《统计学原理(第五版)》习题计算题答案详解
统计学教材课后习题详细答案

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)整理by__kiss-ahuang第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第五版课后习题答案(完整版)

统计学(第五版)课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学(第五版)课后答案
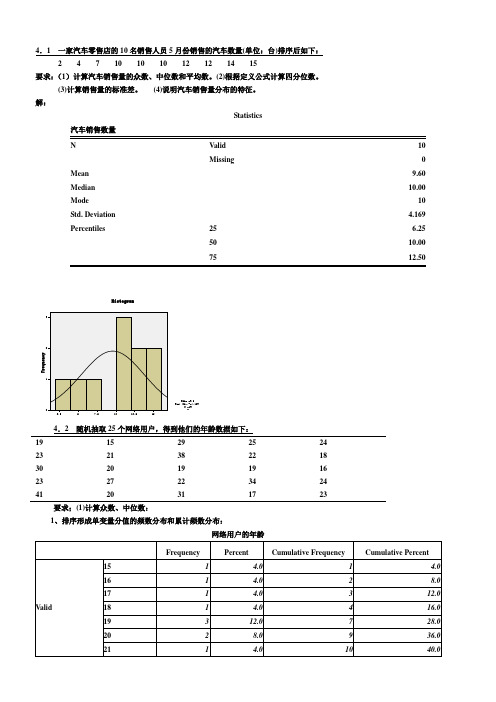
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0 Mean 9.60 Median 10.00 Mode 10 Std. Deviation 4.169 Percentiles 25 6.2550 10.0075 12.504.2 随机抽取25个网络用户,得到他们的年龄数据如下:19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差; Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K=+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄(Binned)分组后的均值与方差:分组后的直方图:4.6 在某地区抽取120家企业,按利润额进行分组,结果如下:要求:(1)计算120家企业利润额的平均数和标准差。
统计学第五版课后练答案

统计学第五版课后练答案(7-8章)(总11页)-本页仅作为预览文档封面,使用时请删除本页-第七章 参数估计(1)x σ==(2)2x z α∆= 1.96=某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x σ==(2)在95%的置信水平下,求估计误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α 因此,x x t σ∆=⋅2x z ασ=⋅0.025x z σ=⋅=×=(3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:22x z x z αα⎛-+ ⎝=()120 4.2,120 4.2-+=(,)22x z x z αα⎛-+ ⎝=104560±=(,) 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,x N n σμ⎛⎫ ⎪⎝⎭或2,s x N n μ⎛⎫⎪⎝⎭置信区间为:22x z x z αα⎛-+ ⎝= (1)构建μ的90%的置信区间。
2z α=0.05z =,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(,)(2)构建μ的95%的置信区间。
2z α=0.025z =,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(,) (3)构建μ的99%的置信区间。
2z α=0.005z =,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(,)(1)2x z α±=25 1.96±=(,) (2)2x z α±=119.6 2.326±=(,)(3)2x z α±=3.419 1.645±=(,)(1)2x z α±=8900 1.96±=(,)(2)2x z α±=8900 1.96±=(,)(3)2x z α±=8900 1.645±=(,) (4)2x z α±=8900 2.58±=(,)某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36解:(1)样本均值x =,样本标准差s=1α-=,t=2z α=0.05z =,2x z α±=3.32 1.645±=(,)1α-=,t=2z α=0.025z =,2x zα±3.32 1.96±=(,)1α-=,t=2z α=0.005z =,2x z α±3.32 2.76±(,)x t α±=10 2.365±某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是: 10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。
统计学(第五版)贾俊平_课后思考题和练习题答案(最终完整版)

第一部分 思考题
第一章思考题 1.1 什么是统计学 统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得 出结论。 1.2 解释描述统计和推断统计 描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。 推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。 1.3 统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果, 数据表现为类别,用文字来表述; (定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这 些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件 下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 1.4 解释分类数据,顺序数据和数值型数据 答案同 1.3 1.5 举例说明总体,样本,参数,统计量,变量这几个概念 对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百 个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的 数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是 统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 1.6 变量的分类 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。 1.7 举例说明离散型变量和连续性变量 离散型变量,只能取有限个值,取值以整数位断开,比如“企业数” 连续型变量,取之连续不断,不能一一列举,比如“温度” 。 1.8 统计应用实例 人口普查,商场的名意调查等。 1.9 统计应用的领域 经济分析和政府分析还有物理,生物等等各个领域。
统计学原理(第五版)第四章计算题答案

