Hadoop生态系统概述以及版本演化
Hadoop 生态系统介绍

Hadoop 生态系统介绍Hadoop生态系统是一个开源的大数据处理平台,它由Apache基金会支持和维护,可以在大规模的数据集上实现分布式存储和处理。
Hadoop生态系统是由多个组件和工具构成的,包括Hadoop 核心,Hive、HBase、Pig、Spark等。
接下来,我们将对每个组件及其作用进行介绍。
一、Hadoop核心Hadoop核心是整个Hadoop生态系统的核心组件,它主要由两部分组成,一个是Hadoop分布式文件系统(HDFS),另一个是MapReduce编程模型。
HDFS是一个高可扩展性的分布式文件系统,可以将海量数据存储在数千台计算机上,实现数据的分散储存和高效访问。
MapReduce编程模型是基于Hadoop的针对大数据处理的一种模型,它能够对海量数据进行分布式处理,使大规模数据分析变得容易和快速。
二、HiveHive是一个开源的数据仓库系统,它使用Hadoop作为其计算和存储平台,提供了类似于SQL的查询语法,可以通过HiveQL 来查询和分析大规模的结构化数据。
Hive支持多种数据源,如文本、序列化文件等,同时也可以将结果导出到HDFS或本地文件系统。
三、HBaseHBase是一个开源的基于Hadoop的列式分布式数据库系统,它可以处理海量的非结构化数据,同时也具有高可用性和高性能的特性。
HBase的特点是可以支持快速的数据存储和检索,同时也支持分布式计算模型,提供了易于使用的API。
四、PigPig是一个基于Hadoop的大数据分析平台,提供了一种简单易用的数据分析语言(Pig Latin语言),通过Pig可以进行数据的清洗、管理和处理。
Pig将数据处理分为两个阶段:第一阶段使用Pig Latin语言将数据转换成中间数据,第二阶段使用集合行处理中间数据。
五、SparkSpark是一个快速、通用的大数据处理引擎,可以处理大规模的数据,支持SQL查询、流式数据处理、机器学习等多种数据处理方式。
hadoop发展史

hadoop发展史摘要:一、Hadoop 概述1.Hadoop 定义2.Hadoop 的核心组件二、Hadoop 发展史1.Hadoop 的起源2.Hadoop 的快速发展3.Hadoop 生态系统的形成4.Hadoop 2.0 时代的到来三、Hadoop 在各领域的应用1.互联网行业2.金融行业3.政府与公共服务4.制造业四、Hadoop 的未来发展1.大数据技术的发展趋势2.Hadoop 与人工智能的结合3.Hadoop 在云计算领域的应用正文:Hadoop 是一个开源的分布式计算平台,旨在解决海量数据的存储和处理问题。
它由Apache 基金会开发,已成为大数据领域的核心技术之一。
Hadoop 的核心组件包括Hadoop 分布式文件系统(HDFS)、MapReduce 编程模型和YARN 资源调度系统。
Hadoop 的发展史可以追溯到2003 年,当时谷歌发表了一篇关于分布式计算框架的论文,这成为了Hadoop 的灵感来源。
2004 年,Hadoop 项目正式启动,2006 年发布了第一个版本。
随着互联网行业的飞速发展,Hadoop 逐渐成为了大数据领域的热门技术。
2008 年,Hadoop 开始广泛应用于雅虎、Facebook 等互联网公司。
2011 年,Hadoop 进入金融行业,包括高盛、摩根大通等金融机构开始使用Hadoop 进行数据分析。
2013 年,Hadoop 2.0 版本发布,引入了YARN 资源调度系统,进一步优化了Hadoop 的性能。
Hadoop 在各领域得到了广泛应用。
在互联网行业,Hadoop 被用于网站日志分析、用户行为分析等场景。
在金融行业,Hadoop 被用于风险管理、反欺诈、信用评分等业务。
在政府与公共服务领域,Hadoop 被用于气象预测、人口普查等大数据处理任务。
在制造业,Hadoop 被用于工业物联网、生产过程优化等场景。
展望未来,大数据技术将继续发展,Hadoop 将与其他技术如云计算、人工智能等领域更加紧密地结合。
《Hadoop生态系统全景介绍

