批量自动查询并保存结果通用方法
易查分 批量爬取成绩 -回复

易查分批量爬取成绩-回复“易查分批量爬取成绩”是一个可以帮助用户快速、批量地获取成绩信息的工具。
它利用网络爬虫技术,自动从相关教育机构的网站上抓取学生成绩数据,并将其组织形成易于查询的报告。
本文将详细介绍“易查分批量爬取成绩”工具的运行原理、应用场景、使用方法以及可能面临的问题和解决方案。
首先,我们来了解“易查分批量爬取成绩”是如何工作的。
该工具利用网络爬虫技术,自动模拟用户在教育机构网站上进行查询成绩的操作,然后将查询结果保存下来。
它可以通过模拟登录、表单提交等方式来实现自动化操作,从而节省用户大量手动查询成绩的时间和精力。
“易查分批量爬取成绩”工具的应用场景十分广泛。
对于教育机构来说,它可以帮助学校、学院、班级等单位快速获取学生成绩信息,进行综合评估和教学管理。
对于学生和家长来说,它可以方便地获取个人成绩信息,并进行对比、分析和反馈。
同时,该工具也适用于一些教育咨询机构、家教机构等服务机构,可以根据客户需求,批量获取学生成绩数据,进行评估和分析。
接下来,我们来看一下“易查分批量爬取成绩”工具的使用方法。
首先,用户需要安装相关的爬虫软件,并了解目标教育机构网站的结构和数据查询接口。
然后,通过编写相应的爬虫代码,定义数据抓取的规则和操作步骤。
在运行爬虫程序之前,用户需要提供相关的登录信息和查询条件。
一旦爬虫程序运行起来,它将按照用户的设定,自动从网站上爬取学生成绩数据,并保存为可查询的报告形式。
最后,用户可以使用查询界面,输入学生相关信息,即可快速查询该学生的成绩信息。
当然,在使用“易查分批量爬取成绩”工具的过程中,也会遇到一些可能的问题和障碍。
其中一个常见的问题是网站的反爬策略。
为了防止爬虫程序的入侵和滥用,一些教育机构会设置反爬虫的安全机制,如验证码、限制访问频率等。
针对这种情况,用户可以通过调整爬虫程序的访问频率、使用自动识别验证码的技术等方式来应对。
另一个问题是学生成绩数据的格式和结构可能会因不同的教育机构而异。
根据域名批量查ip的方法

根据域名批量查ip的方法
根据域名批量查询IP地址的方法有多种,以下列举三种常见的方式:
1. 使用命令行工具:在终端或命令提示符窗口中,可以输入nslookup命令来查询域名对应的IP地址。
如果要批量查询多个域名,可以将域名列表保存到一个文本文件中,然后在命令行中逐行读取文件并执行nslookup命令。
2. 使用在线工具:许多在线工具提供了通过域名查询IP的功能。
可以在搜索引擎中搜索类似的关键词,然后选择一个工具进行查询。
通常,这些工具提供一个输入框,只需输入域名并点击查询按钮即可获取结果。
如果要批量查询多个域名,可以使用多线程或脚本自动化工具来自动提交查询请求。
3. 使用编程语言:如果熟悉编程语言,可以使用编程语言来查询域名对应的IP。
例如,使用Python语言,可以编写一个简单的脚本,使用socket模块来查询域名对应的IP地址。
如果要批量查询多个域名,可以将域名列表作为输入参数传递给脚本,并使用循环结构逐个查询每个域名的IP地址。
以上方法仅供参考,请注意网络安全,谨慎操作。
输入身份证查询姓名

输入身份证查询姓名在中国,身份证是每个公民的必备证件,一般由户籍管理部门发放。
身份证上包含了个人的基本信息,如姓名、性别、出生日期、身份证号码等。
身份证号码是唯一的且具有区域特征码,这使得身份证成为识别个人身份的重要依据。
因此,通过输入身份证号码进行姓名查询是一种常见的需求。
身份证号码是一个18位的数字和字母组合,其中最后一位是校验位,用于验证身份证号码的准确性。
通过输入身份证号码进行姓名查询,需要一定的查询工具和方法。
以下是其中一种常见的方法:1. 手动查询方法这种方法适用于少量的查询需求或者没有条件使用自动查询工具的情况。
首先,您需要打开浏览器,并进入相关的身份证查询网站。
然后,在网站上找到身份证查询的入口,一般会有一个输入框或者查询按钮。
接下来,您需要将要查询的身份证号码输入到查询框中,并点击查询按钮。
系统会进行身份证号码的验证,并在查询结果页面显示相应的姓名信息。
请注意,有些身份证查询网站可能需要您提供其他的个人信息,如姓名、手机号码等。
这是为了进行更全面的查询和验证,以防止身份信息被滥用。
2. 自动查询工具对于大量的身份证号码查询需求,使用自动查询工具会更加高效和方便。
自动查询工具是一种基于计算机程序开发的软件工具,可以批量输入身份证号码,并自动查询相关的姓名信息。
这种工具适用于机构、企业等需要批量查询身份证信息的场景。
使用自动查询工具,您需要安装相应的软件,并按照工具的使用指南进行操作。
一般来说,您只需将待查询的身份证号码存储在一个文本文件中,然后将该文件导入到工具中进行批量查询。
工具会自动逐个查询身份证号码,并将查询结果保存在另一个文件中。
自动查询工具的优点是速度快、效率高,可以一次性查询大量的身份证号码。
但是,使用自动查询工具需要一定的技术和操作经验,对于普通用户可能比较复杂。
3. 服务窗口查询如果您不善于使用计算机或者不方便自行查询,还可以前往相关的服务窗口进行人工查询。
一般来说,户籍管理部门、派出所或社区服务中心等机构都提供身份证查询服务。
oracle批量查询建表语句

