构造文法的SLR分析表
SLR(1)文法分析实验报告

《编译原理》课程设计报告—SLR(1)分析的实现学院计算机科学与技术专业计算机科学与技术学号学生姓名指导教师姓名2015年12月26日目录1.设计的目的与内容 (1)1.1课程设计的目的 (1)1.2设计内容 (1)1.3设计要求 (1)1.4理论基础 (1)2算法的基本思想 (2)2.1主要功能函数 (2)2.2算法思想 (3)SLR文法构造分析表的主要思想: (3)解决冲突的方法: (3)SLR语法分析表的构造方法: (4)3主要功能模块流程图 (5)3.1主函数功能流程图 (5)4系统测试 (6)5 结论 (11)附录程序源码清单 (12)1.设计的目的与内容1.1课程设计的目的编译原理课程设计是计算机专业重要的教学环节,它为学生提供了一个既动手又动脑,将课本上的理论知识和实际有机的结合起来,独立分析和解决实际问题的机会。
●进一步巩固和复习编译原理的基础知识。
●培养学生结构化程序、模块化程序设计的方法和能力。
●提高学生对于编程语言原理的理解能力。
●加深学生对于编程语言实现手段的印象。
1.2设计内容构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
1.3设计要求1)SLR(1)分析表的生成可以选择编程序生成,也可选择手动生成;2)程序要求要配合适当的错误处理机制;3)要打印句子的文法分析过程。
1.4理论基础由于大多数适用的程序设计语言的文法不能满足LR(0)文法的条件,即使是描述一个实数变量说明这样简单的文法也不一定是LR(0)文法。
因此对于LR(0)规范族中有冲突的项目集(状态)用向前查看一个符号的办法进行处理,以解决冲突。
这种办法将能满足一些文法的需要,因为只对有冲突的状态才向前查看一个符号,以确定做那种动作,因而称这种分析方法为简单的LR(1)分析法,用SLR(1)表示。
2算法的基本思想2.1主要功能函数class WF{WF(char s1[],char s2[],int x,int y)WF(const string& s1,const string& s2,int x,int y)bool operator<(const WF& a)constbool operator==(const WF& a)constvoid print()};class Closure{void print(string str)bool operator==(const Closure& a)const};void make_item()void dfs(const string& x)void make_first()void append(const string& str1,const string& str2)bool _check(const vector<int>& id,const string str)void make_follow()void make_set()void make_V()void make_cmp(vector<WF>& cmp1,int i,char ch)void make_go()void make_table()void print(string s1,string s2,string s3,string s4,string s5,string s6, string s7)stringget_steps(int x)stringget_stk(vector<T>stk)stringget_shift(WF& temp)void analyse(string src)2.2算法思想SLR文法构造分析表的主要思想:许多冲突性的动作都可能通过考察有关非终结符的FOLLOW集而获解决。
编译原理期末复习题

3.2是非判断,对下面的陈述,正确的在陈述后的括号内写T,否则写F。
(1)有穷自动机接受的语言是正则语言。
()(2)若r1和r2是Σ上的正规式,则r1|r2也是。
()(3)设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
()(4)令Σ={a,b},则Σ上所有以b为首的字构成的正规集的正规式为b*(a|b)*。
()(5)对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
()(6)对一个右线性文法G,必存在一个左线性文法G',使得L(G)=L(G'),反之亦然。
()答案(1) T (2) T (3) F(4) F (5) T (6) T3.3描述下列各正规表达式所表示的语言。
(1) 0(0|1)*0(2) ((ε|0)1*)*(3) (0|1)*0(0|1)(0|1)(4) 0*10*10*10*(5) (00|11)*((01|10)(00|11)*(01|10)(00|11)*)*答案(1) 以0开头并且以0结尾的,由0和1组成的符号串。
(2) {α|α∈{0,1}*}(3) 由0和1组成的符号串,且从右边开始数第3位为0。
(4) 含3个1的由0和1组成的符号串。
{α|α∈{0,1}+,且α中含有3个1 }(5) {α|α∈{0,1}*,α中0和1为偶数}3.4对于下列语言分别写出它们的正规表达式。
(1) 英文字母组成的所有符号串,要求符号串中顺序包含五个元音。
(2) 英文字母组成的所有符号串,要求符号串中的字母依照词典顺序排列。
(3) Σ={0,1}上的含偶数个1的所有串。
(4) Σ={0,1}上的含奇数个1的所有串。
(5) 具有偶数个0和奇数个1的有0和1组成的符号串的全体。
(6) 不包含子串011的由0和1组成的符号串的全体。
(7) 由0和1组成的符号串,把它看成二进制数,能被3整除的符号串的全体。
答案(1) 令Letter表示除这五个元音外的其它字母。
SLR_分析报告表地生成以及分析报告程序

