哈工大尹海洁社会统计学PPT课件 第三章 两个类别变量关系的描述统计
合集下载
统计学课件ppt(全)

统计是以数据为食物的动物 统计的本业是消化数据, 并产生有营养的结果。
Data—— Statistics ——Information
经济学家、教育家、人口学家 原北京大学校长 马寅初
• 学者不能离开统计而研究 • 政治家不能离开统计而施政 • 企业家不能离开统计而执业
第一节 统计与统计学
• 统计与统计学的含义 • 统计数据的规律与统计方法
二、统计数据的规律与统计方法
以上例子说明,通过多次观察或试验可 以得到大量的统计数据,利用统计方法是 可以探索其内在的数量规律性。因为客观 事物本身是必然性与偶然性的对立统一, 必然性反映了事物的本质特征,偶然性反 映了事物表现形式的差异。(举例学生的 平均分,标准差)
举例3:《2011年武汉地区高校毕业 生就业报告》
• 即使入职相同行业,不同部门间的收入差 距也较大。从总体看,高校毕业生薪资起 点呈现“研发岗”>“销售岗”>“职能 岗”>“行政岗”的总体态势。 • 在不同性质的企业中,应届高校毕业生工 资最高的是外资企业,达2500元以上的占 到62.3%,达5000元以上的占到8.2%。接 近半数的应届毕业生,工资水平集中在 1500元-2500元之间。
举例5:文学也与统计有关
据统计学家(复旦大学李贤平教授)对《红 楼梦》各回的虚词(47个虚词:之,其,或,呀, 吗,可,便,就……)出现的频率进行统计分析 (原因是由于个人写作特点和习惯的不同,所用 的虚词是不会一样的),采用聚类分析,(物以 聚类,人以群分)发现前80回和后40回明显不同, 出自不同的人,进一步运用判别分析,发现前80 回是曹雪芹缩写,后40回不是高鹗一人所写,而 是曹雪芹亲友将其草稿整理而成,宝黛故事为一 人所写,贾府衰败情景为另一人所写等等,这个 论证在红学界轰动很大。
社会统计学PPT课件
• 所谓重点单位,是着眼于现象量的方面,尽 管这些单位在全部单位中只是一部分,但是 它们的某一标志的标志总量在总体标志总量 中占有绝大比重。
四、典型调查
(一)含义:
根据调查的目的任务,对所研究的现象总体进行初步 分析的基础上,有意识地选取若干具有代表性的单 位进行调查和研究,借以认识事物发展变化的规律。
(一)研究对象 大量社会现象总体的数量方面,即现象总体的数 量特征、数量关系及数量界限。
(二)统计学研究对象的特点 1、数量性 2、总体性 3、具体性 4、社会性
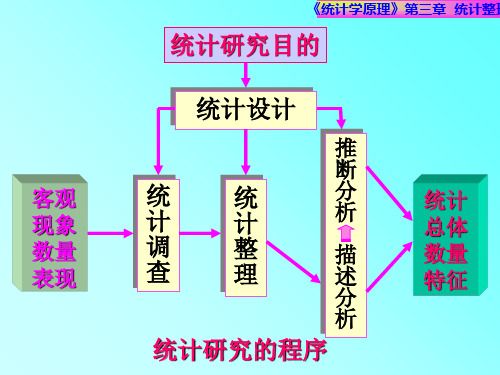
第二节 统计研究的方法与过程
一、统计工作的过程
(一)统计设计:对统计活动各个方面和各个环节所作的通
盘考虑和合理安排。
(二)统计调查:根据一定的目的,通过科学的调查方法,
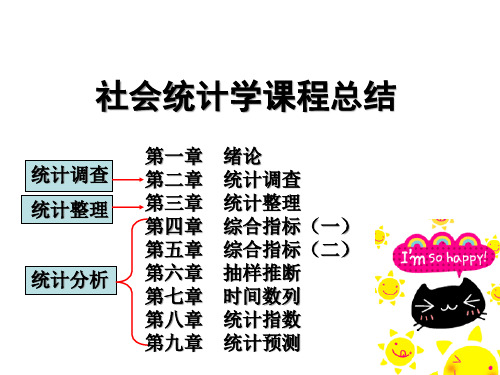
社会统计学课程总结
统计调查 统计整理
统计分析
第一章 第二章 第三章 第四章 第五章 第六章 第七章 第八章 第九章
绪论 统计调查 统计整理 综合指标(一) 综合指标(二) 抽样推断 时间数列 统计指数 统计预测
第一章 绪论
第一节 统计与统计学
一、统计的含义
(一)统计工作
(二)统计资料
(三)统计学
二、社会统计的产生与发展 三、社会统计研究的对象和特点
(三)标志与指标的主要联系
有些统计指标的数值是从总体单位的数 量标志值汇总得到的。 在一定的研究范围内,指标和数量标志 之间存在着变换关系,当研究目的改变,原 来的总体变为总体单位,则相应的统计指 标就变为数量标志了,反之亦然。
第二章 统计调查
• 统计调查方案 • 统计调查组织形式 • 统计调查问卷 • 撰写统计调查报告
(二)统计总体的特点:
1.大量性:
四、典型调查
(一)含义:
根据调查的目的任务,对所研究的现象总体进行初步 分析的基础上,有意识地选取若干具有代表性的单 位进行调查和研究,借以认识事物发展变化的规律。
(一)研究对象 大量社会现象总体的数量方面,即现象总体的数 量特征、数量关系及数量界限。
(二)统计学研究对象的特点 1、数量性 2、总体性 3、具体性 4、社会性
第二节 统计研究的方法与过程
一、统计工作的过程
(一)统计设计:对统计活动各个方面和各个环节所作的通
盘考虑和合理安排。
(二)统计调查:根据一定的目的,通过科学的调查方法,
社会统计学课程总结
统计调查 统计整理
统计分析
第一章 第二章 第三章 第四章 第五章 第六章 第七章 第八章 第九章
绪论 统计调查 统计整理 综合指标(一) 综合指标(二) 抽样推断 时间数列 统计指数 统计预测
第一章 绪论
第一节 统计与统计学
一、统计的含义
(一)统计工作
(二)统计资料
(三)统计学
二、社会统计的产生与发展 三、社会统计研究的对象和特点
(三)标志与指标的主要联系
有些统计指标的数值是从总体单位的数 量标志值汇总得到的。 在一定的研究范围内,指标和数量标志 之间存在着变换关系,当研究目的改变,原 来的总体变为总体单位,则相应的统计指 标就变为数量标志了,反之亦然。
第二章 统计调查
• 统计调查方案 • 统计调查组织形式 • 统计调查问卷 • 撰写统计调查报告
(二)统计总体的特点:
1.大量性:
第三章--统计整理-幻灯片(1)
如某班学生按年龄分组:17岁,18岁,19岁, 20岁, 21岁,22岁。
组距式分组
将作为分组依据的数量标志的整个取 值范围依次划分为若干个满足互斥性
和包容性的区间,用这些数值区间作
为组的名称。
某班学生统计 学原理成绩分 组
60分以下 60—70分 70—80分 80—90分 90分以上
组距式分组中的一些概念 《统计学原理》第三章 统计整理
对教师 的分类
按性别分类
男性 女性
高级 按职称分类 中级 共计7组
初级 2+3+2
青年 按年龄分类
中年
复合分组体系
对教师 的分类
按性别 分类
按职称 分类
按年龄 分类
《统计学原理》第三章 统计整理
共计12组 男 2×3×2
女 高级
中级
初级 青年 中年
《统计学原理》第三章 统计整理
统计资料的再分组
• 统计资料的再分组就是把统计分 组资料按某种要求,重新划定各 组界限,再将资料中的单位数或 比重分布重新做出调整。
对总体单位而言,是“合”,即将性质相同的 个体组合起来,在同一组内则保持着相同的性 质。
分组
《统计学原理》第三章 统计整理
25%
33%
分组前
分组后
42%
作用:1·区分事物的性质
例:按所有制性质划分,我国现有8种经济类型:
国有经济;集体经济;私营经济;个体经济 联营经济;股份制经济;外商投资经济;港 澳台投资经济
将统计调查得到的原始资料进行科
