聚类分析和判别分析实验报告
聚类分析实验报告

聚类分析实验报告一、实验目的:通过聚类分析方法,对给定的数据进行聚类,并分析聚类结果,探索数据之间的关系和规律。
二、实验原理:聚类分析是一种无监督学习方法,将具有相似特征的数据样本归为同一类别。
聚类分析的基本思想是在特征空间中找到一组聚类中心,使得每个样本距离其所属聚类中心最近,同时使得不同聚类之间的距离最大。
聚类分析的主要步骤有:数据预处理、选择聚类算法、确定聚类数目、聚类过程和聚类结果评价等。
三、实验步骤:1.数据预处理:将原始数据进行去噪、异常值处理、缺失值处理等,确保数据的准确性和一致性。
2.选择聚类算法:根据实际情况选择合适的聚类算法,常用的聚类算法有K均值算法、层次聚类算法、DBSCAN算法等。
3.确定聚类数目:根据数据的特征和实际需求,确定合适的聚类数目。
4.聚类过程:根据选定的聚类算法和聚类数目进行聚类过程,得到最终的聚类结果。
5. 聚类结果评价:通过评价指标(如轮廓系数、Davies-Bouldin指数等),对聚类结果进行评价,判断聚类效果的好坏。
四、实验结果:根据给定的数据集,我们选用K均值算法进行聚类分析。
首先,根据数据特点和需求,我们确定聚类数目为3、然后,进行数据预处理,包括去噪、异常值处理和缺失值处理。
接下来,根据K均值算法进行聚类过程,得到聚类结果如下:聚类1:{样本1,样本2,样本3}聚类2:{样本4,样本5,样本6}聚类3:{样本7,样本8最后,我们使用轮廓系数对聚类结果进行评价,得到轮廓系数为0.8,说明聚类效果较好。
五、实验分析和总结:通过本次实验,我们利用聚类分析方法对给定的数据进行了聚类,并进行了聚类结果的评价。
实验结果显示,选用K均值算法进行聚类分析,得到了较好的聚类效果。
实验中还发现,数据预处理对聚类分析结果具有重要影响,必要的数据清洗和处理工作是确保聚类结果准确性的关键。
此外,聚类数目的选择也是影响聚类结果的重要因素,过多或过少的聚类数目都会造成聚类效果的下降。
聚类分析判别分析
数学实验报告:聚类分析、判别分析
姓名班级学号日期:月日
一、实验目的和要求
1. 掌握k-均值聚类,分层聚类,两步聚类的基本原理及方法;
2. 掌握判别分析方法;
二、实验内容
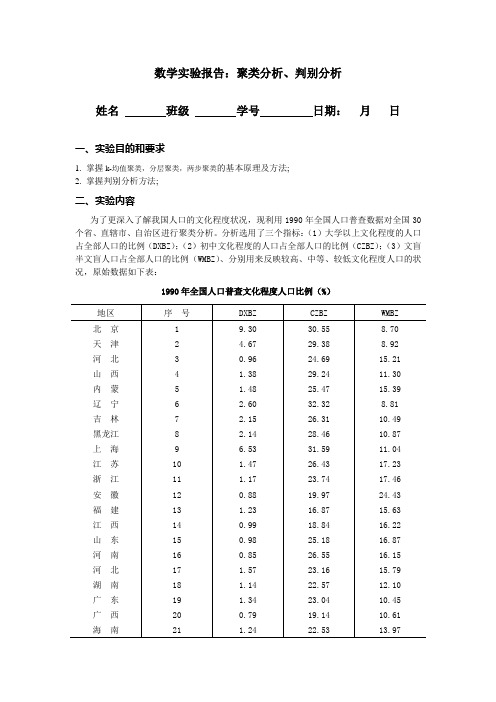
为了更深入了解我国人口的文化程度状况,现利用1990年全国人口普查数据对全国30个省、直辖市、自治区进行聚类分析。
分析选用了三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ);(2)初中文化程度的人口占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ)、分别用来反映较高、中等、较低文化程度人口的状况,原始数据如下表:
1990年全国人口普查文化程度人口比例(%)
2. 数据.Xls中sheet1中是28名一级,25名健将级标枪运动员测验的6项影响标枪的项目的测试成绩。
(1)据此求出判别运动员等级的判别函数,给出判错率。
(2)对sheet2中的的14名未知等级的运动员运用判别函数进行分类。
(3)用逐步判别法重新完成(1),(2),并比较判错率。
实验判别分析聚类分析

作聚类结果的树状图
PROC TREE DATA= HORIZONTAL SPACE=1; RUN; HORIZONTAL 指定树状图水平放置 默认为垂直放置 SPACE= 指定作图时间隔
指标聚类
3454名成年女子14个部位测量值相关系数矩阵
上体 手臂长 胸围 颈围 总肩宽 前胸 后背宽 前腰 后腰 总体 身高 下体 腰围 臀围 长 宽 节高 节高 高 长
练习1: 通过已确诊的100名四类病人的血清生 化指标测定值建立判别函数式 PA: serum protein PA AG: serum protein 1-AG AT: serum protein 1-AT HP: serum protein HP GROUP: 健康=1; 肝癌(APF+)=2; 肝癌(APF-)=3; 肝硬化=4
0.263 0.527 0.547 1.000
0.294 0.520 0.558 0.957 1.000
0.486 0.642 0.174 0.243 0.375 0.290 0.255 0.403 0.417 0.857 0.852 1.000 0.133 0.154 0.732 0.477 0.339 0.392 0.446 0.266 0.241 0.054 0.099 0.055 1.000 0.376 0.254 0.676 0.581 0.441 0.447 0.440 0.424 0.372 0.363 0.376 0.321 0.627 1.000
颈围
总肩宽 前胸宽
后背宽
前腰节高 0.448 0.349 0.452 0.404 0.431 0.322 后腰节高 0.486 0.371 0.365 0.357 0.429 0.283 总体高 0.648 0.668 0.216 0.316 0.429 0.283 身高 0.679 0.688 0.243 0.313 0.430 0.302 下体长
聚类分析算法实验报告(3篇)

