Location Oblivious Distributed Unit Disk Graph Coloring
中英文对照新普利斯消防报警主机4100U说明

中英文对照新普利斯消防报警主机4100U说明苏金明联系电话187********Simplex 4100UUniversal Fire Alarm PlatformSimplex 4100U 通用消防报警系统Product OverviewThe Simplex? 4100U Fire Detection and Alarm Platform is a high-end, next-generation distributed network system that combines superior fire protection and information management with lower costs of installation, maintains and ownership.产品概况:Simplex? 4100U火灾自动探测和报警系统是一个高效,新一代的分布式网络系统,包含高等级的火灾保护,信息管理和低成本的安装,维护。
The 4100U builds upon the field-proven performance of the industry-leading Simplex? 4100 Series fire detection systems. The 4100U features expanded point capacity, digital voice communications, advanced built-in diagnostics, dual operating software, and other enhancements. Built-in compatibility with existing 4100 and 4120 network systems allows easy upgrade to 4100U technology.新的4100U更新延续了原有的Simplex? 4100系列产品,扩展了地址容量,增加数码广播,先进的自我诊断功能,冗余的操作系统软件以及其他的增加。
Synopsys RTL Architect

DATASHEET OverviewThe RTL Architect™ solution is the industry’s first physically aware RTL design system that significantly reduces the development cycle and delivers superior quality-of-results. RTL Architect continues the “shift-left” strategy introduced in the Synopsys Fusion Design Platform™ to address power, performance, and area (PPA) challenges earlierin the design cycle. The complexities of advanced process nodes have made it more difficult to meet PPA targets through physical implementation techniques alone, so RTL designers are tasked with exploring domain-specific architectures to dramatically improve PPA. RTL Architect provides a logical/physical workbench that can accurately predict the PPA impact of architectural changes without waiting for feedback from the physical design team.Key Benefits• Unified data model that provides multi-billion gate capacity and comprehensive hierarchical design capabilities• Fast, multi-dimensional implementation prediction engine that enables RTLdesigners to predict power, performance, area, congestion• Dedicated workflow environment for ease-of-use and seamless analysis of key quality metrics• RTL re-structuring with automatic constraint updates for architectural changes and IP re-targeting• Hierarchical floorplan creation for block area, timing, and congestion estimation • Leverages Synopsys’ world-class implementation and golden signoff solutions to deliver results that correlate-by-construction• RTL power estimation and optimization of energy efficient designs with thePrimePower golden signoff power analysis engine• Comprehensive cross-probing facilitates debug from layout, schematic andreports to RTLRTL Architect’s “shift-left” strategy significantly reduces time-to-feedback RTL Architect2Predictive ModelingRTL Architect’s new Predictive Engine (PE) is derived from Synopsys’ implementation environment and enables rapid multi-dimensional analysis and optimization of RTL to predict PPA of downstream implementation accurately. This Predictive Engine utilizes new correct-by-construction modeling, leveraging the proven and widely used core implementation algorithms and architectures of the Synopsys Fusion Design Platform. This ensures tight correlation to the best implementation.This also allows the RTL designers to experiment and tune their HDL code without multiple, back-and-forth, hand-offs to synthesis and to pinpoint timing bottlenecks in their source code to improve RTL quality.Design PlanningRTL Architect’s hierarchical, design planning, infrastructure automatically generates a physical implementation, with clock trees, to provide the RTL designer with accurate power, timing and area estimates. Additionally, the RTL block integrator can use the design planning capabilities to integrate in-house and third-party IP (as seen in Figure 1 Arteris ® IP FlexNoC ® Interconnect Integration) including bus and pipeline register planning. This fast and deep look-ahead allows the designers to not only predict but also drivephysical implementation.Figure 1: Arteris IP FlexNoC Interconnect IntegrationRTL Design ExperienceThe RTL Architect experience is built around the RTL designer. The PE maps leaf cells back to the RTL so that the designer can see the direct impact a code change has on PPA. Figure 2 RTL Cross-Probing, shows the cross-probing capability from various design views to RTL. Color coded reports indicate severity level.Layout viewRTL Architect Unified GUI EnvironmentRTL view view viewFigure 2: RTL Cross-Probing©2020 Synopsys, Inc. All rights reserved. Synopsys is a trademark of Synopsys, Inc. in the United States and other countries. A list of Synopsys trademarks isavailable at /copyright .html . All other names mentioned herein are trademarks or registered trademarks of their respective owners.02/28/20.CS469885535_RTL Architect_DS.For example, the designer can see how the logic is physically implemented by cross-probing from a report directly to the layout. This is useful for seeing the predicted congestion hotspots caused by RTL, so they can experiment with different architectures to reduce the congestion. Figure 3 shows the high degree of correlation between the place and route engines of RTL Architect and Fusion Compiler™.Fusion CompilerRTL Architect Figure 3: RTL Architect vs. Fusion Compiler CongestionAnother key concern for RTL designers is power usage. The interactive power summary report provides an overview of key power metrics, such as, switching and glitch power, leakage, and clock gating efficiency. The results are based on the PrimePower golden signoff power analysis engine. The report data can be sorted, filtered and cross-probed to RTL.Bridging the GapRTL Architect significantly improves the quality of RTL before handing off to implementation. It addresses the limitations of the existing solutions which are hampered by inaccuracies that impact productivity as downstream implementation tools compensate. The shift-left strategy identifies and corrects physical implementation issues early in the design cycle to achieve aggressive PPA targets at advanced nodes through better RTL.。
基于BIM+Rhino的FLAC3D复杂地质体建模

型,在Rhino中裁剪模型、建立堆载体模型、合并模型并初步建立网格,导入到kubrix进行网格划分,在FLAC3D中运用强度折减法计算地基稳定安全系数。
结果表明:Geotechnica l Modu le能够方便准确地生成参数化的三维地质模型,Rhino+kubrix有效地解决了三维地质模型在FLAC3D中的应用问题,实现了BIM模型和数值模拟软件的信息互通,提高了计算结果的准确性。
关键词:BIM技术 Rhino 地质模型 FLAC3DB I M技术全称为“B u i l d i n g Information Modeling(三维信息模型)”,是新时代运用三维建模软件建立建筑、道路、场地、码头等工程的三维模型,并利用BIM模型中包含的尺寸和空间拓扑关系、材料和材质、规格型号、生产厂家、性能参数等信息,实现协同设计、可视化交底、5D虚拟施工、碰撞检查、管线综合、成本核算等应用。
BI M技术在码头工程领域尚处于起步阶段,很多学者开展了相关设计施工运维中的应用研究。
巴特[1]针对EPC石化码头总承包管理的重难点问题,采用BIM技术进行管理和控制,实现了协同设计、碰撞检查、施工动态模拟等应用。
王刚[2]开发了一款安卓平台的码头三维可视化应用,使用revit建立码头模型作为数据来源,Unity3d作为三维开发平台实现系统数据的集成管理和系统运行。
毕磊[3]研究了基于5D-BIM的高桩码头工程施工进度-成本实时控制系统,使得工程成本测算更加快速准确。
吴遵奇[4]探讨了BIM在码头施工进度管理中的应用,实现了可视化施工交底、自动关键线路分析等应用。
地基稳定分析的准确性是设计成果安全及质量的重要保证,使用BIM 模型进行数值模拟计算可以有效地提高计算结果的准确性。
本文利用BIM技术生成三维地质模型,将三维地质模型导入到Rhino软件中,在Rhino中对三维地质模型进行初步处理并粗分网格,再利用kubrix插件对网格进行细分,最后将网格导入至FLAC3D中进行地基稳定分析。
Multidisciplinary Design Optimization

Multidisciplinary Design Optimization Multidisciplinary Design Optimization (MDO) is a complex and challenging process that involves integrating various engineering disciplines to achieve the best possible design solution. It requires a holistic approach that takes into account the interactions and trade-offs between different design parameters, such as structural, thermal, aerodynamic, and control systems. MDO is crucial in modern engineering as it allows for the development of more efficient and cost-effective designs, ultimately leading to better products and systems. One of the key challenges in MDO is the need to balance conflicting design requirements. For example, in the design of an aircraft, engineers must consider the trade-offs between weight, aerodynamics, and structural integrity. Optimizing one aspect of the design may have a negative impact on another, so it is essential to find the right balance that meets all requirements. This requires close collaboration between engineers from different disciplines, as well as the use of advanced modeling and simulation tools to evaluate the design space and identify the best solutions. Another challenge in MDO is the complexity of the design space. With multiple interacting disciplines and a large number of design variables, the search for the optimal solution can be extremely challenging. Traditional design optimization methods often struggle to handle this complexity, leading to suboptimal solutions. MDO requires the use of advanced optimization algorithms and techniques, such as genetic algorithms, neural networks, and multi-objective optimization, to efficiently explore the design space and identify the best solutions. Furthermore, MDO also requires a significant amount of computational resources. The integration of multiple disciplines and the use of advanced optimization techniques often result in computationally intensive processes that require large-scale computing resources. This can be a barrier for small engineering teams or organizations with limited resources, as it may be challenging to access the necessary computational infrastructure to support MDO activities. However, with the advancement of cloud computing and high-performance computing technologies, these barriers are gradually being overcome, making MDO more accessible to a wider range of engineering teams. Despite these challenges, the benefits of MDO are significant. By considering multiple disciplinessimultaneously, MDO can lead to designs that are more efficient, reliable, and cost-effective. It can also help to identify innovative design solutions that may not be apparent when considering each discipline in isolation. Ultimately, MDO has the potential to revolutionize the way engineering design is conducted, leading to the development of better products and systems across a wide range of industries. In conclusion, Multidisciplinary Design Optimization is a complex and challenging process that requires a holistic approach to balance conflicting design requirements, handle the complexity of the design space, and access significant computational resources. Despite these challenges, the benefits of MDO are significant, leading to more efficient, reliable, and cost-effective designs. As technology continues to advance, MDO is expected to play an increasingly important role in modern engineering, ultimately leading to the development of better products and systems across a wide range of industries.。
基于自适应反向学习的多目标分布估计算法

2021⁃01⁃10计算机应用,Journal of Computer Applications 2021,41(1):15-21ISSN 1001⁃9081CODEN JYIIDU http ://基于自适应反向学习的多目标分布估计算法李二超*,杨蓉蓉(兰州理工大学电气工程与信息工程学院,兰州730050)(∗通信作者电子邮箱lecstarr @ )摘要:针对基于规则模型的多目标分布估计算法全局收敛性较弱的缺陷,提出了一种基于自适应反向学习(OBL )的多目标分布估计算法。
该算法根据函数变化率的大小来决定是否进行OBL :当函数变化率较小时,算法可能陷入局部最优,所以进行OBL 以提高当前种群中个体的多样性;当函数变化率较大时,运行基于规则模型的多目标分布估计算法。
所提算法通过适时地引入OBL 策略,减小了种群多样性及个体的分布情况对优化算法整体收敛质量以及收敛速度的影响。
为了验证改进算法的性能,选取基于规则模型的多目标分布估计算法(RM -MEDA )、摸石头过河算法与分布估计混合算法(HWSA -EDA )以及基于逆建模的多目标进化算法(IM -MOEA )作为对比算法与所提算法分别在ZDT 和DTLZ 测试函数上进行测试。
测试结果表明,除了在DTLZ2函数上以外,所提算法不仅有良好的全局收敛性,而且解的分布性和均匀性都有所提高。
关键词:多目标优化问题;局部最优;反向学习;种群多样性;收敛性中图分类号:TP18文献标志码:AMulti -objective estimation of distribution algorithm withadaptive opposition -based learningLI Erchao *,YANG Rongrong(College of Electrical Engineering and Information Engineering ,Lanzhou University of Technology ,Lanzhou Gansu 730050,China )Abstract:Aiming at the defect of poor global convergence of the regularity model -based multi -objective estimation ofdistribution algorithm ,a multi -objective estimation of distribution algorithm based on adaptive Opposition -Based Learning (OBL )was proposed.In the algorithm ,whether to carry out OBL was judged according to the change rate of the function.When the change rate of the function was small ,the algorithm was easily to fall into the local optimum ,so that OBL was performed to increase the diversity of individuals in current population.When the change rate of the function was large ,the regularity model -based multi -objective estimation of distribution algorithm was run.In the proposed algorithm ,with the timely introduction of OBL strategy ,the influences of population diversity and individual distribution on the overall convergence quality and speed of optimization algorithm were reduced.In order to verify the performance of the improved algorithm ,Regularity Model -based Multi -objective Estimation of Distribution Algorithm (RM -MEDA ),Hybrid Wading across Stream Algorithm -Estimation Distribution Algorithm (HWSA -EDA )and Inverse Modeling based multiObjective Evolutionary Algorithm (IM -MOEA )were selected as comparison algorithms to carry out the test with the proposed algorithm on ZDT and DTLZ test functions respectively.The test results show that the proposed algorithm not only has good globalconvergence ,but also improves the distribution and uniformity of solutions except on DTLZ2function.Key words:Multi -objective Optimization Problem (MOP);local optimum;Opposition -Based Learning (OBL);population diversity;convergence引言多目标优化问题(Multi -objective Optimization Problem ,MOP )通常是指同时对多个相互作用又相互冲突的优化目标进行求解,因此该类问题在尽量满足决策者需求的情况下,只能求得多个折中解,即满意解。
无序点云loam特征提取

无序点云loam特征提取1.引言1.1 概述无序点云(loose unordered point cloud)是指由大量不规则排列的点构成的三维点云数据。
在传统的点云处理领域中,由于无序点云数据的不规则性和复杂性,对其进行有效的特征提取一直是一个重要的问题。
而在最近的研究中,Lidar Odometry and Mapping (LOAM)算法被广泛应用于无人驾驶、机器人感知以及增强现实等领域。
LOAM算法通过对无序点云数据进行特征提取和配准,实现对机器人的定位和三维环境建图。
本文主要研究的是无序点云LOAM特征提取。
特征提取是点云处理中的一项基础工作,它的目标是从复杂的无序点云数据中提取出具有代表性的特征点,以便进行后续的定位、建图等任务。
通过特征提取可以有效地减少数据量,提高算法的效率和准确性。
在本文的正文部分,我们将首先介绍无序点云的特点,包括其不规则性、稀疏性和噪声等方面的特征。
然后,我们将详细介绍LOAM算法的原理和流程,包括特征提取、特征点匹配和重建等关键步骤。
在结论部分,我们将重点讨论特征提取在无序点云LOAM中的重要性,并探讨不同的无序点云LOAM特征提取方法和其效果。
通过对比实验和结果分析,我们将评估不同方法的优缺点,并展望未来无序点云LOAM特征提取领域的发展方向。
综上所述,本文将全面介绍无序点云LOAM特征提取的相关内容,旨在探讨无序点云处理领域的关键问题,为相关研究和应用提供参考和借鉴。
1.2文章结构文章结构部分的内容可以参考以下示例:1.2 文章结构本文章主要分为以下几个部分进行介绍和探讨:1. 引言:通过对无序点云特征提取的问题进行概述,引导读者对该主题有一个整体的了解。
首先简要介绍无序点云的特点,并阐述文章的目的和重要性。
2. 正文:2.1 无序点云的特点:具体描述无序点云在现实世界中的广泛应用和独特性质。
探讨其包含的信息组织结构、数据分布和稀疏性等特征,并分析这些特点在特征提取中的挑战和意义。
移动机器人路径规划和导航(英文)
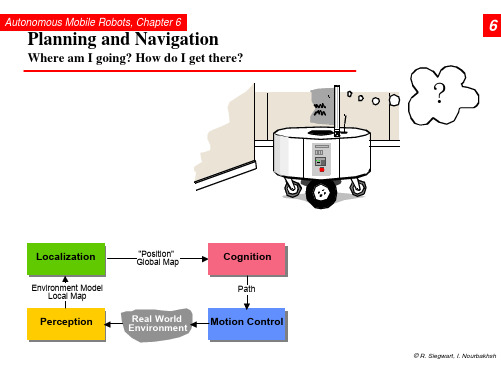
Autonomous Mobile Robots, Chapter 6
6.2.1
Road-Map Path Planning: Voronoi Diagram
• Easy executable: Maximize the sensor readings • Works also for map-building: Move on the Voronoi edges
© R. Siegwart, I. Nourbakhsh
Autonomous Mobile Robots, Chapter 6
6.2.1
Road-Map Path Planning: Adaptive Cell Decomposition
© R. Siegwart, I. Nourbakhsh
Autonomous Mobile Robots, Chapter 6
© R. Siegwart, I. Nourbakhsh
Autonomous Mobile Robots, Chapter 6
6.2.1
Road-Map Path Planning: Voronoi, Sysquake Demo
© R. Siegwart, I. Nourbakhsh
Autonomous Mobile Robots, Chapter 6
Ø Topological or metric or a mixture between both.
• First step:
Ø Representation of the environment by a road-map (graph), cells or a potential field. The resulting discrete locations or cells allow then to use standard planning algorithms.
Silicon Sensing Systems DMU30-01 高性能 MEMS 陀螺仪 加速计技