《Hadoop生态系统全景介绍Hadoop是一个开源、分布式、高可扩展性的计算平台,用于存储和处理大数据。
并且它采用了MapReduce和HDFS技术来处理和存储大数据。
Hadoop 的开源社区成员和个人贡献者实现了Hadoop生态系统,它支撑了各种大数据处理任务。
在本文中,我们将讨论Hadoop生态系统中的各种组件和应用程序,以及这些组件和应用程序如何协同工作,以提高数据处理和存储的效率。
Hadoop生态系统的核心组件包括Hadoop Distributed File System (HDFS)和MapReduce。
HDFS是一个分布式文件系统,用于存储大型数据集。
它的目标是提供可靠的、高容错性的存储,并能在不同节点上快速访问文件。
MapReduce是一种编程模型,用于处理海量数据集,它可用于通过分布式计算生成大量数据。
Hadoop生态系统还有一些扩展组件,可以提供更广泛的实用和效益。
其中一些组件包括HBase、Hive、Pig、Spark、Mahout和Sqoop。
下面将对这些组件一一进行介绍。
HBase是一个基于Hadoop的分布式列式数据库,可实现随机实时读\/写访问大型数据集。
它可存储大量数据,并以列的形式在多台计算机上进行分布式计算。
HBase用于流行的电子商务网站,包括Facebook、Twitter和Yahoo等等,因其可扩展性和高吞吐量被广泛采用。
Hive是一个数据仓库,可用于将大型数据集存储在Hadoop集群中,并使用SQL语言进行查询。
它与HDFS紧密集成,可快速存储和检索数据。
它也是一个数据分析工具,它提供了一个称为HQL(Hive查询语言)的SQL 接口。
通过Hive,用户可以对存储在Hadoop集群中的数据进行透明查询。
Pig是一种基于Hadoop的处理语言,用于处理大规模的数据集。
它可以用于各种数据分析应用,包括ETL(抽取、转换、加载),实时数据流处理,以及复杂的数据流管道的构建。
hadoop生态系统及简介
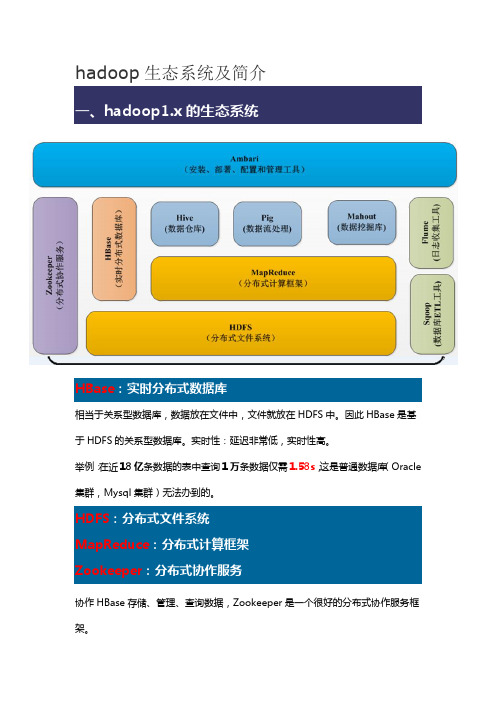
hadoop生态系统及简介HBase:实时分布式数据库相当于关系型数据库,数据放在文件中,文件就放在HDFS中。
因此HBase是基于HDFS的关系型数据库。
实时性:延迟非常低,实时性高。
举例:在近18亿条数据的表中查询1万条数据仅需1.58s,这是普通数据库(Oracle 集群,Mysql集群)无法办到的。
HDFS:分布式文件系统MapReduce:分布式计算框架Zookeeper:分布式协作服务协作HBase存储、管理、查询数据,Zookeeper是一个很好的分布式协作服务框架。
Hive数据仓库:比如给你一块1000平方米的仓库,让你放水果。
如果有春夏秋冬四季的水果,让你放在某一个分类中。
但是水果又要分为香蕉、苹果等等。
然后又要分为好的水果和坏的水果。
因此数据仓库的概念也是如此,他是一个大的仓库,然后里面有很多格局,每个格局里面又分小格局等等。
对于整个系统来说,比如文件系统。
文件如何去管理?Hive 就是来解决这个问题。
Hive:分类管理文件和数据,对这些数据可以通过很友好的接口,提供类似于SQL语言的HiveQL查询语言来帮助你进行分析。
其实Hive底层是转换成MapReduce的,写的HiveQL进行执行的时候,Hive提供一个引擎将其转换成MapReduce再去执行。
Hive设计目的:方便DBA很快地转到大数据的挖掘和分析中。
Pig基于MapReduce的,基于流处理的。
写了动态语言之后,也是转换成MapReduce 进行执行。
和Hive类似。
Mahout基于图形化的数据碗蕨。
SqoopELT:提取--> 转换--> 加载。
从数据库中获取数据,并进行一系列的数据清理和清洗筛选,将合格的数据转换成一定格式的数据进行存储,将格式化的数据存储到HDFS文件系统上,以供计算框架进行数据分析和挖掘。
格式化数据:TSV 格式:每行数据的每列之间以制表符(tab \t)进行分割CVS 格式:每行数据的每列之间以逗号进行分割Sqoop:将关系型数据库中的数据与HDFS(HDFS 文件,HBase中的表,Hive 中的表)上的数据进行相互导入导出。
Hadoop生态体系简介

资源调度系统YARN
资源调度系统YARN
• Resource Manager (RM)负责管理集群的container分 配 • Node Manager管理每个节点上的资源和任务,主要有 两个作用,定期向RM汇报该节点的资源使用情况和各 个container的运行状态,接收并处理AM的任务启动、 停止等请求 • Application Master (AM),每个应用专属,负责该应用 下任务的调度和协调 • 每个container可看做是一个资源的封装实体,包括 CPU资源和内存资源
Hive优化技巧
原语句:SELECT COUNT( DISTINCT id ) FROM TABLE_NAME 由于语句没有group by,hive只在一个reduce处理数据 改写为:SELECT COUNT(*) FROM (SELECT DISTINCT id FROM TABLE_NAME) T
Hadoop发行版本
• • • • Cloudera Hadoop (CDH) Hortonworks Data Platform (HDP) MapR Intel
Hadoop生态体系结构
分布式文件系统HDFS
客户端读取HDFS中的数据
客户端将数据写入HDFS
HDFS复本如何存放
• 在运行客户端的节点上放第一个复本 • 第二个复本放在与第一个不同且随机另外选择 的机架中的节点上 • 第三个复本与第二个复本放在同一个机架上, 且随机选择另一个节点
Reduce阶段
• • • • Reduce通过http从NodeM输出到磁盘 最后把接收到的文件合并起来输入reduce 执行用户reducer方法,结果输出到hdfs
Hadoop生态系统,hadoop介绍