第四章 动态数列 1. 见教材P435 2. 见教材P435-436(1)首先第一步库存量是时点指标,题目给出的数据都是月初的数据,比如1月1日、2月1日…….;2月1号(2月初)的库存量其实就是1月31日(1月末)的库存量,所以1月份的平均库存量为(8.14+7.83)/2;那么2月份的平均库存量为(7.83+7.25)/2;3月份的平均库存量为(7.25+8.28)/2。
所以(首末折半法公式)吨第一季度平均库存量)(76.73228.825.783.7214.8 3228.825.7225.783.7283.714.8=+++=+++++=当然如果理解透了就直接按照我上课讲的思路,第一季度以月为间隔,间隔相等,用“首末折半法”。
“首末折半法”的公式是由普通算法推导出来的。
时点指标有月初、月末之分。
我们这题是月初库存问题,书上P140表4-5例题还有一例题(是月末库存问题),看一下,好好理解一下。
(2)时点数列,第二季度以月为间隔,间隔不相等,用“分层平均法”。
6月1日的库存量是等于5月31日的库存量,7月1日就是6月30日的库存量。
所以按照“分层平均法”公式计算。
第二季度平均库存量:()吨45.9121276.912.102212.1028.82=+⨯++⨯+=a(3)10月1日是9月30日的库存量,第三季度包括7、8、9三个月,所以也很容易理解以下的公式(“分层平均法”):第三季度平均库存量:(4)同样的次年1月1日的库存量为12月31日的库存量,也很容易理解以下公式(“分层平均法”):第四季度平均库存量:(5)全年平均库存当然等于每个季度的简单平均数,公式如下:全年平均库存量:3. 见教材P4364. 见教材P4375. (1) 见教材P438(2) ① 增减速度=发展速度-1(或100%)② 0n 1i i a an 1i a a =∏=- (环比发展速度的连乘积等于定基发展速度) ③ 100%1基期发展水平的绝对值增长=④ 增减速度增减量的绝对值增长=%1⑤ 0n 1i i a a n1i )a (a -=∑=-- (逐期增减量之和等于累计增减量)⑥ n x x ∏= (平均发展速度等于环比发展速度的连乘积开n 次方) ⑦ 平均增减速度=平均发展速度-1(或100%) 6. 见教材P438 7. 见教材P438-439()39.769.82329.793a +´==吨()吨84.932256.904.101204.1082.94=⨯++⨯+=a ()12347.769.459.799.849.2144a a a a a ++++++===吨9.17t2214.03y 9.17b 2214.038990b 824053066421 tb t ty tb N yc 2+=∴⎩⎨⎧==∴⎩⎨⎧==⇒⎪⎩⎪⎨⎧+=+=∑∑∑a a a a 代入方程组:因为本资料二级增长量大体相等,所以投资额发展的趋势接近于抛物线型。
统计学)第五版课后习题答案(部分)_人大出版社

解:H0:μ1=μ2=μ3H1:μ1,μ2,μ3不全相等从方差分析表可以看到,由于F=11.75573>F0.052,15=3.68232,所以拒绝原假设H0,表明μ1,μ2,μ3之间的差异是显著的,即管理者的层次不同会导致评分的显著差异。
解:首先对两个因素分别提出如下假设:行因素(品牌)H0:μ1=μ2=μ3=μ4=μ5H1:μ1,μ2,μ3,μ4,μ5不全相等列因素(施肥方案)H0:μ1=μ2=μ3=μ4H1:μ1,μ2,μ3,μ4不全相等从方差分析表可以看到,由于F R=7.239716>F0.05=3.259167,所以拒绝原假设H0,表明μ1,μ2,μ3,μ4,μ5之间的差异是显著的,即种子的不同品种对收获量的影响显著。
由于F C=6.0605>F0.05=3.259167,所以拒绝原假设H0,表明μ1,μ2,μ3,μ4之间的差异是显著的,即不同的施肥方案对收获量的影响显著。
10.12解:首先对两个因素分别提出如下假设:行因素(广告方案)H0:μ1=μ2=μ3H1:μ1,μ2,μ3不全相等列因素(广告媒体)H0:μ1=μ2H1:μ1,μ2不全相等其次,对两个因素的交互作用提出如下假设:H0:广告方案和广告媒体的交互作用对销售量的影响不显著H1:广告方案和广告媒体的交互作用对销售量的影响显著从方差分析表可以看到,由于F R=10.75>F0.05=5.14325,所以拒绝原假设H0,表明μ1,μ2,μ3之间的差异是显著的,即广告方案对销售量的影响显著。
由于F C=3>F0.05=5.98738,所以不拒绝原假设H0,表明μ1,μ2之间的差异是不显著的,即广告媒体对销售量的影响不显著。
从方差分析表可以看到,由于P−value=0.25193>ð=0.05所以不拒绝原假设H0,即广告方案和广告媒体的交互作用对销售量的影响不显著。
大学统计学第五版习题答案

