必背经典算法(高级pascal)
信息学奥赛经典算法

信息学奥赛经典算法信息学奥赛是一项涉及算法和数据结构的比赛。
算法是指解决问题的具体步骤和方法,而数据结构是指存储和组织数据的方式。
在信息学奥赛中,掌握经典算法是非常重要的,可以提高解题的效率和成功的概率。
下面我将介绍一些经典的算法。
1.贪心算法(Greedy Algorithm)贪心算法是一种简单直观的算法思想,其基本策略是每一步都选择当前状态下的最优解,从而希望最终能够得到全局最优解。
贪心算法通常应用于问题的最优化,比如找出能够覆盖所有区域的最少选择。
然而,贪心算法并不是所有问题都适用,因为它可能会导致局部最优解,并不能得到全局最优解。
2.动态规划(Dynamic Programming)动态规划是一种通过将问题分解成更小的子问题来求解复杂问题的方法。
其主要思想是通过记录中间计算结果并保存起来,以避免重复计算。
动态规划常用于求解最优化问题,例如寻找最长递增子序列、最短路径等。
动态规划是一个非常重要的算法思想,也是信息学奥赛中常见的题型。
3.深度优先(Depth First Search,DFS)深度优先是一种常见的图遍历算法,其基本思想是从一个顶点开始,沿着路径向深度方向遍历图,直到无法继续前进,然后回溯到上一个节点。
DFS通常用于解决图的连通性问题,例如寻找图的强连通分量、欧拉回路等。
DFS的一个重要应用是解决迷宫问题。
4.广度优先(Breadth First Search,BFS)广度优先是一种图遍历算法,其基本思想是从一个顶点开始,按照广度方向遍历图,逐层往下遍历,直到找到目标节点或者遍历完整个图。
BFS通常用于解决最短路径问题,例如在一个迷宫中找到从起点到终点的最短路径。
5.分治算法(Divide and Conquer)分治算法是一种将问题分成更小的子问题并独立地求解它们的方法,然后通过合并子问题的结果来得到原始问题的解。
分治算法是一种递归的算法思想,通常在解决问题时能够显著提高效率。
经典算法实例范文

经典算法实例范文算法是一系列解决问题的步骤或规则,是计算机科学中非常重要的概念。
经典算法是指在计算机科学领域被广泛应用并被证明相对高效的算法。
本文将介绍几个经典算法的实例。
一、排序算法排序算法是最基本、最常用的算法之一、下面将介绍两个经典的排序算法。
1.冒泡排序冒泡排序是一种简单的排序算法,它的基本思路是多次遍历数组,每次将相邻的两个元素逐个比较,如果顺序不对则交换位置。
这样一次遍历后,最大的元素会被移到最后。
重复n-1次遍历,就可以完成排序。
冒泡排序的时间复杂度是O(n^2)。
2.快速排序快速排序是一种高效的排序算法,它的基本思路是选择一个基准元素,通过一趟排序将待排序的序列分成两个独立的部分,其中一部分的所有元素都小于基准,另一部分的所有元素都大于等于基准。
然后对这两个部分分别进行递归排序,最后合并两个部分得到有序序列。
快速排序的时间复杂度是 O(nlogn)。
二、查找算法查找算法是在给定的数据集合中一些特定元素的算法。
下面将介绍两个常用的查找算法。
1.二分查找二分查找也称为折半查找,是一种在有序数组中查找一些特定元素的算法。
它的基本思路是首先确定数组中间位置的元素,然后将要查找的元素与中间元素进行比较,如果相等则返回位置,如果小于则在左部分继续查找,如果大于则在右部分继续查找。
二分查找的时间复杂度是 O(logn)。
2.哈希查找哈希查找是通过哈希函数将关键字映射到哈希表中的位置,然后根据映射位置在哈希表中查找关键字。
哈希查找的时间复杂度是O(1)。
三、图算法图是由节点和边组成的一种数据结构,图算法主要用于解决与图相关的问题。
下面将介绍两个常用的图算法。
1.广度优先广度优先是一种用于图的遍历和的算法。
它的基本思路是从图的其中一顶点出发,遍历所有与之相邻的顶点,然后再依次遍历这些相邻顶点的相邻顶点,以此类推,直到访问完所有顶点,或者找到目标顶点。
广度优先使用队列来实现,时间复杂度是O(,V,+,E,),其中,V,表示图的顶点数,E,表示图的边数。
Pascal高精度

所谓的高精度运算,是指参与运算的数(加数,减数,因子……)范围大大超出了标准数据类型(整型,实型)能表示的范围的运算。
例如,求两个200位的数的和。
这时,就要用到高精度算法了。
在这里,我们先讨论高精度加法。
高精度运算主要解决以下三个问题:一、加数、减数、运算结果的输入和存储运算因子超出了整型、实型能表示的范围,肯定不能直接用一个数的形式来表示。
在Pascal中,能表示多个数的数据类型有两种:数组和字符串。
数组:每个数组元素存储1位(在优化时,这里是一个重点!),有多少位就需要多少个数组元素;用数组表示数的优点:每一位都是数的形式,可以直接加减;运算时非常方便。
用数组表示数的缺点:数组不能直接输入;输入时每两位数之间必须有分隔符,不符合数值的输入习惯;字符串:字符串的最大长度是255,可以表示255位。
用字符串表示数的优点:能直接输入输出,输入时,每两位数之间不必分隔符,符合数值的输入习惯;用字符串表示数的缺点:字符串中的每一位是一个字符,不能直接进行运算,必须先将它转化为数值再进行运算;运算时非常不方便;综合以上所述,对上面两种数据结构取长补短:用字符串读入数据,用数组存储数据: vars1,s2:string;a,b,c:array [1..260] of integer;i,l,k1,k2:integer;beginwrite('input s1:');readln(s1);write('input s2:');readln(s2); {读入两个数s1,s2,都是字符串类型}l:=length(s1);{求出s1的长度,也即s1的位数;有关字符串的知识。
} k1:=260;for i:=l downto 1 dobegina[k1]:=ord(s1)-48;{将字符转成数值}k1:=k1-1;end;k1:=k1+1; {以上将s1中的字符一位一位地转成数值并存在数组a中;低位在后(从第260位开始),高位在前(每存完一位,k1减1),完后,k1指向最高位} 对s2的转化过程和上面一模一样。
PASCAL算法