统计整理 学的分类和汇总,使之成为系统化、
条理化的综合资料,以反映研究总 体的特征。
地位 是统计调查的继续,统计分析的前提 和基础,起着承前启后的作用。
统计学ppt课件

配对样本非参数检验
包括Wilcoxon符号秩次检验、McNemar检验等,用于比较同一组 样本在两个不同条件下的差异。
多元线性回归模型构建
1 2
多元线性回归模型基本概念 介绍自变量、因变量、误差项等概念,以及模型 的数学表达式。
多元线性回归模型的参数估计 通过最小二乘法等方法估计模型参数,得到回归 方程。
概率可以通过古典概型、几何概型、频率等方法进行计算。古典概型适用于等可能 事件,几何概型适用于连续型随机变量,而频率则是在大量重复试验中出现的相对 频率。
02 描述性统计方法
数值型数据描述
集中趋势度量
01
平均数、中位数、众数
离散程度度量
02
极差、四分位差、方差、标准差
偏态与峰态度量
03
偏度系数、峰度系数
统计学ppt课件
目录
• 统计学基本概念与原理 • 描述性统计方法 • 推论性统计方法 • 非参数检验与多元统计分析 • 实验设计与抽样技术 • 数据可视化与报告撰写技巧
01 统计学基本概念 与原理
统计学定义及作用
统计学的定义
统计学是一门研究如何收集、整理、 分析、解释和呈现数据的科学。
统计学的作用
数据分布形态判断
正态性检验
直方图、QQ图、P-P图、Shapiro-Wilk检验等方 法
对称性检验
通过观察频数分布表或图形判断
峰度与偏度检验
通过计算峰度系数和偏度系数判断
03 推论性统计方法
参数估计原理及应用
点估计与区间估计
利用样本数据对总体参数进行估计,包括点估计和区间估计两种方 法。
估计量的评价标准
3
多元线性回归模型的假设检验 对模型参数进行显著性检验,判断自变量对因变 量的影响是否显著。
包括Wilcoxon符号秩次检验、McNemar检验等,用于比较同一组 样本在两个不同条件下的差异。
多元线性回归模型构建
1 2
多元线性回归模型基本概念 介绍自变量、因变量、误差项等概念,以及模型 的数学表达式。
多元线性回归模型的参数估计 通过最小二乘法等方法估计模型参数,得到回归 方程。
概率可以通过古典概型、几何概型、频率等方法进行计算。古典概型适用于等可能 事件,几何概型适用于连续型随机变量,而频率则是在大量重复试验中出现的相对 频率。
02 描述性统计方法
数值型数据描述
集中趋势度量
01
平均数、中位数、众数
离散程度度量
02
极差、四分位差、方差、标准差
偏态与峰态度量
03
偏度系数、峰度系数
统计学ppt课件
目录
• 统计学基本概念与原理 • 描述性统计方法 • 推论性统计方法 • 非参数检验与多元统计分析 • 实验设计与抽样技术 • 数据可视化与报告撰写技巧
01 统计学基本概念 与原理
统计学定义及作用
统计学的定义
统计学是一门研究如何收集、整理、 分析、解释和呈现数据的科学。
统计学的作用
数据分布形态判断
正态性检验
直方图、QQ图、P-P图、Shapiro-Wilk检验等方 法
对称性检验
通过观察频数分布表或图形判断
峰度与偏度检验
通过计算峰度系数和偏度系数判断
03 推论性统计方法
参数估计原理及应用
点估计与区间估计
利用样本数据对总体参数进行估计,包括点估计和区间估计两种方 法。
估计量的评价标准
3
多元线性回归模型的假设检验 对模型参数进行显著性检验,判断自变量对因变 量的影响是否显著。
统计学完整ppt课件完整版

假设检验的基本思想:小概率事件原 理
假设检验中的两类错误:第一类错误 、第二类错误
假设检验的步骤:建立假设、选择检 验统计量、确定拒绝域、计算p值、 作出决策
假设检验的实例分析:单样本t检验 、双样本t检验等
方差分析(ANOVA)方法介绍
方差分析的基本原理:F分布与 方差分析的关系
多因素方差分析的实现方法: 析因设计、随机区组设计等
通过观察数据的峰度,判 断是否存在尖峰或平峰分 布
03
推论性统计方法
参数估计原理及应用
01
参数估计的基本概念: 点估计、区间估计
02
估计量的评价标准:无 偏性、有效性、一致性
03
参数估计的方法:矩估 计法、最大似然估计法
04
参数估计的应用:总体 均值的区间估计、总体 比例的区间估计等
假设检验流程与实例分析
ABCD
数据筛选与排序
介绍如何使用Excel进行数据筛选和排序,以便 更好地查看和分析数据。
函数与公式应用
分享一些常用的Excel函数和公式,以便更高效 地处理和分析数据。
案例分享:使用统计软件解决实际问题
案例一
使用SPSS进行市场调研数据分析,包 括描述性统计、交叉表分析、回归分析
等。
案例三
使用Python进行电商数据分析,包 括用户行为分析、销售预测、推荐系
据的科学。
统计学的作用
描述数据特征
推断总体参数 预测未来趋势
评估决策效果
数据类型与来源
数据类型 定量数据(连续型与离散型)
定性数据(分类数据与顺序数据)
数据类型与来源
01
数据来源
02
03
04
观察数据(实验数据与观测数 据)
假设检验中的两类错误:第一类错误 、第二类错误
假设检验的步骤:建立假设、选择检 验统计量、确定拒绝域、计算p值、 作出决策
假设检验的实例分析:单样本t检验 、双样本t检验等
方差分析(ANOVA)方法介绍
方差分析的基本原理:F分布与 方差分析的关系
多因素方差分析的实现方法: 析因设计、随机区组设计等
通过观察数据的峰度,判 断是否存在尖峰或平峰分 布
03
推论性统计方法
参数估计原理及应用
01
参数估计的基本概念: 点估计、区间估计
02
估计量的评价标准:无 偏性、有效性、一致性
03
参数估计的方法:矩估 计法、最大似然估计法
04
参数估计的应用:总体 均值的区间估计、总体 比例的区间估计等
假设检验流程与实例分析
ABCD
数据筛选与排序
介绍如何使用Excel进行数据筛选和排序,以便 更好地查看和分析数据。
函数与公式应用
分享一些常用的Excel函数和公式,以便更高效 地处理和分析数据。
案例分享:使用统计软件解决实际问题
案例一
使用SPSS进行市场调研数据分析,包 括描述性统计、交叉表分析、回归分析
等。
案例三
使用Python进行电商数据分析,包 括用户行为分析、销售预测、推荐系
据的科学。
统计学的作用
描述数据特征
推断总体参数 预测未来趋势
评估决策效果
数据类型与来源
数据类型 定量数据(连续型与离散型)
定性数据(分类数据与顺序数据)
数据类型与来源
01
数据来源
02
03
04
观察数据(实验数据与观测数 据)
第一章社会统计学概述——社会统计学课件PPT

1.什么是社会统计学? 2.狭义社会统计学的三种范围是什么? 3.为什么要开展主观指标的搜集工作呢?
