Unit (DU) JPG 里按 DU 为单位的编码次序如下:1) for (counter_y=1;counter_y<=VY;counter_y++)for (counter_x=1;counter_x<=HY;counter_x++){ 对 Y 的 Data Unit 编码 }2) for (counter_y=1;counter_y<=VCb ;counter_y++)for (counter_x=1;counter_x<=HCb;counter_x++){ 对 Cb 的 Data Unit 编码 }3) for (counter_y=1;counter_y<=VCr;counter_y++)for (counter_x=1;counter_x<=HCr;counter_x++){ 对 Cr 的 Data Unit 编码 }按我上面的例子: (HY=2, VY=2 ; HCb=VCb =1, HCr,VCr=1) 就是这样一个次序YDU,YDU,YDU,YDU,CbDU,CrDU这些就描述了一块 16x16 的图形. 16x16 = (Hmax*8 x Vmax*8) 这里 Hmax=HY=2 Vmax=VY=2一个 (Hmax*8,Vmax*8) 的块被称作 MCU (Minimun Coded Unix) 前面例子中一个MCU = YDU,YDU,YDU,YDU,CbDU,CrDU如果 HY =1, VY=1HCb=1, VCb=1HCr=1, VCr=1这样 (Hmax=1,Vmax=1), MCU 只有 8x8 大, MCU = YDU,CbDU,CrDU对于灰度 JPG, MCU 只有一个 DU (MCU = YDU)JPG 文件里, 图象的每个组成部分的采样系数定义在 SOF0 (FFC0) 标记后13. 简单说一下 JPG 文件的解码-------------------------解码程序先从 JPG 文件中读出采样系数, 这样就知道了 MCU 的大小, 算出整个图象有几个 MCU. 解码程序再循环逐个对 MCU 解码, 一直到检查到 EOI 标记. 对于每个MCU, 按正规的次序解出每个 DU, 然后组合, 转换成 (R,G,B) 就 OK 了附:JPEG 文件格式~~~~~~~~~~~~~~~~- 文件头 (2 bytes): $ff, $d8 (SOI) (JPEG 文件标识)- 任意数量的段 , 见后面- 文件结束 (2 bytes): $ff, $d9 (EOI)段的格式:~~~~~~~~~- header (4 bytes):$ff 段标识n 段的类型 (1 byte)sh, sl 该段长度, 包括这两个字节, 但是不包括前面的 $ff 和 n.注意: 长度不是 intel 次序, 而是 Motorola 的, 高字节在前, 低字节在后!- 该段的内容, 最多 65533 字节注意:- 有一些无参数的段 (下面那些前面注明星号的)这些段没有长度描述 (而且没有内容), 只有 $ff 和类型字节.- 段之间无论有多少 $ff 都是合法的, 必须被忽略掉.段的类型:~~~~~~~~~*TEM = $01 可以忽略掉SOF0 = $c0 帧开始 (baseline JPEG), 细节附后SOF1 = $c1 ditoSOF2 = $c2 通常不支持SOF3 = $c3 通常不支持SOF5 = $c5 通常不支持SOF6 = $c6 通常不支持SOF7 = $c7 通常不支持SOF9 = $c9 arithmetic 编码(Huffman 的一种扩展算法), 通常不支持 SOF10 = $ca 通常不支持SOF11 = $cb 通常不支持SOF13 = $cd 通常不支持SOF14 = $ce 通常不支持SOF14 = $ce 通常不支持SOF15 = $cf 通常不支持DHT = $c4 定义 Huffman Table, 细节附后JPG = $c8 未定义/保留 (引起解码错误)DAC = $cc 定义 Arithmetic Table, 通常不支持*RST0 = $d0 RSTn 用于 resync, 通常被忽略*RST1 = $d1*RST2 = $d2*RST3 = $d3*RST4 = $d4*RST5 = $d5*RST6 = $d6*RST7 = $d7SOI = $d8 图片开始EOI = $d9 图片结束SOS = $da 扫描行开始, 细节附后DQT = $db 定义 Quantization Table, 细节附后DNL = $dc 通常不支持, 忽略DRI = $dd 定义重新开始间隔, 细节附后DHP = $de 忽略 (跳过)EXP = $df 忽略 (跳过)APP0 = $e0 JFIF APP0 segment marker (细节略)APP15 = $ef 忽略JPG0 = $f0 忽略 (跳过)JPG13 = $fd 忽略 (跳过)COM = $fe 注释, 细节附后其它的段类型都保留必须跳过SOF0: Start Of Frame 0:~~~~~~~~~~~~~~~~~~~~~~~- $ff, $c0 (SOF0)- 长度 (高字节, 低字节), 8+components*3- 数据精度 (1 byte) 每个样本位数, 通常是 8 (大多数软件不支持 12 和 16) - 图片高度 (高字节, 低字节), 如果不支持 DNL 就必须 >0- 图片宽度 (高字节, 低字节), 如果不支持 DNL 就必须 >0- components 数量(1 byte), 灰度图是 1, YCbCr/YIQ 彩色图是 3, CMYK 彩色图是 4- 每个 component: 3 bytes- component id (1 = Y, 2 = Cb, 3 = Cr, 4 = I, 5 = Q)- 采样系数 (bit 0-3 vert., 4-7 hor.)- quantization table 号DRI: Define Restart Interval:~~~~~~~~~~~~~~~~~~~~~~~~~~~~~- $ff, $dd (DRI)- 长度 (高字节, 低字节), 必须是 4- MCU 块的单元中的重新开始间隔 (高字节, 低字节),意思是说, 每 n 个 MCU 块就有一个 RSTn 标记.