算法设计题集第一章算法初步第一节程序设计与算法一、算法算法是解决问题方法的精确描述,但是并不是所有问题都有算法,有些问题经研究可行,则相应有算法,但这并不是说问题就有结果。
上述的“可行”,是指对算法的研究。
1.待解问题的描述待解问题表述应精确、简练、清楚,使用形式化模型刻划问题是最恰当的。
例如,使用数学模型刻划问题是最简明、严格的,一旦问题形式化了,就可依据相应严格的模型对问题求解。
2.算法设计算法设计的任务是对各类具体问题设计良好的算法及研究设计算法的规律和方法。
常用的算法有:穷举搜索法、递归法、回溯法、贪心法、分治法等。
3.算法分析算法分析的任务是对设计出的每一个具体的算法,利用数学工具,讨论各种复杂度,以探讨某种具体算法适用于哪类问题,或某类问题宜采用哪种算法。
算法的复杂度分时间复杂度和空间复杂度。
.时间复杂度:在运行算法时所耗费的时间为f(n)(即n的函数)。
.空间复杂度:实现算法所占用的空间为g(n)(也为n的函数)。
称O(f(n))和O(g(n))为该算法的复杂度。
二、程序设计1.程序程序是对所要解决的问题的各个对象和处理规则的描述,或者说是数据结构和算法的描述,因此有人说,数据结构+算法=程序。
2.程序设计程序设计就是设计、编制和调试程序的过程。
3.结构化程序设计结构化程序设计是利用逐步求精的方法,按一套程式化的设计准则进行程序的设计。
由这种方法产生的程序是结构良好的。
所谓“结构良好”是指:(1)易于保证和验证其正确性;(2)易于阅读、易于理解和易于维护。
按照这种方法或准则设计出来的程序称为结构化的程序。
“逐步求精”是对一个复杂问题,不是一步就编成一个可执行的程序,而是分步进行。
.第一步编出的程序最为抽象;.第二步编出的程序是把第一步所编的程序(如过程、函数等)细化,较为抽象;.…….第i步编出的程序比第i-1步抽象级要低;.…….直到最后,第n步编出的程序即为可执行的程序。
所谓“抽象程序”是指程序所描述的解决问题的处理规则,是由那些“做什么”操作组成,而不涉及这些操作“怎样做”以及解决问题的对象具有什么结构,不涉及构造的每个局部细节。
pascal常用算法代码

//求无向图割顶的算法,割顶:若在图的dfs树上,i 存在儿子节点 s ,使得 s 及 s 的所有子孙的后向边不指向 i 的祖先(可以指向i),输出的是一个点I,尝试写成过程,然后找到其应用
ary(多进制2-16转十进制).pas
program ary;
var a:array [1..10000] of longint;
program ary;
var a:array [1..10000] of longint;
k:array [1..10000] of char;
s,j,b,t:longint;
begin
readln(s);
readln(b);
while s<>0 do
begin
'B':a[j]:=11;
'C':a[j]:=12;
'D':a[j]:=13;
'E':a[j]:=14;
'F':a[j]:=15;
end;
inc(j);
end;
for i:=1 to j do
if a[i]>=b then
for k:=1 to n do if (i<>k)and(j<>k)then
if (a[i,j]<>maxlongint)and(d[i]<>maxlongint)and(d[j]>d[i]+a[i,j])then
d[j]:=d[i]+a[i,j];
for i:=1 to n do
begin
case a[j] of
PASCAL语言程序设计知识讲解资料

PASCAL语言程序设计知识讲解资料PASCAL是一种结构化程序设计语言,起初由尼科劳斯·维尔特设计于1968年。
它是一种意图激发清晰结构化编程方法的语言,因此在计算机科学教育中得到广泛应用。
现在,PASCAL仍然是一种非常流行的教学语言,用于教授编程基础和算法。
1.结构化编程:PASCAL语言的一个重要设计目标是通过结构化编程来提高代码的可读性和可维护性。
PASCAL提供了块、子程序、循环结构和条件语句等结构来帮助程序员组织代码并降低编程错误的可能性。
2.关注类型安全:PASCAL是一种静态类型语言,它要求在编译时为每个变量明确指定数据类型。
这样做有助于提前发现类型错误,并增加程序的可靠性。
PASCAL还支持用户自定义类型,使程序员能够创建抽象数据类型来更好地组织和管理数据。
3.丰富的标准库:PASCAL提供了丰富的标准库,其中包括文件操作、字符串处理、图形绘制、数学计算等常用功能。
这些库函数使程序员能够更轻松地开发复杂的应用程序,同时也可以节省大量的编写和调试代码的时间。
4. 跨平台支持:PASCAL编译器可以生成适用于不同操作系统的可执行代码,包括Windows、Mac和Linux等。
这种跨平台支持使得程序员可以在不同的操作系统上编写和运行PASCAL程序,而无需进行太多的修改。
5.功能强大:虽然PASCAL是一种教学语言,但它仍然具备很强的功能。
它支持递归、指针操作、动态内存分配等高级特性,为程序员提供了更多的灵活性和控制力。
下面是一个简单的示例程序,展示了PASCAL的基本语法和特性:```program HelloWorld;varname: string;beginwriteln('Please enter your name:');readln(name);writeln('Hello, ', name, '!');end.```在这个例子中,程序首先输出提示用户输入姓名的消息,然后读取用户输入的姓名,并输出欢迎消息。
学习编程的十大经典算法