第一章 社会统计学的研究 范围与内容
第一节社会统计学的 研究范围与特征
一、社会统计概念 1.广义的社会及广义社会统计 2.狭义的社会及狭义社会统计
二、狭义社会统计学的三 种统计范围
(一)我国社会统计学的发展 (二)对狭义社会统计学的研究
范围的认识
三、社会统计学学科 体系的特征
(一)社会统计学的概念 (二)社会统计学学科体系的特征:
学者不能离开统计而研究 政治家不能离开统计而施政 企业家不能离开统计而执业
马寅初
社会统计学 主讲人:丛春霞
课程内容
第一章 社会统计学概述 第二章 人口与人力资源统计 第三章 住户活动统计 第四章 社会保障统计 第五章 公共部门统计 第六章 非市场服务产出统计 第七章 社会发展的统计描述和评价
统计学相对应的宏观性、综合性统计学科,它是研究客体与 一般统计方法结合的产物,属于特有统计方法 . (二)社会统计学为人口统计学、文化统计学、教育统计学、体 育统计学、卫生统计学、人民生活统计学等专业统计提供一 般统计理论和方法,它属于一般统计方法。
思考题
一是对社会统计学研究对象、研究内容、研究范围、体系结构等所作的系统研究;
1.研究客体的独立性。 2.研究方法的特有性。 3.内容结构的系统性与层次性。 4.与专业统计的相互渗透性。 5.学科体系的发展性
四、我国社会统计学研 究的发展
(一)第一阶段自80年代初至1983 年
(二)第二阶段自1983年至90年代 初
(三)第三阶段自90年代初起
五、社会统计指标的种类
(一)主观指标与客观指标 为什么要开展主观指标的搜集工
第一章 社会统计学的研究 范围与内容
第一节社会统计学的 研究范围与特征
一、社会统计概念 1.广义的社会及广义社会统计 2.狭义的社会及狭义社会统计
二、狭义社会统计学的三 种统计范围
(一)我国社会统计学的发展 (二)对狭义社会统计学的研究
范围的认识
三、社会统计学学科 体系的特征
(一)社会统计学的概念 (二)社会统计学学科体系的特征:
学者不能离开统计而研究 政治家不能离开统计而施政 企业家不能离开统计而执业
马寅初
社会统计学 主讲人:丛春霞
课程内容
第一章 社会统计学概述 第二章 人口与人力资源统计 第三章 住户活动统计 第四章 社会保障统计 第五章 公共部门统计 第六章 非市场服务产出统计 第七章 社会发展的统计描述和评价
统计学相对应的宏观性、综合性统计学科,它是研究客体与 一般统计方法结合的产物,属于特有统计方法 . (二)社会统计学为人口统计学、文化统计学、教育统计学、体 育统计学、卫生统计学、人民生活统计学等专业统计提供一 般统计理论和方法,它属于一般统计方法。
思考题
一是对社会统计学研究对象、研究内容、研究范围、体系结构等所作的系统研究;
1.研究客体的独立性。 2.研究方法的特有性。 3.内容结构的系统性与层次性。 4.与专业统计的相互渗透性。 5.学科体系的发展性
四、我国社会统计学研 究的发展
(一)第一阶段自80年代初至1983 年
(二)第二阶段自1983年至90年代 初
(三)第三阶段自90年代初起
五、社会统计指标的种类
(一)主观指标与客观指标 为什么要开展主观指标的搜集工
分类变量的描述性统计-医学统计学课件

Байду номын сангаас
描述性统计的常用指标有哪些?
1 频数
2 百分比
统计每个类别的观察次数, 反映各类别在样本中的分 布。
计算每个类别在样本中的 所占比例,用于比较不同 类别的相对频率。
3 累计百分比
计算每个类别及其前面所 有类别的累计频率,描述 数据的积累情况。
如何绘制频数表?
频数表是一种统计表格,用于展示各类别的频数和频率。通过表格形式,可 以清晰地展示数据的分布情况,方便比较和分析。
如何绘制条形图?
条形图是一种可视化方法,用长条的长度代表各类别的频数或频率,直观地展示各类别之间的差异,便于观察 和理解数据的分布情况。
堆叠条形图
展示多个分类变量在不同分组中的频数或频率,比 较各类别在不同分组中的差异。
簇状条形图
将多个分类变量的频数或频率放在同一条形图中, 直观地比较各类别之间的差异。
分类变量的描述性统计医学统计学课件
本课件介绍分类变量的描述性统计方法,包括常用指标和可视化方法,以及 如何进行多个变量的比较和分析。通过本课件,您将更好地理解医学统计学 中的数据分析方法。
什么是分类变量?
分类变量是指变量的取值分属于有限个类别,例如血型、性别和疾病类型等。通过描述性统计方法,我们可以 对分类变量进行分析和解释。
如何使用交叉表进行分析?
交叉表是一种用于统计分析的工具,将两个或多个分类变量的取值组合在一起,展示各类别之间的频数和频率。 通过交叉表分析,可以更深入地了解分类变量之间的关系。
如何进行卡方检验?
卡方检验是一种统计方法,用于分析两个分类变量之间的关联性。通过计算 观察频数与期望频数的差异,判断两个变量之间是否存在显著的关联。
如何进行列联表分析?
描述性统计的常用指标有哪些?
1 频数
2 百分比
统计每个类别的观察次数, 反映各类别在样本中的分 布。
计算每个类别在样本中的 所占比例,用于比较不同 类别的相对频率。
3 累计百分比
计算每个类别及其前面所 有类别的累计频率,描述 数据的积累情况。
如何绘制频数表?
频数表是一种统计表格,用于展示各类别的频数和频率。通过表格形式,可 以清晰地展示数据的分布情况,方便比较和分析。
如何绘制条形图?
条形图是一种可视化方法,用长条的长度代表各类别的频数或频率,直观地展示各类别之间的差异,便于观察 和理解数据的分布情况。
堆叠条形图
展示多个分类变量在不同分组中的频数或频率,比 较各类别在不同分组中的差异。
簇状条形图
将多个分类变量的频数或频率放在同一条形图中, 直观地比较各类别之间的差异。
分类变量的描述性统计医学统计学课件
本课件介绍分类变量的描述性统计方法,包括常用指标和可视化方法,以及 如何进行多个变量的比较和分析。通过本课件,您将更好地理解医学统计学 中的数据分析方法。
什么是分类变量?
分类变量是指变量的取值分属于有限个类别,例如血型、性别和疾病类型等。通过描述性统计方法,我们可以 对分类变量进行分析和解释。
如何使用交叉表进行分析?
交叉表是一种用于统计分析的工具,将两个或多个分类变量的取值组合在一起,展示各类别之间的频数和频率。 通过交叉表分析,可以更深入地了解分类变量之间的关系。
如何进行卡方检验?
卡方检验是一种统计方法,用于分析两个分类变量之间的关联性。通过计算 观察频数与期望频数的差异,判断两个变量之间是否存在显著的关联。
如何进行列联表分析?