第一个标记是 RST0, 然后是 RST1 等, RST7 后再从 RST0 重复DQT: Define Quantization Table:~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~- $ff, $db (DQT)- 长度 (高字节, 低字节)- QT 信息 (1 byte):bit 0..3: QT 号(0..3, 否则错误)bit 4..7: QT 精度, 0 = 8 bit, 否则 16 bit- n 字节的 QT, n = 64*(精度+1)备注:- 一个单独的 DQT 段可以包含多个 QT, 每个都有自己的信息字节- 当精度=1 (16 bit), 每个字都是高位在前低位在后DAC: Define Arithmetic Table:~~~~~~~~~~~~~~~~~~~~~~~~~~~~~法律原因, 现在的软件不支持 arithmetic 编码.不能生产使用 arithmetic 编码的 JPEG 文件DHT: Define Huffman Table:~~~~~~~~~~~~~~~~~~~~~~~~~~- $ff, $c4 (DHT)- 长度 (高字节, 低字节)- HT 信息 (1 byte):bit 0..3: HT 号 (0..3, 否则错误)bit 4 : HT 类型, 0 = DC table, 1 = AC tablebit 5..7: 必须是 0- 16 bytes: 长度是 1..16 代码的符号数. 这 16 个数的和应该 <=256- n bytes: 一个包含了按递增次序代码长度排列的符号表(n = 代码总数)备注:- 一个单独的 DHT 段可以包含多个 HT, 每个都有自己的信息字节COM: 注释:~~~~~~~~~~- $ff, $fe (COM)- 注释长度 (高字节, 低字节) = L+2- 注释为长度为 L 的字符流SOS: Start Of Scan:~~~~~~~~~~~~~~~~~~~- $ff, $da (SOS)- 长度 (高字节, 低字节), 必须是 6+2*(扫描行内组件的数量)- 扫描行内组件的数量 (1 byte), 必须 >= 1 , <=4 (否则是错的) 通常是 3 - 每个组件: 2 bytes- component id (1 = Y, 2 = Cb, 3 = Cr, 4 = I, 5 = Q), 见 SOF0- 使用的 Huffman 表:- bit 0..3: AC table (0..3)- bit 4..7: DC table (0..3)- 忽略 3 bytes (???)备注:- 图片数据 (一个个扫描行) 紧接着 SOS 段.。
JPG文件结构分析

表8:DHT(定义Huffman表)
--------------------------------------------------------------------------
名 称 字节数 值 说明
--------------------------------------------------------------------------
段 标识 1 FF
段类型 1 FE
段长度 2 其值=注释字符的字节数+2
段 内容 注释字符
--------------------------------------------------------------------------
说明:有的文章也将DNL段(标记码=DC,定义扫描行数)列为必须段。
3.以下按一般JPEG文件的段排列顺序详细介绍 各种段的结构:
表3:SOI(文件头)
-----------------
名称 字节数 值
-----------------
段 标识 1 FF
段类型 1 D8
HT值表 n n=表头16个数的和
--------------------------------------------------------------------------
③JPEG2000:新一代的影像压缩法,压缩品质更好,其压缩率比标准JPEG高约30%左右,同时支持有损 和无损压缩。一个极其重要的特征在于它能实现渐进传输,即先传输图像的轮廓,然后逐步传输数据,让图像由朦胧到清晰显示。
以一幅24 位彩色图像为例,JPEG的压缩分为四个步骤:
①颜色转换:在将彩色图像进行压缩之前,必须先对颜色模式进行数据转换。转换完成之后 还需要进行数据采样。
JPG图片文件结构分析

JPG文件结构分析2010-04-06 22:32【转自网络作者:一江秋水】一、简述JPEG是一个压缩标准,又可分为标准 JPEG、渐进式JPEG及JPEG2000三种:①标准JPEG:以24位颜色存储单个光栅图像,是与平台无关的格式,支持最高级别的压缩,不过,这种压缩是有损耗的。
此类型图片在网页下载时只能由上而下依序显示图片,直到图片资料全部下载完毕,才能看到全貌。
②渐进式 JPEG:渐进式JPG为标准JPG的改良格式,支持交错,可以在网页下载时,先呈现出图片的粗略外观后,再慢慢地呈现出完整的内容,渐进式JPG的文件比标准JPG的文件要来得小。
③JPEG2000:新一代的影像压缩法,压缩品质更好,其压缩率比标准JPEG高约30%左右,同时支持有损和无损压缩。
一个极其重要的特征在于它能实现渐进传输,即先传输图像的轮廓,然后逐步传输数据,让图像由朦胧到清晰显示。
以一幅24 位彩色图像为例,JPEG的压缩分为四个步骤:①颜色转换:在将彩色图像进行压缩之前,必须先对颜色模式进行数据转换。
转换完成之后还需要进行数据采样。
②DCT变换:是将图像信号在频率域上进行变换,分离出高频和低频信息的处理过程,然后再对图像的高频部分(即图像细节)进行压缩。
首先以象素为单位将图像划分为多个8×8的矩阵,然后对每一个矩阵作DCT 变换。
把8×8的象素矩阵变成8×8的频率系数矩阵(所谓频率就是颜色改变的速度),频率系数都是浮点数。
③量化:由于下面第四步编码过程中使用的码本都是整数,因此要对频率系数进行量化,将之转换为整数。
数据量化后,矩阵中的数据都是近似值,和原始图像数据之间有了差异,这一差异是造成图像压缩后失真的主要原因。
这一过程中,质量因子的选取至为重要。
值选得大,可以大幅度提高压缩比,但是图像质量就比较差,质量因子越小图像重建质量越好,但是压缩比越低。
④编码:编码是基于统计特性的方法。
四个步骤都完成后的JPEG文件,其基本数据结构为两大类型:“段”和经过压缩编码的图像数据。
JPEG头文件结构及组成