学习编程的十大经典算法学习编程是现代社会中一个非常重要的技能,而掌握经典算法是成为一个优秀的程序员的必备条件之一。
下面将介绍十大经典算法,详细解释它们的原理和应用。
1. 二分查找算法(Binary Search)二分查找算法是一种在有序数组中快速查找特定元素的算法。
它将查找范围不断缩小一半,直到找到目标元素或确定目标元素不存在。
二分查找算法的时间复杂度为O(log n)。
2. 冒泡排序算法(Bubble Sort)冒泡排序算法是一种简单但效率较低的排序算法。
它通过多次遍历数组,将相邻的元素进行比较并交换位置,使得较大(或较小)的元素逐渐移动到数组的末尾。
冒泡排序的时间复杂度为O(n^2)。
3. 快速排序算法(Quick Sort)快速排序算法是一种高效的排序算法。
它通过选择一个基准元素,将数组分为左右两个子数组,并对子数组进行递归排序。
快速排序算法的时间复杂度为O(n log n),在大多数情况下具有较好的性能。
4. 归并排序算法(Merge Sort)归并排序算法是一种分治思想的排序算法。
它将数组一分为二,递归地对子数组进行排序,然后将排好序的子数组合并成一个有序的数组。
归并排序算法的时间复杂度为O(n log n),稳定且适用于大规模数据的排序。
5. 插入排序算法(Insertion Sort)插入排序算法是一种简单且稳定的排序算法。
它通过将未排序的元素逐个插入已排序的序列中,以达到整体有序的目的。
插入排序的时间复杂度为O(n^2),但对于小规模数据或基本有序的数组,插入排序具有较好的性能。
6. 选择排序算法(Selection Sort)选择排序算法是一种简单但效率较低的排序算法。
它通过多次遍历数组,选择出最小(或最大)的元素,并放置到已排序的序列中。
选择排序的时间复杂度为O(n^2),但它适用于小规模数据或交换成本较高的情况。
7. 堆排序算法(Heap Sort)堆排序算法是一种高效的排序算法。
Pascal入门教程 (3)

第四章循环程序设计内容提要本章介绍了循环结构程序设计的思路,FOR,WHILE,REPEAT...UNTIL三种循环语句的用法和一些常见算法。
学习要求在本章的学习中,要理解循环程序设计的思路,弄清循环的流程,对FOR循环,WHILE循环,REPEAT三种循环语句能熟练运用,能用多重循环解决实际问题。
在编程中,经常遇到这种问题:对于某个操作要执行许多次,而每次操作都是重复的动作。
在这种情况下,我们便希望计算机能自动完成这些重复的动作。
这就是循环设计的基本思路。
第一节FOR循环我们现在要打印一千个“*”。
这分明是一个重复的动作:把打印一个“*”的动作重复一千次就可以了。
我们只需写出一个打印一个“*”的WRITE语句,然后将该语句执行一千次。
每执行一个WRITE(“*”)语句,程序便统计一次,直到一千。
那么,谁来统计这个数呢?这就是FOR语句。
它的基本格式如下:FOR 循环变量:=初值 TO 终值 DO(循环体)在这个语句中,初值和终值可以取整型,字符型,枚举型,子界型。
循环变量首先被赋予初值,再和终值比较,如小于等于终值就执行下面的循环体,再把循环变量中的值变成它的后继值(如:1的后继值为2,3的后继值为4,“A”的后继值为“B”,“x”的后继值为“y”),又和终值进行比较,如小于等于终值,又执行下面的循环体,直到大于终值为止......后面是它的流程图。
那么,打印一千个“*”的程序可以这样写:例1PROGRAM e1(input,output);VAR i :integer;BEGINfor i:=1 to 1000 dowrite(‘*’);END.在设计FOR语句时有这样一些规则:(1)循环变量的类型一定要与初值和终值的类型一致。
(2)循环变量的初值和终值可以是常量,变量或表达式。
(3)循环体可以不止一个语句,如有多个语句,则用BEGIN 和END语句构成复合句。
(4)如果初值大于终值,则本循环不执行。
C语言入门必学—10个经典C语言算法

C语言入门必学—10个经典C语言算法C语言是一种广泛使用的编程语言,具有高效、灵活和易学的特点。
它不仅在软件开发中被广泛应用,也是计算机科学专业的必修课。
在学习C语言的过程中,掌握一些经典的算法是非常重要的。
本文将介绍10个经典C语言算法,帮助读者更好地了解和掌握C语言。
一、冒泡排序算法(Bubble Sort)冒泡排序算法是最简单、也是最经典的排序算法之一。
它通过不断比较相邻的元素并交换位置,将最大(或最小)的元素逐渐“冒泡”到数组的最后(或最前)位置。
二、选择排序算法(Selection Sort)选择排序算法是一种简单但低效的排序算法。
它通过不断选择最小(或最大)的元素,并与未排序部分的第一个元素进行交换,将最小(或最大)的元素逐渐交换到数组的前面(或后面)。
三、插入排序算法(Insertion Sort)插入排序算法是一种简单且高效的排序算法。
它通过将数组分为已排序和未排序两个部分,依次将未排序部分的元素插入到已排序部分的合适位置。
四、快速排序算法(Quick Sort)快速排序算法是一种高效的排序算法。
它采用了分治的思想,通过将数组分为较小和较大两部分,并递归地对两部分进行排序,最终达到整个数组有序的目的。
五、归并排序算法(Merge Sort)归并排序算法是一种高效的排序算法。
它采用了分治的思想,将数组一分为二,递归地对两个子数组进行排序,并将结果合并,最终得到有序的数组。
六、二分查找算法(Binary Search)二分查找算法是一种高效的查找算法。
它通过不断将查找范围折半,根据中间元素与目标值的大小关系,缩小查找范围,最终找到目标值所在的位置。
七、递归算法(Recursive Algorithm)递归算法是一种通过自我调用的方式解决问题的算法。
在C语言中,递归算法常用于解决树的遍历、问题分解等情况。
八、斐波那契数列算法(Fibonacci Sequence)斐波那契数列是一列数字,其中每个数字都是前两个数字的和。
PASCAL基础知识

