多元线性回归分析范例
多元线性回归分析范例

多元线性回归分析范例多元线性回归是一种用于预测因变量和多个自变量之间关系的统计分析方法。
它假设因变量与自变量之间存在线性关系,并通过拟合一个多元线性模型来估计因变量的值。
在本文中,我们将使用一个实际的数据集来进行多元线性回归分析的范例。
数据集介绍:我们选取的数据集是一份汽车销售数据,包括了汽车的价格(因变量)和多个与汽车相关的特征(自变量),如车龄、行驶里程、汽车品牌等。
我们的目标是通过这些特征来预测汽车的价格。
数据集包括了100个样本。
数据集的构成如下:车龄(年),行驶里程(万公里),品牌,价格(万元)----------------------------------------5,10,A,153,5,B,207,12,C,10...,...,...,...建立多元线性回归模型:我们首先需要将数据集划分为自变量矩阵X和因变量向量y。
其中,自变量矩阵X包括了车龄、行驶里程和品牌等特征,因变量向量y包括了价格。
在Python中,我们可以使用NumPy和Pandas库来处理和分析数据。
我们可以使用Pandas的DataFrame来存储数据集,并使用NumPy的polyfit函数来拟合多元线性模型。
首先,我们导入所需的库并读取数据集:```pythonimport pandas as pdimport numpy as np#读取数据集data = pd.read_csv('car_sales.csv')```然后,我们将数据集划分为自变量矩阵X和因变量向量y:```python#划分自变量矩阵X和因变量向量yX = data[['车龄', '行驶里程', '品牌']]y = data['价格']```接下来,我们使用polyfit函数来拟合多元线性模型。
我们将自变量矩阵X和因变量向量y作为输入,并指定多项式的次数(线性模型的次数为1):```python#拟合多元线性模型coefficients = np.polyfit(X, y, deg=1)```最后,我们可以使用拟合得到的模型参数来预测新的样本。
多元线性回归分析案例

多元线性回归分析案例1. 引言多元线性回归分析是一种用于探索多个自变量与一个连续型因变量之间关系的统计分析方法。
本文将以一个虚构的案例来介绍多元线性回归分析的应用。
2. 背景假设我们是一家电子产品创造公司,我们想了解哪些因素会对产品销售额产生影响。
为了解决这个问题,我们采集了一些数据,包括产品的价格、广告费用、竞争对手的产品价格和销售额。
3. 数据采集我们采集了100个不同产品的数据,其中包括以下变量:- 产品价格(自变量1)- 广告费用(自变量2)- 竞争对手的产品价格(自变量3)- 销售额(因变量)4. 数据分析为了进行多元线性回归分析,我们首先需要对数据进行预处理。
我们检查了数据的缺失情况和异常值,并进行了相应的处理。
接下来,我们使用多元线性回归模型来分析数据。
模型的方程可以表示为:销售额= β0 + β1 × 产品价格+ β2 × 广告费用+ β3 × 竞争对手的产品价格+ ε其中,β0、β1、β2、β3是回归系数,ε是误差项。
5. 结果解释我们使用统计软件进行回归分析,并得到了以下结果:- 回归系数的估计值:β0 = 1000, β1 = 10, β2 = 20, β3 = -5- 拟合优度:R² = 0.8根据回归系数的估计值,我们可以解释模型的结果:- β0表示当产品价格、广告费用和竞争对手的产品价格都为0时,销售额的估计值为1000。
- β1表示产品价格每增加1单位,销售额平均增加10单位。
- β2表示广告费用每增加1单位,销售额平均增加20单位。
- β3表示竞争对手的产品价格每增加1单位,销售额平均减少5单位。
拟合优度R²的值为0.8,说明模型可以解释销售额的80%变异程度。
这意味着模型对数据的拟合程度较好。
6. 结论根据我们的多元线性回归分析结果,我们可以得出以下结论:- 产品价格、广告费用和竞争对手的产品价格对销售额有显著影响。
《2024年多元线性回归分析的实例研究》范文