JPEG头文件结构及组成最近在做关于图片显示方面的嵌入式程序.发现国内这方面资料介绍得还是比较少的,所以发表在这里.Before the image data is ever loaded when a JPEG image is selected for viewing the markers must be read. In a JPEG image, the very first marker is the SOI, or Start Of Image, marker. This is the first "hey, I'm a JPEG" declaration by the file. The JPEG standard, as written by the Joint Picture Expert's Group, specified the JPEG interchange format. This format had several shortcomings for which the JFIF (JPEG File Interchange Format) was an attempted remedy. The JFIF is the format used by almost all JPEG file readers/writers. It tells the image readers, "Hey, I'm a JPEG that almost anyone can understand."Most markers will have additional information following them. When this is the case, the marker and its associated information is referred to as a "header." In a header the marker is immediately followed by two bytes that indicate the length of the information, in bytes, that the header contains. The two bytes that indicate the length are always included in that count.A marker is prefixed by FF (hexadecimal). The marker/header information that follows does not specify all known markers, just the essential ones for baseline JPEG.A component is a specific color channel in an image. For instance, an RGB image contains three components; Red, Green, and Blue.1998 by James R. WeeksStart of Image (SOI) marker -- two bytes (FFD8)JFIF marker (FFE0)•length -- two bytes•identifier -- five bytes: 4A, 46, 49, 46, 00 (the ASCII code equivalent of a zero terminated "JFIF" string)•version -- two bytes: often 01, 02o the most significant byte is used for major revisions o the least significant byte for minor revisions•units -- one byte: Units for the X and Y densitieso0 => no units, X and Y specify the pixel aspect ratio o 1 => X and Y are dots per incho 2 => X and Y are dots per cm•Xdensity -- two bytes•Ydensity -- two bytes•Xthumbnail -- one byte: 0 = no thumbnail•Ythumbnail -- one byte: 0 = no thumbnail•(RGB)n -- 3n bytes: packed (24-bit) RGB values for the thumbnail pixels, n = Xthumbnail * YthumbnailDefine Quantization table marker (FFDB)•the first two bytes, the length, after the marker indicate the number of bytes, including the two length bytes, that this header contains•until the length is exhausted (loads two quantization tables for baseline JPEG)o the precision and the quantization table index -- one byte: precision is specified by the higher four bits and index is specified by the lower four bits▪precision in this case is either 0 or 1 and indicates the precision of the quantized values; 8-bit (baseline)for 0 and up to 16-bit for 1o the quantization values -- 64 bytes▪the quantization tables are stored in zigzag formatDefine Huffman table marker (FFC4)•the first two bytes, the length, after the marker indicate the number of bytes, including the two length bytes, that this header contains•until length is exhausted (usually four Huffman tables)o index -- one byte: if >15 (i.e. 0x10 or more) then an AC table, otherwise a DC tableo bits -- 16 byteso Huffman values -- # of bytes = the