oracle批量查询建表语句Oracle数据库是一种常见的关系型数据库系统,常常被用于存储和处理大量数据。
在进行数据分析和数据挖掘时,我们常常需要从Oracle中查询大量的数据,并在本地进行分析。
这时,我们就需要将Oracle中的数据导出到本地进行处理。
但是,如果需要导出的数据非常多,手动创建大量的表格显然是不现实的,这时我们就需要使用Oracle批量查询建表语句,自动化地将数据导出到对应的表格中。
一、准备工作在进行批量查询建表语句之前,我们需要先创建一个包含需要导出数据的查询语句的文件。
这个文件可以是一个普通的txt文件,每一行表示一个查询语句。
比如,我们可以将以下查询语句保存到一个名为“query.txt”的文件中:select * from employees where department_id = 10;select * from employees where department_id = 20;select * from employees where department_id = 30;二、使用SQL*Plus创建表格SQL*Plus是Oracle提供的一个命令行工具,可以方便地从Oracle数据库中查询数据。
在本地电脑上安装了Oracle的客户端之后,我们就可以使用SQL*Plus来进行批量查询建表语句了。
1. 开启SQL*Plus在Windows系统下,我们可以通过Win+R快捷键打开“运行”窗口,然后输入“cmd”命令,进入命令行界面。
接着,输入“sqlplus username/password@database”连接到Oracle数据库。
其中,username表示Oracle数据库的用户名,password表示密码,database表示连接的数据库名。
2. 执行查询语句在SQL*Plus中执行查询语句的方式非常简单。
我们只需要输入查询语句,按下回车键,就可以得到查询结果。
ExcelVBA编程与宏自动查询如何设定宏的自动查询和批量查询

ExcelVBA编程与宏自动查询如何设定宏的自动查询和批量查询在Excel中,VBA编程和宏是一种强大的工具,可以帮助用户实现自动查询和批量查询的功能。
通过设定宏的自动查询和批量查询,用户可以节省时间和精力,提高工作效率。
本文将介绍如何使用Excel VBA编程来实现宏的自动查询和批量查询的功能。
一、宏的自动查询设置1. 首先,在Excel中打开需要进行自动查询的工作表。
2. 点击“开发工具”选项卡,在“代码”组中选择“宏”按钮。
然后,在弹出的对话框中输入宏的名称,并点击“创建”按钮。
3. 在“宏编辑器”界面中,编写VBA代码来实现自动查询的功能。
以下是一个示例代码:```vbaSub AutoQuery()Dim rng As RangeDim cell As Range'设置查询范围Set rng = Range("A1:A10")'遍历查询范围For Each cell In rng'在这里编写查询的代码'...'...Next cellEnd Sub```在这个示例代码中,我们首先定义了一个范围变量`rng`,并将其设置为需要查询的范围(例如A1:A10)。
然后,使用`For Each`循环遍历查询范围中的每个单元格,并在循环体内编写查询的代码。
4. 编写完VBA代码后,保存并关闭“宏编辑器”。
5. 接下来,我们需要将宏与某个事件关联,以实现自动查询的功能。
例如,我们可以将宏与工作表的“激活”事件关联,当用户切换到指定的工作表时,宏会自动执行查询操作。
6. 在“宏”按钮的下拉菜单中,选择“宏选项”。
然后,在弹出的对话框中选择需要关联宏的事件(例如“激活”事件),并点击“确定”按钮。
7. 最后,保存并关闭工作表。
当用户切换到该工作表时,宏会自动执行查询操作。
二、宏的批量查询设置1. 在Excel中打开需要进行批量查询的工作表。
2. 创建一个新的模块用于编写VBA代码。
经纬度查询快速精准的方法