《多元线性回归分析的实例研究》篇一一、引言多元线性回归分析是一种统计方法,用于研究多个变量之间的关系。
在社会科学、经济分析、医学等多个领域,这种分析方法的应用都十分重要。
本实例研究以一个具体的商业案例为例,展示了如何应用多元线性回归分析方法进行研究,以便深入理解和探索各个变量之间的潜在关系。
二、背景介绍以某电子商务公司的销售额预测为例。
电子商务公司销售量的影响因素很多,包括市场宣传、商品价格、消费者喜好等。
因此,本文通过收集多个因素的数据,使用多元线性回归分析,以期达到更准确的销售预测和因素分析。
三、数据收集与处理为了进行多元线性回归分析,我们首先需要收集相关数据。
在本例中,我们收集了以下几个关键变量的数据:销售额(因变量)、广告投入、商品价格、消费者年龄分布、消费者性别比例等。
这些数据来自电子商务公司的历史销售记录和调查问卷。
在收集到数据后,我们需要对数据进行清洗和处理。
这包括去除无效数据、处理缺失值、标准化处理等步骤。
经过处理后,我们可以得到一个干净且结构化的数据集,为后续的多元线性回归分析提供基础。
四、多元线性回归分析1. 模型建立根据所收集的数据和实际情况,我们建立了如下的多元线性回归模型:销售额= β0 + β1广告投入+ β2商品价格+ β3消费者年龄分布+ β4消费者性别比例+ ε其中,β0为常数项,β1、β2、β3和β4为回归系数,ε为误差项。
2. 模型参数估计通过使用统计软件进行多元线性回归分析,我们可以得到每个变量的回归系数和显著性水平等参数。
这些参数反映了各个变量对销售额的影响程度和方向。
3. 模型检验与优化为了检验模型的可靠性和准确性,我们需要对模型进行假设检验、R方检验和残差分析等步骤。
同时,我们还可以通过引入交互项、调整自变量等方式优化模型,提高预测精度。
五、结果分析与讨论1. 结果解读根据多元线性回归分析的结果,我们可以得到以下结论:广告投入、商品价格、消费者年龄分布和消费者性别比例均对销售额有显著影响。
—多元线性回归分析案例

t=(2.184942) (3.849318) (12.80847)
(7.130844)
R2 0.963517 R 2 0.959307 F 228.2846 df 26
模型检验:拟合优度可决系数 R2 0.963517 较高, 修正的可决系数 R 2 0.959307 也较高,表明模型 拟合较好。
t0025260684因为各解释变量的参数对应的t统计量均大于0684这说明在5的显著水平下斜率系数均显著不为零表明三大产业的增长率对gdp增长都有显著影响
多元线性回归分析 案例
目录
• 1.建立模型 • 2.模型参数估计 • 3.检验 • 4.预测 • 5.软件操作
1.建立模型
考察三大产业的增长对我国经济增长 的贡献
F检验: 针对H0: b1=b2=b3=0
F 228.2846
给定 0.05,得临界值F0.0(5 k,n k 1) F0.05(3,26) 2.98 由于228.2846>2.98,故拒绝H0 回归方程是显著的。
t检验: 给定 0.05,查自由度t分布表得:t0.025(26)=0.684 因为各解释变量的参数对应的t统计量均大于0.684, 这说明在5%的显著水平下,斜率系数均显著不为零, 表明三大产业的增长率对GDP增长都有显著影响。
8.3
2.8
8.4
10.3
1987 11.6
4.7
13.7
14.4 2002
9.1
2.9
9.8
10.4
1988 11.3
2.5
14.5
13.2 2003 10.0
2.5
商务统计学课件-多元线性回归分析实例应用

6.80
13.65
14.25
27
8.27
6.50
13.70
13.65
28
7.67
5.75
13.75
13.75
29
7.93
5.80
13.80
13.85
30
9.26
6.80
13.70
14.25
销售周期
1
销售价格/元
其他公司平均销售价格
/元
多元线性回归分析应用
多元线性回归分析应用
解
Y 表示牙膏销售量,X 1 表示广告费用,X 2表示销售价格, X 3
个自变量之间的线性相关程度很高,回归方程的拟合效果较好。
一元线性回归分析应用
解
广告费用的回归系数检验 t1 3.981 ,对应的 P 0.000491 0.05
销售价格的回归系数检验 t2 3.696 ,对应的 P 0.001028 0.05
其它公司平均销售价格的回归系数检验
…
14
1551.3
125.0
45.8
29.1
15
1601.2
137.8
51.7
24.6
16
2311.7
175.6
67.2
27.5
17
2126.7
155.2
65.0
26.5
18
2256.5
174.3
65.4
26.8
万元
表示其他公司平均销售价格。建立销售额的样本线性回归方程如
下:
Yˆi 15.044 0.501X 1i 2.358 X 2i 1.612 X 3i
一元线性回归分析应用
多元线性回归分析案例

多元线性回归分析案例多元线性回归分析是统计学中常用的一种分析方法,它可以用来研究多个自变量对因变量的影响,并建立相应的数学模型。
在实际应用中,多元线性回归分析可以帮助我们理解变量之间的关系,预测未来的趋势,以及制定相应的决策。
本文将通过一个实际案例来介绍多元线性回归分析的基本原理和应用方法。
案例背景。
假设我们是一家电子产品制造公司的市场营销团队,我们想要了解产品销量与广告投入、产品定价和市场规模之间的关系。
我们收集了过去一年的数据,包括每个月的产品销量(千台)、广告投入(万元)、产品定价(元/台)和市场规模(亿人)。
数据分析。
首先,我们需要对数据进行描述性统计分析,以了解各变量的分布情况和相关性。
我们计算了产品销量、广告投入、产品定价和市场规模的均值、标准差、最大最小值等统计量,并绘制了相关性矩阵图。
通过分析发现,产品销量与广告投入、产品定价和市场规模之间存在一定的相关性,但具体的关系还需要通过多元线性回归分析来验证。
多元线性回归模型。
我们建立了如下的多元线性回归模型:\[Sales = \beta_0 + \beta_1 \times Advertising + \beta_2 \times Price + \beta_3 \times MarketSize + \varepsilon\]其中,Sales表示产品销量,Advertising表示广告投入,Price表示产品定价,MarketSize表示市场规模,\(\beta_0, \beta_1, \beta_2, \beta_3\)分别为回归系数,\(\varepsilon\)为误差项。
模型验证。
我们利用最小二乘法对模型进行参数估计,并进行了显著性检验和回归诊断。
结果表明,广告投入、产品定价和市场规模对产品销量的影响是显著的,模型的拟合效果较好。
同时,我们还对模型进行了预测能力的验证,结果表明模型对未来产品销量的预测具有一定的准确性。
决策建议。
—多元线性回归分析案例