分类变量的描述性统计讲解

因 过去
病人 非病人 合计
有吸烟史 a
c a+c
无吸烟史 b
d b+d
合计 a+b
c+d N
Odds1=(a/a+b)/(b/(a+b)=p(E1)/(1-p(E1)) Odds2=(c/c+d)/(d/(c+d)=p(E2)/(1-p(E2))
OR=odds1/odds2=ad/bc
病人
表3-2 COPD病人与非病人的吸烟情况资料
二、优势比(odds ratio ,OR): 1. 常用于流行病学的病例对照研究 2. 病例组某危险因素的优势与非病例组某危险因素的优势之比。
一、相对危险度
危险度( risk)是医学研究中常用的一个统计指标, 常用概率(或频率)表示。如发病、患病或死亡的危险 度是指发病、患病或死亡的危险性,这种危险性用发病 率( incidence of a disease )。患病率( prevalence rate)、死亡率( death rate)表示。如吸烟者肺癌、 COPD的患病率高,也可以说吸烟是肺癌、 COPD的高 危因素,吸烟者患肺癌、 COPD的危险度大。
事物内部各部分的观察 单位数总和 特 点 : 1. 各 部 分 构 成 比 的 合 计 等 于 1 0 0 % 或 1 。
2. 事 物 内 部 某 一 部 分 的 构 成 比 发 生 变 化 时,其它部分的构成比也相应地发生变化。
表3-1 吸毒与非吸毒人群职业构成对比分析
职业 学生 无业 个体 工人 司机 其它
二、比: 1. 构成比(constituent ratio ):部分与全部之比 2. 相对比(relative ratio ):两指标之比
统计学讲稿演示文稿PPT课件

n1=n2
C σ21、σ22未知、且σ21≠σ22、 n1≠n2
第50页/共67页
(二)两个总体均值之差的估计:匹 配样本
(1)大样本
(2)小样本
第51页/共67页
二 两个总体比率之差的区间估计
第52页/共67页
第四节 样本容量的确定
第53页/共67页
一 估计总体均值时样本容量的确定 二 估计总体比率时样本容量的确定
1 正态分布 2 非正态分布 (1)大样本 (2)小样本
第31页/共67页
三 样本均值抽样分布的特征 1 均值 2 方差 (1)重复抽样时 (2)不重复抽样时
第32页/共67页
四 样本比率的抽样分布 1 比率
2 样本比率的抽样分布 (1)均值 (2)方差
重复抽样时 不重复抽样时
第33页/共67页
变量:P10
(变量值)
三
样本:P10
第2页/共67页
第五节 统计学与其它学科的关系
一 统计学与数学的关系 1 联系 2 区别
二 统计学与其它学科的关 系
第3页/共67页
第二章 统计数据的描述
第一节 数据的计量尺度 一 数据的计量尺度 1 列名尺度(定类尺度):P17 2 顺序尺度(定序尺度):P17 3 间隔尺度(定距尺度):P17
第20页/共67页
第七节 分布偏态与峰度的测度
一 偏态及其测度 1 比较法(皮尔逊偏度)
2 动差法 二 峰度及其测度
第21页/共67页
第八节 茎叶图与箱线图
第22页/共67页
第九节 统计表与统计图
第23页/共67页
第四章 抽样与抽样分布
样本统计量 参数
抽样调查
第24页/共67页
C σ21、σ22未知、且σ21≠σ22、 n1≠n2
第50页/共67页
(二)两个总体均值之差的估计:匹 配样本
(1)大样本
(2)小样本
第51页/共67页
二 两个总体比率之差的区间估计
第52页/共67页
第四节 样本容量的确定
第53页/共67页
一 估计总体均值时样本容量的确定 二 估计总体比率时样本容量的确定
1 正态分布 2 非正态分布 (1)大样本 (2)小样本
第31页/共67页
三 样本均值抽样分布的特征 1 均值 2 方差 (1)重复抽样时 (2)不重复抽样时
第32页/共67页
四 样本比率的抽样分布 1 比率
2 样本比率的抽样分布 (1)均值 (2)方差
重复抽样时 不重复抽样时
第33页/共67页
变量:P10
(变量值)
三
样本:P10
第2页/共67页
第五节 统计学与其它学科的关系
一 统计学与数学的关系 1 联系 2 区别
二 统计学与其它学科的关 系
第3页/共67页
第二章 统计数据的描述
第一节 数据的计量尺度 一 数据的计量尺度 1 列名尺度(定类尺度):P17 2 顺序尺度(定序尺度):P17 3 间隔尺度(定距尺度):P17
第20页/共67页
第七节 分布偏态与峰度的测度
一 偏态及其测度 1 比较法(皮尔逊偏度)
2 动差法 二 峰度及其测度
第21页/共67页
第八节 茎叶图与箱线图
第22页/共67页
第九节 统计表与统计图
第23页/共67页
第四章 抽样与抽样分布
样本统计量 参数
抽样调查
第24页/共67页
哈工大尹海洁社会统计学PPT课件 第十六章 时间序列分析

(四)随机波动 随机波动是指除上述三种因素外其他一些偶然性因素使时间序列呈现出的 不规则波动。也有一些时间序列仅受到随机性波动的影响,其观察值基本 上围绕某个固定水平做大致恒定振幅的波动,不同的时间段波动的程度不 同,不存在某种规律。
第十六章 时间序列分析 第二节 时间序列的描述性分析
一、时间序列的图表描述 图表直观地显示出观察数据随时间的变化情况,从中可以寻找现象 进一步的发展趋势,为下一步的分析和预测奠定基础。因此,图表 描述是观察时间序列的重要方法。 (一)统计表
第十六章 时间序列分析
1 时间序列概述 时间序列的描述性分析
2 时间序列的预测方法
3 Exe 本章习题
第十六章 时间序列分析
➢前面各章节所介绍的统计分析方法都是针对截面数据来使用的。
截面数据是通过一次调查所获得的数据,描述某一社会现象在某一
个时间点上的状态。 ➢社会学研究中,为研究事物发展变化规律,也需要对同一现象在
为了更直观、 明晰地显示时 间序列的增长 模式与速度, 通常需要借助 于线图方法。
第十六章 时间序列分析 第二节 时间序列的描述性分析
一、时间序列的图表描述 (二)折线图 图形更加直观、形象,为后期的选择预测模型提供基本依据。
随机波动
线性增长趋势
第十六章 时间序列分析 第二节 时间序列的描述性分析
不同时间点上做多次同样内容的调查,此种研究称为纵贯研究。
➢纵贯研究的结果就获得了与时间相关的数据,这类数据就是时间 序列数据。如历年的人口数、公民的收入水平等。 ➢除社会学者自己进行调查获取数据之外,我们还可以通过各种统 计年鉴等资料性文件获取大量的时间序列资料。 ➢对时间序列数据进行分析的目的,是要发现所研究的现象随时间 变化的规律,并根据此规律对未来的情况进行预测。 ➢时间序列数据与截面数据有较大差异,分析方法也有所不同。
第十六章 时间序列分析 第二节 时间序列的描述性分析
一、时间序列的图表描述 图表直观地显示出观察数据随时间的变化情况,从中可以寻找现象 进一步的发展趋势,为下一步的分析和预测奠定基础。因此,图表 描述是观察时间序列的重要方法。 (一)统计表
第十六章 时间序列分析
1 时间序列概述 时间序列的描述性分析
2 时间序列的预测方法
3 Exe 本章习题
第十六章 时间序列分析
➢前面各章节所介绍的统计分析方法都是针对截面数据来使用的。
截面数据是通过一次调查所获得的数据,描述某一社会现象在某一
个时间点上的状态。 ➢社会学研究中,为研究事物发展变化规律,也需要对同一现象在
为了更直观、 明晰地显示时 间序列的增长 模式与速度, 通常需要借助 于线图方法。
第十六章 时间序列分析 第二节 时间序列的描述性分析
一、时间序列的图表描述 (二)折线图 图形更加直观、形象,为后期的选择预测模型提供基本依据。
随机波动
线性增长趋势
第十六章 时间序列分析 第二节 时间序列的描述性分析
不同时间点上做多次同样内容的调查,此种研究称为纵贯研究。