SLR 分析表的生成以及分析程序SLR语法分析自动生成程序实验文档1. 在程序中表示文法1.1 文法的输入和读取为了程序读取的方便,非/终结符相互间以空格分开。
例如应该输入:E -> E + TT -> T * F | TF -> ( E ) | idE -> T而不是输入:E->E+T|T……文法先保存到文件中然后程序读取文件。
1.2 文法的拓展为了在LR分析时能够指示分析器正确停止并接受输入,一般在所有输入文法前加上一个新的产生式,以上面文法为例,我们要保存的文法应该是如此:E’ -> E + TE -> T *F | T……1.3 文法的保存格式设计一个类Grammar来对文法进行各种处理。
首先把文件中的文法保存到一个序偶表中,以上面的文法为例子,我们保存的格式类似于下面的表非终结符产生试右部EE + TTTT * FTF( E )id也就是说,每一个项是一个2元组,记录了终结符,和产生式右部。
其中非终结符可以用字符串(string)类型表示,产生式右部可用字符串数组( vector<string > )表示。
而在保存的同时又可记录下文法的所有非终结符(因为文法的产生式左部会出现所有的非终结符),然后再对已经记录的文法的产生式右部再扫描一遍,记录下所有的终结符。
在本程序中,我虽然记录了原始的符号串,但是在具体过程处理时使用的是符号串对应的下标来进行的,因此再对原始形式的文法再扫描一遍,生成对应的以下标形式保存的文法。
同时我对终结符号和非终结符号的保存位于不同的数组中,于是下标就会产生冲突,我采用方式是建立一个下标数据结构 Index 来保存下标struct Index{int index; // [非终结符或者终结符的下标]bool teminal; // [为真表示该下标保存的是终结符]bool is_nonteminal(); // [返回! terminal]}现在往类Grammar 中加入数据成员为:vector< pair< string,vector<string > > > m_str_grammar ; // [记录以字符串形式保存的文法]vector< vector<vector<Index > > > m_idx_grammar; // [记录以下标保存的文法]MyCollection m_str_nonteminals; // [记录原始的非终结符号串]MyCollection m_str_terminals; // [记录原始的终结符号串]接下来要对文法进行相关处理了。
编译原理课件04(6)SLR(1)分析法

a
S5
S6 r5
S2 S3
ACTION b c
$
acc
GOTO S A
1 4 7
r1
S2 r2 S9 r1
r1
r2 S8 r1
r1
r2 r1
0. 1. 2. 3. 4. 5.
S'→S S →Sb S →bAa A →aSc A →aSb A →a
r3 r4
4.5.3 SLR(1)分析法
I9={ A →aSb·, S →Sb· }
由于有 FOLLOW(A) ∩FOLLOW(S) ={a}∩{b, c, $}=Φ, I9中的归约—归约冲突 也可用SLR(1)方法解决。
所以该文法是SLR(1)文法。相应的 SLR(1)分析表如下表:
4.5.3 SLR(1)分析法
因此,当一个LR(0)项目集规范族中存 在一个含移进—归约冲突和归约—归约冲 突的项目集时
IK={ X→δ· A→α·B→r· bB, , }
则在分析表第K行中遇输入符号b必然 会出现多重定义元素。 对含冲突的项目集,仅根据LR(0)项目 本身的信息是无法解决冲突的。需要向前 查看一个输入符号以考察当前所处的环境。
(
I8:F→ (E· ) E→E· +T 0 1 2 3 4 5 6 E'→E E→E+T E→T T→T*F T→F F→(E) F→id
F I7: T→T*·
F→· (E) F→· id
I0: E'→· E
id
*
E→· E+T E T E→· T T→· T*F I2: E→T· T T→· F T→T· *F id F→· (E) ( F→· id I5: F→id· ( * F I7: T→T*· id F→· (E) F F→· id
LL(1)文法分析表的构造和分析过程示例