PASCAL基础知识第一节数据类型1.常数:整型常量maxint表示计算机系统所允许的最大整数,-maxint-1表示最小整数实常数包括正实常数和负实常数。
有两种表示法:十进制表示法和科学计数法。
科学计数法:有位数,底数和指数构成。
字符常量:单个引号括起来布尔常量:符号常量:在使用常量之前必须定义符号常量2.变量:自定义标识符必须以字母(包括下划线)开头,后面的字符可以是字母或数字。
3.算术表达式:常用的6个算术运算符:+,-,*,/(实数除),div(整除),mod(求余)。
/(实数除法)的结果是实数为4/2=2.0,而不是2。
div(整数除)要求参与运算的两个数都是整型,结果也为整形。
10div3=3,5div10=0,div运算只取商的整数部分。
Mod(余数)只能用于整数运算,结果也是整数4帕斯卡标准函数:odd()判断变量是否为奇数abs()绝对值sqr()求平方sqrt()求平方根Chr(数值表达式)返回用数值表达式的值编码的字符。
数值表达式的取值范围为0-255。
Ord()返回字符的ASCII码,结果是一个整数。
在字符范围内,和Chr()函数是彼此的反函数。
TRUNC(1.999)是一个值为1的截断函数。
Round()取整函数random()随机函数mod()余数函数succ(x)求x的后继succ(‘b’)=’c’succ(5)=6succ(false)=truepred(x)求x的前导pred(‘b’)=’a’pred(5)=4pred(true)=false第三节输出语句(写入语句)1.write语句write(表达式1,表达式2,表达式3,....);2.Writeln语句Writeln(表达式1、表达式2、表达式3等);和写的区别在于输出之后有换行。
第四节输入语句1.写语句的输出格式:对整数的默认输出格式是十进制形式,对实数的输出,默认的形式这是科学计算的形式。
在Pascal中,数据占用的宽度称为“字段宽度”或“字段宽度”。
世界十大经典算法

世界十大经典算法世界十大经典算法算法是计算机科学中非常重要的概念,它是一种解决问题的方法和步骤的描述。
以下是世界上广泛应用且被业界认可的十大经典算法: 1. 二分查找算法(Binary Search Algorithm):在有序数组中查找目标元素的算法。
通过将目标元素与数组中间元素进行比较,可以将搜索范围缩小一半,从而提高搜索效率。
2. 快速排序算法(Quick Sort Algorithm):一种基于分治法的排序算法。
它通过选择一个基准元素,将数组分为两个子数组,其中一个子数组的元素都小于等于基准元素,另一个子数组的元素都大于等于基准元素,然后递归地对子数组进行排序。
3. 归并排序算法(Merge Sort Algorithm):一种基于分治法的排序算法。
它将数组分成两个子数组,然后递归地对子数组进行排序,并将排序好的子数组合并成一个有序的数组。
4. 广度优先搜索算法(Breadth-First Search Algorithm):用于图遍历的一种算法。
它从图的某个顶点开始,逐层遍历其邻接顶点,直到遍历完所有顶点。
广度优先搜索常用于寻找最短路径或解决迷宫等问题。
5. 深度优先搜索算法(Depth-First Search Algorithm):用于图遍历的一种算法。
它从图的某个顶点开始,沿着一条路径一直向下遍历,直到无法继续为止,然后回溯到上一个没有遍历完的邻接顶点,继续遍历其他路径。
深度优先搜索常用于生成迷宫、图的连通性问题等。
6. Dijkstra算法(Dijkstra's Algorithm):用于求解单源最短路径问题的一种算法。
它根据权重赋值给每条边,计算出从源节点到其他节点的最短路径。
7. 动态规划算法(Dynamic Programming Algorithm):一种基于分治法的优化算法。
动态规划在问题可分解为重叠子问题时,通过保存子问题的解,避免重复计算,从而提高算法效率。
程序员必学的10大算法

程序员必学的10大算法程序员在编程中经常会遇到各种问题,需要使用算法来解决。
掌握一些经典算法能够提高程序效率、减少bug的数量,并且对于面试中的算法题也有帮助。
下面是程序员必学的10大算法。
1.排序算法:排序算法是最基本也是最常用的算法之一、常见的排序算法有冒泡排序、选择排序、插入排序、快速排序、归并排序等。
排序算法能够让数据按照一定的顺序排列,提高数据的查找和处理效率。
2.查找算法:查找算法是在一组数据中找到目标数据的过程。
常见的查找算法有顺序查找、二分查找、哈希查找等。
查找算法能够帮助程序员快速定位目标数据,提高程序效率。
3.哈希算法:哈希算法将任意长度的数据映射为固定长度的数据。
常见的哈希算法有MD5、SHA、CRC等。
哈希算法在密码加密、唯一标识生成等场景中应用广泛。
4.最短路径算法:最短路径算法是在带权图中找到两个节点之间最短路径的过程。
常见的最短路径算法有迪杰斯特拉算法、弗洛伊德算法、贝尔曼-福特算法等。
最短路径算法在网络路由、导航系统等领域有重要应用。
5.动态规划算法:动态规划算法是在求解多阶段决策过程的最优解问题时使用的一种算法。
常见的动态规划算法有背包问题、最长公共子序列等。
动态规划算法能够解决很多实际问题,提高程序的效率和准确性。
6.贪心算法:贪心算法是一种在每一步选择中都采取当前状态下最优的选择,从而希望最终能得到全局最优解的算法。
常见的贪心算法有霍夫曼编码、最小生成树等。
贪心算法适用于那些可以通过局部最优选择来达到全局最优的问题。
7.图算法:图算法是解决图结构中的问题的一种算法。
常见的图算法有深度优先、广度优先、拓扑排序、最小生成树等。
图算法在社交网络分析、网络流量优化等领域有广泛应用。
8. 字符串匹配算法:字符串匹配算法是在一个较长的字符串中查找出现的目标子串的过程。
常见的字符串匹配算法有暴力匹配、KMP算法、Boyer-Moore算法等。
字符串匹配算法在文本、模式匹配等场景中非常重要。
pascal常见算法整理