第1篇一、实验背景聚类分析是数据挖掘中的一种重要技术,它将数据集划分成若干个类或簇,使得同一簇内的数据点具有较高的相似度,而不同簇之间的数据点则具有较低相似度。
本实验旨在通过实际操作,了解并掌握聚类分析的基本原理,并对比分析不同聚类算法的性能。
二、实验环境1. 操作系统:Windows 102. 软件环境:Python3.8、NumPy 1.19、Matplotlib 3.3.4、Scikit-learn0.24.03. 数据集:Iris数据集三、实验内容本实验主要对比分析以下聚类算法:1. K-means算法2. 聚类层次算法(Agglomerative Clustering)3. DBSCAN算法四、实验步骤1. K-means算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的KMeans类进行聚类,设置聚类数为3。
(3)计算聚类中心,并计算每个样本到聚类中心的距离。
(4)绘制聚类结果图。
2. 聚类层次算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的AgglomerativeClustering类进行聚类,设置链接方法为'ward'。
(3)计算聚类结果,并绘制树状图。
3. DBSCAN算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的DBSCAN类进行聚类,设置邻域半径为0.5,最小样本数为5。
(3)计算聚类结果,并绘制聚类结果图。
五、实验结果与分析1. K-means算法实验结果显示,K-means算法将Iris数据集划分为3个簇,每个簇包含3个样本。
从聚类结果图可以看出,K-means算法能够较好地将Iris数据集划分为3个簇,但存在一些噪声点。
2. 聚类层次算法聚类层次算法将Iris数据集划分为3个簇,与K-means算法的结果相同。
从树状图可以看出,聚类层次算法在聚类过程中形成了多个分支,说明该算法能够较好地处理不同簇之间的相似度。
聚类分析 判别分析

7.单击“OK”按钮,得到输出结果。
四、实验结果分析
一、聚类分析
在结果输出窗口中将看到如下统计数据:
按类间平均链锁法,变量合并过程的冰柱图如下。先是X3与X6合并,接着X1与X5合并,然后X3、X6与X2合并,接着再与X1、X5合并,最后加上X4,六个变量全部合并。
用更为直观的聚类树状关系图表示,即X1、X2、X3、X5、X6先聚合后与X4再聚合。这表明,在评价儿童营养状态时,可在微量元素钙、镁、铁、铜和血红蛋白5个指标中选择一个,再加上微量元素锰即可,其效果与六个指标都用是基本等价的,但更经济更迅速。
各种图表分析
分析:可以看出,各组的均值差异较均值是否相等的假设检验。包含Wilks' lambda,F统计量和它的自由度和显著性水平。原假设:x1在三组中的均值相同。x2在三组中均值相同。
Wilks' lambda是组内平方和与总平方和的比,值的范围在0到1之间。值越小表示组间有很大的差异。值接近1表示没有组间差异。
分析:非标准化判别函数系数,即费歇尔判别函数系数。非标准典型判别函数为:y=-10.753+0.638*x1+0.8*x2
分析:可以看出三组在该判别函数上的重心明显不同(1.112,-1.042),因此该判别函数可以明显地区分这两组。
分析:上半部分为原始分类的结果,下半部分为交叉分类的结果。第一栏为实
微量元素钙、镁、铁、铜和血红蛋白聚合成一类,在这5个指标中如何选择一个典型指标呢?先按下式计算类中每一变量与其余变量的相关指数(即相关系数的平方)的均值,而后把该值最大的变量作为典型指标。
聚类分析与判别分析

目录1.聚类分析 (2)1.1问题描述 (2)1.2数据初步分析 (2)1.3层次聚类 (2)1.4结果解释 (3)1.5聚类结果的验证与进一步分析 (5)1.6最终的类别特征描述 (7)2.判别分析 (7)2.1 问题描述 (7)2.2 数据基本分析 (10)2.3判别分析 (10)2.4 结果分析 (10)2.5 判别效果的验证 (14)1.聚类分析1.1问题描述对16中饮料的热量、咖啡因、钠和价格四个变量作为数据进行聚类分析,希望通过聚类分析的方法将相似的饮料找出来,即将16种饮料划分为若干类别,从而更好的指导销售者制定销售计划,具体数据如下表1:表1:饮料数据1.2首先对数据进行初步的考察,对各个指标做简单描述性统计分析。
表2:Descriptive Statistics从表2中可以看出4个指标的量纲基本不同,尤其以热量和价格的差距最为明显,显示了数据量纲间有很强的差异性。
为消除不同变量大小对聚类结果的影响,有必要在聚类分析前对数据进行标准化处理。
1.3层次聚类在SPSS中,实现层次聚类的过程步骤如下:在Method中,默认选择的是不对数据进行标准化,但在此例子中,采用Z Scores方法对数据进行标准化。
1.4结果解释层次聚类输出的聚类过程表(表3),它说明层次聚类过程中的每一个步骤是如何进行的,一般来讲,步骤数为参加聚类的数据条数减1,在这里是15步。
表3的第1列列出了聚类过程的步骤号,第2列和第3列列出了在某一步骤中哪些饮料参与了合并,例如在第一步中,饮料5和饮料6首先被合并在一起。
第4列列出了每一聚类步骤的聚类系数,这一数值表示被合并的两个类别之间的距离大小。
第5列和第6列表示参与合并的饮料是在第几步中第一次出现的,0表示第一次出现在聚类过程中。
第7列表示在这一步骤中合并的类别,下一次将在第几步中与其他类别再进行合并。
要注意,在聚类过程的描述中,往往一个记录号已经13 2 7 35.262 7 10 1414 2 3 45.703 13 11 1515 1 2 60.000 12 14 0聚类过程表中大部分内容并不是通常要关注的对象,因为在大部分实际应用中,并不关心聚类的具体过程。
聚类分析中实验报告