➢纵贯研究的结果就获得了与时间相关的数据,这类数据就是时间 序列数据。如历年的人口数、公民的收入水平等。 ➢除社会学者自己进行调查获取数据之外,我们还可以通过各种统 计年鉴等资料性文件获取大量的时间序列资料。 ➢对时间序列数据进行分析的目的,是要发现所研究的现象随时间 变化的规律,并根据此规律对未来的情况进行预测。 ➢时间序列数据与截面数据有较大差异,分析方法也有所不同。
统计学 第3章 数据的整理与显示课件

第3章 数据的图表显示
• 重点:了解分组方法,掌握数值型数据的整理与 显示。 • 难点:针对不同类型的数据进行统计分组,区分 不同图、表的应用。
第1节 数据的预处理
• 审核:完整、准确 适用、时效 • 筛选: 剔除 保留
• 排序:递增、递减 升序、降序
数据审核—原始数据 (raw data) 1. 完整性审核 – 应调查的单位或个体是否有遗漏 – 所有的调查项目或变量是否填写齐全 2. 准确性审核 – 数据是否真实反映实际情况,内容是否符合 实际 – 数据是否有错误,计算是否正确等
例:某校新生按民族分组表
按民族分组 汉族
少数民族 合计
学生人数 900
200 1100
比率(%) 81.82
18.18 100.00
年收入在10000美元以下——“贫困” 年收入在10000至30000美元——“中下” 年收入在30000至50000美元——“中等” 年收入在50000至100000美元——“中上” 年收入在100000美元以上——“富裕”
数据的审核——二手数据 (second hand data) 1. 适用性审核 – 弄清楚数据的来源、数据的口径以及 有关的背景材料 – 确定数据是否符合自己分析研究的需 要 2. 时效性审核 – 尽可能使用最新的数据 3. 确认是否有必要做进一步的加工整理
数据筛选 (data filter)
1. 当数据中的错误不能予以纠正,或者有些数据 不符合调查的要求而又无法弥补时,需要对数 据进行筛选 2. 数据筛选的内容 将某些不符合要求的数据或有明显错误的数 据予以剔除 将符合某种特定条件的数据筛选出来,而不 符合特定条件的数据予以剔除
比重(%) 10.00 23.33 41.67
• 重点:了解分组方法,掌握数值型数据的整理与 显示。 • 难点:针对不同类型的数据进行统计分组,区分 不同图、表的应用。
第1节 数据的预处理
• 审核:完整、准确 适用、时效 • 筛选: 剔除 保留
• 排序:递增、递减 升序、降序
数据审核—原始数据 (raw data) 1. 完整性审核 – 应调查的单位或个体是否有遗漏 – 所有的调查项目或变量是否填写齐全 2. 准确性审核 – 数据是否真实反映实际情况,内容是否符合 实际 – 数据是否有错误,计算是否正确等
例:某校新生按民族分组表
按民族分组 汉族
少数民族 合计
学生人数 900
200 1100
比率(%) 81.82
18.18 100.00
年收入在10000美元以下——“贫困” 年收入在10000至30000美元——“中下” 年收入在30000至50000美元——“中等” 年收入在50000至100000美元——“中上” 年收入在100000美元以上——“富裕”
数据的审核——二手数据 (second hand data) 1. 适用性审核 – 弄清楚数据的来源、数据的口径以及 有关的背景材料 – 确定数据是否符合自己分析研究的需 要 2. 时效性审核 – 尽可能使用最新的数据 3. 确认是否有必要做进一步的加工整理
数据筛选 (data filter)
1. 当数据中的错误不能予以纠正,或者有些数据 不符合调查的要求而又无法弥补时,需要对数 据进行筛选 2. 数据筛选的内容 将某些不符合要求的数据或有明显错误的数 据予以剔除 将符合某种特定条件的数据筛选出来,而不 符合特定条件的数据予以剔除
比重(%) 10.00 23.33 41.67
社会统计学课件

300.0
400.0
500.0
600.0
700.0
800.0
月总支出(元)
3、多边形图
将直方图中各矩形顶端的中点用直线连接起来而成的图形。
4、常用曲线:洛仑兹曲线和基尼系数
将一国总人口按收入由低到高排列,考虑收入最低任意百分比人口所得到的收入 百分比,这样得到的人口累计百分比(横轴)和收入累计百分比(纵轴)的对应关系图形 即洛仑兹曲线。
洛仑兹曲线中,不平等面积与完全不平等面积之比。基尼系数是衡量一 个国家贫富差距的标准。
G=A/(A+B),0≤G≤1 G:基尼系数,A:不平等面积,A+B:完全不平等面积
二、集中趋势测量法
(一)定类变量:众值
变量取值中出现次数最多的值。
(二)定序变量:中位数
将全部调查个案的变量取值按等级顺序排列后,位于中央位置的值。
Statistics
父亲 文化程 度
N
Valid
219
Missing
0
Median
2.00
Mode
2
1、根据原始资料求中位数
Md 位置=(n+1)/2 其中,若 n 为偶数,则将位于中央的两个数值的平均值作为中位数。 2、根据分组资料求中位数
(n − cf ↑)
Md = L + 2
(U Percent Valid Percent
16.0
16.0
36.1
36.1
21.9
21.9
15.5
15.5
10.0
10.0
.5
.5
100.0
100.0
Cumulative Percent 16.0 52.1 74.0 89.5 99.5 100.0
《统计学》完整ppt课件

如销售额、经济增长率等。
.
3. 数据的四个等级 定类数据 也称定名数据,这种数据只对事物的某
种属性和类别进行具体的定性描述。
例如,对人口按性别划分为男性和女性 两类。
定类数据
能够进行的唯一运算是计数,即计算每一 个类型的频数或频率(即比重)。
定序数据,也称序列数据,是对事物所具 有的属性顺序进行描述。
.
(二)数据分类的原则
互斥原则:每一个数据只能划归到某一类型中,而 不能既是这一类,又是那一类 。 穷尽原则:所有被观察的数据都可被归属到适当的 类型中,没有一个数据无从归属。
(三)数据的类型
1. 定性数据和定量数据 定性数据:用文字描述的 。 如在本章的“统计引例”中消费者对永美所提供服 务的总体评价等都属于文字描述的定性数据。
.
定量数据:用数字描述的。
如企业的净资产额、净利润额等。 2. 离散型数据和连续型数据
变量 若我们所研究现象的属性和特征的具体表现在 不同时间、不同空间或不同单位之间可取不同 的数值,则可称这种数据为变量。
离散型变量:数据只能取整数。 类型 如一家公司的职工人数。
连续型变量的数据可以取介于两个数 值之间的任意数值。
(一)普查、抽样、统计报表制度和重点调查
1.普查 特点:工作量大,时间性强,需要大量人力和财力。 任务:搜集重要的国情国力和资源状况的全面资
料,为政府制定规划、方针政策提供依据。
方式:建立专门机构,配备专门人员调查。
利用基层单位原始记录和核算资料进行调查。
也称比率数据,是比定距数据更高一级的 定量数据。它不仅可以进行加减运算,而 且还可以作乘除运算。
如产量、产值、固定资产投资额、居民 货币收入和支出、银行存款余额等。
.
3. 数据的四个等级 定类数据 也称定名数据,这种数据只对事物的某
种属性和类别进行具体的定性描述。
例如,对人口按性别划分为男性和女性 两类。
定类数据
能够进行的唯一运算是计数,即计算每一 个类型的频数或频率(即比重)。
定序数据,也称序列数据,是对事物所具 有的属性顺序进行描述。
.
(二)数据分类的原则
互斥原则:每一个数据只能划归到某一类型中,而 不能既是这一类,又是那一类 。 穷尽原则:所有被观察的数据都可被归属到适当的 类型中,没有一个数据无从归属。
(三)数据的类型
1. 定性数据和定量数据 定性数据:用文字描述的 。 如在本章的“统计引例”中消费者对永美所提供服 务的总体评价等都属于文字描述的定性数据。
.