3、归并排序
program gbpx;
const maxn=7;
type arr=array[1..maxn] of integer;
var a,b,c:arr;
i:integer;
procedure merge(r:arr;l,m,n:integer;var r2:arr);
a[i+d]:=t;
end;
end;
write('output data:');
for i:=1 to n do write(a[i]:6);
writeln;
end.
程序2:(子序列是冒泡排序)
program xepx;
const n=7;
type
arr=array[1..n] of integer;
while (i<n) and bool do
begin
bool:=false;
for j:=n downto i+1 do
if a[j-1]<a[j] then
begin t:=a[j-1];a[j-1]:=a[j];a[j]:=t;bool:=true end;
for i:=1 to n do write(a[i]:6);
writeln;
end.
i,j,k,t:integer;
begin
write('Enter date:');
for i:= 1 to n do read(a[i]);
writeln;
for i:=2 to n do
begin
k:=a[i];j:=i-1;
Pascal的运算符及表达式
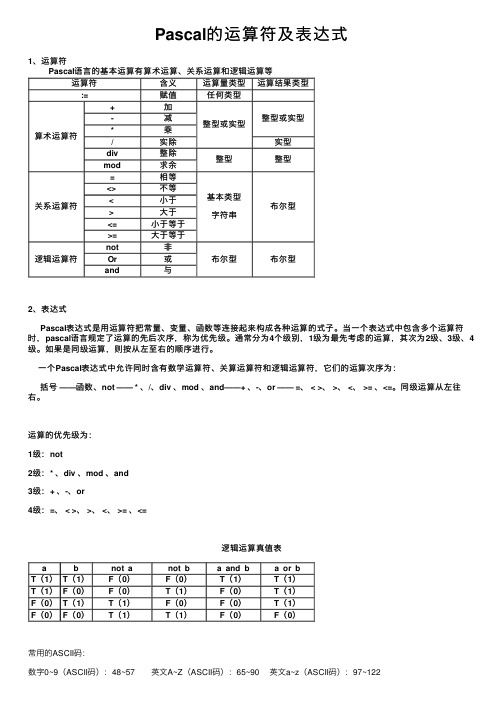
Pascal的运算符及表达式1、运算符Pascal语⾔的基本运算有算术运算、关系运算和逻辑运算等运算符含义运算量类型运算结果类型:=赋值任何类型算术运算符+加整型或实型整型或实型-减*乘/实除实型div整除整型整型mod求余关系运算符=相等基本类型字符串布尔型<> 不等< ⼩于> ⼤于<=⼩于等于>=⼤于等于逻辑运算符not⾮布尔型布尔型Or或and与2、表达式Pascal表达式是⽤运算符把常量、变量、函数等连接起来构成各种运算的式⼦。
当⼀个表达式中包含多个运算符时,pascal语⾔规定了运算的先后次序,称为优先级。
通常分为4个级别,1级为最先考虑的运算,其次为2级、3级、4级。
如果是同级运算,则按从左⾄右的顺序进⾏。
⼀个Pascal表达式中允许同时含有数学运算符、关算运算符和逻辑运算符,它们的运算次序为:括号 ——函数、not —— * 、/、div 、mod 、and——+ 、-、or ——=、 < >、 >、 <、 >= 、<=。
同级运算从左往右。
运算的优先级为:1级:not2级:* 、div 、mod 、and3级:+ 、-、or4级:=、 < >、 >、 <、 >= 、<=逻辑运算真值表a b not a not b a and b a or bT(1)T(1)F(0)F(0)T(1)T(1)T(1)F(0)F(0)T(1)F(0)T(1)F(0)T(1)T(1)F(0)F(0)T(1)F(0)F(0)T(1)T(1)F(0)F(0)常⽤的ASCII码:数字0~9(ASCII码):48~57 英⽂A~Z(ASCII码):65~90 英⽂a~z(ASCII码):97~122。
Pascal经典教程(1—3章)