大学统计学第五版习题答案大学统计学第五版习题答案统计学作为一门重要的学科,对于各个领域的研究和实践都具有重要的意义。
在大学学习统计学时,习题是巩固知识、提高能力的重要途径。
大学统计学第五版是一本经典的教材,其中的习题涵盖了各个知识点,对于学生来说是一次很好的训练机会。
下面将给出一些大学统计学第五版习题的答案,希望对学生们的学习有所帮助。
第一章:统计学导论1. 样本容量的确定答案:样本容量的确定需要考虑到以下几个因素:总体大小、总体方差、置信水平和允许的误差范围。
一般来说,总体大小越大,样本容量越小;总体方差越大,样本容量越大;置信水平越高,样本容量越大;允许的误差范围越小,样本容量越大。
第二章:统计学数据的描述1. 描述性统计的应用答案:描述性统计是对数据进行整理、总结和分析的方法。
它可以帮助我们了解数据的特征、趋势和分布情况。
在实际应用中,描述性统计可以用于制定市场调研报告、分析销售数据、评估产品质量等方面。
第三章:概率1. 概率的计算答案:概率的计算可以通过频率法和几何法来进行。
频率法是通过实验或观察来估计事件发生的可能性,即事件发生的次数除以总次数。
几何法是通过对样本空间和事件发生的区域进行几何分析来计算概率。
第四章:离散型随机变量和概率分布1. 二项分布的应用答案:二项分布是离散型随机变量的一种常见分布。
它适用于只有两个可能结果的实验,如抛硬币、生男生女等。
在实际应用中,二项分布可以用于预测产品合格率、判断市场需求等方面。
第五章:连续型随机变量和概率分布1. 正态分布的性质答案:正态分布是连续型随机变量的一种常见分布。
它具有对称性、钟形曲线和均值和标准差唯一确定等性质。
正态分布在实际应用中非常广泛,例如用于身高体重的统计、质量控制等方面。
第六章:抽样分布和点估计1. 置信区间的计算答案:置信区间是用于估计总体参数的范围。
计算置信区间时需要考虑样本容量、样本均值、样本标准差和置信水平等因素。
《统计学原理(第五版)》习题计算题答案详解

《统计学原理(第五版)》习题计算题答案详解第二章统计调查与整理1. 见教材P402 2. 见教材P402-403 3. 见教材P403-404第三章综合指标1. 见教材P4322. %86.1227025232018=+++=产量计划完成相对数3.所以劳动生产率计划超额1.85%完成。
4. %22.102%90%92(%)(%)(%)===计划完成数实际完成数计划完成程度指标 一季度产品单位成本,未完成计划,还差2.22%完成计划。
5.6. 见教材P432 7. 见教材P433理工作做得好。
但由于甲村的平原地所占比重大,山地所占比重小,乙村则相反,由于权数的作用,使得甲村的总平均单产高于乙村。
9.11.%74.94963.09222.09574.03=⨯⨯=G X 或参照课本P9912.%49.51X %49.105 08.107.105.104.102.1 X 1624632121=-=⨯⨯⨯⨯=∑⋅⋅⋅⋅⋅⋅=G ff n f f G nX X X 平均年利率:平均本利率为:(2)R=500-150=350(千克/亩) (3)“(4)根据以上计算,294.5千克/亩>283.3千克/亩>277.96千克/亩,即M 0>Me>X ,故资料分布为左偏(即下偏)。
(2) 15. 见教材P435 16. 见教材P40417.%86.1227025232018=+++=产量计划完成相对数18.%85.101%108%110%%(%)===计划为上年的实际为上年的计划完成程度指标 劳动生产率计划超额1.85%完成19. %22.102%90%92(%)(%)(%)===计划完成数实际完成数计划完成程度指标一季度产品单位成本未完成计划,实际单位成本比计划规定数高2.22%20. %105%103% %%(%) 计划为上年的计划为上年的实际为上年的计划完成程度指标=∴=1.94% %94.101103%105%% 即计划规定比上年增长计划为上年的解得:==21. 见教材P405 22. 见教材P405理工作做得好。
统计学(贾俊平)第五版课后习题答案(完整版)