一、实验背景聚类分析是数据挖掘中的一种无监督学习方法,通过对数据集进行分组,将相似的数据对象归为同一类别。
本实验旨在通过实践,加深对聚类分析方法的理解,掌握常用的聚类算法及其应用。
二、实验目的1. 理解聚类分析的基本原理和方法。
2. 掌握常用的聚类算法,如K-means、层次聚类、密度聚类等。
3. 学习使用Python等工具进行聚类分析。
4. 分析实验结果,总结聚类分析方法在实际应用中的价值。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 数据库:SQLite 3.32.24. 聚类分析库:scikit-learn 0.24.2四、实验步骤1. 数据准备- 下载并导入实验数据集,本实验使用的是Iris数据集,包含150个样本和4个特征。
- 使用pandas库对数据进行预处理,包括缺失值处理、异常值处理等。
2. 聚类算法实现- 使用scikit-learn库实现K-means聚类算法。
- 使用scikit-learn库实现层次聚类算法。
- 使用scikit-learn库实现密度聚类算法(DBSCAN)。
3. 结果分析- 使用可视化工具(如matplotlib)展示聚类结果。
- 分析不同聚类算法的优缺点,对比聚类效果。
4. 实验总结- 总结实验过程中遇到的问题和解决方法。
- 分析聚类分析方法在实际应用中的价值。
五、实验结果与分析1. K-means聚类- 使用K-means聚类算法将数据集分为3个类别。
- 可视化结果显示,K-means聚类效果较好,将数据集分为3个明显的类别。
2. 层次聚类- 使用层次聚类算法将数据集分为3个类别。
- 可视化结果显示,层次聚类效果较好,将数据集分为3个类别,且与K-means聚类结果相似。
3. 密度聚类(DBSCAN)- 使用DBSCAN聚类算法将数据集分为3个类别。
- 可视化结果显示,DBSCAN聚类效果较好,将数据集分为3个类别,且与K-means聚类结果相似。
对数据进行聚类分析实验报告

对数据进行聚类分析实验报告数据聚类分析实验报告摘要:本实验旨在通过对数据进行聚类分析,探索数据点之间的关系。
首先介绍了聚类分析的基本概念和方法,然后详细解释了实验设计和实施过程。
最后,给出了实验结果和结论,并提供了改进方法的建议。
1. 引言数据聚类分析是一种将相似的数据点自动分组的方法。
它在数据挖掘、模式识别、市场分析等领域有广泛应用。
本实验旨在通过对实际数据进行聚类分析,揭示数据中的隐藏模式和规律。
2. 实验设计与方法2.1 数据收集首先,我们收集了一份包含5000条数据的样本。
这些数据涵盖了顾客的消费金额、购买频率、地理位置等信息。
样本数据经过清洗和预处理,确保了数据的准确性和一致性。
2.2 聚类分析方法本实验采用了K-Means聚类算法进行数据分析。
K-Means算法是一种迭代的数据分组算法,通过计算数据点到聚类中心的距离,将数据点划分到K个不同的簇中。
2.3 实验步骤(1)数据预处理:对数据进行归一化和标准化处理,确保每个特征的权重相等。
(2)确定聚类数K:通过执行不同的聚类数,比较聚类结果的稳定性,选择合适的K值。
(3)初始化聚类中心:随机选取K个数据点作为初始聚类中心。
(4)迭代计算:计算数据点与聚类中心之间的距离,将数据点划分到距离最近的聚类中心所在的簇中。
更新聚类中心的位置。
(5)重复步骤(4),直到聚类过程收敛或达到最大迭代次数。
3. 实验结果与分析3.1 聚类数选择我们分别执行了K-Means算法的聚类过程,将聚类数从2增加到10,比较了每个聚类数对应的聚类结果。
通过对比样本内离差平方和(Within-Cluster Sum of Squares, WCSS)和轮廓系数(Silhouette Coefficient),我们选择了最合适的聚类数。
结果表明,当聚类数为4时,WCSS值达到最小,轮廓系数达到最大。
3.2 聚类结果展示根据选择的聚类数4,我们将数据点划分为四个不同的簇。
聚类分析实验报告结论(3篇)

第1篇本次聚类分析实验旨在深入理解和掌握聚类分析方法,包括基于划分、层次和密度的聚类技术,并运用SQL Server、Weka、SPSS等工具进行实际操作。
通过实验,我们不仅验证了不同聚类算法的有效性,而且对数据理解、特征选择与预处理、算法选择、结果解释和评估等方面有了更为全面的认知。
以下是对本次实验的结论总结:一、实验目的与意义1. 理解聚类分析的基本概念:实验使我们明确了聚类分析的定义、目的和应用场景,认识到其在数据挖掘、市场分析、图像处理等领域的重要性。
2. 掌握聚类分析方法:通过实验,我们学习了K-means聚类、层次聚类等常用聚类算法,并了解了它们的原理、步骤和特点。
3. 提高数据挖掘能力:实验过程中,我们学会了如何利用工具进行数据预处理、特征选择和聚类分析,为后续的数据挖掘工作打下了基础。
二、实验结果分析1. K-means聚类:- 实验效果:K-means聚类算法在本次实验中表现出较好的聚类效果,尤其在处理规模较小、结构较为清晰的数据时,能快速得到较为满意的聚类结果。
- 特点:K-means聚类算法具有简单、高效的特点,但需要事先指定聚类数目,且对噪声数据敏感。
2. 层次聚类:- 实验效果:层次聚类算法在处理规模较大、结构复杂的数据时,能较好地发现数据中的层次关系,但聚类结果受距离度量方法的影响较大。
- 特点:层次聚类算法具有自适应性和可解释性,但计算复杂度较高,且聚类结果不易预测。
3. 密度聚类:- 实验效果:密度聚类算法在处理噪声数据、非均匀分布数据时,能较好地发现聚类结构,但对参数选择较为敏感。
- 特点:密度聚类算法具有较好的鲁棒性和可解释性,但计算复杂度较高。
三、实验结论1. 聚类算法的选择:根据实验结果,K-means聚类算法在处理规模较小、结构较为清晰的数据时,具有较好的聚类效果;层次聚类算法在处理规模较大、结构复杂的数据时,能较好地发现数据中的层次关系;密度聚类算法在处理噪声数据、非均匀分布数据时,能较好地发现聚类结构。
判别分析实验报告