sum of the previous 16 bytesStart of frame marker (FFC0)•the first two bytes, the length, after the marker indicate the number of bytes, including the two length bytes, that this header contains•P -- one byte: sample precision in bits (usually 8, for baseline JPEG)•Y -- two bytes•X -- two bytes•Nf -- one byte: the number of components in the image o 3 for color baseline JPEG imageso 1 for grayscale baseline JPEG images•Nf times:o Component ID -- one byteo H and V sampling factors -- one byte: H is first fourbits and V is second four bitso Quantization table number-- one byteThe H and V sampling factors dictate the final size of the component they are associated with. For instance, the color space defaults to YCbCr and the H and V sampling factors for each component, Y, Cb, and Cr, default to 2, 1, and 1, respectively (2 for both H and V of the Y component, etc.) in the Jpeg-6a library by the Independent Jpeg Group. While this does mean that the Y component will be twice the size of the other two components--giving it a higher resolution, the lower resolution components are quartered in size during compression in order to achieve this difference. Thus, the Cb and Cr components must be quadrupled in size during decompression.Start of Scan marker (FFDA)•the first two bytes, the length, after the marker indicate the number of bytes, including the two length bytes, that this header contains•Number of components, n -- one byte: the number of components in this scan•n times:o Component ID -- one byteo DC and AC table numbers -- one byte: DC # is first four bits and AC # is last four bits•Ss -- one byte•Se -- one byte•Ah and Al -- one byteComment marker (FFFE)•the first two bytes, the length, after the marker indicate thenumber of bytes, including the two length bytes, that this header contains•whatever the user wantsEnd of Image (EOI) marker (FFD9)•the very last markerJPEG文件由八个部分组成,每个部分的标记字节为两个,首字节固定为:0xFF,当然,准许在其前面再填充多个0xFF,以最后一个为准。
JPEG图片文件编解码详解

2.初步了解图像数据流的结构1)理论说明分析图像数据流的结构,笔者准备以一个从宏观到微观的顺序为读者详细剖析,即:数据流 最小编码单元 数据单元与颜色分量。
a) 在图片像素数据流中,信息可以被分为一段接一段的最小编码单元(Minimum Coded Unit,MCU)数据流。
所谓MCU,是图像中一个正方矩阵像素的数据。
矩阵的大小是这样确定的:查阅标记SOF0,可以得到图像不同颜色分量的采样因子,即Y、Cr、Cb三个分量各自的水平采样因子和垂直采样因子。
大多图片的采样因子为4:1:1或1:1:1。
其中,4:1:1即(2*2):(1*1):(1*1));1:1:1即(1*1):(1*1):(1*1)。
记三个分量中水平采样因子最大值为Hmax,垂直采样因子最大值为Vmax,那么单个MCU矩阵的宽就是Hmax*8像素,高就是Vmax*8像素。
如果,整幅图像的宽度和高度不是MCU宽度和高度的整数倍,那么编码时会用某些数值填充进去,保证解码过程中MCU的完整性(解码完成后,可直接忽视图像宽度和高度外的数据)。
在数据流中,MCU的排列方法是从左到右,从上到下。
b) 每个MCU又分为若干个数据单元。
数据单元的大小必定为8*8,所以每个MCU的数据单元个数为Hmax*Vmax。
另外JPEG的压缩方法与BMP文件有所不同,它不是把每个像素的颜色分量连续存储在一起的,而是把图片分成Y,Cr,Cb三张子图,然后分别压缩。
而三个颜色分量的采样密度(即采样因子)可能一样(例如1:1:1)也可能不一样(例如4:1:1)。
每个MCU内部,数据的顺序是Y、Cr、Cb。
如果一个颜色分量有多个数据单元,则顺序是从左到右,从上到下。
2)举例说明下面通过一幅32*35的图像,对上面两个问题列出两种采样因子的具体说明。
图1 整张完整的图像(4:1:1)图 2 将图像的MCU1放大图1及图3中灰色部分为实际图像大小(32px*35px);粗虚线表示各个MCU的分界;细虚线表示MCU内部数据单元的分界。
摄影:你真的了解JPEG格式吗?