统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学原理第5版第一章习题答案

统计学原理第5版第一章习题答案第一章绪论(第五版)(P1518)一.单项选择题1.统计有三种含义,其基础是 ( B )A.统计学B.统计活动(工作)C.统计方法D.统计资料解: P5,L1~102.一个统计总体 ( D )A.只能有一个标志B.只能有一个指标C.可以有多个标志D.可以有多个指标解:P12,L22标志是说明总体单位特征的;指标是说明总体特征的总体单位可以有多个标志,总体也可以有多个指标3.下列变量中,属于离散变量的是 ( D )A.一包谷物的重量B.一个轴承的直径C.在过去一个月中平均每个销售代表接触的期望客户数D.一个地区接受失业补助的人数解:P13,L21~23长度(几何度量)、重量、时间是连续变量数学期望可能不是整数比如掷骰子的所得的点数为X ,则E (X )=3.5这里平均每个销售代表接触的期望客户数是每个销售代表接触的客户数的数学期望的平均值(平均了2次)4.某班学生数学考试成绩分别为65分、71分、80分和87分,这四个数字是 ( D )A. 指标B. 标志C. 变量 D .标志值解:P12,L4~5, P13,L16~17标志的分类:品质标志:说明总体单位质的特征。
例如:性别、民族、技术等级、职称标志数量标志:说明总体单位量的特征。
例如:年龄、工资、身高、体重=可变标志:总体中所有的总体单位的标志值不全相同。
标志不变标志:总体中所有的总体单位的标志值相同。
例如:学校所有学生构成的总体,标志身高,则该标志是可变的例如:学校所有学生构成的总体,标志成份,则该标志是不变的标志值:标志的不同具体表现称为标志值(和本书的描述有所不同)可变的数量标志称为变量,变量值就是可变的数量标志的值若此题问的是成绩是什么,则可以选B 也可以选C5.下列属于品质标志的是 ( B )A.工人年龄B.工人性别C.工人体重D.工人工资6.现要了解某机床厂的生产经营情况,该厂的产量和利润是( D )A.连续变量B.离散变量C.前者是连续变量,后者是离散变量D.前者是离散变量,后者是连续变量解:产量是生产的机床数量,单位是台,是离散变量;利润是金额,是连续变量(见题3)7.劳动生产率是( B )A.动态指标B.质量指标C.流量指标D.强度指标解:(这里的详细内容在第三章中阐述)P14,L13~L20按指标反映的总体内容可分为::数量指标说明总体规模和水平的各种总量指标,故又称为总量指标指标:质量指标说明总体社会经济效益和工作质量的各种相对指标和平均指标按指标的作用和表现形式可分为:总量指标指标相对指标平均指标总量指标是反映社会经济现象在一定的时间、地点、条件下的总规模或总水平的统计指标.总量指标即为数量指标,又称绝对指标或绝对数(P69,L12~14)相对指标是两个有联系的指标数值之比,又称为相对数(P73,L7)五大相对数(P74~83):(1)计划完成相对数、(2)结构相对数(比例相对数与之合并)(3)比较相对数(4)强度相对数(5)动态相对数平均指标是说明同质总体内某一数量标志在一定条件下一般水平的综合指标.又称为平均数(P86,L3~5)五大平均数(P87~106):(1)算数平均数(2)调和平均数(3)几何平均数(4)众数(5)中位数(P15)流量:流量是指一定时期内发生的某种经济变量变动的数值,它是在一定时期内测度的,其大小有时间维度。
统计学(贾俊平)第五版课后习题答案(完整版)

统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
《统计学原理》教材课后习题参考答案

2.给定显著性水平。取显著性水平 ,由于是双侧检验,因此需要确定上下两个临界值 和 。查表得到 ,所以。拒绝区间为小于-1.96或者大于1.96。
3.检验统计量
4.检验判断。
由于z的实际值在-1.96和1.96之间,没有落入拒绝区间,所以接受原假设,认为净重是符合规定
(五)计算题
1.因为2000年计划完成相对数是110%,所以
实际产值=
2000年计划产值比1999年增长8%,
所以1999年的计划产值=
那么2000年实际产值比1999年计划产值增长=
2.(1)
从第四年第四季度到第五年第三季度这一年的时间,实际上这一年的产量达到
则
这一题规定年末产量应达到170,所以提前时间按照水平法来算。
3..根据题意,样本的平均数和标准差为
根据样本信息,计算统计量
4.检验判断。因为 ,所以在显著性水平0.01下,拒绝原假设,也就是说,含量是超过规定界限
第九章相关与回归
(一)判断题
1.×2.√3.√4.√5.×6.×7.×8.×
(二)单项选择题
1.① 2.① 3.③ 4.④ 5.④6.②7.②8.④
2.由题意
=8.89
3.由题意
令这个数为a。则
4.由题意
5.
销售额
售货员人数
组中值
20000-30000
30000-40000
40000-50000
50000-60000
60000-70000
70000-80000
80000以上
8
20
40
100
82
10
5
25000
35000
统计学(贾俊平)第五版课后习题答案(完整版)