定量数据:用数字描述的。
如企业的净资产额、净利润额等。 2. 离散型数据和连续型数据
变量 若我们所研究现象的属性和特征的具体表现在 不同时间、不同空间或不同单位之间可取不同 的数值,则可称这种数据为变量。
离散型变量:数据只能取整数。 类型 如一家公司的职工人数。
连续型变量的数据可以取介于两个数 值之间的任意数值。
(一)普查、抽样、统计报表制度和重点调查
1.普查 特点:工作量大,时间性强,需要大量人力和财力。 任务:搜集重要的国情国力和资源状况的全面资
料,为政府制定规划、方针政策提供依据。
方式:建立专门机构,配备专门人员调查。
利用基层单位原始记录和核算资料进行调查。
也称比率数据,是比定距数据更高一级的 定量数据。它不仅可以进行加减运算,而 且还可以作乘除运算。
如产量、产值、固定资产投资额、居民 货币收入和支出、银行存款余额等。
哈工大尹海洁社会统计学PPT课件 第六章 概率与随机变量的概率分布

(此页可删)
目录
1 绪论 2 单变量的描述统计分析 3 两个类别变量关系的描述统计 4 两个尺度变量关系的描述统计 5 类别变量与尺度变量关系的描述统计 6 概率与随机变量的概率分布 7 大数定律、中心极限定理与抽样分布 8 参数估计 9 假设检验的基本原理 10 总体均值与方差的假设检验 11 两个类别变量关系的假设检验 12 两个尺度变量关系的假设检验 13 类别变量与尺度变量关系的假设检验 14 非参数检验 15 抽样 16 时间序列
(三)频率与概率 2、概率:
有理由相信, 当 N 时
f (E) 0.5
实际上,0.5就是女性出现的概率
定义:若对某随机事件E进行N次试验或
观察,E出现的频率为f(E),当N→∞ 时,f(E)=P 即为概率。
因为在抽样中,N→∞是不可能的,所
以,当N足够大时,可以把频率作为概 率的近似值。
3、频率和概率的关系: • 频率是实验值,具有随机性; • 概率是理论值,具有唯一性; • 当N足够大时,可以把频率作为概率的近似值。
总体 Population
样本 Sample
• 用随机抽样结果推论总体,是以概率论和数理统计为基 础进行的。概率论与数理统计从理论上证明了随机样本 与总体的一致性。
第六章 概率与随机变量的概率分布 第一节 概率及其计算
• 一、随机现象与随机变量 • (一)确定性现象和非确定性现象 • 1、确定性现象:在一定条件下必然发生的现象。如,抛石必
第六章 概率与随机变量的概率分布
1 概率及其计算 2 随机变量的描述统计 3 几个常用离散型随机变量的分布特征 4 几个常用连续型随机变量的分布特征 Exe 本章习题
第六章 概率与随机变量的概率分布
• 现代社会学研究中,最普遍应用的方法是抽样调查。 • 抽样可以分为随机抽样和非随机抽样。 • 要从定量的角度准确地推论总体,必须进行随机抽样。
目录
1 绪论 2 单变量的描述统计分析 3 两个类别变量关系的描述统计 4 两个尺度变量关系的描述统计 5 类别变量与尺度变量关系的描述统计 6 概率与随机变量的概率分布 7 大数定律、中心极限定理与抽样分布 8 参数估计 9 假设检验的基本原理 10 总体均值与方差的假设检验 11 两个类别变量关系的假设检验 12 两个尺度变量关系的假设检验 13 类别变量与尺度变量关系的假设检验 14 非参数检验 15 抽样 16 时间序列
(三)频率与概率 2、概率:
有理由相信, 当 N 时
f (E) 0.5
实际上,0.5就是女性出现的概率
定义:若对某随机事件E进行N次试验或
观察,E出现的频率为f(E),当N→∞ 时,f(E)=P 即为概率。
因为在抽样中,N→∞是不可能的,所
以,当N足够大时,可以把频率作为概 率的近似值。
3、频率和概率的关系: • 频率是实验值,具有随机性; • 概率是理论值,具有唯一性; • 当N足够大时,可以把频率作为概率的近似值。
总体 Population
样本 Sample
• 用随机抽样结果推论总体,是以概率论和数理统计为基 础进行的。概率论与数理统计从理论上证明了随机样本 与总体的一致性。
第六章 概率与随机变量的概率分布 第一节 概率及其计算
• 一、随机现象与随机变量 • (一)确定性现象和非确定性现象 • 1、确定性现象:在一定条件下必然发生的现象。如,抛石必
第六章 概率与随机变量的概率分布
1 概率及其计算 2 随机变量的描述统计 3 几个常用离散型随机变量的分布特征 4 几个常用连续型随机变量的分布特征 Exe 本章习题
第六章 概率与随机变量的概率分布
• 现代社会学研究中,最普遍应用的方法是抽样调查。 • 抽样可以分为随机抽样和非随机抽样。 • 要从定量的角度准确地推论总体,必须进行随机抽样。
社会统计学Social Statistics.ppt

感谢你的观看
16
第二章 单变量的描述统计分析 第一节 单变量的分布及其描述方法
一、变率分布中的频率按变量的取值排
列顺序逐项累加就形成累积频率分布。分布可以表示为:
2019年8月23
例如:调查1000户家庭,7种家 庭类型户数的累计频率分布为:
2. 卢淑华,《社会统计学》(第三版),北京大学出版社,2005年5月。
3. 戴维.K.希尔德布兰德、加德曼.R.爱沃森、约翰.H.奥尔德里奇等著,
《社会统计方法与技术》,社会科学文献出版社,2005年6月。
4. 浙江大学数学系高等数学教研组编,《概率论与数理统计》,人民教
育出版社1979年3月
5. 尹海洁、刘耳著,《社会统计软件SPSS15.0 for Windows 简明教
20
第二章 单变量的描述统计分析 第一节 单变量的分布及其描述方法
二、统计表 (三)描述尺度变量分布特征的统计表——分组表 • 1、分组表的特点:尺度变量取值很多,可以采用分组表来表
现尺度变量的分布特征。分组表的主词是将变量的取值按一定 的标准分组或分段的统计表。主词中每个组的最大值称为组上 限,最小值称为组下限 。(教材表2-3)
个体也称个案,是构成总体的最小单位,是具体调查分析对象。
(二)样本(Sample)
是从总体中抽出的用于实施调查研究的对象集合。
二、抽样方法与统计分析方法的选择
•应用随机原则获得的样本称为随机样本,否则是非随机样本。
•社会统计学的内容可分为两大部分:描述统计与推论统计。
•全面调查,只使用描述统计即可。
2019年8月23
感谢你的观看
4
第一章 绪论 第一节 社会学研究的过程及统计学的应用
《社会统计学》人大版

社会统计学
Social Statistics
尹海洁,李树林. 社会统计学[M]. 北京:中国人民大学出版社,2013年
目录
1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16
绪论 单变量的描述统计分析 两个类别变量关系的描述统计 两个尺度变量关系的描述统计 类别变量与尺度变量关系的描述统计 概率与随机变量的概率分布 大数定律、中心极限定理与抽样分布 参数估计 假设检验的基本原理 总体均值与方差的假设检验 两个类别变量关系的假设检验 两个尺度变量关系的假设检验 类别变量与尺度变量关系的假设检验 非参数检验 抽样 时间序列
(二)描述类别变量分布特征的统计表——简单表 • 简单表:主词按变量的取值一一列出,适用于表现类别变量的 分布。主词是类别变量的取值,宾词是各个取值出现的频次、 频率或百分比及累计频率或累计百分比等。 (教材表2-2)。
制 作 原 则
(1)表的正上方须有标题,简明、扼要、准确地说明表的内容。 (2)表的左上方应有表的编号。 (3)数字部分横行间不必标划线条,两侧不画纵线,呈开口式。 (4)数字书写要工整,小数点上下对位。 (5)当某项数字缺少时用“—”表示。 (6)如有对表的其它说明可在表的下面写出表注。
第一章 绪论 本章习题 • 1-1 结合社会学研究的过程谈谈统计学在其中所起的作用 是什么? • 1-2 社会调查资料具有哪些特点? • 1-3 解释总体、个体、样本这几个概念。 • 1-4 变量可以分为哪些类型? • 1-5 类别变量与尺度变量的区别是什么? • 1-6 简要陈述不同层次变量的功能。 • 1-7 举例说明统计学在社会学研究中的应用。