Hadoop生态系统知识介绍首先我们先了解一下Hadoop的起源。
然后介绍一些关于Hadoop生态系统中的具体工具的使用方法。
如:HDFS、MapReduce、Yarn、Zookeeper、Hive、HBase、Oozie、Mahout、Pig、Flume、Sqoop。
Hadoop的起源Doug Cutting是Hadoop之父,起初他开创了一个开源软件Lucene(用Java语言编写,提供了全文检索引擎的架构,与Google类似),Lucene后来面临与Google同样的错误。
于是,Doug Cutting学习并模仿Google解决这些问题的办法,产生了一个Lucene的微缩版Nutch。
后来,Doug Cutting等人根据2003-2004年Google公开的部分GFS和Mapreduce 思想的细节,利用业余时间实现了GFS和Mapreduce的机制,从而提高了Nutch的性能。
由此Hadoop产生了。
Hadoop于2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年3月份,Map-Reduce和Nutch Distributed File System(NDFS)分别被纳入Hadoop的项目中。
关于Hadoop名字的来源,是Doug Cutting儿子的玩具大象。
Hadoop是什么Hadoop是一个开源框架,可编写和运行分布式应用处理大规模数据。
Hadoop框架的核心是HDFS和MapReduce。
其中HDFS 是分布式文件系统,MapReduce 是分布式数据处理模型和执行环境。
在一个宽泛而不断变化的分布式计算领域,Hadoop凭借什么优势能脱颖而出呢?1. 运行方便:Hadoop是运行在由一般商用机器构成的大型集群上。
Hadoop在云计算服务层次中属于PaaS(Platform-as-a- Service):平台即服务。
2. 健壮性:Hadoop致力于在一般的商用硬件上运行,能够从容的处理类似硬件失效这类的故障。
hadoop发展史

hadoop发展史Hadoop是一个开源的分布式计算框架,它的发展史可以追溯到2003年。
下面我将从多个角度全面地回答关于Hadoop的发展史。
1. 起源与发展初期:Hadoop最初是由Doug Cutting和Mike Cafarella于2003年创建的,最初的目标是构建一个能够处理大规模数据集的分布式文件系统。
Doug Cutting以Google的GFS(Google File System)和MapReduce为基础,开发了Hadoop Distributed File System (HDFS)和Hadoop MapReduce。
2006年,Hadoop成为Apache软件基金会的顶级项目,开始吸引了越来越多的开发者和用户。
2. 生态系统的建立:随着Hadoop的发展,一个庞大的生态系统逐渐形成。
Hadoop 生态系统包括了许多相关的项目和工具,如Hive、Pig、HBase、ZooKeeper等。
这些项目扩展了Hadoop的功能,使得用户可以更方便地处理和分析大数据。
3. 商业化应用:Hadoop的商业化应用也逐渐增加。
越来越多的企业开始意识到大数据的重要性,并开始采用Hadoop来处理和分析大数据。
一些大型互联网公司,如Facebook、Yahoo等,成为Hadoop的早期用户和贡献者。
同时,一些公司也开始提供基于Hadoop的商业解决方案,如Cloudera、Hortonworks等。
4. Hadoop的发展和改进:随着时间的推移,Hadoop不断发展和改进。
Hadoop的核心组件HDFS和MapReduce也经历了多个版本的迭代和改进。
Hadoop 2.x引入了YARN(Yet Another Resource Negotiator)作为资源管理器,使得Hadoop可以同时运行多个计算框架。
Hadoop 3.x进一步提高了性能和可靠性,并引入了Containerization和GPU支持等新特性。
Hadoop生态系统基本介绍

基于QJM的HDFS HA架构概述
• 在HA模式的HDFS有如下的守护进程
a. Active NameNode(主) b. standby NameNode(主) c. DataNode(从) d. JournalNode(奇数个) e. ZKFC(主备)
写文件流程
HDFS client
1:create 3:write
• 2007年1月 研究集群增加到900个节点 • 2007年4月 研究集群增加到两个集群1000个节点 • 2008年4月 在900个节点上运行1TB的排序测试集仅需要209秒,成为全球最快 • 2008年10月 研究集群每天状态10TB的数据 • 2009年3月 17个集群共24000个节点 • 2009年4月 在每分钟排序中胜出,59秒内排序500GB(1400个节点上)和173分钟
Data store n
map
(Key 1, Values…)
Байду номын сангаас
(Key 2, Values…)
(Key 3, Values…)
==Barrier== : Aggregates intermediate values by output key
Key 1, Intermediate Values
Key 2, Intermediate Values
the aardvark sat on the sofa
• Intermediate data produced:
(the, 1), (cat, 1), (sat, 1), (on, 1), (the, 1) (mat, 1), (the, 1), (aardvark, 1), (sat, 1) (on, 1), (the, 1), (sofa, 1)
Hadoop生态系统的原理与应用场景