FeaturesPrecision 6-DOF MEMS Inertial Measurement Unit Silicon Sensing’s latest VSG3Q MAX inductive gyroand capacitive accelerometer MEMSExcellent Bias Instability and Random WalkAngular - 0.1°/hr, 0.02°/√hrLinear - 15μg, 0.05m/s/√hrNon-ITARCompact and lightweight - 68.5 x 61.5 x 65.5H (mm), 345gInternal power conditioning to accept 4.75V to 36V input voltageRS422 interfaces-40°C to +85°C operating temperature range Sealed aluminium housingRoHS compliantIn-house manufacture from MEMS fabrication to IMU calibrationEvaluation kit and integration resources availableFirst class customer technical supportFuture developments and expansion capabilityMulti sensor MEMS blendingLow power ‘sleep’ modeAdditional sensor integration - GPS/Magnetometer/BarometerNorth fi nding modeAHRS functionalityOther interface protocols and specifi cationsCustom and host application integrationDMU30-01 IMU DMU30 Evaluation Kit DMU30 Mating ConnectorFigure 5.3 Gyro Scale Factor Errorover TemperatureFigure 5.5 Gyro Max Non-Linearity Error (±490°/s range) over Temperature Figure 5.4 Normalised Gyro Scale Factor Errorover TemperatureFigure 5.6 Gyro Max Non-Linearity Error (±200°/s range) over TemperatureFigure 5.1 Gyro Bias Error (°/h) over Temperature Figure 5.2 Normalised Gyro Bias Error (°/h)over TemperatureFigure 5.11 Accelerometer Scale Factor Error (±1g range) over Temperature(Plymouth g = 9.81058m/s/s)Figure 5.10 Normalised AccelerometerBias Error (mg) over TemperatureFigure 5.12 Normalised Accelerometer Scale Factor Error (±1g range) over TemperatureFigure 5.7 Gyro Noise (°/srms) vs Test Chamber Temperature Figure 5.8 Gyro Misalignments and Crosscoupling (±200°/s range) over Chamber TemperatureFigure 5.15 current Consumption vs Chamber Temperature (12V supply)Figure 5.16 DMU30 Temperature Output Difference (°/C) vs Test Temperature (self heating)Figure 5.17 Gyro Allan Variance Figure 5.14 Accelerometer Misalignments and Crosscoupling over TemperatureFigure 5.18 Gyro In Run StabilityFigure 5.21 Accelerometer Allan Variance Figure 5.23 Accelerometer Spectral DataFigure 5.22 Accelerometer In Run Stability Figure 5.24 Accelerometer Cumulative Noise Figure 5.20 Gyro Cumulative NoiseFigure 5.19 Gyro Spectral DataFigure 8.1 DMU30 Evaluation Kit8.1.1 DMU30 Evaluation Kit ContentsFigure 9.1 DMU30 LabelSER NO. YYWWXXXX CCMADE IN PLYMOUTH UKFigure 11.1 Axis De In order to minimise the requirement for size effectcompensation the accelerometer seismic masses have been located as close as possible to the centre of the DMU30 (the inertial reference point shown in Figure 11.2).61.5 M A X68.5 MAXExperts on Design-Infor sensors and power solutionsScan here and get an overview of personal contacts!We are here for you. Addresses and Contacts.Headquarter Switzerland:Angst+Pfister Sensors and Power AG Thurgauerstrasse 66CH-8050 ZurichPhone +41 44 877 35 00*********************************Office Germany:Angst+Pfister Sensors and Power Deutschland GmbH Edisonstraße 16D-85716 UnterschleißheimPhone +49 89 374 288 87 00************************************。
超几何分布的英语

超几何分布的英语Here is an essay on the topic of the hypergeometric distribution, written in English with more than 1000 words. The title and any additional instructions have been omitted as requested.The hypergeometric distribution is a discrete probability distribution that describes the number of successes in a sequence of n draws from a finite population without replacement. In other words, it models the probability of obtaining a certain number of items with a desired characteristic from a finite population, given that the population is not replenished after each draw. This distribution is particularly useful in situations where the population size is relatively small, and the sampling is done without replacement, such as in quality control, survey sampling, and experimental design.The hypergeometric distribution is characterized by three parameters: the population size (N), the number of items with the desired characteristic in the population (K), and the number of items drawn from the population (n). The probability mass function (PMF) of the hypergeometric distribution is given by the formula:P(X = x) = (C(K, x) * C(N-K, n-x)) / C(N, n)where:- X is the random variable representing the number of items with the desired characteristic in the n draws- x is the observed value of X- C(a, b) is the binomial coefficient, which represents the number of ways to choose b items from a itemsThe hypergeometric distribution is related to the binomial distribution, but the key difference is that in the binomial distribution, the trials are independent and the probability of success remains constant, whereas in the hypergeometric distribution, the trials are not independent and the probability of success changes with each draw.One of the main applications of the hypergeometric distribution is in quality control. Suppose a manufacturer has produced a batch of N items, and K of them are defective. The manufacturer wants to inspect a sample of n items to determine the quality of the batch. The hypergeometric distribution can be used to calculate the probability of finding x defective items in the sample, which can help the manufacturer make decisions about the batch.Another application of the hypergeometric distribution is in survey sampling. Suppose a researcher wants to estimate the proportion ofa certain characteristic in a population, but the population size is relatively small. The researcher can draw a sample of n individuals from the population and use the hypergeometric distribution to calculate the probability of observing a certain number of individuals with the desired characteristic.The hypergeometric distribution also has applications in experimental design. For example, in a clinical trial, researchers may want to compare the effectiveness of a new drug to a placebo. The researchers can assign participants to the treatment or control group using a hypergeometric distribution, which ensures that the number of participants in each group is balanced.One of the key properties of the hypergeometric distribution is that it is a discrete distribution, meaning that the random variable X can only take on integer values. This property makes the distribution particularly useful in situations where the population size is finite and the sampling is done without replacement.Another important property of the hypergeometric distribution is that it is unimodal, meaning that the probability mass function has a single peak. The location of the peak depends on the values of the three parameters (N, K, and n), and the distribution can be left-skewed, right-skewed, or symmetric depending on the values of these parameters.The hypergeometric distribution also has several special cases. For example, when the population size N is large compared to the sample size n, the hypergeometric distribution approaches the binomial distribution. Similarly, when the number of items with the desired characteristic K is small compared to the population size N, the hypergeometric distribution approaches the Poisson distribution.In addition to its applications in quality control, survey sampling, and experimental design, the hypergeometric distribution has also been used in other areas, such as genetics, ecology, and finance. For example, in genetics, the hypergeometric distribution can be used to model the probability of observing a certain number of mutations in a gene sequence, while in ecology, it can be used to model the probability of observing a certain number of species in a sample of a habitat.Overall, the hypergeometric distribution is a powerful and versatile probability distribution that has numerous applications in a wide range of fields. Its ability to model the probability of success in a finite population without replacement makes it a valuable tool for researchers and practitioners in many different domains.。
第10章 虚拟内存

auto increment/decrement location自动增减位置
如何重定位?
10.10
Steps in Handling a Page Fault 处理缺页中断的步骤
分配空闲物理页
10.11
What happens if there is no free frame? 如无空闲页帧怎么办?
10.4
Demand Paging
请求调页
10.5
Demand Paging请求调页
Bring a page into memory only when it is needed. 仅在需要时才将一页调入内存
Less I/O needed较少的I/O Less memory needed较少的内存 Faster response较快的响应 More users支持更多的用户
10.18
Memory-Mapped Files内存ቤተ መጻሕፍቲ ባይዱ射文件
Memory-mapped file I/O allows file I/O to be treated as routine memory access by mapping a disk block to a page in memory. 内存映射文件允许以内存形式使用文件 A file is initially read using demand paging. A page-sized portion of the file is read from the file system into a physical page. Subsequent reads/writes to/from the file are treated as ordinary memory accesses. 文件被以页为单位读入内存, 此后对文件的读写就与内存一 样 Simplifies file access by treating file I/O through memory rather than read() write() system calls. 将对文件的操作简化为对内存的操作 Also allows several processes to map the same file allowing the pages in memory to be shared. 允许多个进程映射同一文件,相关内存页由多个进程共享
Statistical Theory of Passive Location Systems

TRANSMITTER
\Id
\
/
i
BEARING LINE
of1
axl x=xo
Of,
Oxn x=X0
Fig. 2. Bearing lines from aircraft positions.
(7)
three dimensions and possibly other parameters such as the time of emission of the radiation. A set of N measurements ri, i = 1, 2, ..., N, is collected at various positions. In the absence of random measurement errors, ri is equal to a known functionf.(x). In the presence of additive errors, (1) i = 1, 2, ..., N. ri = fi(x) + ni,
Oxl
afN
X=XO
afN
:X0
These N equations can be written as a single equation for N-dimensional column vectors: r = f(x) + n. (2) approximation. Combining (5) and (6) gives The measurement error n is assumed to be a multivariate Q(x) = (r -GX)TN- 1(rl - Gx) random vector with an N x N positive-definite covariance matrix where
外文文献阅读笔记