亲爱的,一章一章来,肯定能弄完的,你是最棒的!统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
解释分类数据,顺序数据和数值型数据答案同举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学(第五版)课后答案
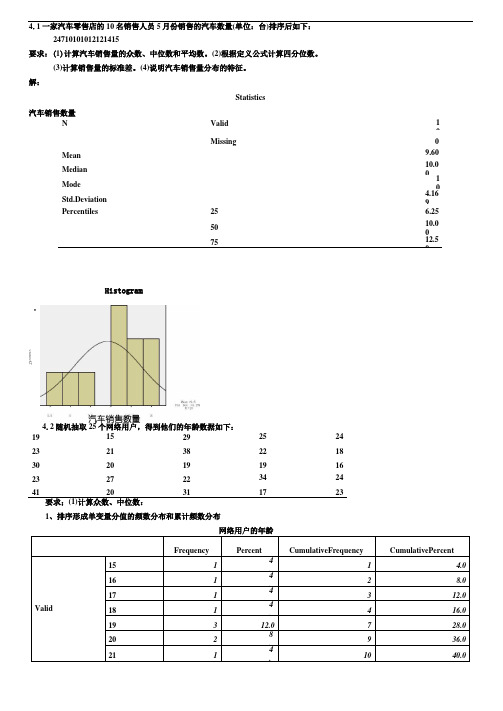
4.1一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:24710101012121415要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量NValid 10Missing0 Mean9.60 Median10.00 Mode10 Std.Deviation4.169 Percentiles25 6.25 5010.007512.5019 15 29 25 24 23 21 38 22 18 30 20 19 19 16 23 2722 34 24 4120311723要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布Histogram34.2随机抽取25个网络用户,得到他们的年龄数据如下:vcneuoeKT22 2 8.12 48.0 23 3 12.0 15 60.0 24 2 8.17 68.0 25 1 4.18 72.0 27 1 4.19 76.0 29 1 4.20 80.0 30 1 4.21 84.0 31 1 4.22 88.0 34 1 4.23 92.0 38 1 4.24 96.0 411 4.25100.0Total25100.0从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2) 根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3X 25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75X 2=26.5。
(3) 计算平均数和标准差;Mean=24.00;Std.Deviation=6・652 (4) 计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5) 对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
《统计学原理》习题及答案

《统计学原理》习题及答案(第四章)一、判断题1、总体单位总量和总体标志总量是固定不变的,不能互相变换。
(×)2、相对指标都是用无名数形式表现出来的。
(×)3、按人口平均的粮食产量是一个平均数。
(×)4、在特定条件下,加权算术平均数等于简单算术平均数。
(√)5、用总体部分数值与总体全部数值对比求得的相对指标。
说明总体内部的组成状况,这个相对指标是比例相对指标。
(×)6、国民收入中积累额与消费额之比为1:3,这是一个比较相对指标。
(×)7、标志变异指标数值越大,说明总体中各单位标志值的变异程度就越大,则平均指标的代表性就越小。
(√)二、单项选择1、总量指标数值大小( A )A、随总体范围扩大而增大B、随总体范围扩大而减小C、随总体范围缩小而增大D、与总体范围大小无关2、直接反映总体规模大小的指标是( C )A、平均指标B、相对指标C、总量指标D、变异指标3、总量指标按其反映的时间状况不同可以分为( D )A、数量指标和质量指标B、实物指标和价值指标C、总体单位总量和总体标志总量D、时期指标和时点指标4、由反映总体各单位数量特征的标志值汇总得出的指标是( B )A、总体单位总量B、总体标志总量C、质量指标D、相对指标5、计算结构相对指标时,总体各部分数值与总体数值对比求得的比重之和( C )A、小于100%B、大于100%C、等于100%D、小于或大于100%6、相对指标数值的表现形式有 ( D )A、无名数B、实物单位与货币单位C、有名数D、无名数与有名数7、下列相对数中,属于不同时期对比的指标有( B )A、结构相对数B、动态相对数C、比较相对数D、强度相对数8、假设计划任务数是五年计划中规定最后一年应达到的水平,计算计划完成程度相对指标可采用( B )A、累计法B、水平法C、简单平均法D、加权平均法9、按照计划,今年产量比上年增加30%,实际比计划少完成10%,同上年比今年产量实际增长程度为( D )。
统计学第五版课后题答案