Geocoding经纬度批量查询工具,经纬度批量查询,地址反查经纬度,批量生成地图
1、首先进入经纬度批量查询工具
2、输入要查询的地址:比如北京市海淀区中关村南大街27号
地址格式:省市区县街道,名胜古迹、标志性建筑物名称,*路与*路交叉口3、添加好后,直接按开始查询
4、批量生成地图
可以把查询结果生成地图,以便用于其他用途之中。
地图可以用地址命名,经纬度命名,按时间命名,按序列号命名等
在表格上选择要生成地图的记录,然后点击生成地图,选择存放的文件夹后,就可以生成了。
生成结果(以地址命名):
5、可以把记录导出来,以Excel、CSV、HTML、Txt等格式在表格上选择要导出的记录,或者直接选择导出全部行
选择要导出的格式,然后点击保存
导出Excel格式结果:
6、地址反查经纬度,选择反查询经纬度
7、添加经纬度值
格式:经度值,纬度值,比如:116.322987,39.983424
如果输入的格式是纬度值,经度值,比如:39.983424,116.322987,
那么就把纬-经这个复选框打勾,以便软件用纬度值,经度值的格式来查询。
8、经纬度值添加好后,直接点击下面的开始查询,就可以了。
9、地图设置
10、可以设置地图的高-宽,缩放大小,以及用什么方式命名等。
设置好后,点确定按钮,可以预览设置的结果。
网页脚本注入执行任意代码--突破本地脚本验证图文案例
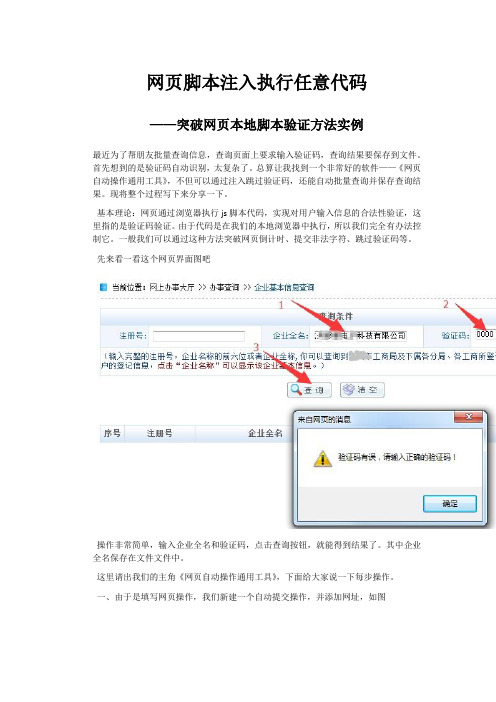
网页脚本注入执行任意代码——突破网页本地脚本验证方法实例最近为了帮朋友批量查询信息,查询页面上要求输入验证码,查询结果要保存到文件。
首先想到的是验证码自动识别,太复杂了。
总算让我找到一个非常好的软件——《网页自动操作通用工具》,不但可以通过注入跳过验证码,还能自动批量查询并保存查询结果。
现将整个过程写下来分享一下。
基本理论:网页通过浏览器执行js脚本代码,实现对用户输入信息的合法性验证,这里指的是验证码验证。
由于代码是在我们的本地浏览器中执行,所以我们完全有办法控制它。
一般我们可以通过这种方法突破网页倒计时、提交非法字符、跳过验证码等。
先来看一看这个网页界面图吧操作非常简单,输入企业全名和验证码,点击查询按钮,就能得到结果了。
其中企业全名保存在文件文件中。
这里请出我们的主角《网页自动操作通用工具》,下面给大家说一下每步操作。
一、由于是填写网页操作,我们新建一个自动提交操作,并添加网址,如图二、我们设置让程序自动输入公司名称,打开提交内容选项卡,添加提交内容。
打开自动获取功能,等待网页打开后,将鼠标移到公司全名输入框,点击右键菜单中的获取元素,程序自动分析获取方法,只需再次点击“添加元素”即可再看下图,第1小步的内容已经通过自动获取自动填写了,第2我们要自动填写,就是改变这个元素的value属性,第3选择从文本文件批量输入数据。
最后点击确定添加这个输入条目。
三、分析提交代码,注入破解脚本代码,由于我们想办法跳过验证码,所以不再设置验证码输入。
直接进入提交环节设置如下图,将鼠标移到“查询”按钮处,可以看到相关代码。
<IMG onclick="doQuery('1')" style="CURSOR: pointer" border=0 src="images/chaxun.jpg"> 我们再去查找"doQuery('1')"这个提交方法我们得到了关键的代码段var reply =function(data){if(data=='error'){document.getElementById("show").style.display="none";alert("验证码有误,请输入正确的验证码!");refreshimg();return false;}else{form1.action="ggtz.do?method=getqyjbxxdetail";form1.submit();}这里就是判断验证码的。
易查分 批量爬取成绩

易查分批量爬取成绩近年来,随着教育信息化的推进,学生的学习成绩逐渐以电子化的形式存储,提供了方便快捷的查询途径。
然而,由于学校系统限制和学生数量庞大,单个查询成绩的操作效率较低,不利于学生和家长了解学生的学习情况。
因此,开发一种易查分批量爬取成绩的工具成为刻不容缓的任务。
一、工具简介易查分批量爬取成绩工具基于网络爬虫技术,旨在提供一种集成化的成绩查询工具,能够定期自动获取学生的成绩信息,以提高查询效率。
该工具采用Python语言编写,具有良好的可读性和扩展性。
二、实现方式1. 目标学校教务系统登录通过分析目标学校教务系统的登录接口,使用Python的requests库发送POST请求,实现模拟登录。
使用正则表达式解析登录返回结果,获取登录成功后的cookie。
2. 批量获取学生学号根据学校学生的学号规律,使用循环生成学生学号。
通过发送GET请求到目标学校的学生信息查询接口,根据返回结果判断学生是否存在。
3. 批量查询成绩利用学生学号以及已获取的cookie,构造查询成绩接口的请求参数。
通过发送GET请求到目标学校的成绩查询接口,获取学生的成绩信息。
可将查询到的成绩保存为Excel文件或导入数据库,方便后续使用。
4. 定期自动执行通过设置定时任务,定期执行查询成绩的操作。
可根据实际情况选择每日、每周或每月执行一次,以保证查询结果的及时性。
三、工具优势1. 提高查询效率通过批量查询的方式,能够快速获取大量学生的成绩信息,减少了人工查询的繁琐步骤,提高了工作效率。
2. 自动化操作采用定时任务的方式,无人值守地执行成绩查询操作。
大大减少了人工操作的时间和精力消耗。
3. 数据备份和管理将查询到的成绩信息保存为Excel文件或导入数据库,方便后续数据备份和管理。
同时,也为后续的数据分析提供了便捷的数据源。
四、使用注意事项1. 合法性问题在使用该工具之前,应确保获得了学校相关方的授权,并遵守法律法规。
未经授权擅自查询他人成绩属于不道德行为。
jdbc批量查询的用法(二)

jdbc批量查询的用法(二)JDBC批量查询的用法什么是JDBC批量查询JDBC批量查询是指在一次数据库连接中执行多个查询操作的技术。
它可以提高查询效率,减少网络开销,特别适合处理大量的查询请求。
批量查询的优势1.减少网络开销:JDBC批量查询可以减少与数据库的通信次数,从而降低了网络开销。
2.提高查询效率:由于批量查询可以一次发送多个查询请求,所以能够减少CPU的使用时间,提高查询速度。
3.节省系统资源:批量查询可以减少对数据库连接和关闭的操作,从而节省了系统资源的使用。
批量查询的准备工作在进行批量查询之前,需要先创建JDBC连接,可以使用DriverManager类来获取数据库连接。
具体的步骤如下:1.加载数据库驱动程序:("");2.建立数据库连接:Connection conn = ("jdbc: "username", "password");执行批量查询在创建好数据库连接之后,可以开始执行批量查询了。
下面是几个常用的批量查询用法:1. Statement 批量查询使用Statement对象执行批量查询,示例代码如下:Statement stmt = ();("SELECT * FROM table1");("SELECT * FROM table2");("SELECT * FROM table3");int[] results = ();上述代码创建了一个Statement对象,然后通过addBatch方法添加了三条查询语句,最后使用executeBatch执行批量查询,并将结果保存在results数组中。
2. PreparedStatement 批量查询使用PreparedStatement对象执行批量查询,示例代码如下:String sql = "SELECT * FROM table WHERE id = ?"; PreparedStatement pstmt = (sql);(1, 1);();(1, 2);();(1, 3);();int[] results = ();上述代码创建了一个PreparedStatement对象,并使用addBatch方法添加了三个查询参数的批量查询语句,最后使用executeBatch执行批量查询,并将结果保存在results数组中。
查询模式的分类