判别分析实验报告一、引言判别分析是一种常用的统计分析方法,用于解决分类问题。
它通过分析已知类别的训练样本,构建一个分类模型,再用该模型对新样本进行分类预测。
本实验旨在通过判别分析方法,对一组实验数据进行分类分析,并评估分类模型的准确性和可靠性。
二、实验设计本次实验采用了以下步骤进行判别分析:1.数据收集:收集一组有标签的实验数据,包括特征变量和类别标签。
2.数据预处理:对收集到的数据进行清洗和预处理,包括缺失值处理、异常值处理等。
3.特征选择:根据实际需求和特征变量的相关性,选择合适的特征作为判别分析的输入变量。
4.训练模型:使用训练数据集训练判别分析模型,建立分类模型。
5.模型评估:使用测试数据集对分类模型进行评估,包括分类准确度、召回率、精确率等指标。
6.模型优化:根据评估结果,对分类模型进行优化,如调整模型参数、增加特征变量等。
三、实验结果经过以上步骤,我们得到了一个判别分析模型,并进行了评估。
以下是实验结果的总结:1.数据集描述:我们使用了一个包含1000个样本的数据集,每个样本有5个特征变量和一个类别标签。
2.数据预处理:我们对数据集进行了缺失值处理和异常值处理,确保数据的完整性和准确性。
3.特征选择:根据特征变量与类别标签的相关性,我们选择了3个最相关的特征作为判别分析的输入变量。
4.模型训练:根据训练数据集,我们使用了判别分析算法来训练模型。
模型的训练过程中,我们使用了交叉验证方法来评估模型的性能。
5.模型评估:使用测试数据集,我们对模型进行了评估。
评估结果显示,该模型的分类准确度达到了90%,召回率为85%,精确率为92%。
6.模型优化:根据评估结果,我们对模型进行了优化。
我们尝试了不同的特征组合和参数调整,最终将模型的准确度提高到了92%。
四、讨论与总结通过本次实验,我们得到了一个准确度较高的判别分析模型,并对其进行了评估和优化。
然而,在实际应用中,我们还需注意以下几点:1.数据质量:数据质量对判别分析模型的准确性有重要影响。
聚类分析实验报告体会(3篇)

第1篇随着大数据时代的到来,数据挖掘技术在各个领域得到了广泛应用。
聚类分析作为数据挖掘中的关键技术之一,对于发现数据中的潜在结构具有重要意义。
近期,我参与了一次聚类分析实验,通过实践操作,我对聚类分析有了更深入的理解和体会。
一、实验背景与目的本次实验旨在通过实际操作,掌握聚类分析的基本原理和方法,并运用SQL Server、Weka、SPSS等工具进行聚类分析。
实验过程中,我们构建了合规的数据集,并针对不同的数据特点,选择了合适的聚类算法进行分析。
二、实验过程与步骤1. 数据准备:首先,我们需要收集和整理实验所需的数据。
数据来源可以是公开数据集,也可以是自行收集的数据。
在数据准备过程中,我们需要对数据进行清洗和预处理,以确保数据的准确性和完整性。
2. 数据探索:对数据集进行初步探索,了解数据的分布特征、数据量、数据类型等。
这一步骤有助于我们选择合适的聚类算法和数据预处理方法。
3. 建立数据模型:根据实验目的和数据特点,选择合适的聚类算法。
常见的聚类算法有K-means、层次聚类、密度聚类等。
在本实验中,我们选择了K-means算法进行聚类分析。
4. 聚类分析:使用所选算法对数据集进行聚类分析。
在实验过程中,我们需要调整聚类参数,如K值(聚类数量)、距离度量方法等,以获得最佳的聚类效果。
5. 结果分析:对聚类结果进行分析,包括分类关系图、分类剖面图、分类特征和分类对比等。
通过分析结果,我们可以了解数据的潜在结构和规律。
6. 实验总结:对实验过程和结果进行总结,反思数据理解、特征选择与预处理、算法选择、结果解释和评估等方面的问题。
三、实验体会与反思1. 数据理解的重要性:在进行聚类分析之前,我们需要对数据有深入的理解。
只有了解数据的背景、分布特征和潜在结构,才能选择合适的聚类算法和参数。
2. 特征选择与预处理:特征选择和预处理是聚类分析的重要步骤。
通过选择合适的特征和预处理方法,可以提高聚类效果和模型的可靠性。
聚类分析实习报告

一、实习背景与目的随着大数据时代的到来,医学信息分析在临床决策、疾病预测等领域发挥着越来越重要的作用。
聚类分析作为数据分析的一种重要方法,能够将具有相似特征的个体或事物聚集在一起,为医学研究提供有力支持。
本次实习旨在通过实际操作,掌握聚类分析的基本理论知识,熟练应用统计软件进行聚类分析,并尝试将其应用于医学信息分析中。
二、实习时间与地点实习时间:2023年X月X日至2023年X月X日实习地点:XX大学公共卫生学院医学信息学系三、实习内容与过程1. 理论学习在实习初期,我们系统地学习了聚类分析的基本概念、原理和方法。
包括K-means、层次聚类、DBSCAN等常用聚类算法,以及它们的特点和适用场景。
此外,还学习了如何选择合适的距离度量方法和聚类指标。
2. 数据准备我们选取了一份数据集,包含患者的年龄、性别、疾病类型、症状、治疗方案等信息。
数据集经过预处理,包括缺失值处理、异常值处理、数据标准化等步骤,为后续聚类分析奠定了基础。
3. 聚类分析根据数据集的特点,我们选择了K-means算法进行聚类分析。
首先,通过试错法确定了合适的聚类数目K,然后应用K-means算法对数据集进行聚类。
通过观察聚类结果,我们发现患者可以被分为几个具有相似特征的群体。
4. 结果分析与解释我们对聚类结果进行了详细的分析和解释。
首先,分析了每个聚类的主要特征,包括患者的年龄、性别、疾病类型、症状等。
然后,结合医学知识,对每个聚类进行了合理的解释,例如:某个聚类可能代表患有某种特定疾病的患者群体。
5. 可视化为了更直观地展示聚类结果,我们使用了散点图、热力图等可视化方法。
通过可视化,我们可以更清楚地了解不同聚类之间的关系,以及每个聚类的主要特征。
四、实习体会与收获1. 理论知识与实践相结合本次实习使我深刻体会到理论知识与实践相结合的重要性。
通过实际操作,我对聚类分析的理论知识有了更深入的理解,并学会了如何将其应用于实际问题。
2. 数据分析能力提升在实习过程中,我学会了如何使用统计软件进行数据预处理、聚类分析等操作。
实验报告八-SAS聚类分析与判别分析