LL(1)⽂法分析表的构造和分析过程⽰例在考完编译原理之后才弄懂,悲哀啊。
不过懂了就好,知识吗,不能局限于考试。
⽂法:E→TE'E'→+TE'|εT→FT 'T'→*FT'|εF→id| (E)⼀、⾸先判断是不是 LL(1)⽂法--------------------------------------------------------------------------------------------------------⽂法G的任意两个具有相同左部的产⽣式 A --> α|β满⾜下列条件:1、如果α和β不能同时推导出ε,则 FIRST(α)∩FIRST(β) = 空2、α和β⾄多有⼀个能推导出ε3、如果β --*--> ε ,则 FIRST(α)∩ FOLLOW(A)=空--------------------------------------------------------------------------------------------------------对于 E'→+TE'|ε,显然ε --> ε, First(+TE') = {+} ,Follow(E') = {{),#} 显然⼆者交集为空满⾜。
对于 F→id|(E) ,First(id) = {id} First((E)) = {(} 显然⼆者交集为空满⾜。
所以该⽂法是LL(1)⽂法。
⼆、计算出First集和Follow集参考:三、构建LL(1)分析表输⼊:⽂法G输出:分析表M步骤:1、对G中任意⼀个产⽣式 A --> α执⾏第2步和第3步2、for 任意a ∈ First(α),将 A --> α填⼊M[A,a]3、if ε∈ First(α) then 任意a ∈ Follow(A),将 A --> α填⼊M[A,a]if ε∈ First(α) & # ∈Follow(A), then 将 A --> α填⼊M[A,#] (觉得这步没⽤)4、将所有没有定义的M[A,b] 标上出错标志(留空也可以)--------------------------------------------------------------------------------------------------------过程就不赘述了,结果:四、分析过程步骤:1、如果 X = a = # 则分析成功并停机2、如果 X = a != # 则弹出栈顶符号X, 并将输⼊指针移到下⼀个符号上3、如果 X != a,查询分析表M[X,a] , 如果 M[X,a] = {X --> UVW},则⽤UVW (U在栈顶) 替换栈顶符号 X。
实验报告五SLR 分析表的生成以及语法分析

{
token_head=new token;
token_head->next=NULL;
token_tail=new token;
token_tail->next=NULL;
number_head=new number;
number_head->next=NULL;
number_tail=new number;
temp1->value=num_value;//把数字的值赋给结点
input2(temp1);
return;
}
else
{
err=1;
cout<<nl<<"行"<<"错误:非法字符! "<<ch<<endl;
return;
}
}
void out3(char ch,string word)
{
token *temp;
err=0;//初始化词法分析错误标志
nl=1;//初始化读取行数
scan();
if(err==0)
{
char m;
cout<<"词法分析正确完成!"<<endl<<endl<<"下边将输出结果,如果将结果保存到文件中请输入y,否则请输入其它键:";
cin>>m;
output();
if(m=='y')
ch=fgetc(fp);
flag=judge(ch);
if(flag==1 || flag==4 || flag==5 || flag==6)
第9讲SLR表