查询模式的分类查询模式是一种用于从数据库或其他数据源中获取信息的方法。
它可以根据用户提供的条件和要求来获取所需的数据。
不同的查询模式可以根据查询类型、查询语言、查询结果等方面进行分类。
本文将介绍几种常见的查询模式,并对其进行分类和解释。
一、基本查询模式基本查询模式是最简单的查询模式,它只包含一个查询语句和一个查询结果。
用户可以根据自己的需求编写查询语句,并通过查询结果来获取所需的信息。
基本查询模式适用于简单的数据查询和检索需求。
二、高级查询模式高级查询模式是相对于基本查询模式而言的,它包含更复杂和更丰富的查询功能。
高级查询模式可以支持多个查询语句的组合和嵌套,可以进行多表关联查询、排序、分组、聚合等操作。
高级查询模式适用于复杂的数据查询和统计分析需求。
三、动态查询模式动态查询模式是一种根据用户的输入动态生成查询语句的查询模式。
用户可以通过界面输入查询条件,系统会根据用户的输入自动生成相应的查询语句,并返回查询结果。
动态查询模式适用于需要根据用户输入进行动态查询的应用场景,如电商网站的商品搜索功能。
四、预定义查询模式预定义查询模式是一种事先定义好的查询模式,用户只需要选择相应的查询条件即可完成查询。
预定义查询模式可以通过界面或命令行等方式提供给用户选择,用户可以根据自己的需求选择相应的查询模式进行查询。
预定义查询模式适用于用户对查询语句不熟悉或不愿意编写查询语句的情况。
五、自然语言查询模式自然语言查询模式是一种使用自然语言进行查询的查询模式。
用户可以用自然语言描述查询需求,系统会将自然语言转换为查询语句,并返回相应的查询结果。
自然语言查询模式适用于用户对查询语言不熟悉或不愿意编写查询语句的情况。
六、图形化查询模式图形化查询模式是一种通过可视化界面进行查询的查询模式。
用户可以通过拖拽、点击等操作选择查询条件,系统会根据用户的选择生成相应的查询语句,并返回查询结果。
图形化查询模式适用于用户对查询语句不熟悉或不愿意编写查询语句的情况。
如何批量查企业年检报告

如何批量查企业年检报告1. 引言企业年检报告是企业在每年末进行的一项重要工作,它记录了企业在过去一年的运营情况、财务状况以及合规情况等信息。
对于投资者、合作伙伴以及政府部门来说,了解企业的年检报告可以更好地评估企业的经营状况和风险水平。
然而,对于大量企业来说,逐一查找、下载和整理年检报告是一项繁琐且耗时的任务。
本文将介绍一种批量查企业年检报告的方法,帮助用户高效地获取需要的信息。
2. 方法2.1 数据来源目前,许多国家的政府部门都提供了公开的企业信息数据库,其中包括了企业的年检报告。
用户可以通过这些数据库来查找企业的年检报告。
常见的公开数据库包括国家工商行政管理总局和税务局等。
具体使用哪个数据库取决于用户所在的地区和需要查询的企业。
2.2 数据查询根据用户所在地区和需要查询的企业,选择相应的公开数据库进行查询。
大多数数据库提供了企业名称或注册号的查询入口,用户可以通过这些信息进行查询。
对于需要批量查询的情况,可以将所有待查询的企业名称或注册号整理成一个列表,逐一查询,并将结果保存。
2.3 数据下载和整理查询到企业的年检报告后,用户可以选择将报告下载保存至本地或进行在线查看。
对于批量查询,最好将年检报告保存至本地,以便后续整理。
为了方便整理和管理,可以将每个企业的年检报告保存在单独的文件夹中,并用企业名称或注册号进行命名。
2.4 数据分析获取到企业的年检报告后,用户可以对这些报告进行进一步的分析。
常见的数据分析方法包括财务分析、经营风险评估以及合规性评估等。
用户可以利用财务软件、数据分析工具或自行编写脚本来实现。
3. 工具推荐在进行批量查询企业年检报告时,可以借助一些自动化工具来提高效率。
3.1 查询工具- [企查查](- [天眼查](以上两个工具都提供了企业信息查询的服务,用户可以通过企业名称或注册号来进行查询。
3.2 批量下载工具- [批量下载助手](该工具是一个Chrome插件,可以帮助用户批量下载网页上的文件。
利用MySQL的IN语句实现批量数据查询

利用MySQL的IN语句实现批量数据查询数据库是现代应用程序的核心组成部分之一。
它不仅可以存储和管理大量数据,还能够提供可靠的数据访问方法。
MySQL是一个广泛使用的数据库管理系统,它提供了丰富的功能和高效的性能。
在实际应用中,经常需要进行批量数据查询,而MySQL的IN语句是一种十分有效的方法。
本文将介绍IN语句的使用方式以及相关的注意事项。
IN语句是MySQL中的一个重要查询操作符,它允许我们在查询中指定一个条件,以便查询满足特定条件的值。
IN语句可以与其他查询条件组合使用,进一步提高查询的灵活性和准确性。
IN语句的语法非常简单,只需在查询条件中使用关键字IN并指定一个值列表即可。
下面是一个示例查询,该查询将返回名为“employees”的数据表中员工姓名为Alice、Bob和Charles的记录:```SELECT * FROM employees WHERE name IN ('Alice', 'Bob', 'Charles');```上述查询语句中,IN语句后的值列表中包含了三个员工姓名。
MySQL将根据这个值列表来查找满足条件的记录,并将其返回给用户。
使用IN语句进行批量数据查询的好处之一是它可以实现高效的查询操作。
相比于使用多个OR条件进行查询,IN语句可以将多个值组合在一个查询中,减少了查询的次数,提高了查询的效率。
这对于包含大量数据的数据表来说尤为重要。
除了使用固定的值列表,IN语句还可以与子查询一同使用,以实现更加灵活和动态的查询操作。
下面是一个使用子查询的示例查询:```SELECT * FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE name = 'Sales');```上述查询中,IN语句的值列表是一个子查询。
vlookup函数的使用批量查找方法