摄影:你真的了解JPEG格式吗?来源:动力视觉JPEG是最常见的图像储存格式之一,它是一种经过压缩的文件格式,所以在不少图像处理软件中,当储存JPEG格式档案时,都会有些关于压缩级别的选项让用户调校。
拍摄一张RAW照片,大约是每100万像素1MB数据量,但是JPEG档案的大小就远远低于这个水平,一般情况下,JPEG照片的大小只有RAW档案的一半至三分一。
之所以会有这个分别,就是因为JPEG是经过压缩的档案,可以节省更多的空间。
那JPEG的压缩原理是什么呢?大家都知道计算机档案其实是大量代码串连而成,即使是图像也不例外。
最理想的储存方式是照片中每一点都有独立的代码去表达,但这样的文件就会非常大。
所以JPEG其实就是把一些不必要的代码省略或者把代码的长度缩短,这样在计算机中所须的储存空间就会减少。
大家可能会认为,照片中每一点都有数据,没有缩减的空间。
其实在JPEG的压缩过程中,有很多数据会被省去,出现画质下降,照片失真的现象。
虽然JPEG是失真的档案,但是只要压缩不是太多,以我们的眼睛是难以分辨出来的。
所以大家在计算机中储存JPEG档案时,要小心选择压缩的程度。
在Photoshop之中,当大家把照片储存为JPEG格式时,Photoshop提供的选项主要有2个,分别是「图像选项」及「格式选项」。
前者较易理解,就是JPEG的压缩程度,以Photoshop为例,分为0至12个质量的等级,0级为压缩最多,12级为压缩最少,照片压缩得愈少,档案的资料失去愈少,影像质素就当然愈好。
而「格式选项」则较为深奥了,在储存JPEG时,计算机会根据一个数据转换表,把特定的数据转换成较为节省储存空间的代码。
颜色愈多照片愈大除了压缩程度之外,照片的颜色亦会影响JPEG档案大小,因为照片中相同颜色的点愈多,压缩时就愈能够把这些点归纳,以更短的代码表达更多的数据,相反,如果照片颜色丰富,每种颜色都要独立代码表示,所需的储存空间就自然更多。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
JPG文件结构分析
2010-04-06 22:32
【转自网络作者:一江秋水】
一、简述
JPEG是一个压缩标准,又可分为标准 JPEG、渐进式JPEG及JPEG2000三种:
①标准JPEG:以24位颜色存储单个光栅图像,是与平台无关的格式,支持最高级别的压缩,不过,这种压缩是有损耗的。
此类型图片在网页下载时只能由上而下依序显示图片,直到图片资料全部下载完毕,才能看到全貌。
②渐进式 JPEG:渐进式JPG为标准JPG的改良格式,支持交错,可以在网页下载时,先呈现出图片的粗略外观后,再慢慢地呈现出完整的内容,渐进式JPG
的文件比标准JPG的文件要来得小。
③JPEG2000:新一代的影像压缩法,压缩品质更好,其压缩率比标准JPEG高约30%左右,同时支持有损和无损压缩。
一个极其重要的特征在于它能实现渐进传输,即先传输图像的轮廓,然后逐步传输数据,让图像由朦胧到清晰显示。
以一幅24 位彩色图像为例,JPEG的压缩分为四个步骤:
①颜色转换:在将彩色图像进行压缩之前,必须先对颜色模式进行数据转换。
转换完成之后还需要进行数据采样。
②DCT变换:是将图像信号在频率域上进行变换,分离出高频和低频信息的处理过程,然后再对图像的高频部分(即图像细节)进行压缩。
首先以象素为单位将图像划分为多个8×8的矩阵,然后对每一个矩阵作DCT 变换。
把8×8的象素矩阵变成8×8的频率系数矩阵(所谓频率就是颜色改变的速度),频率系数都是浮点数。
③量化:由于下面第四步编码过程中使用的码本都是整数,因此要对频率系数进行量化,将之转换为整数。
数据量化后,矩阵中的数据都是近似值,和原始图像数据之间有了差异,这一差异是造成图像压缩后失真的主要原因。
这一过程中,质量因子的选取至为重要。
值选得大,可以大幅度提高压缩比,但是图像质量就比较差,质量因子越小图像重建质量越好,但是压缩比越低。
④编码:编码是基于统计特性的方法。
四个步骤都完成后的JPEG文件,其基本数据结构为两大类型:“段”和经过压缩编码的图像数据。
二、数据结构
1.段的一般结构如下表所示:
表1:段的一般结构
-----------------------------------------------------------------
名称字节数数据说明
-----------------------------------------------------------------