第一章 绪论 第三节 抽样方法与统计分析方法的选择
社会调查从研究的范围来分类可以分为全面调查与非全面调查, 抽样调查是非全面调查的重要方式。 一、总体、个体与样本 (一)总体( population )与个体( case ) 总体是研究对象的全体。 个体也称个案,是构成总体的最小单位,是具体调查分析对象。 (二)样本(Sample) 是从总体中抽出的用于实施调查研究的对象集合。 二、抽样方法与统计分析方法的选择 •应用随机原则获得的样本称为随机样本,否则是非随机样本。 •社会统计学的内容可分为两大部分:描述统计与推论统计。 •全面调查,只使用描述统计即可。 •应用推论统计的必要前提是样本必须是随机样本。
Social Statistics
尹海洁,李树林. 社会统计学[M]. 北京:中国人民大学出版社,2013年
目录
1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16
绪论 单变量的描述统计分析 两个类别变量关系的描述统计 两个尺度变量关系的描述统计 类别变量与尺度变量关系的描述统计 概率与随机变量的概率分布 大数定律、中心极限定理与抽样分布 参数估计 假设检验的基本原理 总体均值与方差的假设检验 两个类别变量关系的假设检验 两个尺度变量关系的假设检验 类别变量与尺度变量关系的假设检验 非参数检验 抽样 时间序列
(二)描述类别变量分布特征的统计表——简单表 • 简单表:主词按变量的取值一一列出,适用于表现类别变量的 分布。主词是类别变量的取值,宾词是各个取值出现的频次、 频率或百分比及累计频率或累计百分比等。 (教材表2-2)。
制 作 原 则
(1)表的正上方须有标题,简明、扼要、准确地说明表的内容。 (2)表的左上方应有表的编号。 (3)数字部分横行间不必标划线条,两侧不画纵线,呈开口式。 (4)数字书写要工整,小数点上下对位。 (5)当某项数字缺少时用“—”表示。 (6)如有对表的其它说明可在表的下面写出表注。
第一章 绪论 本章习题 • 1-1 结合社会学研究的过程谈谈统计学在其中所起的作用 是什么? • 1-2 社会调查资料具有哪些特点? • 1-3 解释总体、个体、样本这几个概念。 • 1-4 变量可以分为哪些类型? • 1-5 类别变量与尺度变量的区别是什么? • 1-6 简要陈述不同层次变量的功能。 • 1-7 举例说明统计学在社会学研究中的应用。
第一章 绪论 第三节 抽样方法与统计分析方法的选择
社会调查从研究的范围来分类可以分为全面调查与非全面调查, 抽样调查是非全面调查的重要方式。 一、总体、个体与样本 (一)总体( population )与个体( case ) 总体是研究对象的全体。 个体也称个案,是构成总体的最小单位,是具体调查分析对象。 (二)样本(Sample) 是从总体中抽出的用于实施调查研究的对象集合。 二、抽样方法与统计分析方法的选择 •应用随机原则获得的样本称为随机样本,否则是非随机样本。 •社会统计学的内容可分为两大部分:描述统计与推论统计。 •全面调查,只使用描述统计即可。 •应用推论统计的必要前提是样本必须是随机样本。
相关主题
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
40.0%
30.0%
性别
男 女
20.0%
10.0%
0.0%
未上 小学 初中 高中 中专 大学
过学
专科
及以
上
文化程度
图3-1 不同性别的残疾人文化程度分布的条形图
第三章 两个类别变量关系的描述统计 第二节 分类图
• 二、分类饼图
• 描述变量各取值上的 男 个案数在总数中所占
的比例。
女
• 多个圆形可以分开画, 也可以从大到小叠在 一起。
• 对测量层次不同的变量之间的关系,其分析方法也不同。
• 分析两个类别变量的关系,如性别与职业的关系、性别与文化 程度的关系、文化程度与生活满意度之间的关系等等,可采用 三种方法:
• 交叉列表:从两个变量的交叉分布来分析两者关系。 • 分类图:直观地表现变量间的关系。 • 相关系数:精确地描述变量之间关系的强度。
(此页可删)
目录
1 绪论 2 单变量的描述统计分析 3 两个类别变量关系的描述统计 4 两个尺度变量关系的描述统计 5 类别变量与尺度变量关系的描述统计 6 概率与随机变量的概率分布 7 大数定律、中心极限定理与抽样分布 8 参数估计 9 假设检验的基本原理 10 总体均值与方差的假设检验 11 两个类别变量关系的假设检验 12 两个尺度变量关系的假设检验 13 类别变量与尺度变量关系的假设检验 14 非参数检验 15 抽样 16 时间序列
社会统计学
Social Statistics
课件格式和使用方法说明
• 课件格式: • 一级标题,一、22号黑体加粗,红色 • 二级标题,(一)、22黑体,蓝色 • 三级标题,1、22号黑体,黑色 • 正文22号宋体,黑色。仅重点文字加粗或变色。
• 使用方法: • 点击课件总目录中的章标题左边的数字,可直接跳至相应章。 • 点击各章首页的章目录中的各节左边的数字,可跳至相应各节。 • 点击每页右下方的箭头,可直接回到课件总目录。
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 三、列联表的种类 • (二)频率分布的列联表
• 四、列联表中的分布
• (一)联合分布:即列联表中间部分的数据 nij或 pij,它们 都是由两个变量共同决定的。
• (二)边缘分布:列联表中最下面一行nj或 pj是变量y的分 布,最右面一列ni或pi是变量x的分布。
移项
第三章 两个类别变量关系的描述统计 第二节 分类图
• 一、分类条形图
• 以一个变量的取值作 为横轴的标记,用另 一个变量的取值来分 类。以不同标志点上 分类变量的频次或频 率作为条的长度绘制 条形图。
• 如果在每个标志点上 分类变量各个条长基 本相等,则说明两个 变量基本不相关。
百 50.0% 分 比
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 一、两个类别变量相关的概念
• 如果有两个类别变量,在一个变量取不同类别时,另一个变量 的分布有显著差异。则认为两个类别变量相关。如果一个变量 取不同类别时,另一个变量的分布没有显著差异,就认为这两 个变量不相关。
• 两个类别变量之间的关系要通过两个变量的交叉分布来描述。 这种分析方法称为交叉列表分析,构成的表格称为交叉表或列 联表。两个类别变量之间的相关也称为列联相关。
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 二、列联表的结构 • 列联表也是统计表的一种,它与简单表和分组表不同的是,在
一个表中表现了两个不同变量的分布,因此也被称为复合表。 • 表的主词和表头分别是两个变量的取值。表身中单元格的数据
是两个变量交叉后的频次或频率分布。
• 三、列联表的种类
图3-3 不同性别的残疾人文化程度分布的折线图
第三章 两个类别变量关系的描述统计 第三节 列联相关系数
• 图表法只能粗略说明两个变量间是否相关,为精确度量变量之 间关系的强度和方向,统计学家根据不同测量层次的变量建构 了一系列的统计指标,这就是相关系数。
• 两个无序类别变量之间的关系可以用列联相关系数来描述。在 多年的统计实践过程中,统计学家建构了多个列联相关系数。 概括起来,基于两种方法,一是基于消减误差比例的方法来建 构,二是基于卡方值来建构。后者将在卡方检验中予以介绍, 本节只介绍基于消减误差比例的方法建构的列联相关系数。
• 五、列联表中变量的相互独立性
• 在列联表中,可以通过比较条件分布来研究类别变量之间的关 系。当一个变量取不同类别时,另一个变量的分布有差异,即 说明两个变量是相关的。
• 从频率分布看,两个变量相互独立的表现形式是条件分布等于 边缘分布。(推导见教材式3-1到3-4)
一般化
等号左侧 分子分母 同乘于n