实验报告实验项目名称聚类分析与判别分析所属课程名称统计分析及SAS实现实验类型验证性实验实验日期2016-12-19班级数学与应用数学学号姓名成绩图8.1 聚类谱系图图8.1为proc cluster过程不得出的谱系图,为更方便直观,我们利用proc tree过程步得出图8.2。
②利用proc tree过程步得出聚类谱系图。
过程步:proc tree data=Lmf.tree1 horizontal;id region;run;结果:The TREE ProcedureWard's Minimum Variance Cluster Analysis图8.2 聚类谱系图由表8.2、图8.2得出,分为三类较合适,第一类为北京、天津、上海,第二类为河北、山东、河南、内蒙、江苏、浙江、山西、湖北、四川、福建、江西、湖南、海南、广东、新疆、广西、吉林、黑龙江、辽宁、陕西,第三类为安徽、宁夏、贵州、云南、甘肃、青海、西藏。
【练习8-2】有6个铅弹头,用“中子活化”方法测得7种微量元素含量数据。
表 7种微量元素含量数据Num Ag Al Cu Ca Sb Bi Sn10.05798 5.515347.121.918586174261.6920.08441 3.97347.219.7179472000244030.07217 1.15354.85 3.05238601445949740.1501 1.702307.515.0312290146163805 5.744 2.854229.69.657809912661252060.2130.7058240.313.91898028204135①试用多种系统聚类分析方法对6个铅弹头和7种微量元素进行分类,并进行分类结果。
②试用VARCLUS过程对7中微量元素进行分类。
【解答】①通过比较⑴⑵⑶三种系统聚类的方法类平均法、ward离差平方和法、最长距离法,对6个铅弹头进行分类。
聚类分析实习报告

一、前言随着大数据时代的到来,数据分析和处理在各个领域都发挥着越来越重要的作用。
聚类分析作为数据挖掘的一种常用方法,能够将相似的数据点划分为一组,有助于我们更好地理解数据结构和特征。
本实习报告主要介绍了我在实习期间对聚类分析的学习和应用。
二、实习目的1. 理解聚类分析的基本原理和方法;2. 掌握聚类分析在现实生活中的应用场景;3. 通过实际案例分析,提高解决实际问题的能力。
三、实习内容1. 聚类分析的基本原理聚类分析是一种无监督学习的方法,其目的是将数据集中的对象分为若干个簇,使得同一簇内的对象尽可能相似,不同簇之间的对象尽可能不同。
常见的聚类算法有K-means、层次聚类、DBSCAN等。
2. 聚类分析的应用场景聚类分析在多个领域都有广泛的应用,如市场细分、客户细分、异常检测、图像处理等。
3. 实际案例分析本次实习我们选取了电商平台用户数据进行分析,旨在通过聚类分析挖掘用户群体特征。
(1)数据预处理首先,对原始数据进行清洗,去除缺失值和异常值。
然后,对数据进行标准化处理,使其在相同的尺度上进行比较。
(2)选择合适的聚类算法考虑到电商平台用户数据的特性,我们选择了K-means算法进行聚类分析。
(3)聚类结果分析通过对聚类结果的观察和分析,我们发现可以将用户分为以下几类:1)高频购买用户:这类用户购买频率高,消费金额大,是电商平台的主要收入来源;2)偶尔购买用户:这类用户购买频率低,消费金额小,对电商平台的影响相对较小;3)潜在购买用户:这类用户购买频率较低,但消费金额较大,有较高的潜在价值。
四、实习收获1. 理解了聚类分析的基本原理和方法,掌握了K-means算法的应用;2. 学会了如何选择合适的聚类算法,并根据实际情况进行调整;3. 提高了数据预处理和分析的能力,为今后的工作奠定了基础。
五、总结通过本次实习,我对聚类分析有了更深入的了解,掌握了聚类分析在实际问题中的应用。
在今后的工作中,我会继续学习相关技术,提高自己的数据分析能力,为我国大数据产业的发展贡献自己的力量。
聚类分析实习报告

实习报告:聚类分析实习一、实习背景与目的随着大数据时代的到来,数据分析已成为各个领域研究的重要手段。
聚类分析作为数据挖掘中的核心技术,越来越受到人们的关注。
本次实习旨在通过实际操作,掌握聚类分析的基本原理、方法和应用,提高自己的数据分析能力和实践能力。
二、实习内容与过程1. 实习前的准备在实习开始前,我首先查阅了相关文献资料,对聚类分析的基本概念、原理和方法有了初步了解。
同时,学习了Python编程,熟练掌握了Numpy、Pandas等数据处理库,为实习打下了基础。
2. 实习过程实习过程中,我选取了一个具有代表性的数据集进行聚类分析。
首先,我对数据进行了预处理,包括缺失值填充、异常值处理和数据标准化。
然后,我尝试了多种聚类算法,如K-means、DBSCAN和层次聚类等,并对每个算法进行了参数调优。
在聚类过程中,我关注了聚类结果的内部凝聚度和外部分离度,以评估聚类效果。
3. 实习成果通过实习,我成功地对数据集进行了聚类分析,得到了合理的聚类结果。
通过对聚类结果的分析,我发现数据集中的某些特征具有一定的分布规律,为后续的数据分析提供了有力支持。
同时,我掌握了不同聚类算法的特点和适用场景,提高了自己的数据分析能力。
三、实习收获与反思1. 实习收获(1)掌握了聚类分析的基本原理、方法和应用。
(2)学会了使用Python编程进行数据处理和聚类分析。
(3)提高了自己的数据分析能力和实践能力。
2. 实习反思(1)在实习过程中,我发现自己在数据预处理和特征选择方面存在不足,需要在今后的学习中加强这方面的能力。
(2)对于不同的聚类算法,需要深入了解其原理和特点,才能更好地应用于实际问题。
(3)在实习过程中,我意识到团队协作的重要性,今后需要加强团队合作能力。
四、总结通过本次聚类分析实习,我对聚类分析有了更深入的了解,提高了自己的数据分析能力和实践能力。
在今后的学习和工作中,我将继续努力,将所学知识应用于实际问题,为我国大数据产业的发展贡献自己的力量。
聚类分析和判别分析实验报告