Pascal经典教程(1—3章)⽆论做任何事情,都要有⼀定的⽅式⽅法与处理步骤。
计算机程序设计⽐⽇常⽣活中的事务处理更具有严谨性、规范性、可⾏性。
为了使计算机有效地解决某些问题,须将处理步骤编排好,⽤计算机语⾔组成“序列”,让计算机⾃动识别并执⾏这个⽤计算机语⾔组成的“序列”,完成预定的任务。
将处理问题的步骤编排好,⽤计算机语⾔组成序列,也就是常说的编写程序。
在Pascal语⾔中,执⾏每条语句都是由计算机完成相应的操作。
编写Pascal程序,是利⽤Pascal语句的功能来实现和达到预定的处理要求。
“千⾥之⾏,始于⾜下”,我们从简单程序学起,逐步了解和掌握怎样编写程序。
程序结构和基本语句在未系统学习Pascal语⾔之前,暂且绕过那些繁琐的语法规则细节,通过下⾯的简单例题,可以速成掌握Pascal程序的基本组成和基本语句的⽤法,让初学者直接模仿学习编简单程序。
[例1.1]编程在屏幕上显⽰“Hello World!”。
Pascal程序:Program ex11;BeginWriteln(‘Hello World!’);ReadLn;End.这个简单样例程序,希望⼤家的程序设计学习能有⼀个良好的开端。
程序中的Writeln是⼀个输出语句,它能命令计算机在屏幕上输出相应的内容,⽽紧跟Writeln语句后是⼀对圆括号,其中⽤单引号引起的部分将被原原本本地显⽰出来。
[例1.2]已知⼀辆⾃⾏车的售价是300元,请编程计算a辆⾃⾏车的总价是多少?解:若总售价⽤m来表⽰,则这个问题可分为以下⼏步处理:①从键盘输⼊⾃⾏车的数⽬a;②⽤公式 m=300*a 计算总售价;③输出计算结果。
Pascal程序:Program Ex12; {程序⾸部}Var a,m : integer; {说明部分}Begin {语句部分}Write(‘a=’);ReadLn(a); {输⼊⾃⾏车数⽬}M := 300*a; {计算总售价}Writeln(‘M=’,m); {输出总售价}ReadLn; {等待输⼊回车键}End.此题程序结构完整,从中可看出⼀个Pascal 程序由三部分组成:(1)程序⾸部由保留字Program开头,后⾯跟⼀个程序名(如:Exl1);其格式为:Program 程序名;程序名由⽤户⾃⼰取,它的第⼀个字符必须是英⽂字母,其后的字符只能是字母或数字和下划线组成,程序名中不能出现运算符、标点符和空格。
Pascal算法-3.递推算法

图20 倒推到第二步
为了在I=2处贮藏1000公升汽油,卡车至少从I=3处开三趟满载油的 车至I=2处。所以I=3处至少贮有3*500公升汽油,即oil[3]=500*3=1500。 加上I=2至I=3处的二趟返程空车,合计5次。路途耗油亦应500公升,即 d23=500/5, Way[3]=Way[2]+d23=Way[2]+500/5; 此时的状况如图21所示。
(1 n) * (1 m) * n * m s=(1+2+┉┉+n)*( 1+2+┉┉+m)= 4
3.长宽不等的长方形个数s2 显然,s2=s-s1
(1 n) * (1 m) * n * m = 4
min{m, n}1 i 0
(n i ) * (m i )
由此得出算法: program ex7_3; var m,n,m1,n1,s1,s2:longint; begin readln(m,n); m1:=m;n1:=n; s1:=m1*n1; while (m1<>0)and(n1<>0)do begin m1:=m1-1;n1:=n1-1; s1:=s1+m1*n1; end; s2:=((m+1)*(n+1)*m*n) div 4-s1; writeln(s1,' ',s2); end.
//计算正方形的个数s1
// 计算长方形的个数s2
【例4】贮油点
一辆重型卡车欲穿过1000公里的沙漠,卡车耗汽油为1升/公里,卡车总载油 能力为500公升。显然卡车装一次油是过不了沙漠的。因此司机必须设法在沿途 建立若干个贮油点,使卡车能顺利穿过沙漠。试问司机如怎样建立这些贮油点? 每一贮油点应存储多少汽油,才能使卡车以消耗最少汽油的代价通过沙漠?(结 果保留小数点后两位) 编程计算及打印建立的贮油点序号,各贮油点距沙漠边沿出发的距离以及存 油量。格式如下: No. Distance(k.m.) Oil(litre)
完整的Pascal讲义(word)

第一课初识Pascal语言信息学奥林匹克竞赛是一项益智性的竞赛活动,核心是考查选手的智力和使用计算机解题的能力。
选手首先应针对竞赛中题目的要求构建数学模型,进而构造出计算机可以接受的算法,之后要写出高级语言程序,上机调试通过。
程序设计是信息学奥林匹克竞赛的基本功,在青少年朋友参与竞赛活动的第一步必须掌握一门高级语言及其程序设计方法。
一、Pascal 语言概述PASCAL语言也是一种算法语言,它是瑞士苏黎世联邦工业大学的N.沃思(Niklaus Wirth)教授于1968年设计完成的,1971年正式发表。
1975年,对PASCAL语言进行了修改,作为"标准PASCAL语言"。
PASCAL语言是在ALGOL 60的基础上发展而成的。
它是一种结构化的程序设计语言,可以用来编写应用程序。
它又是一种系统程序设计语言,可以用来编写顺序型的系统软件(如编译程序)。
它的功能强、编译程序简单,是70年代影响最大一种算法语言。
二、Pascal 语言的特点从使用者的角度来看,PASCAL语言有以下几个主要的特点:⒈它是结构化的语言。
PASCAL语言提供了直接实现三种基本结构的语句以及定义"过程"和"函数"(子程序)的功能。
可以方便地书写出结构化程序。
在编写程序时可以完全不使用GOTO语句和标号。
这就易于保证程序的正确性和易读性。
PASCAL语言强调的是可靠性、易于验证性、概念的清晰性和实现的简化。
在结构化这一点上,比其它(如BASIC,FORTRAN77)更好一些。
⒉有丰富的数据类型。
PASCAL提供了整数、实型、字符型、布尔型、枚举型、子界型以及由以上类型数据构成的数组类型、集合类型、记录类型和文件类型。
此外,还提供了其它许多语言中所没有的指针类型。
沃思有一个著名的公式:"算法+数据结构=程序"。
指出了在程序设计中研究数据的重要性。
丰富的数据结构和上述的结构化性质,使得PASCAL可以被方便地用来描述复杂的算法,得到质量较高的程序。
pascal-经典算法