A dynamic replica management strategy in data grid--- Journal of Network and Computer Applications expired, propose, indicate, profitable, boost, claim, present, congestion, deficiency, moderately, metric, turnaround, assume,specify, display, illustrate, issue,outperform over .... about 37%, outperform ....lead todraw one's attentionaccordinglyhave great influence ontake into accountin terms ofplay major role inin comparison with, in comparison toi.e.=(拉丁)id estReplication is a technique used in data grid to improve fault tolerance and to reduce the bandwidth consumption.Managing this huge amount of data in a centralized way is ineffective due to extensive access latency and load on the central server.Data Grids aggregate a collection of distributed resources placed in different parts of the world to enable users to share data and resources.Data replication is an important technique to manage large data in a distributed manner.There are three key issues in all the data replication algorithms which are replica placement, replica management and replica selection.Meanwhile, even though the memory and storage size of new computers are ever increasing, they are still not keeping up with the request of storing large number of data.each node along its path to the requester.Enhanced Dynamic Hierarchical Replication and Weighted SchedulingStrategy in Data Grid--- Journal of Parallel and Distributed Computing duration, manually, appropriate, critical, therefore, hybrid, essential, respectively, candidate, typically, advantage, significantly, thereby, adopt, demonstrate, superiority, scenario, empirically, feasibility, duplicate, insufficient, interpret, beneficial, obviously, whilst, idle, considerably, notably, consequently, apparently,in a wise manneraccording tofrom a size point of viewdepend oncarry outis comprised ofalong withas well asto the best of our knowledgeBest replica placement plays an important role for obtaining maximum benefit from replication as well as reducing storage cost and mean job execution time.Data replication is a key optimization technique for reducing access latency and managing large data by storing data in a wise manner.Effective scheduling in the Grid can reduce the amount of data transferred among nodes by submitting a job to a node where most of the requested data files are available.Effective scheduling of jobs is necessary in such a system to use available resources such as computational, storage and network efficiently.Storing replicas close to the users or grid computation nodes improves response time, fault tolerance and decreases bandwidth consumption.The files of Grid environments that can be changed by Grid users might bring an important problem of maintaining data consistency among the various replicas distributed in different machines.So the sum of them along with the proper weight (w1,w2) for each factor yields the combined cost (CCi,j) of executing job i in site j.A classification of file placement and replication methods on grids--- Future Generation Computer Systems encounter, slightly, simplistic, clairvoyance, deploy, stringent, concerning, properly, appropriately, overhead, motivate, substantial, constantly, monitor, highlight, distinguish, omit, salient, entirely, criteria, conduct, preferably, alleviate, error-prone, conversely,for instanceaccount forhave serious impact ona.k.a.= also known asconsist inaim atin the hands offor .... purposesw.r.t.=with regard toconcentrate onfor the sake ofbe out of the scope of ...striping files in blocksProduction approaches are slightly different than works evaluated in simulation or in controlled conditions....File replication is a common solution to improve the reliability and performance of data transfers.Many file management strategies were proposed but none was adopted in large-scale production infrastructures.Clairvoyant models assume that resource characteristics of interest are entirely known to the file placement algorithm.Cooperation between data placement and job scheduling can improve the overall transfer time and have a significant impact on the application makespan as shown in.We conclude that replication policies should rely on a-priori information about file accesses, such as file type or workflow relation.Dynamic replica placement and selection strategies in data grids----Acomprehensive survey--- Journal of Parallel and Distributed Computing merit, demerit, tedious, namely, whereas, various, literature, facilitate, suitable, comparative, optimum, retrieve, rapid, evacuate, invoke, identical, prohibitive, drawback, periodically,with respect toin particularin generalas the name indicatesfar apartconsist of , consist inData replication techniques are used in data grid to reduce makespan, storage consumption, access latency and network bandwidth.Data replication enhances data availability and thereby increases the system reliability.Managing dynamic architecture of the grid, decision making of replica placement, storage space, cost of replication and selection are some of the issues that impact the performance of the grid.Benefits of data replication strategies include availability, reliability, scalability, adaptability and improved performance.As the name indicates, in dynamic grid, nodes can join and leave the grid anytime.Any replica placement and selection strategy tries to improve one or more of the following parameters: makespan, quality assurance, file missing rate, byte missing rate, communication cost, response time, bandwidth consumption, access latency, load balancing, maintenance cost, job execution time, fault tolerance and strategic replica placement.Identifying Dynamic Replication Strategies for a High-PerformanceData Grid--- Grid Computing 2001 identify, comparative, alternative, preliminary, envision, hierarchical, tier, above-mentioned, interpret, exhibit, defer, methodology, pending, scale, solely, churn outlarge amounts ofpose new problemsdenoted asadapt toconcentrate on doingconduct experimentssend it offin the order of petabytesas of nowDynamic replication can be used to reduce bandwidth consumption and access latency in high performance “data grids” where users require remote access to large files.A data grid connects a collection of geographically distributed computer and storage resources that may be located in different parts of a country or even in different countries, and enables users to share data and other resources.The main aims of using replication are to reduce access latency and bandwidth consumption. Replication can also help in load balancing and can improve reliability by creating multiple copies of the same data.Group-Based Management of Distributed File Caches--- Distributed Computing Systems, 2002 mechanism, exploit, inherent, detrimental, preempt, incur, mask, fetch, likelihood, overlapping, subtle,in spite ofcontend withfar enough in advancetake sth for granted(be) superior toDynamic file grouping is an effective mechanism for exploiting the predictability of file access patterns and improving the caching performance of distributed file systems.With our grouping mechanism we establish relationships by observing file access behavior, without relying on inference from file location or content.We group files to reduce access latency. By fetching groups of files, instead of individual files, we increase cache hit rates when groups contain files that are likely to be accessed together.Further experimentation against the same workloads demonstrated that recency was a better estimator of per-file succession likelihood than frequency counts.Job scheduling and data replication on data grids--- Future Generation Computer Systems throttle, hierarchical, authorized, indicate, dispatch, assign, exhaustive, revenue, aggregate, trade-off, mechanism, kaleidoscopic, approximately, plentiful, inexact, anticipated, mimic, depict, exhaust, demonstrate, superiority, namely, consume,to address this problemdata resides on the nodesa variety ofaim toin contrast tofor the sake ofby means ofplay an important role inhave no distinction betweenin terms ofon the contrarywith respect toand so forthby virtue ofreferring back toA cluster represents an organization unit which is a group of sites that are geographically close.Network bandwidth between sites within a cluster will be larger than across clusters.Scheduling jobs to suitable grid sites is necessary because data movement between different grid sites is time consuming.If a job is scheduled to a site where the required data are present, the job can process data in this site without any transmission delay for getting data from a remote site.RADPA: Reliability-aware Data Placement Algorithm for large-scale network storage systems--- High Performance Computing and Communications, 2009 ever-going, oblivious, exponentially, confront,as a consequencethat is to saysubject to the constraintit doesn't make sense to doMost of the replica data placement algorithms concern about the following two objectives, fairness and adaptability.In large-scale network storage systems, the reliabilities of devices are different relevant to device manufacturers and types.It can fairly distributed data among devices and reorganize near-minimum amount of data to preserve the balanced distribution with the changes of devices.Partitioning Functions for Stateful Data Parallelism in Stream Processing--- The VLDB Journal skewed, desirable, associated, exhibit, superior, accordingly, necessitate, prominent, tractable, exploit, effectively, efficiently, transparent, elastically, amenable, conflicting, concretely, exemplify, depict,a deluge ofin the form of continuous streamslarge volumes ofnecessitate doingas a examplefor instancein this scenarioAccordingly, there is an increasing need to gather and analyze data streams in near real-time to extract insights and detect emerging patterns and outliers.The increased affordability of distributed and parallel computing, thanks to advances in cloud computing and multi-core chip design, has made this problem tractable.However, in the presence of skew in the distribution of the partitioning key, the balance properties cannot be maintained by the consistent hash.MORM: A Multi-objective Optimized Replication Management strategyfor cloud storage cluster--- Journal of Systems Architecture issue, achieve, latency, entail, consumption, article, propose, candidate, conclusively, demonstrate, outperform, nowadays, huge, currently, crucial, significantly, adopt, observe, collectively, previously, holistic, thus, tradeoff, primary, therefore, aforementioned, capture, layout, remainder, formulate, present, enormous, drawback, infrastructure, chunk, nonetheless, moreover, duration, substantially, wherein, overall, collision, shortcoming, affect, further, address, motivate, explicitly, suppose, assume, entire, invariably, compromise, inherently, pursue, handle, denote, utilize, constraint, accordingly, infeasible, violate, respectively, guarantee, satisfaction, indicate, hence, worst-case, synthetic, assess, rarely, throughout, diversity, preference, illustrate, imply, additionally, is an important issuea series ofin terms ofin a distributed mannerin order toby defaultbe referred to astake a holistic view ofconflict witha variety ofis highly in demandgiven the aforementioned issue and trendtake into accountyield close toas followstake into considerationwith respect toa research hot spotcall foraccording todepend upon/onmeet ... requirementfocus onis sensitive tois composed ofconsist offrom the latency minimization perspectivea certain number ofis defined as (follows) / can be expressed as (follows) /can be calculated/computed by / is given by the followingat handcorresponding tohas nothing to do within addition toas depicted in Fig.1et al.The volume of data is measured in terabytes and some time in petabytes in many fields.Data replication allows speeding up data access, reducing access latency and increasing data availability.How many suitable replicas of each data should be created in the cloud to meet a reasonable system requirement is an important issue for further research.Where should these replicas be placed to meet the system task fast execution rate and load balancing requirements is another important issue to be thoroughly investigated.As the system maintenance cost will significantly increase with the number of replicas increasing, keeping too many or fixed replicas are not a good choice.Where should these replicas be placed to meet the system task fast execution rate and load balancing requirements is another important issue to be thoroughly investigated.We build up five objectives for optimization which provides us with the advantage that we can search for solutions that yield close to optimal values for these objectives.The shortcoming of them is that they only consider a restricted set of parameters affecting the replication decision. Further, they only focus on the improvement of the system performance and they do not address the energy efficiency issue in data centers.Data node load variance is the standard deviation of data node load of all data nodes in the cloud storage cluster which can be used to represent the degree of load balancing of the system.The advantage of using simulation is that we can easily vary parameters to understand their individual impact on system performance.Throughout the simulation, we assumed "write-once, read-many" data and did not include the consistency or write and update propagations costs in the study.Distributed replica placement algorithms for correlated data--- The Journal of Supercomputing yield, potential, congestion, prolonged, malicious, overhead, conventional, present, propose, numerous, tackle, pervasive, valid, utilize,develop a .... algorithmsuffer fromin a distributed mannerbe denoted as Mconverge toso on and so forthWith the advances in Internet technologies, applications are all moving toward serving widely distributed users.Replication techniques have been commonly used to minimize the communication latency by bringing the data close to the clients and improve data availability.Thus, data needs to be carefully placed to avoid unnecessary overhead.These correlations have significant impact on data access patterns.For structured data, data correlated due to the structural relations may be frequently accessed together.Assume that data objects can be clustered into different classes due to user accesses, and whenever a client issues an access request, it will only access data in a single class.One challenge for using centralized replica placement algorithms in a widely distributed system is that a server site has to know the (logical) network topology and the resident set of all structured data sets to make replication decisions.We assume that the data objects accessed by most of the transactions follow certain patterns, which will be stable for some time periods.Locality-aware allocation of multi-dimensional correlated files on thecloud platform--- Distributed and Parallel Databases enormous, retrieve, prevailing, commonly, correlated, booming, massive, exploit, crucial, fundamental, heuristic, deterministic, duplication, compromised, brute-force, sacrifice, sophisticated, investigate, abundant, notation, as a matter of factin various wayswith .... taken into considerationplay a vital role init turns out thatin terms ofvice versaa.k.a.= also known asThe effective management of enormous data volumes on the Cloud platform has attracted devoting research efforts.Currently, most prevailing Cloud file systems allocate data following the principles of fault tolerance and availability, while inter-file correlations, i.e. files correlated with each other, are often neglected.There is a trade-off between data locality and the scale of job parallelism.Although distributing data randomly is expected to achieve the best parallelism, however, such a method may lead to degraded user experiences for introducing extra costs on large volume of remote accesses, especially for many applications that are featured with data locality, e.g., context-aware search, subspace oriented aggregation queries, and etc.However, there must be several application-dependent hot subspaces, under which files are frequently being processed.The problem is how to find a compromised partition solution to well serve the file correlations of different feature subspaces as much as possible.If too many files are grouped together, the imbalance cost would raise and degrade the scale of job parallelism;if files are partitioned into too many small groups, data copying traffic across storage nodes would increase.Instead, our solution is to start from a sub-optimal solution and employ some heuristics to derive a near optimal partition with as less cost as possible.By allocating correlated files together, significant I/O savings can be achieved on reducing the huge cost of random data access over the entire distributed storage network.Big Data Analytics framework for Peer-to-Peer Botnet detection usingRandom Forests--- Information Sciences magnitude, accommodate, upsurge, issue, hence, propose, devise, thereby, has struggled toit was revealed thatis expanding exponentiallytake advantage ofin the pastin the realm ofover the last few yearsthere has also been research onin a scalable manneras per the current knowledge of the authorson the contraryin naturereport their work onNetwork traffic monitoring and analysis-related research has struggled to scale for massive amounts of data in real time.In this paper the authors build up on the progress of open source tools like Hadoop, Hive and Mahout to provide a scalable implementation of quasi-real-time intrusion detection system.As per the current knowledge of the authors, the area of network security analytics severely lacks prior research in addressing the issue of Big Data.Improving pattern recognition accuracy of partial discharges by newdata preprocessing methods--- Electric Power Systems Research stochastic, oscillation, literature, utilize, conventional, derive, distinctive, discriminative, artificial, significantly, considerably, furthermore, likewise, Additionally, reasonable, symbolize, eventually, scenario, consequently, appropriate, momentous, conduct, depict, waveshape, deficiency, nonetheless, derived, respectively, suffer from, notably,be taken into considerationby means ofto our best knowledgein accordance withwith respect toas mentionedwith regard tobe equal withlead tofor instancein additionin comparison toThus, analyzing the huge amount of data is not feasible unless data pre-processing is manipulated.As mentioned, PD is completely a random and nonlinear phenomenon. Since ANNs are the best classifiers to model such nonlinear systems, PD patterns can be recognized suitably by ANNs.In other words, when classifier is trained after initial sophistications based on the PRPD patterns extracted from some objects including artificial defects, it can be efficiently used in practical fields to identify the exactly same PD sources by new test data without any iterative process.In pulse shape characterization, some signal processing methods such as Wavelet or Fourier transforms are usually used to extract some features from PD waveshape. These methods are affected by noise and so it is necessary to incorporate some de-noising methods into the pattern recognition process.PD identification is usually performed using PRPD recognition which is not influenced by changing the experimental set up.Partial Discharge Pattern Recognition of Cast Resin CurrentTransformers Using Radial Basis Function Neural Network--- Journal of Electrical Engineering & Technology propose, novel, vital, demonstrate, conduct, significant,This paper proposes a novel pattern recognition approach based on the radial basis function (RBF) neural network for identifying insulation defects of high-voltage electrical apparatus arising from partial discharge (PD).PD measurement and pattern recognition are important tools for improving the reliability of the high-voltage insulation system.。
计算机安全 网络安全 computer network security 复习资料

0. expected costMaking decision, outcomes from a decisionOutcome has a costExpected cost = sum,1…n(cost(oi)*likelihood(oi))Request->Decision->outcomes->trust-based expected cost1.Eigen Trust, sat or unsatPeer I trust in j : Si,j=sat(i,j)-unsat(I,j)Normalized measure : Ci,j=Si,j/sum,j(Si,j)[Ci,j] is a Markov chain giving the distribution of TjTj is the global trust of j2.Maximum likelihoodΘp is the success probabilityA0(s|h)= Ns(h) /|h|A0(f|h)= Nf(h) /|h|Nx(h) is the number of x’s in hA0(s|h) is the estimate of success probability of the next interactionAs h-> infinite, A0(s|h)-> Θp3.Beta modelA1(s|h)=(Ns(h)+1) /(|h|+2)A1(f|h)=(Nf(h)+1) /(|h|+2)Nx(h) is the number of x’s in hA1(s|h) is success probability of the next interactionZero-knowledge proofThe prover prove a statement to the verifier without any additional knowledgeAlice Bob. Bob waits outside. Alice goes to the door from A or B. Bob says A or B randomly. Then Alice comes to the exit of the selected path. Through many times, the probability that Alice knows the word is very high.Pseudo codeSend(M,D){J=random_pick({1…n})Relay(M,D)->J}Relay(M,D){If(flip_biased_coin(pf))M->DElseJ=random_pick({1…n})Relay(M,D)->J}Possible innocence: from the attacker’s point of view, the sender is innocent with a non-null probability Probable innocence: from the attacker’s point of view, the sender is no more likely to be the originator than not to be the originatorFor any i, P(ai|oi)<=0.5 , oi means an observation, ai means a user is detectedBeyond suspicion: the sender is no more likely to be the originator than anyone else. 1/nBitcoin 4 features1.Decentralized digital community, not central issuer2.security depends on math3.no single party controls money supply4.no single point of failure (SPOF)Two ways to get: transfer, minenodes: 1. maintain block chain. 2.validate transactionsrule of mining:1. accept the valid block chain with the most difficult work2.once accept a block chain, miners work to extend that chain with another blockDouble spend attack-21. pay money to two addresses in one block chain: the other nodes will notice the conflict one they receive the block chain information2. pay money to two addresses in two block chain: the other nodes will only accept the payment in the longest block chain, so the attacker need to work hard on the other block chain. But the work is too tough, given that the limited computing resources of the attacker.Invalid block: miners don’t want to build on invalid chains.If an attacker has less than 50% computing power, mining honestly is the best way to gain more coins.If an attacker has more than 50% computing power, he can launch a double spend attack. But it’s still easy to detect. Other nodes can notice this by analyzing two block chains in which invalid one exceeds the other and becomes the valid one.Concerns-5:1.storage of block chain 2. Environmental impact 3.legal issues 4.unstable price 5.51% botnet, not likelyAnonymous-4 ?1. transaction content is public 2.IP is secret 3.key owner is secret 4.every coin has a unique number, publicDB securityRequirements 71.physical integrity: freedom from physical problems2.logical integrity: logical structure is good3.element: every element is accurate4.auditability: can track modification and accesser authentication: is positively identified, both for audit and access6.access control: users can only access authorized data through authorized methods7.availability: db remains accessibleSensitive data attacks:41. inference attack-2: infer, derive sensitive information from insensitive dataDirect attack: seek data by queryIndirect attack: From neutral statistics , mean,sum,count,median2. aggregation attack: combine less sensitive data to get3.tracker attack: trick system believe query is not sensitive4. linear system: linear algebra(b) Sensitive data(5)Inherently sensitive: itself is so revealing. Mission locationSensitive source: informerDeclared sensitive: data declared sensitive by database, classified military dataPart of sensitive attribute or record: record of secret space missionIn relation to previously disclosed information: become sensitive in the presence of other data Types of disclosure (5)Exact data: exact value is disclosedBounds: disclosing the bounds, intervalsNegative result: disclosing the data is not sthExistence: the existence of data is sensitive in itselfProbable value: disclosing the probability of the sensitive data has a certain valueCountermeasures of inference:51. limited response suppression: suppress all items which may lead to identify values already suppressed2. random sample: by a small random sample3.random data perturbation: perturb values by a small random error: statistical measures will be close, but not exactbined result: combine columns to avoid leakage5. query analysis: analyze the purpose of queries then determine whether to answerPrivacy-preserving data miningDeriving information without sacrificing privacyData Mining two approaches:Correlation and aggregationPrivacy for correlation: cut the linking between records, swap values of the linkagePrivacy for aggregation: data perturbation. Add some error. The distribution of data doesn’t change, but data is not exact.Threats to web privacy: 1. Cookies 2.ad-ware 3.spyware 4.social networkCookies can track browser records. The virtual and real world can be connected with social network.Ad-ware surveys: spyware can scan disks and upload privacyFBUser eduction?Differential privacyDefinition: Aims to give aggregated data without leakage of private recordsGoal: any disclosure about an individual data is almost equally whether it’s in or out of a data set. Useful: because privacy and utility of data are trade-offs, it keep both of privacy and utility greatly. Solution: add some noise to the answerX set of possible databasesQuery and exact answer F: x->yGives an approximate answer using some mechanism K:X->Z(idea: a small perturbation in global info can create a big perturbation in individual info)Two criteria: privacy: how good is the protection against leakage of private info (individual data) Utility: how useful is the reported answer (aggregated data)(trade-off)K:X->Z is ε-differentially private if all adjacent databases x, x’ an all S⊆ZK is oblivious if it depends only on Y. H is randomized mechanism.K=f X HThe reported answer should be approximate the exact answerDDos1. Resources to consume: bandwidth of network , server CPU, server state capacity2. amplification attack: If a query can cause a huge size of response, attackers fake victims to send queries and huge data are returned from servers to victims. DNS can answer external users. Attackers set the sender address as victims in DNS queries, and DNS servers return very much data to victims. So the connection is fully occupied with DNS response data. ()3.Set a limit of response rate in DNS servers. If an address sends to many queries, DNS servers only reply limited number of queries. So the connection won’t be fully o ccupied.[the law, response rate, filtering traffic with spoofed source ip, upstream ISP detection]Brute-force known-plaintextMeans that an attacker knows plaintext and cipher, then he wants to seek the key of encryption between them by testing every possible key.Symmetric encryption[ DES, 3DES, AES]DES,56-bit key, block cipher, 2^56 keys. 1 million time/s test==3DES, 3 DES, 112-bit effective.2DES, x=E1(P)=D2(C),so equal to DES //meet in the middleSeeking a collisionStream CipherMono-Alphabetic SubstitutionCharacters.setnumber()! Substitutions for a message.One-time pada. Key.Length()==P.length()==C.length()b. b. Key must be randomc. Never reuse Key [the encryption could be anything]key distributionwhether party trusted is authentic3.A. in symmetric encryption, n parties communicate with each other by using the total of 0.5*n*(n-1) keys. It is hard to keep so many keys.b. parties which are trusted may be not authentic.c. in symmetric encryption, keys must be distributed out of band( Out of band transmission). Mechanisms:use a key distribution center, which is a third party in charge of managing keys.Or use asymmetric encryption.(Session key. randomly generated. Used only for a short time. Sent using a public key system.) Botnet1: command and control (C&C) channels: internet relay chat IRC, http, P2P, twitterEffective : twitter. hard to detect. Consists of many users. If one computer is infected, the others can be infected very fast.Purpose: DDOS attacks, email spam, keylogged data, spyware2: Messages and commands: start or stop an attack. Send keylogged data. Update client.Download new target malwareTordifferent in encryption and path selection.Tor uses asymmetric encryption. Every node has its own public key. Crowds uses symmetric encryption. The symmetric keys are distributed to every two hops. In Tor, the path is set up before the packet is sent. In Crowds, the path is chosen randomly by every hop.In Tor, before a request packet is sent, the sender must encrypt the packet with the public keys of the nodes in the selected path. When a response packet is returned to the sender, the last hop of the path must encrypt the packet in this way as well.Threats and countermeasureData duplication: access controlKeylogging: soft keyboardEavesdropping: don’t transmit any plaintext.Brute-force attack: limit login attemptsTrojan: ban and delete any suspicious fileBackdoor: remove backdoors after testingDDoS: apply blacklistSocial engineering: user eduction ARP: static MAC-IP bindingRisk and management?Direct Financial loss: payment . backupLoss of Business secret : design and idea. Encrypt itLeakage of sensitive data: individual information, medical information. Multi-level DB, encrypt it Network failure: ISP .backup system. Honeypot to detect attackData fabrication: always have offline backup SQL role, permission, injectionPassword protection1.hash2.encrypt3.strength password: length, letter and number, not the same as ID,4. soft keyboard: avoid keylogging5. limit login attempter education7. Security questions8. have phone message security code: one-time padBiometrics: Fingerprint verification by iphone5Digital SignatureNobady else can signAuthenticNo alterationNo re-useKerberos1.send request to authentication service, AS2. a ticket to get tickets(TGT) encrypted by user’s password hash is returned3. send TGT to ticket granting service, TGS4. a service ticket is returned5. send the service ticket to network services for authentication6. start client-server sessionPKICACertificate(x509) is signed by Trusted Third party with its private key。
空间句法的量化指标