—多元线性回归分析案例多元线性回归分析是一种广泛使用的统计分析方法,用于研究多个自变量对一个因变量的影响程度。
在实际应用中,多元线性回归可以帮助我们理解变量之间的相互关系,并预测因变量的数值。
下面我们将以一个实际案例来介绍多元线性回归分析的应用。
假设我们是一家电子产品制造商,我们想研究影响手机销量的因素,并尝试通过多元线性回归模型来预测手机的销量。
我们选择了三个自变量作为影响因素:广告投入、价格和市场份额。
我们收集了一段时间内的数据,包括这三个因素以及对应的手机销量。
现在我们将利用这些数据来进行多元线性回归分析。
首先,我们需要将数据进行预处理和清洗。
我们检查数据的完整性和准确性,并去除可能存在的异常值和缺失值。
然后,我们对数据进行描述性统计分析,以了解数据的整体情况和变量之间的关系。
接下来,我们将建立多元线性回归模型。
我们将销量作为因变量,而广告投入、价格和市场份额作为自变量。
通过引入这些自变量,我们可以预测手机销量,并分析它们对销量的影响程度。
为了进行回归分析,我们需要估计模型的系数。
这可以通过最小二乘法来实现,该方法将使得模型的预测结果与实际观测值之间的残差平方和最小化。
接下来,我们将进行统计检验,以确定自变量对因变量的显著影响。
常见的统计指标包括回归系数的显著性水平、t值和p值。
在我们的案例中,假设多元线性回归模型的方程为:销量=β0+β1×广告投入+β2×价格+β3×市场份额+ε。
其中,β0、β1、β2和β3为回归系数,ε为误差项。
完成回归分析后,我们可以进行模型的诊断和评估。
我们可以检查模型的残差是否呈正态分布,以及模型的拟合程度如何。
此外,我们还可以通过交叉验证等方法评估模型的准确性和可靠性。
最后,我们可以利用训练好的多元线性回归模型来进行预测。
通过输入新的广告投入、价格和市场份额的数值,我们可以预测手机的销量,并根据预测结果制定相应的市场策略。
综上所述,多元线性回归分析是一种强大的统计工具,可用于分析多个自变量对一个因变量的影响。
多元线性回归分析实例
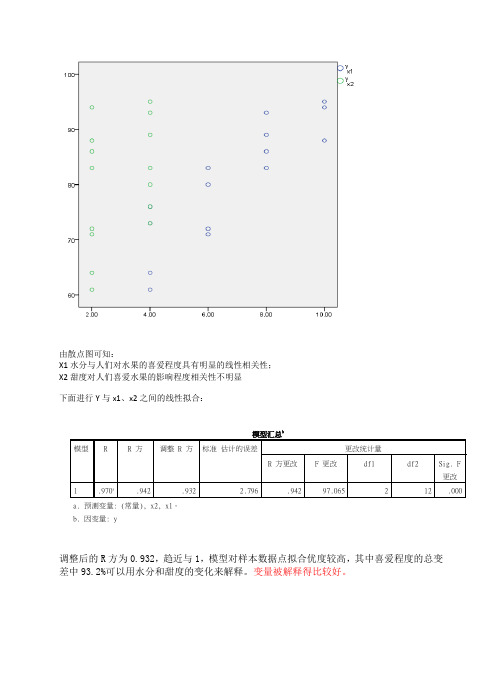
由散点图可知:
X1水分与人们对水果的喜爱程度具有明显的线性相关性;
X2甜度对人们喜爱水果的影响程度相关性不明显
下面进行Y与x1、x2之间的线性拟合:
调整后的R方为0.932,趋近与1,模型对样本数据点拟合优度较高,其中喜爱程度的总变差中93.2%可以用水分和甜度的变化来解释。
变量被解释得比较好。
H0:β
=0 (水果甜度和人们对水果的喜爱程度无显著线性关系)
2
H1:β
≠0(水果甜度和人们对水果的喜爱程度有显著线性关系)
2
P值0.000,小于0.05,拒绝原假设,接受对立假设,即水果甜度和人们对水果的喜爱程度有显著线性关系
线性回归方程:
Y=4.395x1+4.326x2+37.955
方程的解释:
在水果甜度不变的前提下,水果水分每增加1个单位,人们对水果的喜爱程度增加4.395个单位
在水果水分不变的前提下,水果甜度每增加1个单位,人们对水果的喜爱程度增加4.326个单位
残差的正态性检验:
H0:该模型的误差项符合正态性检验
H1:该模型的误差项不符合正态性检验
K-S检验的P值为0.763,大于0.05,接受原假设,该模型符合正态性检验,说明误差项的正态性假设是合理的。
残差的方差齐性检验:
上述散点图水果水分与误差近似分布在一条水平的带状线中,那么就可以认为残差的齐性假设是合理的。
散点图水果甜度与误差近似分布在一条垂直的带状线中,可以认为残差的齐性假设是不合理的。
多元线性回归实例分析