Hadoop生态系统的原理与应用场景一、Hadoop生态系统的概述Hadoop是一种开源的分布式计算框架,能够处理大规模的数据集。
它的核心由两部分组成:分布式文件系统Hadoop Distributed File System(HDFS)和用于大规模数据处理的MapReduce编程模型。
除此之外,Hadoop还由许多组件和工具组成,形成了一个完整的生态系统,包括Hive、Pig、HBase、Sqoop、Flume等。
二、Hadoop生态系统的原理1. HDFSHDFS是Hadoop的核心组件之一,它是一个分布式文件系统,适用于存储海量数据。
它采用主从架构,由一个NameNode和多个DataNode组成。
NameNode作为控制节点,维护了文件系统的目录树和每个文件的块信息。
DataNode则负责存储文件数据块。
HDFS的优点是高容错性和高可靠性,同时它还支持数据的随机读写和高并发处理。
2. MapReduceMapReduce是Hadoop的另一核心组件,是一种分布式计算编程模型。
它将大规模数据处理分解成两个步骤:Map和Reduce。
Map阶段先将数据切分为若干数据块,然后每个数据块由Map处理成一系列中间结果。
Reduce阶段将中间结果汇总起来,进行合并计算得到最终结果。
3. HiveHive是Hadoop生态系统中的一个关系型数据仓库管理工具,它能够将结构化数据转换为Hadoop上的MapReduce任务。
Hive提供了SQL语言的扩展,支持数据的查询、分区、连接等,同时它还支持自定义函数和UDF。
Hive将SQL转换成MapReduce任务的实现,大大提高了数据仓库的效率。
4. PigPig是Hadoop生态系统中的另一个大数据处理工具,它是一种高级脚本语言,支持数据的流式处理和查询。
Pig支持多种数据源,包括HDFS、HBase、Amazon S3等。
它可以将脚本转换成MapReduce任务,在Hadoop中执行各种数据处理操作。
hadoop发展史 -回复

hadoop发展史-回复Hadoop是一个分布式计算框架,主要用于处理大规模数据集的分布式存储和计算。
它的发展历程可以追溯到2005年,由Doug Cutting和Mike Cafarella共同创建。
Hadoop的发展史可以分为以下几个阶段:1. 初始阶段(2005-2010年)在Hadoop刚刚诞生的时候,它只是一个开源的分布式文件系统(Hadoop Distributed File System,简称HDFS)和一个自带的分布式计算框架(MapReduce)。
Doug Cutting将其命名为Hadoop,源自于他儿子的一个玩具大象的名字。
初始阶段的Hadoop主要被用于搜索引擎领域,例如Yahoo等公司开始使用它来处理大规模的日志文件。
2. 社区扩大(2010-2012年)随着Hadoop的逐渐成熟,越来越多的公司开始关注和采用它。
2010年,Apache基金会将Hadoop列为顶级项目,并且Hadoop的社区开始扩大。
这一阶段的关键进展包括引入了Hadoop的第二个顶级项目——HBase,这是一个基于HDFS的分布式数据库。
此外,Hadoop还吸引了一些大型企业的注意,如Facebook、Twitter和亚马逊,它们开始积极地投入到Hadoop的开发和使用中。
3. 商业化推广(2012-2014年)在这一阶段,Hadoop不仅得到了企业的重视,还开始走向商业化。
很多公司开始提供基于Hadoop的商业解决方案,比如Cloudera、Hortonworks和MapR等。
同时,Hadoop的生态系统也得到了极大的丰富,涌现出了很多与Hadoop相关的开源项目和工具。
4. 组件升级(2014-2016年)随着大数据的不断增长,Hadoop的一些组件开始出现性能瓶颈。
为了应对这种情况,Hadoop社区推出了一系列升级和改进的工作。
2014年,Hadoop 2.0发布,引入了Hadoop YARN(Yet Another Resource Negotiator),将计算和资源管理分离,提高了Hadoop的灵活性和可扩展性。
Hadoop生态系统概述以及版本演化

Hadoop构成 YARN(资源管理系统)
Hadoop构成 YARN(资源管理系统)
Hadoop构成 MapReduce(分布式计算框架)
源自于Google的MapReduce论文
发表于2004年12月 Hadoop MapReduce是Google MapReduce克隆版
MapReduce特点
Spark …
(内存计算)
YARN
(分布式计算框架)
HDFS
(分布式存储系统)
Flume (日志收集 )
Hadoop构成 Hive(基于MR的数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统 计问题;
ETL(Extraction-Transformation-Loading)工具
Hadoop构成 YARN(资源管理系统)
YARN是什么
Hadoop 2.0新增系统 负责集群的资源管理和调度 使得多种计算框架可以运行在一个集群中
YARN的特点
良好的扩展性、高可用性 对多种类型的应用程序进行统一管理和调度 自带了多种多用户调度器,适合共享集群环境
Hadoop构成 YARN(资源管理系统)
Hadoop介绍 概述
分布式存储系统HDFS(Hadoop Distributed File System)
分布式存储系统 提供了高可靠性、高扩展性和高吞吐率的数据存储服务
资源管理系统YARN(Yet Another Resource Negotiator)
负责集群资源的统一管理和调度
分布式计算框架MapReduce
构建在Hadoop之上的数据仓库;
数据计算使用MR,数据存储使用HDFS
Hive 定义了一种类 SQL 查询语言——HQL;
【八斗学院】2.Hadoop及Hadoop生态系统简介