3.5 LR分析器 E E EE+T|T
T T * F | F
I4:
F ( E ) | id
F (·E )
E ·E + T
E ·T
T ·T * F
T ·F
F ·(E)
F ·id
I0: E ·E E ·E + T E ·T T ·T * F T ·F F ·(E) F ·id
I0: E ·E
I1:
E E·
E ·E + T
E E·+ T
E ·T
T ·T * F T ·F
I2: E T·
F ·(E)
T T·* F
F ·id
I3: T F·
I0: E ·E E ·E + T E ·T T ·T * F T ·F F ·(E) F ·id
I3:
EE EE+T|T
T F·
T T * F | F
F ( E ) | id
T I2
F I3
( I4
id I5
3.5 LR分析器
E
I0
I1
I4:
F (·E )
E ·E + T
T I2
F I3
( I4
E ·T T ·T *F ·F F ·( E ) F ·id
活前缀
输 入
sm Xm sm-1 Xm-1 … s0
a1 … ai …an $
LR分析程序 action goto
输 出
简单的LR方法(SLR) 规范的LR方法 向前看的LR方法(LALR)
LR分析器的模型
3.5 LR分析器
点的左边代表历史信
息,右边代表展望信
LR(0)和SLR分析表的构造

此文略长。
我也没想到这写起来这么多,但对构造过程绝对清楚,一步步慢慢看吧。
LR的第一个L和LL的第一个L含义相同,即从左到右扫描句子,第二个R表示Ri ght most最右推导。
在通常的描述中,后面还有一个括号里面的数字如,LR(0)、LR(1)这样,括号里面的数字表示用于决策所需的后续token分词数。
首先看一下LR分析器的模型图可惜看出,LR分析器最关键的部分就是LR分析表了,而LR分析表的构建是由已构造出的LR(0)项目集规范族来进行构造的。
LR分析法貌似是不要求掌握的,而且这部分比我想象的还要复杂,今天看了好多。
才勉强搞清楚这个项目集规范族的构造,但是用来锻炼思维确实不错啊。
项目集,那么字面上看就是项目的集合了,项目是什么呢。
这个也确实不好说,书上是说在文法G中每个产生式的右部适当位置添加一个圆点构成LR(0)项目,举个例子吧。
比如对于A->xyz这条产生式可以构造的LR(0)项目就有4个A->.xyz A->x.yz A->xy.z A->xyz.这样很清楚了吧,就是用.分割。
这个分割产生的四个项目在进行真正的语法分析的时候对应不同的操作,比如规约还是移位。
这里不讨论。
重点是项目集规范族的构造,在知道了LR(0)项目后,可以来看看项目集规范族的定义,对于构成识别一个文法活前缀的DFA项目集(状态)的全体我们称之为这个文法的LR(0)项目集规范族。
至于什么是活前缀呢,定义如下对于任一文法G[S],若S’经过任意次推导得到αAω,继续经过一次推导得到αβω,若γ是αβ的前缀,则称γ是G的一个活前缀。
现在知道了LR(0)项目,了解了活前缀,和项目集规范族的定义,还须引入LR(0)项目集的闭包函数CLOSURE和状态转换函数GO两个概念,先给出数学上的定义,如果你觉得麻烦可以跳过,后面会给出一道例题。
①闭包函数CLOSURE(I)的定义如下:a)I的项目均在CLOSURE(I)中。
编译原理 第7章 习题解答
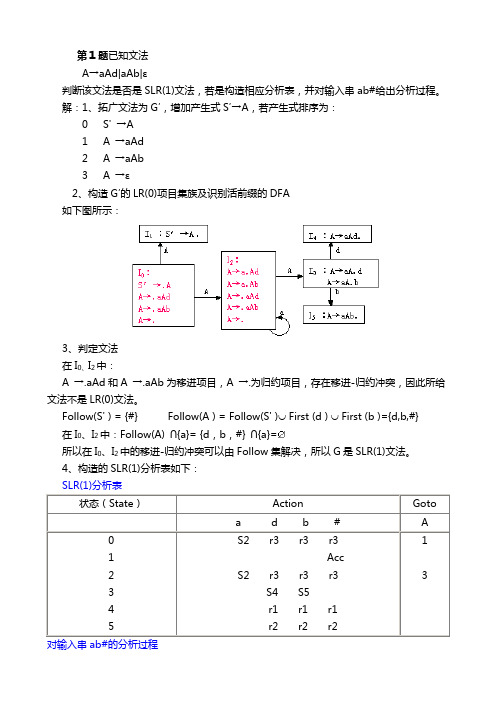
第1题已知文法A→aAd|aAb|ε判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
解:1、拓广文法为G′,增加产生式S′→A,若产生式排序为:0 S' →A1 A →aAd2 A →aAb3 A →ε2、构造G′的LR(0)项目集族及识别活前缀的DFA如下图所示:3、判定文法在I0、I2中:A →.aAd和A →.aAb为移进项目,A →.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
Follow(S' ) = {#} Follow(A ) = Follow(S' )⋃ First (d ) ⋃ First (b )={d,b,#} 在I0、I2中:Follow(A) ∩{a}= {d,b,#} ∩{a}=所以在I0、I2中的移进-归约冲突可以由Follow集解决,所以G是SLR(1)文法。
4、构造的SLR(1)分析表如下:SLR(1)分析表状态(State)Action Gotoa db # A0 1 2 3 4 5 S2 r3 r3 r3AccS2 r3 r3 r3S4 S5r1 r1 r1r2 r2 r21.32、若有定义二进制数的文法如下:S→L.L|L L→LB|B B→0|1(1) 试为该文法构造LR分析表,并说明属哪类LR分析表。
(2) 给出输入串101.110的分析过程。
解:1、拓广文法为G′,增加产生式S′→S,若产生式排序为:0 S' →S 1 S →L.L 2 S →L3 L →LB4 L →B5 B →06 B →12、G′的LR(0)项目集族及识别活前缀的DFA3、判定文法在S2、S8中::B →.0和B →.1为移进项目,S →L.(S →L.L )为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
文法中:Follow(S' ) = {#} Follow(S ) = {#}Follow(L ) = {.,0,1,#} Follow(B ) = {.,0,1,#}在S2、S8中:Follow(s)∩{0}∩{1}= { #}∩{0}∩{1}=所以在I2、I8中的移进-归约冲突可以由Follow集解决,所以G是SLR(1)文法。
《SLR分析表的构造》课件