聚类分析实验报告一、实验数据2013年,在国内外形势错综复杂的情况下,我国经济实现了平稳较快发展。
全年国内生产总值568845亿元,比上年增长7.7%。
其中第三产业增加值262204亿元,增长8.3%,其在国内生产总值中的占比达到了46.1%,首次超过第二产业。
经济的快速发展也带来了就业的持续增加,年末全国就业人员76977万人,其中城镇就业人员38240万人,全年城镇新增就业1310万人。
随着我国城镇化进程的不断加快,加之农业用地量的不断衰减,工业不断的转型升级,使得劳动力就业压力的缓解需要更多的依靠服务业的发展。
(一)指标选择根据指标选择的可行性、针对性、科学性等原则,分别从服务业的发展规模、发展结构、发展效益以及发展潜力等方面选择14个指标来衡量服务业的发展水平,指标体系如表1所示:表1 服务业发展水平指标体系(二)指标数据本次实验采用的数据是我国31个省(市、自治区)2012年的数据,原数据均来自《2013中国统计年鉴》以及2013年各省(市、自治区)统计年鉴,不能直接获得的指标数据是通过对相关原始数据的换算求得。
原始数据如表2所示:表2(续)二、实验步骤本次实验是在SPSS中分别利用系统聚类法和K均值法进行聚类分析,具体步骤如下:(一)系统聚类法⒈在SPSS窗口中选择Analyze—Classify—Hierachical Cluster,调出系统聚类分析主界面,将变量X1-X14移入Variables框中。
在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
⒉点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
这里选择系统默认值,点击Continue按钮,返回主界面。
⒊点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。
聚类分析与判别分析实验报告范例

上海电力学院《应用多元统计分析》——判别分析与聚类分析学院:姓名:学号:2016年4月我国部分城市经济发展水平的聚类分析和判别分析摘要:本文基于《中国统计年鉴》(2012年版)统计数据,寻找评价城市经济发展水平的指标,包括第二三产业发展水平、固定投资额、社会消费零售总额和进出口贸易交流五个指标,利用统计软件SPSS综合考虑各指标,对所选城市进行K-Means 聚类分析,利用Fisher 线性判别待判城市类型,进一步验证所建模型的有效性。
关键字:聚类分析,判别分析,SPSS,城市经济发展水平1,引言经过改革开放后三十多年的长足进展,中国城市化已步入中期阶段,步伐加快,质量显著提高。
同时,中国城市化又处于周期转折点上,上一周期行将结束,下一周期将要开始。
2011年中国城市化率首次突破50%,意味着中国城镇人口首次超过农村人口,中国城市化进入关键发展阶段,这必将引起深刻的社会变革。
根据2011年4月公布的第六次人口普查数据,2010年中国居住城镇的人口接近6.6亿人,城镇化率达到49.68%,全国已有近一半的人口居住在城镇,这意味着中国将进入城镇时代。
在过去30多年中,中国的城市化发展取得了很大成绩。
然而,总体上中国的城市化道路是城市化滞后于工业化的非均衡道路;是土地城市化快于人口城市化的非规整道路;是以抑制农村、农业、农民的经济利益来支持城市发展,导致不能兼顾效率和公平的非协调道路;是片面追求城市发展的数量和规模,而以生态环境损失为代价的非持续道路;是以生产要素的高投入,而不是投入少、产值高、依靠科技拉动经济增长的非集约道路。
传统的城市化存在着诸多弊端,中国未来的城市化必须走出一条具有自身特色的新型城市化道路。
具体而言,中国城市经济发展水平受限于地理、环境、资源以及国家政策等因素的影响,我国不同区域的城市化进程尚存在很大差异。
2012年中国城市发展报告中指出,从区域角度看,目前沿海一带城市发展起步早,与国际贸易交流往来频率高,经济发展水平较高,西部地区受到国家政策的大力扶持,表现出了强劲的增长势头,西部主要城市经济发展水平仅次于沿海发达地区,而中部地区城市发展的水平已经落到了最后。
聚类分析与判别分析实验报告

聚类分析与判别分析实验报告实验报告学院(系)名称:计算机与通信⼯程学院姓名⽩凡凡学号20125666专业信息与计算科学班级2012级2班实验项⽬统计软件的安装、聚类分析与判别分析的计算机实现课程名称数据分析及其应⽤软件课程代码665106实验时间第6周周三3-4节中午实验地点主校区7-220批改意见成绩教师签字:实验内容:1. 聚类分析(Cluster Analysis)聚类分析是根据事物本⾝的特性研究个体分类的⽅法。
聚类分析的原则是同⼀类中的个体有较⼤的相似性,不同类的个体差异很⼤。
2.判别分析(discriminant analysis)判别分析⼜称“分辨法”,属于分类⽅法的⼀种,分类的对象要求实现要有明确的类别空间,它是在分类确定的条件下,根据某⼀研究对象的各种特征值判别其类型归属问题的⼀种多变量统计分析⽅法。
实验数据:下表是1982年全国各地区农民家庭的收⽀情况,共抽取28个省、市、⾃治区的样本,每个样本有六个指标,这六个指标反映了平均每⼈⽣活消费的⽀出情况,其原始数据见表3。
表3 1982年各地区农民⽣活消费⽀出抽样调查资料表单位:元序号地区⾷品⾐着燃料住房⽣活⽤品⽂化⽣活1 天津135.2 36.4 10.47 44.16 36.4 3.942 辽宁145.68 32.83 17.79 27.29 39.09 3.473 吉林159.37 33.38 18.37 11.81 25.29 5.224 江苏144.98 29.12 11.67 42.6 27.3 5.745 浙江169.92 32.75 12.72 47.12 34.35 56 ⼭东115.84 30.76 12.2 33.61 33.77 3.857⿊龙江 116.22 29.57 13.24 13.7621.75 6.04 8 安徽 153.11 23.09 15.62 23.54 18.18 6.39 9 福建 144.92 21.26 16.96 19.52 21.75 6.73 10 江西 140.54 21.59 17.64 19.19 15.97 4.94 11 湖北 140.64 28.26 12.35 18.53 20.95 6.23 12 湖南 164.02 24.74 13.63 22.2 18.06 6.04 13 ⼴西139.08 18.47 14.68 13.41 20.66 3.85 14 四川 137.8 20.74 11.07 17.74 16.49 4.39 15 贵州 121.67 21.53 12.58 14.49 12.18 4.57 16 新疆 123.24 38 13.72 4.64 17.77 5.75 17 河北 95.21 22.83 9.3 22.44 22.81 2.8 18 ⼭西 104.78 25.11 6.46 9.89 18.17 3.25 19 内蒙 128.41 27.63 8.94 12.58 23.99 3.27 20 河南 101.18 23.26 8.46 20.2 20.5 4.3 21 云南 124.27 19.81 8.89 14.2215.53 3.03 22 陕西 106.02 20.56 10.94 10.11 18 3.29 23 ⽢肃 95.65 16.82 5.7 6.03 12.36 4.49 24 青海 107.12 16.45 8.98 5.4 8.78 5.93 25 宁夏 113.74 24.11 6.46 9.61 22.92 2.53 26 北京 190.33 43.77 9.73 60.54 49.01 9.04 27 上海 221.11 38.64 12.53 115.65 50.82 5.89 28⼴州182.5520.5218.3242.436.9711.68【实验过程记录(结果分析及⼼得体会等)】 1. 聚类分析(Cluster Analysis)5、“保存”中选择“单⼀⽅案”,聚类数为3.6、点击“确定”。
聚类分析法实训报告范文