Hadoop 及Hadoop 生态系统简介来源:八斗学院Hadoop 是一个由Apache 基金会所开发的开源分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。
适合处理非结构化数据,包括HDFS ,MapReduce 基本组件。
一、Hadoop 版本衍化历史由于Hadoop 版本混乱多变对初级用户造成一定困扰,所以对其版本衍化历史有个大概了解,有助于在实践过程中选择合适的Hadoop 版本。
Apache Hadoop 版本分为分为1.0和2.0两代版本,我们将第一代Hadoop 称为Hadoop 1.0,第二代Hadoop 称为Hadoop 2.0。
下图是Apache Hadoop 的版本衍化史:第一代Hadoop 包含三个大版本,分别是0.20.x ,0.21.x 和0.22.x ,其中,0.20.x 最后演化成1.0.x ,变成了稳定版。
第二代Hadoop 包含两个版本,分别是0.23.x 和2.x ,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation 和YARN 两个系统,相比于0.23.x ,2.x 增加了NameNode HA 和Wire-compatibility 两个重大特性。
Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本,其中比较出名的一是Cloudera公司的发行版,该版本称为CDH(Cloudera Distribution Hadoop)。
截至目前为止,CDH共有4个版本,其中,前两个已经不再更新,最近的两个,分别是CDH3(在Apache Hadoop 0.20.2版本基础上演化而来的)和CDH4在Apache Hadoop 2.0.0版本基础上演化而来的),分别对应Apache的Hadoop 1.0和Hadoop 2.0。
hadoop发展史 -回复

hadoop发展史-回复Hadoop发展史:从起源到广泛应用Hadoop是由Apache软件基金会开发和维护的一套开源软件框架,它可以处理和存储大规模数据集。
1. 起源和早期发展(2003-2008)Hadoop的起源可以追溯到2003年,当时Google发表了一篇众所周知的论文,描述了他们用于处理大规模数据集的分布式存储和计算框架。
这篇论文影响了一位名叫Doug Cutting的工程师,他决定开发一个类似的开源版本。
于是,在2006年,Cutting和他的团队发布了Hadoop的第一个版本。
该版本的Hadoop包含了两个核心组件:Hadoop分布式文件系统(HDFS)和MapReduce分布式计算模型。
Hadoop分布式文件系统允许将大数据集分散存储在多台机器上,并提供高容错性和可靠性。
MapReduce模型则允许在这些分散存储的数据上进行分布式计算。
在早期的发展阶段,Hadoop主要被用于学术研究和科学实验室中的数据处理任务。
它还被广泛应用于大规模数据分析和搜索引擎等领域。
2008年之前,Hadoop主要是一个刚刚起步的技术,还没有获得广泛的应用推广。
2. 商业化和扩展(2008-2012)2008年,Yahoo成立了一个团队,专门负责开发和推广Hadoop。
他们将Hadoop用于处理Yahoo的大规模数据,并取得了显著的成功。
Yahoo 不仅将Hadoop应用于搜索引擎的数据处理,还将其应用于个性化推荐、广告优化和日志分析等领域。
通过Yahoo的成功案例,Hadoop开始引起更广泛的关注。
随着Hadoop 的商业化应用,越来越多的公司开始投入研发资源,为Hadoop提供更多的功能和解决方案。
在这个阶段,Hadoop的生态系统开始蓬勃发展。
一些重要的项目如HBase(一种分布式数据库)、Hive(一种数据仓库工具)和Pig(一种高级分析编程语言)相继推出。
这些项目帮助Hadoop更加易用和灵活。
hadoop发展史

hadoop发展史【引言】在当今大数据时代,Hadoop成为了大数据处理领域的基石。
本文将为您介绍Hadoop的发展史,让我们一同回顾这段历程,了解这个开源项目的起源、发展、挑战以及未来趋势。
【Hadoop的起源和发展背景】Hadoop的起源可以追溯到2002年,当时Google发表了一篇题为《MapReduce: Simplified Data Processing on Large Clusters》的论文。
MapReduce是一种分布式数据处理模型,为大数据处理提供了新的思路。
2004年,Apache基金会开始孵化Hadoop项目,旨在实现一个基于MapReduce的开源框架。
【Hadoop的核心组件和技术原理】Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)、MapReduce计算模型、YARN资源调度器和HBase等。
HDFS提供了高度可靠的数据存储,MapReduce实现了分布式数据处理,YARN负责资源调度,而HBase则提供了分布式数据库功能。
【Hadoop的发展历程和重要版本】Hadoop的发展历程可分为几个重要版本。
2006年,Hadoop 0.1版发布,标志着Hadoop项目的正式诞生。
随后,Hadoop 0.16(2008年)、Hadoop 0.20(2009年)和Hadoop 1.0(2011年)等版本陆续发布,不断完善和优化了框架的功能和性能。
Hadoop 2.0(2016年)引入了多项新技术,如Tez引擎和Ranger数据安全管理等,进一步提高了系统的性能和安全性。
【Hadoop生态系统及其衍生项目】Hadoop的成功催生了一个庞大的生态系统,包括Pig、Hive、Avro、Chukwa、Oozie、HBase、Sqoop等多个项目。
这些项目涵盖了数据存储、处理、分析和传输等各个环节,共同构成了一个完整的大数据处理平台。
【Hadoop在我国的应用和发展】我国对Hadoop技术的应用和发展给予了高度重视。
hadoop发展史 -回复