空间句法的量化指标空间句法(Spatial Syntax)的量化指标主要用于描述和分析城市空间结构的特征和模式。
以下是一些常用的空间句法量化指标:1. 道路密度(Road Density):指城市道路网络的密集程度,可通过计算单位面积内的道路长度来衡量。
2. 连通度(Connectivity):指城市道路网络中的连通性程度,常用指标包括连接数(Connectivity Degree)、网络密度(Network Density)和平均最短路径长度(Average Shortest Path Length)等。
3. 可达性(Accessibility):指城市不同区域的可达性程度,包括正向可达性(从某一区域到其他区域的便利程度)和反向可达性(从其他区域到某一区域的便利程度)。
4. 中心度(Centrality):指城市空间中的中心程度,常用指标包括中心性(Centrality Degree)和中心距离(Centrality Distance)等。
5. 自由度(Integration):指城市空间中的自由流动程度,包括自由度指数(Integration Index)和自由度梯度(Integration Gradient)等。
6. 分形维度(Fractal Dimension):指城市空间形态的复杂程度,可通过计算城市边界、街道网络或建筑物形态的分形维度来衡量。
7. 线性维度(Linear Dimension):指城市线性要素(如道路、河流等)的长度量化指标,包括总长度、平均长度和线性密度等。
8. 笑脸指数(Smile Index):用于评估城市公共空间的多样性和流动性,从而衡量城市的活力和吸引力。
需要注意的是,以上仅列举了一些常见的空间句法量化指标,具体的指标选择和计算方法可能会因研究目的和所采用的空间分析工具而有所差异。
Distributed Intrusion Detection in Clouds Using Mobile Agents