段标识 1 FF 每个新段的开始标识
段类型 1 类型编码(称作“标记码”)
段长度 2 包括段内容和段长度本身,不包括段标识和段类型
段内容≤65533字节
-----------------------------------------------------------------
说明:
①JPG文件中所有关于宽度高度长度间隔这一类数据,凡是>1字节的,均采用Motorola格式,即:高位在前,低位在后。
② 有些段没有长度描述也没有内容,只有段标识和段类型。
文件头和文件尾均属于这种段。
③段与段之间无论有多少FF都是合法的,这些FF称为“填充字节”,必须被忽略掉。
2.段类型有30种,但只有10种是必须被所有程序识别的,其它的类型都可以忽略。
所以下面只列出这 10种类型。
表2:段类型
---------------------------------------
名称标记码说明
---------------------------------------
SOI D8 文件头
EOI D9 文件尾
SOF0 C0 帧开始(标准 JPEG)
SOF1 C1 同上
DHT C4 定义 Huffman 表(霍夫曼表)
SOS DA 扫描行开始
DQT DB 定义量化表
DRI DD 定义重新开始间隔
APP0 E0 定义交换格式和图像识别信息
COM FE 注释
-----------------------------------------------------------
说明:有的文章也将DNL段(标记码=DC,定义扫描行数)列为必须段。
3.以下按一般JPEG文件的段排列顺序详细介绍各种段的结构:
表3:SOI(文件头)
-----------------
名称字节数值
-----------------
段标识 1 FF
段类型 1 D8
-----------------
说明:这两个字节构成了 JPEG文件头。
表4:APP0(图像识别信息)
--------------------------------------------------------------------------
名称字节数值说明
--------------------------------------------------------------------------
段标识 1 FF
段类型 1 E0
段长度 2 0010 如果有 RGB缩略图就=16+3n
(以下为段内容)
交换格式 5 4A46494600 “JFIF”的ASCII码
主版本号 1
次版本号 1
密度单位 1 0=无单位;1=点数/英寸;2=点数/厘米
X像素密度 2 水平方向的密度
Y像素密度 2 垂直方向的密度
缩略图X像素 1 缩略图水平像素数目
缩略图Y像素 1 缩略图垂直像素数目
(如果“缩略图X像素”和“缩略图Y像素”的值均>0,那么才有下面的数据)RGB缩略图3×n n=缩略图像素总数=缩略图X像素×缩略图Y像素
--------------------------------------------------------------------------
说明:
①JFIF是JPEG File Interchange Format的缩写,即JPEG文件交换格式,另外还有TIFF等格式,很少用
②“如果有RGB缩略图就=16+3n”是什么意思呢?比如说“缩略图X像素”和“缩略图Y像素”的值均为48,就表示有一个48×48像素的缩略图(n=
48×48),缩略图是24位真彩位图,用3个字节来表示一个像素,所以共占用3n个字节。
但大多数JPG文件都没有这个“鸡肋”缩略图。
表 5:COM(注释)
--------------------------------------------------------------------------
名称字节数值说明
--------------------------------------------------------------------------
段标识 1 FF
段类型 1 FE
段长度 2 其值=注释字符的字节数+2
段内容注释字符
--------------------------------------------------------------------------
说明:有的JPEG文件没有这个段。