• (三)条件分布: • 如果将一个变量取固定值,另一个变量的分布就是条件分布。 • 使用条件分布的目的是要看当一个变量取不同类别时另一个变
量的分布是否有差异。这种差异通过频次分布难以表现,所以 条件分布大都是采用频率分布。 • 用单元格的频次除以对应列的总频次,即nij/nj构成的分布称 为关于x的条件分布,也就是当y取固定值时x的分布。 • 同理, nij/ni*构成的分布称为关于y条件分布。
第三章 两个类别变量关系的描述统计
1 列联表分析 2 分类图 3 列联相关系数 4 等级相关系数 Exe 本章习题
第三章 两个类别变量关系的描述统计
• 社会学研究中不仅要对单个变量的分布进行描述,更多的是要 分析变量之间的关系。比如,分析性别与体育爱好的关系、职 业与政治参与的关系、文化程度与生育子女数量的关系、收入 与住房面积的关系等等。
• 设 x与y是两个类别变量, x分为x1, x2…xr共r 类,y分为 y1, y2…yc共c 类,数据总个数为n 。
• 根据列联表中单元格数据的不同,列联表可分为频次分 布的列联表和频率分布的列联表。
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 三、列联表的种类 • (一)频次分布的列联表
• 如果在不同的圆形中 各个扇形所占的比例 基本相同,就可以认 为两个变量不相关。
文化程度
未上过学 小学
初中
高中
中专
大学专科
图3-2 不同性别的残疾人文化程度分布的饼图
第三章 两个类别变量关系的描述统计 第二节 分类图
• 三、折线图 • 在坐标系内绘制分类
变量取不同值时,另 一个变量分布的多条 折线。 • 如果这些折线基本重 合,或者相差不大, 则认为两个变量不相 关。
30.0%
性别
男 女
20.0%
10.0%
0.0%
未上 小学 初中 高中 中专 大学
过学
专科
及以
上
文化程度
图3-1 不同性别的残疾人文化程度分布的条形图
第三章 两个类别变量关系的描述统计 第二节 分类图
• 二、分类饼图
• 描述变量各取值上的 男 个案数在总数中所占
的比例。
女
• 多个圆形可以分开画, 也可以从大到小叠在 一起。
• 对测量层次不同的变量之间的关系,其分析方法也不同。
• 分析两个类别变量的关系,如性别与职业的关系、性别与文化 程度的关系、文化程度与生活满意度之间的关系等等,可采用 三种方法:
• 交叉列表:从两个变量的交叉分布来分析两者关系。 • 分类图:直观地表现变量间的关系。 • 相关系数:精确地描述变量之间关系的强度。
(此页可删)
目录
1 绪论 2 单变量的描述统计分析 3 两个类别变量关系的描述统计 4 两个尺度变量关系的描述统计 5 类别变量与尺度变量关系的描述统计 6 概率与随机变量的概率分布 7 大数定律、中心极限定理与抽样分布 8 参数估计 9 假设检验的基本原理 10 总体均值与方差的假设检验 11 两个类别变量关系的假设检验 12 两个尺度变量关系的假设检验 13 类别变量与尺度变量关系的假设检验 14 非参数检验 15 抽样 16 时间序列
社会统计学
Social Statistics
课件格式和使用方法说明
• 课件格式: • 一级标题,一、22号黑体加粗,红色 • 二级标题,(一)、22黑体,蓝色 • 三级标题,1、22号黑体,黑色 • 正文22号宋体,黑色。仅重点文字加粗或变色。
• 使用方法: • 点击课件总目录中的章标题左边的数字,可直接跳至相应章。 • 点击各章首页的章目录中的各节左边的数字,可跳至相应各节。 • 点击每页右下方的箭头,可直接回到课件总目录。
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 三、列联表的种类 • (二)频率分布的列联表
• 四、列联表中的分布
• (一)联合分布:即列联表中间部分的数据 nij或 pij,它们 都是由两个变量共同决定的。
• (二)边缘分布:列联表中最下面一行nj或 pj是变量y的分 布,最右面一列ni或pi是变量x的分布。
移项
第三章 两个类别变量关系的描述统计 第二节 分类图
• 一、分类条形图
• 以一个变量的取值作 为横轴的标记,用另 一个变量的取值来分 类。以不同标志点上 分类变量的频次或频 率作为条的长度绘制 条形图。
• 如果在每个标志点上 分类变量各个条长基 本相等,则说明两个 变量基本不相关。
百 50.0% 分 比
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 一、两个类别变量相关的概念
• 如果有两个类别变量,在一个变量取不同类别时,另一个变量 的分布有显著差异。则认为两个类别变量相关。如果一个变量 取不同类别时,另一个变量的分布没有显著差异,就认为这两 个变量不相关。
• 两个类别变量之间的关系要通过两个变量的交叉分布来描述。 这种分析方法称为交叉列表分析,构成的表格称为交叉表或列 联表。两个类别变量之间的相关也称为列联相关。
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 二、列联表的结构 • 列联表也是统计表的一种,它与简单表和分组表不同的是,在
一个表中表现了两个不同变量的分布,因此也被称为复合表。 • 表的主词和表头分别是两个变量的取值。表身中单元格的数据
是两个变量交叉后的频次或频率分布。
• 三、列联表的种类
图3-3 不同性别的残疾人文化程度分布的折线图
第三章 两个类别变量关系的描述统计 第三节 列联相关系数
• 图表法只能粗略说明两个变量间是否相关,为精确度量变量之 间关系的强度和方向,统计学家根据不同测量层次的变量建构 了一系列的统计指标,这就是相关系数。
• 两个无序类别变量之间的关系可以用列联相关系数来描述。在 多年的统计实践过程中,统计学家建构了多个列联相关系数。 概括起来,基于两种方法,一是基于消减误差比例的方法来建 构,二是基于卡方值来建构。后者将在卡方检验中予以介绍, 本节只介绍基于消减误差比例的方法建构的列联相关系数。
• 五、列联表中变量的相互独立性
• 在列联表中,可以通过比较条件分布来研究类别变量之间的关 系。当一个变量取不同类别时,另一个变量的分布有差异,即 说明两个变量是相关的。
• 从频率分布看,两个变量相互独立的表现形式是条件分布等于 边缘分布。(推导见教材式3-1到3-4)
一般化
等号左侧 分子分母 同乘于n
• (三)条件分布: • 如果将一个变量取固定值,另一个变量的分布就是条件分布。 • 使用条件分布的目的是要看当一个变量取不同类别时另一个变
量的分布是否有差异。这种差异通过频次分布难以表现,所以 条件分布大都是采用频率分布。 • 用单元格的频次除以对应列的总频次,即nij/nj构成的分布称 为关于x的条件分布,也就是当y取固定值时x的分布。 • 同理, nij/ni*构成的分布称为关于y条件分布。
第三章 两个类别变量关系的描述统计
1 列联表分析 2 分类图 3 列联相关系数 4 等级相关系数 Exe 本章习题
第三章 两个类别变量关系的描述统计
• 社会学研究中不仅要对单个变量的分布进行描述,更多的是要 分析变量之间的关系。比如,分析性别与体育爱好的关系、职 业与政治参与的关系、文化程度与生育子女数量的关系、收入 与住房面积的关系等等。
• 设 x与y是两个类别变量, x分为x1, x2…xr共r 类,y分为 y1, y2…yc共c 类,数据总个数为n 。
• 根据列联表中单元格数据的不同,列联表可分为频次分 布的列联表和频率分布的列联表。
第三章 两个类别变量关系的描述统计 第一节 列联表分析
• 三、列联表的种类 • (一)频次分布的列联表
• 如果在不同的圆形中 各个扇形所占的比例 基本相同,就可以认 为两个变量不相关。
文化程度
未上过学 小学
初中
高中
中专
大学专科
图3-2 不同性别的残疾人文化程度分布的饼图
第三章 两个类别变量关系的描述统计 第二节 分类图
• 三、折线图 • 在坐标系内绘制分类
变量取不同值时,另 一个变量分布的多条 折线。 • 如果这些折线基本重 合,或者相差不大, 则认为两个变量不相 关。