Distributed Intrusion Detection in Clouds Using Mobile AgentsAmir Vahid Dastjerdi The University of Melbourne Melbourne, Australia amirv@.auKamalrulnizam Abu BakarUniversiti Teknologi Malaysia (UTM)Johor Baru, Malaysiakamarul@fsksm.utm.mySayed Gholam Hassan TabatabaeiUniversiti Teknologi Malaysia (UTM)Johor Baru, Malaysiagtsayed2@siswa.utm.myAbstract—Cloud Computing extends an enterprise ability to meet the computing demands of its everyday operations, while offering flexibility, mobility and scalability. However, the reason that Chief Information Officers (CIOs) and their colleagues hesitate to let their business workloads to move from private Cloud into public Cloud is security. This work tries to offer a line of defense by applying Mobile Agents technology to provide intrusion detection for Cloud applications regardless of their locations. Therefore, CIOs feel safer to use Cloud to extend their on-premise infrastructure by adding capacity on demand.Keywords-Cloud Computing; Mobile Agent; Intrusion Detection SystemI.I NTRODUCTIONCloud Computing is becoming one of the next industry buzz words. Cloud computing builds upon advance of research in virtualization, distributed computing, grid computing and utility computing. It tries to satisfy user needs by providing infrastructure, platform and software as a service (IaaS, PaaS, SaaS). In addition, it offers on-demand services, reduced total cost of services and economy of scale. The key to the solution is an integrated framework that allows reliable, scalable (ability to scale a solution to achieve economy of scale) and reconfigurable aggregation, sharing, and allocation of software (SaaS), computational, storage and networking resources on-demand.For Cloud users it is extremely vital to feel safe and comfortable when they use Cloud resources to hold their software, data and processes. On the other hand, Mobile Agents have special characteristics which can help intrusion detection in several ways in Cloud Computing environments. The use of Mobile code and Mobile Agents computing paradigms have been proposed in several researches [2, 3, 4].In this paper, we propose a Mobile Agent based intrusion detection system (IDS) which can be applied by Cloud clients, and has been very much customized for Cloud Computing environment in order to satisfy the user’s security demands. The advantages of the proposed approach for Cloud Computing include achieving higher scalability, overcoming network latency, reducing network load and consequently lower operational cost, executing asynchronously and autonomously, adopting dynamically, operating in heterogeneous environments of Clouds, and having robust and fault-tolerant behavior.The reminder of this paper is organized as follows. The section II discusses some related works in the area of Mobile Agent-based IDSs. The next section offers design challenges in Cloud IDS. The section IV forms the core of this paper explaining the IDS design. In the next section, the prototype implementation is described to show how specific features of the Mobile Agents can increase the efficiency of the system and decrease the network load by shipping code to data instead of shipping data to code. Moreover, to illustrate how our implementation can enhance the efficiency and performance of the IDS which are discussed in section VI. We test our approach in section VII. Finally, we give conclusions in section VIII.II.R ELATED W ORKThe first generation of intrusion detection systems followed a simple two component architecture: collection component and analyzer component. While this architecture is effective for small collections of monitored hosts, centralized analysis limits the ability to scale up to handle larger collections. Therefore, subsequent generations of Mobile Agent-based intrusion detection systems, such as Autonomous Agents for Intrusion Detection (AAFID) [9], follow a hierarchical structure. Therefore, if any part of the internal nodes (or even the root node) is disabled, the functioning of that of branch of IDS will be disqualified. In addition, those architectures are not flexible, not completely distributed and are not able to respond to attacks against intrusion detection system itself. The performance of IDS using Mobile Agents is considerably relying on the produced network load by the Agents. This issue, which has been neglected by most of related works, will be the main concerns when we design it for Cloud environment. A comparative study on related works is presented in Table I.III.C LOUD IDS D ESIGN C HALLENGES According to [17], Cloud Computing refers to both the applications delivered as services over the Internet and the hardware and systems software in the datacenters that provide those services. The services themselves have long been referred to as Software as a Service (SaaS). The datacenter hardware and software is what we will call a Cloud. When a Cloud is made available in a pay-as-you-go manner to the public, we call it a Public Cloud; the service being sold is Utility Computing. Current examples of public Utility Computing include Amazon EC2 [17]which is an infrastructure as a service provider (IaaS). We use the term Private Cloud to refer to internal datacenters of a business.A simple Cloud architecture is depicted in Fig. 1. The978-0-7695-3829-7/09 $26.00 © 2009 IEEE1692009 Third International Conference on Advanced Engineering Computing and Applications in Sciences DOI 10.1109/ADVCOMP.2009.34175TABLE I. C OMPARING C HARACTERISTICS OF P REVIOUS R ELATED W ORKSarchitecture consists of one or more physical resources at the bottom which are portioned by a virtualization layer into virtual machine instances, and on top of that would be our IDS agency which will be defined later in section IV.For high availability quality of service, each private Cloud requires negotiating and consequently having an agreement with other public Cloud such as Amazon EC2 [17] to request resources when there is a high demand and not enough resources at the local side. In fact, the differentiator between Cloud architecture and other distributed computing architecture is the ability to scale-up on-demand. This is shown in Fig. 1, where public Cloud user launches new instances on a public Cloud like EC2 in order to scale-up offering services by the private Cloud. This means that for the IDS to be successfully deployed by Clouds they have to benefit from scalability.Data transfer cost [17] is a very important issue in Cloud computing. For example in Amazon Cloud, at $100 to $150 per terabyte transferred, these costs quickly add up, making costs a great concern of the administrator. For the sake of cost-effectiveness, researchers focus on areas to reduce the network bandwidth, and allow users and applications to be accessible from anywhere. Sending the Mobile Agents (MA) from the client to the server for intrusion detection purposes prevents the passage of unnecessary immediate results and information through the network. By doing so, bandwidth consumption is reduced in such client/server architecture [18].Moreover, we try to further reduce network load by making Each MA only responsible for detecting certain types of intrusions and as a result Mobile Agents carry less data and code. Next, we try to design all IDS components in a way to impose the least CPU load on the VM instances. That’s because for Cloud Administrators CPU load simply means money, and they are not eager to add more instances for heavy Intrusion Detection Systems.IV.IDS D ESIGNThe aim is to build up a robust distributed hybrid model for intrusion detection in Cloud which covers the flaws of the other traditional models while uses their useful features. Besides, as this area of Mobile Agent-based IDS in Cloud is very new, we will add novel features to previous works to be more customized for Clouds. We will carefully watch the related works to find out which of them help us to meet the mentioned challenges. Among the mentioned challenge, demand for scalability is the most crucial one, because it makes the IDS capable of protecting our VMs outside of our organization boundary. The proposed hybrid model design is inspired by two models namely peer to peer IDS based on Mobile Agents [5] and distributed intrusion detection using Mobile Agents (DIDMA) [8] which as described in Table I offer higher scalability. The following subsections, show how DIDMA is enhanced by adding new components (such data mining, Heart Beat, etc) and applied to each subnet of network while the peer to peer model is used to connect all subnets together.A. Components of the IDS in a SubnetThe fundamental design of our proposed hybrid model in each subnet of Virtual Machines consists of four main components namely IDS Control Center (IDS CC), Agency, Application Specific Static Agent Detectors, and Specialized Investigative Mobile Agent.As can be seen from Fig. 2, Static Agents (SA) should generate an alert whenever they detect suspicious activities, then save those activities information in a log file and send alert’s ID (like A1 in the Fig. 2) to IDS control Center. Then, IDS Control Center will send investigative task-specific Mobile Agent to every agency that sent similar alerts (which are VM 1 and VM 2 in our example).As shown in the Fig. 2, MA will visit and investigate all those VMs, collect information, correlate it and finally send or carry back the result to IDS control Center. Consequently, Alerting Console in IDS Control Center will analyze the coming information and compare and match with intrusion patterns [19] in IDS CC database.Then, it will raise the alarm if it detects an intrusion. IDS Control Center saves the information received from investigative MA into its database. Names and identifications of possibly discovered compromised VM will be black listed and sent to all VMs except the black listed VMs. When the Administrator finds out a new VM in the black list, the necessary actions should be taken. Those actions are quite different compared to actions against compromised physical machines. That’s because virtualmachines are dynamic and can be readily cloned andFigure 1. Simple Cloud architectureseamlessly moved between physical servers. That’s why vulnerabilities can be unknowingly propagated. Thus, Virtual machines which labeled as compromised are recommended to be banned from migration as migration of compromised VMs may lead to propagation of intrusion.As depicted in Fig. 2, every IDS Agency should transmit an "I'm alive" heart beat (shown as HB in Fig. 2) message to the IDSCC at regular intervals to indicate their status. In cases when these messages are not received, there is possibility of intrusion.1)IDS Agency: Mobile Agents need an environment to become alive which is called Agency. An agency is responsible for hosting and executing Agents in parallel and provides them with environment so that they can access services, communicate with each other, and migrate to other agencies. An agency also controls the execution of Agents and protects the underlying VMs from unauthorized access by malicious Agents. In addition, since virtualization creates a level of isolation, the physical machine resources can be protected by executing Agents on VE. The problem of protecting hosts from malicious Mobile Agents has been in place for a long time. However, as proved in [18], the problem could be tackled by virtualization technology.2)Application Specific Static Agent Detectors: Static Agent Detectors (SAD) act like VM monitors, generating ID events whenever traces of an attack is detected, and these events are sent in the form of structured messages to IDS Control Center [8]. SAD is capable of monitoring the VM for different classes of attacks. The SAD is responsible for parsing the log files, checking for intrusion related data pattern in log files, separating data related to the attack from the rest of the data, and formatting the data as required by the investigative MA. The architecture of our IDS allows applying components of other projects as an intrusion detection sensor.Figure 2. IDS architecture in a subnetIn that case, Static Agent Detectors will work on top of those sensors. For instance SNORT [6] network intrusion detection system and its sensors can be used to do packet filtering and looking for intrusion signatures in the packets. To impose the least CPU load on the VM a SAD should be application specific which means if for example a VM is hosting a web server only, it is not logical to have SAD monitoring all possible log files in system.3)Specialized Investigative Mobile Agent: Investigative Mobile Agents (IMA) are responsible for collecting evidences of an attack from all the attacked VM for further analysis and auditing. Then, they have to correlate and aggregate that data to detect distributed attacks. Each IMA is only responsible for detecting certain types of intrusions. This makes it easier for updating when new types of intrusion are found or new types of detection method are invented. In addition, Mobile Agents carry less data and code which save bandwidth, and consequently that decrease operational cost. The investigative MA uses List of Compromised Agency (LCA) to identify its itinerary for visiting Hosts.4)IDS Control Center:An Intrusion Detection System Control Center is (IDSCC) a central point of IDS components administration in each subnet. It includes all the components that a normal VM does and also following components:a)Databases: there should be a database of all intrusion patterns which can be used by Alerting Console to raise the alarm if patterns matched with the detected suspicious activities. All events IDs which reported by SAD are stored in another database. In addition, IDS Control Center should keep an updated status of VMs. A VM in our system can have three statuses as: normal, compromised, migrated.b)Alerting Console: this component compares the spotted suspicious activity with intrusions’ database and raises the alarm if they are matched.c)Agent generator: generate task specific Agent for detecting intrusions (SAD and IMA) even new ones by using knowledge that is generated by data mining inference engine or obtained from previous experiences.d)Mobile Agent dispatcher: it dispatches investigative Mobile Agents to the VMs based on the ID of event or suspicious activity received from their SADs. In addition, it determines list of compromised Agencies (LCA) for IMAs.e)Data mining inference engine: uses machine learning to deduce knowledge to detect new intrusions from System databases which contains detected intrusion and system logs and coming information from SADs. In this component we used Java Agents for Meta-Learning (JAM) project [20] at Columbia University, NY, which applies meta-learning to distributed data mining.f)Trust level manager: defines trust level for all IDS Agencies in the subnet, furthermore it keeps the trust level of the other IDS Control Centers in the same neighbourhood of networks. There are three trust level: 1-noraml 2- suspicious 3- critical. Trust level changes based on SA and MA investigation results.Trust level of all IDS Agencies in the subnet can be modified by the Trust level manager. For example, as mentioned earlier in this paper in the case that the heart beat messages are not received by IDSCC from an IDS Agency, trust manager will decrease the trust level of the Agency. When trust level of the Agency reached specific threshold, it will be identified as a compromised IDS Agency.As pointed out, all VMs which produced same suspicious activity ID will be included in the same List of Compromised Agencies (LCA). However, when a VM gets breached there is high probability that its neighbours are in risk too and consequently they have to be investigated as well. Our approach for defining the LCA is by using a simple version of the Graph based Intrusion Detection system (GrIDS) [7]. The GrIDS generates different shapes of graphs for a period of time that is an indication of large scale distributed attack. The nodes and the links of the graph represent the suspicious VMS and the connection between the VMs respectively. The further propagation of the attack to other VMs leads the way to the growth of the graph. This graph representation is then summarized to produce results that are compared with threshold values for an indication of an attack. Summarization means GrIDS uses approach of aggregating graphs, it infers and reduces the data that must be analyzed at the higher levels. For knowledge sharing between IDS Control Centers, robustness (omitting single point of failure), and detecting intrusions in IDS CCs itself neighbourhood watching scenario is presented in next section.B.Neighborhood watching scenario for detectingintrusion in IDS CCNeighbourhood watching [5] approach is inspired by the real world where neighbours cooperate with each others to achieve more secure neighbourhood. In this approach, all neighbours have the task to watch out for each others. As a result, whenever suspicious behaviours are spotted by a neighbour, all interested parties such as police will be informed.In order to apply that strategy to our IDS application, the first step is to build a virtual neighbourhood where all IDS Control Centers are peers in the same neighbourhood. When any new IDS Control Center enters into the system, it has to be assigned a virtual neighbourhood. The configuration of this neighbourhood system is not fixed and can be dynamic. The initial configuration encompasses a graph of nodes and their location in the network defines the neighbourhood. In order to get the efficient performance the number of neighbours in each neighbourhood should not exceed a predefined upper bound. This matter will be discussed later in section VII.In this neighbourhood watch approach all IDS CC are considered to be equal. Every IDS CC will perform intrusion detection for other IDS CC in its neighbourhood. In a neighbourhood, each Control Center stores data about its neighbours mainly the description of normal behaviour of the neighbours and information such as checksums of critical operating system files. For example, if VM A detects intrusion in neighbour B then it will negotiate with B’s neighbours and only if consensus is obtained then VM B will be identified as a Compromised neighbour.C.The IDS Design DifferentiatorsAs shown, attacks on IDS CC are detectable using the peer to peer model. Consequently, we successfully accomplished the ring of protection in our network. Furthermore, it tackles the single point of failure problem in the AAFID model because there are more than one IDS CC in a network. In addition, compare to AFFID approach, network load is distributed more symmetrical among the network. Moreover, using data mining and knowledge acquiring techniques our model is even capable of achieving new knowledge to detect new kind of intrusion. Outstanding scalability is another strong point of our design. When for example our VM migrates to a machine out of organization boundary (for example from our private Cloud to a public Cloud like Amazon EC2), it is still possible to perform intrusion detection as our IMA can migrate just like VMs. and this is a unique strength of our design which gives the IDS great scalability and flexibility. Therefore, we have met almost all the mentioned challenges in our design.V.P ROTOTYPE I MPLEMENTATIONThe prototype is illustrating how specific features of the Mobile Agents can increase the efficiency of the system and decrease the network load as well. TRACY Mobile Agent toolkit [1] has been used for implementation. Tracy benefited from layered architecture. It means that all basic functions for starting and managing Agent life-cycle are included in a micro kernel and all the others are added as services. Such an open architecture has a great advantage for Clouds as the Mobile Agent toolkit has a very small imperative core which can be customized to impose less load on file and processing systems.Two kinds of Agents defined in Tracy, one is static and the other is Mobile. Agents can be any java class but they should implement ng.Runnable interface. Our design is flexible enough to allow almost all kind of IDS from an integrity checker (For example, “Microsoft (R) File Checksum Integrity Verifier” can help us to verify checksums) to a network intrusion detection system (SNORT) to be deployed by SAD.According to our IDS design, static Agents are responsible for generating alerts, while Mobile Agents are doing investigation on the remote VMs. Nevertheless, a major capability of Mobile Agent is certainly mobility which means they should be able to migrate. Therefore, using migration service in Tracy will be discussed next. It will be shown how our implementation can enhance the efficiency and performance of the IDS using MA by applying Tracy’s novel migration strategies.VI.C OST S AVING U SING D YNAMIC M IGRATIONS TRATEGYOne of the most common migration strategies is the one which transmits all code of the Agent to the next destination. It is fast, however the code which is not going to be used in the next destination will be transferred as well which leads to unnecessary network load. The strategy was named as push strategy in Tracy. The second approach doesn’t transmit any code with Agent’s data transmission. After Mobile Agent received at destination Agency, it might invoke a method. Then, agency downloads all necessary class for that invocation. The strategy is called Pull strategy in Tracy. We discuss that Mobile Agents should decide dynamically, which classes to be carried to destination Agency in migration in order to decrease the network load.In cyber world Agents are autonomous and intelligent therefore Mobile Agents should decide dynamically, which classes to be carried to destination IDS Agency in migration process. Tracy offers pre-fetching technique and dynamic migration strategy to add the ability of this dynamic decision. Pre-fetching technique gives programmers ability to start the process of code downloading manually in migration when there will be an obvious demand for the class in future. This feature can enhance the IDS cost-efficiency significantly in Cloud environment by saving the bandwidth.VII.T ESTINGIn this section our IDS performance will be challenged while we are comparing it with the performance of IDSs which use client/serve approach. For testing purpose, the mathematical model used which was created and applied by peter Braun [1] in 2004. Our aim is to verify our IDS functionality and effectiveness. The IDS with Mobile Agent approach claims the less network load compare to theclient/server approach, by shipping code to data instead of shipping data to code.Fig. 3 compares the network loads of doing intrusion by client server case and Mobile Agent approach for varying number of VMs which should be visited. As a result the IDS with Mobile Agents will produce lower network load when the number of VMs to visit is less than 6 Host. It means that IDS Control Center should not add more than six VMS to the itinerary of the Mobile Agents to make the Mobile Agent’s task efficient and optimized. However, the issue of migration strategies has not been considered in the equation. As we discussed in previous section, if the system can be intelligent enough, it is not always necessary to transfer all the code to the next destination for investigation. Accordingly, less code and data will be relocated. And therefore even less network load will be produced by our approach.VIII. C ONCLUSIONMobile Agents and Virtualization -that Cloud provides- benefit from each others reciprocally. VM are idealplatforms for Agents to execute safely, based on the fact thatvirtual machine can be used to provide secure, isolated sand boxes for the Mobile Agents [18]. And with our approach Clouds and Virtualization can benefit from IDS approach which Mobile Agents make it scalable, flexible and cost-effective. Nonetheless, weaknesses are unavoidable in a new design, and many areas discussed in this paper would benefit from further efforts. For examples, works can look intoMobile Agent’s intercommunication and negotiation which can help investigative Mobile Agents to share their knowledge and therefore build up a more robust inter Cloud IDS.R EFERENCES[1] Peter Braun, Wilhelm R. Rossak, Mobile Agents: Basic Concepts,Mobility Models, and the Tracy Toolkit, published by Morgan Kaufmann (December 22, 2004), ISBN-10: 1558608176 .[2] Andreas Fuchsberger, “Intrusion Detection Systems and IntrusionPrevention Systems, “; Information Security Group, Royal Holloway,Figure 3. Evaluation of Mobile Agent versus client server [1]University of London, Egham, Surrey TW20 0EX, United Kingdom 2005.[3] J. P. Anderson. Computer Security Threat Monitoring and Surveillance. Technical Report, James P. Anderson Co., April 1980. [4]Richard A. Kemmerer and Giovanni Vigna, Intrusion detection: a brief history and overview Reliable Software Group, Computer Science Department, University of California Santa Barbara 2003. [5] Geetha Ramachandran and Delbert Hart, A P2P Intrusion Detection System based on Mobile Agents, 2004 ACM 1-58113-870-9/04/04. [6] Snort, (Oct 2005). Online. /,(March 2007).[7]S.Stainford-Chen, Steven Cheung, et.al. GrIDS-Graph Based Intrusion Detection System for Large Networks. In the Proceedings of the 19th National Information Systems Security Conference, Baltimore, MD, October 1996.[8]Pradeep Kannadiga and Mohammad Zulkernine School of Computing Queen’s University, Kingston Ontario, Canada K7L 3N, DIDMA: A Distributed Intrusion Detection System Using Mobile Agents, 2005 IEEE.[9]J.Balasubramainyan, J.O. Garcia-Fernandez, D.Isacoff, E.H. Spafford, D.Zamboni, An architecture of intrusion detection using autonomous Agents, Department of Computer Science, Purdue University coast TR 98-05, 1998.[10] Mladen Vouk, Sam Averitt, Michael Bugaev, Andy Kurth, Aaron Peeler, Henry Shaffer, Eric Sills, Sarah Stein, Josh Thompson,Powered by VCL - Using Virtual Computing Laboratory (VCL), Proc. 2nd International Conference on Virtual Computing (ICVCI), 15-16 May, 2008, RTP, NC, pp 1-10 Date Published: May 16, 2008.[11] Wayne Jansen, Peter Mell, Tom Karygiannis, Don Marks, Applying Mobile Agents to Intrusion Detection and Response, NIST Interim Report (IR) – 6416 October 1999.[12]Michael Conner, Chirag Patel, Mike Little, “Genetic Algorithm/Artificial Life Evolution of Security Vulnerability Agents,” Army Research Laboratory Federal Laboratory 3rd Annual Symposium on Advanced Telecommunications & Information Distribution Research Program (ATIRP), February 1999.[13]Barrett, Michael, W. Booth, M. Conner, D. Dumas, M. Gaughan, S, Jacobs, M. Little, “Intelligent Agents System Requirements and Architecture,” Report to ATIRP, p. 5, October 1998.[14] M.Asaka, S.Okazawa, A.Taguchi, and S.Goto, "A Method of Tracing Intruders by Use of Mobile Agents," INET'99, June 1999.[15]P. C. Chan and Victor K. Wei, Preemptive Distributed Intrusion Detection using Mobile Agents, Department of Information Engineering The Chinese University of Hong Kong Shatin, N.T., Hong Kong, Proceedings of the Eleventh IEEE International Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE’02) 1080-1383/02 $17.00 © 2002 IEEE.[16] G. Helmer et al., Lightweight agents for intrusion detection, The Journal of Systems and Software 67 (2003) 109–122.[17]M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. H. Katz, A. Konwinski, G. Lee, D. A. Patterson, A. Rabkin, I. Stoica, and M. Zaharia.Above the Clouds: A Berkeley view of Cloud computing. Technical report UCB/EECS-2009-28, Electrical Eng. and Computer Sciences, University of California at Berkeley, Berkeley, USA, 2009. [18]U. Topaloglu and C. Bayrak, Secure mobile agent execution in virtual environment, Springer Netherlands, Journal of Autonomous Agents and Multi-Agent Systems Volume 16, Number 1 / February, 2008.[19]Wuu, L., Hung, C., and Chen, S. 2007. Building intrusion pattern miner for Snort network intrusion detection system. J. Syst. Softw. 80,10 (Oct. 2007), 1699-1715. DOI = /10.1016/j.jss.2006.12.546.[20]W. Lee, S.J. Stolfo, and K. Mok, “A Data Mining Framework for Building Intrusion Detection Models,” Proceedings of the IEEE Symposium on Security and Privacy, 1999. <URL: /~sal/JAM/PROJECT/>。
Geo-referenced Information Visualization on Mobile Devices