一、实训背景随着大数据时代的到来,数据分析在各个领域都扮演着越来越重要的角色。
聚类分析法作为一种重要的数据分析方法,能够帮助我们根据数据的特点和特征,将相似的数据归为一类,从而发现数据中隐藏的规律和模式。
为了提高我们对聚类分析法的理解和应用能力,我们进行了本次实训。
二、实训目标1. 掌握聚类分析的基本概念和原理。
2. 熟悉常用的聚类分析方法,如K-means聚类、层次聚类等。
3. 学会使用SPSS等软件进行聚类分析。
4. 通过实际案例,提高运用聚类分析法解决实际问题的能力。
三、实训内容1. 聚类分析的基本概念和原理聚类分析是将一组数据根据相似性或距离进行分组的过程。
通过聚类分析,我们可以将数据划分为若干个类别,使得同一类别内的数据尽可能相似,不同类别之间的数据尽可能不同。
聚类分析的基本原理如下:(1)相似性度量:选择合适的相似性度量方法,如欧氏距离、曼哈顿距离等。
(2)聚类算法:选择合适的聚类算法,如K-means聚类、层次聚类等。
(3)聚类结果评估:评估聚类结果的合理性,如轮廓系数、内聚度和分离度等。
2. 常用的聚类分析方法(1)K-means聚类:K-means聚类是一种迭代优化算法,通过迭代计算聚类中心,将数据点分配到最近的聚类中心所在的类别。
(2)层次聚类:层次聚类是一种自底向上的聚类方法,通过不断合并距离最近的类别,形成树状结构。
3. 软件应用本次实训使用SPSS软件进行聚类分析。
SPSS软件具有操作简便、功能强大等特点,能够满足我们对聚类分析的需求。
四、实训案例案例一:客户细分某银行希望通过聚类分析,将客户分为不同的类别,以便更好地进行客户管理和营销。
我们收集了以下数据:- 客户年龄- 客户收入- 客户储蓄量- 客户消费频率使用K-means聚类方法,将客户分为四个类别:- 高收入、高消费群体- 中等收入、中等消费群体- 低收入、低消费群体- 高收入、低消费群体通过聚类分析,银行可以根据不同客户群体的特点,制定相应的营销策略。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
聚类分析实验报告一、实验数据2013年,在国内外形势错综复杂的情况下,我国经济实现了平稳较快发展。
全年国内生产总值568845亿元,比上年增长7.7%。
其中第三产业增加值262204亿元,增长8.3%,其在国内生产总值中的占比达到了46.1%,首次超过第二产业。
经济的快速发展也带来了就业的持续增加,年末全国就业人员76977万人,其中城镇就业人员38240万人,全年城镇新增就业1310万人。
随着我国城镇化进程的不断加快,加之农业用地量的不断衰减,工业不断的转型升级,使得劳动力就业压力的缓解需要更多的依靠服务业的发展。
(一)指标选择根据指标选择的可行性、针对性、科学性等原则,分别从服务业的发展规模、发展结构、发展效益以及发展潜力等方面选择14个指标来衡量服务业的发展水平,指标体系如表1所示:表1 服务业发展水平指标体系(二)指标数据本次实验采用的数据是我国31个省(市、自治区)2012年的数据,原数据均来自《2013中国统计年鉴》以及2013年各省(市、自治区)统计年鉴,不能直接获得的指标数据是通过对相关原始数据的换算求得。
原始数据如表2所示:表2(续)二、实验步骤本次实验是在SPSS中分别利用系统聚类法和K均值法进行聚类分析,具体步骤如下:(一)系统聚类法⒈在SPSS窗口中选择Analyze—Classify—Hierachical Cluster,调出系统聚类分析主界面,将变量X1-X14移入Variables框中。
在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
⒉点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
这里选择系统默认值,点击Continue按钮,返回主界面。
⒊点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。
选中Dendrogram复选框和Icicle栏中的None单选按钮,即只给出聚类树形图,而不给出冰柱图。
单击Continue按钮,返回主界面。
⒋点击Method按钮,设置系统聚类的方法选项。
Cluster Method下拉列表用于指定聚类的方法,这里选用W ard’s method,Measure中的Interval中选择Squared Euclidean distance,在Transform Values中的Standardize中选择Z scores,表示对原始数据进行标准化,其他选择默认选项。
单击Continue 按钮,返回主界面。
⒌点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新变量。
这里选用Range of solutions,并在后面的两个矩形框中分别输入3和4,即生产三个新的分类变量,分别表示将样品分为3类、4类和5类时的聚类结果。
点击Continue,返回主界面。
(二)K均值法1.在SPSS窗口中选择Analyze—Descriptive Statistics—Descriptives…,调出Descriptives主界面,将变量X1-X14移入Variables 框中,选中Save standardized values as variables复选框,然后点击OK,即对原始数据进行标准化,以消除量纲的影响。
2.在SPSS窗口中选择Analyze—Classify—K-Means Cluster,调出K均值聚类分析主界面,将变量X1-X14移入Variables框中。
将标志变量Region移入Label Case by框中,在Method框中选择Iterate classify,即使用K-means 算法不断计算新的类中心,并替换旧的类中心。
在Number of Cluster后面的矩形框中输入想要把样品聚成的类数,这里输入4,即将31个省、市、自治区分为4类,其他按钮均为系统默认。
⒊点击Iterate按钮,对迭代参数进行设置,这里采用系统默认的标准。
单击Continue,返回主界面。
⒋点击Save按钮,设置保存在数据文件中的表明聚类结果的新变量,选中Cluster membership(建立一个代表聚类结果的变量,默认变量名为qcl_1)和Distance from cluster center(建立一个新变量,代表各观测变量与其所属类中心的欧几里得距离),单击Continue按钮返回主界面。