vlookup函数的使用批量查找方法vlookup函数是Excel中常用的函数之一,它可以帮助用户在一个数据表中查找特定值,并返回与该值相关联的数据。
该函数的使用方法非常灵活,用户可以通过简单的设置实现批量的查找操作。
下面将介绍vlookup函数的使用批量查找方法,以及一些使用该函数的注意事项。
一、vlookup函数的基本语法在Excel中,vlookup函数的基本语法为:```=vlookup(lookup_value, table_array, col_index_num, [range_lookup])```其中,各个参数的含义如下:- lookup_value:要查找的值。
- table_array:要进行查找的数据表区域。
- col_index_num:要返回的值所在的列数。
- range_lookup:可选参数,定义查找方式。
1表示近似匹配,0或FALSE表示精确匹配。
默认为近似匹配。
二、vlookup函数的批量查找方法通常情况下,用户需要查找的值可能不只一个,而是一批值。
在这种情况下,vlookup函数可以通过一些技巧,实现批量查找。
1.批量查找数据表中的多个值如果要查找的值位于数据表的一列中,可以使用vlookup函数的数组公式功能。
具体操作如下:1)在结果单元格中输入vlookup函数,并将lookup_value参数设置为要查找的值;2)在table_array参数中选择要查找的数据表区域;3)在col_index_num参数中设置为1,表示要返回匹配值所在的第一列;4)将函数设置为数组公式,即在输入完函数后,按住Ctrl+Shift+Enter键。
2.批量查找多个值在数据表中的位置如果要查找的值位于数据表的不同位置,并想查找出它们在数据表中的位置,可以借助MATCH函数和INDEX函数来实现。
具体操作如下:1)在结果单元格中输入MATCH函数,并将lookup_value参数设置为要查找的值;2)在table_array参数中选择要查找的数据表区域的一列;3)将range_lookup参数设置为0,表示进行精确匹配;4)将函数设置为数组公式,按住Ctrl+Shift+Enter键;5)在另一个单元格中输入INDEX函数,通过指定位置参数,返回查找到的值在数据表中的位置。
java 避免java中循环查sql的方法 -回复

java 避免java中循环查sql的方法-回复Java中避免循环查SQL的方法在使用Java开发中,经常会遇到需要从数据库中查询大量数据的情况。
然而,如果我们使用传统的循环方式逐条查询数据库的话,会导致性能低下和资源浪费的问题。
所以,本文将介绍一些避免循环查SQL的方法,以提高程序的性能和效率。
1. 批量查询最常见的避免循环查SQL的方法是批量查询。
批量查询是指一次查询多条数据,可以大大减少查询次数,提高程序的运行效率。
在Java中,可以通过使用JDBC的批量处理机制来实现批量查询。
具体步骤如下:步骤一:创建一个PreparedStatement对象,使用带有占位符的SQL语句,并将占位符的值设置为需要查询的数据。
javaString sql = "SELECT * FROM table WHERE id = ?"; PreparedStatement statement = connection.prepareStatement(sql);步骤二:循环遍历需要查询的数据,并将数据设置到PreparedStatement对象中。
javafor (int i = 0; i < ids.size(); i++) {statement.setInt(i + 1, ids.get(i));}步骤三:执行批量查询,并获取结果集。
javaResultSet resultSet = statement.executeQuery();2. 分页查询另一种避免循环查SQL的方法是分页查询。
分页查询是指将查询结果划分为多个页面来逐页显示,每次查询只返回部分数据,从而避免一次性查询所有数据。
在Java中,可以通过使用LIMIT和OFFSET子句来实现分页查询。
具体步骤如下:步骤一:在SQL语句中添加LIMIT和OFFSET子句,指定每页返回的数据量和偏移量。
javaString sql = "SELECT * FROM table LIMIT ? OFFSET ?"; PreparedStatement statement = connection.prepareStatement(sql);步骤二:循环遍历需要查询的页数,并将每次查询的LIMIT和OFFSET值设置到PreparedStatement对象中。
fofa批量获取通用规则

fofa批量获取通用规则一、什么是fofa?1.1 fofa的定义1.2 fofa的特点1.3 fofa的应用场景二、什么是通用规则?2.1 通用规则的概念2.2 通用规则的作用2.3 通用规则的分类三、fofa批量获取通用规则的方法3.1 fofa的高级搜索功能3.2 fofa的过滤器3.3 fofa的混合查询3.4 fofa的下载结果功能四、如何构建有效的通用规则?4.1 确定目标4.2 收集信息4.3 确定过滤条件4.4 优化规则效果五、案例分析:使用fofa批量获取通用规则的实际应用5.1 案例1:寻找暴露的数据库5.2 案例2:寻找未经授权的访问控制5.3 案例3:寻找存在安全漏洞的设备六、安全注意事项6.1 遵守法律法规6.2 避免滥用信息6.3 保护个人隐私七、总结传统的信息搜集方法往往需要耗费大量的时间和人力,而使用fofa批量获取通用规则可以极大地提高效率。
本文首先介绍了fofa的定义、特点和应用场景,然后详细解释了通用规则的概念、作用和分类。
接着,我们探讨了fofa批量获取通用规则的方法,包括高级搜索、过滤器、混合查询和下载结果功能。
为了构建有效的通用规则,我们提供了确定目标、收集信息、确定过滤条件和优化规则效果的步骤。
最后,通过案例分析展示了fofa批量获取通用规则在实际应用中的价值,并强调了安全注意事项。
在使用fofa批量获取通用规则的过程中,务必遵守法律法规、避免滥用信息和保护个人隐私。
通过合理利用fofa批量获取通用规则,我们可以更高效地进行信息搜集和安全评估工作。
采购与供应链管理成绩查询