03
分析销售趋势
通过图表展示销售数据,分析销售趋 势,如月销售量、季度销售量等。
客户购买行为分析
分析客户购买习惯、偏好和忠诚度, 以便更好地满足客户需求。
05
04
产品销量分析
分析各类产品销售情况,了解哪些产 品更受欢迎。
案例二:用户行为分析
总结词
通过用户行为数据,了解用户 使用产品或服务的习惯、偏好 和需求,优化产品设计和服务
、数据类型转换等。
数据分类
根据分析指标和目的,对数据进 行分类和编码,以便更好地进行
后续的数据分析和挖掘。
数据排序
对数据进行排序,以便更好地展 示数据和发现数据中的规律和趋
势。
构建表格
设计表格结构
根据分析目标和指标,设计SLR分析表的表格结构 ,包括表头、列名、行等。
填充表格数据
根据整理后的数据,将数据填充到SLR分析表中。
收集数据
数据来源
根据分析指标和范围,选择合适 的数据来源,包括数据库、调查
问卷、政府机构等。
数据采集方法
根据数据来源和类型,选择合适的 数据采集方法,如网络爬虫、问卷 调查、人工录入等。
数据质量保证
在数据采集过程中,应保证数据的 准确性和完整性,对异常数据进行 处理或剔除。
整理数据
数据清洗
对收集到的数据进行清洗和处理 ,包括缺失值填充、异常值处理
建立更新机制
建立一套有效的更新机制,以确保分析表能够及时、准确 地反映最新情况。
掘数据背后的规律和趋势。
可视化呈现
02
将分析结果以图表、图像等形式进行可视化呈现,使结果更加
直观易懂。
假设检验
03
根据分析结果,提出假设并进行检验,以确定结果是否具有统
《SLR分析表的构造》PPT课件