第一章导论1.1(1)数值型变量。
(2)分类变量。
(3)离散型变量。
(4)顺序变量。
(5)分类变量。
1.2(1)总体是该市所有职工家庭的集合;样本是抽中的2000个职工家庭的集合。
(2)参数是该市所有职工家庭的年人均收入;统计量是抽中的2000个职工家庭的年人均收入。
1.3(1)总体是所有IT从业者的集合。
(2)数值型变量。
(3)分类变量。
(4)截面数据。
1.4(1)总体是所有在网上购物的消费者的集合。
(2)分类变量。
(3)参数是所有在网上购物者的月平均花费。
(4)参数(5)推断统计方法。
第二章数据的搜集1.什么是二手资料?使用二手资料需要注意些什么?与研究内容有关的原始信息已经存在,是由别人调查和实验得来的,并会被我们利用的资料称为“二手资料”。
使用二手资料时需要注意:资料的原始搜集人、搜集资料的目的、搜集资料的途径、搜集资料的时间,要注意数据的定义、含义、计算口径和计算方法,避免错用、误用、滥用。
在引用二手资料时,要注明数据来源。
2.比较概率抽样和非概率抽样的特点,举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。
概率抽样是指抽样时按一定概率以随机原则抽取样本。
每个单位被抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽中的概率,概率抽样的技术含量和成本都比较高。
如果调查的目的在于掌握和研究总体的数量特征,得到总体参数的置信区间,就使用概率抽样。
非概率抽样是指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。
非概率抽样操作简单、实效快、成本低,而且对于抽样中的专业技术要求不是很高。
它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。
非概率抽样也适合市场调查中的概念测试。
3.调查中搜集数据的方法主要有自填式、面方式、电话式,除此之外,还有那些搜集数据的方法?实验式、观察式等。
统计学第五版(贾俊平)课后习题答案