多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为:毫无疑问,多元线性回归方程应该为:上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示:那么,多元线性回归方程矩阵形式为:其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样)1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。
2:无偏性假设,即指:期望值为03:同共方差性假设,即指,所有的随机误差变量方差都相等4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。
通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。
数据如下图所示:点击“分析”——回归——线性——进入如下图所示的界面:将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入)如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于,当概率值大于等于时将会被剔除)“选择变量(E)" 框内,我并没有输入数据,如果你需要对某个“自变量”进行条件筛选,可以将那个自变量,移入“选择变量框”内,有一个前提就是:该变量从未在另一个目标列表中出现!,再点击“规则”设定相应的“筛选条件”即可,如下图所示:点击“统计量”弹出如下所示的框,如下所示:在“回归系数”下面勾选“估计,在右侧勾选”模型拟合度“ 和”共线性诊断“ 两个选项,再勾选“个案诊断”再点击“离群值”一般默认值为“3”,(设定异常值的依据,只有当残差超过3倍标准差的观测才会被当做异常值)点击继续。
多元线性回归方法及其应用实例

多元线性回归方法及其应用实例多元线性回归方法(Multiple Linear Regression)是一种广泛应用于统计学和机器学习领域的回归分析方法,用于研究自变量与因变量之间的关系。
与简单线性回归不同,多元线性回归允许同时考虑多个自变量对因变量的影响。
多元线性回归建立了自变量与因变量之间的线性关系模型,通过最小二乘法估计回归系数,从而预测因变量的值。
其数学表达式为:Y=β0+β1X1+β2X2+...+βnXn+ε,其中Y是因变量,Xi是自变量,βi是回归系数,ε是误差项。
1.房价预测:使用多个自变量(如房屋面积、地理位置、房间数量等)来预测房价。
通过建立多元线性回归模型,可以估计出各个自变量对房价的影响权重,从而帮助房产中介或购房者进行房价预测和定价。
2.营销分析:通过分析多个自变量(如广告投入、促销活动、客户特征等)与销售额之间的关系,可以帮助企业制定更有效的营销策略。
多元线性回归可以用于估计各个自变量对销售额的影响程度,并进行优化。
3.股票分析:通过研究多个自变量(如市盈率、市净率、经济指标等)与股票收益率之间的关系,可以辅助投资者进行股票选择和投资决策。
多元线性回归可以用于构建股票收益率的预测模型,并评估不同自变量对收益率的贡献程度。
4.生理学研究:多元线性回归可应用于生理学领域,研究多个自变量(如年龄、性别、体重等)对生理指标(如心率、血压等)的影响。
通过建立回归模型,可以探索不同因素对生理指标的影响,并确定其重要性。
5.经济增长预测:通过多元线性回归,可以将多个自变量(如人均GDP、人口增长率、外商直接投资等)与经济增长率进行建模。
这有助于政府和决策者了解各个因素对经济发展的影响力,从而制定相关政策。
在实际应用中,多元线性回归方法有时也会面临一些挑战,例如共线性(多个自变量之间存在高度相关性)、异方差性(误差项方差不恒定)、自相关(误差项之间存在相关性)等问题。
为解决这些问题,研究人员提出了一些改进和扩展的方法,如岭回归、Lasso回归等。
多元线性回归模型案例分析报告

多元线性回归模型案例分析报告多元线性回归模型案例分析——中国人口自然增长分析一·讨论目的要求中国从1971年开头全面开展了方案生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,临近世代更替水平。
此后,人口自然增长率(即人口的生育率)很大程度上与经济的进展等各方面的因素相联系,与经济生活息息相关,为了讨论此后影响中国人口自然增长的主要缘由,分析全国人口增长逻辑,与猜想中国将来的增长趋势,需要建立计量经济学模型。
影响中国人口自然增长率的因素有无数,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的凹凸可能会间接影响人口增长率。
(3)文化程度,因为教导年限的凹凸,相应会改变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。
二·模型设定为了全面反映中国“人口自然增长率”的全貌,挑选人口增长率作为被解释变量,以反映中国人口的增长;挑选“国名收入”及“人均GDP”作为经济整体增长的代表;挑选“居民消费价格指数增长率”作为居民消费水平的代表。
暂不考虑文化程度及人口分布的影响。
从《中国统计年鉴》收集到以下数据(见表1):表1 中国人口增长率及相关数据设定的线性回归模型为:1222334t t t t t Y X X X u ββββ=++++三、估量参数利用EViews 估量模型的参数,办法是:1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对话框“Workfile Range ”。
在“Workfile frequency ”中挑选“Annual ” (年度),并在“Start date ”中输入开头时光“1988”,在“end date ”中输入最后时光“2022”,点击“ok ”,浮现“Workfile UNTITLED ”工作框。
多元线性回归模型的案例分析