I11:B d • I9:BcB •
同一个活前缀,可能存在若干个项目对它都是有效的 ,而且告诉我们应做的事情各不相同,相互冲突。
这种冲突通过向前多看几个输入符号, 或许能够获得 解决。
5.3.3 SLR分析表的构造
SLR(1)分析法的引入:
• LR(0)文法的活前缀识别自动机的每一状态
从初态出发,经读出活 前缀γ后,而到达的项 目集称为活前缀γ的 有效项目集
a
c
I4:Ac•A A •cA
A d
A •d
c
d
I2:Ea•A
A •cA A
A •d
I0: S'•E E •aA
E •bB
E
I1: S' E •
b I3: Eb•B B B •cB
识别文法 活前缀的DFA
考虑下面的拓广文法 (文法5.8) (0) S E (1) E E+T (2) E T (3) T T*F (4) T F (5) F (E) (6) F I
构造其LR(0)项目集规范族
例5.11 p111
I0: S ·E E ·E + T E ·T T ·T * F T ·F F ·(E) F ·i
(0) S E (1) E E+T (2) E T (3) T T*F (4) T F (5) F (E) (6) F I
I1: S E· E E ·+ T
• FOLLOW(S′) = { # }, • {#}∩{+}=φ,因此I1中的冲
突可解决。
• 遇 ‘+’移进 ,遇 ‘#’接受 • 其它情况则报错。
同时含有n个归约项目: B1→α 1·, B2→α 2·, …, Bn→α n·
7.3 SLR(1)分析

SLR(1)是采用向前查看一个符号的办法来处理 是采用向前查看一个符号的办法来处理LR(0)规 是采用向前查看一个符号的办法来处理 规 范族中出现冲突的问题。它是最简单的LR(1)方法。 范族中出现冲突的问题。它是最简单的 方法。 方法 例1:已知拓展文法G’[S’]: (实数说明文法) 已知拓展文法 (0)S’→S (1)S→rD (2)D→D, i (3)D→i 构造文法G’的分析表 构造文法 的分析表
SLR(1)中冲突的解决方法 中冲突的解决方法
若LR(0)规范族含有m个移进项目 A1→α1·a1β1,A1→α2·a2β2,…, Am→αm·amβm 同时含有n个归约项目 B1→γ1·,B2→γ2·,…,Bn→γn· 则只要集合 1 , a2 ,…, am}和FOLLOW(B1), FOLLOW(B2) , …, 只要集合{a 只要集合 和 FOLLOW(Bn)两两交集都为空 两两交集都为空,那么上述规则仍可用于解决 两两交集都为空 LR(0)规范族中的冲突。 1) 若a∈{a1,a2,…, am},则移进。 2) 若a∈FOLLOW(Bi),i=1,2…n,则用Bi→γi进行归约。 3) 此外,报错。
SLR(1)分析表的构造 分析表的构造
改进:对所有归约项目都采取SLR(1)的处理思想 凡是归 的处理思想,凡是归 改进:对所有归约项目都采取 的处理思想
约项目仅当面临输入符号包含在该归约项目左部非终结符 集合中, 的FOLLOW集合中,才采取用该产生式归约的动作。 集合中 才采取用该产生式归约的动作。 改进的SLR(1)分析表的构造方法如下: 改进的 分析表的构造方法如下: 分析表的构造方法如下 假设已构造出文法的LR(0)项目集规范族C={I0,I1,…,In},令包 含S’→·S项目的集合Ik的下标k为分析器初态,求出所有非 终结符的FOLLOW集。则SLR(1)分析表构造步骤为
SLR(1)分析法