采购与供应链管理成绩查询1. 引言采购与供应链管理是企业中十分重要的一个环节,它涉及到产品供应、成本控制、供应商管理等诸多方面。
为了评估和监控采购与供应链管理的效果,成绩查询是一项必要的工作。
本文将介绍采购与供应链管理成绩查询的流程和方法。
2. 查询流程采购与供应链管理成绩查询的流程一般包括以下几个步骤:2.1 登录系统首先,使用查询人员的账号和密码登录系统。
系统可以是企业内部自行开发的信息管理系统,也可以是第三方供应商提供的采购与供应链管理平台。
2.2 选择查询类型登录系统后,查询人员需要选择查询的类型。
采购与供应链管理成绩查询可以按照时间段、项目、供应商等多种方式进行。
查询人员根据自己的需要,选择相应的查询类型。
2.3 输入查询条件在选择查询类型后,查询人员需要输入相应的查询条件。
例如,如果选择按时间段查询,则需要输入起始时间和结束时间;如果选择按项目查询,则需要输入项目名称等信息。
2.4 提交查询请求在输入完查询条件后,查询人员需要点击提交按钮,将查询请求发送给系统后台进行处理。
2.5 等待查询结果查询人员需要等待系统后台处理查询请求,并返回查询结果。
查询结果一般以表格的形式展示,包括采购与供应链管理的各项指标和评分。
2.6 查看与导出成绩查询人员可以通过系统界面查看查询结果,并根据需要导出成绩报表。
成绩报表可以保存为Excel或其他格式,以便后续分析和使用。
3. 查询方法采购与供应链管理成绩查询的方法主要包括以下几种:3.1 手动查询手动查询是最基本的查询方法,需要查询人员手动输入查询条件并提交查询请求。
这种方法适用于查询范围较小的情况,例如单个项目或特定供应商的成绩。
3.2 批量查询批量查询是指通过批量处理的方式,同时查询多个项目或供应商的成绩。
这种方法可以提高查询效率,但需要提前准备好查询条件的批量输入文件。
3.3 自动定时查询自动定时查询是指通过设置查询条件和查询时间规则,实现定时自动查询成绩的方法。
Mybatis如何根据List批量查询List结果

Mybatis如何根据List批量查询List结果⽬录根据List批量查询List结果mapper接⼝mapper.xml⽂件根据多条件List查询mapper⽂件DAO⽚段根据List批量查询List结果mapper接⼝/*** 根据剧典id list查询剧典*/public List<Drama> selectByIds(@Param("dramaIds")List<Long> dramaIds);mapper.xml⽂件<!-- 根据剧典id list查询剧典 --><select id="selectByIds" resultMap="DramaImageResultMap">select * from drama where drama_id in<foreach collection="dramaIds" item="dramaId" open="(" close=")" separator=",">#{dramaId}</foreach></select>数组参数//接⼝⽅法ArrayList<User> selectByIds(Integer [] ids);//xml映射⽂件<select id="selectByIds" resultMap="BaseResultMap">select*from user where id in<foreach item="item" index="index" collection="array" open="(" separator="," close=")">#{item}</foreach></select>List参数//接⼝⽅法ArrayList<User> selectByIds(List<Integer> ids);//xml映射⽂件<select id="selectByIds" resultMap="BaseResultMap">Select<include refid="Base_Column_List" />from jria where ID in<foreach item="item" index="index" collection="list" open="(" separator="," close=")">#{item}</foreach></select>根据多条件List查询mapper⽂件<select id="selectWhere" resultMap="BaseResultMap">select<include refid="Base_Column_List" />from table<where>table.a = a and table.b in<foreach collection="list" item="item" index="index" open="(" separator="," close=")">'${item}'</foreach></where></select>DAO⽚段List<T> selectWhere(@Param("list")List<String> list ,@Param("a") String a);以上为个⼈经验,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
数据库批量查询语句

数据库批量查询语句数据库批量查询语句是指一次性查询多条数据的方法。
在实际的数据库操作中,批量查询可以提高查询效率,减少与数据库的交互次数,从而提升系统的性能。
下面列举了10个常用的数据库批量查询语句。
1. 批量查询某个表中的所有数据:```SELECT * FROM 表名;```这条语句会返回指定表中的所有数据,可以将结果集保存到一个数组或集合中进行后续处理。
2. 批量查询某个表中满足条件的数据:```SELECT * FROM 表名 WHERE 条件;```通过在WHERE子句中添加条件,可以筛选出满足条件的数据。
3. 批量查询某个表中的部分字段:```SELECT 字段1, 字段2 FROM 表名;```在SELECT子句中指定需要查询的字段,可以只查询表中的部分字段。
4. 批量查询某个表中的排序结果:```SELECT * FROM 表名 ORDER BY 排序字段;```通过在ORDER BY子句中指定排序字段,可以按照指定的字段对查询结果进行排序。
5. 批量查询某个表中的分页数据:```SELECT * FROM 表名 LIMIT 起始位置, 查询数量;```通过使用LIMIT关键字,可以指定查询结果的起始位置和数量,实现分页功能。
6. 批量查询多个表的关联数据:```SELECT * FROM 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段; ```通过使用JOIN语句,可以查询多个表中关联的数据,可以根据需要使用不同的JOIN类型。
7. 批量查询某个表中的去重数据:```SELECT DISTINCT 字段 FROM 表名;```通过使用DISTINCT关键字,可以去除查询结果中重复的数据,只返回不重复的数据。
8. 批量查询某个表中的聚合结果:```SELECT 聚合函数(字段) FROM 表名;```通过使用聚合函数(如SUM、AVG、COUNT等),可以对表中的数据进行统计和计算。
oracle批量查询