多元线性回归模型的案例分析在实际生活中,多元线性回归模型可以广泛应用于各个领域。
以下是一个案例分析,以说明多元线性回归模型的应用。
案例:房价预测背景:城市的房地产公司想要推出一款房屋估价服务,帮助人们预测房屋的销售价格。
他们收集了一些相关数据,如房屋的面积、房间的数量、地理位置等因素,并希望通过建立一个多元线性回归模型来实现房价的预测。
步骤:1.数据收集:收集相关数据。
在本案例中,我们收集到了50个样本数据,每个样本包含了房屋的面积、房间的数量和房屋的销售价格。
2.数据预处理:对数据进行预处理,包括缺失值处理、异常值处理等。
在本案例中,我们假设数据已经经过清洗,没有缺失值和异常值。
3.特征选择:选择合适的特征变量。
在本案例中,我们选择房屋的面积和房间的数量作为特征变量,房屋的销售价格作为目标变量。
4.模型建立:建立多元线性回归模型。
根据特征变量和目标变量的关系,建立多元线性回归方程。
在本案例中,假设多元线性回归方程为:房价=β0+β1×面积+β2×房间数量+ε,其中β0、β1和β2分别为回归系数,ε为误差项。
5.模型训练:使用样本数据对模型进行训练。
通过最小二乘法等方法,估计出回归系数的取值。
6.模型评估:评估模型的性能。
通过计算模型的均方误差(MSE)、决定系数(R²)等指标,评估模型的拟合效果和预测能力。
7.模型应用:将模型用于房价的预测。
当有新的房屋数据输入时,通过模型的预测方程,可以得到该房屋的预测销售价格。
通过上述步骤,我们可以建立一个多元线性回归模型,并通过该模型对房价进行预测。
这个模型可以帮助房地产公司提供房价估价服务,也可以帮助购房者了解合理的房价范围。
第三章 多元线性回归模型案例及作业

1. 表1列出了中国2000年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y ,资产合计K 及职工人数L 。
序号 工业总产值Y/亿元资产合计K/亿元职工人数L/万人序号 工业总产值Y/亿元资产合计K/亿元职工人数L/万人1 3722.700 3078.220 113.0000 17 812.7000 1118.810 43.000002 1442.520 1684.430 67.00000 18 1899.700 2052.160 61.000003 1752.370 2742.770 84.00000 19 3692.850 6113.110 240.00004 1451.290 1973.820 27.00000 20 4732.900 9228.250 222.00005 5149.300 5917.010 327.0000 21 2180.230 2866.650 80.000006 2291.160 1758.770 120.0000 22 2539.760 2545.630 96.000007 1345.170 939.1000 58.00000 23 3046.950 4787.900 222.00008 656.7700 694.9400 31.00000 24 2192.630 3255.290 163.00009 370.1800 363.4800 16.00000 25 5364.830 8129.680 244.0000 10 1590.360 2511.990 66.00000 26 4834.680 5260.200 145.0000 11 616.7100 973.7300 58.00000 27 7549.580 7518.790 138.0000 12 617.9400 516.0100 28.00000 28 867.9100 984.5200 46.00000 13 4429.190 3785.910 61.00000 29 4611.390 18626.94 218.0000 14 5749.020 8688.030 254.0000 30 170.3000 610.9100 19.00000 15 1781.370 2798.900 83.00000 31325.5300 1523.190 45.00000161243.070 1808.440 33.00000设定模型为:Y AK L e αβμ=(1) 利用上述资料,进行回归分析;(2) 回答:中国2000年的制造业总体呈现规模报酬不变状态吗? 将模型进行双对数变换如下:ln ln ln ln Y A K L αβμ=+++1)进行回归分析:得到如下回归结果:于是,样本回归方程为:ˆ=++Y K Lln 1.1540.609ln0.361ln(1.59) (3.45) (1.79)20.8099,0.7963,59.66===R R F从回归结果可以看出,模型的拟合度较好,在显著性水平0.1的条件下,各项系数均通过了t检验。
多元线性回归模型案例