⒌点击Options 按钮,指定要计算的统计量,选中Initial cluster centers 和Cluster information for each case复选框,这样在输出窗口中将给出聚类的初始类中心和每个观测量的分类信息,包括分配到哪一类和该观测量距所属类中心的距离,单击Continue按钮返回主界面。
6.点击OK,进行K均值聚类分析程序。
三、实验结果(一)系统聚类法结果在结果输出窗口中可以看到分类结果表(表3)和聚类树形图(图1),具体见表1和图2所示:从表3和图1可以清楚的看到,可将样品分成如下四类:第一类:北京、天津、上海第二类:河北、辽宁、安徽、福建、河南、湖北、湖南、四川第三类:山西、内蒙古、吉林、黑龙江、江西、广西、海南、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆第四类:江苏、浙江、山东、广东Dendrogram using Ward MethodRescaled Distance Cluster CombineC A S E 0 5 10 15 20 25Label Num +---------+---------+---------+---------+---------+湖北 17 -+湖南 18 -+河北 3 -+-+河南 16 -+ |四川 23 -+ +--------+安徽 12 -+ | |辽宁 6 -+-+ |福建 13 -+ |贵州 24 -+-+ +--------------------------------------+ 宁夏 30 -+ +----+ | | 内蒙古 5 ---+ | | | 吉林 7 -+ | | | 新疆 31 -+ | | | 青海 29 -+ +---+ | 江西 14 -+ | | 广西 20 -+---+ | | 云南 25 -+ | | | 甘肃 28 -+ | | | 陕西 27 -+ +-+ | 山西 4 -+ | | 重庆 22 -+-+ | | 黑龙江 8 -+ +-+ | 海南 21 -+-+ | 西藏 26 -+ | 江苏 10 -+ | 浙江 11 -+-+ | 山东 15 -+ +-------------------+ | 广东 19 ---+ +---------------------------+ 天津 2 -----+---+ |上海 9 -----+ +-------------+北京 1 ---------+图1 聚类树形图(二)K均值法结果由表4可知,将31个省(直辖市、自治区)分为四类的结果为:第一类:北京第二类:天津、上海第三类:河北、山西、内蒙古、吉林、黑龙江、安徽、福建、江西、河南、湖北、湖南、广西、海南、重庆、四川、贵州、云南、西藏、山西、甘肃、青海、宁夏、新疆第四类:辽宁、江苏、浙江、山东、广东(三)聚类结果分析从系统聚类结果和K均值法聚类结果可以看出,二者最终的聚类结果是有差距的。
因而,在实际的聚类案例中,我们应该具体问题具体分析,选择合适的聚类方法,进行合理的聚类。
判别分析实验报告为研究我国服务业发展水平,已按系统聚类法将27个已知省(直辖市、自治区)分为4类,现对另4个未知省(直辖市、自治区)分属哪一类进行判别,指标含义及原始数据分别如表1和表2所示:表1 服务业发展水平指标含义表2 2012年我国服务业发展水平统计数据表表2(续)一、操作步骤(一)在SPSS窗口中选择Analyze—Descriptive Statistics—Descriptives…,调出Descriptives主界面,将变量X1-X14移入Variables 框中,选中Save standardized values as variables复选框,然后点击OK,即对原始数据进行标准化,以消除量纲的影响。
(二)在SPSS窗口中选择Analyze—Classify—Discriminate,调出判别分析主界面,将左边的变量列表中的type变量选入分组变量Grouping Variable 中,将X1-X14变量选入自变量Independents中,并选择Enter independents together单选按钮,即使用所有自变量进行判别分析。
(三)点击Define Range按钮,定义分组变量的取值范围。
这里分类变量的范围为1到4,所以在最小值和最大值中分别输入1和4。
单击Continue按钮,返回主界面。
(四)单击Statistics…按钮,指定输出的描述统计量和判别函数系数。
选中Function Coefficients栏中的Fisher’s(给出贝叶斯判别函数的系数)和Unstandardized(给出为标准化的费希尔判别函数),单击Continue按钮,返回主界面。
(五)单击Classify…按钮,定义判别分组参数和选择输出结果。
选择Display栏中的Casewise results,输出一个判别结果表,包括每个样品的判别分数、后验概率、实际组合预测编号等。
其余的均保留系统默认选项。
单击Continue按钮,返回主界面。
(六)单击Save按钮,指定在数据文件中生成代表判别分组结果和判别得分的新变量,生成的新变量的含义分别为:Predicted group membership(存放判别样品所属组别的值);Discriminant scores(存放费希尔判别得分的值);Probabilities of group membership(存放样品属于各组的贝叶斯后验概率),这里将三个复选框均选中,单击Continue按钮返回主界面。
(七)返回判别分析主界面,单击OK按钮,运行判别分析过程。
二、个案观察结果表3为标准化典型判别函数的系数表,由该表可以得到典型判别函数为:Y 1=-1.077X1-0.951X2+1.890X3-0.862X4-26.097X5+5.976X6-1.408X7+1.183X8+19.433X9+0.268X10-11.585X11+1.764X12+0.443X13+0.687X14Y 1=-2.380X1+1.143X2+17.628X3-0.176X4-1.867X5+0.835X6+1.174X7+0.108X8+1.796X9-0.220X10-1.507X11+0.030X12-0.374X13+0.576X14Y 1=-1.699X1+1.285X2+6.112X3-0.533X4-7.635X5+2.285X6-0.992X7-0.120X8+6.959X9-0.279X10-3.211X11+0.885X12+0.628X13+0.465X14表4为未标准化的典型判别函数的系数表。