2009-11-02 | oracle批量绑定table类型变-- forall bulk collect用法以及测试案例采用bulk collect可以将查询结果一次性地加载到collections中。
而不是通过cursor一条一条地处理。
可以在select into,fetch into,returning into语句使用bulk collect。
注意在使用bulk collect时,所有的into变量都必须是collections.--在select into语句中使用bulk collectDECLARETYPE SalList IS TABLE OF emp.sal%TYPE;sals SalList;BEGIN-- Limit the number of rows to 100.SELECT sal BULK COLLECT INTO sals FROM empWHERE ROWNUM <= 100;-- Retrieve 10% (approximately) of the rows in the table.SELECT sal BULK COLLECT INTO sals FROM emp SAMPLE 10;--在fetch into中使用bulk collectDECLARETYPE DeptRecTab IS TABLE OF dept%ROWTYPE;dept_recs DeptRecTab;CURSOR c1 ISSELECT deptno, dname, loc FROM dept WHERE deptno > 10;BEGINOPEN c1;FETCH c1 BULK COLLECT INTO dept_recs;END;/--在returning into中使用bulk collectCREATE TABLE emp2 AS SELECT * FROM employees;DECLARETYPE NumList IS TABLE OF employees.employee_id%TYPE;enums NumList;TYPE NameList IS TABLE OF st_name%TYPE;names NameList;BEGINDELETE FROM emp2 WHERE department_id = 30RETURNING employee_id, last_name BULK COLLECT INTO enums, names;dbms_output.put_line('Deleted ' || SQL%ROWCOUNT || ' rows:');FOR i IN enums.FIRST .. STLOOPdbms_output.put_line('Employee #' || enums(i) || ': ' || names(i));END LOOP;END;/DROP TABLE emp2;oracle批量绑定forall bulk collect批量绑定(Bulk binds)可以通过减少在PL/SQL和SQL引擎之间的上下文切换(context switches )提高了性能.量绑定(Bulk binds)包括:(i) Input collections, use the FORALL statement,用来改善DML(INSERT、UPDATE 和DELETE) 操作的性能(ii) Output collections, use BULK COLLECT clause,一般用来提高查询(SELECT)的性能10g开始forall语句可以使用三种方式:i in low..upi in indices of collection 取得集合元素下标的值i in values of collection 取得集合元素的值forall语句还可以使用部分集合元素sql%bulk_rowcount(i)表示forall语句第i元素所作用的行数CREATE TABLE parts1 (pnum INTEGER, pname VARCHAR2(15));CREATE TABLE parts2 (pnum INTEGER, pname VARCHAR2(15));CREATE TABLE parts3 (pnum INTEGER, pname VARCHAR2(15));CREATE TABLE parts4 (pnum INTEGER, pname VARCHAR2(15));set serveroutput on --把屏幕显示开关置上DECLARETYPE NumTab IS TABLE OF parts1.pnum%TYPE INDEX BY PLS_INTEGER;TYPE NameTab IS TABLE OF parts1.pname%TYPE INDEX BY PLS_INTEGER;pnums NumTab;pnames NameTab;iterations CONSTANT PLS_INTEGER := 50000;t1 INTEGER; t2 INTEGER; t3 INTEGER; t4 INTEGER; t5 INTEGER; stmt_str varchar2(255);table_name varchar2(255);BEGINFOR j IN 1..iterations LOOP -- load index-by tablespnums(j) := j;pnames(j) := 'Part No. ' || TO_CHAR(j);END LOOP;FOR i IN 1..iterations LOOP -- use FOR loopINSERT INTO parts1 VALUES (pnums(i), pnames(i));END LOOP;FORALL i IN 1..iterations -- use FORALL statementINSERT INTO parts2 VALUES (pnums(i), pnames(i));t3 := dbms_utility.get_time;table_name:='parts3';stmt_str := 'INSERT INTO ' || table_name || ' values (:num, :pname)'; FOR i IN 1..iterations LOOP -- use FORALL statementEXECUTE IMMEDIATE stmt_str USING pnums(i), pnames(i);END LOOP;t4 := dbms_utility.get_time;table_name:='parts4';stmt_str := 'INSERT INTO ' || table_name || ' values (:num, :pname)'; FORALL i IN 1..iterations-- use FORALL statementEXECUTE IMMEDIATE stmt_str USING