多元线性回归模型案例多元线性回归是一种常见的统计分析方法,用于建立一个因变量与多个自变量之间的关系模型。
该模型可以帮助我们理解自变量对因变量的影响,并用于预测新数据的因变量取值。
本文将介绍一个实际案例,说明如何使用多元线性回归模型进行分析。
假设我们是一家电商公司,想要探究哪些因素会对在线销售额产生影响。
为了实现这一目标,我们收集了一年内的销售数据,并选取了以下变量作为自变量:1.广告费用:对于每个月,我们记录了投入到在线广告的费用。
2.促销活动:我们将每种促销活动的销售额记录成一个二进制变量,代表该促销活动是否进行。
3.季节性:我们记录了每个月的季节性变量,例如,一年中的第一个季度为1,第二个季度为2,以此类推。
同时,我们将每月的销售额作为因变量。
基于这些数据,我们将应用多元线性回归模型来分析这些自变量对销售额的影响。
首先,我们需要进行数据预处理。
这包括处理缺失值,检查异常值,并将分类变量进行独热编码转换。
我们还可以计算自变量之间的相关性,以了解它们是否具有高度相关性。
如果有,我们可能需要进行变量转换或删除一些自变量。
接下来,我们可以使用多元线性回归模型来建立销售额与自变量之间的关系。
模型可以表示如下:销售额=β₀+β₁×广告费用+β₂×促销活动+β₃×季节性+ɛ其中,β₀,β₁,β₂,β₃是回归系数,ɛ是误差项。
我们的目标是估计这些回归系数,以便预测新数据的销售额。
为了估计这些回归系数,我们可以使用最小二乘法。
最小二乘法的核心思想是最小化残差平方和,即模型预测值与实际值之间的差异。
通过最小化这个差异,我们可以找到使模型最拟合数据的回归系数。
在我们的案例中,我们可以使用各种统计软件或编程语言(如R或Python)来实现多元线性回归,并计算回归系数的估计值。
这些软件和语言通常具有内置的回归函数,只需提供数据和自变量就可以进行回归分析。
一旦我们获得了估计的回归系数,我们可以进行模型的解释和推断。
多元线性回归案例分析

多元线性回归案例分析案例背景:我们假设有一家制造业公司,想要研究员工的工作效率与其工作经验、教育水平和工作时间之间的关系。
公司收集了100名员工的数据,并希望通过多元线性回归模型来分析这些变量之间的关系。
数据收集:公司收集了每个员工的工作效率(因变量)、工作经验、教育水平和工作时间(自变量)的数据。
假设工作效率由工作经验、教育水平和工作时间这三个因素决定。
根据所收集的数据,我们可以建立如下的多元线性回归模型:工作效率=β0+β1*工作经验+β2*教育水平+β3*工作时间+ε在这个模型中,β0、β1、β2和β3分别是待估参数,代表截距和自变量的系数;ε是误差项,代表模型中未被解释的因素。
模型参数的估计:通过最小二乘法可以对模型中的参数进行估计。
最小二乘法的目标是让模型的预测值与观测值之间的残差平方和最小化。
模型诊断:在对模型进行参数估计后,我们需要对模型进行诊断,以评估模型的质量和稳定性。
常见的模型诊断方法包括:检查残差的正态分布、残差与自变量的无关性、残差的同方差性等。
模型解释和预测:根据参数估计结果,可以对模型进行解释和预测。
例如,我们可以解释每个自变量与因变量之间的关系,并分析它们的显著性。
我们还可以通过模型进行预测,比如预测一位具有一定工作经验、教育水平和工作时间的员工的工作效率。
结果分析:根据对模型的诊断和解释,我们可以对结果进行分析。
我们可以得出结论,一些自变量对因变量的影响显著,而其他自变量对因变量的影响不显著。
这些结论可以帮助公司更好地理解员工工作效率与工作经验、教育水平和工作时间之间的关系,并采取相应的管理措施来提高工作效率。
总结:通过以上的案例分析,我们可以看到多元线性回归在实际中的应用。
它可以帮助我们理解多个自变量与一个因变量之间的关系,并对因变量进行预测和解释。
通过多元线性回归分析,我们可以更好地了解因素对于结果的作用,并根据分析结果进行决策和管理。
然而,需要注意的是,多元线性回归的结果可能受到多种因素的影响,我们需要综合考虑所有的因素来做出准确的分析和决策。
多元线性回归分析范例

国际旅游外汇收入是国民经济发展的重要组成部分, 影响一个国家或地区旅游收入的因素包 括自然、文化、社会、经济、交通等多方面的因素,本例研究第三产业对旅游外汇收入的影响。
《中国统计年鉴》 把第三产业划分为12个组成部分, 分别为 x 农林牧渔服务业 ,x 21地质勘查水利 管理业 ,x 交通运输仓储和邮电通信业 ,x 批发零售贸易和餐饮业 ,x 金融保险 534业,x 房地产业 ,x 社会服务业 ,x 卫生体育和社会福利业, x 教育文化艺术和广播 ,x 科学研106987究和综合艺术 ,x 党 政机关, x 其他行业。
采用 1998年我国 31 个省、市、自治区的数据, 1211以国际旅游外汇收入 (百 万美元)为因变量 y ,以如上 12 个行业为自变量做多元线性回归,其中自变量单位为亿元人民 币。
即样本量n=31,变量 p=12。
利用 SPSS 软件对数据进行处理,输出:图1 输入/移除变量图 1 即输入了所有模型中的变量,分别为x :农林牧渔服务业 1x :地质勘查水利管理业 2x 电通信业 3x :批发零售贸易和餐饮业 4x :金融保险业 6x :社会服务业 7x :卫生体育和社会福利业 8x 播 9 x :科学研究和综合艺术 10x :党政机关 11x12 .图2 模型概述2=0.935R 。
由决 即回归方程对样本观测值的拟合程度,复相关系数R=0.875,决定系数2决定,得出回归拟合的效果较好,但是并不能作为严格的显著性检验。
由R 定系数接近 1 模型优劣时需慎重,尤其是样本量与自变量个数接近时。
:交通运输仓储和邮5x :房地产业 :教育文化艺术和广 :其他行业图3 回归方程显著性的F检验F=10.482,F(n,n-p-1)=F(30,18)=2.11(α =0.05),P值=0.000,表明回归方程高度显著,αα即12 个自变量整体对因变量y 产生显著线性影响。
但是并不能说明回归方程中所有自变量都对因变量y 有显著影响,因此还要对回归系数进行检验。
《2024年多元线性回归分析的实例研究》范文