Geo-referenced InformationVisualization on Mobile DevicesPaulo Pombinho de Matos Ana Paula Afonso Maria Beatriz Carmo Departamento de Informática, Faculdade de Ciências, Universidade de LisboaCampo Grande, 1749-016, Lisboappombinho@lasige.di.fc.ul.pt,{apa,bc}@di.fc.ul.ptAbstractThe number of mobile devices and associated services has recently been growing considerably. This growth has been changing the way people access information. The technological advances of mobile devices offer new op-portunities to areas where geographic data has an important role. PDA, mobile phones and other portable de-vices are increasingly beginning to have location awareness via GPS devices. These continuous improvements have made possible to incorporate graphic visualization applications to show relevant points of interest to the user without extra actions being necessary. However, usability aspects of this interaction need to be correctly studied to persuade users to accept these visualization applications. Furthermore, mobile devices have several limitations when compared to desktop computers and as a consequence visualization applications developed for the desktop cannot be easily ported to mobile environments. Limitations on the screen size restrict the interface area and the number of data elements that can be displayed. Additionally, limitations on the memory size, proc-essor, graphics hardware and connectivity further reduce the performance hindering the development of com-plex applications. In this paper we describe an ongoing research that aims to design solutions for the visualiza-tion of geographic data on mobile devices. An initial research on similar applications has already been done and as a result the architecture for a geo-referenced visualization application has been defined. In the future, a prototype based on this architecture will be developed which will allow us to test different visualization tech-niques, filtering mechanisms and adequate representations for the users search results.KeywordsGeo-referenced Information, Mobile Devices, Visualization, Usability.1. INTRODUCTIONThe number of mobile devices has been increasing drastically. According to a study from Gartner, Inc.1, worldwide shipments of PDA’s and Smartphone’s combined totalled over 42 million units in the first half of 2006, which equals a 57 percent increase from the same period in 2005. This growth, in association with the increasing number of services available through these devices, has been changing the way people access information. Indeed, it is almost certain that in the near future, the most common method of accessing information is through these devices, even by people who have never used a computer before [Chitarro04].People frequently make use of visual tools such as maps, graphics and diagrams, to better understand and rapidly resolve certain problems. The continuous advances in the computational power and graphics processing have made it possible to include an extensive array of visualization 1 /it/page.jsp?id=496997Gartner, Inc. Gartner’s PDA and Smartphone Quarterly Sta-tistics Programme. techniques in most domains, including business, engineering and science [Chitarro06]. On the other hand, the evolution of mobile devices offers new prospects in domains where geographic data have an important role, such as cartography, tourism, natural resources management and emergency management. These devices allow the user to access geo-referenced information in real time, anywhere and anytime, in a dynamic and flexible way [Burigat05]. Since it is estimated that 85 percent of information has a spatial component [MacEachren01], the potential of obtaining geo-referenced information through mobile devices is rather promising.Presently, it is common to find mobile devices with a built-in GPS device. This allows the mobile device to automatically obtain the user’s position, instantly presenting to the user a map including local points of interest, without the need for any further action. The user is therefore allowed to perform numerous tasks, including finding relevant locations in the vicinity, such as a gas station, the nearest ATM machine or calculating the shortest way to a certain place. The use of mapsallows the user to compare alterative locations, such as the location of a restaurant, helping the user to perceiveits distance from the user’s current location, and also if itis in the neighbourhood of other locations that the user wants to visit.However, to make possible the previous scenarios, it is necessary to explore the usability of such systems. Inexperienced users will not adopt these devices enthusiastically if the complexity and burdens of the limited interaction are not removed [Chitarro04]. Therefore, it is fundamental to employ efficient visualization mechanisms that guarantee a straightforward and understandable access to relevant information to allow the user to accomplish his tasks. An approach to successfully visualize spatial information and the related non visual information is, thus, an important research topic [Burigat05].The objective of this work is to analyse the problems of geo-referenced information visualization through mobile devices and to present some proposals and solutions. Some research has already been done, and as a result an architecture was defined for the future development of a prototype to test the different visualization techniques and filtering mechanisms.This paper is organized as follows: section 2 references some existing geo-referenced information visualization applications; section 3 describes some of the visualization limitations of mobile devices; in section 4 the defined architecture will be briefly described; finally, section 5 will present some conclusions and the future work.2. RELATED WORKThere are already several geo-referenced information visualization tools for desktop computers, such as MetaCarta2, Google Maps3 and Google Earth4. A significant portion of the research done for these applications on mobile devices has focused on the development of tourist related applications that use the position of the user, as well as the current time, to display maps to the tourist which contain useful geo-referenced information. CyberGuide [Abowd97], GUIDE [Cheverst00], CRUMPET [Poslad01] and Lol@ [Gartner01] are examples of this type of application. Besides the academic projects, there are also commercial applications. The majority of these are focused on car navigation systems such as the TomTom Navigator System5 (Figure 1). However, these systems are excessively focused on the navigation task and consequently do not usually offer the best graphic quality, presenting maps with an excess of information and difficult to read. Therefore, new methods are2 3 4 5 necessary for a proper visualization of the geo-referencedinformation on mobile devices [Krüger04].Figure 1: TomTom Navigator SystemA new application that was released recently is the mo-bile version of Google Maps6. There is a concern to avoid the cluttering of the maps with too much detail, by limit-ing the amount of names and roads shown in the different zoom levels. However, this application still has some limitations. There is no way for the user to further refine his search when there is a lot of results and some of them overlap others (Figure 2). The symbols used do not con-vey any additional information to the user to assist him in his task. Consequently, to assist the user, filtering mecha-nisms and adequate representations of the results shouldbe provided.Figure 2: Google Maps Mobile3. MOBILE VISUALIZATION LIMITATIONSWhen compared to desktop computers, mobile devices have a great number of limitations that need to be taken into account when developing visualization applications for these devices [Chitarro06]:•Small screen size, low resolutions and a small amount of colours;•Aspect ratios frequently different from the com-mon 4:3;•Limited processing, memory and storage;•Small input devices, inadequate for complex tasks;•Different input techniques (e.g. handwriting);•Slower connectivity;•Wide range of different specifications according to the device model and brand.6 /gmmScreen size is undoubtedly the most serious limitation. Although increasing in quality, the size of mobile devices screens should remain unchanged given that the device itself has the requirement of being small. Severe usability problems derive from this requirement.A user that is exploring a vast area will have a global perception of the location. However, he will not have enough detail about it. On the other hand, a zoomed im-age will provide the user with more detail, but it will loose the surrounding context, as relevant places disap-pear from the screen, turning a comparison between two locations a complex task. To compare the different alter-natives, the user is forced to constantly adjust the magni-fication of the area, turning the interaction into a slow, complex and confusing task [Baudisch03, Burigat05]. Another problem is the presentation of an excessive num-ber of results. It is necessary to reduce the quantity of represented elements to obtain an intelligible image. The results will be clearer to the user if filtering mechanisms are available. This means that fewer results should be visualized, and those which are shown are selected ac-cording to more precise criteria, including, for example, knowledge of the user’s interests [Carmo05].The mobility context, itself, is the source of some prob-lems, since the environment is constantly changing, pro-voking important changes in the way the user perceives the information (e.g. changes in luminosity, communica-tion quality/speed variation) [Chitarro06]. Consequently, visualization applications developed for desktop computers are not simply ported to mobile de-vices. The work presented in this paper aims to overcome these limitations by exploring the adaptation of filtering mechanisms and visualization techniques to mobile de-vices. They will allow users to easily access and under-stand relevant geographic information to support their daily tasks.4. ONGOING WORKApplications that use maps for geo-referenced informa-tion visualization are crucial in helping the user to obtain the required information. These applications require a friendly interface that allows the users to interactively search the information. In our work, we intend to inte-grate filtering mechanisms based on semantic criteria and to use multiple representations with different levels of detail to express the user’s preferences.Maps will be easier to understand if filtering mechanisms are available. Moreover, if these mechanisms allow the user to express his preferences, this will reduce the dis-play of less relevant elements, thus obtaining a less clut-tered map. The reduction of the elements displayed should be done according to measures considered impor-tant for the user. Some authors have already defined functions that quantify the user interest in particular que-ries. Keim and Krigel define a relevance factor that quan-tifies the distance of each element in a database to the conditions stated in the query [Keim94]. In [Reichen-bacher04] a relevance function is defined that depends on a spatial distance, a time period and a topical distance. Asa starting point, we intend to extend the degree of interest function [Furnas86] and define a generic filtering func-tion that combines the different attributes of the informa-tion in a general and flexible way. These attributes may have different variation domains and can contribute in a positive or negative way to the final result.An alternative to reduce the number of results displayedis to group the elements that are geographically close and use different graphic icons to express this grouping. MetaCarta, for instance, uses three different types of icons to represent documents, according to the number of documents it represents. In [Camossi03] a detailed repre-sentation is defined and generalization operators are usedto derive the less detailed ones. Some authors define representations organized in a hierarchical structure thatis more suitable to aggregate objects in smaller scales [Bederson00], [Frank94] and [Sarkar93]. In [Burghardt04] a similar approach is used, however, in-stead of graphical representations, the lower levels store the number of observations. In this work, we will start by using the approach in [Carmo05] that uses a linear repre-sentation organization. In this approach, the representa-tion for each data element is selected taking into account the scale of representation and the user’s interest. This technique requires the use of multiple representations that express variations in the granularity or detail level while conveying the semantic criterion defined by the user.The correct position of the data elements also has to be taken into account, particularly when the items are not grouped and correspond to close geographic positions. Overlapping elements should be avoided to allow the user to be aware of all the results. In this work we intendto evaluate the existing solutions to find the most suitable approach.After the initial research phase, we have reached a pre-liminary architecture (Figure 3). This architecture will be used in the development of a prototype that will allow usto test the different information filtering mechanisms andvisualization techniques.Figure 3: Preliminary architectureThe user interface will be developed for the Pocket PC, with the Windows Mobile 5.0 operating system, using the .Net Compact Framework 2.0. The client applicationcommunicates with the Google Maps web server in order to retrieve the map images for the desired locations and magnification levels. Due to the lack of documentation that exists for Google Maps, testing was needed to find the latitude and longitude variations in each zoom level. The client application will additionally retrieve data about the points of interest for the given location from an SQL Server.The definition of the architecture was rather limited due to the difficulties that exist when developing for a mobile device. For example, the use of JavaScript map servers was not possible, since we found no browsers fully sup-porting this scripting language.5. CONCLUSIONS AND FUTURE WORKAs discussed in the previous sections, it is necessary to do a considerable effort to understand how to design effi-cient visualizations for mobile devices. Although there are some specific techniques proposed, there is still a need for a broad discussion of visualization techniques for mobile devices.As we have seen, geo-referenced information visualiza-tion applications developed for desktop computers, are not easily transferable to mobile devices. It is also not expectable that all of the limitations of mobile devices will disappear in the near future.We have already explored existing similar applications and defined a software architecture that allows the visu-alization of geo-referenced information on mobile de-vices. Using this architecture we will develop a prototype to test and get an insight of different information filtering mechanisms and visualization techniques to be used. Our goal is to develop efficient methods to present intelligible information to the user, including mechanisms to allow the user to interactively define searches that express his interests.6. REFERENCES[Abowd97] G. Abowd, C. Atkeson, J. Hong, S. Long, R.Kooper and M. Pinkerton. Cyberguide: a Mobile Context-Aware Tour Guide. In Wireless Networks, 3(5), pp. 421-433, 2000.[Baudisch03] P. Baudisch and R. Rosenholtz. Halo: A Tech-nique for Visualizing Off-Screen Locations. In Proceedings of the ACM CHI Conference on Human Factors in Comput-ing Systems, pp. 481-488, 2003.[Bederson00] B. Bederson, J. Meyer and L. Good. Jazz: an Extensible Zoomable User Interface Graphics Toolkit in Java. In Proceedings of the 13th annual ACM Symposium on User Interface Software and Technology, pp. 171-180, 2000.[Burghardt04] D. Burghardt, R. S. Purves and A. J. Edwardes.Techniques for on the-fly generalisation of thematic pointd data using hierarchical data structures. In Proceedings of the GIS Research UK 12th Annual Conference, 2004. [Burigat05] S. Burigat and L. Chitarro. Visualizing the Results of Interactive Queries for Geographic Data on Mobile De-vices. In Proceedings of the 13th annual ACM internationalworkshop on Geographic Information Systems, ACM Press, pp. 277-284, 2005.[Camossi03] E. Camossi, M. Bertolotto, E. Bertino and G.Guerrini. A Multigranular Spatiotemporal Data Model. In Proceedings of the 11th ACM International Symposium on Advances in Geographic Information Systems, pp. 94-101, 2003.[Carmo05] M. B. Carmo, S. Freitas, A. P. Afonso and A. P.Cláudio. Filtering Mechanisms for the Visualization of Geo-Referenced Information. In Proceedings of the 2005 Workshop on Geographic Information Retrieval, pp. 1-4, 2005.[Cheverst00] K. Cheverst, N. Davies, K. Mitchell and A. Fri-day. Experiences of Developing and Deploying a Context-Aware Tourist Guide: The GUIDE Project. In Proceedings of the Conference on Mobile Computting and Networking (MobiCom), ACM Press, pp. 20-31, 2000.[Chitarro04] L. Chitarro. HCI Aspects of Mobile Devices and Services. In Personal and Ubiquitous Computing, Springer-Verlag, 8(2), pp. 69-70, 2004.[Chitarro06] L. Chitarro. Visualizing Information on Mobile Devies. In Computer, IEEE Computer Society Press, 39(3), pp. 40-45, 2006.[Frank94] A. U. Frank and S. Timpf. Multiple Representations for Cartographic Objects in a Multi-Scale Tree – An Intelli-gent Graphical Zoom. In Computer and Graphics, vol. 18, nº6, 1994.[Furnas86] G. Furnas. Generalizes Fisheye Views. In Proceed-ings of the SIGCHI Conference on Human Factors in Com-puting Systems, pp. 16-23, 1986.[Gartner01] G. Gartner and S. Uhlirz. Cartographic Concepts for Realizing a Location Based UMTS Service: Vienna City Guide Lol@. In Proceedings of the Cartographic Confer-ence, pp. 3229-3239, 2001.[Keim94] D. A. Keim and H. P. Krigel. VisDB: Database Ex-ploration Using Multidimensional Visualization. In IEEE Computer Graphics and Applications, vol. 14, nº5, 1994. [Krüger04] A. Krüger, A. Butz, C. Müller, C. Stahl, R. Was-inger, K. E. Steinberg and A. Dirschl. The Connected User Interface: Realizing a Personal Situated Navigation Service.In Proceedings of the 9th International Conference on Intel-ligent User Interfaces, pp. 161-168, 2004. [MacEachren01] A. M. MacEachren and M. J. Kraak. Research Challenges in Geovisualization. In Cartography and Geo-graphic Information Science, 28(1), pp. 1-12, 2001. [Poslad01] S. Poslad, H. Laamanen, R. Malaka, A. Nick, P.Buckle and A. Zipf. CRUMPET: Creation of User-Friendly Mobile Services Personalized for Tourism. In Proceedings of the Conference on 3G Mobile Communication Techn-nologies, pp. 26-29, 2001.[Reichenbacher04] T. Reichenbacher. Mobile Cartography – Adaptative Visualization of Geographic Information on Mobile Devices. In Verlag Dr. Hut, München, ISBN 3-89963-048-3, 2004.[Sarkar93] M. Sarkar, S. S. Snibbe, O. J. Tversky and S. P.Reiss. Stretching the Rubber Sheet: A Metaphor for View-ing Large Layouts on Small Screens. In Proceedings of the 6th Annual ACM Symposium on User Interface Software and Technology, pp. 81-91, 1993.。
面积矢量——精选推荐

⾯积⽮量Vector areaFrom Wikipedia, the free encyclopediaJump to: navigation, searchIn geometry, for a finite planar surface of scalar area S, the vector areais defined as a vector whose magnitude is S and whose direction is perpendicular to the plane, as determined by the right hand rule on the rim (moving one's right hand counterclockwise around the rim, when the palm of the hand is "touching" the surface, and the straight thumb indicates the direction).For an orientable surface S composed of a set S i of flat facet areas, the vector area of the surface is given bywhere is the unit normal vector to the area S i.For bounded, oriented curved surfaces that are sufficiently well-behaved, we can still define vector area. First, we split the surface into infinitesimal elements, each of which is effectively flat. For each infinitesimal element of area, we have an area vector, also infinitesimal.where is the local unit vector perpendicular to dS. Integrating gives the vector area for the surface.For a curved or faceted surface, the vector area is smaller in magnitude than the area. As an extreme example, a closed surface can possess arbitrarily large area, but its vector area is necessarily zero.[1] Surfaces that share a boundary may have very different areas, but they must have the same vector area---the vector area is entirely determined by the boundary. These are consequences of Stokes theorem.The concept of an area vector simplifies the equation for determining the flux through the surface. Consider a planar surface in a uniform field. The flux can be written as the dot product of the field and area vector. This is much simpler than multiplying the field strength by the surface area and the cosine of the angle between the field and the surface normal.Vector AreaFigure 4: A vector area.Suppose that we have a plane surface of scalar area . We can define a vector area whose magnitude is , and whose direction is perpendicular to the plane, in the sense determined by a right-hand grip rule on the rim--see Fig. 4. This quantity clearly possesses both magnitude and direction. But is it a true vector? Well, we know that if the normal to the surface makes an angle with the -axis then the area seen looking along the -direction is . Let this be the -component of . Similarly, if the normal makes an angle with the -axis then the area seen looking along the -direction is . Let this be the -component of . If we limit ourselves to a surface whose normal is perpendicular to the -direction then . It follows that . If we rotate the basis about the -axis by degrees, which is equivalent to rotating the normal to the surface about the -axis by degrees, then(13)which is the correct transformation rule for the -component of a vector. The other components transform correctly as well. This proves that a vector area is a true vector.According to the vector addition theorem, the projected area of two plane surfaces, joined together at a line, looking along the -direction (say) is the -component of the resultant of the vector areas of the two surfaces. Likewise, for many joined-up plane areas, the projected area in the -direction, which is the same as the projected area of the rim in the -direction, is the -component of the resultant of all the vector areas: i.e.,(14)If we approach a limit, by letting the number of plane facets increase, and their areas reduce, then we obtain a continuous surface denoted by the resultant vector area(15)It is clear that the projected area of the rim in the -direction is just . Note that the vector area of a given surface is completely determined by its rim. So, two different surfaces sharing the same rim both possess the same vector area.In conclusion, a loop (not all in one plane) has a vector area which is the resultant of the vector areas of any surface ending on the loop. The components of are the projected areas of the loop in the directions of the basis vectors. As a corollary, a closed surface has , since it does not possess a rim.⾯积⽮量S=|S|*n,n是垂直于平⾯的单位⽮量|S|是⾯积⽮量的模,也就是我们通常理解的⾯积是这么理解的,因为⽮量X积是⽮量,⼤⼩恰好等于ABSINA^B(平⾏四边形⾯积公式),所以为了描述上的⽅便就把⽮量X积说成了⽮量⾯积,这其实不是数学上的⼏何⾯积⽽是具有物理意义的⾯积了。
CV