hadoop发展史-回复Hadoop发展史Hadoop是一个开源的分布式计算框架,从2005年开始诞生至今,经历了多个版本的迭代和演变。
本文将一步一步回答关于Hadoop发展史的问题,以帮助读者了解这个强大的分布式计算框架。
一、Hadoop的起源是什么?Hadoop的起源可以追溯到2003年,当时谷歌的两位工程师Doug Cutting和Michael J. Cafarella开发了一个叫做Nutch的网络搜索引擎项目,由于其规模非常大,需要处理成千上万个Web页面,传统的计算方法变得非常困难。
为了应对这一挑战,他们开始寻找一种可以处理大规模数据的解决方案。
二、Hadoop是什么?Hadoop最初是基于Nutch项目的需求而开发的,它是一个分布式计算框架,旨在提供一种可靠、灵活和可扩展的方式来处理大规模数据集。
Hadoop的核心组件包括Hadoop Distributed File System(HDFS)和MapReduce计算模型。
三、Hadoop的发展历程是怎样的?1. 2005年- Hadoop的诞生2005年,Doug Cutting加入了雅虎,他将Nutch的代码重构为Hadoop,并改善了其灵活性和可扩展性。
雅虎决定将Hadoop开源,并成立了Apache软件基金会的Hadoop子项目。
2. 2006年- Hadoop的早期应用2006年,Hadoop开始在雅虎内部得到广泛应用,尤其是用于搜索、广告优化和日志分析等领域。
雅虎的成功经验吸引了其他公司开始尝试使用Hadoop。
3. 2008年- Hadoop取得重大突破2008年,Hadoop取得了重大突破,发布了Hadoop1.0版本。
该版本引入了Hadoop分布式文件系统(HDFS)和MapReduce计算模型,为处理大规模数据集提供了更好的解决方案。
4. 2009年- Hadoop生态系统的发展2009年,Hadoop生态系统开始快速发展。
Hadoop生态系统及其版本演化

第 0节简介以“互联网日志分析系统”这一大数据应用案例为主线,依次介绍相关的大数据技术,涉及数据收集、储存,数据分析以及可视化,最终会形成一个完整的大数据项目。
每个公司都要自己的日记分析系统,大部分系统跟日志分析系统是沾边的。
也许相关的周边系统,互联网公司对人才的需求,其中一半是日志相关的需求,日志分析,涉及到分布式的所有系统,包括数据收集、存储,数据分析以及可视化,我们课程紧紧围绕这些模块进行的,以目前最新版的hadoop稳定版2.7.3作为基础,同时兼介绍3.0的特性,只要是2.0以上版本,这个课程所介绍的都适用的。
深入浅出介绍Hadoop生态系统原理及应用,包括Hadoop各组件(Flume/HDSF/YARN/Hive/Presto)基本原理、使用方法、实战经验以及在线演示。
基础要求:1.Linux基础,java语言基础(java是大数据语言,大数据相关的一定要学习java);2. 项目构建工具,maven一定要知道,学习java的话,maven一定是知道的,3.集成开发工具eclipse要知道怎么用,intellij idea 也行,一般用eclips4.代码管理工具git,所有代码放在git上,最好git怎么用?大数据对基础要求门槛比较高,这些基础你都具备,不需要非常熟练,有点经验、有点应用就行了,java不需要掌握很复杂的语法,linux懂基本使用即行,无需研究到内核,java能写简单的或复杂的程序,不需要很复杂就OK了,难度不高,最高5个苹果,基础型的。
1预期收益:1. 掌握一个完整的大数据项目架构和技术原型;2. 利用Hadoop处理大数据问题;3. 具备一定的Hadoop程序调优技能;4. 学习一些通用的大数据学习思路和方法。
第一节:Hadoop的生态系统概述以及版本演化第一节课,实战不多,重要是理论,通过这节课,让大家构建一个对大数据生态系统的一个认知,知识框架上有个整体的把握,为后续的课程对应到这个体系中,共分为5部分,首先介绍大数据生态体系,第二部分介绍Hadpoop生态系统,第三部分介绍Hadoop版本演化以及安装部署,就是Hadoop如何安装如2何部署?第四部分,介绍本课程的项目:分布式日志分析系统,我会详细介绍该系统的背景、挑战、目标、架构,架构中分多个模块,后面每节课讲一块,最后对这个做个总结。
Hadoop生态系统浅析