pnums(i), pnames(i);t5 := dbms_utility.get_time;dbms_output.put_line('Execution Time (secs)');dbms_output.put_line('---------------------');dbms_output.put_line('FOR loop: ' || TO_CHAR((t2 - t1)/100));dbms_output.put_line('FORALL: ' || TO_CHAR((t3 - t2)/100));dbms_output.put_line('FOR loop: ' || TO_CHAR((t4 - t3)/100));dbms_output.put_line('FORALL: ' || TO_CHAR((t5 - t4)/100));END;/DROP TABLE parts1;DROP TABLE parts2;bulk collect 语句:用于取得批量数据,只适用于select into ,fetch into 及DML语句的返回子句TYPE type_emp IS TABLE OF scott.emp%ROWTYPE INDEX BY BINARY_INTEGER;tab_emp type_emp;TYPE type_ename IS TABLE OF scott.emp.ename%TYPE INDEX BY BINARY_INTEGER;tab_ename type_ename;CURSOR c ISSELECT *SELECT * BULK COLLECTINTO tab_empFROM scott.emp;dbms_output.put_line(tab_emp(i).ename);DELETE scott.emp RETURNING ename BULK COLLECT INTO tab_ename; FOR i IN 1 .. tab_emp.COUNT LOOPdbms_output.put_line(tab_emp(i).ename);END LOOP;FETCH c BULK COLLECTINTO tab_emp;dbms_output.new_line;FOR i IN 1 .. tab_emp.COUNT LOOPdbms_output.put_line(tab_emp(i).sal);*/使用Bulk Collect提高Oracle查询效率Oracle8i中首次引入了Bulk Collect特性,该特性可以让我们在PL/SQL中能使用批查询,批查询在某些情况下能显著提高查询效率。
1功能操作手册__通用操作
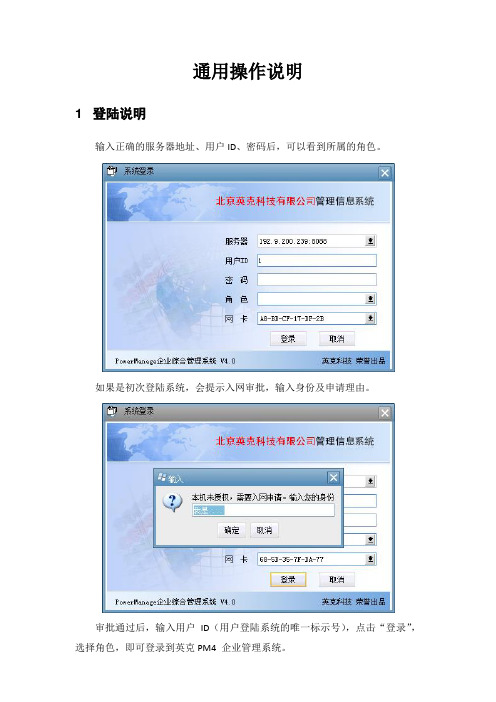
通用操作说明1 登陆说明输入正确的服务器地址、用户ID、密码后,可以看到所属的角色。
如果是初次登陆系统,会提示入网审批,输入身份及申请理由。
审批通过后,输入用户ID(用户登陆系统的唯一标示号),点击“登录”,选择角色,即可登录到英克PM4 企业管理系统。
2 主界面布局说明 2.1 主界面布局界面左边是“系统模块菜单”面板,界面中边是“系统功能菜单”面板,界面右边是“推送平台”面板。
2.2 使用说明操作时,先选择左侧“系统模块菜单”,然后单机右侧“系统功能菜单”相系统模块菜单系统功能菜单推送平台区域消息平台区域报表中心菜单关功能,即可进入对应功能界面内。
特别地,可通过界面右上角“”菜单进行“切换用户”、“切换角色”、“设置密码”、“系统信息”和“退出系统”操作,如下图:2.2.1设置密码点击“设置密码”,输入原密码、新密码,则可重新设置登录密码。
2.2.2切换登录点击“切换登录”,即重新进入登录界面,输入用户ID号、密码,可以重新登录系统。
2.2.3切换角色点击“切换角色”,即重新进入角色选择界面,可使用目前登入用户的其他角色登入系统2.2.4系统信息点击“系统信息”,可以查看当前登录服务器的信息。
2.2.5退出系统点击“退出”,则可退出系统,当然,直接点击界面右上角的“”按钮也可退出系统。
3 功能界面风格说明在功能界面中,根据被编辑信息所包含的属性的不同,主要分为以下三种界面类型。
3.1 单表界面单表界面主要指界面包含“单一信息项”,即该信息没有从属信息项;或者用更通俗一点的语言来描述就是:该界面只包含“一级信息项”。
如:独立单元管理3.2 总单细单界面总单细单界面主要指界面包含“一主信息项,一从信息项”,或者称之为界面包含“二级信息项”。
如:生产厂商管理总单信息3.3 总单细单明细界面总单细单明细界面主要指界面包含“一主信息项,一从信息项和明细信息项”,或者称之为界面包含“三级信息项”。
如:波次管理细单信息总单信息3.4 多标签页界面多标签页界面主要指界面包含“一主信息项,多个标签页信息项”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
批量查询后保存查询结果
相信很多人都是有着批量查询成绩或者是某些数据后还要一个个保存的烦恼。
那本次的教程就教大家怎么使用《网页自动操作通用工具》来批量查询后保存查询结果。
这里以查询成绩为例子,保存查询的总分!
首先做以下声明:1、本教程只是做学习使用,不得用于非法目的,否则一切后果由使用者承担。
教程开始
首先需要准备两个txt文档,分别是学号.txt 和密码.txt
这里说明下,txt文档里面的都是一行一个学号或账号。
软件一次提取txt文档里面的一行
先来看下软件的界面。
老样子,我们需要添加网址,如下图所示。
添加好网址不要忘记自动获取网页编码!
然后就是提交内容了,点击“添加”按钮来添加学号输入元素的获取
点击自动获取:
等待网页加载完以后,鼠标指向学号的输入框,然后右键,自动获取就可以了。
获取以后,我们是要批量查询,当然就需要多个账号来输入了,这里我们是从一个叫“学号”的txt文本中获取学号来输入的。
到上一步学号的输入基本就是完成了。
密码的设置和学号的一样。
不一样的就是要准备另一个叫“密码”的txt文本来输入密码
然后是提交,这里在“提交方法” 中自动获取。
然后出现下图,用样的设置,选中登录按钮之后右键自动获取元素。
这里的登录设置基本就完成了,接下来是提交时间,这个看自己的设置来决定啦
这里有必要说下在“其他监控”这里,需要勾上“无条件启动监控报警”。
接下来是到了监控设置界面了如下图,还是需要点击添加。
点击“自动获取”之后,就会打开网页,这里就只需要一次手动登录进去来获取元素就好了。
登录之后,然后就到了下图所示,选中总成绩,右键自动获取元素。
如下图设置,
然后就到了保存元素,在“报警提醒”这里,有个保存元素值到文件的勾选,然后浏览到需要保存的地方去就好了
这样保存元素就完成了,这里保存了几个测试结果。
如下图:这里特别说明一下,我们所保存的元素在这里是包括了账号和密码的!就是在前面的操作中所有输入中的网页元素都保存了下来的(比如登录所用的账号、学号。
密码这些)。
本教程就到此结束了。
欢迎大家搜索:木头软件站。