统计学第五版(贾俊平)课后题答案第4章 数据的归纳性气宇(1)众数:100=M 。
中位数:5.5211021=+=+=n 中位数位置,1021010=+=e M 。
平均数:6.91096101514421==++++==∑= nxx ni i。
(2)5.24104===n Q L 位置 ,5.5274=+=LQ 。
5.7410343=⨯==n Q U 位置,1221212=+=U Q 。
(3)2.494.156110)6.915()6.914()6.94()6.92(1)(222212==--+-++-+-=--=∑= n x xs ni i(4)由于平均数小于中位数和众数,所以汽车销售量为左偏散布。
(1)从表中数据能够看出,年龄出现频数最多的是19和23,所以有两个众数,即190=M 和230=M 。
将原始数据排序后,计算的中位数的位置为:13212521=+=+=n 中位数位置,第13个位置上的数值为23,所以中位数23=e M 。
(2)25.64254===n Q L 位置,19)1919(25.019=-⨯+=L Q 。
75.184253=⨯=位置U Q ,56.252-7257.052=⨯+=)(U Q 。
(3)平均数242560025231715191==++++==∑= n xx ni i。
65.61251062125)2423()2417()2415()2419(1)(222212=-=--+-++-+-=--=∑= n x xs ni i(4)偏态系数:()08.165.6)225)(125(242533=⨯---=∑i x SK 。
峰态系数:[]77.065.6)325)(225)(125()125()24(3)24()125(254224=⨯-------+=∑∑i i x x K 。
(5)分析:从众数、中位数和平均数来看,网民年龄在23~24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大不同。
统计学(贾俊平等)第五版课后习题答案(完整版)人大出版社
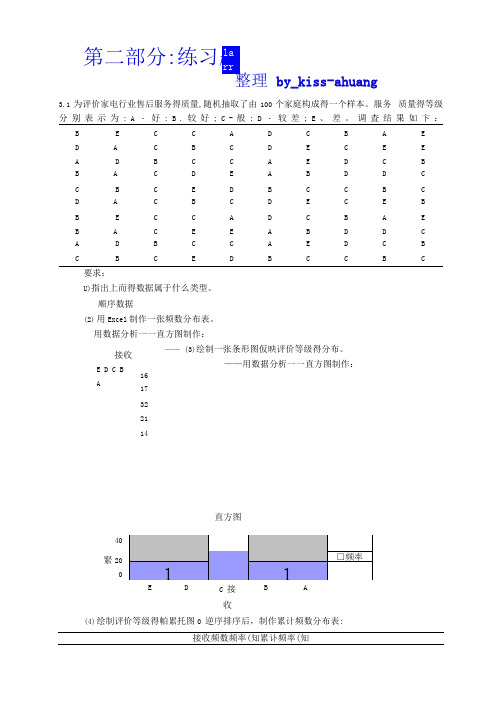
by _kiss-ahuang3.1为评价家电行业售后服务得质量,随机抽取了由100个家庭构成得一个样本。
服务 质量得等级分别表示为:A ・好:B .较好;C -般:D ・较差;E 、差。
调査结果如卞:B E CC AD C B AE D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C E E A B D D C AD B C C AE D C B CBCEDBCCBC要求:U)指出上而得数据属于什么类型。
顺序数据(2) 用Excel 制作一张频数分布表。
用数据分析一一直方图制作:—— (3)绘制一张条形图仮映评价等级得分布。
——用数据分析一一直方图制作:16 17 32 21 14(4) 绘制评价等级得帕累托图0 逆序排序后,制作累计频数分布表:接收频数频率(知累讣频率(知第二部分:直方图DBAC 接收40緊20E接收E D C B AC 32 32 32 B 21 21 53D 17 17 70 E16 16 86 A14141003・2某行业管理局所属40个企业2002年得产品销售收入数据如下: 152 124 129 H6 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 9788123115H9138112146113126要求:(1)根摇上而得数据进行适当得分组,编制频数分布表,并计算出累积频数与累积频率。
1、确定组数:2 +髓-罟十蹤心2心2、 确定组距:组距=(最大值-最小值)+组数={152-87)4-6=10. 83,取103、 分组频数表(2)按规世,销售收入在125万元以上为先进企业,115-125万元为良好企业,105〜115万 元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行■频数 T 一累计频率(%)分组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《统计学原理(第五版)》习题计算题答案详解
第二章 统计调查与整理
1. 见教材P402 2. 见教材P402-403 3. 见教材P403-404
第三章 综合指标
1. 见教材P432
所以劳动生产率计划超额1.85%完成。
一季度产品单位成本,未完成计划,还差2.22%完成计划。
2. 见教材P432
工作做得好。
但由于甲村的平原地所占比重大,山地所占比重小,乙村则相
5. %74.94963.09222.09574.03=⨯⨯=G X P99
(2)
R=500-150=350(千克/亩)
(3)
“
(4) 根据以上计算,294.5千克/亩>283.3千克/亩>277.96千克/亩,即
(2)
6.见教材P435
7.见教材P404
劳动生产率计划超额1.85%完成
一季度产品单位成本未完成计划,实际单位成本比计划规定数高2.22% 8.见教材P405
工作做得好。
但由于甲村的平原地所占比重大,山地所占比重小,乙村则相
(2)
R=500-150=350(千克/亩)
(3)
“标准差”不要求用组距数列的简捷法计算
(4) 根据以上计算,294.5千克/亩>283.3千克/亩>277.96千克/亩,故资料分
(2)
(1)
(2)
第四章 动态数列
1. 见教材P407
2. 见教材P407-408
3. 见教材P408
4. 见教材P409
5. (1) 见教材P409-410
(2) ① 增减速度=发展速度-1(或100%)
② 0
n 1i i a a
n 1i a a =∏
=- (环比发展速度的连乘积等于定基发展速度) ③ 100%1基期发展水平
的绝对值增长=
④ 增减速度
增减量
的绝对值增长=%1
⑤ 0n 1i i a a n
1
i )a (a -=∑=-- (逐期增减量之和等于累计增减量)
⑥ n x x ∏= (平均发展速度等于环比发展速度的连乘积开n 次方)