• 已知文法GB:B → bB | dDb • D → aD | ε • 提示: .ε=ε.=. 且 |ε|=0 • ① 求出每个非终结符的First集、Follow集和 Select集;判定该文法是LL(1)文法。 • ② 构造GB的递归下降分析程序。 • ③ 构造GB的预测分析表。 • ④ 给出字符串bdab的LL(1)分析过程。
说明:产生式 编号可以不从1 开始,但是与归 约符r的下标必 须一致; SLR(1)表中 的行可以任意排 列,但是必须与 项目集编号一致。
• ⑥ SLR(1)分析表构造如下:
⑦ 显然项目集I3、I6中有“移进--归约”冲突,GB不是LR(0)文法。
因为SLR(1)分析表中无多重入口,所以GB是S范句型活前缀的自 动机。 ⑥ 构造SLR(1)分析表。 ⑦ GB是LR(0)文法吗?GB是SLR(1)文法吗?为什么? ⑧ 给出字符串bdab的SLR(1)分析过程。 解: 每个非终结符的First集、Follow集:
• ⑤ 识别GB拓广文法的所有LR(0)项目的DFA构造如下:
⑧字符串bdab的SLR(1)分析过程如下:
SLR1文法构造方法

步骤三、
对状态中的表达式依次移入终结符或者非终结符, 这里我们从上到下依次移入, 产生的新的 表达式加入我们自定义的新状态,如 I1 , I 2 , I 3 , I 4 ... 如图依次移入 E, T , F ,(, id ,产生了新的状态 I1 , I 2 , I3 , I 4 , I5 , 其中 在 I 4 中由于,‘.’的右边 即将移入的是非终结符 E , 所以对其求闭包, 求的闭包就是我们课本中每个状态集合中有深 色颜色的部分。 如此继续做下去,那么我们的自动机就成功了,有的人称之为 NFA ,我不知道对不对。
E E T |T T T *F | F F ( E ) | id
好,我们开始了:
步骤一:
对产生式进行编号,如龙书 148 页例 4.31 所示,我写到下面: 将表达中的 | 拆开,分成了两个表达式。
(1) E E T (2) E T (3)T T * F (4)T F (5) F ( E ) (6) 表,语法分析表是根据我们的自动机的图画出来的。 分别建立三个栏目,状态, ACTION , GOTO 。 在 ACTION 中写下我们的终结符,包括我们的接受状态符号 $ ,在 GOTO 中写下我们的所 有非终结符,在状态栏,写下我们自动机图中的所有状态。 然后看我们的自动机图,状态 I 0 。
以上都是我个人为了考试花了一天学习编译原理对比了四五本书得出的结论可能有些叙述不正确或者观点不正确的如果你看到这份文档并且对我说的有不同看法或者要修改可以使用不同颜色在原位置标注并写上你的签名并将最后修改之后的文档发到邮箱aihujianfeiqqcom在邮件主题中注明修改的是哪一个科目的什么文档我会更新该文档以此造福广大为了考试不得不看但看着就想自杀的编译原理的学生
ll1 slr1 lrk文法

ll1 slr1 lrk文法
LR(1)文法范围最大,而LR(0)文法范围最小。
同时也说明了四种文法分析过程的强弱,即LR(1)文法分析最强,而LR(0)文法分析最弱。
那为什么没有LL(1)文法呢?因为它和上面的四种文法是不同的。
LL(1)分析法是自上而下的分析法。
LR(0),LR(1),SLR(1),LALR(1)是自
下而上的分析法。
自上而下:从开始符号出发,根据产生式规则推导给定的句子。
用的是推导。
自下而上:从给定的句子规约到文法的开始符号。
用的是归约。
下面就主要来讲解他们的不同点,LL(1)单独讲,其他四种文法
分析过程基本有三大步:写出自动机(即LR(0)或LR(1)项集族,后面都称作自动机)-> 构造文法分析表-> 进行文法分析过程。
其中后两步都是类似或者说几乎完全一样的,第一步中的自动机有两种: LR(0)自动机和LR(1)自动机。
LR(0) 和SLR文法分析用的是LR(0)自动机,LR(1)和LALR文法分析用的是LR(1)自动机。
而LR(1)自动机构造方法和LR(0)自动机的构造方法相同,只是多增加了向前搜索符号。