Hadoop生态系统浅析摘要:Apache Hadoop是一种著名的大数据技术。
通过在Hadoop社区添加模块,用户可以根据自己的目标和应用需求形成满足自己所需的个性化的Hadoop生态系统。
本文从数据存储、数据处理、数据查询、数据访问、数据分析等几个方面对Hadoop及其组件组成的生态系统进行了分析,为用户在进行大数据分析工具进行选择时提供帮助和支持。
关键词:Hadoop;生态系统;HDFS;HBase;1 Hadoop简介Apache Hadoop是一种著名的大数据技术,并行集群和分布式文件系统的架构使得它能够快速处理大型数据集。
Hadoop平台的强大功能基于两个主要的子组件:Hadoop分布式文件系统(HDFS)和MapReduce框架。
在Hadoop社区,用户可以根据自己的目标和应用需求,如容量、性能、可靠性、可扩展性、安全性等在Hadoop之上添加模块从而丰富其生态系统,而IT供应商也可以在Hadoop分布中提供特殊的企业强化特性。
上述这些特色,使得Hadoop拥有强大的大数据处理能力,并且具有蓬勃的生命力。
下面我们将从数据存储、数据处理、数据查询、数据访问、数据分析等几个方面,对Hadoop生态系统进行介绍。
2数据存储层:HDFS和HBaseHadoop依赖于它的文件系统HDFS和一个名为Apache HBase的非关系数据库进行数据存储。
2.1 Hadoop分布式文件系统(HDFS)HDFS[1]是为高延迟操作批处理而设计的一种数据存储系统,支持一个集群中几百个节点的管理,可以处理结构化和非结构化数据,能保存大小大于1 TB的文件,支持跨异构硬件和软件平台的移植,通过将计算操作移到数据存储附近来减少网络拥塞和提高系统性能。
但HDFS不构成通用文件系统,也不提供文件中的快速记录查找。
HDFS基于主从架构,将大量数据分布在集群中,由一个唯一的主节点管理文件系统操作,许多的从节点来管理和协调单个计算代码上的数据存储。
hadoop发展历程