⑦ 平均增减速度=平均发展速度-1(或100%) 6. 见教材P410 7. 见教材P410-411 8. (1) 见教材P411
型。
(2) ⎪⎩⎪
⎨⎧+==+=⇒⎪⎪⎩⎪⎪⎨⎧++=++=++=∑∑∑∑∑∑∑∑∑∑∑708c 6010095460b
727260c 914673 t
c t b t y t t c t b t ty t c t b N y 4322322
a a a a a 代入方程: (3)当t=5,即2004年基建投资额y c =1562.5+121.2×5+10.2×25=2423.5(万元)
当t=6,即2005年基建投资额y c =1562.5+121.2×6+10.2×36=2656.9(万元) 指数曲线型。
(2)代入方程组:
(3)当t=3时,即该地区2004年底人口数为: lgy c =lga+tlgb=1.55982+3×0.08192=1.80558 ∴y c =63.9(万人) 11. 见教材P412-413
y c =7.42+0.85×19=23.57(千件)
23.57×0.5088(第一季度的季节比率)=11.99(千件)
同样方法,得到2004年第二、三、四各季度的销售量估计值依次为:18.78千件、30.44千件、39.64千件。
(1) 2010年达到翻一番的目标,即人均绿化面积为:4平方米×2=8平方米,根据已知条件,得:
即每年的平均发展速度=107.18%。
(2) 若在2008年就达到翻一番目标,则每年的平均增长速度为:
%
05.9%100%05.109%1002%1004/8%100/%1008800202008=-=-=-=-=-n G a a X 即每年的平均增长数度=9.05%。
(3) 若2001年和2002年的平均发展速度都为110%,那么后8年的平均发展速度为:
即后8年每年的平均发展速度=106.48%
(4) 假定2007年的人均绿化面积为人均6.6平方米,以2000年为基期,那么其平均年增长量是:
第三季度销售值=24÷4×115%=6.9(万元)
第四季度销售值=24÷4×95%=5.7(万元) (3)第三季度比第一季度销售值的变动比率为: (4) )20(2216y 2t 2003万元时,当年=⨯+==
即经季节性调整后的2003年第一季度的估计值=20÷4×90%=4.5(万元) 14. 见教材P416
第五章 统计指数
1. (1)
%04.11315
.13
.1q q %76.1118.66.7p p
%83.9520.115.1q q %67.10682.192.1p p
%77.12346.452.5q q %91.1102.244.2p p %1040.52
.5q q %33.13330.040.0p p 0101010101010101====================水产品个体销售量指数水产品个体物价鲜蛋个体销售量指数鲜蛋个体物价猪肉个体销售量指数猪肉个体物价蔬菜个体销售量指数蔬菜个体物价 (2)
(3)
(2)
5. 产量总指数
6. 商品销售量指数
由于销售量变动使商品销售额增加 9.602-8.60=1.002(亿元) 7. (1)销售量指数 (2)价格指数
(3)销售量变动对销售额的影响 8. 零售物价指数
(1) 以t 代表工人劳动生产率,q 代表工人人数
149.2
51.8200 ; 129.48%111.56%144.44% )(2.149714)640
450
714650(
)q t -(t %
130640450
714650t t )(8.51640
450
)640714()t q -(q %
56.111640714
q q )
(200450650q t q t %44.144450
650
q t q t 101010010100110011+=⨯=∴=⨯-==÷==⨯
-====-=-===
万元绝对值产值的影响:程度工人劳动生产率变动对万元绝对值度动对产值变动影响:程其中:生产工人人数变万元总产值指数 (2) 以m 代表产值,q 代表职工数,t 代表生产工人人数 其中:①职工人数变动影响:
② 生产工人占职工人数比重变动影响:
③ 由于工人劳动生产率变动对总产值的影响: 9. 各期的原材料费用总额计算如下:
第六章 抽样调查
1. (1)N=5000,000 n=500
(2) 0.68%
0.12% 0.00680.00120.0028
0.0040.00280.0040.0028
0.00281t μΔ0.0028
500
99.6%
0.4%μ 0.0028)5000,000500(150099.6%0.4%μ6994040140140≤≤≤≤+≤≤-=⨯===⨯==-⨯=
⨯=⨯==P P P %
.%.%).-(%.-p)% p(.p p p 即
2. (1) (2)
3. (1) (2)
4. (1)
(2) )(220.03
2%
98%2
块=⨯=n 5. p
(2)
(3)
(4)
(5)
通过以上计算可以看到,抽样单位数和概率之间是正比关系,即当概率提高时,抽样单位数也会增加;抽样单位数和允许误差(极限误差)之间是反比关系,即当极限误差范围扩大时,相应的抽样单位数就会减少。
提出假设H0:μ=μ0=250
H1:μ≠μ0=250
方法①选择检验统计量
方法②如果求出的区间包含μ,就不否定原假设H
0,否则就否定H
∵μ的95%的区间为:
第七章相关分析
(1)工龄为自变量
(2)散点图
(3)从散点图上看,该公司员工工龄与效率分数之间没有高度相关关系。
(1) 参见教材P329-330图示
(2)
(3)
(1)
(2)当x=8 y=3.1+1.45×8=14.7(千元/人)
(3)
(1)
(2)
(3)b=10.18,说明可比产品成本降低率每增加1%时,销售利润率平均增加10.18万元。
(4)
(1)
(2)
(1)
(3)每当产量增加1万件时,单位成本就减少1.8077元。
(4)相关系数
页眉内容
(5)估计标准差:
(6)当产量为8万件时,单位成本为:
第八章国民经济核算
1. 见教材P423
2. 见教材P423。