《多元线性回归分析的实例研究》篇一一、引言多元线性回归分析是一种统计方法,用于研究多个变量之间的关系。
在社会科学、经济学、管理学等多个领域中,它被广泛用于预测和解释一个变量如何受到多个其他变量的影响。
本文将通过一个实际案例,详细介绍多元线性回归分析的应用过程和结果。
二、案例背景假设我们关注的是某城市房价的影响因素。
为了更全面地了解房价的变动,我们选取了该城市的一个住宅小区,收集了该小区近五年内若干套房子的售价数据,以及与房价相关的多个因素,如房屋面积、房龄、小区内设施、周边环境等。
我们的目标是找出这些因素对房价的影响程度,以及它们之间的相互关系。
三、数据收集与处理首先,我们需要收集相关的数据。
对于这个案例,我们可以从房地产网站、房产交易中心等渠道获取房屋售价、房屋面积、房龄等信息。
同时,我们还需要考虑一些可能影响房价的其他因素,如小区内设施(如绿化、健身房等)、周边环境(如学校、医院、商场等)等。
这些数据可以通过问卷调查、实地考察等方式获取。
在收集到数据后,我们需要对数据进行清洗和处理。
这包括去除重复数据、处理缺失值、对数据进行标准化或归一化等。
此外,我们还需要对自变量和因变量进行相关性分析,以确定哪些因素对房价有显著影响。
四、多元线性回归分析在完成数据预处理后,我们可以开始进行多元线性回归分析。
首先,我们需要建立多元线性回归模型。
假设房价为因变量Y,房屋面积、房龄、小区内设施、周边环境等为自变量X1、X2、X3...Xn。
那么,我们可以建立一个多元线性回归方程:Y = β0 + β1X1 + β2X2 + ... + βnXn。
其中,β0为截距项,β1、β2...βn为各变量的回归系数。
接下来,我们需要利用统计软件(如SPSS、SAS等)对模型进行估计。
在估计过程中,我们需要考虑模型的拟合优度、变量的显著性等因素。
通过分析模型的参数估计结果,我们可以得出各个自变量对因变量的影响程度。
五、结果分析根据多元线性回归分析的结果,我们可以得出以下结论:1. 房屋面积、房龄、小区内设施、周边环境等因素对房价均有显著影响。
多元线性回归分析案例
SPSS19.0实战之多元线性回归分析(2011-12-09 12:19:11)转载▼分类:软件介绍标签:文化线性回归数据(全国各地区能源消耗量与产量)来源,可点击协会博客数据挖掘栏:国泰安数据服务中心的经济研究数据库。
1.1 数据预处理数据预处理包括的内容非常广泛,包括数据清理和描述性数据汇总,数据集成和变换,数据归约,数据离散化等。
本次实习主要涉及的数据预处理只包括数据清理和描述性数据汇总。
一般意义的数据预处理包括缺失值填写和噪声数据的处理。
于此我们只对数据做缺失值填充,但是依然将其统称数据清理。
1.1.1 数据导入与定义单击“打开数据文档”,将xls格式的全国各地区能源消耗量与产量的数据导入SPSS中,如图1-1所示。
图1-1 导入数据导入过程中,各个字段的值都被转化为字符串型(String),我们需要手动将相应的字段转回数值型。
单击菜单栏的“ ”-->“ ”将所选的变量改为数值型。
如图1-2所示:图1-2 定义变量数据类型1.1.2 数据清理数据清理包括缺失值的填写和还需要使用SPSS分析工具来检查各个变量的数据完整性。
单击“ ”-->“ ”,将检查所输入的数据的缺失值个数以及百分比等。
如图1-3所示:图1-3缺失值分析能源数据缺失值分析结果如表1-1所示:单变量统计N均值标准差缺失极值数目a计数百分比低高能源消费总量309638.506175.9240.001煤炭消费量309728.997472.2590.002焦炭消费量30874.611053.0080.002原油消费量281177.511282.7442 6.701汽油消费量30230.05170.2700.001煤油消费量2845.4066.1892 6.704柴油消费量30392.34300.9790.002燃料油消费量30141.00313.4670.003天然气消费量3019.5622.0440.002电力消费量30949.64711.6640.003原煤产量269125.9712180.689413.302焦炭产量291026.491727.7351 3.302原油产量181026.481231.7241240.000燃料油产量2590.72134.150516.703汽油产量26215.18210.090413.302煤油产量2048.4462.1301033.300柴油产量26448.29420.675413.301天然气产量2029.2849.3911033.303电力产量30954.74675.2300.000表2-1 能源消耗量与产量数据缺失值分析表1-1 能源消耗量与产量数据缺失值分析SPSS提供了填充缺失值的工具,点击菜单栏“ ”-->“ ”,即可以使用软件提供的几种填充缺失值工具,包括序列均值,临近点中值,临近点中位数等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