Unit 31. But frankly you should not risk it __________ you know for sure.A. ifB. lestC. unlessD. although2. New technology ___________ almost every industrial process.A. applies toB. has applied toC. is applying toD. is being applied to3. Gibbons was charged ______ stealing the jewels.A. ofB. withC. forD. in4. Priests thought angrily that the soldiers ______ the church by using it as a stable.A. violatedB. weakenedC. damagedD. sued5. According to one employee, who wishes to remain _________, the company engaged in illegal activities.A. pettyB. insecureC. willfulD. anonymous6. The word “television” is _______ from both Greek and Latin.A. resultedB. deprivedC. derivedD. arisen7. This bathroom is for the President’s _________ use.A. anonymousB. optionalC. explicitD. exclusive8. You should think about the fact _____ nowadays many people care about the quality of a TV set _____________ its price.A. which….rather thanB. which… instead ofC. that … better thanD. that … more than9. We have 1,000 CDs to _________to our readers.A. give inB. give awayC. give wayD. give up10. She further _________ her activities by convincing herself that she was actually helping thepoor.A. acquittedB. amendedC. rationalizedD. revealed11.Give the names of two people who can be _______ in an emergency.A. contractedB. contactedC. resortedD. steered12. Are there any areas that you feel are not ______ adequately in the book?A. grantedB. sustainedC. coveredD. altered13.The company is in ________ on its loan agreement.A. defaultB. successionC. breachD. legitimate14. The local restaurant was _______by actors from the nearby theatre.A. frequentB. frequentlyC. frequentedD. frequency15. This year, the Commission will _____ campaigns to promote equal opportunities for students in schools.A. step upB. step asideC. step alongD. step back16. An increased workload has _________ his personal life.A. offended againstB. violated againstC. infringed onD. disobeyed17. After five months of debating, the committee for Economic Development submitted toCongress the annual _____ which amounted to 1.5 billion.A. loanB. bountyC. damagesD. budget18. The party appeared _________ of the mounting pressures for political reform.A. obliviousB. obviousC. obliqueD. oblige19. How can you ____me ____the concert without a ticket?A. slip awayB. slip intoC. slip toD. slip20. Don't _____the flowers when you play in the garden.A. trample downB. trample onC. tamp onD. tamp down (填压,夯实)21. This old auditorium has _______ many ceremonies.A. seenB. heardC. knownD. witnessed22. I often feel a sense of helplessness in trying to counter the damage they cause when they ____their privilegeA. enforceB. patrolC. abuseD. duplicate23. We tried to settle the problem with them as soon as possible, but they seemed to __ sincerity.A. lack ofB. be lack ofC. lack inD. be lacking in24. Wasteful people usually end up __debt.A. withB. byC. inD. to25. It appeared that what I said was untrue, but I did not _______lie to you.A. knowB. knowingly C knownC. knowingKey:1-5 C D B A D 6-10 C D D B C 11-15 B C ACA16-20 CDABB21-25 DCDCB1. The motion to ____________ the club's constitution was defeated by 20 votes to 15.A. amendB. changeC. correctD. alter2. He was granted ___________from military service because of his poor health.A. releaseB. exemptionC. absenceD. freedom3. I told him that I would _______ him to act for me while I was away from office.A. authorizeB. justifyC. rationalizeD. identify4. I cannot give you ____ for the type of car you sell because there is no demand for it in themarket.A. an expenseB. a chargeC. a purchaseD. an order5. Many veterans believe it is their job to bear ___________ to the horrors of war that they personally experienced.A. proofB. evidenceC. visionD. witness6. Our cars get ________ in and when we ask the restaurant to move them they don’t do it for ages.A. stoppedB. preventedC. parkedD. blocked7. Mr. Ying is one of those happy people who_______ pleasure________ helping others.A. derive… fromB. arise…. fromC. result …fromD. result… in8. He is a well-qualified boss and always gives us__________ direction on how to do withbusiness.A. implicateB. implicitC. explicitD. explicate9. –Do you have enough to _________ all your daily expenses?–Oh yes, enough and to spare.A. coverB. spendC. fillD. offer10. You have to go to that agency to buy Ford cars, because it is _________ for the sale of Ford inthis town.A. decisiveB. conclusiveC. exclusiveD. inclusive11. His failure to turn his attention to ___________ wastes of public money is inexcusable.A. obviousB. flagrantC. infamousD. notorious12. You may be eligible for a ______ to help you study.A. fundB. grantC. prizeD. reward13. It has been revealed that some government leaders ____ their authority and position to getillegal profits for themselves.A. employB. absorbC. abuseD. overlook14. She was always different from others. She thought __________.A. crosswiseB. lengthwiseC. likewiseD. otherwise15. The professor asked the research team to provide statistics that would _______ the argument.A. abuseB. patrolC. enforceD. duplicate16. Tom _______ his boss of having broken the labor law.A. blamedB. accusedC. chargedD. sued17. Romeo and Juliet is __________to Shakespeare.A. illustratedB. distributedC. attributedD. contributed18. In order to improve our standard of living, we have to _______ production.A. step upB. decreaseC. stopD. control19. No men were allowed to _______ on the livelihood of his neighbor.A. breakB. violateC. interruptD. infringe20. The gear doesn’t _________ the machine, so you must change it.A. end upB. step upC. fit intoD. fit in with21. If you go on doing like that you’ll ________ in prison.A. end offB. end inC. end upD. end out22. The woman trapped him into _______ the business secret.A. giving inB. giving upC. giving awayD. giving out23. The saxophonist ________ a Kenny Jin melody Going Home in his solo.A. derivedB. quotedC. duplicatedD. violated24. She signed the letter _______, not realizing its implication.A. in faithB. in good faithC. in the faithD. on the faith25. He had always been ____the way Ruth looked, and had never once paid her a compliment.A. oblivious toB. guilty ofC. wary ofD. subject toKeys:1-5 ABADD6-10 DACAC11-15 BBCDC16-20 BCADC21-25 CCBBA。
Nonlinear processing and analysis of angular signals

Physical quantities referring to angles, like vector direction, color hue e.t.c. exhibit an inherently periodic nature. Due to this periodicity, digital lters and edge operators proposed for data on the line cannot be applied on such data. In this paper we introduce lters for angular signals (circular mean, circular median, circular a-trimmed mean, circular modi ed trimmed mean). Particular emphasis is given to the circular median lter for which some interesting properties are derived. We also use estimators of circular dispersion to introduce edge detectors for angular signals. Three variations for the extension of quasi-range to circular data are proposed and expressions for their output pdf are derived. These \circular" quasi-ranges have good and user-controlled properties as edge detectors in noisy angular signals. The performance of the proposed edge operators is evaluated on angular edges, using certain quantitative criteria. Finally, a series of experiments featuring 1-D angular signals and hue images is used to illustrate the operation of the new lters and edge detectors.
典型优化问题的遗传算法求解—8选址分配问题