动态规划(一)
• 0-1背包 • 完全背包 • 乘法问题 • 数塔问题 • 装箱问题
动态规划(二)
• 最长上升序列(LIS) • 最长公共子串(• 归并排序 • 最近点对问题 • 求最大子序列和的O(nlogn)算法 • Hanoi塔问题及其变种 • 棋盘覆盖问题 • 循环赛日程表问题
贪心
• 最优装载问题 • 部分背包问题 • 独立区间的选择 • 覆盖区间的选择 • 区间的最小点覆盖 • 点的最小区间覆盖
递推
• Fibonacci数的若干应用 • Catalan数的若干应用 • 拆分数 • 差分序列
数据结构(二)
• ★平衡二叉树 • ★树状数组 • ★线段树 • ★块状链表
排列与组合
• 生成所有排列 • 生成所有组合 • 生成下一个排列 • 生成下一个组合
计算几何(一)
• 计算斜率 • 计算点积 • 计算余弦 • 计算平面两点的距离 • 计算空间两点的距离 • ★计算广义空间两点的距离 • 判断三点是否共线
语言与计算机
• 递归调用 • 向前引用 • 随机化 • 指针类型 • 按位运算
排序(一)
• 冒泡排序(起泡排序) • 选择排序 • 插入排序 • ★ Shell排序 • 快速排序
排序(二)
• 线性时间排序 • 查找第k大元素 • 带第二关键字的排序
数论(一)
• 素性判断 • 筛选建立素数表 • 分解质因数 • 进制转换 • 二分取幂 • ★二分求解线性递推方程
图论:二分图
• 验证二分图 • 匈牙利算法 • ★KM算法 • ★稳定婚姻系统
树
• 求树的最短链 • 二叉树的四种遍历 • 已知先序中序求后序 • 已知中序后序求先序 • ★已知先序后序求中序 • ★LCA问题的Tarjan离线算法 • ★Huffman编码
十大经典算法范文