hadoop发展历程Hadoop是一个开源的分布式计算平台,具有处理大数据的高性能和可扩展性。
下面是Hadoop的发展历程:2002年:Doug Cutting和Mike Cafarella开发了一个基于Nutch的分布式文件系统NDFS(Nutch Distributed File System),用于存储和处理大规模数据。
2004年:Doug Cutting将GFS(Google File System)的论文作为参考,对NDFS进行了改进,并正式命名为HDFS(Hadoop Distributed File System)。
2006年:Hadoop的第一个版本0.1.0发布,包括HDFS和MapReduce两个核心组件。
2007年:Yahoo开始采用Hadoop并贡献了很多代码,推动了Hadoop的发展。
同时,Apache将Hadoop纳入自己的孵化器项目。
2008年:Hadoop变得更加稳定和成熟。
新的版本0.18.0发布,包括许多新的特性和改进。
2009年:Apache Hadoop 0.20版本发布,引入了新的容错特性和提高了性能。
2011年:Apache Hadoop 0.23版本发布,引入了新的YARN (Yet Another Resource Negotiator)框架,将资源管理和作业调度进行了分离,使得Hadoop更加通用和灵活。
2012年:Hadoop 2.0版本发布,正式将YARN作为Hadoop的核心模块。
YARN架构的引入进一步提高了Hadoop的可伸缩性和容错性。
2014年:Apache Hadoop 2.6版本发布,引入了许多新的特性和改进,包括更好的集群资源利用率和更强大的数据处理能力。
2017年:Hadoop的生态系统不断壮大,涵盖了许多与Hadoop 集成的工具和应用,如HBase、Hive、Pig、Sqoop等。
总结起来,Hadoop经过多年的发展,不断演进和改进,成为目前大数据处理领域最重要的开源平台之一。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
小象科技
让你的数据产生价值
Hadoop构成
MapReduce(分布式计算框架)
小象科技
让你的数据产生价值
Hadoop构成
MapReduce(分布式计算框架)
小象科技
让你的数据产生价值
Hadoop构成
MapReduce(分布式计算框架)
小象科技
让你的数据产生价值
目录
1. Hadoop生态系统特点 2. Hadoop介绍
小象科技
让你的数据产生价值
Hadoop 1.0与2.0
1. Hadoop生态系统特点 2. Haቤተ መጻሕፍቲ ባይዱoop介绍
3. Hadoop生态系统
4. Hadoop生态系统版本衍化
5. 总结
小象科技
让你的数据产生价值
4
议程
1. Hadoop生态系统特点
2. Hadoop介绍
3. Hadoop生态系统
4. Hadoop生态系统版本衍化
LDA
Spectral Clustering
谱聚类
Minhash Clustering Top Down Clustering
自上而下聚类
小象科技
让你的数据产生价值
Mahout介绍
Logistic Regression
逻辑回归
分类算法
Bayesian
贝叶斯分类算法
(分布式存储系统)
小象科技
让你的数据产生价值
Flume
(分布式计算框架)
(日志收集)
MapReduce
(数据库 TEL工具)
Sqoop
Hive
Pig
Mahout
Hadoop生态系统 2.0时代
Ambari
(安装部署工具)
Oozie
(作业流调度系统) (分布式数据库)
Hive Pig Hive2 Pig2 Shark
小象科技
让你的数据产生价值
Hadoop构成
Mahout实现的算法
Classification Clustering
Dimension Reduction
Freq. Pattern Mining
Examples
Non-MR Algorithms
Recommenders
Regression
Evolution
HBase数据模型
小象科技
让你的数据产生价值
Hadoop构成
HBase数据模型
Table:表 类似于传统传统数据库中的表 Column Family:列簇 Table在水平方向有一个或者多个Column Family 组成 一个Column Family中可以由任意多个Column组 成 Row Key: 行键 Table的主键 Table中的记录按照Row Key排序 Timestamp: 时间戳 每行数据均对应一个时间戳 版本号
… …
(数据库 TEL工具)
(分布式协调服务)
Zookeeper
Hbase
MapReduce
(离线计算)
Tez
(DAG计算)
Spark
(内存计算)
YARN
(分布式计算框架) (日志收集)
HDFS
(分布式存储系统)
小象科技
让你的数据产生价值
Flume
Sqoop
Hadoop构成
Hive(基于MR的数据仓库)
源自于Google的GFS论文
发表于2003年10月
HDFS是GFS克隆版
HDFS特点
良好的扩展性 高容错性 适合PB级以上海量数据的存储
小象科技
让你的数据产生价值
Hadoop构成
基本原理
HDFS(分布式文件系统)
将文件切分成等大的数据块,存储到多台机器上 将数据切分、容错、负载均衡等功能透明化
由facebook开源,最初用于解决海量结构化的日志数据统
计问题;
ETL(Extraction-Transformation-Loading)工具
构建在Hadoop之上的数据仓库;
数据计算使用MR,数据存储使用HDFS
Hive 定义了一种类 SQL 查询语言——HQL;
类似SQL,但不完全相同
5. 总结
小象科技
让你的数据产生价值
5
Hadoop介绍
分布式存储系统
概述
分布式存储系统HDFS(Hadoop Distributed File System)
提供了高可靠性、高扩展性和高吞吐率的数据存储服务
资源管理系统YARN(Yet Another Resource Negotiator)
• Regression
– Locally Weighted Linear Regression
• Dimension Reduction
– – – – – SVD Stochastic SVD with PCA PCA Independent Component Analysis Gaussian Discriminative Analysis
Hive语句
SELECT word, COUNT(*) FROM doc LATERAL VIEW explode(split(text, ' ')) lTable as word GROUP BY word;
小象科技
让你的数据产生价值
WordCount
Pig语句
-- ① 加载数据 input = load ‘/input/data’ as (line:chararray); -- ② 将字符串分割成单词 words = foreach input generate flatten(TOKENIZE(line)) as word; -- ③ 对单词进行分组 grpd = group words by word; -- ④ 统计每组中单词数量 cntd = foreach grpd generate group, COUNT(words); -- ⑤ 打印结果 dump cntd;
集群管理
配置同步
小象科技
让你的数据产生价值
Hadoop构成
负责集群资源的统一管理和调度
分布式计算框架MapReduce
分布式计算框架
具有易于编程、高容错性和高扩展性等优点
小象科技
让你的数据产生价值
Hadoop介绍
概述
MapReduce(分布式计算层)
YARN(集群资源管理层)
HDFS(分布式存储层)
小象科技
让你的数据产生价值
Hadoop构成
HDFS(分布式文件系统)
LOGO
Hadoop生态系统概述以及版本演化
讲师:董西成
议程
1. Hadoop生态系统特点
2. Hadoop介绍
3. Hadoop生态系统
4. Hadoop生态系统版本衍化
5. 总结
小象科技
让你的数据产生价值
2
Hadoop生态系统
特点
源代码开源(免费) 社区活跃、参与者众多 涉及分布式存储和计算的方方面面 已得到企业界验证
小象科技
让你的数据产生价值
Hadoop构成
HBase架构
小象科技
让你的数据产生价值
Hadoop构成
Zookeeper(分布式协作服务)
源自Google的Chubby论文
发表于2006年11月
Zookeeper是Chubby克隆版纳
解决分布式环境下数据管理问题
统一命名 状态同步
Support Vector Machines
支持向量机
Perceptron and Winnow
感知器算法
Neural Network
神经网络
Random Forests
随机森林
Restricted Boltzmann Machines
有限波尔兹曼机
Online Passive Aggressive Boosting Hidden Markov Models
YARN的特点
良好的扩展性、高可用性
对多种类型的应用程序进行统一管理和调度
自带了多种多用户调度器,适合共享集群环境
小象科技
让你的数据产生价值
Hadoop构成
YARN(资源管理系统)
小象科技
让你的数据产生价值
Hadoop构成
YARN(资源管理系统)
小象科技
让你的数据产生价值
Hadoop构成
定义了一种数据流语言——Pig Latin
通常用于进行离线分析
小象科技
让你的数据产生价值
Hadoop实例
wordcount问题
小象科技
让你的数据产生价值
WordCount
MapReduce程序
小象科技
让你的数据产生价值
WordCount
MapReduce程序
小象科技
让你的数据产生价值
WordCount
3. Hadoop生态系统
4. Hadoop生态系统版本衍化
5. 总结
小象科技
让你的数据产生价值
19
Hadoop生态系统 1.0时代
Ambari
(安装部署工具)
Oozie
(作业流调度系统)
(分布式数据库)
(分布式协调服务)
Hbase
Zookeeper
(数据仓库)
(工作流引擎)
(数据挖掘库)
HDFS
海量结构化数据离线分析 低成本进行数据分析(不直接编写MR)