国际旅游外汇收入是国民经济发展的重要组成部分,影响一个国家或地区旅游收入的因素包括自然、文化、社会、经济、交通等多方面的因素,本例研究第三产业对旅游外汇收入的影响。
《中国统计年鉴》把第三产业划分为12个组成部分,分别为x1农林牧渔服务业,x2地质勘查水利管理业,x3交通运输仓储和邮电通信业,x4批发零售贸易和餐饮业,x5金融保险业,x6房地产业,x7社会服务业,x8卫生体育和社会福利业,x9教育文化艺术和广播,x10科学研究和综合艺术,x11党政机关,x12其他行业。
采用1998年我国31 个省、市、自治区的数据,以国际旅游外汇收入(百万美元)为因变量y,以如上12 个行业为自变量做多元线性回归,其中自变量单位为亿元人民币。
即样本量n=31,变量p=12。
利用SPSS软件对数据进行处理,输出:
图1 输入/移除变量
图1即输入了所有模型中的变量,分别为
x1:农林牧渔服务业
x2:地质勘查水利管理业
x3:交通运输仓储和邮电通信业
x4:批发零售贸易和餐饮业
x5:金融保险业
x6:房地产业
x7:社会服务业
x8:卫生体育和社会福利业
x9:教育文化艺术和广播
x10:科学研究和综合艺术
x11:党政机关
x12:其他行业
图2 模型概述
即回归方程对样本观测值的拟合程度,复相关系数R=0.875,决定系数R 2=0.935。
由决定系数接近1,得出回归拟合的效果较好,但是并不能作为严格的显著性检验。
由R 2决定模型优劣时需慎重,尤其是样本量与自变量个数接近时。
图3 回归方程显著性的F 检验
F=10.482,F α(n,n-p-1)=F α(30,18)=2.11(α=0.05),P 值=0.000,表明回归方程高度显著,即12个自变量整体对因变量y 产生显著线性影响。
但是并不能说明回归方程中所有自变量都对因变量y 有显著影响,因此还要对回归系数进行检验。
图4 回归系数的显著性t 检验(t 0.05(20)=1.725)
y 对12个自变量的线性回归方程为:
1234
5678
9101112y 205.388 1.438 2.622 3.2970.9465.521 4.068 4.16215.40417.3389.15510.536 1.37x x x x x x x x x x x x =--++--++-++-+
但是,负的回归系数显然是不合理的,其原因可能是自变量之间的共线性。
所以这一回归方程并不理想,所选自变量数目过多,部分回归系数的显著性检验不能通过,这就是样本量个数n太小,而自变量个数p又较多造成R2虚假现象。
如果样本量再稍作改变,未知参数就会发生较大变化,即表现出很不稳定的状况。
在一元线性回归中,回归系数显著性的t检验与回归方程显著性的F检验是等价的,而在多元线性回归中,这两种检验是不等价的,某个或某几个自变量的系数不显著,回归方程显著性的F检验仍可能是显著的,即F检验只说明自变量整体对因变量y产生显著线性影响。
图5相关系数阵和协方差阵
由图可知部分自变量自身的方差较大,与其他自变量之间也存在较明显的相关关系。
所以这一回归方程并不理想,所选自变量数目过多,部分回归系数的显著性检验不能通过,在一定程度上说明它们对应的自变量在回归方程中可有可无,为使模型简化,需剔除不显著的自变量,重新建立回归方程。
但
应用后退法剔除多余变量。
当有多个自变量对因变量y无显著影响时,由于自变量之间的交互作用,不能一次剔除掉所有不显著的变量。
原则上每次只剔除一个变量,先剔除其中t的绝对值最小的(或p值最大的)一个变量,然后再对求得的新回归方程进行检验,有不显著的变量再剔除,直到保留的变量对y有显著影响为止。
也可以根据对问题的定性分析选择t值较小的变量先剔除。
下面是剔除多余变量后的回归方程及回归诊断
剔除顺序为x1,x2,x12,x4,x7,x6,x5,中间过程省略
t 0.05(25)=1.708,即后退法终止。
修正后,y 对自变量的线性回归方程为: 1110983998.12644.11334.17188.20325.4690.184x x x x x y -++-+-= x 3交通运输仓储和邮电通信业 x 8卫生体育和社会福利业 x 9教育文化艺术和广播 x 10科学研究和综合艺 x 11党政机关。