十大经典算法范文1.算法:算法用于在大量数据中找到目标值或满足特定条件的值。
最常用的算法有二分查找和深度优先(DFS)。
2.排序算法:排序算法用于将一组数据按照一定的顺序排列。
最著名的排序算法有冒泡排序、插入排序、选择排序、快速排序和归并排序。
3.哈希算法:哈希算法将输入数据映射到一个固定大小的哈希值,用于数据的快速查找和存储。
最常用的哈希算法有MD5和SHA算法。
4.动态规划算法:动态规划算法是一种解决多阶段决策过程最优化问题的方法。
它将问题分解成一系列子问题,通过求解子问题的最优解来得到原问题的最优解。
5. 贪心算法:贪心算法是一种求解最优化问题的策略,它每次选择局部最优解,并希望通过这种选择得到全局最优解。
经典的贪心算法有Prim算法和Kruskal算法。
6. 图算法:图算法用于解决与图相关的问题,如最短路径问题、最小生成树问题和网络流问题。
最著名的图算法有Dijkstra算法、Floyd-Warshall算法和BFS算法。
7.字符串匹配算法:字符串匹配算法用于在一个字符串中查找特定的子串。
最常用的字符串匹配算法有朴素字符串匹配算法和KMP算法。
8. 最小生成树算法:最小生成树算法用于从一个连通图中找到最小的生成树,该树包含图中的所有顶点,并且边的权重之和最小。
最著名的最小生成树算法有Prim算法和Kruskal算法。
9.图像处理算法:图像处理算法用于对图像进行各种处理,如图像的平滑、锐化、边缘检测和图像的压缩等。
最常用的图像处理算法有模糊算法和卷积算法。
10.机器学习算法:机器学习算法是一种将数据输入模型中进行训练,并通过学习得到模型的参数,并用于预测未来的数据。
最常用的机器学习算法有线性回归、逻辑回归、决策树和支持向量机等。
以上是十大经典算法的介绍。
这些算法在计算机科学与算法领域具有重要的地位和广泛的应用,对于理解和解决各种问题都非常有帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、数论算法1.求两数的最大公约数function gcd(a,b:integer):integer;beginif b=0 then gcd:=aelse gcd:=gcd (b,a mod b);end ;2.求两数的最小公倍数function lcm(a,b:integer):integer;beginif a<b then swap(a,b);lcm:=a;while lcm mod b>0 do inc(lcm,a);end;3.素数的求法A.小范围内判断一个数是否为质数:function prime (n: integer): Boolean;var I: integer;beginfor I:=2 to trunc(sqrt(n)) doif n mod I=0 then beginprime:=false; exit;end;prime:=true;end;B.判断longint范围内的数是否为素数(包含求50000以内的素数表): procedure getprime;vari,j:longint;p:array[1..50000] of boolean;beginfillchar(p,sizeof(p),true);p[1]:=false;i:=2;while i<50000 do beginif p[i] thenbeginj:=i*2;while j<50000 dobegin {筛选法}p[j]:=false;inc(j,i);end;end;inc(i);end;l:=0;for i:=1 to 50000 doif p[i] then begininc(l);pr[l]:=i;end;end;{getprime}function prime(x:longint):boolean;var i:integer;beginprime:=false;for i:=1 to l doif pr[i]>=x then breakelse if x mod pr[i]=0 then exit;prime:=true;end;{prime}二、图论算法1.最小生成树A.Prim算法:procedure prim(v0:integer);varlowcost,closest:array[1..maxn] of integer;i,j,k,min:integer;beginfor i:=1 to n do beginlowcost:=cost[v0,i];closest:=v0;end;for i:=1 to n-1 do begin{寻找离生成树最近的未加入顶点k}min:=maxlongint;for j:=1 to n doif (lowcost[j]<min) and (lowcost[j]<>0) then begin min:=lowcost[j];k:=j;end;lowcost[k]:=0; {将顶点k加入生成树}{生成树中增加一条新的边k到closest[k]}{修正各点的lowcost和closest值}for j:=1 to n doif cost[k,j]<lwocost[j] then beginlowcost[j]:=cost[k,j];closest[j]:=k;end;end;end;{prim}B.Kruskal算法:(贪心)按权值递增顺序删去图中的边,若不形成回路则将此边加入最小生成树。
function find(v:integer):integer; {返回顶点v所在的集合}var i:integer;begini:=1;while (i<=n) and (not v in vset) do inc(i);if i<=n then find:=i else find:=0;end;procedure kruskal;vartot,i,j:integer;beginfor i:=1 to n do vset:=;{初始化定义n个集合,第I个集合包含一个元素I}p:=n-1; q:=1; tot:=0; {p为尚待加入的边数,q为边集指针}sort;{对所有边按权值递增排序,存于e中,e.v1与e.v2为边I所连接的两个顶点的序号,e.len为第I条边的长度}while p>0 do begini:=find(e[q].v1);j:=find(e[q].v2);if i<>j then begininc(tot,e[q].len);vset:=vset+vset[j];vset[j]:=[];dec(p);end;inc(q);end;writeln(tot);end;2.最短路径A.标号法求解单源点最短路径:vara:array[1..maxn,1..maxn] of integer;b:array[1..maxn] of integer; {b指顶点i到源点的最短路径}mark:array[1..maxn] of boolean;procedure bhf;varbest,best_j:integer;beginfillchar(mark,sizeof(mark),false);mark[1]:=true; b[1]:=0;{1为源点}repeatbest:=0;for i:=1 to n doIf mark then {对每一个已计算出最短路径的点}for j:=1 to n doif (not mark[j]) and (a[i,j]>0) thenif (best=0) or (b+a[i,j]<best) then beginbest:=b+a[i,j]; best_j:=j;end;if best>0 then beginb[best_j]:=best;mark[best_j]:=true;end;until best=0;end;{bhf}B.Floyed算法求解所有顶点对之间的最短路径:procedure floyed;beginfor I:=1 to n dofor j:=1 to n doif a[I,j]>0 then p[I,j]:=I else p[I,j]:=0; {p[I,j]表示I到j的最短路径上j的前驱结点}for k:=1 to n do {枚举中间结点}for i:=1 to n dofor j:=1 to n doif a[i,k]+a[j,k]<a[i,j] then begina[i,j]:=a[i,k]+a[k,j];p[I,j]:=p[k,j];end;end;C. Dijkstra 算法:vara:array[1..maxn,1..maxn] of integer;b,pre:array[1..maxn] of integer; {pre指最短路径上I的前驱结点} mark:array[1..maxn] of boolean;procedure dijkstra(v0:integer);beginfillchar(mark,sizeof(mark),false);for i:=1 to n do begind:=a[v0,i];if d<>0 then pre:=v0 else pre:=0;end;mark[v0]:=true;repeat {每循环一次加入一个离1集合最近的结点并调整其他结点的参数}min:=maxint; u:=0; {u记录离1集合最近的结点}for i:=1 to n doif (not mark) and (d<min) then beginu:=i; min:=d;end;if u<>0 then beginmark[u]:=true;for i:=1 to n doif (not mark) and (a[u,i]+d[u]<d) then begind:=a[u,i]+d[u];pre:=u;end;end;until u=0;end;3.计算图的传递闭包Procedure Longlink;VarT:array[1..maxn,1..maxn] of boolean;BeginFillchar(t,sizeof(t),false);For k:=1 to n doFor I:=1 to n doFor j:=1 to n do T[I,j]:=t[I,j] or (t[I,k] and t[k,j]);End;4.无向图的连通分量A.深度优先procedure dfs ( now,color: integer);beginfor i:=1 to n doif a[now,i] and c=0 then begin {对结点I染色}c:=color;dfs(I,color);end;end;B 宽度优先(种子染色法)5.关键路径几个定义:顶点1为源点,n为汇点。
a. 顶点事件最早发生时间Ve[j], Ve [j] = max{ Ve [j] + w[I,j] },其中Ve (1) = 0;b. 顶点事件最晚发生时间 Vl[j], Vl [j] = min{ Vl[j] – w[I,j] },其中 Vl(n) = Ve(n);c. 边活动最早开始时间 Ee, 若边I由<j,k>表示,则Ee = Ve[j];d. 边活动最晚开始时间 El, 若边I由<j,k>表示,则El = Vl[k] – w[j,k]; 若 Ee[j] = El[j] ,则活动j为关键活动,由关键活动组成的路径为关键路径。
求解方法:a. 从源点起topsort,判断是否有回路并计算Ve;b. 从汇点起topsort,求Vl;c. 算Ee 和 El;6.拓扑排序找入度为0的点,删去与其相连的所有边,不断重复这一过程。
例寻找一数列,其中任意连续p项之和为正,任意q 项之和为负,若不存在则输出NO.7.回路问题Euler回路(DFS)定义:经过图的每条边仅一次的回路。
(充要条件:图连同且无奇点)Hamilton回路定义:经过图的每个顶点仅一次的回路。
一笔画充要条件:图连通且奇点个数为0个或2个。
9.判断图中是否有负权回路 Bellman-ford 算法x,y,t分别表示第I条边的起点,终点和权。
共n个结点和m条边。
procedure bellman-fordbeginfor I:=0 to n-1 do d:=+infinitive;d[0]:=0;for I:=1 to n-1 dofor j:=1 to m do {枚举每一条边}if d[x[j]]+t[j]<d[y[j]] then d[y[j]]:=d[x[j]]+t[j];for I:=1 to m doif d[x[j]]+t[j]<d[y[j]] then return false else return true;end;10.第n最短路径问题*第二最短路径:每举最短路径上的每条边,每次删除一条,然后求新图的最短路径,取这些路径中最短的一条即为第二最短路径。