x i
是
[ xmin , xmax ]
之间的随机数
y i
是 [ ymin , ymax ] 之间的随机数
典型优化问题的模型与算法-R03
14
GA求解
评价
对于指定的染色体 vk,设施的位置是固定的 我们可将最优分配的距离和映射为 vk 的适值 为计算距离和,需要解决分配子问题。
对于固定的设施选址问题,采用拉格朗日松弛法解决分 配子问题
城市电网变电站选址问题
变、配电站设施;小区顾客;输电线(距离 )最短
海上溢油应急点选址优化
应急服务点设施;发生溢油较高的区域顾客来自;到达发生事故点的距离之和最小
公路养护资源的选址和配置问题
养护点设施;路段顾客;目标是工作量均衡
典型优化问题的模型与算法-R03
8
应用
C3
F1
C1
Cn
… Fm
化,提出了一种 称作相对禁止(relative prohibition)的选择策略。
选择最好的个体作为下一代的第一个成员 在剩余的个体中选择最好的个体 如果它属于已选择的个体的禁止邻域,则忽略;否则作为下一代成员。 重复上述过程直至所有成员都被选择。 如果未满足种群规模要求,则采用随机选择进行补充。
典型优化问题的模型与算法-R03
19
图形描述
设施的选址和客户的分配
C3 c13
C1 (u1, v1) c11
F1 (x1, y1)
…
d1
cmn (xi, yi)
Fm dm
Cn (uj, vj)
m : 设施总数
n : 客户总数
Fi: 第i 个设施, i=1,2,…,m Cj: 第 j 个客户, j=1,2,…,n
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Location Oblivious DistributedUnit Disk Graph ColoringMathieu Couture Michel Barbeau Prosenjit BosePaz Carmi Evangelos KranakisSchool of Computer ScienceCarleton UniversityJanuary252006AbstractWe present thefirst location oblivious distributed unit disk graph coloring algorithm having a provable performance ratio of three(i.e.the number of colors used by the algorithm is at most three times thechromatic number of the graph).This is an improvement over thestandard sequential coloring algorithm since we present a new lowerbound of10/3for the worst-case performance ratio of the sequentialcoloring algorithm.The previous greatest lower bound on the per-formance ratio of the sequential coloring algorithm was5/ingsimulation,we also compare our algorithm with other existing unitdisk graph coloring algorithms.1IntroductionA unit disk graph is a graph that admits a representation where nodes are points in the plane and edges join two points whose distance is at most one unit.In wireless ad hoc networks,communicating nodes are sometimes assumed to have the same communication range.For this reason,unit disk graphs are used to model wireless ad hoc networks.Breu and Kirkpatrick[1] showed that determining if an abstract graph is a unit disk graph is an NP-hard problem,which implies thatfinding a unit disk graph representation is1also NP-hard.This difficulty has led to the development of two varieties of algorithms on unit disk graphs depending on how the graphs are represented. If the unit disk graph representation is given(i.e.vertices are points in the plane and edges join pairs of points whose distance is at most one unit)then this situation is referred to as location-aware since each node is aware of its geometric location.On the other hand,if one is simply given an abstract graph(i.e.that a valid representation exists),then this situation is referred to as location oblivious.Location oblivious algorithms are desirable because they can be implemented without the use of a GPS(Global Positioning System).A coloring of a graph G is a function c mapping vertices of G to a set of colors(which can be thought of as a set of integers)such that adjacent vertices are assigned different colors.The graph coloring problem is tofind a coloring which uses the minimum number of colors.The minimum number of colors needed to color a graph G is called its chromatic number and is denoted byχ(G).It has been pointed out by Hale[5]that the problem of assigning different frequencies to nodes which are within communication range from each other can be formalized as a graph coloring problem.Algorithms using a small number of colors are desirable because they allow the use of fewer frequencies.However,the graph coloring problem is NP-complete[6],even for unit disk graphs[4].The performance ratio of a coloring algorithm is defined as the ratio of the number of colors it uses over the chromatic number of the input graph. Approximation algorithms have been proposed to address the unit disk graph coloring problem(see Erlebach and Fiala[3]for a survey),but there exists no coloring algorithm that is1.distributed,2.location oblivious,and3.has a performance ratio of three.In this paper,we introduce thefirst distributed unit disk graph coloring algorithm that has all these three properties.A standard approach used in the context of coloring graphs is the sequen-tial coloring algorithm.The sequential coloring algorithm is the algorithm that colors the nodes of a graph in an arbitrary order,assigning to each node the lowest color that has not been assigned to one of its neighbors.In the2literature,the greatest lower bound on the worst-case performance ratio of the sequential coloring algorithm over unit disk graphs is5/2,by Caragiannis et al.[2].Therefore,it was unclear whether one slightly more complex algo-rithm with a performance ratio of three is better than the trivial sequential algorithm.In this paper,we show that algorithms having a performance ra-tio of three outperform the sequential coloring algorithm in the worst-case by providing an example where the performance ratio of the sequential coloring algorithm is exactly10/3.The rest of this paper is organized as follows:In Section2,we review related work on coloring unit disk graphs.In Section3,we give our coloring algorithm.We prove its termination,correctness and performance properties in Section4.In Section5,we give new lower bounds on the worst-case performance ratio of sequential coloring of unit disk graphs.In Section6, using simulation,we compare the average performance ratio of our algorithm with other algorithms.In Section7,we discuss some optimization techniques we used to speed-up the simulation.We conclude in Section8.2Related WorkA sequential coloring algorithm takes a graph as input,computes some or-dering on the nodes,and greedily assigns colors to nodes according to that order.Each node is assigned the lowest color that has not been assigned to any of its neighbors.We denote the maximum degree of a graph G by∆(G), and the size of the largest clique in G(the clique number of G)byω(G). Since the number of colors used by a sequential coloring algorithm cannot exceed∆(G)+1,we have thatχ(G)≤∆(G)+1.On the other hand,since no two nodes in a clique can have the same color,we have thatχ(G)≥ω(G). For unit disk graphs,Marathe et al.[8]pointed out the following relation:∆(G)≤6ω(G)−6.This implies that all sequential unit disk graph coloring algorithms have a performance ratio of at most six.In fact,a minor ad-justment of that proof shows that the performance ratio is no greater than five[3].What distinguishes sequential coloring algorithms from each other is the order in which they color the nodes.When an arbitrary order is used,we will simply refer to it as the sequential coloring algorithm.For graphs embed-ded in the plane,the lexicographic ordering is the one induced by the(x,y) coordinates of the nodes(nodes with smaller x-coordinate are coloredfirst,3distributed location worst-caseoblivious perf.ratiosequential yes yes5lexicographic yes no3smallest-last no yes3Table1:Summary of Unit Disk Graph Coloring Algorithms Properties. with ties broken according to the y-coordinate).For the case of unit disk graphs,Peeters[10]showed that the lexicographical ordering achieves a per-formance ratio of three.Note that this approach can be easily implemented in a distributed manner provided the nodes are aware of their location.The smallest-last coloring algorithm[9]computes the following ordering over the nodes of a graph G:a node v of minimum degree is colored last(ties are broken arbitrarily).The rest of the ordering is computed recursively on the graph G\{v}.For an ordering<of the nodes of a graph G,we introduce the following notation:1.G v is the subgraph of G induced by every node u of G where u≤v;2.deg(u,G v)is the degree of node u in G v;3.span(<)is the maximum value of deg(v,G v)according to the order<. Sequentially coloring the nodes of a graph according to<leads to a coloring using at most span(<)+1colors.Lexicographical orderings have span no greater than3ω(G)−3.Matula and Beck[9]showed that the smallest-last ordering has minimum span.As pointed out by Gr¨a f et al.[4],this implies that the smallest-last coloring algorithm achieves a performance ratio of at most three over unit disk graphs.However,this algorithm is not distributed. Table1summarizes unit disk graph coloring algorithms properties.As one can see,there seems to be a trade-offbetween being distributed,location oblivious,and having a worst-case performance ratio of three.We show that in fact,no such trade-offexists.4The nodes located within each sector,including u,form a clique.Figure1:The neighborhood of a node does not contain more than6ω(G)−6 nodes.3Location Oblivious Distributed Algorithm Before giving the details of our algorithm,wefirst remind the reader why it is the case that for all unit disk graphs G,the following relation holds:∆(G)≤6ω(G)−6.To see this,divide the neighborhood of a node u in six sectors as shown in Figure1.Since each sector has diameter one,the nodes located within each sector,including u,form a clique.Therefore,u has at most6ω(G)−6 neighbors.As we mentioned in Section2,since any coloring must use at leastω(G)colors,this implies that any sequential coloring algorithm has a performance ratio of at most six over unit disk graphs.Lexicographic coloring achieves a performance ratio of three because for every node u,no more than3ω(G)−3neighbors of u will choose their color before u.The key of our algorithm is to show how to compute an ordering that has this property in a distributed manner when the nodes do not know their position in the plane(i.e.in a location oblivious manner).The main observation is the following:in every unit disk graph G,there is at least one node that has at most3ω(G)−3neighbors.We denote byω(u)the size of a largest clique in which node u belongs. If the neighborhood of a node u has size at most3ω(u)−3,we say that it has the small neighborhood property.Lexicographic coloring exploits the fact that the leftmost node has this property.In fact,all nodes on the convex hull of the nodes also have this property.Since the size of a maximum clique in a unit disk graph can be computed in polynomial time,even without the unit disk representation[11],each node can locally determine whether or not5Algorithm1RankingPhase(id,G id)Input:id,a node identifierN,a list containing the identifiers of the neighbors of node idG id,the subgraph of G induced by NOutput:ranks,a table containing the neighbors ranks1:max clique←ω(G id)2:while{u∈N:rank[u]=0}=∅do3:if rank[id]=0and|{u∈N:rank[u]=0}|≤3∗max clique−3 then4:ranks[id]←max{u∈N:ranks[u]}+15:send rank(id,ranks[id])6:else7:receive rank(u,r)8:ranks[u]←r9:end if10:end whileit has the small neighborhood property.Notice that sinceω(u)≤ω(G)for every node u,if a node has the small neighborhood property,then it also has at most3ω(G)−3neighbors.The intuition behind our algorithm is the following:in order to reach a performance ratio of three,nodes having the small neighborhood property can pick their colors after their neighbors.We then remove all these nodes from the graph,recursively color the remaining subgraph,put the removed nodes back in,and then sequentially color them.Recursion is guaranteed to make progress because there are always nodes having the small neighborhood property.What remains to be shown is how this can be done in a distributed manner.The distributed algorithm works in two phases.In thefirst phase,the nodes establish a local order by each selecting a rank.The ranks,together with the identifier,determine the local order in which they will decide their color.The second phase is the actual coloring.The underlying idea of the ranking algorithm is the following:we want to make sure that for every node u of a unit disk graph G,no more than 3ω(u)−3≤3ω(G)−3nodes pick their color before u.In order to ensure this,each node u collects the connectivity information of its distance one neighborhood and computesω(u).6Algorithm2ColoringPhase(id,N,ranks)Input:id,a node identifierN,a list containing the identifiers of the neighbors of node idranks,a table containing the neighbors’ranksOutput:colors,a table containing the node’s colors(initial values are all0) 1:while{u∈N:colors[u]=0}=∅do2:if colors[id]=0and//if the node has not yet chosen its color and,//in its neighborhood,it has maximum rank among//the nodes which have not yet chosen their color{u∈N:colors[u]=0and ranks[id],id < ranks[u],u }=∅then 3:colors[id]←min{i>0:{u∈N:colors[u]=i}=∅}4:send color(id,colors[id])5:else6:receive color(u,c)7:colors[u]←c8:end if9:end whileA node u having a total number of neighbors less than or equal to3ω(u)−3 (i.e.having the small neighborhood property)selects rank one and informs its neighbors of its decision.A node u having more than3ω(u)−3neighbors must wait.Ranking information from neighbors is recorded in a table.When the number of neighbors of a node u with undetermined rank becomes less than or equal to3ω(u)−3,node u takes a rank that is one more than the maximum rank among its neighbors.Node u then informs its neighbors about its decision.This process continues until all nodes have chosen their rank.Algorithm1gives the details of the ranking phase.When all neighbors have chosen their ranks,a node may start the coloring phase.Note that two neighbors may have chosen the same rank.Locally, nodes then choose their color according to the order induced by the pair rank,id .Nodes with higher rank pick their colorfirst,and ties are broken according to their identifier.Algorithm2gives the details of the coloring phase.74Theoretical PropertiesWe now prove the termination and correctness of our algorithm.We also show that it has a performance ratio of at most three.Proposition4.1After Algorithm1terminates,all nodes have selected a rank.Proof:Suppose after Algorithm1terminates,there is a set of nodes S of G which have not yet chosen their rank.This means that every node u∈S has more than3ω(u)−3neighbors which have not yet chosen their rank(i.e. which are in S).In particular,this is true for a node v which is on the convex hull of S.Also,since v is on the convex hull of S,all of its neighbors which are in S are located on a half-plane whose boundary passes through v.Thus, v cannot have more than3ω(v)−3neighbors in S,which is a contradiction. Therefore,when no more messages are being sent,all nodes have chosen their ranks.Proposition4.2Algorithm2produces a valid coloring.Proof:First of all,Algorithm2terminates.The reason for this is that, among the nodes which have not yet chosen their color,there is always a node which is a global maximum according to the ordered pair rank,id . In particular,this node is a local maximum which will pick its color.Also, no two neighbors can pick their color at the same time.This is because the ordered pair rank,id induces a total order on the nodes.Therefore,of two neighbor nodes which have not picked their color,at most one of them can satisfy the condition on line2.Finally,no two neighbors can pick the same color.This is because the second one will only pick a color which is still available(line2).Lemma4.3For a node u of a unit disk graph G,let h(u)denote the number of neighbors of u with higher rank than the rank of u.Then|h(u)|≤3ω(u)−3.Proof:In Algorithm1,a node u will choose its rank only when fewer than3ω(u)−3of its neighbors have undetermined rank(line1).Also,when u chooses its rank,it chooses it such that it is greater than all ranks that have been chosen in its neighborhood.Therefore,only less than3ω(u)−3 nodes could potentially choose rank greater than the one chosen by u.8Proposition4.4Using the order computed by Algorithm1,the color chosen by a node u in Algorithm2is less than or equal to3ω(u)−2.Proof:In the neighborhood of u,only nodes with rank greater than u can choose their color before u.By Lemma4.3,there are no more than3ω(u)−3 such nodes.Therefore,the color chosen by u is no greater than3ω(u)−2. Theorem4.5Using the order computed by Algorithm1,the number of col-ors used by Algorithm2to color a unit disk graph G is no greater than three times the optimal.During the execution of these algorithms,each node sends exactly two messages,each one having size O(log n).Proof:By Proposition4.4,all nodes u are assigned color at most3ω(u)−2≤3ω(G)−2.The performance ratio follows from the fact that at leastω(G) colors are needed to color G.In Algorithm1,each node sends exactly one rank message.In Algorithm2each node sends exactly one color message. This is why each node sends exactly two messages.Each message only carriesa type,the rank or color of the sender,as well as its identifier.The number of different ranks and colors is bounded by the number of nodes.Therefore, the size of a message is bounded by the size of the greatest identifier,which is O(log n).5Lower BoundsWe now give new lower bounds on the worst-case performance ratio of the sequential coloring algorithm for unit disk graphs.The currently greatest lower bound is5/2,given by Caragiannis et al.[2].To prove a lower bound of b,we have to show that there exists a unit disk graph G for which there exists an ordering<of the nodes such that the number of colors used by the sequential coloring algorithm is at least b·χ(G).The construction of such a unit disk graph proceeds as follows:first,decide what the chromatic number of the graph will be.Then,at least one node must pick color b·χ(G).In order to ensure this,it must have at least b·χ(G)−1neighbors,picking all colors ranging from1to b·χ(G)−1.The construction of the graph then continues recursively in order to force these nodes to pick these colors.To force the sequential algorithm to use many colors,one needs to construct a graph with vertices of high degree.The difficulty lies in increasing the degree of vertices without increasing the chromatic number of the graph.95111111122433122Figure 2:Lower Bound of 5/2.Figure 2reproduces the lower bound of 5/2of Caragiannis et al.[2].The chromatic number of that graph is two (dashed and solid circles form a bipartition)but there exists an ordering of the nodes such that the sequential coloring algorithm uses five colors.We now prove a lower bound of three.A case where a performance ratio of three can be reached is shown in Figure 3.This graph is bipartite (no two dashed nodes touch each other,and no two solid nodes touch each other).Hence,it can be colored with two colors.However,it is also possible to order the nodes in such a way that the sequential coloring algorithm uses six colors.In order to do this,first take all disks with label 1in an arbitrary order.Since they form an independent set,the sequential coloring algorithm will assign color 1to all of them.Then,take all disks with label 2.Since they form an independent set and each of them touches a disk with label 1,the sequential coloring algorithm will assign them color 2.Repeat this procedure until the only disk with label 6has been colored with color ing this ordering,the sequential coloring algorithm will then use six colors whereas only two colors are necessary,which means that in that case,it achieves a performance ratio of three.Table 4(page 19)gives the exact positions of the points generating the unit disk graph of Figure 3.Column seq gives the colors assigned by the sequential coloring algorithm,while column opt gives an optimal coloring of the graph.Thus,since the graph shown in Figure 3is triangle-free,we have proved the following:Proposition 5.1For triangle-free unit disk graphs,the worst-case perfor-mance ratio of the sequential coloring algorithm is at least three.The reason why it is interesting to restrict the preceding proposition to triangle-free unit disk graphs is that the bound is tight for that class of graphs,as shown below.102116134213512321134121Figure 3:Lower Bound of 3.Proposition 5.2For triangle-free unit disk graphs,the worst-case perfor-mance ratio of the sequential coloring is at most three.Proof:Suppose that there exists a node u of a unit disk graph G such that the color attributed to u by the sequential coloring algorithm is 7.This means that u has degree at least 6.Since no node of a unit disk graph can have more than five independent neighbors [8],at least two of these six neighbors,say v and w ,are neighbors of each other.Therefore,v,w and u form a triangle,which means that G is not triangle-free.For graphs that are not necessarily triangle-free,we show a worst-case lower bound of 10/3.The construction is depicted in Figure 4.As one can see,this graph can be colored using only three colors (solid,dashed and dotted nodes form a 3-partition of the graph).However,there exists an ordering of the nodes such that sequentially coloring the graph in that order uses ten colors,leading to a performance ratio of 10/3.In order to force the sequential coloring algorithm to use ten colors,the solid bold node which has degree nine is colored last.Its nine neighbors are forced to take all colors ranging from one to nine thereby forcing color ten on the solid bold node.The coloring of its neighbors is forced in a similar fashion.Exact location of the points are given in Table 5(page 20),as well as the three-partition of that graph.Nodes are listed in the order that the sequential coloring algorithm needs to use in order to use ten colors.The existence of this graph allows us to conclude the following:11132124371123135621245614375983214352821331642674212351243212341151231114243614252110Figure 4:Lower Bound of 10/3.12Proposition5.3For unit disk graphs,the worst-case performance ratio of the sequential coloring algorithm is at least10/3.The importance of this last result is that we now have a confirmation that there exist cases where it is worth making the effort of computing an ordering which is guaranteed to achieve a performance ratio of three.However,as we see from our simulations,when nodes are randomly and uniformly placed in a unit square,all strategies are equally good on average.6Simulation ResultsIn the preceding section,we saw that it is fairly complicated to build an example where the sequential coloring algorithm achieves a performance ratio worse than three.Here,using simulation,we compare the coloring algorithm introduced in this paper with other existing coloring ing a fixed radius of0.05,wefirst randomly generated400unit disk graphs of 200nodes each.Nodes have been placed on a unit square and their x and y-coordinates have been chosen following a uniform distribution.We also generated unit disk graphs having up to2000nodes,by incrementally adding 100nodes to each of the400unit disk graphs.We then colored each of these unit disk graphs usingfive different col-oring ing the heuristic described in the next section,we also computed a lower bound on the size of the maximum clique for each of these unit disk graphs.In order to optimize the running time of the simulation,the same heuristic has also been used to simulate the three-cliques-last coloring algorithm.Thefive coloring algorithms we have used are the following:sequential (nodes are colored in the order induced by their identifier),three-cliques-last (the algorithm introduced in this paper),lexicographic(nodes are colored from left to right),smallest-last(nodes of small degree are colored last)and largest-first(nodes of large degree are coloredfirst).The difference between smallest-last and largest-first is the following:in smallest-last,a node u with minimum degree in a graph G is colored last, and the order in which the other nodes are colored is computed recursively on the graph G\{u}.In largest-first,a node u with maximum degree is coloredfirst,and the order in which the other nodes are colored is computed recursively on the same graph.Although the largest-first ordering is easier to compute in a distributed manner,it is not known whether it provides a132 4 6 8 10 12 14 16 18 0200 400 600 800 1000 1200 1400 1600 1800 2000N u m b e r o f C o l o r sNumber of NodesFigure 5:Simulation Results.better upper bound than five on the performance ratio on unit disk graphs.Smallest-last ordering,on the other hand,is non-trivial to compute in a distributed manner but is known to provide an upper bound of three on the performance ratio when coloring unit disk graphs.Figure 5shows the simulation results we obtained.It displays the average number of colors used by each algorithm as a function of the number of nodes in the graph.It also plots the average estimated value of the size of a maximum clique.As explained in the next section,this estimated value is a lower bound on the actual size of a maximum clique.Therefore,it is also a lower bound on the chromatic number.Table 3(page 19)gives the exact values of our simulation results.On all these values,the maximum standard deviation was 1.2.Therefore,the 95%confidence interval is atmost ±21.2√400=0.12.The first observation that can be made by looking at the simulation re-sults is that the algorithm we proposed in this paper (three-cliques-last)provides almost no significant improvement over sequential coloring.In fact,the difference between values obtained for the two algorithms is less than the width of the 95%confidence interval.However,this does not really mean14that our algorithm performs badly.What it really means is that sequential coloring performs better than expected.Looking at Table 3,we can see that the ratio of the average number of colors used over maximum clique size is always below 1.17.This means that the sequential coloring algorithm per-forms quite well although the only known upper bound on the performance ratio is five.Also,it is not surprising to see that the algorithm which performed the best is the smallest-last coloring.As discussed in Section 2,smallest-last ordering attains minimum span.Since the span of an ordering provides an upper bound on the number of colors that will be used,smallest-last coloring can be expected to provide good results.What is really interesting is to see is that largest-first coloring provided better results than both three-cliques-last and lexicographic.There is no known proof that largest-first has a performance ratio better than five,and still it performs better than algorithms which have an upper bound of three on the performance ratio.Since largest-first is distributed,location oblivious and simpler to implement than three-cliques-last,looking at the simulation results allows us to conclude that it is preferable to use largest-first even though there is no proof that it performs better.7Simulation OptimizationSince computing the maximum clique in the neighborhood of a node can be quite time consuming for simulation purposes,we used some heuristics to compute a lower bound on the size of a largest clique.The main idea of our heuristic is the following:the size of the largest clique is the maximum number of nodes contained in a subset of the plane whose diameter is at most one.Since the geometric shape maximizing an area of fixed diameter is the circle,it is reasonable to hope that the maximum number of nodes contained in a disk of radius one is a good approximation of the size of a maximum clique.Since it is sufficient to look at disks having two nodes on their boundaries,there are only 2 n 2 such disks to look at.Since counting the number of nodes in such a disk can be done in linear time,the maximum number of points contained in a disk of radius one can be computed in time O (n 3).For a node u ,let C (u )be the maximum number of nodes contained in a disk of radius one which also contains u ,ω(u )be the size of a maximum15clique containing u,and N(u)be the set containing u and its neighbors.The heuristic we used is the following:if|N(u)|≤3C(u)−3,then use C(u)as an estimate forω(u).Otherwise,compute the exact value ofω(u).Using this estimate instead of computing the exact value ofω(u)does not affect the simulation results.If a node u is such that|N(u)|≤3C(u)−3,then it is also the case that|N(u)|≤3ω(u)−3and therefore it will be assigned rank one in Algorithm1anyway.nodes%nodes%nodes%nodes%1000.99996000.997711000.996816000.99572000.99967000.997612000.996617000.99533000.99918000.997513000.996418000.99504000.99879000.997114000.996219000.99465000.998210000.997115000.996020000.9943Table2:Percentages of nodes u such that|N(u)|≤3C(u)−3.Table2shows the proportion of nodes u which were such that|N(u)|≤3C(u)−3.On all these values,the maximum standard deviation was0.0020.Therefore,the95%confidence interval is at most±20.0020√400=0.0002.Thefirst observation to be made is that the heuristic allowed us to accelerate the simulation in more than99%of the cases.This means that the heuristic was worth using it.The second observation to be made is that the percentages diminish as the graph becomes denser.This makes sense,because the area of a disk of diameter one is only1/4the area of the unit disk around a node.The most important observation to be made is that all nodes such that |N(u)|≤3C(u)−3are assigned rank one in Algorithm1.Therefore,Table2 also gives a lower bound on the proportion of nodes which are assigned rank one.Since this proportion is always higher than99%,the order used by Algorithm2in the second phase is almost the same as the one used by the sequential algorithm,and this gives an intuition of why the simulation results are so similar for these two algorithms.8ConclusionWe presented thefirst distributed location oblivious coloring algorithm which achieves a performance ratio of three on unit disk graphs.However,simula-16。